Что такое кодировка UTF-8? Руководство для непрограммистов
Что такое UTF-8?
Двоичный: как компьютеры хранят информацию
ASCII: преобразование символов в двоичные
Юникод: способ хранить каждый символ, когда-либо
UTF-8: последний кусок головоломки
Символы UTF-8 в веб-разработке
UTF-8 против UTF-16
Расшифровка мира кодировки UTF-8
Текст: его важность в Интернете само собой разумеется. Это первая буква «Т» в «HTTP», единственная буква «Т» в «HTML», и практически каждый веб-сайт каким-то образом использует ее, будь то URL-адрес, рекламный текст, обзор продукта, вирусный твит или Сообщение блога. (Всем привет!)
Но веб-текст на самом деле может быть не таким простым, как вы думаете. Рассмотрим тысячи языков, на которых сегодня говорят, или все знаки препинания и символы, которые мы можем добавить, чтобы улучшить их, или тот факт, что создаются новые смайлики, чтобы уловить каждую человеческую эмоцию. Как веб-сайты все это хранят и обрабатывают?
Как веб-сайты все это хранят и обрабатывают?
По правде говоря, даже такая простая вещь, как текст, требует хорошо скоординированной, четко определенной системы для отображения в веб-браузерах. В этом посте я объясню основы одной технологии, которая имеет ключевое значение для текста в Интернете, UTF-8. Мы изучим основы хранения и кодирования текста и обсудим, как это помогает размещать привлекательные слова на вашем сайте.
Прежде чем мы начнем, вы должны быть знакомы с основами HTML и готовы погрузиться в легкую информатику.
Что такое UTF-8?
UTF-8 означает «Формат преобразования Unicode – 8 бит». Это пока не помогает нам, поэтому давайте вернемся к основам.
Двоичный: как компьютеры хранят информацию
Для хранения информации компьютеры используют двоичную систему. В двоичном формате все данные представлены в виде последовательностей единиц и нулей. Самая основная единица двоичного кода – это бит, который представляет собой всего лишь 1 или 0. Следующая по величине единица двоичного кода, байт, состоит из 8 бит. Пример байта – «01101011».
Следующая по величине единица двоичного кода, байт, состоит из 8 бит. Пример байта – «01101011».
Каждый цифровой актив, с которым вы когда-либо сталкивались – от программного обеспечения до мобильных приложений, от веб-сайтов до историй в Instagram – построен на этой системе байтов, которые связаны друг с другом таким образом, что это имеет смысл для компьютеров. Когда мы говорим о размерах файлов, мы имеем в виду количество байтов. Например, килобайт – это примерно тысяча байт, а гигабайт – примерно миллиард байтов.
Текст – это один из многих ресурсов, которые компьютеры хранят и обрабатывают. Текст состоит из отдельных символов, каждый из которых представлен в компьютерах строкой битов. Эти строки собираются в цифровые слова, предложения, абзацы, любовные романы и т.д.
ASCII: преобразование символов в двоичные
Американский стандартный код обмена информацией (ASCII) был ранней стандартизированной системой кодирования текста. Кодирование – это процесс преобразования символов человеческих языков в двоичные последовательности, которые могут обрабатывать компьютеры.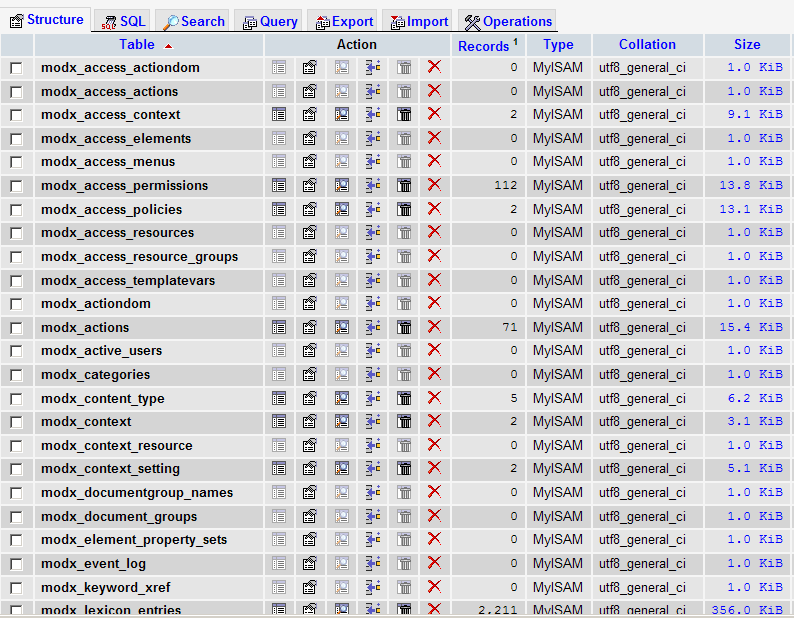
Библиотека ASCII включает все буквы в верхнем и нижнем регистре латинского алфавита (A, B, C…), каждую цифру от 0 до 9 и некоторые общие символы (например, /,! И?). Он присваивает каждому из этих символов уникальный трехзначный код и уникальный байт.
