Кодировка HTML уроки для начинающих академия
❮ Назад Дальше ❯
Для правильного отображения HTML-страницы веб-обозреватель должен знать, какой набор символов (кодировка) следует использовать.
Что такое кодировка символов?
ASCII был первым стандартом кодировки символов (также называемым набором символов). ASCII определены 128 различных буквенно-цифровых символов, которые могут быть использованы в Интернете: цифры (0-9), английские буквы (a-Z), и некоторые специальные символы, как! $ +-() @ < >.
ANSI (Windows-1252) был оригинальный набор символов Windows, с поддержкой 256 различных кодов символов.
ISO-8859-1 был стандартным набором символов для HTML 4. Этот набор символов также поддерживает 256 различные коды символов.
Так как ANSI и ISO-8859-1 были настолько ограничены, HTML 4 также поддерживал UTF-8.
UTF-8 (Юникод) охватывает почти все символы и символы в мире.
Кодировка символов по умолчанию для HTML5 — UTF-8.
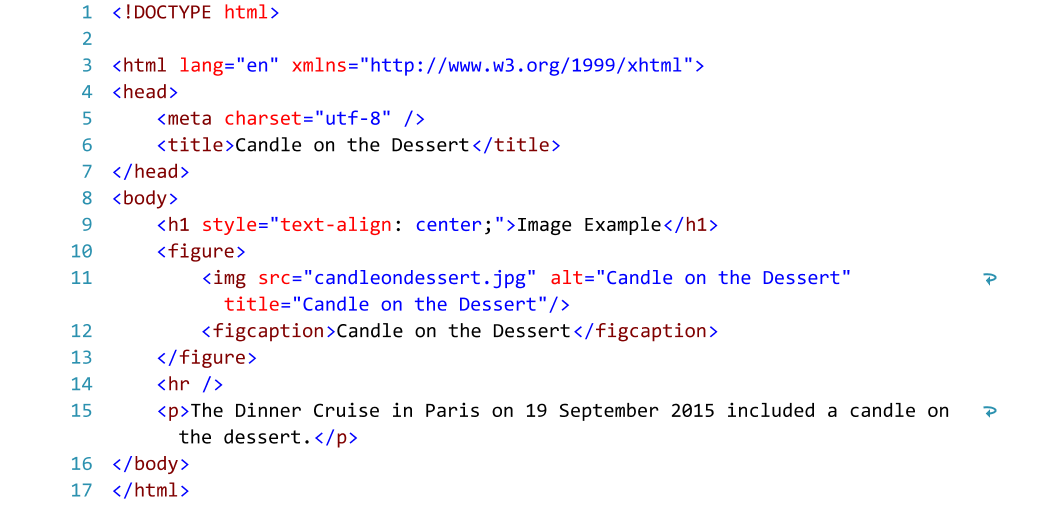
Атрибут HTML-кодировки
Для правильного отображения HTML-страницы веб-обозреватель должен знать кодировку, используемую на странице.
Это указано в теге <meta> :
Для HTML4:
<meta http-equiv=»Content-Type» content=»text/html;charset=ISO-8859-1″>
Для HTML5:
<meta charset=»UTF-8″>
Если браузер обнаруживает ISO-8859-1 на веб-странице, по умолчанию используется ANSI, так как ANSI идентичен ISO-8859-1 за исключением того, что ANSI имеет 32 дополнительных символов.
Различия между наборами символов
В следующей таблице показаны различия между наборами символов, описанными выше:
| Numb | ASCII | ANSI | 8859 | UTF-8 | Описание |
|---|---|---|---|---|---|
| 32 | space | ||||
| 33 | ! | ! | ! | ! | exclamation mark |
| 34 | « | « | « | « | quotation mark |
| 35 | # | # | # | # | number sign |
| 36 | $ | $ | $ | $ | dollar sign |
| 37 | % | % | % | % | percent sign |
| 38 | & | & | & | & | ampersand |
| 39 | ‘ | ‘ | ‘ | ‘ | apostrophe |
| 40 | ( | ( | ( | ( | left parenthesis |
| 41 | ) | ) | ) | ) | right parenthesis |
| 42 | * | * | * | * | asterisk |
| 43 | + | + | + | + | plus sign |
| 44 | , | , | , | , | comma |
| 45 | — | — | — | — | hyphen-minus |
| 46 | . | . | . | . | full stop |
| 47 | / | / | / | / | solidus |
| 48 | 0 | 0 | 0 | 0 | digit zero |
| 49 | 1 | 1 | 1 | 1 | digit one |
| 50 | 2 | 2 | 2 | 2 | digit two |
| 51 | 3 | 3 | 3 | 3 | digit three |
| 52 | 4 | 4 | 4 | 4 | digit four |
| 53 | 5 | 5 | 5 | 5 | digit five |
| 54 | 6 | 6 | 6 | 6 | digit six |
| 55 | 7 | 7 | 7 | 7 | digit seven |
| 56 | 8 | 8 | 8 | 8 | digit eight |
| 57 | 9 | 9 | 9 | 9 | digit nine |
| 58 | : | : | : | : | colon |
| 59 | ; | ; | ; | ; | semicolon |
| 60 | < | < | < | < | less-than sign |
| 61 | = | = | = | = | equals sign |
| 62 | > | > | > | > | greater-than sign |
| 63 | ? | ? | ? | ? | question mark |
| 64 | @ | @ | @ | @ | commercial at |
| 65 | A | A | A | A | Latin capital letter A |
| 66 | B | B | B | B | Latin capital letter B |
| 67 | C | C | C | C | Latin capital letter C |
| 68 | D | D | D | D | Latin capital letter D |
| 69 | E | E | E | E | Latin capital letter E |
| 70 | F | F | F | F | Latin capital letter F |
| 71 | G | G | G | G | Latin capital letter G |
| 72 | H | H | H | H | Latin capital letter H |
| 73 | I | I | I | I | Latin capital letter I |
| 74 | J | J | J | J | Latin capital letter J |
| 75 | K | K | K | K | Latin capital letter K |
| 76 | L | L | L | L | Latin capital letter L |
| 77 | M | M | M | M | Latin capital letter M |
| 78 | N | N | N | N | Latin capital letter N |
| 79 | O | O | O | O | Latin capital letter O |
| 80 | P | P | P | P | Latin capital letter P |
| 81 | Q | Q | Q | Q | Latin capital letter Q |
| 82 | R | R | R | R | Latin capital letter R |
| 83 | S | S | S | S | Latin capital letter S |
| 84 | T | T | T | T | Latin capital letter T |
| 85 | U | U | U | U | Latin capital letter U |
| 86 | V | V | V | V | Latin capital letter V |
| 87 | W | W | W | W | Latin capital letter W |
| 88 | X | X | X | X | Latin capital letter X |
| 89 | Y | Y | Y | Y | Latin capital letter Y |
| 90 | Z | Z | Z | Z | Latin capital letter Z |
| 91 | [ | [ | [ | [ | left square bracket |
| 92 | \ | \ | \ | \ | reverse solidus |
| 93 | ] | ] | ] | ] | right square bracket |
| 94 | ^ | ^ | ^ | ^ | circumflex accent |
| 95 | _ | _ | _ | _ | low line |
| 96 | ` | ` | ` | ` | grave accent |
| 97 | a | a | a | a | Latin small letter a |
| 98 | b | b | b | b | Latin small letter b |
| 99 | c | c | c | c | Latin small letter c |
| 100 | d | d | d | d | Latin small letter d |
| 101 | e | e | e | e | Latin small letter e |
| 102 | f | f | f | f | Latin small letter f |
| 103 | g | g | g | g | Latin small letter g |
| 104 | h | h | h | h | Latin small letter h |
| 105 | i | i | i | i | Latin small letter i |
| 106 | j | j | j | j | Latin small letter j |
| 107 | k | k | k | k | Latin small letter k |
| 108 | l | l | l | l | Latin small letter l |
| 109 | m | m | m | m | Latin small letter m |
| 110 | n | n | n | n | Latin small letter n |
| 111 | o | o | o | o | Latin small letter o |
| 112 | p | p | p | p | Latin small letter p |
| 113 | q | q | q | q | Latin small letter q |
| 114 | r | r | r | r | Latin small letter r |
| 115 | s | s | s | s | Latin small letter s |
| 116 | t | t | t | t | Latin small letter t |
| 117 | u | u | u | u | Latin small letter u |
| 118 | v | v | v | v | Latin small letter v |
| 119 | w | w | w | w | Latin small letter w |
| 120 | x | x | x | x | Latin small letter x |
| 121 | y | y | y | y | Latin small letter y |
| 122 | z | z | z | z | Latin small letter z |
| 123 | { | { | { | { | left curly bracket |
| 124 | | | | | | | | | vertical line |
| 125 | } | } | } | } | right curly bracket |
| 126 | ~ | ~ | ~ | ~ | tilde |
| 127 | DEL | ||||
| 128 | | euro sign | |||
| 129 | | | | NOT USED | |
| 130 | | single low-9 quotation mark | |||
| 131 | | Latin small letter f with hook | |||
| 132 | | double low-9 quotation mark | |||
| 133 | horizontal ellipsis | ||||
| 134 | | dagger | |||
| 135 | | double dagger | |||
| 136 | | modifier letter circumflex accent | |||
| 137 | | per mille sign | |||
| 138 | | Latin capital letter S with caron | |||
| 139 | | single left-pointing angle quotation mark | |||
| 140 | | Latin capital ligature OE | |||
| 141 | | | | NOT USED | |
| 142 | | Latin capital letter Z with caron | |||
| 143 | | | | NOT USED | |
| 144 | | | | NOT USED | |
| 145 | | left single quotation mark | |||
| 146 | | right single quotation mark | |||
| 147 | | left double quotation mark | |||
| 148 | | right double quotation mark | |||
| 149 | | bullet | |||
| 150 | | en dash | |||
| 151 | | em dash | |||
| 152 | | small tilde | |||
| 153 | | trade mark sign | |||
| 154 | | Latin small letter s with caron | |||
| 155 | | single right-pointing angle quotation mark | |||
| 156 | | Latin small ligature oe | |||
| 157 | | | | NOT USED | |
| 158 | | Latin small letter z with caron | |||
| 159 | | Latin capital letter Y with diaeresis | |||
| 160 | no-break space | ||||
| 161 | ¡ | ¡ | ¡ | inverted exclamation mark | |
| 162 | ¢ | ¢ | ¢ | cent sign | |
| 163 | £ | £ | £ | pound sign | |
| 164 | ¤ | ¤ | ¤ | currency sign | |
| 165 | ¥ | ¥ | ¥ | yen sign | |
| 166 | ¦ | ¦ | ¦ | broken bar | |
| 167 | § | § | § | section sign | |
| 168 | ¨ | ¨ | ¨ | diaeresis | |
| 169 | © | © | © | copyright sign | |
| 170 | ª | ª | ª | feminine ordinal indicator | |
| 171 | « | « | « | left-pointing double angle quotation mark | |
| 172 | ¬ | ¬ | ¬ | not sign | |
| 173 | | | soft hyphen | ||
| 174 | ® | ® | ® | registered sign | |
| 175 | ¯ | ¯ | ¯ | macron | |
| 176 | ° | ° | ° | degree sign | |
| 177 | ± | ± | ± | plus-minus sign | |
| 178 | ² | ² | ² | superscript two | |
| 179 | ³ | ³ | ³ | superscript three | |
| 180 | ´ | ´ | ´ | acute accent | |
| 181 | µ | µ | µ | micro sign | |
| 182 | ¶ | ¶ | ¶ | pilcrow sign | |
| 183 | · | · | · | middle dot | |
| 184 | ¸ | ¸ | ¸ | cedilla | |
| 185 | ¹ | ¹ | ¹ | superscript one | |
| 186 | º | º | º | masculine ordinal indicator | |
| 187 | » | » | » | right-pointing double angle quotation mark | |
| 188 | ¼ | ¼ | ¼ | vulgar fraction one quarter | |
| 189 | ½ | ½ | ½ | vulgar fraction one half | |
| 190 | ¾ | ¾ | ¾ | vulgar fraction three quarters | |
| 191 | ¿ | ¿ | ¿ | inverted question mark | |
| 192 | À | À | À | Latin capital letter A with grave | |
| 193 | Á | Á | Á | Latin capital letter A with acute | |
| 194 | Â | Â | Â | Latin capital letter A with circumflex | |
| 195 | Ã | Ã | Ã | Latin capital letter A with tilde | |
| 196 | Ä | Ä | Ä | Latin capital letter A with diaeresis | |
| 197 | Å | Å | Å | Latin capital letter A with ring above | |
| 198 | Æ | Æ | Æ | Latin capital letter AE | |
| 199 | Ç | Ç | Ç | Latin capital letter C with cedilla | |
| 200 | È | È | È | Latin capital letter E with grave | |
| 201 | É | É | É | Latin capital letter E with acute | |
| 202 | Ê | Ê | Ê | Latin capital letter E with circumflex | |
| 203 | Ë | Ë | Ë | Latin capital letter E with diaeresis | |
| 204 | Ì | Ì | Ì | Latin capital letter I with grave | |
| 205 | Í | Í | Í | Latin capital letter I with acute | |
| 206 | Î | Î | Î | Latin capital letter I with circumflex | |
| 207 | Ï | Ï | Ï | Latin capital letter I with diaeresis | |
| 208 | Ð | Ð | Ð | Latin capital letter Eth | |
| 209 | Ñ | Ñ | Ñ | Latin capital letter N with tilde | |
| 210 | Ò | Ò | Ò | Latin capital letter O with grave | |
| 211 | Ó | Ó | Ó | Latin capital letter O with acute | |
| 212 | Ô | Ô | Ô | Latin capital letter O with circumflex | |
| 213 | Õ | Õ | Õ | Latin capital letter O with tilde | |
| 214 | Ö | Ö | Ö | Latin capital letter O with diaeresis | |
| 215 | × | × | × | multiplication sign | |
| 216 | Ø | Ø | Ø | Latin capital letter O with stroke | |
| 217 | Ù | Ù | Ù | Latin capital letter U with grave | |
| 218 | Ú | Ú | Ú | Latin capital letter U with acute | |
| 219 | Û | Û | Û | Latin capital letter U with circumflex | |
| 220 | Ü | Ü | Ü | Latin capital letter U with diaeresis | |
| 221 | Ý | Ý | Ý | Latin capital letter Y with acute | |
| 222 | Þ | Þ | Þ | Latin capital letter Thorn | |
| 223 | ß | ß | ß | Latin small letter sharp s | |
| 224 | à | à | à | Latin small letter a with grave | |
| 225 | á | á | á | Latin small letter a with acute | |
| 226 | â | â | â | Latin small letter a with circumflex | |
| 227 | ã | ã | ã | Latin small letter a with tilde | |
| 228 | ä | ä | ä | Latin small letter a with diaeresis | |
| 229 | å | å | å | Latin small letter a with ring above | |
| 230 | æ | æ | æ | Latin small letter ae | |
| 231 | ç | ç | ç | Latin small letter c with cedilla | |
| 232 | è | è | è | Latin small letter e with grave | |
| 233 | é | é | é | Latin small letter e with acute | |
| 234 | ê | ê | ê | Latin small letter e with circumflex | |
| 235 | ë | ë | ë | Latin small letter e with diaeresis | |
| 236 | ì | ì | ì | Latin small letter i with grave | |
| 237 | í | í | í | Latin small letter i with acute | |
| 238 | î | î | î | Latin small letter i with circumflex | |
| 239 | ï | ï | ï | Latin small letter i with diaeresis | |
| 240 | ð | ð | ð | Latin small letter eth | |
| 241 | ñ | ñ | ñ | Latin small letter n with tilde | |
| 242 | ò | ò | ò | Latin small letter o with grave | |
| 243 | ó | ó | ó | Latin small letter o with acute | |
| 244 | ô | ô | ô | Latin small letter o with circumflex | |
| 245 | õ | õ | õ | Latin small letter o with tilde | |
| 246 | ö | ö | ö | Latin small letter o with diaeresis | |
| 247 | ÷ | ÷ | ÷ | division sign | |
| 248 | ø | ø | ø | Latin small letter o with stroke | |
| 249 | ù | ù | ù | Latin small letter u with grave | |
| 250 | ú | ú | ú | Latin small letter u with acute | |
| 251 | û | û | û | Latin small letter with circumflex | |
| 252 | ü | ü | ü | Latin small letter u with diaeresis | |
| 253 | ý | ý | ý | Latin small letter y with acute | |
| 254 | þ | þ | þ | Latin small letter thorn | |
| 255 | ÿ | ÿ | ÿ | Latin small letter y with diaeresis |
Набор символов ASCII
ASCII использует значения от 0 до 31 (и 127) для управляющих символов.
ASCII использует значения от 32 до 126 для букв, цифр и символов.
ASCII не использует значения от 128 до 255.
Набор символов ANSI (Windows-1252)
ANSI идентичен ASCII для значений от 0 до 127.
ANSI имеет собственный набор символов для значений от 128 до 159.
