Механизмы поисковых систем — Поисковые системы в интернете
Сам поиск в интернете, ровно так же как просмотр веб сайтов возможен при помощи интернет обозревателя — браузера. Только после того, как пользователь задал свой запрос в строке поиска, осуществляется непосредственно и сам поиск.
Любая поисковая система содержит программную часть, на которой основан весь поисковой механизм, его называют поисковым движком — это программный комплекс и обеспечивающий возможность поиска информации. После обращению к поисковику, формирования человеком поискового запроса и ввода его в строку поиска, поисковая система генерирует страницу со списком результатов поиска, наиболее релевантные, по мнению поисковика тут располагаются выше.
Релевантность поиска – поиск наиболее отвечающих запросу пользователя материалов и расположение на них гиперссылок на странице выдачи с более точными результатами выше других. Само распределение результатов называется ранжированием сайтов.

Сбору информации в сети способствует уникальный для каждой поисковой системы робот или по-другому бот, обла
дающий так же рядом других синонимов как краулер или паук, а саму работу системы поиска можно разделить на три этапа:
К первому этапу работы поисковой системы можно отнести сканирование сайтов в глобальной сети и сбор на свои собственные серверы копий веб страниц. Это образует огромное количество пока ещё не обработанной и не пригодной информации для поисковой выдачи.
Второй этап работы поисковика сводится к приведению в порядок полученной ранее, на первом этапе информации от сайтов. Производится такая сортировка, которая за наименьшее время будет благоприятствовать тому самому качественному поиску, которого собственно и ждут пользователи от поисковой системы. Этап называют индексацией, это значит, что страницы уже являются подготовленными к выдаче, а актуальная база будет считаться индексом.
Как раз третий этап и обуславливает поисковую выдачу, после приёма запроса от своего к
Поиск в Интернет. Каталоги. Информационно-поисковые системы. Механизмы поиска в Интернет.
ИПС (информационно-поисковая система) – это система, обеспечивающая поиск и отбор необходимых данных в специальной базе с описаниями источников информации (индексе) на основе информационно-поискового языка и соответствующих правил поиска.
Главной задачей любой ИПС является поиск информации релевантной информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска – релевантность.
Релевантность – это соответствие результатов поиска сформулированному запросу.
Далее мы будем, в основном, рассматривать ИПС для всемирной паутины (WWW). Основными показателями ИПС для WWW являются пространственный масштаб и специализация.
По пространственному масштабу ИПС можно разделить на локальные, глобальные, региональные и специализированные. Локальные поисковые системы могут быть разработаны для быстрого поиска страниц в масштабе отдельного сервера.
Региональные ИПС описывают информационные ресурсы определенного региона, например, русскоязычные страницы в Интернете. Глобальные поисковые системы в отличие от локальных стремятся объять необъятное – по возможности наиболее полно описать ресурсы всего информационного пространства сети Интернет.
Кроме того, ИПС также могут специализироваться по поиску различных источников информации, например, документов WWW, файлов, адресов и т.д.
Рассмотрим подробнее основные задачи, которые должны решить разработчики ИПС. Как следует из определения, ИПС для WWW проводят поиск в собственной базе (индексе) с описанием распределенных источников информации.
Следовательно, сначала нужно описать информационные ресурсы и создать индекс. Построение индекса начинается с определения начального набора URL источников информации. Затем проводится процедура индексирования.
Индексирование – описание источников информации и построение специальной базы данных (индекса) для эффективного поиска.
В некоторых информационно-поисковых системах описание источников информации проводится персоналом ИПС, то есть, людьми, которые составляют краткую аннотацию на каждый ресурс. Затем, как правило, проводится сортировка аннотаций по темам (составление тематического каталога). Конечно, описание, составленное человеком, будет совершенно адекватно источнику. Правда, в этом случае процедура описания занимает значительный период времени, поэтому формируемый индекс имеет, как правило, ограниченный объем. Зато поиск в подобной системе можно будет проводить так же легко, как в тематических каталогах библиотек.
В ИПС второго типа процедура описания информационных ресурсов автоматизирована. Для этого разрабатывается специальная программа-робот, которая по определенной технологии обходит ресурсы, описывает их (проводит индексирование) и анализирует ссылки с текущей страницы для расширения области поиска. Как может описать документ программа? Чаще всего просто составляется список слов, которые встречаются в тексте и других частях документа, при этом учитывается частота повторения и местоположение слова, то есть, слову приписывается своеобразный весовой коэффициент в зависимости от его значимости. Например, если слово находится в названии Web-страницы, робот пометит этот факт для себя. Поскольку описание автоматизировано, затраты времени невелики, и индекс может оказаться очень большим по размеру.
Следовательно, следующей задачей для ИПС второго типа является разработка робота-индексировщика. Для поиска в системах данного типа пользователю придется научиться составлять запросы, в простейшем случае состоящие из нескольких слов. Тогда ИПС будет искать в своем индексе документы, в описаниях которых встречаются слова из запроса. Для проведения более качественного поиска необходимо разрабатывать специальный язык запросов для пользователя. В зависимости от особенностей построения модели индекса и поддерживаемого языка запросов разрабатывается механизм поиска и алгоритм сортировки результатов поиска. Поскольку индекс имеет значительный объем, количество найденных документов может оказаться достаточно большим. Следовательно, чрезвычайно важно, как поисковая машина проведет поиск и отсортирует его результаты.
Не последнее значение имеет внешний вид поисковой системы, предстающий перед пользователем, поэтому одной из задач является разработка удобного и красивого интерфейса. Наконец, исключительно важна форма представления результатов поиска, поскольку пользователю необходимо узнать как можно больше о найденном источнике информации, чтобы принять правильное решение о необходимости его посещения.
Для обращения к поисковому серверу пользователь использует стандартную программу-клиент для всемирной паутины, то есть браузер. По адресу домашней страницы ИПС пользователь работает с интерфейсом поисковой системы, который служит для общения пользователя с поисковым аппаратом системы (системой формирования запросов и просмотра результатов поиска).
Существующие интернетовские поисковые механизмы — Безопасность в Интернет
В WEB нет настоящего оглавления или указателя, но есть поисковые механизмы. Они похожи на каталоги карточек или указатели, которые можно найти в WEB. Они используют замысловатые программы для того, чтобы каталогировать десятки миллионов WEB страниц по всему миру. Эти каталоги часто обновляются, и они предоставляются вам в таком виде, чтобы в них можно было осуществлять поиск с помощью поисковых механизмов.
Поисковые механизмы полезны для того, чтобы отслеживать людей, проявляющих активность в Интернете. Если кто-либо послал открытое сообщение, разместил объявление в службе рекламных объявлений на сайте или оставил запрос.
У некоторых провайдеров Белых страниц из предыдущего раздела тоже есть листинги.
Мы сделаем обзор главных поисковых механизмов, но сначала посмотрим, как они работают
Как работают поисковые механизмы
Поисковые механизмы находятся на сайтах. Посетите один, и вы обнаружите формат, в который можно ввести запрос.
Поисковый механизм использует ваш запрос для того, чтобы составить список страниц, удовлетворяющих критериям, указанным в вашем запросе.
Ключевые слова и термины поиска
Пусть термин «запрос» не собьет вас с толку. Нельзя просто напечатать вопрос и получить ответ. Для того чтобы поисковый механизм начал работать, необходимо ввести определенные ключевые слова или словосочетания (иначе называемые терминами поиска).
Ключевое слово — это слово, которое связано с тем, что вы ищете. Когда вы хотите кого-то найти в вашей базе данных имен и адресов, вы вводите фамилию. Точно так же для поиска информации на определенную тему необходимо ввести основное связанное с ней слово.
Например, ключевым словом для поиска информации о жизни мусульман в Российской империи 19 века будет слово «мусульманин» (muslim). Если вы введете его в формат запроса поискового механизма, вы получите листинг из примерно 40 тысяч страниц.
Поисковые механизмы ищут запрошенную вами информацию на основании содержания WEB страниц. Таким образом, если вы запрашиваете поисковый механизм с помощью ключевого слова, вы просите его показать вам все страницы, содержащие указанное слово. Такое слово, как мусульманин, соберет всевозможные страницы — текущие новости, религиозные эссе, личные биографии и так далее.
Зная, что поисковые механизмы смотрят на все содержание каталогизируемых ими страниц, можно сузить область поиска. Чтобы ограничить число попаданий, вам нужно высказаться более конкретно, добавив несколько ключевых слов. В данном случае это может быть «Россия» и «79. Поисковый механизм будет знать, что вам нужны только те страницы, которые содержат слова «мусульманин», «Россия» и «79». В таком случае вы получите не такое большое количество страниц и сможете просмотреть их вручную, чтобы найти то, что вам нужно.
Поисковые словосочетания
Многие поисковые механизмы позволяют использовать словосочетания в качестве терминов поиска. (На этом пути может поджидать разочарование. Не у всех одинаковый образ мышления, поэтому словосочетание, которое, как вы полагаете, должно быть включено в любой документ по данной теме, может вообще отсутствовать.) Например, если вы введете «Жизнь мусульман в Российской империи 19 века», вы увидите список страниц, содержащих это словосочетание слово в слово, то есть именно эти слова и именно в этом порядке.
Как сделать, чтобы поисковый механизм работал
Каждый поисковый механизм работает по-своему. Они расходятся в том, как надо вводить ключевые слова, словосочетания и так далее. Например, в AltaVista требуется, чтобы вы вводили несколько ключевых слов, связанных знаком «и», то есть +Muslim +Russian +19th.
Этот набор ключевых слов сообщает AltaVista, что вы хотите посмотреть все страницы WEB, содержащие Muslim И Russian И 19th. Такой поиск известен также под названием «поиск с логическим И» (AND search). Без знака + AltaVista
поймет ваш запрос как «Покажите мне все страницы WEB, включающие любое из этих слов», то есть Muslim ИЛИ Russian ИЛИ 19th. Такой подход, называемый «поиск с логическим ИЛИ» (OR search), принесет вам сотни тысяч страниц WEB. Другие поисковые механизмы могут потребовать, чтобы вы ввели несколько ключевых слов, разделенных только пробелами.
Управление поиском
В некоторых поисковых механизмах есть кнопки или возможности выделения, позволяющие выбрать между «И-поиском» и «ИЛИ-поиском».
