Парсинг YouTube, включая подгружаемые данные, без YouTube API / Хабр
Чтобы подгрузить данные контента на ютубе, обычно используют либо Selenium, либо YouTube API. Однако везде есть свои минусы.
- Selenium слишком медленный для парсинга. Представьте себе парсинг плейлиста из ~1000 роликов селениумом.
- YouTube API, конечно, наилучший вариант, если у вас какое-то свое приложение или проект, но там требуется зарегистрировать приложение и т.д. В «пробной» версии вам нужно постоянно авторизовываться для использования апи, еще там присутствует быстро заканчиваемая квота.
- В нашем методе, я бы сказал, очень сложные структуры данных, выдаваемыми ютубом. Особенно нестабильно работает парсинг поиска ютуб.
Как подгружать данные на ютубе?
Для этого есть токен, который можно найти в html коде страницы. Потом в дальнейшем его используем, как параметр для запроса к ютубу, выдающему нам новый контент. Сам ютуб прогружает контент с помощью запроса, где как раз используется этот токен.
Сам ютуб прогружает контент с помощью запроса, где как раз используется этот токен.
Там есть дополнительные исходящие параметры, которые нам будут нужны в следующем шаге.
Получение токена через скрипт
Составляем параметр headers для запроса к ютубу. Помимо user-agent вставляем два дополнительных, которые вы видите ниже.
headers = {
'User-Agent': 'Вы можете взять свой или сгенерировать онлайн, но возможно он не будет работать',
'x-youtube-client-name': '1',
'x-youtube-client-version': '2.20200529.02.01'
}
Делаем запрос с помощью библиотеки requests. Ставляете ссылку на страницу, которую нужно прогрузить, а также добавляете headers.
token_page = requests.get(url, headers=headers)
Токен невозможно найти парсерами, т.к он спрятан в тэге script. Чтобы сохранить его в переменную, я прописываю такой некрасивый код:
nextDataToken = token_page.text.split('"nextContinuationData":{"continuation":"')[1].split('","')[0]
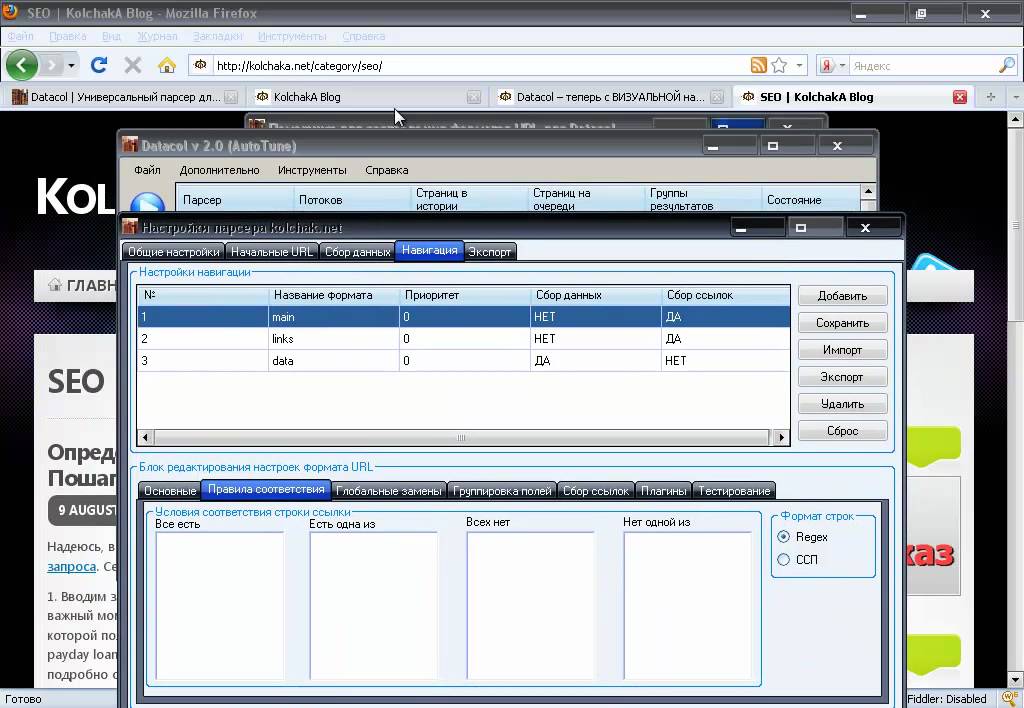 text.split('"nextContinuationData":{"continuation":"')[1].split('","')[0]
text.split('"nextContinuationData":{"continuation":"')[1].split('","')[0]
Обычно это токен длиной 80 символов.
