Как создать свой поисковик и возможно ли это сделать самостоятельно?
Каждый пользователь в интернете может назвать несколько популярных поисковых систем. Но при этом некоторые из них не оставляют идею создать собственную такую систему, поэтому вопрос: «Как создать свой поисковик?» остается на слуху.
Свой поисковик может быть двух типов:
большая поисковая система, которая будет работать по всему интернету и составлять конкуренцию Google, Яндекс, Bing и др.;
небольшой поисковик, организованный на своем сайте с различными свойства поиска.
Как создать свой поисковик и создать конкуренцию известным «поисковым гигантам»
Создать свой поисковик наподобие Гугла и Яндекса, на самом деле, не так сложно. Любой более-менее уверенный в себе разработчик сможет это сделать. Любой поисковик состоит из 3-х основных элементов:
Пользовательский интерфейс.
Базы данных с сайтами для их индекса.
Поисковый робот, который будет обходить сайты и обновлять/добавлять информацию о них в базу данных.
Техническая реализация поисковой системы не так сложна, как кажется. Плюс в сети есть уже много готовых скриптов как платных, так и бесплатных, с помощью которых вы сможете реализовать свою идею. Создать свой поисковик можно самостоятельно или в небольшой команде. В принципе, если найти соратников в команду, которые готовы поработать на голом энтузиазме, создать свой поисковик можно практически бесплатно.
Но проблема в другом. Сможете ли вы создать действительно конкурирующий программный продукт? Ведь для того, чтобы конкурировать с известными поисковиками, вам нужно будет:
нанять высококвалифицированных специалистов и организовать им рабочее пространство;
оборудовать собственный дата-центр или арендовать мощности у надежной компании;
быть готовым в течение нескольких лет терпеть убытки.
И при этом никто не даст гарантий, что ваш поисковик станет популярным и вы сможете его монетизировать. Потому что пока вы будете развивать свой продукт, Гугл с Яндексом также будут развиваться. А чтобы их «переплюнуть», вам нужно будет внедрить в свой продукт какую-нибудь «фишку» или ноу-хау, чтобы переманить к себе пользователей — это что касается функционала. А с технической стороны ваш поиск должен быть точнее, быстрее и эффективнее, чем у ваших конкурентов, чтобы пользователи это «почувствовали» и перешли на вашу сторону.
Почему люди в основном пользуются Гуглом или Яндексом (или другими)? Потому что им там комфортно и им там нравится. Поэтому, чтобы пользователи перешли именно к вашему поисковику, вы должны стать лучше.
Вот и получается, что создать свой поисковик нетрудно, но вот развивать его и сделать конкурентоспособным — на это потребуется немало усилий и финансовых вложений. Но с другой стороны, Гугл тоже когда-то был в позиции «новичка», а в кого он превратился спустя годы упорного труда — мы все прекрасно видим.
Другое дело с локальными поисковиками, которые вы можете организовать на собственном сайте.
Как создать небольшой локальный поисковик на своем сайте
Небольшой локальный поисковик — это более «приземленная» идея поисковой системы. И в некоторых ситуациях подобный поисковик будет работать эффективнее, чем глобальный Гугл с Яндексом. Например, когда вам нужно ограничить объем поиска. Допустим, у вас есть некий веб-ресурс, который ведет взаимоотношения с 500 поставщиками и 400 различными партнерами, плюс в качестве дополнительной информации вы используете еще 900 разных источников. Вы можете организовать собственную поисковую систему на 1000+ источников, чтобы вашим клиентам было проще искать нужную информацию, касающуюся ваших услуг или товаров. Если они будут это делать через глобальную поисковую систему, то в выдаче у них будет очень много «мусора», который, по сути, им никогда не пригодится. А ваша ПС даст именно те результаты, которые нужны вашим клиентам.
В качестве дополнения собственная тематическая ПС — это:
удобство поиска для ваших клиентов;
дополнительный способ монетизации вашего проекта;
много плюсов к вашему престижу, брендингу и узнаваемости.
Что самое интересное — подобные локальные системы организовать довольно просто. В сети есть масса готовых решений по этому поводу. Самое узнаваемое решение — это создать свой поисковик, используя поисковый потенциал Google. Для этого пройдите по ссылке.
Заключение
Теперь вы знаете, как можно создать свой поисковик. Если это будет глобальная поисковая система, то к этому нужно подготовиться финансово и морально. Если локальный поисковик на собственном сайте, то самый простой способ — это использовать готовое решение. При этом если вы с программированием на «ты», то для вас не составит труда создать свой собственный поисковик с нуля.



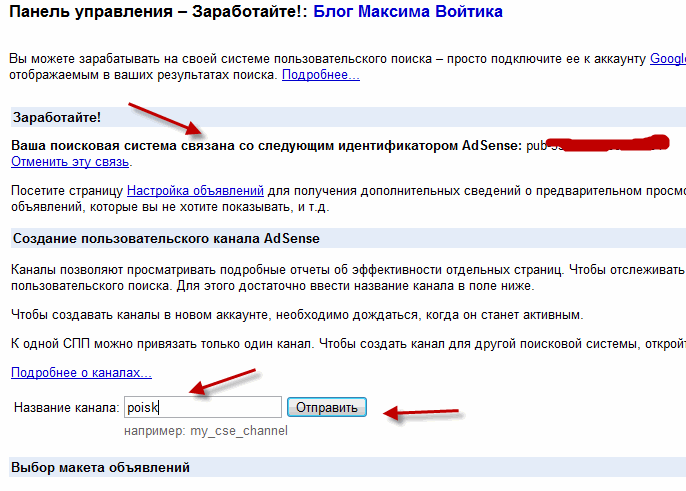
Как создать собственную поисковую систему c помощью CSE. Урок продвинутого сорсинга — Карьера на vc.ru
1271 просмотров
Custom Search Engine (CSE) — мощный инструмент профессионального сорсера. С его помощью можно создать поисковый движок, который будет находить нужных вам кандидатов именно в тех источниках, которые вы укажете.
