У Intel получилось. Первые тесты процессора Core i7-10710U показывают, на что способна новинка
Как известно, процессоры Intel Core десятого поколения доступны на рынке в виде мобильных решений в двух линейках: 10-нанометровые Ice Lake и 14-нанометровые Comet Lake.

Источник протестировал CPU Core i7-10710U, который относится ко второму. Это шестиядерный CPU с частотами 1,1-4,7 ГГц, TDP 15/25 Вт и ценой 443 доллара. В мобильном сегменте процессоры по цене сравнивать бессмысленно, поэтому нельзя внятно сказать, какому CPU пришёл на смену Core i7-10710U. Но стоит отметить, что те же Core i7-9750H или Core i7-8665U дешевле.
Итак, перейдём к тестам.
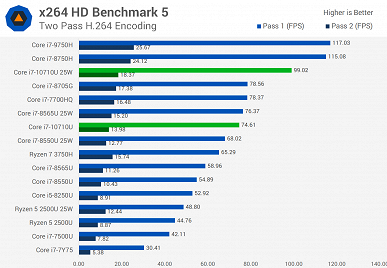
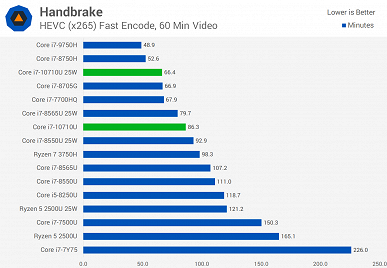
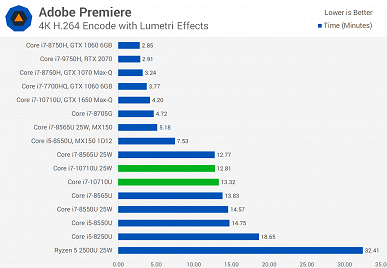
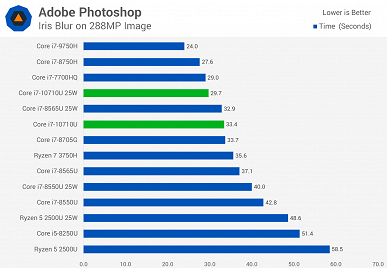
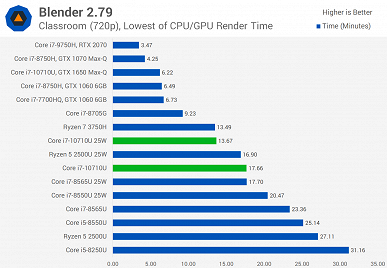
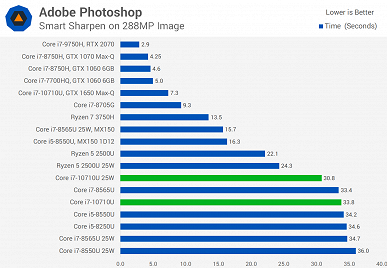
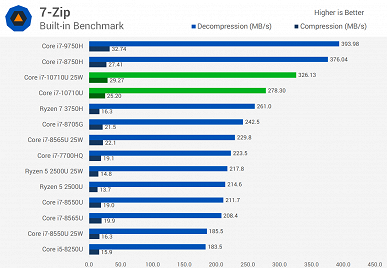
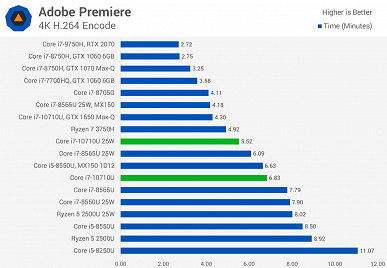
Источник протестировал новинку как в 15-ваттном режиме, так и в 25-ваттном. Разница достаточно велика, поэтому при покупке ноутбука лучше заранее уточнить этот момент. Хотя, к примеру, тестовый ноутбук, а это был MSI Prestige 14 A10SC, позволяет выбирать, в каком режиме будет работать CPU.
В целом можно видеть, что Core i7-10710U показывает себя весьма неплохо, но линейка Comet Lake у Intel получилась достаточно специфической. В частности, у Core i7-10710U шесть ядер, высокая пиковая частота, но крайне низкая базовая. Поэтому лучше, конечно, стоит смотреть на результаты в тех тестах, которые интересны конкретному пользователю. Если же брать в целом, то ситуация следующая.
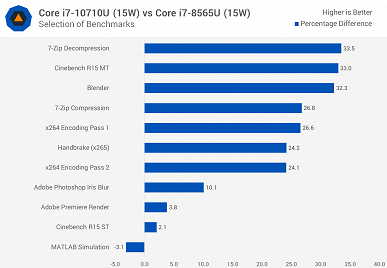
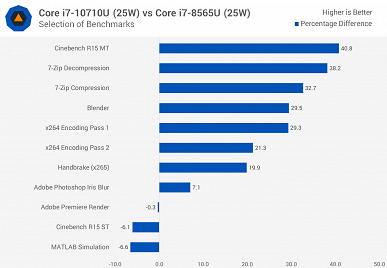
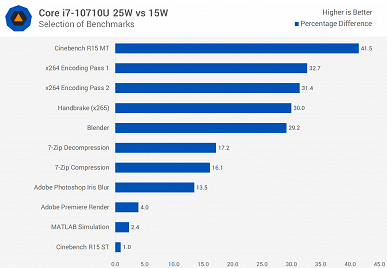
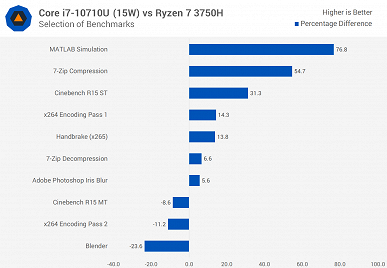
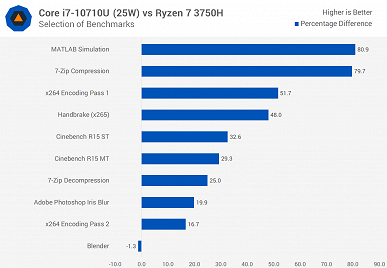
Новинка почти всегда быстрее Core i7-8565U, причём зачастую Core i7-10710U в 15-ваттном режиме быстрее, чем Core i7-8565U в 25-ваттном. Но это вполне ожидаемо, учитывая разницу в количестве ядер.
