Как добавить простое поисковое окно Google, Yahoo! или Bing на ваш сайт WordPress
Поиск – это наиболее часто используемая и существенная функция Интернета. Поисковые движки ежедневно обрабатывают миллиарды поисковых запросов, но всё еще есть сайты и блоги, которым лишь предстоит добавить эту важную функцию.
Не смотря на то, что обработанные реализации поискового окна предлагаются различными бизнес-компаниями, я предпочитаю использовать только основные поисковые движки: Google, Yahoo! или Bing. Многие коммерческие предложения предоставляют пробный период, для того чтобы заинтересовать клиентов. Такие пробные версии часто включают размещённую на заметном месте рекламу, что может отпугнуть часть посетителей сайта.
Давайте добавим окно поиска на ваш сайт WordPress.
Стандартное окно поиска Google
Если для вашего сайта или блога важно свободное пространство, Вы можете легко разместить маленькое поисковое окно Google, которое удовлетворит ваши потребности. Код является комбинацией HTML и Javascript:
<form method="get" action="http://www.google.com/search"> <div> <table border="0" align="center" cellpadding="0"> <tr><td> <input type="text" name="q" size="25" maxlength="255" value="Google site search" onfocus="if(this.value==this.defaultValue)this.value=''; this.style.color='black';" onblur="if(this.value=='')this.value=this.defaultValue; "/> <input type="submit" value="Go!" /> <input type="hidden" name="sitesearch" value="yoursite.com" /></td></tr> </table> </div> </form>
Вы можете вставить этот код, например, в Текстовый виджет (Text widget) в разделе Внешний вид > Виджеты (Appearance > Widgets) вашей админ панели WordPress.
Это поисковое окно почти сразу готово к работе. Просто измените «yoursite.com» в третей с конца строке на ваш домен. Другие настройки, такие как ширина строки, отступ перед ячейкой, и сообщение, которое отображается перед полем поиска, можно легко изменить перед загрузкой вашего скрипта на сайт.
Окно поиска Google с кнопками-переключателями
Выше описанное поисковое окно позволяет найти содержимое на указанном сайте. Однако, некоторые владельцы сайтов хотят дать пользователям сайта возможность выполнять поиск по ключевым словам и во всей сети Интернет.
В этом случае, самым простым решением является размещение поискового окна с двумя кнопками-переключателями: одна для Интернета и вторая для сайта, как это показано ниже:
Код для такого поискового окна выглядит следующим образом:
<form method="get" action="http://www.google.com/search"> <div> <table border="0" align="center" cellpadding="0"> <tr><td> <input type="text" name="q" size="25" maxlength="255" value="" /> <input type="submit" value="Google Search" /></td></tr> <tr><td align="center"> <input type="radio" name="sitesearch" value="" />The Web <input type="radio" name="sitesearch" value="yoursite.com" checked /> Only Your Site<br /> </td></tr></table> </div> </form>
Как и в предыдущем примере, просто измените “yoursite.com” на ваше название домена, и поисковое окно будет готово к работе. Обратите внимание, что по умолчанию выбран поиск по сайту.
Поисковое окно Bing с кнопками-переключателями
Для того чтобы добавить на сайт такое же поисковое окно, но с использованием поискового движка Bing, используйте следующие строки кода:
<form method="get" action="http://www.bing.com/search"> <div> <table border="0" align="center" cellpadding="0"> <tr><td> <input type="text" name="q" size="25" maxlength="255" value="" /> <input type="submit" value="Bing Search" /></td></tr> <tr><td align="center"> <input type="radio" name="q1" value="" />The Web <input type="radio" name="q1" value="site:yoursite.com" /> Only Your Site<br /> </td></tr></table> </div> </form>
В этом интерфейсе не выбрана ни одна из кнопок-переключателей. Если гость сайта вводит слово или фразу в поисковое окно, он по умолчанию получит результаты из сети Интернет.
Если гость сайта вводит слово или фразу в поисковое окно, он по умолчанию получит результаты из сети Интернет.
Поисковое окно Yahoo с флаговой кнопкой
Последнее простое поисковое окно довольно интересное — оно содержит одну флаговую кнопку, а не две кнопки:
По умолчанию выбран поиск в указанном домене. Когда пользователь убирает галочку с флаговой кнопки, выполняется поиск по указанно ключевому слову или фразе в сети Интернет.
Вот и всё. Простые способы добавления окна поиска, описанные в этой статье, готовы к использованию и просты в добавлении в практически любой сайт. Учитывая небольшую разницу в функциях, Вы можете взять то, что нужно из одного стиля и применить к другому.
Если Вы хотите ознакомиться с большим количеством шаблонов, ознакомьтесь с нашей большой коллекцией шаблонов WordPress!
Как добавить поиск Google на свой сайт
Многие пользователи любят WordPress из-за его возможностей при управлении контентом. Эта CMS позволяет нам создать сайт в течение нескольких минут, наполнить его содержанием и включить десятки виджетов и меню, но что касается поиска, то эта не самая сильная сторона этого движка. Функция поиска WordPress была проблемной с самого начала. Результаты поиска не так точны, как они должны были быть, критерии поиска устанавливаются по дате, а не по релевантности. Разработчики предлагают решения, такие как плагины и пользовательские функции, но есть лучшая альтернатива нативному поиску WordPress.
Лучший способ создания поиска на любом веб-сайте — это воспользоваться возможностями мирового лидера в поисковых технологиях — компании Google. Google выпустила сервис под названием «Google Custom Search Engine», который может быть интегрирован в любой веб-сайт. Не волнуйтесь, в результатах поиска не будут выводится сайты со всей Сети, результаты поиска ограничиваются только контентом с вашего сайта. Кроме того, у Вас будет возможность зарабатывать деньги с объявлений Google, которые отображаются в результатах поиска.
В данной статье описывается интеграция поиска Google в сайт работающий на WordPress. Первое, что вам нужно сделать, это настроить поисковую систему для вашего сайта. Перейдите на страницу http://www.google.com/cse/ и следуйте инструкциям Google:
Нажмите на кнопку «Войти в Систему пользовательского поиска».
Введите имя и описание для своей поисковой системы и выберите язык для неё. Добавьте URL своего сайта, чтобы Google мог отображать результаты поиска на его страницах. «Стандартный пакет» для создания поиска бесплатный, но в результатах поиска будут выводится рекламные объявления, с которых вы также будете получать процент прибыли. Но если вы не хотите, чтобы рекламные объявления отображались в результатах поиска, вам придется платить 100 долларов США в год.
На следующей странице, у Вас есть возможность выбрать готовые стили или настроить собственные для ваших результатов поиска: поисковая строка, цвет текста, заголовка, шрифт, кнопки поиска, результаты и даже стили для рекламных объявлений. (Нажмите на изображение для его увеличения)
После настройки стилей нажмите на кнопку Далее. На третьей странице вы сможете получить сгенерированный код для поисковой системы.
Это обычный код JavaScript, который может быть разделен на две части: первая, это код, который должен быть добавлен перед закрывающим тегом </ head> на вашем сайте, а вторая часть добавляется в тело страницы, в то место где будет выводится форма поиска. Это стандартный код для поиска, который будет показывать результаты на этой же странице. Это означает, что если вы поместите вторую часть кода, например, в боковой панели, то и результаты будут отображаться в боковой панели, и это, конечно, не то, что нам необходимо. Поэтому настроим нашу пользовательскую форму поиска, чтобы она возвращала результаты поиска Google на отдельной странице. Следующее, что вам нужно сделать, это нажать на ссылку «Изменить внешний вид»:
Следующий шаг, выберите иконку «Только результаты», затем нажмите «Сохранить и получить код».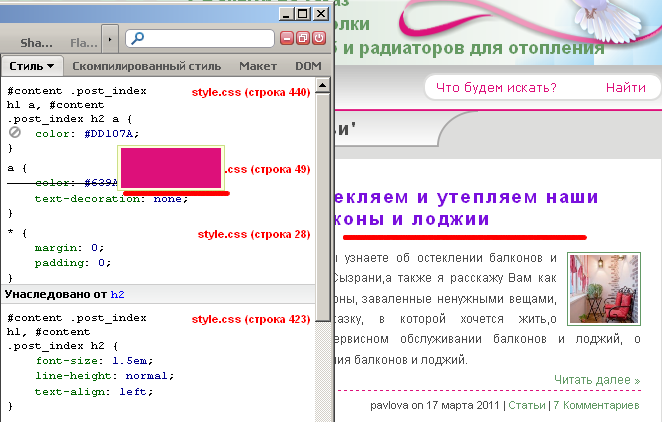
Далее вы можете указать имя параметра запроса, который будет встраиваться в URL, таким образом «http://www.webmasters.by/search-results/?q=wordpress».
Получив код, разместите первую его часть в header.php в вашей теме WordPress, перед закрывающим тегом </ head>:
<!— Put the following javascript before the closing </head> tag. —>
<script>
(function() {
var cx = ‘00107852214872578004:xgt8vpuak’;
var gcse = document.createElement(‘script’); gcse.type = ‘text/javascript’; gcse.async = true;
gcse.src = (document.location.protocol == ‘https:’ ? ‘https:’ : ‘http:’) +
‘//www.google.com/cse/cse.js?cx=’ + cx;
var s = document.getElementsByTagName(‘script’)[0]; s.parentNode.insertBefore(gcse, s);
})();
</script>
Теперь мы должны создать шаблон страницы, на которой Google может выводить результаты поиска. В папке вашей темы WordPress, создайте новый файл, назовите его «template-search.php» и вставьте в него следующий код (я использовал файл page.php из темы TwentyTwelve в качестве основы для структуры страницы. Вы же должны использовать page.php из папки со своей темой для создания шаблона):
<?php
/*
Template Name: Результаты поиска
*/
?>
<?php get_header(); ?>
<div>
<div role=»main»>
<?php while ( have_posts() ) : the_post(); ?>
<!— This tag will render search results: —>
<gcse:searchresults-only></gcse:searchresults-only>
<?php endwhile; // end of the loop. ?>
</div><!— #content —>
</div><!— #primary —>
<?php get_sidebar(); ?>
<?php get_footer(); ?>
Теперь, когда вы создали шаблон страницы поиска, перейдите в админку WordPress, создайте новую страницу и примените к ей шаблон «Результаты поиска».
Давайте теперь создадим пользовательскую форму поиска. Если у вас нет файла под названием «searchform.php» в папке с темой WordPress, то создайте его и добавьте следующий код:
<form method=»get» action=»http://www.webmasters.by/search-results/»>
<input type=»text» name=»q» value=»<?php the_search_query(); ?>»>
<input type=»submit» value=»Search»>
</form>
Примечание: я добавил для параметра «action» адрес пользовательской страницы, которую мы создали на предыдущем шаге, а для параметра «name» указал значение «q», установленное нами в панели управления Google. Эти значения являются обязательными для того, чтобы форма поиска корректно работала.
Последний шаг, добавляем форму поиска на сайт. Многие темы WordPress используют виджеты, чтобы включить наш виджет поиска, перейдите в меню админки Внешний вид -> Виджеты и перетащите внутрь нужной области виджет «Поиск».
Теперь откройте ваш сайт и задайте поиск по каким либо ключевым словам:
И это всё, таким образом вы можете заменить стандартный поиск WordPress на самый мощный инструмент поиска в мире от компании Google.
Перевод статьи с rockablethemes.com
Если у Вас возникли вопросы, то для скорейшего получения ответа рекомендуем воспользоваться нашим форумом
Раскрывающаяся строка поиска на чистом HTML и СSS | Покоди с СODI
Код:
HTML:
<!doctype html>
<html lang=»ru»>
<head>
<meta charset=»UTF-8″>
<script src=»https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.14.0/js/all.min.js»></script>
 cloudflare.com/ajax/libs/font-awesome/5.14.0/js/all.min.js»></script>
cloudflare.com/ajax/libs/font-awesome/5.14.0/js/all.min.js»></script><link rel=»stylesheet» href=»style.css»>
<title>Search That Opens</title>
</head>
<body>
<div>
<input type=»text» placeholder=»Search…»>
<a>
<i></i>
</a>
</div>
</body>
</html>
CSS:
* {
margin: 0;
padding: 0;
}
body {
background: linear-gradient(45deg, #ffa500, #ff2400);
display: flex;
min-height: 100vh;
justify-content: center;
align-items: center;
}
.search {
display: flex;
background: #2f3640;
height: 40px;
border-radius: 40px;
padding: 10px;
}
.searchBtn {
width: 40px;
height: 40px;
border-radius: 50%;
background: #2f3640;
display: flex;
justify-content: center;
align-items: center;
transition: 0.4s;
color: white;
cursor: pointer;
}
.searchBtn > i {
font-size: 30px;
}
.
 search:hover > .searchText {
search:hover > .searchText {width: 240px;
padding: 0 6px;
}
.searchText {
border: none;
background: none;
outline: none;
padding: 0;
color: #ffffff;
font-size: 16px;
transition: 0.4s;
line-height: 40px;
width: 0;
font-weight: bold;
}
.search:hover > .searchBtn {
background: linear-gradient(45deg, #ff2400, #ffa500);
color: #ffffff;
}
.search:hover > .searchBtn:hover {
background: linear-gradient(45deg, #ffa500, #ff2400);
}
Подписывайтесь, на мой YouTube-канал
Как сделать в html поиск
Как сделать поиск по сайту — делаем красивый поиск по сайту
Существует столько сайтов, но как выделится на фоне остальных, как найти такую «фишку», чем бы ваш сайт запомнился на фоне остальных. Чтобы человек вспоминал сайт и он ассоциировался с каким-нибудь элементом сайта, который оформлен необычно. И я расскажу и покажу как можно из простой поиск на сайте — оформить красиво и оригинально!
Реальный пример поиска:
Уроки о том, как оформить красиво элементы на сайте:
С помощью статей выше вы можете оформить обычные элементы на сайте оригинальным образом.
Полноэкранный поиск по сайту
Идея действительно интересная и заключается в том, что при нажатии на поле ввода появляется поле для ввода на весь экран, а также дополнительная информация: кто автор, популярные статьи и последние статьи. Но здесь нет динамического поиска.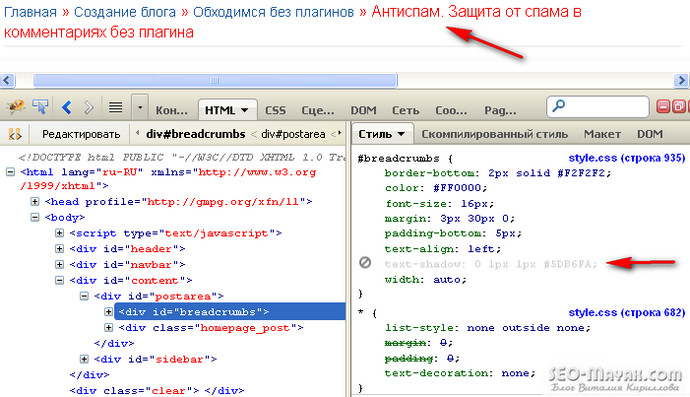
Для этого эффекта использовались переходы CSS, которые и создают анимацию. Тут сразу хочу сказать что данное оформление поиска является экспериментальным и тестировалось только в современных браузерах, которые поддерживают свойства CSS3. На демо форма поиска находится в правом верхнем углу страницы.
При нажатии на форму ввода, появляется белый фон, на котором форма для поиска значительно больше. Плюс к этому выводятся популярные новости и последние статьи.
Видео по установке формы поиска на WordPress
Процесс установки я решил не писать, а снять видео об этом. Я думаю это будет в более понятной для вас форме. Вам лишь нужно просто повторять за мной.
Урок получился небольшой, но это если не учитывать видео. Думаю, благодаря видео каждый способен установить такую форму поиска на свой сайт. Она необычна и пока что я не видел сайтов в рунете, которые использовали бы такой вид формы поиска. Если вам понравилась данная форма поиска — попробуйте сделать ее на своём сайте, ведь вы сможете убрать ее в любое время, если она не приживется.
Успехов!
Источник: Оригинал
С Уважением, Юрий Немец
Понравилась статья — расскажи друзьям! 🙂
Вконтакте
Одноклассники
Google+
Как найти элемент в коде
Здравствуйте уважаемые начинающие веб-мастера.
В следующей статье, мы приступим к редактированию шаблона, и нам придётся находить нужные элементы в коде темы.
Если кто-то ещё не видел, что из себя представляет код шаблона, то зайдите в Консоль — Внешний вид — Редактор.
Перед Вами откроется код файла style.css. Покрутите его вниз, и первое, что придёт Вам в голову будет: ё-моё, как же в этой массе английских слов, цифр и символов, найти то, что нам будет нужно.
Для полноты ощущения, можно открыть один из php файлов, которые расположены в колонке справа от поля редактора.
Только сразу отгоните мысль типа: «Я в этом до самой смерти не разберусь». Разберётесь, и я Вам в этом помогу.
