Синтаксис JavaScript
← предыдущая следующая →
Синтаксис JavaScript – это набор правил, как создаются программы JavaScript. В этом уроке мы рассмотрим базовые лексические структуры языка.
Набор символов
При написании программ на JavaScript используется набор символов Unicode. В отличие от 7-разрядной кодировки ASCII, подходящей только для английского языка, и 8-разрядной кодировки ISO Latin-1, подходящей только для английского и основных западноевропейских языков, 16-разрядная кодировка Unicode поддерживает практически все письменные языки, имеющиеся на планете. Стандарт ECMAScript v3 требует, чтобы реализации JavaScript обеспечивали поддержку стандарта Unicode версии 2.1 или выше, а стандарт ECMAScript v5 требует, чтобы реализации обеспечивали поддержку стандарта Unicode версии 3 или выше.
var str = "hello, world!"; // Используется латиница var стр = "Привет, мир!"; // Используется кириллица
Пробельные символы
Интерпретатор JavaScript игнорирует все пробельные символы которые могут присутствовать между языковыми конструкциями и воспринимает текст программы как сплошной поток кода.
Кроме того, JavaScript также, по большей части, игнорирует символы перевода строки. Поэтому пробелы и символы перевода строки могут без ограничений использоваться в исходных текстах программ для форматирования и придания им удобочитаемого внешнего вида.
Пробельные символы улучшают читаемость исходного кода, но эти символы, как правило, не нужны для функциональности js-сценария.
| Код символа | Название | Сокращение | Описание | Escape последовательность |
|---|---|---|---|---|
| U + 0009 | Горизонтальная табуляция | <HT> | Перемещает позицию печати к следующей позиции горизонтальной табуляции | \t |
| U + 000B | Вертикальная табуляция | <VT> | Перемещает позицию печати к следующей позиции вертикальной табуляции | \v |
| U + 000C | Прогон страницы, смена страницы | <FF> | Выбрасывает текущую страницу и начинает печать со следующей | \f |
| U + 0020 | Пробел | <SP> | Интервал между буквами | |
| U + 00A0 | Неразрывный пробел | <NBSP> | Символ, отображающийся внутри строки подобно обычному пробелу, но не позволяющий разорвать в этом месте строку |
В дополнение к пробельным символам символы конца строки также используются для улучшения читаемости исходного текста.
Следующие символы распознаются интерпретаторами JavaScript как символы конца строки:
| Код символа | Название | Сокращение | Описание | Escape последовательность |
|---|---|---|---|---|
| U + 000A | Перевод строки | <LF> | Перемещает позицию печати на одну строку вниз | \n |
| U + 000D | Возврат каретки | <CR> | Перемещает позицию печати в крайнее левое положение | \r |
| U + 2028 | Разделитель строк | <LS> | Разделяет строки текста, но не абзацы | |
| U + 2029 | Сепаратор абзацев | <PS> | Разделяет абзацы текста |
Точка с запятой
Программа (сценарий) на языке JavaScript представляет собой перечень «инструкций», которые выполняются веб-браузером.
В JavaScript инструкции, как правило, разделяются точкой с запятой (;).
Если несколько инструкций располагаются на одной строке, то между ними следует поставить знак «точка с запятой» (;).
Выполнить код »
Во многих случаях JavaScript интерпретирует переход на новую строчку как разделитель команд для автоматического ввода точек с запятой (ASI) для завершения инструкций.
Выполнить код »
Одна инструкция может располагаться на нескольких строчках:
Выполнить код »
В этом случае JavaScript ждёт завершение выражения и поэтому автоматически не вставляет «виртуальную» точку с запятой между строчками.
Тем не менее, рекомендуется всегда добавлять точки с запятой – это позволит избежать побочных эффектов:
Выполнить код »
Примечание: Хотя точки с запятой в конце инструкций необязательны, рекомендуется всегда добавлять их.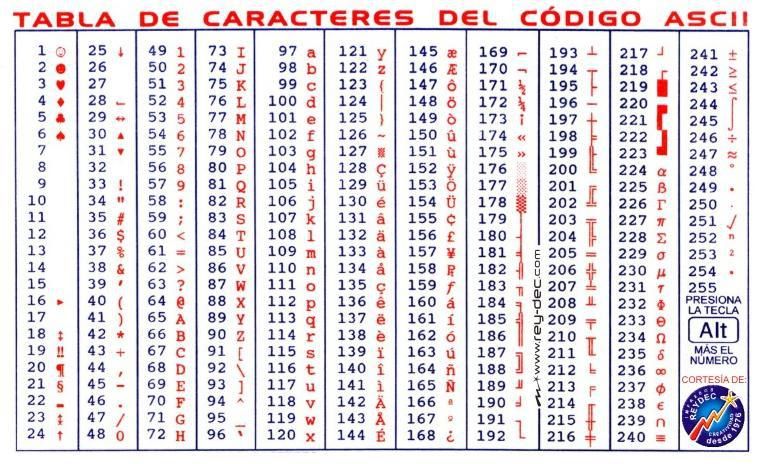 Сейчас это правило, которому следуют все большие проекты.