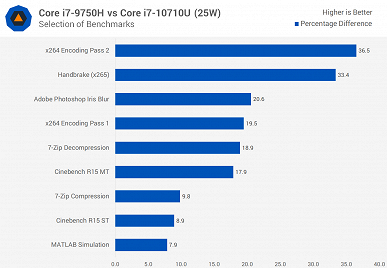
А вот 45-ваттный Core i7-9750H всегда быстрее новичка, что обусловлено разнице в частотах, на которых большую часть времени работает CPU.
Если говорить о соперничестве с AMD, Ryzen 7 3750H почти всегда проигрывает, особенно, если говорить о 25-ваттной версии Core i7-10710U.
При этом прирост у 25-ваттной версии Core i7-10710U относительно 15-ваттной составляет от 1% до 41,5%.
Также можно взглянуть на то, на каких частотах новый CPU работает под нагрузкой в разных режимах.
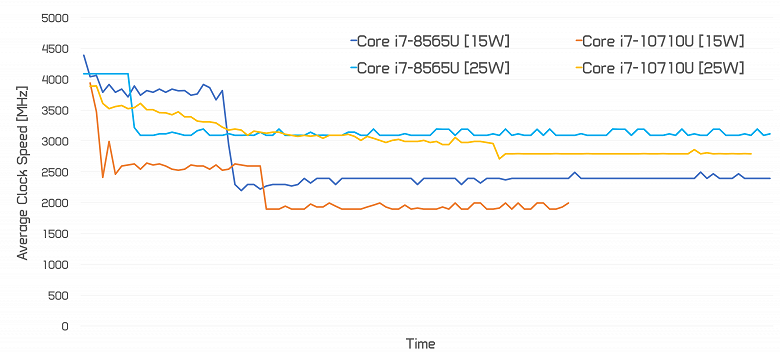
В итоге у Intel получился весьма интересный процессор. Он почти всегда быстрее любого четырёхъядерного 15-ваттного Core U, хотя серьёзно не дотягивает до 45-ваттных Core H. При этом он дороже всех процессоров, с которыми источник его сравнивал. Хотя в случае ноутбуков это мало что решает.
С другой стороны, есть два нюанса. Во-первых, Core i7-10710U — единственный шестиядерный процессор в линейке Comet Lake. То есть интереснее посмотреть всё же на Core i7-10510U и Core i5-10210U. Во-вторых, TDP в 15 или 25 Вт ещё вовсе не означает, что CPU потребляет именно столько, так что вопрос реального энергопотребления открыт. И мы знаем, что у процессоров Intel с этим есть проблемы.
Модульная командная строка QoS в Cisco / Habr
Добрый день, в данной статье хотел бы немного рассказать о методе построения правил QoS в устройствах Cisco. Для начала хочу дать краткое определение понятию QoS.QoS — это способность сети, обеспечивать улучшенное обслуживание сетевого трафика независимо от выбранных технологий, включая Frame Relay, ATM, Ethernet или IP сеть с маршрутизацией.
Основная функция QoS — это предоставление усовершенствованного и более предсказуемого поведения сетевых служб, при помощи таких механизмов как:
- Выделенная полоса пропускания
- Улучшенная характеристика потерь
- Предотвращение и управление перегрузками
- Деление трафика
- Приоритезация трафика
MQC разделяет задачи связанные с QoS на следующие модули:
- Определение потока трафика
- Классификация его на принадлежность к класcу QoS
- Применение политик QoS для данного класса
- Определение интерфейсов на которых политика должна быть приведена в исполнение.
Ниже указанна схема примерного взаимодействия данного алгоритма.
Постараюсь подробнее рассмотреть команды относящиеся к данному режиму конфигурации.Switch(config)# class-map cisco
Switch(config-cmap)#
Команда class-map используется для того, чтобы описать класс трафика
- Назначение класса трафика — классифицировать или идентифицировать трафик который будет передан конкретному QoS.
- Трафик который соответствует определенным критериям.
- Имя (name)
- Набор команд match
- Если существует больше одной команды match, класс должен содержать инструкции по вычислению
Ниже приведу пример, весь трафик который разрешен, через ACL test будет частью класса известного как cisco.
Switch(config)# class-map cisco
Switch(config-cmap)# match access-group name testКоманда match используется для определения различных критериев классификации пакетов.
Если пакет совпадает с указанными критериями:
- Пакет начинает относиться к данному классу
- Пакет пересылается следуя спецификациям QoS указанных в политике трафика.
Пакеты которые не совпали в указанными критериями:
- Классифицируются как класс по умолчанию.
- Распределяются по другим политикам трафика.
— class-map match-any или
— class-map match-all
Если используется match-any, то трафик будет будет двигаться исходя из правила, «должен соответствовать одному из указанных критериев»
Если используется match-all, то трафик будет двигаться исходя из правила, «должен соответствовать всем указанным критериям»
Switch(config)# class-map match-any cisco
Switch(config-cmap)# match access-group name test
Switch(config-cmap)# match interface fastethernet 0/1
Если трафик совпадает с утверждением «разрешено» в ACL test или трафик создается интерфейсом Fa0/1, он будет признан частью трафика известного как cisco.
Команда policy-map используется для создания политики трафика
— Назначение политики трафика — это конфигурирование функций QoS, которые должны быть связаны с трафиком который был классифицирован как трафик описанный пользователем.
Политика трафика состоит также из трех элементов:
- Имя политики (Policy name)
- Класс трафика (обозначается командой class)
- политики QoS которые будут применены к каждому классу.
