Как закрыть сайт от индексации в robots.txt
Поисковые роботы сканируют всю информацию в интернете, но владельцы сайтов могут ограничить или запретить доступ к своему ресурсу. Для этого нужно закрыть сайт от индексации через служебный файл robots.txt.
Если закрывать сайт полностью не требуется, запрещайте индексацию отдельных страниц. Пользователям не следует видеть в поиске служебные разделы сайта, личные кабинеты, устаревшую информацию из раздела акций или календаря. Дополнительно нужно закрыть от индексации скрипты, всплывающие окна и баннеры, тяжелые файлы. Это поможет уменьшить время индексации и снизит нагрузку на сервер.
Как закрыть сайт полностью
Обычно ресурс закрывают полностью от индексации во время разработки или редизайна. Также закрывают сайты, на которых веб-мастера учатся или проводят эксперименты.
Запретить индексацию сайта можно для всех поисковиков, для отдельного робота или запретить для всех, кроме одного.
| Запрет для всех |
User-agent: * Disallow: / |
| Запрет для отдельного робота |
User-agent: YandexImages Disallow: / |
| Запрет для всех, кроме одного робота |
User-agent: * Disallow: / User-agent: Yandex Allow: / |
Как закрыть отдельные страницы
Маленькие сайты-визитки обычно не требуют сокрытия отдельных страниц. Для ресурсов с большим количеством служебной информации закрывайте страницы и целые разделы:- административная панель;
- служебные каталоги;
- личный кабинет;
- формы регистрации;
- формы заказа;
- сравнение товаров;
- избранное;
- корзина;
- каптча;
- всплывающие окна и баннеры;
- поиск на сайте;
- идентификаторы сессий.
Желательно запрещать индексацию т.н. мусорных страниц. Это старые новости, акции и спецпредложения, события и мероприятия в календаре. На информационных сайтах закрывайте статьи с устаревшей информацией. Иначе ресурс будет восприниматься неактуальным. Чтобы не закрывать статьи и материалы, регулярно обновляйте данные в них.
Запрет индексации
| Отдельной страницы |
User-agent: * Disallow: /contact.html |
| Раздела |
User-agent: * Disallow: /catalog/ |
| Всего сайта, кроме одного раздела |
User-agent: * Disallow: / Allow: /catalog |
| Всего раздела, кроме одного подраздела |
User-agent: * Disallow: /product Allow: /product/auto |
| Поиска на сайте |
User-agent: * Disallow: /search |
| Административной панели |
User-agent: * Disallow: /admin |
Как закрыть другую информацию
Файл robots.txt позволяет закрывать папки на сайте, файлы, скрипты, utm-метки. Их можно скрыть полностью или выборочно. Указывайте запрет для индексации всем роботам или отдельным.
Запрет индексации
| Типа файлов |
User-agent: * Disallow: /*.jpg |
| Папки |
User-agent: * Disallow: /images/ |
| Папку, кроме одного файла |
User-agent: * Disallow: /images/ Allow: file.jpg |
| Скриптов |
User-agent: * Disallow: /plugins/*.js |
| utm-меток |
User-agent: * Disallow: *utm= |
| utm-меток для Яндекса | Clean-Param: utm_source&utm_medium&utm_campaign |
Как закрыть сайт через мета-теги
Альтернативой файлу robots.txt является мета-тег robots. Прописывайте его в исходный код сайта в файле index.html. Размещайте в контейнере <head>. Указывайте, для каких краулеров сайт закрыт от индексации. Если для всех, напишите robots. Если для одного робота, укажите его название. Для Google — Googlebot, для Яндекса — Yandex. Существуют два варианта записи мета-тега.
Вариант 1.Вариант 2.
<meta name=”robots” content=”none”/>
Атрибут “content” имеет следующие значения:
- none — индексация запрещена, включая noindex и nofollow;
- noindex — запрещена индексация содержимого;
- nofollow — запрещена индексация ссылок;
- follow — разрешена индексация ссылок;
- index — разрешена индексация;
- all — разрешена индексация содержимого и ссылок.
Таким образом, можно запретить индексацию содержимого, но разрешить ссылки. Для этого укажите content=”noindex, follow”. На такой странице ссылки будут индексироваться, а текст — нет. Используйте для разных случаев сочетания значений.
Если закрыть сайт от индексации через мета-теги, создавать robots.txt отдельно не нужно.
Какие встречаются ошибки
Логические — когда правила противоречат друг другу. Выявляйте логические ошибки через проверку файла robots.txt в инструментах Яндекс.Вебмастере и Google Robots Testing Tool.
Синтаксические — когда неправильно записаны правила в файле.
К наиболее часто встречаемым относятся:
- запись без учета регистра;
- запись заглавными буквами;
- перечисление всех правил в одной строке;
- отсутствие пустой строки между правилами;
- указание краулера в директиве;
- перечисление множества вместо закрытия целого раздела или папки;
- отсутствие обязательной директивы disallow.
Шпаргалка
-
Для запрета на индексацию сайта используйте два варианта. Создайте файл robots.txt и укажите запрет через директиву disallow для всех краулеров. Другой вариант — пропишите запрет через мета-тег robots в файле index.html внутри тега .
-
Закрывайте служебные информацию, устаревающие данные, скрипты, сессии и utm-метки. Для каждого запрета создавайте отдельное правило. Запрещайте всем поисковым роботам через * или указывайте название конкретного краулера. Если вы хотите разрешить только одному роботу, прописывайте правило через disallow.
-
При создании файла robots.txt избегайте логических и синтаксических ошибок. Проверяйте файл через инструменты Яндекс.Вебмастер и Google Robots Testing Tool.
Материал подготовила Светлана Сирвида-Льорентэ.
Как закрыть сайт от индексации за 1 минуту: 3 способа
Иногда возникают ситуации, когда необходимо закрыть сайт от индексации.

