JavaScript виджет таблица (Grid) – Webix HTML DataTable
Редактируйте данные
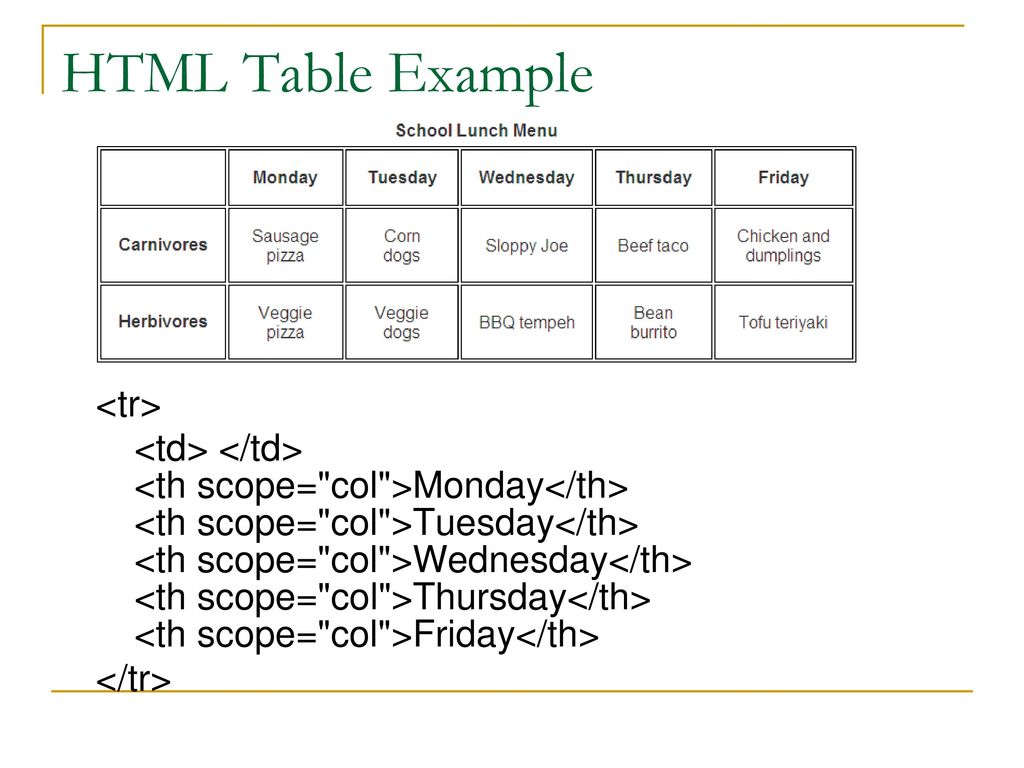
JavaScript таблица позволяет легко вводить новые данные. По щелчку на любую ячейку, вы можете легко редактировать ее содержимое с помощью ввода нового значения в поле или выбрав значение из выпадающего списка.
Щелкните по любой ячейке, чтобы отредактировать значение в ней
Сортируйте данные
Все строки таблицы можно сортировать в один щелчок по заголовку колонки. Вы можете использовать функцию сортировки DataTable, чтобы определить свой собственный критерий для упорядочивания данных.
Щелкните по заголовку любой колонки, чтобы отсортировать данные в таблице
Фильтруйте данные
Строки таблицы можно отфильтровать с помощью встроенных фильтров, помещаемых в заголовки колонок. Вы можете использовать функцию фильтрации DataTable, чтобы задать свои критерии для поиска данных.
Валидация
JavaScript Table позволяет вам проверять вводимые данные. Используя валидацию, вы можете проверить, соответствуют ли значения конкретных ячеек таблицы заданным правилам. Если нет, строка с неправильными данными будет подсвечена и пользователь получит уведомление об этом.
Если нет, строка с неправильными данными будет подсвечена и пользователь получит уведомление об этом.
Заполните пустые ячейки
Пейджинг
Если вы планируете загружать в DataTable большие данные, можно разбить таблицу на несколько страниц. Легко настраиваемые кнопки с номерами страниц и стрелками помогают с легкостью переходить между страницами.
Нажмите на кнопки, чтобы просмотреть другие страницы таблицы
Сохраняйте текущее состояние Data Table
Благодаря этому свойству, вы сможете хранить состояние DataTable в cookie-файлах, локальном или сессионном хранилище и затем восстанавливать его после обновления страницы. Информация обо всех действиях над данными в виджете будет сохраняться, благодаря чему пользователи не потеряют текущее состояние DataTable.