Основатель кадрового агентства Tech-recruiter и Академии IT-рекрутинга Язиля Насибуллина объяснила, как создать и настроить CSE. А для тех, кто не хочет возиться с настройками, Язиля рассказала про готовые движки для поиска на GitHub, LinkedIn, Behance, Хабр Карьере и в других источниках.
Язиля Насибуллина
основатель агентства Tech-recruiter, автор канала IT-рекрутинг
Зачем сорсеру CSE
CSE — это инструмент от компании Гугл, который позволяет настроить поиск под свои задачи:
- выбрать ресурсы или даже разделы сайтов, которые нужно сканировать;
- искать в определенных регионах;
- задать синонимы, которые будут автоматически подставляться в запрос;
- нацелить поиск на конкретные типы файлов;
- и многое другое, о чем я еще расскажу.


Владельцы сайтов пользуются CSE, чтобы организовать внутренний поиск по своим ресурсам. А сорсеры применяют этот инструмент, чтобы экономить время и получать максимально качественные выдачи.
Когда полезен Custom Search Engine:
- Не хватает возможностей X-ray и внутреннего поиска по сайту. Например, можно создать поисковый движок для GitHub и LinkedIn, используя операторы, которые работают только внутри CSE. Кроме того, поисковый запрос в Гугле ограничен 32 словами — Custom Search Engine позволяет обойти этот лимит.
- Нужно ограничить поиск на определенных сайтах, добавить или исключить конкретные регионы. В стандартном поиске Гугла это сделать сложнее — часто в выдачу попадают нерелевантные результаты, несмотря на оператор «-».
- Надо настроить поиск для начинающих ресечеров и рекрутеров. Например, опытный сорсер создает набор движков, которыми будут пользоваться его коллеги — просто вбивать название должности и получать резюме. Но нужно учитывать, что один и тот же запрос может давать разные результаты в зависимости от настроек и страны нахождения пользователя.
- Необходимо найти редкого эксперта с уникальным стеком — можно создать под него отдельный движок. И наоборот: чем стандартнее запрос и больше кандидатов на рынке, тем меньше нужны все эти «сорсинговые штучки».
 Но нужно учитывать, что один и тот же запрос может давать разные результаты в зависимости от настроек и страны нахождения пользователя.
Но нужно учитывать, что один и тот же запрос может давать разные результаты в зависимости от настроек и страны нахождения пользователя.Как создать поисковый движок
Зайдите в сервис «Программируемая поисковая система» и выберите, в каком интерфейсе будете работать — в стандартном или новом.
Создание движка в стандартном интерфейсе
Здесь нужно указать:
- сайты для поиска;
- язык;
- название системы — желательно осмысленное, чтобы быстро находить нужный вариант, когда у вас будет набор движков на все случаи жизни.
Например, создаю систему для поиска по профилям пользователей на LinkedIn:
Здесь я указываю адрес linkedin. com/in, где хранятся личные страницы пользователей, и использую символ *, чтобы искать по всем доменам соцсети. В поле «Язык» можно выбрать язык выдаваемого профиля, но я не советую этого делать. Даже если вы ищете русскоязычных разработчиков, то стоит помнить — это международный сайт, поэтому многие пользователи заполняют профиль на английском.
com/in, где хранятся личные страницы пользователей, и использую символ *, чтобы искать по всем доменам соцсети. В поле «Язык» можно выбрать язык выдаваемого профиля, но я не советую этого делать. Даже если вы ищете русскоязычных разработчиков, то стоит помнить — это международный сайт, поэтому многие пользователи заполняют профиль на английском.
Как только докажу, что я не робот, и нажму на кнопку «Создать», меня перебросит на следующую страницу со ссылкой на поисковую систему — движок уже будет работать.
Создание движка в новом интерфейсе
Сначала нужно выбрать название системы и указать сайты, по которым надо искать. Потом этот список сайтов можно будет изменить в настройках. Например, создам движок для Хабр Карьеры:
Кстати, можно не ограничиваться конкретными сайтами, а задать целые доменные зоны, например так: *. ru или *. com. Когда я нажму кнопку «Создать», мне предложат настроить систему:
- Выбрать регион поиска — разрешается указать только один. По моему опыту, лучше оставить «Все регионы», а зоны поиска корректировать с помощью доменов и ключевых слов.
- Добавить в поиск новые сайты.
- Исключить из поиска какие-то адреса. Можно убрать из области поиска не только сайт целиком, но и отдельные веб-страницы или разделы (www. example. com/jobs/*), а также весь домен (*. example. com).
 По моему опыту, лучше оставить «Все регионы», а зоны поиска корректировать с помощью доменов и ключевых слов.
