«Мы делаем космические корабли» / Habr
Компания GridGain Systems, разработчик программных решений на базе Apache Ignite, предоставила клиентам доступ к решениям GridGain In-Memory Data Fabric на облачной платформе Microsoft Azure. Это позволит компаниям-поставщикам финансовых услуг использовать возможности интегрированных облачных служб Microsoft для быстрого развертывания продуктов GridGain и перенести вычисления в оперативную память компьютера.
По оценке аналитиков из IDC, к 2019 году рынок данных вырастет на 50% до $187 миллиардов. Отдельную ценность имеют вычисления в режиме реального времени.
GridGain — один из лидеров в этом сегменте. Будучи небольшим стартапом, компании удалось обойти крупных конкурентов и заключить контракты по всему миру. Причина успеха компании — технологическое ноу-хау? Или, может быть, просто везение?
О нелегкой судьбе наукоемкого ИТ-стартапа, о конкуренции на рынке данных и его перспективах мы поговорили с основателем и генеральным директором компании Никитой Ивановым.
Традиционный вопрос. Как вы пришли к созданию компании, как появилась идея?
GirdGain занимается разработкой программного обеспечения в сфере in-memory computing. Мы позволяем хранить и обрабатывать данные в памяти компьютера. Это гораздо быстрее, чем на диске. Мы позволяем делать это в распределенном режиме, на более чем 2 000 НОДах.
Начну издалека. Я начал работать с in-memory computing лет 17 назад. Тогда была совершенно другая экономика, другие темпы развития. В 2000 году я начал работать техническим директором одной японской компании. Там я начал создавать прообраз того, что сегодня называется GridGain. В этой компании я познакомился со своим партнером, сооснователем GridGain, Димой Сетракяном.
В 2005 году мы решили создать свою компанию. История GridGain начинается в 2005 году. И первая строчка кода была написана мною в этом же году.
В 2010 году мы организовали компанию, подняли первые инвестиции здесь, в США. С этого времени вокруг проекта образовалась коммерческая компания.
Ваша компания базируется в США. Часть сотрудников работает в России. Почему так?
Во-первых, я учился в БГТУ «Военмех» в Питере. На последних курсах я уже работал в Германии, в Daimler-Benz. Потом я сдал диплом и через две недели уже был в Америке. Компания является чисто американской, стандартный американский стартап, с местными деньгами, менеджментом и всем остальным. Мы находимся в Кремниевой долине.
Что касается Питера, здесь у нас инженерная команда находится. На это есть совершенно ясные причины. Программирование – та область, в которой ничего не нужно, кроме головы, книжки и компьютера. Светлые головы есть и в США, и в России… Но светлая голова в Питере стоит дешевле, чем здесь. Мы можем достаточно удобно так удаленно работать с Питером, потому что и я, и мой кофаундер, и основной технический менеджмент русскоговорящие. Нам проще работать с Россией, чем с Китаем, Восточной Европой и др.
Ваши коллеги (основатели других компаний), которые тоже одновременно работали в США и в России, говорили, что им нравится нанимать сотрудников, которые в прошлом участвовали в олимпиадах по программированию. Вы как относитесь к этому, учитывая, что в Петербурге одна из самых сильных команд?
Ну сколько таких ребят? Мы не хотим конкурировать с «Яндексом» и другими гигантами, которые их принимают за любые деньги. Я сам из 521 школы в Питере. Специфика того, что мы делаем, очень интересная. То, что мы делаем, в России не умеет никто. Людей, которые имеют нужный нам опыт, даже в Долине нет. Поэтому искать кого-то в России прицельно бесполезно. Все, кто обладает нужными нам знаниями, уже работают в нашей компании.
Мы просто берем толковых специалистов и стараемся быстро (в течение 8-12 месяцев) научить их тому, что мы делаем. Нам проще брать людей, которые подходят нам психологически, по интересам, и быстро их развивать. Это мой достаточно жесткий принцип. Естественно, есть какие-то базовые знания, которые требуются для работы с нашим продуктом: мы разрабатываем на Java, разрабатываем на Scala. Базовые навыки необходимы. Часто люди приходят с достаточно серьезным опытом за плечами.
Я терпеть не могу примадонн в технической команде. Вот в менеджменте дело может обстоять немного по-другому.
Почему вы не стали дальше работать программистом по найму, а организовали свою компанию?
Есть разные типы людей. Живя в Калифорнии, ты можешь иметь гораздо более спокойную и обеспеченную жизнь, просто на кого-то работая. Работы здесь огромное количество. Если голова есть, платят очень хорошо.
Мне достаточно скучно работать на кого-то. У меня много своих идей. Идей гораздо больше, чем времени. Я практически всегда работаю над несколькими проектами. GridGain самый удачный из них на данный момент.
Трудно сказать, почему я это сделал. Есть какие-то идеи, хочешь делать что-то свое — начинаешь это делать.
Вы сказали, что мало готовых специалистов для работы в GridGain. Поэтому, наверное, мало и конкурентов, особенно стартапов, конкурирующих с вами?
Отчасти да. Это не какая-то социальная сеть или игрушка на телефоне. То, что мы делаем, вещь достаточно наукоемкая. Нам понадобилось 10 лет, чтобы поднять наш проект на ноги. Вдумайся, 10 лет твоей жизни! Не только как бизнес, но и как технологию.
У нас действительно очень мало конкурентов, это имеет свои плюсы. Но с другой стороны, это очень плохо для бизнеса. Бизнес терпеть не может сложных, тяжелых, наукоемких решений. Это не академия, где всю жизнь можно сидеть и решать уравнения. В бизнесе нужно делать все достаточно быстро.
Мы делаем «космические корабли», которые нужно очень немногим. В бизнесе почти все строится на удаче. Нам повезло. В 2005 году этот рынок был микроскопический: это нужно было Wall Street, это нужно было Лондону и определенным проектам в обороне. Больше, пожалуй, никому.
Но за последние 3-4 года ситуация изменилась кардинально. Практически в каждом телефоне появились 64-битные процессоры. Стоимость памяти, где GridGain позволяет хранить данные, здорово упала. Теперь можно зайти на Amazon и купить компьютер с терабайтом памяти. Появились мощные системы у таких производителей, как Fujitsu или Hewlett Packard, с 64 ТБ памяти на одном компьютере. То есть появился целый спектр различных in-memory hardware, а цена за мегабайт памяти упала в разы.
Интерес к данным технологиям возрос очень. Все поняли, что хранить данные можно в памяти, это становится экономически доступно, есть и необходимый для этого софт. Мы попали в эту волну. Удачно попали. Наш рынок растет, мы растем вместе с ним.
Научная составляющая технологии несет в себе и определенные трудности для нашего бизнеса. Мы не можем отражать стоимость разработки в ценообразовании конечного продукта.
Людей в команду найти не просто, но мы двигаемся. Это не тот проект, где нужна огромная поддержка. Сейчас нас примерно 60 человек. Мы все еще стартап.
Какие компании были вашими конкурентами вначале и кто является ими сейчас?
Количество конкурентов со временем уменьшилось как ни странно. Кто-то не дожил, кого-то купили, кто-то вообще непонятно где находится. Когда мы начинали, с нами конкурировали Oracle Coherence, Gigaspace. Позже появилась Terracotta, но потом ее купили, и она умерла.
Сейчас Coherence мы очень часто заменяем везде. Из новых компаний Hazelcast является нашим конкурентом, ну и SAP HANA. Сами цифры очень маленькие: у нас нет и десятка конкурентов.
Если спросить Gartner, они скажут, что для разработки подобного софта требуется 5-7 лет. Это просто, чтобы выпустить продукт. А ведь еще нужно время на развитие бизнеса. Поэтому вряд ли у нас ни с того ни с сего появится много новых конкурентов. Такого не будет.
Как инвесторы реагируют на ваш бизнес? Наверняка, они ждали какого-то результата, а специфика проекта предполагает медленный темп разработки.
Инвесторы у нас очень разные – фонд Леонида Богуславского, Almaz Capital, Сбербанк. Скоро надеемся получить еще китайские и американские инвестиции. Но сами мы не старались их найти.
Когда мы привлекли первые деньги, наш софт в мире запускался каждые 10 секунд. Несмотря на его сложность и узкую направленность, уже тогда мы добились вполне внушительного масштаба.
В тот период, кстати, я просто «жил» в самолете. Я объехал весь мир, посещал всевозможные конференции, я всем рассказывал про возможности технологии и показывал наш продукт.
Первых привлеченных (seed) денег обычно хватает только для того, чтобы «выйти из гаража», снять офис. Сначала все мы работали буквально из своих спален.
Всегда привожу в пример, как мы продали нашу систему компании Apple лет 7 назад. Я помню, что вел телефонный разговор с директором проектов в Apple, находясь в спальне с ноутбуком на коленях. У нас не было офиса. Семья была в одной комнате, а в другой я вел с ним переговоры. Так все работали. Анекдотично выглядело все это поначалу.
Ну а потом все стало развиваться. Немало было проблем. Мы сделали огромное количество ошибок поначалу. Собственно, как и все. Я убежден, что ошибки — это нормально. Главное не допустить ошибок, которые могут просто убить компанию. Нам повезло. Мы были близки к этому, но все же смогли не сделать их. Затем мы подняли второй, третий раунд, нашли правильный менеджмент.
На каждом этапе бизнеса инвесторов интересует разное. На первом этапе их интересует технология и благоприятные условия на рынке. Затем, конечно, бизнес-результаты.
Сравнительно недавно договор о сотрудничестве с вами заключил Сбербанк. Вы будете продолжать с ними работать в этом направлении?
Нам теперь трудно не работать с ними: Сбербанк стал нашим инвестором. Сбербанк — уникальный пример. Хотя с Barclays у нас очень похожий use case: глобальный переход на GridGain. Сбербанк также полностью переводит ИТ-инфраструктуру на GridGain. Задача очень комплексная, на мой взгляд. Она требует огромных усилий с обеих сторон — по своей масштабности Сбербанк превосходит всех наших заказчиков, поэтому в процессе внедрения появляется большое количество новых требований к платформе.
Причем формализация и реализация этих требований может быть сделана только совместно — важен опыт каждой из сторон. 2017 год пройдет для нас под знаком передачи решения на базе GridGain на поддержку, что потребует дополнительной доработки существующих механизмов отказоустойчивости. Сейчас мы сконцентрированы на том, чтобы вместе со Сбербанком развивать GridGain In-Memory Data Fabric для достижения общей цели.