Измените состояние таблицы (измените ширину столбцов, примените фильтр, отсортируйте строки, покажите или спрячьте колонки) и затем обновите страницу
Drag-n-drop строк
Вы можете изменить порядок строк, перетаскивая их. Режим ‘order’ определяет возможность менять порядок строк в пределах одной таблицы. Если у вас на странице две таблицы, вы можете перетаскивать строки из одной таблицы в другую, в то время как номера строк первой таблицы изменятся соответственно. Дополнительная настройка позволит вам запретить перетаскивание отдельных строк, перетаскивание любых строк в определенные позиции в таблице и т.д.
Режим ‘order’ определяет возможность менять порядок строк в пределах одной таблицы. Если у вас на странице две таблицы, вы можете перетаскивать строки из одной таблицы в другую, в то время как номера строк первой таблицы изменятся соответственно. Дополнительная настройка позволит вам запретить перетаскивание отдельных строк, перетаскивание любых строк в определенные позиции в таблице и т.д.
Перетащите любую строку из одной таблицы в другую
Drag-n-drop колонок
Вы можете разрешить перетаскивание колонок в JavaScript таблице. В режиме ‘order’ вы сможете менять порядок строк в пределах одной таблицы.
Нажмите на хедер и удерживайте его, чтобы перетащить колонку
Работа с буфером обмена
Вы можете копировать данные из этого виджета в буфер обмена и вставлять их в другие виджеты или HTML-контейнеры. Работа с буфером обмена поддерживается во всех современных браузерах, включая Firefox, Opera, Chrome и Safari. Кроме того, вы можете копировать данные из DataTable в Excel-документ.
Используйте сочетания клавиш ‘Ctrl+C’ и ‘Ctrl+V’ для копирования и вставки содержимого ячеек
Изменяйте размеры колонок и строк
Вы можете изменять размеры колонок и строк, перетаскивая вертикальные или горизонтальные границы ячеек.
Наведите курсор на любую границу, затем перетащите ее
Фиксируйте строки и колонки
Вы можете создать DataTable с фиксированными колонками и строками, которые не будут перемещаться при прокрутке.
Прокрутите таблицу вправо
TreeTable
Разновидность виджета DataTable может отображать древовидные структуры данных подобно компоненту Tree. Виджет TreeTable позволяет создавать неограниченное число поддеревьев. Вы можете фильтровать данные в таких структурах по всему дереву или на конкретном уровне.
Выделение блоков ячеек
Кроме выделения ячейки, строки и колонки, вы можете выделять блоки ячеек. Кликните по первой ячейке из нужной вам области и протащите зажатый курсор дальше. Вы также можете использовать клавишу Shift чтобы выделить дополнительные ячейки.
Щелкните по любой ячейке и тяните курсор, чтобы выделить несколько ячеек
Дополнительные редакторы в Data Table
Вы можете добавлять более сложные редакторы для изменения данных в JavaScript Table: Multi-select, Grid Editor и DataView Editor. Редактор Multi-select позволяет выбирать несколько опций из списка, редактор Grid и DataView выводят доступные опции внутри виджетов DataTable и DataView соответственно.
Используйте редактор ‘richselect’ для изменения названий и ‘combo’ для изменения дат.
Дополнительные фильтры
С помощью функции фильтрации DataTable вы можете изменять содержимое таблицы, выбирая нужные значения из выпадающего списка (фильтры rich-select, multi-select) или выбирая даты во встроенном календаре.
Примените фильтры к таблице
Rowspan и colspan
Благодаря возможности объединять ячейки по горизонтали и вертикали, вы можете отображать сложные данные как в любой HTML таблице.
Меню заголовка таблицы
С помощью меню вы можете выбирать, какие колонки таблицы показывать.
Щелкните правой клавишей мыши по заголовку любой колонки.
Группировка колонок
Благодаря этому свойству пользователи Webix могут разворачивать или сворачивать колонки таблицы в один клик. Вы сами можете определять, какие колонки группировать и затем настраивать группировку.
Нажмите на ‘плюс’ и ‘минус’ в заголовке таблицы
Вертикальные заголовки
Вы можете размещать текст заголовков не только горизонтально, но и вертикально. Поворот текста в заголовке поможет вам сэкономить пространство в Data Table для другой информации.
Sparkline
Sparklines — это небольшие диаграммы, которые вы можете вставить в ячейки JavaScript Table. Доступны несколько видов Sparkline: линейная, двумерная, столбчатая диаграммы, Сплайн-диаграмма, Сплайн-диаграмма с областями и круговая диаграмма. Вы также можете добавить всплывающие подсказки (tooltip), которые появятся на экране, когда пользователь наведет курсор на диаграмму. Вы можете изменить цвета Sparklines. Кроме DataTable, Sparklines можно добавлять в другие виджеты, например, в List.
