Universal online Cyrillic decoder — recover your texts
Universal online Cyrillic decoder — recover your texts Version: 20220421 By the same author: Virtour.fr — visites virtuelles Հայերեն —
Башҡорт — Беларуская — Български —
Иронау —
Қазақша —
Кыргызча — Македонски —
Монгол
Нохчийн — O’zbek — Русский — Slovensky — Српски — Татарча — Тоҷикӣ — Українська — Чaваш — Français — English
Output
The resulting text will be displayed here…
| Guestbook Please link to this site! | Custom Work For a small fee I can help you quickly recode/recover large pieces of data — texts, databases, websites… or write custom functions you can use (invoice available).  FAQ and contact information. |
About the program
Welcome! You may find this site useful, if you have recieved some texts that you believe are written in the Cyrillic alphabet, but instead are displayed in some strange combination of bizarre characters. This program will try to guess the encoding, and if it does not, it will show samples, examples of all encoding-combinations, so as you will be able to select the good one.
How to
- Paste the text to decode in the big text area. The first few words will be analyzed so they should be (scrambled) in supposed Cyrillic.
- The program will try to decode the text and will print the result below.
- If the translation is successful, you will see the text in Cyrillic characters and will be able to copy it and save it if it’s important.
- If the translation isn’t successful (still the text is not in Cyrillic but in the same or other unintelligible characters), you can choose from the newly created select-listbox the variant that is in Cyrillic (if there are more than one, select the longest).
 By pressing the button OK you will have the correct text converted.
By pressing the button OK you will have the correct text converted. - If the text is not totally converted, try all other variants in Cyrillic from the select-listbox.
 By pressing the button OK you will have the correct text converted.
By pressing the button OK you will have the correct text converted.Limits
- If your text contains question marks «???? ?? ??????», the problem is with the sender and no recovery will be possible. Ask them to resend the text, eventually as an ordinary text file or in LibreOffice/OpenOffice/MSOffice format.
- There is no claim that every text is recoverable, even if you are certain that the text is in Cyrillic.
- The analyzed and converted text is limited to 100 KiB.
- A 100% precision is not always achieved — in a conversion from a codepage to another code page, some characters may be lost, like the Bulgarian quotes or rarely some single letters. Some of this depends on your Windows Clipboard character handling.
- The program will try a maximum of 7245 variants in two or three levels: if there had been a multiple encoding like koi8(utf(cp1251(utf))), it will not be detected or tested. Usually the possible and displayed correct variants are between 32 and 255.
- If a part of the text is encoded with one code page, and another part — with another code page, the program could recognize only one of the parts at a time.
 Usually the possible and displayed correct variants are between 32 and 255.
Usually the possible and displayed correct variants are between 32 and 255.Terms of use
Please notice that this freeware program is created with the hope that it would be useful, but has no warranty, not even an implied warranty for fitness for any particular use. Please use it at your own risk.
If you have very long texts to translate, please make sure you have a backup copy.
What’s new
- March 2021 : After a server upgrade, the program stopped working and some parts of it had to be rewritten.
- May 2020 : Added Тоҷикӣ/Tajik translation, thanks to Анвар/Anvar.
- October 2017 : Added «Select all / Copy» button.
- July 2016 : SSL Certificate installed, you can now access the Decoder on a secure connection.
- October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
- March 2013 : My hosting provider sent me a warning that the Decoder is using too much server CPU power and its processes were killed more than 100 times. I am making some changes so that the program will use less CPU, especially when reposting a previously sampled text, however, the decoded form may load somewhat slower. Please contact me if you have some difficulties using the program.
- 2012-08-09 : Added French translation, thanks to Arnaud D.
- 2011-03-06 : Added Belorussian translation, thanks to Зыль and Aliaksandr Hliakau.
- 31.07.10 : Added Serbian translation, thanks to Miodrag Danilovic (Boston — Beograd).
- 07.05.09 : Raised limit of MAX text size to 50 kiB.
- may 2009 : Added Ukrainian interface thanks to Barmalini.
- 2008-2009 : A number of small fixes and tweaks of the detection algorithm. Changed interface to default to automatic decoding.
- 12.08.07 : Fixed Russian language translation, thanks to Petr Vasilyev. This page will be significantly restructured in the near future.
- 10.11.06 : Three new postfilters added: «base64», «unix-to-unix» и «bin-to-hex», theoretically the tested combinations are 4725. Changes to the frequency analysis function (testing).
- 11.10.06 : The main site is on a new hardware server, should run faster.
- 11.09.06 : The program now uses PHP5 and should run times faster.
- 19.08.06 : Because of a broken DNS entry, this site was inaccessible from 06:00 on 15 august up to 15:00 on 18 august. That was the reason for me to set two «mirror» sites (5ko.free.fr/decode and www.accent.bg/decode) with the same program. If the original has a problem, you can find the copies in Google and recover your texts.
