HTML5 и алгоритм разметки документов / Хабр
Данная статья вышла в далеком 2011 году, но до сих пор не потеряла актуальности, и собственно говоря я не нашел ничего лучше и понятнее по этой теме. Перевел для вас Кинзябулатов Рамиль.
Вступление
Все мы уже знаем, что для создания веб-сайтов лучше всего использовать HTML5. Сейчас мы обсудим то, как правильно использовать HTML5. Одной из важных частей HTML5, которую до сих пор не все понимают, является разделение содержимого на разделы: section, article, aside и nav. Чтобы понять разделение содержимого, нам нужно понять алгоритм разметки документа.
Понимание алгоритма структурирования документа может оказаться непростой задачей, но оно того стоит. Вы больше не будете ломать голову над тем, какой элемент использовать — section или div — вы будете знать это сразу. Более того, вы будете знать, почему эти элементы используются, и именно знание их значения является самым большим достоинством изучения алгоритма.
Дальнейшее чтение на SmashingMag:
Важность элементов разметки HTML5
Кодирование макета HTML 5 с нуля
Наша бессмысленная гонка за значимостью семантики
Что такое алгоритм структурирования документов?
Алгоритм структурирования документов — это механизм для создания кратких описаний веб-страниц на основе их разметки. У каждой веб-страницы есть своя структура, которую легко просмотреть с помощью очень простого бесплатного онлайн-инструмента, который мы сейчас рассмотрим.
Итак, давайте начнем с примера схемы. Представьте, что вы создали сайт для конезаводчика, и ему нужна страница для рекламы лошадей, которых он продает. Структура страницы может выглядеть примерно так:
Лошади на продажу
Кобылы
Pink Diva
Ring a Rosies
Chelsea’s Fancy
Жеребцы
Korah’s Fury
Sea Pioneer
Brown Biscuit
Пример 1: Как может быть структурирована страница о лошадях на продажу.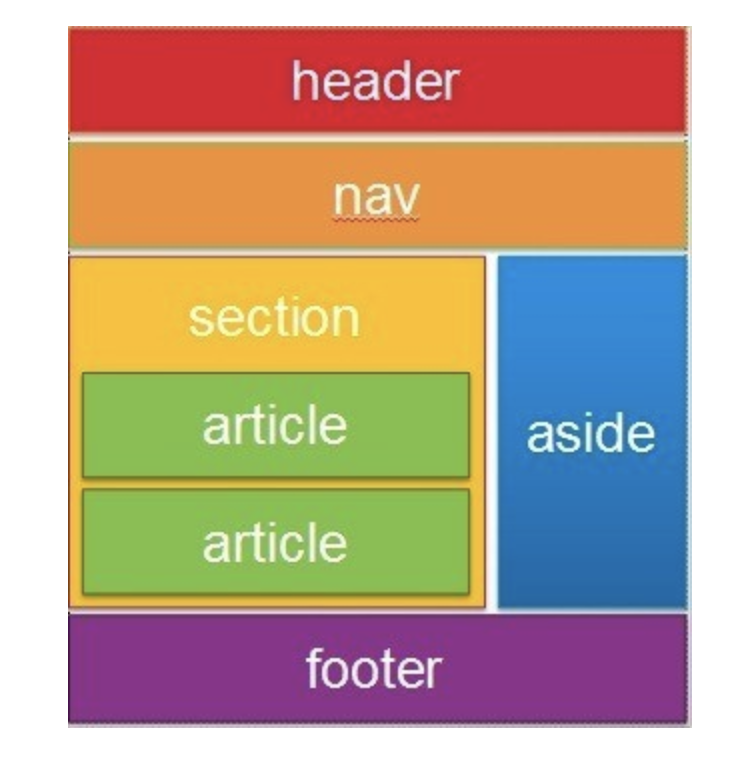
Вот и все: красивый, чистый, легко читаемый список заголовков, отображаемый в иерархии — подобно оглавлению.
Если говорить еще проще, то только две вещи в вашей разметке влияют на внешний вид веб-страницы:
Очевидно, что секционирование содержимого — это новый способ HTML5 для создания разметки. Но прежде чем перейти к этому, давайте вернемся к HTML 101 и рассмотрим, как мы должны использовать заголовки.
Создание разметки с использованием заголовков
Чтобы создать структуру для страницы лошадей, показанной на примере 1, мы могли бы использовать разметку, подобную следующей:
<div> <h2>Лошади на продажу</h2> <h3>Кобылы</h3> <h4>Pink Diva</h4> <p>Pink Diva родила трех победителей Grand National.</p> <h4>Ring a Rosies</h4> <p>Ring a Rosies трижды выигрывала Дерби.</p> <h4>Chelsea’s Fancy</h4> <p>Chelsea’s Fancy родила трех обладателей Золотого кубка.</p> <h3>Жеребцы</h3> <h4>Korah’s Fury</h4> <p>Korah’s Fury стал отцом трех чемпионских скаковых лошадей.</p> <h4>Sea Pioneer</h4> <p>Sea Pioneer трижды выигрывал "The Oaks".</p> <h4>Brown Biscuit</h4> <p>Brown Biscuit не стал отцом никого примечательного.</p> <p>Все наши лошади поставляются с полным пакетом документов и родословной.</p> </div>
 </p>
<h3>Жеребцы</h3>
<h4>Korah’s Fury</h4>
<p>Korah’s Fury стал отцом трех чемпионских скаковых лошадей.</p>
<h4>Sea Pioneer</h4>
<p>Sea Pioneer трижды выигрывал "The Oaks".</p>
<h4>Brown Biscuit</h4>
<p>Brown Biscuit не стал отцом никого примечательного.</p>
<p>Все наши лошади поставляются с полным пакетом документов и родословной.</p>
</div>
</p>
<h3>Жеребцы</h3>
<h4>Korah’s Fury</h4>
<p>Korah’s Fury стал отцом трех чемпионских скаковых лошадей.</p>
<h4>Sea Pioneer</h4>
<p>Sea Pioneer трижды выигрывал "The Oaks".</p>
<h4>Brown Biscuit</h4>
<p>Brown Biscuit не стал отцом никого примечательного.</p>
<p>Все наши лошади поставляются с полным пакетом документов и родословной.</p>
</div>Пример 2: Наша страница «Лошади на продажу», размеченная с помощью заголовков.
Все очень просто. Контур на примере 1 создан уровнями заголовков.
Чтобы вы знали, что я не выдумываю, скопируйте и вставьте приведенный выше код в превосходный инструмент Джеффри Снеддона для создания схем. Нажмите большую кнопку «Outline this», и вуаля!
Схема, созданная таким образом с использованием заголовков, состоит из скрытых, или неявных разделов. Каждый заголовок создает свой собственный неявный раздел, а любой последующий заголовок более низкого уровня создает внутри него еще один уровень, неявный подраздел.
Неявный раздел завершается заголовком того же уровня или выше. В нашем примере раздел «Кобылы» заканчивается началом раздела «Жеребцы», а каждый раздел, содержащий подробную информацию об отдельной лошади, заканчивается началом следующего.
Пример 3 ниже — пример неявного раздела, который заканчивается заголовком того же уровня. А пример 4 — неявный раздел, который заканчивается заголовком более высокого уровня.
<h4>Sea Pioneer</h4><!-- начало неявного раздела --> <p>Sea Pioneer трижды выигрывал "The Oaks".</p> <h4>Brown Biscuit</h4><!-- Этот заголовок начинает новый неявный раздел, поэтому предыдущий, - "Sea Pioneer" закрывается -->
Пример 3: Неявный раздел закрывается заголовком того же уровня
<h4>Chelsea’s Fancy</h4><!-- начало неявного раздела --> <p>Chelsea’s родила трех обладателей Золотого кубка.</p> <h3>Stallions</h3><!-- с этого заголовка начинается новый неявный раздел используя заголовок более высокого уровня, так что "Chelsea`s Fancy" теперь закрыт -->
Пример 4: Неявный раздел закрывается заголовком более высокого уровня.
Создание схемы с помощью разделения содержимого
Теперь, когда мы знаем, как содержимое заголовка работает при создании схемы, давайте разметим нашу страницу с лошадьми, используя некоторые новые структурные элементы HTML5:
<div> <h6>Лошади на продажу</h6> <section> <h2>Кобылы</h2> <article> <h2>Pink Diva</h2> <p>Pink Diva родила трех победителей Grand National.</p> </article> <article> <h5>Ring a Rosies</h5> <p>Ring a Rosies трижды выигрывала Дерби.</p> </article> <article> <h3>Chelsea’s Fancy</h3> <p>Chelsea’s Fancy родила трех обладателей Золотого кубка.</p> </article> </section> <section> <h6>Жеребцы</h6> <article> <h4>Korah’s Fury</h4> <p>Korah’s Fury стал отцом трех чемпионских скаковых лошадей.
 </p>
</article>
<article>
<h4>Sea Pioneer</h4>
<p>Sea Pioneer трижды выигрывал "The Oaks".</p>
</article>
<article>
<h2>Brown Biscuit</h2>
<p>Brown Biscuit не стал отцом никого примечательного.</p>
</article>
</section>
<p>Все наши лошади поставляются с полным пакетом документов и родословной.</p>
</div>
</p>
</article>
<article>
<h4>Sea Pioneer</h4>
<p>Sea Pioneer трижды выигрывал "The Oaks".</p>
</article>
<article>
<h2>Brown Biscuit</h2>
<p>Brown Biscuit не стал отцом никого примечательного.</p>
</article>
</section>
<p>Все наши лошади поставляются с полным пакетом документов и родословной.</p>
</div>Пример 5: Страница лошадей, размеченная с помощью новых структурных элементов HTML5.
Я знаю, о чем вы подумали, но я не лишился рассудка с этими безумными заголовками. Я делаю очень важный вывод, который заключается в том,
Скопируйте и вставьте этот код в outliner, и вы увидите, что уровни заголовков абсолютно не влияют на схему, в которой используется содержимое разделов.
Элементы section, article, aside и nav — вот что создает схему, и на этот раз разделы называются явными разделами.
Одной из самых обсуждаемых особенностей HTML5 является то, что разрешено использовать несколько элементов h2, и вот почему. Это не призыв размечать каждый заголовок на странице как h2; скорее, это признание того, что там, где используется разделение содержимого на секции, оно создает схему, и что каждая явная секция имеет свою собственную структуру заголовков.
В той части спецификации HTML5, которая посвящена заголовкам и разделам, это четко указано:
Разделы могут содержать заголовки любого ранга, но авторам настоятельно рекомендуется либо использовать только элементы h2, либо использовать элементы соответствующего ранга для уровня вложенного раздела.
