Инструкция по переходу на UTF-8
Вычислительная система кафедры перешла на использование многобайтовой кодировки UTF-8 для файловых систем и пользовательского окружения вместо однобайтовой кодировки KOI8-R. В данной инструкции рассматриваются типичные проблемы, которые могли возникнуть у пользователей в связи с данным переходом и предлагаются способы их решения (изменения настроек, команды и т.п.).
Основные понятия
Юнико́д, или Унико́д (англ. Unicode™) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
UTF-8 (от англ. Unicode Transformation Format — формат преобразования Юникода) — кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста.
Важно понимать, что один символ в кодировке UTF-8 может быть
представлен более чем одним байтом. С этим связано, например, то, что
файл, содержащий текст в кодировке UTF-8 будет иметь больший размер по
сравнению с файлом, содержащим тот-же текст в кодировке KOI8-R.
Пример: команда wc имеет ключ -c для подсчета байтов и ключ -m для подсчета символов.
$ echo -n "Слово." | wc -c 11 $ echo -n "Слово." | wc -m 6
Имена файлов
Имена файлов были перекодированы автоматически с помощью утилиты convmv:
convmv -r -f koi8-r -t utf-8 --notest <каталог>
Каждому пользователю, в домашнем каталоге которого утилита convmv переименовала хотя бы один файл, был автоматически выслан журнал переименований.
При необходимости можно выполнить обратное преобразование:
convmv -r -f utf-8 -t koi8-r <файлы и каталоги>
После проверки вывода команды повторить с ключем —notest. Ключ -r включает рекурсивный обход каталогов.
Содержимое файлов
Для того, чтобы преобразовать содержимое файлов из кодировки KOI8-R в кодировку UTF-8 можно воспользоваться командой:
recode koi8-r..utf-8 <filename>
Для потокового перекодирования используется команда:
iconv -f koi8-r <filename>
Редактор Emacs может автоматически распознать кодировку текста при
открытии файла. Принудительно задать кодировку открытия или сохранения
файла в редакторе Emacs можно следующим образом:
Принудительно задать кодировку открытия или сохранения
файла в редакторе Emacs можно следующим образом:
- Ввести комбинацию клавиш
C-x RET c. - Внизу экрана будет запрошена кодировка, которую вы хотите применить для следующей команды.
- Введите команду, которая будет выполнена с применением введенной на предыдущем шаге кодировки, например:
- комбинацию клавиш для открытия файла:
C-x C-f; - комбинацию клавиш для сохранения файла:
C-x C-s.
- комбинацию клавиш для открытия файла:
Приложения
Текстовый терминал из Windows
Для корректного отображения русского текста при входе на серверы кафедры с помощью терминального клиента PuTTY нужно указать в настройках:
- Раздел Window/Translation
- Character set translation on recieved data: UTF-8
Текстовый терминал из Linux
Если системная локаль не UTF-8, то необходимо запустить X-терминал с поддержкой UTF-8 и выполнить вход по ssh из него.
Если системная локаль UTF-8, то никаких дополнительных действий предпринимать не надо.
Если по какой-то причине при входе по ssh не установились правильно переменные окружения локали (вывод команды locale не содержит строки LANG=ru_RU.UTF-8), то необходимо выполнить команду:
export LANG=ru_RU.UTF-8
WinSCP
Для корректного отображения русских имен файлов:
- Раздел Environment
- UTF-8 encoding for filenames: On
TEX
- После выполнения перекодировки содержимого tex-файла (см. Содержимое файлов) необходимо сменить кодировку в преамбуле:
Было:
\usepackage[koi8-r]{inputenc}
Стало:
\usepackage[utf8x]{inputenc}
- Также необходимо подключить пакет ucs:
\usepackage{ucs}
- Для установки диакритических знаков (ударений) нужно использовать полную форму стандартной записи \’, т.е.:
Б\'{о}льшую
Bibtex
Bib-файлы, содержащие описание литературы, хранятся в кодировке KOI8-R. После выполнения команды bibtex
необходимо сначала перекодировать получившийся bbl-файл в кодировку
UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию
tex-файлов, подключающих этот список литературы.
После выполнения команды bibtex
необходимо сначала перекодировать получившийся bbl-файл в кодировку
UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию
tex-файлов, подключающих этот список литературы.
Кодирование строк — ASCII, Unicode, UTF-8
Главная / Блог / Кодирование строк
Дата: 10 сентября 2020
Автор: Михаил Макарик
Чтобы компьютер смог отобразить передаваемые ему символы, они должны быть представлены в конкретной кодировке. Навряд ли найдется человек, который никогда не сталкивался с кракозябрами: открываешь интернет-страницу, а там – набор непонятных знаков; хочешь прочесть книгу в текстовом редакторе, а вместо слов получаешь сплошные знаки вопроса. Причина заключается в неверной процедуре декодирования текста (если сильно упростить, то программа пытается представить американцу, например, букву «Щ», осуществляя поиск в английском алфавите).
