сравнение строк — npm
JavaScript-реализация tdebatty/java-string-similarity
Библиотека, реализующая различные меры сходства строк, расстояния и sortMatch. В настоящее время реализована дюжина алгоритмов (в том числе расстояние редактирования Левенштейна и одноуровневые элементы, самая длинная общая подпоследовательность, косинусное сходство и т. д.). Полный список см. в сводной таблице ниже…
- Загрузка и использование
- Обзор
- Нормализованный, метрический, сходство и расстояние
- (нормализованное) сходство и расстояние
- Левенштейн
- Самая длинная общая подпоследовательность
- Метрика Самая длинная общая подпоследовательность
- Подобие косинуса
- Коэффициент Соренсена-Дайса
- API
- сходство
- параметры
- возврат
- расстояние
- параметры
- возврат
- параметры
- возврат
- Параметры
- Возврат
- сходство
- Примечания к выпуску
- 1.
 x версия
x версия
- 1.
- Массачусетский технологический институт
 x версия
x версияЗагрузка и использование
загрузка
npm install string-comparison --save пряжа добавить сравнение строк
использование
let stringComparison = require('string-comparison')
const Thanos = «исцеленный»
const Rival = 'запечатанный'
const Avengers = ['Эдвард', 'запечатанный', 'театр']
// используем по косинусу
пусть cos = stringComparison.cosine
console.log(cos.similarity(Танос, Соперник))
console.log(cos.distance(Танос, Соперник))
console.log(cos.sortMatch(Танос, Мстители)) Обзор
Основные характеристики каждого реализованного алгоритма представлены ниже. Столбец «стоимость» дает оценку вычислительной стоимости для вычисления сходства между двумя строками длины m и n соответственно.
| Мера(ы) | нормализовано? | Метрическая? | Тип | Стоимость | Типичное использование | |
|---|---|---|---|---|---|---|
| Индекс Жаккара | сходство расстояние sortMatch | Да | Да | Комплект | О(м+п) | |
| Подобие косинуса | сходство расстояние sortMatch | Да | № | Профиль | О(м+п) | |
| Коэффициент Серенсена-Дайса | сходство расстояние sortMatch | Да | № | Комплект | О(м+п) | |
| Левенштейн | сходство расстояние sortMatch | № | Да | О(м*н) | ||
| Яро-Винклер | расстояние подобия sortMatch | Да | О(м*н) | исправление опечатки |
Нормализованный, метрический, сходство и расстояние
Хотя тема может показаться простой, существует множество различных алгоритмов для измерения сходства текста или расстояния. Поэтому библиотека определяет некоторые интерфейсы для их классификации.
Поэтому библиотека определяет некоторые интерфейсы для их классификации.
(Нормализованное) сходство и расстояние
- StringSimilarity : Алгоритмы реализации определяют сходство между строками (0 означает, что строки совершенно разные).
- NormalizedStringSimilarity : алгоритмы реализации определяют сходство между 0,0 и 1,0, как, например, Jaro-Winkler.
- StringDistance : Алгоритмы реализации определяют расстояние между строками (0 означает, что строки идентичны), например, Левенштейн. Максимальное значение расстояния зависит от алгоритма.
- NormalizedStringDistance : этот интерфейс расширяет StringDistance. Для реализующих классов вычисленное значение расстояния находится в диапазоне от 0,0 до 1,0. NormalizedLevenshtein является примером NormalizedStringDistance.
Левенштейн
Расстояние Левенштейна между двумя словами — это минимальное количество односимвольных правок (вставок, удалений или замен), необходимых для замены одного слова другим.