В таблице ниже показаны примеры символов ASCII с соответствующими кодами и байтами.
| символ | Код ASCII | БАЙТ |
| А | 065 | 01000001 |
| а | 097 | 01100001 |
| B | 066 | 01000010 |
| б | 098 | 01100010 |
| С УЧАСТИЕМ | 090 | 01011010 |
| с участием | 122 | 01111010 |
| 0 | 048 | 00110000 |
| 9 | 057 | 00111001 |
| ! | 033 | 00100001 |
| ? | 063 | 00111111 |
Подобно тому, как символы объединяются в слова и предложения в языке, двоичный код делает это в текстовых файлах.
01010100 01101000 01100101 00100000 01110001 01110101 01101001 01100011 01101011 00100000 01100010 01110010 01101111 01110111 01101110 00100000 01100110 01101111 01111000 00100000 01101010 01110101 01101101 01110000 01110011 00100000 01101111 01110110 01100101 01110010 00100000 01110100 01101000 01100101 00100000 01101100 01100001 01111010 01111001 00100000 01100100 01101111 01100111 00101110
Это мало что значит для нас, людей, но это хлеб с маслом для компьютера.
Количество символов, которые может представлять ASCII, ограничено количеством доступных уникальных байтов, поскольку каждый символ получает один байт. Если вы посчитаете, то обнаружите, что существует 256 различных способов группировки восьми единиц и нулей вместе. Это дает нам 256 различных байтов или 256 способов представления символа в ASCII. Когда в 1960 году был представлен ASCII, это было нормально, поскольку разработчикам требовалось всего 128 байт для представления всех необходимых им английских символов и символов.
Но по мере глобального распространения компьютерных технологий компьютерные системы начали хранить текст не только на английском, но и на других языках, многие из которых использовали символы, отличные от ASCII. Были созданы новые системы для сопоставления других языков с тем же набором из 256 уникальных байтов, но использование нескольких систем кодирования было неэффективным и запутанным. Разработчикам требовался лучший способ кодирования всех возможных символов с помощью одной системы.
Юникод: способ хранить каждый символ, когда-либо
Используйте Unicode, систему кодирования, которая решает проблему пространства ASCII. Как и ASCII, Unicode присваивает каждому символу уникальный код, называемый кодовой точкой. Однако более сложная система Unicode может генерировать более миллиона кодовых точек, чего более чем достаточно для учета каждого символа на любом языке.
Юникод теперь является универсальным стандартом для кодирования всех человеческих языков. И да, он даже включает смайлы.
Ниже приведены несколько примеров текстовых символов и соответствующих им кодовых точек. Каждая кодовая точка начинается с буквы «U» для «Unicode», за которой следует уникальная строка символов для представления символа.
| символ | Кодовая точка |
| А | U+0041 |
| а | U+0061 |
| 0 | U+0030 |
| 9 | U+0039 |
| ! | U+0021 |
| ОСТРОВ | U + 00D8 |
| ڃ | U+0683 |
| Ch | U + 0C9A |
| 𠜎 | U+2070E |
| 😁 | U+1F601 |
Если вы хотите узнать, как генерируются кодовые точки и что они означают в Unicode, ознакомьтесь с этим подробным объяснением.