Сейчас это правило, которому следуют все большие проекты.
Это правило предотвращает некоторые ошибки, например незавершенный ввод, а также позволяет сжимать кoд за счет удаления пустых мест. Сжатие кода без точек с запятой приводит к синтаксическим ошибкам. Кроме того, наличие точек с запятой препятствует снижению быстродействия, потому что синтаксические анализаторы пытаются исправлять предполагаемые ошибки, добавляя недостающие точки с запятой.
Чувствительность к регистру
Для написания JavaScript-пpoгpaмм используется набор символов Unicode, который включает в себя наборы ASCII и Latin-1 и поддерживается практически всеми языками и платформами.
В JavaScript все элементы, включая имена переменных, функций и операторов, чувствительны к регистру и должны всегда содержать одинаковые наборы прописных и строчных букв. Например, ключевое слово while должно набираться как «while», а не «While» или «WHILE».
Аналогично num, NUM и Num – это три разные переменные:
Выполнить код »
Комментарии
Комментарии позволяют выделить фрагмент программы, который не выполняется интерпретатором JavaScript, а служит лишь для пояснений содержания программы.
Комментарии в JS могут быть однострочными и многострочными.
Однострочные комментарии начинаются с двойного слэша //. Текст считается комментарием до конца строки:
Выполнить код »
Многострочный комментарий начинается с слэша и звездочки (/*), а заканчивается ими же в обратном порядке (*/). Так можно закомментировать одну и более строк:
Выполнить код »
Совет: Не пренебрегайте комментариями в своих кодах. Они пригодятся вам при отладке и сопровождении программ. На этапе разработки бывает лучше закомментировать ненужный фрагмент программы, чем просто удалить. А вдруг его придется восстанавливать?
Идентификаторы
Идентификатор — это последовательность букв, цифр, символов подчёркивания (_) и знаков доллара ($). Цифра не может быть первым символом идентификатора, т. к. тогда интерпретатору JavaScript труднее отличать идентификаторы от чисел. Идентификаторы выступают в качестве имён переменных, функций, свойств объекта и т. д.
тогда интерпретатору JavaScript труднее отличать идентификаторы от чисел. Идентификаторы выступают в качестве имён переменных, функций, свойств объекта и т. д.
Для совместимости и простоты редактирования для составления идентификаторов обычно используются только символы ASCII и цифры. Однако в ECMAScript v3 идентификаторы могут содержать буквы и цифры из полного набора символов Unicode. Это позволяет программистам давать переменным имена на своих родных языках и использовать в них математические символы:
var имя = 'Макс'; var Π = 3.14;
Исторически, программисты использовали разные способы объединения нескольких слов для записи идентификаторов. Сегодня есть два устоявшихся негласных стиля: camelCase и snake_case.
В JavaScript наиболее популярным стилем именования идентификаторов, состоящих из нескольких слов, является camelCase – «верблюжья» нотация. Это означает, что первая буква является строчной, а первые буквы всех последующих слов – прописными, например:
var firstSecond; var myCar = "audi"; var doSomethingImportant;
Хотя это не является требованием, рекомендуется следовать этому правилу, чтобы не отступать от формата встроенных функций и объектов ECMAScript.
Внимание: В JavaScript объединение нескольких слов для записи идентификаторов с применением дефисов запрещено. Они зарезервированы для математических вычитаний.
На заметку: В JavaScript ключевые слова, зарезервированные слова и значения true, false и null не могут быть идентификаторами.
Ключевые и зарезервированные слова
Стандарт ЕСМА-262 определяет набор ключевых слов (keywords), которые не могут использоваться в качестве идентификаторов. Зарезервированные слова имеют определенное значение в языке JavaScript, так как они являются частью синтаксиса языка. Использование зарезервированных слов приведет к ошибке компиляции при загрузке скрипта.