Ну, например вы решили сменить дизайн блога и не хотите, чтобы в это время на ресурс заходили поисковые боты. Или просто вы только что создали сайт и установили на него движок, соответственно если на ресурсе нет полезной информации, то показывать его поисковым ботам не стоит. В данной статье вы узнаете о том, как закрыть сайт от индексации в Яндексе, Гугле, или сразу во всех поисковых системах. Но перед тем вы также можете прочитать еще одну похожую статью: «Как закрыть ссылку от индексации?» А теперь приступим.
1. Закрываем сайт от индексации с помощью файла robots.txt.
Для начала вам нужно создать файл robots.txt. Для этого создаете на своем компьютере обычный текстовый документ с названием robots и расширением .txt. Вот я только что создал его:

Теперь этот файл нужно загрузить в корневую папку своего блога. Если ресурс сделан на движке вордпрес, то корневая папка находится там, где папки wp-content, wp-includes и т. д.
Итак, мы загрузили пустой файл на хостинг, теперь нужно с помощью этого файла как-то закрыть блог от индексации. Это можно сделать, как я уже написал только для Яндекса, Гугла или сразу всех поисковиков. Давайте обо всем по порядку.
Как закрыть сайт от индексации только для Яндекса?
Пропишите в файле robots.txt вот такую строчку:
User-agent: Yandex
Disallow: /
Для того чтобы убедиться в том, что вы запретили индексировать свой ресурс Яндексу, добавьте сначала сайт в Яндекс Вебмастер, если вы этого еще не сделали, а потом перейдите на эту страницу. Дальше введите несколько страниц своего сайта и нажмите на кнопку «Проверить». Если страницы запрещены к индексации, то вы увидите примерно такую картину:

Как закрыть сайт от индексации только для Google?
Откройте файл robots.txt и пропишите там вот такую строчку:
User-agent: Googlebot
Disallow: /
Для того чтобы проверить, что Гугл не индексирует сайт, создайте аккаунт, добавьте свой ресурс в Google Webmaster и зайдите в него. Здесь также нужно ввести несколько страниц и нажать на кнопку «проверить».
Если страница разрешена к индексированию, то будет писать «Разрешено», в таком случае вы сделали что-то не так. Если документ запрещен к индексации, то будет писать «Заблокировано по строке», и Гугл укажет строку, с помощью которой страница запрещена к индексации. Вы также можете прочитать статью о том, как проверить индексацию сайта.

Я заметил, что поисковая система Google индексирует даже те документы, которые запрещены в файле robots.txt и заносит их в дополнительный индекс, так называемые «сопли». Почему, не знаю, но вы должны понимать, что запретить сайт или отдельную страницу с помощью файла robots.txt на 100 % нельзя. Этот файл, как я понял, только рекомендация для Гугла, а он уже сам решает, что ему индексировать, а что нет.
Как закрыть сайт от индексации для всех поисковых систем?
Чтобы запретить сразу всем поисковикам индексировать ваш ресурс, пропишите в robots.txt вот такую строчку:
User-agent: *
Disallow: /
Теперь вы также можете перейти в Яндекс или Гугл Вебмастер и проверить запрет индексации.
Свой файл robots.txt вы можете увидеть по такому адресу:
Вашдомен.ru/robots.txt
Все что вы прописали в этом файле должно отображаться в браузере. Если при переходе по этому адресу перед вами выскакивает ошибка 404, значит, вы не туда загрузили свой файл.
Кстати, мой robots.txt находиться здесь. Если ваш ресурс сделан на движке wordpress, то можете просто скопировать его. Он правильно настроен для того, чтобы поисковые боты индексировали только нужные документы и что бы на сайте не было дублей.
2. Закрываем сайт от индексации с помощью панели инструментов.
Этот способ подойдет только для тех, чей ресурс сделан на вордпрес. Зайдите в «Панель управление» — «Настройки» — «Чтение». Здесь нужно поставить галочку напротив надписи «Рекомендовать поисковым машинам не индексировать сайт».

Обратите внимание, что ниже находиться очень интересная надпись: «Поисковые машины сами решают, следовать ли Вашей просьбе». Это как раз то, о чем я писал выше. Яндекс скорее всего не будет индексировать страницы, которые запрещены к индексации, а вот с Гуглом могут возникнуть проблемы.
3. Закрываем сайт от индексации вручную.
Когда вы закрываете целый ресурс или страницу от индексации, то в исходном коде автоматически появляется вот такая строчка:
meta name=»robots» content=»noindex,follow»
Она и говорит поисковым ботам, что документ индексировать нельзя. Вы можете просто вручную прописать эту строчку в любом месте своего сайта, главное чтобы она отображалась на всех страницах и тогда ресурс будет закрыт от индексации.
Кстати, если вы создаете ненужный документ на своем сайте, и не хотите чтобы поисковые боты его индексировали, то можете также вставить в исходном коде эту строчку.
После обновления откройте исходный код страницы (CTRL + U) и посмотрите, появилась ли эта строчка там. Если есть, значит все хорошо. На всякий случай можете еще проверить с помощью инструментов для вебмастеров от Яндекса и Гугла.
На этом все на сегодня. Теперь вы знаете, как закрыть сайт от индексации. Надеюсь, эта статья была полезна для вас. Всем пока.
Как закрыть сайт от индексации?
Приветствую вас, посетители сайта Impuls-Web!
Когда вы только приступили к созданию сайта и не хотите, что бы поисковые системы индексировали его до завершения работ, вы может закрыть сайт от индексации в поисковых системах.
Навигация по статье:
Так же такая необходимость может возникнуть для тестового сайта, или для сайта, который предназначен для закрытого пользования определенной группой лиц, и вам не нужно, чтобы внутренние ссылки попали в выдачу поисковиков.
Я хочу вам сегодня показать несколько достаточно простых способов, как можно закрыть сайт от индексации.
Как закрыть сайт от индексации в WordPress?
Данный способ, наверное, самый простой, и владельцам сайтов, которые созданы на базе CMS WordPress, очень повезло. Дело в том, что в данной CMS предусмотрена возможность закрытия сайта от индексации при установке движка на хостинг. В случае если вы не сделали этого при установке, вы всегда можете это сделать в настройках. Для этого вам нужно:
- 1.В админпанели переходим в раздел «Настройки» → «Чтение».
- 2.Перелистываем открывшуюся страницу в самый низ, и отмечаем галочкой опцию показанную на скриншоте:

- 3.Сохраняем изменения.