Весь код Вам пока знать не обязательно.
В статье, которая последует сразу за этой, я покажу, как с помощью специального инструмента, который называется веб-инспектор, находить код, того элемента контента, на который мы хотим воздействовать, то есть изменить его внешний вид, или положение.
Сейчас же посмотрим, как этот код найти в файле, чтоб при редактировании шаблона, Вы сразу смогли применить эти знания.
Допустим Вам захотелось изменить внешний вид и положение заголовка сайта.
С помощью веб инспектора Вы определите, что заголовок заключён в тег
, а стили (оформление) его находятся в файле style.css, и расположены в селекторе site-title.Значит идём в Консоль — Внешний вид — Редактор, и когда он откроется, нажимаем комбинацию клавиш Ctrl-F.
После этого, в правом верхнем углу редактора откроется поле поиска, куда и нужно ввести словосочетание site-title
Как только Вы это сделаете, искомый элемент в коде выделится жёлтым цветом. Возможно, что селекторов будет несколько, и все они будут подкрашены.
Точно так же можно найти любой элемент кода в, куда более сложном файле php.
И это Вам очень пригодится, для редактирования функций темы, и внедрения микро-разметки.
Этот же способ используется для нахождения элемента в коде страницы.
Если щёлкнуть правой клавишей мыши, выбрать «Просмотреть код страницы», затем комбинация клавиш Contrl-F, то точно так же появится окно поиска, в которое можно ввести искомый элемент кода.
И вот он — пожалуйста.
Желаю творческих успехов.
Неужели не осталось вопросов? СпроситьПеремена
— Мам, ну почему ты думаешь, что если я была на дне рождения, то сразу пила?! — Дочь а нечего что я папа? Объявление в метро: «при обнаружении подозрительных предметов сделайте подозрительное лицо.
В раздел > > > Исправляем шаблон WordPress. Веб-инспектор
Веб-инспектор
Как сделать поиск по сайту
В том случае если у вас достаточно большой с точки зрения информативности сайт, то самое время задуматься над оптимизацией поиска. Что же это такое?
Наверное, ни для кого не секрет, что такое поисковые системы. Всем нам знаком Google и Яндекс. Так вот поиск по сайту носит тот же принцип, а в некоторых случаях и вовсе происходит интеграция популярных поисковиков на свой сайт.
И если с самим понятием все более ли менее ясно, то остается главный вопрос: Как сделать поиск по сайту? Именно на него мы с вами и ответим ниже в нашей статье.
Наверняка вам кажется это очень просто сделать. Но на самом деле вы удивитесь, сколько вариаций и способов существует. Из нашей статьи вы сможете узнать, как сделать поиск на сайте html, как сделать поиск по слову на сайте, а также некоторые другие варианты.
Простой поиск для сайта
Давайте начнем с самого распространенного варианта. Мы с вами рассмотрим способ, как сделать поиск по сайту html. Для начала следует отметить, что выглядит такая графа достаточно привычно для любого интернет пользователя. Вы можете увидеть его на изображении ниже.
Как всем известно, простой сайт на html пишется посредством кодов. И когда возникает вопрос того, как сделать поиск по сайту в html, то ответ, конечно же, прост. Необходимо написать код. Но как правильно его выстроить, чтобы получить самый простой вариант поиска? Для этого вы можете воспользоваться нашей визуальной подсказкой, которую мы разместили ниже. Просто напишите данный кодовый набор в формате HTML.
Таким образом, вы сможете создать самый простой вариант поиска по вашему сайту.
Форма поиска с подсветкой
Стоит отметить, что строка поиска не обязательно должна иметь стандартный вид. Вы вполне можете сделать ее, к примеру, с подсветкой. Для этого стоит просто введите код, который мы разместили ниже, на вашем сайте в тег между форма поиска.
Внешний вид такого поиска выглядит, как серая полоса поиска, которая исчезает при введении запроса. Такая форма поиска обязательно понравиться посетителям вашего сайта.
Такая форма поиска обязательно понравиться посетителям вашего сайта.
Простая но красивая форма поиска
Всем нам хочется красивый визуальный ряд нашего сайта. Однако совсем не хочется изучать много информации по программированию, для того чтобы узнать, как сделать поиск на сайте по слову с красивым дизайном. Мы предлагаем вам простой и визуально привлекательный вариант. Введите данный код на странице сайта, так же как и предыдущий.
В последней графе, вы видите url(1.png) – это картинка, которую вы можете внести в графу поиска. Соответственно вы просто добавляете свое изображение в код и получаете свой индивидуальный поиск по сайту.
Резиновая форма поиска
Вы наверно думаете, что мы явно что-то путаем. Как форма поиска может быть резиновой? Но не волнуйтесь, мы не сошли с ума. Просто именно так обозначается тот вариант, когда изначально строка поиска занимает мало пространства, а после наведения на нее курсора вытягивается в длину.
Чтобы активировать данный поиск, введите следующий код:
Красивая форма поиска
Мы с вами уже рассмотрели основные формы поиска, но наверняка большинство из вас предпочли бы более, эстетический вариант. Как же его сделать? Конечно же, посредством html-кода, как и предыдущие варианты. Он наиболее длинный из всех, вот почему мы решили не останавливаться на данном вопросе, а просто разместить, изображение такого поиска, в качестве ознакомительного фрагмента.
Поиск по сайту через Google поиск для сайта
Конечно, сложно себе представить более популярную поисковую систему, чем Google. Как известно она занимает лидирующие позиции во всем мире. Но мало, кто знает, что именно благодаря Google вы можете установить удобную поисковую систему на ваш веб-портал.
Как вы сами можете видеть на изображении выше, данный вариант не является бесплатным. То есть вам необходимо будет оплатить минимум 100$ за 20000 поисковых запросов. В том же случае, если поток ваших посетителей, и соответственно и запросов будет больше, стоит рассмотреть более дорогой пакет услуг.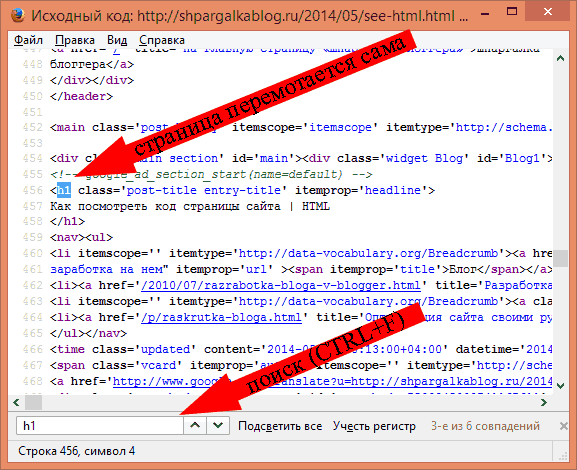 Но какие же плюсы у данного предложения за эту сумму? Давайте разбираться.
Но какие же плюсы у данного предложения за эту сумму? Давайте разбираться.
Основные преимущества поиска по сайту от компании Гугл:
- Индивидуальный подход. Вы сами выбираете, как будет выглядеть ваша форма поиска. Если хотите можете заменить лого Google на свое, изменить цвет и т.д.
- Языковые возможности. Поиск будет выполнен вне зависимости от того, на каком языке был выполнен запрос.
- Ручная настройка. Вы сами можете настроить рейтинг и результаты поиска в зависимости от даты публикации.
- Поиск иллюстраций.
- Никакой рекламы.
- Вне зависимости от того создали ли вы новый материал, или решили отредактировать старый вы сможете отправить робота Google зафиксировать обновления.
- Вы вручную сможете настраивать и контролировать список подсказок, которые открываются у пользователя при начале ввода запроса.
- Вы можете осуществлять поиск не по одному сайту, а по нескольким.
- Поддержка компании. На Google Analytics вы сможете отслеживать статистику запросов и поведение посетителей, а сервис Google Реклама позволит вам зарабатывать на размещении рекламы.
Инструкция как вставить яндекс поиск на сайт
Рассмотрев информацию по поисковой системе Google, у многих резонно возникает вопрос: А как же Яндекс? Что ж давайте рассмотрим и этот вариант, напоследок.
- Заходим на сайт «Яндекс поиск для сайта» и нажимаем «Установить поиск».
- Далее следует заполнить все графы небольшой анкеты, а именно, указать название сайта и его данные. После чего можно переходить ко второму шагу.
- Далее следует настроить внешний вид нашей формы поиска. Как это сделать становиться понятно из граф на странице установки.
- Далее идут точные настройки поиска. А именно то, как он будет располагаться на какой странице. Также на данном этапе внизу размещается вариант просмотра результата. Это необходимо для того, чтобы вы наглядно посмотрели на тот вариант, который у вас получается.
- На четвертом шаге вы проверяете, работает ли поиск по вашему сайту, а на пятом копируете код доступа и вставляете его на сайт. Для этого заходим в административную панель и переходим в раздел «Документы сайта»-«Колонка на главной»-«Вставить текстовый блок». В появившемся окне вставляем скопированный нами код и активируем его. Сохраняем и обновляем страницу. Если вы все сделали правильно, поиск от Яндекса станет работать на вашей странице.
Мы с вами рассмотрели основные вариации того, как установить поиск на своем сайте. Надеемся информация пригодиться вам и вы сможете установить необходимую форму на своем веб-портале. А нам остается лишь пожелать вам хорошего настроения и удачи!
Создание и настройка поиска на сайте в Джанго (Django Framework)
В данном руководстве мы освоим базовый поиск по сайту Django и затронем способы улучшить его с более продвинутыми возможностями.
Полный исходный код можно найти на GitHub.
Для начала, давайте создадим новый проект Django (перейдите сюда, если нужна помощь). В вашей командной строке, введите следующие команды для установки последней версии при помощи Pipenv, создайте проект под названием citysearch_project, настройте внутреннюю базу данных через migrate и запустите локальный веб сервер при помощи runserver.
$ pipenv install django==2.2.1 $ pipenv shell $ django-admin startproject citysearch_project . $ python manage.py migrate $ python manage.py runserver
$ pipenv install django==2.2.1 $ pipenv shell $ django-admin startproject citysearch_project . $ python manage.py migrate $ python manage.py runserver |
Если вы перейдете на http://127.0.0.1:8000/, вы увидите приветствие Django, которое подтверждает, что все настроено правильно. Локальный сервер не выражает все моменты реальной работы сайта на сервере, можете ознакомиться со списком хостингов https://hostinghub.![]() ru/top/vds на которых вы можете запустить полноценный сайт на Python.
ru/top/vds на которых вы можете запустить полноценный сайт на Python.
Создаем приложение Cities в Django
Теперь мы создадим одно приложение под названием cities для хранения списка названий городов. Мы осознанно не будем выходить за рамки простых основ. Остановите локальный сервер при помощи Ctrl+C и используйте команду startapp для создания нашего нового приложения.
$ python manage.py startapp cities
$ python manage.py startapp cities |
Затем обновите INSTALLED_APPS внутри нашего файла settings.py, чтобы сообщить Django о новом приложении.
# citysearch_project/settings.py INSTALLED_APPS = [ … ‘cities.apps.CitiesConfig’, # new ]
# citysearch_project/settings.py INSTALLED_APPS = [ … ‘cities.apps.CitiesConfig’, # new ] |
Теперь перейдем к моделям. Мы назовем нашу единственную модель City. В ней будет два поля: name и state. Так как админка Django по умолчанию будет менять имя приложения во множественном числе на Citys, мы также настроим verbose_name_plural. И наконец настроим __str__ для отображения названия города.
# cities/models.py from django.db import models class City(models.Model): name = models.CharField(max_length=255) state = models.CharField(max_length=255) class Meta: verbose_name_plural = «cities» def __str__(self): return self.name
# cities/models.py from django.db import models
class City(models.Model): name = models.CharField(max_length=255) state = models.CharField(max_length=255)
class Meta: verbose_name_plural = «cities»
def __str__(self): return self. |
 name
nameОтлично, все настроено. Мы можем создать файл миграции для этого изменения, затем добавить его в нашу базу данных через migrate.
$ python manage.py makemigrations cities $ python manage.py migrate
$ python manage.py makemigrations cities $ python manage.py migrate |
Есть несколько способов наполнить базу данных, но самый простой, на мой взгляд, это через admin. Создайте аккаунт суперпользователя, чтобы мы смогли зайти в админку.
$ python manage.py createsuperuser
$ python manage.py createsuperuser |
Теперь нам нужно обновить cities/admin.py для отображения нашего приложения внутри админки.
# cities/admin.py from django.contrib import admin from .models import City class CityAdmin(admin.ModelAdmin): list_display = («name», «state»,) admin.site.register(City, CityAdmin)
# cities/admin.py from django.contrib import admin
from .models import City
class CityAdmin(admin.ModelAdmin): list_display = («name», «state»,)
admin.site.register(City, CityAdmin) |
Еще раз запустите сервер при помощи python manage.py runserver и направьтесь в админку по http://127.0.0.1:8000/admin, затем зайдите в свой аккаунт суперпользователя.
Нажмите на раздел cities и добавьте несколько записей. Здесь видно четыре моих примера.
Домашняя страница и страница выдачи поиска Django
У нас есть заполненная база данных, однако все еще есть несколько шагов, которые нужно выполнить, перед тем как она может быть отображена на нашем сайте Django. В конце концов, нам нужна только домашняя страница и страница выдачи поиска. Каждой странице нужен надлежащий вид, url и шаблон. Порядок, в котором мы их будем создавать не принципиальный. Все должно быть на сайте для правильной работы.
Каждой странице нужен надлежащий вид, url и шаблон. Порядок, в котором мы их будем создавать не принципиальный. Все должно быть на сайте для правильной работы.
В целом, я предпочитаю начинать с URL-ов, добавить views, и в конце создать шаблоны, чем мы и займемся.
Сначала нам нужно добавить путь URL для нашего приложения, это можно сделать, импортировав include и настроив путь к нему.
# citysearch_project/urls.py from django.contrib import admin from django.urls import path, include # new urlpatterns = [ path(‘admin/’, admin.site.urls), path(», include(‘cities.urls’)), # new ]
# citysearch_project/urls.py from django.contrib import admin from django.urls import path, include # new
urlpatterns = [ path(‘admin/’, admin.site.urls), path(», include(‘cities.urls’)), # new ] |
Далее, нам нужнен файл urls.py внутри приложения cities, однако Django не создает такой для нас по команде startapp. Не нужно беспокоиться, мы можем создать его в командной строке. Останавливаем сервер при помощи Ctrl+C, если он еще работает.
Внутри этого файла мы импортируем еще не созданные представления (views) для каждой HomePageView и SearchResultsView, и указать путь к каждому из них. Обратите внимание на то, что мы указываем опциональное название URL для каждого из них.
Вот так это будет выглядеть:
# cities/urls.py from django.urls import path from .views import HomePageView, SearchResultsView urlpatterns = [ path(‘search/’, SearchResultsView.as_view(), name=’search_results’), path(», HomePageView.as_view(), name=’home’), ]
# cities/urls.py from django.urls import path
from .views import HomePageView, SearchResultsView
urlpatterns = [ path(‘search/’, SearchResultsView. path(», HomePageView.as_view(), name=’home’), ] |
 as_view(), name=’search_results’),
as_view(), name=’search_results’),В третьих, нам нужно настроить наши два представления (views). Домашняя страница будет простым шаблоном с итоговой поисковой строкой. Для Django отлично подойдет TemplateView для этой цели. Страница поисковой выдачи упорядочит необходимые результаты, что хорошо ложится под ListView.
# cities/views.py from django.views.generic import TemplateView, ListView from .models import City class HomePageView(TemplateView): template_name = ‘home.html’ class SearchResultsView(ListView): model = City template_name = ‘search_results.html’
# cities/views.py from django.views.generic import TemplateView, ListView
from .models import City
class HomePageView(TemplateView): template_name = ‘home.html’
class SearchResultsView(ListView): model = City template_name = ‘search_results.html’ |
Последний шаг — наши шаблоны. Мы можем добавить шаблоны внутри нашего приложения cities, однако я нашел более простой подход, а именно — создание папку проектных шаблонов.
Создайте папку с шаблонами и затем оба шаблона: home.html и search_results.html.
$ mkdir templates $ touch templates/home.html $ touch templates/search_results.html
$ mkdir templates $ touch templates/home.html $ touch templates/search_results.html |
Обратите внимание на то, что нам также нужно обновить наш settings.py, чтобы указать Django на проектную папку с шаблонами. Это вы можете найти в разделе TEMPLATES.
# citysearch_project/settings.py
TEMPLATES = [
{
…
‘DIRS’: [os.path.join(BASE_DIR, ‘templates’)], # new
. ..
}
]
..
}
]
# citysearch_project/settings.py TEMPLATES = [ { … ‘DIRS’: [os.path.join(BASE_DIR, ‘templates’)], # new … } ] |
Домашная страница выведет только заголовок.