Зарезервированные ключевые слова по версии ECMAScript® 2015
breakcasecatchclassconstcontinuedebuggerdefaultdeletedoelseexportextendsfinallyforfunctionifimportininstanceofnewreturnsuperswitchthisthrowtrytypeofvarvoidwhilewithyield
Ключевые слова, зарезервированные на будущее
Кроме того, ЕСМА-262 содержит набор зарезервированных слов (reserved words), которые также нельзя использовать как идентификаторы или имена свойств.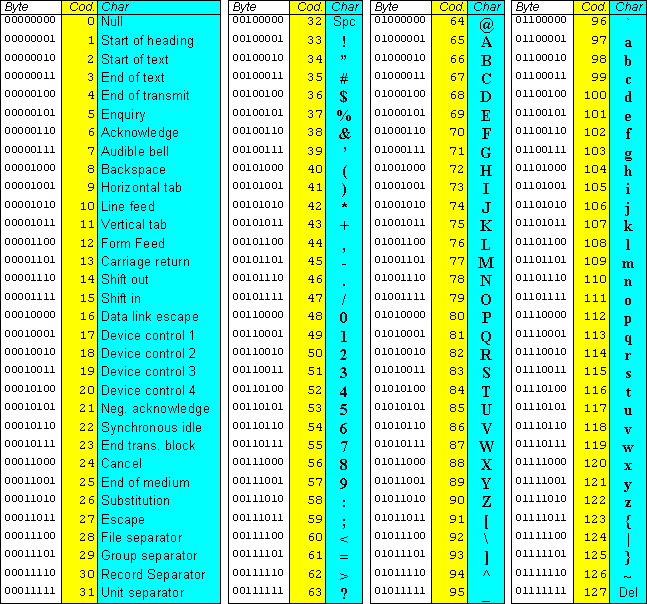 За ними сейчас не стоит никакой функциональности, но она может появиться в будущих версиях:
За ними сейчас не стоит никакой функциональности, но она может появиться в будущих версиях:
enumawait
В строгом (strict) режиме в этот список добавляются следующие слова:
implementspackageprotectedstaticinterfaceprivatepublic
Зарезервированные ключевые слова в версиях ECMAScript® от 1 по 3
abstractbooleanbytechardoublefinalfloatgotointlongnativeshortsynchronizedtransientvolatile
В 5-й редакции ECMAScript немного изменены правила употребления ключевых и зарезервированных слов. Как и прежде они не могут быть идентификаторами, но теперь их допустимо использовать как имена свойств в объектах. Тем не менее, для обеспечения совместимости с прошлыми и будущими редакциями ECMAScript всё-же лучше не использовать ключевые и зарезервированные слова как идентификаторы и имена свойств.
Как и прежде они не могут быть идентификаторами, но теперь их допустимо использовать как имена свойств в объектах. Тем не менее, для обеспечения совместимости с прошлыми и будущими редакциями ECMAScript всё-же лучше не использовать ключевые и зарезервированные слова как идентификаторы и имена свойств.
Итоги
- Интерпретатор JavaScript игнорирует все пробельные символы которые могут присутствовать между языковыми конструкциями и воспринимает текст программы как сплошной поток кода.
Кроме того, JavaScript также, по большей части, игнорирует символы перевода строки. Поэтому пробелы и символы перевода строки могут без ограничений использоваться в исходных текстах программ для форматирования и придания им удобочитаемого внешнего вида. - Пропуск точек с запятой нельзя признать правильной практикой программирования, и поэтому желательно выработать привычку их использовать.
- В JavaScript все элементы, включая имена переменных, функций и операторов, чувствительны к регистру и должны всегда содержать одинаковые наборы прописных и строчных букв.

- Не пренебрегайте комментариями в своих кодах. Они пригодятся вам при отладке и сопровождении программ. Не переживайте насчет увеличения размера кода, т.к. существуют инструменты сжатия JavaScript, которые, при публикации, легко удалят комментарии.
-
Идентификаторы выступают в качестве имён переменных, функций, свойств объекта и состоят из последовательности букв, цифр, символов подчёркивания
(_)и знаков доллара($). - Ключевые слова JavaScript, применяемые для обозначения элементов синтаксиса языка, а также другие слова, зарезервированные на будущее, нельзя использовать в качестве имен переменных, функций и объектов.

← предыдущая следующая →
Please enable JavaScript to view the comments powered by Disqus.метод JavaScript substring() — RUUD
09-06-2018 12:10
Содержание статьи:
- Синтаксис и использование метода
- Примеры извлечения подстроки
- Теория и практика строчных операций
Язык браузера JavaScript предоставляет разработчику возможность эффективной работы со строками и полный доступ к дереву DOM, которое строит для каждой страницы, открываемой посетителем сайта.
Арсенал строчных функций, доступных через методы объекта string, достаточно велик. Преобразование различных типов данных в строки выполняется автоматически, когда в этом возникает необходимость. Извлечение данных через метод JavaScript substring() является востребованной операцией.
Синтаксис и использование метода
Вам будет интересно:Использование метода JavaScript replace()
Любая строчная операция манипулирует символами. Прежде всего, это обязательность учета кодировки. Разработчик должен иметь в виду: важно не только, в какой кодировке строка. Очень важно, в какой кодировке находится страница, в которой находится код, обрабатывающий строку.
Метод JavaScript substring() имеет два параметра: номер символа, с которого начинается извлечение и номер символа, перед которым извлекаемая подстрока заканчивается.
Примеры извлечения подстроки
В приведенных примерах, используются две строчки клавиатуры в латинской и кириллической кодировке. Показано действие при различных параметрах метода.
Показано действие при различных параметрах метода.
Экспериментировать с нулевыми и отрицательными значениями допускается, но эффект будет адекватным. Представленный выше, JavaScript substring пример, убеждает, что предпочтительно использовать разумные значения начала извлечения и его конца, нежели экспериментировать.