ANSI идентичен UTF-8 для значений от 160 до 255.
Кодировка ISO-8859-1
8859-1 идентичен ASCII для значений от 0 до 127.
8859-1 не использует значения от 128 до 159.
8859-1 идентичен UTF-8 для значений от 160 до 255.
Кодировка UTF-8
UTF-8 идентичен ASCII для значений от 0 до 127.
UTF-8 не использует значения от 128 до 159.
UTF-8 идентичен ANSI и 8859-1 для значений от 160 до 255.
UTF-8 продолжается от значения 256 с более чем 10 000 различных символов.
Для более пристального взгляда, изучите наш полный набор символов HTML.
❮ Назад Дальше ❯
HTML — кодировки символов — CoderLessons.com
Кодировка символов – это метод преобразования байтов в символы.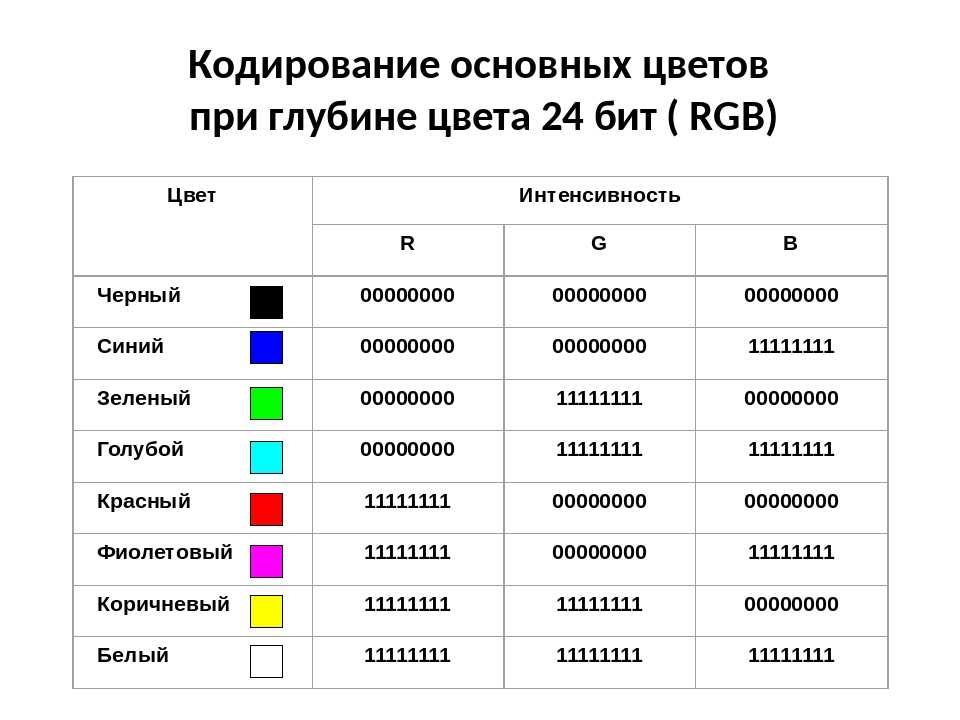 Чтобы правильно проверить или отобразить документ HTML, программа должна выбрать правильную кодировку символов.
Чтобы правильно проверить или отобразить документ HTML, программа должна выбрать правильную кодировку символов.
Наиболее распространенным набором символов или кодировкой символов, используемой на компьютерах, является ASCII – американский стандартный код для обмена информацией , и это, вероятно, наиболее широко используемый набор символов для электронного кодирования текста.
Кодировка ASCII поддерживает только прописные и строчные буквы латинского алфавита, цифры 0-9 и некоторые дополнительные символы, которые в сумме составляют 128 символов. Вы можете взглянуть на полный набор печатных символов ASCII
Тем не менее, во многих языках используются либо латинские символы с акцентом, либо совершенно разные алфавиты. ASCII не обращается к этим символам; поэтому вам нужно узнать о кодировках символов, если вы хотите использовать любые символы, не входящие в ASCII.
Международная организация стандартов создала ряд наборов символов для работы с различными национальными символами. Для документов на английском и большинстве других западноевропейских языков используется широко поддерживаемая кодировка ISO-8859-1.
Для документов на английском и большинстве других западноевропейских языков используется широко поддерживаемая кодировка ISO-8859-1.
Вот список Наборов символов, используемых во всем мире вместе с их описанием.
| Sr.No | Набор символов и описание |
|---|---|
| 1 | ISO-8859-1 Латинский алфавит часть 1 Покрытие Северной Америки, Западной Европы, Латинской Америки, Карибского бассейна, Канады, Африки |
| 2 | ISO-8859-2 Латинский алфавит часть 2 Покрытие Восточной Европы |
| 3 | ISO-8859-3 Латинский алфавит часть 3 Покрытие SE Europe, эсперанто, разные другие |
| 4 | ISO-8859-4 Латинский алфавит часть 4 Покрытие Скандинавия / Прибалтика (и другие, не входящие в ISO-8859-1) |
| 5 | ISO-8859-5 Латиница / кириллица часть 5 |
| 6 | ISO-8859-6 Латиница / арабский алфавит часть 6 |
| 7 | ISO-8859-7 Латинский / греческий алфавит часть 7 |
| 8 | ISO-8859-8 Латиница / иврит алфавит часть 8 |
| 9 | ISO-8859-9 Латинский 5 алфавит часть 9 То же, что ISO-8859-1 за исключением того, что турецкие символы заменяют исландские |
| 10 | ISO-8859-10 Латинская 6 Латинская 6 Лапландская, скандинавская и эскимосская |
| 11 | ISO-8859-15 То же, что ISO-8859-1, но с добавлением большего количества символов |
| 12 | ISO-2022-JP Латиница / японский алфавит часть 1 |
| 13 | ISO-2022-JP-2 Латинский / японский алфавит часть 2 |
| 14 | ISO-2022-KR Латинский / корейский алфавит часть 1 |
ISO-8859-1
Латинский алфавит часть 1
Покрытие Северной Америки, Западной Европы, Латинской Америки, Карибского бассейна, Канады, Африки
ISO-8859-2
Латинский алфавит часть 2
Покрытие Восточной Европы
ISO-8859-3
Латинский алфавит часть 3
Покрытие SE Europe, эсперанто, разные другие
ISO-8859-4
Латинский алфавит часть 4
Покрытие Скандинавия / Прибалтика (и другие, не входящие в ISO-8859-1)
ISO-8859-5
Латиница / кириллица часть 5
ISO-8859-6
Латиница / арабский алфавит часть 6
ISO-8859-7
Латинский / греческий алфавит часть 7
ISO-8859-8
Латиница / иврит алфавит часть 8
ISO-8859-9
Латинский 5 алфавит часть 9
То же, что ISO-8859-1 за исключением того, что турецкие символы заменяют исландские
ISO-8859-10
Латинская 6 Латинская 6 Лапландская, скандинавская и эскимосская
ISO-8859-15
То же, что ISO-8859-1, но с добавлением большего количества символов
ISO-2022-JP
Латиница / японский алфавит часть 1
ISO-2022-JP-2
Латинский / японский алфавит часть 2
ISO-2022-KR
Латинский / корейский алфавит часть 1
Консорциум Unicode был тогда создан, чтобы разработать способ показа всех символов разных языков вместо того, чтобы иметь эти разные несовместимые коды символов для разных языков.
Поэтому, если вы хотите создавать документы, которые используют символы из нескольких наборов символов, вы сможете сделать это, используя одиночные кодировки символов Unicode.
Поэтому Юникод определяет кодировки, которые могут обрабатывать строку особым образом, чтобы освободить место для огромного набора символов, который он охватывает. Они известны как UTF8, UTF-16 и UTF-32.
| Sr.No | Набор символов и описание |
|---|---|
| 1 | UTF-8 , Формат перевода Unicode, который поставляется в 8-битных единицах, то есть в байтах. Символ в UTF8 может иметь длину от 1 до 4 байтов, что делает UTF8 переменной ширины. |
| 2 | UTF-16 Формат перевода Unicode, который поставляется в 16-битных единицах, то есть в шортах. Это может быть 1 или 2 шорты длиной, что делает UTF16 переменной ширины. |
| 3 | UTF-32 Формат перевода Unicode, который поставляется в 32-битных единицах, то есть в длинных. |
 Это формат с фиксированной шириной и всегда 1 “длинный” в длину.
Это формат с фиксированной шириной и всегда 1 “длинный” в длину.UTF-8 ,
Формат перевода Unicode, который поставляется в 8-битных единицах, то есть в байтах. Символ в UTF8 может иметь длину от 1 до 4 байтов, что делает UTF8 переменной ширины.
UTF-16
Формат перевода Unicode, который поставляется в 16-битных единицах, то есть в шортах. Это может быть 1 или 2 шорты длиной, что делает UTF16 переменной ширины.
UTF-32
Формат перевода Unicode, который поставляется в 32-битных единицах, то есть в длинных. Это формат с фиксированной шириной и всегда 1 “длинный” в длину.
Первые 256 символов наборов символов Unicode соответствуют 256 символам ISO-8859-1.
По умолчанию процессоры HTML 4 должны поддерживать UTF-8, а процессоры XML должны поддерживать UTF-8 и UTF-16; поэтому все XHTML-совместимые процессоры также должны поддерживать UTF-16.
Кодировки символов в HTML | это.
 .. Что такое Кодировки символов в HTML?
.. Что такое Кодировки символов в HTML?| HTML |
|---|
|
Язык гипертекстовой разметки HTML используется с 1991 года, но версия 4.0 (1997) была первой, где представление символов, отличных от ASCII (то есть, английского языка), достаточно стандартизировано.
Содержание
|
Определение кодировки средствами HTTP
При отображении HTML-страницы браузерами последним нужно сообщить в какой кодировке сохранена страница. Для этого можно воспользоваться двумя методами:
При передаче документа HTML по HTTP (скажем, в WWW) набор символов документа задаётся в заголовке HTTP, например для текста в русском варианте кодировки КОИ-8:
Content-Type: text/html; charset=koi8-r
Информацию о кодировке можно вставить в сам документ HTML, используя тег meta в раздел <head> HTML-документа. Например, в случае кодировки UTF-8 тег meta будет выглядеть следующим образом:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
В стандарте для языка HTML 5 мета тег информирующий браузер о кодировке страницы записывается отлично от правил принятых в более ранних стандартах HTML. Так пример приведенный выше в HTML 5 будет выглядеть следующим образом:
Так пример приведенный выше в HTML 5 будет выглядеть следующим образом:
<meta charset="utf-8">
Такой способ неплохо работает для файлов, но при выдаче документа по HTTP его успешность будет зависеть от действий HTTP-сервера, пожелает ли он указать эту информацию в заголовке. Согласно HTTP/1.1, отсутствие указания charset в заголовке приравнивается к использованию набора символов ISO 8859-1.
То есть, приоритетным фактором для браузера по вопросу «в какой кодировке отображать документ» может являться переданный сервером заголовок. В этом случае браузер обязан игнорировать соответственные директивы в теге META.
Настройка заголовков, передаваемых сервером
1. Можно использовать файл .htaccess. В нём нужно указать директивы серверу касательно кодировок по умолчанию: AddDefaultCharset UTF-8 В приведенном примере кодировкой по умолчанию в заголовках сервера будет назначена UTF-8.
В случае кодировки windows-1251: AddDefaultCharset windows-1251
Данные директивы файла . htaccess наиболее часто применимы. Но в каждом отдельно взятом случае могут и не сработать. Все зависит от настроек сервера.
htaccess наиболее часто применимы. Но в каждом отдельно взятом случае могут и не сработать. Все зависит от настроек сервера.
Есть менее популярные директивы, действие которых направлено на отключение заголовков сервера. При их отключении браузер будет выбирать кодировку в зависимости от указаний в теге МЕТА.
charsetdisable on
AddDefaultCharset Off
Зачастую, проблемы отображения кодировок связаны с тем, что устаревшее ПО для Web (например, сайт, CMS и т.д.) использует национальную кодировку в то время как сервер настроен для работы с UTF-8. В этом случае, принудительно указывается язык, кодировка необходимая ПО (например, cp1251) для web-сервера, и (как правило) интерпретатора PHP.
DefaultLanguage ru
AddDefaultCharset windows-1251
php_value default_charset "cp1251"
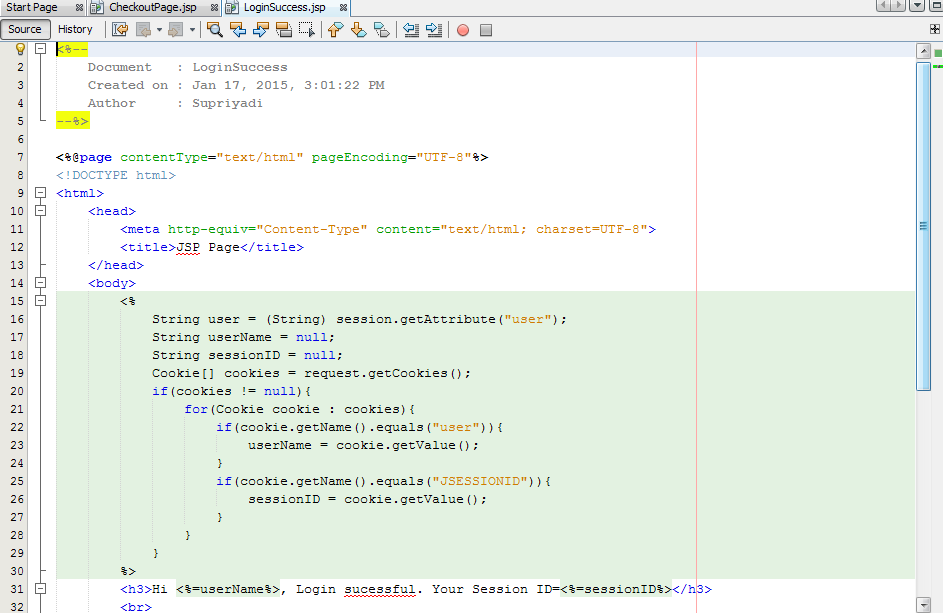
2. Директива php-кодом: В начале php-файла можно указать php-код, который передаст инструкции браузеру по выбору кодировки: <?php header('Content-type: text/html; charset=utf-8')?>
Определение кодировки средствами XML
В XHTML можно также указывать кодировку в преамбуле XML, например:
<?xml version="1.0" encoding="utf-8"?>
 0" encoding="utf-8"?>
0" encoding="utf-8"?>
Мнемоники HTML и коды Unicode
Символы, имеющие специальные названия (см. Мнемоники в HTML), могут быть закодированы в виде &entity;, например:
- «à» → «à»
- «α» → «α»
- «<» → «<»
- «>» → «>»
- « » → « » (пробел)
В то же время все символы могут быть также закодированы в числовом обозначении с использованием десятичного (&#DD;) или шестнадцатеричного (&#xHHHH;) кода Unicode.
- «à» = «à» → «à»
- «α» = «α» → «α»
Правильный браузер будет отображать символы, заданные вышеназванным путём, независимо от текущей кодировки документа и, в частности, даже в случае, когда такие символы ею не могут быть охвачены. Таким образом, возможен японский текст в HTML-документе, написанном в Windows-1251, и т.д.
| Кодировки символов | |||
|---|---|---|---|
| Основы → | алфавит • текст ( файл • данные ) • набор символов • конверсия | ||
| Исторические кодировки → | Докомп. : семафорная (Макарова) • Морзе • Бодо • МТК-2 : семафорная (Макарова) • Морзе • Бодо • МТК-2 | Комп.: 6 бит • УПП • RADIX-50 • EBCDIC ( ДКОИ-8 ) • КОИ-7 • ISO 646 | |
| совре- менное 8-битное представ- ление | символы → | ASCII ( управляющие • печатные ) | не-ASCII ( псевдографика ) |
| 8бит. код.стр. | Разные → Кириллица: КОИ-8 • ГОСТ 19768-87 • MacCyrillic | ||
| ISO 8859 → | 1(лат.) 2 3 4 5(кир.) 6 7 8 9 10 11 12 13 14 15(€) 16 | ||
| Windows → | 1250 1251(кир.) 1252 1253 1254 1255 1256 1257 1258 | WGL4 | ||
| IBM&DOS → | 437 • 850 • 852 • 855 • 866 «альт.» • ( МИК ) • ( НИИ ЭВМ ) | ||
| Много- байтные | Традиционные → | DBCS ( GB2312 ) • HTML | |
| Unicode → | UTF-16 • UTF-8 • список символов ( кириллица ) | ||
| Связанные темы → | интерфейс пользователя • раскладка клавиатуры • локаль • перевод строки • шрифт • кракозябры • транслит • нестандартные шрифты • текст как изображение | Утилиты: iconv • recode | |
Html указать кодировку страницы • Вэб-шпаргалка для интернет предпринимателей!
Содержание
- 1 Немного о кодировках
- 1. 1 Кодировка UTF-8
- 1.2 Как установить кодировку в HTML и PHP
- 1.3 Глобальные настройки кодировки
- 1.4 Изменение кодировки базы данных
- 1.