Список попаданий
Результатом поиска является список попаданий (hit list) WEB страниц, временное пользовательское меню в формате гипертекста. Мышью можно выбрать элемент (URL). Если описание или контекст, сопровождающий URL в списке попаданий, недостаточно подробен, большинство поисковых механизмов предлагают разные варианты показа элементов списка — с объяснениями или без, а если с объяснениями, то с краткими или многословными.
Некоторые поисковые механизмы предлагают усовершенствованные версии поисков «И» и «ИЛИ», применяющие булевскую логику. С их помощью можно указывать знаки, такие как И, ИЛИ или даже НИ (NOR), чтобы включать документы с данным словосочетанием, но без данного слова.
Результаты по порядку
Некоторые поисковые механизмы, такие как Lycos, не производят поисков «И», но интерпретируют вхождение из нескольких ключевых слов как поиск «ИЛИ», Поисковые механизмы, работающие таким образом, однако, обычно предоставляют вам список, где результаты расставлены по порядку, то есть страницы, включающие все три слова, перечислены первыми, затем — страницы с двумя из трех слов и так далее.
Крупнейшие поисковые механизмы
В WEB есть несколько сотен поисковых механизмов. Многие избыточны, поскольку предлагают такие же данные, как и другие. Следующий список показывает наиболее популярные и эффективные инструменты общего поиска в WEB.
- AltaVista;
- Excite;
- Hotbot;
- InfoSeek;
- Lycos;
- Magellan;
- GNets Search.Com;
- Webcrawler;
- Yahoo!.
Некоторые поисковые механизмы, например Yahoo!, каталогируют сайты и страницы в так называемом иерархическом указателе (hierarchical index). (Другие, такие как Lycos, используют это для каталогов.) Иерархический указатель состоит из элементов, разбитых (нередко на основании личного мнения) на разные группы, или иерархии. В содержании страниц этих каталогов можно осуществлять поиск, но скорее по терминам указателя или группам, чем собственно по содержанию. Это означает, что в списке попаданий не обязательно будет именно тот термин, который вы использовали.
Стратегии поиска в Web
Как уже отмечалось, поисковые механизмы каталогизируют содержание посещаемых ими страниц (за исключением тех поисковых сайтов, где содержание организовано по родственным группам, с указателями, составленными людьми). Таким образом, вы можете использовать их для того, чтобы находить людей разными способами. Электронные адреса, запущенные через общий поисковый механизм, часто приносят личные или деловые страницы, на которых еще больше полезной информации. Электронные адреса могут также появляться в книгах отзывов на WEB страницах, BBS, рубрицированных объявлениях и статьях в Usenet. Имейте также в виду, что словосочетания, специфический лексикон или правописание, или даже характерные опечатки могут быть использованы для того, чтобы проследить искомое лицо.
Будьте точны
Если у вас есть только электронный адрес, можно осуществлять поиск с помощью целого адреса или просто ID в начале адреса. Если у вас есть имя, используйте его в качестве точного термина поиска. («Точный» означает, что вы должны приказать поисковому механизму находить все слова в том порядке, в котором вы их предоставляете, желательно с учетом заглавных букв.)
Если вы ищете кого-то на основании часто используемого словосочетания, особенностей орфографии или характера печатания, можно ввести это словосочетание или другой термин как точный. Я считаю AltaVista одним из самых лучших поисковых механизмов с этой точки зрения, потому что он ищет точные совпадения со всем, что заключено в кавычки. Это также относится к специфическому использованию заглавных букв, «например Такому.»
Сужение поиска
Если ваш поиск принес слишком много попаданий, сузьте его, добавив ожидаемое слово — может быть, сокращенное название штата, где находится искомое лицо, или какое-нибудь необычное слово, которое это лицо использует в своей электронной почте или открытых сообщениях.
Обнаружение скрытой информации
Когда вы посещаете страницы из списка попаданий, но не видите там того, что ищете, не сдавайтесь. Используйте поисковые функции вашего браузера (выберите Find. в меню Edit), чтобы осуществить поиск в содержании страниц для вашего поискового термина, на случай если вы его пропустили.
Также посмотрите код источника страницы. Поисковые механизмы иногда каталогизируют слова в источнике кода, который не появляется, когда вы просматриваете страницу обычным способом. Также исследуйте все возможные ссылки на страницу; некоторые поисковые механизмы каталогизируют страницу, потому что она содержит ссылки на страницу, которая, в свою очередь, содержит поисковый термин, который вы ищете.
Поиск в телеконференциях Usenet
Как я уже отмечал, каждый, кто активен в Сети, скорее всего посылал статьи в телеконференции Usenet. Спамеры часто начинают с телеконференций и заменяют свои регистрационные имена, когда переключаются на рассылку почтовой макулатуры. Завзятые спорщики, борцы за идею и даже сетевые психопаты, — то есть все те же люди, которые в один прекрасный день могут приняться за вас, — пишут в телеконференциях. Принимая это во внимание, телеконференции могут стать настоящей золотой жилой информации, когда вы пытаетесь кого-то проследить.
Осуществление поиска в телеконференциях Usenet может на первый взгляд показаться безнадежным делом. Начать с того, что существует около 20 тысяч телеконференций. Внутри большинства групп ежедневно рассылаются сотни новых статей, причем старые статьи уходят. Сам объем текста, который нужно просмотреть, исключает всяческую возможность поиска вручную.
К счастью, нам нет необходимости искать вручную. Как отмечалось выше, некоторые поисковые механизмы могут быть направлены на поиск в телеконференциях Usenet. Это:
- AltaVista
- Excite
- Hotbot
- InfoSeek
Они бесценны, если вам нужно просмотреть текущую (или более раннюю) дискуссию на данную тему. Используйте их так же, как при осуществлении поиска в WEB. Единственная разница в том, что поиск нужно перенаправить в телеконференции.
Общие поисковые механизмы осуществляют поиск только в текущих статьях Usenet.
Безусловно, лучшим поисковым механизмом для телеконференций является Deja Neivs, он является базой данных всех статей в телеконференциях с начала 1990-х годов и по сей день.
Преимущество Deja News в том, что в его распоряжении больше статей телеконференций, чем у любого другого архива или указателя.
С течением времени в базах данных Deja News будет находиться практически все, разосланное в телеконференции Usenet со дня их появления на свет в 1979 году. Что касается поиска людей, статей за пять лет больше чем достаточно. Если вы ищете кого-то, кто писал что-либо в телеконференции, он несомненно сделал это за последние пять лет.
6 Принципы работы метапоисковых систем. Механизмы поиска в интернет. Язык запросов.
При работе метапоисковой системы из полученного от поисковых систем множества документов необходимо выделить наиболее релевантные, то есть соответствующие запросу пользователя.
Простейшие метапоисковые системы реализуют стандартный подход, представленный на рис. 1. В таких системах анализ полученных описаний документов не производится, что может поставить нерелевантные документы, идущие первыми в одной поисковой системе, выше релевантных в другой, чем существенно понизить качество самого поиска.
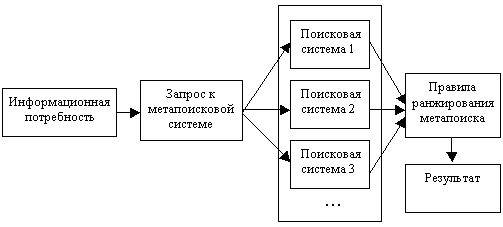
Рис.1 Стандартная метапоисковая система
При разработке следующего поколения метапоисковых систем были учтены недостатки, присущие стандартным метапоисковым системам. Были созданы системы с возможностью выбора тех поисковых машин, в которых, по мнению пользователя, он с большей вероятностью может найти то, что ему нужно (рис. 2)
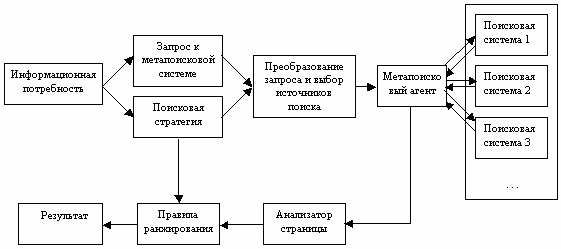
Рис. 2. Следующее поколение метапоисковых систем
Кроме этого, такой подход позволяет уменьшить используемые вычислительные ресурсы метапоискового сервера, не перегружая его слишком большим объемом ненужной информации и серьезно сэкономить трафик. Здесь нужно отметить, что в любой системе метапоиска наиболее узким местом в основном является пропускная способность канала передачи данных, так как обработка страниц с результатами поиска, полученными от нескольких десятков поисковых серверов не является слишком трудоемкой операцией, потому что затраты времени на обработку информации на порядки меньше времени прихода страниц, запрошенных у поисковых серверов.
Как пример систем, имеющих подобную организацию, можно назвать Profusion, Ixquick, SavvySearch, MetaPing.
Примером метапоисковой системы является Nigma (Нигма. РФ) — российская интеллектуальная метапоисковая система.
Программа ускоренного поиска – это программа с возможностями метапоисковой системы, устанавливаемая на локальном компьютере.
Принципиальным отличием метапоисковых систем и программ ускоренного поиска от ИПС является отсутствие своего собственного индекса. Зато они превосходно умеют использовать результаты работы других поисковых систем.
Механизмы поиска
Обобщенная технология поиска состоит из следующих этапов:
Пользователь формулирует запрос
Система проводит поиск документов (или их поисковых образов)
Пользователь получает результат (сведения о документах)
Пользователь совершенствует или реформирует запрос
Организация нового поиска…
Как правило, поисковые машины поддерживают два режима: режим простого поиска и режим расширенного поиска. Рассмотрим обобщенные возможности.
Формирования запроса в режиме простого поиска. Можно просто вводить через пробел одно или несколько слов; поиск слов со всевозможными окончаниями моделируется символом * в конце слова. Многие системы позволяют искать словосочетания или фразу, для этого необходимо ее заключить в кавычки. Возможно обязательное включение или исключение определенных слов.
Основная проблема поиска по примитивно составленному запросу (в виде перечисления ключевых слов) заключается в том, что поисковая машина найдет все страницы, на которых указанные слова встречаются в любой части документа. Как правило, количество найденных страниц будет слишком велико.
Для улучшения качества поиска в режиме простого поиска допустимо использование логических операторов и операторов, позволяющих ограничить область поиска, а также выбор определенной категории документов из представленного списка.
Многие поисковые системы включают в свой язык составления запросов специальные операторы, позволяющие проводить поиск в определенных зонах документа, например, в его заголовке, или искать документ по известной части его адреса.