Делаем запрос на получение контента
service = 'https://www.youtube.com/browse_ajax'
params = {
"ctoken": nextDataToken,
"continuation": nextDataToken
}
r = requests.post(service, params=params, headers=headers)
Разные типы подгружаемых данных имеют разные service ссылки. Наша подойдет для плейлистов и видео с каналов.
Данные Ютуб присылает в json формате. Поэтому пишем r.json(), но вам прилетит список, нам нужен второй элемент списка, поэтому r.json()[1]. Далее у нас уже имеются данные. Остается парсить.
Парсинг json ответа
Можно увидеть длинные цепочки словарей, но мы их сократим, чтобы было более менее понятно.
r_jsonResponse = r_json['response'] dataContainer = r_jsonResponse["continuationContents"]["playlistVideoListContinuation"] nextDataToken = dataContainer["continuations"][0]["nextContinuationData"]["continuation"]
Здесь мы получаем новый токен для дальнейшего запроса. Если подгружаемые данные закончились, то токена вы не увидите.
Если подгружаемые данные закончились, то токена вы не увидите.
for content in dataContainer["contents"]: videoId = content['playlistVideoRenderer']['videoId']
Вот так можно извлечь id видеоролика, дописав шаблонную часть, вы получите ссылку на видеоролик.
Чтобы получить следующие данные, вы должны проделать тоже самое — запрос токеном, парсинг и потом снова.
Полностью рабочий код выглядит вот так:
import requests, json
url = input('url: ')
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36",
'x-youtube-client-name': '1',
'x-youtube-client-version': '2.20200429.03.00',
}
token_page = requests.get(url, headers=headers)
nextDataToken = token_page.text.split('"nextContinuationData":{"continuation":"')[1].split('","')[0]
sleep = False #Цикл будет завершен, когда не будет токенов
ids = []
while not sleep:
service = 'https://www. youtube.com/browse_ajax'
params = {
"ctoken": nextDataToken,
"continuation": nextDataToken
}
r = requests.post(service, params=params, headers=headers)
r_json = r.json()[1]
r_jsonResponse = r_json['response']
dataContainer = r_jsonResponse["continuationContents"]["playlistVideoListContinuation"]
try: #пробуем найти токен
nextDataToken = dataContainer["continuations"][0]["nextContinuationData"]["continuation"]
except:
#токен не найден. Значит, далее запроса не будет. Остается собрать оставшийся контент
sleep = True
for content in dataContainer["contents"]:
videoId = content['playlistVideoRenderer']['videoId']
ids.append(videoId)
print(len(ids))
 youtube.com/browse_ajax'
params = {
"ctoken": nextDataToken,
"continuation": nextDataToken
}
r = requests.post(service, params=params, headers=headers)
r_json = r.json()[1]
r_jsonResponse = r_json['response']
dataContainer = r_jsonResponse["continuationContents"]["playlistVideoListContinuation"]
try: #пробуем найти токен
nextDataToken = dataContainer["continuations"][0]["nextContinuationData"]["continuation"]
except:
#токен не найден. Значит, далее запроса не будет. Остается собрать оставшийся контент
sleep = True
for content in dataContainer["contents"]:
videoId = content['playlistVideoRenderer']['videoId']
ids.append(videoId)
print(len(ids))
youtube.com/browse_ajax'
params = {
"ctoken": nextDataToken,
"continuation": nextDataToken
}
r = requests.post(service, params=params, headers=headers)
r_json = r.json()[1]
r_jsonResponse = r_json['response']
dataContainer = r_jsonResponse["continuationContents"]["playlistVideoListContinuation"]
try: #пробуем найти токен
nextDataToken = dataContainer["continuations"][0]["nextContinuationData"]["continuation"]
except:
#токен не найден. Значит, далее запроса не будет. Остается собрать оставшийся контент
sleep = True
for content in dataContainer["contents"]:
videoId = content['playlistVideoRenderer']['videoId']
ids.append(videoId)
print(len(ids))
Вы можете посмотреть мои парсеры каналов, плейлистов, видеороликов Ютуба на GitHub.