У Сбербанка очень амбициозный план, а я работал со многими банками в мире. Пообщавшись лично с Грефом и его топ-менеджментом, мы сделали вывод, что, как это ни парадоксально звучит, Сбербанк — очень продвинутый банк в технологическом плане. По крайней мере, с точки зрения их идей и планов. Да, далеко не все из них пока реализованы. Но более современного и продвинутого банка я не встречал, что просто удивительно для России.
У вас есть Тинькофф, который считается более технологичным, но он намного меньше, а по сравнению со Сбербанком это микроскопический банк, и в нем легче делать все что угодно.
Да, конечно, мы будем вплотную работать со Сбербанком и дальше. Мы не просто продали свой софт и получили деньги.
В случае со Сбербанком нужно отдать должное Грефу, потому что он человек неординарный в этом смысле. Сбербанк — это тот редкий случай, когда мы разговариваем с людьми про наши технологии, и нас прекрасно понимают. Обычно в России этого никогда не случалось. Почему раньше у нас не было продаж в этой стране? Здесь это никому не нужно было. Сбербанк – первая компания, которая не только поняла, что это нужно, но еще и сама умудрилась нас найти. Мы прошли огромный конкурс.
Я не буду спрашивать, почему вы победили. Спрошу по-другому: почему сейчас вы все чаще заменяете конкурирующие продукты? Какие у вашей технологии преимущества? Или дело в маркетинге?
Нет, дело не в маркетинге. Мы закрыли крупную сделку со Сбербанком по телефону и email. У нас не было ни одного человека в Москве. Я с Грефом первый раз встретился, когда мы уже подписывали договор о сотрудничестве.
Года 3-4 назад они с нами связались. Опять по телефону. Они сказали, что изучают рынок in-memory computing и хотели бы присмотреться к нам тоже. Мы дали принципиальное согласие и забыли про все это. У нас в России тогда никого не было, мы с ней не работали, нам она была не интересна.
Но они стали общаться с нами дальше. Через полтора года Сбербанк купил у нас лицензию на небольшой проект. Тогда мы стали с ними более активно работать, интересоваться, что у них там происходило. Но, несмотря на это, у нас по-прежнему не было никакого фокуса на России.
Года полтора назад с нами вновь связались представители Сбербанка, которые рассказали, что планируется тендер. Таким образом они собирались найти софт для их новых проектов. Тогда речь зашла уже о глобальном переходе на in-memory computing.
Мы согласились участвовать в этом тендере. Компаний участвовало много, включая гигантские корпорации. Была проделана огромная документальная работа.
Мне казалось, шансов у нас практически ноль, потому что в Москве у нас вообще никого не было. Мы могли оформить все бумажки, отправить им туда. Зная, как ведется в России бизнес (особенно на таком уровне), мы ни на что не надеялись. Но не поленились, все сделали и отослали.
Потом было самое интересное: в течение трех месяцев мы узнали, что вошли в тройку финалистов. Началась очень тесная работа со Сбербанком. Выяснилось, что те результаты работы продуктов GridGain, которые мы предоставили, были в разы быстрее, чем у конкурентов. Нас попросили приехать в Москву.
Мы показали им то, что сделали. На одном из тестов на 10 блейдах (стандартные Intel blades), общая емкость которых была 1 ТБ памяти, мы достигли миллиарда финансовых транзакций в секунду. Все это «железо» стоит порядка $20 тысяч сегодня. Мы превысили показатели конкурентов почти в 100 раз. Естественно, что это могло вызвать у Сбербанка недоверие.
Потом мы потратили еще месяцев шесть на то, чтобы убедить, что это можно делать на базе open source. Мы являемся open source компанией и полностью базируемся на Apache Ignite. GridGain является небольшой надстройкой над ним.
Надо отдать должное Грефу и его команде: они понимали, что такое open source компания, и решили, что с определенной долей риска можно полагаться на стартап. Обычно банки являются очень консервативными компаниями.
Мы выиграли тендер. Сбербанк инвестировал в нас. Вероятно, в том числе для того, чтобы убедиться, что наш стартап никуда не денется. Мы предоставили им гораздо лучшую, более перспективную технологию, которая стоит гораздо дешевле, чем у конкурентов.
Если можно, про историю с open source расскажите поподробнее. В одном из источников сказано, что в 2014 году GridGain «пожертвовал» Apache свою базу ядра.
Слово «пожертвовал» здесь неуместно. Никто ничего не жертвовал. Никакого donation здесь не было. GridGain всю жизнь был и есть open source продуктом. Все, что менялось, – это сама лицензия, под которой мы этот продукт распространяли: сначала была GPL, потом LGPL, потом была Apache. И мы подумали, почему мы просто взяли Apache-лицензию, надо вступить в Apache-организацию. А один из ключевых моментов при вступлении в эту организацию – смена акционера проекта. Поэтому иногда это обозначается как donation. Термин, конечно, немного странный.
Преимущество Apache Foundation в том, что он позволяет создавать большое сообщество. Это большой плюс. Все остальное – минусы (смеется). Мы являемся частью Apache, находимся в той же «семье», что и Hadoop, Spark и так далее. В top-level проектах мы вторые после Spark, потому что мы пришли в Apache уже как здоровый, взрослый проект.
Что насчет планов дальнейшего развития?
Планов много, но все зависит от того, как будет развиваться технология in-memory computing. И здесь мы, что называется, плывем по течению. Сейчас очень интересное для нас время.
Что такое in-memory computing? Это технологии хранения и обработки данных в памяти компьютера. В 50-х годах были ленточные накопители. Первый такой накопитель выпустила компания, которая ранее производила ружья. Она увидела, что зарождается новый рынок и выпустила продукт. Потом были жесткие диски. К концу 90-х Toshiba выпустила флэш-память. Внешние накопители развивались, и у них все быстрее увеличивалась емкость.
Но флэш становится медленной и имеет свои проблемы. Где еще можно хранить данные? Остаются другие виды памяти внутри компьютера. Да, можно хранить данные в оперативной памяти.
Теперь мы использовали все возможности по внешнему хранению и по внутреннему. In-memory computing – та модель, на которую мы будем работать до тех пор, пока мы фундаментально не поменяем архитектуру наших компьютеров. Это последний этап. За ним ничего нет.
Есть еще бизнес-составляющая. Кто только не производит беспилотники сейчас: Apple, Uber. Каждый гараж делает свои беспилотные машины. Колоссальным образом сейчас развиваются технологии обработки огромного количества данных – NLP-processing, cognitive computing.
В большинстве случаев это обработка в режиме реального времени. Еще один пример: в тело человека вставляется чип. Он посылает данные о состоянии тела провайдеру. То есть, он может предупреждать болезни: анализировать кровь, пульс и так далее. Это колоссальный рынок. Миллиардный, если не триллионный, рынок.
Может быть, сегодня Сбербанку эти технологии совершенно не нужны. Но они понимают, что через 10-15 лет сегодняшняя технологическая база приведёт банк к краху: он не выдержит никакой конкуренции.
Я считаю, что мы в очень выгодном положении. Мы лидируем на рынке, несмотря на то, что являемся маленьким стартапом. Перспективы здесь только радужные. У нас есть проекты, связанные с беспилотными автомобилями, проекты по распознаванию человеческой речи, cognitive computing.
Если 2-3 года назад это были единичные истории, то через 2-3 года таких проектов будут десятки или даже сотни.
Мы хотим сделать так, чтобы наша технология постоянно эволюционировала. Тогда мы сможем во всеоружии подойти ко всем вызовам рынка.
GridGain Systems о in-memory computing, open source, российском рынке и не только / JUG Ru Group corporate blog / Habr
О проекте Apache Ignite слышно всё чаще. Но, как ранее заметил на Хабре один из его разработчиков Владимир Озеров, в двух словах описать проект сложно — а в результате у многих остаются вопросы, начиная с самых базовых. Что проект вообще представляет собой? Как соотносятся Apache Ignite и компания GridGain? Как соотносятся понятия «in-memory data grid» и «in-memory data fabric»?
В программу JBreak и JPoint 2017 вошли доклады спикеров из GridGain, а сама компания стала спонсором обеих конференций — и прямо перед JBreak мы задали накопившиеся у многих вопросы. А ответили на них:
- Владимир devozerov Озеров (архитектор)
- Алексей Дмитриев (генеральный директор российского отделения / VP of Engineering)
- Ирина Тищенко (HR-директор)
Владимир Озеров (архитектор)
— Начнём с простого: что проект представляет собой и чем отличается от схожих продуктов?
— Apache Ignite — это универсальная платформа для распределённых in-memory вычислений. Первыми компонентами, появившимися около 10 лет назад, были распределённый кэш (data grid) и map-reduce (compute grid). На тот момент и мы, и наши конкуренты позиционировали свои решения как «distributed cache». Со временем требования бизнеса росли, мы добавляли новые модули. Среди основных: поддержка ANSI SQL’99, потоковая загрузка данных (streaming), развёртывание пользовательских приложений в кластере (service grid), возможность сохранять объекты, не имея их Java-классов на сервере (binary objects), интеграции с большим количеством сторонних интерфейсов и платформ (web sessions, Spring cache, Hibernate L2 cache, Hadoop, Spark, Kafka, JDBC, ODBC, и т.д.).
В какой-то момент устоявшиеся понятия «distributed cache» и «in-memory data grid» перестали отражать суть продукта. Тогда появился термин «in-memory data fabric» — это ПО для распределённых вычислений в памяти, с большим количеством интерфейсов для различных источников данных и их потребителей. Именно это выделяет нас на фоне аналогичных решений, которые не торопятся выходить за рамки термина «in-memory data grid».
— Проект не сразу пришёл к open source — как это произошло?
— Первое время продукт развивался как закрытое коммерческое решение GridGain. Осознав потенциал open source, мы открыли большую часть исходного кода на GitHub, но контроль над разработкой оставался в руках компании. Это распространённая бизнес-модель: смотри, используй, но не вмешивайся. Но мы пошли дальше. В 2015 году открытая часть была передана под контроль Apache Software Foundation. Решение далось нелегко: мы теряли контроль над кодом, и были вынуждены искать новое название. Так появился Apache Ignite. Ставка была сделана на то, что бренд Apache и теперь уже честный open source дадут серьезный импульс проекту, увеличив его популярность. И мы не ошиблись: количество пользователей начало расти экспоненциально.
Что интереснее, люди стали активно вкладывать свои силы в проект: генерировать идеи, исправлять ошибки, улучшать документацию, разрабатывать новые фичи и модули, писать книги и выступать на конференциях. Это просто фантастика! Мы продолжаем прилагать усилия для привлечения новых контрибьюторов. Любой из читающих это интервью может внести свой вклад, получив опыт разработки действительно сложной системы.
— Звучит здорово, но где в этой схеме деньги? Как соотносятся GridGain и Apache Ignite?