Расстояние в метрической строке. В этой реализации используется динамическое программирование (алгоритм Вагнера-Фишера) только с двумя строками данных. Таким образом, требуемое пространство составляет O (m), а алгоритм работает за O (m.n).
const Танос = «исцелен»
const Rival = 'запечатанный'
const Avengers = ['Эдвард', 'запечатанный', 'театр']
пусть ls = Сходство.левенштейн
console.log(ls.similarity(Танос, Соперник))
console.log(ls.distance(Танос, Соперник))
console.log(ls.sortMatch(Танос, Мстители))
// выход
0,8333333333333334
1
[
{участник: 'Эдвард', индекс: 0, рейтинг: 0,16666666666666663},
{участник: 'театр', индекс: 2, рейтинг: 0,4285714285714286},
{ Участник: 'запечатанный', индекс: 1, рейтинг: 0,8333333333333334 }
] Самая длинная общая подпоследовательность
Задача о самой длинной общей подпоследовательности (LCS) состоит в поиске самой длинной общей подпоследовательности, общей для двух (или более) последовательностей. Он отличается от задач поиска общих подстрок: в отличие от подстрок, подпоследовательности не обязаны занимать последовательные позиции в исходных последовательностях.
Используется утилитой diff, Git для согласования множественных изменений и т. д.
Расстояние LCS между строками X (длиной n) и Y (длиной m) равно n + m — 2 |LCS(X, у)| мин = 0 макс = п + м
Расстояние LCS эквивалентно расстоянию Левенштейна, когда разрешены только вставка и удаление (без замены) или когда стоимость замены в два раза превышает стоимость вставки или удаления.
Этот класс реализует подход динамического программирования, который требует пространства O(m.n) и вычислительных затрат O(m.n).
В «Длине максимальных общих подпоследовательностей» К.С. Ларсен предложил алгоритм, вычисляющий длину LCS за время O(log(m).log(n)). Но алгоритм требует памяти O(m.n²) и поэтому здесь не реализован.
const Танос = «исцелен»
const Rival = 'запечатанный'
const Avengers = ['Эдвард', 'запечатанный', 'театр']
пусть lcs = сходство.lcs
console.log(lcs.similarity(Танос, Соперник))
console.log(lcs.distance(Танос, Соперник))
console.log(lcs.sortMatch(Танос, Мстители))
// выход
0,8333333333333334
2
[
{участник: 'Эдвард', индекс: 0, рейтинг: 0,5},
{участник: 'театр', индекс: 2, рейтинг: 0,6153846153846154},
{ Участник: 'запечатанный', индекс: 1, рейтинг: 0,8333333333333334 }
] Метрика Самая длинная общая подпоследовательность
Метрика расстояния, основанная на самой длинной общей подпоследовательности, из примечаний Даниэля Баккелунда «Метрика строки на основе LCS». http://heim.ifi.uio.no/~danielry/StringMetric.pdf
http://heim.ifi.uio.no/~danielry/StringMetric.pdf
Расстояние вычисляется как 1 — |LCS(s1, s2)| / max(|s1|, |s2|)
const Thanos = 'исцеление'
const Rival = 'запечатанный'
const Avengers = ['Эдвард', 'запечатанный', 'театр']
пусть mlcs = сходство.mlcs
console.log(mlcs.similarity(Танос, Соперник))
console.log(mlcs.distance(Танос, Соперник))
console.log(mlcs.sortMatch(Танос, Мстители))
// выход
0,8333333333333334
0,16666666666666663
[
{участник: 'Эдвард', индекс: 0, рейтинг: 0,5},
{участник: 'театр', индекс: 2, рейтинг: 0,5714285714285714},
{ Участник: 'запечатанный', индекс: 1, рейтинг: 0,8333333333333334 }
] Косинусное сходство
Как и расстояние Q-грамм, входные строки сначала преобразуются в наборы n-грамм (последовательности из n символов, также называемые k-гонтами), но на этот раз мощность каждой n-граммы не учитывается. . Каждая входная строка представляет собой просто набор n-грамм. Затем индекс Жаккара вычисляется как |V1 между V2| / |V1 объединение V2|.
Расстояние вычисляется как 1 — сходство. Индекс Жаккара — это метрическое расстояние.
Коэффициент Серенсена-Дайса
Аналогичен индексу Жаккара, но на этот раз сходство вычисляется как 2 * |V1 между V2| / (|V1| + |V2|).
Расстояние вычисляется как 1 — сходство.
