HTML Кодировки
Чтобы правильно отобразить html-документ, браузер должен знать какая кодировка символов использовалась при создании документа.
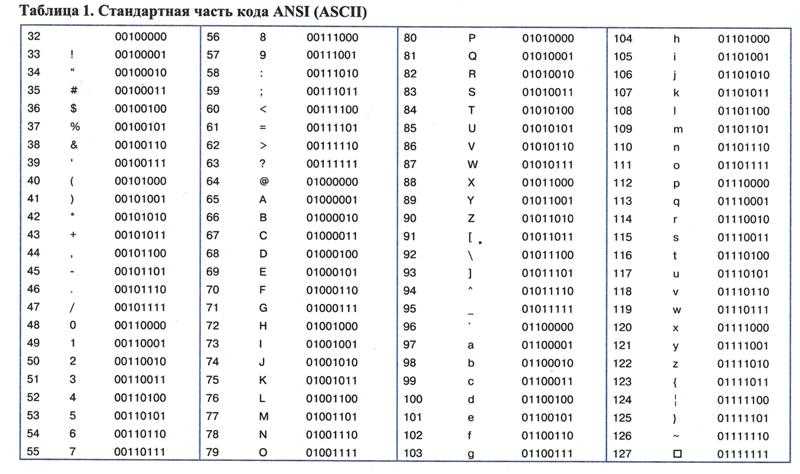
ASCII — одна из самых старых компьютерных кодировок, в которой каждому символу соответствует строго определенное число. Например, символу «a» соответствует число 97, а символу «A» — число 65.
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
ASCII — это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
Вы можете посмотреть на полный комплект Печатаемых символов ASCII.
Позже ASCII была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в кодировку ASCII символы национальных языков разных стран, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8 (Код Обмена Информацией, 8 бит) — это тоже расширенная кодировка ASCII. KOI8 включала в себя цифры, буквы латинского и русского алфавита, а также знаки пунктуации, спецсимволы и псевдографику.
Кодировка ISO
Организация Международных стандартов (International Standards Organization) создала диапазон кодировок для различных алфавитов/языков.
| Кодировка | Описание |
|---|---|
| ISO 8859-1 (Latin-1) | Расширенная латиница, включающая символы большинства западноевропейских языков (английский, датский, ирландский, исландский, испанский, итальянский, немецкий, норвежский, португальский, ретороманский, фарерский, шведский, шотландский (гэльский) и частично голландский, финский, французский), а также некоторых восточноевропейских (албанский) и африканских языков (африкаанс, суахили). В Latin-1 отсутствуют знак евро и заглавная буква Ÿ. Эта кодовая страница считается кодировкой по умолчанию для HTML-документов и сообщений электронной почты. Также этой кодовой странице соответствуют первые 256 символов Юникода. В Latin-1 отсутствуют знак евро и заглавная буква Ÿ. Эта кодовая страница считается кодировкой по умолчанию для HTML-документов и сообщений электронной почты. Также этой кодовой странице соответствуют первые 256 символов Юникода. |
| ISO 8859-2 (Latin-2) | Расширенная латиница, включающая символы центральноевропейских и восточноевропейских языков (боснийский, венгерский, польский, словацкий, словенский, хорватский, чешский). В Latin-2, как и в Latin-1, отсутствуют знак евро. |
| ISO 8859-3 (Latin-3) | Расширенная латиница, включающая символы южноевропейских языков (мальтийский, турецкий и эсперанто). |
| ISO 8859-4 (Latin-4) | Расширенная латиница, включающая символы североевропейских языков (гренландский, эстонский, латышский, литовский и саамские языки). |
| ISO 8859-5 (Latin/Cyrillic) | Кириллица, включающая символы славянских языков (белорусский, болгарский, македонский, русский, сербский и частично украинский). |
| ISO 8859-6 (Latin/Arabic) | Символы, используемые в арабском языке. Символы других языков с письмом на основе арабского не поддерживаются. Для корректного отображения текста в кодировке ISO 8859-6 требуется поддержка двунаправленного письма и контекстно-зависимых форм символов. |
| ISO 8859-7 (Latin/Greek) | Символы современного греческого языка. Может использоваться также для записи древнегреческих текстов в монотонической орфографии. |
| ISO 8859-8 (Latin/Hebrew) | Символы современного иврита. Используется в двух вариантах: с логическим порядком следования символов (требует поддержки двунаправленного письма) и с визуальным порядком следования символов. |
| ISO 8859-9 (Latin-5) | Вариант Latin-1, в котором редко используемые символы исландского языка заменены на турецкие. Используется для турецкого и курдского языков. |
| ISO 8859-10 (Latin-6) | Вариант Latin-4, более удобный для скандинавских языков. |
| ISO 8859-11 (Latin/Thai) | Символы тайского языка. |
| ISO 8859-13 (Latin-7) | |
| ISO 8859-14 (Latin-8) | Расширенная латиница, включающая символы кельтских языков, таких как шотландский (гэльский) и бретонский. |
| ISO 8859-15 (Latin-9) | Вариант Latin-1, в котором редко используемые символы заменены на необходимые для полной поддержки финского, французского и эстонского языков. Кроме того, в Latin-9 был добавлен знак евро. |
| ISO 8859-16 (Latin-10) | Расширенная латиница, включающая символы южноевропейских и восточноевропейских (албанский, венгерский, итальянский, польский, румынский, словенский, хорватский), а также некоторых западноевропейских языков (ирландский в новой орфографии, немецкий, финский, французский). Как и в Latin-9, в Latin-10 был добавлен знак евро. |
Для документов на английском и большинстве других западноевропейских языков, широко поддерживается кодирование ISO-8859-1.
Таблица кодов символов ISO-8859-1
В HTML ISO-8859-1 является кодировкой по умолчанию (в XHTML и в HTML5 кодировкой по умолчанию является UTF-8).
При использовании кодировки страницы, отличной от ISO-8859-1, вам необходимо указать это в теге <meta>.
Для HTML4:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1">
Для HTML5:
<meta charset="UTF-8">
Примером ANSI-кодировки является всем известная Windows-1251.
Windows-1251 выгодно отличается от других 8 битных кириллических кодировок (таких как CP866 и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только знак ударения). Она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Ниже приведены десятичные значения символов кодировки Windows-1251.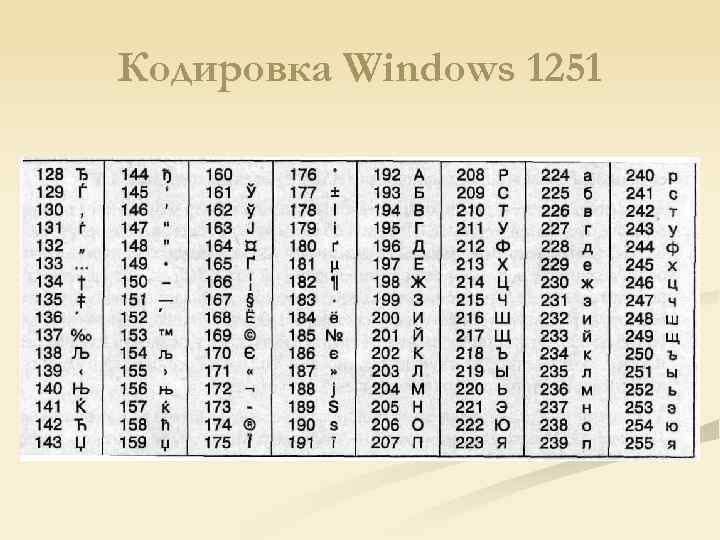
Для отображения символов таблицы в HTML-документе воспользуйтесь следующим синтаксисом:
&# + код + ;
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ђ 402 | Ѓ 403 | ‚ 201A | ѓ 453 | „ 201E | … 2026 | † 2020 | ‡ 2021 | € 20AC | ‰ 2030 | Љ 409 | ‹ 2039 | Њ 40A | Ќ 40C | Ћ 40B | Џ 40F |
| 9.  | ђ 452 | ‘ 2018 | ’ 2019 | “ 201C | ” 201D | • 2022 | – 2013 | — 2014 | ™ 2122 | љ 459 | › 203A | њ 45A | ќ 45C | ћ 45B | џ 45F | |
| A. | A0 | Ў 40E | ў 45E | Ј 408 | ¤ A4 | Ґ 490 | ¦ A6 | § A7 | Ё 401 | © A9 | Є 404 | « AB | ¬ AC | AD | ® AE | Ї 407 |
| B.  | ° B0 | ± B1 | І 406 | і 456 | ґ 491 | µ B5 | ¶ B6 | · B7 | ё 451 | № 2116 | є 454 | » BB | ј 458 | Ѕ 405 | ѕ 455 | ї 457 |
| C. | А 410 | Б 411 | В 412 | Г 413 | Д 414 | Е 415 | Ж 416 | З 417 | И 418 | Й 419 | К 41A | Л 41B | М 41C | Н 41D | О 41E | П 41F |
| D.  | Р 420 | С 421 | Т 422 | У 423 | Ф 424 | Х 425 | Ц 426 | Ч 427 | Ш 428 | Щ 429 | Ъ 42A | Ы 42B | Ь 42C | Э 42D | Ю 42E | Я 42F |
| E. | а 430 | б 431 | в 432 | г 433 | д 434 | е 435 | ж 436 | з 437 | и 438 | й 439 | к 43A | л 43B | м 43C | н 43D | о 43E | п 43F |
| F.  | р 440 | с 441 | т 442 | у 443 | ф 444 | х 445 | ц 446 | ч 447 | ш 448 | щ 449 | ъ 44A | ы 44B | ь 44C | э 44D | ю 44E | я 44F |
Таблица кодов символов Windows-1251
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).
Unicode transformation format — UTF).
UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
Таблица кодов символов UTF-8 кирилица
Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста.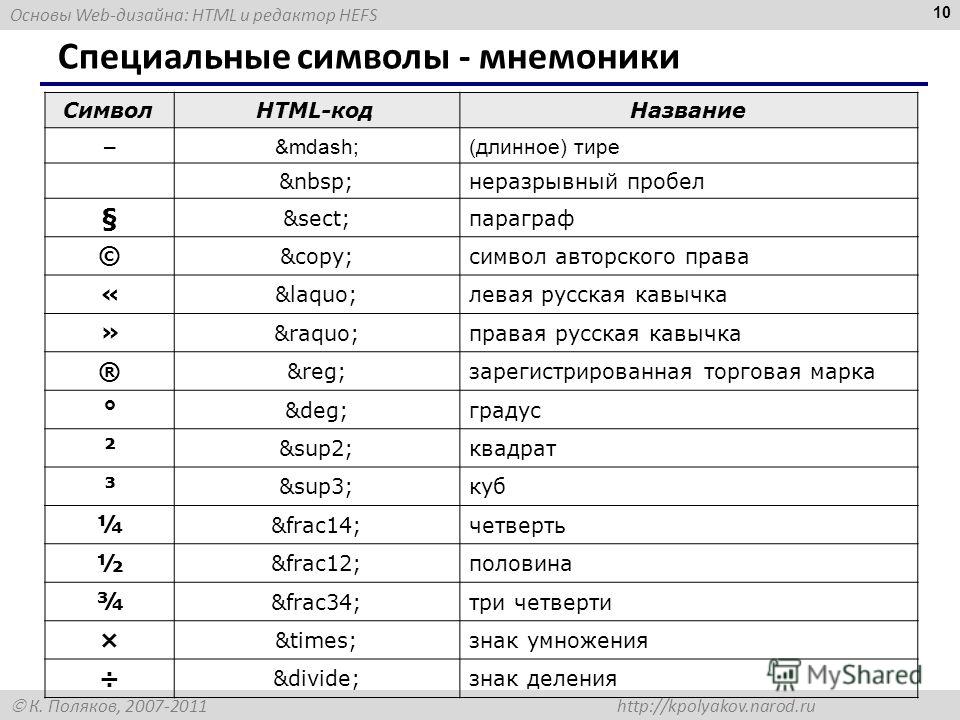 Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
-
Общие сведения о кодировке текста
-
Выбор кодировки при открытии файла
-
Выбор кодировки при сохранении файла
-
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
К началу страницы
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
-
Откройте вкладку Файл.
-
Нажмите кнопку Параметры.
-
Нажмите кнопку Дополнительно.

-
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
-
Закройте, а затем снова откройте файл.
-
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
-
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.


Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
-
Нажмите кнопку Пуск и выберите пункт Панель управления.
-
На панели управления выберите раздел Удаление программы.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
-
На панели управления щелкните элемент Установка и удаление программ.
-
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
-
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
-
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
-
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
 org/ListItem»>
org/ListItem»>
Выполните одно из указанных ниже действий.
В Windows 7
В Windows Vista
 org/ListItem»>
org/ListItem»>
На панели управления выберите раздел Удаление программы.
В Windows XP

Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
(Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
К началу страницы
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
-
Откройте вкладку Файл.
-
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
-
В поле Имя файла введите имя нового файла.
-
В поле Тип файла выберите Обычный текст.
-
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
-
В диалоговом окне Преобразование файла выберите подходящую кодировку.
-
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
-
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
-
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
-
-
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке.
Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
-
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
 org/ListItem»>
org/ListItem»>
Нажмите кнопку Сохранить.
 Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.К началу страницы
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
|
Система письменности |
Кодировки |
Используемый шрифт |
|---|---|---|
|
Многоязычная |
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7) |
Стандартный шрифт для стиля «Обычный» локализованной версии Word |
|
Арабская |
Windows 1256, ASMO 708 |
Courier New |
|
Китайская (упрощенное письмо) |
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ |
SimSun |
|
Китайская (традиционное письмо) |
BIG5, EUC-TW, ISO-2022-TW |
MingLiU |
|
Кириллица |
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866 |
Courier New |
|
Английская, западноевропейская и другие, основанные на латинице |
Windows 1250, 1252-1254, 1257, ISO8859-x |
Courier New |
|
Греческая |
Windows 1253 |
Courier New |
|
Иврит |
Windows 1255 |
Courier New |
|
Японская |
Shift-JIS, ISO-2022-JP (JIS), EUC-JP |
MS Mincho |
|
Корейская |
Wansung, Johab, ISO-2022-KR, EUC-KR |
Malgun Gothic |
|
Тайская |
Windows 874 |
Tahoma |
|
Вьетнамская |
Windows 1258 |
Courier New |
|
Индийские: тамильская |
ISCII 57004 |
Latha |
|
Индийские: непальская |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: конкани |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: хинди |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: ассамская |
ISCII 57006 |
|
|
Индийские: бенгальская |
ISCII 57003 |
|
|
Индийские: гуджарати |
ISCII 57010 |
|
|
Индийские: каннада |
ISCII 57008 |
|
|
Индийские: малаялам |
ISCII 57009 |
|
|
Индийские: ория |
ISCII 57007 |
|
|
Индийские: маратхи |
ISCII 57002 (деванагари) |
|
|
Индийские: панджаби |
ISCII 57011 |
|
|
Индийские: санскрит |
ISCII 57002 (деванагари) |
|
|
Индийские: телугу |
ISCII 57005 |
-
Для непальского, ассамского, бенгальского, гуджарати, малаялам и ория доступна только ограниченная поддержка.
 org/ListItem»>
org/ListItem»>
Для использования индийских языков необходима их поддержка в операционной системе и наличие соответствующих шрифтов OpenType.
К началу страницы
Коды языков HTML — Стоматология в Химках
Кодировка для русского языка
В HTML коды языков могут использоваться для указания языка веб-страницы или ее части. Это поможет поисковой системе, а также браузеру правильно обработать страницу.
Пример кода указания языка страницы lang HTML документа
Пример указания языка на HTML веб странице:
Пример для спецификации XHTML:
Стандарт ISO 639-1 кодов языков
HTML использует стандарт кодов языков ISO 639-1.
Таблица кодов языков ниже содержит HTML код языка с указанием перевода на русский и английский.
В HTML коды языков могут использоваться для указания языка веб-страницы или ее части. Это поможет поисковой системе, а также браузеру правильно обработать страницу.
Пример указания языка на HTML веб странице:
Пример для спецификации XHTML:
Коды языков HTML.
Guruweba. com
15.06.2017 14:27:32
2017-06-15 14:27:32
Источники:
Https://guruweba. com/html/kody-yazykov-html/
Кодировка русского языка в html: Атрибут charset | — | Создание и продвижение сайтов » /> » /> .keyword { color: red; }
Кодировка для русского языка
Кодировка HTML страницы и атрибуты — Знакомство с HTML — codebra
Дополнительное видео по теме
Как добавить кодировку страницы?
Вы когда-нибудь видели на странице в интернете какие-то знаки вопроса, квадратики и прочее вместо текста? Думаю, что видели. Так вот, у этого сайта проблема с кодировкой, вполне возможно разработчик ее не указал. Кодировка, простыми словами, это таблица содержащая набор символов. Для того чтобы добавить кодировку сайта, нужен многофункциональный тег, о нем написан целый урок. Итак, чтобы браузер понял, какую кодировку вы используете, применяйте эту строку:
Так вот, у этого сайта проблема с кодировкой, вполне возможно разработчик ее не указал. Кодировка, простыми словами, это таблица содержащая набор символов. Для того чтобы добавить кодировку сайта, нужен многофункциональный тег, о нем написан целый урок. Итак, чтобы браузер понял, какую кодировку вы используете, применяйте эту строку:
Что такое кодировка?
Кодировка, это набор символов, представленный в таблице. Таблица содержит сам символ и его код, например, двоичный (нули и единицы). Термин «набор символов» редко используется, чаще всего говорят «кодировка». На данный момент популярны две кодировки: ASCII и UTF-8. На нашем сайте используется кодировка UTF-8 .
Подробнее о кодировке?
Кодировка ASCII является американской и разрабатывалась для английского языка. Так как, к примеру, французский язык имеет надстрочные знаки, а русский алфавит не похож на английский, был разработан стандарт Unicode для расширения кодировки ASCII. Но и в Unicode, со временем, стало не хватать места для размещения новых символов. Поэтому на основе Unicode создали кодировку UTF-8, которая исправила эти недостатки. UTF-8 позволяет кодировать до 2 миллиардов символов, поэтому она доминирует в интернете.
Поэтому на основе Unicode создали кодировку UTF-8, которая исправила эти недостатки. UTF-8 позволяет кодировать до 2 миллиардов символов, поэтому она доминирует в интернете.
В UTF-8 коды от 0 до 127 используются для представления символов ASCII. Если символ не входит в набор ASCII, то старший бит первого байта устанавливается в 1, что свидетельствует о дополнительном использовании байтов. То есть если в документе используются только символы из ASCII, то каждый символ в UTF-8 будет кодироваться восьмью битами.
Что такое атрибуты?
Настало время познакомиться с атрибутами в HTML. Вы их уже встречали, просто на них не акцентировалось внимание. Атрибуты – это дополнение к тегам, расширяющее их возможности. Они всегда указываются в открывающемся теге. Атрибут состоит из имени и значения, разделенного знаком равенства.
Имя атрибута необходимо писать в нижнем регистре. Хотя HTML5 и позволяет писать в любом регистре и не использовать кавычки, все же так не рекомендуется делать.
Виды кодировок символов [АйТи бубен]
В общем случае кодировка или Кодовая таблица — это однозначное соответствие между подмножеством целых чисел (как правило, идущих подряд) и некоторым набором символов. Ключевым здесь является понятие символа. Символ может быть буквой (а может и не быть), может соответствовать звуку речи (а может и не соответствовать) и может быть представлен графическим знаком (но может обходиться и без какого бы то ни было видимого образа). Символ — это атом смысла, мельчайшая неделимая частица информации.
Так, латинское «А» и кириллическое «А» — это разные символы, потому что они употребляются в разных контекстах и несут в себе разную информацию.
Определяющим для любой кодировки является количество охватываемых ею кодов и, соответственно, символов. Поскольку тексты в компьютере хранятся в виде последовательности байтов, большинство кодировок естественным образом распадаются на однобайтовые, или восьмибитные, способные закодировать не больше 256 символов, и двухбайтовые, или шестнадцатибитные, чья емкость может достигать 65636 знакомест.
Если кодировка ISO 8859-5 для кириллицы так и не прижилась, первая из этой серии — кодировка ISO 8859-1, известная также под именем Latin-1, — сумела стать общепринятым стандартом для кодирования «расширенной» латиницы. В эту кодировку включены почти все символы, употребляющиеся в письменностях западноевропейских языков — французского, немецкого, испанского и т. д.
Внедрение Юникода привело к изменению подхода к традиционным 8-битным кодировкам. Если раньше кодировка задавалась шрифтом, то теперь она задаётся таблицей соответствия между данной кодировкой и Юникодом. Фактически 8-битные кодировки превратились в форму представления некоторого подмножества Юникода. Это намного упростило создание программ, которые должны работать с множеством разных кодировок: теперь, чтобы добавить поддержку ещё одной кодировки, надо всего лишь добавить ещё одну таблицу перекодировки в Юникод.
В 1991 году была предпринята попытка создать единую универсальную двухбайтовую кодировку, охватывающую все алфавиты и иероглифические системы мира.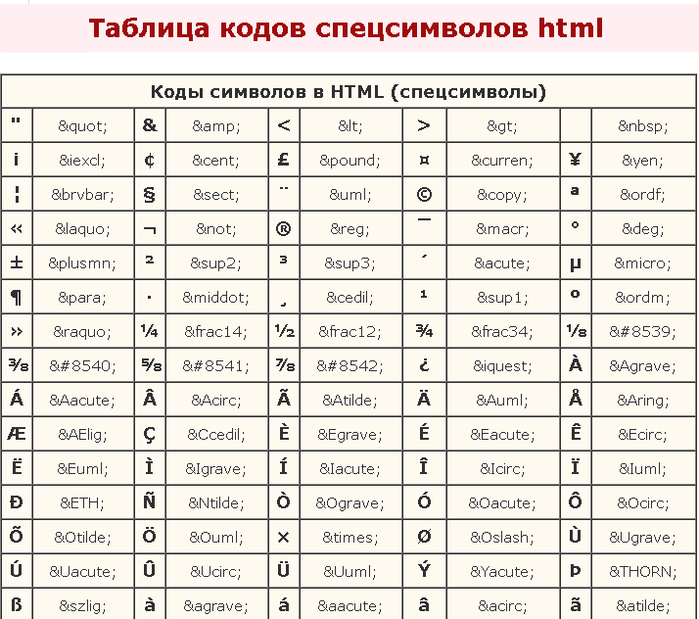 Результатом стал стандарт под названием Unicode, покрывающий не только системы письменности всех живых и большинства мертвых языков мира, но и множество музыкальных, математических, химических и прочих символов. Массовое применение Unicode в документах и программах остается делом будущего, для web — дизайнера эта кодировка имеет особое значение, так как именно она объявлена «стандартной кодировкой документа» в HTML начиная с версии 4.
Результатом стал стандарт под названием Unicode, покрывающий не только системы письменности всех живых и большинства мертвых языков мира, но и множество музыкальных, математических, химических и прочих символов. Массовое применение Unicode в документах и программах остается делом будущего, для web — дизайнера эта кодировка имеет особое значение, так как именно она объявлена «стандартной кодировкой документа» в HTML начиная с версии 4.
В ближайшее время все более важную роль будет играть особый формат Unicode (и ISO 10646) под названием UTF-8. Эта «производная» кодировка пользуется для записи символов цепочками байтов различной длины (от одного до шести), которые с помощью несложного алгоритма преобразуются в Unicode — коды, причем более употребительным символам соответствуют более короткие цепочки. Главное достоинство этого формата — совместимость с ASCII не только по значениям кодов, но и по количеству бит на символ, так как для кодирования любого из первых 128 символов в UTF-8 достаточно одного байта (хотя, например, для букв кириллицы нужно уже по два байта).
Для указания кодировки символов web-страницы используются следующие обозначения кодовых таблиц:
На web — странице указать кодировку документа можно двумя cпособами:
Элемент meta является дочерним по отношению к разделу заголовка документа (head) и служит для указания типа и кодировки содержимого страницы. Типом содержимого является структурированный текст в формате html (text/html), используемая кодировка кириллица windows (charset=windows-1251).