По моему опыту, лучше оставить «Все регионы», а зоны поиска корректировать с помощью доменов и ключевых слов.Я настраиваю поиск кандидатов по Хабр Карьере, так что исключу разделы с вакансиями, курсами и информацией о компаниях:
Продвинутая настройка CSE
Предупрежу сразу: все настройки я буду проводить в стандартном интерфейсе — так привычнее. Кроме того, на момент выхода этой статьи новая версия панели управления считается предварительной — многое еще может поменяться. В целом, различия между версиями косметические. Если научиться работать в старом интерфейсе, то будет легко найти аналогичные разделы в новой панели.
Самые полезные настройки находятся в подразделе «Функции в результатах поиска» раздела «Изменение поисковой системы»:
Добавление запроса
Можно прописать дополнительные запросы, которые будут включаться в поиск автоматически. Для этого:
Для этого:
- В разделе «Функции в результатах поиска» нужно перейти во вкладку «Дополнительно».
- Открыть там раздел «Настройки веб-поиска».
- В поле «Добавление запроса» вписать фразу, которая будет подставляться автоматически — писать ее при каждом запросе не придется.
Например, сделаю движок для поиска файлов в формате pdf и docx — предполагается, что это будут резюме. Использую оператор «filetype»:
Уточнения
Усовершенствую движок для LinkedIn — настрою поиск так, чтобы отдельно показывались профили кандидатов с контактными данными. Это можно сделать с помощью уточнений.
В разделе «Функции в результатах поиска» нужно перейти во вкладку «Уточнения», нажать на кнопку «Добавить» и создать дополнительные условия поиска. Результаты по каждому условию будут выводиться на отдельную вкладку.
Например, добавлю поиск по всем профилям, в которых есть почта на gmail. com и ссылка на телеграм:
com и ссылка на телеграм:
Синонимы
Вручную прописывать десятки синонимов через OR при каждом запросе утомительно. В CSE для каждого ключевого слова можно задать набор синонимов, которые будут добавляться автоматически.
Для этого надо:
- Перейти в раздел «Функции в результатах поиска», а оттуда — во вкладку «Синонимы».
- Нажать на кнопку «Добавить».
- На верхней строчке написать ключевое слово, а на нижней — набор синонимов к нему.
Как искать с помощью CSE
Если перейдете по ссылке вашего поискового движка, то вы увидите обычную поисковую строку и больше ничего. Не нужно писать «site:» и название сайта для поиска — этот запрос скрыт «под капотом» системы, как и остальные настройки. А в остальном здесь работают все стандартные операторы, в том числе: OR, —, “” .
Например, так будет выглядеть запрос в движке для LinkedIn на поиск PHP-разработчиков из Москвы:
Сейчас движок сканирует всю страницу пользователя целиком. Но существуют операторы, которые позволяют ориентировать его поиск по конкретным блокам и элементам профиля. Например, в LinkedIn, Xing, ResearchGate, Google Scholar и Speakerhub работают такие операторы:
Но существуют операторы, которые позволяют ориентировать его поиск по конкретным блокам и элементам профиля. Например, в LinkedIn, Xing, ResearchGate, Google Scholar и Speakerhub работают такие операторы:
- «more:p:person-jobtitle:» — поиск по позиции;
- «more:p:person-org:» — поиск по компании или учебному заведению;
- «more:p:person-role:» — поиск в заголовке страницы.
А у GitHub есть свой оператор, который обращается к строке «о себе» — «more:p:metatags-og_description:».
Телеграм-канал Хантфлоу
https://t. me/huntflow
Подписывайтесь🔥
Готовые поисковые движки
Вам не обязательно создавать движок самостоятельно — можно воспользоваться готовыми вариантами, если они подходят под ваши задачи. Например, поисковики от Ирины Шамаевой и Балажа Парочай:
- XING,
- HackerRank,
- MeetUp,
- ResearchGate.

Мои поисковые системы:
- GitHub.
- Behance — поиск резюме. Настройки самые простые: в сайтах для поиска я указала «behance. net/*/resume» — раздел, где хранятся резюме пользователей.
- Хабр Карьера. Здесь к каждому допросу автоматически добавляется фраза «последний визит», чтобы искать только по личным страницам пользователей.
- Европейский LinkedIn. Я занимаюсь международным рекрутингом и ищу кандидатов по всей Европе. Для этого сделала движок поиска по доменным областям LinkedIn тех стран, которые мне интересны.
Наш блог читают более 12 000 рекрутеров и профессионалов HR-индустрии. Подкасты, интервью, тематические статьи и экспертные мнения. Переходите по ссылке:
Создание собственной поисковой системы с нуля | Дэвид Ястремский
Сколько раз в день вы просматриваете Интернет? 5, 20, 50? Если Google является вашей предпочтительной поисковой системой, вы можете просмотреть свою историю поиска здесь.
Несмотря на то, насколько глубоко поиск лежит в основе нашей повседневной деятельности и взаимодействия с миром, немногие из нас понимают, как он работает. В этом посте я работаю, чтобы осветить основы поиска. Это от реализации поисковой системы, основанной на оригинальной реализации Google.
Photo by Benjamin Dada on UnsplashСначала мы рассмотрим предварительный шаг: понимание веб-серверов . Что такое клиент-сервер инфраструктура ? Как ваш компьютер подключается к веб-сайту?
Вы увидите, что происходит, когда поисковая система подключается к вашему компьютеру, веб-сайту или чему-либо еще.