Итак, теперь у нас есть стандартизированный способ представления каждого символа, используемого каждым человеческим языком, в единой библиотеке. Это решает проблему нескольких систем маркировки для разных языков – любой компьютер на Земле может использовать Unicode.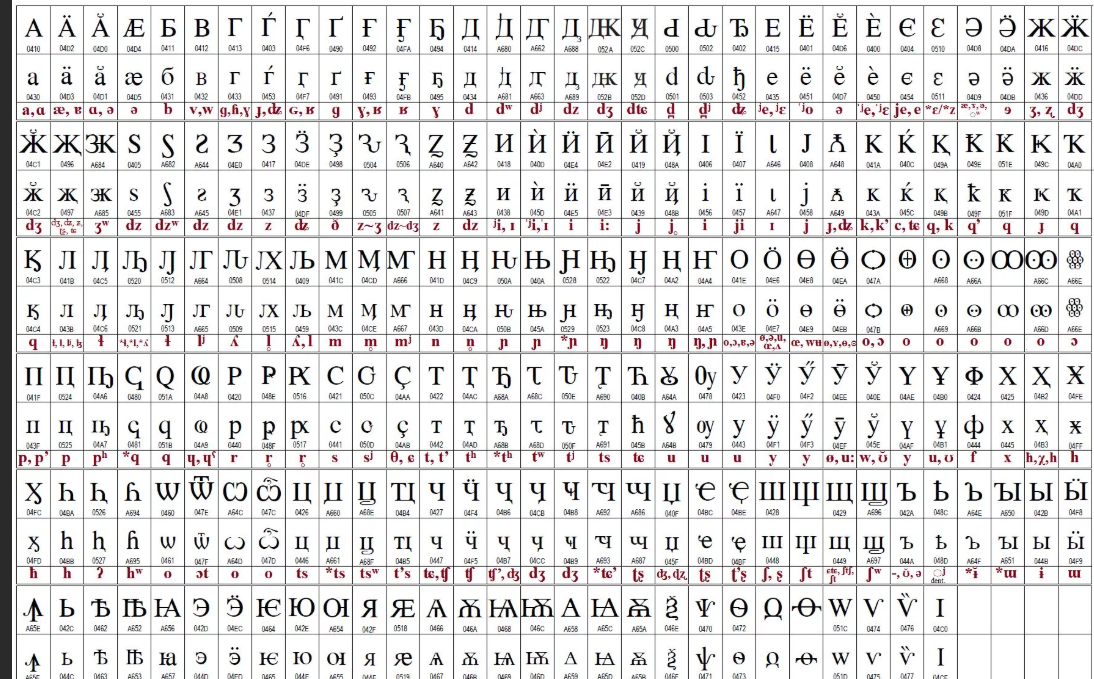
Но один только Unicode не хранит слова в двоичном формате. Компьютерам нужен способ перевода Unicode в двоичный код, чтобы его символы можно было хранить в текстовых файлах. Вот где пригодится UTF-8.
UTF-8: последний кусок головоломки
UTF-8 – это система кодирования Unicode. Он может преобразовывать любой символ Юникода в соответствующую уникальную двоичную строку, а также может преобразовывать двоичную строку обратно в символ Юникода. Это значение «UTF» или «Формат преобразования Unicode».
Помимо UTF-8, существуют и другие системы кодирования Unicode, но UTF-8 уникален, поскольку представляет символы в однобайтовых единицах. Помните, что один байт состоит из восьми бит, отсюда и «-8» в его названии.
Более конкретно, UTF-8 преобразует кодовую точку (которая представляет один символ в Unicode) в набор от одного до четырех байтов. Первые 256 символов в библиотеке Unicode, включая символы, которые мы видели в ASCII, представлены как один байт. Символы, которые появляются позже в библиотеке Unicode, кодируются как двухбайтовые, трехбайтовые и, возможно, четырехбайтовые двоичные единицы.
Ниже приведена та же таблица символов, что и выше, с выводом UTF-8 для каждого добавленного символа. Обратите внимание, что некоторые символы представлены одним байтом, а другие используют больше.
| символ | Кодовая точка | Двоичная кодировка UTF-8 |
| А | U+0041 | 01000001 |
| а | U+0061 | 01100001 |
| 0 | U+0030 | 00110000 |
| 9 | U+0039 | 00111001 |
| ! | U+0021 | 00100001 |
| ОСТРОВ | U + 00D8 | 11000011 10011000 |
| ڃ | U+0683 | 11011010 10000011 |
| Ch | U + 0C9A | 11100000 10110010 10011010 |
| 𠜎 | U+2070E | 11110000 10100000 10011100 10001110 |
| 😁 | U+1F601 | 11110000 10011111 10011000 10000001 |
Почему UTF-8 преобразовывает одни символы в один байт, а другие – в четыре байта? Короче для экономии памяти.