Обычно используют оба способа одновременно. Например, для указания кодировки КОИ8 для украинского языка на web-странице, используют следующую структуру документа:
При сохранении текста выбирайте ту же кодировку, что указали на web-странице.
Поэкспериментируйте с различными кодировками, и вы убедитесь, что символы латинского алфавита, цифры и знаки пунктуации передаются без изменений в подавляющем большинстве из них.
@charset | CSS | WebReference
Команда @charset применяется для задания кодировки внешнего CSS-файла.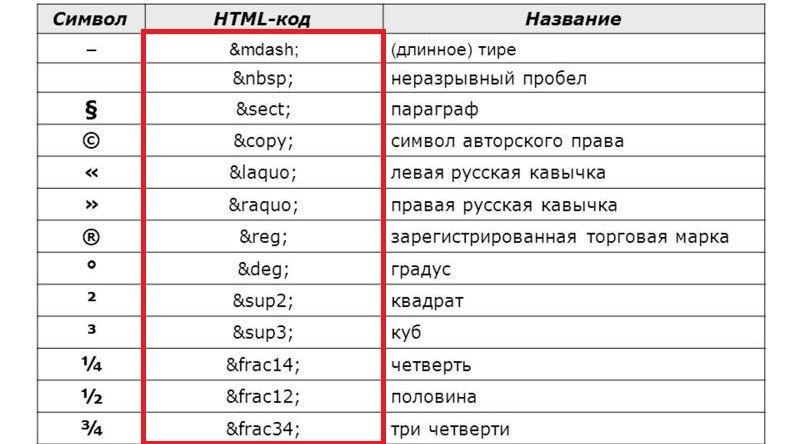 Это имеет значение в том случае, если в CSS-файле используются символы национального алфавита.
Это имеет значение в том случае, если в CSS-файле используются символы национального алфавита.
Для внешней таблицы стилей браузер последовательно просматривает следующие пункты для определения кодировки таблицы стилей:
кодировка, которую отдает сервер; правило @charset; атрибут charset элемента (данный атрибут устарел, не используйте его).
Приведённый список имеет чётко выраженную иерархию — чем выше находится пункт, тем выше его приоритет. Если ни один из пунктов не найден, будет установлена кодировка UTF-8.
Синтаксис
Обозначения
Значения
Для русского языка обычно указывается кодировка windows-1251 или utf-8. Значение кодировки обязательно должно быть взято в кавычки.
Пример
Примечание
В браузере Internet Explorer до версии 7 включительно название кодировки допускается писать без кавычек, что противоречит спецификации CSS.
Спецификация
Каждая спецификация проходит несколько стадий одобрения.
- Recommendation (Рекомендация) — спецификация одобрена W3C и рекомендована как стандарт.
 Candidate Recommendation (Возможная рекомендация) — группа, отвечающая за стандарт, удовлетворена, как он соответствует своим целям, но требуется помощь сообщества разработчиков по реализации стандарта. Proposed Recommendation (Предлагаемая рекомендация) — на этом этапе документ представлен на рассмотрение Консультативного совета W3C для окончательного утверждения. Working Draft (Рабочий проект) — более зрелая версия черновика после обсуждения и внесения поправок для рассмотрения сообществом. Editor’s draft (Редакторский черновик) — черновая версия стандарта после внесения правок редакторами проекта. Draft (Черновик спецификации) — первая черновая версия стандарта.
Candidate Recommendation (Возможная рекомендация) — группа, отвечающая за стандарт, удовлетворена, как он соответствует своим целям, но требуется помощь сообщества разработчиков по реализации стандарта. Proposed Recommendation (Предлагаемая рекомендация) — на этом этапе документ представлен на рассмотрение Консультативного совета W3C для окончательного утверждения. Working Draft (Рабочий проект) — более зрелая версия черновика после обсуждения и внесения поправок для рассмотрения сообществом. Editor’s draft (Редакторский черновик) — черновая версия стандарта после внесения правок редакторами проекта. Draft (Черновик спецификации) — первая черновая версия стандарта.Браузеры
В таблице браузеров применяются следующие обозначения.
- — свойство полностью поддерживается браузером со всеми допустимыми значениями; — свойство браузером не воспринимается и игнорируется; — при работе возможно появление различных ошибок, либо свойство поддерживается лишь частично, например, не все допустимые значения действуют или свойство применяется не ко всем элементам, которые указаны в спецификации.
Число указывает версию браузера, начиная с которой свойство поддерживается.
Автор и редакторы
Автор: Влад Мержевич
Последнее изменение: 30.08.2017
Редакторы: Влад Мержевич
URL кодирование и декодирование
Для тех кто не любит нудных объяснений 🙂
Введите строку в одно из полей и нажмите соответствующую кнопку
Строка в закодированном виде
Строка в нормальном виде
Для тех кто любит «во всем разобраться» 😉
Кодирование URL и просто двоичных данных в последовательность букв, цифр и некоторых специальных знаков латинского алфавита в интернете было связано с ограничением физических устройств на передачу только алфавитно-цифровых символов. В URL такое кодирование обычно применяется для передачи символов в формате Unicode (как правило UTF-8) в последовательность из двух байт, записанных в шестнадцатиричном представлении. Каждый байт предваряется знаком %. При таком кодировании строчка «корова» будет иметь вид: %D0%BA%D0%BE%D1%80%D0%BE%D0%B2%D0%B0. То есть русской букве к будет соответствовать последовательность %D0%BA и. т.д. Такое кодирование является общепринятым для путей к файлам или папкам, входящим в URL.
То есть русской букве к будет соответствовать последовательность %D0%BA и. т.д. Такое кодирование является общепринятым для путей к файлам или папкам, входящим в URL.
Подмножесто символов, которые разрешены в URL немного шире чем алфавитно-цифровые символы, так, в URL можно использовать дефис и подчеркивание, но нельзя, например, использовать одинарные или двойные кавычки. Некоторые символы используют для разделения параметров в URL, и их кодирование в этом случае будет неправомочным. В зависимости от отношения к кодированию специальных символов в javascript различают функции encodeURI и decodeURI, которые могут работать с полным URL, и, функции encodeURIComponent / decodeURIComponent, применяемые для параметров, входящих в URL.
Вообще говоря, кодирование параметров может быть достаточно произвольным. Здесь разработчик может использовать любую схему кодировки, если состав ее символов будет коректно передаваться через сеть. Так, вместо строки кириллицы в utf-8 можно применить строку в кодировке Windows 1251.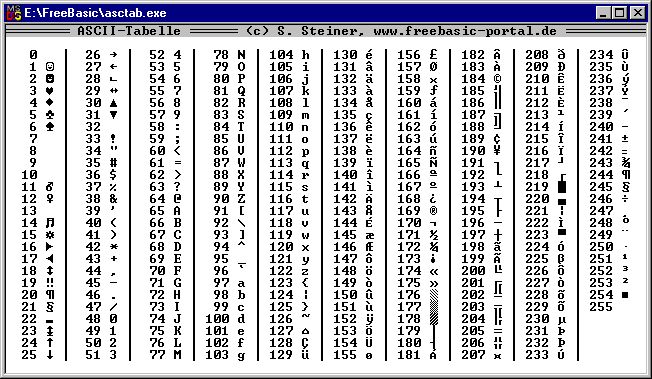 В этом случае слово «корова» будет выглядеть как %EA%EE%F0%EE%E2%E0. То есть, символу к будет соответствовать последовательность из двух букв со знаком процента перед ними — %EA. Закодировать в строки с процентами кириллицу из других кодировок можно в нашем HTML кодировщике. В принципе, допустимы также другие способы кодирования, например, escape/unescape функцию javascript. Слово «корова» в этом случае будет выглядеть как %u043A%u043E%u0440%u043E%u0432%u0430.
В этом случае слово «корова» будет выглядеть как %EA%EE%F0%EE%E2%E0. То есть, символу к будет соответствовать последовательность из двух букв со знаком процента перед ними — %EA. Закодировать в строки с процентами кириллицу из других кодировок можно в нашем HTML кодировщике. В принципе, допустимы также другие способы кодирования, например, escape/unescape функцию javascript. Слово «корова» в этом случае будет выглядеть как %u043A%u043E%u0440%u043E%u0432%u0430.
URL кодировщик с расширенными возможностями
Как прописать кодировку в html?
Нужно правильно раскодировать сигналы, которые наш мозг получает из окружающей среды. Проще говоря, следует правильно « настроить » свой взгляд на жизнь. Ну, вроде не полупустой кошелек, а наполовину полный. То есть, требуется использовать нужную кодировку. Для интернета чаще всего правильной является кодировка utf :
Немного о кодировках
Наверное, не является секретом тот факт, что основным типом содержимого во всемирном веб-пространстве является текст. Конечно, сейчас с этим утверждением можно поспорить, но буквально какой-то десяток лет назад это было так.
Конечно, сейчас с этим утверждением можно поспорить, но буквально какой-то десяток лет назад это было так.
Но передача текста в цифровом формате происходит совсем иначе, чем у нас на экране. Для перевода текста в машинный код используется двоичная система исчисления, состоящая лишь из 0 и 1.
Следующим этапом передачи текста в виртуальном пространстве является его отображение на клиентских машинах с помощью браузера, интерпретирующего html. Вот тут и начинается самое интересное, когда браузер клиента и веб-страница содержат в себе текстовые данные в разных кодировках. Тогда пользователь на своем мониторе видит не текст, а какие-то непонятные ( нечитаемые ) символы:
Чаще всего нужно всего лишь поменять кодировку веб-страницы на кодировку utf8. Ведь она является наиболее распространенной во всем интернете.
Кодировка UTF-8
Наиболее распространенная среди стандартизированных и общепринятых текстовых кодировок. Расшифровывается как « восьмибитный формат преобразования Юникода » или « Unicode Transformation Format ».
Стандарт был разработан еще в 1992 году. В настоящее время он широко применяется не только во всемирной паутине, но и на прикладном уровне ( локальные машины и операционные системы ). Основным достоинством кодировки является ее совместимость с ASCII:
ASCII («American standard code for information interchange») еще одна (но более старая) кодировка представления текстовых данных. В ее таблице символов значения печатных и непечатных знаков заданы с помощью чисел в шестнадцатеричной системе исчисления.
При использовании UTF-8 для передачи данных в формате ASCII используются 7 первых битов. Последний ( восьмой ) служит для вывода « мусора » ( некорректно раскодированных данных ). Что при использовании кодировки для латинских символов существенно уменьшает объем текстовых данных.
Как уже говорилось, часто для корректного отображения текста достаточно лишь поменять кодировку документа. Рассмотрим, как это можно сделать в различных дисциплинах, применяемых для построения веб-пространства.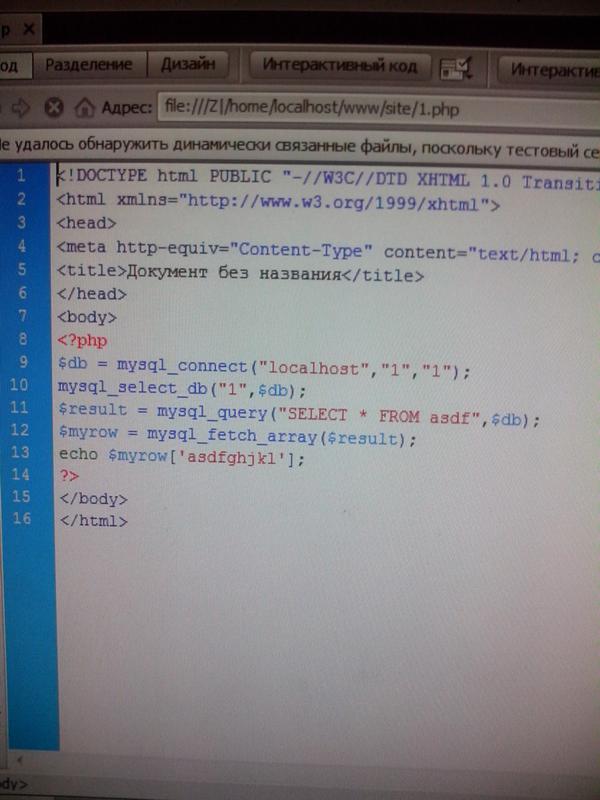
Как установить кодировку в HTML и PHP
Для установки utf 8 кодировки в html используется специальный тег. Он объединяет в себе в форме атрибутов значение метатегов.
Метатеги используются для передачи и хранения информации, предназначенной для браузеров и поисковиков. Одним из атрибутов тега является charset. Он служит для установки кодировки веб-страницы. Пример использования:
Также можно установить кодировку некоторым элементам страницы. Например, ссылке. Для этого также используется атрибут charset, значением которого выступает нужная кодировка:
Кроме этого можно присваивать значения непосредственно заголовкам http, которые передаются вместе с ответом на запрос от браузера к серверу. В таком случае кодировка сайта utf 8 , переданная через заголовок, будет доминирующей над значением, заданным внутри веб-страницы.
Многие из страниц ресурсов не являются статическими, а динамически создаются благодаря использованию серверных языков программирования. Чаще всего для построения сайтов применяют PHP. Поэтому важно знать о его средствах, позволяющих «на лету» поменять кодировку генерируемой веб-страницы.
Поэтому важно знать о его средствах, позволяющих «на лету» поменять кодировку генерируемой веб-страницы.
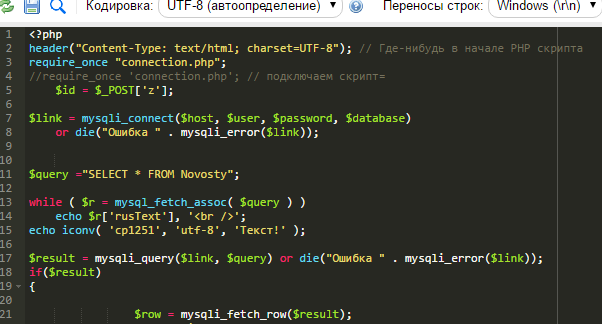
Для установки и модификации значений заголовка используется функция header() . Ее синтаксис:
Чтобы корректно задать в php кодировку utf 8 , вызов функции header() в коде должен находиться выше всех тегов html.
Глобальные настройки кодировки
Описанные выше методы могут использоваться для отдельных веб-страниц или небольших сайтов. Но что делать, если вы имеете дело с ресурсом, состоящим из нескольких сотен страниц и десятка разделов? Давайте разберемся, как установить кодировку utf 8 для всего сайта.
Для этого нужно вносить изменения в дополнительный файл конфигурации ресурса. Он носит название. htaccess. Сначала его нужно открыть в любом текстовом редакторе, а затем добавить туда строку:
В качестве более глобального способа изменения кодировки стоит рассмотреть пример на основе любого локального сервера. Для большей наглядности мы возьмем Denwer, который довольно широко распространен в наших краях.
Чтобы изменить кодировку всех ресурсов, размещенных на нашем сервере Apache, нужно отредактировать содержимое конфигурационного файла httpd. conf. Он находится по пути:
Как и в предыдущем примере, в нем нужно заменить значение AddDefaultCharset на нужное. В нашем случае это utf-8 :
Изменение кодировки базы данных
Изменение кодировки рассмотрим на примере MySQL. Так как это одна из самых востребованных и распространенных СУБД, применяемых в сайтостроении. Все изменения можно произвести в файле my. ini. В Денвере он находится по пути:
Здесь нужно поменять значение нескольких полей на utf-8 :
- default-character-set ; character-set-server ; init-connect = «set names» ; default-character-set.
И затем добавить строку skip-character-set-client-handshake :
Подобные изменения можно внести не только для всех баз данных на сервере, но и для отдельно взятой в php базы mysql. Сделать это можно через пользовательский интерфейс оболочки PHPMyAdmin.
Сначала узнаем, какие кодировки установлены по умолчанию в нашей базе данных. Для этого вводим запрос SQL :
Вот какой ответ мы должны получить:
Если какие-либо значения нас не удовлетворяют, то нужно их изменить. Воспользуемся для этого запросом к ядру сервера СУБД:
В результате мы получим новые значения переменных character_set_connection, character_set_results и character_set_client.
К сожалению, не все так просто обстоит с изменением кодировки в таблицах Excel. Для этого придется воспользоваться сторонней программой для перекодирования файлов. Или обработать данные с помощью громоздких функций.
Мы рассмотрели все основные способы изменения веб-документов на кодировку utf. Надеемся, что этот материал поможет вам не только выбрать правильную кодировку текста, но и « установить » правильный взгляд на жизнь.
Первая серьёзная проблема, с которой сталкиваются большинство новичков при создании HTML-страниц, связана с набором символов (англ. Character set). Выражается эта проблема с кодировкой в, так называемых, «кракозябриках», которые мы получаем вместо указанных в HTML-файле символов. В данной статье я хочу остановиться на проблеме с кодировкой подробнее, постараться расставить всё по полочкам и дать варианты решения.
Выражается эта проблема с кодировкой в, так называемых, «кракозябриках», которые мы получаем вместо указанных в HTML-файле символов. В данной статье я хочу остановиться на проблеме с кодировкой подробнее, постараться расставить всё по полочкам и дать варианты решения.
- Что такое кодировка? Кодировка файла (редактирование в Notepad++) Кодировка отображения (просмотр в браузере) Как указать кодировку HTML-страницы? (метатег charset) Всё ещё есть проблема с кодировкой? (header charset в php)
Что такое кодировка?
Условно говоря, каждый Символ (знак) состоит из Кода и Картинки. Здесь Код – это уникальный идентификатор символа в наборе символов, который определяется выбранной Кодировкой, а Картинка – это визуальное представление символа, которое содержится в Файле шрифта в соответствующей коду символа ячейке.
Другими словами, Кодировка (англ. Charset) – это набор взаимосвязей Кодов символов с их Визуальными представлениями в шрифте.
Кодировка файла
HTML-страница представляет собой обычный текстовый файл, кодировка которого выбирается при его создании и/или сохранении на запоминающее устройство (жёсткий диск, флэшка и т. д.) .
В случае с Notepad++, кодировка нового документа задаётся в настройках текстового редактора. Выбираем в меню: Опции > Настройки… – и переходим на вкладку «Новый документ». Здесь нас интересует секция «Кодировка». По умолчанию, выбрана кодировка ANSI.
Настройка кодировки нового документа в Notepad++
Напомню, что это кодировка, в которой будет храниться HTML-файл.
Впрочем, Вы всегда можете преобразовать кодировку HTML-страницы, используя соответствующие функции текстового редактора. Например, в Notepad++ для этого кликните пункт меню «Кодировки» и выберите нужное преобразование.
Преобразование кодировки текущей HTML-страницы в Notepad++
В данном случае файл был в кодировке ANSI и я преобразовал его в UTF-8 (без BOM) . О том, что такое этот BOM Вы можете прочитать в моей статье: PHP: как удалить BOM в WordPress — проследовав по этой ссылке.
Кодировка отображения
Важно разделять Кодировку файла и Кодировку отображения. Независимо от того, в какой кодировке хранится файл, он может быть отображен и в любой другой кодировке. Это и является одной из причин проблем с кодировкой.
Например, если Вы сохранили HTML-страницу в кодировке ANSI и откроете её в браузере, вместо русских символов Вы можем получить, так называемые, «кракозябрики».
Проблемы с кодировкой отображения HTML-страницы в браузере Firefox
В данном случае нам надо убедиться, что Кодировка файла совпадает с Кодировкой отображения файла в браузере. Для этого в Firefox кликните иконку меню, а потом пункт «Кодировка». Если такого у Вас нет, кликните пункт «�?зменить» и добавьте элемент «Кодировка» в меню.
Смена кодировки отображения HTML-страницы в браузере Firefox
Как вы видите, браузер отображает файл в кодировке «Юникод» (например, UTF-8) , в то время как файл был сохранён в кодировке ANSI (например, Windows-1251) . Выбрав нужную кодировку, мы получим нужный нам результат.
Проблема с кодировкой решена
В случае с Notepad++ также имеется возможность выбора кодировки отображения. Для этого кликните пункт меню «Кодировки», а потом нужный вариант используемой для отображения кодировки.
Смена кодировки отображения HTML-страницы в Notepad++
В данном случае я изменил кодировку отображения ANSI на UTF-8 (без BOM) .
Как указать кодировку HTML-страницы?
�? так, мы уже разобрались с тем, что такое кодировка и в чём состоит отличие кодировки файла и кодировки отображения. Теперь нам нужно решить проблему с кодировкой, которая заключается в Неправильной интерпретации браузером (или любым другим клиентом) кодировки HTML-страницы.
Почему возникают проблемы с кодировкой? Определить кодировку HTML-страницы не просто, а зачастую и не возможно, т. к. у того же браузера нет информации о ней или она указана неправильно.
Для того чтобы указать кодировку HTML-страницы используется специальный метатег. В HTML5 он имеет следующий урезанный вид:
В данном случае указана кодировка UTF-8 (Юникод) .
В более старых версиях HTML этот метатег имеет следующий вид:
Этот метатег создаёт HTTP-заголовок Content-Type, в котором указывается тип документа text/html и его кодировка Windows-1251 (ANSI) .
Лично я рекомендую использовать именно этот вариант, т. к. с ним будет меньше всего проблем. Главное чтобы такой метатег присутствовал в секции HEAD, и указанная в нём кодировка соответствовала кодировке файла. В большинстве случаев этого будет достаточно.
Всё ещё есть проблема с кодировкой?
В некоторых случаях указать метатег с кодировкой HTML-страницы будет недостаточно. Такая проблема может быть вызвана настройками самого сервера, на котором находится файл HTML-страницы. Дело в том, что сервер способен выдавать Свой HTTP-заголовок Content-Type, который будет, условно говоря, иметь приоритет перед метатегом.
В данном случае эту проблему можно решить путём внесения изменений в настройки сервера. Я не буду вдаваться в детали данного вопроса и порекомендую лишь отключать всю эту перекодировку через файл .htaccess, например:
Также можно производить изменения HTTP-заголовка Content-Type и программными средствами. В том же PHP для этого используется функция header() , например:
8 декабря 2016 г., 19:56 Удалить комментарий
Я так понимаю, вот я в программе создаю html страницу. Если я в тексте напишу хотя бы один английский символ, то кодировка автоматически станет Юникод?
А в браузере по умолчанию отображаются все страницы в ANSI, поэтому мой файл в Юникоде как раз и будет с кракозябрами?
15 февраля 2017 г., 11:57 Удалить комментарий
Буквы на английском имеют одинаковые коды во всех кодировках, так что с ними проблем не возникает, а вот с той же кириллицей могут быть проблемы.
По сути, действительно, если использовать только буквы на английском, то кодировка часто определяется браузерами как «Кириллица (Windows)» или тип того, просто он не может распознать кодировку не имея «нестандартных» символов.
Впрочем, даже если есть символы и прописан meta тег, не факт, что браузер поймёт в как отображать страницу, т. к. в основном ориентируется на http заголовки сервера.
15 февраля 2017 г., 18:25 Удалить комментарий
Спасибо огромное за полезную статью.
Но у меня остался таки вопрос. как изменить кодировку по умолчанию в браузере firefox я поняла, зашла в настройки, а там нет нужного мне юникода. файлы создаю в нотепаде++ с юникодом. посоветуйте пожалуйста, как поступить в моем случае. писать в кириллице, чтобы совпадало с фаерфоксом? либо как. а вообще хотела использовать юникод везде))
Автор статьи: Сергей Каминский
При создании сайта у начинающих веб-мастеров часто появляются вопросы: в какой кодировке делать сайт, чем отличается UTF-8 от windows-1251 и как ее прописывать в META Charset HTML-страницы сайта. Ответы на все эти вопросы в данной статье.
Что такое кодировка сайта и как она работает
Кодировку можно представить в виде таблицы, состоящей из разных букв, цифр и других символов понятных человеку, которые закодированы определенным образом. Когда вы открываете текстовый файл, к которым относятся в том числе HTML-страницы, то компьютер считывает из заголовка файла в какой кодировке он был сохранен и выводит текст в соответствующей кодировке преобразовывая компьютерные данные в вид понятный человеку сопоставляя эти данные с таблицей кодировки. Если информация о кодировке из заголовка файла совпадает с кодировкой в которой сохранены данные в HTML-странице, то пользователь видит привычные ему буквы, цифры и другие символы. Если же есть несовпадение, то в результате пользователю выводится непонятный набор символов, особенно часто это происходит в старых почтовых программах. Если пользователь получил письмо с непонятными крякозябрами, то просто перебирая разные кодировки, обычно получается угадать и выбрать ту, в которой написано письмо, и в результате непонятный набор символов превращается в понятный человеку текст.