скрапинг видео, комментариев и других данных
Перевод статьи YouTube Scraper 101: How to Scrape YouTube video, comments… от JudithbConnerv.
Photo by Lianhao Qu on UnsplashИщете подходящий YouTube-скрапер? В этой статье вы найдёте лучшие веб-скраперы, которые можно использовать для извлечения данных из YouTube, а также узнаете об особенностях создания собственного скрапера.
YouTube — это второй по популярности после Google поисковой движок. Но тут важнее не популярность YouTube как поисковика, а огромное количество видео на этом ресурсе, а также сопутствующих данных, комментариев. Возможно, вы сейчас гадаете: в чём же польза от скрапинга YouTube?
На самом деле, данным с YouTube найдётся масса применений, таких как мониторинг рейтингов, анализ настроений комментариев пользователей, создание базы описаний видео и многое другое. Для маркетологов YouTube и независимых исследователей такие данные представляют большую ценность.
YouTube предоставляет очень ограниченные возможности для доступа к общедоступным данным с некоторыми ограничениями. Если вам нужно обойти эти ограничения правильно, обычно приходится договариваться и платить. Далеко не все могут пойти этим путём, поэтому самый распространённый способ сбора общедоступных данных – использование веб-скраперов – программ, написанных специально для автоматизации добычи данных с YouTube.
В этой статье мы расскажем вам о лучших веб-скраперах для YouTube. Также вы узнаете, как распарсить его самостоятельно с помощью Python, Requests и Beautiful Soup. Но сперва мы рассмотрим основные особенности скрапинга YouTube.
Также вы узнаете, как распарсить его самостоятельно с помощью Python, Requests и Beautiful Soup. Но сперва мы рассмотрим основные особенности скрапинга YouTube.
Данные, которые мы можем вытянуть из YouTube, – это видео, комментарии, рекомендации видео, рейтинги, реклама внутри видео. Интересовались ли вы когда-нибудь, что YouTube думает об использовании веб-скраперов на его страницах? Он не разрешает собирать данные с их помощью: выгоднее, чтобы вы пользовались именно платным API.
В общем, YouTube не любит, чтобы его скрапили. Но делает ли это такой способ добычи данных незаконным? Однозначно, нет. Судебный процесс против HiQ со стороны LinkedIn и последующие иски и решения прояснили кое-что насчёт веб-скрапинга: на общих основаниях он полностью законен, и вы можете прибегать к нему, не спрашивая разрешения.
Photo by Azamat E on UnsplashНо на пути у вас всё ещё стоят anti-scraping и anti-bot системы YouTube. Этот ресурс обладает умной anti-scraping системой, предназначенной для обнаружения и предотвращения работы ботов. Если вам всё-таки нужно вытянуть оттуда данные, вам понадобится скрапер, который сможет пройти все проверки anti-scraping и anti-bot систем. К счастью, существует много таких программ для разных платформ.
Если вам всё-таки нужно вытянуть оттуда данные, вам понадобится скрапер, который сможет пройти все проверки anti-scraping и anti-bot систем. К счастью, существует много таких программ для разных платформ.
Интересно, что при наличии навыков программирования вы сможете написать свой скрапер самостоятельно. Если не получится, всегда можно вернуться к этому списку и воспользоваться одним из готовых решений.