- 2 Что такое кодировка?
- 3 Кодировка файла
- 4 Кодировка отображения
- 5 Как указать кодировку HTML-страницы?
- 6 Всё ещё есть проблема с кодировкой?
- 7 Метатеги для поисковых механизмов
- 7.1 description
- 7.2 keywords
- 8 Автозагрузка страниц
- 9 Кодировка
- 9.1 Рекомендуем к прочтению
 1 Кодировка UTF-8
1 Кодировка UTF-8Нужно правильно раскодировать сигналы, которые наш мозг получает из окружающей среды. Проще говоря, следует правильно « настроить » свой взгляд на жизнь. Ну, вроде не полупустой кошелек, а наполовину полный. То есть, требуется использовать нужную кодировку. Для интернета чаще всего правильной является кодировка utf :
Немного о кодировках
Наверное, не является секретом тот факт, что основным типом содержимого во всемирном веб-пространстве является текст. Конечно, сейчас с этим утверждением можно поспорить, но буквально какой-то десяток лет назад это было так.
Конечно, сейчас с этим утверждением можно поспорить, но буквально какой-то десяток лет назад это было так.
Но передача текста в цифровом формате происходит совсем иначе, чем у нас на экране. Для перевода текста в машинный код используется двоичная система исчисления, состоящая лишь из 0 и 1.
Следующим этапом передачи текста в виртуальном пространстве является его отображение на клиентских машинах с помощью браузера, интерпретирующего html . Вот тут и начинается самое интересное, когда браузер клиента и веб-страница содержат в себе текстовые данные в разных кодировках. Тогда пользователь на своем мониторе видит не текст, а какие-то непонятные ( нечитаемые ) символы:
Чаще всего нужно всего лишь поменять кодировку веб-страницы на кодировку utf8. Ведь она является наиболее распространенной во всем интернете.
Кодировка UTF-8
Наиболее распространенная среди стандартизированных и общепринятых текстовых кодировок. Расшифровывается как « восьмибитный формат преобразования Юникода » или « Unicode Transformation Format ».
Стандарт был разработан еще в 1992 году. В настоящее время он широко применяется не только во всемирной паутине, но и на прикладном уровне ( локальные машины и операционные системы ). Основным достоинством кодировки является ее совместимость с ASCII:
ASCII («American standard code for information interchange») еще одна (но более старая) кодировка представления текстовых данных. В ее таблице символов значения печатных и непечатных знаков заданы с помощью чисел в шестнадцатеричной системе исчисления.
При использовании UTF-8 для передачи данных в формате ASCII используются 7 первых битов. Последний ( восьмой ) служит для вывода « мусора » ( некорректно раскодированных данных ). Что при использовании кодировки для латинских символов существенно уменьшает объем текстовых данных.
Как уже говорилось, часто для корректного отображения текста достаточно лишь поменять кодировку документа. Рассмотрим, как это можно сделать в различных дисциплинах, применяемых для построения веб-пространства.
Как установить кодировку в HTML и PHP
Для установки utf 8 кодировки в html используется специальный тег . Он объединяет в себе в форме атрибутов значение метатегов.
Метатеги используются для передачи и хранения информации, предназначенной для браузеров и поисковиков. Одним из атрибутов тега является charset . Он служит для установки кодировки веб-страницы. Пример использования:
Также можно установить кодировку некоторым элементам страницы. Например, ссылке. Для этого также используется атрибут charset , значением которого выступает нужная кодировка:
Кроме этого можно присваивать значения непосредственно заголовкам http , которые передаются вместе с ответом на запрос от браузера к серверу. В таком случае кодировка сайта utf 8 , переданная через заголовок, будет доминирующей над значением, заданным внутри веб-страницы.
Многие из страниц ресурсов не являются статическими, а динамически создаются благодаря использованию серверных языков программирования. Чаще всего для построения сайтов применяют PHP . Поэтому важно знать о его средствах, позволяющих «на лету» поменять кодировку генерируемой веб-страницы.
Чаще всего для построения сайтов применяют PHP . Поэтому важно знать о его средствах, позволяющих «на лету» поменять кодировку генерируемой веб-страницы.
Для установки и модификации значений заголовка используется функция header() . Ее синтаксис:
Чтобы корректно задать в php кодировку utf 8 , вызов функции header() в коде должен находиться выше всех тегов html .
Глобальные настройки кодировки
Описанные выше методы могут использоваться для отдельных веб-страниц или небольших сайтов. Но что делать, если вы имеете дело с ресурсом, состоящим из нескольких сотен страниц и десятка разделов? Давайте разберемся, как установить кодировку utf 8 для всего сайта.
Для этого нужно вносить изменения в дополнительный файл конфигурации ресурса. Он носит название .htaccess . Сначала его нужно открыть в любом текстовом редакторе, а затем добавить туда строку:
В качестве более глобального способа изменения кодировки стоит рассмотреть пример на основе любого локального сервера. Для большей наглядности мы возьмем Denwer , который довольно широко распространен в наших краях.
Для большей наглядности мы возьмем Denwer , который довольно широко распространен в наших краях.
Чтобы изменить кодировку всех ресурсов, размещенных на нашем сервере Apache , нужно отредактировать содержимое конфигурационного файла httpd.conf . Он находится по пути:
Как и в предыдущем примере, в нем нужно заменить значение AddDefaultCharset на нужное. В нашем случае это utf-8 :
Изменение кодировки базы данных
Изменение кодировки рассмотрим на примере MySQL . Так как это одна из самых востребованных и распространенных СУБД, применяемых в сайтостроении. Все изменения можно произвести в файле my.ini . В Денвере он находится по пути:
Здесь нужно поменять значение нескольких полей на utf-8 :
- default-character-set ;
- character-set-server ;
- init-connect = «set names» ;
- default-character-set .
И затем добавить строку skip-character-set-client-handshake :
Подобные изменения можно внести не только для всех баз данных на сервере, но и для отдельно взятой в php базы mysql . Сделать это можно через пользовательский интерфейс оболочки PHPMyAdmin .
Сделать это можно через пользовательский интерфейс оболочки PHPMyAdmin .
Сначала узнаем, какие кодировки установлены по умолчанию в нашей базе данных. Для этого вводим запрос SQL :
Вот какой ответ мы должны получить:
Если какие-либо значения нас не удовлетворяют, то нужно их изменить. Воспользуемся для этого запросом к ядру сервера СУБД:
В результате мы получим новые значения переменных character_set_connection , character_set_results и character_set_client.
К сожалению, не все так просто обстоит с изменением кодировки в таблицах Excel . Для этого придется воспользоваться сторонней программой для перекодирования файлов. Или обработать данные с помощью громоздких функций.
Мы рассмотрели все основные способы изменения веб-документов на кодировку utf . Надеемся, что этот материал поможет вам не только выбрать правильную кодировку текста, но и « установить » правильный взгляд на жизнь.
Первая серьёзная проблема, с которой сталкиваются большинство новичков при создании HTML-страниц, связана с набором символов (англ. character set). Выражается эта проблема с кодировкой в, так называемых, «кракозябриках», которые мы получаем вместо указанных в HTML-файле символов. В данной статье я хочу остановиться на проблеме с кодировкой подробнее, постараться расставить всё по полочкам и дать варианты решения.
character set). Выражается эта проблема с кодировкой в, так называемых, «кракозябриках», которые мы получаем вместо указанных в HTML-файле символов. В данной статье я хочу остановиться на проблеме с кодировкой подробнее, постараться расставить всё по полочкам и дать варианты решения.
- Что такое кодировка?
- Кодировка файла (редактирование в Notepad++)
- Кодировка отображения (просмотр в браузере)
- Как указать кодировку HTML-страницы? (метатег charset)
- Всё ещё есть проблема с кодировкой? (header charset в php)
Что такое кодировка?
Условно говоря, каждый символ (знак) состоит из кода и картинки. Здесь код – это уникальный идентификатор символа в наборе символов, который определяется выбранной кодировкой, а картинка – это визуальное представление символа, которое содержится в файле шрифта в соответствующей коду символа ячейке.
Другими словами, кодировка (англ. charset) – это набор взаимосвязей кодов символов с их визуальными представлениями в шрифте.
charset) – это набор взаимосвязей кодов символов с их визуальными представлениями в шрифте.
Кодировка файла
HTML-страница представляет собой обычный текстовый файл, кодировка которого выбирается при его создании и/или сохранении на запоминающее устройство (жёсткий диск, флэшка и т.д.) .
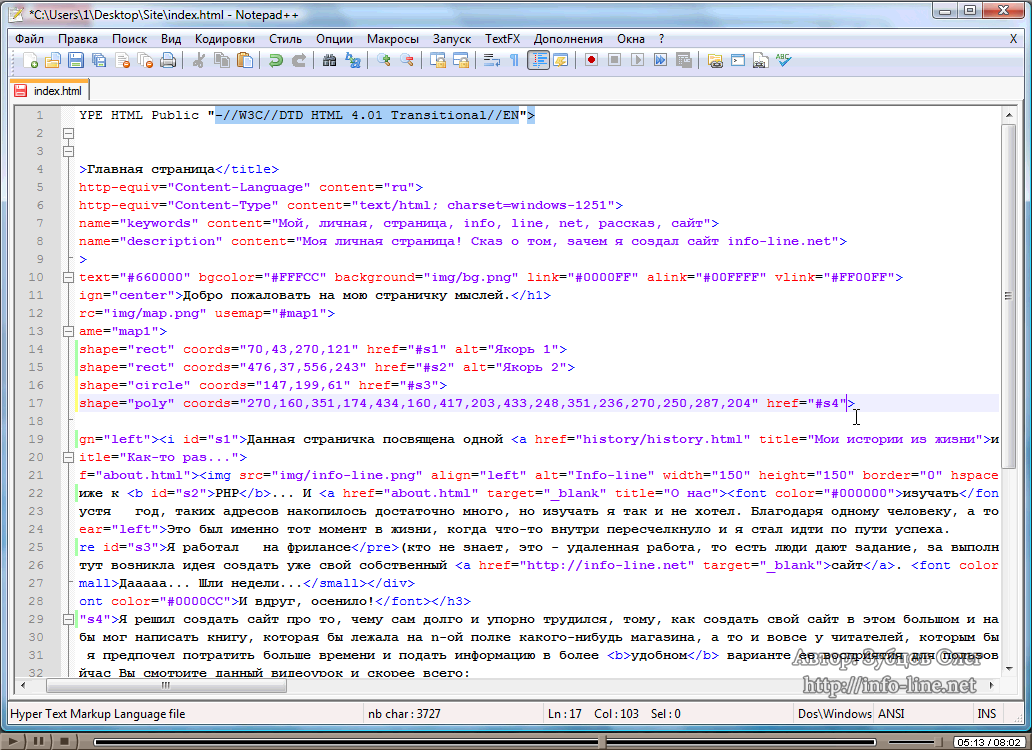
В случае с Notepad++, кодировка нового документа задаётся в настройках текстового редактора. Выбираем в меню: Опции > Настройки… – и переходим на вкладку «Новый документ». Здесь нас интересует секция «Кодировка». По умолчанию, выбрана кодировка ANSI.
Настройка кодировки нового документа в Notepad++
Напомню, что это кодировка, в которой будет храниться HTML-файл.
Впрочем, Вы всегда можете преобразовать кодировку HTML-страницы, используя соответствующие функции текстового редактора. Например, в Notepad++ для этого кликните пункт меню «Кодировки» и выберите нужное преобразование.
Преобразование кодировки текущей HTML-страницы в Notepad++
В данном случае файл был в кодировке ANSI и я преобразовал его в UTF-8 (без BOM) . О том, что такое этот BOM Вы можете прочитать в моей статье: PHP: как удалить BOM в WordPress — проследовав по этой ссылке.
О том, что такое этот BOM Вы можете прочитать в моей статье: PHP: как удалить BOM в WordPress — проследовав по этой ссылке.
Кодировка отображения
Важно разделять кодировку файла и кодировку отображения. Независимо от того, в какой кодировке хранится файл, он может быть отображен и в любой другой кодировке. Это и является одной из причин проблем с кодировкой.
Например, если Вы сохранили HTML-страницу в кодировке ANSI и откроете её в браузере, вместо русских символов Вы можем получить, так называемые, «кракозябрики».
Проблемы с кодировкой отображения HTML-страницы в браузере Firefox
В данном случае нам надо убедиться, что кодировка файла совпадает с кодировкой отображения файла в браузере. Для этого в Firefox кликните иконку меню, а потом пункт «Кодировка». Если такого у Вас нет, кликните пункт «�?зменить» и добавьте элемент «Кодировка» в меню.
Смена кодировки отображения HTML-страницы в браузере Firefox
Как вы видите, браузер отображает файл в кодировке «Юникод» (например, UTF-8) , в то время как файл был сохранён в кодировке ANSI (например, Windows-1251) . Выбрав нужную кодировку, мы получим нужный нам результат.
Выбрав нужную кодировку, мы получим нужный нам результат.
Проблема с кодировкой решена
В случае с Notepad++ также имеется возможность выбора кодировки отображения. Для этого кликните пункт меню «Кодировки», а потом нужный вариант используемой для отображения кодировки.
Смена кодировки отображения HTML-страницы в Notepad++
В данном случае я изменил кодировку отображения ANSI на UTF-8 (без BOM) .
Как указать кодировку HTML-страницы?
�? так, мы уже разобрались с тем, что такое кодировка и в чём состоит отличие кодировки файла и кодировки отображения. Теперь нам нужно решить проблему с кодировкой, которая заключается в неправильной интерпретации браузером (или любым другим клиентом) кодировки HTML-страницы.
Почему возникают проблемы с кодировкой? Определить кодировку HTML-страницы не просто, а зачастую и не возможно, т.к. у того же браузера нет информации о ней или она указана неправильно.
Для того чтобы указать кодировку HTML-страницы используется специальный метатег. В HTML5 он имеет следующий урезанный вид:
В данном случае указана кодировка UTF-8 (Юникод) .
В более старых версиях HTML этот метатег имеет следующий вид:
Этот метатег создаёт HTTP-заголовок Content-Type , в котором указывается тип документа text/html и его кодировка Windows-1251 (ANSI) .
Лично я рекомендую использовать именно этот вариант, т.к. с ним будет меньше всего проблем. Главное чтобы такой метатег присутствовал в секции HEAD , и указанная в нём кодировка соответствовала кодировке файла. В большинстве случаев этого будет достаточно.
Всё ещё есть проблема с кодировкой?
В некоторых случаях указать метатег с кодировкой HTML-страницы будет недостаточно. Такая проблема может быть вызвана настройками самого сервера, на котором находится файл HTML-страницы. Дело в том, что сервер способен выдавать свой HTTP-заголовок Content-Type , который будет, условно говоря, иметь приоритет перед метатегом.
В данном случае эту проблему можно решить путём внесения изменений в настройки сервера. Я не буду вдаваться в детали данного вопроса и порекомендую лишь отключать всю эту перекодировку через файл .htaccess, например:
Также можно производить изменения HTTP-заголовка Content-Type и программными средствами. В том же PHP для этого используется функция header() , например:
8 декабря 2016 г., 19:56 Удалить комментарий
Я так понимаю, вот я в программе создаю html страницу. Если я в тексте напишу хотя бы один английский символ, то кодировка автоматически станет Юникод?
А в браузере по умолчанию отображаются все страницы в ANSI, поэтому мой файл в Юникоде как раз и будет с кракозябрами?
15 февраля 2017 г., 11:57 Удалить комментарий
Буквы на английском имеют одинаковые коды во всех кодировках, так что с ними проблем не возникает, а вот с той же кириллицей могут быть проблемы.
По сути, действительно, если использовать только буквы на английском, то кодировка часто определяется браузерами как «Кириллица (Windows)» или тип того, просто он не может распознать кодировку не имея «нестандартных» символов.
Впрочем, даже если есть символы и прописан meta тег, не факт, что браузер поймёт в как отображать страницу, т.к. в основном ориентируется на http заголовки сервера.
15 февраля 2017 г., 18:25 Удалить комментарий
спасибо огромное за полезную статью.
но у меня остался таки вопрос. как изменить кодировку по умолчанию в браузере firefox я поняла,зашла в настройки, а там нет нужного мне юникода. файлы создаю в нотепаде++ с юникодом. посоветуйте пожалуйста, как поступить в моем случае. писать в кириллице,чтобы совпадало с фаерфоксом? либо как. а вообще хотела использовать юникод везде))
Метатеги используются для хранения информации предназначенной для браузеров и поисковых систем. Например, механизмы поисковых систем обращаются к метатегам для получения описания сайта, ключевых слов и других данных.
Метатеги для поисковых механизмов
Среди разработчиков сайтов существует мнение, что правильно написанные метатеги позволяют подняться к верхним строчкам поисковых серверов. На самом деле это не так, на одних метатегах высоко не поднимешься, но и неудачно выполненное содержимое метатегов может ухудшить рейтинг сайта.