Режим расширенного или детального запроса в разных системах реализован индивидуально, но чаще всего это бланк, в котором упомянутые операторы и ключевые элементы реализуются простой установкой соответствующих флажков или выбором параметров из списка.
Ниже в качестве примера приведены сведения из раздела помощь поисковой системы Yandex: окно расширенного поиска, язык запросов, искать в найденном.
Искать в найденном Если в результате запроса Яндекс нашел много документов, но по более широкой теме, чем вам хочется, вы можете сократить этот список, уточнив запрос. Еще один вариант — включить флажок в найденном в форме поиска, задать дополнительные ключевые слова, и следующий поиск будет вестись только по тем документам, которые были отобраны в предыдущем поиске.
6 Принципы работы метапоисковых систем. Механизмы поиска в интернет. Язык запросов.
При работе метапоисковой системы из полученного от поисковых систем множества документов необходимо выделить наиболее релевантные, то есть соответствующие запросу пользователя.
Простейшие метапоисковые системы реализуют стандартный подход, представленный на рис. 1. В таких системах анализ полученных описаний документов не производится, что может поставить нерелевантные документы, идущие первыми в одной поисковой системе, выше релевантных в другой, чем существенно понизить качество самого поиска.

Рис.1 Стандартная метапоисковая система
При разработке следующего поколения метапоисковых систем были учтены недостатки, присущие стандартным метапоисковым системам. Были созданы системы с возможностью выбора тех поисковых машин, в которых, по мнению пользователя, он с большей вероятностью может найти то, что ему нужно (рис. 2)

Рис. 2. Следующее поколение метапоисковых систем
Кроме этого, такой подход позволяет уменьшить используемые вычислительные ресурсы метапоискового сервера, не перегружая его слишком большим объемом ненужной информации и серьезно сэкономить трафик. Здесь нужно отметить, что в любой системе метапоиска наиболее узким местом в основном является пропускная способность канала передачи данных, так как обработка страниц с результатами поиска, полученными от нескольких десятков поисковых серверов не является слишком трудоемкой операцией, потому что затраты времени на обработку информации на порядки меньше времени прихода страниц, запрошенных у поисковых серверов.
Как пример систем, имеющих подобную организацию, можно назвать Profusion,Ixquick,SavvySearch,MetaPing.
Примером метапоисковой системы является Nigma (Нигма. РФ)— российскаяинтеллектуальнаяметапоисковаясистема.
Программа ускоренного поиска – это программа с возможностями метапоисковой системы, устанавливаемая на локальном компьютере.
Принципиальным отличием метапоисковых систем и программ ускоренного поиска от ИПС является отсутствие своего собственного индекса. Зато они превосходно умеют использовать результаты работы других поисковых систем.
3.3 Механизмы поиска
Обобщенная технология поиска состоит из следующих этапов:
Пользователь формулирует запрос
Система проводит поиск документов (или их поисковых образов)
Пользователь получает результат (сведения о документах)
Пользователь совершенствует или реформирует запрос
Организация нового поиска…
Как правило, поисковые машины поддерживают два режима: режим простого поиска и режим расширенного поиска. Рассмотрим обобщенные возможности.
Формирования запроса в режиме простого поиска. Можно просто вводить через пробел одно или несколько слов; поиск слов со всевозможными окончаниями моделируется символом * в конце слова. Многие системы позволяют искать словосочетания или фразу, для этого необходимо ее заключить в кавычки. Возможно обязательное включение или исключение определенных слов.
Основная проблема поиска по примитивно составленному запросу (в виде перечисления ключевых слов) заключается в том, что поисковая машина найдет все страницы, на которых указанные слова встречаются в любой части документа. Как правило, количество найденных страниц будет слишком велико.
Для улучшения качества поиска в режиме простого поиска допустимо использование логических операторов и операторов, позволяющих ограничить область поиска, а также выбор определенной категории документов из представленного списка.
Многие поисковые системы включают в свой язык составления запросов специальные операторы, позволяющие проводить поиск в определенных зонах документа, например, в его заголовке, или искать документ по известной части его адреса.
Режим расширенного или детального запроса в разных системах реализован индивидуально, но чаще всего это бланк, в котором упомянутые операторы и ключевые элементы реализуются простой установкой соответствующих флажков или выбором параметров из списка.
Ниже в качестве примера приведены сведения из раздела помощь поисковой системы Yandex: окно расширенного поиска, язык запросов, искать в найденном.
Искать в найденном Если в результате запроса Яндекс нашел много документов, но по более широкой теме, чем вам хочется, вы можете сократить этот список, уточнив запрос. Еще один вариант — включить флажок в найденном в форме поиска, задать дополнительные ключевые слова, и следующий поиск будет вестись только по тем документам, которые были отобраны в предыдущем поиске.

Памятка по использованию языка запросов
Пример | Значение |
«К нам на утренний рассол» | Слова идут подряд в точной форме |
«Прибыл * посол» | Пропущено слово в цитате |
полгорбушки & мосол | Слова в пределах одного предложения |
снаряжайся && добудь | Слова в пределах одного документа |
глухаря | куропатку | кого-нибудь | Поиск любого из слов |
не смогешь << винить | Неранжирующее «и»: выражение после оператора не влияет на позицию документа в выдаче |
я должон /2 казнить | Расстояние в пределах двух слов в любую сторону (то есть между заданными словами может встречаться одно слово) |
государственное дело && /3 улавливаешь нить | Расстояние в 3 предложения в любую сторону |
нешто я ~~ пойму | Исключение слова пойму из поиска |
при моем /+2 уму | Расстояние в пределах двух слов в прямом порядке |
чай ~ лаптем | Поиск предложения, где слово чай встречается без слова лаптем |
щи /(-1 +2) хлебаю | Расстояние от одного слова в обратном порядке до двух слов в прямом |
!Соображаю !что !чему | Слова в точной форме с заданным регистром |
получается && (+на | !мне) | Скобки формируют группы в сложных запросах |
!!политика | Словарная форма слова |
title:(в стране) | Поиск по заголовкам документов |
url:ptici.narod.ru/ptici/kuropatka.htm | Поиск по URL |
беспременно inurl:vojne | Поиск с учетом фрагмента URL |
host:lib.ru | Поиск по хосту |
rhost:ru.lib.* | Поиск по хосту в обратной записи |
site:http://www.lib.ru/PXESY/FILATOW | Поиск по всем поддоменам и страницам заданного сайта |
mime:pdf | Поиск по одному типу файлов |
lang:en | Поиск с ограничением по языку |
domain:ru | Поиск с ограничением по домену |
date:200712* | Поиск с ограничением по дате |
государственное дело && /3 улавливаешь нить | Расстояние в 3 предложения в любую сторону |
нешто я ~~ пойму | Исключение слова пойму из поиска |
Интересной возможностью является поиск документов в сети, ссылающиеся на страницу с указанным вами адресом (URL). Таким образом, можно найти в сети страницы, на которых есть ссылки на ваш Web-сайт. Некоторые системы позволят ограничить область поиска внутри указанного домена.
В качестве дополнительных специальных операторов можно выделить:
Операторы поиска документов с определенным графическим файлом;
Операторы ограничения по дате искомых страниц;
Операторы близости между словами;
Операторы учета словоформы;
Операторы сортировки результатов (по релевантности, свежести, старости).
Следует заметить, что, к великому сожалению, на сегодняшний день не существует стандарта на количество и синтаксис поддерживаемых операторов для различных поисковых систем. Попытки разработать стандарт на синтаксис поддерживаемых операторов предпринимаются, поэтому есть надежда на то, что разработчики поисковых систем позаботятся об удобстве пользователей. На данном этапе развития средств поиска, пользователь, обращаясь к определенной поисковой системе, непременно должен в первую очередь ознакомиться с ее правилами составления запросов. Как правило, на домашней странице будет обязательно присутствовать ссылка Помощь (Help), по которой вы перейдете к справочной информации.
Различные поисковые системы описывают разное количество источников информации в Интернет. Поэтому нельзя ограничиваться поиском только в одной из указанных поисковых системах.
Рассмотрим способы представления результатов поиска в поисковых машинах.
Чаще всего количество найденных документов превышает несколько десятков, а в отдельных случаях может достигать сотен тысяч! Поэтому в качестве формы выдачи составляется список документов по 5-10-15 единиц на странице с возможностью перехода к следующей порции внизу страницы. Обязательно указывается заголовок и URL(адрес) найденного документа, иногда система указывает в процентах степень релевантности документа.
В описании документа чаще всего содержится несколько первых предложений или выдержки из текста документа с выделением ключевых слов. Как правило, указана дата обновления (проверки) документа, его размер в килобайтах, некоторые системы определяют язык документа и его кодировку (для русскоязычных документов).
Что можно делать с полученными результатами? Если название и описание документа соответствует вашим требованиям, можно немедленно перейти к его первоисточнику по ссылке. Это удобнее делать в новом окне, чтобы иметь возможность далее анализировать результаты выдачи. Многие поисковые системы позволяют проводить поиск в найденных документах, причем вы можете уточнить ваш запрос введением дополнительных терминов.
Если интеллектуальность системы высока, вам могут предложить услугу поиска похожих документов. Для этого вы выбираете особо понравившийся документ и указываете его системе в качестве образца для подражания.
Однако, автоматизация определение похожести – весьма нетривиальная задача, и зачастую эта функция работает неадекватно вашим надеждам. Некоторые поисковики позволяют провести пересортировку результатов. Для экономии вашего времени можно сохранить результаты поиска в виде файла на локальном диске для последующего изучения в автономном режиме.
Компьютерная графика. Воспроизведение цвета; параметры изображений на экране и при печати.
У практики отображения информации в графическом виде много синонимов, но в последнее время чаще всего используются два — визуализация данных и инфографика. Визуализация даных — это отображение больших массивов числовой и семантической информации в виде графических объектов. Продукты визуализации данных предназначены для дальнейшей интеграции в информационные системы и системы поддержки принятия решений.
Визуализация данных находит применение в самых разных сферах человеческой деятельности. Для примера назовем медицину (компьютерная томография), научные исследования (визуализация строения вещества, векторных полей и других данных), моделирование тканей и одежды, опытно-конструкторские разработки, статистика и отчеты и др.
