HTML кодировка страницы. В какой кодировке сохранять web-страницу? Урок №14
Главная » Все про HTML » HTML кодировка страницы. В какой кодировке сохранять web-страницу? Урок №14
Бывали ли у вас ситуации, когда на web-странице вместо читабельного текста открывались кракозябры? Я уверен, что бывали или, по крайне мере, вы видели их на других сайтах. Если не видели, посмотрите на пример снизу:
Что такое HTML кодировка?
HTML кодировка – это таблицы соответствия кодов и символов алфавита. То есть, наш компьютер по кодировке поменяет код на понятные читабельные буквы.
Популярные кодировки.
На сегодняшний день существуют две самые популярные кодировки в русскоязычном интернете. Это кодировка windows-1251 и utf-8. Частенько веб-мастерам приходится выбирать, в какой кодировке делать им веб-страничку.
В какой кодировке следует сохранять HTML файл?
Большинство веб-мастеров выбирают кодировку utf-8.
Поэтому я рекомендую вам сохранять HTML файлы в кодировке utf-8.
Как задать кодировку UTF-8 для файла?
Чтобы задать кодировку для HTML файла, используют различные редакторы. Я пользуюсь текстовым редактором Notepad++.
Откройте текстовый редактор Notepad++.
Если нужно, создайте новый документ.
Перейдите в меню сверху по вкладке «Кодировки» => «Кодировать в UTF-8 (без BOM)»:
Чтобы сообщить браузеру, в какой кодировке HTML файл, существует специальный META-тег
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
В HTML документе это будет выглядеть вот так:
<html> <head> <title>кодировка HTML</title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> </head> <body> </body> </html>
Как задать кодировку windows-1251 для файла?
Откройте текстовый редактор Notepad++.
Если нужно, создайте новый документ.
Перейдите в меню сверху по вкладке «Кодировки» => «Кодировать в ANSI»:
Чтобы сообщить браузеру, в какой кодировке HTML файл, существует специальный META-тег
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
В HTML документе это будет выглядеть вот так:
<html> <head> <title>кодировка HTML</title> <meta http-equiv="Content-Type" content="text/html; charset=windows-1251"> </head> <body> </body> </html>
Пример перекодировки файла из windows-1251 в utf-8
Если в HTML документе был прописан код в кодировке windows-1251 (ANSI), а вам нужно перекодировать на utf-8 (или на оборот), тогда сделайте так:
Откройте текстовый редактор Notepad++. В текстовом редакторе перейдите в меню сверху по вкладке «Кодировки» => «Преобразовать в UTF-8 (без BOM)»:
Внимание, если бы вы нажали «Кодировать в UTF-8 (без BOM)», то в результате вы бы увидели вместо любимого русского текста, красивые караказябли .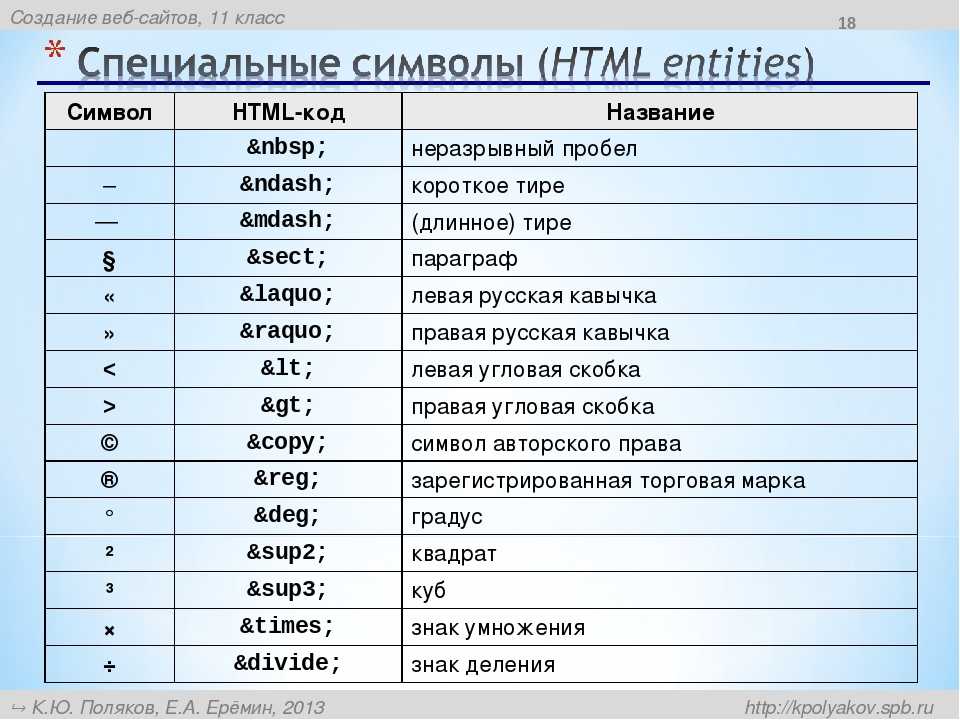
Понравился пост? Помоги другим узнать об этой статье, кликни на кнопку социальных сетей ↓↓↓
Добавить комментарий
Метки: html, основы
HTML кодирование и декодирование
Кодировщик символов в HTML коды