Вложенные строки и виджеты
В DataTable можно добавить вложенные строки и встроить другие виджеты. Они будут отображаться под каждой строкой таблицы. Содержимое вложенной строки можно задать с помощью template, а встроенным виджетом может быть любой Webix виджет. Вы можете сворачивать/разворачивать вложенные строки и виджеты по щелчку на иконку соответствующей строки таблицы.
Нажмите ‘плюс’, чтобы открыть вложенные строки и таблицы
Готовые шаблоны таблиц с формулами // УРОК ОТ ДЖУЛИИ /: mangiana_irina — LiveJournal
?<table><tr><td>Текст1</td><td>Текст2</t
| Текст1 | Текст2 |
Теперь добавим рамку к нашей таблице. Для этого нужно в тег <table> добавить border=»3″ Этот параметр определяет ширину бордюра таблицы. Усли нужна рамка толщиной 10 пиксель то 3 меняем на 10. А если мы хотим сделать нашу таблицу на каком-нибудь фоне, то добавим к таблице параметр background и укажем адрес нашего фона
Усли нужна рамка толщиной 10 пиксель то 3 меняем на 10. А если мы хотим сделать нашу таблицу на каком-нибудь фоне, то добавим к таблице параметр background и укажем адрес нашего фона
<table border=»3″ background=»http://s60.radikal.ru/i170/0905/cf/597b1b96c0fc.jpg»><tr><td>Текст1</td><td>Текст2</td>
| Текст1 | Текст2 |
Теперь создадим вот такую таблицу
| Первая строка. Текст1 | Первая строка. Текст2 |
| Последняя строка. Текст1 | Последняя строка. Текст2 |
| Текст1 | Текст2 |
<table border=»1″><thead align=»left»><tr><td>Первая строка. Текст1</td><td>Первая строка. Текст2</td></tr></thead><thead align=»right»><tr><td>Последняя cтрока. Текст1</td><td>Последняя строка. Текст2</td></tr></thead><tbody align=»center»><tr><td>Текст1</td><td>Те
Текст1</td><td>Последняя строка. Текст2</td></tr></thead><tbody align=»center»><tr><td>Текст1</td><td>Те
В первой строке текст размещен слева, в последней строке — справа, а в центральной строке — посередине
Таблица с заголовками
Тег <th> предназначен для создания одной ячейки таблицы, которая обозначается как заголовочная.
Располагается этот тег только внутри тега <tr>
<table border=»1″><tbody align=»center»><tr><th>Заголовок1</th><t
Заголовок1 | Заголовок2 |
|---|---|
| Текст1 | Текст2 |
Объеденим несколько ячеек таблицы. Для этого в теге <td> нужно указать colspan — объединяет горизонтальные ячейки, rowspan — вертикальные
Объеденим 2 ячейки первой строки в одну ячейку
| Текст1 | |
| Текст2 | Текст3 |
Объеденим 2 ячейки первого столбца в одну ячейку
<table border=»1″><tbody align=»center»><tr><td colspan=»1″ rowspan=»2″>Текст1</td><td>Текст2</td></t
| Текст1 | Текст2 |
| Текст3 |
Параметры тега <table> cellpadding — отступ от рамки до содержимого ячейки и cellspacing- расстояние между ячейками.
<table border=»1″ cellspacing=»10″ cellpadding=»30″><tbody align=»center»><tr><td>Текст1</td><td>Те
| Текст1 | Текст2 |
| Текст3 | Текст3 |
Желаю удачи!
Источник: blogs.mail.ru/mail/moisin/tag/%ef%ee%ec%e
****************************************
Таблица
<table border=»1″> <tr align=»center»><td>1 ячейка</td> <td>2 ячейка</td> <td>3 ячейка</td> </tr><tr align=»center»> <td>4 ячейка</td> <td>5 ячейка</td> <td>6 ячейка</td> </tr><tr align=»center»> <td>7 ячейка</td> <td>8 ячейка</td> <td>9 ячейка</td></tr></table></b></em></font>
Tags: #уроки, таблицы, уроки, шаблоны
SubscribeТАБЛИЦЫ ОТ ЭЛЕН ДАРСИ
ячейка 1 ячейка 2 ячейка 3 ячейка 4 ячейка 5 <table border=»1″><tr><td…
КАРТИНКИ В РЯД // формулы из инета /
2 картинки — <table border=»0″ cellspacing=»8″ cellpadding=»0″> <tr> <td> Картинка </td>…
РАЗБИВКА ТЕКСТА НА ДВЕ КОЛОНКИ
Если вам по каким-то причинам нужно разбить текст на две колонки, то можно воспользоваться вот этими формулами: <table…
УРОК ПО ТАБЛИЦАМ
Сегодня я расскажу Вам, о таблицах.