Возникают вопросы: что происходит, кто виноват? Ответ не будет коротким.
1. Компьютер – человек
Так сложилось, что компьютерная техника оперирует единицами и нулями. На вашей же клавиатуре представлено не менее 100 клавиш. Все, что вы вводите при печати, в итоге преобразуется в те самые бинарные величины.
В этом суть кодировки. ПК запоминает любые буквы, числа и знаки в виде определенного значения из единиц и нулей. Для примера: английская буква «Y» в двоичном коде выглядит как «0b1011001», а в шестнадцатеричном как «0x59».
Для осмысленного диалога пользователя и компьютера требуется двусторонний переводчик:
– «человеческие» строки необходимо перекодировать в байты;
– «компьютерную» речь требуется преобразовать в воспринимаемые пользователем осмысленные структуры.
В языке Python за это отвечают функции encode / decode. Важно кодировать и декодировать сообщение в одинаковой кодировке, чтобы не столкнуться с проблемой бессмысленных наборов символов. _`{|}~
_`{|}~
С другими свойствами модуля можете ознакомиться самостоятельно.
Время шло, компьютеризация общества ширилась, 128 символов стало не хватать. Оставшийся последний 8-ой бит также выделили для кодирования (а это еще 128 знаков). В итоге появилось большое количество кодировок (кириллическая, немецкая и т.п.). Такая ситуация привела к проблемам. Уже в то время англичанин, получающий электронное письмо из России, мог увидеть не русские буквы, а набор непонятных закорючек.
Потребовалось указание кодировок в заголовках документов.
3. Юникод-стандарт
Как вы считаете, сколько нужно символов, чтобы хватило всем и навсегда? 10_000? Конечно, нет. Уже сегодня более 100_000 знаков имеет свое числовое представление. И это не предел. Люди постоянно придумывают новые «буквы».
Откройте свой телефон и создайте пустое сообщение. Зайдите в раздел «смайликов». Да их тут больше сотни! И это не картинки в большинстве своем. Они являются символами определенной кодировки. Если вы застали времена, когда SMS-технологии только начинали развиваться, то этих самых «смайлов» было не более десятка. Лет через 10 их количество станет «неприличным».
Они являются символами определенной кодировки. Если вы застали времена, когда SMS-технологии только начинали развиваться, то этих самых «смайлов» было не более десятка. Лет через 10 их количество станет «неприличным».
Упомянутая выше кодировка ASCII в своем расширенном варианте породила большое количество новых. Основная беда: имея 128 вариантов обозначить символ, мы никак не сумеем внедрить туда буквы других языков. В частности, какой-нибудь символ под номером 201 в кириллице даст совсем не русскую букву, если отослать его в Румынию. Следовательно, говоря кому-то «посмотри на 201-ый символ» мы не даем никакой гарантии, что собеседник увидит то же.
Для решения задачи был разработан стандарт Unicode. Отметим, что это не определенная кодировка, а именно набор правил. Суть юникода – связь символа и определенного числа без возможного повторения. Если мы кого-то попросим показать символ, скрытый под номером «1000», то в любой точке планеты он будет одним и тем же графическим элементом.
Пример Unicode символов
Всего в Unicode стандарте на сегодня имеется место под более чем 1,1 млн знаков:
- UTF-8 – кодировка символов юникод в двоичном виде. Использует от 1 до 4 байт. Так как наиболее часто используемые символы занимают 1 байт (в частности, аски-символы), то UTF-8 оптимальна для английского текста, но не для азиатского.
- UTF-16 используется для кодирования 2-мя или 4-мя байтами. Считается удобным способом для пользователей азиатских стран с иероглифическим письмом.
- UTF-32 представляет все символы при помощи 4 байт. Используется редко, так как потребляет много памяти. Тем не менее, быстро работает при наличии мощностей.
4. Кодирование и декодирование строк
Пользователям Python 3 версии повезло. Все символы и документы заранее приводятся к кодировке UTF-8. И если где-то в коде вы напишете строку «Ёжик в тумане» или «אֱלִיעֶזֶר וְהַגֶזֶר», то будьте уверены, они не превратятся в абракадабру и не приведут к ошибкам.
Тем не менее, строковые методы decode / encode не потеряли свою актуальность. По умолчанию все преобразования осуществляются в кодировке UTF-8, но никто не мешает задать нужную вам.
Пример – Интерактивный режим
>>> 'Ёжик'.encode()
b'\xd0\x81\xd0\xb6\xd0\xb8\xd0\xba'
>>> 'Ёжик в тумане'.encode().decode()
'Ёжик в тумане'
>>> 'Ёжик в тумане'.encode().decode('utf-16')
'臐뛐룐뫐퀠₲苑菑볐냐뷐뗐'Поясним полученные результаты и принцип работы этих методов.