Как скрапить YouTube с помощью Python, Requests, и Beautiful Soup
Будучи программистом, вы можете разработать собственный веб-скрапер, но это не так просто, как может показаться.
Во-первых, вы должны понимать, что скрапер, написанный для пары страниц, отличается от того, что потребуется для обработки сотен или тысяч.
Простой скрапер разбирает 20 страниц (а может, и больше), не встречая никаких преград. Но если вы будете скрапить намного больше страниц, вам придётся иметь дело с блокировщиками IP и капчами. Anti-scraping технологий много, но обход капчей и блокировщиков решает большую часть проблем.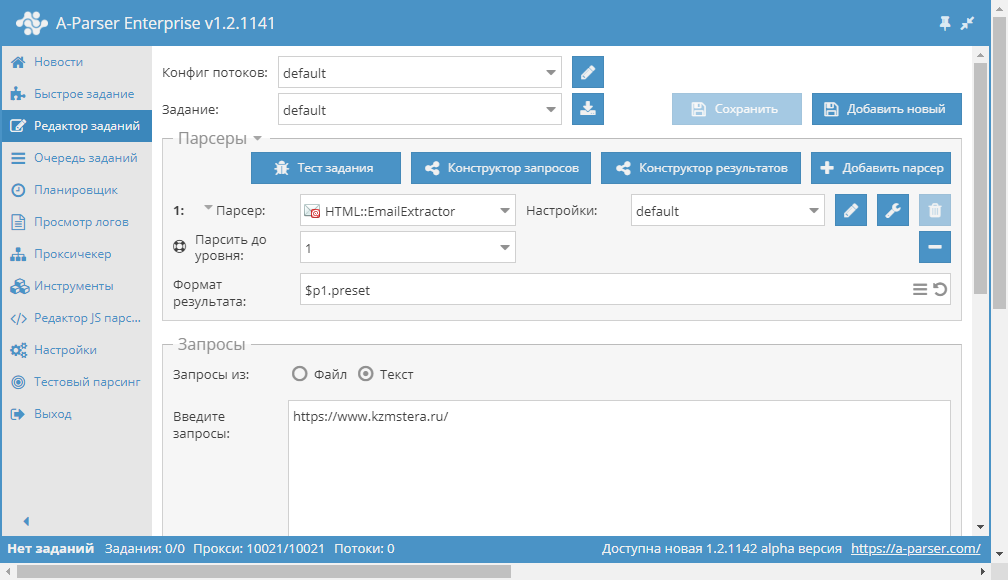
Реализовать такой скрапер проще всего на Python, так как этот язык предоставляет библиотеки и фреймворки, которые упростят разработку.
То, какие библиотеки вам понадобятся, в большинстве случаев зависит от типа данных, которые нужно собрать. Если выполнение скриптов и JavaScript-рендеринг не нужны, подойдут Requests и Beautiful Soup, Scrapy тоже будет хорошим выбором. Но если требуется выполнить js-скрипты, чтобы вытянуть данные, лучшим решением будет Selenium.
Разрабатывая веб-скрапер для YouTube, нужно обеспечить избегание блокировки IP и прохождение капчей. Скрыть IP и избежать блокировки вам помогут прокси, а расправиться с капчами при их срабатывании — решатели капчей.
Если вы собираетесь обработать большое количество страниц, а процесс требуется ускорить, стоит задуматься о применении многопоточности. Ниже представлен простой скрапер YouTube, который принимает URL видео и возвращает количество его просмотров.