API
-
сходство. -
расстояние. -
sortMatch
сходство
Алгоритмы реализации определяют сходство между строками
параметры
- танос [строка]
- соперник [Строка]
return
Возвращает сходство между 0,0 и 1,0
Distance
Алгоритмы реализации определяют расстояние между строками (0 означает, что строки идентичны)
параметры
- танос [строка]
- соперник [Строка]
возврат
Возврат числа
sortMatch
параметры
- танос [строка]
- мстители [. ..String]
 ..String]
..String]return
Возвращает массив объектов. пример:
[
{участник: 'Эдвард', рейтинг: 0.16666666666666663},
{участник: 'театр', рейтинг: 0,4285714285714286},
{участник: 'отправлено по почте', рейтинг: 0,5},
{участник: 'запечатанный', рейтинг: 0,83333333333333334}
] ЖУРНАЛ ИЗМЕНЕНИЙ
ЖУРНАЛ ИЗМЕНЕНИЙ
MIT
MIT
Сравнение схожести строк в JS с примерами | by Suman Kunwar
В этой статье мы собираемся обсудить различные типы алгоритмов, используемых при сопоставлении строк, и определить, насколько они похожи, на различных примерах.
Нечеткое сопоставление строк — это тип поиска, который соответствует результату, даже если пользователь вводит слова с ошибкой или часть слова поиска. Он также известен как приблизительное сопоставление строк. минимальное количество односимвольных правок, необходимых для замены одного слова на другое, поэтому результатом является положительное целое число, зависящее от длины строки. Что затрудняет рисование узора.
Что затрудняет рисование узора.
Например,
- расстояние Левенштейна между «Foo» и «бар» — 3
- . люди, пара « красавицы»/«красавица» гораздо больше похожа, чем пара « foo»/«бар» . Но расстояние Левенштейна то же самое.
Пример levenshtein.js:
Производительность JS: https://jsperf.com/levenshtein-distances/1
Сравнение триграмм
Алгоритм триграммы представляет собой n-грамму, непрерывную последовательность из n (в данном случае трех) элементов из данной выборки. В нашем случае имя приложения — это образец, а символ — предмет.
Итак, последовательность «марфа» имеет 4 триграммы { mar art rth tha } .
Мы можем использовать метод Trigram для сравнения двух строк.
Возьмем к примеру «марфа» и то же слово с опечаткой, «Мархта» , и мы можем вычислить их триграммы:
Триграммы «Martha» : {Mar Art Tha}
Триграммы «Marhta» : {Marhta »: , Для измерения сходства мы делим количество совпадающих триграмм в обеих строках: 1 { mar } на количество уникальных триграмм: 7 { mar art rth tha arh rht hta }
Результат: 1/7 = 14%