Метод извлечения подстроки из строки ссылается на первый символ подстроки и тот, который следует за последним. Важно, второй параметр — это не количество, а номер символа. Это не привычное решение. Обычно в операциях извлечения подстроки из строки указывается «с какого и сколько». В методе JavaScript substring() — это не так: оба параметра — это номера позиций, оба могут быть нулем, «NaN» или иметь отрицательное значение.
Теория и практика строчных операций
JavaScript — очень красивый и востребованный язык программирования. В той или иной мере его обязан знать каждый квалифицированный разработчик, даже если область его компетенции — только серверные скрипты или каскадные таблицы стилей.
Все взаимосвязано. Нельзя принимать действенное участие в разработке сайта, не имея никаких представлений о языке браузера. Обычно курсы JavaScript предлагают другой метод объекта строки — substr:
- ‘строка’.substr(ПозицияПервогоСимвола[, ДлинаИзвлекаемойПодстроки])
Здесь извлекаемая строка характеризуется позицией начала и длиной. Привычное решение, которое принято на других языках. Но JavaScript — особенный язык.
JS нельзя позиционировать отдельно от других языков программирования, но его тесная связь с браузером, деревом страницы DOM и особенностями «среды обитания» приводит к особенностям реализации функциональности и особенностям в ее использовании. В частности, сказанное касается метода JavaScript substring().
Далеко не во всех случаях известна извлекаемая подстрока, как по ее положению, так и по ее длине. По большому счету, работа со строками в JS отсутствует. Здесь работают с объектами, в частности, со строчными объектами. Метод JavaScript substring() — это функциональность объекта строка, как и substr(). Первый рассматривает извлечение подстроки:
Первый рассматривает извлечение подстроки:
- позиция начала и конца;
второй:
- позиция начала и длина.
Это удобно для компактной записи алгоритма в каждом конкретном случае по конкретным причинам. В следующем примере (четыре функции, убирающие лишние пробелы слева и справа от значащих символов строки), удобно использование substr.
JavaScript позволяет формулировать алгоритм максимально лаконично без лишних «слов». В одних случаях удобно substr, в других pop и push — хотя они совсем не имеют отношения к строкам (это методы массивов), но при использовании пары split и join можно совсем иначе смотреть на применение substring.
JavaScript открывает возможности. Как и чем воспользоваться, определяет разработчик.
Источник
Автор: Валентина Лермонтова
Похожие статьи
«Система «Виндовс» защитила ваш компьютер»: как отключить появление этого сообщения? Простейшие методы
Ошибка статуса VPN в «Хамачи»: способы быстрого решения проблемы
Как сделать рассылку в «Вайбере»: подробная инструкция и способы
Как сделать бизнес-аккаунт в «Фейсбук»: создание, настройка и раскрутка
Как восстановить переписку в «Телеграмме»: пошаговая инструкция, советы
Как получить в «ES Проводник» Root-права?
Как отключить «Протект» в «Яндекс.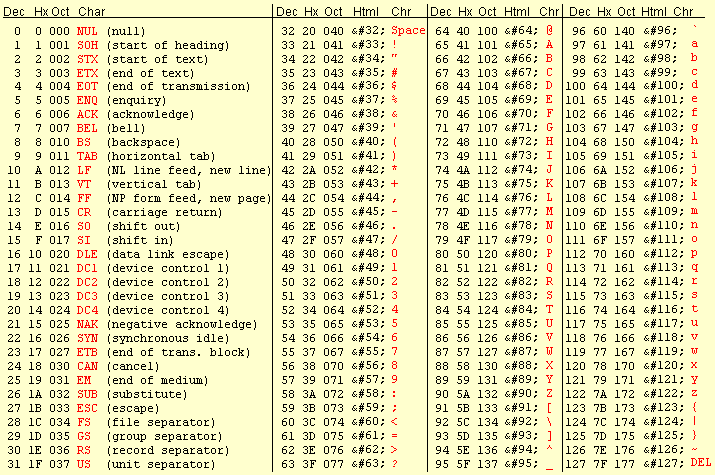 Браузере» на компьютере?
Браузере» на компьютере?
Как сохранять контакты в «Гугл»: простые способы, правила переноса, рекомендации и советы
Как на «Андроиде» переименовать приложение: подробная инструкция
Продукты «Гугла»: список, функции и возможности, отзывы
Коды символов Javascript (ключевые коды)
Интерактивная демонстрация и таблица поиска
By Steve on Четверг, 11 января 2007 г.
Обновлено 4 июля 2016 г.
Просмотрено 6 120 932 раз. ( 128 раз сегодня.)