Switch(config)# policy-map policy1
Switch(config-pmap)# class cisco
Switch(config-pmap-c)# bandwidth 3000
Switch(config-pmap)# class class-default
Switch(config-pmap-c)# bandwidth 2000
Данный policy-map создает политику трафика называющуюся policy1
- Политика применяется ко всему трафику классифицируемому заранее описанным классом трафика «cisco». Указывает, что трафику в данном примере следует выделить полосу пропускания 3000 kbps.
- Весь трафик который не принадлежит данному классу «cisco» формирует часть класса class-default. Ему будет предоставлена полоса пропускания 2000 kbps.
Switch(config)# interface fastethernet 0/1
Switch(config-if)# service-policy output policy1Команда service policy используется для присоединения политики трафика, указанную командой policy-map, на интерфейс.
— Может быть применен как для входящих так и для исходящих пакетов на указанном интерфейсе, поэтому в данной команде необходимо указывать направление трафика.
Switch(config)#interface fastethernet 0/1
Switch(config-if)#service-policy output policy1
Switch(config-if)#exit
Все пакеты покидающие указанные интерфейс должны быть совместимы с критериями указанными в политике трафика названной policy1.
Теперь попробуем объединить все что у нас получилось в единую конфигурацию, с небольшими разъяснениями:
1. Добавляем политику трафика к интерфейсу.Switch(config)#interface fastethernet 0/12. Идентифицируем функцию QoS данной политики, используя классы.
Switch(config-if)#service-policy output policy1Switch(config)#policy-map policy1
Switch(config-pmap)#class cisco
Switch(config-pmap-c)#bandwidth 3000
Switch(config-pmap)#class class-default
Switch(config-pmap-c)#bandwidth 2000
3. Классификация потока трафика, как принадлежащего к указанному классу QoS.Switch(config)# class-map match-any cisco
Switch(config-cmap)# match access-group name test
Switch(config-cmap)# match interface fastethernet 0/1
Примерно так и функционирует модель QoS основанная на Cisco IOS, надеюсь я хоть немного смог раскрыть алгоритм данного функционала. Конечно данная статья является только лишь верхушкой айсберга под названием QoS, но надеюсь, что она поможет приобрести небольшую базу в построении политик QoS на устройствах Cisco.
Всё, что вы хотели знать о Ethernet фреймах, но боялись спросить, и не зря / Habr
Статья получилась довольно объёмная, рассмотренные темы — форматы Ethenet фреймов, границы размеров L3 Payload, эволюция размеров Ethernet заголовков, Jumbo Frame, Baby-Giant, и много чего задето вскользь. Что-то вы уже встречали в обзорной литературе по сетям передачи данных, но со многим, однозначно, не сталкивались, если глубоко не занимались изысканиями.Начнём с рассмотрения форматов заголовков Ethernet фреймов в очереди их появления на свет.
Форматы Ehternet фреймов.
1) Ethernet II
Рис. 1
Preamble – последовательность бит, по сути, не являющаяся частью ETH заголовка определяющая начало Ethernet фрейма.
DA (Destination Address) – MAC адрес назначения, может быть юникастом, мультикастом, бродкастом.
SA (Source Address) – MAC адрес отправителя. Всегда юникаст.
E-TYPE (EtherType) – Идентифицирует L3 протокол (к примеру 0x0800 – Ipv4, 0x86DD – IPv6, 0x8100- указывает что фрейм тегирован заголовком 802.1q, и т.д. Список всех EtherType — standards.ieee.org/develop/regauth/ethertype/eth.txt )
Payload – L3 пакет размером от 46 до 1500 байт
FCS (Frame Check Sequences) – 4 байтное значение CRC используемое для выявления ошибок передачи. Вычисляется отправляющей стороной, и помещается в поле FCS. Принимающая сторона вычисляет данное значение самостоятельно и сравнивает с полученным.
Данный формат был создан в сотрудничестве 3-х компаний – DEC, Intel и Xerox. В связи с этим, стандарт также носит название DIX Ethernet standard. Данная версия стандарта была опубликована в 1982г (первая версия, Ehernet I – в 1980г. Различия в версиях небольшие, формат в целом остался неизменным). В 1997г. году данный стандарт был добавлен IEEE к стандарту 802.3, и на данный момент, подавляющее большинство пакетов в Ethernet сетях инкапсулированы согласно этого стандарта.
2) Ethernet_802.3/802.2 (802.3 with LLC header)
Рис. 2
Как вы понимаете, комитет IEEE не мог смотреть спокойно, как власть, деньги и женщины буквально ускользают из рук. Поэтому, занятый более насущными проблемами, за стандартизацию технологии Ethernet взялся с некоторым опозданием (в 1980 взялись за дело, в 1983 дали миру драфт, а в 1985 сам стандарт), но большим воодушевлением. Провозгласив инновации и оптимизацию своими главными принципами, комитет выдал следующий формат фрейма, который вы можете наблюдать на Рисунке 2.
Первым делом обращаем внимание на то, что “ненужное” поле E-TYPE преобразовано в поле Length, которое указывало на количество байт следующее за этим полем и до поля FCS. Теперь, понять у кого длинее можно было уже на втором уровне системы OSI. Жить стало лучше. Жить стало веселее.
Но, указатель на тип протокола 3его уровня был нужен, и IEEE дало миру следующую инновацию — два поля по 1 байту — Source Service Access Point(SSAP) и Destination Service Access Point (DSAP). Цель, таже самая, – идентифицировать вышестоящий протокол, но какова реализация! Теперь, благодаря наличию двух полей в рамках одной сессии пакет мог передаваться между разными протоколами, либо же один и тот же протокол мог по разному называться на двух концах одной сессии. А? Каково? Где ваше Сколково?