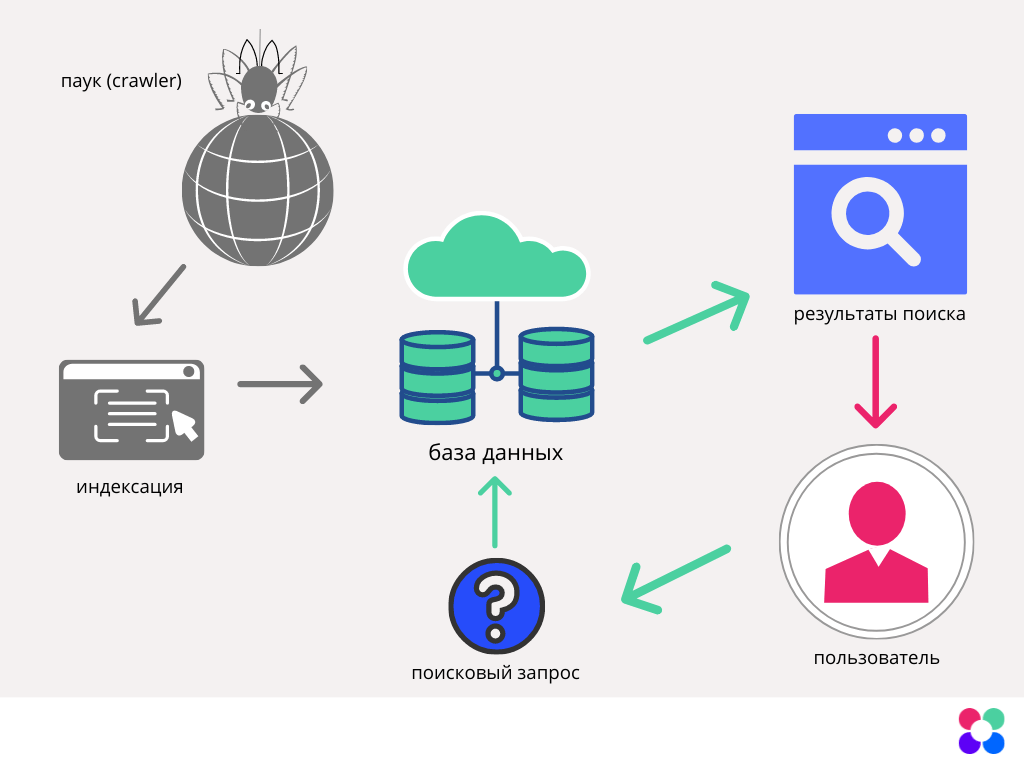
Затем мы рассмотрим три основные части поисковой системы: сканер, индексатор и алгоритм PageRank . Каждый из них даст вам глубокое понимание связей, составляющих паутина это интернет.
Наконец, мы рассмотрим, как эти компоненты объединяются, чтобы получить наш финальный приз: поисковую систему ! Готовы погрузиться? Пойдем!
Мощный веб-сервер! Веб-сервер — это то, с чем ваш компьютер связывается каждый раз, когда вы ищете URL-адрес в своем браузере. Ваш браузер действует как клиент, отправляя запрос, подобно бизнес-клиенту. Сервер — это торговый представитель, который принимает все эти запросы и обрабатывает их параллельно.
Ваш браузер действует как клиент, отправляя запрос, подобно бизнес-клиенту. Сервер — это торговый представитель, который принимает все эти запросы и обрабатывает их параллельно.
Запросы являются текстовыми. Сервер знает, как их читать, поскольку ожидает их в определенной структуре (самый распространенный протокол/структура сейчас — HTTP/1.1).
Пример запроса:
GET /hello HTTP/1.1
Агент пользователя: Mozilla/4.0 (совместимый; MSIE5.01; Windows NT)
Хост: www.sample-why-david-y.com
Accept-Language : en-us
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: user=why-david-y
Запрос может иметь аргументы, заданные его списком файлов cookie. У него может быть тело с дополнительной информацией. Ответ следует аналогичному формату, позволяя серверу возвращать аргументы и тело для чтения клиентами. Интернет становится все более интерактивным, вся тяжелая работа по созданию контента выполняется на сервере.
Если вы когда-нибудь захотите запрограммировать веб-сервер или клиент, вам доступно множество библиотек для выполнения большей части синтаксического анализа и низкоуровневой работы. Просто имейте в виду, что запросы клиентов и ответы сервера — это всего лишь способ структурирования текста. Это значит, что мы все говорим на одном языке!
Если вы создаете поисковую систему, поисковый робот — это то, на что вы тратите большую часть времени. Сканер просматривает открытый Интернет, начиная с предопределенного списка сидов (например, Wikipedia.com, WSJ.com, NYT.com). Он прочитает каждую страницу, сохранит ее и добавит новые ссылки к своей границе URL-адреса, которая является его очередью ссылок для сканирования
Фото Кевина Грива на Unsplash google.com/robots.txt. На этой странице указаны правила, которые должен соблюдать сканер, чтобы не нарушать какие-либо законы и не считаться спамером. Например, некоторые поддомены не могут быть просканированы, и между каждым сканированием может пройти минимальное время.
Почему здесь так много времени? Интернет очень неструктурирован, мечта анархиста. Конечно, у нас могут быть некоторые нормы, с которыми мы согласны, но вы никогда не поймете, насколько они нарушены, пока не напишете сканер .
Например, ваш поисковый робот читает HTML-страницы, поскольку они имеют структуру. Автор все еще может, например, поместить не-ссылки в теги ссылок, которые нарушат некоторую неявную логику в вашей программе. Это могут быть электронные письма ([email protected]), предложения и другой текст, который может быть пропущен при проверке.