<!— templates/home.html —> <h2>HomePage</h2>
<!— templates/home.html —> <h2>HomePage</h2> |
Запустите веб сервер еще раз при помощи python manage.py runserver. Теперь мы можем увидеть домашнюю страницу на http://127.0.0.1:8000/.
Теперь, для страницы поисковой выдачи, которая будет выполнять цикл на object_list, вернется имя от контекстного объекта ListView. Затем мы выведем name и state для каждой записи из базы данных.
<!— templates/search_results.html —> <h2>Search Results</h2> <ul> {% for city in object_list %} <li> {{ city.name }}, {{ city.state }} </li> {% endfor %} </ul>
<!— templates/search_results.html —> <h2>Search Results</h2>
<ul> {% for city in object_list %} <li> {{ city.name }}, {{ city.state }} </li> {% endfor %} </ul> |
Все готово! Наша страница поисковой выдачи доступна на http://127.0.0.1:8000/search/.
Формы и наборы запросов в Django
В конечном итоге базовая реализация поиска сводится к форме, которая передает пользовательский запрос — сам фактический поиск — и затем к набору запросов, который будет фильтровать результаты на основе этого запроса.
Мы можем начать с любого из них, но мы начнем с настройки фильтрации, после чего перейдем к форме.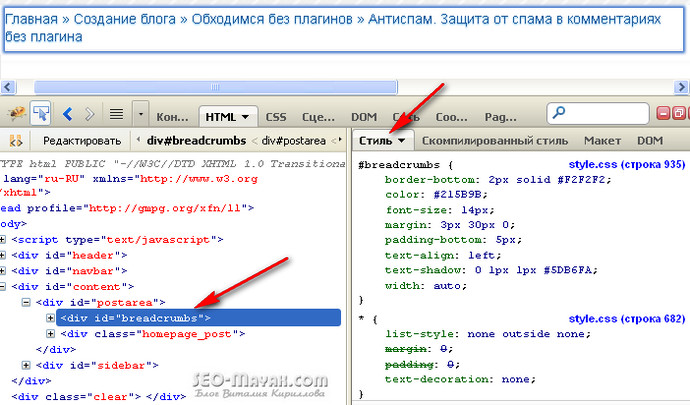
Базовая фильтрация запросов в Django
В Django, QuerySet используется для фильтрации выдачи из модели базы данных. В данный момент, наша модель City выводит все свое содержимое. В итоге нам нужно ограничить страницу поисковой выдачи для фильтрации выведенных результатов, на основании поискового запроса от пользователя.
Есть несколько способов настроить набор запросов, и фактически возможно выполнить фильтрацию через менеджер самой модели, однако, чтобы сохранять простоту решений, мы можем добавить фильтр всего в одну строку. Давайте сделаем это.
Здесь мы обновляем метод queryset из ListView и добавляем фильтр, так что возвращается только город под названием Бостон. В итоге, мы заменим это переменной, которая представляет пользовательский поисковый запрос.
# cities/views.py class SearchResultsView(ListView): model = City template_name = ‘search_results.html’ queryset = City.objects.filter(name__icontains=’Boston’) # новый
# cities/views.py class SearchResultsView(ListView): model = City template_name = ‘search_results.html’ queryset = City.objects.filter(name__icontains=’Boston’) # новый |
Обновите страницу поисковой выдачи и вы увидите, что отображается только Бостон.
Также можно настроить queryset, переопределив метод get_queryset(), для изменения списка выданных городов. Явного преимущества в этом для нас нет, но этот подход мне кажется более гибким, чем просто указать атрибуты набора запросов.
# cities/views.py … class SearchResultsView(ListView): model = City template_name = ‘search_results.html’ def get_queryset(self): # новый return City.objects.filter(name__icontains=’Boston’)
# cities/views.py … class SearchResultsView(ListView): model = City template_name = ‘search_results.
def get_queryset(self): # новый return City.objects.filter(name__icontains=’Boston’) |
 html’
html’Большую часть времени, встроенных методов filter(), all(), get(), или exclude() из QuerySet будет достаточно. Однако есть очень надежный и детализированный API QuerySet.
Объекты Q в Django
Использование filter() — эффективно, с ним даже можно связать фильтры вместе. Однако, вам могут понадобиться более сложные запросы, такие как ИЛИ (OR). В таких случаях приходит время объектов Q.
Вот пример того, где мы настраиваем фильтр на поиск результата, который совпадает с названием города Бостон, или название штата, которое содержит аббревиатуру NY. Это также просто, как импорт Q вверху файла, и затем слегка поменять наш существующий запрос
# cities/views.py from django.db.models import Q # новый … class SearchResultsView(ListView): model = City template_name = ‘search_results.html’ def get_queryset(self): # новый return City.objects.filter( Q(name__icontains=’Boston’) | Q(state__icontains=’NY’) )
# cities/views.py from django.db.models import Q # новый …
class SearchResultsView(ListView): model = City template_name = ‘search_results.html’
def get_queryset(self): # новый return City.objects.filter( Q(name__icontains=’Boston’) | Q(state__icontains=’NY’) ) |
Обновите вашу страницу поисковой выдачи, чтобы увидеть результат.
Теперь, вернемся к нашей HTML-форме поиска для замены текущих прописанных значений переменными поискового запроса.
Формы для ввода данных на сайте в Django
По сути, веб формы — это просто: они берут ввод пользователя и направляют его в URL либо через метод GET, либо через POST. Однако на практике, это фундаментальное поведение веба может быть монструозно сложным.
Однако на практике, это фундаментальное поведение веба может быть монструозно сложным.
Первая проблема — это отправка данных формы: куда на самом деле идут данные, и как мы их будет обрабатывать? Не говоря уже о множественных проблемах с безопасностью, когда вы разрешаете пользователям отправлять данные на веб-сайт.
Существует только два варианта того, как отправлять форму: либо через HTTP метод GET, либо через POST.
POST связывает данные формы, кодирует их для передачи, отправляет их на сервер и затем получает ответ. Любой запрос, который меняет состояние базы данных (создает, редактирует, или удаляет данные) — должен использовать POST.
GET связывает данные формы в строку, которая вносится в URL. GET должен быть использован для такого запроса, который не влияет на состояние приложения, например — поиск, где ничего внутри базы данных не меняется. Мы просто выполняем отфильтрованный просмотр списка.
Если вы взгляните на URL после поиска в гугле, вы увидите свой поисковый запрос в самом URL страницы результатов поиска ?q=.
Для дополнительной информации, Mozilla предоставляет подробные руководства как для отправки данных из формы, так и валидации форм данных, с которыми стоит ознакомиться, если вы не владеете основами.
Поисковая форма для сайта на Django
Впрочем, для наших целей, мы можем создать базовую форму поиска к существующей домашней странице уже сейчас. Вот так это выглядит. Мы рассмотрим каждую часть примера ниже.
<!— templates/home.html —> <h2>HomePage</h2> <form action=»{% url ‘search_results’ %}» method=»get»> <input name=»q» type=»text» placeholder=»Search…»> </form>
<!— templates/home.html —> <h2>HomePage</h2>
<form action=»{% url ‘search_results’ %}» method=»get»> <input name=»q» type=»text» placeholder=»Search. </form> |
 ..»>
..»>Для формы, параметр action определяет, куда направлять пользователя после нажатия на кнопку поиска. Мы используем URL нашей страницы поисковой выдачи. Затем мы определим использование GET в качестве нашего метода.
Пример кода из данной статьи будет работать и на полноценном сервере, можете выбрать хостинг для проектов на Python которые поддерживают фреймворк Django и запустить свой собственный сайт на Python в интернете.
Внутри нашего одиночного ввода возможно иметь несколько вводов, или добавить кнопку по желанию. Мы назовем ее q, к чему мы и сошлемся далее. Определяем type как text. Затем добавляем значение к placeholder для запроса пользователя.
И все! Теперь, попробуйте ввести запрос на главной странице, например — san diego.
После нажатия кнопки Enter, вас перенаправит на страницу поисковой выдачи. Обратите внимание на то, что URL содержит наш поисковый запрос: http://127.0.0.1:8000/search/?q=san+diego.
Однако результат не изменился! Это связано с тем, что наш SearchResultsView все еще содержит изначально вписанные значения. Последний шаг — это взять пользовательский поисковый запрос, представленный нашим q bp URL, и передать его дальше в логику нашего приложения.
# cities/views.py … class SearchResultsView(ListView): model = City template_name = ‘search_results.html’ def get_queryset(self): # новый query = self.request.GET.get(‘q’) object_list = City.objects.filter( Q(name__icontains=query) | Q(state__icontains=query) ) return object_list
# cities/views.py … class SearchResultsView(ListView): model = City template_name = ‘search_results.html’
def get_queryset(self): # новый query = self. object_list = City.objects.filter( Q(name__icontains=query) | Q(state__icontains=query) ) return object_list |
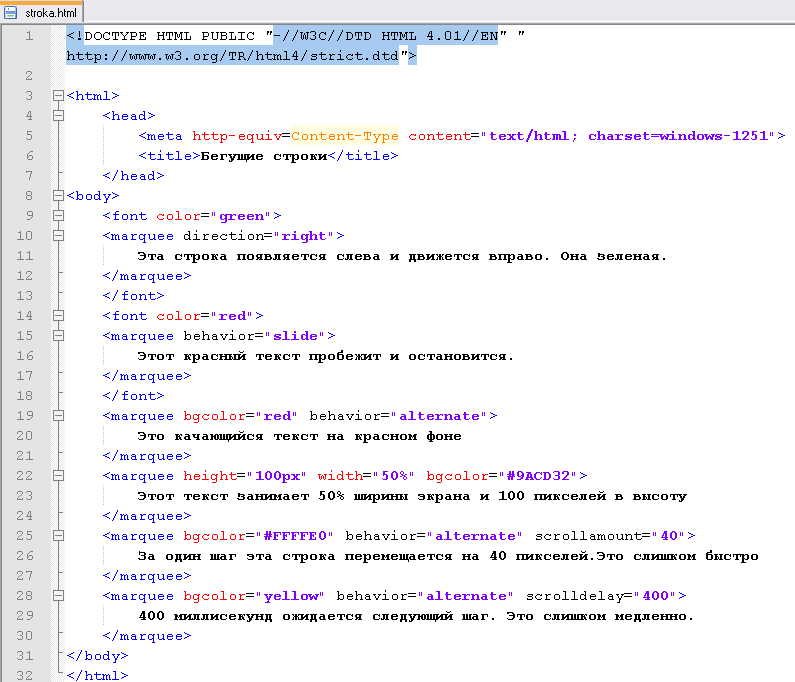 request.GET.get(‘q’)
request.GET.get(‘q’)Мы добавили переменную запроса, которая принимает значение q из формы поискового запроса. Далее, мы обновляем наш фильтр для названий города и штата. И все! Обновите страницу поисковой выдачи — у нее все еще тот же URL с нашим запросом, и мы получаем ожидаемый результат.
Если вы хотите сравнить свой код с официальным источником, вы можете найти его на GitHub (ссылку мы указали в начале этого урока).
Дальнейшие шаги
Наши основы поиска в Django готовы и изучены! Может, вы хотите добавить кнопку в поисковую форму, которую также можно нажать, как и Enter? Или хотите добавить какую-нибудь валидацию формы?
Помимо фильтрации с использованием AND и OR, есть и другие факторы, если вам нужен поиск уровня гугла с релевантностью и прочим. На этом выступлении DjangoCon 2014 показывается, насколько глубока может быть поисковая кроличья нора!
Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: [email protected]
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
4 полезных совета по работе с Safari на iPhone и iPad
Панель интеллектуального поиска в Safari представляет собой гибрид старой адресной строки и панели поиска, объединенных в одно универсальное место для ввода текста и перехода по ссылкам. Это очень удобно, поскольку можете получить доступ к поисковой системе по умолчанию, истории просмотров, сохраненным закладкам и даже определенным словам на веб-страницах через единую панель интеллектуального поиска в верхней части окна просмотра браузера Safari. Но почему-то не все пользуются этим инструментом, хотя он экономит уйму времени.
Это очень удобно, поскольку можете получить доступ к поисковой системе по умолчанию, истории просмотров, сохраненным закладкам и даже определенным словам на веб-страницах через единую панель интеллектуального поиска в верхней части окна просмотра браузера Safari. Но почему-то не все пользуются этим инструментом, хотя он экономит уйму времени.
Думаете, вы используете Safari по-максимуму? Проверьте
Как искать закладки и историю с помощью Safari на iPhone и iPad
Например, можно не заходить в панель закладок или историю, а посмотреть ее прямо в строке поиска.
- Запустите Safari с главного экрана.
- Коснитесь панели интеллектуального поиска в верхней части браузера.
- Введите несколько ключевых слов, по которым вы хотите выполнить поисковый запрос в Интернете (я искал «Apple»).
- Нажмите на сайт или закладку, к которой вы хотите перейти, под заголовком «Закладки» и «История».
Закладки и история доступны прямо из панели поиска
Как искать текст на странице в Safari на iPhone и iPad
- Откройте Safari на своем iPhone или iPad.
- Откройте веб-страницу в Safari.
- Коснитесь панели интеллектуального поиска наверху.
- Введите слово или фразу, которую хотите найти на странице.
- Прокрутите вниз до поля «На этой стр.»
- Нажмите кнопки навигации, чтобы перейти ко всем совпадениям поиска, если их несколько.
До сих пор многие не умеют пользоваться поиском в Safari
Как изменить поиск по умолчанию в Safari на iPhone и iPad
У каждого есть любимая поисковая машина. При использовании панели интеллектуального поиска в Safari убедитесь, что выбрана правильная поисковая система.
- Нажмите «Настройки» на главном экране.
- Выберите Safari (возможно, вам придется прокрутить вниз, чтобы найти его).
- Зайдите в меню «Поисковая машина».
- Выберите поисковую систему, которую хотите.
Лучше всего использовать Яндекс или Google, но можно и другие
В следующий раз, когда вы откроете Safari и наберете что-то в строке интеллектуального поиска, он будет использовать вашу недавно настроенную поисковую систему.
Как искать в Safari из поиска на главном экране в iOS 14
В iOS 14 появилась новая функция поиска, доступная по свайпу влево от главного экрана. Когда вы введете поисковый запрос в поиск Spotlight, то увидите предложенные варианты поиска в Интернете и даже веб-сайты, основанные на вашем запросе.
- Проведите по главному экрану вправо, чтобы перейти к поиску.
- Введите поисковый запрос в строку поиска.
- Коснитесь желаемого результата поиска.
Можно даже не открывать Safari, чтоб перейти на наш сайт
Как вы можете видеть в приведенном выше примере, поисковые запросы, которые iOS нашла для «AppleInsider», автоматически откроют наш сайт Safari и выполнят поиск в Интернете с использованием этого слова.
Другими лайфхаками Safari вы можете поделиться в комментариях и в нашем Telegram-чате.
Apple, как правило, сначала предлагает обновления для iOS, iPadOS, watchOS, tvOS и macOS в виде закрытых предварительных версий для разработчиков или общедоступных бета-версий. Хотя бета-версии содержат новые функции, они также часто бывают с ошибками, которые могут помешать нормальному использованию вашего iPhone, iPad, Apple Watch, Apple TV или Mac. Они не предназначены для повседневного использования на основном устройстве. Вот почему мы настоятельно рекомендуем держаться подальше от предварительных версий для разработчиков, если они вам не нужны для разработки программного обеспечения, и использовать общедоступные бета-версии с осторожностью. Если вам дорог свой айфон, дождитесь финальной версии.
Работа с HTML-публикацией [BS Docs 4]
HTML-публикацию можно использовать для публикации на внутреннем или внешнем Интернет-портале, передачи специалистам и сотрудникам компании, а также для проведения презентаций.
Для передачи HTML-публикации другим сотрудникам достаточно передать им папку, в которую была произведена публикация.
Внимание!
HTML-публикация является серверным решением. Это означает, что компьютер, на котором размещается HTML-публикация, выполняет роль сервера публикации. При этом к данной HTML-публикации можно получить доступ с других компьютеров через веб-браузер по ссылке, если открыть HTML-публикацию для общего доступа (подробнее об этом описано ниже в Таблице 1). Для запуска серверного решения необходимо на сервере публикации однократно запустить веб-сервер публикации — файл «HTML-publication.exe» (работа обеспечивается запускаемыми приложениями MySQL и Apache).
Для публикации в сети необходимо разместить папку со сформированной HTML-публикацией на компьютере, который будет выполнять роль веб-сервера, и запустить из нее файл «HTML-publication.exe». В результате в веб-браузере, установленном по умолчанию, откроется страница с HTML-публикацией со ссылкой вида http://localhost:<Номер порта, на котором открылась HTML-публикация>/businessmodel.php?lang=ru-ru, по которой публикация будет доступна с данного компьютера, а в области уведомлений Windows появится ее иконка .