Выберите кодировкуUTF-8windows-1251KOI8-Rcp866ISO-8859-5ISO-8859-1
Введите строку в одно из полей и нажмите соответствующую кнопку
Строка в нормальном виде
Строка в закодированном виде
Кодирование символов, имеющих специальное назначение в html
Кодирование символов, для которых есть мнемонические имена в html
Кодирование всех символов
Исключая диапазон latin1
Побайтное представление (дамп) HEXDECIMALBINARY
кодирование в base64
Основные возможности кодировщика
-
Выбор кодировки — нажатие на кнопку GO меняет кодировку страницы, но текст внутри окон: Cтрока в нормальнов виде и Cтрока в закодированном виде
 Это дает возможность насладиться разными «Крякозябрами», но может быть полезно и для перекодировки кириллицы.
Будьте внимательны изменение в выпадающем списке кодировок не будут иметь силу, если кнопка GO не будет нажата.
Это дает возможность насладиться разными «Крякозябрами», но может быть полезно и для перекодировки кириллицы.
Будьте внимательны изменение в выпадающем списке кодировок не будут иметь силу, если кнопка GO не будет нажата.
- Кодирование символов, имеющих специальное назначение в html
— опция
заменяет символы
< > & » ‘ мнемоническими ссылками html, используется для безопасной вставки фрагмента html кода в виде текста в html страницу . - Кодирование символов, для которых есть мнемонические имена — опция заменяет все символы html, для которых определены мнемонические имена, их мнемоническими html ссылками, опция помогает быстро узнать название того или иного знака.
-
Кодирование всех символов — опция кодирует любые символы с помощью html ссылок с кодом символа (unicode). Так как отображение символов, заданных с
помощью html ccылок одинаково, в любых кодировках, то
эта опция позволяет получить кириллический текст,
не зависящий от установок кодовой страницы браузера. Если будет нажат значок Исключая диапазон latin1, то ASCII символы кодироваться не будут (первые 127 символов диапазона UNICODE). Эта опция позволяет шифровать содержимое HTML, не нарушая разметку.
- Побайтное представление — опция выдает байты строк, как в шестнадцатиричном представлении, так и в десятичном. Для мультибайтовой кодировки utf-8, каждый кириллический символ кодируется двумя байтами. Эта опция может быть полезна, для анализа строк и выявления неисправностей. Она совместима с режимом кодирования для URL.
- Кодирование в base64 — опция применяется для кодирования в MIME base64.
 Это дает возможность насладиться разными «Крякозябрами», но может быть полезно и для перекодировки кириллицы.
Будьте внимательны изменение в выпадающем списке кодировок не будут иметь силу, если кнопка GO не будет нажата.
Это дает возможность насладиться разными «Крякозябрами», но может быть полезно и для перекодировки кириллицы.
Будьте внимательны изменение в выпадающем списке кодировок не будут иметь силу, если кнопка GO не будет нажата.