Все. Теперь ваш сайт не будет индексироваться. Если открыть страницу в браузере и нажать комбинацию клавиш CTRL+U, мы сможем просмотреть код страницы, и увидим вот такую строку кода:

Данная запись была добавлена автоматически, после того как мы включили опцию запрета индексации в настройках.
Главное не забыть отключить эту опцию после завершения работ:)
Как закрыть сайт от индексации name=»robots»?
Данный способ заключается в самостоятельном добавлении записи, показанной на предыдущем скриншоте. Данный вариант подойдет для тех сайтов, которые создаются без использования CMS.
Вам всего лишь нужно в начале каждой страницы, перед закрытием тега </head> добавить эту запись:
<meta name=’robots’ content=’noindex,follow’ />
<meta name=’robots’ content=’noindex,follow’ /> |
В поле content можно задать следующие условия:
Запрещающие условия:
- none – запрет для страниц и ссылок;
- noindex – запрет для страниц;
- nofollow – запрещает индексацию ссылок на странице;
Разрещающие условия:
- all – разрешает индексацию страниц и ссылок;
- index — разрешает индексацию страниц;
- follow – разрешает индексацию ссылок на странице;
Зная данный набор условий, мы можем составить альтернативную запись для полного запрета для сайта и ссылок на нем. Выглядеть она будет вот так:
<meta name=’robots’ content=’none’ />
<meta name=’robots’ content=’none’ /> |
Как закрыть сайт от индексации в robots.txt?
Показанные выше варианты закрытия сайта от индексации работают для всех поисковиков, а это бывает не всегда нужно. Так же, предыдущий способ достаточно неудобен в случае, если ваш ресурс состоит из большого количества страниц, и каждую из них нужно закрыть от индексации.
В этом случае лучше воспользоваться еще одним способом закрытия сайта от индексации. Данный вариант дает нам возможность более гибко закрывать от индексации не только сайт в целом, но и отдельные страницы, медиафайлы и папки.
Для полного закрытия от индексации вам нужно создать в редакторе кода NotePad++ файл с названием robots.txt и разместить в нем такую запись:
User-agent: * Disallow: /
User-agent со значением * означает, что данное правило предназначено для всех поисковых роботов. Так же вы можете запретить индексацию для какой-то поисковой системы в отдельности. Для этого в User-agent указываем имя конкретного поискового робота. Например:
В этом случае запись будет работать только для Яндекса.
Обратите внимание. В строке User-agent может быть указан только один поисковый робот, и соответственно директивы Disallow, указанные ниже будут работать только для него. Если вам нужно запретить от индексацию в нескольких ПС, то вам нужно это сделать по отдельность для каждой. Например:User-agent: Googlebot Disallow: / User-agent: Yandex Disallow: /
User-agent: Googlebot Disallow: /
User-agent: Yandex Disallow: / |
Так же, директива Disallow позволяет закрывать отдельные элементы. Данная директива указывается отдельно для каждого закрываемого элемента. Например:
User-agent: Yandex Disallow: *.jpg Disallow: /about-us.php
User-agent: Yandex Disallow: *.jpg Disallow: /about-us.php |
Здесь для поискового робота Yandex закрыты для индексации все изображение с расширением .jpg и страница /about-us.php.
Каждый из показанных приемов удобен по своему в зависимости от сложившейся ситуации. Надеюсь у меня получилось достаточно подробно рассказать вам о способах закрытия сайта от индексации, и данный вопрос у вас не вызовет трудностей в будущем.
Если данная информация была для вас полезно, обязательно оставьте свой комментарий под статьей и поделитесь ею в социальных сетях.
Желаю вам успехов в создании сайтов. До встречи в следующих статьях!
С уважением Юлия Гусарь
Правильный файл robots.txt для сайта
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример:
User-agent: Yandex Allow: / sitemap: https://example.com/site_structure/my_sitemaps1.xml sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Crawl-delay
Директива работает только с роботом Яндекса.
Если сервер сильно нагружен и не успевает отрабатывать запросы робота, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Перед тем, как изменить скорость обхода сайта, выясните к каким именно страницам робот обращается чаще.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот обращается к служебным страницам, запретите их индексирование в файле robots.txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
Директива Clean-param
Директива работает только с роботом Яндекса.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex
Disallow:
Clean-param: ref /some_dir/get_book.plробот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&..&pn] [path]В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.phpозначает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php
Clean-param: sid&sort /forum/*.php
Clean-param: someTrash&otherTrashДиректива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads Sitemap: http://site.ru/sitemap.xml # адрес карты сайтаUser-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично
Robots.txt пример для Joomla
User-agent: *Disallow: /administrator/Disallow: /cache/Disallow: /includes/Disallow: /installation/Disallow: /language/Disallow: /libraries/Disallow: /media/Disallow: /modules/Disallow: /plugins/Disallow: /templates/Disallow: /tmp/Disallow: /xmlrpc/Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для Bitrix
User-agent: *Disallow: /*index.php$Disallow: /bitrix/Disallow: /auth/Disallow: /personal/Disallow: /upload/Disallow: /search/Disallow: /*/search/Disallow: /*/slide_show/Disallow: /*/gallery/*order=*Disallow: /*?print=Disallow: /*&print=Disallow: /*register=Disallow: /*forgot_password=Disallow: /*change_password=Disallow: /*login=Disallow: /*logout=Disallow: /*auth=Disallow: /*?action=Disallow: /*action=ADD_TO_COMPARE_LISTDisallow: /*action=DELETE_FROM_COMPARE_LISTDisallow: /*action=ADD2BASKETDisallow: /*action=BUYDisallow: /*bitrix_*=Disallow: /*backurl=*Disallow: /*BACKURL=*Disallow: /*back_url=*Disallow: /*BACK_URL=*Disallow: /*back_url_admin=*Disallow: /*print_course=YDisallow: /*COURSE_ID=Disallow: /*?COURSE_ID=Disallow: /*?PAGENDisallow: /*PAGEN_1=Disallow: /*PAGEN_2=Disallow: /*PAGEN_3=Disallow: /*PAGEN_4=Disallow: /*PAGEN_5=Disallow: /*PAGEN_6=Disallow: /*PAGEN_7=Disallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*PAGE_NAME=searchDisallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*SHOWALLDisallow: /*show_all=Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для MODx
User-agent: *Disallow: /assets/cache/Disallow: /assets/docs/Disallow: /assets/export/Disallow: /assets/import/Disallow: /assets/modules/Disallow: /assets/plugins/Disallow: /assets/snippets/Disallow: /install/Disallow: /manager/Sitemap: http://site.ru/sitemap.xml
Robots.txt пример для Drupal
User-agent: *Disallow: /database/Disallow: /includes/Disallow: /misc/Disallow: /modules/Disallow: /sites/Disallow: /themes/Disallow: /scripts/Disallow: /updates/Disallow: /profiles/Disallow: /profileDisallow: /profile/*Disallow: /xmlrpc.phpDisallow: /cron.phpDisallow: /update.phpDisallow: /install.phpDisallow: /index.phpDisallow: /admin/Disallow: /comment/reply/Disallow: /contact/Disallow: /logout/Disallow: /search/Disallow: /user/register/Disallow: /user/password/Disallow: *register*Disallow: *login*Disallow: /top-rated-Disallow: /messages/Disallow: /book/export/Disallow: /user2userpoints/Disallow: /myuserpoints/Disallow: /tagadelic/Disallow: /referral/Disallow: /aggregator/Disallow: /files/pin/Disallow: /your-votesDisallow: /comments/recentDisallow: /*/edit/Disallow: /*/delete/Disallow: /*/export/html/Disallow: /taxonomy/term/*/0$Disallow: /*/edit$Disallow: /*/outline$Disallow: /*/revisions$Disallow: /*/contact$Disallow: /*downloadpipeDisallow: /node$Disallow: /node/*/track$Disallow: /*&Disallow: /*%Disallow: /*?page=0Disallow: /*sectionDisallow: /*orderDisallow: /*?sort*Disallow: /*&sort*Disallow: /*votesupdownDisallow: /*calendarDisallow: /*index.phpAllow: /*?page=Disallow: /*?Sitemap: http://путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, понадобиться закрыть от индексации другие страницы. В зависимости от цели, запрет на индексацию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
Сделать это можно при помощи специального инструмента от Яндекс — Яндекс.Вебмастер, еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список — выберите Анализ robots.txt или по ссылке http://webmaster.yandex.ru/robots.xml