 Много говорят и пишут о них но мало кто понимает для чего они нужны..Мы обычно отмахиваемся от того что нам…
Много говорят и пишут о них но мало кто понимает для чего они нужны..Мы обычно отмахиваемся от того что нам…УРОК ПО ТАБЛИЦАМ
Сегодня мы поговорим не о том как выстроить в своем посте фото, картинки и разную разность..а о том как удобнее расположить в посте картинки и…
ТЕКСТ МЕЖДУ КАРТИНОК
Текст между двух картинок! По сути, это та же таблица, только без рамки. Итак, формула: <table align=center…
 Много говорят и пишут о них но мало кто понимает для чего они нужны..Мы обычно отмахиваемся от того что нам…
Много говорят и пишут о них но мало кто понимает для чего они нужны..Мы обычно отмахиваемся от того что нам…Photo
Hint http://pics.livejournal.com/igrick/pic/000r1edq
Вертикальная таблица HTML | Знаете, как создать вертикальную таблицу в HTML?
Обновлено 20 марта 2023 г.
В следующей статье представлен обзор вертикальной таблицы HTML. В таблице HTML каждая новая запись вставляется в виде строк и столбцов в базу данных. Строки считаются горизонтальными, а столбцы вертикальными в БД. Таблицы HTML действительно используются для представления информации для таких фреймворков, как Bootstrap; мы можем легко улучшить внешний вид стола. Таблицы используются для большинства приложений, таких как веб-приложения, настольные или мобильные приложения; также это важно для предоставления информации конечным пользователям. Использование фреймворка начальной загрузки и множества других функций для предоставления функций стилизации и оптимизации представления для различных элементов, таких как таблицы.
Таблицы используются для большинства приложений, таких как веб-приложения, настольные или мобильные приложения; также это важно для предоставления информации конечным пользователям. Использование фреймворка начальной загрузки и множества других функций для предоставления функций стилизации и оптимизации представления для различных элементов, таких как таблицы.
Как создать вертикальную таблицу в HTML?
В общем мы создали таблицу с помощью тегов
| , | . В этом | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| указывает заголовки таблиц, | указывает значения в HTML. Мы видели несколько примеров ниже:Пример#1Код:
<голова>
<стиль>
стол, т, тд {
граница: 1px сплошной черный;
граница коллапса: коллапс;
}
й, тд {
отступ: 5px;
выравнивание текста: по левому краю;
}
<тело>
<таблица>
|

 По умолчанию опция вертикальной прокрутки включена для табличных данных. Мы также включили параметры горизонтальной прокрутки, если это необходимо.
По умолчанию опция вертикальной прокрутки включена для табличных данных. Мы также включили параметры горизонтальной прокрутки, если это необходимо.
Мы видели границы для приведенных выше примеров; это регламентированная граница; мы также используем некоторые другие границы, такие как пунктирная линия и т. д.
Как центрировать изображение по вертикали в HTML?
Мы также выравниваем изображения по вертикали для HTML; используя стиль CSS, мы должны назначить настройки в теге стиля, и мы отобразили изображение в вертикальном режиме.
Код:
<тело bgcolor="#ffffff"> <центр> <таблица bgcolor="#a3ddc4"><тд выравнивание = "центр"> <таблица bgcolor="#ff6f6f"> <центр>
Вывод:
В приведенном выше примере показано, что изображение находится в вертикальном режиме; мы также меняем ориентацию, если это необходимо.
Внешние и внутренние ячейки HTML-таблицы наследуют значение по умолчанию для выравнивания атрибутов родительской и дочерней строк таблицы. Он также выводит значение по умолчанию для использования атрибутов valign во внешней таблице HTML с помощью тега
, даже иногда тег тела также не используется, и это значение времени находится посередине, поэтому, если заблокированное содержимое внутри ячейки внешнего HTML таблица будет автоматически выровнена по центру по вертикали в области веб-браузеров. Использование 
Если мы используем внутреннюю таблицу для HTML, это та, которая находится внутри ячеек внешней таблицы HTML. Он может не устанавливать высоту и ширину таблиц. Затем размер регулируется автоматически, чтобы вместить содержимое, независимо от того, какие размеры мы установили. Если ширина и высота большие, это означает, что области веб-браузера будут автоматически отображаться в центре.