Разработчик Инструменты и таблицы Javascript
Javascript часто используется на стороне клиента браузера для выполнения простых задач, которые в противном случае потребовали бы полной обратной передачи на сервер. Многие из этих простых задач включают обработку текста или символов, введенных в элемент формы на веб-странице, и часто необходимо знать код клавиши javascript, связанный с символом.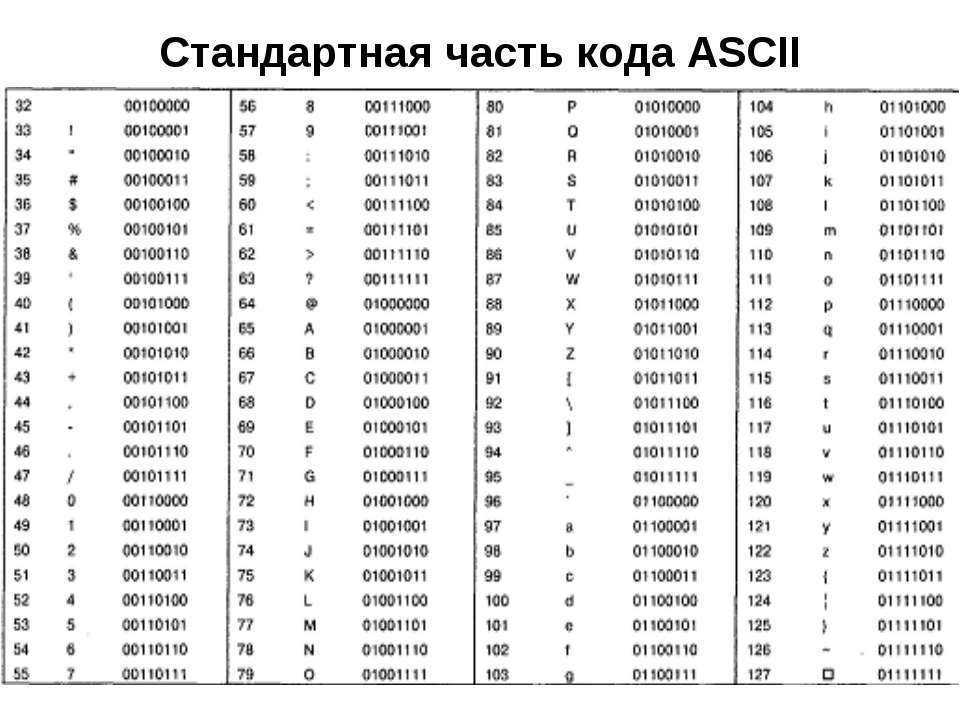 Вот ссылка.
Вот ссылка.
Нажмите клавишу в текстовом поле ниже, чтобы увидеть соответствующий код клавиши Javascript. Или прокрутите вниз, чтобы увидеть полный список.
Попробуйте!
|
|
|
Эскейп-последовательности символов JavaScript · Матиас Байненс
Недавно написав о ссылках на символы в HTML и эскейп-последовательностях в CSS, я подумал, что было бы интересно также изучить экранирование символов JavaScript.
Коды символов, кодовые точки и кодовые единицы
Кодовая точка (также известная как «код символа» ) представляет собой числовое представление определенного символа Unicode.
Например, код символа авторского права © равен 169 , что может быть записано как 0xA9 в шестнадцатеричном формате.
В JavaScript String#charCodeAt() можно использовать для получения числовой кодовой точки Unicode любого символа до U+FFFF (т. е. символа с кодовой точкой 9).0673 0xFFFF , то есть 65535 в десятичном виде).
Поскольку внутри JavaScript используется кодировка UCS-2, более высокие кодовые точки представлены парой (с более низким значением) «суррогатных» псевдосимволов, которые используются для составления реального символа. Чтобы получить фактический код символов с более высокими кодовыми точками в JavaScript, вам придется проделать дополнительную работу. По сути, JavaScript использует кодовые единицы, а не кодовые точки.
Теперь, когда это не так, давайте взглянем на различные типы управляющих последовательностей символов в строках JavaScript.
Существуют некоторые зарезервированные escape-последовательности из одного символа для использования в строках:
-
\b: backspace (U+0008 BACKSPACE) -
\f: подача страницы (U+000C ПОДАЧА ФОРМЫ) -
\n: перевод строки (U+000A LINE FEED) -
\r: возврат каретки (U+000D ВОЗВРАТ КАРЕТКИ) -
\t: горизонтальная вкладка (U+0009 ТАБЛИЦА СИМВОЛОВ) -
\v: вертикальная вкладка (U+000B LINE TABULATION) -
\0: нулевой символ (U+0000 NULL) (только если следующий символ не является десятичной цифрой; в противном случае это восьмеричная управляющая последовательность) -
\': одинарная кавычка (U+0027 АПОСТРОФ) -
\": двойная кавычка (U+0022 QUOTATION MARK) -
\\: обратная косая черта (U+005C ОБРАТНАЯ СОЛИДУС)
Все одиночные escape-символы можно легко запомнить с помощью следующего регулярного выражения: \\[bfnrtv0'"\\] .