- 17.06.06 : Added two more antique Cyrillic encodings, MIK и KOI-7, but you better not need them.
- 03.03. 06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
- 15.02.06 : More encodings added and tested.
- 20.10.05 : Small improvement to the frequency-analysis function: for texts, written in all-capital letters.
- 14.10.05 : Two more gmail-Cyrillic encodings were added. Theoretically the tested combinations are 2112.
- 15.06.05 : Russian language interface was added. Big thanks to chAlx!
- 16.02.05 : One more postfilter decoding is added, for strings like this: «%u043A%u0438%u0440%u0438%u043B%u0438%u0446%u0430».
- 05.02.05 : More encodings tests added, the number of tested encodings is doubled, but thus the program may work slightly slower.
- 03.02.05 : The frequency analysis function that detects the original encoding works much better now. Currently the program recognises most of the encodings if the first few words are not too weird. It although still needs some improvement.
- 15.01.05 : The input text limit is raised from 10 to 20 kB.
- 01.12.04 : First public release.
 If you notice any problem, please notify me ASAP.
If you notice any problem, please notify me ASAP.
 06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
Back to the Latin to Cyrillic convertor.
Что нужно знать каждому разработчику о кодировках и наборах символов для работы с текстом / Хабр
Это первая часть перевода статьи What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With Text
Если вы работаете с текстом в компьютере, вам обязательно нужно знать про кодировки. Даже если вы посылаете электронные письма. Даже если вы их только получаете. Необязательно понимать каждую деталь, но надо хотя бы знать, что из себя представляют кодировки. И вот первая хорошая новость: статья может быть немного запутанной, но основная идея очень и очень простая.
Эта статья о кодировках и наборах символов.
Статья Джоеэля Спольски под названием «Абсолютный минимум о Unicode и наборе символов для каждого разработчика(без исключений!)» будет хорошей вводной и мне доставляет большое удовольствие перечитывать ее время от времени. Я стесняюсь отсылать к ней тех людей, которые испытывают трудности с пониманием проблем с кодировкам, хотя она довольно легкая в плане технических деталей. Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Я стесняюсь отсылать к ней тех людей, которые испытывают трудности с пониманием проблем с кодировкам, хотя она довольно легкая в плане технических деталей. Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Основы
Все более или менее слышали об этом, но каким-то образом знание испаряется, когда дело доходит до обсуждения, так что вот вам: компьютер не может хранить буквы, числа, картинки или что-либо еще. Он может запомнить только биты. Бит имеет только два значения: ДА или НЕТ, ПРАВДА или ЛОЖЬ, 1 или 0 или любую другую пару, которую вы можете вообразить. Раз уж компьютер работает с электричеством, бит представлен электрическим зарядом: он либо есть, либо его нет. Людям проще представлять это в виде 1 и 0, так что я буду придерживаться этих обозначений.
01100010 01101001 01110100 01110011
b i t s
В этой кодировке, 01100010 представляет из себя ‘b’, 01101001 — ‘i’, 01110100 — ‘t’, 01110011 — ‘s’. Конкретная последовательность бит соответствует букве, а буква – конкретной последовательности битов. Если вы можете запомнить последовательности для 26 букв или умеете действительно быстро находить нужное соответствие, то вы сможете читать биты, как книги.
Упомянутая схема носит название ASCII. Строка с нолями и единицами разбивается на части по 8 бит(по байтам). Кодировка ASCII определяет таблицу перевода байтов в человеческие буквы. Вот небольшой кусочек этой таблицы:
bits character01000001 A
01000101 E
01000010 B
01000011 C
01000100 D
01000110 F
В ней 95 символов, включая буквы от A до Z, в нижнем и верхнем регистре, цифры от 0 до 9, с десяток знаков препинания, амперсанд, знак доллара и прочие. В нее также включены 33 значения, такие как пробел, табуляция, перевод строки, возврат символа и прочие. Это непечатаемые символы, хотя они видимы человеку и используются им. Некоторые значения полезны только компьютеру, такие как коды начала и конца текста. Всего в кодировку ASCII включены 128 символов — прекрасное ровное число для тех, кто смыслит в компьютерах, так как оно использует все комбинации 7ми битов (от 0000000 до 1111111).
В нее также включены 33 значения, такие как пробел, табуляция, перевод строки, возврат символа и прочие. Это непечатаемые символы, хотя они видимы человеку и используются им. Некоторые значения полезны только компьютеру, такие как коды начала и конца текста. Всего в кодировку ASCII включены 128 символов — прекрасное ровное число для тех, кто смыслит в компьютерах, так как оно использует все комбинации 7ми битов (от 0000000 до 1111111).