— Коммерческие компании редко могут себе позволить работу с чистым open source, особенно в критических бизнес-приложениях. Кто добавит недостающую функциональность, оперативно исправит баг и ответит на вопросы? Всё это доступно в рамках базового коммерческого продукта — GridGain Professional Edition. Это кодовая база Apache Ignite плюс поддержка и хот-фиксы.
Кроме того, бизнес зачастую предъявляет повышенные требования к безопасности, отказоустойчивости и высокой доступности. Эта функциональность реализована в GridGain Enterprise Edition. Он включает в себя Community Edition плюс набор дополнительных фич: аутентификация и авторизация пользователей (security), репликация данных между дата-центрами (data center replication), возможность обновления версии GridGain без остановки кластера (rolling upgrades), а также утилиты для мониторинга состояния системы.
— С продуктами разобрались, давайте поговорим про техническую составляющую. Как вы ведете R&D?
— Технические обсуждения происходят публично, на dev-листе. Мы ставим задачу, собираем мнения, после чего определяем архитектуру, и конкретный план действий. У каждого компонента есть ментор, который хорошо знает соответствующий функционал. В сложных случаях именно он собирает всё в кучу. Для принятия грамотных решений зачастую приходится работать с литературой и научными публикациями. Иногда готовых ответов просто нет, и ты становишься первопроходцем. Это и делает нашу работу увлекательной.
— А как тестируете код?
— Это многоуровневый процесс. Разработчик пишет код, и покрывает его тестами. Причем, это не только unit-тесты, но и интеграционное тестирование. Ты проверяешь код изолированно, потом на одном узле, на нескольких, моделируешь многопоточность и отказы. Тесты бегают на публичном CI-сервере (TeamCity). Далее код проходит обязательный peer review. Второй частью процесса управляет QA-отдел. Они прогоняют функционал через набор своих тест-кейсов, преимущественно автоматических (Python, Java). В комплексе это позволяет нам удерживать качество на необходимом уровне.
— К вопросу о «любой может внести свой вклад» — есть ощущение, что всё-таки не любой, поскольку проект нерядовой. Какие требования к разработчикам GridGain, и где вы находите людей?
— Действительно, Apache Ignite — наукоёмкий продукт, поэтому фундаментальные знания важны. Начиная с классических алгоритмов, структур данных и многопоточности, и заканчивая принципами создания распределённых систем и внутренним устройством СУБД. Найти человека с такими багажом — задача сложная. Мы это понимаем, поэтому ищем людей с хорошим фундаментом, а подтягиваем до нужного уровня уже в бою. В этом очень помогает открытость процесса. Любой сотрудник может участвовать в архитектурных обсуждениях на dev-листе. В добавок к этому, у нас достаточно плоская организационная структура, все пишут код, что также способствует адаптации.
Алексей Дмитриев (генеральный директор российского отделения / VP of Engineering)
— При взгляде со стороны кажется, что компания GridGain обогнала своё время: когда она появилась, интерес к in-memory computing был куда ниже нынешнего, а вот теперь приходит её время. Согласны ли вы с этим?
— Скорее я бы сказал, что компания пришла ровно в то время, когда рынок был готов для новой технологии. Основателям компании в своё время удалось правильно уловить технологические тенденции и сделать правильные шаги. Поэтому сейчас, когда эта технология очень востребована, компания имеет возможность приходить к своим клиентам с уже готовым и зрелым продуктом.
— Какими вы видите тенденции рынка — ожидаете и дальнейшего бурного роста?
— Объём данных, который необходимо обработать, растёт, а потребность обработать эти данные быстро актуальна сейчас практически для всех крупных компаний как в финансовой сфере, так и в телекоме и в других областях. Наша технология позволяет масштабировать решение практически неограниченно. В данный момент появляются всё более и более быстрые аппаратные решения как для оперативной памяти, так и для диска. Наш проект архитектурно готов к этим новым решениям и их внедрение, безусловно, раскроет нам новые горизонты. Поэтому, да, я ожидаю дальнейшего бурного роста и активности в области распределённых решений, и в частности, вокруг нашего продукта.
— У вас есть крупные клиенты вроде Сбербанка — а ваше решение и подходит гигантам с большими бюджетами, или небольшим компаниям тоже?
— Это решение подходит всем. У Сбербанка очень много данных, поэтому они задействуют коллосальный аппаратный комплекс, чтобы оперировать с такими данными быстро. У небольших компаний, как правило, данных меньше и затраты существенно скромнее. Кроме того, наш продукт сейчас позволяет дифференцировать данные по частоте обращения к ним и держать в оперативной памяти только те, к которым приложения обращаются наиболее часто. Ну и самое главное: наш продукт работает не только на доргих многопроцессорных серверах, но и на простых дешёвых офисных компьютерах. Вам нужно просто подключить их в одну сеть и поставить на них GridGain. Вам не понадобится никакое сверхдорогое специфическое «железо».
— У GridGain любопытные взаимоотношения с Россией: компания американская, но основатели русскоговорящие, разработка во многом ведётся силами российских программистов, а в 2016-м одним из инвесторов и ключевых клиентов стал Сбербанк. Насколько Россия для вас приоритетна и как рынок для продаж, и как место поиска новых кадров?
— GridGain — далеко не первая известная американская компания с русскими основателями. Если вы хотите сделать разработку нового и сложного продукта очень быстро и качественно, то Россия будет на первом месте среди стран, где можно найти инженеров, способных это сделать, причём дешевле, чем в США или Европе. У нас очень сильная инженерная команда в России, и основная разработка ведётся именно здесь. И это не находится в прямой зависимости от того, что Сбербанк — один из наших крупнейших клиентов, хотя и является тут несомненным плюсом.
Сбербанк, на мой взгляд, один из самых динамично развивающихся в сфере ИТ клиентских банков в мире. Он является примером для подражания для многих компаний как в Европе, так и в России. Многие наши потенциальные клиенты в России внимательно смотрят сейчас на нашу совместную работу со Сбербанком, поэтому я думаю, что с точки зрения продаж этот рынок для нас один из самых важных.
Ирина Тищенко (HR-директор)
— GridGain написан на Java — соответственно, и разработчики у вас джависты, или всё хитрее?
— Конечно, ядро продукта — это сотни тысяч строк Java-кода. Но есть нюансы. Например, модули, обеспечивающие интеграцию нашей платформы с C++ и .NET кодом, написаны, соответственно, на этих языках. Наша красноярская команда разрабатывает консоль управления и мониторинга Apache Ignite / GridGain: это приложение создаётся с использованием различных веб-технологий.
Но главное то, что наши сотрудники — талантливые инженеры, обладающие отличной алгоритмической подготовкой. Одна из основных задач development-команды — это performance. Решение задач оптимизации производительности в распределённой многопоточной системе требует очень серьезных ментальных усилий. Поэтому при выборе сотрудников мы, в первую очередь, ориентируемся на их умение думать, а уже потом на конкретные знания.
— Известно, что ещё в 2006-м основатели GridGain подключили к разработке петербуржцев — а в каких городах сейчас у компании ведётся разработка?
Основной офис разработки GridGain по-прежнему находится в Питере. Но Питером, конечно, российская география нашей компании не ограничивается. Так, веб-консоль управления разрабатывается в Красноярске. Московская и новосибирская команды GridGain, несмотря на то, что их спектр функций намного шире, также участвуют в разработке продукта.
Головной офис GridGain неизменно находится в Silicon Valley. И, в целом, учитывая активнейшее развитие нашей компании, мы совершенно смело можем предположить, что GridGain-у понадобятся разработчики и в Западной Европе, и даже в Азии.
— Вдогонку предыдущему: происходит ли релокация между разными городами?
— Конечно! Как следует из предыдущего ответа, для GridGain нет границ! В нашей команде работают ребята практически со всех уголков России и не только России.
Мы с удовольствием помогаем в релокации, и, как я уже сказала, не скованы в ее направлениях.
— Чего GridGain ждёт от участия в JPoint и JBreak? У GridGain есть упоминавшаяся выше сложность «описать продукт в двух словах проблематично» — а конференции, где тему разбирают куда подробнее двух слов, помогают донести до других разработчиков суть проекта?
ignite.apache.org — вместо тысячи слов! 🙂 А если серьёзно, да, нашим ребятам действительно есть, о чём рассказать. И эти события — хороший повод для нашей встречи с теми, кому интересен и полезен опыт команды GridGain, так сказать, из первых уст.
И в Новосибирск, и в Москву мы едем с докладом о масштабируемости распределённых систем и командой наших сотрудников-разработчиков, которые будут рады диалогу с участниками конференций на стенде GridGain. Посему мы надеемся на шквал вопросов. Мы его не боимся, ведь мы привыкли работать в режиме многопоточности 🙂
Новосибирцы уже увидели сегодня упомянутый доклад на JBreak (и увлеклись опросом из буклета компании — ответы на него GridGain опубликуют на следующей неделе в своём хабрааккаунте). А посетителям московской JPoint всё это только предстоит — и пока что в ожидании можно вспомнить доклад Владимира Озерова «(Почти) неблокирующая синхронизация» с прошлогоднего JPoint:
Развёртывание системы GridGain для решения реальной математической задачи
В данной работе рассмотрен вариант использования промежуточного программного обеспечения GridGainдля создания сети распределённой обработки данных и реализации на ней реальной математической задачи обнаружения аномалий во временном ряду.
Ключевые слова:GridGain, MapReduce, In-Memory Data Grid, распределённые вычисления, обнаружение выбросов, контекстные аномалии.
Введение
Распределённые вычисления — способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров, чаще всего объединённых в параллельную вычислительную систему [1]. Распределённые вычисления применимы также в распределённых системах управления.
Последовательные вычисления в распределённых системах выполняются с учётом одновременного решения многих задач. Особенностью распределённых многопроцессорных вычислительных систем, в отличие от локальных суперкомпьютеров, является возможность неограниченного наращивания производительности за счёт масштабирования. Слабосвязанные, гетерогенные вычислительные системы с высокой степенью распределения выделяют в отдельный класс распределённых систем — грид.
Современный уровень развития вычислительной техники и средств удалённого доступа к ней предоставляет значительные возможности при организации распределённой обработки данных, когда для осуществления трудоёмких вычислений привлекаются ресурсы нескольких обособленных высокопроизводительных компьютерных (или суперкомпьютерных) систем. Такой способ решения сложных в вычислительном плане задач имеет целый ряд преимуществ, основными среди которых являются наиболее эффективное использование включённых в распределённую вычислительную систему обобщённых вычислительных ресурсов и постоянный доступ к ним участников консорциума. Научное применение распределённых вычислений очень широко: математика (поиск простых чисел, чисел Фибоначчи), криптография (экспериментальные переборы шифров), биология/биохимия/медицина (поиск лекарств, синтез и анализ белков, исследования генома человека), естественные науки (проверка научных гипотез, моделирование климата и Земли, расчёты и поиск элементарных частиц, обработка сигналов телескопов) [2].