Задача encode() – представить строку в виде объекта типа bytes (предваряется литералом b). Если знак относится к ASCII
, то его байтовое представление будет выглядеть как оригинальный символ. В случае когда он выходит за пределы ASCII, то заменяется байтовым представлением (\x — эскейп-последовательность для обозначения 16-ричных чисел в языке Python).
Пример — интерактивный режим
>>> 'Python'.encode() b'Python' >>> 'Пайтон'.encode() B'\xd0\x9f\xd0\xb0\xd0\xb9\xd1\x82\xd0\xbe\xd0\xbd'
Метод decode() преобразует последовательность байтов в привычную нам строку. Если задать другую кодировку, то можем получить либо неожиданный результат (как в последнем примере, где русские слова превратились в набор корейских иероглифов), либо ошибку UnicodeDecodeError, если в требуемой кодировке нет такого сочетания байтов или они выходят за ее границы.
Читайте также
Программирование на Python. Урок 4. Работа со строками
Строки в Python. Тип данных: str. Учимся выполнять основные действия над строковым типом данных в Python: создание, экранирование, конкатенация и умножение, срезы, форматирование, строковые методы.
5. Инструментарий для работы с кодировками
В Python встроено большое разнообразие функций и методов для работы с кодированием-декодированием строк. Часть из них менее актуальна, но на практике могут встречаться.
Часть из них менее актуальна, но на практике могут встречаться.
Перечислим те, которые вам могут понадобиться, а затем опробуем их на практике:
6. Практические примеры
Для усвоения материала попрактикуемся в применении изученного.
А. Функция ascii
Примеры – Интерактивный режим
>>> ascii(12)
'12'
>>> ascii('cat')
"'cat'"
>>> ascii('шапка')
"'\\u0448\\u0430\\u043f\\u043a\\u0430'" Экранирование русского слова связано с тем, что ни один из символов не включен в стандартный набор знаков ascii (т.е. не имеет 1-байтового представления).
Б. Применение функции str для получения строк
Примеры – Интерактивный режим
>>> str(123) '123' >>> str(b'\xd0\x9f\xd0\xb0\xd0\xb9\xd1\x82\xd0\xbe\xd0\xbd', 'utf8') 'Пайтон'
В. Функция bytes
Превращает в объект bytes не только строки или числа, но и последовательности чисел (каждое из которых соответствует определенному символу).
Примеры – Интерактивный режим
>>> bytes('well done', 'ascii')
b'well done'
>>> bytes('Юта', 'utf16')
b'\xff\xfe.\x04B\x040\x04'
>>> bytes((80, 77, 99, 101))
b'PMce'Г. Модуль unicodedata
Позволяет узнать имя любого юникод-символа, а также отобразить его по имени. С другими свойствами можете ознакомиться самостоятельно.
Примеры – Интерактивный режим
>>> import unicodedata
>>> unicodedata.name('Я')
'CYRILLIC CAPITAL LETTER YA'
>>> unicodedata.lookup('GIRL')
'????'
>>> unicodedata.lookup('Trigram for Heaven')
'☰'Задачи по темам
Задачник по Python. Тема 1. Целые числа.
Решаем задачи и отвечаем на вопросы по теме «Целые числа»: работаем с типом данных int
Задачник по Python. Тема 2. Числа с плавающей точкой
Решаем задачи и отвечаем на вопросы по теме «Числа с плавающей точкой»: работаем с типом данных float
Задачник по Python.
Решаем задачи и отвечаем на вопросы по теме «Логический тип данных»: работаем с типом данных bool
Задачник по Python. Тема 8. Работа со строками
Строки как тип данных в Python. Основные методы и свойства строк. Примеры работы со строками, задачи с решениями.
Д. Отображение любого Юникод-символа
Функция chr() может принимать числа любой стандартной системы счисления (десятичной, двоичной, восьмеричной или шестнадцатеричной).
Функция ord() возвращает десятичное число, соответствующее символу юникод. Если требуется, мы это число можем преобразовать к любому иному основанию.
Примеры – Интерактивный режим
>>> chr(0o144)
'd'
>>> chr(0b1100100)
'd'
>>> chr(0x64)
'd'
>>> chr(100)
'd'
>>> ord('d')
100Также попробуем немного экзотики. Если какой-то из символов не отображается, у вас нет шрифта в системе, который поддерживает эти знаки.
Если какой-то из символов не отображается, у вас нет шрифта в системе, который поддерживает эти знаки.
Примеры – Интерактивный режим
>>> chr(0x131B0) # Египетский иероглиф ???? >>> chr(0x1F5A4) # Черное сердечко '????' >>> chr(0x265E) # Черный конь '♞' >>> chr(0x111E1) # Сингальское число 1 ???? >>> chr(0x4E78) # Китайский иероглиф '乸'
Воспользовавшись базой данных символов юникод, вы сумеете просмотреть все доступные варианты на сегодняшний день с указанием имени, кода, принадлежности.