КОМПЬЮТЕРНАЯ ГРАФИКА
Существует специальная область информатики, изучающая методы и средства создания и обработки изображений с помощью программно-аппаратных вычислительных комплексов, – компьютерная графика, получившая развитие в середине 50-х годов для больших ЭВМ, применявшихся в научных и военных исследованиях. С тех пор графический способ отображения данных стал неотъемлемой принадлежностью подавляющего числа компьютерных систем, в особенности персональных. Графический интерфейс пользователя сегодня является стандартом для программного обеспечения разных классов, начиная с операционных систем.
Графический редактор — программа (или пакет программ), позволяющая создавать и редактировать двух- и трёхмерные изображения с помощью компьютера. Современные графические редакторы изображений используются как программы для рисования с нуля, и как программы для редактирования фотографий.
В зависимости от способа формирования изображений компьютерную графику принято подразделять на растровую, векторную и фрактальную.
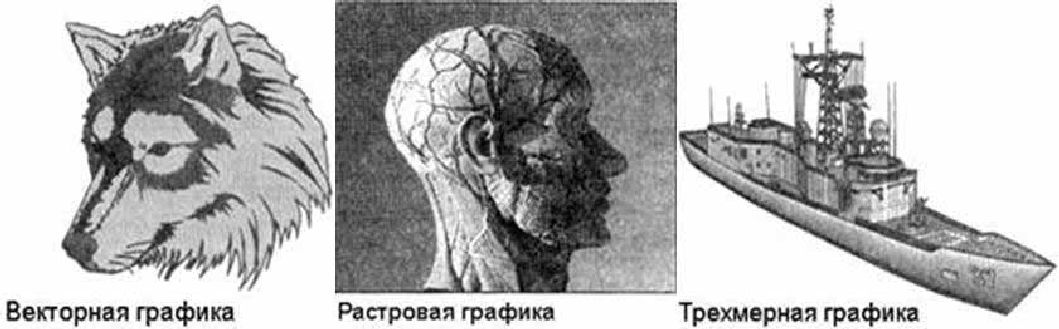
Рис. 1. Различные виды графики.
Отдельным предметом считается трехмерная (3D) графика, изучающая приёмы и методы построения объемных моделей объектов в виртуальном пространстве. Как правило, в ней сочетаются векторный и растровый способы формирования изображений.
Особенности цветового охвата характеризуют такие понятия, как чёрно-белая и цветная графика. На специализацию в отдельных областях указывают названия некоторых разделов: инженерная графика, научная графика, Web-графика, компьютерная полиграфия и прочие.
На стыке компьютерных, телевизионных и кинотехнологий зародилась и стремительно развивается новая область компьютерной графики и анимации.
Компьютерная графика является одной из наиболее бурно развивающихся отраслей информатики и во многих случаях выступает «локомотивом», тянущим за собой всю компьютерную индустрию.
Передача цвета
Для передачи и хранения цвета в компьютерной графике используются различные формы его представления. В общем случае цвет представляет собой набор чисел, координат в некоторой цветовой системе.
Стандартные способы хранения и обработки цвета в компьютере обусловлены свойствами человеческого зрения. Наиболее распространены системы RGB (Red-красный, Green — зеленый, Blue — синий) для дисплеев и CMYK для работы в типографском деле. Иногда используется система с большим, чем три, числом компонент. Кодируется спектр отражения или испускания источника, что позволяет более точно описать физические свойства цвета. Такие схемы используются в фотореалистичном трёхмерном рендеринге.
|

Рис. 2. Система цветопередачи RGB. Рис. 3. Схема субтрактивного синтеза в CMYK
Растровая графика. Векторная графика. Достоинства и недостатки растровой и векторной графики.
Растровая графика — прямоугольная матрица, состоящая из множества очень мелких неделимых точек (пикселей). Каждый такой пиксель может быть окрашен в какой-нибудь один цвет. Например, монитор, с разрешением 1024х768 пикселей имеет матрицу, содержащую 786432 пикселей, каждый из которых (в зависимости от глубины цвета) может иметь свой цвет. Т.к. пиксели имеют очень маленький размер, то такая мозаика сливается в единое целое и при хорошем качестве изображения (высокой разрешающей способности) человеческий глаз не видит «пикселизацию» изображения.
При уменьшении изображения происходит обратный процесс — компьютер просто «выбрасывает» лишние пиксели. Отсюда главный минус растровой графики — зависимость качества изображение от его размеров.
Растровую графику следует применять для изображений с фотографическим качеством, на котором присутствует множество цветовых переходов. Размер файла, хранящего растровое изображение зависит от двух факторов: размера изображения; от глубины цвета изображения (чем больше цветов представлено на картинке, тем больше размер файла).


Рис. 3. Изменение растровой картинки при увеличении.
Для растровых изображений, состоящих из точек, особую важность имеет понятие разрешения, выражающее количество точек, приходящихся на единицу длины. При этом следует различать: разрешение оригинала; разрешение экранного изображения; разрешение печатного изображения.
Разрешение оригинала. Разрешение оригинала при печати измеряется в точках на дюйм (dots per inch – dpi) и зависит от требований к качеству изображения и размеру файла, способу оцифровки и создания исходной иллюстрации, избранному формату файла и другим параметрам. Чем выше требование к качеству, тем выше должно быть разрешение оригинала.
Разрешение экранного изображения. Для экранных копий изображения элементарная точка растра называется пикселом. Размер пиксела варьируется в зависимости от выбранного экранного разрешения (из диапазона стандартных значений), разрешение оригинала и масштаб отображения. Мониторы для обработки изображений с диагональю 20–21 дюйм обеспечивают стандартные экранные разрешения 640х480, 800х600, 1024х768,1280х1024,1600х1200,1600х1280, 1920х1200, 1920х1600 точек. Расстояние между соседними точками люминофора у качественного монитора составляет 0,22–0,25 мм. Для экранной копии достаточно разрешения 72 dpi, для распечатки на цветном или лазерном принтере 150–200 dpi, для вывода на фотоэкспонирующем устройстве 200–300 dpi. Обычно при распечатке величина разрешения оригинала должна быть в 1,5 раза больше, чем линиатура растра устройства вывода.
Интенсивность тона (так называемую светлоту) принято подразделять на 256 уровней. Большее число градаций не воспринимается зрением человека и является избыточным. Меньшее число ухудшает восприятие изображения (минимально допустимым для качественной полутоновой иллюстрации принято значение 150 уровней). Нетрудно подсчитать, что для воспроизведения 256 уровней тона достаточно иметь размер ячейки растра 256=16х16 точек.
Связь между параметрами изображения и размером файла. Средствами растровой графики принято иллюстрировать работы, требующие высокой точности в передаче цветов и полутонов. Однако размеры файлов растровых иллюстраций стремительно растут с увеличением разрешения. Фотоснимок, предназначенный для домашнего просмотра (стандартный размер 10х15 см, оцифрованный с разрешением 200-300 dpi, цветовое разрешение 24 бита), занимает в формате TIFF с включенным режимом сжатия около 4 Мбайт. Оцифрованный с высоким разрешением слайд занимает 45-50 Мбайт. Цветоделенное цветное изображение формата А4 занимает 120-150 Мбайт.
Масштабирование растровых изображений. Одним из недостатков растровой графики является так называемая пикселизация изображений при их увеличении (если не приняты специальные меры). Раз в оригинале присутствует определенное количество точек, то при большем масштабе увеличивается и их размер, становятся заметны элементы растра, что искажает саму иллюстрацию. Для противодействия пикселизации принято заранее оцифровывать оригинал с разрешением, достаточным для качественной визуализации при масштабировании. Другой приём состоит в применении стохастического растра, позволяющего уменьшить эффект пикселизации в определенных пределах. Наконец, при масштабировании используют метод интерполяции, когда увеличение размера иллюстрации происходит не за счет масштабирования точек, а путем добавления необходимого числа промежуточных точек.
Некоторый класс растровых графических редакторов предназначен не для создания изображений «с нуля», а для обработки готовых рисунков с целью улучшения их качества и реализации творческих идей. К таким программам, в частности, относятся Adobe Photoshop, Photostyler, Picture Publisher и др. Исходная информация для обработки на компьютере может быть получена разными путями: сканированием 1т цветной иллюстрации, загрузкой изображения, созданного в другом редакторе, или вводом изображения от цифровой фото- или видеокамеры.
Ве́кторная гра́фика — использование геометрических примитивов, таких как точки, линии, сплайны и многоугольники, для представления изображений в компьютерной графике. Термин используется в противоположность к растровой графике, которая представляет изображения как матрицу пикселей (точек).
Векторная графика описывает изображение с помощью математических формул. Основное преимущество векторной графики состоит в том, что при изменении масштаба изображения оно не теряет своего качества. Отсюда следует и ещё одно преимущество — при изменении размеров изображения не изменяется размер файла.
Если в растровой графике базовым элементом изображения является точка, то в векторной графике – линия. Линия описывается математически как единый объект, и потому объем данных для отображения объекта средствами векторной графики существенно меньше, чем в растровой графике.
Линия – элементарный объект векторной графики. Как и любой объект, линия обладает свойствами: формой (прямая, кривая), толщиной, цветом, начертанием (сплошная, пунктирная). Замкнутые линии приобретают свойство заполнения. Охватываемое ими пространство может быть заполнено другими объектами (текстуры, карты) или выбранным цветом. Простейшая незамкнутая линия ограничена двумя точками, именуемыми узлами. Узлы также имеют свойства, параметры которых влияют на форму конца линии и характер сопряжения с другими объектами. Все прочие объекты векторной графики составляются из линий. Например, куб можно составить из шести связанных прямоугольников, каждый из которых, в свою очередь, образован четырьмя связанными линиями. Возможно, представить куб и как двенадцать связанных линий, образующих ребра.
Рассмотрим подробнее способы представления различных объектов в векторной графике.
Точка. Этот объект на плоскости представляется двумя числами (х, у), указывающими его положение относительно начала координат.
Прямая линия. Ей соответствует уравнение y=kx+b. Указав параметры k и b, всегда можно отобразить бесконечную прямую линию в известной системе координат, то есть для задания прямой достаточно двух параметров.
Отрезок прямой. Он отличается тем, что требует для описания ещё двух параметров – например, координат x1 и х2 начала и конца отрезка.
Кривая второго порядка. К этому классу кривых относятся параболы, гиперболы, эллипсы, окружности, то есть все линии, уравнения которых содержат степени не выше второй. Кривая второго порядка не имеет точек перегиба.