Я бы настоятельно рекомендовал, пока браузеры — и, что более важно, программы чтения с экрана — не поймут, что разделение содержимого вводит подраздел, использование нескольких элементов h2 менее безопасно, чем использование структуры заголовков, которая отражает уровень каждого заголовка в документе, как показано на примере 6 ниже.
Это означает, что пользовательские агенты, которые не реализовали алгоритм разметки, могут использовать неявное разделение, а те, которые его реализовали, могут эффективно игнорировать уровни заголовков и использовать секционирование содержимого для создания схемы.
На момент написания этой статьи ни один браузер или программа для чтения не реализовали алгоритм выделения контуров, поэтому нам нужны сторонние инструменты тестирования, такие как аутлайнер. Последние версии Chrome и Firefox по-разному стилизуют элементы h2 во вложенных разделах, но это очень отличается от реальной реализации алгоритма.
Когда большинство пользовательских агентов, наконец, будут поддерживать его, использование h2 в каждом явном разделе станет предпочтительным вариантом. Это позволит инструментам синдикации обрабатывать статьи без необходимости переформатирования уровней заголовков в исходном контенте.
<div> <h2>Лошади на продажу</h2> <section> <h3>Кобылы</h3> <article> <h4>Pink Diva</h4> <p>Pink Diva родила трех победителей Grand National.</p> </div>
 </p>
</article>
<article>
<h4>Ring a Rosies</h4>
<p>Ring a Rosies трижды выигрывала Дерби.</p>
</article>
<article>
<h4>Chelsea’s Fancy</h4>
<p>Chelsea’s родила трех обладателей Золотого кубка.</p>
</article>
</section>
<section>
<h3>Жеребцы</h3>
<article>
<h4>Korah’s Fury</h4>
<p>Korah’s Fury стал отцом трех чемпионских скаковых лошадей.</p>
</article>
<article>
<h4>Sea Pioneer</h4>
<p>Sea Pioneer трижды выигрывал "The Oaks".</p>
</article>
<article>
<h4>Brown Biscuit</h4>
<p>Brown Biscuit не стал отцом никого примечательного.</p>
</article>
</section>
<p>Все наши лошади поставляются с полным пакетом документов и родословной.
</p>
</article>
<article>
<h4>Ring a Rosies</h4>
<p>Ring a Rosies трижды выигрывала Дерби.</p>
</article>
<article>
<h4>Chelsea’s Fancy</h4>
<p>Chelsea’s родила трех обладателей Золотого кубка.</p>
</article>
</section>
<section>
<h3>Жеребцы</h3>
<article>
<h4>Korah’s Fury</h4>
<p>Korah’s Fury стал отцом трех чемпионских скаковых лошадей.</p>
</article>
<article>
<h4>Sea Pioneer</h4>
<p>Sea Pioneer трижды выигрывал "The Oaks".</p>
</article>
<article>
<h4>Brown Biscuit</h4>
<p>Brown Biscuit не стал отцом никого примечательного.</p>
</article>
</section>
<p>Все наши лошади поставляются с полным пакетом документов и родословной.
Пример 6: Страница наших лошадей с разумной разметкой.
Еще один момент, на который стоит обратить внимание, — это положение абзаца «Все наши лошади поставляются с полным пакетом документов и родословной». В примере, где для создания схемы использовались заголовки (прим. 2), этот абзац является частью неявного раздела, созданного заголовком «Brown Biscuit». Читатели ясно увидят, что этот текст относится ко всему документу, а не только к Brown Biscuit.
Секционирование контента решает эту проблему довольно легко, перемещая его обратно на верхний уровень, возглавляемый заголовком «Лошади на продажу».
Смешивание
Итак, что происходит, когда комбинируются неявные и явные разделы? Если вы помните, что неявные разделы могут находиться внутри явных разделов, но не наоборот, то все будет в порядке. Например, следующий вариант работает хорошо и является абсолютно правильным:
<h2>Лошади на продажу</h2> <section> <h3>Кобылы</h3> <h4>Pink Diva</h4> <p>Pink Diva родила трех победителей Grand National.
 </p>
<h4>Ring a Rosies</h4>
<p>Ring a Rosies трижды выигрывала Дерби.</p>
<h4>Chelsea’s Fancy</h4>
<p>Chelsea’s родила трех обладателей Золотого кубка.</p>
</section>
</p>
<h4>Ring a Rosies</h4>
<p>Ring a Rosies трижды выигрывала Дерби.</p>
<h4>Chelsea’s Fancy</h4>
<p>Chelsea’s родила трех обладателей Золотого кубка.</p>
</section>И это создает разумную иерархическую схему:
Horses for sale
Mares
Pink Diva
Ring a Rosies
Chelsea’s Fancy
Пример 7: Скрытые разделы, созданные заголовками внутри явного раздела.
Однако если вы надеетесь добиться такой же схемы , вложив явный раздел в скрытый, ничего не выйдет. Элемент секционирования просто закроет скрытый раздел, созданный заголовком, и создаст совсем другую схему, как показано ниже:
<h2>Лошади на продажу</h2> <h3>Кобылы</h3> <article> <h4>Pink Diva</h4> <p>Pink Diva родила трех победителей Grand National.</p> </article> <article> <h4>Ring a Rosies</h4> <p>Ring a Rosies трижды выигрывала Дерби.
 </p>
</article>
<article>
<h4>Chelsea’s Fancy</h4>
<p>Chelsea’s Fancy родила трех обладателей Золотого кубка.</p>
</article>
</p>
</article>
<article>
<h4>Chelsea’s Fancy</h4>
<p>Chelsea’s Fancy родила трех обладателей Золотого кубка.</p>
</article>В результате получится следующая схема:
Horses for sale
Mares
Pink Diva
Ring a Rosies
Chelsea’s Fancy
Пример 8: Явные секции не могут находиться внутри скрытых секций.
Не существует способа заставить явные разделы, созданные элементами article, стать подразделами неявного раздела Mare.
Вы можете использовать заголовки для разделения содержимого элементов секционирования, но не наоборот.
На что следует обратить внимание
Разделы без названия
До сих пор мы не рассматривали nav и aside, но они работают точно так же, как section и article. Если у вас есть второстепенный контент, который в целом связан с вашим сайтом — скажем, советы по дрессировке лошадей и новости отрасли — вы пометите его как «в сторону», что создаст явный раздел в схеме документа. Аналогично, основная навигация должна быть обозначена как nav, что также создает явный раздел.
Аналогично, основная навигация должна быть обозначена как nav, что также создает явный раздел.
Нет требования использовать заголовки для aside и nav, поэтому они могут появиться в конспекте как разделы без названия. Попробуйте использовать следующий код в программе outliner:
<nav> <ul> <li><a href="/">home</a></li> <li><a href="/about.html">about us</a></li> <li><a href="/лошади.html">horses for sale</a></li> </ul> </nav> <h2>Лошади на продажу</h2> <section> <h3>Кобылы</h3> </section> <section> <h3>Жеребцы</h3> </section>
Пример 9: Безымянная <nav>.
nav отображается как раздел без названия. Как правило, это не является проблемой и не считается плохим кодом HTML5, хотя в своей недавней статье HTML5 Doctor об изложении Майк Робинсон рекомендует использовать заголовки для всех разделов контента, чтобы повысить доступность.
Элементы section и article без названия, с другой стороны, обычно следует избегать. На самом деле, если вы не уверены, стоит ли использовать section или article, хорошее правило — посмотреть, есть ли у контента естественный, логичный заголовок. Если нет, то, скорее всего, лучше использовать старый добрый div.
На самом деле, спецификация не требует, чтобы элементы section имели заголовок. Она гласит:
Элемент section представляет собой общий раздел документа или приложения. В данном контексте раздел — это тематическая группировка содержимого, обычно с заголовком.
Ваша интерпретация этого, вероятно, зависит от вашего понимания слова «обычно». Я понимаю это как то, что вам нужна чертовски веская причина не использовать заголовки с section элементами. Я не считаю, что это означает, что вы можете игнорировать его всякий раз, когда вам захочется использовать новый элемент HTML5.
Там, где указан элемент article, спецификация идет еще дальше, показывая пример комментариев в блогах, помеченных как article без заголовка, так что исключения есть.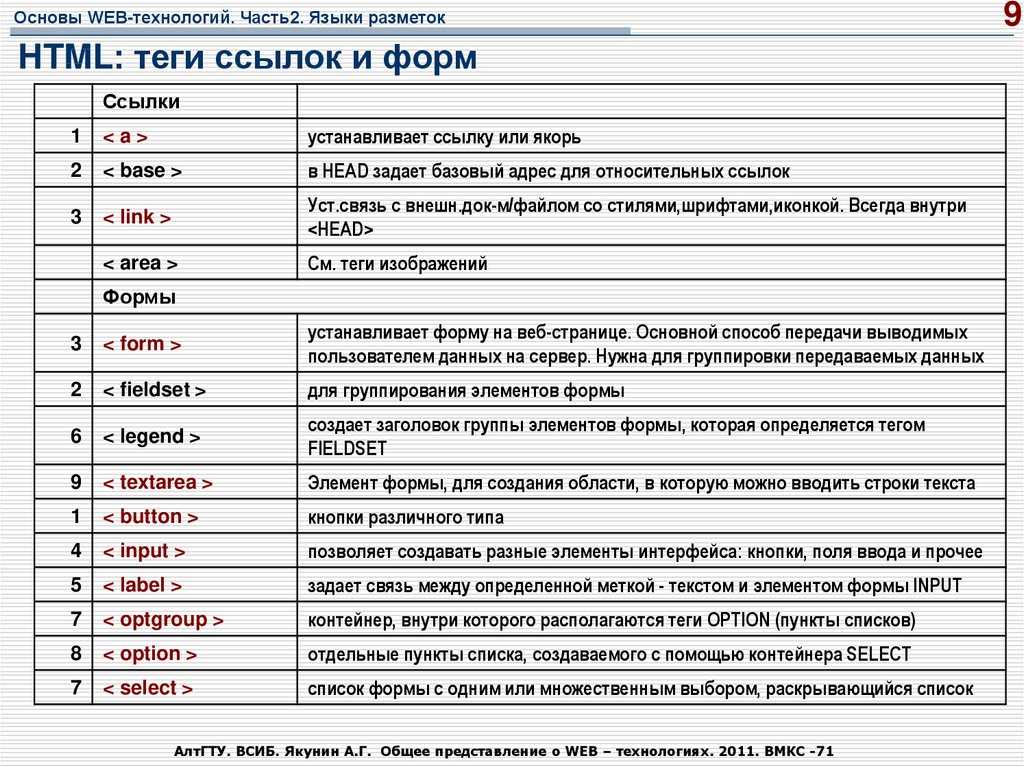 Однако если вы видите в схеме section или article без названия, убедитесь, что у вас есть веская причина не давать им название.