На самом деле это не так, на одних метатегах высоко не поднимешься, но и неудачно выполненное содержимое метатегов может ухудшить рейтинг сайта.
Два метатега предназначены специально для поисковых серверов: description (описание) и keywords (ключевые слова). Некоторые вебмастера добавляли в раздел keywords ключевые слова, которые не имеют никакого отношения к теме сайта, но зато пользовались определенным успехом среди посетителей поисковиков. Однако, через некоторое время, поисковые системы научились бороться с таким явлением и проверяют содержимое веб-страницы на соответствие заявленным ключевым словам.
Некоторые принципы, относящиеся к метатегам:
- не включайте ключевые слова, которые не содержатся на ваших страницах;
- не повторяйте ключевые слова;
- используйте метатеги по их прямому назначению;
- делайте описание и список ключевых слов различными для каждой страницы сайта с учетом содержимого.
description
Большинство поисковых серверов отображают содержимое поля description (пример 1) при выводе результатов поиска. Если этого тега нет на странице, то поисковый движок просто перечислит первые встречающиеся слова на странице, которые, как правило, оказываются не очень-то и в тему.
Если этого тега нет на странице, то поисковый движок просто перечислит первые встречающиеся слова на странице, которые, как правило, оказываются не очень-то и в тему.
Пример 1. Использование Description
keywords
Этот метатег был предназначен для описания ключевых слов, встречающихся на странице (пример 2). Но в результате действия людей, желающих попасть в верхние строчки поисковых систем любыми средствами, теперь дискредитирован. Поэтому многие поисковики пропускают этот параметр.
Пример 2. Использование Keywords
Ключевые слова можно перечислять через пробел или запятую. Поисковые системы сами приведут запись к виду, который они используют.
Автозагрузка страниц
Чтобы автоматически загружать новый документ через определенный промежуток времени используется инструкция http-equiv=»refresh» (пример 3).
Пример 3. Автозагрузка страницы
Браузер поймет эту запись, как ожидать 5 секунд, а затем загрузить новую страницу, указанную в параметре URL , в данном случае это переход на сайт htmlbook. ru.
ru.
Этот метатег позволяет создавать перенаправление (редирект) на другой сайт. Если URL не указан, произойдет автоматическое обновление текущей страницы через количество секунд, заданных в атрибуте content .
Кодировка
Чтобы сообщить браузеру, в какой кодировке находятся символы веб-страницы, необходимо установить параметр . Для операционной системы Windows и кириллицы charset обычно принимает значение utf-8 или windows-1251 (пример 4).
Пример 4. Выбор текущей кодировки
Если указание кодировки отсутствует, браузер пытается сам определить, какой тип символов используется в документе и выбирает необходимую кодировку автоматически. Браузер не всегда может точно распознать язык веб-страницы и в некоторых случаях предлагает вьетнамскую кодировку вместо кириллицы. По этой причине лучше всегда указывать приведенную строчку. Тем не менее, возникают обстоятельства, когда указание кодировки может принести определенный вред. Например, веб-сервер автоматически использует перекодирование данных в KOI-8, а браузер, встретив параметр charset=windows-1251 , переводит текст в кодировку Windows.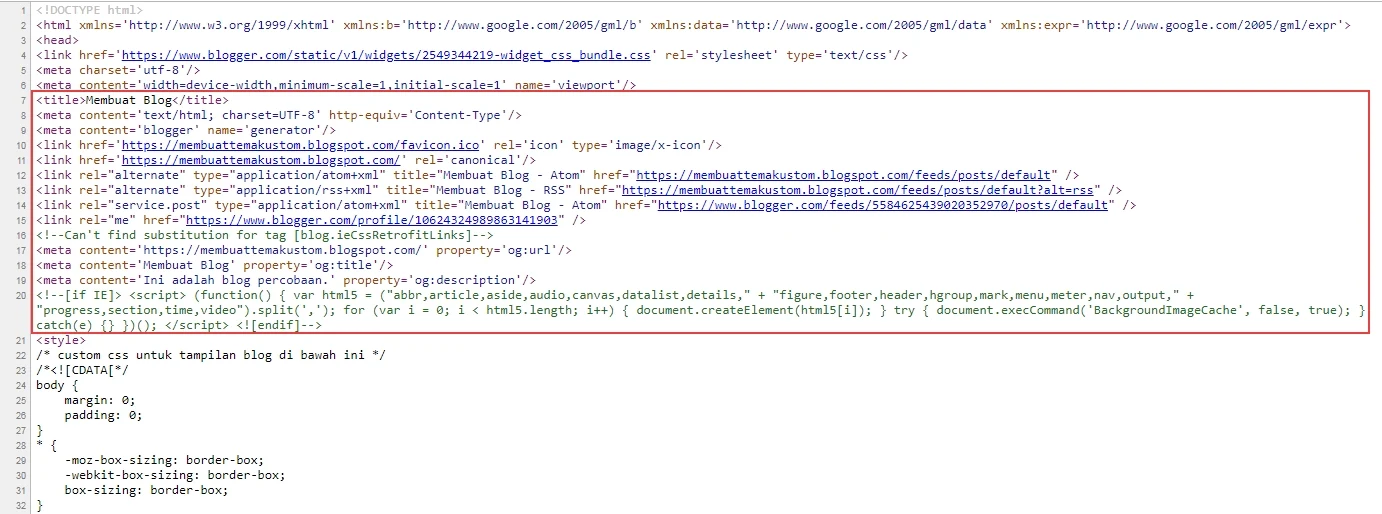 Получается двойное изменение символов, прочитать такой текст не просто. К счастью, подобная проблема уже отходит в прошлое, во всяком случае, ее легко можно выявить и нейтрализовать на уровне сервера.
Получается двойное изменение символов, прочитать такой текст не просто. К счастью, подобная проблема уже отходит в прошлое, во всяком случае, ее легко можно выявить и нейтрализовать на уровне сервера.
Кодировки символов в HTML
Список ссылок на символьные сущности см. Список ссылок на символьные сущности XML и HTML.
Для исправления ссылок в Википедии см. Справка: процентное кодирование § Исправление ссылок с неподдерживаемыми символами.
HTML (Язык гипертекстовой разметки) используется с 1991 года, но HTML 4.0 (декабрь 1997 года) был первой стандартизированной версией, в которой символы получили достаточно полное лечение. Когда HTML-документ включает специальные символы вне семибитного диапазона ASCII, стоит рассмотреть две цели: информационная честность, и универсальный браузер отображать.
Содержание
- 1 Указание кодировки символов документа
- 2 Разрешенные кодировки
- 3 Ссылки на символы
- 3.1 Ссылки на символы HTML
- 3. 2 Ссылки на символы XML
- 4 Смотрите также
- 5 Рекомендации
- 6 внешняя ссылка
 2 Ссылки на символы XML
2 Ссылки на символы XMLУказание кодировки символов документа
Есть несколько способов указать, какая кодировка символов используется в документе. Во-первых, веб сервер может включать кодировку символов или «кодировка» в Протокол передачи гипертекста (HTTP) Тип содержимого заголовок, который обычно выглядит так:[1]
Content-Type: текст / html; charset = ISO-8859-4
Этот метод дает HTTP-серверу удобный способ изменить кодировку документа в соответствии с согласование содержания; определенное программное обеспечение HTTP-сервера может это сделать, например Apache с модуль mod_charset_lite.[2]
Для HTML эту информацию можно включить в голова элемент в верхней части документа:[3]
<мета http-Equiv="Тип содержимого" содержание="текст / html; charset = utf-8">
HTML5 также позволяет следующий синтаксис означать то же самое:[3]
<мета кодировка=«УТФ-8»>
XHTML у документов есть третий вариант: выразить кодировку символов через XML декларация следующего содержания:[4]
<?xml version="1.
 0" encoding="ISO-8859-1"?>
0" encoding="ISO-8859-1"?>Поскольку кодировка символов не может быть известна до этого[требуется разъяснение ] объявление анализируется, может возникнуть проблема, зная, какая кодировка используется для самого объявления. Главный принцип заключается в том, что объявление должно быть закодировано в чистом ASCII, и поэтому (если объявление находится внутри файла) кодировка должна быть Расширение ASCII. Для того чтобы кодировки не были обратно совместимы с ASCII, браузеры должны иметь возможность анализировать объявления в таких кодировках. Примеры таких кодировок: UTF-16BE и UTF-16LE.
Начиная с HTML5 рекомендуемая кодировка UTF-8.[3] В спецификации определен «алгоритм сниффинга кодирования» для определения кодировки символов документа на основе нескольких источников ввода, включая:
- Явная инструкция пользователя
- Явный метатег в первых 1024 байтах документа.
- А Отметка порядка байтов в пределах первых трех байтов документа
- Тип содержимого HTTP или другая информация транспортного уровня
- Анализ байтов документа на предмет определенных последовательностей или диапазонов значений байтов,[5] и другие механизмы предварительного обнаружения.
Для ASCII-совместимых кодировок символов следствием неправильного выбора является то, что символы за пределами печатаемого диапазона ASCII (от 32 до 126) обычно отображаются неправильно. Это создает несколько проблем для английский — говорящие пользователи, но для других языков обычно — в некоторых случаях всегда — требуются символы вне этого диапазона. В CJK В средах, где используется несколько различных многобайтовых кодировок, также часто применяется автоматическое обнаружение. Наконец, браузеры обычно позволяют пользователю переопределить неверный метку кодировки вручную.
Многоязычные веб-сайты и веб-сайты на незападных языках все чаще используют UTF-8, что позволяет использовать одну и ту же кодировку для всех языков. UTF-16 или же UTF-32, которые также могут использоваться для всех языков, менее широко используются, поскольку их сложнее обрабатывать в языках программирования, которые предполагают байтовый Кодирование расширенного набора ASCII, и они менее эффективны для текста с высокой частотой символов ASCII, что обычно имеет место для документов HTML.
Успешный просмотр страницы не обязательно означает, что ее кодировка указана правильно. Если создатель страницы и читатель оба предполагают кодировку символов, зависящую от платформы, и сервер не отправляет никакой идентифицирующей информации, то читатель, тем не менее, будет видеть страницу так, как задумал создатель, но другие читатели на других платформах или с разными родными языками не увидит страницу должным образом.
Разрешенные кодировки
В WHATWG Стандарт кодирования, на который ссылаются последние стандарты HTML (текущий WHATWG HTML Living Standard, а также ранее конкурирующий W3C HTML 5.0 и 5.1) определяет список кодировок, которые браузеры должны поддерживать. Стандарты HTML запрещают поддержку других кодировок.[6][7][8] Стандарт кодирования также предусматривает, что новые форматы, новые протоколы (даже когда используются существующие форматы) и авторы новых документов должны использовать UTF-8 исключительно.[9]
Помимо UTF-8, следующие кодировки явно перечислены в самом стандарте HTML со ссылкой на стандарт кодирования:[8]
- ISO-8859-2
- ISO-8859-7
- ISO-8859-8
- Окна-874[а]
- Окна-1250
- Окна-1251
- Окна-1252[b]
- Окна-1254[c]
- Окна-1255
- Окна-1256
- Окна-1257
- Окна-1258
- GB18030[d]
- Big5[e]
- Shift JIS[f]
- ISO-2022-JP[грамм]
- EUC-KR[час]
- UTF-16BE[я]
- UTF-16LE[j]
- x-определяемый пользователем[k]
- ^ Также указано для
ТИС-620,ISO-8859-11и связанные ярлыки. В спецификации используется тот же индекс, что и для Shift JIS (поскольку он находится в пределах досягаемости набора кодов EUC 1), то есть включает расширения NEC. JIS X 0212 включен только для декодирования.[25]
 В спецификации используется тот же индекс, что и для Shift JIS (поскольку он находится в пределах досягаемости набора кодов EUC 1), то есть включает расширения NEC. JIS X 0212 включен только для декодирования.[25]
В спецификации используется тот же индекс, что и для Shift JIS (поскольку он находится в пределах досягаемости набора кодов EUC 1), то есть включает расширения NEC. JIS X 0212 включен только для декодирования.[25]Следующие кодировки указаны как явные примеры запрещенных кодировок:[8]
- ЦЭСУ-8
- UTF-7
- BOCU-1
- ГКГУ
- EBCDIC
- UTF-32
Стандарт также определяет «замещающий» декодер, который отображает весь контент, помеченный как определенные кодировки, в замещающий символ ( ), вообще отказываясь его обрабатывать. Это предназначено для предотвращения атак (например, межсайтовый скриптинг ), которые могут использовать разницу между клиентом и сервером в поддерживаемых кодировках для маскировки вредоносного содержимого.[26] Хотя та же проблема безопасности относится к ISO-2022-JP и UTF-16, которые также позволяют по-разному интерпретировать последовательности байтов ASCII, этот подход не рассматривался как выполнимый для них, поскольку они сравнительно чаще используются в развернутом контенте.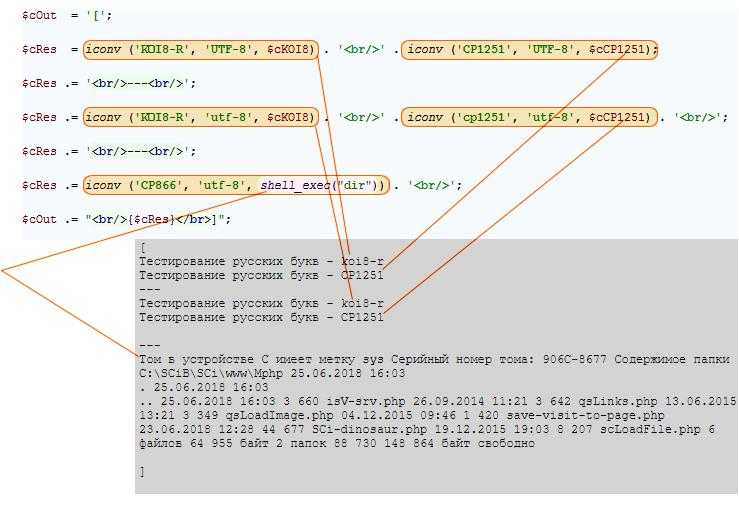 [27] Следующие кодировки обрабатываются так:[28]
[27] Следующие кодировки обрабатываются так:[28]
- ISO-2022-KR
- ISO-2022-CN
- ISO-2022-CN-EXT
- HZ-GB-2312
Ссылки на символы
Основные статьи: Ссылка на сущность символа и Ссылка на числовые символы
Помимо собственной кодировки символов, символы также могут быть закодированы как ссылки на символы, который может быть ссылки на числовые символы (десятичный или же шестнадцатеричный ) или же ссылки на символьные сущности. Ссылки на символьные сущности также иногда называют названные объекты, или же HTML-объекты для HTML. Использование символьных ссылок в HTML происходит от SGML.
Ссылки на символы HTML
А ссылка на числовой символ в HTML относится к символу по его Универсальный набор символов /Unicode кодовая точка, и использует формат
&#nnnn;
или же
Иксхххх;
куда nnnn это кодовая точка в десятичный форма, и хххх это кодовая точка в шестнадцатеричный форма. В Икс в XML-документах должен быть строчным. В nnnn или же хххх может быть любым количеством цифр и может включать в себя ведущие нули. В хххх может смешивать прописные и строчные буквы, хотя прописные буквы являются обычным стилем.
В Икс в XML-документах должен быть строчным. В nnnn или же хххх может быть любым количеством цифр и может включать в себя ведущие нули. В хххх может смешивать прописные и строчные буквы, хотя прописные буквы являются обычным стилем.
Не все веб-браузеры или же почтовые клиенты используется получателями HTML-документов, или текстовые редакторы используется авторами документов HTML, сможет отображать все символы HTML. Большинство современных программ способно отображать большинство или все символы языка пользователя, а также рисовать прямоугольник или другой четкий индикатор для символов, которые они не могут отобразить.
Для кодов от 0 до 127 исходный 7-битный ASCII стандартный набор, большинство этих символов можно использовать без ссылки на символ. Все коды от 160 до 255 могут быть созданы с помощью имена персонажей. Только несколько кодов с более высокими номерами могут быть созданы с использованием имен сущностей, но все они могут быть созданы с помощью ссылки на символ десятичного числа.
Ссылки на символьные сущности также могут иметь формат &имя; куда имя представляет собой буквенно-цифровую строку с учетом регистра. Например, «λ» также может быть закодировано как & лямбда; в HTML-документе. Ссылки на сущность персонажа & lt;, & gt;, & quot; и & amp; предопределены в HTML и SGML, потому что <, >, " и & уже используются для разграничения разметки. В частности, это не включало XML & апос; (‘) сущность до HTML5. Для получения списка всех названных ссылок на сущности символов HTML вместе с версиями, в которых они были представлены, см. Список ссылок на символьные сущности XML и HTML.