10 АВГУСТА / 2020
Как вам материал?
| ПОКАЗАТЬ КОММЕНТАРИИ |
Читайте также
МСК10-С. Кодировка символов: проблемы, связанные с UTF8 — стандарт кодирования SEI CERT C
Перейти к концу метаданных
UTF-8 — это кодировка с переменной шириной для Unicode. UTF-8 использует от 1 до 4 байтов на символ, в зависимости от символа Unicode.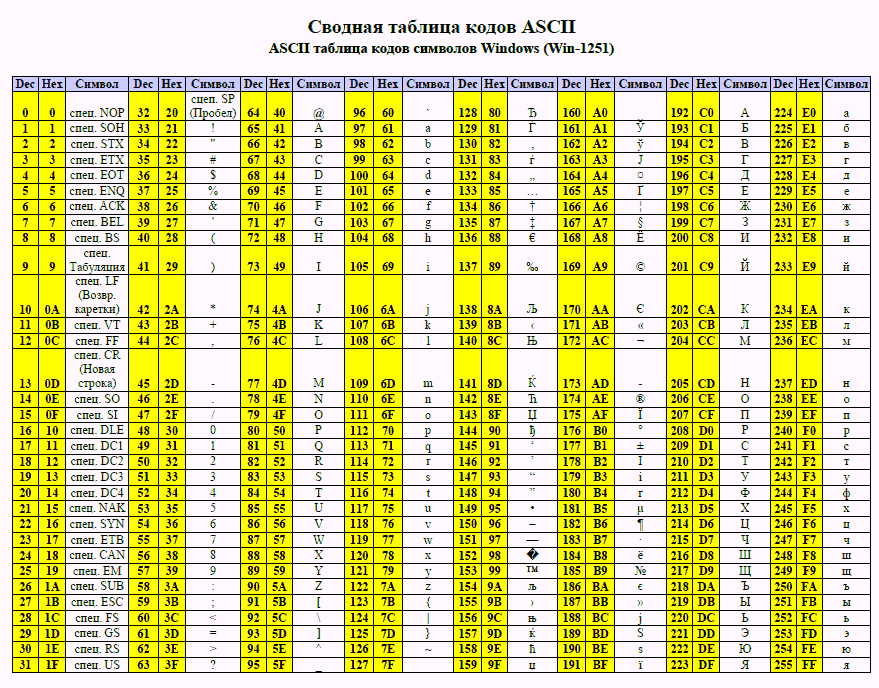 UTF-8 имеет следующие свойства:
UTF-8 имеет следующие свойства:
- Классические символы US-ASCII (от 0 до 0x7f) кодируются сами по себе, поэтому файлы и строки, закодированные значениями ASCII, имеют одинаковую кодировку как в ASCII, так и в UTF-8.
- Легко конвертировать между представлениями UTF-8 и UCS-2 и UCS-4 с фиксированной шириной символов. 921 код UCS можно закодировать с помощью UTF-8.
Как правило, программы должны проверять данные UTF-8 перед выполнением других проверок. В следующей таблице перечислены правильные последовательности байтов UTF-8.
| Bits of code point | First code point | Last code point | Bytes in sequence | Byte 1 | Byte 2 | Byte 3 | Byte 4 | ||
|---|---|---|---|---|---|---|---|---|---|
| 7 | U+0000 | U+007F | 1 | 0xxxxxxx | |||||
| 11 | U+0080 | U+07FF | 2 | 110xxxxx | 10xxxxxx | ||||
| 16 | U+0800 | U+FFFF | 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| 21 | U+10000 | U+1FFFFF | 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxxxxxxxxxxxxxxxxxxxxx | 10xxxxxxxxxx | 10xxxxxxxxx |
Несмотря на то, что у UTF-8. Как правило, многие системы Unicode поддерживают только нижний 16-битный диапазон, а не полное 21-битное кодовое пространство ISO 10646 [ISO/IEC 10646:2012].
Как правило, многие системы Unicode поддерживают только нижний 16-битный диапазон, а не полное 21-битное кодовое пространство ISO 10646 [ISO/IEC 10646:2012].
Согласно RFC 2279: UTF-8, формат преобразования ISO 10646 [Yergeau 1998],
Разработчики UTF-8 должны учитывать аспекты безопасности при обработке недопустимых последовательностей UTF-8. Вполне возможно, что при некоторых обстоятельствах злоумышленник сможет использовать неосторожный синтаксический анализатор UTF-8, отправив ему последовательность октетов, не разрешенную синтаксисом UTF-8.
Особенно изощренная форма этой атаки может быть применена к синтаксическому анализатору, который выполняет критическую с точки зрения безопасности проверку допустимости входных данных в кодировке UTF-8, но интерпретирует некоторые недопустимые последовательности октетов как символы. Например, синтаксический анализатор может запретить нулевой символ, если он закодирован как последовательность из одного октета 9.