Прямые линии являются всего лишь частным случаем кривых второго порядка. Формула кривой второго порядка в общем виде может выглядеть, например, так:
x2+a1y2+a2xy+a3x+a4y+a5=0.
Таким образом, для описания бесконечной кривой второго порядка достаточно пяти параметров. Если требуется построить отрезок кривой, понадобятся еще два параметра.

Рис. 4. Объекты векторной графики
Программные средства для работы с векторной графикой предназначены для создания иллюстраций и в меньшей степени для их обработки. Такие средства широко используют в рекламных агентствах, дизайнерских бюро, редакциях и издательствах. Оформительские работы, основанные на применении шрифтов и простейших геометрических элементов, решаются средствами векторной графики проще. Имеются примеры высокохудожественных произведений, созданных средствами векторной графики, но они скорее исключение, чем правило.
В векторной графике основным элементом изображения является линия, при этом не важно, прямая это линия или кривая. В векторной графике объём памяти, занимаемый линией, не зависит от размеров линии, поскольку линия представляется в виде формулы, а точнее говоря, в виде нескольких параметров. Чтобы ни делали с этой линией, меняются только её параметры, хранящиеся в ячейках памяти. Количество же ячеек остается неизменным для любой линии. Линия – это элементарный объект векторной графики. Все, что есть в векторной иллюстрации, состоит из линий. Простейшие объекты объединяются в более сложные, например, объект четырехугольник можно рассматривать как четыре связанные линии, а объект куб еще более сложен: его можно рассматривать либо как двенадцать связанных линий, либо как шесть связанных четырехугольников. Из-за такого подхода векторную графику часто называют объектно-ориентированной графикой.
Объекты векторной графики хранятся в памяти в виде набора параметров, но на экран все изображения все равно выводятся в виде точек. Перед выводом на экран каждого объекта программа производит вычисления координат экранных точек в изображении объекта, поэтому векторную графику иногда называют вычисляемой графикой. Аналогичные вычисления производятся и при выводе объектов на принтер.
Таким образом, выбор растрового или векторного формата зависит от целей и задач работы с изображением. Если нужна фотографическая точность цветопередачи, то предпочтительнее растр. Логотипы, схемы, элементы оформления удобнее представлять в векторном формате. Понятно, что и в растровом и в векторном представлении графика (как и текст) выводятся на экран монитора или печатное устройство в виде совокупности точек. В Интернете графика представляется в одном из растровых форматов, понимаемых броузерами без установки дополнительных модулей – GIF, JPG, PNG.
Без дополнительных плагинов (дополнений) наиболее распространенные броузеры понимают только растровые форматы – .gif, .jpg и .png (последний пока мало распространен). На первый взгляд, использование векторных редакторов становится неактуальным. Однако большинство таких редакторов обеспечивают экспорт в .gif или .jpg с выбираемым Вами разрешением. А рисовать начинающим художникам проще именно в векторных средах – если рука дрогнула и линия пошла не туда, получившийся элемент легко редактируется. При рисовании в растровом режиме Вы рискуете непоправимо испортить фон.
Плаги́н — независимо компилируемый программный модуль, динамически подключаемый к основной программе, предназначенный для расширения и/или использования её возможностей. Также может переводиться как «модуль». Плагины обычно выполняются в виде разделяемых библиотек.
Из-за описанных выше особенностей представления изображения, для каждого типа приходится использовать отдельный графический редактор – растровый или векторный. Разумеется, у них есть общие черты – возможность открывать и сохранять файлы в различных форматах, использование инструментов с одинаковыми названиями (карандаш, перо и т.д.) или функциями (выделение, перемещение, масштабирование и т.д.), выбирать нужный цвет или оттенок… Однако принципы реализации процессов рисования и редактирования различны и обусловлены природой соответствующего формата. Так, если в растровых редакторах говорят о выделении объекта, то имеют в виду совокупность точек в виде области сложной формы. Процесс выделения очень часто является трудоемкой и кропотливой работой. При перемещении такого выделения появляется«дырка». В векторном же редакторе объект представляет совокупность графических примитивов и для его выделения достаточно выбрать мышкой каждый из них. А если эти примитивы были сгруппированы соответствующей командой, то достаточно «щелкнуть» один раз в любой из точек сгруппированного объекта. Перемещение выделенного объекта обнажает нижележащие элементы.
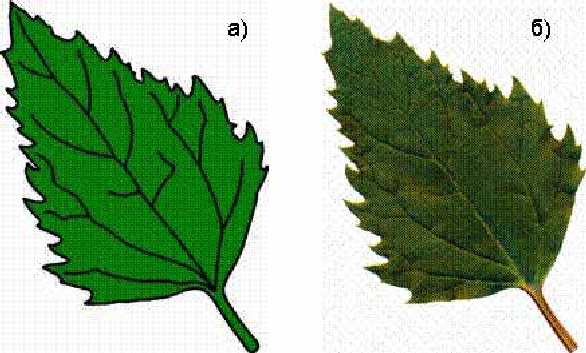
Рис. 5. Пример векторного (а) и растрового (б) изображений
Тем не менее, существует тенденция к сближению. Большинство современных векторных редакторов способны использовать растровые картинки в качестве фона, а то и переводить в векторный формат части изображения встроенными средствами (трассировка). Причём обычно имеются средства редактирования загруженного фонового изображения хотя бы на уровне различных встроенных или устанавливаемых фильтров.
Форматы графических данных. Графические редакторы.
В компьютерной графике применяют три десятка форматов файлов для хранения изображений. Но лишь часть из них стала стандартом. Несовместимые форматы имеют файлы растровых, векторных, трехмерных изображений, хотя существуют форматы, позволяющие хранить данные разных классов. Многие приложения ориентированы на собственные специфические форматы, перенос их файлов в другие программы вынуждает использовать специальные фильтры или экспортировать изображения в стандартный формат.
TIFF (Tagged Image File Format). Формат предназначен для хранения растровых изображений высокого качества (расширение имени файла .TIF). Относится к числу широко распространенных, отличается переносимостью между платформами (IBM PC и Apple Macintosh), обеспечен поддержкой со стороны большинства графических, верстальных и дизайнерских программ. Предусматривает широкий диапазон цветового охвата – от монохромного черно-белого до 32-разрядной модели цветоделения CMYK. Начиная с версии 6.0 в формате TIFF можно хранить сведения о масках изображений. Для уменьшения размера файла применяется встроенный алгоритм сжатия LZW.
PSD (PhotoShop Document). Собственный формат программы Adobe Photoshop (расширение имени файла .PSD), один из наиболее мощных по возможностям хранения растровой графической информации. Позволяет запоминать параметры слоев, каналов, степени прозрачности, множества масок. Поддерживаются 48-разрядное кодирование цвета, цветоделение и различные цветовые модели. Основной недостаток выражен в том, что отсутствие эффективного алгоритма сжатия информации приводит к большому объему файлов.
JPEG (Joint Photographic Experts Group). Формат предназначен для хранения растровых изображений (расширение имени файла .JPG). Позволяет регулировать соотношение между степенью сжатия файла и качеством изображения. Применяемые методы сжатия основаны на удалении “избыточной” информации, поэтому формат рекомендуют использовать только для электронных публикаций.
GIF (Graphics Interchange Format). Стандартизирован в 1987 как средство хранения сжатых изображений с фиксированным (256) количеством цветов (расширение имени файла .GIF). Получил популярность в Интернете благодаря высокой степени сжатия. Последняя версия формата GIF89a позволяет выполнять чересстрочную загрузку изображений и создавать рисунки с прозрачным фоном. Ограниченные возможности по количеству цветов обусловливают его применение исключительно в электронных публикациях.
PNG (Portable Network Graphics). Формат хранения изображений для их публикации в Интернете (расширение имени файла .PNG). Поддерживаются три типа изображений – цветные с глубиной 8 или 24 бита и черно-белое с градацией 256 оттенков серого. Сжатие информации происходит практически без потерь, предусмотрены 254 уровня альфа-канала, чересстрочная развертка.
PDF (Portable Document Format). Формат описания документов, разработанный фирмой Adobe (расширение имени файла .PDF). Хотя этот формат в основном предназначен для хранения документа целиком, его впечатляющие возможности позволяют обеспечить эффективное представление изображений. Формат является аппаратно-независимьм, поэтому вывод изображений допустим на любых устройствах – от экрана монитора до фотоэкспонирующего устройства. Мощный алгоритм сжатия со средствами управления итоговым разрешением изображения обеспечивает компактность файлов при высоком качестве иллюстраций.
Графические редакторы позволяют создавать, сканировать и редактировать картинки на экране. Наиболее известные разработки — Image Editor, Corel Draw, Fotoshop, 3d Studio (трехмерная графика с анимацией) и многие другие. Пакеты деловой и научной графики предназначены для более наглядного изображения информации — диаграмм, графиков на основе таблиц. Как правило, они входят в состав других систем.
Примеры графических редакторов
CorelDRAW – векторный графический редактор, разработанный канадской корпорацией Corel.
Текущая версия продукта — CorelDRAW Graphics Suite X4, доступна только для Microsoft Windows. Более ранние версии выпускались также для Apple Macintosh и для GNU/Linux. Последняя версия для GNU/Linux — 9-я версия, выпущенная в 2000. В 2002 вышла последняя 11-я версия для Macintosh. В пакет CorelDRAW Graphics Suite также входит редактор растровой графики Corel PHOTO-PAINT и другие программы, например, для захвата изображений с экрана Corel CAPTURE. Программа векторизации растровой графики Corel TRACE, до 12 версии входила в пакет, как самостоятельная программа.

Рис. 8. Примеры работы в программеCorelDRAW
В комплект фирма Corel включила множество программ, в том числе Corel Photo-Paint. Новый пакет располагает бесспорно самым мощным инструментарием среди всех программ обзора, а при этом по сравнению с предыдущей версией интерфейс стал проще, а инструментальные средства рисования и редактирования узлов — более гибкими. Однако что касается новые функций, в частности подготовки публикаций для Web, то здесь CorelDraw уступает CorelXara. Работа CorelDraw с цветами CMYK оставляет желать лучшего. Цвета файлов GIF и JPEG заметно отличались от цветов, выводимых для пробного отпечатка Matchprint, в то время как пакет FreeHand воспроизводил одинаковые цвета на экране, в файлах Web и на принтерах.