Замечание: В жизни же это мало пригодилось и SSAP/DSAP значения обычно совпадают. К примеру SAP для IP – 6, для STP — 42 (полный список значений — standards.ieee.org/develop/regauth/llc/public.html)
Не давая себе передышки, в IEEE зарезервировали по 1 биту в SSAP и DSAP. В SSAP под указание command или response пакета, в DSAP под указание группового или индивидуального адреса (см. Рис. 6). В Ethernet сетях эти вещи распространения не получили, но количество бит в полях SAP сократилось до 7, что оставило лишь 128 возможных номера под указание вышестоящего протокола. Запоминаем этот факт, к нему мы ещё вернёмся.
Было уже сложно остановиться в своём стремлении сделать лучший формат фрейма на земле, и в IEEE фрейм формате появляется 1 байтное поле Control. Отвечающее, не много, не мало, за Connection-less или же Connection-oriented соединение!
Выдохнув и осмотрев своё детище, в IEEE решили взять паузу.
Замечание: Рассматриваемые 3 поля — DSAP, SNAP и Control и являются LLC заголовком.
3) «Raw» 802.3
Рис. 3
Данный «недостандарт» явил в мир Novell. Это были лихие 80-ые, все выживали, как могли, и Novell не был исключением. Заполучив ещё в процессе разработки спецификации стандарта 802.3/802.2, и лёгким движением руки выкинув LLC заголовок, в Novell получили вполне себе неплохой фрейм формат (с возможность измерения длины на втором уровне!), но одним существенным недостатком – отсутствием возможности указания вышестоящего протокола. Но, как вы уже могли догадаться, работали там ребята не глупые, и по здравому размышлению выработали решение – «а обратим ка мы свои недостатки в свои же достоинства», и ограничили этот фрейм-формат исключительно IPX протоколом, который сами же и поддерживали. И задумка хорошая, и план был стратегически верный, но, как показала история, не фортануло.
4) 802.3 with SNAP Header.
Время шло. В комитет IEEE приходило осознание того, что номера протоколов и деньги кончаются. Благодарные пользователи засыпали редакцию письмами, где 3-х байтный LLC заголовок ставился в один ряд с такими великими инновациями человечества, как оборудование собаки 5ой ногой, или же с рукавом, который можно использовать для оптимизации женской анатомии. Выжидать дальше было нельзя, настало время заявить о себе миру повторно.
Рис. 4
И в помощь страждущим от нехватки номеров протоколов (их всего могло быть 128 – мы упоминали), IEEE вводит новый стандарт фрейма Ethernet SNAP (Рис. 4). Основное нововведение — добавление 5-ти байтного поля Subnetwork Access Protocol (SNAP), которое в свою очередь состоит из двух частей – 3х байтного поля Organizationally Unique Identifier (OUI) и 2х байтного Protocol ID (PID) — Рис. 5.
Рис. 5
OUI или же vendor code – позволяет идентифицировать пропиетарные протоколы указанием вендора. К примеру, если вы отловите WireShark`ом пакет PVST+, то в поле OUI увидите код 0x00000c, который является идентификатором Cisco Systems (Рис. 6).
Рис. 6
Замечание: Встретить пакет с инкапсуляцией в формат фрейма 802.3 SNAP довольно легко и сейчас – это все протоколы семейства STP, протоколы CDP, VTP, DTP.
Поле PID это, по сути, то же поле EtherType из DIX Ethernet II — 2 байта под указание протокола вышестоящего уровня. Так как ранее, для этого использовались DSAP и SSAP поля LLC заголовка, то для указания того, что тип вышестоящего протокола нужно смотреть в поле SNAP, поля DSAP и SSAP принимают фиксированное значение 0xAA (также видно на Рис. 6)
Замечание: При использовании для переноса IP пакетов формата фрейма LLC/SNAP, IP MTU снижается с 1500 до 1497 и 1492 байт соответственно.
По заголовкам в формате фрейма в принципе всё. Хотел бы обратить внимание на ещё один момент в формате фрейма – размер payload. Откуда взялся этот диапазон — от 46 до 1500 байт?
Размер L3 Payload.
Откуда взялось нижнее ограничение, знает, пожалуй, каждый, кто хотя бы читал первый курикулум CCNA. Данное ограничение является следствием ограничения в размер фрейма в 64 байта (64 байта – 14 байт L2 заголовок — 4 байта FCS = 46 байт ) накладываемого методом CSMA/CD – время требуемое на передачу 64 байт сетевым интерфейсом является необходимым и достаточным для определения коллизии в среде Ethernet.
Замечание: В современных сетях, где возникновение коллизий исключено, данное ограничение уже не актуально, но требование сохраняется. Это не единственный «аппендикс» оставшийся с тех времен, но о них поговорим в другой статье.
А вот откуда взялись эти пресловутые 1500 байт, вопрос сложнее. Я нашел следующее объяснение — предпосылок на введение верхнего ограничения размера фрейма было несколько:
- Задержка при передаче – чем больше фрейм, тем дольше длится передача. Для ранних сетей, где Collision домен не ограничивался портом, и все станции должны были ждать завершения передачи, это было серьёзной проблемой.
- Чем больше фрейм, тем больше вероятность того что фрейм при передаче будет поврежден, что приведет к необходимости повторной передачи, и все устройства в collision домене будут вынуждены опять ожидать.
- Ограничения, накладываемые памятью используемой под интерфейс буферы – на тот момент (1979г) увеличение буферов значительно удорожало стоимость интерфейса.
- Ограничение, вносимое полем Length/Type – в стандарте закреплено, что все значения выше 1536 (от 05-DD до 05-FF.) указывают на EtherType, соответственно длина должна быть меньше 05-DC. (У меня правда есть подозрение, что это скорее следствие, чем предпосылка, но вроде инфа от разработчиков стандарта 802.3)
Итого, в стандарте 802.3 размер фрейма ограничивался 1518 байтами сверху, а payload 1500 байтами (отсюда и дефолтный размер MTU для Ethernet интерфейса).