0048 00 , но разрешить недопустимую последовательность из двух октетов
C0 80и интерпретировать ее как нулевой символ. Другим примером может быть синтаксический анализатор, который запрещает последовательность октетов2F 2E 2E 2F("/../"), но разрешает недопустимую последовательность октетов2F C0 AE 2E 2F.
 0048 00 , но разрешить недопустимую последовательность из двух октетов
0048 00 , но разрешить недопустимую последовательность из двух октетов Ниже приведены более конкретные рекомендации.
Должна быть разрешена только "кратчайшая" форма UTF-8. Наивные декодеры могут принимать более длинные кодировки, чем необходимо, что позволяет потенциально опасным входным данным иметь несколько представлений. Например,
- Процесс A выполняет проверки безопасности, но не проверяет наличие некратчайших форм UTF-8.
- Процесс B принимает последовательность байтов от процесса A и преобразует ее в UTF-16 при интерпретации возможных некратчайших форм.
- Текст UTF-16 может содержать символы, которые должны были быть отфильтрованы процессом A и могут быть потенциально опасными. Эти «некратчайшие» атаки UTF-8 использовались для обхода проверок безопасности в высококлассных продуктах, таких как веб-сервер Microsoft IIS.
 Эти «некратчайшие» атаки UTF-8 использовались для обхода проверок безопасности в высококлассных продуктах, таких как веб-сервер Microsoft IIS.
Эти «некратчайшие» атаки UTF-8 использовались для обхода проверок безопасности в высококлассных продуктах, таких как веб-сервер Microsoft IIS.Исправление №1: Кратчайшая форма UTF-8 стандарта Unicode [Unicode 2006] описывает изменения, внесенные в версию 3.0 стандарта Unicode, запрещающие интерпретацию некратчайших форм.
Декодеры UTF-8 не имеют единообразного поведения при обнаружении недопустимого ввода. Ниже приведены несколько способов поведения декодера UTF-8 в случае недопустимой последовательности байтов. Обратите внимание, что реализация этих вариантов поведения требует тщательных соображений безопасности.
- Замена символа замены «U+FFFD» или подстановочного знака, такого как «?» когда U+FFFD недоступен.
- Игнорировать байты (например, удалить недопустимый байт перед процессом проверки; дополнительные сведения см. в «Техническом отчете Unicode № 36, 3.5 Удаление кодовых точек»).
- Интерпретируйте байты в соответствии с другой кодировкой символов (часто используется карта символов ISO-8859-1; известно, что другие кодировки, такие как Shift_JIS, запускают self-XSS и поэтому потенциально опасны).
- Не заметить, но декодировать, как если бы байты были чем-то вроде бита UTF-8.
- Остановить декодирование и сообщить об ошибке.

Следующая функция из книги Джона Виеги «Защита конфиденциальных данных в памяти» [Viega 2003] обнаруживает недопустимые последовательности символов в строке, но не отклоняет неминимальные формы. Он возвращает 1 , если строка состоит только из допустимых последовательностей; в противном случае возвращается 0 .
int spc_utf8_isvalid (const unsigned char * input) {
внутренний номер;
const unsigned char *c = input;
for (c = input; *c; c += (nb + 1)) {
если (!(*c & 0x80)) nb = 0;
иначе если ((*c & 0xc0) == 0x80) вернуть 0;
иначе если ((*c & 0xe0) == 0xc0) nb = 1;
иначе если ((*c & 0xf0) == 0xe0) nb = 2;
иначе если ((*c & 0xf8) == 0xf0) nb = 3;
иначе если ((*c & 0xfc) == 0xf8) nb = 4;
иначе если ((*c & 0xfe) == 0xfc) nb = 5;
в то время как (nb-- > 0)
если ((*(c + nb) & 0xc0) != 0x80) вернуть 0;
}
вернуть 1;
}
Запрещается кодирование отдельных или неупорядоченных суррогатных половин. Сломанные суррогаты недопустимы в Unicode и вносят неоднозначность, когда появляются в данных Unicode. Сломанные суррогаты часто являются признаком плохой передачи данных. Они также могут указывать на внутренние ошибки в приложении или преднамеренные попытки найти уязвимости в системе безопасности.
Сломанные суррогаты недопустимы в Unicode и вносят неоднозначность, когда появляются в данных Unicode. Сломанные суррогаты часто являются признаком плохой передачи данных. Они также могут указывать на внутренние ошибки в приложении или преднамеренные попытки найти уязвимости в системе безопасности.
Неправильная обработка данных в кодировке UTF8 может привести к нарушению целостности данных или атаке типа «отказ в обслуживании».