Вот вам способ представить человеческую строку, используя только единицы и нули:
01001000 01100101 01101100 01101100 01101111 00100000
01010111 01101111 01110010 01101100 01100100«Hello World»
Важные термины
Для кодирования чего-либо в ASCII двигайтесь справа налево, подменяя буквы на биты. Для декодирования битов в символы, следуйте по таблице слева направо, подменяя биты на буквы.
encode |enˈkōd|
verb [ with obj. ]
convert into a coded form
code |kōd|
noun
a system of words, letters, figures, or other symbols substituted for other words, letters, etc.

Кодирование – это представление чего-либо чем-нибудь другим. Кодировка – это набор правил, описывающий способ перевода одного представления в другое.
Прочие термины, заслуживающие прояснения:
Набор символов, чарсет, charset – Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов». Синоним к кодировке.
Кодовая страница – страница кодов, закрепляюшая за символом набор битов. Таблица. Синоним к кодировке.
Строка – пачка чего-нибудь, объединенных вместе. Битовая строка – это пачка бит, такая как 00011011. Символьная строка – это пачка символов, например «Вот эта». Синоним к последовательности.
Двоичный, восьмеричный, десятичный, шестнадцатеричный
Существует множество способов записывать числа. 10011111 – это бинарная запись для 237 в восьмеричной, 159 в десятичной и 9F в шестнадцатиричной системах. Значения у всех этих чисел одинаково, но шестнадцатиричная система короче и проще для понимания, чем двоичная. Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Excusez-Moi?
Раз уж мы теперь знаем, о чем говорим, заметим: 95 символов – это совсем немного, когда речь идет о языках. Этот набор покрывает базовый английский, но как насчет французских символов? А вот это Straßen¬übergangs¬änderungs¬gesetz из немецкого языка? А приглашение на smörgåsbord в шведском? В-общем, не получится. Не в ASCII. Спецификация на представление é, ß, ü, ä, ö просто отсутствует.
“Постойте-ка”, скажут европейцы, “в обычных компьютерах с 8 битами в байте, ASCII никак не использует бит, который всегда равен 0! Мы можем использовать его, чтобы расширить таблицу еще на 128 значений”. И было так. Но способов обозначить звучание гласных еще слишком много. Не все сочетания букв и значений, используемые в европейских языках, влезают в таблицу из 256 записей. Так мир пришел к изобилию кодировок, стандартов, стандартов де-факто и недостандартов, которые покрывают все субнаборы символов. Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Не забывайте о русском, хинди, арабском, корейском и множестве других живых языков планеты. Про мертвые уж молчим. Как только вы найдете способ писать документ, использующий несколько языков, попробуйте добавить китайский. Или японский. Оба содержат тысячи символов. И у вас всего 256 значений. Вперед!
Многобайтные кодировки
Для создания таблиц, которые содержат более 256 символов, одного байта просто недостаточно. Двух байтов (16 бит) хватит для кодировки 65536 различных значений. Big-5 например, кодировка двухбайтная. Вместо разбиения последовательности битов в блоки по 8, она использует блоки по 16 битов и содержит большую(я имею ввиду БОЛЬШУЮ) таблицу с соответствием. Big-5 в своем основном виде покрывает большинство символов традиционного китайского. GB18030 – это похожая кодировка, но она включает как традиционный, так и упрощенный китайский.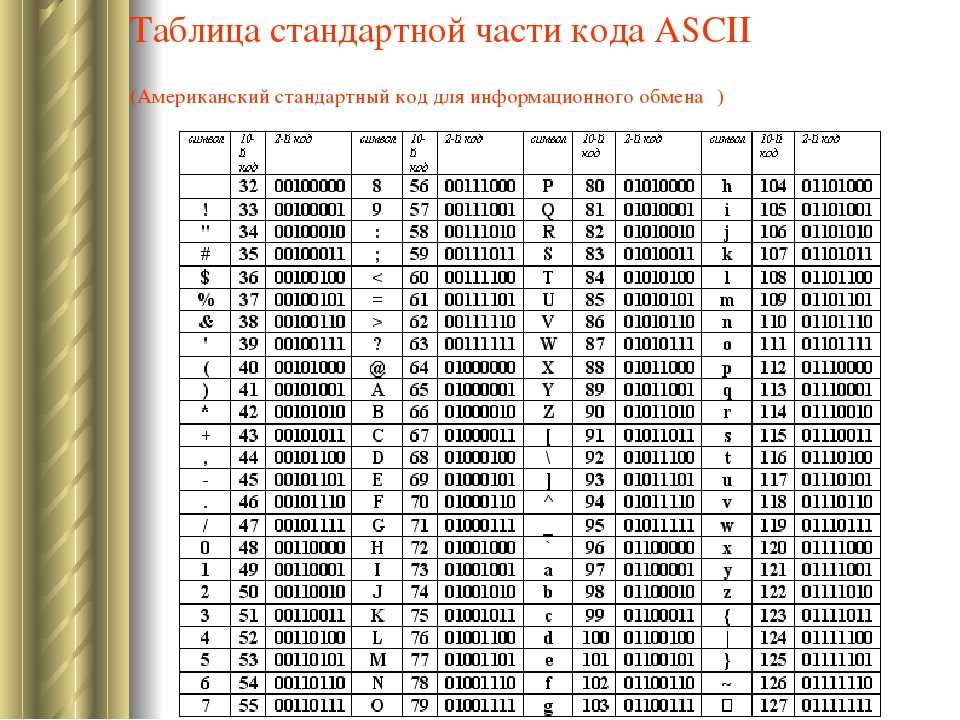 И, прежде чем вы спросите, да, есть кодировки только для упрощенного китайского. А разве одной недостаточно?