Возможно, вы сканируете страницу, которая каждый раз выглядит по-разному, но на самом деле генерирует динамическое содержимое, например включая текущее время? Что, если страница A перенаправляет на B, B перенаправляет на C, а C перенаправляет на A? Что, если в календаре есть бесчисленные ссылки на будущие годы или дни?
Это некоторые из многих случаев, которые могут возникнуть при сканировании миллионов страниц , и каждый пограничный случай должен быть покрыт или устранен .
После того, как вы сохранили просканированный контент в базе данных, наступает очередь индексации! Когда пользователь ищет термин, он хочет получить точные результаты быстро. Вот где индексация так важна. Вы сами решаете, какие показатели для вас наиболее важны, а затем извлекаете их из просканированного документа. Вот некоторые из них:
- Прямой индекс : Это структура данных, содержащая список документов со связанными с ними словами по порядку. Например:
документ1, <слово1, слово2, слово3>
документ2, <слово2, слово3>
- Инвертированный индекс : Это структура данных, содержащая список слов с документами, содержащими это слово. Например:
слово1, <документ2, документ3, документ4>
слово2, <документ1, документ2>
- Частота терминов (TF) : это показатель, сохраняемый для каждого уникального слова в каждом документе. Обычно он рассчитывается как количество вхождений этого слова, деленное на количество слов в документе, в результате чего получается значение от 0 до 1. Некоторые слова могут иметь больший вес (например, специальные теги), и TF может быть нормализован. предотвращение экстремальных значений.
- Обратная частота документа (IDF) : Это показатель, сохраняемый для каждого уникального слова. Обычно он рассчитывается делением количества документов с этим словом на общее количество документов. Учитывая, что для этого требуется количество документов, оно обычно рассчитывается после сканирования или во время запроса. Это может быть нормализовано, чтобы предотвратить экстремальные значения.
 Некоторые слова могут иметь больший вес (например, специальные теги), и TF может быть нормализован. предотвращение экстремальных значений.
Некоторые слова могут иметь больший вес (например, специальные теги), и TF может быть нормализован. предотвращение экстремальных значений. С помощью этих четырех значений вы можете разработать индексатор, который позволит вам возвращать точные результаты. Благодаря оптимизации текущих баз данных результаты также будут достаточно быстрыми . Используя MongoDB, наш проект использовал их для возврата результатов примерно за 2 секунды даже для более длинных запросов. Вы можете сделать еще больше, используя только эти четыре показателя, например, разрешая запросы на точное соответствие.
Это были основные показатели, используемые поисковыми системами в первые дни. Теперь поисковые системы используют их и многое другое для дальнейшей точной настройки своих результатов.
Как их объединить для получения результатов? Мы обсудим это в разделе интеграции.
PageRank — это алгоритм, определяющий авторитетность страницы в Интернете. Скажем, кто-то ищет «День Земли». Нам нужно посмотреть, насколько надежна страница. Если мы этого не сделаем, наша поисковая система может отправить их на случайную страницу блога, на которой снова и снова написано «День Земли», а не на страницу Википедии или EarthDay.org. При распространении SEO и маркетологов, пытающихся привлечь трафик на страницу, как мы можем гарантировать, что пользователи получат качественные результаты?
PageRank просматривает ссылки между страницами, рассматривая их как граф (набор узлов и вершин) . Каждая вершина представляет собой соединение между двумя узлами в направлении, в котором она указывает (URL-адрес источника к URL-адресу назначения)
На каждой итерации алгоритм просматривает все URL-адреса, указывающие на страницу, скажем, Google.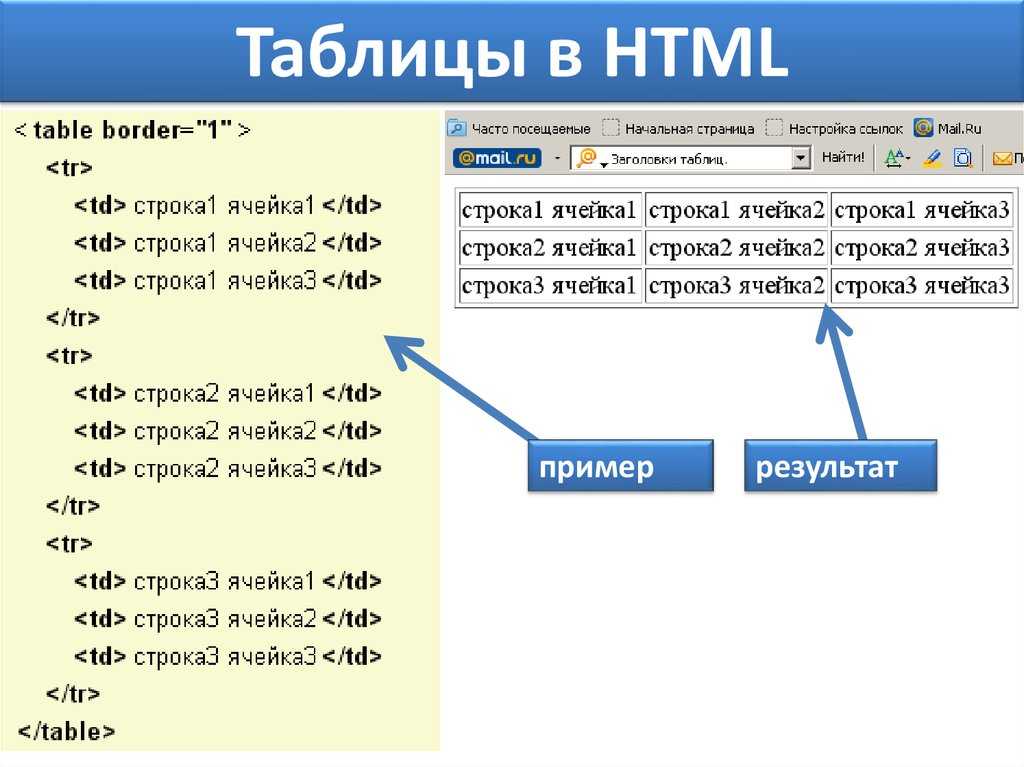 com. Он дает Google некоторый процент от PageRank своих рефереров в зависимости от того, сколько других URL-адресов также указывают эти страницы. После нескольких итераций значения PageRank становятся относительно стабильными, и алгоритм завершает работу.