Однако если вы видите в схеме section или article без названия, убедитесь, что у вас есть веская причина не давать им название.
Если вы не уверены, является ли ваш раздел без названия nav, aside, section или article, очень удобное расширение Opera позволит вам узнать, какой тип содержимого раздела вы оставили без названия. Этот инструмент также позволит вам просмотреть схему, не покидая страницу, что может быть очень полезно при отладке разделов.
Корень секционирования
Самые зоркие из вас заметили, что когда я сказал, что содержимое раздела не может создавать подсекцию скрытого раздела, в содержимом раздела не было h2 («Лошади на продажу»), за которым сразу следовал section («Кобылы»), и содержимое раздела действительно создавало подсекцию h2.
Причиной этого является корень секционирования. Как сказано в спецификации, секционирующие элементы создают подразделы своего ближайшего предшественника — секционирующего корня или секционирующего содержимого.
Элементы содержимого рубрики всегда считаются подразделами своего ближайшего предшественника — корня рубрики или ближайшего предшественника- элемента содержимого рубрики, в зависимости от того, какой из них ближайший, независимо от того, какие подразумеваемые разделы могли создать другие рубрики.
Элемент body является корнем секционирования. Таким образом, если вы вставите код с примера 7 в outliner, h2 будет корневым заголовком секционирования, а элемент section будет подразделом корневого элемента секционирования body.
Элемент body — не единственный, который действует как корень секционирования. Есть еще пять других:
blockquote
details
fieldset
figure
td
Статус этих элементов как секционирующего корня имеет два последствия. Во-первых, каждый из них может иметь свою собственную схему. Во-вторых, схема вложенного корня секционирования не появляется в схеме родительского корня секционирования и не влияет на него.
На практике это означает, что заголовки внутри любого из пяти вышеперечисленных элементов корня секционирования не влияют на схему документа, частью которого они являются.
Последнее (вы будете рады это услышать), что я скажу о корне секционирования, это то, что первый заголовок в документе, который не находится внутри содержимого секционирования, считается заголовком документа.
Попробуйте следующий код в outliner, чтобы посмотреть, что произойдет:
<section> <h2>this is an h2</h2> </section> <h6>this h6 comes first in the source</h6> <h2>this h2 comes last in the source</h2>
Пример 10: Как уровни заголовков на корневом уровне влияют на схему.
Я не буду пытаться объяснить вам это, потому что это, вероятно, только запутает нас обоих, поэтому я позволю вам поиграть с этим в аутлайнере. Подсказка: попробуйте использовать разные уровни заголовков для неявных разделов, чтобы посмотреть, как это повлияет на контур; например, h4 и h5 или два h5.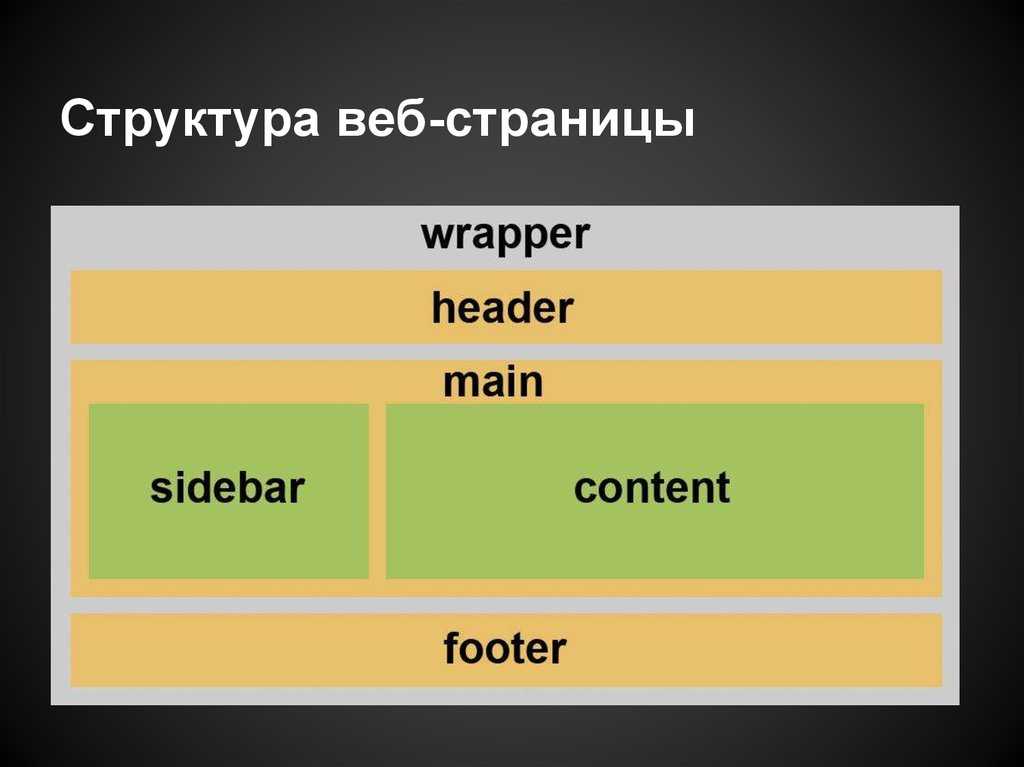
Неназванные документы
Если ни один заголовок не находится на корневом уровне документа (т.е. не внутри секционирующего содержимого), то сам документ будет без заголовка. Это довольно серьезная проблема, и она может возникнуть либо из-за небрежности, либо, как это ни парадоксально, из-за тщательного продумывания того, как следует использовать содержимое секций.
Роджер Йоханссон рассматривает этот вопрос в своей замечательной статье о схемах документов и HTML5, а также в последующей статье.
Йоханссон спрашивает, как правильно создать схему документа для статьи в блоге или другой новости с использованием HTML5. Если вы придерживаетесь мнения, что ваш логотип или название сайта не должны находиться в элементе h2, вы можете разметить свою запись в блоге следующим образом:
<body> <article> <h2>Blog post title</h2> <p>Blog post content</p> </article> </body>
Документ не имеет названия. С некоторой неохотой Йоханссон решает выделить заголовок сайта в h2 и использовать еще один h2 для выделения заголовка статьи. Это разумное решение, и его подтверждают результаты опроса пользователей экранных считывателей WebAIM, в котором большинство респондентов высказались за два заголовка верхнего уровня именно в таком формате.
С некоторой неохотой Йоханссон решает выделить заголовок сайта в h2 и использовать еще один h2 для выделения заголовка статьи. Это разумное решение, и его подтверждают результаты опроса пользователей экранных считывателей WebAIM, в котором большинство респондентов высказались за два заголовка верхнего уровня именно в таком формате.
Этот же подход широко используется на статических страницах, построенных с использованием структурных элементов HTML5, и он может быть очень полезен для пользователей скринридеров. Представьте себе, что вы используете программу для чтения с экрана, чтобы найти достойный рецепт куриного пирога, и у вас есть несколько сайтов с рецептами, открытых для сравнения. Возможность быстро определить, на каком сайте вы находитесь, используя клавишу быстрого доступа к заголовкам, была бы гораздо полезнее, чем видеть на каждом из них только «куриный пирог».
Не слишком далеко от двух заголовков верхнего уровня в опросе пользователей скринридеров ушел один заголовок верхнего уровня для документа. Это, вероятно, предпочтительный вариант в большинстве случаев; но, как мы уже видели, он создает body без заголовка, что нежелательно.
Это, вероятно, предпочтительный вариант в большинстве случаев; но, как мы уже видели, он создает body без заголовка, что нежелательно.
На мой взгляд, есть простой способ обойти эту проблему: не используйте article в качестве обертки для постов в одном блоге, новостей или основного содержимого статической страницы. Помните, что article — это секционирование контента: он создает подраздел документа. Но в этих случаях документ — это содержимое, а содержимое — это документ. Если отбросить название элемента, зачем нам создавать подраздел документа еще до того, как он начался?
Помните, что вы все еще можете использовать div!
HGROUP
Это последний пункт в списке того, чего следует остерегаться, и его очень легко понять. Элемент hgroup может содержать только заголовки (от h2 до h6), и его назначение — удалить из схемы все заголовки, кроме самого высокоуровневого, который он содержит.
Он был и остается предметом споров, и его включение в спецификацию отнюдь не является само собой разумеющимся. Однако на данный момент он делает именно то, о чем говорится на упаковке: он группирует заголовки в один, что касается алгоритма структурирования.
Однако на данный момент он делает именно то, о чем говорится на упаковке: он группирует заголовки в один, что касается алгоритма структурирования.
В заключение
Логику, лежащую в основе алгоритма построения документа, бывает трудно понять, а спецификация иногда напоминает физику: она понятна, пока вы ее читаете, но когда вы пытаетесь подтвердить свое понимание, оно растворяется, и вы обнаруживаете, что перечитываете ее снова и снова.
Но если вы запомните основы — что section, article, aside и nav создают подразделы на веб-страницах, — то вы уже на 90 % на правильном пути. Привыкайте размечать контент с помощью элементов секционирования и проверять свои страницы в аутлайнере, потому что чем больше вы будете практиковаться в создании хорошо оформленных документов, тем быстрее вы поймете алгоритм.
Я обещаю, что уже после нескольких попыток вы поймете его и никогда не оглянетесь назад. И с этого момента каждая созданная вами веб-страница будет структурированным, семантическим, надежным, хорошо изложенным контентом.
html5 — HTML 5 и микроразметка Schema.org
Есть проблема. Пытаюсь делать SEO для сайта. Наткнулся на такую штуку как микроразметка. Нужна ли она вообще? наверное да, для сниппетов и роботов поисковых систем.
Дело в том, что после микроразметки летит к чертям HTML5 по валидатору W3. Как найти выход? Есть ли варианты проще разметить данные. Видел мельком через ассоциативные массивы вроде можно как то сделать. Кто сталкивался? как найти выход, чтобы совместить и HTML5 и микроразметку Schema.org или другую разметку.
На всякий скину пример:
` <!-- Footer -->
<footer>
<div>
<div>
<div>
<h5>О нас</h5>
<div>
<div itemscope>
<p>
<span itemprop="name">ДОМИНАНС</span> - экстерьер начинается с нас
</p>
<p>
<b><i>График работы</i></b>:<br>
<span itemprop="openingHours" datetime="Mo-Fr, 9:00−18:00"><b>пн-пт</b>: 8:00 -
18:00<br></span>
<span itemprop="openingHours" datetime="Sa, 9:00−18:00"><b>сб</b>: 8:00 -
15:00</span>
</p>
</div>
<p><a href="about. html">Подробнее о нас</a></p>
</div>
</div>
<div>
<h5>Свяжитесь с нами</h5>
<div>
<div itemscope>
<p><i></i> Адрес: <a
href="https://www.google.com/maps/place/%D0%94%D0%BE%D0%BC%D0%B8%D0%BD%D0%B0%D0%BD%D1%81/@56.1341376,47.295553,16.5z/data=!4m12!1m6!3m5!1s0x0:0x4575d79e5a35c424!2z0JTQvtC80LjQvdCw0L3RgQ!8m2!3d56.1340451!4d47.298796!3m4!1s0x0:0x4575d79e5a35c424!8m2!3d56.1340451!4d47.298796">г.