Обратите внимание, что escape-символ \ делает специальные символы буквальными. ; // true
\ , за которым следует новая строка, — это не управляющая последовательность символов, а LineContinuation . Новая строка не становится частью строки. строка на нескольких строках (например, для более удобного редактирования кода), без фактического включения в строку каких-либо символов новой строки. Я полагаю, вы могли бы подумать о \ , за которым следует новая строка в качестве escape-последовательности для пустой строки.
Символы без специального значения также могут быть экранированы (например, '\a' == 'a' ), но это, конечно, не требуется. Однако использование \u вне escape-последовательности Unicode или \x вне шестнадцатеричной escape-последовательности запрещено спецификацией и приводит к тому, что некоторые механизмы выдают синтаксическую ошибку.
Примечание: IE < 9 обрабатывает ‘\v’ как 'v' вместо вертикальной табуляции ( '\x0B' ). Если вас беспокоит межбраузерная совместимость, используйте
Если вас беспокоит межбраузерная совместимость, используйте \x0B вместо \v .
Следует также отметить, что в строках JSON не разрешены escape-последовательности \v и \0 .
Восьмеричные escape-последовательности
Любой символ с кодом ниже 256 (т. е. любой символ в расширенном диапазоне ASCII) может быть экранирован с помощью его восьмеричного кода с префиксом \ . (Обратите внимание, что это тот же диапазон символов, который можно экранировать с помощью шестнадцатеричных экранов.)
Чтобы использовать тот же пример, символ авторского права ( '©' ) имеет код символа 169 , что дает 251 в восьмеричное представление, поэтому вы можете записать его как '\251' .
Восьмеричные символы могут состоять из двух, трех или четырех символов. '\1' , '\01' и '\001' эквивалентны; заполнение нулями не требуется.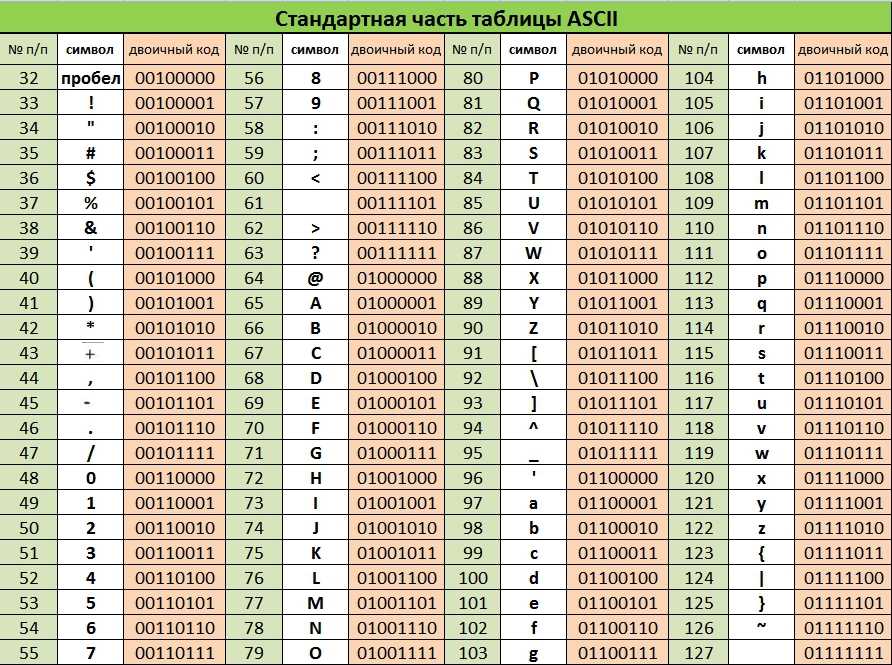 Однако, если восьмеричный escape (например,
Однако, если восьмеричный escape (например, '\1' ) является частью большей строки, и за ним сразу следует символ в диапазоне [0-7] (например, 1 ), следующий символ будет считаться частью управляющей последовательности до тех пор, пока совпало не более трех цифр. Другими словами, '\12' (один восьмеричный escape-символ, эквивалентный '\012' ) не совпадает с '\0012' (восьмеричный escape-символ '\001' , за которым следует неэкранированный символ '2' ). Вы можете избежать этой проблемы, просто заполняя восьмеричные escape-последовательности нулями.
Обратите внимание, что здесь есть одно исключение: \0 само по себе не является восьмеричной управляющей последовательностью. Это выглядит как единица и даже равно \00 и \000 , обе из которых являются восьмеричными escape-последовательностями, но если за ними не следует десятичная цифра, они действуют как односимвольные escape-последовательности. Или, в специальном жаргоне:
Или, в специальном жаргоне: EscapeSequence :: 0 [lookahead ∉ DecimalDigit] . Вероятно, проще всего определить синтаксис восьмеричного перехода, используя следующее регулярное выражение: \\(?:[1-7][0-7]{0,2}|[0-7]{2,3}) .