C помощью пунктов контекстного меню, вызванного от этой иконки, осуществляется управление доступом к публикации, открытие статьи справочной системы, закрытие HTML-публикации или ее открытие в браузере. Описание назначения пунктов этого контекстного меню приведено в Таблице 1.
| Пункт меню | Назначение |
|---|---|
| Открыть | Открывает HTML-публикацию в веб-браузере, установленном по умолчанию. |
| Опубликовать для общего доступа / Прекратить общий доступ | Пункт меню Опубликовать для общего доступа открывает публикацию для внешнего доступа. При этом в веб-браузере, установленном по умолчанию, открывается страница со ссылкой вида http://<Имя компьютера, на котором запущена HTML-публикация>:<Номер порта, на котором открылась HTML-публикация>/businessmodel.php?lang=ru-ru, по которой с других машин можно открыть HTML-публикацию в веб-браузере. Эта ссылка может быть передана сотрудникам компании для доступа к HTML-публикации. Пункт меню Прекратить общий доступ прекращает общий доступ к публикации. При этом в веб-браузере, установленном по умолчанию, открывается страница со ссылкой вида http://localhost:<Номер порта, на котором открылась HTML-публикация>/businessmodel.php?lang=ru-ru, по которой публикация будет доступна с данного компьютера. |
| Помощь | Открывает страницу HTML-публикации в справочной системе. |
| Выход | Закрывает HTML-публикацию. Если публикация была опубликована для внешнего доступа, после выполнения этой команды доступ будет прекращен. |
Таблица 1. Пункты меню управления HTML-публикацией
Внимание!
Для того чтобы пользователи имели доступ к HTML-публикации, на компьютере, где она запущена, должен быть открыт соответствующий порт (номер порта см. в адресной строке браузера после наименования компьютера, на котором запущена HTML-публикация). При выполнении для HTML-публикации пункта меню Опубликовать для общего доступа будет сделана попытка открыть доступ к этому порту. В случае если попытка не удастся, необходимо будет открыть порты самостоятельно.
На компьютере может одновременно быть запущено несколько HTML-публикаций из разных папок.
В случае если сформирована новая HTML-публикация и требуется запустить ее таким образом, чтобы ссылка на нее оказалась той же, что и для одной из запущенных в текущий момент HTML-публикаций, следует действовать так:
- Закройте эту запущенную HTML-публикацию при помощи пункта меню Выход контекстного меню, вызванного от иконки этой HTML-публикации в области уведомлений Windows;
- Откройте новую HTML-публикацию, запустив из нее файл «HTML-publication.exe»;
- Опубликуйте новую HTML-публикацию для доступа по сети при помощи пункта меню Опубликовать для общего доступа контекстного меню, вызванного от иконки HTML-публикации в области уведомлений Windows.
Окно HTML-публикации (Рис. 1) разделено на 3 области:
В шапке (верхняя область) размещается логотип организации, управляющие элементы, а также главное меню, которое в данном случае содержит одну вкладку Бизнес-модель компании.
В области отчета (правая область) находится панель с полем выбора отчета текущего объекта, кнопки для выгрузки отчета в форматах doc и pdf, отправления ссылки на отчет по почте, печати отчета, а также сам выбранный отчет.
В случае если используется мобильная версия, на экране может быть показан или Навигатор, или область отчета. Переход из Навигатора к области отчета осуществляется выбором объекта в дереве. При этом панель Навигатора сворачивается. Переход от показа отчета к показу дерева Навигатора осуществляется нажатием на свёрнутую панель Навигатора.
Шапка окна HTML-публикации
Шапка окна HTML-публикации содержит:
- логотип организации, который задается в параметре «Логотип компании» в Настройках для всех пользователей (Главное меню → Главная → Настройки для всех пользователей → вкладка Основные) (см. Настройка HTML-публикации).
- главное меню, которое для HTML-публикации состоит из одной вкладки Бизнес-модель компании.
управляющие элементы, описание назначения которых приведено в Таблице 2.
Таблица 2. Элементы шапки окна HTML-публикации
Шапку окна HTML-публикации можно свернуть для увеличения области показа отчета, нажав на кнопку горизонтальной панели. Впоследствии эту область можно вернуть на экран, нажав на кнопку этой панели.
Навигатор
В Навигаторе отображается дерево объектов, выбранных для выгрузки в HTML-публикацию.
Выбор объекта в дереве Навигатора приводит к отображению отчета, сформированного для этого объекта, в области отчета.
Подвижная граница между областью отчета и Навигатором позволяет каждому пользователю настроить окно HTML-публикации в соответствии со своими предпочтениями.
Навигатор можно свернуть для увеличения области показа отчета, нажав на кнопку вертикальной панели. Впоследствии эту область можно вернуть на экран, нажав на кнопку этой панели.
Область отчета HTML-публикации
Основную часть области отчета занимает отчет, сформированный для текущего объекта дерева. Также в этой области над отчетом выводится панель инструментов для работы с ним. Выбор отчета, показываемого в данной области, осуществляется в поле выбора отчета из выпадающего списка (например, на Рис. 1 для объекта «Директор» выведен на показ отчет «Описание должности»), расположенного на этой панели. Назначение описания кнопок панели инструментов приведено в Таблице 3.
| Кнопка | Назначение |
|---|---|
| Выгрузка текущего отчета в формате MS Office (DOCX, XLSX). Формат выгрузки зависит от формата шаблона отчета. | |
| Выгрузка текущего отчета в формате PDF. | |
| Отправка ссылки на текущий отчет другому пользователю. По нажатию на кнопку открывается окно настроенной почтовой программы со ссылкой на текущий отчет HTML-публикации. | |
| Открытие отчета в виде для печати. Отчет открывается на всю страницу и далее может быть распечатан средствами веб-браузера. |
Таблица 3. Кнопки области отчета окна HTML-публикации
В нижней части области отчета находится ссылка на текущую страницу HTML-публикации. Данную ссылку можно передать другому сотруднику. Также с помощью данной ссылки можно найти объект, по которому построен данный отчет, в Навигаторе Business Studio, воспользовавшись кнопкой на панели инструментов Навигатора (см. Панель инструментов и контекстное меню Навигатора).
Для представленных в области отчета диаграмм доступна функция масштабирования (при использовании браузеров Google Chrome, Mazilla Firefox, Opera): наведя курсор на область диаграммы, зажав клавишу Ctrl и используя вращение колёсика мыши, можно масштабировать именно саму диаграмму, без масштабирования остальных элементов области отчёта и всего окна HTML-публикации (Рис. 2).
Рисунок 2. Окно HTML-публикации с увеличенной диаграммойСтраница расширенного поиска
На странице расширенного поиска, вызываемой гиперссылкой Поиск с основной страницы HTML-публикации, задается:
строка, по которой производится поиск;
- разделы HTML-публикации, в которых ведется поиск;
- отчёты HTML-публикации, в которых ведётся поиск;
дополнительные параметры (Рис. 3).
Поиск запускается нажатием на кнопку Искать. Результаты поиска отображаются в нижней части страницы.
Нажатие мышью по любому из найденных результатов переводит к соответствующему отчету, где была найдена искомая фраза.
В группе Слова расположены задается требуемое место расположения искомой фразы в отчетах HTML-публикации. Группа содержит следующие радиокнопки:
везде — поиск заданной фразы осуществляется как в названиях объектов дерева, так и в тексте отчетов;
в теле документа — поиск заданной фразы осуществляется только в тексте отчетов;
в названии элемента — поиск заданной фразы осуществляется только в названиях объектов дерева.
С помощью радиокнопок группы Искать задается «жесткость» поиска. Группа содержит следующие радиокнопки:
все слова в любом порядке — осуществляется поиск всех слов заданной фразы, причем порядок следования слов не важен;
любое из слов — осуществляется поиск каждого из слов заданной фразы;
точное совпадение фразы — осуществляется поиск заданной фразы, порядок следования слов должен совпадать с заданным.
Для каждой из групп Слова расположены и Искать обязательно должна быть выбрана одна из радиокнопок.
С помощью области Место поиска указывается перечень справочников, по которым требуется произвести поиск. Может быть выбрано любое число справочников. В случае, когда не выбран ни один из пунктов, поиск производится по всему содержимому HTML-публикации.
С помощью области Искать в отчётах указывается перечень отчётов, в которых требуется произвести поиск. Может быть выбрано любое число отчётов. В случае, когда не выбран ни один из пунктов, поиск производится по всем отчётам, выгруженным в HTML-публикацию.
Запрос строки запроса | Руководство по Elasticsearch [7.12]
Строка запроса «мини-язык» используется
Строка запроса и q Параметр строки запроса в API поиска .
Строка запроса разбивается на серию из терминов и операторов . А
термин может быть одним словом — quick или brown — или фразой, окруженной
двойные кавычки — "quick brown" — поиск всех слов в
фразу в том же порядке.
позволяют настраивать поиск — доступные параметры объяснено ниже.
В синтаксисе запроса можно указать поля для поиска:
, где поле статуса
активныхстатус: активный
, где
заголовокполе содержитquickиликоричневыйназвание: (быстрое ИЛИ коричневый)
, где поле
authorсодержит точную фразу"john smith"автор: "Джон Смит"
, где поле имени
Алиса(обратите внимание, как нам нужно избежать пробел с обратной косой чертой)имя \ имя: Алиса
где любое из полей
книга.название,кн. содержаниеиликн. датасодержитquickиликоричневый(обратите внимание, как нам нужно экранировать*обратной косой чертой):книга. \ * :( быстро ИЛИ коричневый)
, где поле
titleимеет любое ненулевое значение:_exists_: название
Поиск с подстановочными знаками может выполняться на отдельных условиях, используя ? заменить
один символ и * для замены нуля или более символов:
qu? Ck брат *
Имейте в виду, что запросы с подстановочными знаками могут использовать огромный объем памяти и
работают очень плохо — просто подумайте, сколько терминов нужно запросить
соответствует строке запроса "a * b * c *" .
Чистые подстановочные знаки \ * переписываются на существует запросов для повышения эффективности.
Как следствие, подстановочный знак "поле: *" будет соответствовать документам с пустым значением.
например:
{
"поле": ""
} … и не совпадет с , если поле отсутствует или установлено с явным нулем значение, подобное следующему:
{
"поле": ноль
} Использование подстановочного знака в начале слова (например, "* ing" ) особенно важно.
тяжелый, потому что все термины в указателе нужно проверить, на всякий случай
они совпадают.Ведущие подстановочные знаки можно отключить, установив allow_leading_wildcard — ложь .
Только части цепочки анализа, которые работают на уровне персонажа, являются применяемый. Так, например, если анализатор выполняет и нижний регистр, и стемминг будет применяться только в нижнем регистре: было бы неправильно выполнять происходит от слова, в котором отсутствуют некоторые буквы.
Если для analysis_wildcard установлено значение true, запросы, заканчивающиеся на * , будут
проанализированы, и логический запрос будет построен из разных токенов,
обеспечение точных совпадений на первых токенах N-1 и совпадения префиксов на последних
токен.
Шаблоны регулярных выражений могут быть встроены в строку запроса с помощью
заключая их в косую черту ( "/ ):
имя: / joh? N (ath [oa] n) /
Поддерживаемый синтаксис регулярных выражений объясняется в Синтаксис регулярных выражений .
Параметр allow_leading_wildcard не контролирует
регулярные выражения. Строка запроса, подобная следующей, заставит
Elasticsearch для посещения каждого термина в индексе:
/.* п /
Используйте с осторожностью!
Мы можем искать термины, которые похожи, но не совсем на наши поисковые запросы, с использованием «нечеткого» оператор:
quikc ~ brwn ~ foks ~
Здесь используется Расстояние Дамерау-Левенштейна найти все термины с максимальным количеством два изменения, где изменение — это вставка, удаление или замена одного символа, или перестановка двух соседних символы.
Расстояние редактирования по умолчанию — 2 , но расстояние редактирования 1 должно быть
достаточно, чтобы поймать 80% всех человеческих орфографических ошибок.Его можно указать как:
quikc ~ 1
Избегайте смешивания нечеткости с подстановочными знаками
Смешивание операторов нечетких и подстановочных знаков не поддерживается . При смешивании один из операторов не применяется. Например,
вы можете искать приложение ~ 1 (нечеткое) или приложение * (подстановочный знак), но поиск app * ~ 1 не применять нечеткий оператор ( ~ 1 ).
В то время как фразовый запрос (например, "john smith" ) ожидает, что все термины будут точно
в том же порядке, запрос близости позволяет указанным словам быть дальше
отдельно или в другом порядке.Точно так же, как нечеткие запросы могут
указать максимальное расстояние редактирования для символов в слове, поиск по близости
позволяет указать максимальное расстояние редактирования слов во фразе:
"лисица ская" ~ 5
Чем ближе текст в поле к исходному порядку, указанному в
строка запроса, тем более релевантным считается этот документ. Когда
по сравнению с приведенным выше примером запроса фраза "quick fox" будет
считается более актуальным, чем "Быстрая бурая лисица" .
Можно указать диапазоны для полей даты, числовых или строковых полей. Инклюзивные диапазоны
указаны в квадратных скобках [min TO max] , а исключительные диапазоны — с
фигурные скобки {min TO max} .
Всего дней в 2012 году:
Дата: [2012-01-01 TO 2012-12-31]
Числа 1..5
количество: [от 1 до 5]
Теги между
alphaиomega, за исключениемalphaиomega:тег: {alpha TO omega}Числа от 10 до
количество: [10 TO *]
До 2012 г.
Дата: {* TO 2012-01-01}
Фигурные и квадратные скобки можно комбинировать:
Диапазоны с одной неограниченной стороной могут использовать следующий синтаксис:
Возраст:> 10 возраст:> = 10 возраст: <10 возраст: <= 10
Чтобы объединить верхнюю и нижнюю границы с упрощенным синтаксисом, вы
нужно будет объединить два предложения с оператором И :
возраст: (> = 10 И <20) возраст: (+> = 10 + <20)
Анализ диапазонов в строках запроса может быть сложным и подверженным ошибкам.4
По умолчанию все термины являются необязательными, если совпадает один термин. Поиск
для foo bar baz найдет любой документ, содержащий один или несколько из foo или bar или baz . Мы уже обсуждали default_operator выше, что позволяет принудительно указать все условия, но есть
также логических операторов , которые могут использоваться в самой строке запроса
чтобы обеспечить больший контроль.
Предпочтительные операторы: + (должен присутствовать термин , ) и - (этот термин не должен присутствовать ). "~ *?: \ /
Неспособность правильно экранировать эти специальные символы может привести к синтаксической ошибке, которая препятствует выполнению вашего запроса.
< и > вообще не могут быть экранированы. Единственный способ предотвратить их
попытка создать запрос диапазона - удалить их из строки запроса
полностью.
Пробелы и пустые запросыправить
Пробел не считается оператором.
Если строка запроса пуста или содержит только пробелы, запрос будет дает пустой набор результатов.
Избегайте использования запроса
query_string для вложенных документов query_string поиска не возвращают вложенные документы.Искать
вложенные документы используйте вложенный запрос .
Искать по нескольким полямправить
Вы можете использовать параметр fields для выполнения поиска query_string по
несколько полей.
Идея выполнения запроса query_string для нескольких полей состоит в том, чтобы
дополните каждый термин запроса оператором ИЛИ следующим образом:
поле1: запрос_терм ИЛИ поле2: запрос_терм | ...
Например, следующий запрос
GET / _search
{
"запрос": {
"Строка запроса": {
"поля": ["содержание", "имя"],
"query": "это И то"
}
}
} соответствует тем же словам, что и
GET / _search
{
"запрос": {
"Строка запроса": {
"запрос": "(содержание: это ИЛИ имя: это) И (содержание: это ИЛИ имя: это)"
}
}
} Поскольку несколько запросов генерируются из отдельных условий поиска,
их объединение выполняется автоматически с помощью запроса dis_max с параметром tie_breaker .5 "],
"query": "это И то ИЛИ, таким образом",
"tie_breaker": 0
}
}
}
Простой подстановочный знак также можно использовать для поиска "внутри" определенных внутренних
элементы документа. Например, если у нас есть объект city с
несколько полей (или внутренний объект с полями) в нем, мы можем автоматически
искать по всем полям "город":
GET / _search
{
"запрос": {
"Строка запроса" : {
"поля": ["город. *"],
"запрос": "это И то ИЛИ так"
}
}
} Другой вариант - предоставить поиск по полям с подстановочными знаками в запросе.
сама строка (правильно экранирующая знак * ), например: г.\ *: что-то :
GET / _search
{
"запрос": {
"Строка запроса" : {
"запрос": "город. \\ * :( это И то ИЛИ таким образом)"
}
}
} Поскольку \ (обратная косая черта) является специальным символом в строках json, необходимо
быть экранированным, следовательно, две обратные косые черты в приведенном выше query_string .