 Так как отображение символов, заданных с
помощью html ccылок одинаково, в любых кодировках, то
эта опция позволяет получить кириллический текст,
не зависящий от установок кодовой страницы браузера. Если будет нажат значок Исключая диапазон latin1, то ASCII символы кодироваться не будут (первые 127 символов диапазона UNICODE). Эта опция позволяет шифровать содержимое HTML, не нарушая разметку.
Так как отображение символов, заданных с
помощью html ccылок одинаково, в любых кодировках, то
эта опция позволяет получить кириллический текст,
не зависящий от установок кодовой страницы браузера. Если будет нажат значок Исключая диапазон latin1, то ASCII символы кодироваться не будут (первые 127 символов диапазона UNICODE). Эта опция позволяет шифровать содержимое HTML, не нарушая разметку.Теоретические основы кодирования и комментарии к работе программы читайте в статье о принципах работы html кодировщика.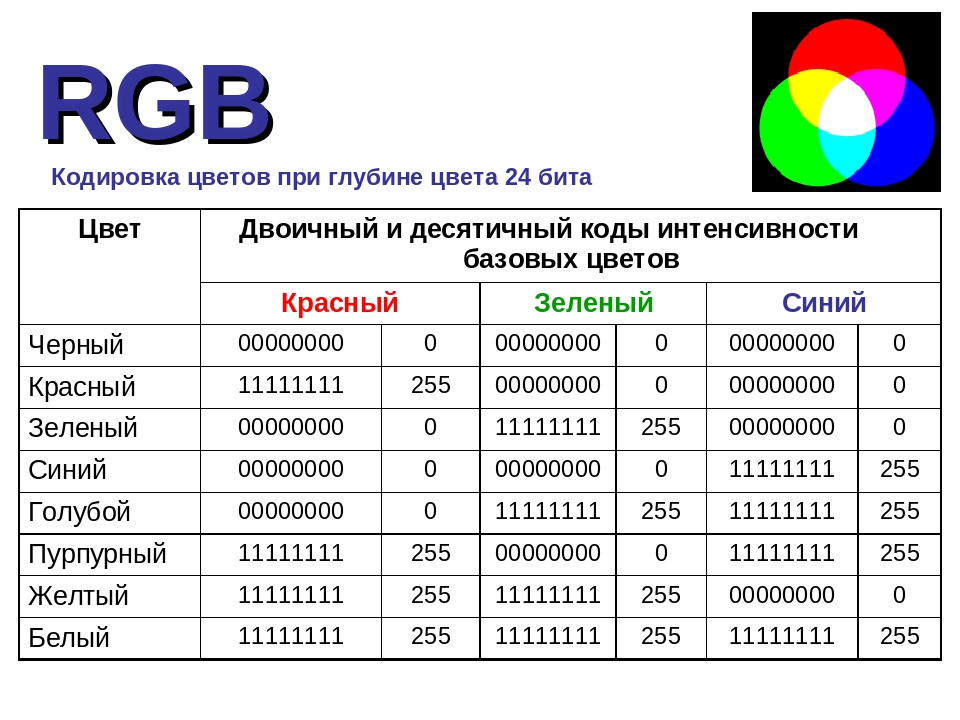 Для просмотра начального диапазона символов Unicode (первые 64К) можно воспользоваться динамической таблицей символов блоков Unicode.
Для изучения основ Unicode воспользуйтесь официальной документацией на Unicode (на английском).
Для просмотра начального диапазона символов Unicode (первые 64К) можно воспользоваться динамической таблицей символов блоков Unicode.
Для изучения основ Unicode воспользуйтесь официальной документацией на Unicode (на английском).
Кодировка символов в HTML | Блог W3C
Вначале в Интернете был ASCII. И это было хорошо. Но тогда не совсем. Европейцы и их странный акцент были проблемой.