Излишнее использование ссылок на символы HTML может значительно снизить удобочитаемость HTML. Если кодировка символов для веб-страницы выбрана надлежащим образом, то ссылки на символы HTML обычно требуются только для символов-разделителей разметки, как указано выше, и для нескольких специальных символов (или вообще без них, если Unicode кодирование как UTF-8 используется). Неправильное экранирование HTML-объекта также может открыть уязвимости безопасности для атак с использованием инъекций, таких как межсайтовый скриптинг. Если атрибуты HTML не заключены в кавычки, некоторые символы, что наиболее важно пробел, такие как пробел и табуляция, должны быть экранированы с помощью сущностей. В других языках, связанных с HTML, есть свои методы экранирования символов.
Неправильное экранирование HTML-объекта также может открыть уязвимости безопасности для атак с использованием инъекций, таких как межсайтовый скриптинг. Если атрибуты HTML не заключены в кавычки, некоторые символы, что наиболее важно пробел, такие как пробел и табуляция, должны быть экранированы с помощью сущностей. В других языках, связанных с HTML, есть свои методы экранирования символов.
Ссылки на символы XML
В отличие от традиционного HTML с его большим диапазоном ссылок на символьные сущности, в XML имеется только пять предопределенных ссылок на символьные сущности. Они используются для экранирования символов, чувствительных к разметке в определенных контекстах:[29]
& amp;→ & (амперсанд, U + 0026)& lt;→& gt;→> (знак больше, U + 003E)& quot;→ «(кавычка, U + 0022)& апос;→ ‘(апостроф, U + 0027)
Все остальные ссылки на символьные сущности должны быть определены до того, как их можно будет использовать. Брей, Т.; Paoli, J .; Сперберг-Маккуин, К.; Maler, E .; Йерго, Ф. (26 ноября 2008 г.), «Ссылки на персонажей и сущностей», XML, W3C, получено 8 марта 2010
Брей, Т.; Paoli, J .; Сперберг-Маккуин, К.; Maler, E .; Йерго, Ф. (26 ноября 2008 г.), «Ссылки на персонажей и сущностей», XML, W3C, получено 8 марта 2010
внешняя ссылка
- Инструмент кодирования и декодирования HTML-сущностей онлайн
- Ссылки на символьные сущности в HTML4
- Полное руководство по кодированию веб-символов
- Глава HTML Entity Encoding в Руководстве по безопасности браузера — дополнительная информация о текущих браузерах и работе с ними
- Вики-статья проекта Open Web Application Security Project о межсайтовых сценариях (XSS)
Как прописать кодировку в html?
Содержание
- Немного о кодировках
- Кодировка UTF-8
- Как установить кодировку в HTML и PHP
- Глобальные настройки кодировки
- Изменение кодировки базы данных
- Что такое кодировка?
- Кодировка файла
- Кодировка отображения
- Как указать кодировку HTML-страницы?
- Всё ещё есть проблема с кодировкой?
- Что такое кодировка сайта и как она работает
- Самые распространенные кодировки
- Проблемы с кодировкой не только в HTML-странице
- META Charset HTML-документа
Нужно правильно раскодировать сигналы, которые наш мозг получает из окружающей среды.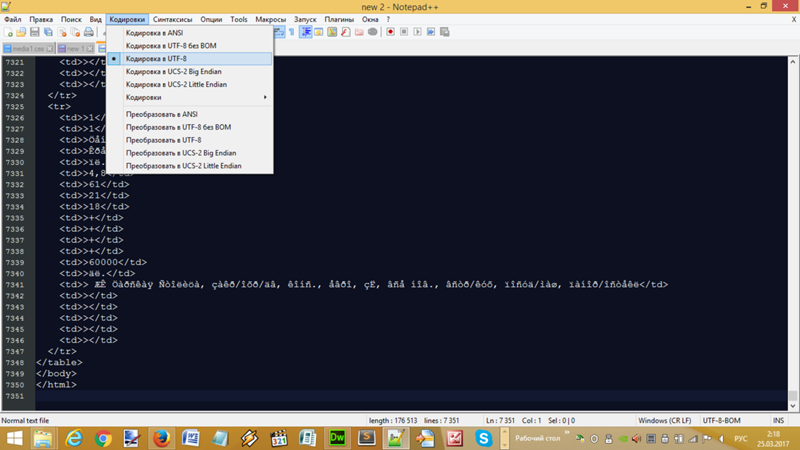 Проще говоря, следует правильно « настроить » свой взгляд на жизнь. Ну, вроде не полупустой кошелек, а наполовину полный. То есть, требуется использовать нужную кодировку. Для интернета чаще всего правильной является кодировка utf :
Проще говоря, следует правильно « настроить » свой взгляд на жизнь. Ну, вроде не полупустой кошелек, а наполовину полный. То есть, требуется использовать нужную кодировку. Для интернета чаще всего правильной является кодировка utf :
Немного о кодировках
Наверное, не является секретом тот факт, что основным типом содержимого во всемирном веб-пространстве является текст. Конечно, сейчас с этим утверждением можно поспорить, но буквально какой-то десяток лет назад это было так.
Но передача текста в цифровом формате происходит совсем иначе, чем у нас на экране. Для перевода текста в машинный код используется двоичная система исчисления, состоящая лишь из 0 и 1.
Следующим этапом передачи текста в виртуальном пространстве является его отображение на клиентских машинах с помощью браузера, интерпретирующего html . Вот тут и начинается самое интересное, когда браузер клиента и веб-страница содержат в себе текстовые данные в разных кодировках. Тогда пользователь на своем мониторе видит не текст, а какие-то непонятные ( нечитаемые ) символы:
Чаще всего нужно всего лишь поменять кодировку веб-страницы на кодировку utf8. Ведь она является наиболее распространенной во всем интернете.
Ведь она является наиболее распространенной во всем интернете.
Кодировка UTF-8
Наиболее распространенная среди стандартизированных и общепринятых текстовых кодировок. Расшифровывается как « восьмибитный формат преобразования Юникода » или « Unicode Transformation Format ».
Стандарт был разработан еще в 1992 году. В настоящее время он широко применяется не только во всемирной паутине, но и на прикладном уровне ( локальные машины и операционные системы ). Основным достоинством кодировки является ее совместимость с ASCII:
ASCII («American standard code for information interchange») еще одна (но более старая) кодировка представления текстовых данных. В ее таблице символов значения печатных и непечатных знаков заданы с помощью чисел в шестнадцатеричной системе исчисления.
При использовании UTF-8 для передачи данных в формате ASCII используются 7 первых битов. Последний ( восьмой ) служит для вывода « мусора » ( некорректно раскодированных данных ). Что при использовании кодировки для латинских символов существенно уменьшает объем текстовых данных.
Как уже говорилось, часто для корректного отображения текста достаточно лишь поменять кодировку документа. Рассмотрим, как это можно сделать в различных дисциплинах, применяемых для построения веб-пространства.
Как установить кодировку в HTML и PHP
Для установки utf 8 кодировки в html используется специальный тег . Он объединяет в себе в форме атрибутов значение метатегов.
Метатеги используются для передачи и хранения информации, предназначенной для браузеров и поисковиков. Одним из атрибутов тега является charset . Он служит для установки кодировки веб-страницы. Пример использования:
Также можно установить кодировку некоторым элементам страницы. Например, ссылке. Для этого также используется атрибут charset , значением которого выступает нужная кодировка:
Кроме этого можно присваивать значения непосредственно заголовкам http , которые передаются вместе с ответом на запрос от браузера к серверу. В таком случае кодировка сайта utf 8 , переданная через заголовок, будет доминирующей над значением, заданным внутри веб-страницы.
Многие из страниц ресурсов не являются статическими, а динамически создаются благодаря использованию серверных языков программирования. Чаще всего для построения сайтов применяют PHP . Поэтому важно знать о его средствах, позволяющих «на лету» поменять кодировку генерируемой веб-страницы.
Для установки и модификации значений заголовка используется функция header() . Ее синтаксис:
Чтобы корректно задать в php кодировку utf 8 , вызов функции header() в коде должен находиться выше всех тегов html .
Глобальные настройки кодировки
Описанные выше методы могут использоваться для отдельных веб-страниц или небольших сайтов. Но что делать, если вы имеете дело с ресурсом, состоящим из нескольких сотен страниц и десятка разделов? Давайте разберемся, как установить кодировку utf 8 для всего сайта.
Для этого нужно вносить изменения в дополнительный файл конфигурации ресурса. Он носит название .htaccess . Сначала его нужно открыть в любом текстовом редакторе, а затем добавить туда строку:
В качестве более глобального способа изменения кодировки стоит рассмотреть пример на основе любого локального сервера.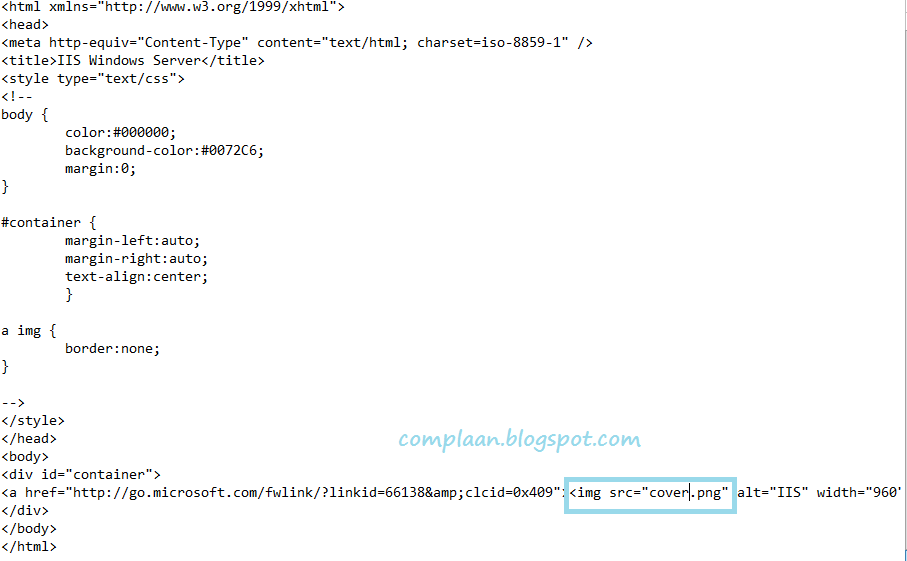 Для большей наглядности мы возьмем Denwer , который довольно широко распространен в наших краях.
Для большей наглядности мы возьмем Denwer , который довольно широко распространен в наших краях.
Чтобы изменить кодировку всех ресурсов, размещенных на нашем сервере Apache , нужно отредактировать содержимое конфигурационного файла httpd.conf . Он находится по пути:
Как и в предыдущем примере, в нем нужно заменить значение AddDefaultCharset на нужное. В нашем случае это utf-8 :
Изменение кодировки базы данных
Изменение кодировки рассмотрим на примере MySQL . Так как это одна из самых востребованных и распространенных СУБД, применяемых в сайтостроении. Все изменения можно произвести в файле my.ini . В Денвере он находится по пути:
Здесь нужно поменять значение нескольких полей на utf-8 :
- default-character-set ;
- character-set-server ;
- init-connect = «set names» ;
- default-character-set .
И затем добавить строку skip-character-set-client-handshake :
Подобные изменения можно внести не только для всех баз данных на сервере, но и для отдельно взятой в php базы mysql . Сделать это можно через пользовательский интерфейс оболочки PHPMyAdmin .
Сделать это можно через пользовательский интерфейс оболочки PHPMyAdmin .
Сначала узнаем, какие кодировки установлены по умолчанию в нашей базе данных. Для этого вводим запрос SQL :
Вот какой ответ мы должны получить:
Если какие-либо значения нас не удовлетворяют, то нужно их изменить. Воспользуемся для этого запросом к ядру сервера СУБД:
В результате мы получим новые значения переменных character_set_connection , character_set_results и character_set_client.
К сожалению, не все так просто обстоит с изменением кодировки в таблицах Excel . Для этого придется воспользоваться сторонней программой для перекодирования файлов. Или обработать данные с помощью громоздких функций.
Мы рассмотрели все основные способы изменения веб-документов на кодировку utf . Надеемся, что этот материал поможет вам не только выбрать правильную кодировку текста, но и « установить » правильный взгляд на жизнь.
Первая серьёзная проблема, с которой сталкиваются большинство новичков при создании HTML-страниц, связана с набором символов (англ. character set). Выражается эта проблема с кодировкой в, так называемых, «кракозябриках», которые мы получаем вместо указанных в HTML-файле символов. В данной статье я хочу остановиться на проблеме с кодировкой подробнее, постараться расставить всё по полочкам и дать варианты решения.
character set). Выражается эта проблема с кодировкой в, так называемых, «кракозябриках», которые мы получаем вместо указанных в HTML-файле символов. В данной статье я хочу остановиться на проблеме с кодировкой подробнее, постараться расставить всё по полочкам и дать варианты решения.
- Что такое кодировка?
- Кодировка файла (редактирование в Notepad++)
- Кодировка отображения (просмотр в браузере)
- Как указать кодировку HTML-страницы? (метатег charset)
- Всё ещё есть проблема с кодировкой? (header charset в php)
Что такое кодировка?
Условно говоря, каждый символ (знак) состоит из кода и картинки. Здесь код – это уникальный идентификатор символа в наборе символов, который определяется выбранной кодировкой, а картинка – это визуальное представление символа, которое содержится в файле шрифта в соответствующей коду символа ячейке.
Другими словами, кодировка (англ. charset) – это набор взаимосвязей кодов символов с их визуальными представлениями в шрифте.
charset) – это набор взаимосвязей кодов символов с их визуальными представлениями в шрифте.
Кодировка файла
HTML-страница представляет собой обычный текстовый файл, кодировка которого выбирается при его создании и/или сохранении на запоминающее устройство (жёсткий диск, флэшка и т.д.) .
В случае с Notepad++, кодировка нового документа задаётся в настройках текстового редактора. Выбираем в меню: Опции > Настройки… – и переходим на вкладку «Новый документ». Здесь нас интересует секция «Кодировка». По умолчанию, выбрана кодировка ANSI.
Настройка кодировки нового документа в Notepad++
Напомню, что это кодировка, в которой будет храниться HTML-файл.
Впрочем, Вы всегда можете преобразовать кодировку HTML-страницы, используя соответствующие функции текстового редактора. Например, в Notepad++ для этого кликните пункт меню «Кодировки» и выберите нужное преобразование.
Преобразование кодировки текущей HTML-страницы в Notepad++
В данном случае файл был в кодировке ANSI и я преобразовал его в UTF-8 (без BOM) . О том, что такое этот BOM Вы можете прочитать в моей статье: PHP: как удалить BOM в WordPress — проследовав по этой ссылке.
О том, что такое этот BOM Вы можете прочитать в моей статье: PHP: как удалить BOM в WordPress — проследовав по этой ссылке.
Кодировка отображения
Важно разделять кодировку файла и кодировку отображения. Независимо от того, в какой кодировке хранится файл, он может быть отображен и в любой другой кодировке. Это и является одной из причин проблем с кодировкой.
Например, если Вы сохранили HTML-страницу в кодировке ANSI и откроете её в браузере, вместо русских символов Вы можем получить, так называемые, «кракозябрики».
Проблемы с кодировкой отображения HTML-страницы в браузере Firefox
В данном случае нам надо убедиться, что кодировка файла совпадает с кодировкой отображения файла в браузере. Для этого в Firefox кликните иконку меню, а потом пункт «Кодировка». Если такого у Вас нет, кликните пункт «�?зменить» и добавьте элемент «Кодировка» в меню.
Смена кодировки отображения HTML-страницы в браузере Firefox
Как вы видите, браузер отображает файл в кодировке «Юникод» (например, UTF-8) , в то время как файл был сохранён в кодировке ANSI (например, Windows-1251) . Выбрав нужную кодировку, мы получим нужный нам результат.
Выбрав нужную кодировку, мы получим нужный нам результат.
Проблема с кодировкой решена
В случае с Notepad++ также имеется возможность выбора кодировки отображения. Для этого кликните пункт меню «Кодировки», а потом нужный вариант используемой для отображения кодировки.
Смена кодировки отображения HTML-страницы в Notepad++
В данном случае я изменил кодировку отображения ANSI на UTF-8 (без BOM) .
Как указать кодировку HTML-страницы?
�? так, мы уже разобрались с тем, что такое кодировка и в чём состоит отличие кодировки файла и кодировки отображения. Теперь нам нужно решить проблему с кодировкой, которая заключается в неправильной интерпретации браузером (или любым другим клиентом) кодировки HTML-страницы.
Почему возникают проблемы с кодировкой? Определить кодировку HTML-страницы не просто, а зачастую и не возможно, т.к. у того же браузера нет информации о ней или она указана неправильно.
Для того чтобы указать кодировку HTML-страницы используется специальный метатег. В HTML5 он имеет следующий урезанный вид:
В данном случае указана кодировка UTF-8 (Юникод) .
В более старых версиях HTML этот метатег имеет следующий вид:
Этот метатег создаёт HTTP-заголовок Content-Type , в котором указывается тип документа text/html и его кодировка Windows-1251 (ANSI) .
Лично я рекомендую использовать именно этот вариант, т.к. с ним будет меньше всего проблем. Главное чтобы такой метатег присутствовал в секции HEAD , и указанная в нём кодировка соответствовала кодировке файла. В большинстве случаев этого будет достаточно.