GridGain
GridGain это основанное на Java промежуточное программное обеспечение для обработки внутри памяти больших данных в распределённой среде. Основано на высокопроизводительных платформах данных внутри памяти, в которую интегрирована самая быстрая в мире реализации MapReduce с технологией In-Memory Data Grid, обладающей простотой в использовании и простотой в масштабировании. Используя GridGain можно обработать террабайты данных на тысячи узлов за одну секунду [3]. GridGain является бесплатной реализации MapReduce с открытым исходным кодом на языке Java.
Работа MapReduce состоит из двух шагов: Map и Reduce. На Map-шаге происходит предварительная обработка входных данных. Для этого один из компьютеров (называемый главным узлом — master node) получает входные данные задачи, разделяет их на части и передает другим компьютерам (рабочим узлам — worker node) для предварительной обработки. На Reduce-шаге происходит свёртка предварительно обработанных данных. Главный узел получает ответы от рабочих узлов и на их основе формирует результат — решение задачи, которая изначально формулировалась [4].
Задача In-Memory Data Grid — обеспечить сверхвысокую доступность данных посредством хранения их в оперативной памяти в распределённом состоянии. Современные In-Memory Data Grid способны удовлетворить большинство требований к обработке больших массивов данных [5].
Философия системы GridGain такова, что специалисту необходимо развернуть узлы на некоторых компьютерах, подключённых в сеть, и они автоматически должны найти друг друга и создать топологию. Так же специалист может сам указать на одном узле адрес другого узла в этой сети. Все что необходимо после этого, это создать задачи для этих узлов. Задачи создаются с помощью программ, написанных на JAVA или Scalar (надстройка над Scala). Цель работы данных программ заключается в указании данных и участка кода, который будет их обрабатывать на каждом узле.
Развёртывание и настройка узла
Для развёртывания GridGain в первую очередь необходимо скачать дистрибутив с официального сайта (http://www.gridgain.com/), разархивировать его в любое место на компьютере, задать переменные окружения GRIDGAIN_HOME и JAVA_HOME (пути к папке инсталляции GridGain и виртуальной машины JAVA соответственно). Далее, для проверки, нужно лишь запустить файл \bin\ggstart.bat (в случае, если используется ОС Windows). В данном случае запустится узел GridGain с настройками по умолчанию [6].
Запустив два узла на локальном компьютере или в локальной сети, они обнаружат друг друга и создадут топологию (см. рисунок 1).
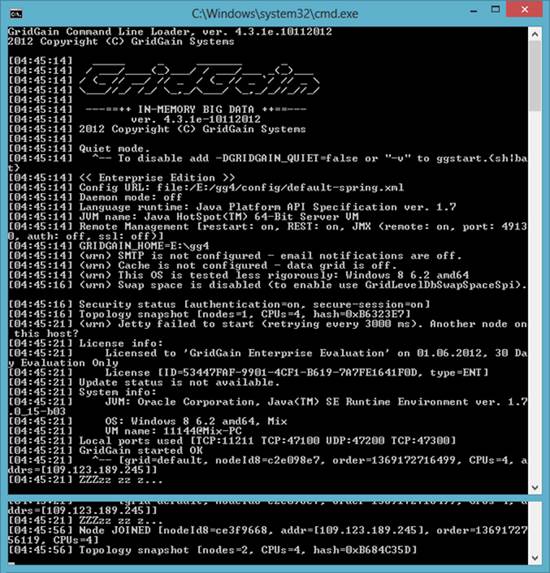
Рис. 1. Результат запуска двух узлов с настройками по умолчанию
Когда запускается GridGain со стандартной конфигурацией, запускается стандартная реализация Service provider interface (IP-multicast обнаружение и основанная на TCP/IP связь). Название сети по умолчанию, «default». Путь к GridGain определяется переменной среды GRIDGAIN_HOME. Многие другие настройки также задаются по умолчанию.
Настройка GridGain осуществляется с помощью интерфейса GridConfiguration. Эта конфигурация применима к методу GridFactory.start(GridConfiguration). Так же возможна настройка с помощью конфигурационных файлов Spring Framework, в частности, если запуск производится с помощью пакетного bat-файла. Стандартный файл настроек расположен по адресу \config\default-spring.xml.
Задача
В качестве задачи для распараллеливания была выбрана задача обнаружения выбросов и аномалий во временном ряду. Таким образом, на вход программе должны подаваться данные каких-либо измерений с течением времени. В результате своей работы, программа должна вывести список единиц входных данных, которые были признаны аномальными.
Аномалии в подобных данных относятся к контекстным аномалиям. Все нормальные экземпляры в контексте будут, в то время как аномалии будут отличаться от других экземпляров в контексте. Общий подход для данной проблемы заключается в идентификации контекста вокруг экземпляра и определении являются ли данный экземпляр аномальным, учитывая контекст. Задачу можно свести к задаче определения точечных аномалий, разбив входные данные на сегменты (по контексту) и применив к ним традиционные критерии определения аномалий [7].
Критерии определения выбросов условно можно разделить на две группы: когда гипотеза о нормальном распределении совокупности верна и когда она неверна. Для задачи поиска контекстных аномалий больше всего подходит второй вариант. В результате анализа MAD-теста и теста Граббса [8, c. 73–77] было установлено, что в общем случае аномальными признаются минимальные/максимальные значения из выборки. Таким образом, был разработан собственный алгоритм нахождения аномалий.
Суть разработанного алгоритма заключается в разделении входных данных на определённые сегменты фиксированной длины. Причём, начало каждого следующего сегмента является следующим к началу предыдущего. Таким образом, сегменты должны пересекаться.
В каждом сегменте выполняется поиск минимального и максимального значения данных. У каждых таких значений в каждом сегменте повышается вес на единицу. Далее, из всех значений аномалиями признаются те, вес которых превышает 75 % от размера сегмента.
Представленный алгоритм хорошо поддаётся распараллеливанию. Так, обработка каждого сегмента может быть распределена. Это позволит повысить скорость обработки.
Программное обеспечение
Согласно выбранной задаче и алгоритму её решения, была разработана программа на языке JAVA. Использовались библиотеки GridGain версии 4.3. Работа программы осуществляется в консольном режиме, так как задача разработки удобного и наглядного пользовательского интерфейса не стояла.
В качестве входных данных был выбран температурные показатели по городу Томску за 2012 год. Архив фактической погоды был взят из открытого источника — сайта «Расписание погоды» (http://rp5.ru/).
Разработанная программа была протестирована как на локальном компьютере, так и на сети компьютеров с запущенными узлами GridGain. Результат работы программного обеспечения приведён на рисунке 2.
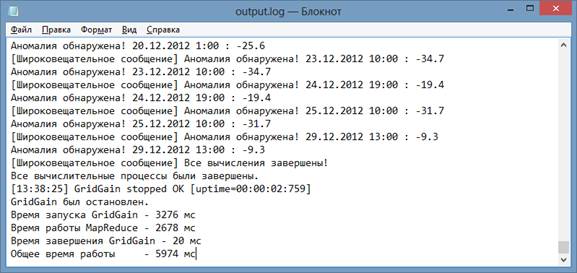
Рис. 2. Результат работы программного обеспечения
Для проведения сравнения также была разработана линейная (без распараллеливания) реализация алгоритма. Разработка велась на языке высокого уровня VB.NET в среде Visual Studio. В качестве входных использовались те же данные, что и в предыдущем примере. Результат работы программы представлен на рисунке 3.
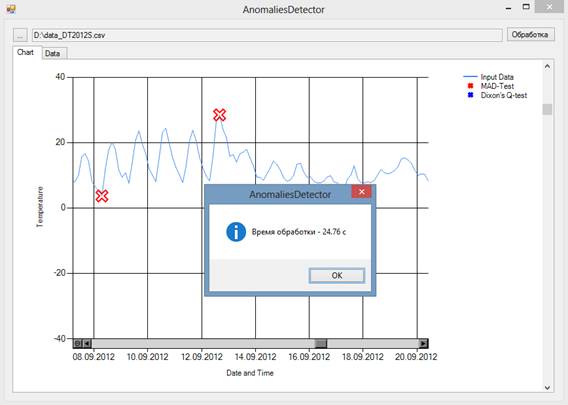
Рис. 3. Результат работы линейной реализации алгоритма
Таким образом, результаты работы двух программ наглядно демонстрируют, что алгоритм работает быстрее, когда обработка данных распределена между узлами.
Заключение
В результате проведённого исследования был проведён обзор системы GridGain и технологии MapReduce, который включает в себя рекомендации и описание установки, развёртывания и тестирования программного продукта. Так же приведена реализация распараллеливания задачи обнаружения аномалий во временном ряду погодных данных при помощи системы GridGain. Работа данной реализации была сравнена с линейной реализацией алгоритма.
Литература:
1. Распределённые вычисления [Электронный ресурс]: Википедия. — США: wikipedia.org, 2013. — Режим доступа: http://ru.wikipedia.org/wiki/Распределённые_вычисления, свободный. — Дата обращения 25.08.2013.
2. В. П. Демкин, А. В. Старченко. Распределённые вычисления: принципы и технологии // Телематика’2009. Труды XVI Всероссийской научно-методической конференции. Том 1. 2009. C. 452
3. GridGain [Электронный ресурс]: Официальный сайт GridGain. — США: gridgain.com, 2013. — Режим доступа: http://www.gridgain.com/, свободный. — Дата обращения 17.05.2013.
4. MapReduce [Электронный ресурс]: Википедия. — США: wikipedia.org, 2013. — Режим доступа: http://ru.wikipedia.org/wiki/MapReduce, свободный. — Дата обращения 25.08.2013.
5. Что такое In-Memory Data Grid [Электронный ресурс]: Хабрахабр. — Россия: habrahabr.ru, 2012. — Режим доступа: http://habrahabr.ru/post/160517/, свободный. — Дата обращения 25.08.2013.
6. Использование Scala и GridGain для разработки распределенных систем с высокой производительностью [Видеозапись, Электронный ресурс]: Интернет архив видеороликов. — Россия: video.yandex.ru, 2011. — Режим доступа: http://video.yandex.ru/users/xpinjection/view/40/, свободный. — Дата обращения 25.08.2013.