И, прежде чем вы спросите, да, есть кодировки только для упрощенного китайского. А разве одной недостаточно?
Вот кусок таблицы GB18030:
bits character
10000001 01000000 丂
10000001 01000001 丄
10000001 01000010 丅
10000001 01000011 丆
10000001 01000100 丏
GB18030 покрывает довольно большой диапазон символов, включая большую часть латинских символов, но в конце концов, это всего лишь еще одна кодировка среди многих других.
Путаница с Unicode
В итоге тем, кому больше всех надоела эта каша, пришла в голову идея разработать единый стандарт, объединяющий все кодировки. Этим стандартом стал Unicode. Он определяет невероятную таблицу из 1 114 112 пунктов, используемую для всех вариантов букв и символов. Этого хватит для кодирования всех европейских, средне-азиатских, дальневосточных, южных, северных, западных, доисторических и будущих символов, о которых человечеству известно. Unicode позволяет создать документ на любом языке любыми символами, которые можно ввести в компьютер. Это было невозможно, или очень затруднительно до эры Unicode. В стандарте есть даже неофициальная секция под клингонский. Вы поняли, Unicode настолько большой, чтобы допускает неофициальные секции.
Это было невозможно, или очень затруднительно до эры Unicode. В стандарте есть даже неофициальная секция под клингонский. Вы поняли, Unicode настолько большой, чтобы допускает неофициальные секции.
Итак, и сколько же байт использует Unicode для кодирования? Нисколько. Потому что Unicode – это не кодировка.
Смущены? Не вы одни. Unicode в первую и главную очередь определяет таблицу пунктов для символов. Это такой способ сказать «65 – A, 66 – B, 9731 – »(я не шучу, так и есть). Как эти пункты кодируются в байты является предметом другого разговора. Для представления 1 114 112 значений двух байт недостаточно. Трех достаточно, но 3 – странное число, так что 4 является комфортным минимумом. Но, пока вы не используете китайский, или другой язык со множеством символов, которые требуют большого количества битов для кодирования, вам никогда не придет в голову использовать толстую колбасу из 4х байт. Если “A” всегда кодируется в 00000000 00000000 00000000 01000001, а “B” – в 00000000 00000000 00000000 01000010, то документ, использующий такую кодировку, распухнет в 4 раза.
Существует несколько способов решения этой проблемы. UTF-32 – это кодировка, которая переводит все символы в наборы из 32 бит. Это простой алгоритм, но изводящий много места впустую. UTF-16 и UTF-8 являются кодировками с переменной длиной кодирования. Если символ может быть закодирован одним байтом(потому что номер пункта символа очень маленький), UTF-8 закодирует его одним байтом. Если нужно 2 байта, то используется 2 байта. Кодировка сообщает старшими битами, сколькими битами кодируется текущий символ. Такой способ экономит место, но так же и тратит его в случае, если эти сигнальные биты часто используются. UTF-16 является компромиссом: все символы как минимум двухбайтные, но их размер может увеличиваться до 4 байт, если нужно.
character encoding bits
A UTF-8 01000001
A UTF-16 00000000 01000001
A UTF-32 00000000 00000000 00000000 01000001
あ UTF-8 11100011 10000001 10000010
あ UTF-16 00110000 01000010
あ UTF-32 00000000 00000000 00110000 01000010
И все..jpg) Unicode – это огромная таблица соответствия символов и чисел, а различные UTF кодировки определяют, как эти числа переводятся в биты. В-общем, Unicode – это просто еще одна схема. Ничего особенного, она просто пытается покрыть все, что можно, оставаясь эффективной. И это хорошо.
Unicode – это огромная таблица соответствия символов и чисел, а различные UTF кодировки определяют, как эти числа переводятся в биты. В-общем, Unicode – это просто еще одна схема. Ничего особенного, она просто пытается покрыть все, что можно, оставаясь эффективной. И это хорошо.