То же самое происходит и с HTML-страницами сайта. Если документ был сохранен, например, в кодировке UTF-8, а в самом документе прописан META-тег указывающий что это кодировка windows-1251, то браузер опять же будет сопоставлять сохраненные в файле данные с таблицей указанной ему кодировки и так как символы закодированы по-разному, то браузер выведет вместо привычного текста непонятный набор символов или же часть букв может быть в нормальном виде, а другие буквы или символы могут выводиться, например, в виде знаков вопроса. Все выше сказанное относится в том числе и к отображению имен файлов.
Создавая новый документ в текстовом редакторе лучше сразу убедиться что выбрана нужная кодировка. Современные редакторы позволяют преобразовать текст открытого документа из одной кодировки в другую, а стандартный Блокнот позволяет выбрать кодировку только при сохранении файла.
Самые распространенные кодировки
Из предыдущего пункта вы уже знаете что такое кодировка и почему настолько важно правильно прописать ее в коде страниц сайта. Давайте теперь выясним какую из множества кодировок лучше выбрать для будущего сайта. Поскольку самой распространенной и наиболее понятной в освоении всегда была операционная система Windows, то большинство веб-разработчиков создавали HTML-страницы в кодировке windows-1251 (ANSI), которая использовалась по-умолчанию. Но windows-1251 поддерживает не очень большое количество букв и символов, а разработчики хотят использовать в своих текстах различные стрелочки, сердечки, квадратики и другие символы, в том числе есть необходимость совмещать слова из разных языков в одном документе, поэтому на смену ей уже давно пришла более расширенная UTF-8 и большинство разработчиков используют именно эту кодировку.
Проблемы с кодировкой не только в HTML-странице
Сайт, независимо от того является ли он просто набором статических HTML-документов или сложных динамических скриптов генерирующих страницы на лету, размещается на веб-сервере, который также работает с определенной кодировкой. И если сервер выдает информацию в одной кодировке, а ваши страницы или скрипты сохранены в другой кодировке, то опять же могут быть проблемы с отображением страниц в браузере пользователя. Многие хостинги позволяют менять настройки и выбрать кодировку в соответствии с той, которая используется в файлах сайта, через панель управления или же прописать ее в файле. htaccess, если на хостинге используется популярный веб-сервер Apache.
Практически ни один современный сайт не обходится без использования базы данных MySQL и она также может стать источником проблем с кодировкой. Если файлы сайта сохранены в одной кодировке, а информация в базе данных в другой, то на странице та часть информации, которая выводится из базы данных может отображаться в виде все тех же знаков вопросов или других непонятных символов. Чтобы избежать проблем с кодировкой она должна быть одинаковой для веб-сервера, базы данных MySQL, в скриптах, в HTML-страницах сайта и в META-теге, который прописывается в HTML-коде. Если есть проблемы с отображением текста, то проверяйте на наличие проблемы все выше перечисленное.
META Charset HTML-документа
Чтобы сообщить браузеру и поисковым системам в какой кодировке сохранены страницы сайта в их коде прописывается META Charset.
Для кодировки windows-1251:
Для кодировки UTF-8:
Теперь вы знаете что такое кодировка сайта и где искать проблемы если в какой-либо части сайта неправильно отображается текст.
Другие записи по теме в разделе статьи по HTML и CSS
Как поменять кодировку текста в Word
Набор символов, которые мы видим на экране при открытии документа, называется кодировкой. Когда она выставлена неправильно, вместо понятных и привычных букв и цифр вы увидите бессвязные символы. Эта проблема часто возникала на заре развития технологий, но сейчас текстовые процессоры умеют сами автоматически выбирать подходящие комплекты. Свою роль сыграло появление и развитие utf-8, так называемого Юникода, в состав которого входит множество самых разных символов, в том числе русских. Документы в такой кодировке не нуждаются в смене и настройке, так как показывают текст правильно по умолчанию.
Современные текстовые редакторы определяют кодировку при открытии документа
С другой стороны, такая ситуация всё же иногда случается. И получить нечитаемый документ очень досадно, особенно если он важный и нужный. Как раз для таких случаев в Microsoft Word есть возможность указать для текста кодировку. Это вернёт его в читаемый вид.
Принудительная смена
Если вы получили из какого-то источника текстовый файл, но не можете прочитать его содержимое, то нужна операция ручной смены кодировки. Для этого зайдите в раздел «Сведения» во вкладке «Файл». Тут собраны глобальные настройки распознавания и отображения, и если вы будете изменять их в открытом документе, то для него они станут индивидуальными, а для остальных — не изменятся. Воспользуемся этим. В разделе «Дополнительно» появившегося окна находим заголовок «Общие» и ставим галочку «Подтверждать преобразование файлов при открытии». Подтвердите изменения и закройте Word. Теперь откройте документ снова, как бы применяя настройки, и перед вами появится окно преобразования файла. В нём будет список возможных форматов, среди которых находим «Кодированный текст», и получим следующий диалог.
В этом новом окне будет три переключателя. Первый, по умолчанию, — это CP-1251, кодировка Windows. Второй — MS-DOS. Нам нужен третий пункт — ручной выбор, справа от него перечислены разнообразные наборы символов. Но, как правило, пользователь не знает, какими символами был набран текст предыдущим автором, поэтому в нижней части этого окна есть поле под названием «Образец», в котором фрагмент из текста будет в реальном времени отображаться при выборе того или иного комплекта символов. Это очень удобно, потому что не нужно каждый раз закрывать и отрывать документ снова, чтобы подобрать нужную.
Перебирая варианты по одному и глядя на текст в поле образцов, выберите ту кодировку, при которой символы будут русскими. Но обратите внимание, что это ещё ничего не значит, — внимательно смотрите, чтобы они складывались в осмысленные слова. Дело в том, что для русского языка есть не одна кодировка, и текст в одной из них не будет отображаться корректно в другой. Так что будьте внимательны.
Нужно сказать, что с файлами, сделанными на современных текстовых процессорах, крайне редко возникают подобные проблемы. Однако есть ещё и такой бич современного информационного общества, как несовместимость форматов. Дело в том, что существует целый ряд текстовых редакторов, и каждым кто-то пользуется. Возможно, для кого-то не нужна функциональность Ворда, кто-то не считает нужным за него платить и т. п. Причин может быть множество.
Если при сохранении документа автор выбрал формат, совместимый в MS Word, то проблем возникнуть не должно. Но так бывает нечасто. Например, если текст сохранён с расширением. rtf, то диалог выбора кодировки отобразится перед вами сразу же при открытии текста. А вот форматы другого популярного текстового процессора OpenOffice Ворд даже не откроет, поэтому, если им пользуетесь, не забывайте выбирать пункт «Сохранить как», когда отправляете файл пользователю Office.
Сохранение с указанием кодировки
У пользователя может возникнуть ситуация, когда он специально указывает определённую кодировку. Например, такое требование ему предъявляет получатель документа. В этом случае нужно будет сохранить документ как обычный текст через меню «Файл». Смысл в том, что для заданных форматов в Ворде есть привязанные глобальными системными настройками кодировки, а для «Обычного текста» такой связи не установлено. Поэтому Ворд предложит самостоятельно выбрать для него кодировку, показав уже знакомое нам окно преобразования документа. Выбирайте для него нужную вам кодировку, сохраняйте, и можно отправлять или передавать этот документ. Как вы понимаете, конечному получателю нужно будет сменить в своём текстовом редакторе кодировку на такую же, чтобы прочитать ваш текст.
Заключение
Вопрос смены кодировки в Вордовских документах перед рядовыми пользователями встаёт не так уж часто. Как правило, текстовый процессор может сам автоматически определить требуемый для корректного отображения набор символов и показать текст в читаемом виде. Но из любого правила есть исключения, так что нужно и полезно уметь сделать это самому, благо, реализован процесс в Word достаточно просто.
То, что мы рассмотрели, действительно и для других программ из пакета Office. В них также могут возникнуть проблемы из-за, скажем, несовместимости форматов сохранённых файлов. Здесь пользователю придётся выполнить всё те же действия, так что эта статья может помочь не только работающим в Ворде. Унификация правил настройки для всех программ офисного пакета Microsoft помогает не запутаться в них при работе с любым видом документов, будь то тексты, таблицы или презентации.
Напоследок нужно сказать, что не всегда стоит обвинять кодировку. Возможно, всё гораздо проще. Дело в том, что многие пользователи в погоне за «красивостями» забывают о стандартизации. Если такой автор выберет установленный у него шрифт, наберёт с его помощью документ и сохранит, у него текст будет отображаться корректно. Но когда этот документ попадёт к человеку, у которого такой шрифт не установлен, то на экране окажется нечитаемый набор символов. Это очень похоже на «слетевшую» кодировку, так что легко ошибиться. Поэтому перед тем как пытаться раскодировать текст в Word, сначала попробуйте просто сменить шрифт.
Полезная информация и краткая ретроспектива
- Главная -> Материалы -> Кодировки: полезная информация и краткая ретроспектива
Reg. ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
Перейти на сайт->
Бесплатный Курс «Практика HTML5 и CSS3»
Освойте бесплатно пошаговый видеокурс
По основам адаптивной верстки
На HTML5 и CSS3 с полного нуля.
Фреймворк Bootstrap: быстрая адаптивная вёрстка
Пошаговый видеокурс по основам адаптивной верстки в фреймворке Bootstrap.
Научитесь верстать просто, быстро и качественно, используя мощный и практичный инструмент.
Верстайте на заказ и получайте деньги.
Получить в подарок->
Бесплатный курс «Сайт на WordPress»
Хотите освоить CMS WordPress?
Получите уроки по дизайну и верстке сайта на WordPress.
Научитесь работать с темами и нарезать макет.
Бесплатный видеокурс по рисованию дизайна сайта, его верстке и установке на CMS WordPress!
Получить в подарок->
*Наведите курсор мыши для приостановки прокрутки.
Кодировки: полезная информация и краткая ретроспектива
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых Кракозябров, т. е. нечитаемых символов.
Что такое кодировка?
Упрощенно говоря, Кодировка — это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т. е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов, которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII.
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это Однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т. д.
Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII Символы национальных языков, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R — это тоже расширенная кодировка ASCII, предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок.
По сути это были те же Расширенные версии ASCII, однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало «свободных мест».
Примером такой ANSI-кодировки является всем известная Windows-1251. Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
ANSI-кодировка — это собирательное название. В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми Кракозябрами — нечитаемым бессмысленным набором символов.
Причина их появления проста — это Попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу.
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, Русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере.
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст — вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т. д.
Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать Универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда.
Юникод — универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32.
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита, т. е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно В 4 раза больше битов, что «утяжеляет» файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка — UTF-16.
Как очевидно из названия, в этой кодировке один символ кодируют Уже не 32 бита, а только 16 (т. е. 2 байта). Очевидно, это делает любой символ вдвое «легче», чем в UTF-32, однако и вдвое «тяжелее» любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т. е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, Была предпринята еще одна попытка создания чего-то универсального, и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 — это Многобайтовая кодировка с переменной длинной символа. Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется От 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII. Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет «тратить» на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не «утяжеляя» без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++, PhpDesigner, Rapid PHP и т. д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
— ANSI
— UTF-8
— UTF-8 без BOM
Сразу скажу, что выбирать всегда стоит именно последний вариант — UTF-8 без BOM.
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark. Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM. Для нас главный вывод следующий: Использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом, в результате чего возникают ошибки в работе скриптов.
Поэтому, при работе с UTF-8 используйте именно вариант «UTF-8 без BOM». Также лучше не используйте редакторы, в которых в принципе нельзя указать кодировку (скажем, Блокнот из стандартных программ в Windows).
Кодировка текущего файла, открытого в редакторе кода, как правило, указывается в нижней части окна.
Обратите внимание, что запись «ANSI as UTF-8» в редакторе Notepad++ означает то же самое, что и «UTF-8 без BOM». Это одно и то же.
В программе PhpDesigner нельзя сразу точно сказать, используется BOM, или нет. Для этого нужно кликнуть правой кнопкой мыши по надписи «UTF-8», после чего во всплывающем окне можно увидеть, используется ли BOM (опция Save with BOM).
В редакторе Rapid PHP кодировка UTF-8 без BOM обозначается как «UTF-8*».
Как вы понимаете, в разных редакторах все выглядит немного по-разному, однако главную идею вы поняли.
После того, как документ сохранен в UTF-8 без BOM, нужно также убедиться, что верная кодировка указана в специальном метатэге в секции Head вашего html-документа:
Соблюдение этих простых правил уже позволит вам избежать многих пробелем с кодировками.
На этом все, надеюсь, что данный небольшой экскурс и пояснения помогли вам лучше понять, что такое кодировки, какие они бывают и как работают.
Если вам интересна эта тема с более прикладной точки зрения, то рекомендую вам изучить мой видеоурок Полный UTF-8: чеклист для начинающих.
Дмитрий Науменко.
P. S. Присмотритесь к премиум-урокам по различным аспектам сайтостроения, а также к бесплатному курсу по созданию своей CMS-системы на PHP с нуля. Все это поможет вам быстрее и проще освоить различные технологии веб-разработки.
Понравился материал и хотите отблагодарить?
Просто поделитесь с друзьями и коллегами!
Смотрите также:
Как разработать кириллическую HTML-страницу
Как разработать кириллическую HTML-страницу
На этой странице объясняется, как разработчик может создать файл .html с кириллическим текстом внутри.
Примечание. Английский алфавит как частный случай (отличный от немецкого).
Кириллический набор символов, как и любой другой набор символов в мире (Японский, китайский, центральноевропейский и др.) содержит, помимо национальной символики, набор символов называется ASCII — в каждой устаревшей кодировке символы ASCII занимают первые 128 позиций таблицы кодировок, а национальные буквы занимают вторую половину таблицы.Символы ASCII (например, знаки препинания и т. Д.) Включают также Английский алфавит .
То есть английские буквы являются частью набора символов кириллицы!Таким образом, наличие веб-страницы с русскими и английскими буквами означает, что , а не , означает, что у вас есть Многоязычная страница .Нет, на этой странице используется одна кодировка кириллицы, и эта кодировка содержит английский язык. буквы (точнее — символы ASCII).
Другой случай: реальные Многоязычных страниц, где, скажем, русские буквы должны сочетаться с немецкими буквы либо польские, либо японские.
Этот случай описан на другой странице моего сайта — «Как разработать Многоязычную HTML-страницу»
То есть эта статья — о создании кириллической (например, русской) веб-страницы, т. е.е. Интернет страница, которая объявляет себя Кириллицей (указана кириллица).
Очень Разных сценариев : когда вы хотите создать не кириллическую веб-страницу (например, Страница западноевропейской кодировки) и просто поместите туда пару русских слов —
Это НЕ рассматривается здесь, это описано в Другой статье , одна упомянута выше —
«Как разработать Многоязычную HTML-страницу»
Шрифт создан для определенной кодировки, и поскольку каждая кодировка содержит ASCII, каждый шрифт в мире также содержит ASCII. Итак, любой кириллический шрифт содержит Английских букв.
Чтобы создать кириллический (или кириллица + английский) HTML-файл, то есть текст с одним набором символов, разработчик просто пишет немного кириллического (+ английского) текста при использовании кириллического шрифта и соответствующий режим клавиатуры.
Большинство русскоязычных веб-страниц (более 90% наверняка) в настоящее время выполнены в кодировке Windows-1251 a. k.а. «Кириллица (Windows)», просто потому, что большинство авторов в настоящее время работают под MS Windows, а 1251 — это то, что Microsoft использует для кириллицы, поэтому встроенные шрифты Windows Cyrillic и Клавиатура инструменты предназначены для кодирования Windows-1251.
Поэтому гораздо проще набрать текст в кодировке «Кириллица (Windows-1251)» в текстовом редакторе Windows. чем набирать текст в кодировке «Кириллица (KOI8-R)».
Набрать текст в кодировке «Кириллица, ISO-8859-5» под MS Windows практически невозможно.
Но на самом деле , а не , имеет значение, какую кодировку использовал автор — основные браузеры отлично работают с Все кодировок кириллицы, и если веб-страница сделана правильно (ниже), она будет отображаться конечному пользователю тоже правильно. Последняя часть этой страницы обсуждает создание страницы KOI8-R — на всякий случай.
Как Написать по-русски с помощью шрифтов и клавиатуры — с индикатором «RU» на панели задач — объясняется в «Введение. Кириллица в Windows » раздел моего сайта «Кириллица (русская): инструкция для Windows и Интернета»
Если кириллица написана правильно, то конечный пользователь сможет прочитать эту страницу, например, переключившись на кириллицу в браузере (например, View / Encoding / Cyrillic (Windows) или Просмотр / Кодирование / Кириллица (KOI8-R) в Internet Explorer) если на странице не указана ее кодировка.
Примечание. Кириллица в странице TITLE
Если вы или ваши будущие читатели работаете под нерусской Windows, то это , а не . хорошая идея использовать кириллические буквы в заголовке вашей страницы
(текст внутри HTML-тегов и ).Например, MS Internet Explorer вер. 5 и выше (а также Netscape версии 7.
Может отображать такой заголовок Только под Windows 2000 / XP и не может под Windows 95/98 / ME / NT, а Netscape 4.x — 7.0x вообще не сможет этого сделать.Вот моя тестовая страница (написана действительно для выпуска закладок в Netscape — это текст заголовка который идет в закладки) , который объясняет это:
«Заголовок с текстом, отличным от системной кодовой страницы Windows»
Теперь давайте рассмотрим некоторые методы создания текста HTML с русским языком.
1. Текстовые редакторы — код разработчика HTML вручную
В таком случае все, что нужно сделать разработчику, — это выбрать кириллический шрифт в качестве рабочего шрифта в простом тексте. редактор, которым он пользуется. Переведите клавиатуру в режим «RU» и начните печатать.
Вот и все. Зная, как использовать шрифты и клавиатуру, чтобы писать по-русски, это разработчик просто вводит содержимое HTML-файла — текст и теги.
Я лично использую очень хороший условно-бесплатный текстовый редактор. UltraEdit очень подходит для HTML.
Он использует цвет для HTML-тегов, а также позволяет мне создавать свои собственные макросы. Например, Я нажимаю Ctrl / L и сразу вижу в тексте следующую конструкцию:
Все, что мне нужно сделать, чтобы начать писать кириллический HTML, — это выбрать кириллический шрифт, например:
Просмотр / установка шрифта — «Courier New», шрифт — «Cyrillic»
Теперь, переключаясь между «EN» и «RU», я могу писать теги HTML и немного англо-русского контента.
2. WYSIWYG HTML-редактор — создает HTML-текст для вас
Если вы работаете с каким-либо редактором WYSIWYG HTML (который записывает HTML-код / теги будущей веб-страницы для вас молча, «за кадром»), то вы Должны узнать, как для создания таких кириллических (+ английских) файлов HTML —
Распространенная проблема — когда автор делал , а не , настраивал редактор для Кириллица До , начало разработки и, следовательно, HTML-файл создается как файл « Western »
(charset = windows-1252 или charset = iso-8859-1 или charset = us-ascii)
А не как страница « Cyrillic » (ф. е. кодировка = windows-1251).
Обычно в таком случае бывает , нет кириллица. буквы в этом HTML-файле — только объекты SGML, такие как & aacute; или некоторые числовые коды, например & # 1076; — вместо букв кириллицы.
В вашем браузере, когда вы делаете View / Source для такой страницы, есть Нет читаемого русского текста — явный признак того, что эта кириллическая страница была Неправильно написана .
Кроме того, вверху такой некорректно разработанной страницы «Кириллица» можно было увидеть, что он помечен как «Western», потому что в нем есть строка
Как настроить редактор WYSIWYG HTML для создания
Каждый HTML-редактор WYSIWYG требует уникальной настройки для кириллицы, и разработчик должен выяснить это До того, как начнет писать код. Некоторые редакторы может вообще не работать с кириллицей …
Ниже приведены инструкции по настройке для некоторых редакторов WYSIWYG HTML.
Важно. После вы читаете инструкцию по настройке для выбранного вами редактора, сделать , а не , забыть прочесть общий (применимо для любого редактора) «Заключительные примечания для кириллицы HTML» часть этой страницы, в которой перечислено около Распространенных ошибок, которые совершают человек в результате страница становится Нечитаемой для некоторых читателей.
Я лично пробовал шаги настройки кириллицы Только для следующих редакторов WYSIWYG HTML:
- Netscape Composer MS Front Page 2000 MS Word 97 и MS Word 2000 (настройка Word XP , вероятно, такая же, как и для Word 2000)
Есть еще пара редакторов, которые я видел , а не , но нашел шаги по настройке в Интернете:
Вот инструкции по настройке (на примере кодировки кириллицы (Windows-1251)):
- MS Передняя страница 2000
Откройте новый документ и сразу укажите, что вы создаете Cyrillic Текст HTML, а не западный:
- Файл / Свойства / Язык В обоих полях раздела «Кодировка HTML» укажите «Кириллица»
(что на самом деле означает «Кириллица, Windows-1251»)
Это будет гарантировать, что, когда вы не введете текст, будут представлены кириллические буквы. правильно — как обычные буквы, а не какие-то числовые значения.
Примечание. Насколько я слышал, есть проблема с загрузкой в новая версия Dreamweaver некоторые файлы, которые были , а не , были созданы с использованием вышеуказанного rules, и поэтому , а не , содержится внутри строки спецификации кодирования .
То есть Dreamweaver не знает, что это кириллический файл. Так что на кириллице компьютер, скажем, западный, такой файл загружается как файл западной кодировки и теперь он поврежден.
Обходной путь — это (опубликовано В. Зиновьевым в Группа новостей macromedia. dreamweaver) :
- после загрузки такого файла перейдите в Modify / Page properties / Title / Encoding. выберите там «Кириллица (Windows)» (или в любой другой кодировке, в которой, по вашему мнению, находится этот файл) нажмите «Обновить»
Теперь файл будет перезагружен с указанной кодировкой, и DW будет теперь знаю, что такое кодировка.
Важно! Если вы НЕ набираете русский текст прямо в Dreamwever но вместо этого вы Копируете текст, скажем, из MS Word, тогда вы можете столкнуться с проблемой:
Вы получите просто набор вопросительных знаков — . вместо русского текста в результате копирования / вставки.
В таком случае см. Решения в главе 2 «Копирование / вставка». раздела «Юникод и кириллица» на моем сайте.
Вот прямая ссылка на эту главу:
«Unicode: проблемы копирования / вставки».
1. Создание нового текста HTML
- Файл / Новый / Веб-страница Сообщите Word сразу, что вы создаете файл HTML Cyrillic —
Перейдите в Инструменты / Параметры и:
- в окне вкладки «Общие» нажмите кнопку «Параметры Интернета» в окне «Параметры Интернета» перейдите на вкладку «Кодировка» выберите «Кириллица (Windows)» в списке «Сохранить этот документ как»
Вновь созданный HTML-файл будет содержать внутри обычные буквы кириллического алфавита, а также Word. вставляет следующую строку вверху HTML-кода (вы можете увидеть это, используя Просмотр / HTML-код):
Заключительные замечания относительно
После того, как вы разработали кириллическую HTML-страницу «вручную» (с помощью текстового редактора и набирая HTML-код / теги самостоятельно) или позволяя редактору WYSIWYG HTML писать HTML-код / теги за вас, Вам необходимо убедиться, что эта кириллическая веб-страница будет Читаемой для любого конечного пользователя.
Вот несколько распространенных ошибок, которые допускает разработчик, из-за чего страница нечитаемые для некоторых пользователей (в зависимости от их браузера и / или типа компьютера).
Первые два уже упоминались выше, но стоит перечислить здесь И все в одном месте.