Лучшие скраперы YouTubeimport requests from bs4 import BeautifulSoup class YoutubeScraper: def __init__(self, url): self.
 url = url
def scrape_video_count(self):
content = requests.get(self.url)
soup = BeautifulSoup(content.text, "html.parser")
view_count = soup.find("div", {"class": "watch-view-count"}).text
return view_count
url = "https://www.youtube.com/watch?v=VpTKbfZhyj0"
x = YoutubeScraper(url)
x.scrape_video_count()
url = url
def scrape_video_count(self):
content = requests.get(self.url)
soup = BeautifulSoup(content.text, "html.parser")
view_count = soup.find("div", {"class": "watch-view-count"}).text
return view_count
url = "https://www.youtube.com/watch?v=VpTKbfZhyj0"
x = YoutubeScraper(url)
x.scrape_video_count()Если же вы не программист, вы можете найти готовые скраперы для YouTube (вам не придется написать ни строчки кода). Впрочем, не все из них «non-code» – некоторые потребуют от вас определённых навыков. Ниже представлены лучшие программы, которые можно использовать для скрапинга YouTube.
Octoparse- Цена: от $75/месяц
- Бесплатные пробные версии: 14 дней бесплатно с ограничениями
- Формат данных: CSV, Excel, JSON, MySQL, SQLServer
- Платформы: Cloud, Desktop
Если вам надоели блокировки, представляем вам Octoparse — скрапер, который поможет справиться с проверками безопасности даже на самых продвинутых сайтах. Пожалуй, это один из лучших веб-скраперов на рынке. Вы можете использовать его для добычи общедоступных текстовых данных с YouTube.
Пожалуй, это один из лучших веб-скраперов на рынке. Вы можете использовать его для добычи общедоступных текстовых данных с YouTube.
Octoparse облегчает процесс скрапинга, ведь в нём уже есть готовые шаблоны для работы с популярными сайтами, что избавляет вас от необходимости с нуля прописывать все правила для определённых сайтов.
ScrapeStorm- Цена: от $49.99 /месяц
- Бесплатные пробные версии: Starter plan бесплатно с ограничениями
- Формат данных: TXT, CSV, Excel, JSON, MySQL, Google Sheets, и т.д.
- Платформы: Desktop
ScrapeStorm – один из наиболее универсальных скраперов, так как его можно использовать для скрапинга почти всех сайтов (и YouTube в том числе). Поддерживается он всеми наиболее популярными операционными системами. Также доступна версия на базе облачных технологий.
Этот инструмент использует искусственный интеллект, который в большинстве случаев автоматически распознаёт данные и парсит их без вмешательства человека.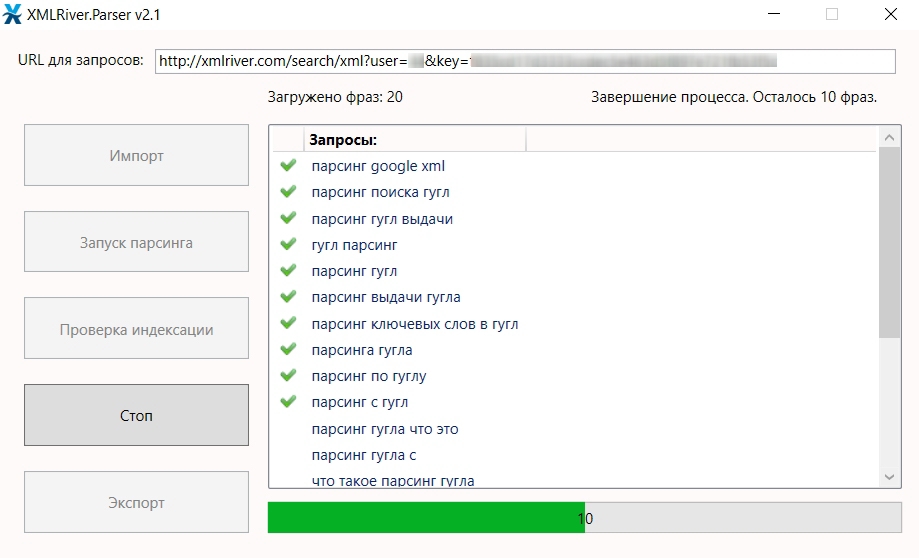
- Цена: от $19/месяц
- Бесплатные пробные версии: стартовый план (500 страниц) бесплатно
- Формат данных: CSV, Excel
- Платформы: браузеры Chrome и Edge
Data Miner – расширение для браузера с поддержкой Chrome и Microsoft Edge. Data Miner также может использоваться для скрапинга YouTube. С таким скрапером можно не бояться обнаружения, потому что он умеет скрывать подозрительное поведение.