com. Он дает Google некоторый процент от PageRank своих рефереров в зависимости от того, сколько других URL-адресов также указывают эти страницы. После нескольких итераций значения PageRank становятся относительно стабильными, и алгоритм завершает работу.
Используются и другие уловки, такие как случайный просмотр, который предполагает, что некоторый процент времени пользователь получает скучно и переходит на новую страницу. Эти уловки направлены на то, чтобы избежать угловых случаев с PageRank. Например, приемники — это страницы, которые могут поглотить весь PageRank из-за отсутствия исходящих ссылок.
Теперь у вас есть основные части для поисковой системы.
Когда пользователь выполняет поиск по фразе, вы ищете, в каких документах содержится каждое из условий запроса. Ваша база данных возвращает документы, которые соответствуют всем терминам.
Для каждого документа вы можете взять TFIDF (TF * IDF) для каждого термина запроса и суммировать их вместе. Затем объедините сумму с PageRank этой страницы (например, перемножив их вместе) . Это больше искусство, чем наука, так что оставьте время, чтобы увидеть, что работает, настраивая по ходу дела .
Затем объедините сумму с PageRank этой страницы (например, перемножив их вместе) . Это больше искусство, чем наука, так что оставьте время, чтобы увидеть, что работает, настраивая по ходу дела .
Теперь ваш движок может возвращать отсортированные результаты всякий раз, когда клиент отправляет запрос на URL-адрес вашего сервера. Как обсуждалось в части 0, вся эта работа выполняется на сервере. Клиент делает запрос, и ваш сервер возвращает результаты клиенту в ожидаемом формате.
Отсюда вы можете:
- Добавить новые показатели индексации в свою базу данных для получения более качественных результатов
- Оптимизировать запросы для ускорения выполнения запросов
- Встроить новые функции в свой движок теперь вы можете создать свою собственную поисковую систему! Фото Маркуса Винклера на Unsplash
Пять шагов для создания интеллектуальной поисковой системы с нуля
Иногда, устав от общих поисковых систем, наши клиенты хотят сделать что-то другое или более конкретное.
В этом случае было бы неплохо создать собственную поисковую платформу с собственным хостингом. Сегодня несложно создать интеллектуальную поисковую программу с помощью существующих технологий с открытым исходным кодом.Конечно, этот процесс непрост и в некоторых моментах довольно сложен. Вы также должны быть готовы к длительному бегу. На сканирование всех данных, а также их обработку и анализ уходит не один месяц.
Благодаря нашему опыту даже новичок может разработать простую поисковую систему для полуструктурированных данных примерно за несколько недель. Но каждый раз разработка поисковой системы — это немного другой процесс из-за постоянного развития технологий.
Надеюсь, есть несколько общих шагов, с которыми мы обычно сталкиваемся, отвечая на вопрос о том, как создать поисковую систему с нуля. И эти шаги мы раскрываем в этой статье. Наша команда надеется, что эта статья поможет вам понять ключевые этапы и сэкономит вам несколько дней на первоначальных исследованиях.
АНАЛИЗ ИСХОДНЫХ ДАННЫХ
Перед началом разработки нам необходимо проанализировать исходные данные, чтобы понять, какие алгоритмы поиска лучше всего подходят для ваших данных.
Типы данных можно разделить на структурированные, неструктурированные и частично структурированные :
- Например, структурированные данные — это любые данные, содержащие фиксированное поле, определенный файл или запись. Матрицы, структурированные таблицы и реляционные (SQL) базы данных мы также должны рассматривать как структурированные данные. Во время начального анализа данных специалист по данным изучает, очищает и преобразует данные, чтобы найти атрибуты.
- Если мы работаем со структурированными данными, мы можем классифицировать данные по разным группам, используя атрибуты данных — уникальные свойства, которые отличают одну запись от другой.
- Если данные неструктурированы — например, фотографии, видео, изображения, документы — самый простой способ поиска в этих данных — преобразовать их в структурированный или полуструктурированный формат с использованием различных методов. В зависимости от типа данных специалисты по данным разрабатывают способ обработки этих данных, чтобы предотвратить ложноположительные результаты.
Этот важный шаг позволяет нам продвинуться к важному результату. По нашему опыту, это занимает около 40 за все время.
АНАЛИЗ ЗАПРОСОВ ПОЛЬЗОВАТЕЛЯ
Следующим шагом в развитии поисковой системы является анализ запросов пользователей.
На этом этапе специалист по данным анализирует:- Как пользователь формирует входящий запрос
- Как извлечь из него параметры
- Как эти параметры взаимосвязаны.