Вам необходимо проверить исходный HTML-код, созданный для вас редактором WYSIWYG HTML, чтобы убедиться, что вы не совершали типичных ошибок, перечисленных ниже.
Вы можете проверить исходный HTML-текст с помощью опции View / Source вашего браузера, редактора HTML или открытием. html в текстовом редакторе, который позволяет вам просматривать простой текст Cyrillic — HTML-текст — это простой текст, такой же, как в файле. TXT.
Ошибка 1. Кириллица в HTML-тексте Не содержит обычных букв кириллического алфавита.
Обычно это происходит, когда автор использует какой-нибудь WYSIWYG HTML-редактор, который был настроен на , а не на . создание HTML-текста Cyrillic .
В результате View / Source будет показывать на странице следующее вместо кириллицы письма:
- Субъекты SGML, такие как & aacute;
Или числовые коды (значения Unicode), например & # 1076;
Ошибка 2. Страница объявляется как «западноевропейская», а не как «кириллица».
То есть кодировка Значение (кодировка) для этой страницы не кириллическое. (например, Windows-1251 ), но «Western» — Iso-8859-1 или Windows-1252 или Us-ascii .
Значение набора символов (кодировки) может быть установлено либо в заголовке HTTP, отправленном веб-сервером. в браузер вместе с самой страницей или в «теле» HTML-текста этой страницы, в его части заголовка, например
Примечание. Создание страницы
Хотя в настоящее время большинство русскоязычных веб-страниц имеют кодировку кириллицы (Windows-1251), одна мог разработать русскую страницу в кодировке кириллицы ( KOI8-R ).
Как было объяснено в разделе «Кириллические шрифты и кодировки» раздел моего сайта «Кириллица (русская): инструкции для Windows и Интернета»,
Современные приложения, такие как Netscape 4 + / Mozilla, Internet Explorer, Front Page 2000 и т. д. позволяют пользователю работать с родным для MS Windows набором шрифтов и клавиатурных инструментов — кодирования «Кириллица (Windows-1251)» и обработать KOI8-R Автоматически , без KOI8-R шрифты и инструменты клавиатуры.
Для разработчика кириллической HTML-страницы это означает следующее:
- разработчик вводит текст будущей страницы KOI8-R, используя шрифты Windows-1251, такие как «Arial (Cyrillic)» и инструменты клавиатуры Windows-1251 («RU» на панели задач), так что то, что он / она действительно имеет в окне редактора, — это текст Windows-1251 (или Unicode), а не текст KOI8-R Но если в качестве кодировки для этого HTML-файла был указан KOI8-R, то современные Редакторы WYSIWYG HTML незаметно «за кулисами» Конвертируют текст из Windows-1251 — KOI8-R и поместите текст KOI8-R на жесткий диск в формате. HTML
Они также поместят следующую строку вверху HTML-текста:
Коды HTML для символов греческого языка
Даже если ваш сайт написан только на английском языке и не включает многоязычные переводы, вам может потребоваться добавить символы греческого языка на этот сайт на определенных страницах или для определенных слов.
В приведенный ниже список включены коды HTML, необходимые для использования греческих символов, которые не входят в стандартный набор символов и не встречаются на клавишах клавиатуры. Не все браузеры поддерживают все эти коды (в основном, старые браузеры могут вызывать проблемы; новые браузеры подойдут), поэтому обязательно проверьте свои HTML-коды перед их использованием.
Некоторые греческие символы могут быть частью набора символов Unicode, поэтому вам необходимо указать это в заголовке ваших документов:
Вот различные символы, которые вам могут понадобиться.
| Α | И альфа; | & # 913; | & # x391; | Капитал Альфа |
| Α | & альфа; | & # 945; | & # x3b1; | Строчная Альфа |
| Β | И бета; | & # 914; | & # x392; | Capital Beta |
| Β | И бета; | & # 946; | & # x3B2; | Строчная бета |
| Γ | И гамма; | & # 915; | & # x393; | Capital Gamma |
| Γ | & гамма; | & # 947; | & # x3B3; | Гамма в нижнем регистре |
| Δ | И Дельта; | & # 916; | & # x394; | Capital Delta |
| Δ | & дельта; | & # 948; | & # x3B4; | Дельта строчная |
| Ε | И Эпсилон; | & # 917; | & # x395; | Капитал Эпсилон |
| Ε | & epsilon; | & # 949; | & # x3B5; | Строчная Epsilon |
| Ζ | И Зета; | & # 918; | & # x396; | Capital Zeta |
| Ζ | И дзета; | & # 950; | & # x3B6; | Строчная Zeta |
| Η | & Eta; | & # 919; | & # x397; | Capital Eta |
| Η | & eta; | & # 951; | & # x3B7; | Строчная Eta |
| Θ | И Theta; | & # 920; | & # x398; | Капитал Тета |
| Θ | & theta; | & # 952; | & # x3B8; | Строчная Тета |
| Ι | И йота; | & # 921; | & # x399; | Капитал Йота |
| Ι | И йота; | & # 953; | & # x3B9; | Строчная Йота |
| Κ | И Каппа; | & # 922; | & # x39A; | Капитал Каппа |
| Κ | И каппа; | & # 954; | & # x3BA; | Каппа строчная |
| Λ | И лямбда; | & # 923; | & # x39B; | Заглавная лямбда |
| Λ | & лямбда; | & # 955; | & # x3BB; | Лямбда в нижнем регистре |
| Μ | И Mu; | & # 924; | & # x39C; | Capital Mu |
| Мкм | & mu; | & # 956; | & # x3BC; | Строчная Mu |
| Ν | И Nu; | & # 925; | & # x39D; | Capital Nu |
| Ν | & nu; | & # 957; | & # x3BD; | Nu строчные |
| Ξ | И Си; | & # 926; | & # x39E; | Капитал Си |
| Ξ | И xi; | & # 958; | & # x3BE; | Строчная Xi |
| Ο | И Omicron; | & # 927; | & # x39F; | Капитал Омикрон |
| Ο | & omicron; | & # 959; | & # x3BF; | Строчная Omicron |
| Π | И пи; | & # 928; | & # x3A0; | Capital Pi |
| Π | И пи; | & # 960; | & # x3C0; | Пи строчные |
| Ρ | И Rho; | & # 929; | & # x3A1; | Capital Rho |
| Ρ | & rho; | & # 961; | & # x3C1; | Строчная Rho |
| Σ | И Sigma; | & # 931; | & # x3A3; | Capital Sigma |
| Σ | & сигма; | & # 963; | & # x3C3; | Строчная сигма |
| Σ | И сигмаф; | & # 962; | & # x3C4; | Финальная сигма в нижнем регистре |
| Τ | И Тау; | & # 932; | & # x3A4; | Капитал Тау |
| Τ | & тау; | & # 964; | & # x3C4; | Строчная Тау |
| Υ | И Upsilon; | & # 933; | & # x3A5; | Капитал Ипсилон |
| Υ | И ипсилон; | & # 965; | & # x3C5; | Ипсилон строчные |
| Φ | И Phi; | & # 934; | & # x3A6; | Capital Phi |
| Φ | И phi; | & # 966; | & # x3C6; | Фи в нижнем регистре |
| Χ | И Чи; | & # 935; | & # x3A7; | Capital Chi |
| Χ | И чи; | & # 967; | & # x3C7; | Чи строчная |
| Ψ | И пси; | & # 936; | & # x3A8; | Заглавная буква Psi |
| Ψ | & psi; | & # 968; | & # x3C8; | Строчная Psi |
| Ом | И Омега; | & # 937; | & # x3A9; | Капитал Омега |
| Ω | & омега; | & # 969; | & # x3C9; | Строчная Омега |
Использовать эти символы просто. В разметке HTML вы должны разместить эти коды специальных символов там, где вы хотите, чтобы греческий символ отображался. Они используются аналогично другим кодам специальных символов HTML, которые позволяют добавлять символы, которых также нет на традиционной клавиатуре, и поэтому их нельзя просто ввести в HTML для отображения на веб-странице.
Помните, что эти коды символов могут использоваться на англоязычном веб-сайте, если вам нужно отобразить слово с одним из этих символов. Эти символы также будут использоваться в HTML, который фактически отображает полные греческие переводы, независимо от того, действительно ли вы кодировали эти веб-страницы вручную и имели полную греческую версию сайта, или если вы использовали более автоматизированный подход к многоязычным веб-страницам и перешли с таким решением, как Google Translate.
Отредактировал Джереми Жирар
Ascii для кодировки кириллицы (CP855)
Американский стандартный код для обмена информацией ( ASCII ) — широко используемая система кодирования Символов , представленная в 1963 году.
Исходный набор символов, который теперь называется стандартным набором символов, изначально состоял из 128 символов (7-битный код). Первые 32 символа — это управляющие символы (также называемые непечатаемыми символами), которые используются для управления потоками данных, а также такими устройствами, как принтеры. Позже он был расширен для поддержки 256 символов (8-битный код), чтобы обеспечить языковые символы, различные символы, а также символы для рисования прямоугольников: элементы, используемые для целей презентации, позволяющие рисовать различные типы рамок и прямоугольников. Символы в диапазоне 128–255 называются расширенным ASCII.
Кодовая страница 855 — это альтернативная Кодовая страница , используемая для написания языков на основе кириллицы: белорусский, боснийский, болгарский, македонский, русский, сербский, украинский (славянские языки) и казахский, киргизский, молдавский, монгольский, таджикский, узбекский ( неславянский).Он не очень популярен, наиболее широко используется кодовая страница 866. Только расширенный набор символов отличается от исходной кодовой страницы, причем как управляющие символы, так и стандартный набор символов представляют собой простой ASCII.
В приведенной ниже таблице Символов показано графическое представление каждого символа с точностью до пикселя вместе с текстовым описанием.
Управляющие символы (0 — 31):
Стандартный набор символов (32-127):
Расширенный набор символов (128-255):
Руководство пользователя Глава 6: Поддержка Unicode и не-ASCII
Глава 6.Поддержка Unicode и не-ASCII
6.1 Формат для печати в кавычках
6.2 Символы не-ASCII в заголовках
6.3 Unicode и UTF-8
6.4 Поддержка UTF-8 в AspEmail
6.5 Допустимые значения CharSet
6.1 Формат цитируемой печати
AspEmail может отправлять сообщения в алфавитах, отличных от US-ASCII. за счет поддержки формата «Цитата для печати». Этот формат описан в RFC-2045.Идея формата заключается в том, что символы с кодами меньше 33 и больше чем 126 представлены знаком «=», за которым следует двузначное шестнадцатеричное представление.
AspEmail кодирует тело сообщения в формате Quoted-Printable автоматически, если для свойства ContentTransferEncoding установлено значение строка «Quoted-Printable» (регистр букв не имеет значения).Вы также можете установить свойство Charset к соответствующему набору символов. Следующий фрагмент кода отправляет сообщение на русском языке:
Директива предписывает интерпретатор ASP для обработки жестко запрограммированных символов в сценарии в виде русских символов (1251 — русская кодовая страница).Как результат, Body получит русскую строку Unicode.
6.2 Символы не-ASCII в заголовках
Если вы хотите отправить сообщение с определенными заголовками, например, Тема: , To: или From: , содержащие символы, отличные от US-ASCII, следует использовать метод Mail.
6.3 Юникод и UTF-8
Из MSDN: «Юникод — это 16-битный стандарт кодировки символов фиксированной ширины, который охватывает практически все символы, обычно используемые на компьютерах сегодня. Это включает в себя большинство письменных языков мира, а также издательские персонажи, математические и технические символы и знаки препинания «.
Из Unicode. org: «Компьютеры … хранят буквы и другие символы присвоение номера каждому. До изобретения Unicode существовало сотни различных систем кодирования для присвоения этих чисел. Ни одна кодировка не может содержать достаточно символов … Unicode предоставляет уникальный номер для каждого символа, независимо от того, какая платформа, какая программа, на каком языке ».
Например, основная латинская буква «А» имеет шестнадцатеричный код 0041 (65), русский буква имеет код Hex 0416 (1046), а китайский иероглиф имеет код Hex 32A5 (12965).
UTF-8 (формат преобразования Unicode, 8-битная форма кодирования) рекомендуется формат, который будет использоваться для отправки данных на основе Unicode по сетям, в частности, через Интернет. UTF-8 представляет значение Unicode как последовательность из 1, 2 или 3 байтов.
Символы Юникода в диапазоне от 0000 до 007F кодируются просто как байты. 00 до 7F. Это означает, что файлы и строки, содержащие только 7-битный ASCII символы имеют одинаковую кодировку как в ASCII, так и в UTF-8.Следовательно, Unicode 0041 («A») в UTF-8 — это Hex 41.
Символы Юникода в диапазоне от 0080 до 07FF кодируются как последовательность из двух байтов. Например, Unicode 0416 () кодируется как Hex D0 96. Кодируются символы Unicode в диапазоне от Hex 0800 до FFFF. как последовательность из трех байтов. Например, Unicode 32A5 () кодируется как Hex E3 8A A5.
6.4 Поддержка UTF-8 в AspEmail
AspEmail 5.0 предлагает полную поддержку UTF-8 как в теле сообщения, так и в заголовках. Чтобы отправить сообщение в кодировке UTF-8, вы должны установить CharSet свойство к строке « UTF-8 » (регистр не имеет значения), и ContentTransferEncoding на « Quoted-Printable ». Вы также должны передать « UTF-8 » в качестве второго аргумента для EncodeHeader .
В следующем примере кода демонстрируется использование UTF-8:
Перевод Unicode для элементов формы
Session. CodePage = 65001 ‘Код UTF-8Если Запрос («Отправить») «» То
Установите Mail = Server. CreateObject («Persits. MailSender»)
‘введите действительный SMTP-хост
Mail. Host = strHostMail. From = «[email protected]» ‘с адреса
Mail. FromName = Mail. EncodeHeader (Запрос («FromName»), «utf-8»)
Почта. Запрос AddAddress («Кому»)‘тема сообщения
Mail.‘тело сообщения
Mail. Body = Request («Body»)‘Параметры UTF-8
Mail. CharSet = «UTF-8»
Mail. ContentTransferEncoding = «Quoted-Printable»
Mail. Send ‘отправить сообщение
Response. Write «Сообщение отправлено» & Request («To»)
Конец, если
%>AspEmail: Unicode. asp
В этом примере кода есть несколько важных элементов, которые нельзя упускать из виду:
Этот тег META определяет набор символов для этой страницы как UTF-8.Это, помимо прочего, указывает браузеру кодировать все элементы формы в кодировке UTF8. когда форма отправлена.
Session. CodePage = 65001
Эта строка указывает нашему сценарию ASP преобразовывать элементы формы в кодировке UTF8. (возвращается коллекцией Request. Form) обратно к обычным строкам Unicode. Номер 65001 — это кодовая страница UTF-8.
Mail. Subject = Mail. EncodeHeader (Запрос («Тема»), «utf-8»)
Второй необязательный аргумент установлен в «UTF-8» для правильного кодирования заголовка.
Mail. CharSet = «UTF-8»
Mail. ContentTransferEncoding = «Quoted-Printable»Эти две строки обеспечивают правильную кодировку UTF-8 тела сообщения.
Щелкните ссылки ниже, чтобы запустить этот пример кода:
Http: //localhost/aspemail/NonAscii/Unicode. asp
Http: //localhost/aspemail/NonAscii/Unicode. aspx
6.5 допустимых значений CharSet
Вы можете указать следующие строковые значения для свойства CharSet , а также второй необязательный аргумент метода EncodeHeader :
Значение Значение «UTF-8» UTF-8 «UTF-7» UTF-7 «Окна-1250»
«cp1250»ANSI — Центральная Европа «Окна-1251»
«cp1251»ANSI — кириллица «Windows-1252»
«cp1252»
«ascii»
«us-ascii»Латиница I «Окна-1253»
«cp1253»ANSI — греческий «Окна-1254»
«cp1254»ANSI — турецкий «Windows-1255»
«cp1255»ANSI — иврит «Окна-1256»
«cp1256»ANSI — арабский «Окна-1257»
«cp1257»ANSI — Балтика «Окна-1258»
«cp1258»ANSI — вьетнамский «ISO-8859-1» Latin I (значение по умолчанию) «ISO-8859-2» Центральная Европа «ISO-8859-3» Латиница 3 «ISO-8859-4» Балтика «ISO-8859-5» Кириллица «ISO-8859-6» Арабский «ISO-8859-7» Греческий «ISO-8859-8» Еврейский «ISO-8859-9» Латиница 5 «ISO-8859-15» Латиница 9 «cp866» Русский DOS «КОИ8-Р» Русский «кои8-у» Украинский Shift_jis Японская Windows «ks_c_5601-1987»
«корейский»Корейский «EUC-KR»
«корейский»EUC — корейский «BIG5» Традиционный китайский Windows «GB2312»
«китайский»Китайский упрощенный «HZ-GB-2312» Упрощенный китайский HZ «EUC-JP» EUC — японский «X-EUC-TW» EUC — традиционный китайский
PostgreSQL: Документация: 9.
3: Поддержка набора символовПоддержка набора символов в PostgreSQL позволяет хранить текст в множество наборов символов (также называемых кодировками), включая однобайтовые наборы символов, такие как серия ISO 8859 и многобайтовые наборы символов, такие как EUC (Extended Unix Code), UTF-8 и Mule внутренний код. Можно использовать все поддерживаемые наборы символов. прозрачно для клиентов, но некоторые из них не поддерживаются для использования внутри сервера (то есть как кодирование на стороне сервера). По умолчанию набор символов выбирается при инициализации кластера базы данных PostgreSQL с помощью initdb. Его можно переопределить при создании база данных, поэтому у вас может быть несколько баз данных с разными набор символов.
Однако важным ограничением является то, что каждая база данных набор символов должен быть совместим с настройками локали базы данных LC_CTYPE (классификация символов) и LC_COLLATE (порядок сортировки строк). Для C или POSIX языковой стандарт, разрешен любой набор символов, но для других языков есть это только один набор символов, который будет работать правильно. (В Windows однако кодировку UTF-8 можно использовать с любой локалью.)
Таблица 22-1 показывает наборы символов, доступные для использования в PostgreSQL.
Таблица 22-1. PostgreSQL Наборы символов
| BIG5 | Большая пятерка | Традиционный китайский | № | 1-2 | WIN950, Windows950 |
| EUC_CN | Расширенный код UNIX-CN | Китайский упрощенный | Есть | 1-3 | |
| EUC_JP | Расширенный код UNIX-JP | Японский | Есть | 1-3 | |
| EUC_JIS_2004 | Расширенный код UNIX-JP, JIS X 0213 | Японский | Есть | 1-3 | |
| EUC_KR | Расширенный код UNIX-KR | Корейский | Есть | 1-3 | |
| EUC_TW | Расширенный код UNIX-TW | Китайский традиционный, тайваньский | Есть | 1-3 | |
| ГБ18030 | Национальный стандарт | Китайский | № | 1-4 | |
| ГБК | Национальный стандарт расширенный | Китайский упрощенный | № | 1-2 | WIN936, Windows936 |
| ISO_8859_5 | ISO 8859-5, ECMA 113 | Латиница / кириллица | Есть | 1 | |
| ISO_8859_6 | ISO 8859-6, ECMA 114 | Латинский / арабский | Есть | 1 | |
| ISO_8859_7 | ISO 8859-7, ECMA 118 | Латинский / греческий | Есть | 1 | |
| ISO_8859_8 | ISO 8859-8, ECMA 121 | Латиница / Иврит | Есть | 1 | |
| JOHAB | JOHAB | Корейский (хангыль) | № | 1-3 | |
| KOI8R | КОИ8-Р | Кириллица (русская) | Есть | 1 | КОИ8 |
| КОИ8У | КОИ8-У | Кириллица (украинская) | Есть | 1 | |
| LATIN1 | ISO 8859-1, ECMA 94 | Западноевропейская | Есть | 1 | ISO88591 |
| LATIN2 | ISO 8859-2, ECMA 94 | Центральноевропейская | Есть | 1 | ISO88592 |
| LATIN3 | ISO 8859-3, ECMA 94 | Южноевропейский | Есть | 1 | ISO88593 |
| LATIN4 | ISO 8859-4, ECMA 94 | Северо-Европейский | Есть | 1 | ISO88594 |
| LATIN5 | ISO 8859-9, ECMA 128 | Турецкий | Есть | 1 | ISO88599 |
| LATIN6 | ISO 8859-10, ECMA 144 | Северный | Есть | 1 | ISO885910 |
| LATIN7 | ISO 8859-13 | Балтика | Есть | 1 | ISO885913 |
| LATIN8 | ISO 8859-14 | Селтик | Есть | 1 | ISO885914 |
| LATIN9 | ISO 8859-15 | LATIN1 с евро и акцентами | Есть | 1 | ISO885915 |
| LATIN10 | ISO 8859-16, ASRO SR 14111 | Румынский | Есть | 1 | ISO885916 |
| MULE_INTERNAL | Мул внутренний код | Многоязычный Emacs | Есть | 1-4 | |
| SJIS | Сдвиг JIS | Японский | № | 1-2 | Мсканджи, ShiftJIS, WIN932, Окна932 |
| SHIFT_JIS_2004 | Сдвиг JIS, JIS X 0213 | Японский | № | 1-2 | |
| SQL_ASCII | Не указано (см. Текст) | Любой | Есть | 1 | |
| UHC | Единый код хангыль | Корейский | № | 1-2 | WIN949, Windows949 |
| UTF8 | Unicode, 8 бит | Все | Есть | 1-4 | Юникод |
| WIN866 | Окна CP866 | Кириллица | Есть | 1 | ALT |
| WIN874 | Окна CP874 | Тайский | Есть | 1 | |
| WIN1250 | Окна CP1250 | Центральноевропейская | Есть | 1 | |
| WIN1251 | Окна CP1251 | Кириллица | Есть | 1 | ВЫИГРАТЬ |
| WIN1252 | Окна CP1252 | Западноевропейская | Есть | 1 | |
| WIN1253 | Окна CP1253 | Греческий | Есть | 1 | |
| WIN1254 | Окна CP1254 | Турецкий | Есть | 1 | |
| WIN1255 | Окна CP1255 | Еврейский | Есть | 1 | |
| WIN1256 | Окна CP1256 | Арабский | Есть | 1 | |
| WIN1257 | Окна CP1257 | Балтика | Есть | 1 | |
| WIN1258 | Окна CP1258 | Вьетнамский | Есть | 1 | ABC, TCVN, TCVN5712, VSCII |
Не все клиентские API поддерживают все перечисленные наборы символов. Например, драйвер PostgreSQL JDBC не поддерживает MULE_INTERNAL, LATIN6, LATIN8 и ЛАТИНСКИЙ 10.
Параметр SQL_ASCII ведет себя значительно отличается от других настроек. Когда сервер набор символов — SQL_ASCII, сервер интерпретирует байтовые значения 0-127 в соответствии со стандартом ASCII, а байтовые значения 128–255 считаются неинтерпретируемыми символами. Нет преобразование кодировки будет выполнено, если установлено значение SQL_ASCII. Таким образом, этот параметр не так уж и хорош. объявление, что используется определенная кодировка, как объявление незнание кодировки. В большинстве случаев, если вы работаете с любыми данными, отличными от ASCII, неразумно использовать параметр SQL_ASCII, потому что PostgreSQL не сможет вам помочь преобразование или проверка символов, отличных от ASCII.
Initdb определяет символ по умолчанию установить (кодировку) для PostgreSQL кластер. Например,
Устанавливает набор символов по умолчанию на EUC_JP (расширенный код Unix для японского языка). Ты можешь используйте —encoding вместо — E, если вы предпочитаете более длинные строки параметров. Если нет — E или —encoding задана опция, initdb пытается определить подходящую кодировку для использования на основе указанного или языковой стандарт по умолчанию.
Вы можете указать нестандартную кодировку при создании базы данных. время, при условии, что кодировка совместима с выбранной язык:
Это создаст базу данных с именем korean, которая использует набор символов EUC_KR и локаль ko_KR. Другой способ сделать это — использовать эту команду SQL:
Обратите внимание, что приведенные выше команды определяют копирование базы данных template0. При копировании любой другой базы данных, настройки кодировки и локали не могут быть изменены по сравнению с исходной базы данных, поскольку это может привести к повреждению данных. Для дополнительную информацию см. в разделе 21.3.