Data Miner не выдаст ваши данные, а ещё он поддерживает более 15000 сайтов. Здесь есть бесплатный тариф, который, возможно, идеально вам подойдёт, если вы не планируете скрапить в крупных масштабах.
Что вам точно понравится в Data Miner, – это более 50000 предварительно созданных запросов, которые помогут вам выполнить работу одним щелчком мыши. Data Miner заполняет формы, упрощает автоматический парсинг и обеспечивает поддержку пользовательского парсинга.
- Цена: от $149/месяц
- Бесплатные пробные версии: Desktop бесплатна с некоторыми ограничениями
- Формат данных: Excel, JSON
- Платформы: Cloud, Desktop
ParseHub это ещё одно устанавливаемое программное обеспечение, которое можно использовать для скрапинга. ParseHub не является специализированным инструментом для парсинга YouTube, как и другие в этом списке. Тем не менее, он предоставляет средства для добычи общедоступных данных на YouTube, и на данный момент является одним из лучших инструментов на этом рынке.
Десктопная версия ParseHub бесплатна (с некоторыми ограничениями). А вот за облачную версию придётся платить, но она предлагает большое количество дополнительных функций.
Helium Scraper- Цена: лицензия от $99
- Бесплатные пробные версии: весь функционал предоставляется бесплатно на 10 дней
- Формат данных: CSV, Excel, XML, JSON, SQLite
- Платформы: Desktop
Ещё один отличный инструмент, который можно применить для скрапинга видео, комментариев, рейтингов и других общедоступных данных на YouTube. Чтобы использовать Helium Scraper, его нужно установить на компьютер.
Чтобы использовать Helium Scraper, его нужно установить на компьютер.
Большое преимущество этого скрапера – широкий спектр функций, которые позволяют парсить в крупных масштабах. К числу этих функций относятся:
- запланированный скрапинг,
- способность быстро собирать данные со сложной структурой,
- система обнаружения аналогичных элементов,
- ротация прокси,
- экспорт собранных данных в различные форматы и многое другое.
Заключение
Ни один из перечисленных выше скраперов, как вы можете заметить, не предназначен исключительно для YouTube (хотя на рынке есть и такие). Универсальные скраперы позволят вам работать с куда бо́льшим количеством сайтов, если возникнет такая необходимость.
youtube-url-parser — Анализ работоспособности пакета npm
Все уязвимости безопасности относятся к производственных зависимостей прямых и косвенных пакеты. Уязвимости |
Популярные
- С
- Н
- М
- Л
Ваш проект подвержен уязвимостям?
Сканируйте свои проекты на наличие уязвимостей. Быстро исправить с помощью автоматизированного
исправления. Начните работу со Snyk бесплатно.
Быстро исправить с помощью автоматизированного
исправления. Начните работу со Snyk бесплатно.
Начните бесплатно
Еженедельные загрузки (1)
Скачать тренд
- Звезды GitHub
- 0
- Вилки
- 0
- Авторы
- 1
Популярность прямого использования
Пакет npm youtube-url-parser получает в общей сложности 1 загрузка в неделю. Таким образом, мы забили Уровень популярности youtube-url-parser будет ограничен.
На основе статистики проекта из репозитория GitHub для
npm package youtube-url-parser, мы обнаружили, что он
снялся? раз.
Загрузки рассчитываются как скользящие средние за период из последних 12 месяцев, за исключением выходных и известных отсутствующих точек данных.
Частота фиксации
Нет последних коммитов
- Открытые задачи
- 0
- Открыть PR
- 0
- Последняя версия
- 4 года назад
- Последняя фиксация
- 4 года назад
Дальнейший анализ состояния обслуживания youtube-url-parser на основе
каденция выпущенных версий npm, активность репозитория,
и другие точки данных определили, что его обслуживание
Неактивный.