Параметр fields может также включать имена полей на основе шаблонов, позволяя автоматически расширяться до соответствующих полей (динамически введенные поля включены).5 "], "запрос": "это И то ИЛИ так" } } }
Дополнительные параметры для поиска по нескольким полямправить
При выполнении запроса query_string для нескольких полей
Поддерживаются следующие дополнительные параметры.
-
тип (Необязательно, строка) Определяет, как запрос сопоставляет документы и оценивает их. Действительный значения:
-
best_fields(по умолчанию) - Находит документы, соответствующие любому полю, и использует самые высокие
_scoreиз любого подходящего поля.Видетьbest_fields. -
bool_prefix - Создает запрос
match_bool_prefixдля каждого поля и объединяет_scoreиз каждое поле. См.bool_prefix. -
cross_fields - Обрабатывает поля с помощью того же анализатора
cross_fields. -
most_fields - Находит документы, соответствующие любому полю, и объединяет
_scoreиз каждого поля.См.most_fields. -
фраза - Выполняет запрос
match_phraseдля каждого поля и использует_scoreиз лучших поле. См.фразаифраза_префикс. -
фраза_префикс - Выполняет запрос
match_phrase_prefixдля каждого поля и использует_scoreиз лучшее поле. См.фразаифраза_префикс.
ПРИМЕЧАНИЕ: Дополнительные параметры верхнего уровня
multi_matchмогут быть доступны на основетипзначение.-
Синонимы и
query_string queryedit Запрос query_string поддерживает расширение синонимов с несколькими терминами с помощью фильтра токенов synonym_graph. Когда этот фильтр используется, синтаксический анализатор создает запрос фразы для каждого синонима, состоящего из нескольких терминов.
Например, следующий синоним: ny, Нью-Йорк произведет:
(Нью-Йорк)
Также возможно сопоставление синонимов из нескольких терминов с помощью союзов:
GET / _search
{
"запрос": {
"Строка запроса" : {
"default_field": "название",
"query": "ny city",
"auto_generate_synonyms_phrase_query": ложь
}
}
} В приведенном выше примере создается логический запрос:
(нью-йоркский OR (нью-энд-йорк)) город
, который соответствует документам с термином ny или соединением new AND york .По умолчанию для параметра auto_generate_synonyms_phrase_query установлено значение true .
Как
minimum_should_match работает для нескольких полейправить GET / _search
{
"запрос": {
"Строка запроса": {
"поля": [
"заглавие",
"содержание"
],
"query": "this that so",
"minimum_should_match": 2
}
}
} В приведенном выше примере создается логический запрос:
((content: this content: that content: so) | (title: this title: that title: so))
, который сопоставляет документы с дизъюнкцией max по полям title и содержание .Здесь нельзя применить параметр minimum_should_match .
GET / _search
{
"запрос": {
"Строка запроса": {
"поля": [
"заглавие",
"содержание"
],
"запрос": "это ИЛИ то ИЛИ таким образом",
"minimum_should_match": 2
}
}
} При добавлении явных операторов каждый термин следует рассматривать как отдельное предложение.
В приведенном выше примере создается логический запрос:
((content: this | title: this) (content: that | title: that) (content: Таким образом | заголовок: таким образом)) ~ 2
, который сопоставляет документы как минимум с двумя из трех пунктов "следует", каждое из они составлены из дизъюнкции max по полям для каждого члена.
Как
minimum_should_match работает для поиска по нескольким полямправить Значение cross_fields в поле типа указывает поля с одинаковыми
анализаторы группируются вместе при анализе входа.
GET / _search
{
"запрос": {
"Строка запроса": {
"поля": [
"заглавие",
"содержание"
],
"запрос": "это ИЛИ то ИЛИ таким образом",
"type": "cross_fields",
"minimum_should_match": 2
}
}
} В приведенном выше примере создается логический запрос:
(смешанный (условия: [поле2: это, поле1: это]) смешанный (условия: [поле2: то, поле1: то]) смешанный (условия: [поле2: таким образом, поле1: таким образом])) ~ 2
, который сопоставляет документы по крайней мере с двумя из трех смешанных запросов по термину.
Поиск и замена цели в проекте
Вы можете искать текстовую строку в проекте, использовать различные области для сужения процесса поиска, находить вхождения и исключать определенные элементы из поиска.
Найти строку поиска в проекте
В главном меню выберите Ctrl + Shift + F .
В поле поиска введите строку поиска. Либо в редакторе выделите строку, которую хотите найти, и нажмите Ctrl + Shift + F .IntelliJ IDEA помещает выделенную строку в поле поиска.
Чтобы просмотреть список ваших предыдущих поисков, нажмите Alt + Down .
При необходимости укажите дополнительные опции.
IntelliJ IDEA перечисляет строки поиска и файлы, которые их содержат. Если строка поиска встречается несколько раз в одной строке кода, IntelliJ IDEA объединяет результаты в одну строку.
Для выполнения многострочного поиска щелкните значок, чтобы ввести новую строку, и нажмите Ctrl + Alt + Down / Ctrl + Alt + Up , чтобы просмотреть вхождения.
Проверьте результаты в области предварительного просмотра диалогового окна, где вы можете заменить строку поиска или выбрать другую строку, снова нажмите Ctrl + Shift + F и начните новый поиск.
Чтобы просмотреть список вхождений в отдельном окне инструмента, щелкните Открыть в окне поиска. Используйте это окно и его параметры для группировки результатов, предварительного просмотра и дальнейшей работы с ними.
Если вы хотите видеть каждый новый результат поиска на отдельной вкладке в окне инструмента «Найти», щелкните в нижней части диалогового окна «Найти в файлах» и выберите параметр «Открыть результаты в новой вкладке».
Сузьте область поиска
Для настройки процесса поиска можно использовать различные параметры в диалоговом окне «Найти в файлах».
Выберите такие параметры, как Слова () или С учетом регистра (), чтобы найти точное слово в проекте или сопоставить регистр букв.
При выборе IntelliJ IDEA автоматически экранирует специальные символы регулярных выражений с помощью обратной косой черты
\при поиске текстовой строки, содержащей их.Имейте в виду, что если вы сначала скопируете ( Ctrl + C ) строку, а затем вставите ее ( Ctrl + V ) в поле поиска, символы регулярного выражения не будут приняты во внимание.
Дополнительные сведения о регулярных выражениях см. В документации по поиску по регулярным выражениям.
Щелкните значок, чтобы отфильтровать результаты поиска. Например, вы можете отфильтровать поиск, чтобы исключить комментарии или вместо этого искать только в комментариях.
Выберите одну из отображаемых опций, например «Модуль» или «Каталог», чтобы ограничить поиск.
Кроме того, вы можете выбрать опцию Scope, которая предлагает вам список предопределенных областей для вашего поиска. Например, вы можете ограничить свой поиск только открытыми файлами в вашем проекте или вы можете искать в иерархии классов.
Если вы работаете без вкладок, то область «Недавно просмотренные файлы» или «Недавно измененные файлы» может оказаться весьма полезной. Вы также можете создать свою собственную настраиваемую область, щелкнув значок «Обзор» (), чтобы открыть диалоговое окно «Области».
Поиск в файлах определенных типов
Используйте параметр «Маска файла», чтобы сузить область поиска до определенного типа файлов. Вы можете выбрать существующий тип файла из списка, добавить новый тип файла или добавить дополнительный синтаксис маски файла для поиска типов файлов с определенными шаблонами.
В диалоговом окне «Найти в файлах» установите флажок «Маска файла» и из списка типов файлов выберите нужный.
IntelliJ IDEA ограничивает свой поиск указанным типом.
Если вы не можете найти нужный тип файла в списке, введите свой тип файла в поле «Маска файла».
Например, используйте следующий синтаксис для поиска только в файлах gradle: * .gradle.
Поддерживаются другие подстановочные знаки, кроме
*. Вы также можете указать несколько типов файлов, разделив их запятыми.
Заменить строку поиска в проекте
Нажмите Ctrl + Shift + R , чтобы открыть диалоговое окно «Заменить в пути».
В верхнем поле введите строку поиска. В нижнем поле введите заменяющую строку.
Например, если вы хотите заменить имя переменной новым именем для большого проекта, используйте замену в пути вместо рефакторинга переименования, поскольку ваша переменная также может появиться в файлах конфигурации.
Щелкните одну из доступных команд «Заменить».
Работа с результатами поиска в окне инструмента поиска
В диалоговом окне «Найти в файлах» нажмите «Открыть в окне поиска», чтобы открыть список результатов поиска в отдельном окне.
Используя значки и контекстное меню в окне инструмента поиска, вы можете сортировать записи, исключать каталоги, переходить к исходному коду и т. Д.
Отметьте следующие популярные параметры:
Если вы хотите исключить каталог из результатов, выберите каталог и в контекстном меню выберите Исключить.
Чтобы найти результат поиска в редакторе, используйте опцию «Перейти к источнику» из контекстного меню.
Чтобы вернуться в диалоговое окно «Найти в файлах», щелкните на левой панели инструментов.
Для сортировки записей поиска выберите в Показать меню параметров ().
Для получения дополнительной информации о параметрах и ссылках на значки в окне инструмента «Поиск» см. Раздел «Справочник по окну инструмента поиска».
Последнее изменение: 02 апреля 2021 г.
Поиск строки
Этот раздел был идентифицирован как новая область, требующая документ как часть общей перестройки документа.Текст здесь не завершено и требует доработки. Взносы сообщества приглашены.
Разработчикам часто требуется предоставлять простые алгоритмы поиска текста. и спецификации часто пытаются определить API для поддержки этих потребностей. Операции поиска с текстом порождают разные ожидания пользователей и, следовательно, иметь разные требования, отличные от потребности в абсолютной идентичности соответствие, необходимое для форматов документов и протоколов. Это важно обратите внимание, что требования к домену могут налагать дополнительные ограничения или изменить соображения, представленные здесь.
Варианты пользовательского ввода
Одно из основных соображений при поиске по строкам состоит в том, что достаточно часто вводимые пользователем данные не идентичны тому, как ищется закодировано.
Одна из основных причин этого заключается в том, что текст могут различаться способами, которые пользователь не может предсказать. В других случаях это связано с тем, что клавиатура пользователя или метод ввода не обеспечивает быстрый доступ к текстовым вариациям необходимо - или потому что пользователь не может беспокоиться о том, чтобы ввести текст точно.Например, пользователи часто пропускают акценты при вводе языков с латинским алфавитом, особенно на мобильных клавиатурах, даже если текст они ищем включает акценты. В этих случаях пользователи обычно ожидают, что поисковая операция будет больше "беспорядочные", чтобы компенсировать неспособность приложить дополнительные усилия к их вклад.
Например, пользователь может ожидать, что термин, введенный в нижнем регистре, соответствовать эквивалентам в верхнем регистре. И наоборот, когда пользователь тратит больше усилие на вводе - с помощью клавиши Shift для вывода прописных или введя букву с диакритическими знаками вместо основания буква - они могут ожидать, что их результаты поиска будут соответствовать (только) их более конкретный ввод.
Другой случай, когда текст может отличаться по-разному, но пользователь может ввести только один поисковый запрос. Например, В японском языке используются два разных фонетических алфавита, хирагана, . и катакана . Эти сценарии кодируют одни и те же фонемы; таким образом пользователь может ожидать, что при вводе поискового запроса хирагана найдет то же самое слово в катакана .
А другим примером может быть наличие или отсутствие коротких гласных в письменность на арабском и иврите.Для большинства языков в этих скриптах включение кратких гласных совершенно необязательно, но наличие гласных в искомом тексте может помешать сопоставлению, если пользователь не вводит или не знает, как их вводить.
Этот эффект также может зависеть от контекста. Например, человек, использующий физическую клавиатуру, может иметь прямой доступ к акцентированным буквы, а виртуальная или экранная клавиатура может потребовать дополнительных усилий для доступа и выбора тех же букв.
Рассмотрим документ, содержащий следующие строки: «возобновить», «RE-RESUME», «re-resumé» и «RE-RÉSUMÉ».
В приведенной ниже таблице ввод пользователя (слева) может быть считается подходящим по вышеуказанным позициям:
| Пользовательский ввод | Соответствующие строки |
|---|---|
| e (строчная буква "e") | «Возобновить», «ВОЗОБНОВИТЬ», «ВОЗОБНОВИТЬ» и «ВОЗОБНОВИТЬ» |
| E (заглавная буква E) | "RE-RESUME" и "RE-RESUMÉ" |
| é (строчная «е» с острым ударением) | «Повторное резюме» и «РЕ-РЕЗЮМЕ» |
| É (заглавная буква E с острым ударением) | "РЕ-РЕЗЮМЕ" |
Помимо вариантов регистра или использования диакритических знаков, Unicode также имеет массив канонических эквивалентов или символов совместимости (как описанные в разделах выше), которые могут повлиять на поиск строки.
Например, рассмотрим букву «К». Персонажи с совместимостью
отображение на U + 004B ЗАГЛАВНАЯ БУКВА K включает:
- Ķ U + 0136
- Ǩ U + 01E8
- ᴷ U + 1D37
- Ḱ U + 1E30
- Ḳ U + 1E32
- Ḵ U + 1E34
- К U + 212A
- Ⓚ U + 24C0
- ㎅ U + 3385
- ㏍ U + 33CD
- ㏎ U + 33CE
- K U + FF2B
- (различные математические символы, такие как U + 1D40A, U + 1D43E, U + 1D472, U + 1D4A6, U + 1D4DA)
- 🄚 U + 1F11A
- 🄺 U + 1F13A.
Другие отличия включают формы нормализации Unicode (или отсутствие из них). Есть также игнорируемые персонажи (например, вариант селекторы), различия в пробелах, двунаправленные элементы управления и другие кодовые точки, которые могут помешать совпадению.
Пользователи также могут ожидать применения определенных видов эквивалентности к соответствие. Например, пользователь из Японии может ожидать, что хирагана, катакана, и эквиваленты катаканы совместимости половинной ширины все совпадают друг друга (независимо от того, что используется для выполнения выбора или закодировано в тексте).
При поиске по тексту понятие «границы графемы» и "персонажи, воспринимаемые пользователем" могут быть важны. См. Раздел 3 из . Модель персонажа для Интернета: основы [[! CHARMOD]] для описания. Например, если пользователь ввел заглавную "А" в поле поиска, если программа найдет символ À (U + 00C0 ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А С АКЦЕНТОМ)? А как насчет буквы "A", за которой следует U + 0300 (комбинированный акцент могила)? А как насчет систем письма, таких как Деванагари, которые используют комбинирование знаков для подавления или выражения определенных гласных?
содержит | Cypress Documentation
Получите элемент DOM, содержащий текст.Элементы DOM могут содержать на больше , чем желаемый текст, и при этом совпадать. Кроме того, Cypress предпочитает некоторые элементы DOM самому глубокому найденному элементу.
Синтаксис
.contains (содержание)
.contains (контент, параметры)
.contains (селектор, контент)
.contains (селектор, контент, параметры)
cy.contains (контент)
cy.contains (контент, параметры)
cy.contains (селектор, контент)
cy.contains (селектор, контент, параметры)
Использование
Правильное использование
л.get ('. nav'). contains ('О программе')
cy.contains ('Привет')
Неправильное использование
cy.title (). Contains ('Мое приложение')
cy.getCookies (). содержит ('_ ключ')
Аргументы
содержимое (строка, число, регулярное выражение)
Получить элемент DOM, содержащий содержимое.
переключатель (переключатель строки)
Укажите селектор для фильтрации элементов DOM, содержащих текст.Cypress проигнорирует свой порядок предпочтений по умолчанию для указанного селектора. Использование селектора позволяет вам возвращать более мелких элементов (выше в дереве), содержащих конкретный текст.
опционы (Объект)
Передайте объект параметров, чтобы изменить поведение по умолчанию для .contains () .
Урожайность
-
. Содержит ()дает новый найденный элемент DOM.
Примеры
Контент
Найдите первый элемент, содержащий текст
- яблоки
- апельсины
- бананы
Найдите вход
[type = 'submit'] по значениюПолучите элемент формы и найдите в его потомках содержимое "отправить форму!"
<форма>
cy.get ('form'). contains ('отправить форму!'). click ()
Число
Найдите первый элемент, содержащий число
Даже несмотря на то, что является самым глубоким элементом, содержащим «4», Cypress автоматически возвращает элементов по промежуткам из-за его предпочтительного порядка элементов.
Регулярное выражение
Найдите первый элемент, текст которого соответствует регулярному выражению
- яблоки
- апельсины
- бананы
Селектор
Укажите селектор для возврата определенного элемента
Технически , ,
Обычно Cypress возвращает первые
Чтобы переопределить полученный элемент, мы можем передать ul в качестве селектора.
- яблоки
- апельсины
- бананы
cy.contains ('ul', 'яблоки')
Оставить форму как тему
Вот пример, в котором используется селектор, чтобы гарантировать, что остается предметом для будущей цепочки.