Для сложных данных не рекомендуется вводить простой запрос в поле поиска. Вам необходимо разработать специальный язык запросов, который поможет клиенту быстро и эффективно искать данные по комбинации атрибутов.
Если вы ищете альтернативу для разработки определенного языка запросов, мы предлагаем вам попробовать машинное обучение для извлечения данных из поисковых запросов.
Мы можем использовать машинное обучение для создания семантической поисковой системы на основе расширенного модуля анализа текста.Основная особенность семантической поисковой системы — она помогает обрабатывать естественный язык. Более того, автоматически извлекать атрибуты объектов из поисковых запросов. Он также находит отношения между различными входными характеристиками, которые впоследствии используются для эффективного поиска данных.
РАЗРАБОТКА АЛГОРИТМА ПОИСКОВОЙ СИСТЕМЫ
Существуют различные алгоритмы поиска: разные алгоритмы используются для поиска разных типов данных. Применение неправильного алгоритма к конкретным данным может привести к значительной потере производительности. И поиск общих данных может занять гораздо больше времени, чем ожидалось.
Еще один факт, который следует учитывать – существующие реализации конкретных алгоритмов поиска. Наиболее популярными языками программирования для создания поисковых систем являются Python, Java, PHP, Ruby и C#.
Вы можете легко найти различные реализации на GitHub.Но давайте рассмотрим более конкретный пример — алгоритм поиска строк Бойера–Мура — его можно написать с помощью различных языков программирования. Но важно, чтобы алгоритм, разработанный на C++, работал лучше, чем тот же алгоритм, написанный на PHP.
При разработке интеллектуальной поисковой системы вам необходимо понимать слабые места языка программирования и алгоритма, которые вы планируете использовать. Для новичка не проблема, но сложно при разработке решения для крупного предприятия.
Давайте рассмотрим другой пример, текстовый поиск.
Текстовый поиск часто основан на так называемом сопоставлении строк — методе поиска строк, соответствующих определенному шаблону.
Существует несколько типов сопоставления строк: наиболее распространенными являются строгое и нечеткое (приблизительное сопоставление строк). Сопоставление строк — это тип сопоставления, когда данные полностью соответствуют шаблону.
Нечеткое соответствие — когда только часть шаблона соответствует части данных.Если мы копнем немного глубже, мы обнаружим, что одни и те же правила работают как для строк, так и для сложных объектов. Отлично, когда система находит объект, соответствующий запросу пользователя, но чаще всего не может. В этой ситуации движок оценивает существующие записи и ранжирует их.
Машинное обучение может значительно улучшить этот процесс. Он может анализировать не только пользовательский ввод, но и оценивать данные, имеющие атрибуты, аналогичные запрошенному объекту. Вы также можете использовать машинное обучение напрямую. Это даст поисковой системе возможность изучать наиболее релевантные поисковые запросы и постоянно совершенствоваться без ручного программирования.
ОЦЕНКА АТРИБУТОВ И НАСТРОЙКА ДЛЯ ПОИСКОВОЙ ДВИГАТЕЛЯ
Четвертым этапом разработки интеллектуальной поисковой системы является настройка SERP. SERP означает страницу результатов поисковой системы. Это страница, созданная поисковой системой, на которой отображаются все релевантные результаты.
Когда поисковая система находит несколько релевантных результатов, она должна расположить их в правильном порядке, чтобы удовлетворить пользователя. Результаты размещаются в правильном порядке из-за оценки атрибутов. Каждый объект, найденный поисковой системой, имеет набор атрибутов или параметров, описывающих конкретную запись.
Каждый атрибут имеет числовое значение, называемое « вес ». Эти значения суммируются поисковой системой для определения правильного порядка результатов. На этом этапе мы обычно анализируем поведение поисковой системы и настраиваем веса атрибутов, чтобы получить результат, который удовлетворит клиента.
Машинное обучение может значительно улучшить оценку атрибутов. С помощью расширенного машинного обучения мы можем анализировать цепочку поисковых запросов — то, как пользователь ищет конкретную запись.
Принимая во внимание историю поиска, мы можем рассчитать точные веса, динамически корректируя или уменьшая значения в соответствии с уже просмотренными пользователем результатами .
С помощью машинного обучения легко анализировать наиболее популярные записи и автоматически выдвигать их наверх, не искажая пользователя или инженера-программиста. СОЗДАНИЕ СТРАНИЦ РЕЗУЛЬТАТОВ ПОИСКОВОЙ ДВИГАТЕЛЯ
Последним этапом разработки интеллектуальной поисковой системы является генерация SERP. Мы уже упоминали, что SERP — это страница результатов поисковой системы — конкретная страница, на которой пользователь может увидеть релевантные результаты поисковому запросу. Когда обычный человек думает о том, как должны выглядеть результаты поисковой системы, он обычно представляет себе Google или Yahoo.
Что ж, надо признать – Google SERP выглядит хорошо и отображает информацию просто. Но пока мы говорим о более конкретных поисковых системах, пользовательский интерфейс может быть совсем не простым.
Пример страницы результатов поисковой системы из одного из наших последних проектовПоскольку каждая поисковая система обеспечивает поиск данных по различным типам данных, это типичная ситуация, когда страницы результатов выглядят по-разному.
Обычно рекомендуется отображать список атрибутов, извлеченных из поискового запроса. Но иногда это может быть сложно, так как могут быть сотни различных взаимосвязанных атрибутов.Промышленные поисковые системы обычно имеют динамический пользовательский интерфейс , созданный с использованием популярных интерфейсных фреймворков, таких как React или Vue. Эти фреймворки позволяют просматривать богатые результаты поисковой выдачи без перезагрузки страницы, что снижает нагрузку на веб-сервер.