Всё ещё есть проблема с кодировкой?
В некоторых случаях указать метатег с кодировкой HTML-страницы будет недостаточно. Такая проблема может быть вызвана настройками самого сервера, на котором находится файл HTML-страницы. Дело в том, что сервер способен выдавать свой HTTP-заголовок Content-Type , который будет, условно говоря, иметь приоритет перед метатегом.
В данном случае эту проблему можно решить путём внесения изменений в настройки сервера. Я не буду вдаваться в детали данного вопроса и порекомендую лишь отключать всю эту перекодировку через файл .htaccess, например:
Также можно производить изменения HTTP-заголовка Content-Type и программными средствами. В том же PHP для этого используется функция header() , например:
8 декабря 2016 г., 19:56 Удалить комментарий
Я так понимаю, вот я в программе создаю html страницу. Если я в тексте напишу хотя бы один английский символ, то кодировка автоматически станет Юникод?
А в браузере по умолчанию отображаются все страницы в ANSI, поэтому мой файл в Юникоде как раз и будет с кракозябрами?
15 февраля 2017 г., 11:57 Удалить комментарий
Буквы на английском имеют одинаковые коды во всех кодировках, так что с ними проблем не возникает, а вот с той же кириллицей могут быть проблемы.
По сути, действительно, если использовать только буквы на английском, то кодировка часто определяется браузерами как «Кириллица (Windows)» или тип того, просто он не может распознать кодировку не имея «нестандартных» символов.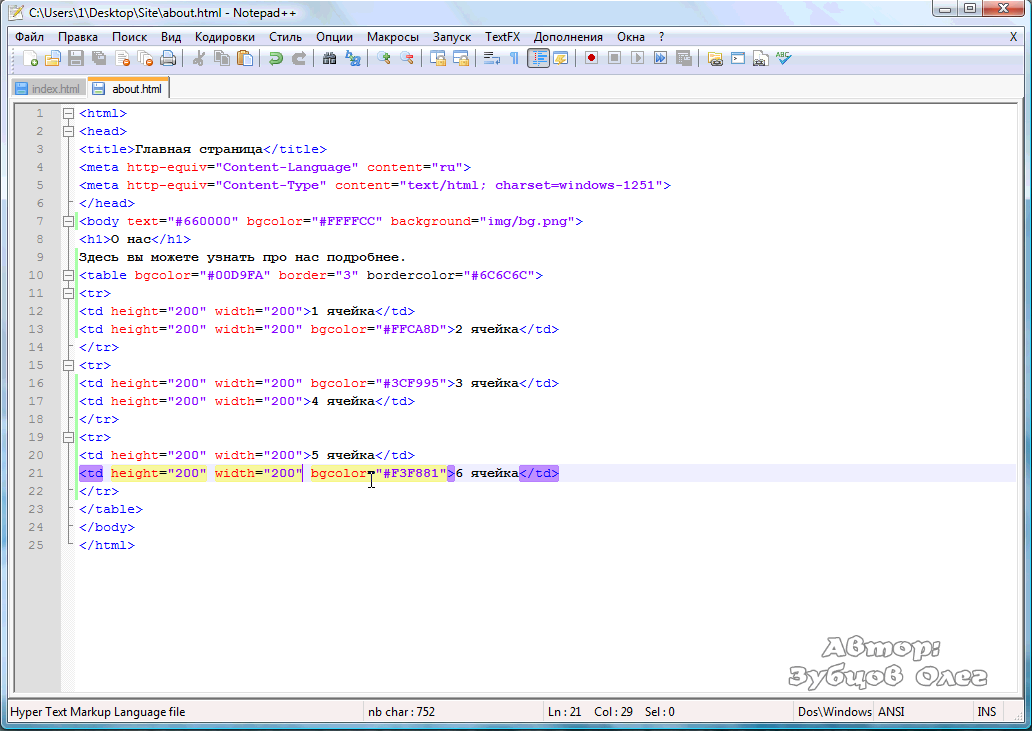
Впрочем, даже если есть символы и прописан meta тег, не факт, что браузер поймёт в как отображать страницу, т.к. в основном ориентируется на http заголовки сервера.
15 февраля 2017 г., 18:25 Удалить комментарий
спасибо огромное за полезную статью.
но у меня остался таки вопрос. как изменить кодировку по умолчанию в браузере firefox я поняла,зашла в настройки, а там нет нужного мне юникода. файлы создаю в нотепаде++ с юникодом. посоветуйте пожалуйста, как поступить в моем случае. писать в кириллице,чтобы совпадало с фаерфоксом? либо как. а вообще хотела использовать юникод везде))
Автор статьи: Сергей Каминский
При создании сайта у начинающих веб-мастеров часто появляются вопросы: в какой кодировке делать сайт, чем отличается UTF-8 от windows-1251 и как ее прописывать в META Charset HTML-страницы сайта. Ответы на все эти вопросы в данной статье.
Что такое кодировка сайта и как она работает
Кодировку можно представить в виде таблицы, состоящей из разных букв, цифр и других символов понятных человеку, которые закодированы определенным образом. Когда вы открываете текстовый файл, к которым относятся в том числе HTML-страницы, то компьютер считывает из заголовка файла в какой кодировке он был сохранен и выводит текст в соответствующей кодировке преобразовывая компьютерные данные в вид понятный человеку сопоставляя эти данные с таблицей кодировки. Если информация о кодировке из заголовка файла совпадает с кодировкой в которой сохранены данные в HTML-странице, то пользователь видит привычные ему буквы, цифры и другие символы. Если же есть несовпадение, то в результате пользователю выводится непонятный набор символов, особенно часто это происходит в старых почтовых программах. Если пользователь получил письмо с непонятными крякозябрами, то просто перебирая разные кодировки, обычно получается угадать и выбрать ту, в которой написано письмо, и в результате непонятный набор символов превращается в понятный человеку текст.
Когда вы открываете текстовый файл, к которым относятся в том числе HTML-страницы, то компьютер считывает из заголовка файла в какой кодировке он был сохранен и выводит текст в соответствующей кодировке преобразовывая компьютерные данные в вид понятный человеку сопоставляя эти данные с таблицей кодировки. Если информация о кодировке из заголовка файла совпадает с кодировкой в которой сохранены данные в HTML-странице, то пользователь видит привычные ему буквы, цифры и другие символы. Если же есть несовпадение, то в результате пользователю выводится непонятный набор символов, особенно часто это происходит в старых почтовых программах. Если пользователь получил письмо с непонятными крякозябрами, то просто перебирая разные кодировки, обычно получается угадать и выбрать ту, в которой написано письмо, и в результате непонятный набор символов превращается в понятный человеку текст.
То же самое происходит и с HTML-страницами сайта. Если документ был сохранен, например, в кодировке UTF-8, а в самом документе прописан META-тег указывающий что это кодировка windows-1251, то браузер опять же будет сопоставлять сохраненные в файле данные с таблицей указанной ему кодировки и так как символы закодированы по-разному, то браузер выведет вместо привычного текста непонятный набор символов или же часть букв может быть в нормальном виде, а другие буквы или символы могут выводиться, например, в виде знаков вопроса. Все выше сказанное относится в том числе и к отображению имен файлов.
Все выше сказанное относится в том числе и к отображению имен файлов.
Создавая новый документ в текстовом редакторе лучше сразу убедиться что выбрана нужная кодировка. Современные редакторы позволяют преобразовать текст открытого документа из одной кодировки в другую, а стандартный Блокнот позволяет выбрать кодировку только при сохранении файла.
Самые распространенные кодировки
Из предыдущего пункта вы уже знаете что такое кодировка и почему настолько важно правильно прописать ее в коде страниц сайта. Давайте теперь выясним какую из множества кодировок лучше выбрать для будущего сайта. Поскольку самой распространенной и наиболее понятной в освоении всегда была операционная система Windows, то большинство веб-разработчиков создавали HTML-страницы в кодировке windows-1251 (ANSI), которая использовалась по-умолчанию. Но windows-1251 поддерживает не очень большое количество букв и символов, а разработчики хотят использовать в своих текстах различные стрелочки, сердечки, квадратики и другие символы, в том числе есть необходимость совмещать слова из разных языков в одном документе, поэтому на смену ей уже давно пришла более расширенная UTF-8 и большинство разработчиков используют именно эту кодировку.
Проблемы с кодировкой не только в HTML-странице
Сайт, независимо от того является ли он просто набором статических HTML-документов или сложных динамических скриптов генерирующих страницы на лету, размещается на веб-сервере, который также работает с определенной кодировкой. И если сервер выдает информацию в одной кодировке, а ваши страницы или скрипты сохранены в другой кодировке, то опять же могут быть проблемы с отображением страниц в браузере пользователя. Многие хостинги позволяют менять настройки и выбрать кодировку в соответствии с той, которая используется в файлах сайта, через панель управления или же прописать ее в файле .htaccess, если на хостинге используется популярный веб-сервер Apache.
Практически ни один современный сайт не обходится без использования базы данных MySQL и она также может стать источником проблем с кодировкой. Если файлы сайта сохранены в одной кодировке, а информация в базе данных в другой, то на странице та часть информации, которая выводится из базы данных может отображаться в виде все тех же знаков вопросов или других непонятных символов. Чтобы избежать проблем с кодировкой она должна быть одинаковой для веб-сервера, базы данных MySQL, в скриптах, в HTML-страницах сайта и в META-теге, который прописывается в HTML-коде. Если есть проблемы с отображением текста, то проверяйте на наличие проблемы все выше перечисленное.
Чтобы избежать проблем с кодировкой она должна быть одинаковой для веб-сервера, базы данных MySQL, в скриптах, в HTML-страницах сайта и в META-теге, который прописывается в HTML-коде. Если есть проблемы с отображением текста, то проверяйте на наличие проблемы все выше перечисленное.
META Charset HTML-документа
Чтобы сообщить браузеру и поисковым системам в какой кодировке сохранены страницы сайта в их коде прописывается META Charset.
Для кодировки windows-1251:
Для кодировки UTF-8:
Теперь вы знаете что такое кодировка сайта и где искать проблемы если в какой-либо части сайта неправильно отображается текст.
Другие записи по теме в разделе статьи по HTML и CSS
Представление HTML-документа
Представление HTML-документапредыдущий следующий содержимое элементы атрибуты индекс
Содержание
- Набор символов документа
- Кодировки символов
- Выбор кодировки
- Примечания по конкретным кодировкам
- Указание символа кодировка
- Выбор кодировки
- Ссылки на символы
- Ссылки на числовые символы
- Ссылки на сущности персонажей
- Неотображаемые символы
В этой главе мы обсудим, как HTML-документы представляются на компьютере. и через Интернет.
и через Интернет.
Раздел о наборе символов документа решает вопрос о том, какие абстрактные символов могут быть частью HTML документ. Символы включают латинскую букву «А», кириллическую букву «I», Китайский иероглиф, означающий «вода» и т. д.
Раздел о кодировках символов касается вопрос о том, как эти символы могут быть представляет в файле или когда переданы через Интернет. Поскольку некоторые кодировки символов не могут быть напрямую представляют все символы, которые автор может захотеть включить в документ, HTML предлагает другие механизмы, называемые ссылками на символы, для обозначения любого персонажа.
Так как в человеческих языках существует большое количество символов, и великое множество способов изобразить эти символы, необходимо проявлять должную осторожность сделано так, чтобы документы могли быть поняты пользовательскими агентами по всему миру.
Для обеспечения совместимости SGML требует, чтобы каждое приложение (включая
HTML) укажите его набор символов документа. Набор символов документа состоит
из:
Набор символов документа состоит
из:
- Репертуар : Набор абстрактных символов, такие как латинская буква «А», кириллическая буква «I», китайский иероглиф означает «вода» и т. д.
- Кодовые позиции : Набор целочисленных ссылок на символы в репертуар.
Каждый документ SGML (включая каждый документ HTML) представляет собой последовательность персонажей из репертуара. Компьютерные системы идентифицируют каждый символ по его кодовая позиция; например, в наборе символов ASCII кодовые позиции 65, 66, и 67 относятся к символам «A», «B» и «C» соответственно.
Набор символов ASCII недостаточен для глобальной информационной системы таких как Интернет, поэтому HTML использует гораздо более полный набор символов, называемый Универсальный набор символов (UCS) , определено в [ISO10646]. Этот стандарт определяет репертуар из тысяч символов, используемых сообществами по всему миру.
Набор символов, определенный в [ISO10646], не соответствует
посимвольный эквивалент Unicode ([UNICODE]). Оба эти стандарта время от времени обновляются.
с новыми символами, и с поправками следует ознакомиться в соответствующем
Веб-сайты. В текущей спецификации «[ISO10646]» используется для обозначения
набор символов документа, в то время как «[UNICODE]» зарезервирован для ссылок на
Двунаправленный текст Unicode
алгоритм.
Оба эти стандарта время от времени обновляются.
с новыми символами, и с поправками следует ознакомиться в соответствующем
Веб-сайты. В текущей спецификации «[ISO10646]» используется для обозначения
набор символов документа, в то время как «[UNICODE]» зарезервирован для ссылок на
Двунаправленный текст Unicode
алгоритм.
Однако набор символов документа недостаточен для того, чтобы пользовательские агенты для правильной интерпретации HTML-документов, как они обычно обмениваются — кодируется как последовательность байтов в файле или во время передачи по сети. Пользователь агенты также должны знать конкретную кодировку символов который использовался для преобразования потока символов документа в байт ручей.
То, что в этой спецификации называется символом кодировка известна под разными именами в других спецификациях
(что может вызвать некоторую путаницу). Тем не менее, концепция во многом одинакова
через Интернет. Кроме того, заголовки протоколов, атрибуты и параметры
ссылаясь на кодировки символов, имеют одно и то же имя — «charset» — и используют
те же значения из
Реестр [IANA] (см. [CHARSETS] для
полный список).
[CHARSETS] для
полный список).
Параметр «charset» определяет кодировку символов, которая является методом преобразования последовательности байтов в последовательность символов. Этот преобразование естественно вписывается в схему веб-активности: серверы отправляют HTML документы для пользовательских агентов в виде потока байтов; пользовательские агенты интерпретируют их как последовательность символов. Метод преобразования может варьироваться от простого один к одному соответствие сложным коммутационным схемам или алгоритмам.
Простой метод кодирования один байт на символ недостаточен для текстовые строки с репертуаром символов размером до [ISO10646]. Есть несколько различных кодировок частей [ISO10646] в дополнение к кодировки всего набора символов (например, UCS-4).
5.2.1 Выбор кодировка
Средства разработки (например, текстовые редакторы) могут кодировать HTML-документы в
кодировку символов по своему выбору, и выбор во многом зависит от
соглашения, используемые системным программным обеспечением. Эти инструменты могут использовать любой удобный
кодировка, покрывающая большинство символов, содержащихся в документе, при условии
кодировка указана правильно. Иногда
символы, выходящие за пределы этой кодировки, могут быть представлены ссылками на символы. Они всегда относятся к документу
набор символов, а не кодировка символов.
Эти инструменты могут использовать любой удобный
кодировка, покрывающая большинство символов, содержащихся в документе, при условии
кодировка указана правильно. Иногда
символы, выходящие за пределы этой кодировки, могут быть представлены ссылками на символы. Они всегда относятся к документу
набор символов, а не кодировка символов.
Серверы и прокси-серверы могут изменить кодировку символов (называется перекодирование ) на лету для удовлетворения запросов пользовательских агентов (см. раздел 14.2 [RFC2616], заголовок HTTP-запроса «Accept-Charset»). Серверы и прокси не должны обслуживать документ в кодировке символов, которая охватывает весь набор символов документа.
Часто используемые кодировки символов на
Интернет включает ISO-8859-1 (также называемый «Latin-1»; подходит для большинства
западноевропейские языки), ISO-8859-5 (с поддержкой кириллицы), SHIFT_JIS (a
японская кодировка), EUC-JP (еще одна японская кодировка) и UTF-8 (кодировка
ISO 10646 с использованием разного количества байтов для разных символов). Имена
для кодировок символов регистр не учитывается, например, «SHIFT_JIS»,
«Shift_JIS» и «shift_jis» эквивалентны.
Имена
для кодировок символов регистр не учитывается, например, «SHIFT_JIS»,
«Shift_JIS» и «shift_jis» эквивалентны.
Эта спецификация не указывает, какую кодировку символов должен использовать пользовательский агент. должны поддерживать.
Соответствующие пользовательские агенты должны правильно отображать в ISO 10646 все символы в любых кодировках, которые они распознают (или они должны вести себя так, как если бы они это сделали).
Примечания по конкретным кодировкам
Когда текст HTML передается в кодировке UTF-16 (charset=UTF-16), текстовые данные должны передаваться в сетевом порядке байтов («прямой порядок байтов», сначала старший байт) в соответствии с [ISO10646], раздел 6.3 и [UNICODE], пункт C3, стр. 3-1.