Вариант 2:
Этот вариант подразумевает, что ваш сайт добавлен в Яндекс Вебмастер и в корне сайта уже есть robots.txt.
Слева выберите Инструменты — Анализ robots.txt

Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь некоторое время.
Проверка robotx.txt для поискового робота Google
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- В Google Search Console выберите ваш сайт, перейдите к инструменту проверки и просмотрите содержание файла
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования. - Внизу на странице интерфейса укажите нужный URL в соответствующем окне.
- В раскрывающемся меню справа выберите робота.
- Нажмите кнопку ПРОВЕРИТЬ.
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН. В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в меню и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл robots.txt на вашем веб-сервере.

Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru.С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru.В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots.txt и загрузить в корневой каталог вашего сайта.
Настройка robots.txt – как узнать, какие страницы необходимо закрывать от индексации
Файл robots.txt представляет собой набор директив (набор правил для роботов), с помощью которых можно запретить или разрешить поисковым роботам индексирование определенных разделов и файлов вашего сайта, а также сообщить дополнительные сведения. Изначально с помощью robots.txt реально было только запретить индексирование разделов, возможность разрешать к индексации появилась позднее, и была введена лидерами поиска Яндекс и Google.
Структура файла robots.txt
Сначала прописывается директива User-agent, которая показывает, к какому поисковому роботу относятся инструкции.
Небольшой список известных и частоиспользуемых User-agent:
- User-agent:*
- User-agent: Yandex
- User-agent: Googlebot
- User-agent: Bingbot
- User-agent: YandexImages
- User-agent: Mail.RU
Далее указываются директивы Disallow и Allow, которые запрещают или разрешают индексирование разделов, отдельных страниц сайта или файлов соответственно. Затем повторяем данные действия для следующего User-agent. В конце файла указывается директива Sitemap, где задается адрес карты вашего сайта.
Прописывая директивы Disallow и Allow, можно использовать специальные символы * и $. Здесь * означает «любой символ», а $ – «конец строки». Например, Disallow: /admin/*.php означает, что запрещается индексация индексацию всех файлов, которые находятся в папке admin и заканчиваются на .php, Disallow: /admin$ запрещает адрес /admin, но не запрещает /admin.php, или /admin/new/ , если таковой имеется.
Если для всех User-agent использует одинаковый набор директив, не нужно дублировать эту информацию для каждого из них, достаточно будет User-agent: *. В случае, когда необходимо дополнить информацию для какого-то из user-agent, следует продублировать информацию и добавить новую.
Пример robots.txt для WordPress:

*Примечание для User agent: Yandex
-
Для того чтобы передать роботу Яндекса Url без Get параметров (например: ?id=, ?PAGEN_1=) и utm-меток (например: &utm_source=, &utm_campaign=), необходимо использовать директиву Clean-param.
-
Ранее роботу Яндекса можно было сообщить адрес главного зеркала сайта с помощью директивы Host. Но от этого метода отказались весной 2018 года.
-
Также ранее можно было сообщить роботу Яндекса, как часто обращаться к сайту с помощью директивы Crawl-delay. Но как сообщается в блоге для вебмастеров Яндекса:
- Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay.
- Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Вместо этой директивы в Яндекс. Вебмастер добавили новый раздел «Скорость обхода».

Проверка robots.txt
Старая версия Search console
Для проверки правильности составления robots.txt можно воспользоваться Вебмастером от Google – необходимо перейти в раздел «Сканирование» и далее «Просмотреть как Googlebot», затем нажать кнопку «Получить и отобразить». В результате сканирования будут представлены два скриншота сайта, где изображено, как сайт видят пользователи и как поисковые роботы. А ниже будет представлен список файлов, запрет к индексации которых мешает корректному считыванию вашего сайта поисковыми роботами (их необходимо будет разрешить к индексации для робота Google).

Обычно это могут быть различные файлы стилей (css), JavaScript, а также изображения. После того, как вы разрешите данные файлы к индексации, оба скриншота в Вебмастере должны быть идентичными. Исключениями являются файлы, которые расположены удаленно, например, скрипт Яндекс.Метрики, кнопки социальных сетей и т.д. Их у вас не получится запретить/разрешить к индексации. Более подробно о том, как устранить ошибку «Googlebot не может получить доступ к файлам CSS и JS на сайте», вы читайте в нашем блоге.
Новая версия Search console
В новой версии нет отдельного пункта меню для проверки robots.txt. Теперь достаточно просто вставить адрес нужной страны в строку поиска.

В следующем окне нажимаем «Изучить просканированную страницу».

Далее нажимаем ресурсы страницы

В появившемся окне видно ресурсы, которые по тем или иным причинам недоступны роботу google. В конкретном примере нет ресурсов, заблокированных файлом robots.txt.

Если же такие ресурсы будут, вы увидите сообщения следующего вида:

Рекомендации, что закрыть в robots.txt
Каждый сайт имеет уникальный robots.txt, но некоторые общие черты можно выделить в такой список:
- Закрывать от индексации страницы авторизации, регистрации, вспомнить пароль и другие технические страницы.
- Админ панель ресурса.
- Страницы сортировок, страницы вида отображения информации на сайте.
- Для интернет-магазинов страницы корзины, избранное. Более подробно вы можете почитать в советах интернет-магазинам по настройкам индексирования в блоге Яндекса.
- Страница поиска.
Это лишь примерный список того, что можно закрыть от индексации от роботов поисковых систем. В каждом случае нужно разбираться в индивидуальном порядке, в некоторых ситуациях могут быть исключения из правил.
Заключение
Файл robots.txt является важным инструментом регулирования отношений между сайтом и роботом поисковых систем, важно уделять время его настройке.
В статье большое количество информации посвящено роботам Яндекса и Google, но это не означает, что нужно составлять файл только для них. Есть и другие роботы – Bing, Mail.ru, и др. Можно дополнить robots.txt инструкциями для них.
Многие современные cms создают файл robots.txt автоматически, и в них могут присутствовать устаревшие директивы. Поэтому рекомендую после прочтения этой статьи проверить файл robots.txt на своем сайте, а если они там присутствуют, желательно их удалить. Если вы не знаете, как это сделать, обращайтесь к нам за помощью.
Как закрыть сайт от индексации в robots.txt, через htaccess и мета-теги
Привет уважаемые читатели seoslim.ru! Некоторые пользователи интернета удивляются, какими же быстродействующими должны быть компьютеры Яндекса, чтобы в несколько секунд просмотреть все сайты в глобальной сети и найти ответ на вопрос?
Но на самом деле за пару секунд изучить все данные WWW не способна ни одна современная, даже самая мощная вычислительная машина.
Давайте сегодня пополним наши знания о всемирной сети и разберемся, как поисковые машины ищут и находят ответы на вопросы пользователей и каким образом можно им запретить это делать.
Что такое индексация сайта
Опубликованный на страницах сайтов контент собирается заранее и хранится в базе данных поисковой системы.
Называется эта база данных Индексом (Index), а собственно процесс сбора информации в сети с занесением в базу ПС называется «индексацией».
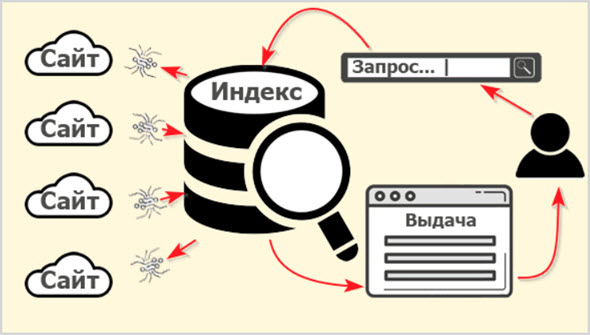
Продвинутые пользователи мгновенно сообразят, получается, что если текст на странице сайта не занесен в Индекс поисковика, так эта информация не может быть найдена и контент не станет доступен людям?
Так оно и есть. Каждый день тысячи веб-мастеров публикуют на своих площадках новые статьи. Однако доступными для поиска эти новые публикации становятся далеко не сразу.
Это полезно знать: Какую роль в работе сайта играют DNS-сервера
В плане индексации Google работает несколько быстрее нашего Яндекса.
- Публикация на сайте станет доступна в поиске Гугл через несколько часов. Иногда индексация происходит буквально в считанные минуты.
- В Яндексе процесс сбора информации относительно нового контента в интернете происходит значительно медленнее. Иногда новая публикация на сайте или блоге появляется в Яндексе через две недели.
Чтобы ускорить появление вновь опубликованного контента, администраторы сайтов могут вручную добавить URL новых страниц в инструментах Яндекса для веб-мастеров. Однако и это не гарантирует, что новая статья немедленно появится в интернете.
С другой стороны, бывают ситуации, когда веб-страница или отдельная часть контента уже опубликованы на сайте, но вот показывать этот контент пользователям нежелательно по каким-либо причинам.
- Страница еще не полностью доработана, и владелец сайта не хочет показывать людям недоделанный продукт, поскольку это производит негативное впечатление на потенциальных клиентов.
- Существует разновидностей технического контента, который не предназначен для широкой публики. Определенная информация обязательно должна быть на сайте, но вот видеть ее обычным людям пользователям не нужно.
- В статьях размещаются ссылки и цитаты, которые необходимы с информационной точки зрения, но вот находиться в базе данных поисковой системы они не должны. Например, эти ссылки выглядят как неестественные и за их публикацию в проект может быть подвергнут штрафным санкциям.
В общем, причин, почему веб-мастеру не хотелось бы, чтобы целые веб-страницы или отдельные блоки контента, ссылки не были занесены в базы поисковиков, может существовать много.
Давайте разберемся, как задачу управления индексацией решить практически.
Как скрыть сайт от индексации поисковыми системами
Сбором информации в интернете и занесением его в базу данных поисковой системы занимаются автоматические программы, называемые роботами-индикаторами. Веб-мастера часто называют этих роботов сокращенно «ботами».
Слово «боты» вы могли уже встречать в различных мессенджерах. В этих системах быстрой коммуникации боты тоже являются компьютерными программами, выполняющими определенные функции или задачи.
Так вот, для того, чтобы роботы-индексаторы не занесли определенные веб-страницы или контент в Index поисковика, следует сформировать специальные команды, которые указывают ботам, что некоторые страницы на сайте посещать запрещено, а некоторый контент не следует заносить в поисковые базы.
Настроить команды запрета индексации можно несколькими способами, которые мы и рассмотрим ниже.
Запрет в robots.txt
В корневой папке сайта на удаленном сервере хостинг-провайдера имеется файл с именем robots.txt.
- Что такое корневая папка сайта? Корневая папка или каталог – это то место, которому в первую очередь производится запрос из браузера, когда пользователь обращается к какому-нибудь ресурсу в интернете. То есть, это исходная папка с которой начинаются все запросы к веб-ресурсу.
- Файл robots.txt – это пакетный командный файл, в котором содержатся директивы для ПС, ответственных за индексацию контента.