Пункты
Символы определяются по их Unicode-пунктам. Эти пункты записаны в шестнадцатеричной системе и предварены “ U+” (просто для удобство, не значит ничего, кроме “Это пункт Unicode”). Символ Ḁ имеет пункт U+1E00. Иными(десятичными) словами, это 7680й символ таблицы Unicode. Он официально называется “ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А С КОЛЬЦОМ СНИЗУ”.
Ниасилил
Суть вышесказанного: любой символ может быть закодирован множеством разных последовательностей бит, и любая последовательность бит может представлять разные символы, в зависимости от используемой кодировки. Причина в том, что разные кодировки используют разное число бит на символ и разные значения для кодирования разных символов.
bits encoding characters11000100 01000010 Windows Latin 1 ÄB
11000100 01000010 Mac Roman ƒB
11000100 01000010 GB18030 腂characters encoding bits
Føö Windows Latin 1 01000110 11111000 11110110
Føö Mac Roman 01000110 10111111 10011010
Føö UTF-8 01000110 11000011 10111000 11000011 10110110
Заблуждения, смущения и проблемы
Имея все вышесказанное, мы приходим к насущным проблемам, которые испытывают множество пользователей и разработчиков каждый день, как они соотносятся с указанным выше, и каковы пути решения. Сама большая проблема – это
Сама большая проблема – это
Какого черта мой текст нечитаем?
ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ
Если вы откроете документ, и он выглядит так, как текст выше, то причина у этого одна: ваша программа ошиблась с кодировкой. И все. Документ не испорчен(по крайней мере, пока), и не нужно никакое волшебство. Вместо него надо просто выбрать правильную кодировку для отображения текста. Предполагаемый документ выше содержит биты:
10000011 01000111 10000011 10010011 10000011 01010010 10000001 01011011
10000011 01100110 10000011 01000010 10000011 10010011 10000011 01001111
10000010 11001101 10010011 11101111 10000010 10110101 10000010 10101101
10000010 11001000 10000010 10100010
Так, быстренько угадали кодировку? Если вы пожали плечами, то вы правы. Да кто знает?
Попробуем с ASCII. Большая часть этих байтов начинается с 1. Если вы правильно помните, ASCII вообще-то не использует этот бит. Так что ASCII не вариант. Как насчет UTF-8? Большая часть байт не является валидными значениями в этой кодировке. Как насчет Mac Roman(еще одна европейская кодировка)? Хм, для нее эти байты являются правильными значениями. 10000011 декодируетися в ”É”, в “G” и так далее. Так что в Mac Roman текст будет выглядеть так: ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ. Правильно? Нет? Может быть? А компьютер-то откуда знает? Может кто-то хотел написать именно это. Насколько я знаю, это может быть последовательностью ДНК! Так и порешим: это Mac Roman, и это ДНК.
Как насчет UTF-8? Большая часть байт не является валидными значениями в этой кодировке. Как насчет Mac Roman(еще одна европейская кодировка)? Хм, для нее эти байты являются правильными значениями. 10000011 декодируетися в ”É”, в “G” и так далее. Так что в Mac Roman текст будет выглядеть так: ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ. Правильно? Нет? Может быть? А компьютер-то откуда знает? Может кто-то хотел написать именно это. Насколько я знаю, это может быть последовательностью ДНК! Так и порешим: это Mac Roman, и это ДНК.
Конечно, это полный бред. Правильный ответ таков: текст закодирован в Japanes Shift-JIS и должен выглядеть как エンコーディングは難しくない. Кто бы мог подумать?
Первая причина нечитаемости текста в том, что кто-то пытается прочитать последовательность байт в неверной кодировке. Компьютеру всегда нужно подсказывать. Сам он не догадается. Некоторые типы документов определяют кодировку своего содержимого, но последовательность байт всегда остается черным ящиком.
Большинство браузеров предоставляют возможность указать кодировку страницы с помощью специального пункта меню. Иные программы тоже имеют аналогичные пункты.
Иные программы тоже имеют аналогичные пункты.
У автора нет разбиения на части, но статья и так длинна. Продолжение будет через пару дней.
Этот онлайн-конвертер предназначен для перевода текста на любом языке в верхний регистр. Все буквы в результате конвертирования станут заглавными, то есть «большими». Преобразование не затрагивает знаки пунктуации, спецсимволы и цифры. Возможно перевести в верхний регистр как весь текст, так и отдельные буквы, фразы и слова. Конвертирование текстов в верхний регистр одним нажатием кнопки. За один раз рекомендуется увеличивать регистр тексту длиной не более 30 тыс. символов.
Ограничение на максимальный объем текста зависит от используемого браузера.