Кодировка для базы данных хранится в системном каталоге. pg_database. Вы можете увидеть это, используя параметр psql — l или команда \ l.
Важно: В большинстве современных операционных систем PostgreSQL может определить, какой набор символов подразумевается настройкой LC_CTYPE, и это заставит использовать только соответствующую кодировку базы данных. На старые системы, вы несете ответственность за использование кодировка, ожидаемая выбранной вами локалью. Ошибка в эта область может привести к странному поведению зависящего от локали такие операции, как сортировка.
PostgreSQL позволит суперпользователи для создания баз данных с кодировкой SQL_ASCII, даже если LC_CTYPE не C или POSIX. Как отмечалось выше, SQL_ASCII не требует, чтобы данные, хранящиеся в база данных имеет какую-либо конкретную кодировку, поэтому этот выбор ставит риски ненадлежащего поведения, зависящего от местных условий. Используя эту комбинацию настройки устарели и когда-нибудь могут быть полностью запрещены.
PostgreSQL поддерживает автоматическую преобразование набора символов между сервером и клиентом наверняка комбинации наборов символов. Информация о преобразовании хранится в системный каталог pg_conversion. PostgreSQL поставляется с некоторыми предопределенные преобразования, как показано в Таблице 22-2. Ты может создать новое преобразование с помощью команды SQL CREATE CONVERSION.
Таблица 22-2. Преобразование набора символов клиент / сервер
| BIG5 | Не поддерживается в качестве сервера кодировка |
| EUC_CN | EUC_CN, MULE_INTERNAL, UTF8 |
| EUC_JP | EUC_JP, MULE_INTERNAL, SJIS, UTF8 |
| EUC_JIS_2004 | EUC_JIS_2004, SHIFT_JIS_2004, UTF8 |
| EUC_KR | EUC_KR, MULE_INTERNAL, UTF8 |
| EUC_TW | EUC_TW, BIG5, MULE_INTERNAL, UTF8 |
| ГБ18030 | Не поддерживается в качестве сервера кодировка |
| ГБК | Не поддерживается в качестве сервера кодировка |
| ISO_8859_5 | ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
| ISO_8859_6 | ISO_8859_6, UTF8 |
| ISO_8859_7 | ISO_8859_7, UTF8 |
| ISO_8859_8 | ISO_8859_8, UTF8 |
| JOHAB | Не поддерживается в качестве сервера кодировка |
| KOI8R | KOI8R, ISO_8859_5, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
| КОИ8У | КОИ8У, UTF8 |
| LATIN1 | LATIN1, MULE_INTERNAL, UTF8 |
| LATIN2 | LATIN2, MULE_INTERNAL, UTF8, WIN1250 |
| LATIN3 | LATIN3, MULE_INTERNAL, UTF8 |
| LATIN4 | LATIN4, MULE_INTERNAL, UTF8 |
| LATIN5 | LATIN5, UTF8 |
| LATIN6 | LATIN6, UTF8 |
| LATIN7 | LATIN7, UTF8 |
| LATIN8 | LATIN8, UTF8 |
| LATIN9 | LATIN9, UTF8 |
| LATIN10 | LATIN10, UTF8 |
| MULE_INTERNAL | MULE_INTERNAL, BIG5, EUC_CN, EUC_JP, EUC_KR, EUC_TW, ISO_8859_5, KOI8R, LATIN1 в LATIN4, SJIS, WIN866, WIN1250, WIN1251 |
| SJIS | Не поддерживается в качестве сервера кодировка |
| SHIFT_JIS_2004 | Не поддерживается в качестве сервера кодировка |
| SQL_ASCII | Любой (конвертации не будет выполнено) |
| UHC | Не поддерживается в качестве сервера кодировка |
| UTF8 | Все поддерживаются кодировки |
| WIN866 | WIN866, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN1251 |
| WIN874 | WIN874, UTF8 |
| WIN1250 | WIN1250, LATIN2, MULE_INTERNAL, UTF8 |
| WIN1251 | WIN1251, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866 |
| WIN1252 | WIN1252, UTF8 |
| WIN1253 | WIN1253, UTF8 |
| WIN1254 | WIN1254, UTF8 |
| WIN1255 | WIN1255, UTF8 |
| WIN1256 | WIN1256, UTF8 |
| WIN1257 | WIN1257, UTF8 |
| WIN1258 | WIN1258, UTF8 |
Чтобы включить автоматическое преобразование набора символов, вы должны указать PostgreSQL набор символов (кодировка), которую вы хотели бы использовать в клиенте. Есть несколько способов добиться этого:
Использование команды \ encoding в psql. \ encoding позволяет изменять кодировку клиента на муха. Например, чтобы изменить кодировку на SJIS, введите:
Libpq (Раздел 31.10) имеет функции для управления клиентская кодировка.
Использование SET client_encoding TO. Параметр кодирование клиента может быть выполнено с помощью этой команды SQL:
Также вы можете использовать стандартный синтаксис SQL SET ИМЕНА для этого:
Для запроса текущей клиентской кодировки:
Для возврата к кодировке по умолчанию:
Использование PGCLIENTENCODING. Если переменная среды PGCLIENTENCODING равна определена в клиентской среде, эта клиентская кодировка автоматически выбирается при подключении к серверу. (Впоследствии это можно изменить, используя любой из других методов. упомянуто выше.)
Использование переменной конфигурации client_encoding. Если установлена переменная client_encoding, эта клиентская кодировка выбирается автоматически при подключении к сервер сделан. (Впоследствии это может быть отменено с помощью любого других методов, упомянутых выше.)
Если преобразование определенного символа невозможно — предположим, вы выбрали EUC_JP для сервера и LATIN1 для клиента, а некоторые Возвращаются японские символы, которые не имеют представления в LATIN1 — сообщается об ошибке.
Если набор символов клиента определен как SQL_ASCII, преобразование кодировки отключено, независимо от набора символов сервера. Как и в случае с сервером, использование SQL_ASCII неразумно, если вы не работа с данными в формате ASCII.
Это хорошие источники для начала изучения различных видов системы кодирования.
CJKV Обработка информации: китайский, Вычислительная техника в Японии, Корее и Вьетнаме
Содержит подробные объяснения EUC_JP, EUC_CN, EUC_KR, EUC_TW.
Веб-сайт Консорциума Unicode.
UTF-8 (8-битный UCS / Unicode Формат преобразования) определяется здесь.
Чтение и запись кириллицы
Если вы используете Windows, вы можете загрузить точный шрифт, использованный для создания этих страниц, нажав ЗДЕСЬ . Если вы установите его на 10 pt., Вы должны получить очень точное совпадение со шрифтами в графике. Компьютеры Macintosh выглядят лучше, если шрифты ER Bukinist установлены на 12 пунктов. Они доступны ЗДЕСЬ . Если вы используете другую платформу, установите размер шрифта 10 pts. должен дать вам наилучшее совпадение со словами действия, встроенными в текст.
После того, как вы установили шрифты KOI8-R на свой компьютер, вы также должны настроить Netscape Navigator или MS Internet Explorer 5.0 для доступа к ним. Чтобы настроить Netscape Navigator 4.5, необходимо выполнить три шага:
Откройте меню «Правка» и выберите «Настройки» и «Шрифты», а затем выберите «Кириллица» в окне «Для кодировки документа». Если у вас есть многоязычная поддержка, вы можете использовать шрифт Times New Roman или Arial. Если вы не используете многоязычную поддержку, выберите шрифты KOI8-R (новый русский или ERBukinist) для «пропорционального шрифта» и KOI8-R Courier (Courier Cyrillic или Bukinist) для выбора «шрифта фиксированной ширины» в Папка «Шрифты».
В разделе «Просмотр» откройте «Набор символов» и установите для него «Кириллица (KOI8-R)»
Наконец, вернитесь в «Набор символов» и нажмите «Установить по умолчанию», если вы хотите, чтобы этот шрифт изначально отображался в навигаторе каждый раз, когда вы его открываете.
Для MS Internet Explorer 5.0 выберите «Свойства обозревателя» в меню «Инструменты». Внизу страницы выберите «Шрифты» и выберите подходящий шрифт для вашего языкового сценария «Кириллица». Все остальное MSIE сделает за вас. Возможно, вам придется установить «Кодировку» в «Вид» для «Кириллица (KOI-8)» для некоторых страниц; однако все страницы в этой грамматике должны автоматически открываться шрифтами KOI8. Однако, хотя страница может открываться в KOI8 автоматически, клавиатура может не работать без ручной настройки кодировки страницы на «Кириллица (KOI8)».
Письменный русский
Если вы хотите записать упражнения в справочную грамматику, помимо установки шрифтов KOI8-R вам необходимо (1) установить кириллическую клавиатуру и (2) настроить ваш браузер для кодирования документов KOI8-R.
KOI8-R Клавиатуры
Чтобы установить буквенно-буквенную кириллическую клавиатуру учащегося, необходимо приобрести ее или загрузить в Интернете. Следуйте инструкциям по его установке. Если вы используете Windows 95/98, загрузите Bucknell KOI8 Keyboard Package здесь. Он основан на Tavultesoft Keyboard Manager Летнего института лингвистики. Пакет Bucknell поставляется со стандартной русской раскладкой клавиатуры и буквенной раскладкой учащегося, где русские буквы соответствуют латинским буквам с таким же или похожим звуком. Инструкции по установке Tavultesoft Keyboard Manager включены в пакет. Теперь есть менеджер клавиатуры Tavultesoft для Windows NT, доступный от автора за 30 долларов.
Если вы используете Mac, вы можете получить клавиатуру с раскладкой, аналогичной латинице, загрузив наш пакет шрифтов ERBukinist , указанный выше. Вы устанавливаете клавиатуру, перетаскивая ее в системный каталог, затем вы должны установить расширение клавиатуры (под яблоком) на KOI8-R.
Печать кириллицей
Если у вас нет цветного принтера, перед печатью этих страниц проверьте параметры файла / страницы в Netscape и убедитесь, что установлен флажок «Черный текст».Когда вы распечатываете эти страницы, сами генерируемые слова будут отображаться как основа + окончание, а не как полностью производное слово. (В конце концов, именно поэтому электронный формат предпочтительнее.)
@documentencoding (GNU Texinfo 6.8)
Команда @documentencoding объявляет входной документ кодирование, а также может влиять на кодировку вывода. Напиши это на отдельная строка с действующей спецификацией кодировки, следующей за начало файла.
Texinfo поддерживает следующие кодировки:
Это не имеет особого значения, но включено для полноты картины.
Обширная глобальная кодировка символов, выраженная в 8-битных байтах.
ISO-8859-1 ¶ ISO-8859-15 ISO-8859-2
Это стандартные кодировки для западноевропейских (первый два) и восточноевропейские языки (третий) соответственно. ISO 8859-15 заменяет некоторые малоиспользуемые символы из 8859-1 (например, предварительно составленные дроби) с более часто используемыми, такими как Символ евро (€).
Полное описание кодировок здесь выходит за рамки наших возможностей; одна полезная ссылка — http://czyborra. com/charsets/iso8859.html.
Это обычно используемая кодировка для русского языка.
Это обычно используемая кодировка украинского языка.
Указание кодировки enc имеет следующие эффекты:
В выводе Info есть так называемая секция «Локальные переменные» (см. Раздел «Файл Переменные в Руководство GNU Emacs ) выводится, включая приложение. Это позволяет читателям Info устанавливать кодировку соответственно. Это выглядит так:
Также, при выводе информации и обычного текста, если опция —disable-encoding передается makeinfo, акцент конструкции и специальные символы, такие как @ ‘e, выводятся как фактический 8-битный символ или символ UTF-8 в данной кодировке, где возможно.
В выводе HTML выводится тег « » в « ». раздел HTML, в котором указано код. Веб-серверы и браузеры сотрудничают, чтобы использовать эту информацию, поэтому правильная кодировка используется для отображения страницы, если поддерживается системой. Это похоже это:
В выводе XML и DocBook всегда используется UTF-8, согласно соглашениям этих форматов.
В выводе TeX символы, которые поддерживаются в стандарте Соответственно выводятся шрифты Computer Modern. Например, это означает использование акцентов, а не заранее составленных глифов. Использование отсутствующего символа генерирует предупреждающее сообщение, как и указание нереализованной кодировки.
Хотя современные системы TeX поддерживают почти все скрипты, используемые в во всем мире эта широкая поддержка недоступна в texinfo. tex, и невозможно дублировать или включать все эти усилия.(Наш план по поддержке других скриптов — создать Серверная часть LaTeX на texi2any, где уже есть поддержка настоящее время.)
Для максимальной переносимости документов Texinfo через множество различных пользовательских сред в мире, мы рекомендуем придерживаться 7-битного ASCII во входных данных, если ваше конкретное руководство не требует значительного количества не-ASCII, например, написано на немецком языке. Вы можете использовать @U команда для вставки случайного необходимого символа (см. Вставка Unicode: @U ).
Примечание. Кириллица в странице TITLE
Если вы или ваши будущие читатели работаете под нерусской Windows, то это , а не . хорошая идея использовать кириллические буквы в заголовке вашей страницы
(текст внутри HTML-тегов и ). Например, MS Internet Explorer вер. 5 и выше (а также Netscape версии 7.1 и выше и Mozilla версии 1.4 и выше)
Может отображать такой заголовок Только под Windows 2000 / XP и не может под Windows 95/98 / ME / NT, а Netscape 4.x — 7.0x вообще не сможет этого сделать. Вот моя тестовая страница (написана действительно для выпуска закладок в Netscape — это текст заголовка который идет в закладки) , который объясняет это:
«Заголовок с текстом, отличным от системной кодовой страницы Windows»
Дополнительное видео по теме
Как добавить кодировку страницы?
Вы когда-нибудь видели на странице в интернете какие-то знаки вопроса, квадратики и прочее вместо текста? Думаю, что видели. Так вот, у этого сайта проблема с кодировкой, вполне возможно разработчик ее не указал. Кодировка, простыми словами, это таблица содержащая набор символов. Для того чтобы добавить кодировку сайта, нужен многофункциональный тег, о нем написан целый урок. Итак, чтобы браузер понял, какую кодировку вы используете, применяйте эту строку:
Что такое кодировка?
Кодировка, это набор символов, представленный в таблице. Таблица содержит сам символ и его код, например, двоичный (нули и единицы). Термин «набор символов» редко используется, чаще всего говорят «кодировка». На данный момент популярны две кодировки: ASCII и UTF-8. На нашем сайте используется кодировка UTF-8 .
Подробнее о кодировке?
Кодировка ASCII является американской и разрабатывалась для английского языка. Так как, к примеру, французский язык имеет надстрочные знаки, а русский алфавит не похож на английский, был разработан стандарт Unicode для расширения кодировки ASCII. Но и в Unicode, со временем, стало не хватать места для размещения новых символов. Поэтому на основе Unicode создали кодировку UTF-8, которая исправила эти недостатки. UTF-8 позволяет кодировать до 2 миллиардов символов, поэтому она доминирует в интернете.
В UTF-8 коды от 0 до 127 используются для представления символов ASCII. Если символ не входит в набор ASCII, то старший бит первого байта устанавливается в 1, что свидетельствует о дополнительном использовании байтов. То есть если в документе используются только символы из ASCII, то каждый символ в UTF-8 будет кодироваться восьмью битами.
Что такое атрибуты?
Настало время познакомиться с атрибутами в HTML. Вы их уже встречали, просто на них не акцентировалось внимание. Атрибуты – это дополнение к тегам, расширяющее их возможности. Они всегда указываются в открывающемся теге. Атрибут состоит из имени и значения, разделенного знаком равенства.
Имя атрибута необходимо писать в нижнем регистре. Хотя HTML5 и позволяет писать в любом регистре и не использовать кавычки, все же так не рекомендуется делать.
- разработчик вводит текст будущей страницы KOI8-R, используя шрифты Windows-1251, такие как «Arial (Cyrillic)» и инструменты клавиатуры Windows-1251 («RU» на панели задач), так что то, что он / она действительно имеет в окне редактора, — это текст Windows-1251 (или Unicode), а не текст KOI8-R Но если в качестве кодировки для этого HTML-файла был указан KOI8-R, то современные Редакторы WYSIWYG HTML незаметно «за кулисами» Конвертируют текст из Windows-1251 — KOI8-R и поместите текст KOI8-R на жесткий диск в формате. HTML
Они также поместят следующую строку вверху HTML-текста:
Коды HTML для символов греческого языка
Полезная информация и краткая ретроспектива
Современные редакторы позволяют преобразовать текст открытого документа из одной кодировки в другую, а стандартный Блокнот позволяет выбрать кодировку только при сохранении файла.
Xn—90abhccf7b. xn--p1ai
25.09.2018 17:19:34
2018-09-25 17:19:34
Источники:
Https://xn--90abhccf7b. xn--p1ai/html/kodirovka-russkogo-yazyka-v-html-atribut-charset-htmlbook-ru. html
Как исправить отображение кириллицы в Windows 10 | » /> » /> .keyword { color: red; }
Кодировка для русского языкаОдна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
В этой инструкции — о том, как исправить «кракозябры» (или иероглифы), а точнее — отображение кириллицы в Windows 10 несколькими способами. Возможно, также будет полезным: Как установить и включить русский язык интерфейса в Windows 10 (для систем на английском и других языках).
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач. Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region). На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale). Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.
После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
Нажмите клавиши Win+R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра. Перейдите к разделу реестраи в правой части пролистайте значения этого раздела до конца. Дважды нажмите по параметру ACP, установите значение 1251 (кодовая страница для кириллицы), нажмите Ок и закройте редактор реестра. Перезагрузите компьютер (именно перезагрузка, а не завершение работы и включение, в Windows 10 это может иметь значение).
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252. nls на c_1251.nls.
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
Зайдите в папку C:\ Windows\ System32 и найдите файл c_1252.NLS, нажмите по нему правой кнопкой мыши, выберите пункт «Свойства» и откройте вкладку «Безопасность». На ней нажмите кнопку «Дополнительно». В поле «Владелец» нажмите «Изменить». В поле «Введите имена выбираемых объектов» укажите ваше имя пользователя (с правами администратора). Если в Windows 10 используется учетная запись Майкрософт, вместо имени пользователя укажите адрес электронной почты. Нажмите «Ок» в окне, где указывали пользователя и в следующем (Дополнительные параметры безопасности) окне. Вы снова окажетесь на вкладке «Безопасность» в свойствах файла. Нажмите кнопку «Изменить». Выберите пункт «Администраторы» (Administrators) и включите полный доступ для них. Нажмите «Ок» и подтвердите изменение разрешений. Нажмите «Ок» в окне свойств файла. Переименуйте файл c_1252.NLS (например, измените расширение на. bak, чтобы не потерять этот файл). Удерживая клавишу Ctrl, перетащите находящийся там же в C:\Windows\System32 файл c_1251.NLS (кодовая страница для кириллицы) в другое место этого же окна проводника, чтобы создать копию файла. Переименуйте копию файла c_1251.NLS в c_1252.NLS. Перезагрузите компьютер.
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач. Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region). На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale). Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.
Зайдите в папку C:\ Windows\ System32 и найдите файл c_1252.NLS, нажмите по нему правой кнопкой мыши, выберите пункт «Свойства» и откройте вкладку «Безопасность». На ней нажмите кнопку «Дополнительно». В поле «Владелец» нажмите «Изменить». В поле «Введите имена выбираемых объектов» укажите ваше имя пользователя (с правами администратора). Если в Windows 10 используется учетная запись Майкрософт, вместо имени пользователя укажите адрес электронной почты. Нажмите «Ок» в окне, где указывали пользователя и в следующем (Дополнительные параметры безопасности) окне. Вы снова окажетесь на вкладке «Безопасность» в свойствах файла. Нажмите кнопку «Изменить». Выберите пункт «Администраторы» (Administrators) и включите полный доступ для них. Нажмите «Ок» и подтвердите изменение разрешений. Нажмите «Ок» в окне свойств файла. Переименуйте файл c_1252.NLS (например, измените расширение на. bak, чтобы не потерять этот файл). Удерживая клавишу Ctrl, перетащите находящийся там же в C:\Windows\System32 файл c_1251.NLS (кодовая страница для кириллицы) в другое место этого же окна проводника, чтобы создать копию файла. Переименуйте копию файла c_1251.NLS в c_1252.NLS. Перезагрузите компьютер.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц.
Remontka. pro
08.09.2020 13:54:50
2020-09-08 13:54:50
Источники:
Https://remontka. pro/fix-cyrillic-windows-10/
Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Обновлено 19 января 2021 Просмотров: 144 451 Автор: Дмитрий ПетровЗдравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.
Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):
Видите, в правом столбце цифры начинаются с 8, т. к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Кодировки русского текста | Практическая информатика
Исторически сложилось так, что для представления печатных символов (кодирования текста) в первых ЭВМ отвели 7 бит. 27=128. Этого количества вполне хватало для кодирования всех строчных и прописных букв латинского алфавита, десяти цифр и различных знаков и скобок. Именно такой, 7-битной, является таблица символов ASCII (американский стандартный код для обмена информацией), подробную информацию о которой вы можете получить при помощи команды man ascii операционной системы Linux.
Когда возникла необходимость кодировать национальные алфавиты, то 128 символов стало недостаточно. Было решено перейти на кодирование с помощью 8 бит (т. е. одного байта). В результате количество символов, которые можно закодировать таким образом стало равно 28=256. При этом символы национальных алфавитов располагались во второй половине кодовой таблицы, т. е. содержали единицу в старшем разряде байта, отведенного для кодирования символа. Так появился стандарт ISO 8859, содержащий множество кодировок для наиболее распространенных языков.
Среди них была и одна из первых таблиц для кодировки русских букв — ISO 8859-5 (воспользуйтесь командой man iso_8859_1 для получения кодов русских букв в этой таблице).
Задачи передачи текстовой информации по сети вынудили разработать еще одну кодировку для русских букв, названную Koi8-R (код отображения информации 8-битный, русифицированный). Рассмотрим ситуацию, когда письмо, содержащее русский текст, отправлено по электронной почте. Случалось, что в процессе путешествия по сетям письмо обрабатывалось программой, которая работала с 7-битной кодировкой и обнуляла восьмой бит. В результате такого преобразования код символа уменьшался на 128, превращаясь в код символа латинского алфавита. Возникла необходимость повысить устойчивость передаваемой текстовой информации к обнулению 8 бита.
К счастью, значительное число букв кириллицы имеет фонетические аналоги в латинском алфавите. Например, Ф и F, Р и R. Есть несколько букв, совпадающих даже по начертанию. Расположив русские буквы в кодовой таблице таким образом, чтобы их код превышал код аналогичных латинских на число 128, добились того, что потеря 8-го бита превращала текст хотя и в состоящий из одной латиницы, но все равно понимаемый русскоязычным пользователем.
Так как из всех операционных систем, распространенных в то время, самыми удобными средствами работы с сетью обладали различные клоны операционной системы Unix, то эта кодировка стала фактическим стандартом в этих системах. Таковой она является и сейчас в ОС Linux. И именно эта кодировка чаще всего применяется для обмена почтой и новостями в Интернет.
Далее наступила эра персональных компьютеров и операционной системы MS DOS. Как выяснилось, кодировка Koi8-R для нее не подходила (так же, как и ISO 8859-5), в ее таблице некоторые русские буквы находились на тех местах, которые многие программы предполагали заполненными псевдографикой (горизонтальные и вертикальные черточки, уголки и т. д.). Поэтому была придумана еще одна кодировка кириллицы, в таблице которой русские буквы «обтекали» со всех сторон графические символы. Назвали эту кодировку альтернативной (alt), поскольку она была альтернативой официальному стандарту — кодировке ISO-8859-5. Неоспоримым достоинством этой кодировки является то, что русские буквы в ней расположены в алфавитном порядке.
После появления ОС Windows от фирмы Microsoft выяснилось, что альтернативная кодировка по некоторым причинам для нее не подходит. Снова передвинув русские буквы в таблице (появилась возможность — ведь псевдографика в Windows не требуется), получили кодировку Windows 1251 (Win-1251).
