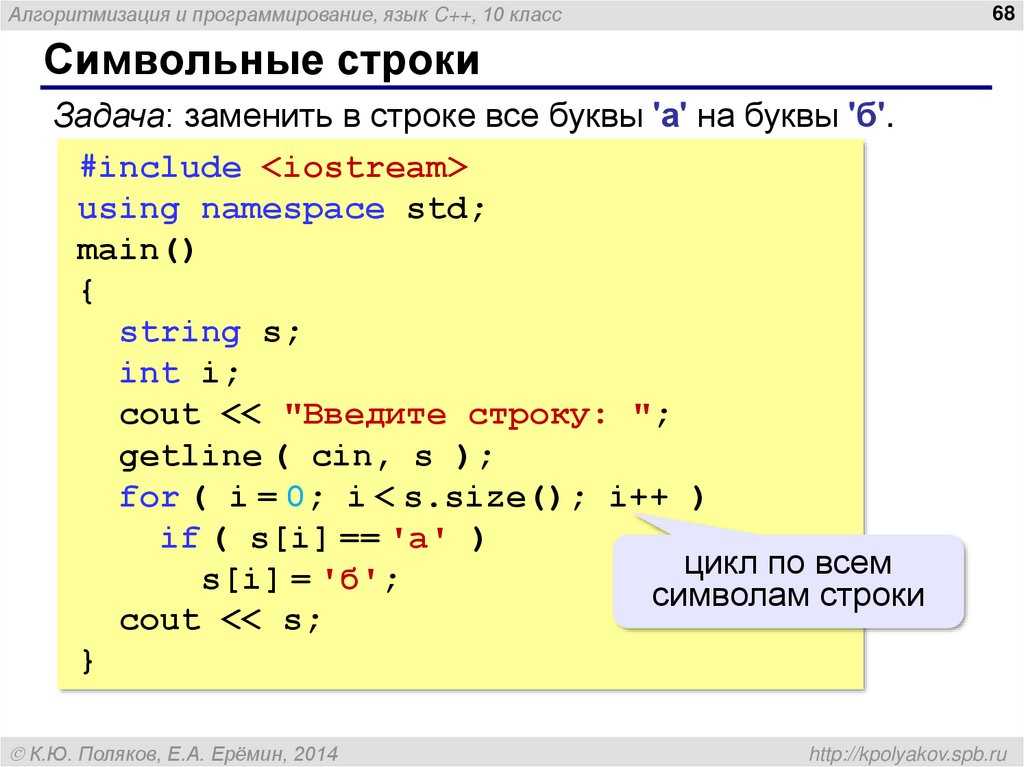
String | JavaScript справочник
| Метод | Описание | Chrome | Firefox | Opera | Safari | IExplorer | Edge |
|---|---|---|---|---|---|---|---|
| charAt() | Возвращает символ по заданному индексу внутри строки. | Да | Да | Да | Да | Да | Да |
| charCodeAt() | Возвращает числовое значение символа по указанному индексу в стандарте кодирования символов Unicode (Юникод). | Да | Да | Да | Да | Да | Да |
| codePointAt() | Возвращает неотрицательное целое число, являющееся значением кодовой точки в стандарте кодирования символов Unicode (Юникод). | 41.0 | 29.0 | 28.0 | 10.0 | Нет | Да |
| concat() | Используется для объединения двух, или более строк в одну, при этом метод не изменяет существующие строки, а возвращает новую строку. |
Да | Да | Да | Да | Да | Да |
| endsWith() | Определяет, совпадает ли конец данной строки с указанной строкой, или символом, возвращая при этом логическое значение. | 41.0 | 17.0 | 28.0 | 9.0 | Нет | Да |
| fromCharCode() | Преобразует значение или значения кодовых точек в стандарте кодирования символов UTF-16 (Юникод) в символы и возвращает строковое значение. | Да | Да | Да | Да | Да | Да |
| fromCodePoint() | Преобразует значение или значения кодовых точек в стандарте кодирования символов Юникод в символы и возвращает строковое значение. Позволяет работать со значениями выше 65535. | 41.0 | 29.0 | 28.0 | 10.0 | Нет | Да |
| includes() | Определяет, содержится ли одна строка внутри другой строки, возвращая при этом логическое значение. |
41.0 | 40.0* | 28.0 | 9.0 | Нет | Да |
| indexOf() | Возвращает позицию первого найденного вхождения указанного значения в строке. | Да | Да | Да | Да | Да | Да |
| lastIndexOf() | Возвращает позицию последнего найденного вхождения указанного значения в строке. | Да | Да | Да | Да | Да | Да |
| localeCompare() | Сравнивает две строки и определяет являются ли они эквивалентными в текущем языковом стандарте. | Да | Да | Да | Да | Да | |
| match() | Производит поиск по заданной строке с использованием регулярного выражения (глобальный объект RegExp) и возвращает массив, содержащий результаты этого поиска. |
Да | Да | Да | Да | Да | Да |
| normalize() | Возвращает форму нормализации в стандарте кодирования символов Unicode (Юникод) для указанной строки. | 34.0 | 31.0 | Да | 10.0 | Нет | Да |
| padEnd() | Позволяет дополнить текущую строку, начиная с её конца (справа) с помощью пробельного символа (по умолчанию), или заданной строкой, таким образом чтобы результирующая строка достигла заданной длины. | 57.0 | 48.0 | 44.0 | 10.0 | Нет | 15.0 |
| padStart() | Позволяет дополнить текущую строку, начиная с её начала (слева) с помощью пробельного символа (по умолчанию), или заданной строкой, таким образом чтобы результирующая строка достигла заданной длины. | 57.0 | 48.0 | 44.0 | 10.0 | Нет | 15.0 |
| raw() | Возвращает необработанную строковую форму строки шаблона. |
41.0 | 34.0 | 28.0 | 10.0 | Нет | Да |
| repeat() | Возвращает новый строковый объект, который содержит указанное количество соединённых вместе копий строки на которой был вызван метод. | 41.0 | 24.0 | 28.0 | 9.0 | Нет | Да |
| replace() | Выполняет внутри строки поиск с использованием регулярного выражения (объект RegExp), или строкового значения и возвращает новую строку, в которой будут заменены найденные значения. | Да | Да | Да | Да | Да | Да |
| search() | Выполняет поиск первого соответствия (сопоставления) регулярному выражению (объект RegExp) внутри строки. | Да | Да | Да | Да | Да | Да |