7. Data Mining for Anomaly Detection [Видеозапись, Электронный ресурс]: Интернет-ресурс видеолекций. — Россия: videolectures.net, 2008. — Режим доступа: http://videolectures.net/ecmlpkdd08_lazarevic_dmfa/, свободный. — Дата обращения 25.08.2013.
8. В. И. Дворкин «Метрология и обеспечение качества количества химического анализа». — М.: Химия, 2001. — 263 с.
Что читают инженеры GridGain. Книги для тех, кто интересуется In-Memory Computing
Не так давно у нас в корпоративном чате развернулась баталия по поводу бумажных книг и книг вообще. Оказалось, что, несмотря на популярность блогов и обучающих видео, любителей полистать хорошую книгу на читалке, или даже в бумаге, у нас достаточно много. Тем более, к некоторым книгам хочется иногда возвращаться, чтобы уложить всё в голове или поискать решение конкретной задачи.Мы даже составили небольшой список книг, которые нам очень нравятся. Ну и еще это подсказка для собеседований по нашим свеженьким вакансиям, конечно. Не в смысле запомнить пару названий, а в смысле прочитать, разумеется.
Новое
Effective Java (3rd Edition) by Joshua Bloch (2018)
Эта книга до нас еще не дошла в бумажном виде, потому что появилась в продаже только 6 января. Но мы уже заказали её в корпоративную библиотеку. Если вы успеваете за год прочитать только одну книгу про Java, то лучше всего эту.
Designing Data-Intensive Applications by Martin Kleppmann (2017)
Наш чемпион по частоте упоминаний в списке прочитанного (или запланированного к прочтению). Масштабируемость, консистентность, отказоустойчивость, реляционные базы данных, документные, графовые… Книга помогает уложить все эти понятия по полочкам и выбрать нужные инструменты для работы. Уже в январе-феврале выйдет русское издание.
Site Reliability Engineering: How Google Runs Production Systems by Google (2016)
Сборник статей от гугловской команды Site Reliability. Вы точно знаете, что у них это: а) действительно большое, б) работает. Скорее всего, мало кто будет читать сборник от корки до корки, но несколько очень полезных статей тут каждый может найти. В августе книга выйдет на русском языке (спасибо за инфу ph_piter).
Проверенная классика
Systems Performance: Enterprise and the Cloud by Brendan Gregg (2013)
Книга архитектора из Netfix достаточно подробная для новичка и при этом достаточно глубокая, чтобы возвращаться к ней, когда у опытного разработчика возникает затруднение в организации взаимодействии базы данных с ОС или оборудованием.
The Art of Software Testing 3rd edition by Myers and others (2013)
Книга про подход к тестированию. Автор логично предполагает, что человек — слишком целеориентированное (или ленивое) существо, чтобы всерьез ломать продукт, который ему нужно создать. Книга содержит простые примеры подхода к процессу тестирования, написана лёгким языком. По мнению коллег из Q&A несколько ортодоксальна, но имеет смысл прочувствовать предложенный подход, а потом попытаться сделать чуточку больше, чтобы помочь разработчикам своими тестами.
Distributed Algorithms: An Intuitive Approach (MIT Press) by Wan Fokkink (2013)
Книга для погружения в распределенные вычисления. Скорее всего, она займёт место на вашей полке рядом с Корменом или Кнутом — небольшой, но фундаментальный обзор алгоритмов в распределённых сетях. В 2017 книга вышла на русском языке.
The Art of Multiprocessor Programming, Revised Reprint by Maurice Herlihy and Nir Shavit (2012)
Лучшая книга для понимания concurrency. Потому что, во-первых, очень понятно написана, а во-вторых, много примеров алгоритмов.
SQL Performance Explained by Markus Winand (2012)
Книга выросла из постов в блоге, и это до сих пор одна из самых кратких и понятных работ по теме. Описываются принципы, применимые практически к любой SQL-базе.
Introduction to Algorithms, 3rd Edition (MIT Press) by Thomas H. Cormen (Author) and others (2009)
Лучшая книга для погружения в тему, практически энциклопедия. В 2016 вышла на русском языке.
Domain Driven Design by Eric Evans (2008)
Книга о самых общих подходах к проектированию и разработке крупных систем. От применения сформулированных в книге принципов может выиграть практически любой проект.
Java Concurrency in Practice by Brian Goetz and others (2006)
Если есть желание разобраться в том, что такое Java concurrency, начать нужно именно с этой книги.
А вы читаете бумажные книги? Кое-что из списка (и именно в бумажном виде) мы планируем разыграть в этом году на наших митапах в Москве и Петербурге.
Что такое In-Memory Data Grid / Habr
Обработка данных in-memory является довольно широко обсуждаемой темой в последнее время. Многие компании, которые в прошлом не стали бы рассматривать использование in-memory технологий из-за высокой стоимости, сейчас перестраивают архитектуру своих информационных систем, чтобы использовать преимущества быстрой транзакционной обработки данных, предлагаемых данными решениями. Это является следствием стремительного падения стоимости оперативной памяти (RAM), в результате чего становится возможным хранение всего набора операционных данных в памяти, увеличивая скорость их обработки более чем в 1000 раз. In-Memory Compute Grid и In-Memory Data Grid продукты предоставляют необходимые инструменты для построения таких решений.Задача In-Memory Data Grid (IMDG) — обеспечить сверхвысокую доступность данных посредством хранения их в оперативной памяти в распределённом состоянии. Современные IMDG способны удовлетворить большинство требований к обработке больших массивов данных.
Упрощенно, IMDG — это распределённое хранилище объектов, схожее по интерфейсу с обычной многопоточной хэш-таблицей. Вы храните объекты по ключам. Но, в отличие от традиционных систем, в которых ключи и значения ограничены типами данных «массив байт» и «строка», в IMDG Вы можете использовать любой объект из Вашей бизнес-модели в качестве ключа или значения. Это значительно повышет гибкость, позволяя Вам хранить в Data Grid в точности тот объект, с которым работает Ваша бизнес-логика, без дополнительной сериализации/де-сериализации, которую требуют альтернативные технологии. Это также упрощает использование Вашего Data Grid-а, поскольку в большинстве случаев Вы можете работать с распределённым хранилищем данных как с обычной хэш-таблицей. Возможность работать с объектами из бизнес-модели напрямую — одно из основных отличий IMDG от In-Memory баз данных (IMDB). В последнем случае пользователи всё ещё вынуждены осуществлять объектно-реляционное отображение (Object-To-Relational Mapping), которое, как правило, приводит к значительному снижению производительности.
Есть и другие функциональные особенности, которые отличают IMDG от других продуктов, таких как IMDB, NoSql или NewSql базы данных. Одна из основных — по-настоящему масштабируемое секционирование данных (Data Partitioning) в кластере. IMDG по сути представляет собой распределённую хэш-таблицу, где каждый ключ хранится на строго определённом сервере в кластере. Чем больше кластер, тем больше данных можно в нем хранить. Принципиально важным в этой архитектуре является то, что обработку данных следует производить на том же сервере, где они расположены (локально), исключая (или сводя к минимуму) их перемещение по кластеру. Фактически, при использовании хорошо спроектированного IMDG, перемещение данных будет полностью отсутствовать за исключением случаев, когда в кластер добавляются новые сервера или удаляются существующие, меняя тем самым топологию кластера и распределение данных в нем.
Нижеприведённая схема показывает классический IMDG с набором ключей {k1, k2, k3}, в котором каждый ключ принадлежит отдельному серверу. Внешняя база данных не является обязательной. Если она присутствует, IMDG, как правило, будет автоматически читать данные из базы или записывать их в нее.
Ещё одной отличительной особенностью IMDG является поддержка транзакционности, удовлетворяющей требованиям ACID (atomicity, consistency, isolation, durability — атомарность, целостность, изоляция, сохранность). Как правило, чтобы гарантировать целостность данных в кластере, используют двухфазную фиксацию (2-phase-commit или 2PC). Разные IMDG могут иметь разные механизмы блокировок, но наиболее продвинутые реализации обычно используют параллельные блокировки (например, GridGain использует MVCC — multi-version concurrency control, управление конкурентным доступом с помощью многоверсионности), сводя тем самым сетевой обмен к минимуму, и гарантируя транзакционную целостность ACID с сохранением высокой производительности.
Целостность данных является одним из главных отличий IMDG от NoSQL баз данных. NoSQL базы данных, в большинстве случаев, спроектированы с использованием подхода, называемого “целостность в конечном итоге” (Eventual Consistency, EC), при котором данные могут некоторое время находиться в несогласованном состоянии, но обязательно станут согласованными *со временем*. В целом, операции записи в EC системах происходят достаточно быстро по сравнению с более медленными операциями чтения (точнее, не превосходящими по скорости операции записи). Последние IMDG с *оптимизированным* 2PC как минимум соответствуют EC системам по скорости записи (если не опережают их), и значительно превосходят их по скорости чтения. Интересно, что индустрия сделала полный круг, двигаясь от тогда ещё медленных 2PC к EC, а теперь от EC к гораздо более быстрым *оптимизированным* 2PC.
Разные продукты могут предлагать разные 2PC оптимизации, но в целом задачами всех оптимизаций являются увеличение параллелизма (concurrency), минимизация сетевого обмена и снижение числа блокировок, требуемых для совершения транзакции. Например, распределённая глобальная база данных Spanner компании Google основана на транзакционном 2PC подходе просто потому, что 2PC предоставил более быстрый и простой способ гарантировать целостность данных и высокую пропускную способность в сравнении с MapReduce или EC.
Даже несмотря на то, что у разных IMDG обычно много общих базовых функциональных возможностей, существует множество дополнительных возможностей и деталей реализации, которые отличаются в зависимости от производителя. Оценивая IMDG продукт, обращайте внимание на механизмы выгрузки данных при переполнении (eviction policies), техники загрузки данных, в том числе, при старте сервера ((pre)loading techniques), параллельное секционирование (concurrent repartitioning), объём дополнительной памяти, требуемый для хранения записей (data overhead), и тому подобное. Также, обращайте внимание на возможность делать запросы (query) в кэш во время выполнения. Некоторые IMDG, например, GridGain, позволяют пользователям осуществлять запросы к данным, хранящимся в памяти, используя обычный SQL с поддержкой распределённых join-ов (distributed joins), что является довольно большой редкостью.