Чтобы сбалансировать недостаток внешних символов (чтобы несколько усилить сходство строк, начинающихся и заканчивающихся одними и теми же триграммами), мы дополняем строку пробелами с обеих сторон, что в этих случаях приводит к еще трем триграммам «_ma», «ha_» и «та_».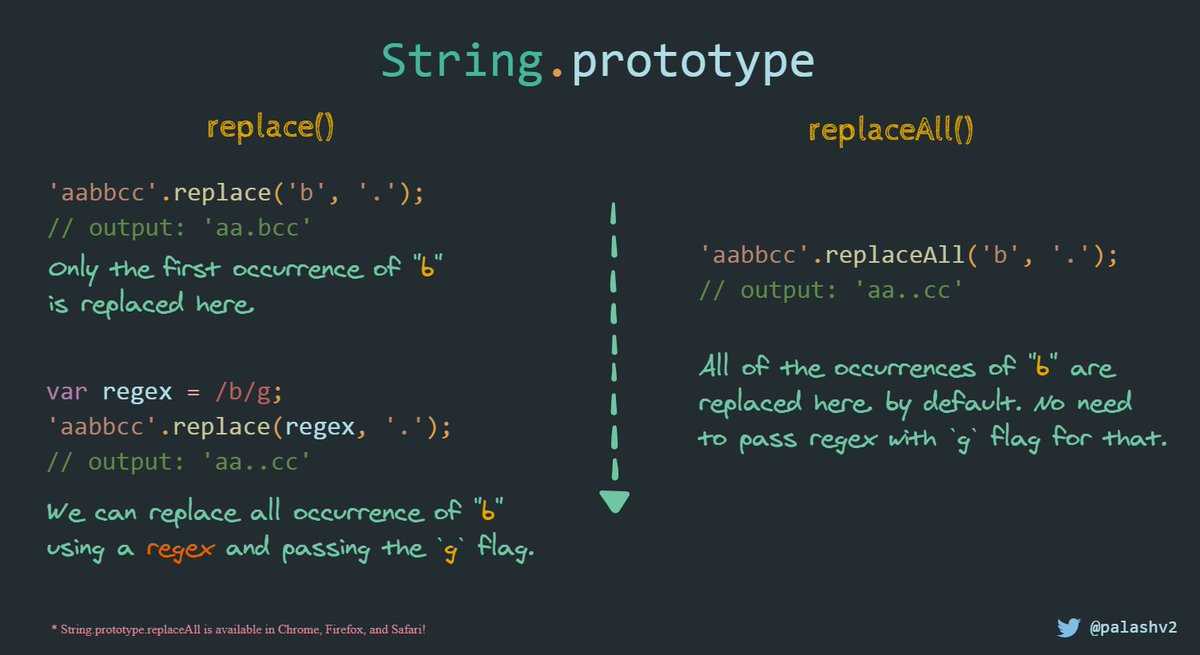
Trigrams “ martha ” : { _ma mar art rth tha ha_ }
Trigrams “ marhta ” : { _ma mar arh rht hta ta_ }
После этого количество совпадающих триграмм достигает: 2 { _ma mar }
Количество всех уникальных триграмм art: 2 { 9034 marthrtharth: 2 { 9034 marth арх рт хта ха_ }
Теперь результат 2/9 = 22% можно найти как скалярное произведение их векторного представления. Существуют различные способы представления предложений/абзацев в виде векторов.сходство = потому что (a, b) = скалярное произведение (a, b) / ( норма (a) * норма (b)) = a.b / ||a|| * ||б||Вот два очень коротких текста для сравнения:
Джули любит меня больше, чем Линда любит меняДжейн любит меня больше, чем Джули любит меняМы хотим знать, насколько похожи эти тексты, чисто с точки зрения количества слов (и игнорируя порядок слов) .
меня Джули любит Линду больше, чем любит ДжейнТеперь посчитаем, сколько раз каждое из этих слов встречается в каждом тексте:
я 2 2
Джейн 0 1
Джули 1 1
Линда 1 0
любит 0 1
любит 2 1
больше 1 1
чем 1 1Однако сами слова нас не интересуют. Нас интересуют только эти два вертикальных вектора отсчетов. Например, в каждом тексте есть два экземпляра «я». Мы собираемся решить, насколько эти два текста близки друг к другу, вычислив одну функцию этих двух векторов, а именно косинус угла между ними.
Два вектора снова равны:
a: [2, 1, 0, 2, 0, 1, 1, 1]b: [2, 1, 1, 1, 1, 0, 1, 1]Косинус угла между ними равен около 0,822.
Эти векторы 8-мерные. Преимущество использования косинусного подобия, очевидно, заключается в том, что оно преобразует вопрос, который человек не может представить себе, в тот, который может быть. В этом случае вы можете думать об этом как об угле около 35 градусов, что является некоторым «расстоянием» от нуля или полного совпадения.
Пример Cosine-Similarity.js:
Производительность JS: https://jsperf.com/consine-similiarity
Алгоритм Яро-Винклера
две последовательности.
Неформально расстояние Джаро между двумя словами — это минимальное количество односимвольных транспозиций, необходимых для преобразования одного слова в другое.
Расстояние Яро-Винклера использует шкалу префиксов, которая дает более благоприятные оценки строкам, которые совпадают с самого начала для заданной длины префикса»
Источник: Википедия .
Присвоение слову с одинаковыми префиксами слова «более важно» сделало расстояние Яро-Винклера очень интересным для нашего случая использования.