Стабильная работа конвертера с текстами большого объема не гарантируется. Вставьте текст для конвертации к верхнему регистру: Для работы конвертера необходимо включить в вашем браузере поддержку JavaScript. ВСЕ СИМВОЛЫ сЛУчаЙнЫе СИмВОлЫ Первая Буква Каждого Слова Первая буква каждого предложения Результат конвертации: Верхний регистр символов используется в тексте в основном для визуального представления начала предложения («с большой буквы»).
Отдельные слова и фразы пишут в верхнем регистре, если хотят сформировать из них заголовки или выделить их из общего контекста.
Весь же текст оформляют в верхнем регистре реже, делают это для усиления эффекта от его восприятия. При конвертировании букв текста в заглавные вы можете указать (задать настройки), какие символы необходимо перевести в верхний регистр:
Для удобства дальнейшего использования конвертированный в верхний регистр текст сразу же выделяется, кликните по нему правой кнопкой мыши и скопируйте в буфер обмена. Как преобразовать текст в верхний регистр?Перевести текст в верхний регистр можно вручную, с помощью специальных программ-конвертеров, текстовых редакторов или онлайн-сервисов. Вручную преобразовать текст в верхний регистр имеет смысл только если он небольшой, иначе задача становится трудоемкой, придется заново вводить весь текст в переключенном режиме. В большинстве текстовых редакторов функция перевода в верхний регистр в своем непосредственном виде практически не представлена.
Несмотря на востребованность этой функции, вы в большинстве случаев не найдете такой кнопки «Перевести в верхний регистр»
даже в специализированных текстовых процессорах для программистов, верстальщиков, журналистов. Если рассматривать конвертер регистра в виде отдельной программы, вы столкнетесь с различными сложностями по ее использованию. Во-первых, придется найти такую программу-конвертер для вашей операционной системы, затем установить ее и научиться ей пользоваться. Если вы используете компьютер на работе, установка сторонних программ и вовсе может быть недоступна по правилам безопасности. Чтобы разрешить сложившуюся ситуацию, мы решили создать онлайн-сервис по переводу текстов в верхний регистр.
Для использования инструмента Капс лок онлайн не потребуется ничего устанавливать и изучать, конвертер работает в любом браузере и на любом устройстве. При наборе текста с клавиатуры верхний регистр символов (UpperCase) можно получить, удерживая при вводе клавишу Shift (Шифт) или включив режим Caps Lock (капслок).
Обычно этот вариант включения ввода заглавных букв установлен по-умолчанию в большинстве компьютерных систем, но бывают и исключения в зависимости от локали, региональных настроек и стандартов.
Выбор регистра пришел к нам со времен печатных машинок, которые использовались для создания печатных документов в докомпьютерную эпоху.
Практически во всех машинках было два регистра, большой и нижний, которые переключались специальной кнопкой. Уточнение. В верхнюю касту способны переводиться не все символы.
В верхний регистр не переводятся цифры, знаки пунктуации и большинство спецсимволов, оставаясь после преобразования без видимых изменений.
Стоит заметить, что некоторые символы в обоих регистрах имеют одинаковое представление (полностью идентичное), поэтому может ошибочно показаться,
что в верхний регистр они также не переводятся и после конвертирования остаются визуально неизменными, хотя с технической точки зрения это совершенно разные символы, имеющие различные коды. Не стоит злоупотреблять капсом, поскольку большой объем текста в верхнем регистре символов может вызвать у читающего неприятную реакцию.
Пост или сообщение пользователя полностью в верхнем регистре вызывает у других ассоциации, что автор сильно раздражен или даже кричит. Вот, например, распространенная ситуация, с которой сталкивались все, кто хотя бы раз набирал тексты в редакторе.
Что делать, если набрал текст маленькими буквами, а нужно было большими? Теперь все переделывать, включать капс и набирать буквы заново.
А если букв много, задача замены букв на большие становится весьма затратной по времени. Как перевести текст в капс автоматически?
Несмотря на важность данной возможности при правке текстов, в большинстве текстовых редакторах функция преобразования регистра отсутствует или реализована так, что ей воспользоваться практически невозможно.
Просто воспользуйтесь нашим онлайн-транслятором риестра и за пару секунд получите текст верхними буквами.