Хранение данных в IMDG — это лишь половина функциональности, требуемой для in-memory архитектуры. Данные, хранимые в IMDG, также должны обрабатываться параллельно и с высокой скоростью. Типичная in-memory архитектура секционирует данные в кластере с помощью IMDG, и затем исполняемый код отправляется именно на те сервера, где находятся требуемые ему данные. Поскольку исполняемый код (вычислительная задача) обычно является частью вычислительных кластеров (Compute Grids), и должен быть правильно развернут (deployment), сбалансирован по нагрузке (load-balancing), обладать отказоустойчивостью (fail-over), а также иметь возможность запуска по расписанию (scheduling), интеграция между Compute Grid и IMDG очень важна. Наибольший эффект можно получить, если IMDG и Compute Grid являются частями одного и того же продукта и используют одни и те же API. Это снимает с разработчика бремя интеграции и обычно позволяет достигнуть наибольшей производительности и надёжности in-memory решения.
IMDG (вместе с Compute Grid) находят свое применение во многих областях, таких как анализ рисков (Risk Analytics), торговые системы (Trading Systems), системы реального времени для борьбы с мошенничеством (Fraud Detection), биометрика (Biometrics), электронная коммерция (eCommerce), онлайн-игры (Online Gaming). По сути, любой продукт, перед которым стоят проблемы масштабируемости и производительности, может выиграть от использования In-Memory Processing и IMDG архитектуры.
где поговорить про распределенные СУБД, In-Memory и open source / GridGain corporate blog / Habr
Если 8 и 9 ноября вы будете на конференции Highload++, это отличный повод для встречи. Оба дня на стенде GridGain (А4) будут присутствовать архитекторы и разработчики, которе ответят на любые вопросы про Apache Ignite и GridgGain. Кроме разговоров и стикеров на стенде можно принять участие в небольшом исследовании. Каждый вечер в 18:15 между ответившими на вопросы будут разыграны полезные книги. А также у нас запланированы 1 доклад, 2 митапа и 1 мини-батл.Присоединяйтесь!
8 ноября
11:00 — комната А.16, митап
Вова Озеров Тестирование распределенных систем на примере Apache IgniteЧто обсуждаемСоздавать новые фичи весело. Но как их протестировать, если ваш продукт — распределенная система, а реальная эксплуатация — это множество ядер и дисков на разных физических серверах, сетевое взаимодействие, отказы оборудования и непредсказуемые действия пользователя?
Расскажем, как происходит тестирование нового функционала Apache Ignite, что мы делаем хорошо, а что не очень:
— почему налегаем на интеграционные тесты, и не очень жалуем unit-ы, mock-и и XP?
— тестирование многопоточных и распределенных алгоритмов
— создание тестового плана и code review
— где мы чаще всего прокалываемся?
15:00 — комната А.13 мини-батл
Любовь, деньги и open source
Мы начнем, а вы присоединяйтесь.
Со стороны open source: Дмитрий Павлов, Apache Ignite Community Manager
Со стороны бизнеса: Станислав Лукьянов из GridGain Customer Success
9 ноября
11:00 — комната А.16, митап
Стас Лукьянов: Release process, или как донести багфикс до пользователяЧто обсуждаемМожно без конца добавлять функционал и исправлять баги в продукте, но всё это не имеет смысла, если новая версия не попадёт к пользователю. И для выпуска новой версии далеко не всегда достаточно всего лишь запустить сборку и тесты. А для выпуск версии — совсем не то же самое, что запуск сборки.
Что делать, если нужно поддерживать много версий продукта? Как сделать так, чтобы переход пользователя с одной версии на другую прошёл без сюрпризов? И при чём здесь open source?
Поговорим о том, какой путь изменения проходят от письма пользователя в customer support до получения им заветной версии с исправлением.
14:00 — зал Шанхай-Пекин, доклад
Иван Раков: Как снять бэкап в распределенной системе, чтобы этого никто не заметил
Отсутствие возможности создания бэкапов распределенной системы в подобных масштабах было камнем преткновения для практического использования нашей платформы крупным бизнесом. Из доклада вы узнаете, как нам удалось ликвидировать этот пробел.
Нам пришлось научиться:
— делать бэкап данных, не останавливая работу пользователя;
— делать данные в бэкапе распределенной системы консистентными и транзакционно целостными;
— делать процедуры создания и восстановления бэкапа устойчивыми к изменению топологии с помощью распределенного конечного автомата;
— реализовать инкрементальные бэкапы, занимающие на порядок меньше места;
— восстанавливать старые бэкапы данных, созданные на существенно отличающейся топологии кластера.
14 ноября Apache Ignite митап в Москве
На очередной встрече сообщества обсудим бенчмарки, что делать с нестабильными тестами и как пилят major features в опенсорсе на примере Transparent Data Encryption в Apache Ignite.
Программа и регистрация
Разворачиваем GridGain кластер на AWS через AWS Marketplace: Часть I
Денис Баталов, архитектор AWS, @dbatalov
Друзья, рад представить вашему вниманию первую часть из серии гостевых постов от коллег из компании GridGain! Платформа GridGain – это современное и технически интересное решение по созданию сверх-производительных распределённых баз данных с реляционным интерфейсом, работающих в основном в оперативной памяти.
Для справки немного о самой компании. GridGain Systems – калифорнийский стартап, который дорос до серьезной и быстрорастущей международной компании с клиентами по всему миру. Среди клиентов GridGain можно встретить таких именитых мастодонтов, как Сбербанк, Barclays, American Express, Microsoft, IBM, Huawei, RingCentral и Workday. Все они тем или иным образом используют GridGain In-Memory Data Fabric – платформу и фреймворк, который представляет из себя распределенное memory-first хранилище и вычислительную систему, масштабируемую горизонтально и дающую колоссальный прирост производительности, благодаря своей архитектуре.
Платформа находит применение во всех отраслях и секторах, начиная от финансового, заканчивая cферой Интернета Вещей. Такая широкая область применения обусловлена обилием компонент, работающих поверх распределенного хранилища данных (таких как распределенный ANSI-99 SQL движок), поддержкой распределенных ACID транзакции, real-time streaming, machine learning и многим другим.
В этой серии статей Денис Магда расскажет о том, как начать работу с GridGain кластером на AWS и доходчиво объяснит, как этот зверь работает “под капотом”.
Денис Магда, GridGain Product Manager
В наше время, когда объемы хранимой и обрабатываемой информации разрастаются с небывалой скоростью, уже нелегко опираться на хранилища и платформы, которые проектировались и создавались совершенно для иных целей. Не каждая компания может позволить себе переход на очередной мэйнфрейм, если необходимо сохранить производительность при колоссально возросших объемах данных, хранимых в классической реляционной базе данных. Более того, зачастую, обновление железа выливается в своего рода временную пилюлю или инъекцию: мы вкладываем огромные деньги на обновление, но получаем непропорциональный прирост производительность и, более того, понимаем, что в скором времени снова упрёмся в потолок и железо, на котором работает СУБД, придется обновлять вновь.
Данный вызов нашего времени породил определенное число распределенных реляционных баз данных, NoSQL хранилищ и Data Grids, которые воплощают в жизнь концепцию горизонтального масштабирования: хранение и обработка данных происходит в кластере состоящего из N-го кол-ва машин, и, если необходимо увеличить производительность при возросшем объеме данных, то достаточно добавить новый узел в кластер, работающий на обычном железе.
GridGain In-Memory Data Fabric – как раз та платформа, которая позволяет организовать хранение данных в RAM (с опциональной возможностью хранение данных на диске) в распределенном кластере машин, ускоряя работу приложений в десятки, сотни, тысячи раз. Платформа построена на базе open source проекта Apache Ignite In-Memory Data Fabric и состоит из множества компонент, позволяющих выполнять распределенные ANSI-99 SQL запросы и транзакции, соответствующие ACID семантике, запускать распределленные вычисление и обрабатывать потоки данных в режиме реального времени, разворачивать микросервисы и многое другое.
Благодаря тому, что GridGain – это распределенное хранилище и вычислительная платформа, продукт находит применение во множестве отраслей и индустрий, таких как телекоммуникации, финансовый сектор, интернет вещей, ритейл. На базе GridGain работают критические продукты Barclays, Сбербанк, RingCentral, Silver Spring Networks и многих других компаний, которые смогли достичь колоссального прироста производительности благодаря горизонтальному масштабированию GridGain. С некоторыми вариантами использования можно ознакомиться на данной странице.
Что касается развертывания GridGain-кластера, то его можно с легкостью запустить на собственном железе, в облаке, либо в контейнерах. В данной статье мы узнаем, как можно быстро развернуть GridGain в AWS облаке, используя AWS Marketplace и начать использовать его в тестовых целях.
Установка GridGain через AWS Marketplace
GridGain Enterprise Edition можно развернуть на AWS, минуя AWS Marketplace, но мы хотим сделать это наиболее быстрым для нас способом, следуя подготовленной инструкции.