| slice() | Позволяет возвратить новую строку, которая содержит копии символов, вырезанных из исходной строки. | Да | Да | Да | Да | Да | Да |
| split() | Позволяет разбить строки на массив подстрок, используя заданную строку разделитель для определения места разбиения. |
Да | Да | Да | Да | Да | Да |
| startsWith() | Определяет, совпадает ли начало данной строки с указанной строкой, или символом, возвращая при этом логическое значение. | 41.0 | 17.0 | 28.0 | 9.0 | Нет | Да |
| substr() | Позволяет извлечь из строки определенное количество символов, начиная с заданного индекса. | Да | Да | Да | Да | Да | Да |
| substring() | Позволяет извлечь символы из строки (подстроку) между двумя заданными индексами, или от определенного индекса до конца строки. | Да | Да | Да | Да | Да | Да |
| toLocaleLowerCase() | Преобразует строку в строчные буквы (нижний регистр) с учетом текущего языкового стандарта. | Да | Да | Да | Да | Да | Да |
| toLocaleUpperCase() | Преобразует строку в заглавные буквы (верхний регистр) с учетом текущего языкового стандарта. |
Да | Да | Да | Да | Да | Да |
| toLowerCase() | Преобразует строку в строчные буквы (нижний регистр). | Да | Да | Да | Да | Да | Да |
| toString() | Возвращает значение строкового объекта. | Да | Да | Да | Да | Да | Да |
| toUpperCase() | Преобразует строку в заглавные буквы (верхний регистр). | Да | Да | Да | Да | Да | Да |
| trim() | Позволяет удалить пробелы с обоих концов строки. | Да | Да | Да | Да | 9.0 | Да |
| valueOf() | Возвращает примитивное значение строкового объекта в виде строкового типа данных. | Да | Да | Да | Да | Да | Да |
Обёртка String — JavaScript — Дока
Кратко
Секция статьи «Кратко»String — это обёртка над примитивным строковым типом, которая содержит дополнительные методы работы со строками:
- поиска по строке;
- строковых преобразований;
- получения отдельных символов.

Строки автоматически оборачиваются в обёртку String при вызове методов над ними.
Как пишется
Секция статьи «Как пишется»Обернуть строку в String можно вручную, вызвав конструктор new :
const primitive = 'приветики'const str = new String('приветики')
const primitive = 'приветики'
const str = new String('приветики')
В этом случае переменные primitive и str будут разных типов:
console.log(typeof primitive)// stringconsole.log(typeof str)// objectconsole.log(str == 'приветики')// true, при приведении к строке значения будут одинаковымиconsole.log(str === 'приветики')// false, потому что разные типы данных
console.log(typeof primitive)
// string
console.log(typeof str)
// object
console.log(str == 'приветики')
// true, при приведении к строке значения будут одинаковыми
console. log(str === 'приветики')
// false, потому что разные типы данных
Если вызывать методы String на примитиве, JavaScript автоматически обернёт его в обёртку:
const primitive = 'привет!'console.log(primitive.toUpperCase())// ПРИВЕТ!
const primitive = 'привет!'
console.log(primitive.toUpperCase())
// ПРИВЕТ!
Как понять
Секция статьи «Как понять»Обычно в JavaScript работают с примитивным строковым типом. Например, const str .
Обёртка содержит дополнительные методы для работы со строками. Они не входят в стандарт типа данных «строка» и поэтому выделены в отдельный модуль.
Обёртка используется автоматически и не требует дополнительной работы от программиста. JavaScript сам оборачивает строку, когда программист вызывает метод, находящийся в обёртке.