Но компьютерные технологии постоянно совершенствуются и в настоящее время все большее число программ начинает поддерживать стандарт Unicode, который позволяет кодировать практически все языки и диалекты жителей Земли.
Итак, в различных ОС предпочтение отдается разным кодировкам. Для того чтобы стало возможным чтение и редактирования текста, набранного в другой кодировке, используются программы перекодирования русского текста. Некоторые текстовые редакторы содержат встроенные перекодировщики, позволяющие читать текст в различных кодировках (Word и др.). Мы для перекодировки файлов будем использовать ряд утилит в ОС Linux, назначение которых ясно из названия: alt2koi, win2koi, koi2win, alt2win, win2alt, koi2alt (откуда, куда, цифра 2 (two) схожа по звучанию с предлогом to, указывающим направление). Эти команды имеют одинаковый синтаксис: команда <входной_файл >выходной_файл.
Пример
Перекодируем текст, набранный в редакторе Edit в среде MS DOS, в кодировку Koi8-R. Для этого выполним команду
alt2koi file1.txt > filenew
Так как в MS DOS и Linux по разному кодируется перевод строки, рекомендуется выполнить еще команду «fromdos»:
fromdos filenew > file2.txt
Команда с обратным действием называется «todos» и имеет такой же синтаксис.
Пример
Отсортируем файл List.txt, содержащий список фамилий и подготовленный в кодировке Koi8-R, в алфавитном порядке. Воспользуемся командой sort, которая сортирует текстовый файл по возрастанию или убыванию кодов символов. Если применить ее сразу, то, например, буква В окажется в конце списка, аналогично соответствующей ей букве латинского алфавита V. Вспомнив, что в альтернативной кодировке русские буквы расположены строго по алфавиту, выполним ряд операций: перекодируем текст в альтернативную кодировку, отсортируем его и снова вернем в кодировку Koi8-R. С использованием конвейера команд получаем
koi2alt List.txt | sort | alt2koi > List_Sort.txt
В современных дистрибутивах ОС Linux решены многие проблемы, связанные с локализацией программного обеспечения. В частности утилита sort теперь учитывает особенности кодировки Koi8-R и для сортировки файла в алфавитном порядке достаточно выполнить команду
sort List.txt > List_Sort.txt
Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Сегодня мы поговорим о том, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная с базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8. Оглавление:
- ASCII — базовая кодировка текста для латиницы
- Расширенные версии Аски — кодировки CP866 и KOI8-R
- Windows 1251 — вариация ASCII и почему вылезают кракозябры
- Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
- Кракозябры вместо русских букв — как исправить
Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (нечитаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки неблагозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания. Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы вроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального варианта ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать о системах счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет собой двойку в степени, начиная с нулевой, и до двойки в седьмой: Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получается 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому способу. Каждый байт информации разбивают на две части по четыре бита. Т.е. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом. Причем в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), нужно выполнить два условия: векторная форма этого знака должна быть в используемом шрифте, и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита, и она являлась расширенной версией ASCII.
То есть, ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика): Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Таким образом, у кириллической буквы «М» в CP866 будет код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте. Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда графические операционные системы не были распространены как сейчас. А в Досе и подобных ей текстовых операционках псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что кириллические буквы в ее таблице идут не в алфавитном порядке, как это сделали в CP866. Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251. По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF. В результате чего один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет-трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16). Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. То есть, базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов. В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы. Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, если вы сохраняете документ в принятом по умолчанию юникоде, это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть). В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами. По идее элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов. Ссылка на первоисточник: Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Как разработать кириллическую HTML-страницу
Как разработать кириллическую HTML-страницуКак разработать кириллическую HTML-страницу
На этой странице объясняется, как разработчик может создать файл .html с кириллическим текстом внутри него.
Примечание. Английский алфавит как особый случай (отличный, скажем, от немецкого).
Набор символов кириллицы, как и любой другой набор символов в мире (японская, китайская, центральноевропейская и др.Символы ASCII (например, знаки препинания и т. д.) включают также английского алфавита .
То есть английские буквы являются частью набора символов кириллицы!Таким образом, наличие веб-страницы с русскими и английскими буквами означает, что , а не , означает, что у вас есть многоязычный страница. Нет, на этой странице используется одна кириллическая кодировка, и эта кодировка содержит английский язык. буквы (точнее — символы ASCII).
Другой случай: настоящие многоязычных страниц, где, скажем, русские буквы должны сочетаться с немецкими буквы или польский или японский.
Этот случай описан на другой странице моего сайта — «Как разработать многоязычную HTML-страницу»То есть эта статья — о создании кириллической (например, русской) веб-страницы, т.
Очень другой сценарий : когда вы хотите создать веб-страницу без кириллицы (например, страницу западноевропейской кодировки) и просто поместите туда пару русских слов —
это НЕ рассматривается здесь, это рассматривается в другой статье , упомянутой выше —
«Как разработать многоязычную HTML-страницу»Шрифт создан для определенной кодировки, и поскольку каждая кодировка содержит ASCII, каждый шрифт в мире также содержит ASCII. Так что любой кириллический шрифт содержит Английский букв.
Чтобы создать кириллический (или кириллический+английский) HTML-файл, то есть текст с одним набором символов, разработчик просто пишет некоторый кириллический (+английский) текст при использовании некоторого кириллического шрифта и соответствующий режим клавиатуры.
Большинство русскоязычных веб-страниц (более 90% точно) сделаны в настоящее время в кодировке Windows-1251, также известной как «Кириллица(Windows)»,
просто потому, что большинство авторов сейчас работают под MS Windows, а 1251 — это то, что Microsoft использует для кириллицы,
так встроенная кириллица винды 9Шрифты 0009 Клавиатура и Инструменты предназначены для кодирования Windows-1251.
Поэтому намного проще набрать текст в кодировке «Кириллица (Windows-1251)» в обычном текстовом редакторе Windows.
чем набирать текст в кодировке «кириллица (KOI8-R)».
Набрать текст в кодировке «Кириллица, ISO-8859-5» под MS Windows практически невозможно.
Но действительно , а не имеет значение, какую кодировку использовал автор — основные браузеры отлично работают с все кодировки кириллицы , и пока веб-страница сделана правильно (ниже), она будет отображаться конечному пользователю тоже правильно. В последней части этой страницы обсуждается создание KOI8-Rpage — на всякий случай.
Как написать по-русски с помощью шрифтов и клавиатуры — с индикатором «RU» на панели задач — объясняется в разделе «Введение. Кириллица в Windows» раздел моего сайта «Кириллица (русская): инструкция для Windows и интернета»
Если кириллическая страница создана правильно, то конечный пользователь сможет прочитать эту страницу,
например, переключившись на кириллицу
в браузере (например, Вид/Кодировка/Кириллица(Windows) или
Просмотр/Кодировка/Кириллица(KOI8-R) в Internet Explorer) если на странице не указана ее кодировка.
Примечание. Кириллица в названии страницы НАЗВАНИЕ
Если вы или ваши будущие читатели работаете под нерусской виндой, то вместо хорошая идея использовать кириллицу в заголовке вашей страницы
(текст внутри тегов HTMLи ).Например, MS Internet Explorer вер. 5 и выше (а также Netscape версии 7.1 и выше и Mozilla версии 1.4 и выше)
может показывать такой заголовок только под Windows 2000/XP и не может под Windows 95/98/ME/NT, в то время как Netscape 4.x — 7.0x вообще не сможет этого сделать.Вот моя тестовая страница (написана действительно для проблемы с закладками в Netscape — это текст заголовка который идет в закладки) , что объясняет это:
«Заголовок с текстом, отличным от кодовой страницы системы Windows»
Теперь давайте рассмотрим некоторые способы создания HTML-текста с русским языком.
1.
Редакторы обычного текста — разработчик кодирует HTML вручную В таком случае все, что нужно сделать разработчику, это выбрать кириллический шрифт в качестве рабочего шрифта в обычном тексте.
редактор, который он использует. Переключите клавиатуру в режим «RU» и начните печатать.
Вот и все. Зная, как использовать шрифты и клавиатуру, чтобы писать по-русски, это
разработчик просто вводит содержимое файла HTML — текст и теги.
Лично я использую очень хороший условно-бесплатный текстовый редактор.
UltraEdit, который очень подходит для HTML.
Он использует цвет для тегов HTML, а также позволяет мне создавать свои собственные макросы. Например,
Нажимаю Ctrl/L и сразу в тексте такая конструкция:
<УЛ>
<ЛИ>
<ЛИ>
<ЛИ>
Все, что мне нужно сделать, чтобы начать писать кириллический HTML, это выбрать кириллический шрифт, например:
Посмотреть/Установить Шрифт — «Курьер Новый», Шрифт — «Кириллица»
Теперь, переключаясь между «EN» и «RU», я могу писать HTML-теги и некоторый англо-русский контент.
2. HTML-редактор WYSIWYG — создает HTML-текст для вас
Если вы работаете с HTML-редактором WYSIWYG (который пишет HTML-код/теги будущей веб-страницы
для вас молча, «за кадром»), то вам должен научиться
для создания таких кириллических (+английских) файлов HTML —
распространенная проблема, когда автор сделал , а не настройку редактора для
Кириллица до начало разработки и соответственно HTML файл
создается как файл « Western »
(charset=windows-1252 или charset=iso-8859-1 или charset=us-ascii)
а не как страница « Cyrillic » (например, charset=windows-1251).
Обычно в таком случае их нет Кириллица
буквы в этом HTML-файле — только объекты SGML, такие как á или некоторые числовые коды, такие как д — вместо букв кириллицы.
В вашем браузере, когда вы выполняете View/Source для такой страницы, есть нет читаемого русского текста есть — явный признак того, что эта кириллическая страница была неправильно авторской.
Также вверху такой некорректно развернутой «кириллицы» можно было увидеть, что
он помечен как «западный», потому что в нем есть строка ..charset=…
(конечный пользователь затем вручную выберет кириллическую кодировку в браузере)
или же
Как настроить HTML-редактор WYSIWYG для создания правильного кириллического HTML
Каждый HTML-редактор WYSIWYG требует уникальной настройки для кириллицы. и разработчик должен это выяснить до начиная писать код. Некоторые редакторы может вообще не уметь работать с кириллицей…
Ниже приведены инструкции по настройке для некоторых HTML-редакторов WYSIWYG.
Важно.
Я лично пробовал шаги настройки кириллицы только для следующих HTML-редакторов WYSIWYG:
- Композитор Netscape
- Передняя страница MS, 2000 г.
- MS Word 97 и MS Word 2000 (настройка Word XP , вероятно, такая же, как и для Word 2000)
Есть еще пара редакторов, которые я сделал , а не , сам видел, но нашел шаги настройки в Интернете:
- Домашний сайт 4.5
- ДримВивер
Вот инструкция по настройке (на примере кириллической (Windows-1251) кодировки):
- Передняя страница MS 2000
Откройте новый документ и сразу укажите, что вы создаете Кириллица HTML-текст, а не западный:
- Файл/Свойства/Язык
- В обоих полях раздела «Кодировка HTML» указать «Кириллица»
(что на самом деле означает «Кириллица, Windows-1251»)
Это гарантирует, что при удалении текста кириллические буквы будут отображаться правильно — как обычные буквы а не какие-то числовые значения.
Front Page 2000 вставит следующую строку вверху исходного HTML-кода:
.Ctrl+U — Категория — Шрифты/Кодировка: Кодировка по умолчанию = Кириллица (Windows1251)
и/или
Ctlr+J — Свойства страницы: Кодировка документа = Кириллица (Windows1251)См. более подробную информацию на странице поддержки Macromedia: «Использование английского Dreamweaver для разработки страниц не на английском языке».
Насколько я слышал, MX линейки Dreamweaver нуждается в дополнительной настройке:
- Закрыть Dreamweaver (обязательно!)
- Открыть (скажем, в блокноте) файл Dreamweaver MX/Configuration/Encodings/ EncodingMenu.xml
- Найдите строку с
macfontscript=7 имя_файла=»iso88595.xml»/>» - Теперь вставка, до строка, указанная выше, следующая строка («приклеить» текст ниже
в одну строку ):
«
macfontscript=7 имя_файла=»Win1251. xml»/>»
Примечание. Насколько я слышал, проблема с загрузкой в новая версия Dreamweaver некоторые файлы, которые были , а не , созданный с использованием вышеуказанного правил и, таким образом, , а не , содержат строку спецификации кодирования .
То есть Dreamweaver не знает, что это кириллический файл. Так на некириллице компьютер, скажем, западный, такой файл загружается как файл в западной кодировке и теперь он поврежден.
Обходной путь — следующий (прислал В.Зиновьев в группа новостей macromedia.dreamweaver) :- после загрузки такого файла перейдите в Modify/Page properties/Title/Encoding
- выберите там «Кириллица (Windows)» (или любую другую кодировку, в которой, по вашему мнению, находится файл)
- нажмите «Обновить»
Теперь файл будет перезагружен с указанной кодировкой, и DW теперь знаю, что такое кодировка.
Важно! Если вы НЕ набираете русский текст прямо в Dreamwever но вместо этого вы копируете текст, скажем, из MS Word, тогда вы можете столкнуться с проблемой:
вы получаете просто набор вопросительных знаков — ??? вместо русского текста в результате копирования/вставки.
Если это так, см. решения в главе 2 «Копирование/вставка». раздела «Юникод и кириллица» на моем сайте.
Вот прямая ссылка на эту главу:
«Юникод: проблемы с копированием/вставкой». - MS Word 2000 (Word XP , вероятно, работает так же)
Это , а не , рекомендуется использовать Word для создания файла HTML, потому что Word создает для вас код HTML, который содержит много ненужных тегов HTML, файл большой и т.д.
Но в любом случае, вот как это сделать в Word 2000.
Есть два разных сценария: либо вы создаете совершенно новый текст HTML, либо конвертируете существующий . doc в .html.1. Создание нового HTML-текста
- Файл/Новый/Веб-страница
- Немедленно сообщите Word, что вы создаете кириллический файл HTML —
перейдите в Инструменты/Параметры и:- в окне вкладки «Общие» нажмите кнопку «Веб-параметры».
- в окне «Веб-параметры» перейдите на вкладку «Кодировка»
- выберите «Кириллица (Windows)» в списке «Сохранить этот документ как»
- Теперь вы можете печатать кириллицей
- Файл/Сохранить как. Не используйте русский язык в имени файла.
Нажмите на кнопку «Заголовок» в диалоговом окне «Файл/Сохранить как», чтобы при необходимости изменить заголовок — это , а не . Хорошая идея использовать кириллицу в заголовке веб-страницы.
Вновь созданный файл HTML будет содержать обычные буквы кириллицы внутри, а также Word вставляет следующую строку вверху HTML-кода (это можно увидеть с помощью Вид / HTML-источник):
Преобразование существующего .doc в HTML
- Открыть кириллический документ (.doc) в Word 2000
- Немедленно сообщите Word, что вы создаете кириллический файл HTML —
перейдите в Инструменты/Параметры и:- в окне вкладки «Общие» нажмите кнопку «Веб-параметры».
- в окне «Веб-параметры» перейдите на вкладку «Кодировка»
- выберите «Кириллица (Windows)» в списке «Сохранить этот документ как»
- Файл / Сохранить как веб-страницу. Не используйте русский язык в имени файла.
Нажмите на кнопку «Заголовок» в диалоговом окне File/SaveAsWebPage, чтобы при необходимости изменить Заголовок — это , а не . Хорошая идея использовать кириллицу в заголовке веб-страницы.
Вновь созданный файл HTML будет содержать обычные буквы кириллицы внутри, а также Word вставляет следующую строку вверху HTML-кода (это можно увидеть с помощью Вид/Источник HTML):
д.
Но в любом случае, вот как это сделать в Word 97:- Откройте кириллический документ (.doc) в Word или введите текст в новом окне
- Файл / Сохранить как HTML. Не используйте русский язык в имени файла.
- Word может выдать предупреждающее сообщение о форматировании. Просто не обращай внимания — нажмите «Да», чтобы продолжить
- Word может выдать вам еще одно предупреждающее сообщение — о символах/кодировке/UTF-8. Просто игнорируйте его — нажмите «ОК», чтобы продолжить.
- Сообщите Word, что вы создаете кириллический файл HTML —
заходим в Файл/Свойства и:- Изменить поле Заголовок, если необходимо (это , а не , хорошая идея иметь кириллицу там )
- Выберите «Кириллица» в списке «Для отображения этой страницы»
- Выберите «Кириллица» в списке «Для сохранения этой страницы»
- Очень важно — выполните File/Save now — чтобы сохранить изменения, сделанные на предыдущем шаге
Теперь HTML-файл будет содержать обычные буквы кириллицы внутри, а также Word вставляет следующую строку вверху HTML-кода (это можно увидеть с помощью Вид/Источник HTML):
4 и выше имеет встроенный HTML-редактор WYSIWYG — Композитор :
- в Netscape 6 — Задача/Композитор или Файл/Новая/Пустая страница для редактирования
- в Netscape 4.x — Communicator/Composer или File/New/Blank Page
Я напишу этапы настройки на примере создания текста Windows-1251, но те же шаги следует выполнить, если вы создаете страницу KOI8-R:
- В меню Композитора выберите нужную кодировку кириллицы:
- Netscape 6 — Вид/Кодировка символов/Кириллица (Windows-1251)
- Netscape 4.5+ — Вид/Набор символов/Кириллица (Windows-1251)
- Netscape 4.0x — Вид/Кодировка/Кириллица (Windows-1251)
- Убедитесь, что имя шрифта не указано, чтобы избежать проблемы FONT FACE=…
- Netscape 6 — формат/шрифт/переменная ширина
- Нетскейп 4 —
найдите небольшое окно на панели инструментов, в котором отображается число (размер используемого шрифта).
Слева от этого окна есть еще одно окно, в котором Netscape показывает либо тип шрифта, например, «Variable Width» , или имя определенного шрифта, если вы выбрали какой-то, например, «Ариал» .
Убедитесь, что у вас НЕ есть имя определенного шрифта.
Вы должны увидеть (или выбрать) в этом окне пункт «Переменная ширина» .
Это означает, что Composer будет использовать шрифты, выбранные для Encoding=Cyrillic в Правка/Настройки/Внешний вид/Шрифты.
В таком случае на вашей странице будет , а не жестко закодированных имен шрифтов, нет тегов HTML FONT FACE=….
Вышеизложенное поможет вам создать правильно оформленный кириллический HTML текст.
После того, как вы разработали кириллическую HTML-страницу либо «вручную» (используя простой текстовый редактор
и введя код/теги HTML самостоятельно) или разрешив редактору WYSIWYG HTML написать код/теги HTML для вас,
вам нужно проверить, что эта кириллическая веб-страница будет читаемой для любого конечного пользователя.
Вот некоторые распространенные ошибки, которые допускает разработчик, из-за чего страница
нечитаемым для некоторых пользователей (в зависимости от типа их браузера и/или компьютера).
Первые два уже упоминались выше, но стоит перечислить все товара здесь, в одном месте.
Вам необходимо проверить исходный HTML-код, созданный WYSIWYG-редактором HTML, чтобы убедиться, что
вы не допустили распространенных ошибок, перечисленных ниже.
Вы можете проверить исходный HTML-текст с помощью параметра «Просмотр/Источник» вашего браузера или вашего HTML-редактора или
открыв файл .html в текстовом редакторе, который позволяет просматривать обычный текст кириллица —
HTML-текст — это обычный текст, такой же, как в файле .TXT.
Ошибка 1. Кириллический HTML-текст , а не содержит обычные буквы кириллического алфавита.
Обычно это происходит, когда автор использует HTML-редактор WYSIWYG версии 9. 0009, а не настроен на
создание кириллического HTML текста.
В результате View/Source будет отображать внутри страницы следующее вместо кириллицы
буквы:
- Сущности SGML, такие как á
или же - числовые коды (значения Unicode), такие как д
Ошибка 2. Страница заявлена как «западноевропейская», а не как «кириллица».
То есть значение charset (кодировка) для этой страницы не является кириллицей
(типа windows-1251 например), но «западные» — iso-8859-1 или windows-1252 или us-ascii .
Значение Charset (кодировки) может быть установлено либо в заголовке HTTP, отправляемом веб-сервером
в браузер вместе с самой страницей или в «теле» HTML-текста этой страницы,
в его заголовочной части, например HTML-теги используются для кириллических строк.
Хорошая, удобочитаемая для всех кириллическая веб-страница должна содержать теги HTML , а не . .
Автор должен , а не предположить, какие именно шрифты на компьютере конечного пользователя
будет содержать кириллицу — как он/она?
Очень возможно, что
на компьютере автора с установленным Office 2000 «Вердана» содержит кириллицу, а
у конечного пользователя в Windows 98 может быть только западный шрифт «Verdana» и, таким образом, будет , а не .
видеть любую читаемую кириллицу, если этот автор окружает кириллицу текстом !
Это верно не только для кириллицы, но и для любой незападноевропейской письменности.
Вы можете прочитать мою отдельную страницу о тегах и (что также может сделать текст нечитаемым):
«Неправильно оформленные, нечитаемые русские страницы».
Если ваш WYSIWYG-редактор окружил ваши кириллические строки такими тегами, вам может потребоваться открыть HTML-файл. в обычном текстовом редакторе (или используйте Source Edit, если такая опция существует в вашем редакторе WYSIWYG)
и вручную удалить таких тегов (только те, которые окружают кириллический текст.
Западноевропейские струны могут иметь его).
Примечание. Создание
КОИ8-Р стр.Несмотря на то, что в настоящее время большинство русскоязычных веб-страниц имеют кириллицу (Windows-1251), одна можно разработать русскую страницу в кириллической ( KOI8-R ) кодировке.
Как было пояснено на «Кириллические шрифты и кодировки» раздел моего сайта «Кириллица (русская): инструкция для Windows и интернета»,
современные приложения, такие как Netscape 4+/Mozilla, Internet Explorer, Front Page 2000 и т. д.
разрешить пользователю работать с родным для MS Windows набором шрифтов и клавиатурных инструментов —
кодировки «Кириллица(Windows-1251)» и процесс KOI8-R автоматически , без
Шрифты KOI8-R и инструменты клавиатуры.
Для разработчика кириллической HTML-страницы это означает следующее:
- разработчик вводит текст будущей страницы KOI8-R, используя шрифты Windows-1251, такие как «Arial (Cyrillic)» и средства клавиатуры Windows-1251 («RU» на панели задач), так что он/она действительно имеет в окне редактора текст Windows-1251 (или Unicode), а не текст KOI8-R
- Но если в качестве кодировки для этого HTML-файла была указана KOI8-R, то современная
HTML-редакторы WYSIWYG молча, «за кулисами» преобразовать текст из
Windows-1251 в KOI8-R и поместите текст KOI8-R на жесткий диск в формате .html
. Они также поместят следующую строку вверху HTML-текста:
.
Таких преобразователей очень много. Два из них обсуждаются в Раздел «Преобразование кодировки» моего сайта. - Вам необходимо указать правильное значение charset (кодировка) для такой страницы:
- , либо имея HTTP-заголовок с charset=koi8-r , отправленный веб-сервером вместе со страницей
или же - , указав его в «теле» вашего HTML-текста —
DOCTYPE и кириллица — HTML и CSS — Форумы SitePointтанцы_матильда
#1
Привет,
Хочу написать чистые xhtml страницы под кириллицу и не могу найти как какой DOCTYPT использовать и какой тег в шапке для языка.Я просто меняю EN в DOCTYPE на RU?
Что лучше сделать понятной кириллица в шапке страницы?Спасибо за ответы и советы.
Танцующая МатильдаРальф
#2
танцующая_матильда:
Я просто меняю EN в DOCTYPE на RU?
Я думаю, что это правильно, но я не буду на этом ругаться. Я определенно видел это раньше:
[COLOR="Красный"][/COLOR]
Вот очень старая, но все еще полезная ветка на эту тему, которая может быть полезна:
Форумы SitePointФорумы SitePoint
Сообщество веб-дизайнеров и разработчиков для обсуждения всего, от HTML, CSS, JavaScript, PHP до Photoshop, SEO и многого другого.