В приведенном выше примере иногда будет выделяться тег , чтобы изображение не отображалось в IE версии 3. Несмотря на то, что мы также установили совместимость браузера в таблицах HTML.
Заключение
В таблицах HTML мы организовали данные и знаем, как семантически размещать табличные данные в HTML, а также проявлять инициативу с помощью стилей CSS. Мы также используем функции начальной загрузки, библиотеки Jquery с использованием Javascript для выделения и изменения порядка таблиц. Если нам нужно использовать плагины Jquery, у него есть много дополнительных функций для таблиц, например, если вы поместите курсор в ячейки таблицы, он автоматически подсветит цвета. Точно так же, если мы используем некоторые расширенные концепции, это может изменить форматы таблиц и выровнять данные.
Точно так же, если мы используем некоторые расширенные концепции, это может изменить форматы таблиц и выровнять данные.
Рекомендуемые статьи
Это руководство по вертикальной таблице HTML. Здесь мы обсудим основную концепцию, а также создадим и центрируем изображение в вертикальной таблице в HTML. Вы также можете ознакомиться со следующими статьями, чтобы узнать больше:
- Выпадающий список в HTML
- Полоса прокрутки в таблице HTML
- Граница таблицы в HTML
- Тег THad в HTML
Надежное руководство по извлечению HTML-таблиц с помощью Python
Табличные данные — один из лучших источников данных в Интернете. Они могут хранить огромное количество полезной информации, не теряя ее удобного для чтения формата, что делает их золотыми приисками для проектов, связанных с данными.
Будь то парсинг футбольных данных или извлечение данных фондового рынка, мы можем использовать Python для быстрого доступа, анализа и извлечения данных из HTML-таблиц благодаря Requests и Beautiful Soup.
Кроме того, в конце у нас есть для вас небольшой черно-белый сюрприз, так что продолжайте читать!
Понимание структуры таблицы HTML
Визуально таблица HTML представляет собой набор строк и столбцов, отображающих информацию в табличном формате. Для этого урока мы будем очищать таблицу выше:
Чтобы иметь возможность очистить данные, содержащиеся в этой таблице, нам нужно немного углубиться в ее кодирование.
Вообще говоря, HTML-таблицы создаются с использованием следующих HTML-тегов:
-
: Отмечает начало HTML-таблицы
или : Определяет строку в качестве заголовка таблицы: Указывает раздел, в котором находятся данные: указывает строку в таблице : определяет ячейку в таблице Однако, как мы увидим в реальных сценариях, не все разработчики соблюдают эти соглашения.
при построении своих таблиц, усложняя одни проекты по сравнению с другими. Тем не менее, понимание того, как они работают, имеет решающее значение для поиска правильного подхода.Давайте введем URL-адрес таблицы (https://datatables.net/examples/styling/stripe.html) в браузере и проверим страницу, чтобы увидеть, что происходит внутри.
Вот почему это отличная страница для практики извлечения табличных данных с помощью Python. Существует четкая пара тегов
, открывающая и закрывающая таблицу, и все соответствующие данные находятся внутри тега. Он показывает только десять строк, что соответствует количеству записей, выбранных во внешнем интерфейсе.
Еще несколько вещей, которые нужно знать об этой таблице: в ней всего 57 записей, которые мы хотим очистить, и, кажется, есть два решения для доступа к данным. Первый — щелкнуть раскрывающееся меню и выбрать «100», чтобы отобразить все записи:
Или нажмите на кнопку «Далее», чтобы перейти по нумерации страниц.
Так кто же будет? Любое из этих решений усложнит наш сценарий, поэтому вместо этого давайте сначала проверим, откуда берутся данные.
Конечно, поскольку это HTML-таблица, все данные должны быть в самом HTML-файле без необходимости внедрения AJAX. Чтобы убедиться в этом, Щелкните правой кнопкой мыши > Просмотр исходного кода страницы . Затем скопируйте несколько ячеек и найдите их в исходном коде.
Мы сделали то же самое еще для пары записей из разных ячеек с разбивкой на страницы, и да, кажется, что все наши целевые данные находятся там, хотя интерфейс их не отображает.
И с этой информацией мы готовы перейти к коду!
Очистка таблиц HTML с помощью Beautiful Soup Python
Поскольку все данные о сотрудниках, которые мы хотим очистить, находятся в файле HTML, мы можем использовать библиотеку Requests для отправки HTTP-запроса и анализа ответа с помощью Beautiful Soup.
Примечание: Если вы новичок в парсинге веб-страниц, мы создали руководство по парсингу веб-страниц в Python для начинающих.