<span itemprop="addressLocality">Чебоксары</span>, <span
itemprop="streetAddress">Складской проезд д.6, ЧувашГосСнаб, склад/офис
51</span></a></p>
<p><i></i> Phone: <span itemprop="telephone"><a href="tel:+79530102499">
+7(953)010 24 99 </a></span></p>
<p><i></i> VK: <a href="https://vk. com/stroymat21"> Мы ВКонтакте
</a></p>
<p><i></i> Instagram: <a
href="https://www.instagram.com/6818mikhail/">@6818mikhail</a></p>
<p><i></i> Email: <span itemprop="email"><a
href="mailto:[email protected]?subject=Запрос_c_сайта">[email protected]</a></span>
</p>
</div>
</div>
</div>
</div>
<div>
<div>
<div></div>
</div>
</div>
<div>
<div>
<p>Copyright 2020 All rights reserved. Template by <a
href="https://azmind. com/free-bootstrap-themes-templates/">Azmind</a>. Created by <a
href="https://vk.com/taramparam">Pavel</a></p>
</div>
<div>
<a href="https://vk.com/stroymat21"><i></i></a>
<a href="https://www.instagram.com/6818mikhail/"><i></i></a>
<a href="https://wa.me/79530102499"><i></i></a>
<!-- <i href="#"><i></i></a> -->
</div>
</div>
</div>
</footer>
 html">Подробнее о нас</a></p>
</div>
</div>
<div>
<h5>Свяжитесь с нами</h5>
<div>
<div itemscope>
<p><i></i> Адрес: <a
href="https://www.google.com/maps/place/%D0%94%D0%BE%D0%BC%D0%B8%D0%BD%D0%B0%D0%BD%D1%81/@56.1341376,47.295553,16.5z/data=!4m12!1m6!3m5!1s0x0:0x4575d79e5a35c424!2z0JTQvtC80LjQvdCw0L3RgQ!8m2!3d56.1340451!4d47.298796!3m4!1s0x0:0x4575d79e5a35c424!8m2!3d56.1340451!4d47.298796">г.
<span itemprop="addressLocality">Чебоксары</span>, <span
itemprop="streetAddress">Складской проезд д.6, ЧувашГосСнаб, склад/офис
51</span></a></p>
<p><i></i> Phone: <span itemprop="telephone"><a href="tel:+79530102499">
+7(953)010 24 99 </a></span></p>
<p><i></i> VK: <a href="https://vk.
html">Подробнее о нас</a></p>
</div>
</div>
<div>
<h5>Свяжитесь с нами</h5>
<div>
<div itemscope>
<p><i></i> Адрес: <a
href="https://www.google.com/maps/place/%D0%94%D0%BE%D0%BC%D0%B8%D0%BD%D0%B0%D0%BD%D1%81/@56.1341376,47.295553,16.5z/data=!4m12!1m6!3m5!1s0x0:0x4575d79e5a35c424!2z0JTQvtC80LjQvdCw0L3RgQ!8m2!3d56.1340451!4d47.298796!3m4!1s0x0:0x4575d79e5a35c424!8m2!3d56.1340451!4d47.298796">г.
<span itemprop="addressLocality">Чебоксары</span>, <span
itemprop="streetAddress">Складской проезд д.6, ЧувашГосСнаб, склад/офис
51</span></a></p>
<p><i></i> Phone: <span itemprop="telephone"><a href="tel:+79530102499">
+7(953)010 24 99 </a></span></p>
<p><i></i> VK: <a href="https://vk. com/stroymat21"> Мы ВКонтакте
</a></p>
<p><i></i> Instagram: <a
href="https://www.instagram.com/6818mikhail/">@6818mikhail</a></p>
<p><i></i> Email: <span itemprop="email"><a
href="mailto:
com/stroymat21"> Мы ВКонтакте
</a></p>
<p><i></i> Instagram: <a
href="https://www.instagram.com/6818mikhail/">@6818mikhail</a></p>
<p><i></i> Email: <span itemprop="email"><a
href="mailto: com/free-bootstrap-themes-templates/">Azmind</a>. Created by <a
href="https://vk.com/taramparam">Pavel</a></p>
</div>
<div>
<a href="https://vk.com/stroymat21"><i></i></a>
<a href="https://www.instagram.com/6818mikhail/"><i></i></a>
<a href="https://wa.me/79530102499"><i></i></a>
<!-- <i href="#"><i></i></a> -->
</div>
</div>
</div>
</footer>
com/free-bootstrap-themes-templates/">Azmind</a>. Created by <a
href="https://vk.com/taramparam">Pavel</a></p>
</div>
<div>
<a href="https://vk.com/stroymat21"><i></i></a>
<a href="https://www.instagram.com/6818mikhail/"><i></i></a>
<a href="https://wa.me/79530102499"><i></i></a>
<!-- <i href="#"><i></i></a> -->
</div>
</div>
</div>
</footer>
После разметки валидатор ругается на все изменения в коде, как раз таки по этой микроразметке
- html5
- вёрстка
- seo
- schema.org
- микроразметка
3
Используйте разметку в формате JSON-LD. Она не требует вносить изменения в HTML-код страницы. Кроме того, на сегодняшний день это рекомендуемый поисковиками способ разметки.
Кроме того, на сегодняшний день это рекомендуемый поисковиками способ разметки.
Подробнее про JSON-LD:
Что такое разметка JSON-LD и почему она лучше для schema.org
ФОРМАТ МИКРОРАЗМЕТКИ JSON-LD: ЧТО ЭТО ТАКОЕ?
8
Ваш ответ
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
HTML5 | Семантическая разметка и микроформаты
101
Веб-программирование — HTML5 — Семантическая разметка и микроформаты
Сейчас вы, наверное, думаете, что в разметке веб-страниц можно было использовать множество других семантических элементов, которых в HTML5 нет. Ну да, имеющимися элементами можно помечать даты и выделять цветом текст, но как насчет других единиц информации — адресов, названий компаний, описания товаров, персональных сведений и т.п.?
Ну да, имеющимися элементами можно помечать даты и выделять цветом текст, но как насчет других единиц информации — адресов, названий компаний, описания товаров, персональных сведений и т.п.?
Создатели HTML5 преднамеренно обошли эту область, т.к. не хотели загромождать язык десятками специализированных элементов, необходимых одним разработчикам, но полностью бесполезных для других. Чтобы по-настоящему перейти на следующий уровень в семантике, необходимо выйти за пределы базового языка HTML5 и рассмотреть некоторые другие стандарты, которые можно применять в разработке веб-страниц.
Идея семантически осмысленной разметки не является новой. В действительности, давным-давно, когда HTML5 существовал только в задумках Яна Хиксона (Ian Hickson), редактора группы WHATWG, многие веб-разработчики настойчиво искали методы для создания более осмысленной разметки. Не всегда их требования — совпадали: одни хотели улучшить доступность своих веб-страниц, другие — возможность для интеллектуального анализа данных, а третьим просто хотелось повысить фактор впечатляемости своего резюме. Но никто из них не смог найти то, что им требовалось в стандартном языке HTML, вследствие чего было создано несколько новых стандартов, чтобы заполнить этот пробел.
Но никто из них не смог найти то, что им требовалось в стандартном языке HTML, вследствие чего было создано несколько новых стандартов, чтобы заполнить этот пробел.
В последующих разделах мы рассмотрим аж четыре таких стандарта. Сначала мы познакомимся со стандартом ARIA, предназначенным для улучшения доступности веб-страниц для программ чтения экрана. Потом мы вкратце рассмотрим три конкурирующих подхода к описанию содержимого самых разнообразных типов, будь то подробная контактная информация, названия компаний или просто все что угодно, что можно вставить в теги HTML-страницы.
Стандарт Accessible Rich Internet Applications
Развивающийся стандарт Accessible Rich Internet Applications (ARIA, доступные активные веб-приложения) позволяет предоставлять дополнительную информацию для программ чтения экрана (скрин-ридеров) с помощью атрибутов любого элемента HTML. Среди прочих, в нем вводится атрибут role, который указывает назначения данного элемента.
Например, назначение представляющего верхний колонтитул элемента:
<div>
можно довести до сведения программ чтения экрана, присвоив атрибуту role значение banner:
<div role="banner">
Но, опять же, как мы уже узнали, стандарт HTML5 предоставляет нам более осмысленный способ обозначения верхних колонтитулов. Поэтому нам следует использовать что-то наподобие следующего:
Поэтому нам следует использовать что-то наподобие следующего:
<header role="banner">
Этот пример иллюстрирует два важных факта. Первый: стандарт ARIA требует использования одного из коротких списков рекомендованных названий ролей. Второй: некоторые части стандарта ARIA перекрывают семантические элементы HTML5, что вполне логично, т.к. ARIA появился раньше HTML5. Но это не совсем полное перекрытие. Например, некоторые названия ролей дублируют элементы HTML5 (скажем, banner и article в то время как другие являются более продвинутыми (например, toolbar и search).
Стандарт ARIA также вводит два атрибута для работы с HTML-формами. Атрибут aria-required в текстовом поле указывает, что пользователю нужно ввести значение. А атрибут aria-invalid указывает на недействительность текущего значения в текстовом поле. Польза от этих атрибутов в том, что программы чтения экрана могут пропустить визуальные подсказки, которыми руководствуются пользователи с нормальным зрением при заполнении форм, например, звездочку рядом с заполненным полем или красный мигающий восклицательный знак рядом с полем с неправильным введенным значением.
Чтобы правильно применять стандарт ARIA, необходимо изучить его и потратить некоторое время на исследование разрабатываемой разметки. С учетом того, что стандарт ARIA все еще находится в процессе развития и HTML5 предоставляет некоторые такие же возможности, но меньшей ценой, мнение веб-разработчиков касательно ценности такого вложения усилий и времени в этот стандарт неоднозначно.
Но если вы хотите создать веб-сайт по настоящему доступный уже сегодня, нужно использовать оба стандарта, т.к. новые программы чтения экрана поддерживают стандарт ARIA, а стандарт HTML5 — еще нет.
Стандарт Resource Description Framework
Стандарт Resource Description Framework (RDFa — инфраструктура для описания ресурсов — в атрибутах) определяет правила для интегрирования подробных метаданных в веб-документы посредством атрибутов. У стандарта RDFa есть значительное преимущество перед другими подходами: это стабильный, установившийся стандарт.