Кроме того, чтобы максимизировать шансы на правильную интерпретацию, рекомендуется
что документы, передаваемые как UTF-16, всегда начинаются с НУЛЕВОЙ ШИРИНЫ
НЕРАЗРЫВНЫЙ ПРОБЕЛ (шестнадцатеричный FEFF, также называемый знаком порядка байтов). (BOM)), который при перестановке байтов становится шестнадцатеричным FFFE, символом
гарантированно никогда не будет присвоено. Таким образом, пользовательский агент, получающий шестнадцатеричный
FFFE как первые байты текста будет знать, что байты должны быть перевернуты для
остаток текста.
(BOM)), который при перестановке байтов становится шестнадцатеричным FFFE, символом
гарантированно никогда не будет присвоено. Таким образом, пользовательский агент, получающий шестнадцатеричный
FFFE как первые байты текста будет знать, что байты должны быть перевернуты для
остаток текста.
Формат преобразования UTF-1 [ISO10646] (зарегистрированный IANA как ISO-10646-UTF-1) не следует использовать. За информацию об ISO 8859-8 и двунаправленном алгоритме см. раздел о двунаправленности и кодировка символов.
5.2.2 Указание кодировка символов
Как сервер определяет, какая кодировка символов применяется к документу
это служит? Некоторые серверы проверяют первые несколько байтов документа или проверяют
против базы данных известных файлов и кодировок. Многие современные серверы предоставляют Web
осваивает больше контроля над конфигурацией кодировки, чем старые серверы. Интернет
Мастера должны использовать эти механизмы для отправки параметра «charset» всякий раз, когда
возможно, но следует позаботиться о том, чтобы не идентифицировать документ с неправильным
значение параметра «charset».
Как пользовательский агент узнает, какая кодировка символов использовалась? сервер должен предоставить эту информацию. Самый простой способ для сервер для информирования пользовательского агента о кодировке символов документа использовать параметр «charset» Поле заголовка «Content-Type» протокола HTTP ([RFC2616], разделы 3.4 и 14.17). Например, следующее Заголовок HTTP сообщает, что используется кодировка символов EUC-JP:
.Тип содержимого: текст/html; кодировка = EUC-JP
Пожалуйста, обратитесь к разделу о соответствии для определение текста/html.
Протокол HTTP ([RFC2616], раздел 3.7.1) упоминает ISO-8859-1 по умолчанию.
кодировка символов, когда параметр «charset» отсутствует в
Поле заголовка Content-Type. На практике эта рекомендация подтвердилась.
бесполезно, потому что некоторые серверы не позволяют отправлять параметр «charset», и
другие могут быть не настроены на отправку параметра. Следовательно, пользовательские агенты должны
не принимайте какое-либо значение по умолчанию для параметра «charset».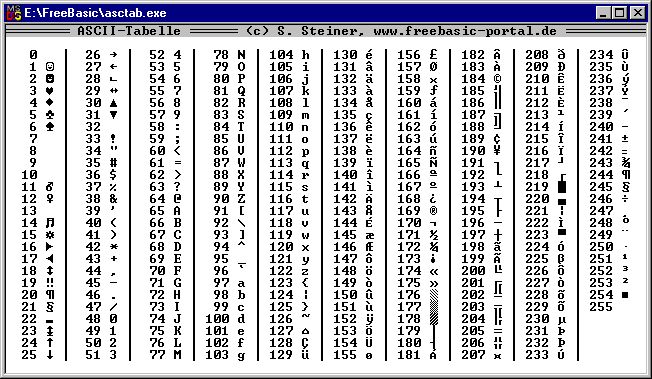
Чтобы устранить ограничения сервера или конфигурации, HTML-документы могут включать явная информация о кодировке символов документа; Элемент META может использоваться для предоставления агентам пользователя этого Информация.
Например, чтобы указать, что кодировка символов текущего документа «EUC-JP», документ должен включать следующие Декларация META :
Объявление META должно использоваться только тогда, когда символ кодировка организована таким образом, что байты со значением ASCII обозначают символы ASCII. (по крайней мере, пока не будет проанализирован элемент META ). Объявления META должны появиться как можно раньше в Элемент HEAD .
Для случаев, когда ни протокол HTTP, ни Элемент META предоставляет информацию о кодировке символов
документ, HTML также предоставляет кодировка атрибут на нескольких
элементы. Комбинируя эти механизмы, автор может значительно улучшить
вероятность того, что когда пользователь получит ресурс, пользовательский агент распознает
кодировка символов.
Комбинируя эти механизмы, автор может значительно улучшить
вероятность того, что когда пользователь получит ресурс, пользовательский агент распознает
кодировка символов.
Подводя итог, соответствующие пользовательские агенты должны соблюдать следующие приоритеты при определении документа. кодировка символов (от высшего приоритета к низшему):
- Параметр «charset» HTTP в поле «Content-Type».
- Объявление META с «http-equiv», установленным на «Content-Type» и значение, установленное для «charset».
- Атрибут charset , установленный для элемента, обозначающего внешний ресурс.
В дополнение к этому списку приоритетов пользовательский агент может использовать эвристику
и пользовательские настройки. Например, многие пользовательские агенты используют эвристику для различения
различные кодировки, используемые для японского текста. Кроме того, пользовательские агенты обычно имеют
определяемая пользователем локальная кодировка символов по умолчанию, которую они применяют в
отсутствие других показателей.
Пользовательские агенты могут предоставлять механизм, который позволяет пользователям информация о «кодировке». Однако, если пользовательский агент предлагает такой механизм, он должен предлагать его только для просмотра, а не для редактирования, чтобы избежать создания Веб-страницы, помеченные неверным параметром «charset».
Примечание. Если для конкретного приложения становится необходимо ссылаться на символы вне [ISO10646], символы должны быть назначены в частную зону, чтобы избежать конфликтов с настоящим или будущим версии стандарта. Однако это крайне нежелательно по причинам портативность.
Данная кодировка символов может не отображать все символы
набор символов документа. Для таких кодировок или когда аппаратное или программное обеспечение
конфигурации не позволяют пользователям напрямую вводить некоторые символы документа,
авторы могут использовать ссылки на символы SGML. Персонаж
ссылки — это независимый от кодировки символьный механизм для ввода любых
символ из набора символов документа.
Ссылки на символы в HTML могут отображаться в двух формах:
- Числовые ссылки на символы (десятичные или шестнадцатеричные).
- Ссылки на сущности персонажей.
Ссылки на символы в комментариях не имеют особого значения; это только данные комментариев.
Примечание. HTML предоставляет другие способы представления символов данные, в частности встроенные изображения.
Примечание. В SGML можно удалить окончательный «;» после ссылки на символ в некоторых случаях (например, на разрыве строки или непосредственно перед тегом). В других обстоятельствах он не может быть устранен (например, в середине слова). Мы настоятельно рекомендуем использовать «;» во всех случаях чтобы избежать проблем с пользовательскими агентами, которые требуют, чтобы этот символ был подарок.
5.3.1 Числовые обозначения символов
Числовой символ
ссылки указать код
положение символа в наборе символов документа. Числовой символ
ссылки могут иметь две формы:
Числовой символ
ссылки могут иметь две формы:
- Синтаксис «&# D ;», где D — десятичное число, относится к десятичному символьному номеру ISO 10646 D .
- Синтаксис «&#x H ;» или «&#X H ;», где H шестнадцатеричное число, относится к шестнадцатеричному символьному номеру ISO 10646 Х . Шестнадцатеричные числа в числовых ссылках на символы нечувствительны к регистру.
Вот несколько примеров числовых ссылок на символы:
- å (в десятичном формате) представляет собой букву «а» с маленьким кружком вверху. оно (используется, например, в норвежском языке).
- å (в шестнадцатеричном формате) представляет один и тот же символ.
- å (в шестнадцатеричном формате) также представляет тот же символ.
- И (в десятичном виде) представляет собой кириллическую заглавную букву «I».
- 水 (в шестнадцатеричном формате) представляет собой китайский иероглиф для
вода.

Примечание. Хотя шестнадцатеричное представление не определено в [ISO8879], ожидается, что он будет в редакции, как описано в [ВЕБСГМЛ]. Это соглашение особенно полезно, поскольку стандарты символов обычно используют шестнадцатеричные представления.
5.3.2 Ссылки на объекты символов
Чтобы предоставить авторам более интуитивно понятный способ обращения к персонажам в набор символов документа, HTML предлагает набор из ссылки на сущности персонажей. Использование ссылок на сущности символов символические имена, чтобы авторам не нужно было запоминать код позиции. Например, ссылка на объект персонажа å относится к строчной букве «а», увенчанной кольцом; «&кольцо;» легче помните, чем å.
HTML 4 не определяет ссылку на сущность символа для каждого символа в
набор символов документа. Например, нет сущности персонажа
ссылка на кириллическую заглавную букву «I». Пожалуйста, ознакомьтесь с полным списком ссылок на символы, определенных в HTML. 4.
4.
Ссылки на символьные объекты чувствительны к регистру. Таким образом, Å относится к другому символу (верхний регистр A, кольцо), чем &кольцо; (строчная а, кольцо).
Ссылки на четырехсимвольные сущности заслуживают особого упоминания, поскольку они часто используется для экранирования специальных символов:
- «<» представляет знак <.
- «>» представляет знак >.
- «&» представляет знак &.
- «» представляет собой метку «.
Авторы, желающие поместить в текст символ «<", должны использовать "<"
(десятичное число ASCII 60), чтобы избежать возможной путаницы с началом тега.
(открывающий разделитель начального тега). Точно так же авторы должны использовать ">" (ASCII
десятичное число 62) в тексте вместо «>», чтобы избежать проблем со старыми пользовательскими агентами.
которые неправильно воспринимают это как конец тега (разделитель закрытия тега), когда
он появляется в значениях атрибутов в кавычках.
Авторы должны использовать «&» (десятичное число ASCII 38) вместо «&» для избегайте путаницы с началом ссылки на символ (ссылка на сущность открытый разделитель). Авторы также должны использовать «&» в значениях атрибутов с ссылки на символы разрешены в пределах Значения атрибута CDATA.
Некоторые авторы используют ссылку на объект персонажа «"» кодировать экземпляры двойной кавычки («»), так как этот символ может использоваться для разграничить значения атрибутов.
Агент пользователя не может отображать все символы в документе осмысленно, например, поскольку у пользовательского агента нет подходящего шрифта, символ имеет значение, которое может не выражаться во внутренней кодировке агента пользователя и т. д.
Поскольку в таких случаях можно сделать много разных вещей, это
документ не предписывает какого-либо конкретного поведения. В зависимости от
реализация, неотображаемые символы
также может обрабатываться базовой системой отображения, а не приложением. сам. При отсутствии более сложного поведения, например, адаптированного к
потребности конкретного сценария или языка, мы рекомендуем следующее
поведение для пользовательских агентов:
сам. При отсутствии более сложного поведения, например, адаптированного к
потребности конкретного сценария или языка, мы рекомендуем следующее
поведение для пользовательских агентов:
- Использовать хорошо заметный, но ненавязчивый механизм для оповещения пользователя о недостающие ресурсы.
- Если отсутствующие символы представлены с использованием их числового представления, используйте шестнадцатеричная (не десятичная) форма, так как это форма, используемая в наборе символов стандарты.
предыдущий следующий содержимое элементы атрибуты индекс
Что это такое и почему это должно быть интересно программистам
Кодировка HTML используется для того, чтобы веб-браузеры анализировали специальные символы, отличные от ASCII, в документах HTML со стандартной формой. это процесс отправить информацию заголовка на сервер , чтобы текст отображался как текст, а не как HTML-коды.
Если вы новичок в программировании HTML, эта статья здесь, чтобы дать вам полное представление о кодировании символов при написании разметки.
Содержание
- Ключевые моменты статьи
- Что такое кодирование символов в HTML
- – Что такое символы в языках кодирования
- – Важность URL-адресов
- Знакомство с кодировкой ASCII и кодировкой в HTML. Справочник по кодировке символов
- Кодировка HTML: набор символов UTF 8
- Кодировка HTML URL: эффективная адресация запросов страниц
- Кодировка символов HTML: процесс применения Документы
- Объявление закодированных символов HTML в HTTP
- Что такое декодирование в HTML
- Экранирующие символы в закодированных документах HTML
- Заключительный совет: никогда не встречайте «?» Опять таки!
- Подведение итогов
Ключевые моменты статьи
- Понимание кодировки символов HTML
- Как объявить кодировку в документах HTML
- Справочник по HTML для кодировки URL
- Что такое кодировка ASCII
- Применение
Большое количество символов, используемых при написании разметки, требует использования кодировки символов . Этот прием особенно необходим авторам разметки при работе с иностранными языками, высокотехнологичными математическими символами и другими специальными символами в дополнение к стандартным латинским буквам и арабским цифрам. Потому что контент часто может конфликтовать со стандартным кодом.
Этот прием особенно необходим авторам разметки при работе с иностранными языками, высокотехнологичными математическими символами и другими специальными символами в дополнение к стандартным латинским буквам и арабским цифрам. Потому что контент часто может конфликтовать со стандартным кодом.
Например, при использовании менее (<) или более (>) знаков — , если они не закодированы должным образом , браузер будет интерпретировать эти символы как начальный и закрывающий теги HTML. Полное неверное толкование, из-за которого ваш контент может выглядеть чужеродным. Итак, вы видите, что это не только вопрос удобочитаемости для человека, серверы и браузеры также должны иметь возможность понимать ваши данные.
Что такое кодировка символов в HTML
Кодировка символов в основном представляет собой 9Метод сопоставления 0006 для определения текста и байтов отдельно в документах HTML. Чтобы понять кодировку символов, авторы должны понимать, что такое символы.
– Что такое символы в языках кодирования
Символы обозначают букв алфавита, знаков препинания, специальных символов и некоторых других элементов, составляющих весь контент. Информация хранится в компьютере в виде последовательности байтов в числовых значениях. Иногда один символ может быть представлен более чем одним байтом.
Текст, изображения, графика, видео, компиляции данных и все другие формы информации, которые появляются у читателя веб-сайта, состоят из «символов» содержимого веб-страницы. Какой ключ использовался для кодирования текста, определяет, как последовательность байтов преобразуется в символы. В этом случае ключ называется кодировкой символов.
– Важность URL-адресов
URL-адрес используется веб-браузерами для запроса страниц с веб-серверов . Веб-браузеры могут расшифровывать только набор символов ASCII, в котором всего 128 символов и только 9 символов. 5 из которых можно распечатать. Но URL-адреса часто нуждаются в символах за пределами 128 символов. В этом случае для определения наборов иностранных символов используется кодировка символов .
5 из которых можно распечатать. Но URL-адреса часто нуждаются в символах за пределами 128 символов. В этом случае для определения наборов иностранных символов используется кодировка символов .
Со стороны браузера документов с разными кодировками HTML будут отображаться по-разному. Надлежащее их использование находится в ведении автора разметки.
Знакомство с кодировкой ASCII и справочником по кодировке символов HTML
ASCII — это код передачи является производным от Американского стандартного кода для обмена информацией, созданного в 1960-х годах. Его можно использовать на основных электронных устройствах и компьютерах для обмена буквами, знаками препинания и цифрами, а также управляющих символов, которые являются непечатаемыми символами на основе телексной технологии, такими как разрывы строк или табуляции.
Коды ASCII работают так же, как работают калькуляторы, в которых двоичные системы управляют всей вычислительной системой. В семи битах — семи цифрах, обозначающих либо ноль, либо единицу — исходный стандарт ASCII определяет другие символы . Всего он определяет только 128 (27) символов, из которых 33 непечатаемых и 95 печатных символов.
В семи битах — семи цифрах, обозначающих либо ноль, либо единицу — исходный стандарт ASCII определяет другие символы . Всего он определяет только 128 (27) символов, из которых 33 непечатаемых и 95 печатных символов.
Традиционно восьмой бит, равный одному полному байту, по-прежнему используется для проверки данных . Именно этот бит используется в расширенных версиях на основе ASCII для увеличения количества доступных символов до 256. (28).
Хотя кодировка UTF-8 стала более важной при представлении текста , 7-битная версия ASCII до сих пор широко используется. UTF-8 обладает привилегией обратной совместимости, поскольку является подмножеством ASCII. Таким образом, он распознает 128 двоичных символов. Старый метод кодирования все еще используется в электронных письмах и URL-адресах, потому что ASCII является наименьшим общим знаменателем большинства новых форм кодирования.
Кодировка HTML Набор символов UTF 8
Существует несколько преимуществ использования UTF-8 , но, прежде всего, он полностью совместим со специальными символами ASCII, что делает его незаменимым инструментом для написания разметки для иностранного языка. страницы.
страницы.