Итак, в Сети появилась iso-latin1. И можно предположить, что HTML использует это по умолчанию (RFC2854, раздел 4). И это было хорошо. Но тогда не совсем. Там был целый мир с множеством систем письма, кучей разных персонажей. Множество различных кодировок символов…
Сегодня у нас есть Unicode, который наконец-то хорошо принят в большинстве современных вычислительных систем и является основным строительным блоком многих веб-технологий. И хотя для документов в Интернете по-прежнему доступно множество различных кодировок символов, это не проблема, поскольку существуют механизмы, например, как в HTTP, так и в HTML, для объявления используемой кодировки, а также вспомогательные инструменты, определяющие, как расшифровать содержимое.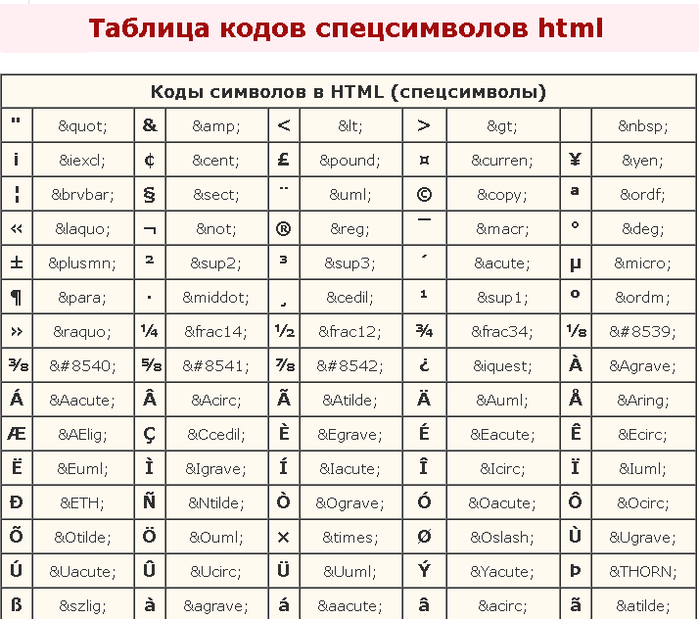
Однако не всегда все так радужно. Первая проблема заключается в том, что существует довольно много механизмов для объявления кодирования, и они не обязательно совпадают. Вторая проблема заключается в том, что не каждый может настроить веб-сервер для объявления кодирования HTML-документов на уровне HTTP.
Множество источников, Одна кодировка
Если на коробке написано «опасно, не открывать», не заглядывайте внутрь коробки… Веб-ресурс должен был лучше знать свою кодировку, или веб-сервер должен быть авторитетным источником.
В лагере «ресурсов» некоторые выдвигали довольно логичный аргумент, что конкретный документ наверняка лучше знает о своих собственных метаданных, чем неправильно настроенный веб-сервер. Кого волнует, думает ли сервер, что все HTML-документы, которые он обслуживает, являются iso-8859-1 , когда я, как автор документа, прекрасно знаю, что я создаю этот конкретный ресурс как utf-8 ?
У другого лагеря было два убийственных аргумента.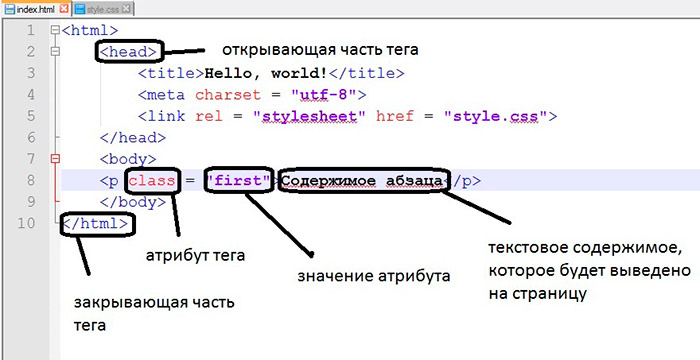
Первый и, возможно, самый простой аргумент был следующим: какой смысл заставлять пользовательские агенты обнюхивать мусор в надежде найти содержимое и, возможно, объявление кодировки символов, когда транспортный протокол имеет способ объявить это? На этом основан принцип авторитетных метаданных. Этот принцип также иногда резюмируют следующим образом: если я хочу показать HTML-документ как источник обычного текста, а не интерпретировать его браузерами, я должен иметь возможность это сделать. Я должен быть в состоянии служить любой документ как
text/plain, если это мой выбор.Вторым убийственным аргументом было перекодирование . По их словам, многие прокси-серверы преобразуют контент, который они проксируют, иногда из одной кодировки символов в другую. Таким образом, даже если в документе может быть сказано: «Я закодирован в
iso-2022-jp», прокси-сервер должен иметь возможность сказать: «На самом деле, поверьте мне, контент, который я вам доставляю, находится вutf-8».