Но у него также два значительных недостатка. Первый — это сложный стандарт. Разметка со вставленными в нее метаданными RDFa получается намного объемистей и существенно неуклюжей, чем обычная HTML-разметка. Второй — стандарт этот разработан для применения с XHTML, а не с HTML5. В настоящее время несколько сверхинтеллектуальных веб-гуру занимается разработкой лучших способов адаптирования RDFa для работы с HTML5. Но, возможно, что RDFa просто не приживется в мире HTML5, т.к. ему больше подходят строгий синтаксис и железные правила XML.
Первый — это сложный стандарт. Разметка со вставленными в нее метаданными RDFa получается намного объемистей и существенно неуклюжей, чем обычная HTML-разметка. Второй — стандарт этот разработан для применения с XHTML, а не с HTML5. В настоящее время несколько сверхинтеллектуальных веб-гуру занимается разработкой лучших способов адаптирования RDFa для работы с HTML5. Но, возможно, что RDFa просто не приживется в мире HTML5, т.к. ему больше подходят строгий синтаксис и железные правила XML.
Здесь стандарт RDFa не рассматривается. Но если вы хотите узнать больше о нем, солидный обзор можно получить на странице en.wikipedia.org/wiki/RDFa. А на веб-сайте Google Rich Snippets можно ознакомиться с версиями RDFa для всех примеров расширенных фрагментов Google.
Микроформаты
Микроформаты предоставляют простой, прямолинейный подход к внедрению метаданных в веб-страницы, не придерживаются какого-либо определенного официального стандарта и не являются таковым. Лучше всего микроформаты можно описать как несвязанный набор соглашений, которые позволяют веб-страницам предоставлять структурированную информацию, не требуя сложных стандартов.
Благодаря этому подходу микроформаты пользуются огромным успехом; в недавнем исследовании, проведенном Google, было обнаружено, что у 94% страниц, содержащих какой-либо тип расширенных метаданных, эти метаданные предоставляются микроформатами.
Если судить на основе популярности микроформатов, то можно подумать, что исход битвы за семантический Интернет уже решен. Такое заключение будет преждевременным по нескольким причинам. Прежде всего, подавляющее большинство веб-страниц не содержит расширенных семантических данных вообще. Вдобавок, в большинстве веб-страниц, применяющих микроформаты, это делается только для обозначения контактной информации и событий. И наконец, простота форматов может удерживать их от применения для более продвинутых задач, особенно когда уровень возможности HTML5 сравняется с их уровнем. Поэтому микроформаты никуда в ближайшее время не исчезнут, игнорировать их конкурентов тоже не стоит.
Прежде чем помечать данные микроформатом, нужно выбрать, какой именно микроформат использовать для этого.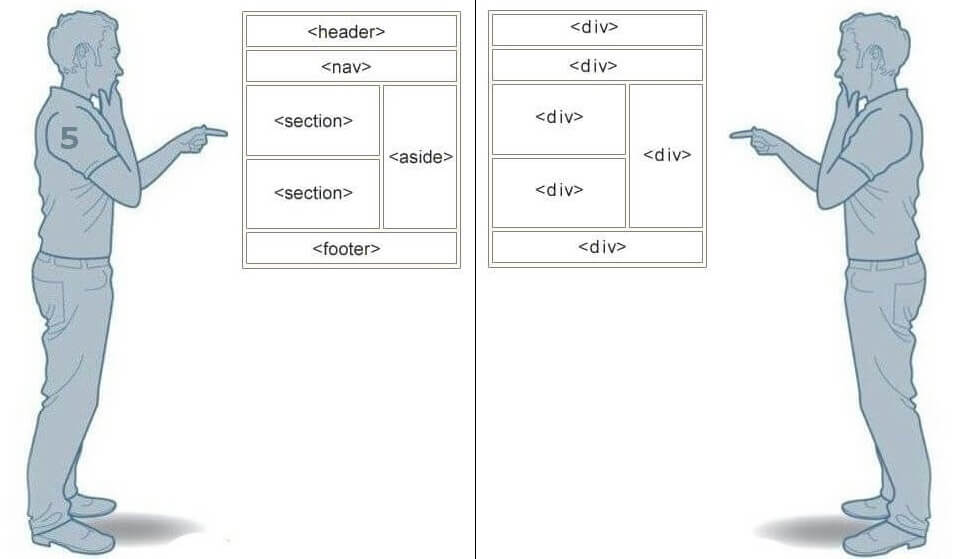 Широко применяется всего лишь пара десятков микроформатов, большинство из которых продолжает совершенствоваться и обновляться. Информацию о доступных микроформатах и подробное описание каждого из них можно найти на веб-сайте Microformats. Наибольшей популярностью среди всех этих микроформатов пользуются два — hCard и hCalender, которые мы и рассмотрим.
Широко применяется всего лишь пара десятков микроформатов, большинство из которых продолжает совершенствоваться и обновляться. Информацию о доступных микроформатах и подробное описание каждого из них можно найти на веб-сайте Microformats. Наибольшей популярностью среди всех этих микроформатов пользуются два — hCard и hCalender, которые мы и рассмотрим.
Обозначение контактной информации с помощью микроформата hCard
Микроформат hCard предоставляет универсальный способ обозначения контактной информации для физического лица, компании или места. По результатам последнего подсчета Интернет содержит свыше 2 млрд hCard, что делает этот микроформат безоговорочно самым популярным.
Микроформаты работают по инновационному методу — они добавляют свою информацию поверх атрибута class, который обычно используется для форматирования. Данные помечаются, используя определенные стандартные названия стилей, на основе типа данных. Потом такую разметку может прочитать другая программа, извлечь помеченные данные и по атрибутам определить их значение.
Для создания hCard требуется корневой элемент, который присваивает атрибуту class значение vcard. Внутри этого элемента необходимо посредством другого элемента предоставить, по крайней мере, отформатированное имя. Атрибуту class этого внутреннего элемента нужно присвоить значение fn. Вот приводится пример такого определения:
<div> <p>Привет, это я - <b>Александр Ерохин</b>.</p> </div>
При использовании для микроформата атрибута class в создании соответствующего стиля с именем этого класса нет надобности, более того, это, скорее всего, только создаст путаницу. Вместо этого атрибуту class дается другое задание объявлять, что его содержимое является хорошо структурированными, осмысленными данными.
Хотя единственной обязательной единицей информации для микроформатов является имя, большинство из них содержит дополнительные подробности, такие как почтовый адрес и адрес электронной почты, URL веб-сайта, номер телефона, дата рождения, фотография, должность, название организации и т. п. При условии использования правильных названий классов все эти подробности можно вставить в элемент, содержащий класс vcard. В следующем листинге приводится пример определения hCard, содержащего разные типы персональной информации:
п. При условии использования правильных названий классов все эти подробности можно вставить в элемент, содержащий класс vcard. В следующем листинге приводится пример определения hCard, содержащего разные типы персональной информации:
<div>
<img src="face.jpg" alt="Mike's Face">
<p>Привет, это я - <span>веб-разработчик и программист</span> <b>Александр Ерохин</b>.
Мои друзья <b>Big M</b>.</p>
<p>Вы можете связаться со мной в офисе
<span>The Magic Semantic Company</span> (телефон
<span>641-545-0234</span>).</p>
<p>Или зайти в гости:<br>
<span>Leninskiy prospekt 68</span>Ленинский проспект 68<br>
<span>Moscow</span>Москва, <span>119296</span><br>
<span>RUS</span>Россия<br>
<a href="http://www.professorweb. ru">www.professorweb.ru</a>
</div> ru">www.professorweb.ru</a>
</div>
ru">www.professorweb.ru</a>
</div>Теперь давайте рассмотрим, какой результат мы получим в ответ на все наши усилия, приложенные к оформлению микроформатом необходимых данных на странице. Хотя ни один из существующих браузеров не имеет естественной поддержки микроформатов, существуют разнообразные подключаемые модули и сценарии, которые могут дать им эту возможность. Пользу от такой возможности не трудно вообразить.
Например, браузер мог бы обнаружить элементы hCard на странице, вывести их список в боковой панели и предоставить пользователю команды, позволяющие добавить любое лицо из списка в личную адресную книгу пользователя так же быстро, как и добавить страницу в закладки. Информацию о подключаемых модулях браузера для поддержки микроформатов можно получить на странице «Browsers».
Одним из таких расширений является Oomph для Internet Explorer, которое можно загрузить с веб-сайта oomph.codeplex.com. Этот модуль автоматически исследует каждую посещаемую веб-страницу на предмет наличия в ней трех форматов: hCard (для контактной информации), hCalendar (для календарей событий) и hMedia (для изображений, аудио и видео). В случае обнаружения в странице данных, помеченных одним из этих форматов, в левом верхнем углу окна браузера выводится значок Oomp. Щелчок по этому значку выводит в браузере всю обнаруженную информацию, а также элементы управления для обработки.
В случае обнаружения в странице данных, помеченных одним из этих форматов, в левом верхнем углу окна браузера выводится значок Oomp. Щелчок по этому значку выводит в браузере всю обнаруженную информацию, а также элементы управления для обработки.
Но что особенно интересно в этом инструменте, так это возможность использовать его другим способом — через библиотеку JavaScript. Для этого всего лишь нужно добавить в страницу ссылки на сценарии:
<script src="jquery-1.3.2.min.js"></script> <script src="oomph.js"></script>
Теперь все посетители вашей страницы получат возможность доступа к помеченным микроформатами данным страницы, независимо от используемого ими браузера:
Обозначение событий с помощью микроформата hCalendar
Вторым по уровню популярности микроформатом является hCalendar, предоставляющий простой способ для разметки событий. Например, с помощью этого микроформата можно помечать встречи, собрания, праздники, выпуски продукции, открытия магазинов и т.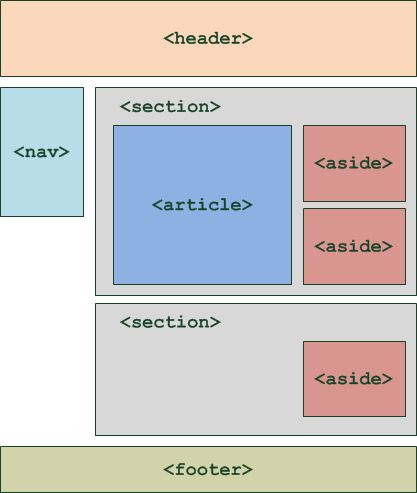 п. В настоящее время в Интернете есть десятки миллионов событий, помеченных микроформатом hCalendar.
п. В настоящее время в Интернете есть десятки миллионов событий, помеченных микроформатом hCalendar.