Смена регистра
Секция статьи «Смена регистра»Для приведения всех символов строки к нижнему регистру используется метод to, а для приведения к верхнему — to:
const lowercased = 'СОБАКА'.const lowercased = 'СОБАКА'.toLowerCase() console.log(lowercased) // собака const uppercased = 'котик'.toUpperCase() console.log(uppercased) // КОТИК
 toLowerCase()console.log(lowercased)// собакаconst uppercased = 'котик'.toUpperCase()console.log(uppercased)// КОТИК
toLowerCase()console.log(lowercased)// собакаconst uppercased = 'котик'.toUpperCase()console.log(uppercased)// КОТИК
Это пригодится для нормализации текста, чтобы сравнивать результаты текстового ввода без учёта регистра:
Открыть демо в новой вкладкеПоиск подстроки
Секция статьи «Поиск подстроки»Для поиска одной строки внутри другой существует целый набор методов:
1️⃣
includes() Секция статьи «1️⃣ includes()»includes принимает аргументом строку, которую нужно найти. Возвращает true, если строка нашлась и false — если нет.
const phrase = 'мама мыла раму'console.log(phrase.includes('мы'))// trueconsole.log(phrase.includes('тикток'))// false
const phrase = 'мама мыла раму'
console. log(phrase.includes('мы'))
// true
console.log(phrase.includes('тикток'))
// false
 log(phrase.includes('мы'))
// true
console.log(phrase.includes('тикток'))
// false
log(phrase.includes('мы'))
// true
console.log(phrase.includes('тикток'))
// false
2️⃣
startsWith() Секция статьи «2️⃣ startsWith()»starts принимает аргументом строку, которую нужно найти. Возвращает true, если текущая строка начинается с искомой и false — если нет.
const phrase = 'папа мыл ногу'console.log(phrase.startsWith('па'))// trueconsole.log(phrase.startsWith('мыл'))// falseconsole.log(phrase.startsWith('тикток'))// false
const phrase = 'папа мыл ногу'
console.log(phrase.startsWith('па'))
// true
console.log(phrase.startsWith('мыл'))
// false
console.log(phrase.startsWith('тикток'))
// false
3️⃣
endsWith() Секция статьи «3️⃣ endsWith()»ends принимает аргументом строку, которую нужно найти.![]() Возвращает
Возвращает true, если текущая строка заканчивается искомой и false — если нет.
const phrase = 'брат мыл яблоко'console.log(phrase.endsWith('яблоко'))// trueconsole.log(phrase.endsWith('мыл'))// falseconsole.log(phrase.endsWith('тикток'))// false
const phrase = 'брат мыл яблоко'
console.log(phrase.endsWith('яблоко'))
// true
console.log(phrase.endsWith('мыл'))
// false
console.log(phrase.endsWith('тикток'))
// false
4️⃣
indexOf() Секция статьи «4️⃣ indexOf()»index принимает аргументом строку, которую нужно найти. Возвращает индекс символа, с которого начинается искомая строка. Если искомая строка не найдена, то возвращает -1.
const phrase = 'сестра мыла посуду'console.log(phrase.indexOf('мыла'))// 7console.log(phrase.indexOf('тикток'))// -1
const phrase = 'сестра мыла посуду'
console. log(phrase.indexOf('мыла'))
// 7
console.log(phrase.indexOf('тикток'))
// -1
 log(phrase.indexOf('мыла'))
// 7
console.log(phrase.indexOf('тикток'))
// -1
log(phrase.indexOf('мыла'))
// 7
console.log(phrase.indexOf('тикток'))
// -1
Если вхождений несколько, будет возвращён индекс первого:
const phrase = 'сестра мыла посуду'console.log(phrase.indexOf('с'))// 0
const phrase = 'сестра мыла посуду'
console.log(phrase.indexOf('с'))
// 0
Вторым аргументом методу можно передать индекс, с которого начинать поиск:
const phrase = 'сестра мыла посуду'console.log(phrase.indexOf('с', 1))// 2
const phrase = 'сестра мыла посуду'
console.log(phrase.indexOf('с', 1))
// 2
Метод index ищет вхождение слева направо. Для поиска в обратном порядке существует зеркальный метод last.
Получение подстроки
Секция статьи «Получение подстроки»Для решения некоторых задач необходимо отдельно обрабатывать часть строки.
Самый удобный способ получить подстроку — это метод substring. Метод substring копирует указанную часть строки и возвращает копию в качестве результата. Метод принимает один или два аргумента.
При вызове с двумя аргументами нужно передать индекс символа, с которого начинать копирование и индекс символа, на котором закончить. Индекс окончания не включается в копию.
const phrase = 'javascript'const substring = phrase.substring(4, 10)console.log(substring)// scriptconsole.log(phrase.substring(4, 9))// scrip
const phrase = 'javascript'
const substring = phrase.substring(4, 10)
console.log(substring)
// script
console.log(phrase.substring(4, 9))
// scrip
Если указан только один аргумент, то результатом будет строка, начинающаяся с указанного индекса и до конца строки:
const phrase = 'javascript'console.log(phrase.substring(0, 4))// javaconsole.const phrase = 'javascript' console.log(phrase.substring(0, 4)) // java console.log(phrase.substring(1)) // avascript console.log(phrase.substring(4)) // script
 log(phrase.substring(1))// avascriptconsole.log(phrase.substring(4))// script
log(phrase.substring(1))// avascriptconsole.log(phrase.substring(4))// script
Существуют два похожих метода — substr и slice. substr — устаревший метод, который будет удалён в будущих версиях языка, не пользуйтесь им.