Кроме того, его можно использовать и с собственной XML-разметкой. Чтобы объявить наборы символов HTML в кодировке UTF-8 , вам понадобится следующий тег:
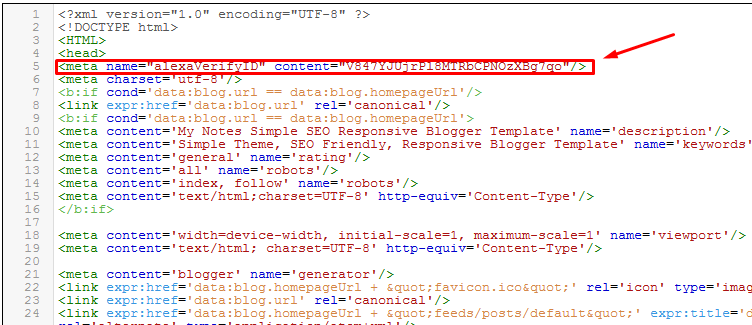 Форматы кодировки символов UTF-8, UTF-16 и UTF-32 были опубликованы организацией на протяжении многих лет. Форматы кодировки символов UTF-8, UTF-16 и UTF-32 были опубликованы организацией на протяжении многих лет.В 2008 году был выпущен формат кодировки символов HTML UTF-8. К 2019 году он будет использоваться на более чем 90 процентов всех веб-сайтов . Консорциум World Web также рекомендует использовать его в качестве кодировки символов HTML по умолчанию. HTML-кодирование URL-адресов: эффективная адресация запросов страницПоскольку Интернет может понимать только набор символов ASCII, кодирование URL-адресов является золотым правилом преобразования всех символов, отличных от ASCII, в читаемые или совместимые символы. Недопустимые символы ASCII заменяются знаком «%» (без кавычек), за которым следуют две шестнадцатеричные цифры в URL-адресе. Пробелы считаются недопустимыми символами в URL-адресах, в большинстве случаев кодировка пробелов HTML заменяет пробел знаком плюс (+) или знаком %20. Таким образом, в кодировке HTML UTF 8 играет ключевую роль, и она не чувствительна к регистру, вы можете печатать как угодно, только убедитесь, что она есть. Кодировка символов HTML: процесс примененияТег в заголовке тщательно закодированных веб-страниц объявляет кодировку для браузера. Если на вашей веб-странице нет этого тега, браузер не сможет интерпретировать страницу с вашим контентом, что приведет к появлению тарабарщины в содержании. Процесс интерпретация символов , элементов и атрибутов в теге HTML в целом называется кодировкой тега . Кодирование тегов особенно важно для платформ с открытым циклом, таких как платежные шлюзы. Представьте, если система выйдет из строя в процессе платежной транзакции! Это серьезная угроза для клиентов и большая ответственность для веб-разработчиков и авторов контента! Так что будьте осторожны. Авторы разметки всегда получают сообщение о том, что объявление HTML-документа — это не то, как вы можете указать серверу изменить байты. 9Текстовый файл 0006 должен быть сохранен в той же кодировке , чтобы завершить процесс. Кодирование HTML: работа с документами XML и XHTMLПоскольку заголовки HTTP часто имеют приоритет над метадекларациями в документе, авторам всегда следует проверять , если заголовок HTTP уже имеет объявление по умолчанию . Конечно, это с учетом того, есть ли у них доступ к нему. Если он уже объявлен, то же самое должно быть и с метаэлементом. Однако, если вы работаете с XML-документами, метаобъявления могут не работать до тех пор, пока вы не перенесете свой HTML-документ в XHTML. В этом случае вы должны использовать атрибут charset и избегать прагм. Во всех случаях сохраняйте документы в кодировке UTF-8. Объявление закодированных символов HTML в HTTP В соответствии с правилами объявления кодировки символов для заголовков HTTP, переопределяет все объявления на странице . Итак, если вы работаете с клиентом или в команде, вам нужно попросить своего клиента или менеджера предоставить вам этот доступ для управления декларациями . Это отчасти единственный способ. В некоторых случаях авторы разметки изменяют объявления с ограниченным доступом к серверу. Проверьте заголовок HTTP, если кодировка символов уже объявлена, вы можете изменить информацию о кодировке либо локально для контента, созданного с помощью языков сценариев, либо через набор файлов на сервере. Существует онлайн-инструментов для проверки сгенерированной сервером кодировки , W3C очень популярен. Наконец, можно использовать параметр набора символов HTTP. Любой текст, обычный текст или HTML-редактор Документы, передаваемые по протоколу HTTP, могут отправлять параметр charset в заголовке HTTP , чтобы указать кодировку символов документа .
Идея состоит в том, что HTTP 1.1 указывает ISO-8859-1 в качестве кодировки по умолчанию, когда нет явного параметра charset, браузеры используют предпочтительную кодировку читателя, потому что слишком много непомеченных документов в других кодировках. Что такое декодирование в HTMLЭто просто то, на что это похоже — декодирование является обратным преобразованием закодированных символов HTML в их прежнюю форму. Да, вы всегда можете это сделать, если возникнет необходимость. Декодирование работает путем преобразования закодированных строк HTML с числовыми ссылками на символы для передачи HTTP в строку, которая была первоначально сформирована. В зависимости от содержимого вывода, вам будет предоставлен результат в виде текста или шестнадцатеричного дампа, а также файл, который вы можете скачать. Вывод простого текста или шестнадцатеричного дампа может быть усечен, если вывод большой, но вывод файла всегда будет полным. Escape-символы в закодированных HTML-документах Escape-символы могут быть особенно полезны для представления символов, которые не поддерживаются кодировкой документа, китайских, хинди, датских символов — некоторые примеры — они нужны вам для настройки неанглоязычного текста , но вы не можете найти символы в наборе символов ASCII. Авторы всегда должны экранировать следующими тремя символами, чтобы они не мешали синтаксису разметки:
И это правило применяется как к документам HTML, так и к документам XML. ‘ Аналогичный прием применяется для с использованием символов одинарной (‘) и двойной кавычки («). Когда вам нужно использовать тот же тип кавычек, что и те, которые окружают значение атрибута, это определенно имеет место в тексте атрибута. Невидимые или неоднозначные символы могут быть представлены escape-последовательностью. Неразрывный пробел U+00A0, например, , может мешать разрывам страниц , отображаясь как пробел. « или « Символ кодирования пространства HTML полезен для ясности. Заключительные слова совета: никогда не сталкивайтесь с «?» Опять таки!Среди нескольких жизненно важных вещей, которые вы можете получить в этой статье, давая вам представление о кодировании в HTML, вот еще один совет: При создании динамических веб-страниц следите за своими шрифтами и макетами, как и с кодировкой. Подведение итоговДавайте повторим все, что мы узнали о кодировании HTML здесь и сейчас:
Теперь, когда у вас есть базовые знания обо всей вышеизложенной информации, попробуйте каждый метод самостоятельно. В конце концов, практика делает его совершенным.
Позиция решает все Должность — это все: ваш ресурс для изучения и создания: CSS, JavaScript, HTML, PHP, C++ и MYSQL. Последние сообщения от Position is Everything (посмотреть все) Справочник по URL-кодированиюСправочник по URL-кодированиюНиже приведены ссылки на символы ASCII в Форма URL-кодирования (шестнадцатеричный формат). Шестнадцатеричные значения могут использоваться для отображения нестандартных букв и символов в браузерах и плагины. URL-кодирование от %00 до %8f
Узнайте, как использовать метакодировкуTL;DR. Указание правильной кодировки HTML предотвратит сбой отображения в браузере специальных символов. Содержание
Понимание кодировки символов HTMLПотребность в кодировке символов возникает из-за огромного выбора доступных символов. Помимо привычных вам латинских букв и арабских цифр, есть также иностранные алфавиты, математические символы и другие специальные символы. Однако документы, для которых определены разные кодировки HTML, могут отображать их по-разному. Неправильно интерпретированный текст приводит к множеству проблем:
Все доступные символы сгруппированы в определенные наборы (также называемые наборами символов для краткости). Определив кодировку HTML, вы позволите браузеру получить доступ к определенному набору и правильно отобразить его символы.
ASCII: самый простой набор символовПервая и простейшая кодировка символов HTML называется ASCII . Большинство современных наборов символов используют его в качестве стандартной базы. ASCII означает Американский стандартный код для обмена информацией. Он был разработан на основе телеграфного кода в начале 1960-х годов и содержит 128 символов , 95 из которых печатные :
33 непечатаемых символа также называются управляющими символами . Это прозрачные символы — например, те, которые позволяют разделять слова или абзацы. Однако популярность ASCII падала по мере роста Интернета международный . Pros
Основные функции
ЭКСКЛЮЗИВ: СКИДКА 75% Плюсы
Основные функции
AS AS. НИЗКАЯ 12,99$ Pros
Основные функции
|
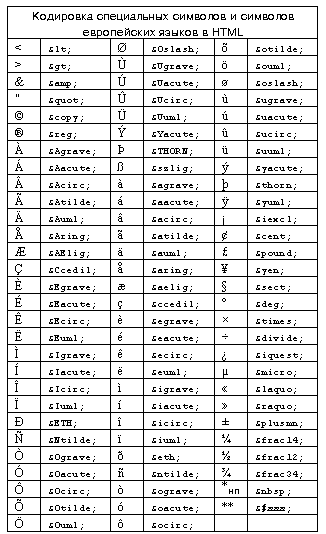
 Если вы используете программное обеспечение для редактирования, оно, скорее всего, будет иметь кодировку UTF-8 по умолчанию. Однако, если вы работаете с локальными файлами на своем компьютере, вы можете перепроверить настройки и, если они еще не находятся в желаемой кодировке, измените их.
Если вы используете программное обеспечение для редактирования, оно, скорее всего, будет иметь кодировку UTF-8 по умолчанию. Однако, если вы работаете с локальными файлами на своем компьютере, вы можете перепроверить настройки и, если они еще не находятся в желаемой кодировке, измените их. До тех пор, пока вы не измените настройки сервера, как упоминалось ранее, вы не сможете получить одно и то же объявление как в заголовке HTTP, так и в теле содержимого.
До тех пор, пока вы не измените настройки сервера, как упоминалось ранее, вы не сможете получить одно и то же объявление как в заголовке HTTP, так и в теле содержимого.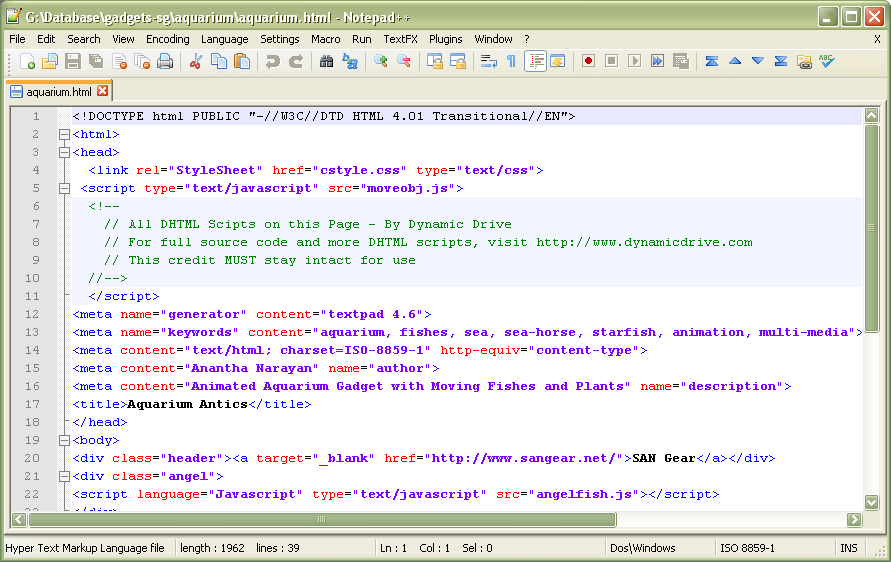 Явно помечая веб-документ, чтобы указать шаблон предпочтения кодирования для браузеров. Синтаксис параметра charset обычно выглядит следующим образом:
Явно помечая веб-документ, чтобы указать шаблон предпочтения кодирования для браузеров. Синтаксис параметра charset обычно выглядит следующим образом: Вы можете найти множество бесплатных онлайн-инструментов и платформ, чтобы сделать это быстро. Существуют инструменты, которые позволяют вводить как текстовые строки, так и файлы. Файловые входные данные более полезны для больших данных, а текстовые входные данные удобны для коротких строковых данных.
Вы можете найти множество бесплатных онлайн-инструментов и платформ, чтобы сделать это быстро. Существуют инструменты, которые позволяют вводить как текстовые строки, так и файлы. Файловые входные данные более полезны для больших данных, а текстовые входные данные удобны для коротких строковых данных. Вы можете сделать это в документе с кодировкой UTF-8.
Вы можете сделать это в документе с кодировкой UTF-8. Не все шрифты поддерживают все символы и оставляют вас со знаком «?».
Не все шрифты поддерживают все символы и оставляют вас со знаком «?». 
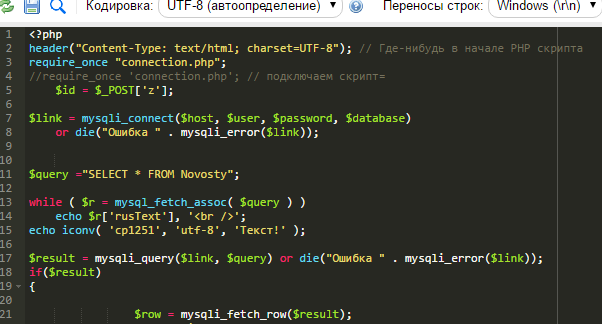 см
см
 Альтернативные кодировки HTML
Альтернативные кодировки HTML
 Только поддержки латинских символов быстро стало недостаточно.
Только поддержки латинских символов быстро стало недостаточно. Он был опубликован в начале 1990-х и имеет несколько кодировок, таких как UTF-8, UTF-16 и UTF-32.
Он был опубликован в начале 1990-х и имеет несколько кодировок, таких как UTF-8, UTF-16 и UTF-32. Однако мы настоятельно рекомендуем вам использовать UTF-8, так как другие кодировки содержат меньший набор символов, что может вызвать проблемы при отображении вашего веб-сайта.
Однако мы настоятельно рекомендуем вам использовать UTF-8, так как другие кодировки содержат меньший набор символов, что может вызвать проблемы при отображении вашего веб-сайта. Вы должны кодировать данные, чтобы предотвратить такое поведение и защитить веб-сайт от атак межсайтового скриптинга (XSS).
Вы должны кодировать данные, чтобы предотвратить такое поведение и защитить веб-сайт от атак межсайтового скриптинга (XSS).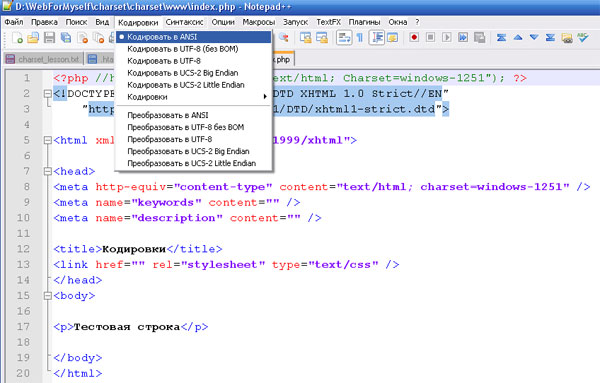 OptionalMark
OptionalMark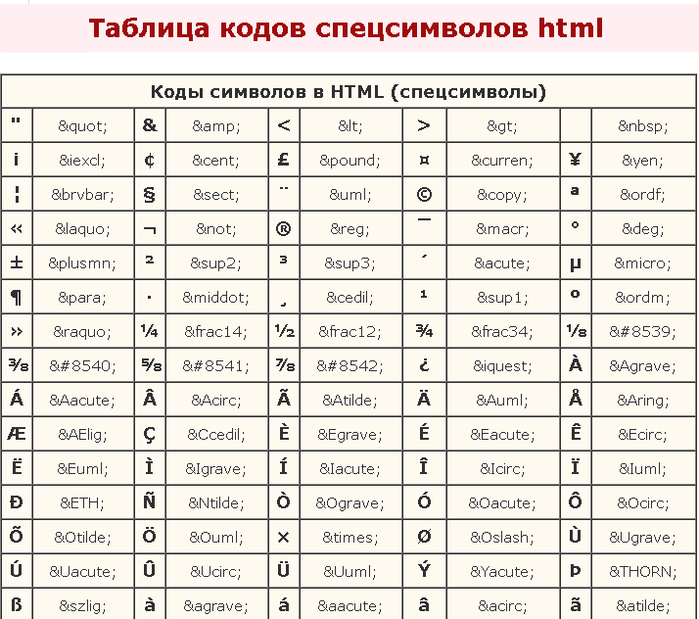 Properties.FastNavProperties.CancelButtonText
Properties.FastNavProperties.CancelButtonText Text CheckBoxExtension.
Text CheckBoxExtension. EncodeHtml кодирует следующие значения свойства ComboBoxExtension:
EncodeHtml кодирует следующие значения свойства ComboBoxExtension: Properties.ClearButton.Text
Properties.ClearButton.Text Вызовите метод HttpUtility.HtmlEncode, чтобы закодировать его.
Вызовите метод HttpUtility.HtmlEncode, чтобы закодировать его.