Recommendation | Severity | Likelihood | Remediation Cost | Priority | Level |
|---|---|---|---|---|---|
MSC10-C | Medium | Unlikely | Высокий | P2 | L3 |
Tool | Version | Checker | Description |
|---|---|---|---|
| LDRA tool suite | 9. 7.1 7.1 | 176 S , 376 S | Реализовано частично |
Поиск уязвимостей, возникших в результате нарушения этого правила, на сайте CERT.
| SEI CERT Стандарт кодирования C++ | ПУСТОЙ MSC10-CPP. Character encoding: UTF8-related issues |
| MITRE CWE | CWE-176, Failure to handle Unicode encoding CWE-116, Improper encoding or escaping of output |
| [ISO/IEC 10646 : 2012] | |||
| [Kuhn 2006] | UTF-8 и FAQ UNICODE для UNIX/Linux | ||
| [Pike 1993] | «Hello World» | ||
| [Pike 1993] | «Hello World» | ||
| [Pike 1993] | «Hello World» | ||
| [Pike 1993] | «Hello World» | ||
| [Pike 1993] | «Hello World» | ||
| [Pike 1993] | «. 0020 0020 | [UNICODE 2006] | |
| [Viega 2003] | Раздел 3.12, «Обреждение незаконных символов UTF-8» | ||
| [Wheeler 2003] | [Wheeler 2003] | 4020. | [Yergeau 1998] | RFC 2279 |
|---|
Выбор и применение кодировки символов
Выбор и применение кодировки символовВопрос
Какую кодировку символов следует использовать для содержимого и как ее применить к моему содержимому?
Содержимое состоит из последовательности символов. Символы представляют собой буквы алфавита, знаки препинания и т. д. Но содержимое хранится в компьютере в виде последовательности байтов, которые представляют собой числовые значения. Иногда для представления одного символа используется более одного байта. Подобно кодам, используемым в шпионаже, способ преобразования последовательности байтов в символы зависит от того, какой ключ использовался для кодирования текста. В связи с этим 9Клавиша 0365 называется кодировкой символов .
В связи с этим 9Клавиша 0365 называется кодировкой символов .
Эта статья предлагает простые советы о том, какую кодировку символов использовать для вашего контента и как ее применять, т.е. как на самом деле создать документ в этой кодировке.
Если вам нужно лучше понять, что такое символы и кодировки символов, см. статью Кодировки символов для начинающих .
Быстрый ответ
Выберите UTF-8 для всего контента и рассмотрите возможность преобразования любого контента в устаревших кодировках в UTF-8.
Если вы действительно не можете использовать кодировку Unicode, убедитесь, что выбранная вами кодировка страницы широко поддерживается браузерами и что эта кодировка не входит в список кодировок, которых следует избегать согласно последним спецификациям.
Проверьте, не повлияют ли на ваш выбор настройки HTTP-сервера.
В дополнение к объявлению кодировки документа внутри документа и/или на сервере вам необходимо сохранить текст в этой кодировке, чтобы применить ее к вашему контенту.
Разработчики также должны убедиться, что различные части системы могут взаимодействовать друг с другом.
Детали
Применение кодировки к содержимому
Авторы контента должны объявить кодировку символов своих страниц, используя один из методов, описанных в Объявление кодировок символов в HTML .
Однако важно понимать, что простое объявление кодировки внутри документа или на сервере фактически не изменит байты; тебе нужно сохраните текст в кодировке , чтобы применить его к своему контенту. (Объявление просто помогает браузеру интерпретировать последовательности байтов, в которых хранится текст.)
При необходимости установите UTF-8 по умолчанию для новых документов в вашем редакторе. На рисунке ниже показано, как это сделать в настройках редактора, такого как Dreamweaver.
Для получения информации о «Форме нормализации Unicode» см. Нормализация в HTML и CSS . Для получения информации о «Подписи Unicode (BOM)» см. Метка порядка байтов (BOM) в HTML .
Метка порядка байтов (BOM) в HTML .
Вам также может потребоваться проверить, что ваш сервер обслуживает документы с правильными объявлениями HTTP, поскольку в противном случае он переопределит информацию в документе (см. ниже).
Разработчики также должны убедиться, что различные части системы могут взаимодействовать друг с другом. Веб-страницы должны иметь возможность беспрепятственно взаимодействовать с внутренними сценариями, базами данных и т.п. Конечно, все они лучше всего работают и с UTF-8. Разработчики могут найти подробный набор вещей для рассмотрения в статье Переход на Unicode .
Зачем использовать кодировку UTF-8?
HTML-страница может быть только в одной кодировке. Вы не можете кодировать разные части документа в разных кодировках.