Пространственная эффективность – ключевое преимущество кодировки UTF-8. Если бы вместо этого каждый символ Unicode был представлен четырьмя байтами, текстовый файл, написанный на английском языке, был бы в четыре раза больше, чем тот же файл, закодированный с помощью UTF-8.
Еще одно преимущество кодировки UTF-8 – обратная совместимость с ASCII. Первые 128 символов в библиотеке Unicode соответствуют символам в библиотеке ASCII, и UTF-8 переводит эти 128 символов Unicode в те же двоичные строки, что и ASCII. В результате UTF-8 может без проблем преобразовывать текстовый файл, отформатированный в ASCII, в читаемый человеком текст.
Символы UTF-8 в веб-разработке
UTF-8 – наиболее распространенный метод кодирования символов, используемый сегодня в Интернете, и набор символов по умолчанию для HTML5. Таким образом хранятся персонажи более 95% всех веб-сайтов, в том числе и ваш собственный. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Таким образом хранятся персонажи более 95% всех веб-сайтов, в том числе и ваш собственный. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Поскольку теперь это стандартный метод кодирования текста в Интернете, все страницы вашего сайта и базы данных должны использовать UTF-8. Система управления контентом или конструктор веб-сайтов по умолчанию сохранят ваши файлы в формате UTF-8, но все же рекомендуется убедиться, что вы придерживаетесь этой передовой практики.
Текстовые файлы, закодированные с помощью UTF-8, должны указывать на это программному обеспечению, обрабатывающему их. В противном случае программа не сможет должным образом преобразовать двоичный код обратно в символы. В файлах HTML вы можете увидеть строку кода, подобную следующей, вверху:
<meta charset="UTF-8">
Это сообщает браузеру, что файл HTML закодирован в UTF-8, чтобы браузер мог преобразовать его обратно в разборчивый текст.
UTF-8 против UTF-16
Как я уже упоминал, UTF-8 – не единственный метод кодирования символов Unicode – существует также UTF-16. Эти методы различаются количеством байтов, необходимых для хранения символа. UTF-8 кодирует символ в двоичную строку из одного, двух, трех или четырех байтов. UTF-16 кодирует символ Unicode в строку из двух или четырех байтов.
Это различие видно из их названий. В UTF-8 наименьшее двоичное представление символа составляет один байт или восемь битов. В UTF-16 наименьшее двоичное представление символа составляет два байта или шестнадцать бит.
И UTF-8, и UTF-16 могут переводить символы Unicode в двоичные файлы, удобные для компьютера, и обратно. Однако они несовместимы друг с другом. Эти системы используют разные алгоритмы для сопоставления кодовых точек с двоичными строками, поэтому двоичный вывод для любого заданного символа будет отличаться от обоих методов:
| символ | Двоичная кодировка UTF-8 | Двоичная кодировка UTF-16 |
| А | 01000001 | 01000001 11011000 00001110 11011111 |
| 𠜎 | 11110000 10100000 10011100 10001110 | 01000001 11011000 00001110 11011111 |
Кодировка UTF-8 предпочтительнее UTF-16 на большинстве веб-сайтов, потому что она использует меньше памяти. Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы в двух или четырех байтах. Это означает, что текстовый файл на английском языке с кодировкой UTF-16 будет как минимум вдвое больше размера того же файла с кодировкой UTF-8.
Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы в двух или четырех байтах. Это означает, что текстовый файл на английском языке с кодировкой UTF-16 будет как минимум вдвое больше размера того же файла с кодировкой UTF-8.
UTF-16 более эффективен, чем UTF-8, только на некоторых неанглоязычных сайтах. Если веб-сайт использует язык с символами, находящимися дальше в библиотеке Unicode, UTF-8 будет кодировать все символы как четыре байта, тогда как UTF-16 может кодировать многие из тех же символов только как два байта. Тем не менее, если ваши страницы заполнены буквами ABC и 123, придерживайтесь UTF-8.
Расшифровка мира кодировки UTF-8
Это было много слов о словах, поэтому давайте резюмируем то, что мы рассмотрели:
- Компьютеры хранят данные, включая текстовые символы, как двоичные (единицы и нули).
- ASCII был ранним способом кодирования или отображения символов в двоичный код, чтобы компьютеры могли их хранить.
 Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.
Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате. - Юникод был решением этой проблемы. Юникод присваивает уникальный «код» каждому символу на каждом человеческом языке.
- UTF-8 – это метод кодировки символов Unicode. Это означает, что UTF-8 берет кодовую точку для данного символа Юникода и переводит ее в строку двоичного кода. Он также делает обратное, считывая двоичные цифры и преобразуя их обратно в символы.
- UTF-8 в настоящее время является самым популярным методом кодирования в Интернете, поскольку он может эффективно хранить текст, содержащий любой символ.
- UTF-16 – еще один метод кодирования, но он менее эффективен для хранения текстовых файлов (за исключением тех, которые написаны на некоторых неанглийских языках).
 Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.
Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.Перевод Unicode – это не то, о чем большинству из нас нужно думать при просмотре или разработке веб-сайтов, и именно в этом суть – создать бесшовную систему обработки текста, которая работает для всех языков и веб-браузеров. Если он работает хорошо, вы этого не заметите.
Если он работает хорошо, вы этого не заметите.
Но если вы обнаружите, что страницы вашего веб-сайта занимают чрезмерно много места или если ваш текст завален буквами and и, пора применить ваши новые знания о UTF-8.
Источник записи: https://blog.hubspot.com
/UTF-8 (установка наборов символов исходного кода и выполнения в UTF-8 )
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Задает как исходную кодировку, так и кодировку выполнения в виде UTF-8 .
Синтаксис
/utf-8
С помощью параметра можно /utf-8 указать как кодировку исходного кода, так и кодировку выполнения, используя UTF-8 . Он эквивалентен указанию /source-charset:utf-8 /execution-charset:utf-8 в командной строке. Любой из этих параметров также включает /validate-charset параметр по умолчанию. Список поддерживаемых идентификаторов кодовых страниц и имен наборов символов см. в разделе идентификаторы кодовых страниц.
по умолчанию Visual Studio обнаруживает метку порядка следования байтов, чтобы определить, имеет ли исходный файл формат в кодировке юникод, UTF-16 например или UTF-8 . Если метка порядка следования байтов не найдена, предполагается, что исходный файл кодируется в кодовой странице текущего пользователя, если не указана кодовая страница с помощью /utf-8 или /source-charset параметра. Visual Studio позволяет сохранить исходный код C++ в любой из нескольких кодировок символов. Сведения о кодировках исходного кода и выполнения см. в разделе наборы символов в документации по языку.
Visual Studio позволяет сохранить исходный код C++ в любой из нескольких кодировок символов. Сведения о кодировках исходного кода и выполнения см. в разделе наборы символов в документации по языку.
установка параметра в Visual Studio или программными средствами
Установка данного параметра компилятора в среде разработки Visual Studio
Откройте диалоговое окно Окна свойств проекта. Подробнее см. в статье Настройка компилятора C++ и свойств сборки в Visual Studio.
Выберите страницу свойств Свойства> конфигурацииC/C++>Командная строка .
В окне Дополнительные параметрыдобавьте
/utf-8параметр, чтобы указать предпочтительную кодировку.Выберите ОК для сохранения внесенных изменений.
Установка данного параметра компилятора программным способом
- См. раздел AdditionalOptions.
См. также
MSVC параметры компилятора
Синтаксис командной строки компилятора MSVC/execution-charset (Задать набор символов выполнения)/source-charset (Задать исходную кодировку)/validate-charset (Проверка для совместимых символов)
Вместо символов на самом деле правильнее ссылаться на кодовых точек при обсуждении систем кодирования. Кодовые точки позволяют абстрагироваться от термина символов и являются элементарной единицей хранения информации в кодировке. Большинство кодовых точек представляют один символ, но некоторые представляют такую информацию, как форматирование.
UTF-8 — это стандарт кодирования «переменной ширины». Это означает, что он кодирует каждую кодовую точку разным количеством байтов, от одного до четырех. В целях экономии места часто используемые кодовые точки представлены меньшим количеством байтов, чем редко появляющиеся кодовые точки.
В целях экономии места часто используемые кодовые точки представлены меньшим количеством байтов, чем редко появляющиеся кодовые точки.
Обратная совместимость с ASCII
UTF-8 использует один байт для представления кодовых точек от 0 до 127. Эти первые 128 кодовых точек Unicode полностью соответствуют сопоставлению символов ASCII, поэтому символы ASCII также являются допустимыми символами UTF-8.