В соответствии с инструкцией, перейдем в AWS Marketplace и введем GridGain в строку поиска или можно сразу же перейти по следующей ссылке:
Нажимаем на “Continue” и, пользуясь “1-Click Launch” опцией, выбираем любую из доступных EC2 виртуальных машин, к примеру, m3.medium:
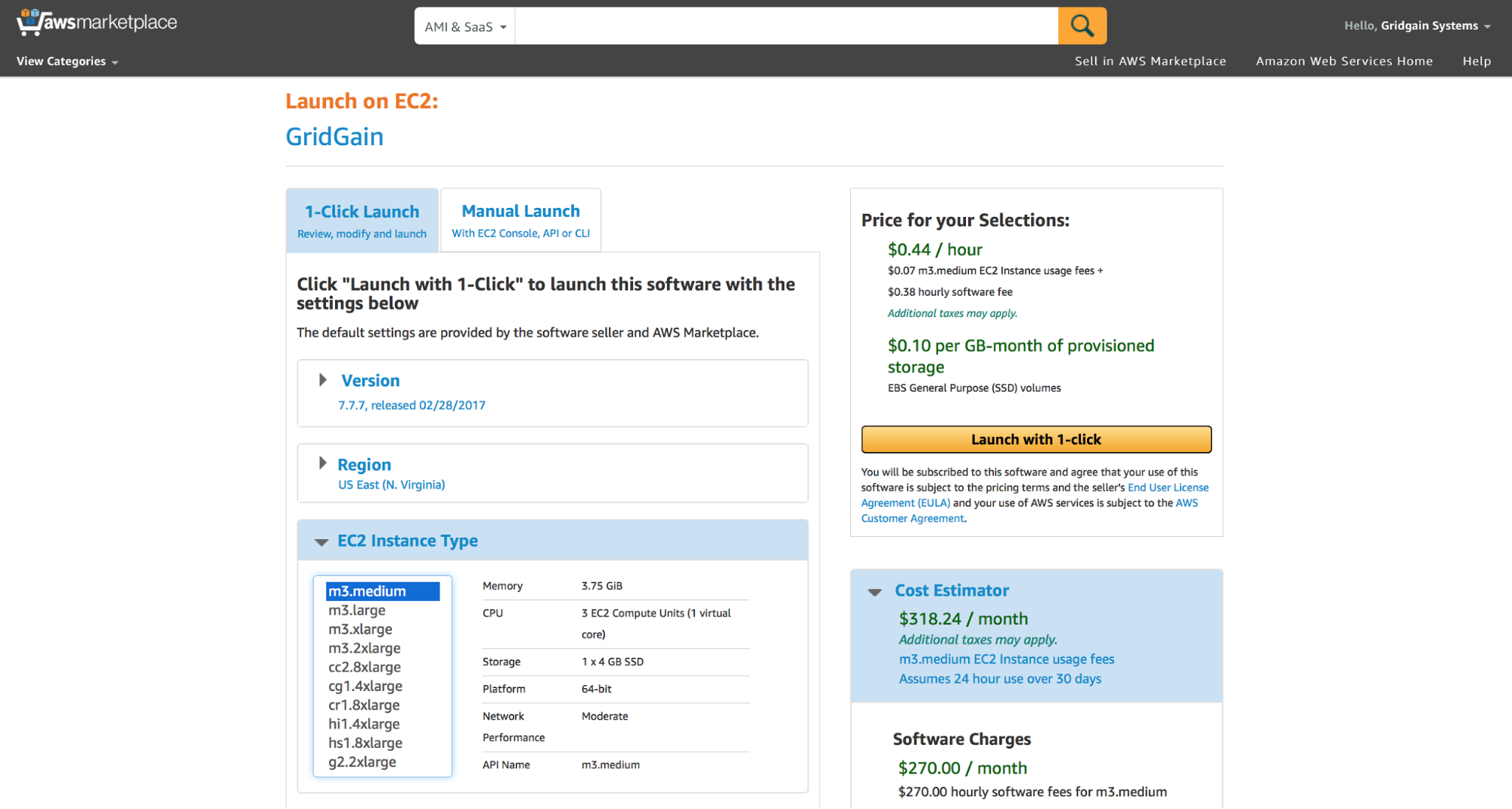
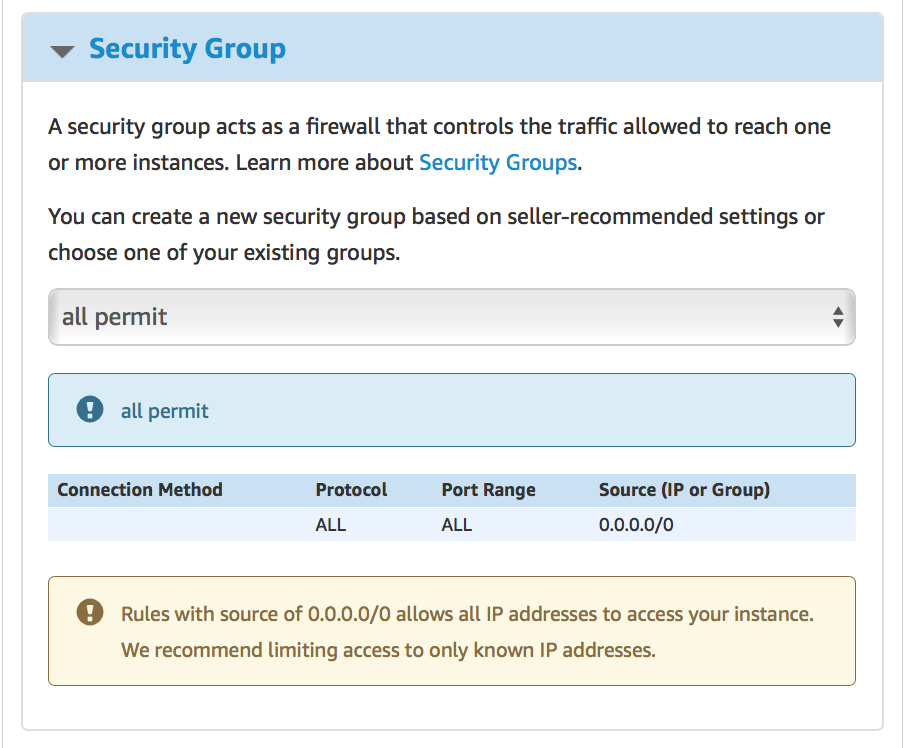
GridGain узлы, которые будут входить в состав кластера взаимодействуют друг с другом через определенные TCP/IP порты на уровне discovery и communication сетевых компонент. В демонстрационных целях мы откроем все порты для наших AWS-узлов через группу безопасности (“Security Group”):
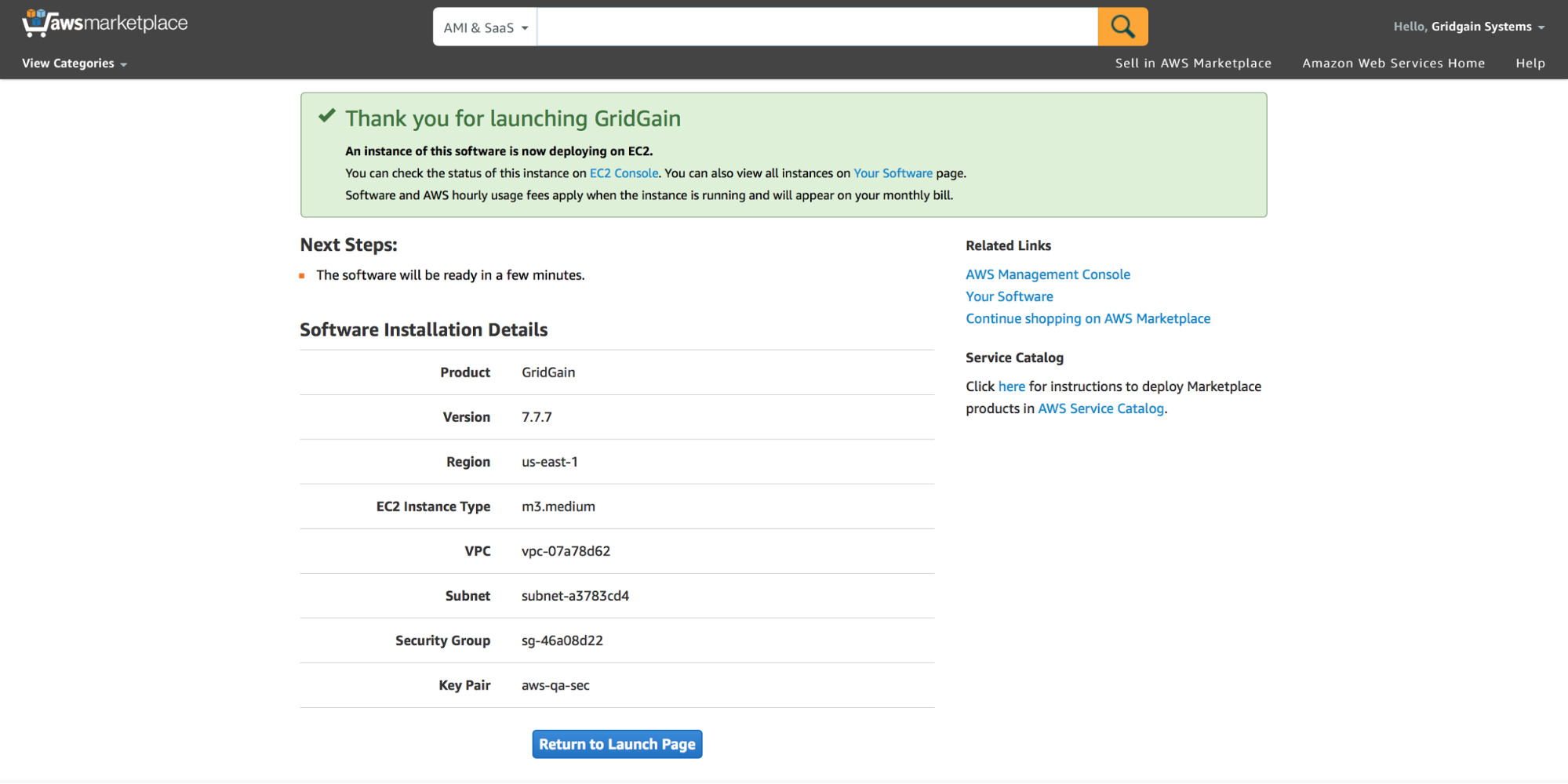
При необходимости настраиваем иные параметры и нажимаем на “Launch with 1-Click”:
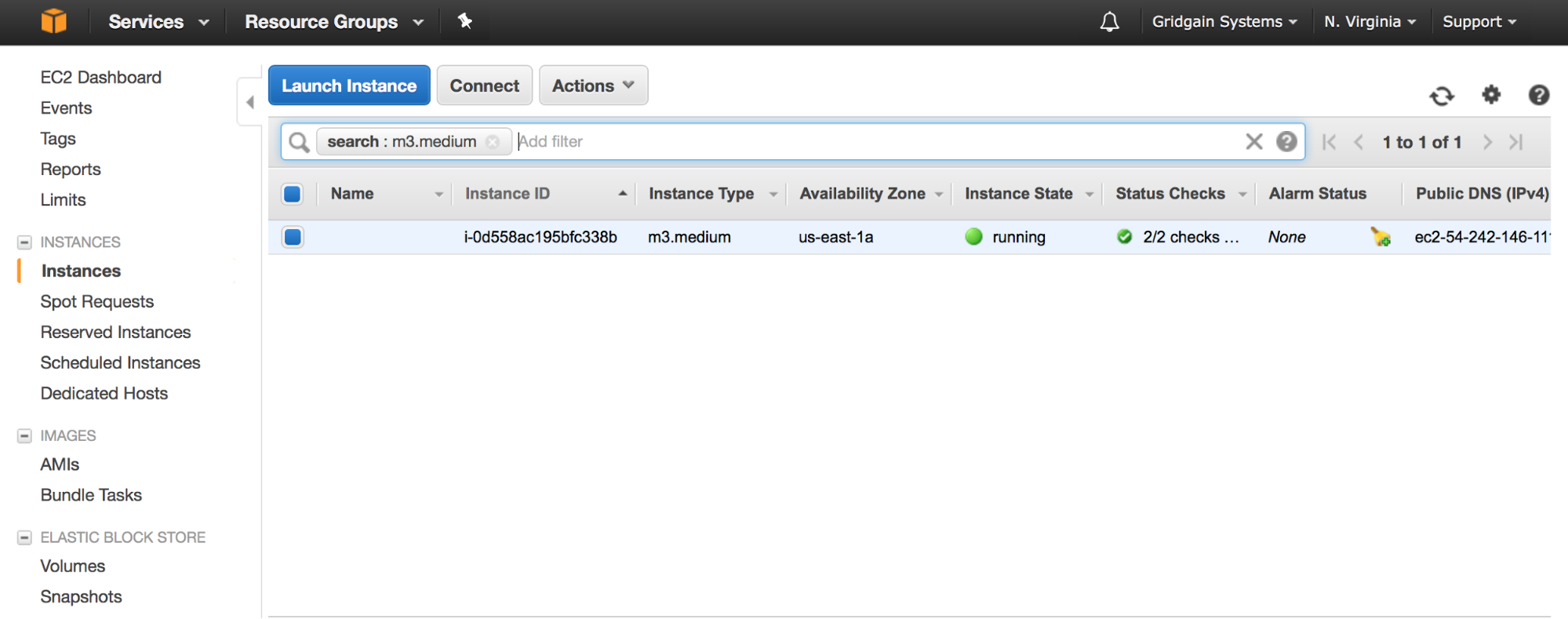
Переходим в EC2 Console и проверяем, что виртуальная машина была успешно запущена:
Запуск GridGain-кластера на AWS
В качестве следующего шага, нам необходимо подключиться к виртуальной машине и запустить GridGain-узлы, которые, соединяясь друг с другом, в итоге формируют распределенный кластер.