slice ведёт себя идентично substring, разница проявляется только если вызвать метод, поменяв местами индекс старта и индекс окончания копирования. В этом случае substring поймёт, что копировать, а slice вернёт пустую строку:
const phrase = 'javascript'console.const phrase = 'javascript' console.log(phrase.substring(10, 4)) // script console.log(phrase.slice(10, 4)) // ''
 log(phrase.substring(10, 4))// scriptconsole.log(phrase.slice(10, 4))// ''
log(phrase.substring(10, 4))// scriptconsole.log(phrase.slice(10, 4))// ''
🤝
Метод substring и slice часто используется в связке с index — сначала находится индекс начала нужной подстроки, а затем этот индекс используется в substring как индекс начала копирования.
slice принимает отрицательные аргументы и удобен, когда нужно получить значение с конца строки. Например, частично скрывать длинный текст при отображении пользователю и показывать только первые и последние пять символов:
const text = 'String — это обёртка над примитивным строковым типом, которая содержит дополнительные методы работы со строками'const spoiler = text.const text = 'String — это обёртка над примитивным строковым типом, которая содержит дополнительные методы работы со строками' const spoiler = text.slice(0, 5) + '...' + text.slice(-5) console.log(spoiler) // Strin...оками
 slice(0, 5) + '...' + text.slice(-5)console.log(spoiler)// Strin...оками
slice(0, 5) + '...' + text.slice(-5)console.log(spoiler)// Strin...оками
Деление строки на слова
Секция статьи «Деление строки на слова»Метод split позволяет разбить строку на отдельные подстроки. Чаще всего это нужно, чтобы разбить строку на слова.
Метод принимает аргументом разделитель, по которому нужно делить строку на подстроки. Возвращает массив получившихся подстрок.
Например, разбить текст на слова по пробелам:
const phrase = 'London is the capital of Great Britain.'const arr = phrase.split(' ')console.log(arr)// [ 'London', 'is', 'the', 'capital', 'of', 'Great', 'Britain.' ]
const phrase = 'London is the capital of Great Britain. '
const arr = phrase.split(' ')
console.log(arr)
// [ 'London', 'is', 'the', 'capital', 'of', 'Great', 'Britain.' ]
 '
const arr = phrase.split(' ')
console.log(arr)
// [ 'London', 'is', 'the', 'capital', 'of', 'Great', 'Britain.' ]
'
const arr = phrase.split(' ')
console.log(arr)
// [ 'London', 'is', 'the', 'capital', 'of', 'Great', 'Britain.' ]
Если не указать разделитель, то результатом вернётся массив из исходной строки:
const phrase = 'London is the capital of Great Britain.'console.log(phrase.split())// [ 'London is the capital of Great Britain.' ]
const phrase = 'London is the capital of Great Britain.'
console.log(phrase.split())
// [ 'London is the capital of Great Britain.' ]
В качестве разделителя можно передавать регулярное выражение или спецсимволы:
const phrase = 'London is the\ncapital of\nGreat Britain.'console.log(phrase.split('\n'))// [ 'London is the', 'capital of', 'Great Britain.' ]
const phrase = 'London is the\ncapital of\nGreat Britain.'
console.log(phrase.split('\n'))
// [ 'London is the', 'capital of', 'Great Britain.' ]
🔗
Склеить массив строк в одну можно методом join, он принимает один аргумент — строку, которая будет использоваться для склейки строк. Например, склеить строки пробелами:
Например, склеить строки пробелами: [ '
Замена подстроки
Секция статьи «Замена подстроки»Для замены одной части строки на другой существует метод replace.
При вызове в него нужно передать два аргумента — какую подстроку менять и на что:
const str = 'Яблоко - вкусный овощ'const correct = str.replace('овощ', 'фрукт')console.log(correct)// Яблоко - вкусный фрукт
const str = 'Яблоко - вкусный овощ'
const correct = str.replace('овощ', 'фрукт')
console.log(correct)
// Яблоко - вкусный фрукт
Если строка на замену не найдена, то замены не произойдёт:
const str = 'Яблоко - вкусный овощ'const notChanged = str.replace('апельсин', 'банан')console. log(notChanged)// Яблоко - вкусный овощ
const str = 'Яблоко - вкусный овощ'
const notChanged = str.replace('апельсин', 'банан')
console.log(notChanged)
// Яблоко - вкусный овощ
 log(notChanged)// Яблоко - вкусный овощ
log(notChanged)// Яблоко - вкусный овощ
Метод replace заменяет подстроку только один раз. Чтобы заменить подстроку более одного раза, необходимо использовать регулярные выражения, циклы, либо метод replace:
const str = 'Какова цена яблока? Какого яблока? Я их не продаю.'const once = str.replace('яблока', 'помидора')console.log(once)// Какова цена помидора? Какого яблока? Я их не продаю.const all = str.replaceAll('яблока', 'помидора')console.log(all)// Какова цена помидора? Какого помидора? Я их не продаю.const correct = str.replace(/яблока/g, 'помидора')console.log(correct)// Какова цена помидора? Какого помидора? Я их не продаю.
const str = 'Какова цена яблока? Какого яблока? Я их не продаю. '
const once = str.replace('яблока', 'помидора')
console.log(once)
// Какова цена помидора? Какого яблока? Я их не продаю.
const all = str.replaceAll('яблока', 'помидора')
console.log(all)
// Какова цена помидора? Какого помидора? Я их не продаю.
const correct = str.replace(/яблока/g, 'помидора')
console.log(correct)
// Какова цена помидора? Какого помидора? Я их не продаю.