Обратите внимание, что восьмеричные escape-последовательности устарели в ES5:
Предыдущие выпуски ECMAScript включали дополнительный синтаксис и семантику для указания восьмеричных литералов и восьмеричных escape-последовательностей. Они были удалены из этой версии ECMAScript. В этом ненормативном приложении представлен унифицированный синтаксис и семантика восьмеричных литералов и восьмеричных escape-последовательностей для совместимости с некоторыми старыми программами ECMAScript.
Кроме того, они выдают синтаксические ошибки в строгом режиме:
Соответствующая реализация при обработке кода строгого режима (см.
EscapeSequenceдля включенияOctalEscapeSequence, как описано в B.1.2.
 10.1.1) не может расширять синтаксис
10.1.1) не может расширять синтаксис Они также запрещены в литералах шаблонов.
TL;DR Не используйте восьмеричные escape-последовательности; вместо этого используйте шестнадцатеричные escape-последовательности.
Шестнадцатеричные управляющие последовательности
Любой символ с кодом ниже 256 (т. е. любой символ в расширенном диапазоне ASCII) можно экранировать, используя его шестнадцатеричный код символа с префиксом \x . (Обратите внимание, что это тот же диапазон символов, который можно экранировать с помощью восьмеричного escape-последовательности.)
Шестнадцатеричные escape-последовательности состоят из четырех символов. Для них требуется ровно два символа после \x . Если шестнадцатеричный код символа состоит только из одного символа (это касается всех кодов символов меньше 16 или 10 в шестнадцатеричном формате), вам нужно будет дополнить его начальным 0 .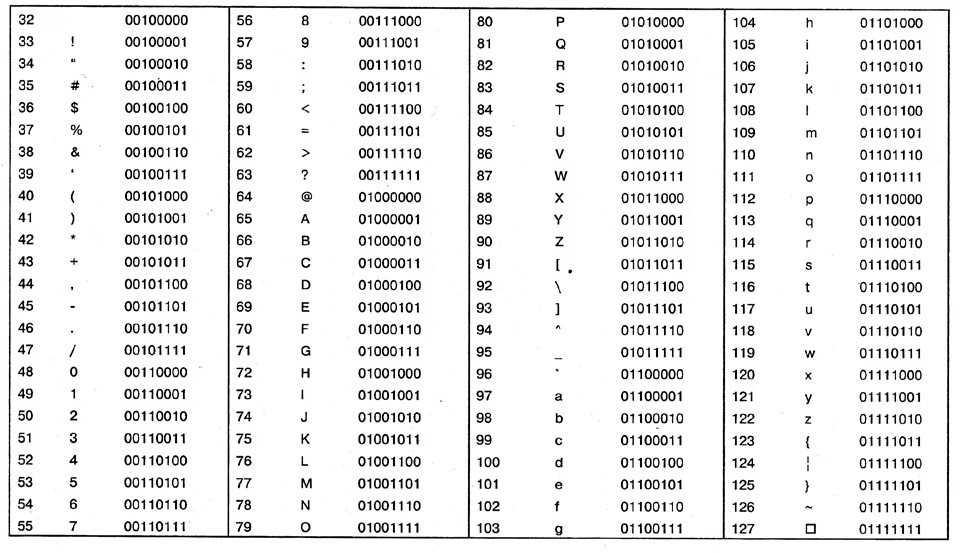
Например, символ авторского права ( '©' ) имеет код символа 169 , что дает A9 в шестнадцатеричном формате, поэтому вы можете записать его как '\xA9' .
Шестнадцатеричная часть этого escape-последовательности нечувствительна к регистру; другими словами, '\xa9' и '\xA9' эквивалентны.
Вы можете определить шестнадцатеричный escape-синтаксис, используя следующее регулярное выражение: \\x[a-fA-F0-9]{2} .
Немного сбивает с толку тот факт, что спецификация называет этот вид escape-последовательности «шестнадцатеричным», поскольку escape-последовательности Unicode также используют шестнадцатеричный код.
escape-последовательности Unicode
Любой символ с кодом ниже 65536 можно экранировать, используя шестнадцатеричное значение кода символа с префиксом \u . (Как упоминалось ранее, более высокие коды символов представлены парой суррогатных символов. )
)
Escape-коды Unicode имеют длину шесть символов. Они требуют ровно четыре символа после \и . Если шестнадцатеричный код состоит только из одного, двух или трех символов, вам необходимо дополнить его ведущими нулями.
Символ копирайта ( '©' ) имеет код символа 169 , что дает A9 в шестнадцатеричном представлении, поэтому вы можете записать его как '\u00A9' . Точно так же '♥' можно записать как '\u2665' .
Шестнадцатеричная часть такого escape-символа нечувствительна к регистру; другими словами, '\u00a9' и '\u00a9' эквивалентны.