Замечание: Фреймы меньше 64 байт называются Runts, фреймы больше 1518 байт называются Giants. Просмотреть кол-во таких фреймов полученных на интерфейсе можно командой show interface gigabitEthernet module/number и show interface gigabitEthernet module/number counters errors. Причём до IOS 12.1(19) в счётчики шли как фреймы с неверным, так и верным CRS (хотя вторые не всегда дропались – зависит от платформы и условий). А вот начиная с 12.1.(19) отображаются в этих счётчиках только те runt и giant фреймы, которые имеют неверный CRS, фреймы меньше 64 байт, но с верным CRS (причина возникновения обычно связана с детегированием 802.1Q или источником фреймов, а не проблемами физического уровня) с этой версии попадают в счётчик Undersize, дропаются они, или же форвардятся дальше, зависит от платформы.
Эволюция размеров Ethernet заголовков.
С развитием технологий и спецификаций линейки IEEE 802 претерпевал изменения и размер фрейма. Основные дальнейшее изменения размера фрейма (не MTU!):
- 802.3AC — увеличивает максимальный размер фрейма до 1522 – добавляется Q-tag – несущий информацию о 802.1Q (VLAN tag) и 802.1p (биты под COS)
- 802.1AD — увеличивает максимальный размер фрейма до 1526, поддержка QinQ
- 802.1AH (MIM) – Provider Bridge Backbone Mac in Mac + 30 байт к размеру фрейма
- MPLS – увеличиваем размер фрейма на стек меток 1518 + n*4, где n – количество меток в стеке.
- 802.1AE – Mac Security, к стандартным полям добавляются поля Security Tag и Message Authentication Code + 68 байт к размеру фрейма.
Все эти фреймы увеличенного размера группируются под одни именем – Baby-Giant frames. Негласное верхнее ограничение по размерам для Baby-Giant – это 1600 байт. Современные сетевые интерфейсы будут форвардить эти фреймы, зачастую, даже без изменения значения HW MTU.
Отдельно обратим внимание на спецификации 802.3AS — увеличивает максимальный размер фрейма до 2000 (но сохраняет размер MTU в 1500 байт!). Увеличение приходится на заголовок и трейлер. Изначально увеличение планировалось на 128 байт – для нативной поддержки стандартом 802.3 вышеперечисленных расширений, но в итоге сошлись на 2х тысячах, видимо, чтобы два раза не собираться (или как говорят в IEEE – this frame size will support encapsulation requirements of the foreseeable future). Стандарт утвержден в 2006 году, но кроме как на презентациях IEEE, я его не встречал. Если у кого есть что добавить здесь (и не только здесь) – добро пожаловать в комменты. В целом тенденция увеличения размера фрейма при сохранении размера PAYLOAD, порождает у меня в голове смутные сомнения в правильности выбранного направления движения.
Замечание: Немного в стороне от перечисленного обосновался FCoE фрейм – размер фрейма до 2500 байт, зачастую, эти фреймы называются mini-jumbo. Для их саппорта необходимо включать поддержку jumbo-frame.
И последний «бастард» Ethernet это Jumbo Frame (хотя если перевести Jumbo, то вырисовывается скорее Ходор – отсылка к Game of Thrones). Под это описание попадают все фреймы превосходящие размером стандарт в 1518 байт, за исключением рассмотренных выше. Jumbo пакеты никак не отражены в спецификациях 802.3 и поэтому реализация остаётся на совести каждого конкретного вендора. Тем не менее, Jumbo фреймы существуют столько же, сколько существует Ethernet. Определено это следующим:
- Выгода соотношения Payload к заголовкам. Чем больше это соотношение, тем эффективней мы можем использовать линии связи. Конечно здесь разрыв будет не такой как в сравнении с использованием пакетов в 64 байт и 1518 байт для TCP сессий. Но свои 3-8 процентов, в зависимости от типа трафика выиграть можно.
- Значительно меньшее количество заголовков генерирует меньшую нагрузку на Forwading Engine, также и на сервисные Engine. К примеру, frame rate для 10G линка загруженного фреймами по 1500 байт равен 812 744 фреймов в секунду, а тот же линк загруженный Jumbo фреймами в 9000 байт генерирует фрейм рейт всего лишь в 138 587 фрейм в секунду. На рисунке 7 приведены график из отчёта Alteon Networks (ссылка будет внизу статьи) утилизации CPU и гигабитного линка, в зависимости от типа используемого размера фрейма.
- Увеличение TCP Throughput при изменении размера MTU — staff.psc.edu/rreddy/networking/mtu.html
Рис. 7
Есть у этой медали и обратная сторона:
- Чем больше фрейм, тем дольше он будет передаваться (Рис. 8):
- Буферы в памяти сетевых устройств заполняются быстрее, что может вызвать нежелательные последствия. По сути, решаемо на стадии проектирования оборудования, но увеличивает стоимость.
- Проприетарная реализация у каждого производителя – все устройства должны поддерживать или одинаковые размеры Jumbo фрейма, или же наборы размеров.
- Использование на больших участках сети находящихся под разным административным контролем, по сути, невозможно, из-за отсутствия механизма Jumbo Frame Discovery – промежуточный узел может не поддерживать Jumbo Frame совсем или определенный размер.
Рис.8
В сумме, плюсы и минусы использования Jumbo фреймов дают нам недвусмысленное указание, где мы можем использовать такой размер фрейма. И так, в каких же приложениях в датацентре мы можем использовать Jumbo Frame к всеобщей выгоде? Выходит такой примерно список (дополнения приветствуются):
- В серверных кластерах
- При бэкапировании
- Network File System (NFS) Protocol
- iSCSI SANs
- FCoE SANs
Замечание: Верхнее ограничение размера есть и у Jumbo MTU. Оно определяется размером поля FCS (4 байт) и алгоритмом Cyclic Redundancy Check и равняется 11 455 байт. На практике же, Jumbo MTU обычно ограничен размером в 9216 байт, на некоторых платформах в 9000 байт, на более старом железе в 8092 байт (речь о Cisco).