В конце концов, очевидный консенсус состоял в том, что сторонники «сервер знает лучше» имеют веские архитектурные аргументы, и поэтому для всего, что в Интернете обслуживается по протоколу HTTP, HTTP имеет приоритет над любым другим методом в определении кодирование (и тип контента и т. д.) ресурсов.
Это означает, что независимо от того, что находится в (x)html документе, если сервер говорит «это документ text/html , закодированный как utf-8 », пользовательские агенты должны следовать этой информации. Второе предположение может принести больше вреда, чем пользы.
Коробки без маркировки могут быть полны сокровищ или полны проблем
Но что, если кодировка символов не объявлена на уровне HTTP? Вот где это становится сложно.
«Старая школа» HTML ввел специфический метатег для объявления кодировки в документе:
На протяжении многих лет мы видели, что у этого метода есть две серьезные проблемы:
Его синтаксис.
Кажется, что никто не понимает его правильно (это просто… слишком сложно!), а в Сети полно приблизительных, иногда комичных вариантов этого синтаксиса. Однако это не повод для смеха для пользовательских агентов, которые даже не могут ожидать, что это объявление кодировки будет правильно размечено!
Мета-элементы
заголовкадокумента, но нет гарантии, что они будут где-то рядом с верхней частью документа. заголовок
Стоит отметить, что текущая работа над html5 пытается обойти эти проблемы, предоставляя более простой альтернативный синтаксис и следя за тем, чтобы объявление кодировки присутствовало в самом начале заголовка .
XML, с другой стороны, имел способ объявить кодировку на уровне документа в объявлении XML. Хорошо то, что это объявление ДОЛЖНО быть в самом начале документа, что облегчает необходимость прослушивания содержимого.
Спецификация XML также определяет в Приложении F рекомендуемый алгоритм обнаружения кодировки.
Рецепт
Учитывая все эти потенциальные источники объявления (или автоматического определения) кодировки символов документа, потенциально противоречащие другим, каким должен быть рецепт, чтобы надежно выяснить, какую кодировку использовать?
Информация о кодировке в HTTP
Заголовок Content-Typeдолжен иметь приоритет. ВсегдаДалее следует информация о наборе символов в объявлении XML. Что может быть, а может и нет.
Для документов XHTML и, в частности, для документов XHTML, обслуживаемых как
text/html, рекомендуется избегать использования объявления XML.Но давайте помнить: XHTML — это XML, а XML требует объявления XML или какого-либо другого метода объявления для документов XML с использованием кодировок, отличных от UTF-8 или UTF-16. (или ascii, что является удобным подмножеством…).
В результате существует высокая вероятность того, что что-то служило как
application/xhtml+xml(илиtext/htmlи очень похоже на XHTML), без объявления кодировки ни на уровне HTTP, ни в объявлении XML, скорее всего, будет UTF-8 или UTF-16Затем идет спецификация, сигнатура для кодировок символов Unicode.
Затем идет поиск
метаинформации, которая может, просто может, предоставить объявление кодировки символов.Дальше — земля дефолтов и эвристик. Вы можете выбрать по умолчанию
iso-8859-1для ресурсовtext/html,utf-8дляприложение/xhtml+xml.Остальное эвристика. Вы можете рискнуть использовать резервные кодировки, такие как
windows-1252, что многие считают безопасной ставкой, но, тем не менее, ставкой.Существует довольно много алгоритмов для определения вероятности одной конкретной кодировки на основе совпадения на уровне байтов. Мартин Дюрст написал регулярное выражение, чтобы проверить, подходит ли документ как utf-8. Если вы знаете другие надежные алгоритмы, не стесняйтесь упоминать их в комментариях, я перечислю их здесь.