<форма>
cy.get ('форма')
.contains ('форма', 'Продолжить')
.Разместить()
Без явного селектора тема изменится на . Использование явного селектора гарантирует, что связанные команды будут иметь в качестве темы .
Чувствительность к регистру
Вот пример использования опции matchCase для игнорирования чувствительности к регистру.
Смертная казнь
cy.get ('div'). Contains ('заглавная фраза')
cy.get ('div'). contains ('заглавная фраза', {matchCase: false})
Банкноты
Прицелы
.contains () действует по-разному, запускает ли он серию команд или связывает существующую серию.
При запуске серии команд:
Это запрашивает содержимое всего документа .
При привязке к существующей серии команд
Это запросит внутри элемента <# checkout-container> .
cy.get ('# checkout-container'). Contains ('Купить сейчас')
Будьте осторожны при объединении в цепочку нескольких содержит
Давайте представим сценарий, в котором вы нажимаете кнопку, чтобы удалить пользователя, и появляется диалоговое окно с просьбой подтвердить это удаление.
cy.contains ('Удалить пользователя'). click (). contains ('Да, удалить!'). click ()
Поскольку второй .contains () связан с командой, которая дала , Cypress будет искать новый контент внутри .
Другими словами, Cypress будет искать содержимое , содержащего «Удалить пользователя»: «Да, удалить!», Что не то, что мы планировали.
Что вы хотите сделать, так это снова позвонить cy , что автоматически создаст новую цепочку, привязанную к документу .
cy.contains ('Удалить пользователя'). Щелкните ()
cy.contains ('Да, удалить!'). click ()
Начальные, конечные и повторяющиеся пробелы не игнорируются в теге
В отличие от других тегов, не игнорирует начальные, конечные или повторяющиеся пробелы, как показано ниже:
Другие теги
Привет, мир!
Предварительный тег
Привет, мир!
Полученный результат:
Чтобы отразить это поведение, Cypress также не игнорирует их.
cy.get ('p'). contains ('Привет, мир!')
cy.get ('p'). contains ('Привет, мир!')
cy.get ('pre'). contains ('Привет, мир!')
cy.get ('pre'). contains ('Привет, мир!')
Пространство неразрывное
Вы можете использовать пробел в cy.contains () для сопоставления текста в HTML, который использует неразрывный пробел & ampnbsp; .
Привет, мир
cy.содержит ('Привет, мир')
Одинарный элемент
Будет возвращен только
первый совпавший элемент
- Добро пожаловать, Джейн Лейн
У этих пользователей 10 контактов с Джейн Лейн
- Джамал
- Патрисия
В приведенном ниже примере будет возвращено #header , поскольку это первый элемент , содержащий текст «Jane Lane».
Если вместо этого вы хотите выбрать , вы можете сузить количество элементов, полученных до .contains () .
cy.get ('# main'). contains ('Джейн Лейн')
Настройки
Порядок предпочтения элемента
.contains () по умолчанию предпочитает элементы выше в дереве, когда они:
-
ввод [type = 'submit'] -
кнопка -
а -
этикетка
Cypress проигнорирует этот порядок предпочтения элементов, если вы передадите аргумент селектора в .содержит () .
Предпочтение
по сравнению с другими более глубокими элементами Даже несмотря на то, что является самым глубоким элементом, содержащим «Поиск», Cypress возвращает элементов на промежутках.
<форма>
<кнопка>
Поиск
cy.contains ('Поиск'). children ('i'). should ('have.class', 'fa-search')
Предпочтение
другим более глубоким элементам Даже несмотря на то, что является самым глубоким элементом, который содержит «Выход», Cypress дает элементы привязки по пролётам.
cy.get ('nav'). contains ('Выйти'). should ('have.attr', 'href', '/ signout')
Преимущество
по сравнению с другими более глубокими элементами Несмотря на то, что является самым глубоким элементом, содержащим "Age", Cypress дает элементов по сравнению с .
<форма>
<метка>
Имя:
<метка>
Возраст:
cy.contains ('Возраст'). find ('input'). type ('29 ')
Правила
Требования
-
. Содержит ()может быть прикован цепьюcyили от команды, которая дает элемент (ы) DOM.
Утверждения
-
. Содержит ()будет автоматически повторить попытку пока элемент (ы) существуют в DOM -
. Содержит ()будет автоматически повторить попытку пока все связанные утверждения не пройдут
Таймауты
-
. Содержит ()может истечь время ожидания элемента (ов) для существуют в DOM . -
. Содержит ()может время ожидания для утверждений, которые вы добавили, истекло.
Журнал команд
Элемент содержит текст «Новый пользователь»
cy.get ('h2'). Contains ('Новый пользователь')
Команды, указанные выше, будут отображаться в журнале команд как:
При нажатии на содержит команду в журнале команд, консоль выводит следующее:
История
| Версия | Изменения |
|---|---|
| 5.2.0 | Добавлена опция includeShadowDom . |
| 4.0.0 | Добавлена поддержка опции matchCase . |
См. Также
Apache Lucene - синтаксис парсера запросов
Обзор
Хотя Lucene предоставляет возможность создавать свои собственные запросы через свой API, он также предоставляет богатый запрос языка через Query Parser, лексер, который интерпретирует строку в запрос Lucene с помощью JavaCC.
Как правило, синтаксис парсера запросов может отличаться от отпустить к выпуску. На этой странице описан синтаксис по состоянию на текущий выпуск. Если вы используете другой версии Lucene, пожалуйста, обратитесь к копии docs / queryparsersyntax.html, который был распространен с версией, которую вы используете.
Прежде чем использовать предоставленный анализатор запросов, обратите внимание на следующее:
- Если вы программно генерируете строку запроса, а затем анализируя его с помощью парсера запросов, вам следует серьезно подумать о создании ваши запросы напрямую через API запросов.Другими словами, запрос парсер предназначен для текста, введенного человеком, а не для программного текст.
- Нетокенизированные поля лучше всего добавлять непосредственно в запросы, а не через парсер запросов. Если значения поля генерируются программно приложением, то также следует запросить предложения для этого поля. Анализатор, который использует парсер запросов, предназначен для преобразования введенных человеком текст к условиям.Создаваемые программой значения, такие как даты, ключевые слова и т. Д., должны последовательно генерироваться программой.
- В форме запроса поля, которые представляют собой общий текст, должны использовать запрос парсер. Все остальные, такие как диапазоны дат, ключевые слова и т. Д., Лучше добавлять. напрямую через API запросов. Поле с ограниченным набором значений, которые можно указать в раскрывающемся меню, не следует добавлять в строка запроса, которая впоследствии анализируется, а скорее добавляется как Предложение TermQuery.
Условия
Запрос разбит на термины и операторы. Есть два типа терминов: отдельные термины и фразы.
Отдельный термин - это отдельное слово, например «тест» или «привет».
Фраза - это группа слов, заключенная в двойные кавычки, например "hello dolly".
Несколько терминов можно комбинировать с логическими операторами, чтобы сформировать более сложный запрос (см. Ниже).
Примечание. Анализатор, используемый для создания индекса, будет использоваться для терминов и фраз в строке запроса.Поэтому важно выбрать анализатор, который не будет мешать терминам, используемым в строке запроса.
Поля
Lucene поддерживает полевые данные. При выполнении поиска вы можете указать поле или использовать поле по умолчанию. Имена полей и поле по умолчанию зависят от реализации.
Вы можете выполнить поиск в любом поле, введя имя поля, двоеточие ":" и затем искомый термин.
В качестве примера предположим, что индекс Lucene содержит два поля, заголовок и текст, а текст является полем по умолчанию.Если вы хотите найти документ под названием «Правильный путь», который содержит текст «не ходи этим путем», вы можете ввести:
заголовок: "Правильный путь" И текст: go
или
title: "Сделай правильно" И правильно
Поскольку текст является полем по умолчанию, индикатор поля не требуется.
Примечание. Поле действительно только для термина, которому оно предшествует, поэтому запрос
title: Сделай правильно
Найдет только «Do» в поле заголовка.Он найдет «это» и «справа» в поле по умолчанию (в данном случае текстовое поле).
Модификаторы терминов
Lucene поддерживает изменение условий запроса, чтобы обеспечить широкий диапазон параметров поиска.
Поиск по шаблону
Lucene поддерживает поиск с использованием одно- и многосимвольных подстановочных знаков в рамках одного термина (не внутри фразовых запросов).
Чтобы выполнить поиск с использованием подстановочных знаков, состоящих из одного символа, используйте "?" условное обозначение.
Чтобы выполнить поиск с использованием подстановочных знаков, состоящих из нескольких символов, используйте символ «*».
Поиск с использованием односимвольных подстановочных знаков ищет термины, соответствующие термину с замененным одиночным символом. Например, для поиска по запросу «текст» или «тест» можно использовать поиск:
te? T
Многосимвольный поиск с подстановочными знаками ищет 0 или более символов. Например, для поиска теста, тестов или тестера можно использовать поиск:
тест *
Вы также можете использовать поиск по шаблону в середине термина.
te * t
Примечание: нельзя использовать * или? символ в качестве первого символа поиска.
Нечеткие поиски
Lucene поддерживает нечеткий поиск на основе алгоритма расстояния Левенштейна или алгоритма редактирования расстояния. Чтобы выполнить нечеткий поиск, используйте символ тильды «~» в конце одного слова Term. Например, чтобы найти термин, похожий по написанию на «бродить», используйте нечеткий поиск:
роуминг ~
В этом поиске будут найдены такие термины, как пена и блуждание.
Начиная с Lucene 1.9 дополнительный (необязательный) параметр может указывать необходимое сходство. Значение находится в диапазоне от 0 до 1, при значении, близком к 1, будут сопоставляться только термины с более высоким сходством.Например:
роуминг ~ 0,8
Если параметр не задан, по умолчанию используется 0,5.
Поиск с близкого расстояния
Lucene поддерживает поиск слов на определенном расстоянии. Чтобы выполнить поиск по близости, используйте символ тильды "~" в конце фразы. Например, для поиска «apache» и «jakarta» в пределах 10 слов друг от друга в документе используйте поиск:
"jakarta apache" ~ 10
Поиск по диапазону
Range Queries позволяют сопоставлять документы, значения полей которых находятся между нижней и верхней границей, указанной в запросе диапазона.Запросы диапазона могут включать или исключать верхнюю и нижнюю границы. Сортировка производится лексикографически.
mod_date: [20020101 TO 20030101]
Это позволит найти документы, поля mod_date которых имеют значения от 20020101 до 20030101 включительно. Обратите внимание, что запросы диапазона не зарезервированы для полей даты. Вы также можете использовать запросы диапазона с полями без даты:
title: {Aida TO Carmen} Здесь находятся все документы, названия которых находятся между Аидой и Кармен, кроме Аиды и Кармен.4 "Apache Lucene"
По умолчанию коэффициент усиления равен 1. Хотя коэффициент усиления должен быть положительным, он может быть меньше 1 (например, 0,2)
Логические операторы
Логические операторы позволяют комбинировать термины с помощью логических операторов. Lucene поддерживает логические операторы AND, «+», OR, NOT и «-» (Примечание: логические операторы должны быть ЗАГЛАВНЫМИ).
Оператор ИЛИ является оператором соединения по умолчанию. Это означает, что если между двумя терминами нет логического оператора, используется оператор OR.Оператор OR связывает два термина и находит соответствующий документ, если какой-либо из терминов существует в документе. Это эквивалентно объединению с использованием множеств. Символ || можно использовать вместо слова ИЛИ.
Для поиска документов, содержащих "jakarta apache" или просто "jakarta", используйте запрос:
"jakarta apache" jakarta
или
"jakarta apache" OR Джакарта
И
Оператор AND сопоставляет документы, в которых оба термина существуют в любом месте текста одного документа.Это эквивалентно пересечению с использованием множеств. Вместо слова AND можно использовать символ &&.
Для поиска документов, содержащих "jakarta apache" и "Apache Lucene", используйте запрос:
"jakarta apache" И "Apache Lucene"
+
Оператор «+» или «обязательный» требует, чтобы термин после символа «+» существовал где-то в поле одного документа.
Для поиска документов, которые должны содержать "jakarta" и могут содержать "lucene", используйте запрос:
+ Джакарта Люцен
НЕ
Оператор NOT исключает документы, содержащие термин после NOT.Это эквивалентно разнице в использовании наборов. Символ ! может использоваться вместо слова НЕ.
Для поиска документов, содержащих "jakarta apache", но не "Apache Lucene", используйте запрос:
"jakarta apache" НЕ "Apache Lucene"
Примечание. Оператор NOT нельзя использовать только с одним термином. Например, следующий поиск не даст результатов:
НЕ "jakarta apache"
–
Оператор «-» или запретить исключает документы, содержащие термин после символа «-».
Для поиска документов, содержащих "jakarta apache", но не "Apache Lucene", используйте запрос:
"jakarta apache" - "Apache Lucene"
Группировка
Lucene поддерживает использование круглых скобок для группировки предложений для формирования подзапросов. Это может быть очень полезно, если вы хотите управлять логической логикой запроса.
Для поиска "jakarta" или "apache" и "website" используйте запрос:
(jakarta OR apache) И веб-сайт
Это устраняет любую путаницу и гарантирует, что этот веб-сайт должен существовать и может существовать либо термин jakarta, либо apache.
Группировка полей
Lucene поддерживает использование круглых скобок для группировки нескольких предложений в одно поле.
Для поиска заголовка, содержащего слово «возврат» и фразу «розовая пантера», используйте запрос:
название: (+ возврат + "розовая пантера")
Экранирование специальных символов
Lucene поддерживает экранирование специальных символов, которые являются частью синтаксиса запроса. "~ *?: \
Чтобы экранировать эти символы, используйте \ перед символом.Например, для поиска (1 + 1): 2 используйте запрос:
\ (1 \ +1 \) \: 2
Findstr - Поиск строк - Windows CMD
Findstr - Поиск строк - Windows CMD - SS64.comПоиск текстовой строки в файле (или нескольких файлах) в отличие от простой команды FIND FINDSTR поддерживает более сложные регулярные выражения.
Синтаксис
FINDSTR строка (s) [ путь (s)]
[/ R] [/ C: " string "] [/ G: StringsFile ] [/ F: file ] [/ D: DirList ]
[/ A: цвет ] [/ OFF [LINE]] [ параметры ]
Ключ
строка (и) Текст для поиска, каждое слово - отдельный поиск. pathname (s) Файл (ы) для поиска.
/ C: строка Использовать строку как буквальную строку поиска (может включать пробелы).
/ R Вычислить как регулярное выражение.
/ R / C: строка Использовать строку как регулярное выражение.
/ G: StringsFile Получить строку поиска из файла (/ означает консоль).
/ F: файл Получить список имен файлов для поиска из файла (/ означает консоль)./ d: dirlist Поиск в списке каталогов, разделенных запятыми.
/ A: цвет Отображение имен файлов в цвете (2 шестнадцатеричные цифры)
опции могут быть любой комбинацией следующих переключателей:
/ I Поиск без учета регистра.
/ S Искать в подпапках.
/ P Пропустить любой файл, содержащий непечатаемые символы
/ OFF [LINE] Не пропускать файлы с установленным атрибутом OffLine.
/ L Дословно использовать поисковые строки.
/ B Соответствует шаблону, если находится в начале строки./ E Соответствует шаблону, если он находится в КОНЦЕ строки.
/ X Печатать строки, которые точно совпадают.
/ V Печатать только строки, которые НЕ содержат совпадений.
/ N Вывести номер строки перед каждой совпадающей строкой.
/ M Печатать только имя файла, если файл содержит совпадение.
/ O Печатать смещение символа перед каждой совпадающей строкой. При использовании / G или / F текстовый файл должен быть простым текстовым файлом ANSI с одной строкой поиска или именем файла / путем в каждой строке.
Если поиск выполняется более чем в одном файле (/ F), к результатам будет добавлен префикс с именем файла, в котором был найден текст.
По умолчанию функция FINDSTR соответствует любому слову, поэтому FINDSTR "голубая планета" будет соответствовать слову синий или слову планета.
Чтобы сопоставить целую фразу / предложение или использовать регулярные выражения, используйте параметры / C и / R.