Если вы разобрались в том, как помечать информацию микроформатом hCard, у вас не будет никаких трудностей и с микроформатом hCalendar. Сначала событие нужно поместить в элемент с названием класса vevent. Внутри этого элемента нужно поместить, по крайней мере, две единицы информации: дату начала (которая помечается классом dtstart) и описание события (которое помечается классом summary).
Микроданные
Еще одним подходом к решению задачи придания семантического смысла разметке веб-страниц являются микроданные. Формат микроданных зародился как часть спецификации HTML5, но потом был выделен в отдельный развивающийся стандарт. В микроданных применяется подход, подобный стандарту RDFa, но проще. В отличие от микроформатов, микроданные имеют собственные атрибуты, что устраняет возможность конфликта с правилами таблиц стилей (или озадачивания веб-разработчиков, пытающихся разобраться в чужом коде).
Такой подход делает форматы микроданных более логичными, чем другие форматы, а также более приспосабливаемыми к использованию с языками собственной разработки других веб-дизайнеров. Но за это приходится платить ценой потери краткости — помеченная микроданными разметка может быть несколько большего объема, чем разметка, помеченная микроформатами.
Чтобы создать блок микроданных, нужно добавить атрибуты itemscope и itemtype в любой элемент (хотя логичнее будет создать элемент <div>, если такого еще нет). Атрибут itemscope указывает на начало нового фрагмента семантического содержимого, а атрибут itemtype — конкретный тип данных, которые помечаются:
<div itemscope itemtype="http://data-vocabulary.org/Review-aggregate">
Тип данных обозначается предопределенной, однозначной текстовой строкой, называющейся пространством имен XML. В данном примере пространством имен XML является формат для кодирования рейтинга http://data-vocabulary.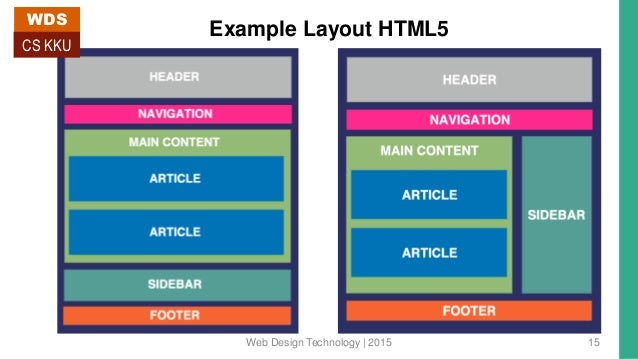 org/Review-aggregate.
org/Review-aggregate.
Пространства имен XML часто даются в виде URL. Иногда по этому URL можно даже просмотреть описание соответствующего типа данных, открыв его в браузере. Но пространства имен XML не обязательно должны соотноситься с настоящими веб-сайтами, а также они не обязательно должны быть указаны в виде URL. Название пространства имен формата просто зависит от того, что лицо (или лица) выберет для него при создании этого формата. В этом отношении преимуществом URL является то, что он может содержать доменное имя, принадлежащее лицу или организации. Это повышает шансы названия пространства имен в плане однозначности, т.е. что никто не создаст иной формат данных с таким же названием пространства имен и тем самым собьет всех с толку.
Следующий шаг после создания элемента-контейнера — это использование внутри его атрибута itemprop, чтобы отловить важные единицы информации. Для этого применяется такой же базовый подход, что и для микроформатов — используется распознаваемое название itemprop, которое позволит другим программным средствам извлекать информацию из связанных элементов.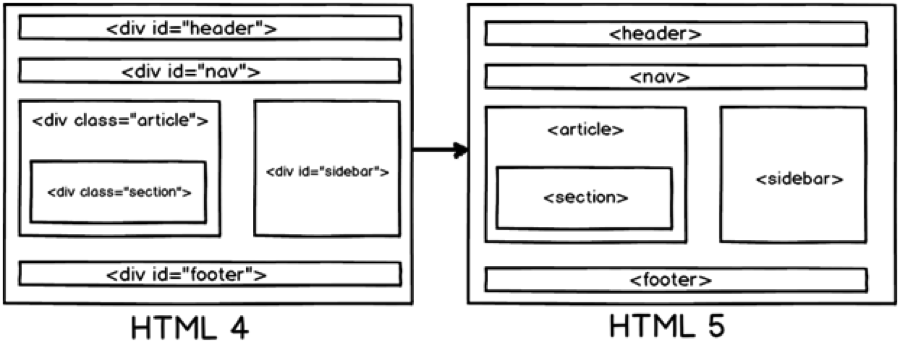
По существу, самая большая разница между микроданными и микроформатами состоит в использовании в первых для маркировки данных атрибута itemprop, а не атрибута class, как в последних.
<div itemscope="" itemtype="http://data-vocabulary.org/Review-aggregate"> <div itemscope itemtype="http://data-vocabulary.org/Review-aggregate"> <h2 itemprop="itemreviewed">Настройка нестандартных окон</h2><meta itemprop="rating" content="4.8"> <span itemprop="votes">28</span>
Данный код реализует возможность ставить рейтинг страницы с помощью специального плагина для браузера Google Chrome. Данную разметку конечный пользователь не видит (естественно за исключением заголовка), но поисковики индексируют эту информацию и могут отображать ее в результатах поиска:
Также в результаты поиска можно добавлять фотографию автора, название компании, дату добавления страницы и т.п. Думаю вы часто видели эту информацию в результатах поиска Google, это как раз реализуется через микроданные.
Семантическая разметка HTML5 и макет страницы
HTML5 представляет совершенно новый набор из семантических элементов . Семантическая разметка — это HTML, который вводит смысл, а не представление. Когда на странице используются семантические элементы, браузер может интерпретировать их назначение в структуре страницы.
Например, когда на странице используется элемент HTML5 , браузер (а также веб-пауки) будет на чище по назначению содержимого элемента. Это позволяет браузерам и другим пользовательским агентам обрабатывать контент особым образом .
Сравните это с распространенным примером, который вы можете использовать при разработке веб-страницы на основе HTML4.01 . В примере с нижним колонтитулом вы должны использовать элемент Изображение над показывает типичную веб-страницу, которая может использовать 6 новых элементов HTML5. Элементы заголовка Элементы На момент написания этой статьи браузеры не имели полной поддержки для конкретных элементов HTML5, поэтому они просто обрабатывают их как определяемые пользователем теги, когда они встречаются на странице. Итак, помимо IE , веб-разработчики смогут безопасно включать эти новые элементы в свои веб-проекты. Поэтому нам нужно иметь дело только с обрабатывает эти элементы для браузеров IE. Поскольку IE не знает, как применять к ним стили, мы можем использовать некоторый JavaScript , чтобы смягчить эту проблему. В Интернете есть хорошо задокументированный метод решения этой проблемы. Простой метод просто требует, чтобы вы создали элемент DOM с тем же именем, что и тег. Как только это будет установлено, IE будет соблюдать стиль. До версии IE9 поддержка элементов HTML5 практически отсутствовала. Так как IE по-прежнему имеет очень высокий процент использования, важно убедиться, что ваша веб-страница работает правильно при доступе к IE. HTML5Shiv — это обходной путь JavaScript, который используется для включения стиля элементов HTML5 в версиях IE до версии 9. Чтобы включить обходной путь HTML5Shiv, поместите следующий раздел кода в элемент Это загрузит HTML5Shiv с веб-сервера при условии, что используемый браузер является версией IE более ранней, чем версия 9. Internet Explorer до версии 9 обработает оператор. Другие не-IE браузеры будут рассматривать условный скрипт как комментарий . Вы можете либо загрузить файл JavaSript, либо указать его непосредственно на сайте Google. Miroslav Gajic HTML/CSS Семантика В Интернете насчитывается более миллиардов веб-сайтов. Одной из наиболее важных особенностей HTML5 является его семантика . Семантический HTML относится к синтаксису, который делает HTML более понятным за счет лучшего определения различных разделов и макета веб-страниц. Это делает веб-страницы более информативными и адаптируемыми, позволяя браузерам и поисковым системам лучше интерпретировать контент. Например, вместо В этом руководстве вы узнаете, как использовать новые семантические теги HTML5 при создании веб-страницы и как сделать контент более информативным для машин. Сначала рассмотрим базовый шаблон HTML-страницы, написанный на несемантическом HTML: HTML Теперь рассмотрим пример семантического HTML, показанный ниже: HTML Основное отличие: мы заменили тега div на 3 новых тега: заголовок , основной и нижний колонтитул . Теги В HTML5 есть тег nav , который заменяет бывший мастер на все руки, div , для переноса ссылок, образующих меню навигации. Например, меню навигации можно вставить в заголовок раздела : HTML Как правило, навигационное меню можно разместить в любом месте на странице, нужно только обернуть его расширением . Однако его не следует помещать внутрь Чтобы добавить некоторый контент в основной раздел JavaScript — богатый и выразительный язык... Понимание операторов, именования переменных, пробелов... Операторы позволяют управлять значениями... Иногда вы хотите запустить блок кода только при определенных условиях. HTML Тег Тег В раздел JavaScript — богатый и выразительный язык... Понимание операторов, именования переменных, пробелов... Операторы позволяют управлять значениями... Иногда вы хотите запустить блок кода только при определенных условиях... Посмотрели 1503 человека Автор: Джон Смит HTML Как видно выше, Элементы рисунка на веб-странице могут быть заключены в Тег Тег Например, фотографии людей, которым понравилась статья, можно прикрепить к тегу Посмотрели 1503 человека Автор: Джон Смит HTML Логотип в 9Раздел заголовка 0130 также должен быть заключен с тегом HTML Обратите внимание, как разделение страницы делает код более понятным и, возможно, улучшает синтаксический анализ контента браузером и поисковой системой. Если вы не уверены, какой семантический тег