Вам это кажется некрасивым и сложным? Вам понравится отличная блок-схема кодирования гадания Филиппа Семанчука, разработчика средства проверки качества сети «Паук Никита».
Или, если это все еще ужасно нечетко после просмотра блок-схемы, почему бы не позволить инструменту сделать это за вас? Perl-модуль HTML::Encoding от Björn Höhrmann делает именно это.
Последнее слово… для авторов HTML
Если вы создаете контент в Интернете и вам никогда не приходится читать и анализировать контент в Интернете, и если вы дочитали до этого места, вы, вероятно, считаете себя очень удачливым прямо сейчас. Но вы можете изменить ситуацию, убедившись, что контент, который вы размещаете в Интернете, использует согласованные кодировки символов и объявит их правильно. Ваша работа на самом деле намного проще , чем хитрая извилистая дорога к определению кодировки документа. В пословице три шага:
Но вы можете изменить ситуацию, убедившись, что контент, который вы размещаете в Интернете, использует согласованные кодировки символов и объявит их правильно. Ваша работа на самом деле намного проще , чем хитрая извилистая дорога к определению кодировки документа. В пословице три шага:
- Использовать
utf-8. Если у вас нет очень специфических потребностей, таких как очень редкие варианты символов в азиатских языках, это должна быть ваша кодировка выбора. Большинство современных текстовых, веб-редакторов или редакторов кода, вероятно, поддерживают UTF-8, некоторые на самом деле только поддерживают эту кодировку. Если возможно, выберите редактор или настройку, которая не будет выводить спецификацию в файлах UTF-8, поскольку известно, что это вызывает некоторые уродливые проблемы с отображением некоторых агентов и даже может привести к сбою включения php. - Если у вас есть доступ к конфигурации вашего веб-сервера, убедитесь, что он обслуживает html как utf-8
- Вот и все.

Как установить кодировку символов для документа в HTML5?
Улучшить статью
Сохранить статью
Нравится Статья
- Последнее обновление: 01 апр, 2021
Улучшить статью
Сохранить статью
Нравится Статья
Кодировка символов — это метод определения соответствия между байтами и текстом. Чтобы правильно отображать HTML-документ, мы должны выбрать правильную кодировку символов.
Различные типы кодировки символов включают:
- Набор символов ASCII: Это первый стандарт кодировки символов. Основным недостатком ASCII является то, что он содержит только ограниченный диапазон символов (128 символов).
- Набор символов ANSI: Этот стандарт был расширенной версией стандартного набора символов ASCII. Он поддерживает 256 символов.
- Набор символов ISO-8859-1: Это кодировка символов по умолчанию в HTML 2. 0. Это также расширение стандарта ASCII с международными символами. Это использовало полные байты (8 бит) для отображения символов.
- Набор символов UTF-8: Этот стандарт охватывает почти все знаки и символы в мире. Ограничения ANSI и ISO-8859-1 удовлетворялись набором символов UTF-8. Кодировка символов по умолчанию для HTML5 — UTF-8.
 0. Это также расширение стандарта ASCII с международными символами. Это использовало полные байты (8 бит) для отображения символов.
0. Это также расширение стандарта ASCII с международными символами. Это использовало полные байты (8 бит) для отображения символов.Спецификация HTML5 рекомендует разработчикам использовать набор символов UTF-8.
Символ может иметь длину от 1 до 4 байтов в стандарте кодирования UTF-8. Это также наиболее предпочтительная кодировка для электронной почты и веб-страниц.
- Кодировку символов можно указать в метатеге HTML.
- Метатег используется для указания метаданных о веб-странице и не будет отображаться на веб-страницах.
- Метатег помогает поисковым системам понять, о чем веб-страница.
- Метатег должен быть размещен с тегом head в HTML.
Синтаксис:
1. Для HTML4
Для HTML4
2. Для HTML5
Кодировкой символов по умолчанию для HTML5 является UTF-8, но вы все равно можете указать ее, чтобы быть особенно осторожным.
Example:
>86666666669666666666666666666666666666666666666666669666666666669н. |