Важным сигналом обслуживания проекта для youtube-url-parser является это не видел никаких новых версий, выпущенных для npm в за последние 12 месяцев и может считаться прекращенным проектом или проектом, который получает мало внимания со стороны его сопровождающих.
За последний месяц мы не обнаружили никаких запросов на вытягивание или изменений в статус issue был обнаружен для репозитория GitHub.
- Совместимость с Node.js
- не определен
- Возраст
- 4 года
- Зависимости
- 0 Прямые
- Версии
- 2
- Установочный размер
- 1 КБ
- Распределенные теги
- 1
- Количество файлов
- 3
- Обслуживающий персонал
- 1
- Типы TS
- Нет
youtube-url-parser имеет более одного и последнего тега по умолчанию, опубликованного для
пакет нпм. Это означает, что для этого могут быть доступны другие теги.
пакет, например рядом, чтобы указать будущие выпуски, или стабильный, чтобы указать
стабильные релизы.
Это означает, что для этого могут быть доступны другие теги.
пакет, например рядом, чтобы указать будущие выпуски, или стабильный, чтобы указать
стабильные релизы.
youtube-title-parse · PyPI
Описание проекта
Проанализируйте название видео на YouTube, чтобы попытаться получить имя исполнителя и песни.
Описание
Заголовки видео на YouTube не имеют строгого формата, поэтому передача заголовков непосредственно музыкальным API для извлечения метаданных вряд ли работает. Этот модуль пытается распознать общие шаблоны (используя регулярное выражение) и извлечь исполнителя и название песни.
Установка
Чтобы установить youtube_title_parse, просто используйте pipenv (или pip, конечно):
pipenv install youtube_title_parse
Использование
Интерфейс командной строки
youtube_title_parse поставляется с интерфейсом командной строки, который вы можете использовать напрямую:
$ youtube_title_parse "Сеул — оставайтесь с нами (официальное видео)"
Сеул - оставайтесь с нами
Модуль
Вы также можете импортировать youtube_title_parse как модуль.
из youtube_title_parse импортировать get_artist_title
artist, title = get_artist_title("Сеул - Оставайтесь с нами (Официальное видео)")
утверждать, что художник == "Сеул"
утверждать title == "Оставайтесь с нами"
Кредиты
Этот модуль изначально представляет собой переписанную Python3 эквивалентную библиотеку npm, get-artist-title , но добавляет некоторые дополнительные функции, чтобы улавливать больше паттернов.
Участие
Вытягивающие запросы и звездочки всегда приветствуются. Для ошибок и запросов функций, пожалуйста, создайте проблему.
License
youtube-title-parse доступен по лицензии MIT.
Детали проекта
Эта версия
1.0.0
1.0.0b3 предварительный выпуск
1.0.0b2 предварительный выпуск
1.0.0b1 предварительный выпуск
Загрузить файлы
Загрузить файл для вашей платформы. Если вы не уверены, что выбрать, узнайте больше об установке пакетов.
Исходный дистрибутив
youtube_title_parse-1.0.0.tar.gz (13,5 КБ посмотреть хеши)
Загружено источник
Встроенный дистрибутив
youtube_title_parse-1.0.0-py2.py3-none-any.whl (9,7 КБ посмотреть хеши)
Загружено ру2 ру3
Закрывать
Хэши для youtube_title_parse-1.0.0.tar.gz
| Алгоритм | Дайджест хэша | |
|---|---|---|
| ША256 | 350cc055c058e8f639ac7e1cbc67a1fb485a4bb5fcd1f9645d79d1ccc8e3518d | |
| MD5 | 682eed5c5584d8cf21e9ac61a69a8261 | |
| БЛЕЙК2б-256 | 347259407b949e51e6f174d4b6ceaa175034a66c6b6770285242cc41d8e2c775 |
Закрывать
Хэши для youtube_title_parse-1.