 '
const once = str.replace('яблока', 'помидора')
console.log(once)
// Какова цена помидора? Какого яблока? Я их не продаю.
const all = str.replaceAll('яблока', 'помидора')
console.log(all)
// Какова цена помидора? Какого помидора? Я их не продаю.
const correct = str.replace(/яблока/g, 'помидора')
console.log(correct)
// Какова цена помидора? Какого помидора? Я их не продаю.
'
const once = str.replace('яблока', 'помидора')
console.log(once)
// Какова цена помидора? Какого яблока? Я их не продаю.
const all = str.replaceAll('яблока', 'помидора')
console.log(all)
// Какова цена помидора? Какого помидора? Я их не продаю.
const correct = str.replace(/яблока/g, 'помидора')
console.log(correct)
// Какова цена помидора? Какого помидора? Я их не продаю.
Очистка строки
Секция статьи «Очистка строки»Пользователи могут поставить лишние пробелы при вводе данных. Такие лишние пробелы могут помешать пользователю войти в систему, если их учитывать.
Для очистки строк от пробелов и символов окончания строки существует метод trim. Он не принимает аргументов, а возвращает строку без пробелов в начале и конце строки:
const email = ' [email protected] 'console.log(email.trim())// '[email protected]'
const email = ' [email protected] '
console.log(email.trim())
// 'another@test. com'
 com'
com'
Если нужно удалять пробелы только в начале или только в конце строки, то есть похожие методы trim и trim.
На практике
Секция статьи «На практике»Дока Дог советует
Секция статьи «Дока Дог советует»🛠 При работе с формами и вводом значений следует очищать поля ввода от замыкающих пробелов вызовом метода trim
🛠 Для множественных замен и поиска удобнее всего пользоваться регулярными выражениями, но это отдельный микроязык, который нужно учить.
основных строковых методов JavaScript | Трей Хаффин
13 наиболее важных функций JavaScript для работы со строками. Индексируйте, нарезайте, разделяйте и обрезайте методы строк JS.
Строки являются фундаментальной частью любого языка программирования, и в JavaScript есть много мощных встроенных функций, упрощающих работу со строками для разработчиков. Этот список охватывает наиболее важные строковые функции, которые вы можете начать использовать в своем коде.
Этот список охватывает наиболее важные строковые функции, которые вы можете начать использовать в своем коде.
Учим JavaScript — Лучшие учебники по JavaScript (2018) | gitconnected
72 лучших курса по JavaScript. Учебники отправляются и голосуются разработчиками, что позволяет вам найти лучшее…
gitconnected.com
Это может показаться очевидным, но, вероятно, это самый важный строковый метод и, несомненно, наиболее часто используемый. Вызов .length для строки вернет количество символов, содержащихся в строке.
Функция trim() удаляет пробелы в начале и в конце строки. Вы обнаружите, что чаще всего используете его при обработке строки пользовательского поля ввода. Легко случайно добавить пробелы, и это гарантирует, что вы обработаете соответствующие символы.
Избавьтесь от необходимости поддерживать и развивать свою карьеру программиста с помощью собственного портфолио и CV/резюме API .
API-интерфейс Portfolio — легко развивайте свою карьеру программиста | gitconnected
Избавьтесь от ручного обновления ваших данных в каждом отдельном месте. Просто измените данные один раз в своем…
gitconnected.com
Обновите один раз и наблюдайте, как изменения распространяются повсюду, используя единую конечную точку API.
Функция include() определяет, содержится ли подстрока в большей строке, и возвращает true или false . У этого есть много приложений, но один из распространенных вариантов использования — сопоставление строк для поиска/анализа.
До того, как include() был введен в спецификацию JavaScript, indexOf() был основным способом проверки существования подстроки в строке. Вероятно, вы все еще будете видеть код, использующий indexOf , поэтому важно понимать, как он работает. Функция возвращает индекс подстроки в строке. Если подстрока не содержится в исходной строке, будет возвращено
Если подстрока не содержится в исходной строке, будет возвращено -1 .
Общий шаблон для indexOf() , который имитирует поведение , включает () , который должен проверить, больше ли индекс, чем -1:
Функция toUpperCase () возвращает строку со всеми буквами верхнего регистра.
Функция toLowerCase() возвращает строку со всеми строчными буквами.
Функция replace() вызывается для строки и возвращает строку с шаблоном , замененным замещающей строкой . Он принимает либо регулярное выражение, либо строку в качестве узор . С помощью регулярного выражения вы можете глобально заменить все совпадения (используя параметр g ), но со строкой оно заменит только первое вхождение. В приведенном ниже примере вы заметите, что world заменяется только один раз в первом вызове, поскольку он использует строковый шаблон.
Метод slice() извлечет часть строки на основе предоставленного индекса и вернет ее как новую строку. Это полезно, когда вы знаете структуру строки и хотите получить определенную часть, или ее можно использовать с
Это полезно, когда вы знаете структуру строки и хотите получить определенную часть, или ее можно использовать с indexOf метод, который мы изучили ранее, где вы можете найти индекс первого вхождения подстроки и использовать его в качестве ориентира для нарезки.
slice() принимает начальный индекс в качестве первого параметра и необязательный конечный индекс в качестве второго параметра — str.slice(beginIndex[ endIndex]) . Если конечный индекс не указан, он срезается до конца строки, начиная с вашего beginIndex . Если используется отрицательный beginIndex , он будет срезаться назад с конца строки. Ниже приведен пример из MDN, в котором показаны эти случаи.