Adobe Photoshop
В обширном классе программ для обработки растровой графики особое место занимает пакет Photoshop компании Adobe. По сути дела, сегодня он является стандартом в компьютерной графике, и все другие программы неизменно сравнивают именно с ним.
Adobe Photoshop – растровый графический редактор, разработанный и распространяемый фирмой Adobe Systems. Этот продукт является лидером рынка в области коммерческих средств редактирования растровых изображений, и наиболее известным продуктом фирмы Adobe. Часто эту программу называют просто Photoshop (Фотошоп).
Несмотря на то, что изначально программа была разработана для редактирования изображений для печати на бумаге (для полиграфии), сейчас она широко используется в веб-дизайне.
Основной формат Photoshop, PSD, может быть экспортирован и импортирован во весь ряд этих программных продуктов. Photoshop CS поддерживает создание меню для DVD. Совместно с Adobe Encore DVD, Photoshop позволяет создавать меню или кнопки DVD. Photoshop CS3 в версии Extended поддерживает также работу с трёхмерными слоями.
Главные элементы управления программы Adobe Photoshop сосредоточены в строке меню и панели инструментов. Особую группу составляют диалоговые окна – инструментальные палитры:
Визуализация данных при составлении научно-технической документации. Программное обеспечение компьютерной визуализации.
Примеры визуального прредтавления данных в научно-технической документации: иллюстрации, графики, диаграммы. Виды диаграмм.
1 Поисковые инструменты
Поиск информации в Интернет. Релевантность, пертитентность.
ИПС (информационно-поисковая система) – это система, обеспечивающая поиск и отбор необходимых данных в специальной базе с описаниями источников информации (индексе) на основе информационно-поискового языка и соответствующих правил поиска.
Главной задачей любой ИПС является поиск информации релевантной информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска – релевантность.
Релевантность – это соответствие результатов поиска сформулированному запросу.
Пертинентность(в информационном поиске) — соответствие полученной информации информационной потребности пользователя.
Пертинентность измеряется степенью соответствие между ожиданиями пользователя и результатами поиска (сравните с релевантностью), которая определяется как отношение объема полезной для пользователя информации к общему объему полученной информации, найденнойпоисковой системой.
Достижение высокой степени пертинентности — основное поле конкурентной борьбы современных поисковых систем. Именно для максимального удовлетворения информационных потребностейпользователей в настоящее время в ИП-системах широко применяются теории и методы семантических сетей, контент-анализа и глубинного анализа текстов (Text mining,интеллектуальный анализ текстов).
Для поиска нужной информации в сети используется адрес ресурса (англ. Uniform Resource Locator (URL) адрес), содержащий имя протокола, по которому нужно обращаться к требуемой информации, адрес сервера и имя файла на этом сервере (рис. 2).

Рис. 2. Пример адреса ресурса
Поиско́вая систе́ма— программно-аппаратный комплекс свеб-интерфейсом, предоставляющий возможность поискаинформациивИнтернете. Под поисковой системой обычно подразумеваетсясайт, на котором размещён интерфейс системы. Программной частью поисковой системы являетсяпоисковая машина(поисковый движок) —комплекс программ, обеспечивающий функциональность поисковой системы и обычно являющийся коммерческой тайной компании-разработчика поисковой системы
Поиск информации в Интернете осуществляется с помощью специальных программ, обрабатывающих запросы — информационно-поисковых систем (ИПС). Существует несколько моделей, на которых основана работа поисковых систем, но исторически две модели приобрели наибольшую популярность — это поисковые каталоги и поисковые указатели.
Поисковые каталоги устроены по тому же принципу, что и тематические каталоги крупных библиотек. Они обычно представляют собой иерархические гипертекстовые меню с пунктами и подпунктами, определяющими тематику сайтов, адреса которых содержатся в данном каталоге, с постепенным, от уровня к уровню, уточнением темы. Поисковые каталоги создаются вручную. Высококвалифицированные редакторы лично просматривают информационное пространство WWW, отбирают то, что по их мнению представляет общественный интерес, и заносят в каталог.
Основной проблемой поисковых каталогов является чрезвычайно низкий коэффициент охвата ресурсов WWW. Чтобы многократно увеличить коэффициент охвата ресурсов Web, из процесса наполнения базы данных поисковой системы необходимо исключить человеческий фактор — работа должна быть автоматизирована.
Автоматическую каталогизацию Web-ресурсов и удовлетворение запросов клиентов выполняют поисковые указатели. Работу поискового указателя можно условно разделить на три этапа:
сбор первичной базы данных. Для сканирования информационного пространства WWW используются специальные агентские программы — черви, задача которых состоит в поиске неизвестных ресурсов и регистрация их в базе данных;
индексация базы данных — первичная обработка с целью оптимизации поиска. На этапе индексации создаются специализированные документы — собственно поисковые указатели;
рафинирование результирующего списка. На этом этапе создается список ссылок, который будет передан пользователю в качестве результирующего. Рафинирование результирующего списка заключается в фильтрации и ранжировании результатов поиска.
Под фильтрацией понимается отсев ссылок, которые нецелесообразно выдавать пользователю (например, проверяется наличие дубликатов). Ранжирование заключается в создании специального порядка представления результирующего списка (по количеству ключевых слов, сопутствующих слов и др.).
Главной задачей любой ИПС является поиск информации релевантной информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска – релевантность.
Релевантность – это соответствие результатов поиска сформулированному запросу.
Поисковые инструменты — это особое программное обеспечение, основная цель которого – обеспечить наиболее оптимальный и качественный поиск информации для пользователей Интернета. Поисковые инструменты размещаются на специальных веб-серверах, каждый из которых выполняет определенную функцию:
Машины веб-поиска — это сервера с огромной базой данных URL-адресов, которые автоматически обращаются к страницам WWW по всем этим адресам, изучают содержимое этих страниц, формируют и прописывают ключевые слова со страниц в свою базу данных (индексирует страницы).
Более того, роботы поисковых систем переходят по встречаемым на страницах ссылкам и переиндексируют их. Так как почти любая страница WWW имеет множество ссылок на другие страницы, то при подобной работе поисковая машина в конечном результате теоретически может обойти все сайты в Интернет.
Именно этот вид поисковых инструментов является наиболее известным и популярным среди всех пользователей сети Интернет. У каждого на слуху названия известных машин веб-поиска (поисковых систем) – Яndex, Rambler, Aport.
Работа машин веб-поиска сводится к следующему:
Анализ веб-страниц и занесение результатов анализа на тот или иной уровень базы данных поискового сервера.
Поиск информации по запросу пользователя.
Обеспечение удобного интерфейса для поиска информации и просмотра результата поиска пользователем.
Приемы работы, используемые при работе с теми или другими поисковыми инструментами, практически одинаковы. При их описании используются следующие понятия:
Интерфейс поискового инструмента представлен в виде страницы с гиперссылками, строкой подачи запроса (строкой поиска) и инструментами активизации запроса.
Индекс поисковой системы – это информационная база, содержащая результат анализа веб-страниц, составленная по определенным правилам.
Запрос – это ключевое слово или фраза, которую вводит пользователь в строку поиска. Для формирования различных запросов используются специальные символы («», , ~), математические символы (*, +, ?).
Схема поиска информации проста. Пользователь набирает ключевую фразу и активизирует поиск, тем самым получает подборку документов по сформулированному (заданному) запросу. Этот список документов ранжируется по определенным критериям так, чтобы вверху списка оказались те документы, которые наиболее соответствуют запросу пользователя. Каждый из поисковых инструментов использует различные критерии ранжирования документов, как при анализе результатов поиска, так и при формировании индекса (наполнении индексной базы данных web-страниц).
В России наиболее крупными и популярными поисковыми указателями являются:
«Яndex» (www.yandex.ru)
«Pамблер» (www.rambler.ru)
«Google» (www.google.ru)
«Апорт2000» (www.aport.ru)
2 Механизмы поиска
Обобщенная технология поиска состоит из следующих этапов:
Пользователь формулирует запрос
Система проводит поиск документов (или их поисковых образов)
Пользователь получает результат (сведения о документах)
Пользователь совершенствует или реформирует запрос
Организация нового поиска…
Как правило, поисковые машины поддерживают два режима: режим простого поиска и режим расширенного поиска. Рассмотрим обобщенные возможности.
Формирования запроса в режиме простого поиска. Можно просто вводить через пробел одно или несколько слов; поиск слов со всевозможными окончаниями моделируется символом * в конце слова. Многие системы позволяют искать словосочетания или фразу, для этого необходимо ее заключить в кавычки. Возможно обязательное включение или исключение определенных слов.
Основная проблема поиска по примитивно составленному запросу (в виде перечисления ключевых слов) заключается в том, что поисковая машина найдет все страницы, на которых указанные слова встречаются в любой части документа. Как правило, количество найденных страниц будет слишком велико.
Для улучшения качества поиска в режиме простого поиска допустимо использование логических операторов и операторов, позволяющих ограничить область поиска, а также выбор определенной категории документов из представленного списка.
Многие поисковые системы включают в свой язык составления запросов специальные операторы, позволяющие проводить поиск в определенных зонах документа, например, в его заголовке, или искать документ по известной части его адреса.
Режим расширенного или детального запроса в разных системах реализован индивидуально, но чаще всего это бланк, в котором упомянутые операторы и ключевые элементы реализуются простой установкой соответствующих флажков или выбором параметров из списка.
Ниже в качестве примера приведены сведения из раздела помощь поисковой системы Yandex: окно расширенного поиска, язык запросов, искать в найденном.
Искать в найденном Если в результате запроса Яндекс нашел много документов, но по более широкой теме, чем вам хочется, вы можете сократить этот список, уточнив запрос. Еще один вариант — включить флажок в найденном в форме поиска, задать дополнительные ключевые слова, и следующий поиск будет вестись только по тем документам, которые были отобраны в предыдущем поиске.