Как работает UTF-8: пример
Первый байт UTF-8 указывает, сколько байтов последует за ним. Затем биты кодовой точки «распределяются» по следующим байтам. Лучше всего это пояснить на примере:
Unicode присваивает французской букве é кодовую точку U+00E9.. Это 11101001 в двоичном формате; он не является частью набора символов ASCII. UTF-8 представляет это восьмибитное число двумя байтами.
Старшие биты обоих байтов содержат метаданные. Первый байт начинается с 110 . Единицы указывают, что это двухбайтовая последовательность, а 0 указывает, что биты кодовой точки будут следовать. Второй байт начинается с 10, чтобы сигнализировать о том, что он является продолжением последовательности UTF-8.
Второй байт начинается с 10, чтобы сигнализировать о том, что он является продолжением последовательности UTF-8.
Остается 11 «слотов» для битов кодовой точки. Помните, что U+00E9кодовая точка требует только восемь бит. UTF-8 дополняет начальные биты тремя 0 с, чтобы полностью «заполнить» оставшиеся пробелы.
Результирующее представление UTF-8 для é (U+00E9): 1100001110101001 .
Как Twilio обрабатывает символы UTF-8?
UTF-8 является доминирующей кодировкой World Wide Web, поэтому ваш код, скорее всего, закодирован в соответствии с этим стандартом.
Для SMS-сообщений Twilio использует самый компактный доступный метод кодирования. Twilio по умолчанию использует GSM-7 и возвращается к UCS-2, если ваше сообщение содержит какие-либо символы, отличные от GSM-7. Использование стандартов кодирования GSM-7 по сравнению со стандартами кодирования UCS-2 может повлиять на количество сегментов, необходимых для отправки вашего сообщения.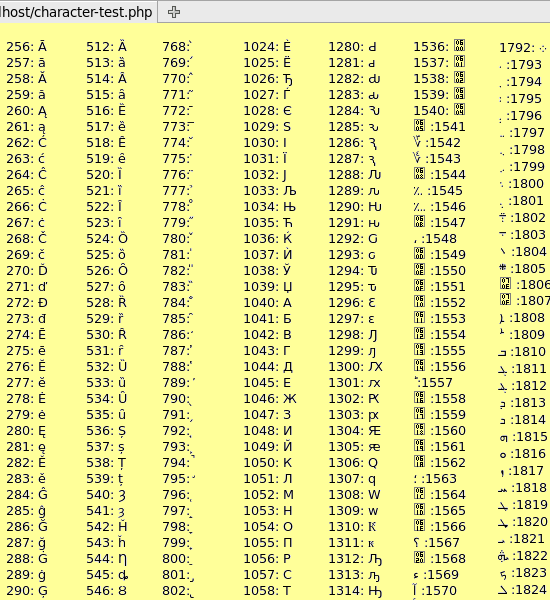
Twilio Copilot автоматически распознает символы Unicode, которые легко пропустить, например умные кавычки (〞) или длинное тире (—), и заменяет их аналогичным символом. Это позволяет максимально снизить количество сегментов сообщений и цены.
Не беспокойтесь, если ваша строка «Ooh làlà» в кодировке UTF-8 придет по SMS — программируемое SMS Twilio поможет вам.
Готовы начать строительство? Зарегистрироваться сейчас.
Оцените эту страницу:1 2 3 4 5
Как работает кодировка Unicode UTF-8
UTF-8 — это умный способ кодирования текста Unicode. Я упоминал об этом пару раз в последнее время, но я не писал в блоге об UTF-8 как таковой. Вот оно.
Проблема, которую решает UTF-8
Американские клавиатуры часто могут выводить 101 символ, что означает, что 101 символа будет достаточно для большинства текстов на английском языке. Семи бит будет достаточно для кодирования этих символов, поскольку 2 7 = 128, и это то, что делает ASCII . Он представляет каждый символ с помощью 8 бит, поскольку компьютеры работают с битами в группах размеров, которые являются степенью двойки, но первый бит всегда равен 0, потому что он не нужен. Расширенный ASCII использует оставшееся пространство в ASCII для кодирования дополнительных символов.
Он представляет каждый символ с помощью 8 бит, поскольку компьютеры работают с битами в группах размеров, которые являются степенью двойки, но первый бит всегда равен 0, потому что он не нужен. Расширенный ASCII использует оставшееся пространство в ASCII для кодирования дополнительных символов.