Метод split() принимает разделитель , на который вы хотите разделить строку, и возвращает массив строк. Это полезно, когда вы знаете, что ваша строка использует определенный символ для разделения данных или если вы хотите работать с определенными подстроками по отдельности.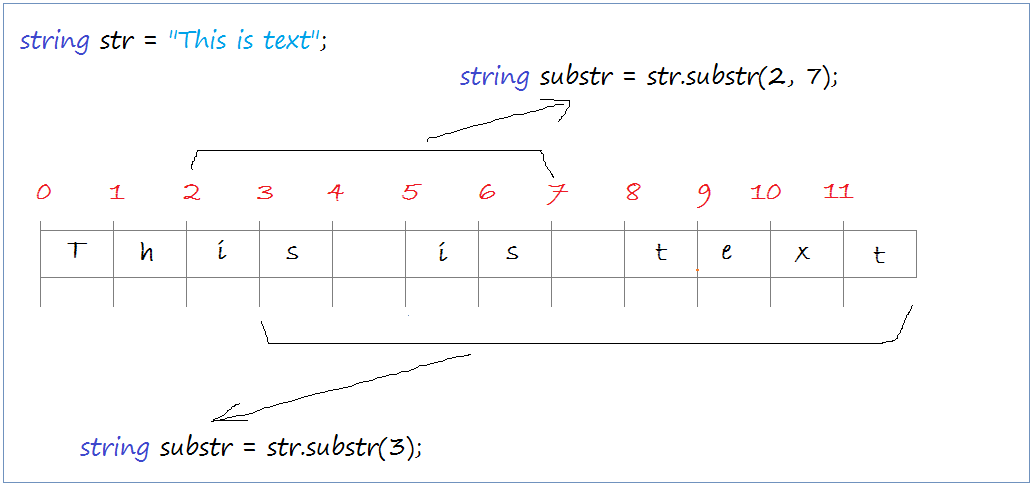
Функция repeat() возвращает строку, состоящую из элементов объекта, повторяющихся заданное количество раз.
Метод match() извлекает совпадения при сопоставлении строка против регулярного выражения . Пример ниже ищет в нашей строке все заглавные буквы. Он возвращает массив строк для значений, соответствующих регулярному выражению.
Функция charAt() возвращает строковый символ с заданным индексом.
Метод charCodeAt() возвращает юникод символа по указанному индексу в строке. Это целое число конуса UTF-16 от 0 до 65535.
Этот список охватывает основной список строковых методов, используемых в JavaScript. . Методы, не включенные в этот список, включают lastIndexOf , search , substring , substr , concat , localeCompare и другие. Дело не в том, что эти функции не важны, но они не являются основными методами, используемыми в JavaScript, и вы гораздо реже будете их видеть или нуждаться в них. Более полный список см. в документации по строке MDN.
Более полный список см. в документации по строке MDN.
Если эта статья оказалась вам полезной, нажмите на значок 👏. Следуйте за мной для получения дополнительных статей о React, JavaScript и программном обеспечении с открытым исходным кодом! Вы также можете найти меня на Twitter или gitconnected .
10 полезных строковых методов в JavaScript
В JavaScript конструктор String имеет множество методов, которые наследуют все строки. Эти методы являются вспомогательными функциями, которые служат различным целям.
В этой статье я расскажу о десяти полезных строковых методах.
TLDR
- split: разбить строку на массив подстрок
- replace: заменить подстроки в строке
- совпадение: возвращает массив подстрок, соответствующих шаблону RegEx
- startsWith и endWith: для проверки того, начинается ли строка с подстроки или заканчивается подстрокой соответственно
- toUpperCase и toLowerCase: для преобразования строк в верхний и нижний регистр соответственно
- включает: для проверки наличия подстроки в строке
- подстрока: для вырезания части строки
- поиск: возвращает индекс первой подстроки, которая соответствует регулярному выражению
- charAt: возвращает char актер по адресу в указанной позиции
- обрезка: удаление пробелов с обоих концов строки
Подробнее об этих методах читайте далее.
10 строковых методов JavaScript
.split()
Этот метод используется для разделения строки на массив подстрок на основе указанной точки останова. Вот синтаксис:
string.split(точка останова) // точка останова может быть строкой или регулярным выражением
Возвращает массив разделенных подстрок.
Этот метод принимает любую строку для использования в качестве точки останова, например:
const string = "Hello world, Holla" const breakpoint = " " // точка останова по пробелу const splitted = string.split(точка останова) console.log(разделенный) // ["Hello", "world,", "Holla"]
И он может принимать регулярное выражение в качестве точки останова. Символы в строке, соответствующие регулярному выражению, будут использоваться в качестве разделителя для строки следующим образом:
const string = "Привет, мир, Холла" // регулярное выражение, которое соответствует символам e или o постоянная точка останова = /e|o/ const splitted = string.
 split(точка останова)
console.log(разделенный)
// ['H', 'll', 'w', 'rld' ]
split(точка останова)
console.log(разделенный)
// ['H', 'll', 'w', 'rld' ] Как вы заметили, регулярное выражение соответствует букве «e» в «Hello», «o» в слове «Hello» и «o» » в мире». Он использует совпадения в качестве точек останова для строки.