Фух, в принципе всё. Что хотел рассмотреть по теории, рассмотрели. По конфигурации размеров MTU и теории с финтами стоящими за этими тремя буквами, прошу в мою прошлую статью – «Maximum Transmission Unit (MTU). Мифы и рифы».
В заключение обещанный линк на отчёт Alteon Networks «Extended Frame Sizes for Next Generation Ethernets» — staff.psc.edu/mathis/MTU/AlteonExtendedFrames_W0601.pdf, и небольшой анонс на следующую статью – в ней мы падём ещё ниже — на физический уровень, и будем разбираться с тяжелым наследием CSMA/CD, энкодингами, и, походя, зацепим ещё чего из злободневного.
Основы клиентского кэширования понятными словами и на примерах. Last-modified, Etag, Expires, Cache-control: max-age и другие заголовки
Кэш играет важную роль в работе практически любого веб-приложения на уровне работы с базами данных, веб-серверами, а также на клиенте.
В рамках этой статьи мы попытаемся разобраться с клиентским кэшированием. В частности, разберемся с тем, какие http-заголовки используются браузерами и веб-серверами и что они значат.
Но для начала давайте выясним, зачем вообще нужно кэширование на стороне клиента?.
Веб-страницы состоят из множества различных элементов: картинок, css и js файлов и т.п. Часть этих элементов используются на нескольких (многих) страницах сайта. Под клиентским кэшированием понимают способность браузеров сохранять копии файлов (ответов сервера), чтобы не загружать их повторно. Это позволяет значительно ускорить повторную загрузку страниц, сэкономить на трафике, а также снизить нагрузку на сервер.
Существует несколько различных HTTP-заголовков для того, чтобы управлять процессами кэширования на стороне клииента. Давайте поговорим о каждом из них.
Http заголовки для управления клиентским кэшированием
Для начала давайте посмотрим, как сервер и браузер взаимодействуют при отсутствии какого-либо кэширования. Для наглядного понимания я попытался представить и визуализировать процесс общения между ними в виде текстового чата. Представьте на несколько минут, что сервер и браузер – это люди, которые переписываются друг с другом 🙂
Без кэша (при отсутствии кэширующих http-заголовков)
Как мы видим, каждый раз при отображении картинки cat.png браузер будет снова загружать ее с сервера. Думаю, не нужно объяснять, что это медленно и неэффективно.
Заголовок ответа Last-modified и заголовок запроса if-Modified-Since.
Идея заключается в том, что сервер добавляет заголовок Last-modified к файлу (ответу), который он отдает браузеру.
Last-modified: Fri, 1 Dec 2014 01:01:01 GMT
Теперь браузер знает, что файл был создан (или изменен) 1 декабря 2014. В следующий раз, когда браузеру понадобится тот же файл, он отправит запрос с заголовком if-Modified-Since.
if-Modified-Since: Fri, 1 Dec 2014 01:01:01 GMT
Если файл не изменялся, сервер отправляет браузеру пустой ответ со статусом 304 (Not Modified). В этом случае, браузер знает, что файл не обновлялся и может отобразить копию, которую он сохранил в прошлый раз.
Таким образом, используя Last-modified мы экономим на загрузке большого файла, отделываясь пустым быстрым ответом от сервера.
Заголовок ответа Etag и заголовок запроса If-None-Match.
Принцип работы Etag очень схож с Last-modified, но, в отличии от него, не привязан ко времени. Время – вещь относительная.
Идея заключается в том, что при создании и каждом изменении сервер помечает файл особой меткой, называемой ETag, а также добавляет заголовок к файлу (ответу), который он отдает браузеру:
ETag: "686897696a7c876b7e"
Теперь браузер знает, что файл актуальной версии имеет ETag равный “686897696a7c876b7e”. В следующий раз, когда брузеру понадобится тот же файл, он отправит запрос с заголовком If-None-Match: "686897696a7c876b7e".
If-None-Match: "686897696a7c876b7e"
Сервер может сравнить метки и, в случае, если файл не изменялся, отправить браузеру пустой ответ со статусом 304 (Not Modified). Как и в случае с Last-modified браузер выяснит, что файл не обновлялся и сможет отобразить копию из кэша.
Подробнее о ETag можно почитать здесь.
Заголовок Expired
Принцип работы этого заголовка отличается от вышеописанных Etag и Last-modified. При помощи Expired определяется “срок годности” (“срок акуальности”) файла. Т.е. при первой загрузке сервер дает браузеру знать, что он не планирует изменять файл до наступления даты, указанной в Expired:
Expired: Fri, 1 Mar 2014 01:01:01 GMT
В следующий раз браузер, зная, что “дата истечения срока годности” еще не наступила, даже не будет пытаться делать запрос к серверу и отобразит файл из кэша.
Такой вид кэша особенно актуален для иллюстраций к статьям, иконкам, фавиконкам, некоторых css и js файлов и тп.
Заголовок Cache-control с директивой max-age.
Принцип работы Cache-control: max-age очень схож с Expired. Здесь тоже определяется “срок годности” файла, но он задается в секундах и не привязан к конкретному времени, что намного удобнее в большинстве случаев.
Для справки:
- 1 день = 86400 секунд
- 1 неделя = 604800 секунд
- 1 месяц = 2629000 секунд
- 1 год = 31536000 секунд
К примеру:
Cache-Control: max-age=2629000;
У заголовка Cache-control, кроме max-age, есть и другие директивы. Давайте коротко рассмотрим наиболее популярные:
public
Дело в том, что кэшировать запросы может не только конечный клиент пользователя (браузер), но и различные промежуточные прокси, CDN-сети и тп. Так вот, директива public позволяет абсолютно любым прокси-серверам осуществлять кэширование наравне с браузером.
private
Директива говорит о том, что данный файл (ответ сервера) является специфическим для конечного пользователя и не должен кэшироваться различными промежуточными прокси. При этом она разрешает кэширование конечному клиенту (браузеру пользователя). К примеру, это актуально для внутренних страниц профиля пользователя, запросов внутри сессии и т.п.