В общей сложности 256 символов могут быть полезны некоторым пользователям, но они не позволят вам представлять, например, китайский язык. Первоначально Unicode хотел использовать два байта вместо одного байта для представления символов, что дало бы 2 16 = 65 536 возможностей, что было бы достаточно для охвата множества систем письма в мире. Но не все, и поэтому Юникод расширен до четырех байт.
Если бы вы хранили текст на английском языке, используя два байта для каждой буквы, половина пространства была бы потеряна для хранения нулей. И если бы вы использовали четыре байта на букву, три четверти пространства были бы потрачены впустую. Без какой-либо кодировки каждый файл, содержащий английский тест, был бы в два-четыре раза больше необходимого . И не только английский, но и все языки, которые могут быть представлены с помощью ASCII.
И не только английский, но и все языки, которые могут быть представлены с помощью ASCII.
UTF-8 — это способ кодирования Unicode, при котором текстовый файл ASCII кодирует сам себя. Никакого лишнего пространства, кроме начального бита каждого байта, который ASCII не использует. И если ваш файл в основном представляет собой текст ASCII с добавлением нескольких символов, отличных от ASCII, символы, отличные от ASCII, просто сделают ваш файл немного длиннее. Вам не нужно внезапно заставлять каждый символ занимать в два или четыре раза больше места только потому, что вы хотите использовать, скажем, знак евро € (U+20AC).
Как это делает UTF-8
Поскольку первый бит символов ASCII установлен в ноль, байты с первым битом, установленным в 1, не используются и могут использоваться специально.
Когда программное обеспечение, читающее кодировку UTF-8, встречает байт, начинающийся с 1, оно подсчитывает, сколько единиц следует за ним, прежде чем встретится с 0. Например, в байте вида 110xxxxx за начальной 1 следует одна 1. Пусть n — количество единиц между начальной 1 и первым 0. Оставшиеся биты в этом байте и некоторые биты в следующих n байт будут представлять символ Unicode. Нет необходимости, чтобы n было больше 3 по причинам, к которым мы вернемся позже. То есть для представления символа Unicode с использованием UTF-8 требуется не более четырех байтов.
Пусть n — количество единиц между начальной 1 и первым 0. Оставшиеся биты в этом байте и некоторые биты в следующих n байт будут представлять символ Unicode. Нет необходимости, чтобы n было больше 3 по причинам, к которым мы вернемся позже. То есть для представления символа Unicode с использованием UTF-8 требуется не более четырех байтов.
Таким образом, байт вида 110xxxxx говорит о том, что первые пять битов символа Юникода хранятся в конце этого байта, а остальные биты идут в следующем байте.
Байт вида 1110xxxx содержит четыре бита символа Unicode и говорит о том, что остальные биты приходятся на следующие два байта.
Байт вида 11110xxx содержит три бита символа Unicode и говорит о том, что остальные биты приходятся на следующие три байта.
После начального байта, уведомляющего о начале символа, распределенного по нескольким байтам, биты сохраняются в байтах формы 10xxxxxx. Поскольку начальные байты многобайтовой последовательности начинаются с двух битов 1, двусмысленности нет: байт, начинающийся с 10, не может обозначать начало новой многобайтовой последовательности. То есть UTF-8 является самопунктуирующим.
То есть UTF-8 является самопунктуирующим.
Итак, многобайтовые последовательности имеют одну из следующих форм.
110ххххх 10хххххх
1110хххх 10хххххх 10хххххх
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Если посчитать крестики в нижнем ряду, их 21. Таким образом, эта схема может представлять только числа длиной до 21 бита. Разве нам не нужны 32 бита? Оказывается, нет.
Хотя символ Unicode якобы является 32-битным числом, на самом деле для кодирования символа Unicode требуется не более 21 бита по причинам, описанным здесь. Вот почему n , количество единиц, следующих за начальной 1 в начале многобайтовой последовательности, должно быть только 1, 2 или 3. Схема кодирования UTF-8 может быть расширена, чтобы разрешить n = 4, 5, или 6, но это необязательно.
Эффективность
UTF-8 позволяет вам взять обычный файл ASCII и считать его файлом Unicode, закодированным с помощью UTF-8. Таким образом, UTF-8 так же эффективен, как ASCII, с точки зрения пространства.