.replace()
Этот метод используется для замены подстрок в строке новыми строками. Вот синтаксис:
string.replace(searchValue, replaceValue) // searchValue может быть строкой или регулярным выражением // replaceValue — это строка
Возвращает новую строку с замененными подстроками.
replaceValue заменяет подстроки в строке, соответствующие searchValue .
searchValue может быть такой строкой:
const string = "hello world" const searchValue = "привет" const replaceValue = "Привет" const replace = string.replace(searchValue, replaceValue) console.log(заменено) // привет мир
или с таким RegEx:
const string = "hello world" const searchValue = /e|o/g константа replaceValue = "--" const replace = string.
 replace(searchValue, replaceValue)
console.log(заменено)
// h--ll-- w--rld
replace(searchValue, replaceValue)
console.log(заменено)
// h--ll-- w--rld В этом случае регулярное выражение должно иметь флаг «g», чтобы оно соответствовало всем вхождениям совпавших строк. Без флага «g» будет заменена только первая совпавшая строка.
Регулярное выражение соответствует «e» или «o», и, как вы можете видеть, в «hello» и «world» совпадающие символы заменяются двойными дефисами.
.match()
Этот метод используется для поиска подстроки в строке, которая соответствует шаблону RegEx. Вот синтаксис:
string.match(regex)
Возвращает массив из:
- первой совпадающей подстроки (вместе с другими свойствами), если флаг
gне находится в регулярном выражении - всех совпавших подстрок (без выраженных свойств)), если в регулярном выражении присутствует флаг
g
Вот пример:
const string = "Hello world"
const регулярное выражение1 = /(e|o).{1}l/
const regex2 = /(e|o). {1}l/g
константа match2 = строка.match(regex1)
console.log(match2)
// ['ell', 'e', index: 1, input: 'Hello world', groups: undefined ]
константа match3 = строка.match(regex2)
console.log(match3)
// ['элл', 'орл'] 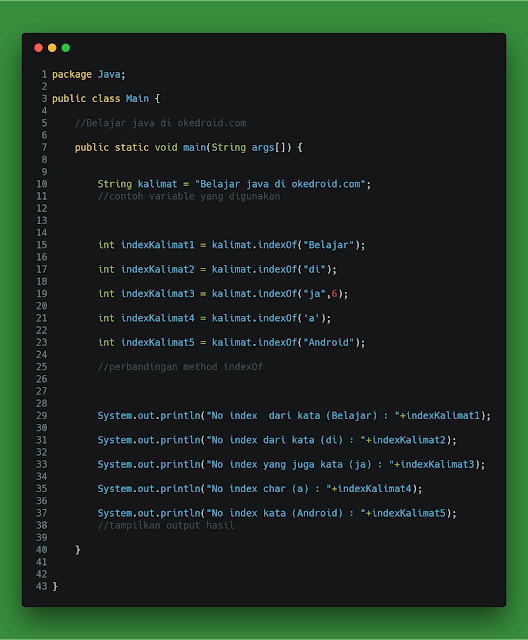 {1}l/g
константа match2 = строка.match(regex1)
console.log(match2)
// ['ell', 'e', index: 1, input: 'Hello world', groups: undefined ]
константа match3 = строка.match(regex2)
console.log(match3)
// ['элл', 'орл']
{1}l/g
константа match2 = строка.match(regex1)
console.log(match2)
// ['ell', 'e', index: 1, input: 'Hello world', groups: undefined ]
константа match3 = строка.match(regex2)
console.log(match3)
// ['элл', 'орл'] Оба шаблона регулярных выражений должны соответствовать подстроке либо с e , либо с o , символом любого типа, за которым следует символ «l».
Первый шаблон не имеет глобального флага, поэтому в выводе вы видите массив с двумя элементами: ‘ell’ (совпадающая подстрока) и ‘e’ (совпадающий символ в скобках), а также другие свойства. .
Второй шаблон с глобальным флагом возвращает массив всех подстрок в строке, соответствующих шаблону.
.startsWith() и .endsWith()
Как следует из названия, эти методы соответственно используются для проверки того, начинается ли строка подстрокой или заканчивается ею. Оба метода чувствительны к регистру.
Для startWith это может быть начало строки по умолчанию, или вы также можете указать позицию для начала проверки.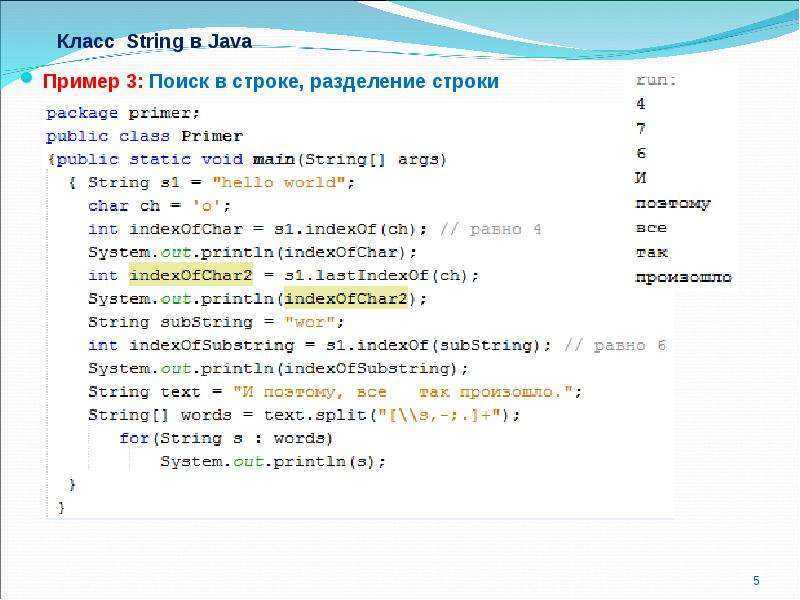 Вот синтаксис:
Вот синтаксис:
string.startsWith(подстрока, позиция) // позиция необязательна и используется по умолчанию // в 0 индекс
Возвращаемое значение равно true или false , если строка начинается с подстроки или нет.