no-cache
Позволяет указать, что клиент должен делать запрос на сервер каждый раз. Иногда используется с заголовком Etag, описанным выше.
no-store
Указывает клиенту, что он не должен сохранять копию запроса или частей запроса при любых условиях. Это самый строгий заголовок, отменяющий любые кэши. Он был придуман специально для работы с конфиденциальной информацией.
must-revalidate
Эта директива предписывает браузеру делать обязательный запрос на сервер для ре-валидации контента (например, если вы используете eTag). Дело в том, что http в определенной конфигурации позволяет кэшу хранить контент, который уже устарел. must-revalidate обязывает браузер при любых условиях делать проверку свежести контента путем запроса к серверу.
proxy-revalidate
Это то же, что и must-revalidate, но касается только кэширующих прокси серверов.
s-maxage
Практически не отличается от мах-age, за исключением того, что эта директива учитывается только кэшем резличных прокси, но не самим браузером пользователя. Буква “s-” исходит из слова “shared” (например, CDN). Эта директива предназначена специально для CDN-ов и других посреднических кэшей. Ее указание отменяет значения директивы max-age и заголовка Expired. Впрочем, если вы не строите CDN-сети, то s-maxage вам вряд ли когда-либо понадобится.
Как посмотреть, какие заголовки используются на сайте?
Вы можете посмотреть заголовки http-запросов (request headers) и ответов (response headers) в отладчике Вашего любимого браузера. Вот например, как это выглядит в хроме:
То-же самое можно увидеть в любом уважающем себя браузере или http-сниффере.
Настройка кэшировения в Аpache и Nginx
Мы не будем пересказывать документацию по настройке популярных серверов. Вы всегда можете посмотреть ее здесь для Nginx и здесь для Apache. Ниже мы приведем несколько примеров из жизни для того, чтобы показать, как выглядят файлы конфигурации.
Пример конфигурации Apache для контроля Expires
Выставляем различный “срок годности” для различных типов файлов. Один год для изображений, один месяц для скриптов, стилей, pdf и иконок. Для всего остального – 2 дня.
<IfModule mod_expires.c>
ExpiresActive On
ExpiresByType image/jpg "access plus 1 year"
ExpiresByType image/jpeg "access plus 1 year"
ExpiresByType image/gif "access plus 1 year"
ExpiresByType image/png "access plus 1 year"
ExpiresByType text/css "access plus 1 month"
ExpiresByType application/pdf "access plus 1 month"
ExpiresByType text/x-javascript "access plus 1 month"
ExpiresByType image/x-icon "access plus 1 year"
ExpiresDefault "access plus 2 days"
</IfModule>
Пример конфигурации Nginx для контроля Expires
Выставляем различный “срок годности” для различных типов файлов. Одна неделя – для изображений, один день – для стилей и скриптов.
server {
#...
location ~* \.(gif|ico|jpe?g|png)(\?[0-9]+)?$ {
expires 1w;
}
location ~* \.(css|js)$ {
expires 1d;
}
#...
}
Пример конфигурации Apache для Cache-control (max-age и public/private/no-cache)
<ifModule mod_headers.c>
<FilesMatch "\.(gif|ico)$">
Header set Cache-Control "max-age=2592000, public"
</FilesMatch>
<FilesMatch "\.(js)$">
Header set Cache-Control "max-age=88000,
private, must-revalidate"
</FilesMatch>
<FilesMatch "\.(php)$">
Header set Cache-Control "private, no-store, no-cache,
must-revalidate, no-transform, max-age=0"
Header set Pragma "no-cache"
</FilesMatch>
</ifModule>
Пример конфигурации Nginx для Cache-control статических файлов
server {
#...
location ~* \.(?:ico|css|js|gif|jpe?g|png)$ {
add_header Cache-Control "max-age=88000, public";
}
#...
}
В заключение
“Кэшировать все то, что можно кэшировать” – хороший девиз для веб-разработчика. Иногда можно потратить всего несколько часов на конфигурацию и при этом значительно улучшить восприятие вашего сайта пользователем, значительно сократить нагрузку на сервер и сэкономить на трафике. Главное – не переусердствовать и настроить все правильно с учетом особенностей Вашего ресурса.
Будем благодарны за рекомендации и поправки в комментариях и не забудьте поделиться статьей с друзьями, если она Вам понравилась 😉
Визуализируем и разбираемся с Hash Match Join
Этот пост является третьей частью серии, посвященной операторам соединения (обязательно прочитайте часть 1 — nested loops joins, и часть 2 — merge joins). Перевод статьи подготовлен специально для студентов курса «MS SQL Server разработчик».
Hash Match Joins — это надежные рабочие лошадки физических операторов соединения.
В то время как Nested Loops Join завершится неудачей, если данных будет слишком много для того, чтобы поместить их в память, а Merge Join потребует, чтобы входные данные были отсортированы, Hash Match соединит любые данные, которые вы подадите на вход (при условии что для соединения выполняется предикат равенства и пока в вашем tempdb достаточно свободного места).
Смотрите видео по теме на YouTube
Алгоритм hash match состоит из двух этапов, которые работают следующим образом:
Во время первого этапа «Build» (построение), SQL Server создает в памяти хеш-таблицу из одной из таблиц, поданных на вход (обычно наименьшей из двух). Хеши вычисляются на основе ключей входных данных и затем сохраняются вместе со строкой в хеш-таблице в соответствующий блок. В большинстве случаев в каждом блоке имеется только одна строка данных, кроме случаев, когда:
- Есть строки с дублирующими ключами.
- Хеш-функция создает коллизию, и совершенно разные ключи получают один и тот же хеш (это редко, но возможно).
После создания хеш-таблицы, начинается этап «Probe» (проверка). На втором этапе SQL Server вычисляет хэш ключа для каждой строки во второй входной таблице и проверяет, существует ли он в хеш-таблице, созданной на первом этапе. Если находится совпадение для этого хеша, то проверяется, действительно ли совпадают ключи строки (строк) в хеш-таблице и строки из второй таблицы (эту проверку необходимо выполнять из-за возможных коллизий).