Кодировка на основе Unicode, такая как UTF-8, может поддерживать многие языки и может вмещать страницы и формы на любом сочетании этих языков. Его использование также
устраняет необходимость в логике на стороне сервера для индивидуального определения кодировки символов для каждой обслуживаемой страницы или каждой входящей отправки формы.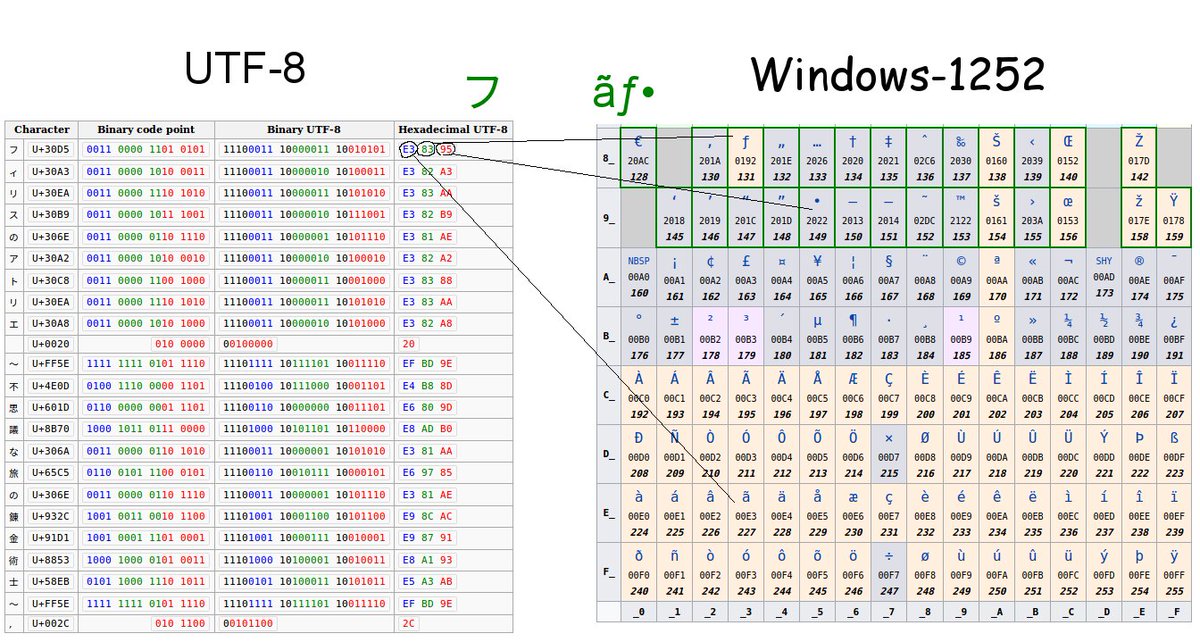 Это значительно снижает сложность работы с многоязычным сайтом или приложением.
Это значительно снижает сложность работы с многоязычным сайтом или приложением.
Кодировка Unicode также позволяет смешивать гораздо больше языков на одной странице, чем любая другая кодировка.
Поддержка данной кодировки, даже кодировки Unicode, не обязательно означает, что пользовательский агент будет правильно отображать текст. Многочисленные шрифты, такие как арабский и индийский, требуют дополнительных правил для преобразования последовательности символов в памяти в соответствующую последовательность глифов шрифта для отображения.
В наши дни любые барьеры для использования Unicode очень низки. Фактически, в январе 2012 года Google сообщил, что более 60% Интернета в их выборке из нескольких миллиардов страниц теперь используют UTF-8. Добавьте к этому цифру для веб-страниц, состоящих только из ASCII (поскольку ASCII является подмножеством UTF-8), и эта цифра возрастет примерно до 80%.
Существует три различных кодировки символов Unicode: UTF-8, UTF-16 и UTF-32.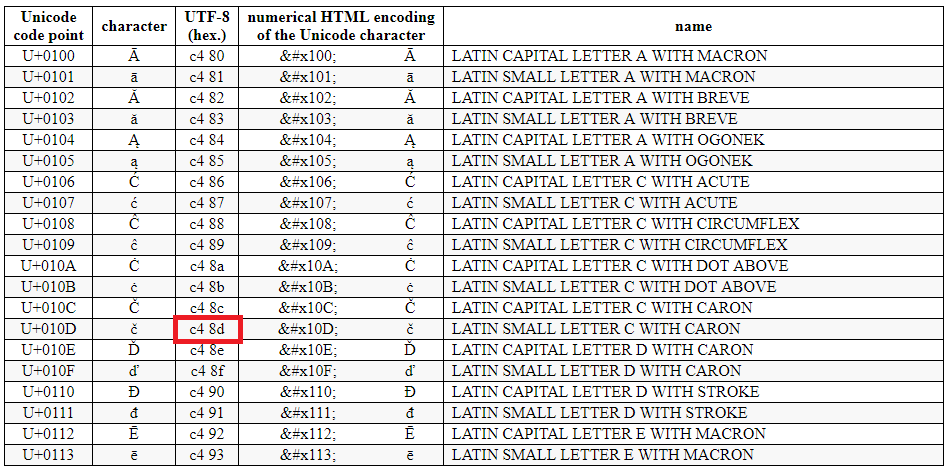 Из этих трех для веб-контента следует использовать только кодировку UTF-8. Спецификация HTML5 гласит: «Авторам рекомендуется использовать UTF-8. Средства проверки соответствия могут посоветовать авторам не использовать устаревшие кодировки. Инструменты разработки должны по умолчанию использовать UTF-8 для вновь созданных документов».