использовать в конкретном случае, вы всегда можете воспользоваться этой замечательной блок-схемой, созданной авторами HTML5Doctor. Микроданные предоставляют дополнительную информацию о содержании веб-страницы и помогают поисковым системам и программам чтения с экрана работать на сайте. Микроданные могут быть добавлены в качестве атрибутов к любому тегу HTML. Например, давайте добавим некоторые данные об авторе статьи в нашем примере. Посмотрели 1503 человека Автор: Джон Смит, старший разработчик программного обеспечения в Google, Маунтин-Вью, Калифорния HTML С включенными микроданными HTML-код раздела HTML Очевидно, что в приведенном выше коде гораздо больше данных, чем в предыдущем коде, но также гораздо больше информации для машин. Как вы могли заметить, мы использовали следующие атрибуты микроданных: Обычно мы используем только несколько свойств для описания элемента, и мы определяем их с помощью Ранее в этом руководстве мы упоминали, что баннер можно описать с помощью микроданных. Итак, код HTML для этого должен выглядеть так: HTML Существует очень полезный инструмент для создания микроданных, называемый генератором микроданных. Согласно этой таблице семантические теги HTML5 хорошо поддерживаются в последних версиях браузеров. Для некоторых старых версий Internet Explorer, Firefox и Safari мы можем использовать HTML5 Shiv или Modernizr (включая HTML5 Shiv). Для получения дополнительной информации по этой теме вы можете прочитать следующие очень полезные статьи: В этом руководстве рассмотрено несколько преимуществ использования семантического HTML. Мы создали семантический HTML-макет и использовали 90 124 микроданных 9.0125, чтобы добавить дополнительную информацию к содержимому веб-страницы. Надеюсь, это руководство дало вам представление о том, как семантический HTML может улучшить взаимодействие веб-страницы и поисковых систем. А с ростом количества браузеров, использующих HTML5, семантические теги неизбежно станут более распространенными, поэтому их освоение сейчас может принести пользу в будущем. Семантическая разметка — это способ написания и структурирования вашего HTML для описания структурной семантики или значения его содержимого, а не для визуального представления содержимого. Другими словами, HTML фокусируется только на структуре вашей веб-страницы, а CSS фокусируется на стиле содержимого вашей веб-страницы. «Написание семантической разметки означает понимание иерархии вашего контента и того, как его будут читать пользователи и машины». Структура является важным способом передачи информации в бумажных и электронных документах. Как и в приведенном выше примере, когда вы смотрите на веб-страницу, вы можете четко определить абзац; тег указывает, что заключенный в него текст является абзацем. Опять же, поскольку это и семантика, и представление, пользователи знают, что это абзац, и браузеры знают, как их отобразить. С другой стороны, если мы используем или в тексте, это не придает разметке никакого дополнительного значения, поскольку они не являются семантическими. Вместо этого они определяют только то, как будет выглядеть текст. Хотя HTML с самого начала включал семантическую разметку, HTML5 представил еще больше семантических тегов, таких как Возможно, вы видели мэшап некоторых веб-страниц с тегами Следующие теги HTML5 можно использовать вместо тегов Давайте возьмем домашнюю страницу CSS Tricks в качестве примера, чтобы увидеть, как мы можем использовать семантическую разметку для создания более значимой структуры веб-страницы. На рисунках ниже вы можете видеть различные цвета блоков, помеченных семантическим тегом, который используется/может использоваться для каждого раздела на странице. Это дает четкое представление о том, как мы можем использовать семантические теги для структурирования веб-страниц. Специальные возможности Не все веб-пользователи могут просматривать содержимое веб-страниц. Зрячие пользователи могут легко идентифицировать и получать доступ к различным частям веб-страницы. Но человеку с некоторыми проблемами со зрением может понадобиться помощь для доступа к веб-странице. Посещение веб-страницы с помощью голосового ридера может быть очень неприятным, если веб-страница не использует семантическую разметку. Например, если вы неправильно пометили навигацию сайта тегом Благодаря семантической разметке как пользователи, так и компьютеры смогут понять структуру содержимого, взаимосвязь между элементами страницы и характер содержимого внутри элемента. Кроме того, доступность веб-приложений обеспечит равный доступ для людей с ограниченными возможностями и принесет пользу всем, предоставляя больше возможностей для индивидуальной настройки. Поисковая оптимизация Сканеры поисковых систем являются наиболее важной частью, когда вы рассматриваете SEO вашей веб-страницы. Семантическая разметка предоставляет этим поисковым роботам лучшие инструкции при сканировании страниц в поисках их содержимого; он сообщает им, какой важный контент находится на странице. Например, ключевые слова, заключенные в тег . Вы можете использовать семантическую разметку, чтобы помочь поисковым системам ранжировать вашу страницу, используя наиболее релевантный и значимый контент на странице. Ясность, с которой вы взаимодействуете с поисковыми системами за счет добавления семантической разметки, гарантирует, что правильные страницы будут доставлены для правильных запросов. Сопровождаемость Семантическая разметка легче обновляется и изменяется, чем веб-страницы, содержащие большое количество разметки представления.
и нижнего колонтитула говорят сами за себя. Элемент nav можно использовать для создания панели навигации. section и article можно использовать для группировки контента. Наконец, элемент в сторону можно использовать для боковой панели связанных ссылок. Давайте подробнее рассмотрим фактическую разметку.
<голова>
<метакодировка="utf-8" />
Основной заголовок
Подзаголовок
<навигация>
<ул>
Статья №1
<раздел>
Это первая статья. <статья>
<заголовок>
<статья>
<заголовок>
Статья №2
<раздел>
Это вторая статья.
<в сторону>
<раздел>
Ссылки
<ул>
Поддержка новых элементов HTML5
 Все основные браузеры, , кроме Internet Explorer , будут отображать нераспознанный элемент как встроенный элемент и предоставлять веб-разработчикам свободу стилизовать их.
Все основные браузеры, , кроме Internet Explorer , будут отображать нераспознанный элемент как встроенный элемент и предоставлять веб-разработчикам свободу стилизовать их. Здесь на помощь приходит JavaScript.
Здесь на помощь приходит JavaScript. HTML5Shiv
head .
Используйте семантические теги HTML5 для улучшения SEO веб-страницы | Pluralsight
Miroslav Gajic
Семантика
 Многие из них сделаны давно и не обновлялись функциями HTML. Таким образом, поисковые системы пропускают эти веб-сайты, и посетители находят эти веб-сайты трудными для чтения.
Многие из них сделаны давно и не обновлялись функциями HTML. Таким образом, поисковые системы пропускают эти веб-сайты, и посетители находят эти веб-сайты трудными для чтения. div вы можете использовать тег заголовка . Макет семантической HTML-страницы
1
2 <голова>
3
 д.
8
9<дел>
10 Место для основного контента сайта
11
12 <дел>
13 Информация в нижнем колонтитуле, ссылки и т. д.
14
15
16
д.
8
9<дел>
10 Место для основного контента сайта
11
12 <дел>
13 Информация в нижнем колонтитуле, ссылки и т. д.
14
15
16 1
2 <голова>
3
header , main и footer являются семантическими , поскольку они используются для представления различных разделов на HTML-странице. Это более описательно, чем теги div , которые усложняют разделение веб-страниц на материальные разделы.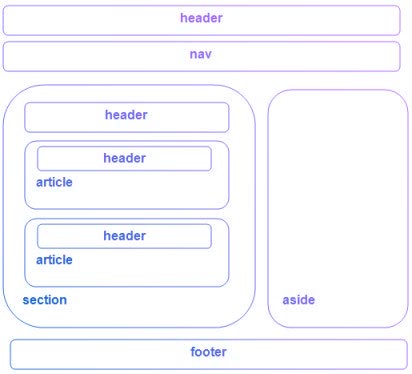
Навигация
1<заголовок>
2
![]() 3 <навигация>
4 Главная
5 Службы
6 Контакт
7 О нас
8
9```
10
11но его также можно добавить после секции _header_:
12
13``HTML
14<заголовок>
15
3 <навигация>
4 Главная
5 Службы
6 Контакт
7 О нас
8
9```
10
11но его также можно добавить после секции _header_:
12
13``HTML
14<заголовок>
15 ![]() 16
17<навигация>
18 Главная
19 Услуги
20 Контакты
21 О нас
22
16
17<навигация>
18 Главная
19 Услуги
20 Контакты
21 О нас
22 main , если навигация не предназначена для этой страницы. Это ограничение существует, потому что
Это ограничение существует, потому что основные элементы должны быть специфичны только для страницы, в то время как верхний и нижний колонтитул обычно являются общими для похожих страниц. Основное содержимое
, мы можем использовать новые теги HTML5, такие как article и section . Эти теги упрощают структуру main , делая ее похожей на: 1<основной>
2 <статья>
3
Основы JavaScript
4 Основы синтаксиса
7 операторов
11 Условный код
15 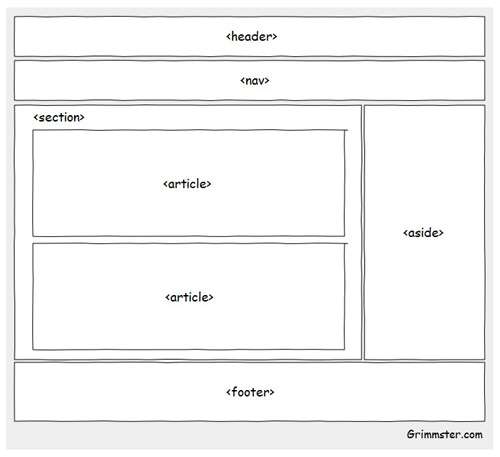 ..