Говоря простыми словами, robots.txt это специальный файл, предназначенный для поисковых роботов. Что, собственно, понятно из самого имени документа – Robots, что означает «роботы».
Отредактировать файл с командами для роботов ПС можно вручную в простом текстовом редакторе, добавить или удалить команды, изменить отдельные записи.
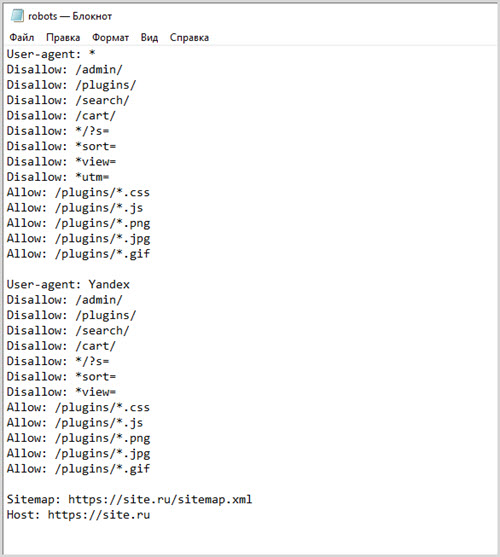
У каждой поисковой системы действует множество роботов, которые ответственны за индексацию разного рода контента. Отдельные роботы ищут и заносят в базу изображения, текст, скрипты и все остальное, что только может иметь значение для нормальной работы интернет-проекта.
Роботов индексаторов довольно много, перечислим только некоторых из них:
- Yandex – главный робот, ответственный за индексацию проекта в поисковой системе Яндекс.
- YaDirectBot – робот, ответственный за индексацию веб-страниц, на которых опубликована реклама контекстной системы Яндекс Директ.
- Yandex/1.02.000 (F) – робот, занимающийся индексации фавиконов, иконок сайта, которые пользователь видит во вкладках браузера и в сниппетах на странице выдачи.
- Yandex Images – индексация изображений.
Как вы понимаете, директивы или команды следует задавать для каждого конкретного робота в том случае, если вы желаете задать правила поведения индексация индексируемых роботов в отношении определенного типа контента.
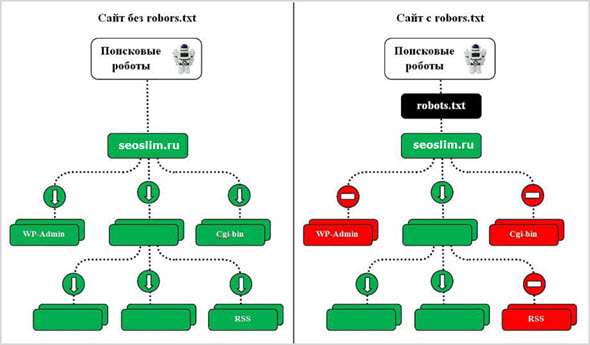
Если же необходимо задать правила индексации для всей поисковой системы, тогда в файле robots.txt прописывается директива для главного робота.
В поисковой системе Google работают свои роботы:
- Googlebot – основной бот Google.
- Googlebot Video – сбор информации о видеороликах, размещенных на площадке.
- Googlebot Images – индексация картинок.
А теперь давайте рассмотрим, как выглядят сами директивы или команды для поисковых роботов.
- Команда User-agent: определяет, какому конкретному роботу предназначена директива. Если в этой команде указана звездочка * – это означает что команда предназначена для всех, любых поисковых роботов.
- Команда Disallow означает запрет индексации, а команда Allow означает разрешение индексации.
Например, команда User-agent: Yandex задает правила поведения для всех поисковых роботов Яндекса. Если юзер-агент не задан, то команды будут действовать для всех поисковых систем.
В общем-то, для того, чтобы вручную редактировать файл robot.txt, не нужно быть опытным программистам.
В профессиональных конструкторах сайтов и системах управления контентом обычно предусмотрен отдельный интерфейс для настройки файла robots.txt. Знать конкретные названия поисковых роботов и разбираться в директивах необходимости нет. Достаточно указать то, что вам нужно в самом файле.
Рассмотрим для примера некоторые команды.
- User-agent: *
- Disallow: /
Эта директива запрещает обход проекта любым роботам всех поисковых систем. Если же будет указана директива Allow — сайт открыт для индексации.
Следующая команда запрещает обход всем поисковым системам, кроме Яндекса.
- User-agent: *
- Disallow: /
- User-agent: Yandex
- Allow: /
Чтобы запретить индексацию только отдельных страниц, создается вот такая команда – запрет на обход страниц «Контакты» и «О компании».
- User-agent: *
- Disallow: /contact/
- Disallow: /about/
Закрыть целый отдельный каталог сайта:
- User-agent: *
- Disallow: /catalog/
Закрыть папку с картинками:
Не индексировать файлы с указанным расширением:
- User-agent: *
- Disallow: /*.jpg
Различных команд, с помощью которых можно управлять поисковыми роботами, существует достаточно много. Веб-мастер может в широких пределах регулировать схему индексации веб-страниц и отдельных типов контента.
Запрет индексации через htaccess
На серверах Apache для управления доступом используется файл .htaccess (hypertext access).
Особенностью функционирования этого файла является то, что его команды распространяются только на папку или каталог, в которых этот файл размещен. Если этот файл помещается в корневой каталог, то его директивы будут действовать на весь ресурс.
Возникает логичный вопрос, зачем использовать более сложный .htaccess, если задать порядок индексации можно в файле robots.txt?
Дело в том, что далеко не все роботы не всех поисковых систем подчиняются команда файла robots.txt. Зачастую поисковые роботы просто игнорируют этот файл.
С другой стороны, директивы .htaccess являются всеобъемлющими по отношению к сайтам, размещенным на серверах типа Apache.
Хотя файл .htaccess тоже является текстовым и может быть отредактирован веб-мастером в простом редакторе, настройка этого файла скорее является прерогативой опытных специалистов техподдержки хостинг-провайдера. Поскольку команд у него намного больше и неопытному человеку очень легко допустить критические ошибки, которые приведут к неправильной работе проекта.
Следующая команда предназначена для запрета индексации сайта определенным поисковым роботам:
SetEnvIfNoCase User-Agent
Далее прописывается конкретный робот поисковой системы.
Для каждого робота команда прописывается отдельной строкой.
SetEnvIfNoCase User-Agent «^Yandex» search_bot
SetEnvIfNoCase User-Agent «^Googlebot» search_bot
Как вы могли заметить, хотя .htaccess является простым текстовым файлом, он не имеет расширения txt, а должен иметь именно указанный формат, в противном случае сервер его не распознает.
С помощью админ панели WordPress
Зайдите в административную панель своего блога на WordPress и выберите раздел «Настройки». Нажмите на пункт Меню «Чтение».
После перехода в интерфейс «Чтение», вы найдете следующие возможности для настройки индексации.
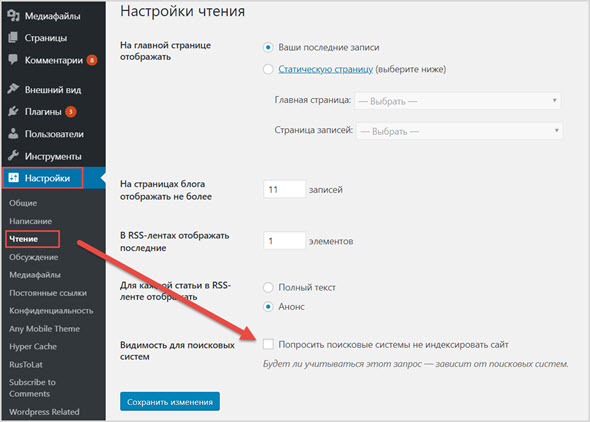
Отметьте пункт «Попросить поисковые системы не индексировать сайт», если не хотите, чтобы контент был доступен в открытом интернете. Не забудьте сохранить изменения.