Памятка по использованию языка запросов
Пример | Значение |
«К нам на утренний рассол» | Слова идут подряд в точной форме |
«Прибыл * посол» | Пропущено слово в цитате |
полгорбушки & мосол | Слова в пределах одного предложения |
снаряжайся && добудь | Слова в пределах одного документа |
глухаря | куропатку | кого-нибудь | Поиск любого из слов |
не смогешь << винить | Неранжирующее «и»: выражение после оператора не влияет на позицию документа в выдаче |
я должон /2 казнить | Расстояние в пределах двух слов в любую сторону (то есть между заданными словами может встречаться одно слово) |
государственное дело && /3 улавливаешь нить | Расстояние в 3 предложения в любую сторону |
нешто я ~~ пойму | Исключение слова пойму из поиска |
при моем /+2 уму | Расстояние в пределах двух слов в прямом порядке |
чай ~ лаптем | Поиск предложения, где слово чай встречается без слова лаптем |
щи /(-1 +2) хлебаю | Расстояние от одного слова в обратном порядке до двух слов в прямом |
!Соображаю !что !чему | Слова в точной форме с заданным регистром |
получается && (+на | !мне) | Скобки формируют группы в сложных запросах |
!!политика | Словарная форма слова |
title:(в стране) | Поиск по заголовкам документов |
url:ptici.narod.ru/ptici/kuropatka.htm | Поиск по URL |
беспременно inurl:vojne | Поиск с учетом фрагмента URL |
host:lib.ru | Поиск по хосту |
rhost:ru.lib.* | Поиск по хосту в обратной записи |
site:http://www.lib.ru/PXESY/FILATOW | Поиск по всем поддоменам и страницам заданного сайта |
mime:pdf | Поиск по одному типу файлов |
lang:en | Поиск с ограничением по языку |
domain:ru | Поиск с ограничением по домену |
date:200712* | Поиск с ограничением по дате |
государственное дело && /3 улавливаешь нить | Расстояние в 3 предложения в любую сторону |
нешто я ~~ пойму | Исключение слова пойму из поиска |
Интересной возможностью является поиск документов в сети, ссылающиеся на страницу с указанным вами адресом (URL). Таким образом, можно найти в сети страницы, на которых есть ссылки на ваш Web-сайт. Некоторые системы позволят ограничить область поиска внутри указанного домена.
В качестве дополнительных специальных операторов можно выделить:
Операторы поиска документов с определенным графическим файлом;
Операторы ограничения по дате искомых страниц;
Операторы близости между словами;
Операторы учета словоформы;
Операторы сортировки результатов (по релевантности, свежести, старости).
Следует заметить, что, к великому сожалению, на сегодняшний день не существует стандарта на количество и синтаксис поддерживаемых операторов для различных поисковых систем. Попытки разработать стандарт на синтаксис поддерживаемых операторов предпринимаются, поэтому есть надежда на то, что разработчики поисковых систем позаботятся об удобстве пользователей. На данном этапе развития средств поиска, пользователь, обращаясь к определенной поисковой системе, непременно должен в первую очередь ознакомиться с ее правилами составления запросов. Как правило, на домашней странице будет обязательно присутствовать ссылка Помощь (Help), по которой вы перейдете к справочной информации.
Различные поисковые системы описывают разное количество источников информации в Интернет. Поэтому нельзя ограничиваться поиском только в одной поисковой системе.
Рассмотрим способы представления результатов поиска в поисковых машинах.
Чаще всего количество найденных документов превышает несколько десятков, а в отдельных случаях может достигать сотен тысяч! Поэтому в качестве формы выдачи составляется список документов по 5-10-15 единиц на странице с возможностью перехода к следующей порции внизу страницы. Обязательно указывается заголовок и URL(адрес) найденного документа, иногда система указывает в процентах степень релевантности документа.
В описании документа чаще всего содержится несколько первых предложений или выдержки из текста документа с выделением ключевых слов. Как правило, указана дата обновления (проверки) документа, его размер в килобайтах, некоторые системы определяют язык документа и его кодировку (для русскоязычных документов).
Что можно делать с полученными результатами? Если название и описание документа соответствует вашим требованиям, можно немедленно перейти к его первоисточнику по ссылке. Это удобнее делать в новом окне, чтобы иметь возможность далее анализировать результаты выдачи. Многие поисковые системы позволяют проводить поиск в найденных документах, причем вы можете уточнить ваш запрос введением дополнительных терминов.
Если интеллектуальность системы высока, вам могут предложить услугу поиска похожих документов. Для этого вы выбираете особо понравившийся документ и указываете его системе в качестве образца для подражания.
Однако, автоматизация определение похожести – весьма нетривиальная задача, и зачастую эта функция работает неадекватно вашим надеждам. Некоторые поисковики позволяют провести пересортировку результатов. Для экономии вашего времени можно сохранить результаты поиска в виде файла на локальном диске для последующего изучения в автономном режиме.
Лекция 3 — Технологии поиска информации в сети Интернет. — Студопедия.Нет
Поисковые системы уже давно стали неотъемлемой частью российского Интернета. Поисковые системы сейчас – это огромные и сложные механизмы, представляющие собой не только инструмент поиска информации.
Поисковая система — это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Типы поисковых систем
Существует два основных метода поиска в Интернете. В первом случае вы ищите web-страницы, относящиеся к определенной теме. Поиск производится путем выбора тематической категории и постепенным ее сужением. Подобные поисковые системы называют поисковыми каталогами. Они удобны, когда вам нужно вые познакомиться с новой для себя темой или добраться до широко известных «классических» ресурсов по данной теме. Второй способ поиска используется, когда тема носит узкий, специфический характер или нужны редкие, малоизвестные ресурсы. В этом случае вы должны представлять себе, какие ключевые слова должны встретиться в документе по интересующей вас теме. Эти слова надо выбрать таким образом, чтобы они, скорее всего, имелись в нужных документах, не имеющих отношения к выбранной теме. Системы, позволяющие выполнять подобный поиск, называют поисковыми указателями. Поисковые каталоги отличаются от поисковых указателей не только методом поиска, но и способом формирования. Любая поисковая система Интернета состоит из двух частей. Специализированная web-страница, доступная всем желающим и позволяющая выполнять поиск, опирается на большую, постоянно пополняемую и обновляемую базу данных, которая содержит сведения о ресурсах Интернета.
Способ пополнения этой базы данных зависит от типа поисковой системы, поисковых каталогов самое главное — это точность отбора. Каждый найденный ресурс должен быть полезным. Тематика страницы определяется или проверяется вручную. Из-за этого объем поисковых каталогов относительно невелик. Когда объем приближается к миллиону страниц, объем ручного труда настолько велик, что дальнейший рост каталога останавливается.
Поисковые указатели, напротив, ориентированы на широту охвата. С определением слов, имеющихся на web-странице, вполне справляется автоматика, данных поискового указателя может охватывать многие миллионы web-страниц. При этом выполнять поиск в указателе труднее, чем в каталоге, потому что одни те же ключевые слова могут встречаться на web-страницах, посвященным разным темам.
История развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации относительно небольшим. В это время задача поиска информации в сети Интернет была далеко не столько актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание каталогов сайтов, в которых ссылки на ресурсы группировались согласно тематике. Первым таким проектом стал сайт Yahoo, открывшийся в апреле 1994 года. После того, как число сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска информации по каталогу. Это, конечно же, не было поисковой системой в полном смысле, так как область поиска была ограничена только ресурсами, присутствующими в каталоге, а не всеми ресурсами сети Интернет.
Принципиальное отличие поисковой системы Yahoo (Яхо) от других систем в том, что вы можете найти необходимую вам информацию без использования запросов, а просто переходя по ссылкам разделов встроенного справочника и последовательно уточняя область ваших интересов.Yahoo является самой популярной системой в США, так как не требует специальной подготовки для поиска информации. Не надо знать правила формирования запросов, достаточно просто переходить по ссылкам в нужные разделы. Однако для русскоязычных пользователей эта система не слишком удобна, так как разбиение на разделы проводилась с учётом американской специфики. Кроме того, в справочнике Yahoo содержится намного меньше ссылок на русскоязычные документы, чем в базе данных AltaVista. Однако для поиска информации по конкретной тематике данная система может оказаться достаточно полезной.
Поисковая система AltaVista была открыта для свободного использования в конце 1995 года. Это система до сих пор является достаточно популярной, хотя в последнее время другие системы составляют ей значительную конкуренцию. Система обеспечивает поиск, как во Всемирной паутине, так и в группах новостей. После ввода ключевых слов вы получаете информацию о количестве найденных документов и их краткие описания со ссылками на информацию в Интернете. Расширенный поиск позволяет использовать логические операторы для формирования сложных запросов.
В 1997 году Сергей Брин и Ларри Пейдж создали Google в рамках исследовательского проекта в Стэнфордском университете. В настоящий момент Google самая популярная поисковая система в мире.
23 сентября 1997 года была официально анонсирована поисковая система Yandex, самая популярная в русскоязычной части Интернет.
В настоящее время существует 3 основных международных поисковых системы – Google, Yahoo и MSN Search, имеющих собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих можно насчитать очень много) использует в том или ином виде результаты 3 перечисленных. Например, поиск AOL (search.aol.com) и Mail.ru используют базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
В России основной поисковой системой является Яндекс, за ним идут Rambler, Google.ru, Aport, Mail.ru и KM.ru.
Поисковые системы
Помочь пользователю найти нужную информацию в Сети призваны поисковые системы. Поисковая система — веб-сайт, предоставляющий возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet.
В поиске нужных ресурсов пользователь вводит одно или несколько ключевых слов, которые, по его мнению, лучше всего отражают суть интересующего вопроса. Поисковая система за считанные секунды просматривает весь собственный каталог веб-ресурсов (индекс), состоящий из десятков и сотен гигабайт информации. В результате предлагается список ссылок на страницы, в которых встречаются указанные слова.
Популярные поисковые системы:
Всеязычные:
Yahoo и принадлежащие этой компании поисковые машины:
Inktomi
AltaVista
Alltheweb
MSN (принадлежит компании «Microsoft»)
Англоязычные и международные:
AskJeeves.
Русскоязычные — большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках — украинском, белорусском, английском и др. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что в основном индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык или другими способами ограничивают своих роботов русскоязычными сайтами.
Яндекс
Rambler
Mail.ru
Nigma
Gogo.ru
Aport
Яndех
Поисковая система Яndех располагается по адресу www.уаndех.ru. Она была официально введена в эксплуатацию 23 сентября 1997 года.
Что же такое Яndех? Вот как отвечают на этот вопрос создатели системы. Яndех — это полнотекстовая информационно-поисковая система (ИПС), учитывающая морфологию русского и английского языков. Система Яndех предназначена для поиска информации в электронных текстах различной структуры и разных способов представления (форматов). Яndех (произносится «яндекс») расшифровывается как «языковый индекс» или, в английском написании, Yandex — YetAnother INDEX. Также можно рассматривать Яndех как частичный перевод слова Index с английского на русский язык («I» означает «Я»).