Система в онлайн-режиме заменит все строчные буквы на заглавные. Итак, подведем итоги. Кэпсовый конвертер (uppercase online text converter) на этой странице поможет вам увеличить регистр или размер текста в онлайн-режиме, перевести литеры нижней кассы в верхнюю. Установите тексту режим кепс лок онлайн простым нажатием кнопки, переведя все литеры текста в верхний режим. Наш апперкейс конвертор или переводчик регистров символов мгновенно выполнит в тексте замену маленьких букв на большие. Требуется поднять регистр? Хотите увеличить буквы текста? Тогда вы зашли на правильную страницу. Согласно нашей информации, функция преобразования регистров очень востребованна среди пользователей. Если в тексте уже есть прописные буквы, при использовании увеличителя регистра они останутся без изменений. Все маленькие буквы после нажатия на кнопку станут большими, то есть все строчные буквы можно заменить на прописные в автоматическом режиме. Отзывы пользователей конвертер верхнего регистра текста
ВЕРХНИЙ РЕГИСТР
нижний регистр
иНВЕРСИЯ рЕГИСТРА
СлуЧаЙнЫй реГИсТр
ЧеРеДоВаНиЕ РеГиСтРоВ
С Большой Буквы
Sлuчаiнyй tраnслiт
Чередование транслита
кодяроп йынтарбО
Хаос букв
Соцсетер
𝓗𝓪𝓷𝓭𝓦𝓻𝓲𝓽𝓮 + 𝕊𝕙𝕒𝕕𝕠𝕨
Готический конвертер 𝕲𝖔𝖙𝖍𝖎𝖈 Жирный (Болд) Курсив (Италик) Подчеркнутый (АндерЛайн) Надчеркнутый (ОверЛайн) |
 Можно переводить в верхний регистр только простой текст: без графики, таблиц, стилей и прочего.
Обратное преобразование верхнего регистра к исходному варианту возможно здесь.
Можно переводить в верхний регистр только простой текст: без графики, таблиц, стилей и прочего.
Обратное преобразование верхнего регистра к исходному варианту возможно здесь. Можно сказать, что верхний регистр текста — это простой и эффективный способ привлечения внимания читающего, если по-другому это сделать невозможно (выбором размера и гарнитуры шрифта, цвета).
Подобное часто применяется в Интернете при размещении объявлений, постинга сообщений на форумах или блогах и прочее.
Можно сказать, что верхний регистр текста — это простой и эффективный способ привлечения внимания читающего, если по-другому это сделать невозможно (выбором размера и гарнитуры шрифта, цвета).
Подобное часто применяется в Интернете при размещении объявлений, постинга сообщений на форумах или блогах и прочее. Каждое нажатие кнопки дажет разный результат.
Для рандомного выставления обоих регистров есть специальный конвертер.
Каждое нажатие кнопки дажет разный результат.
Для рандомного выставления обоих регистров есть специальный конвертер. Из того, что можно найти, это функцию автоматической установки заглавной буквы в начале предложения.
А в текстовом редакторе типа Ворд можно создать для любого куска текста стиль его отображения с настройками «В верхнем регистре»,
но непосредственного преобразования текста в верхний регистр при этом не произойдет.
Если скопировать такой текст в другой текстовый редактор, выбранные стили отображения, скорее всего, потеряются.
Из того, что можно найти, это функцию автоматической установки заглавной буквы в начале предложения.
А в текстовом редакторе типа Ворд можно создать для любого куска текста стиль его отображения с настройками «В верхнем регистре»,
но непосредственного преобразования текста в верхний регистр при этом не произойдет.
Если скопировать такой текст в другой текстовый редактор, выбранные стили отображения, скорее всего, потеряются. Онлайн-перевод всех символов текста в верхний регистр можно осуществить на этой странице с помощью интернет-браузера вашего компьютера, планшета или смартфона.
Вы можете сделать текст большими буквами в любое время, ведь сервис работает круглосуточно.
Процесс конвертации регистра текста в верхний режим происходит всего за пару секунд.
На нашем вебсайте вы можете, как многие говорят, «перевести текст в верхний риестр» бесплатно.
Онлайн-перевод всех символов текста в верхний регистр можно осуществить на этой странице с помощью интернет-браузера вашего компьютера, планшета или смартфона.
Вы можете сделать текст большими буквами в любое время, ведь сервис работает круглосуточно.
Процесс конвертации регистра текста в верхний режим происходит всего за пару секунд.
На нашем вебсайте вы можете, как многие говорят, «перевести текст в верхний риестр» бесплатно. Клавиша Shift (Шифт) имеет неофициальное название «Кнопки Перевода Регистра» или «Клавиши Переключения Регистра».
Кнопка приводила к вертикальному сдвигу молоточка с литерой, который ударял по бумаге.
Вперые это было реализовано в 1870-х и затем широко применялось, на молоточке можно было разместить сразу несколько литер разного размера или стиля (курсив, готика).
Клавиша Caps Lock — «клавиша Замка Регистра», которая фактически фиксировала клавишу перевода регистра в нажатом положении.
Клавиша Shift (Шифт) имеет неофициальное название «Кнопки Перевода Регистра» или «Клавиши Переключения Регистра».
Кнопка приводила к вертикальному сдвигу молоточка с литерой, который ударял по бумаге.