Синтаксис опции
Опции могут иметь префикс / или -
Параметры также могут быть объединены после одного / или -. Однако объединенный список параметров может содержать не более одного параметра с несколькими символами, например OFF или F :, а параметр с несколькими символами должен быть последним параметром в списке.Ниже приведены все эквивалентные способы выражения поиска с использованием регулярного выражения без учета регистра для любой строки, содержащей как «привет», так и «прощай» в любом порядке
FINDSTR / i / r /c:"hello.*goodbye "/c:"goodbye.*hello" Demo.txt
FINDSTR -i -r -c: "hello. * Goodbye" /c:"goodbye.*hello "Demo.txt
FINDSTR /irc:"hello.*goodbye "/c:"goodbye.*hello" Demo.txtИскать более двух элементов в любом порядке становится непрактично, так как вам потребуется каждая перестановка.Альтернативный подход - объединить несколько команд findstr в цепочку:
FINDSTR / ic: "hello" Demo.txt | findstr / ic: "до свидания"
Регулярные выражения (поиск шаблонов текста)
FINDSTR с параметром / R может использовать следующие метасимволы, которые имеют особое значение либо как оператор, либо как разделитель. Поддержка FINDSTR для регулярных выражений ограничена и нестандартные, поддерживаются только следующие метасимволы:
.class] Обратный класс: любой символ, не входящий в набор [x-y] Диапазон: любые символы в указанном диапазоне \ x Escape: буквальное использование метасимвола x \Позиция слова: конец слова Метасимволы наиболее эффективны, когда они используются вместе. Например, сочетание подстановочного знака (.) И символа повторения (*) действует аналогично подстановочному знаку имени файла (*.*)
. * Соответствует любой строке символовВыражение. * Может быть использовано в более крупном выражении для пример a. * b будет соответствовать любой строке, начинающейся с A и заканчивающейся на B.
FINDSTR не поддерживает чередование с вертикальной чертой (|). Несколько регулярных выражений могут быть разделены пробелами, точно так же, как разделение нескольких слов (при условии, что вы не указали буквальный поиск с помощью / C), но это может быть бесполезно, если Само регулярное выражение содержит пробелы.Снарк
$ соответствует любой позиции, непосредственно предшествующей
.. Это означает, что строка поиска регулярного выражения, содержащая $, никогда не будет соответствовать ни одной строке в текстовом файле в стиле Unix, а также не будет соответствовать последней строке текстового файла Windows, если в ней отсутствует маркер EOL .
Итак, чтобы найти snark в конце строки, используйте snark $Примечание. Как подробно описано ниже, переданный по конвейеру и перенаправленный ввод в FINDSTR может иметь добавленный
, которого нет в источнике.в начале и $ в конце строки поиска регулярного выражения. FINDSTR - Экраны и ограничения длины - Подробнее о том, как использовать строки поиска, содержащие кавычки и / или обратную косую черту. Кроме того, максимальная длина строки поиска зависит от версии ОС.
FINDSTR - поиск по разрывам строк
Диапазоны классов символов регулярного выражения [x-y]
Диапазоны классов символов не работают должным образом. См. Этот вопрос / ответ на Stack Exchange: Почему findstr не обрабатывает регистр должным образом (в некоторых случаях)?
Проблема в том, что FINDSTR не сопоставляет символы по их байтовому значению кода (обычно его называют кодом ASCII, но ASCII определяется только от 0x00 до 0x7F).[a-A] "будет соответствовать.
Тип поиска по умолчанию: литерал против регулярного выражения
/ C: "строка" - совпадение по умолчанию аналогично литералу / L, но также допускаются пробелы.
/ R / C: «Строка поиска» - выполняет сопоставление с регулярным выражением, но также принимает пробелы в строке поиска.
«строковый аргумент» - значение по умолчанию зависит от содержимого самой первой строки поиска. (Помните, что <пробел> используется для разграничения строк поиска.) Если первая строка поиска является допустимым регулярным выражением, содержащим хотя бы один неэкранированный метасимвол, тогда все строки поиска рассматриваются как регулярные выражения. В противном случае все строки поиска рассматриваются как литералы. Например, «51.4 200» будет рассматриваться как два регулярных выражения, потому что первая строка содержит неэкранированную точку, тогда как «200 51.4» будет рассматриваться как два литерала, поскольку первая строка не содержит никаких метасимволов.
/ G: file - значение по умолчанию зависит от содержимого первой непустой строки в файле.Если первая строка поиска является допустимым регулярным выражением, содержащим хотя бы один неэкранированный метасимвол, тогда все строки поиска рассматриваются как регулярные выражения. В противном случае все строки поиска рассматриваются как литералы.
Рекомендация- Всегда явно указывайте параметр литерала / L или параметр регулярного выражения / R при использовании «строкового аргумента» или / G: file.
В поисках места
При поиске строка содержит несколько слов, разделенных пробелы, то FINDSTR вернет строки, содержащие слово (ИЛИ).файл "Demo.txt
FINDSTR Выход
Формат вывода соответствующей строки из FINDSTR:
имя_файла : lineNumber : lineOffset : текст
где
fileName = Имя файла, содержащего соответствующую строку. Имя файла не печатается, если запрос был явно для одного файла или при поиске конвейерного ввода или перенаправленного ввода.При печати имя файла всегда будет включать любую предоставленную информацию о пути. Дополнительная информация о пути будет добавлена, если используется параметр / S. Печатный путь всегда относительно предоставленного пути или относительно текущего каталога, если он не указан.
lineNumber = Номер строки соответствующей строки, представленной в виде десятичного числа, где 1 представляет 1-ю строку ввода. Печатается, только если указана опция / N.
lineOffset = Десятичное смещение в байтах начала совпадающей строки, где 0 представляет 1-й символ 1-й строки.«ФАЙЛ> FILE_COPY
Использование файла сценария
С помощью файла сценария можно указать несколько критериев поиска / G
Несколько имен файлов для поиска можно указать с помощью / FПри подготовке файла источника или сценария поместите каждое имя файла или критерии поиска в новую строку.
Если необходимо найти несколько имен файлов, все они должны существовать, иначе FINDSTR завершится с ошибкой.Например: для использования критериев поиска в критериях.txt для поиска файлов, перечисленных в Files.txt:
FINDSTR /g:Criteria.txt /f:Files.txtТрубопровод и перенаправление
Текстовый файл можно передать по конвейеру или перенаправить в FINDSTR:
- Поток данных из канала TYPE file.txt | FINDSTR "searchString"
- Stdin через перенаправление FINDSTR "searchString"
Различные спецификации источников данных являются взаимоисключающими - FINDSTR может работать только с одним из следующих: аргумент (ы) имени файла, / F: параметр файла, перенаправленный ввод или ввод по конвейеру.
Переданный и перенаправленный ввод может иметь добавление
:
- Если ввод передается по конвейеру и последний символ потока не
, то FINDSTR автоматически добавит к вводу. (XP, Vista и Windows 7.) - Если ввод перенаправлен и последний символ файла не
, тогда FINDSTR автоматически добавит к вводу. (Только для Vista). Обратите внимание, что в этом случае XP и Windows 7/2008 будут , а не изменять перенаправленный ввод, что может привести к зависанию FINDSTR на неопределенное время. Поиск текста Unicode в PowerShell
При запуске FINDSTR в оболочке CMD его можно использовать для сопоставления строк Unicode, но выполнение аналогичной команды в PowerShell завершится ошибкой.
Это связано с тем, что выходные данные, передаваемые командлетом PowerShell в собственное приложение, по умолчанию будут иметь формат ASCII. Обычно это разумное значение по умолчанию, потому что большинство собственных команд некорректно обрабатывают Unicode.
Кодировка вывода командлетов PowerShell контролируется переменной $ OutputEncoding, если она установлена, то FINDSTR будет работать с текстом в Юникоде.
$ OutputEncoding = UnicodeEncoding
или же для соответствия кодировке консоли:
$ OutputEncoding = [Console] :: OutputEncodingУровень ошибки
FINDSTR установит% ERRORLEVEL% следующим образом:
0 Совпадение найдено хотя бы в одной строке хотя бы одного файла.
1 Если соответствие не найдено ни в одной строке ни одного файла (или если файл не найден вообще).
2 Неправильный синтаксис
Недопустимый переключатель будет печатать только сообщение об ошибке в потоке ошибок.0-9] "
Если% ERRORLEVEL% EQU 0 echo Строка содержит один или несколько нечисловых символовОшибки
Если последний символ файла, используемого в качестве перенаправленного ввода, не заканчивается на
, то FINDSTR будет зависать на неопределенное время, когда достигнет конца перенаправленного файла. FINDSTR не может искать нулевые байты, обычно встречающиеся в файлах Unicode.
Указание нескольких буквальных строк поиска может дать ненадежные результаты.Следующий пример FINDSTR не может найти совпадение, хотя должен:
echo ffffaaa | findstr / l "ffffaaa faffaffddd"На основе экспериментов FINDSTR может завершиться неудачно, если выполнены все следующие условия:
- При поиске используется несколько буквальных строк поиска
- Строки поиска разной длины
- Короткая строка поиска частично перекрывается с более длинной строкой поиска
- При поиске учитывается регистр (опция / I)
Кажется, что всегда оказываются более короткие строки поиска, которые терпят неудачу, для получения дополнительной информации см. FINDSTR не соответствует нескольким буквальным строкам поиска
В ранних версиях FindStr / F: путь к файлу длиной более 80 символов будет усечен.
Примеры:
Найдите "бабушка" ИЛИ "Смит" в файлах Apples.txt или Pears.txt
FINDSTR "бабушка Смит" Apples.txt Pears.txt
Найдите "бабушка Смит" в файле Contacts.txt (фактически то же самое, что и команда НАЙТИ)
FINDSTR / C: "granny Smith" Contacts.txt
Искать в каждом файле в текущей папке и во всех подпапках слово "Smith", независимо от верхнего / нижнего регистра, обратите внимание, что / S будет искать только ниже текущего каталог:
FINDSTR / s / i smith *.$ "Z: \ source.txt> Z: \ result.txtЧтобы найти каждую строку в файле романа.txt, содержащую слово СМИТ, которому предшествует любое количество пробелов, и для префикса каждой найденной строки последовательным номером:
FINDSTR / b / n / c: "* smith" Roman.txtПоиск строки, только если она окружена стандартными разделителями
Найдите слово «компьютер», но не слова «суперкомпьютер». или "компьютеризировать":
FINDSTR "\ <компьютер \>" C: \ work \ inventory.txtНайти любые слова, начинающиеся с букв "comp", например "компьютеризовать" или «соревнуйтесь»
FINDSTR "\
Кредиты:
Дэйв Бенхэм - Список недокументированных функций и ограничений FINDSTR из StackOverflow«Через двадцать лет вы будете больше разочарованы тем, чего не делали, а не тем, что сделали. Так что сбросьте боулинги, отплывите от безопасной гавани. Поймай быка за гора. Проводить исследования. Мечтать. Откройте для себя »~ Марк Твен
Связанные команды:
FINDSTR - переходы и ограничения длины
FINDSTR - поиск по разрывам строк
FIND - поиск текстовой строки в файле.
VBScript: найти и заменить
Powershell: регулярные выражения
Powershell: Where-Object - фильтрует объекты, переданные по конвейеру.
Эквивалентная команда bash (Linux): grep - Поиск в файле (файлах) строк, соответствующих заданному шаблону.
Авторские права © 1999-2021 SS64.com
Некоторые права защищены14 Strings | R для науки о данных
Введение
Эта глава знакомит вас с манипуляциями со строками в R.Вы узнаете основы того, как работают строки и как создавать их вручную, но в этой главе основное внимание будет уделено регулярным выражениям или, для краткости, регулярным выражениям. Регулярные выражения полезны, потому что строки обычно содержат неструктурированные или частично структурированные данные, а регулярные выражения - это краткий язык для описания шаблонов в строках. Когда вы впервые посмотрите на регулярное выражение, вы подумаете, что кошка шла по клавиатуре, но по мере того, как ваше понимание улучшится, они скоро начнут обретать смысл.
Предпосылки
В этой главе основное внимание уделяется пакету stringr для манипуляций со строками, который является частью основного тидиверса.
Основы работы со струнами
Вы можете создавать строки как в одинарных, так и в двойных кавычках. В отличие от других языков, нет никакой разницы в поведении. Я рекомендую всегда использовать
", если вы не хотите создать строку, содержащую несколько".string1 <- "Это строка" string2 <- 'Если я хочу включить «кавычку» внутри строки, я использую одинарные кавычки »Если вы забудете закрыть цитату, вы увидите
+, символ продолжения:> "Это строка без закрывающей кавычки. + + + ПОМОГИТЕ Я застрялЕсли это случилось с вами, нажмите Escape и попробуйте еще раз!
Чтобы включить буквальную одинарную или двойную кавычку в строку, вы можете использовать
\, чтобы «экранировать» ее:double_quote <- "\" "# или '"' single_quote <- '\' '# или "'"Это означает, что если вы хотите включить буквальную обратную косую черту, вам нужно будет удвоить ее:
"\\".Помните, что напечатанное представление строки не совпадает с самой строкой, потому что напечатанное представление показывает escape-последовательности. Чтобы увидеть необработанное содержимое строки, используйте
writeLines ():x <- c ("\" "," \\ ") Икс #> [1] "\" "" \\ " writeLines (x) #> " #> \Есть несколько других специальных символов. Наиболее распространенными являются
"\ n", новая строка и"\ t", вкладка, но вы можете увидеть полный список, запросив помощь по телефону":? '"'или? "' «.Иногда встречаются строки вроде"\ u00b5", это способ написания неанглийских символов, который работает на всех платформах:x <- "\ u00b5" Икс #> [1] «µ»Несколько строк часто хранятся в векторе символов, который можно создать с помощью
c ():с («один», «два», «три») #> [1] "один" "два" "три"Длина струны
Base R содержит множество функций для работы со строками, но мы будем избегать их, потому что они могут быть несовместимыми, что затрудняет их запоминание.Вместо этого мы будем использовать функции из stringr. У них более интуитивно понятные названия, и все они начинаются с
str_. Например,str_length ()сообщает вам количество символов в строке:str_length (c ("a", "R для науки о данных", NA)) #> [1] 1 18 NAОбщий префикс
str_особенно полезен, если вы используете RStudio, потому что вводstr_вызовет автозаполнение, что позволит вам увидеть все функции Stringr:Объединение струн
Для объединения двух или более строк используйте
str_c ():str_c ("x", "y") #> [1] "ху" str_c ("x", "y", "z") #> [1] "xyz"Используйте аргумент
sep, чтобы контролировать, как они разделяются:str_c ("x", "y", sep = ",") #> [1] "x, y"Как и в большинстве других функций в R, пропущенные значения заразительны.Если вы хотите, чтобы они печатались как
.«NA», используйтеstr_replace_na ():x <- c ("abc", нет данных) str_c ("| -", x, "- |") #> [1] "| -abc- |" NA str_c ("| -", str_replace_na (x), "- |") #> [1] "| -abc- |" "| -NA- |"Как показано выше,
str_c ()векторизован и автоматически перерабатывает более короткие векторы до той же длины, что и самый длинный:str_c ("префикс-", c ("a", "b", "c"), "-suffix") #> [1] «префикс-а-суффикс» «префикс-b-суффикс» «префикс-с-суффикс»Объекты длины 0 отбрасываются без уведомления.Это особенно полезно в сочетании с
, если:имя <- "Хэдли" time_of_day <- "утро" день рождения <- ЛОЖЬ str_c ( "Хорошо", время_дня, "", имя, if (день рождения) "и С ДНЕМ РОЖДЕНИЯ", "." ) #> [1] "Доброе утро, Хэдли".Чтобы свернуть вектор строк в одну строку, используйте
collapse:str_c (c ("x", "y", "z"), collapse = ",") #> [1] "x, y, z"Подмножество строк
Вы можете извлечь части строки с помощью
str_sub ().Помимо строки,str_sub ()принимает аргументыstartиend, которые задают (включительно) позицию подстроки:x <- c («Яблоко», «Банан», «Груша») str_sub (х, 1, 3) #> [1] "App" "Ban" "Pea" # отрицательные числа считают в обратном порядке от конца str_sub (х, -3, -1) #> [1] "ple" "ana" "ear"Обратите внимание, что
str_sub ()не завершится ошибкой, если строка слишком короткая: она просто вернет столько, сколько возможно:str_sub ("а", 1, 5) #> [1] "a"Вы также можете использовать форму назначения
str_sub ()для изменения строк:str_sub (x, 1, 1) <- str_to_lower (str_sub (x, 1, 1)) Икс #> [1] «яблоко» «банан» «груша»Регион
Выше я использовал
str_to_lower (), чтобы изменить текст на нижний регистр.Вы также можете использоватьstr_to_upper ()илиstr_to_title (). Однако изменить регистр сложнее, чем может показаться на первый взгляд, потому что разные языки имеют разные правила изменения регистра. Вы можете выбрать, какой набор правил использовать, указав локаль:# Турецкий имеет два i: с точкой и без точки, и это # имеет другое правило использования заглавных букв: str_to_upper (c ("я", "ı")) #> [1] «Я» «Я» str_to_upper (c ("i", "ı"), locale = "tr") #> [1] "İ" "I"Локаль указывается в виде кода языка ISO 639, который представляет собой двух- или трехбуквенное сокращение.Если вы еще не знаете код своего языка, в Википедии есть хороший список. Если вы оставите языковой стандарт пустым, он будет использовать текущий языковой стандарт, предоставленный вашей операционной системой.