Как видите, при помощи админ панели WordPress можно сделать только общие запреты или разрешения. Для более тонких настроек индексации следует использовать файл robots.txt и .htaccess.
С помощью meta-тега
Управлять индексацией можно и с помощью тегов в HTML-документе веб-страницы.
Директивы добавляются в файле header.php в контейнере <head> … </head>.
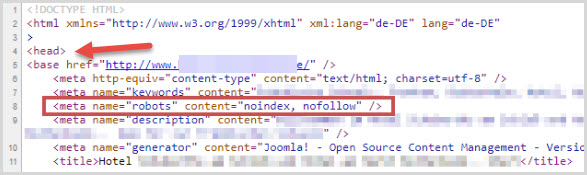
Команда выглядит следующим образом:
<meta name=”robots” content=”noindex, nofollow”/>
Это означает, что поисковым роботам запрещается индексация контента. Если вместо robots указа точное имя бота определенной поисковой машины, то запрет будет касаться только ее роботов.
На этом все, как видите существует много методов, которые позволят скрыть площадку от поисковых систем. Какой использовать вам, решайте сами.
Только помните, что проанализировать правильность директив относительно индексации сайта можно с помощью инструментов Яндекса для веб-мастеров либо через SEO-сервисы.
Как гарантированно закрыть весь сайт от индексации
 Использование метатега robots для блокирования доступа к сайту
Использование метатега robots для блокирования доступа к сайту
Часто по разным причинам веб разработчику требуетсязакрывать сайт от индексации поисковыми системами. Вы меняете дизайн сайта и не хотите, чтобы вашиэксперименты попали в индекс поисковых систем, либовы создаёте новый сайт или меняете платформу и вам также не нужны не завершенные страницы в индексе, общем, причин много. Большинство уверены, что с помощью файла Robots.txt содержащего следующуюзапись они гарантированно закрывают свой сайт отиндексации
User-agent: *
Disallow: /
Будьте уверены, это не так! Если вы используете Robots.txt для скрытия от индекса не удивляйтесь, если вопреки всему он там появится. Причин этому не мало. Гугл индексирует все, что ему вздумается, не смотря на запреты в robots.txt
Выдержка из справки для веб-мастеров от Google:
Хотя Гугл не сканирует и не индексирует контент страниц, заблокированных в файле robots.txt, URL-адреса, обнаруженные на других страницах в Интернете, по-прежнему могут добавляться в индекс. В результате URL страницы, а также другие сведения, например текст ссылок на сайт или заголовок из каталога Open Directory Project (dmoz.org), могут появиться в результатах основного поиска Google.
У Яндекса принцип несколько другой и конечно отличается от гугловского, все страницы закрытые через Robots.txt, не попадают в основной индекс Яндекса, но роботом просматриваются и загружаются.
Из руководства для веб-мастеров от Яндекса:
В разделе «Исключённые страницы» отображаются страницы, к которым обращался робот, но по тем или иным причинам принял решение не индексировать их. В том числе, это могут быть уже несуществующие страницы, если ранее они были известны роботу. Информация об причинах исключения из индекса хранится в течение некоторого времени, пока робот продолжает их проверять. После этого, если страницы по-прежнему недоступны для индексирования и на них не ведут ссылки с других страниц, информация о них автоматически удаляется из раздела «Исключённые страницы».
Обобщая всё вышеперечисленное: закрытые в текстовом файле роботс страницы не попадают в основной индекс но загружаются и просматриваются поисковиками, в Гугле они доступны при изучении дополнительной выдачи (supplemental). Поисковики не будут напрямую индексировать содержимое, указанное в файле robots.txt, однако могут найти эти страницы по ссылкам с других сайтов. Из-за чего в результатах поиска появятся URL и другие общедоступные сведения – например, текст ссылок на сайт.
Какой выход спросите Вы? А выход очень простой:
Закрыть весь сайт от индексации
Данный метод позволит гарантированно исключить вероятность появления контента страницы в индексе Гугл, даже если на нее ссылаются другие сайты.
Выдержка из руководства от Гугл:
Чтобы полностью исключить вероятность появления содержимого страницы в индексе Гугл, даже если на нее ссылаются другие сайты, используйте метатег noindex. Если робот Googlebot станет сканировать страницу, то обнаружит метатег noindex и не будет отображать ее в индексе.
Для чего необходимо на всех страницах, которые необходимо закрыть от индексации, поместить метатег
<meta name="robots" content="noindex,nofollow">
внутри тега <head> </head>.
Важно, эти самые страницы не должны быть закрыты через robots.txt!
Во время разраборки сайта веб-мастеру зачастую необходимо закрыть от индексации весь сайт за исключением главной, для того чтобы уже во время разработки и наполнения поисковые системы могли узнать о существовании сайта. В этом случае вам достаточно разместить метатег «роботс» на всех страницах за исключением главной.
Если Вам понадобится закрыть сайт от индекса только одной поисковой системы, например Google, то вам следует внутри тега <head> </head> разместить следующий код:
<meta name="googlebot" content="noindex">
Если после добавления в код тега «robots» страница всеже находится в индексе поиска, то это значит, что поисковый робот еще не просканировал её и не нашел метатег "noindex"
Комментарии
Sandeebok replied on вс, 20/03/2016 — 21:17
ПОИСКОВОЕ ПРОДВИЖЕНИЕ САЙТОВ SEO
продвижение сайтов дешево mail ru создание и раскрутка сайтов россия продвижение игровых сайта шаг за шагом оптимизация seo продвижение сайта в сети интернет создание и продвижение сайтов и интернет магазинов правила раскрутки сайта раскрутка сайтов в Могилеве продвижение сайтов онлайн раскрутка сайтов в РБ продвижение игровых сайтов обучение
ответить
logikanegix replied on вт, 19/07/2016 — 16:52
ИНТЕРЕСНАЯ СТАТЬЯ
Приветствую всех.
Может не к теме разговора, извините.
Случайно наткнулась на, на мой взгляд, представляющую интерес публикацию.
Спасибо.
ответить
Виктор replied on вс, 13/11/2016 — 04:33
ПРЕДСТАВЛЕНИЕ ТАКСОНОМИИ
perdos.info/video/bolshie_popki_video/telka_s_klassnoj_zadnitsej_trahaetsya
ответить
Петя replied on сб, 07/04/2018 — 14:58
ПУПКИН
<a href=»https://kapriz-online.by»>Доска бесплатных объявлений!</a>