система
#3
здесь речь идет о кодировке, а не о DTD.
во-первых, ваша страница должна быть написана и закодирована с использованием utf-8, которая представляет собой большой набор символов, включая кириллицу. это также спасает жизнь, когда у вас смешанный языковой контент: русский, немецкий, французский.
, тогда вам нужно заставить сервер отправлять соответствующую информацию о кодировке: директивы AddType или AddDefaultCharset для Apache. при этом строка в заголовке HTTP будет выглядеть так: Content-Type: text/html; кодировка=utf-8. как вы увидите, также рекомендуется поместить эту информацию заголовка в раздел заголовка на вашей странице.
и, наконец, вы должны включить их на свою страницу:
вы можете использовать более мелкую кириллицу, например, iso-8859-5 или windows-1251, но utf-8 является более безопасным вариантом.
Stomme_poes
#4
noonope прав: и вы НЕ меняете «EN» в типе документа!
Это не часть набора символов. Вместо этого это связано с опубликованным языком DTD.Держите тип документа таким же, как на любой западной, азиатской или любой другой странице, и установите свой язык, как сказал noonope: с атрибутом lang в теге HTML (или также с атрибутами xml: lang, если вы пишете XHTML), мета content-lang и, самое главное, на вашем сервере (если сервер и ваши метатеги конфликтуют, сервер побеждает).
Наконец, единственное, о чем noonope не упомянул, это сохранить ваш документ также в кодировке UTF-8 (или меньшей кодировке, если вы выберете какую-либо другую кодировку — просто держите их все совместимыми друг с другом). Если редактор документа сохраняет в какой-то другой кодировке, а сервер пытается отправить в другой кодировке, пользователь увидит много ??? везде.
, вы можете использовать более узкую кодировку, например iso-8859-5 или windows-1251, но utf-8 является более безопасным вариантом.
Гораздо безопаснее… Я не работаю под Windows, поэтому мой компьютер не всегда хорошо справляется с кодировками только для Windows (1251, 1252).
dance_mathilde
#5
Большое спасибо за полезную информацию.
«Stomme poes»: ??? Заметил в браузере
Еще раз спасибо.система
#6
Stomme_poes:
Наконец, единственное, о чем noonope не упомянул, это сохранение вашего документа также в UTF-8 (или меньшей кодировке, если вы выберете какую-то другую кодировку — просто держите их все совместимыми друг с другом).
Если редактор документа сохраняет в какой-то другой кодировке, а сервер пытается отправить в другой кодировке, пользователь увидит много ??? везде.но я сделал…
сначала ваша страница должна быть написана и закодирована с использованием utf-8
Stomme_poes
#7
Ах да… Я думаю об этом только как о «сохранении как», потому что в большинстве редакторов кодировка устанавливается при сохранении. Но это также может отличаться для каждого редактора.
система
#8
я использую notepad++ для html и css.
в нем вы можете изменить кодировку вашего файла на лету, используя параметры в меню «Кодировка». и я установил по умолчанию для нового файла в notepad++ значение UTF-8 без спецификации. так что не сохраняйте, как для меня:)это важная часть для контента, отличного от ANSI, на вашей веб-странице: запуск документа в кодировке UTF-8 для вашей страницы, и поэтому я поставил его первым:
, ваша страница должна быть написана и закодирована с использованием utf-8, которая представляет собой большой набор символов, включая кириллицу. это также спасает жизнь, когда у вас смешанный языковой контент: русский, немецкий, французский.
если вы обслуживаете такой файл как UTF-8 на стороне сервера, этого должно быть достаточно. на самом деле нет необходимости в lang=»ru» или charset=utf-8, по крайней мере, чтобы не гарантировать правильное отображение символов на вашем сайте
xhtmlcoder
#9
Я полагаю, вы имеете в виду, что хотели бы изменить человеческий язык, используемый на всей странице, а не использовать комбинацию языков на странице?
Например, азбука, ISO-8859-5, как упоминалось ранее, вы обычно устанавливаете параметр «charset» поля заголовка «Content-Type» протокола HTTP.
В противном случае в (x)html вы, вероятно, использовали бы объявления META Content-Type, которые должны появляться как можно раньше в элементе HEAD, то есть перед TITLE. В качестве окончательной защиты от сбоев вы можете использовать атрибут «charset».
. . .
«ru»>
. . .
Другими словами, если существует конфликт между несколькими объявлениями кодирования в XHTML, следует следующее:- Заголовок HTTP Content-Type
- метка порядка байтов (BOM)
- XML-декларация
- метаэлемент
- атрибут кодировки ссылки
Как уже упоминалось, обычно UTF-8 обычно охватывает большинство вещей, хотя в некоторых случаях могут быть проблемы с отображением из-за шрифтов/глифов, в некоторых языках и т.
д.Unicode, как правило, не включает кириллические буквы с диакритическими знаками. Кодировка KOI8-R популярна для русского текста и используется чаще, чем ISO-8859-5, но поддержка Unicode замедляет их замену.
Не используйте только наборы символов Windows, они абсолютно злые!
Поэс, вероятно, имел в виду «символ замены» (часто черный ромб с белым вопросительным знаком), символ, встречающийся в стандарте Unicode в кодовой точке U+FFFD в таблице Specials.
Stomme_poes
#10
lang=»ru»,
на самом деле не нуженНа самом деле есть. Программы чтения с экрана и другие а11ы должны обращать внимание на атрибуты языка, и они это делают.
Если мой ридер по умолчанию настроен на английский язык, я не хочу, чтобы он пытался читать русский язык с английским произношением. Я не должен слушать, выяснять, что такое язык на самом деле, и возиться с настройками.или кодировка=utf-8,
Я всегда включаю его по двум причинам:
- проверка
- У меня нет контроля над сервером, и я хочу, чтобы несоответствия появлялись, когда на сервере устанавливают дурацкие кодировки. Я также жестко кодирую все свои символы, отличные от ASCII, с десятичными объектами HTML для тех, которые всегда должны отображаться правильно.
Это правда, что если ваш сервер настроен правильно, метатеги не нужны, так как браузер их проигнорирует, но валидатор настаивает на этом.
Поэс, вероятно, имел в виду «замещающий символ» — (часто черный ромб с белым вопросительным знаком) символ, встречающийся в стандарте Unicode в кодовой точке U+FFFD в таблице Specials.
Я заметил, что Safari использует странный вариант, а в автомате Doze просто пустые ящики.
При несоответствии символов вы можете получить �, но если у вас нет шрифта в системе, по крайней мере, в Linux, вы получите поле с маленькими символами внутри.система
#11
xhtmlcoder:
Юникод, как правило, не включает буквы кириллицы с диакритическими знаками.
провел небольшое исследование, и я думаю, что это стоит упомянуть:
Unicode не включает кириллические буквы с ударением, но их можно комбинировать, добавляя U+0301 («сочетание острого ударения») после ударной гласной (например, ы́ э́ ю́ я́). Некоторые языки, в том числе современный церковнославянский, до сих пор не полностью поддерживаются.
www.google.ru также использует utf-8. я думаю, можно с уверенностью предположить, что utf-8 можно использовать для кириллических страниц.
Stomme_poes
#12
Unicode не включает кириллические буквы с ударением, но их можно комбинировать, добавляя U+0301 («сочетание острого ударения») после ударной гласной (например, ы́ э́ ю́ я́). Некоторые языки, в том числе современный церковнославянский, до сих пор не полностью поддерживаются.
Это проблема. Есть много персонажей, которые могут быть представлены либо как один персонаж, либо как комбинация двух. Там буква, я думаю, это была маленькая j, но с циркумфлексом вместо точки сверху? Или какая-то похожая буква, где была двухсимвольная комбинация для прописных букв, но не для строчных, или наоборот… Я читал об этой конкретной букве в книге по регулярным выражениям. Регулярные выражения могут блевать на эти различия. Почему я боюсь зайти слишком далеко в регулярных выражениях и юникоде!
Я думаю, можно с уверенностью предположить, что utf-8 можно использовать для кириллических страниц.
Я бы.
система
№13
Stomme_poes:
На самом деле есть. Программы чтения с экрана и другие а11ы должны обращать внимание на атрибуты языка, и они это делают.
Я всегда включаю его по двум причинам:
- проверка
- У меня нет контроля над сервером, и я хочу, чтобы несоответствия появлялись, когда на сервере устанавливают дурацкие кодировки.
ты прав, но…
на самом деле нет необходимости в lang=»ru» или charset=utf-8, по крайней мере, чтобы не гарантировать правильное отображение символов на вашем сайте
я пытался убедиться, что OP понимает:
каковы минимальные требования для создания кириллической веб-страницы: текстовый файл, содержащий страницу, должен быть правильно закодирован и отправлен с заголовком соответствующего типа содержимого.
какие еще включения для: lang, meta
и ваши дополнения были действительно необходимы, чтобы сделать вещи еще более ясными, есть случаи, когда это необходимо.
Хроникмастер1
№14
Для тех, кто хочет перейти к делу, вот код, который я использую неукоснительно. Я использую XHTML, поэтому мне нужно включить атрибуты lang и xml:lang в тег html. Вы определяете набор символов в метатеге следующим образом.
<голова>«
0″ encoding=»UTF-8″?>» до того, как тип документа будет технически правильным для определения набора символов. Однако это заставляет IE (или, по крайней мере, некоторые версии) таять в маленькие лужицы нефункциональной слизи, поэтому я никогда не использовал его и не рекомендую. Я не использовал метатег для определения языка, однако, не зная какой-либо ключевой причины для его включения, определение любого параметра в нескольких местах является плохой практикой. Как только один обновится, а другой нет, ваша страница будет противоречить сама себе, что может привести к проблемам.
полдень:
, ваша страница должна быть написана и закодирована с использованием utf-8, которая представляет собой большой набор символов, включая кириллицу. это также спасает жизнь, когда у вас смешанный языковой контент: русский, немецкий, французский.
Я думаю, мы должны вернуться к этому. Это настоящая причина, по которой вы используете utf-8.
Существуют всевозможные тонкие сбои, которые могут возникнуть, если вы попытаетесь закодировать одну страницу в одной кодировке, а другую страницу на том же сайте — в другой. Попытка использовать два разных языка на одной странице может сработать в зависимости от того, какие именно символы вы используете, и от того, доступны они или нет… ха-ха… попробуйте следить за ЭТОЙ частью обслуживания на страницах вашего веб-сайта. Это кошмар, из-за которого люди в первую очередь создали Unicode, и я постоянно использую его на всех своих страницах на всех своих веб-сайтах. В редких случаях может возникнуть небольшая проблема, но это ничто по сравнению с попытками управлять альтернативами, особенно если вы создаете веб-сайт для международного использования.Обратите внимание, что это не означает, что вы всегда будете получать хорошее отображение при использовании Unicode. Использование Unicode просто означает, что когда HTTP-ответ, который вы отправляете в браузеры посетителей, с большей вероятностью будет понят, чем при использовании любого другого метода.
К сожалению, отрисовка символов ТАКЖЕ зависит от поддержки шрифтов на компьютере посетителя. Поэтому, если вы используете Unicode, но на вашем компьютере нет шрифтов, содержащих эти глифы, вы увидите вопросительные знаки, или маленькие прямоугольники, или квадраты с четырехзначным кодированием Unicode, или любой другой подстановочный знак, который использует ваша ОС. Это не вина Unicode, это проблема со шрифтом. Другой набор символов не будет лучше отображаться, потому что проблема заключается в отсутствии поддержки шрифтов; плюс у вас есть дополнительная проблема, заключающаяся в том, что набор символов, скорее всего, вызовет проблемы.Вы также можете сделать все правильно, но если ваш веб-хост обслуживает заголовки контента, в которых указан другой набор символов, он переопределит настройки в вашем XHTML. Вам нужно будет связаться с вашим веб-хостингом, чтобы исправить эту ситуацию (и есть некоторые веб-хосты, которые отказываются). К счастью, это гораздо реже, чем раньше, потому что Unicode наконец-то становится доминирующим стандартом.
Кроме того, ВСЕГДА следует указывать язык документа. Вероятно, есть какая-то логика, которая по умолчанию использует английский или что-то в этом роде, но вы можете вызвать серьезные проблемы с удобством использования и доступностью, особенно для небраузерных интерфейсов. Поработав в Институте Брайля, я могу привести пару случаев, когда не указание языка или его неправильное выполнение приводило к полной тарабарщине для некоторых пользователей.
Программы голосового вывода читают пользователям содержимое экрана. У них совершенно разный код, записи, акценты и т. д. в зависимости от указанного вами языка. Если вы сделаете это неправильно, он попытается прочитать английский как французский, русский как английский и т. д. Результат обычно неразборчив.
Дисплеи Брайля отображаются совершенно по-разному в зависимости от языка; это даже не проблема конкретной технологии, а проблема шрифта Брайля. Символы Брайля совершенно разные в каждом языке.
Кто-то может выучить английский шрифт Брайля и читать книги по Брайлю; однако, если они возьмут книгу, написанную французским шрифтом Брайля, все, что они смогут разобрать, — это тарабарщина, даже если они свободно говорят по-французски, символы на самом деле означают совершенно разные комбинации букв. А если английский и французский несовместимы, то можно понять проблемы для неевропейских языков.
фелгалл
№15
Хроникмастер1:
«» до того, как тип документа будет технически правильным для определения набора символов. Однако это заставляет IE (или, по крайней мере, некоторые версии) таять в маленькие лужицы нефункциональной слизи, поэтому я никогда не использовал его и не рекомендую.
Единственными версиями IE, которым не нравится этот тег, являются версии, которые вообще не поддерживают XHTML. У него нет проблем ни в одном браузере, который на самом деле поддерживает XHTML.
Самая ранняя версия IE, действительно поддерживающая XHTML, — IE9. Во всех более ранних версиях вы не можете использовать страницу как XHTML и отображать ее в Internet Explorer (она будет предложена для загрузки, если вы попробуете), поэтому вам придется загружать ее как HTML, если вы хотите, чтобы страница отображалась. Это утверждение недействительно для HTML, но только IE6 действительно имеет какие-либо проблемы с его наличием.
Stomme_poes
№16
- Программы голосового вывода считывают содержимое экрана для пользователей. У них совершенно разный код, записи, акценты и т. д. в зависимости от указанного вами языка. Если вы сделаете это неправильно, он попытается прочитать английский как французский, русский как английский и т. д. Результат обычно неразборчив.
К сожалению, у меня нет нидерландского голоса на моей копии JAWS (если только я не хочу платить около тысячи евро). Для тестирования JAWS любой из моих рабочих страниц это означает, что я должен перевести все, что хочу протестировать, на английский язык. За голландским, произносимым как английский, очень сложно следить.
- Дисплеи Брайля отображаются совершенно по-разному в зависимости от языка; это даже не проблема конкретной технологии, а проблема шрифта Брайля. Символы Брайля совершенно разные в каждом языке. Кто-то может выучить английский шрифт Брайля и читать книги по Брайлю; однако, если они возьмут книгу, написанную французским шрифтом Брайля, все, что они смогут разобрать, — это тарабарщина, даже если они свободно говорят по-французски, символы на самом деле означают совершенно разные комбинации букв. А если английский и французский несовместимы, то можно понять проблемы для неевропейских языков.
Прикольная информация. Мне всегда было интересно, похоже ли это на язык жестов (разные на разных языках).
Этот оператор недействителен для HTML, но только у IE6 есть какие-либо проблемы с его наличием.
Да, они научили IE7 игнорировать XML-тег, даже несмотря на то, что другие комментарии перед типом документа переводят 7 в Quirks Mode.
dance_mathilde
# 17
Большое спасибо за приведенное выше обсуждение, многому научился из него
Я посмотрел настройки сервера и могу выбрать 3 варианта:
- k 018-r
- окна-1251
- x-mac-кириллица
Насколько я понял выше (и понял), лучше всего выбрать вариант «k 018-r».
В html-документе я начинаю с (и удаляю красный код, как объяснил felgall):
Stomme_poes# 18
Ну уж точно не хотите lang=»en» на русскоязычном сайте!
Но вам нужны lang=»ru» и xml:lang=»ru»!
Примечание: почему переходный тип документа? Используйте строго! : )
Примечание 2: наши теги кода (и другие теги) используют квадратные скобки
xhtmlcoder
# 19
Стивен пошутил о том, что большинство живых версий M$IE не могут обрабатывать XHTML, поэтому, вероятно, выступал за HTML 4.01.
[B][/B] <голова> <название> Жадный волшебник <тело>Если вы пишете грамматику XHTML, необходимо, чтобы у вас было пространство имен xml, и обычно рекомендуется добавить значения xml:lang и lang. XHTML обычно использует по умолчанию UTF-8 в отсутствие других протоколов более высокого уровня и т. д.
система
#20
должно быть, насколько я понимаю, у вас есть
а у вас должно быть
или
подробнее об этом здесь.
следующая страница →
Проблемы с кодировкой для русских символов… anycodings
Вопросы : Проблемы с кодировкой для русских символов48
@ http://tinyurl.com/7v67lnh Я работаю над Anycodings_character-кодированием новой страницы для клиента. Используемая мной кодировка символа anycodings_character-encoding — это utf 8:
0″ encoding=»UTF-8″?> Также в anycodings_character-encoding добавлена подпись спецификации Unicode. . Но каким-то образом anycodings_character-encoding русский код в правом сайдбаре — это anycodings_character-encoding искаженный. Есть идеи, почему?
Админы
КОДИРОВАНИЕ СИМВОЛОВ
Всего ответов 3
27
Ответы 1 : проблем с кодировкой символов для русских символовтакже используйте UTF-8 для своей html-страницы, добавьте этот тег anycodings_character-encoding в свой html-код anycodings_character-encoding в теге заголовка
0
Ссылка для ответа
мРахман
2
Ответы 2: проблем с кодировкой символов для русских символовКак упоминалось в комментарии к моему вопросу anycodings_character-encoding:
Решил все это, добавив anycodings_character-encoding AddDefaultCharset UTF-8 в anycodings_character-encoding .
htaccess.
По-видимому, сервер использовал anycodings_character-encoding для другой кодировки символов anycodings_character-encoding, например
Кириллица или Windows.0
Ссылка для ответа
джидам
2
Ответы 3 : проблем с кодировкой символов для русских символовЯ только что удалил тег и anycodings_character-encoding вопросительные знаки изменились на anycodings_character-encoding правильные буквы, но это не идеальное решение anycodings_character-encoding.
0
Ссылка для ответа
раджа
Темы с самым высоким рейтингом
Мультиконтейнер веб-приложения Azure (приложение MEAN), какой URL-адрес для подключения к внутреннему контейнеру узла из внешнего контейнера?
Ошибки Vagrant Provision
Условный фильтр C# NEST в подсписке
IndexOutOfBoundsException при создании одного списка массивов равным другому
Как создать код с помощью signalR в ядре asp.
net и angular и как запустить код в приложении чатаПередовые методы загрузки и извлечения данных, загруженных пользователями
В запросах python отсутствует что-то, что присутствует в curl?
Parquet Двоичное значение, хранящее значение в закодированном формате
JMeter — извлечь значение из переменной, имеющей данные JSON
Обновление MySQL с версии 5.7.12 до 8.0.26 влияние на производительность0007
Angularjs — фильтрация одного столбца с несколькими вариантами выбора ввода
FlickableItem.atYEnd всегда имеет значение false при прокрутке QML
Отслеживание HTTPS-запросов и ответов с помощью Google Cloud Alerts
Потоки результатов JPA и базовые соединения JDBC Перед запуском приложения — Xcode 13 на iOS 15.1.1
Как проверить, активна ли какая-либо среда conda с флагом
Мой таймер обратного отсчета завис, когда экран телефона заблокирован
Раздел рендеринга с блоками использует API рендеринга раздела
Как заставить всех учащихся выйти из системы перед входом в мобильное приложение Moodle
Сбой задания DataflowTemplateOperator в Cloud Composer после обновления до Airflow 2
Я пытаюсь создать Discord Bot , работают только некоторые возможности jQuery; ajax не работает
Я сталкиваюсь с этой проблемой в Andorid Studio.
Как решить эту проблемуКак запустить, если условно, может встретиться дважды
Rod Running In Docker Alpine Get Error «chrome-linux/chrome: no such файл или каталог»
Как получить доступ к программе чтения с экрана и озвучиванию orca, чтобы заставить их произносить некоторые тексты в С#
Значение ошибки Java «SNO: ‘+=’ реконверсия не удалась»?
`django_comments_xtd` совместно используется несколькими моделями классов
Стилизация CalendarDatePicker
Не удается отправить на главную страницу Heroku
Статические веб-приложения Azure неправильно загружают ресурсы страницы. css или javascript файлы
Почему process.start() возвращает null
Как вызвать enumerateObjectsUsingBlock NSArray в lldb?
Асинхронная обработка NodeJS
Выполнение fs.unlink() в узле к файлу в докере с именем Volume восстанавливает объект, если создается файл с таким же именем
Где я могу найти FPDF? «Ошибка FPDF: некоторые данные уже были выведены.
..»Как использовать Android S для создания JAR-файлов Android AOSP для Robolectric?
Общая ошибка во время семантического анализа: Преобразование org.codehaus.groovy.macro.transform.MacroTransformation не может быть запущено
Разобрать и записать файл формата JSON Lines
Использование аргумента DECIMAL(,) в pSQL для создания таблицы с ошибкой
Создание метода потерь BLEU в тензорном потоке дает «Градиент не предоставлен»
Изменение типа шаблона переменной во время выполнения
Запуск тестов (pytest) в CI (gitlab-ci kubernetes runner) для AWS Lambda w/Layer с использованием «sam local invoke»
Как я могу зациклить массив в data()
Использование Spring Data 2.6.1 с Eclipselink и Jakarta 3, возможно ли это?
Как получить ответ json для URL-адреса продукта
Службы, сгенерированные Open API Angular, чтение заголовков
Необходимость в Postgis, если у Postgres уже есть геотип
Подготовка виртуальных машин Azure и назначенное пользователем удостоверение?
Excel: полоса прокрутки в середине листа?
языков, стран и наборов символов
i18n: языки, страны и наборы символовЭта страница больше не поддерживается и может быть неточной.
Предупреждение. Материалы на этой странице больше не поддерживаются, они очень старые и устарело! Мы рекомендуем использовать кодировку UTF-8 везде, где это возможно. Для получения более актуальной информации см. домашнюю страницу деятельности по интернационализации.Языки, страны и обычно используемые для них кодировки
Вот неполный список кодировок, наиболее часто используемых для веб-страниц на разных языках:
Язык кодировка Африкаанс (аф) ISO-8859-1, Windows-1252 Албанский (кв.) ISO-8859-1, Windows-1252 Арабский (ар) ISO-8859-6 Баскский (ЕС) ISO-8859-1, Windows-1252 Болгарский (бг) ISO-8859-5 Белорусский (быть) ISO-8859-5 каталанский (ca) ISO-8859-1, Windows-1252 Хорватский (ч) iso-8859-2, Windows-1250 Чешский (cs) ISO-8859-2 датский (da) ISO-8859-1, Windows-1252 голландский (nl) ISO-8859-1, Windows-1252 Английский (en) ISO-8859-1, Windows-1252 Эсперанто (эо) ISO-8859-3* Эстонский (et) ISO-8859-15 Фарерский (fo) ISO-8859-1, Windows-1252 финский (fi) ISO-8859-1, Windows-1252 Французский (фр. ) ISO-8859-1, Windows-1252 Галисийский (гл) iso-8859-1, окна-1252 Немецкий (де) ISO-8859-1, Windows-1252 Греческий (эль) ISO-8859-7 Иврит (iw) ISO-8859-8 Венгерский (ху) ISO-8859-2 Исландский (есть) ISO-8859-1, Windows-1252 инуитские (эскимосские) языки ISO-8859-10* Ирландский (ga) ISO-8859-1, Windows-1252 Итальянский (it) ISO-8859-1, Windows-1252 Японский (ja) shift_jis, iso-2022-jp, euc-jp Корейский (ко) евро-кр Саам изо-8859-10* ** латышский (lv) ISO-8859-13, Windows-1257 Литовский (lt) ISO-8859-13, Windows-1257 Македонский (мк) ISO-8859-5, Windows-1251 Мальтийский (м) ISO-8859-3* норвежский (нет) ISO-8859-1, Windows-1252 польский (мн. ч.)ISO-8859-2 Португальский (pt) ISO-8859-1, Windows-1252 румынский (ro) ISO-8859-2 Русский (ru) кои8-р, изо-8859-5 шотландский (gd) ISO-8859-1, Windows-1252 Сербский (ср) кириллица Windows-1251, ISO-8859-5*** сербский (ср) латинский ISO-8859-2, Windows-1250 Словацкий (ск) ISO-8859-2 Словенский (сл) iso-8859-2, Windows-1250 Испанский (исп) ISO-8859-1, Windows-1252 Шведский (sv) ISO-8859-1, Windows-1252 Турецкий (tr) ISO-8859-9, Windows-1254 Украинский (Великобритания) ISO-8859-5 * = ограниченная поддержка в браузерах
** = Lapp не имеет двухбуквенного кода, трехбуквенный код (lap) предлагается в NISO Z39. 53.
*** = Сербский может быть написан латиницей (чаще всего используется) и кириллицей (в основном windows-1251)Обратите внимание, что UTF-8 может использоваться для всех языков и является рекомендуемой кодировкой в Интернете. Поддержка этого быстро растет.