В основе поисковой системы Yandex.Ru лежит системное ядро, общее для всех продуктов с префиксом Яndex (Яndex.Site, Яndex.Lib, Яndex.Dict, Яndex.СD). Первые продукты серии Яndex (Яndex.Site, Яndex.Dict) были представлены широкой публике 18 октября 1996 года на выставке Netcom’96. Поисковая машина для «русского Интернета» явилась естественным продолжением линии Яndex. Как уже говорилось, в хорошем вопросе содержится половина ответа. Искать и находить нужное в ворохе текстов в Интернете — умение не только поисковой системы, но и пользователя, задающего запрос. Яndex не требует от пользователя знания специальных команд для поиска достаточно набрать вопрос («где найти дешевые компьютеры» или «нужны телефоны Москвы и Московской области»), и вы получите результат — список страниц, где встречаются эти слова. Независимо от того, в какой форме вы употребили слово в запросе, поиск учитывает все его формы по правилам русского языка. Например, если задан запрос идти, то в результате поиска будут найдены ссылки на документы, содержащие слова «идти», «идет», «шел», «шла» и т.д.
Яndex работает не только с языковыми запросами, но и позволяет выполнять поиск только на определенных серверах ИЛИ же исключить из поиска заведомо ненужные серверы. Появилась возможность поиска изображений по подписям к ним и по именам файлов. Также стали доступными для поиска такие объекты, как сценарии, аппреты и стили (поиск осуществляется по названию). Удобная работа с новыми возможностями предлагается на странице расширенного поиска, где сложный язык запросов сведен к заполнению полей в форме. Кроме стандартной сортировки результатов — по релевантности (то есть по степени соответствия запросу), можно отсортировать документы по дате обновления. Интересной особенностью системы является возможность поиска в Яндексе в любом месте Интернета. Для этого нужно загрузить с сайта http://bar.уаndех.ru программу пол названием Яндекс. Бар и установить ее. После этого в окне браузера появится новая панель. Она предназначена для ввода запроса на поиск (без необходимости открывать страницу Яндекса) и выполнения ряда других функций.
По внешнему виду Яндекс представляет собой типичный портал, на главной странице которого можно найти ссылки на материалы практически любой тематики. Но это не единственное его лицо, для «серьезных» пользователей, которые не хотят тратить время на загрузку ненужной в данный момент информации, существует другой Яндекс. Его страница впечатляет скромностью дизайна и скоростью загрузки. Адрес этой эссенции поисковой машины – www.ya.ru.
AltaVista
AltaVista (www.AltaVista.com) — одна из старейших поисковых систем в Интернете. Первый web-индекс был представлен компанией в 1995 году. Ядро поисковой системы обязано своим рождением странной особенности исследовательской лаборатории компании DigitalEquipmentCorp. Сотрудники этой лаборатории зачем – то хранили всю свою электронную переписку за последние 10 лет. Чтобы эта куча информации не просто занимала дисковое пространство, а приносила хоть какую-то пользу, была создана программа для индексирования документов и поиска нужных слов в ворохе пожелтевшей от времени электронной корреспонденции. Система получилась настолько удачной, что впоследствии с успехом перекочевала на просторы Всемирной паутины.
Индекс AltaVista содержит документы на более чем 25 языках. Локализованные версии сайта AltaVista располагаются в доменах 20 стран. В область поиска можно включить документы на всех поддерживаемых языках или только в документах на определенном языке, а на специальной странице можно узнать несколько языков для поиска на всех выбранных языках одновременно
Yahoo!
Базы данных: в ведении находится служба поиска Internet-ресурсов, новостей, карт, рекламных информаций, спортивная информация, бизнес, номера телефонов, персональные WWW-страницы, и email-адреса (отдельная база данных).
Содержание: Основная директория содержит: адреса (URLs) лляInternet-ресурсов и краткое описание для этих связей.
Поиск: Все Yahoo страницы предлагают не только простое поисковое окно, но и опции для этого поиска, а так, же поиск Usenet или Email-адреса. Поиск может ограничиваться указанием определённого промежутка времени. Boolean операторы (и, или) и последовательный поиск также поддержаны. Отметим: если поиск в Yahoo! не привёл к положительному результату, то процесс поиска автоматически переходит на AltaVista, которая продолжает поиск, и в случае положительных результатов автоматически возвращает найденную информацию в Yahoo!.
Если Yahoo! не может установить связь достаточно быстро с AltaVista, то в этом случае Yahoo! будет обеспечивать страницу связи с набором инструментов поиска. После того как одна из этих связей выбирается, ключевые слова передаются к поисковой машине на ваше усмотрение.
Средством, облегчающим поиск, является наличие “tipsearch”(TS) — поиск с помощью “намека”: Yahoo! Является подчиненным справочником, что означает, что система не имеет так много страниц, как поисковые машины, однако задание наиболее общих ключевых слов позволит найти необходимую тему на странице высокого уровня (первая страница, которая возникает перед пользователем при посещении сайта) для организации или компании.
Результаты: Связи отображаются в соответствии с очерёдностью задаваемых слов последовательностью поиска наряду с их описательным текстом и подчиненной иерархией.
Адрес: http://www.yahoo.com/
Это самая быстрая и самая большая поисковая система. Проиндексировано более полутора миллиарда страниц (из них полностью — около половины, остальные представлены только в виде адреса и текста ссылки). Имеется возможность выбора языка интерфейса. Можно включать или исключать результаты с определенных сайтов или доменов. В отличие от большинства поисковых систем Google также оценивает популярность ресурса по количеству ссылок, ведущих к нему с других страниц. Кроме того, здесь содержится архив с возможностью поиска по всем телеконференциям системы USENET за последние 20 лет.
Международная поддержка
Вы можете искать в Google на 10 различных языках. Вы также можете настроить интерфейс на нужный вам язык. Например, если вы ищите немецкий сайт, то вы можете вводить запрос на немецком языке, и все вспомогательные надписи интерфейса будут на немецком языке. Посмотреть список доступных языков вы можете здесь.
Отличительные особенности
Очень удобной функцией является «cache» . Благодаря этой функцией пользователь может просмотреть проиндексированную страницу даже если эта страница удалена или сервер, на котором расположена страница недоступен. Вы также можете использовать эту функцию для исследования ваших конкурентов, это также помогает лучше понять принцип индексирования страницы поисковым пауком (роботом).
С помощью Google можно найти страницы, которые не содержаться в его базе данных. Это возможно, потому что поисковый паук индексирует текст ссылок со страниц.
Rambler
Поисковая система Рамблер начала свое существование с 1996 года. На сегодняшний день она является одной из самых
Поисковая система Рамблер при поиске учитывает морфологию русского языка, что дает больше возможностей для эффективного поиска информации. Реализована также система так называемых «перевязок», которая позволяет выдавать в результатах поиска не только страницы содержащие запрос, но и слова, которые являются синонимами запроса. Еще одной функцией «перевязок», думаю более значимой, является выдача контекстной рекламы не только по конкретному запросу, но и по запросам, которые тесно связаны с исходным, это позволяет перекрыть большее количество целевой аудитории.
Рамблер находит именно то, что Вам нужно, результаты поиска максимально соответствуют запросу. Вам не придется искать нужные документы среди множества ссылок.
По соответствию запросу оцениваются не только отдельные документы, но и целые сайты. Благодаря объединению по сайтам за одним ответом на Ваш запрос могут стоять десятки найденных документов.
Рамблер по-прежнему остается самой быстрой поисковой системой. На конкурсе «Золотая паутина» информационно-поисковая система Рамблер была отмечена первым призом в номинации «Лучший коммерческий проект года».
Рамблер — это комплексный информационный сервис, охватывающий практически весь российский интернет. Рамблер — самый популярный в российском интернете портал, объединивший поисковую систему, рейтинг-классификатор, а также ряд бесплатных сервисов и информационных проектов.
APORT
http://www.aport.ru/
Поисковая машина «Апорт» была впервые продемонстрирована в феврале 1996 года на пресс-конференции «Агамы» по поводу открытия «Русского клуба». Тогда она искала только по сайту russia.agama.com. Потом она начала искать по четырем, потом по шести серверам… Короче, день рождения и фактический старт системы сильно «размазались» по времени, а официальная презентация «Апорта» состоялась только 11 ноября 1997 года. К тому времени в его базе был проиндексирован первый миллион документов, расположенных на 10 тысячах серверов. Создателем системы выступила компания «Агама» — разработчик программного обеспечения для платформы Windows, главным из которых являлся корректор орфографии «Пропись». Лингвистические разработки «Агамы» использовались при создании поисковой машины, в которой, скажем, в отличие от «Рамблера», изначально учитывалась морфология слов и осуществлялась по желанию клиента проверка орфографии запроса.
Важнейшими свойствами первой версии «Апорта» являлся перевод запроса и результатов поиска на английский язык и обратно, а также реконструкция всех проиндексированных страниц из собственной базы (что означает возможность просмотра страниц, уже несуществующих в оригинале).
В ноябре 1998 года компания «Агама» была куплена за 55 тысяч долларов израильским капиталом в лице Джозефа Авчука (с сохранением торговых марок «Апорт» и «Агама»). В марте 1999 года Авчук входит в долю, а летом того же года окончательно покупает каталог Ау!, торговой марке которого повезло существенно меньше — она была переименована сначала в AtRus, а потом и вовсе уничтожена при экспорте каталога на сайты «России он-лайн», «Омен» и «Апорт». К концу 1999 года Авчук вложил в «Апорт» и AtRus первый миллион долларов, позволивший в октябре того же года представить на компьютерных выставках по обе стороны океана принципиально новую поисковую машину «Апорт 2000», полностью интегрированную с Atrus (ныне «Каталог-Апорт»).
«Апорт 2000» стал первым русским поисковиком, построенным на основе выдачи результатов по отдельно взятым сайтам. Для разделения ресурсов на сайты используется информация, которую «Апорту» предоставляет каталог AtRus или сведения, введенные в «Апорт» владельцами ресурсов. На худой конец, приходится опираться на алгоритм, который позволяет по некоторым формальным признакам выделить отдельные сайты.
Пользователи «Апорта» (в отличие завсегдатаев «Яндекса») мало пользуются расширенным поиском (на 8000 загрузок простой страницы приходится 300 вызовов страницы «Расширенный поиск»).