Начнем с самого начала с формулы расстояния Джаро, как это работает. Не паникуйте, идем шаг за шагом:
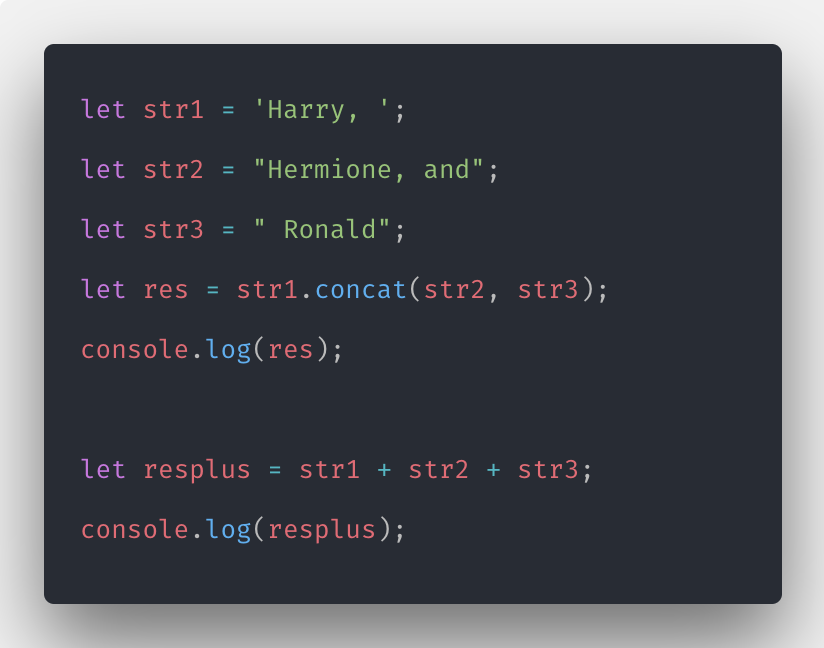
Расстояние Яро между двумя последовательностями s1 и s2 определяется:
Формула расстояния ЯроDJ - это JARO DISMANE
M - это количество соответствующих символов (символы, которые появляются в S1 и в S2 )
tra 66.
|s1| — длина первой строки
|s2| — длина второй строкиС примером. Возьмем «марта» и «марта» .
m = 6
t = 2/2 =1 (2 пары несовпадающих символов, 4-я и 5-я) { t/h ; ч/т }
|s1| = 6
|s2| = 6Просто заменив цифры формулой, мы получим:
dj = (⅓) ( 6/6 + 6/6 + (6–1)/6) = ⅓ 17/6 = 0,944Расстояние Яро = 94,4%Теперь мы знаем, что такое расстояние Яро, давайте перейдем к расстоянию Яро-Винклера.
Подобие Джаро-Винклера использует шкалу префиксов p , которая дает более благоприятные оценки строкам, которые совпадают с начала для заданной длины префикса l.
p — это постоянный коэффициент масштабирования, определяющий, насколько увеличивается оценка за наличие общих префиксов.
l — длина общего префикса в начале строки (максимум 4 символа).
Формула расстояния Яро-ВинклераИтак, вернемся к примеру «martha»/«marhta» , давайте возьмем длину префикса l = 3 (что относится к «mar» ). Получаем:
dw = 0,944 + ((0,1*3)(1–0,944)) = 0,944 + 0,3*0,056 = 0,961Расстояние Яро-Винклера = 96,1%Используя по формуле Яро-Винклера идем от расстояния Яро на 94% сходство с 96%.
Пример Jaro-wrinker.js
JS Производительность: https://jsperf.com/jaro-winker
Источники:
Косинусное сходство между двумя предложениями
Косинусное сходство между двумя предложениями можно найти как точечный продукт их векторного представления. Они различны…
medium.com
Сравнение алгоритмов подобия строк
Как мы настроили почтовые сообщения для пользователей, выбрав и реализовав наиболее подходящий алгоритм.
 Начнем с составления списка слов из обоих текстов:
Начнем с составления списка слов из обоих текстов:
 i-й символ s1 и i-й символ s2 разделить на 2 )
i-й символ s1 и i-й символ s2 разделить на 2 )  Стандартное значение этой константы в работе Винклера равно p=0,1.
Стандартное значение этой константы в работе Винклера равно p=0,1.