Хотя вы сможете следовать без опыта, всегда полезно начинать с основ.1. Отправка нашего основного запроса
Давайте создадим новый каталог для проекта с именем python-html-table , затем новую папку с именем bs4-table-scraper и, наконец, создадим новый python_table_scraper.py файл.54
Из терминала давайте
pip3 установим запросы BeautifulSoup4и импортируем их в наш проект следующим образом:импорт запросов from bs4 import BeautifulSoup
Чтобы отправить HTTP-запросы с запросами, все, что нам нужно сделать, это установить URL-адрес и передать его через request.get(), сохранить возвращенный HTML в переменной ответа и вывести response.status_code.
Примечание. Если вы новичок в Python, вы можете запустить свой код из терминала с помощью команды python3 python_table_scraper.py.
url = 'https://datatables.net/examples/styling/stripe.html' ответ = запросы.get(url) print(response.
status_code)Если он работает, он вернет код состояния 200. Все остальное означает, что ваш IP-адрес отклоняется системами защиты от парсинга, установленными на веб-сайте. Потенциальным решением является добавление пользовательских заголовков в ваш сценарий, чтобы он выглядел более человечно, но этого может быть недостаточно. Другим решением является использование API парсинга веб-страниц, чтобы справиться со всеми этими сложностями за вас.
2. Интеграция ScraperAPI для предотвращения использования систем защиты от очистки данных
ScraperAPI — это элегантное решение, позволяющее избежать применения практически любых методов защиты от очистки данных. Он использует машинное обучение и многолетний статистический анализ для определения лучших комбинаций заголовков и IP-адресов для доступа к данным, обработки CAPTCHA и ротации вашего IP-адреса между каждым запросом.
Для начала давайте создадим новую бесплатную учетную запись ScraperAPI, чтобы активировать 5000 бесплатных API и наш ключ API.
С панели управления нашей учетной записи мы можем скопировать значение нашего ключа, чтобы создать URL-адрес запроса.http://api.scraperapi.com?api_key={Your_API_KEY}&url={TARGET_URL}Следуя этой структуре, мы заменяем держатели нашими данными и снова отправляем наш запрос:
запросы на импорт из bs4 импортировать BeautifulSoup url = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html' ответ = запросы.get(url) print(response.status_code)
Отлично, все работает без сбоев!
3. Создание синтаксического анализатора с помощью Beautiful Soup
Прежде чем мы сможем извлечь данные, нам нужно преобразовать необработанный HTML в отформатированные или проанализированные данные. Мы сохраним этот проанализированный HTML-код в объекте супа следующим образом:
soup = BeautifulSoup(response.text, 'html.parser')
Отсюда мы можем пройти по дереву синтаксического анализа, используя HTML-теги и их атрибуты.
Если мы вернемся к таблице на странице, мы уже увидим, что таблица заключена между
тегов с классом
полосы dataTable, которые мы можем использовать для выбора таблицы.стол = суп.найти('стол', class_ = 'полоса') print(table)Примечание: После тестирования добавление второго класса (dataTable) не вернуло элемент. На самом деле в возвращаемых элементах классом таблицы является только страйп. Вы также можете использовать id = «пример».
Вот что он возвращает:
Теперь, когда мы захватили таблицу, мы можем пройтись по строкам и получить нужные данные.
4. Зацикливание таблицы HTML
Возвращаясь к структуре таблицы, каждая строка представлена элементом
, а внутри них есть элемент , содержащий данные, все это заключено между пара тегов .Чтобы извлечь данные, мы создадим два для просмотра, один для захвата раздела
таблицы (где находятся все строки), а другой для сохранения всех строк в переменной, которую мы можем использовать:для employee_data в table.
find_all('tbody'):
строки = данные_сотрудника.find_all('tr')
print(rows)В строках мы будем хранить все
элементов, найденных в разделе body таблицы. Если вы следуете нашей логике, следующим шагом будет сохранение каждой отдельной строки в одном объекте и циклический просмотр их для поиска нужных данных. Для начала попробуем выбрать имя первого сотрудника в консоли нашего браузера с помощью метода .querySelectorAll(). Действительно полезная особенность этого метода заключается в том, что мы можем углубляться в иерархию, реализуя символ больше, чем (>), чтобы определить родительский элемент (слева) и дочерний элемент, которого мы хотим захватить (справа).
document.querySelectorAll('table.stripe &gt; tbody &gt; tr &gt; td')[0]Лучше и быть не может. Как видите, как только мы захватим все элементы
, они станут нодлистом. Поскольку мы не можем полагаться на то, что класс захватывает каждую ячейку, все, что нам нужно знать, это их положение в индексе, а первое, имя, равно 0. Оттуда мы можем написать наш код следующим образом:
для строки в строке: имя = row.find_all('td')[0].text печать(имя)Проще говоря, мы берем каждую строку, одну за другой, и находим все ячейки внутри, как только у нас есть список, мы берем только первую в индексе (позиция 0) и заканчиваем с помощью метода .text чтобы захватить только текст элемента, игнорируя данные HTML, которые нам не нужны.