Вы можете определить escape-синтаксис Unicode, используя следующее регулярное выражение: \\u[a-fA-F0-9]{4} .
Примечание: Помимо нескольких простых escape-последовательностей, последовательности Unicode являются единственными, разрешенными спецификацией JSON.
ECMAScript 6: escape-последовательности кодовых точек Unicode
ECMAScript 6 представляет новый тип escape-последовательностей в строках, а именно escape-последовательности кодовых точек Unicode. Кроме того, он определит String.fromCodePoint и String#codePointAt , оба из которых принимают кодовые точки, а не кодовые единицы, подобные UCS-2/UTF-16.
Когда это реализовано, любой символ можно экранировать, используя шестнадцатеричное значение его кода символа с префиксом \u{ и суффиксом } . Это разрешено для кодовых точек до 0x10FFFF , что является наивысшей кодовой точкой, определенной Unicode.
Экранированные кодовые точки Unicode состоят не менее чем из пяти символов. По крайней мере один шестнадцатеричный символ может быть заключен в \u{…} . Не существует верхнего предела количества используемых шестнадцатеричных цифр (например, '\u{000000000061}' == 'a' ), но для практических целей вам не потребуется более 6, если только вы не выполняете ненужные нули- обивка.
Тетраграмма для центрального символа ( 𝌆 ) имеет кодовую точку U+1D306, поэтому вы можете записать ее как \u{1D306} . Для сравнения, если бы вы использовали простые escape-последовательности Unicode для представления этого символа, вам пришлось бы записывать суррогатные половины отдельно:0673 ‘\uD834\uDF06’ .
Шестнадцатеричная часть такого escape-символа нечувствительна к регистру; другими словами, '\u{1d306}' и '\u{1D306}' эквивалентны.
Вы можете определить синтаксис escape-кода Unicode, используя следующее регулярное выражение: \\u\{([0-9a-fA-F]{1,})\} .
Управляющие escape-последовательности
В регулярных выражениях (не в строках!), любой символ с кодом больше 0 и меньше 9J в знаке вставки (поскольку 0x000A === 10 и J — 10-я буква алфавита). Таким образом, допустимым регулярным выражением, которое соответствует этому символу, будет /\cJ/ , например.
/\cJ/.test('\n') == true .
Знак вставки, следующий за \c в этом типе escape-символа, нечувствителен к регистру; другими словами, /\cJ/ и /\cj/ эквивалентны.
Вот список всех доступных escape-последовательностей управления и управляющих символов, которым они соответствуют:
| Escape-последовательность | Кодовая точка Юникода |
|---|---|
\ca или \ca | U+0001 НАЧАЛО ЗАГОЛОВКА |
\cb или \cb | U+0002 НАЧАЛО ТЕКСТА |
\cc или \cc | U+0003 КОНЕЦ ТЕКСТА |
\cD или \cd | U+0004 КОНЕЦ ПЕРЕДАЧИ |
\ce или \ce | U+0005 ЗАПРОС |
\cf или \cf | U+0006 ПОДТВЕРЖДЕНИЕ |
\cG или \cg | U+0007 ЗВОНОК |
\ch или \ch | U+0008 НАЗАД |
\ci или \ci | U+0009 ТАБЛИЦА СИМВОЛОВ |
\cJ или \cj | U+000A ПЕРЕВОД СТРОКИ (LF) |
\cK или \ck | U+000B ТАБЛИЦА СТРОК |
\кл или \кл | U+000C ПОДАЧА ФОРМЫ (FF) |
\cM или \см | U+000D ВОЗВРАТ КАРЕТКИ (CR) |
\cN или \cn | U+000E ПЕРЕКЛЮЧЕНИЕ |
\co или \co | U+000F СМЕНА В |
\cP или \cp | U + 0010 ESCAPE КАНАЛА ПЕРЕДАЧИ ДАННЫХ |
\cQ или \cq | U+0011 УСТРОЙСТВО УПРАВЛЕНИЯ ОДИН |
\cr или \cr | U+0012 УСТРОЙСТВО УПРАВЛЕНИЯ ДВА |
\CS или \CS | U+0013 КОНТРОЛЬ УСТРОЙСТВА ТРИ |
\ct или \ct | U+0014 УСТРОЙСТВО УПРАВЛЕНИЯ ЧЕТЫРЕ |
или | U+0015 ОТРИЦАТЕЛЬНОЕ ПОДТВЕРЖДЕНИЕ |
\cv или \cv | U+0016 СИНХРОННЫЙ ХОЛОСТОЙ РЕЖИМ |
\cW или \cw | U+0017 КОНЕЦ БЛОКА ПЕРЕДАЧ |
\cX или \cx | U+0018 ОТМЕНА |
\cY или \cy | U+0019 КОНЕЦ СРЕДСТВА |
\cZ или \cz | U+001A ЗАМЕНА |
Синтаксис escape-последовательности можно определить с помощью следующего регулярного выражения: \\c[a-zA-Z] .