Еще одна важная операция, на которую влияет локаль, - это сортировка. Базовые функции order () и
sort ()в Rсортируют строки, используя текущую локаль. Если вам нужна надежная работа на разных компьютерах, вы можете использоватьstr_sort ()иstr_order (), которые принимают дополнительный аргументlocale:x <- c («яблоко», «баклажан», «банан») str_sort (x, locale = "en") # английский #> [1] "яблоко" "банан" "баклажан" str_sort (x, locale = "haw") # гавайский #> [1] "яблоко" "баклажан" "банан"Упражнения
В коде, который не использует stringr, вы часто встретите
paste ()иpaste0 ().В чем разница между двумя функциями? Какие функции Stringr они эквивалентны? Чем отличаются функции по обработкеNA?Опишите своими словами разницу между
sepиcollapseаргументы дляstr_c ().Используйте
str_length ()иstr_sub ()для извлечения среднего символа из строка. Что вы будете делать, если в строке будет четное количество символов?Что делает
str_wrap ()? Когда вы можете захотеть его использовать?Что делает
str_trim ()? Что противоположноstr_trim ()?Напишите функцию, которая поворачивает (например,g.) вектор
c ("a", "b", "c")в строкаa, b и c. Тщательно подумайте, что ему делать, если задан вектор длиной 0, 1 или 2.Сопоставление шаблонов с регулярными выражениями
Регулярные выражения - очень сжатый язык, который позволяет описывать шаблоны в строках. На их понимание уходит время, но как только вы их поймете, вы найдете их чрезвычайно полезными.
Для изучения регулярных выражений мы будем использовать
str_view ()иstr_view_all ().Эти функции принимают вектор символов и регулярное выражение и показывают, как они совпадают. Мы начнем с очень простых регулярных выражений, а затем постепенно будем усложнять их. Освоив сопоставление с образцом, вы научитесь применять эти идеи с различными строковыми функциями.Основные матчи
Самые простые шаблоны соответствуют точным строкам:
x <- c («яблоко», «банан», «груша») str_view (x, "an")Следующая ступень сложности -
., что соответствует любому символу (кроме новой строки):Но если «
.»соответствует любому символу, как сопоставить символ«.”? Вам нужно использовать «escape», чтобы указать регулярному выражению, которое вы хотите точно ему сопоставить, а не использовать его особое поведение. Подобно строкам, регулярные выражения используют обратную косую черту,\, чтобы избежать особого поведения. Таким образом, чтобы соответствовать., вам нужно регулярное выражение\.. К сожалению, это создает проблему. Мы используем строки для представления регулярных выражений, а\также используется как escape-символ в строках.Итак, чтобы создать регулярное выражение\.нам нужна строка"\\.".# Для создания регулярного выражения нам понадобится \\ точка <- "\\." # Но само выражение содержит только одно: writeLines (точка) #> \. # И это говорит R искать явное. str_view (c ("abc", "a.c", "bef"), "a \\. c")Если
\используется как escape-символ в регулярных выражениях, как вы сопоставите литерал\? Что ж, вам нужно избежать этого, создав регулярное выражение\.Чтобы создать это регулярное выражение, вам нужно использовать строку, которая также должна экранировать\. Это означает, что для сопоставления букв\вам нужно написать"\\\\"- вам нужно четыре обратной косой черты, чтобы соответствовать одному!х <- "а \\ б" writeLines (x) #> a \ b str_view (x, "\\\\")В этой книге я буду писать регулярное выражение как
\.и строки, представляющие регулярное выражение как"\\.".Упражнения
Объясните, почему каждая из этих строк не соответствует
\:"\","\\","\\\".Как бы вы соответствовали последовательности
"'\?Каким шаблонам будет соответствовать регулярное выражение
\ .. \ .. \ ..? Как бы вы представили его в виде строки?Якоря
По умолчанию регулярные выражения соответствуют любой части строки. и
-.Вы можете использовать чередование , чтобы выбрать один или несколько альтернативных шаблонов. Например,
abc | d..fбудет соответствовать либо «abc», либо«глухой». Обратите внимание, что приоритет для|является низким, поэтомуabc | xyzсоответствуетabcилиxyz, а неabcyzилиabxyz. Как и в случае с математическими выражениями, если приоритеты когда-либо сбиваются с толку, используйте круглые скобки, чтобы прояснить, что вы хотите:str_view (c ("серый", "серый"), "gr (e | a) y")Упражнения
Создайте регулярные выражения, чтобы найти все слова, которые:
Начните с гласной.
Это только согласные. (Подсказка: подумайте о сопоставлении «Не» - гласные.)
Заканчивается на
ed, но не наeed.Заканчивается на
ingилиise.Эмпирически проверьте правило «i до e, кроме c».
Всегда ли за «q» следует «u»?
Напишите регулярное выражение, которое соответствует слову, если оно, вероятно, написано на британском, а не на американском английском.
Создайте регулярное выражение, которое будет соответствовать телефонным номерам, как обычно написано в вашей стране.
Повтор
Следующий шаг в развитии - это контроль количества совпадений шаблона:
?: 0 или 1+: 1 или более*: 0 или болееx <- "1888 год - самый длинный год в римских цифрах: MDCCCLXXXVIII" str_view (x, "CC?")Обратите внимание, что приоритет этих операторов высок, поэтому вы можете написать:
colou? Rдля соответствия американскому или британскому написанию.Это означает, что в большинстве случаев требуются круглые скобки, напримерbana (na) +.Также можно точно указать количество совпадений:
{n}: ровно n{n,}: n или более- м
{, m}: не более{n, m}: между n и mПо умолчанию эти совпадения являются «жадными»: они будут соответствовать самой длинной возможной строке. Вы можете сделать их «ленивыми», сопоставив самую короткую строку, указав
?после них.* $"\\ {. + \\}"\ d {4} - \ d {2} - \ d {2}"\\\\ {4}"Создайте регулярные выражения, чтобы найти все слова, которые:
- Начните с трех согласных.
- Имеются три или более гласных подряд.
- Имеются две или более пары гласный-согласный подряд.
Решите кроссворды с регулярными выражениями для начинающих на https://regexcrossword.com/challenges/beginner.
Группировка и обратные ссылки
Ранее вы узнали о скобках как о способе устранения неоднозначности сложных выражений. Круглые скобки также создают группу захвата с номером (номер 1, 2 и т. Д.). Группа захвата хранит часть строки , совпадающую с частью регулярного выражения в круглых скобках. Вы можете ссылаться на тот же текст, который ранее соответствовал группе захвата с обратными ссылками , например
\ 1,\ 2и т. Д.Например, следующее регулярное выражение находит все фрукты с повторяющейся парой букв.str_view (fruit, "(..) \\ 1", match = TRUE)(Вскоре вы также увидите, насколько они полезны в сочетании с
str_match ().)Упражнения
Опишите словами, чему будут соответствовать эти выражения:
(.) \ 1 \ 1"(.) (.) \\ 2 \\ 1"(..) \ 1"(.). \\ 1. \\ 1""(.) (.) (.). * \\ 3 \\ 2 \\ 1"Создавать регулярные выражения для поиска слов, которые:
Начало и конец одного и того же символа.
Содержит повторяющуюся пару букв (например, «церковь» содержит дважды повторяемую букву «ч».)
Содержит одну букву, повторяющуюся не менее чем в трех местах (например, «одиннадцать» содержит три буквы «е».)
Инструменты
Теперь, когда вы изучили основы регулярных выражений, пора научиться применять их к реальным задачам.В этом разделе вы познакомитесь с широким спектром строковых функций, которые позволят вам:
- Определите, какие строки соответствуют шаблону.
- Найдите позиции совпадений.
- Извлечь содержимое совпадений.
- Заменить совпадения новыми значениями.
- Разделить строку на основе совпадения.
Перед тем, как мы продолжим, сделаем небольшое предостережение: поскольку регулярные выражения настолько эффективны, легко попытаться решить любую проблему с помощью одного регулярного выражения.\ [\] \ r \\] | \\.) * \] (?: (?: \ r \ n)? [\ t]) *)) * \> (? 🙁 ?: \ r \ n)? [\ t]) *)) *)?; \ s *)
Это несколько патологический пример (потому что адреса электронной почты на самом деле удивительно сложны), но он используется в реальном коде. Подробнее см. Обсуждение stackoverflow на http://stackoverflow.com/a/201378.
Не забывайте, что вы изучаете язык программирования и в вашем распоряжении есть другие инструменты. Вместо создания одного сложного регулярного выражения часто проще написать серию более простых регулярных выражений.Если вы застряли, пытаясь создать одно регулярное выражение, которое решает вашу проблему, сделайте шаг назад и подумайте, можно ли разбить проблему на более мелкие части, решая каждую задачу, прежде чем переходить к следующей. aeiou] + $») идентичные (no_vowels_1, no_vowels_2) #> [1] ИСТИНА
Результаты идентичны, но я думаю, что первый подход значительно легче понять.Если ваше регулярное выражение становится слишком сложным, попробуйте разбить его на более мелкие части, дать каждой части имя, а затем объединить части с помощью логических операций.
Обычно
str_detect ()используется для выбора элементов, соответствующих шаблону. Вы можете сделать это с помощью логического подмножества или удобной оболочкиstr_subset ():слов [str_detect (words, "x $")] #> [1] "коробка" "секс" "шестерка" "налог" str_subset (слова, "x $") #> [1] «коробка» «пол» «шестерка» «налог»Однако, как правило, ваши строки представляют собой один столбец фрейма данных, и вместо этого вы хотите использовать фильтр:
df <- tibble ( слово = слова, я = seq_along (слово) ) df%>% фильтр (str_detect (слово, "x $")) #> # Стол: 4 x 2 #> слово i #>#> 1 коробка 108 #> 2 пол 747 #> 3 шесть 772 #> 4 налог 841 Вариант
str_detect ()-str_count (): вместо простого да или нет он сообщает вам, сколько совпадений в строке:x <- c («яблоко», «банан», «груша») str_count (x, «а») #> [1] 1 3 1 # Сколько в среднем гласных в слове? означает (str_count (слова, "[aeiou]")) #> [1] 1.aeiou] ") ) #> # Стол: 980 x 4 #> слово i гласные согласные #>#> 1 а 1 1 0 #> 2 в состоянии 2 2 2 #> 3 примерно 3 3 2 #> 4 абсолютное 4 4 4 #> 5 принять 5 2 4 #> 6 счет 6 3 4 #> #… С еще 974 строками Обратите внимание, что совпадения никогда не перекрываются. Например, в
«abababa»сколько раз будет совпадать шаблон«aba»? Регулярные выражения говорят два, а не три:str_count ("abababa", "aba") #> [1] 2 str_view_all ("abababa", "aba")Обратите внимание на использование
str_view_all ().Как вы вскоре узнаете, многие строковые функции работают парами: одна функция работает с одним совпадением, а другая - со всеми совпадениями. Вторая функция будет иметь суффикс_all.Упражнения
Для каждой из следующих задач попробуйте решить ее, используя как одну регулярное выражение и комбинация нескольких вызовов
str_detect ().
Найдите все слова, которые начинаются или заканчиваются на
x.Найдите все слова, которые начинаются с гласной и заканчиваются согласной.
Существуют ли слова, содержащие хотя бы одно из разных гласная буква?
В каком слове больше всего гласных? Какое слово имеет высшее пропорция гласных? (Подсказка: какой знаменатель?)
Групповые матчи
Ранее в этой главе мы говорили об использовании круглых скобок для уточнения приоритета и для обратных ссылок при сопоставлении.] +) " has_noun <- предложения%>% str_subset (имя существительное)%>% голова (10) has_noun%>% str_extract (имя существительное) #> [1] "гладкая" "простыня" "глубина" "курица" "припаркованная" #> [6] "солнышко" "огромный" "мяч" "женщина" "помогает"
str_extract ()дает нам полное совпадение;str_match ()дает каждый отдельный компонент. Вместо вектора символов он возвращает матрицу с одним столбцом для полного соответствия, за которым следует один столбец для каждой группы:has_noun%>% str_match (имя существительное) #> [, 1] [, 2] [, 3] #> [1,] "гладкий" "" "гладкий" #> [2,] "лист" "" "лист" #> [3,] "глубина" "" "глубина" #> [4,] "курица" "a" "курица" #> [5,] "припаркованный" "" "припаркованный" #> [6,] "солнце" "" "солнце" #> [7,] "огромный" "" "огромный" #> [8,] "мяч" "" "мяч" #> [9,] "женщина" "" женщина " #> [10,] «а помогает» «а» «помогает»(Неудивительно, что наша эвристика для определения существительных оставляет желать лучшего, и мы также подбираем такие прилагательные, как гладкий и припаркованный.] +) ", remove = FALSE ) #> # Таблица: 720 x 3 #> предложение статья существительное #>
#> 1 Березовое каноэ скользило по гладким доскам. гладкий #> 2 Приклейте лист к темно-синему фону. Лист #> 3 Глубину колодца определить легко. глубина #> 4 В наши дни куриная ножка - редкое блюдо. курица #> 5 Рис часто подают в круглых мисках. #> 6 Из лимонного сока получается прекрасный пунш. #> #… С еще 714 строками Как и
str_extract (), если вам нужны все совпадения для каждой строки, вам понадобитсяstr_match_all ().Упражнения
Найдите все слова, которые идут после «числа», например «один», «два», «три» и т. Д. Вытяните и число, и слово.
Найдите все схватки.Разделите части до и после апостроф.
Замена спичек
str_replace ()иstr_replace_all ()позволяют заменять совпадения новыми строками. Самый простой способ - заменить шаблон фиксированной строкой:x <- c («яблоко», «груша», «банан») str_replace (x, «[aeiou]», «-») #> [1] "-pple" "p-ar" "b-nana" str_replace_all (x, «[aeiou]», «-») #> [1] "-ppl-" "p - r" "b-n-n-"С помощью
str_replace_all ()вы можете выполнить несколько замен, указав именованный вектор:x <- c («1 дом», «2 машины», «3 человека») str_replace_all (x, c ("1" = "один", "2" = "два", "3" = "три")) #> [1] "один дом" "две машины" "три человека"Вместо замены на фиксированную строку вы можете использовать обратные ссылки для вставки компонентов соответствия.] +) "," \\ 1 \\ 3 \\ 2 ")%>% голова (5) #> [1] «Каноэ-береза скользила по гладким доскам». #> [2] "Приклейте лист к темно-синему фону". #> [3] «Глубину колодца легко определить». #> [4] «В наши дни куриная ножка - редкое блюдо». #> [5] «Рис часто подают в круглых мисках».
Упражнения
Заменить все косые черты в строке обратными.
Реализуйте простую версию
str_to_lower (), используяreplace_all ().Переключение первых и последних букв в
словах. Какая из этих струн еще слова?Расщепление
Используйте
str_split (), чтобы разбить строку на части. Например, мы можем разбить предложения на слова:предложения%>% голова (5)%>% str_split ("") #> [[1]] #> [1] "" березовая "каноэ" скользнула "" по "" "гладью" #> [8] "доски". #> #> [[2]] #> [1] "Приклейте" "" лист "" к "" " #> [6] "темный" "синий" "фон." #> #> [[3]] #> [1] «Легко» «сказать» «о« глубине »» «колодца». #> #> [[4]] #> [1] "В эти" "дни" "" "курица" "нога" "" "" а " #> [8] «редкое» «блюдо». #> #> [[5]] #> [1] "Рис" "часто" подается "в" круглых "мисках."Поскольку каждый компонент может содержать разное количество частей, возвращается список. Если вы работаете с вектором длины 1, проще всего просто извлечь первый элемент списка:
"a | b | c | d"%>% str_split ("\\ |")%>% .[[1]] #> [1] "a" "b" "c" "d"В противном случае, как и другие строковые функции, возвращающие список, вы можете использовать
simpleify = TRUEдля возврата матрицы:предложения%>% голова (5)%>% str_split ("", simpleify = ИСТИНА) #> [, 1] [, 2] [, 3] [, 4] [, 5] [, 6] [, 7] [, 8] #> [1,] "" березовое "каноэ" скользило "" по "" гладким "доскам". #> [2,] "Приклейте" "" лист "" к "" "" темному "" синему "" фону." #> [3,] "" легко "" "сказать" "" глубину "" "" а " #> [4,] "В эти" "дни" "" "курица" "нога" "" "а" "редко" #> [5,] "Рис" "часто" подается "в" круглых "мисках." "" #> [, 9] #> [1,] "" #> [2,] "" #> [3,] "хорошо". #> [4,] "блюдо". #> [5,] ""Вы также можете запросить максимальное количество штук:
поля <- c ("Имя: Хэдли", "Страна: Новая Зеландия", "Возраст: 35") поля%>% str_split (":", n = 2, simpleify = TRUE) #> [, 1] [, 2] #> [1,] "Имя" "Хэдли" #> [2,] "Country" "NZ" #> [3,] "Возраст" "35"Вместо разделения строк по шаблонам вы также можете разделить их по символам, строкам, предложениям и словам.