Для иврита в HTML iso-8859-8 совпадает с iso-8859-8-i («неявная направленность»). Это не похоже на электронную почту, где они разные.
Дополнительные двухбуквенные коды языков см. в ISO 639.
Спасибо Дж.Н. Zonjee за предоставление дополнительных данных о сербско-хорватской семье языков.
Самые популярные кодировки
Исследование, проведенное в первой половине 1997 года командой Babel, дало следующие результаты на выборке из 3239 домашних страниц:
количество процент языка изо-8859-2 1 0,031% Чехия изо-8859-5 2 0,062% Русский макинтош 3 0,093% 1 немецкий, 1 французский, 1 итальянский окна-850 4 0,12% 1 французский, 2 немецкий окна-1251 6 0,19% Русский окна-1250 10 0,31% Чехия euc-jp 12 0,37% японский изо-2022-jp 38 1,2% японский shift_jis 51 1,6% японский Windows-1252 (включая iso-8859-1) 3112 96% 4 малайских, 9 датских, 14 финских, 19 норвежских, 20 голландских, 21 португальский, 30 итальянских, 35 шведских, 38 испанских, 57 французских, 143 немецких, 2722 Английский (Подсчет основан на автоматическом анализе содержимого страницы, а не на фактических метках «набора символов», поскольку они все еще слишком часто отсутствуют или неверно.
)
Берт Бос, координатор i18n
Веб-мастер
Последнее обновление 12 февраля 2002 г.Суп кириллических символов
Суп кириллических символов Несмотря на то, что ISO 8859 содержит стандарт Кириллическая кодировка, есть куча других кириллических кодировок используется на компьютерах по всему миру. Эта страница пытается объяснить, почему это так, давая исторический обзор. Каждый набор символов проиллюстрирован растровым GIF вместе с базовой таблицей отображения Unicode и Шрифт BDF (X/Unix).Кириллица
Братья и православные славянские монахи Кирилл и Мефодий изобрел глаголицу в Македонии в 863 г. зашифрованный греческий алфавит с расширениями для специальных славянских звуков. Их ученый Климент Охридский позже изобрел «кириллицу». более удобочитаемая преобразованная глаголица. В течение века кириллица распространялась и трансформировалась, был модернизирован в его нынешнюю романизированную форму (Гражданка) под Царь Петр Великий.
В настоящее время кириллица используется более чем в 70 языках. начиная от восточноевропейских славянских языков русский (ru), украинский (uk), белорусский (be), болгарский (bg), сербский (sr) и македонский (мк) над алтайскими языками Центральной Азии, такими как азербайджанский (аз), туркменский (тк), курдский (ku), узбекский (uz), казахский (kk), киргизский (ky) и другие, такие как таджикский (тг) и монгольский (мн). В вашей библиотеке может быть буклет «Алфавиты языков народов СССР» Кенесбая Мусаевича Мусаева. опубликовано в 1965.
При маленьком безакцентном алфавите русский и болгарский казались так же хорошо подходит для компьютерной обработки, как и английский язык.
Самая старая стандартизированная кириллическая компьютерная кодировка, которую я нашел (в John Clews’ Language Automation Worldwide) является государственным стандартом. ГОСТ 13052, 7-битная кодировка, кодирующая буквы русского языка. алфавит (который также удовлетворяет все болгарские потребности) поверх соответствующие буквы ASCII напротив регистр (для распознавания русского текста типа «РУССКИЙ ТЕКСТ» по его регистру, когда представлены в ASCII.
я буду называть это свойство соответствием KOI), пожертвовали точками, чтобы сократить алфавит до 32 букв.
в два ряда и опустил редко необходимый ЗАГЛАВНЫЙ ТВЕРДЫЙ ЗНАК, чтобы
предотвратить его столкновение с DELETE в позиции =7F или EOF=-1:
кодировка = кои-0 [ТЕКСТ] [БДФ]Тот факт, что болгарский язык использует ЗАГЛАВНУЮ ТВЕРДЫЙ ЗНАК намного чаще побудил некоторых болгар закодировать свой твердый знак поверх ненужные русские вместо ЕРЫ бИ.
В 1974 году ГОСТ опубликовал еще один ГОСТ 19768-74, с двумя кодировками, обе смешали латиницу и кириллицу в один набор, что сохранило оригинальная идея переписки KOI жива:Первой была еще одна 7-битная кодировка с именем KOI-7, состоящая только из заглавных букв. буквы:
Вторая кодировка, определенная в ГОСТ 19768-74 был знаменитым 8-битным кодом для замены и обработки. Информации (КОИ-8), которая дала расшифровку Текст ASCII, когда старший бит был удален и может быть по праву называется кириллицей ASCII.
кодировка = кои-7 [ТЕКСТ] [БДФ] Вот
изображение его верхней части (G1):
кодировка = koi8-a [ТЕКСТ] [БДФ]KOI-8 использовался на многих сетевых хостах Unix. Естественно, знак доллара ASCII $ прижился. вместо знака международной валюты, хотя это не было политкорректный. И точка (йо) была добавлена в столбец 3, поэтому что такие слова, как e (yeyo), больше не нужно было писать без ударения э.
Вернее, последний шаг не происходил, пока компания Demos не начала портировать Поддержка кириллицы для ПК Unix, таких как Xenix в конце 1980-х и разработал новую русскую кодовую страницу КОИ-8, которая позже стала известна как KOI8-R с пунктиром на его позиции от первый проект ДИС-6937-8/ДИС-8859-5 и все нерусские буквы вычищены и заменены блочной графикой.
Но многие поставщики шрифтов реализовали только подмножество букв. Позволь нам назовите его КОИ8-Б, это расширенная (большая) база КОИ-8, содержащая буквы (буквы) общие (басы) для всех современных вариантов КОИ-8:
кодировка=koi8-b [ТЕКСТ] [БДФ]В середине 1980-х годов ECMA комитет по разработке серии ISO-8859 а его кириллица ISO-8859-5 хотела сохранить совместимость с установил базу десятилетнего стандарта КОИ-8, и изящно добавил недостающие украинские, белорусские, Сербские и македонские буквы в неиспользуемых кодовых точках.
Их черновик был опубликован как 1-е издание стандарта ECMA-113 в 1986 году.
проект международного стандарта DIS-8859-5 в 1987 году и был зарегистрирован
с номером 111 в Международном реестре ISO
наборов символов, которые будут использоваться с экранированием (ISO-2022)
последовательностей, отсюда и название ISO-IR-111 и прозвище
ECMA-кириллица:
кодировка = koi8-e [ТЕКСТ] [БДФ]ISO-IR-111 так и не был принят в качестве окончательного ISO-8859-5 потому что за это время ГОСТ надышался перестройкой и задекларировал установленную базу и КОИ соответствие менее важно и пересмотрел свой стандарт 19768 года с 1974 по 1987 год в несовместим с новым ГОСТ 19768-87, который переместил русские буквы на один ряд составил и упорядочил их в порядке словаря родного русского языка (АБВГД) вместо корреспонденции KOI (ABCDE):
кодировка=ГОСТ-19768-87 [ТЕКСТ] [БДФ]ECMA сразу же последовал за ходом ГОСТ по совету своих советских экспертов, пересмотрев свои первые предложение и изменение их ISO-IR-111 символов на кодовые позиции нового ГОСТ 19768-87.
Дизайнеры не стали до конца еще и сортировать
нерусские буквы в русский алфавит для обеспечения правильного
порядок словаря для всех языков, как вы найдете его, например, в
Стандарт ISO 9 (транслитерация кириллицы). Пересмотренное предложение
опубликовано как 2-е издание ECMA-113:1988 (заменяет оригинал
ECMA-113:1986, который прижился
(популярен благодаря сочетанию нерусских букв с КОИ-8
совместимости) под псевдонимом ECMA-Cyrillic (хотя ECMA ссылается
вам ISO-8859-5 сейчас) или ISO-IR-111) и принят в ISO 8859 (несмотря на то, что Советский Союз проголосовал против
его знак доллара) как окончательный ISO-8859-5 (ISO-IR-144) в 1988 году. Многие
люди, включая меня, считают, что это избавило бы нас от многих
проблема, если исходный KOI8-совместимый DIS-8859-5: 1987 также был выбран ISO-8859-5:1988. Сейчас мы
есть международный стандарт ISO-8859-5, который настолько нестандартен
что почти никто не любит и не использует его:
кодировка = ISO-8859-5 [ТЕКСТ] [БДФ]После RFC 1341 (MIME) предложил использовать кириллицу ISO-8859-5 в электронной почте.
общение, в то время как русский раздел Интернета (группы новостей relcom.*) все еще использовал KOI-8,
Андрей Чернов отправился в
опубликовать его RFC
1489 Регистрация кириллического набора символов «КОИ8-Р» и
установил KOI8-R как стандарт де-факто в Интернете.
KOI8-R, который позже также получил номер CP878, содержит KOI8 с точками и многое другое.
символов рисования коробки:
кодировка=koi8-r [ТЕКСТ] [БДФ]Андрей Чернов предлагает много практической информации о KOI8-R на его сайте.
При всех этих кодировках есть особая украинская проблема. Украинцы читают букву GHE со штрихом вниз как хе. Чтобы написать правильно гхе им нужна украинская буква ГЕ С ВВЕРХОМ которая была был подавлен сталинскими чиновниками и восстановлен в 1990 году.
Можно злоупотреблять GHE с акцентом (македонский GJE) в ISO-IR-111 или ISO-8859-5, чтобы представить GHE С ВВЕРХОМ, но это не похоже на быть предпочтительным вариантом. Украинцы, кажется, предпочитают кодировки, которые включайте настоящий GHE С ПОДЪЕМОМ.
GHE WITH UPTURN присутствует в
CP1251 от Microsoft, KOI8-Unified от Fingertip и, конечно же, в Unicode. Тем не менее, эти варианты не казались близкими
достаточно для KOI8-R, чтобы помешать украинским почтмейстерам разработать
новый КОИ8-У и его издание
как RFC2319 в
Апрель 1998. КОИ8-У добавлены только украинские буквы в позициях
совместим с ISO-IR-111, используемым многими
украинцев и сохранили как можно больше рисунков, потому что
многие пользователи в этом районе все еще застряли в MS-DOS. Потому что
предпочтения, в нем отсутствуют короткое U с белорусским акцентом, а также сербский и
Македонская поддержка:
кодировка = koi8-u [ТЕКСТ] [БДФ]Я предполагаю, что спецификация RFC2319 и RFC1489 пули KOI8-R является математической. U+2219 BULLET OPERATOR — это ошибка, унаследованная от RFC1345 и должна быть исправлена на U+2022 BULLET, как в собственных таблицах Келда Симонсена для IBM437 или KOI8-R. В общем обратите внимание, что RFC1345 и все, что основано на нем, например GNU recode 3.
Питер Кассетта из Fingertip Программное обеспечение, которое также опубликовало красивую кириллицу ссылка на набор символов для его клиентов уже разработана и предложил другое решение: Его KOI8-Unified объединяет все ISO-IR-111 письма украинскими буквами КОИ8-У и базовая блочная графика KOI8-R и некоторые популярные символы из кодовых страниц Windows 1251 и 1252, уравновешивая различные потребности совместимости: 4.1
содержал ряд ошибок, особенно в области кириллицы:
isoir111 больше похож на cp1251, чем на koi8. RFC2319 содержит
дополнительная ошибка, что он кодирует ЗАГЛАВНУЮ БУКВУ УКРАИНСКОГО IE как
U+0403 вместо U+0404.
кодировка = koi8-f [ТЕКСТ] [БДФ]Вы можете использовать этот шрифт koi8-f для отображения всего текста koi8-* и всех буквы будут отображаться правильно, но некоторые из менее используемых графических символы в koi8-r могут отображаться неправильно.
Еще один серьезный игрок на поле — WinCyrillic Windows от Microsoft. кодовая страница CP1251, для которой Microsoft зарегистрировала метку «Windows-1251», которая не должна ошибочно принимают за предшественника сегодняшней Windows95 13-го века. По состоянию на
Декабрь 1997 года, даже новый веб-сервер ГОСТа (Lotus Notes) приветствует вас
with charset=WINDOWS-1251 — ГОСТ (российская стандартизация
органа и организации-члена ISO) не
даже следуя собственным стандартам любой
более!
CP1251 имеет богатый репертуар в порядке, несовместимом ни с ISO-IR-111 (KOI8), ни с ISO-8859.-5:
Макукраинский (= Маккириллица + GHE С ВВЕРХОМ) имеет те же буквы еще в другом порядке:
кодировка = Windows-1251 [ТЕКСТ] [БДФ]
Более старая популярная кодировка — вариант «Альтернативный». MS-DOS CP866:
charset=MacУкраинский [ТЕКСТ] [БДФ]
Болгарка Prawec 16 PC и болгарка карта клавиатуры в Linux использует кодировку MIK:
кодировка=cp866 [ТЕКСТ] [БДФ]
кодировка=болгарский-мик [ТЕКСТ] [БДФ]Вам надоело это изобилие наборов символов, при этом ни один из них не самый лучший? Хотели бы вы иметь одну хорошую кодировку, способную заменит все вышеперечисленное и будет принят везде? Не могли бы вы тоже любите писать на неславянских кириллических языках? Вы получаете все это и многое другое с Unicode (ISO-10646), который просто кодирует все персонажи мира.
Это кириллический блок U+0400 в Unicode. Это следует за порядком ISO-8859-5:
кодировка = Юникод-2-1 [ТЕКСТ] [БДФ]Ольга Лапко утверждает на страницах 175 и 179 блестящего выпуска 17-2 TUGboat (Материалы Ежегодная встреча группы пользователей TeX в 1996 г. в Дубне, Россия), в которой приняло участие около 100 Кириллические буквы по-прежнему отсутствуют в Юникоде. Большинство из них кажутся кодируется с комбинацией акцентов, а остальные могут быть добавлены с помощью процедуры, описанной в Приложение B. Отправка новых символов стандарта Unicode.
Каждая кириллическая буква кодируется двумя байтами в UTF-8. Стандартная схема сжатия для Unicode (SCSU) позволяет уменьшить это до традиционного одного байта на букву.
Я все еще занят написанием своего Unicode-HOWTO для Linux. я добавил Cyrillic.kmap, злоупотребляющий ISO 9 в качестве метода ввода в текстовый редактор Yudit Unicode для системы X Window.
Я призываю вас присылать свои комментарии по адресу roman@czyborra.
com. я благодарен
Кристофер Неханив, Андреас Прилоп, Питер Кассетта Роман Чиборра
1998-05-25 .. 1998-11-30Таблица ASCII для кириллической кодировки (CP855)
Американский стандартный код для обмена информацией ( ASCII ) — широко используемая система кодирования символов , введенная в 1963 году. стандартный набор символов изначально состоял из 128 символов (7-битный код). Первые 32 символа — это управляющие символы (также называемые непечатаемыми символами), которые используются для управления потоками данных, а также такими устройствами, как принтеры. Позже он был расширен для поддержки 256 символов (8-битный код), чтобы предоставить символы, специфичные для языка, различные символы, а также символы для рисования блоков: элементы, используемые для презентационных целей, позволяющие рисовать различные виды рамок и блоков.
Символы в диапазоне 128-255 называются расширенным ASCII.Кодовая страница 855 является альтернативной кодовой страницей , используемой для написания языков на основе кириллицы: белорусского, боснийского, болгарского, македонского, русского, сербского, украинского (славянские языки), а также казахского, киргизского, молдавского, монгольского, таджикского, узбекского. (не славянский). Он не очень популярен, кодовая страница 866 является наиболее широко используемой. Только расширенный набор символов отличается от исходной кодовой страницы, причем как управляющие символы, так и стандартный набор символов представляют собой простой ASCII.
9В приведенной ниже таблице из 1368 символов показано графическое представление каждого символа с точностью до пикселя, а также текстовое описание.
Control characters (0 — 31):
Dec Hex Char Description Dec Hex Char Description 0 0 NUL (Null ) 16 10 DLE (выход канала передачи данных) 1 1 SOH (Start of Header) 17 11 DC1 (Device Control 1) 2 2 STX (Start of Text) 18 12 DC2 (Device Control 2) 3 3 ETX (End of Text) 19 13 DC3 (Device Control 3) 4 4 EOT (End of Transmission) 20 14 DC4 (Device Control 4) 5 5 ENQ (Enquiry) 21 15 NAK (Negative Acknowledge) 6 6 ACK (Acknowledge) 22 16 SYN (Synchronous Idle) 7 7 BEL (Bell) 23 17 ETB (End of Transmission Block) 8 8 BS (BackSpace) 24 18 CAN (Cancel) 9 9 HT (Horizontal Tabulation) 25 19 EM (End of Medium) 10 A LF (Line Feed) 26 1A SUB (Substitute) 11 B VT (Vertical Tabulation) 27 1B ESC (Escape) 12 C FF (подача формы) 28 1C FS (файловый разделитель) 13 D 13 D 13 D 13 D 13 D 13 D D . 1388 GS (Group Separator)14 E SO (Shift Out) 30 1E RS (Record Separator) 15 F SI (Shift In) 31 1F US (Unit Separator) Standard character set (32 — 127):
Dec Hex Char Description Dec Hex Char Description 32 20 Space 80 50 Upper case P 33 21 Exclamation mark 81 51 Upper case Q 34 22 Quotation Mark 82 52 Upper case R 35 23 Hash 83 53 Upper case S 36 24 Dollar 84 54 Upper case T 37 25 процент 85 55 Верхний чехол U 38 269999 38 2699999999999999999999899989988998989898989898989898989898989898989898989898989898989898989898989898989898989898989. 38 26 .1389 Upper case V 39 27 Apostrophe 87 57 Upper case W 40 28 Open bracket 88 58 Upper case X 41 29 Close bracket 89 59 Upper case Y 42 2A Asterisk 90 5A Upper case Z 43 2B Plus 91 5B Open square bracket 44 2C Comma 92 5C Backslash 45 2D Dash 93 5D Close square bracket 46 2E Full stop 94 5E Caret 47 2F Slash 95 5F Underscore 48 30 Zero 96 60 Grave accent 49 31 One 97 61 Lower case a 50 32 Two 98 62 Lower case b 51 33 Three 99 63 Lower case c 52 34 Four 100 64 Lower case d 53 35 Five 101 65 Lower case e 54 36 Six 102 66 Lower case f 55 37 Seven 103 67 . 138157 39 Nine 105 69 Lower case i 58 3A Colon 106 6A Lower case j 59 3B SEMICOLON 107 .1388 6C Lower case l 61 3D Equals sign 109 6D Lower case m 62 3E Greater than 110 6E .1389 40 At 112 70 Lower case p 65 41 Upper case A 113 71 Lower case q 66 42 Верхний чехол B 114 . 1389Lower case s 68 44 Upper case D 116 74 Lower case t 69 45 Upper case E 117 75 Lower case u 70 46 Upper case F 118 76 Lower case v 71 47 Upper case G 119 77 Lower case w 72 48 Upper case H 120 78 Lower case x 73 49 Upper case I 121 79 Lower case y 74 4A Upper case J 122 7A Lower case z 75 4B Upper case K 123 7B Open brace 76 4C Upper case L 124 7C Pipe 77 4D Upper case M 125 7D Close brace 78 4E Upper case N 126 7E Tilde 79 4F Upper case O 127 7F Delete Extended character set ( 128 — 255):
Dec Hex Char Description Dec Hex Char Description 128 80 Cyrillic lower case dje 192 C0 Box drawings light up and right 129 81 Cyrillic upper case DJE 193 C1 Box рисунки с подсветкой вверх и по горизонтали 130 82 Нижний кириллический регистр gje 194 C2 9 рисунков с подсветкой вниз и по горизонтали1389 131 83 Cyrillic upper case GJE 195 C3 Box drawings light vertical and right 132 84 Cyrillic lower case io 196 C4 чертежей коробки. 1389134 86 Cyrillic lower case ukrainian ie 198 C6 Cyrillic lower case ka 135 87 Cyrillic upper case ukrainian IE 199 C7 Cyrillic upper case KA 136 88 Cyrillic lower case dze 200 C8 Box drawings double up and right 137 89 Cyrillic upper case DZE 201 C9 Box drawings double down and right 138 8A Cyrillic lower case byelorussian-ukrainian i 202 CA Чертежи коробок двойные и горизонтальные 139 8B Кириллица заглавная белорусско-украинская I 203 CB Box drawings double down and horizontal 140 8C Cyrillic lower case yi 204 CC Box drawings double vertical and right 141 8D Прописная кириллица YI 205 CD Чертежи коробок двойные горизонтальные 140 9E98881388 Cyrillic lower case je 206 CE Box drawings double vertical and horizontal 143 8F Cyrillic upper case JE 207 CF Currency sign 144 90 Нижний регистр кириллицы lje 208 D0 Cyrillic upper case LJE 209 D1 Cyrillic upper case EL 146 92 Cyrillic lower case nje 210 D2 Cyrillic lower case em 147 93 Cyrillic upper case NJE 211 D3 Cyrillic upper case EM 148 94 Cyrillic lower case tshe 212 D4 Cyrillic lower case en 149 95 Cyrillic upper case TSHE 213 D5 Cyrillic upper case EN 150 96 Cyrillic lower case kje 214 D6 Cyrillic lower case o 151 97 Cyrillic upper case KJE 215 D7 Cyrillic upper case O 152 98 Cyrillic lower case short u 216 D8 Cyrillic lower case pe 153 99 Заглавная кириллица, короткая U 217 D9 Рисунки в коробках светятся вверх и влево 8 1381388 9ACyrillic lower case dzhe 218 DA Box drawings light down and right 155 9B Cyrillic upper case DZHE 219 DB Full block 156 9C Cyrillic lower case yu 220 DC Lower half block 157 9D Cyrillic upper case YU 221 DD Cyrillic upper case PE 158 9E Cyrillic lower case hard sign 222 DE Cyrillic lower case ya 159 9F Групный знак в верхнем корпусе кирилли. 1389Cyrillic lower case a 224 E0 Cyrillic upper case YA 161 A1 Cyrillic upper case A 225 E1 Cyrillic lower case er 162 A2 Cyrillic lower case be 226 E2 Cyrillic upper case ER 163 A3 Cyrillic upper case BE 227 E3 Cyrillic lower case es 164 A4 Cyrillic lower case tse 228 E4 Cyrillic upper case ES 165 A5 Cyrillic upper case TSE 229 E5 Cyrillic lower case te 166 A6 Cyrillic lower case de 230 E6 Cyrillic upper case TE 167 A7 Cyrillic upper case DE 231 E7 Cyrillic lower case u 168 A8 Cyrillic Lower Case IE 232 E8 .
- , либо имея HTTP-заголовок с charset=koi8-r , отправленный веб-сервером вместе со страницей