Подключаемся к AWS через ssh, используя ключ и DNS имя виртуальной машины:
ssh -i "dmagda.pem" [email protected]
В случае отсутствия ранее созданного ключа для SSH доступа к виртуальной машине EC2, такой ключ нужно создать следуя инструкции.
Проставляем следующие переменные окружения:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk.x86_64
export IGNITE_HOME=/usr/local/bin/gridgain/gridgain-enterprise-fabric-7.7.7
export GRIDGAIN_HOME=${IGNITE_HOME}
Примечание: версия GridGain и Java может отличаться в вашем окружении. В результате чего, значение переменных окружения JAVA_HOME и IGNITE_HOME может быть иным.
Переходим в bin-каталог GRIDGAIN_HOME:
cd ${GRIDGAIN_HOME}/bin
Выполняем скрипт ignite-amazonaws-example.sh, который запустит GridGain-узел в собственном JVM-процессе:
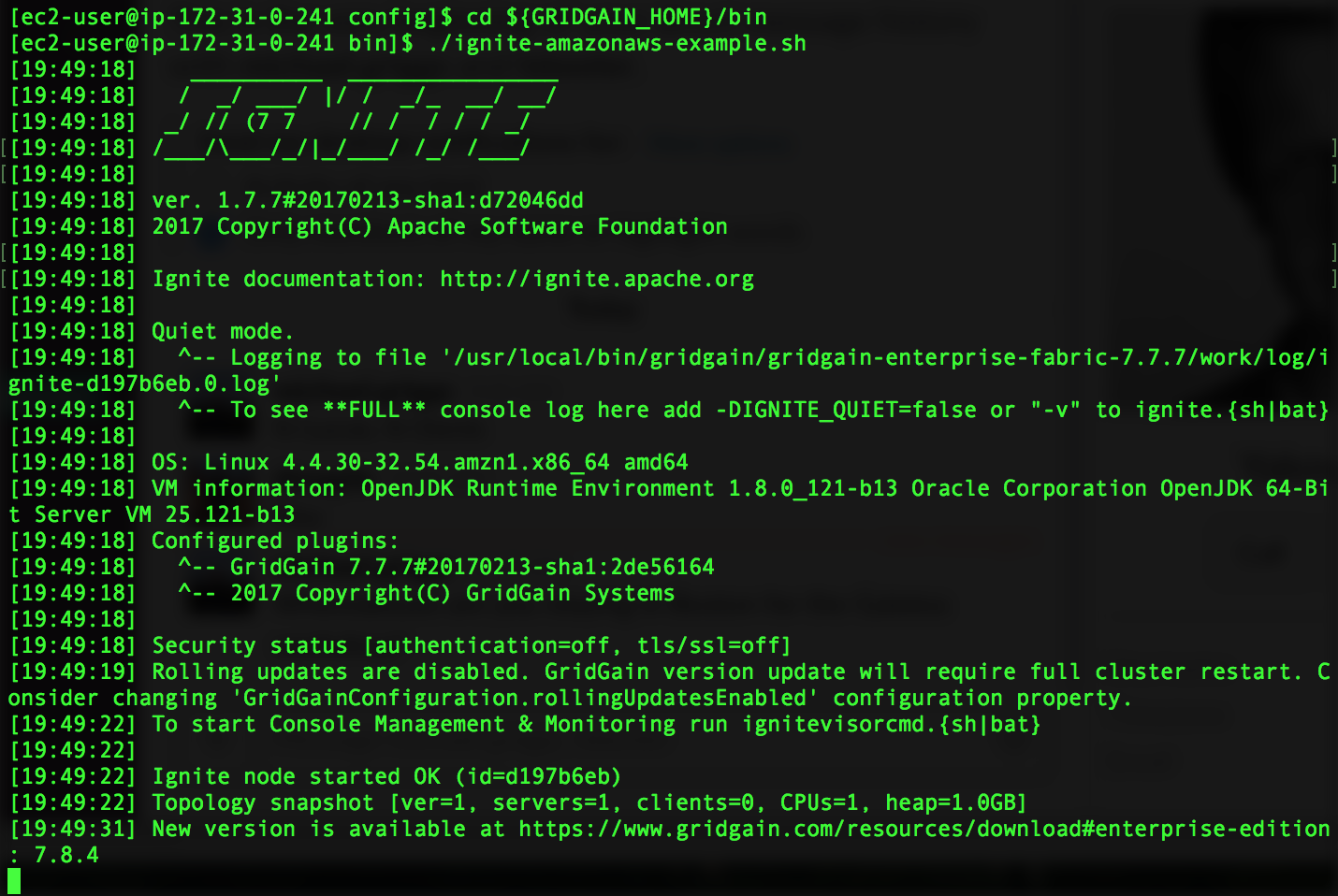
Давайте переведем данный процесс из foreground в background, нажав Ctr+Z и выполнив команду bg. После этого запустим еще один GridGain-узел на той же AWS виртуальной машине с помощью ignite-amazonaws-example.sh:
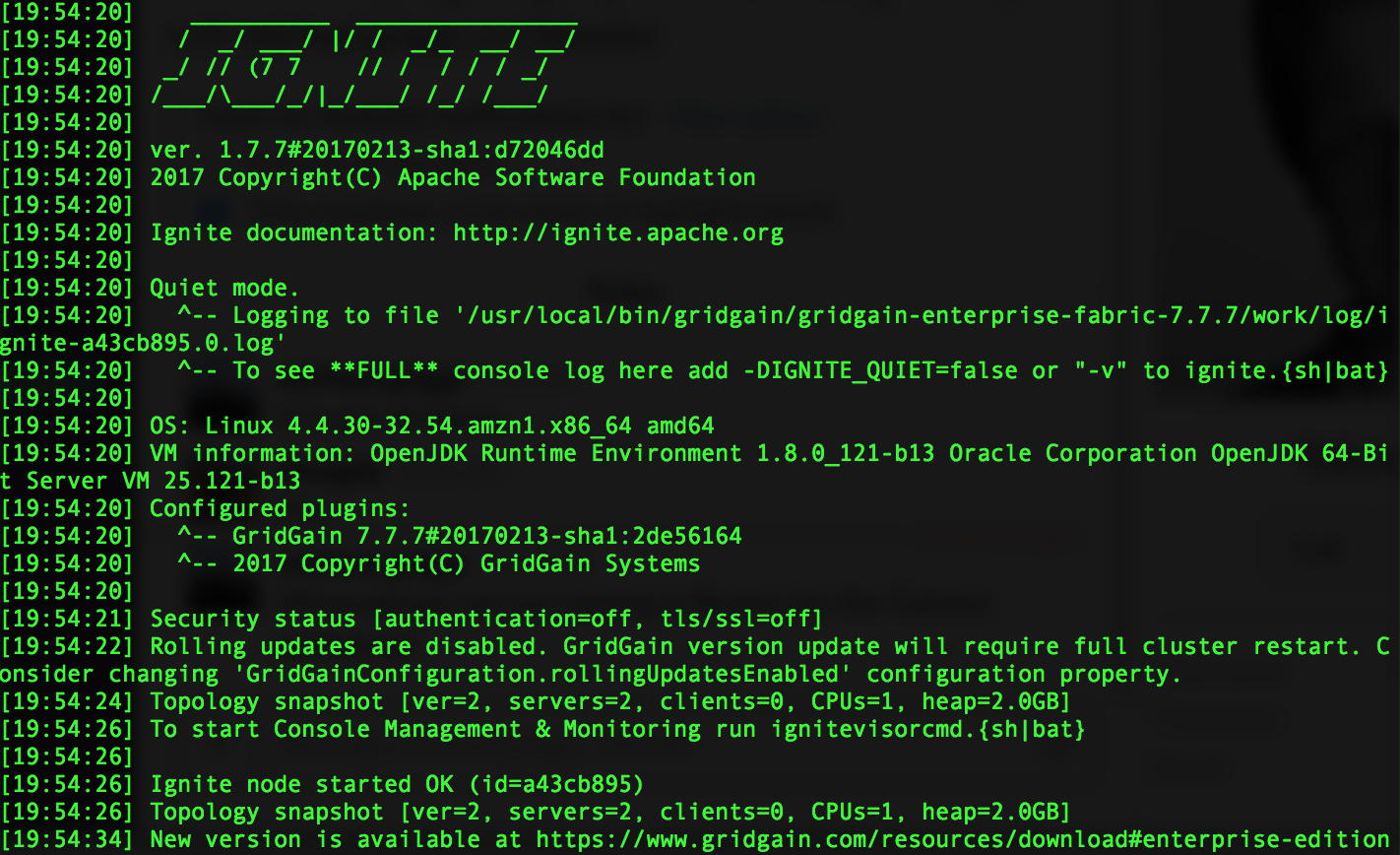
Посмотрев на лог данного узла, мы заметим, что параметр “Topology snapshot” теперь равен 2. Это говорит о том, что мы смогли запустить GridGain-кластер из двух узлов на одной AWS виртуальной машине.
Продолжение следует…
Затратив буквально 5 минут нашего времени, нам удалось запустить кластер GridGain в AWS облаке, используя AWS Marketplace. В следующих постах мы покажем, как запустить кластер на нескольких AWS виртуальных машинах, а также, как подключиться к нему со стороны окружения разработчика, загрузить в него данные и позапускать разного рода приложения, которые будут взаимодействовать с кластером.