Вот они, список всех имен сотрудников! В остальном мы просто следуем той же логике:
position = row.find_all('td')[1].text офис = row.find_all('td')[2].text возраст = row.find_all('td')[3].text start_date = row.find_all('td')[4].text зарплата = row.find_all('td')[5].textОднако печать всех этих данных на нашей консоли не очень полезна. Вместо этого давайте сохраним эти данные в новом, более удобном формате.
5. Хранение табличных данных в файле JSON
Хотя мы могли бы легко создать файл CSV и отправить туда наши данные, это был бы не самый удобный формат, если бы мы могли создать что-то новое, используя очищенные данные.
Тем не менее, вот проект, который мы сделали несколько месяцев назад, объясняя, как создать файл CSV для хранения очищенных данных.
Хорошей новостью является то, что в Python есть собственный модуль JSON для работы с объектами JSON, поэтому нам не нужно ничего устанавливать, просто импортируйте его.
import json
Но прежде чем мы сможем продолжить и создать файл JSON, нам нужно превратить все эти очищенные данные в список. Для этого мы создадим пустой массив вне нашего цикла.
employee_list = []
А затем добавьте к нему данные, при этом каждый цикл добавляет новый объект в массив.
employee_list.append({ «Имя»: имя, «Позиция»: позиция, «Офис»: офис, «Возраст»: возраст, «Дата начала»: start_date, 'зарплата': зарплата })Если мы
print(employee_list), вот результат:Все еще немного беспорядочно, но у нас есть набор объектов, готовых для преобразования в JSON.
Примечание: В качестве теста мы напечатали длину
employee_listи вернули 57, что является правильным количеством строк, которые мы очистили (строки теперь являются объектами в массиве).Для импорта списка в JSON достаточно двух строк кода:
с open('json_data', 'w') в качестве json_file: json.dump(employee_list, json_file, indent=2)- Сначала мы открываем новый файл, передавая имя, которое мы хотим для файла
(json_data), и ‘w’, поскольку мы хотим записать данные в это. - Затем мы используем функцию
.dump()для вывода данных из массива(employee_list)иindent=2, поэтому у каждого объекта есть своя строка, а не все в одной нечитаемой строке.
6. Запуск скрипта и полного кода
Если вы следовали инструкциям, ваша кодовая база должна выглядеть так:
#dependencies запросы на импорт из bs4 импортировать BeautifulSoup импортировать json url = 'http://api.
scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html'
#пустой массив
список_сотрудников = []
#запрос и анализ HTML-файла
ответ = запросы.get(url)
суп = BeautifulSoup(response.text, 'html.parser')
#выбираем стол
таблица = суп.найти('таблица', class_ = 'полоса')
#сохранение всех строк в одну переменную
для employee_data в table.find_all('tbody'):
строки = данные_сотрудника.find_all('tr')
# просматриваем HTML-таблицу для извлечения данных
для строки в строке:
имя = row.find_all('td')[0].text
position = row.find_all('td')[1].text
офис = row.find_all('td')[2].text
возраст = row.find_all('td')[3].text
start_date = row.find_all('td')[4].text
зарплата = row.find_all('td')[5].text
#отправляем очищенные данные в пустой массив
employee_list.append({
«Имя»: имя,
«Позиция»: позиция,
«Офис»: офис,
«Возраст»: возраст,
«Дата начала»: start_date,
'зарплата': зарплата
})
#импорт массива в файл JSON
с open('employee_data', 'w') как json_file:
json. dump(employee_list, json_file, indent=2)Примечание: Мы добавили несколько комментариев для контекста.
И вот посмотрите на первые три объекта из файла JSON:
Хранение очищенных данных в формате JSON позволяет нам повторно использовать информацию для новых приложений или
Очистка HTML-таблиц с помощью Pandas
Перед тем, как покинуть страницу , мы хотим изучить второй подход к очистке HTML-таблиц. В нескольких строках кода мы можем извлечь все табличные данные из HTML-документа и сохранить их в фрейме данных с помощью Pandas.
Создайте новую папку внутри каталога проекта (мы назвали ее pandas-html-table-scraper) и создайте новое имя файла pandas_table_scraper.py.