Вот пример:
const string = "Hello world"
const check1 = string.startsWith("ello")
// ЛОЖЬ
const check2 = string.startsWith("ello", 1)
// true Во второй проверке, используя индекс позиции 1, метод startsWith начинает проверку со второго символа и возвращает true, поскольку второй символ справа начинается с «ello».
Для концовС , это может быть конец строки по умолчанию, или вы также можете указать конечную точку, с которой начинается проверка. Вот синтаксис:
string.endsWith(подстрока, длина) // длина необязательна и используется по умолчанию // в string.length
Возвращаемое значение равно true или false , если строка заканчивается подстрокой или нет.
Вот пример:
const string = "Hello world"
const check1 = string.endsWith("мир")
// ЛОЖЬ
const check2 = string.endsWith ("мир", string.length - 1)
// правда Во второй проверке с использованием указанного аргумента длины string.length - 1 . Это означает, что метод endWith начинает проверку с символа «l», так как это символ указанной длины, и возвращает true, поскольку последний символ слева заканчивается на «worl».
.toUpperCase() и .toLowerCase()
Как следует из названия, оба метода используются для преобразования строки в верхний и нижний регистр соответственно. Их синтаксис:
строка.toUpperCase() string.toLowerCase()
Их возвращаемые значения представляют собой строку (вызывается метод) в верхнем и нижнем регистре соответственно. Примеры:
const string = "Привет, мир" const верхний = string.toUpperCase() // ПРИВЕТ, МИР const нижний = string.toLowerCase() // привет, мир
.
 includes()
includes()Этот метод проверяет, можно ли найти подстроку в строке. Синтаксис:
string.includes(подстрока, позиция) // позиция необязательна и используется по умолчанию // до 0
Подобно методу startWith, он имеет аргумент position , указывающий точку, с которой метод должен начать проверку.
Возвращаемое значение true , если подстрока может быть найдена; иначе ложно . Например:
const string = "Привет, мир"
const check1 = string.includes("llo")
// истинный
const check2 = string.includes("привет", 4)
// false Для второй проверки включает , начинает проверку с позиции 4, символа «o» после «ll», поэтому не находит подстроку «llo» и возвращает ложь .
.substring()
Этот метод используется для вырезания подстроки из всей строки. Вот синтаксис:
string.substring(indexStart, indexEnd) // indexEnd необязателен, и // по умолчанию длина строки
Возвращаемое значение этой строки представляет собой вырезанную подстроку в зависимости от указанной начальной и конечной позиции. Вот пример:
Вот пример:
const string = "Hello world" const sub1 = строка.подстрока (5) // Мир const sub2 = строка.подстрока (5, 8) // работа
Если конечная позиция не указана, метод выполняет срез от начальной позиции до конца строки, но, как вы можете видеть во втором примере, конечная позиция определяет позицию остановки для метода, который нужно разрезать.
.search()
Этот метод используется для поиска в строке подстроки, соответствующей указанному шаблону регулярного выражения. Вот синтаксис:
string.search(regex)
Возвращаемым значением этого метода является индекс первого совпадения или -1 , если совпадений нет. Примеры:
const string = "Привет, мир"
const search2 = string.search(/l.{1}o/)
// 2
const search3 = string.search(/l.{5}o/)
// -1 Первое регулярное выражение ищет «l», любой другой символ, за которым следует «o». Метод search находит, что по индексу 2 . Второе регулярное выражение ищет «l», пять других символов, за которыми следует «o». Он этого не находит, поэтому возвращает
Он этого не находит, поэтому возвращает -1 .
.charAt()
Этот метод используется для получения char актер по указанная позиция. Вот синтаксис:
string.charAt(position) // если позиция не указана // по умолчанию 0
Возвращает строку по указанному индексу. Например:
const string = "Привет, мир" константа char0 = строка.charAt() // Н константа char5 = строка.charAt(6) // w
.trim()
Этот метод используется для удаления пробелов с обоих концов строки. Пробелы здесь включают вкладки, пробелы, точки останова и т. д. Синтаксис:
string.trim()
Возвращает новую строку без пробелов на обоих концах. Вот пример:
const string1 = "Привет, мир"
константная строка2 = `
Привет, мир
`
const trimmed1 = string1.trim()
// Привет, мир
const trimmed2 = string2.trim()
// Привет, мир Он обрезает только пробелы на обоих концах, а не между символами.