.. article используется для переноса автономного контента на страницу. Контент является автономным, если его можно удалить со страницы и разместить на какой-либо другой странице. Тег article может содержать внутри себя несколько тегов section , как в нашем примере. Артикул фактически является автономным разделом . section аналогичен тегу div , но имеет большее значение, поскольку объединяет логические группы связанного содержимого (например, главу статьи). 9Тег 0130 section также можно использовать для упаковки самой статьи, но для этой цели у нас есть тег article . Дополнительный контент
Раздел в сторону
в сторону можно вставить дополнительный контент, не важный для понимания статьи, но относящийся к статье.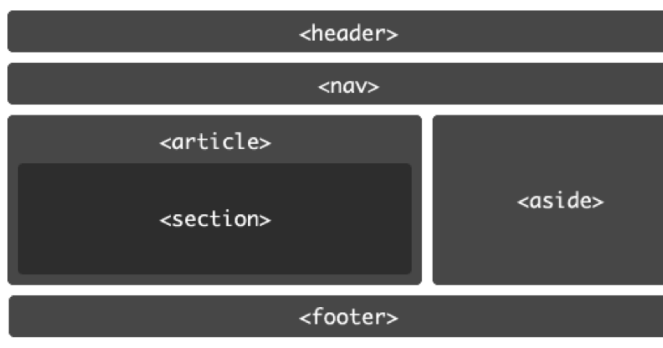 Например, это может быть информация о том, сколько человек прочитало статью, кто является автором статьи и так далее. В этом случае HTML-код статьи будет иметь следующую структуру:
Например, это может быть информация о том, сколько человек прочитало статью, кто является автором статьи и так далее. В этом случае HTML-код статьи будет иметь следующую структуру: 1<основной>
2 <статья>
3
Основы JavaScript
4 Основы синтаксиса
7 операторов
11 Условный код
15 рядом с позволяет поисковым системам быстро получать такую информацию, как автор, просмотры и дата. Этот тег также можно использовать для включения дополнительного контента, относящегося ко всей странице, а не только к конкретной статье.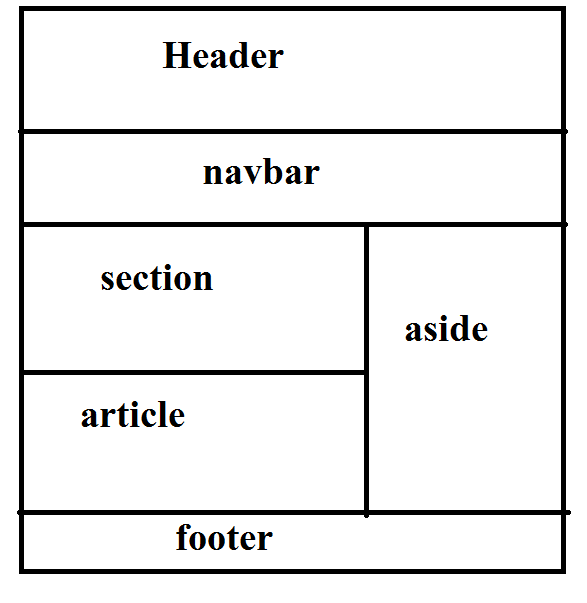 Например,
Например, рядом с может обернуть боковую панель, рекламу, сноску и так далее. Рисунки
рисунок и figcaption теги. фигура используется для разметки фотографий, кодовых блоков, диаграмм, диаграмм, иллюстраций и другого графического содержимого. Как правило, этот тег заключает в себе контент, который можно переместить в приложение. В теге фигура должны быть только изображения, относящиеся к содержимому страницы (например, изображение логотипа). Поэтому изображения, такие как рекламные баннеры, не должны находиться внутри этого тега. Однако есть способ добавить семантику в рекламный баннер, который мы рассмотрим в разделе «Микроданные» этого руководства. figcaption представляет подпись или легенду для рисунка. Это необязательно и может быть опущено. Только один тег
Это необязательно и может быть опущено. Только один тег figcaption может быть вложен в тег figure . Даже если фигура содержит несколько изображений, для всех них может быть только одна figcaption . цифра . Поскольку эта информация не имеет решающего значения для функциональности веб-страницы, ее можно вложить в в сторону раздела статьи. 1<в сторону>
2
 6
6  7
7  8
8 фигура , поэтому наш раздел заголовка , наконец, будет иметь следующий код: 1
png" alt="logo"/>
4
5 <навигация>
6 Главная
7 Услуги
8 Контакт
9 О нас
10
11 Блок-схема элемента HTML5
Микроданные
в сторону раздел статьи будет иметь следующий код: 1<в сторону>
2
aside будет выглядеть так: 1
itemscope , itemtype и itemprop . Итак, что означают все эти атрибуты? itemscope указывает на новую группу микроданных. Группа микроданных называется пункт .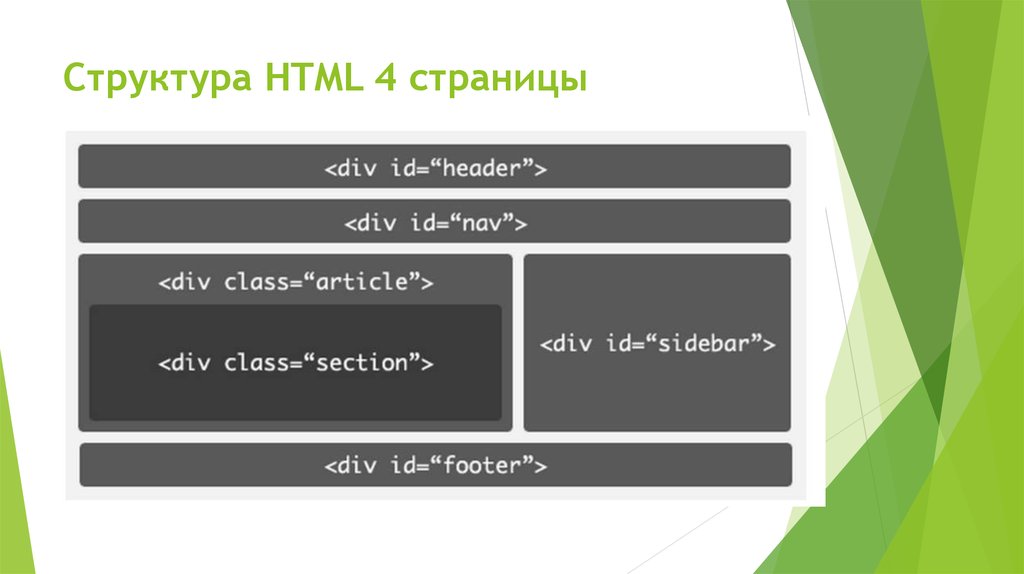 Элементы содержат пары свойств и значений. Тип элемента определяется параметром
Элементы содержат пары свойств и значений. Тип элемента определяется параметром itemtype . На самом деле это URL-адрес веб-страницы, содержащей информацию об элементе. На этой странице мы можем увидеть все свойства, которые может иметь элемент. атрибут itemprop . Значением свойства может быть новый элемент (например, адрес в нашем примере). 1
 3
3 Это может сэкономить время и научить вас правильно использовать микроданные для различных элементов.
Это может сэкономить время и научить вас правильно использовать микроданные для различных элементов. Поддержка браузера
Дополнительные ресурсы
Заключение

Что такое семантическая разметка и почему ее следует использовать | по Сумуду Сиривардана | CodeX
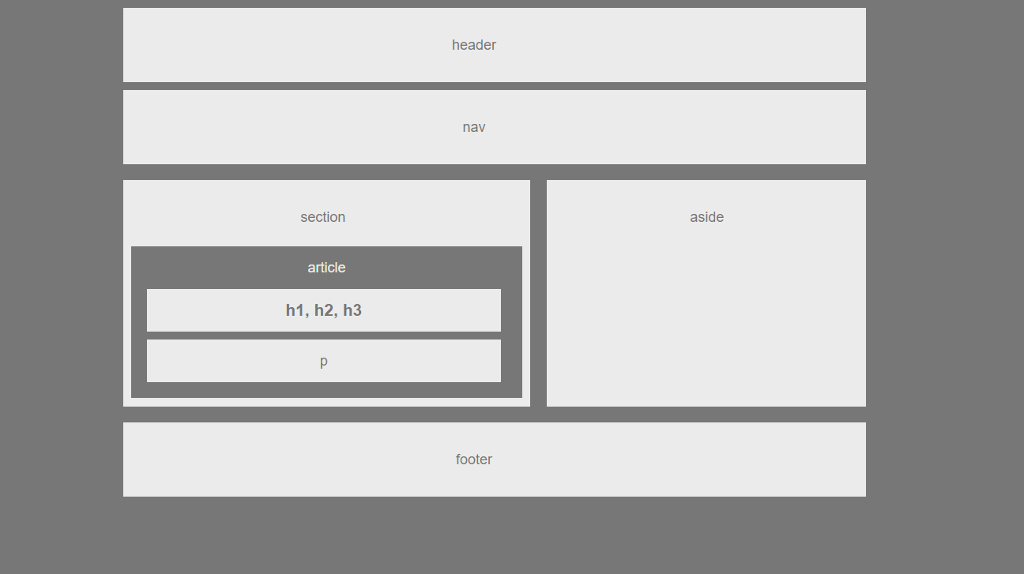
 Например, проверьте приведенные ниже изображения документов. Вы заметите, что эти два документа имеют схожую структуру, поэтому читатели могут понять, что такое заголовки, подзаголовки и абзацы в этих статьях. Такая структура облегчает читателям быстрое понимание иерархии важности и широкого значения информации в документах.
Например, проверьте приведенные ниже изображения документов. Вы заметите, что эти два документа имеют схожую структуру, поэтому читатели могут понять, что такое заголовки, подзаголовки и абзацы в этих статьях. Такая структура облегчает читателям быстрое понимание иерархии важности и широкого значения информации в документах.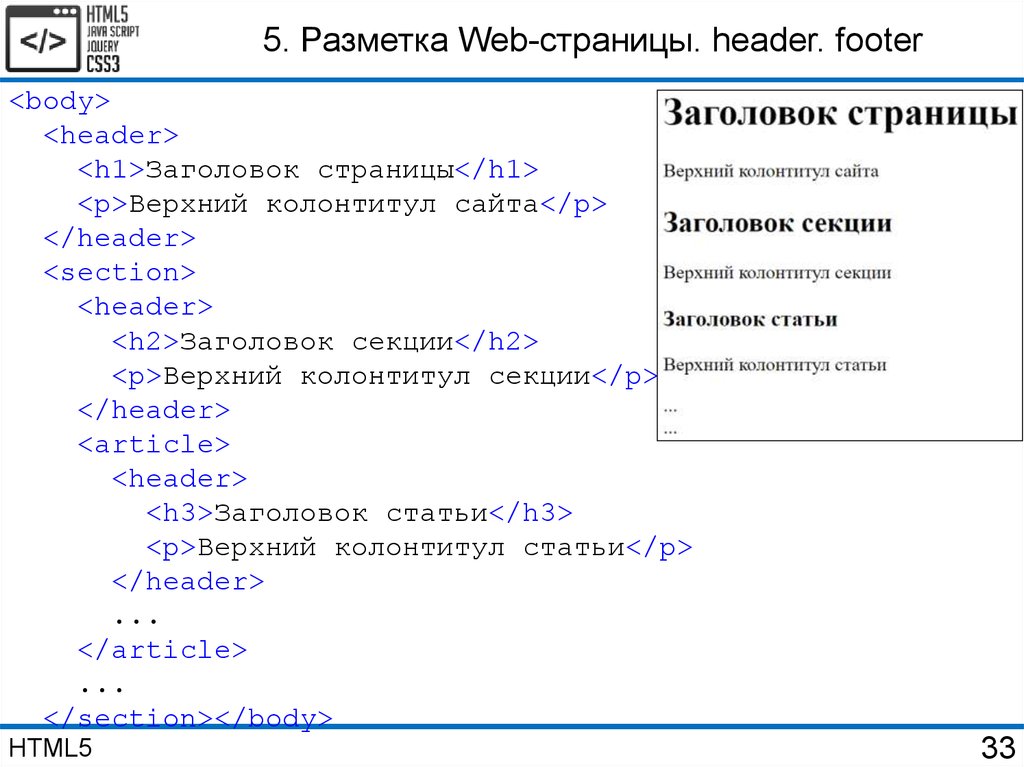
 Некоторые люди с ограниченными возможностями используют различные вспомогательные приложения и устройства для работы с веб-сайтами, такие как переводчики текста в речь, элементы управления размером текста, а также элементы управления цветом и контрастом и т. д.
Некоторые люди с ограниченными возможностями используют различные вспомогательные приложения и устройства для работы с веб-сайтами, такие как переводчики текста в речь, элементы управления размером текста, а также элементы управления цветом и контрастом и т. д.
, имеют большее значение, чем ключевые слова, заключенные в тег