Из этих трех для веб-контента следует использовать только кодировку UTF-8. Спецификация HTML5 гласит: «Авторам рекомендуется использовать UTF-8. Средства проверки соответствия могут посоветовать авторам не использовать устаревшие кодировки. Инструменты разработки должны по умолчанию использовать UTF-8 для вновь созданных документов».
Обратите внимание, в частности, что все символы ASCII в UTF-8 используют те же байты, что и кодировка ASCII, что часто способствует взаимодействию и обратной совместимости.
Принимая во внимание заголовок HTTP
Любое объявление кодировки символов в заголовке HTTP переопределяет объявления внутри страницы. Если заголовок HTTP объявляет кодировку, отличную от той, которую вы хотите использовать для своего контента, это вызовет проблему, если вы не сможете изменить настройки сервера.
Возможно, у вас нет контроля над объявлениями, которые идут с заголовком HTTP, и вам, возможно, придется обратиться за помощью к людям, управляющим сервером. С другой стороны, иногда есть способы исправить проблемы на сервере, если у вас ограниченный доступ к файлам настройки сервера или вы создаете страницы с помощью языков сценариев. Например, см. Установка параметра набора символов HTTP для получения дополнительных сведений о том, как изменить информацию о кодировке либо локально для набора файлов на сервере, либо для содержимого, созданного с использованием языка сценариев.
С другой стороны, иногда есть способы исправить проблемы на сервере, если у вас ограниченный доступ к файлам настройки сервера или вы создаете страницы с помощью языков сценариев. Например, см. Установка параметра набора символов HTTP для получения дополнительных сведений о том, как изменить информацию о кодировке либо локально для набора файлов на сервере, либо для содержимого, созданного с использованием языка сценариев.
Обычно перед этим необходимо проверить, действительно ли заголовок HTTP объявляет кодировку символов. Вы можете использовать средство проверки интернационализации W3C, чтобы узнать, какая кодировка символов, если таковая имеется, указана в заголовке HTTP. Альтернативно, статья Проверка заголовков HTTP указывает на некоторые другие инструменты для проверки информации о кодировании, передаваемой сервером.
Дополнительная информация
Информация в этом разделе относится к вещам, которые вам обычно не нужно знать, но которые включены сюда для полноты картины.
Что делать, если я не могу использовать кодировку UTF-8?
Если вы действительно не можете избежать использования кодировки символов, отличной от UTF-8, вам придется выбирать из ограниченного набора имен кодировок, чтобы обеспечить максимальную совместимость и максимально длительный срок читаемости вашего контента, а также свести к минимуму уязвимости системы безопасности.
До недавнего времени реестр IANA был местом, где можно было найти имена для кодировок. Реестр IANA обычно включает несколько имен для одной и той же кодировки. В этом случае вы должны использовать имя, обозначенное как «предпочтительный».
Новая спецификация Encoding теперь содержит список, протестированный на реальных реализациях браузеров. Список можно найти в таблице в разделе Кодировки. Лучше всего использовать имена из левого столбца этой таблицы.
Обратите внимание, однако, , что наличие имени в любом из этих источников не обязательно означает, что можно использовать эту кодировку. В следующем разделе приведены кодировки, которых следует избегать.
В следующем разделе приведены кодировки, которых следует избегать.
Избегайте этих кодировок
Спецификация HTML5 указывает на ряд кодировок, которых следует избегать.
Документы не должны использовать JIS_C6226-1983 , JIS_X0212-1990 , HZ-GB-2312 , JOHAB (кодовая страница Windows 1361), кодировки на основе ISO-2022 или кодировки на основе EBCDIC . Это связано с тем, что они позволяют кодовым точкам ASCII представлять символы, отличные от ASCII, что представляет угрозу безопасности.
Документы также не должны использовать кодировки CESU-8 , UTF-7 , BOCU-1 или SCSU , поскольку они никогда не предназначались для веб-контента, а спецификация HTML5 запрещает браузерам распознавать их.
Спецификация также настоятельно не рекомендует использовать UTF-16 , а использование UTF-32 «особенно не рекомендуется».
Также следует избегать других кодировок символов, перечисленных в спецификации Encoding . К ним относятся кодировки Big5 и EUC-JP , которые имеют проблемы с совместимостью. ISO-8859-8 (кодировка на иврите для визуально упорядоченного текста) также следует избегать в пользу кодировки, которая работает с логически упорядоченным текстом (т. е. UTF-8, в противном случае ISO-8859-8-и).
Кодировка , заменяющая , указанная в спецификации Encoding , на самом деле не является кодировкой; это запасной вариант, который сопоставляет каждый октет с кодовой точкой Unicode U+FFFD REPLACEMENT CHARACTER. Очевидно, что передавать данные в такой кодировке бесполезно.
Кодировка x-user-defined представляет собой однобайтовую кодировку, младшая половина которой представляет собой ASCII, а верхняя половина отображается в зону частного использования Unicode (PUA).