Давайте откроем новый терминал и перейдем к только что созданной папке (cd pandas-html-table-scraper) и оттуда установим pandas:
pip install pandas
И мы импортируем его в верхняя часть файла.
import pandas as pd
Pandas имеет функцию read_html(), которая в основном очищает целевой URL-адрес для нас и возвращает все таблицы HTML в виде списка объектов DataFrame.
Однако для того, чтобы это работало, HTML-таблица должна быть структурирована хотя бы несколько прилично, так как функция будет искать такие элементы, как
, чтобы идентифицировать таблицы в файле.
Чтобы использовать эту функцию, давайте создадим новую переменную и передадим ей URL-адрес, который мы использовали ранее: ://datatables.net/examples/styling/stripe.html’)
При печати он возвращает список HTML-таблиц на странице.
Если мы сравним первые три строки в DataFrame, они идеально совпадают с тем, что мы очистили с помощью Beautiful Soup.
Для работы с JSON в Pandas может быть встроена функция .to_json(). Он преобразует список объектов DataFrame в строку JSON
Все, что нам нужно сделать, это вызвать метод в нашем DataFrame и передать путь, формат (разделение, данные, записи, индекс и т. д.) и добавить отступ, чтобы сделать его более читабельным:
employee_data[0].to_json('./employee_list.json', orient='index', indent=2)Если мы сейчас запустим наш код, вот результирующий файл:
Обратите внимание, что нам нужно было выбрать нашу таблицу из индекса ([0]), потому что .
 при построении своих таблиц, усложняя одни проекты по сравнению с другими. Тем не менее, понимание того, как они работают, имеет решающее значение для поиска правильного подхода.
при построении своих таблиц, усложняя одни проекты по сравнению с другими. Тем не менее, понимание того, как они работают, имеет решающее значение для поиска правильного подхода.
 Хотя вы сможете следовать без опыта, всегда полезно начинать с основ.
Хотя вы сможете следовать без опыта, всегда полезно начинать с основ. status_code)
status_code) С панели управления нашей учетной записи мы можем скопировать значение нашего ключа, чтобы создать URL-адрес запроса.
С панели управления нашей учетной записи мы можем скопировать значение нашего ключа, чтобы создать URL-адрес запроса.
 find_all('tbody'):
строки = данные_сотрудника.find_all('tr')
print(rows)
find_all('tbody'):
строки = данные_сотрудника.find_all('tr')
print(rows)


 scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html'
#пустой массив
список_сотрудников = []
#запрос и анализ HTML-файла
ответ = запросы.get(url)
суп = BeautifulSoup(response.text, 'html.parser')
#выбираем стол
таблица = суп.найти('таблица', class_ = 'полоса')
#сохранение всех строк в одну переменную
для employee_data в table.find_all('tbody'):
строки = данные_сотрудника.find_all('tr')
# просматриваем HTML-таблицу для извлечения данных
для строки в строке:
имя = row.find_all('td')[0].text
position = row.find_all('td')[1].text
офис = row.find_all('td')[2].text
возраст = row.find_all('td')[3].text
start_date = row.find_all('td')[4].text
зарплата = row.find_all('td')[5].text
#отправляем очищенные данные в пустой массив
employee_list.append({
«Имя»: имя,
«Позиция»: позиция,
«Офис»: офис,
«Возраст»: возраст,
«Дата начала»: start_date,
'зарплата': зарплата
})
#импорт массива в файл JSON
с open('employee_data', 'w') как json_file:
json.
scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html'
#пустой массив
список_сотрудников = []
#запрос и анализ HTML-файла
ответ = запросы.get(url)
суп = BeautifulSoup(response.text, 'html.parser')
#выбираем стол
таблица = суп.найти('таблица', class_ = 'полоса')
#сохранение всех строк в одну переменную
для employee_data в table.find_all('tbody'):
строки = данные_сотрудника.find_all('tr')
# просматриваем HTML-таблицу для извлечения данных
для строки в строке:
имя = row.find_all('td')[0].text
position = row.find_all('td')[1].text
офис = row.find_all('td')[2].text
возраст = row.find_all('td')[3].text
start_date = row.find_all('td')[4].text
зарплата = row.find_all('td')[5].text
#отправляем очищенные данные в пустой массив
employee_list.append({
«Имя»: имя,
«Позиция»: позиция,
«Офис»: офис,
«Возраст»: возраст,
«Дата начала»: start_date,
'зарплата': зарплата
})
#импорт массива в файл JSON
с open('employee_data', 'w') как json_file:
json. dump(employee_list, json_file, indent=2)
dump(employee_list, json_file, indent=2)