Итак, если вы думаете о создании поисковой системы для сложных данных, вам следует подумать о том, как легко визуализировать результаты и какие технологии использовать.
ИТОГ
Мы живем в увлекательном мире данных, поэтому невозможно представить нашу жизнь без современных поисковых систем, таких как Google или Yahoo. Но есть также типы данных, которые обычные поисковые системы не могут обработать, и для этих данных вам, вероятно, понадобится что-то другое.
 В этом случае было бы неплохо создать собственную поисковую платформу с собственным хостингом. Сегодня несложно создать интеллектуальную поисковую программу с помощью существующих технологий с открытым исходным кодом.
В этом случае было бы неплохо создать собственную поисковую платформу с собственным хостингом. Сегодня несложно создать интеллектуальную поисковую программу с помощью существующих технологий с открытым исходным кодом.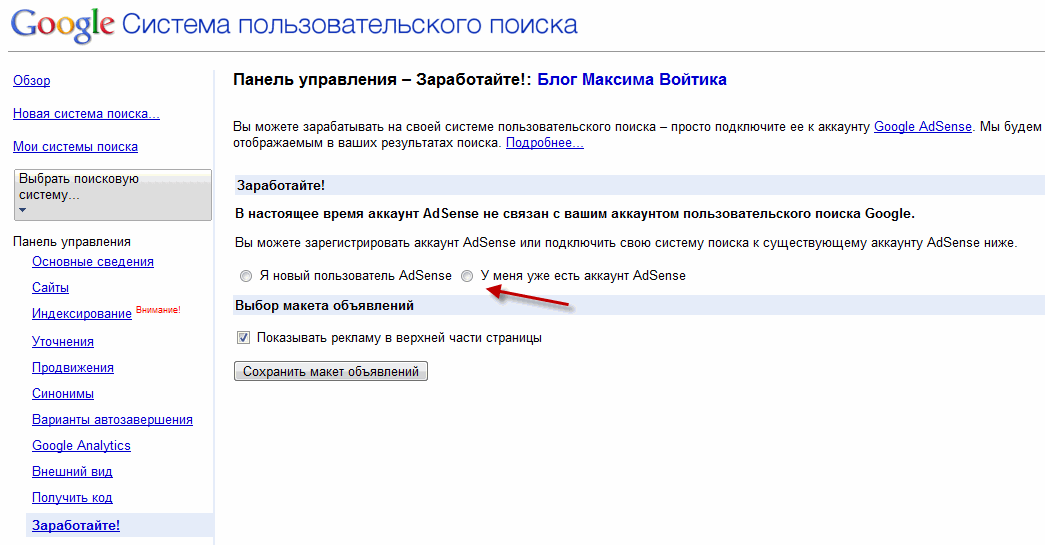
 В зависимости от типа данных специалисты по данным разрабатывают способ обработки этих данных, чтобы предотвратить ложноположительные результаты.
В зависимости от типа данных специалисты по данным разрабатывают способ обработки этих данных, чтобы предотвратить ложноположительные результаты. Мы можем использовать машинное обучение для создания семантической поисковой системы на основе расширенного модуля анализа текста.
Мы можем использовать машинное обучение для создания семантической поисковой системы на основе расширенного модуля анализа текста. Вы можете легко найти различные реализации на GitHub.
Вы можете легко найти различные реализации на GitHub.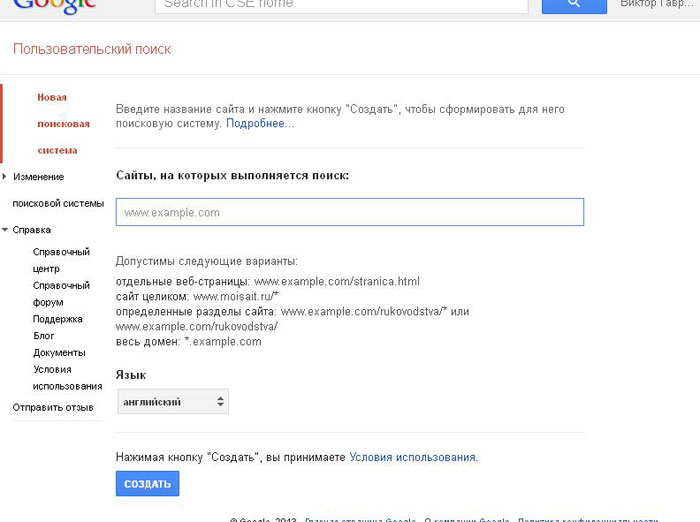 Нечеткое соответствие — когда только часть шаблона соответствует части данных.
Нечеткое соответствие — когда только часть шаблона соответствует части данных.
 С помощью машинного обучения легко анализировать наиболее популярные записи и автоматически выдвигать их наверх, не искажая пользователя или инженера-программиста.
С помощью машинного обучения легко анализировать наиболее популярные записи и автоматически выдвигать их наверх, не искажая пользователя или инженера-программиста.  Обычно рекомендуется отображать список атрибутов, извлеченных из поискового запроса. Но иногда это может быть сложно, так как могут быть сотни различных взаимосвязанных атрибутов.
Обычно рекомендуется отображать список атрибутов, извлеченных из поискового запроса. Но иногда это может быть сложно, так как могут быть сотни различных взаимосвязанных атрибутов.