Распространенный вариант алгоритма hash match возникает, когда на этапе построения не удается создать хеш-таблицу, которая может быть полностью сохранена в памяти:
Это происходит, когда данных больше, чем может быть размещено в памяти, или когда SQL Server предоставляет недостаточно памяти для hash match соединения.
Когда у SQL Server не хватает памяти для хранения хэш-таблицы на этапе построения, он продолжает работать, сохраняя некоторые блоки в памяти, а другие блоки помещая в tempdb.
На этапе проверки SQL Server соединяет строки данных из второй таблицы в блоки из этапа построения, находящиеся в памяти. Если блок, которому эта строка потенциально соответствует, в данный момент отсутствует в памяти, SQL Server записывает эту строку в tempdb для последующего сравнения.
Когда совпадения для одного блока завершены, SQL Server очищает эти данные из памяти и загружает следующие блоки в память. Затем он сравнивает строки второй таблицы (в настоящее время находящиеся в tempdb) с новыми блоками в памяти.
Как и в случае с каждым оператором физического соединения в этой серии, подробности об операторе hash match можно найти в справке Хьюго Корнелиса (Hugo Kornelis) о hash match.
Что показывает Hash Match Join?
Знание внутренних особенностей того, как работает hash match join, позволяет нам определить, что оптимизатор думает о наших данных и вышестоящих операторах соединения, помогая нам сосредоточить усилия на настройке производительности.
Вот несколько сценариев, которые следует рассмотреть в следующий раз, когда вы увидите, что hash match join используется в вашем плане выполнения:
- В то время как hash match join может объединять огромные наборы данных, построение хеш-таблицы из первой входной таблицы является блокирующей операцией, которая препятствует выполнению последующих операторов. В связи с этим я всегда проверяю, существует ли простой способ преобразования hash match в nested loops или merge join. Иногда это невозможно (слишком много строк для nested loops или несортированных данных для merge join), но всегда стоит проверять, приведет ли простое изменение индекса или улучшенные оценки от обновления статистики к тому, что SQL Server выберет неблокирующий hash match join оператор
- Hash match joins отлично подходят для больших соединений, поскольку они могут передаваться в tempdb, это позволяет им выполнять соединения с большими наборами данных, которые могут привести к сбою соединения в памяти с помощью nested loops или merge join операторов.
- Если вы видите оператор hash match join, то это означает, что SQL Server считает, что входные данные слишком велики. Если мы знаем, что наши входные данные не должны быть такими большими, то стоит проверить, есть ли проблемы со статистикой или оценкой, из-за которых SQL Server неправильно выбирает hash match join.
- При выполнении в памяти, hash match join довольно эффективен. Проблемы возникают, когда этап построения переходит в tempdb.
- Если я замечаю маленький желтый треугольник, указывающий, что соединение переходит в tempdb, я смотрю, почему это произошло: если данных больше, чем доступно памяти, здесь мало что можно сделать, но если выделенная память кажется неоправданно малой, это может означать, что у нас, вероятно, есть еще одна проблема со статистикой, которая приводит к слишком низким оценкам оптимизатора SQL Server.
Спасибо за то, что прочитали статью. Вам также может понравиться мой Twitter.
Мы касались этой темы на предыдущем открытом уроке. Ждем ваши комментарии!
Что такое Bootstrap, html5boilerplate и initializr
Первая, она же вводная, часть нашего нового курса, целью которого является помощь начинающим разработчикам в освоении современных frontend инструментов, техник и навыков. Шаг за шагом мы будем создавать генератор CSS3 кнопок, получая опыт на реальном примере. Начнём с обзора Twitter Bootstrap и html5boilerplate!
Twitter Bootstrap
Прежде всего познакомимся с Twitter Bootstrap — наиболее популярным и мощным на сегодняшний день инструментом для лёгкой и быстрой web-разработки. Twitter Bootstrap позволяет максимально ускорить процесс создания web сервиса или сайта, т.к. имеет в своём арсенале практически всё, что может понадобиться для решения самых различных задач: сетки и шаблоны для лэйаута, типографику, таблицы, формы, модальные окна, тултипы, CSS классы на все случаи жизни, а также внушительный javascript инструментарий, включающий даже слайдер!
Одно из основных, на мой взгляд, преимуществ Twitter Bootstrap заключается в том, что разработчик может целиком погрузиться в воплощение своей идеи, не растрачивая драгоценный энтузиазм и время на написание десятков и сотен строк CSS и JS кода и подключения десятков плагинов для тех или иных целей.
Попробуйте поиграться с данным фреймворком сами: официальный сайт twitter bootstrap и его русский перевод.
Html5boilerplate
Следующий инструмент, который обязательно должен быть у вас на вооружении — это html5boilerplate — самый популярный и известный шаблон среди web-разработчиков. В нём собраны все лучшие хаки и настройки для кроссбраузерной совместимости, поддержки html5 и очень много чего ещё. Больше информации вы можете найти на официальном сайте html5boilerplate. А прямо сейчас я предлагаю вам перейти к инструменту, позволяющему соединить html5boilerplate с Twitter Bootstrap. Перед вами:
Initializr
Генератор html5 шаблонов, который помогает нам создавать сборку, включающую только то, что нужно для конкретной цели. В нашем случае, выбираем:
- Pre-configuration — Bootstrap
- HTML/CSS Template — Responsive Bootstrap
- HTML5 Polyfills — Modernizr
- jQuery — Development
- H5BP Optional — по вашему вкусу
Ссылка на Initializr тут.
Теперь мы готовы приступить к созданию CSS3 генератора кнопок!
Потратьте некоторое время на изучение описанных выше инструментов, чтобы сформировалось хотя бы общее видение, однако не стоит слишком беспокоиться, если что-то пока не ясно. Учиться мы будем на практике, а именно на создании вашего собственного генератора CSS3 кнопок!
Рекомендуемые курсы