Вперые это было реализовано в 1870-х и затем широко применялось, на молоточке можно было разместить сразу несколько литер разного размера или стиля (курсив, готика).
Клавиша Caps Lock — «клавиша Замка Регистра», которая фактически фиксировала клавишу перевода регистра в нажатом положении. В конечном итоге все будет зависеть от состава, языка и кодировки текста, который вы собираетесь конвертировать в верхний ригистр, а также региональных настроек вашей системы (локали), операционной системы и прочего.
Если в процессе перевода в верхний регистр для символов вашего текста найдутся соответствующие заглавные эквиваленты, они будут ими заменены, если нет — символы останутся без изменений.
Если после конвертирования регистра часть символов стали «квадратиками», это означает что у вас в системе не установлена поддержка определенных языков (например, славянских, восточных и пр.) или отсутствуют необходимые шрифты.
Устанавливать их специально не нужно, просто скопируйте и перенесите текст в исходный документ.
В конечном итоге все будет зависеть от состава, языка и кодировки текста, который вы собираетесь конвертировать в верхний ригистр, а также региональных настроек вашей системы (локали), операционной системы и прочего.
Если в процессе перевода в верхний регистр для символов вашего текста найдутся соответствующие заглавные эквиваленты, они будут ими заменены, если нет — символы останутся без изменений.
Если после конвертирования регистра часть символов стали «квадратиками», это означает что у вас в системе не установлена поддержка определенных языков (например, славянских, восточных и пр.) или отсутствуют необходимые шрифты.
Устанавливать их специально не нужно, просто скопируйте и перенесите текст в исходный документ. Многие сайты вообще запрещают или ограничивают использование капслока, такого текста в верхнем регистре, или, как его еще называют, кэпса.
Рекомендуется увеличивать верхний регистр только небольшим участкам текста, требующим привлечения внимания.
Многие сайты вообще запрещают или ограничивают использование капслока, такого текста в верхнем регистре, или, как его еще называют, кэпса.
Рекомендуется увеличивать верхний регистр только небольшим участкам текста, требующим привлечения внимания. Такой вот получился онлайн-переводчик в капс.
Такой вот получился онлайн-переводчик в капс. Без конвертера пришлось бы перенабирать его на клавиатуре, включив капс или удерживая Shift. На компьютере это сделать еще более-менее, а на планшете или мобильнике так совсем трудно. Конвертер в капс экономит много времени. Просто вставил текст и сразу же готов результат большими буквами.
Без конвертера пришлось бы перенабирать его на клавиатуре, включив капс или удерживая Shift. На компьютере это сделать еще более-менее, а на планшете или мобильнике так совсем трудно. Конвертер в капс экономит много времени. Просто вставил текст и сразу же готов результат большими буквами. Теперь можно это мгновенно исправить.
Теперь можно это мгновенно исправить.6.
 1 Символы и перевод 6.1 Символы и перевод
1 Символы и перевод 6.1 Символы и переводГарнс Осень 1997
ПРИМЕЧАНИЕ. Здесь я должен использовать «*» для точка, «>» для подковы и «_» для тройника.
Почему логика должна фокусироваться на предложениях?
Логика изучает сохранение истины, а также предложения или утверждения являются носителями истины и лжи.
Истинность составного утверждения систематически зависит от истинность составляющих утверждений.
Формы аргумента, отражающие эту систематическую зависимость, могут быть показаны
быть действительным или недействительным.
Предложения в аргументах
Как простые элементы информации связаны друг с другом?
Как мы можем разбить сложную информацию, предлагаемую в помещениях
найти простую информацию в заключении, что Майкл
Джексон человек?
Майкл Джексон рептилия, только если он может иметь потомство рептилии.
Если он не рептилия,
тогда он либо человек, либо инопланетянин.
Джексон не может иметь потомство рептилий.
И он не инопланетянин.
Итак, Майкл Джексон
человек?
Предпосылки спора
Этот аргумент состоит из четырех предпосылок, каждая из которых предлагает разную информацию.
Ни одна предпосылка не говорит нам, является ли Джексон человеком.
1.
Майкл Джексон — рептилия только в том случае, если у него может быть рептилоидное потомство.
2.
Если он не рептилия, то он либо человек, либо инопланетянин.
3.
У Джексона не может быть потомства рептилий.
4. И он не инопланетянин.
Комплексная информация в помещениях
Посылка 2 выражает отношения между тремя разными утверждениями.
Джексон — рептилия.
Джексон — человек.
Джексон — инопланетянин.
Если первое утверждение неверно, то либо второе, либо третье
правда
2.
Если он не рептилия, то он либо человек, либо инопланетянин.
Простые и составные операторы
Простой оператор не содержит другого оператора в качестве компонента.
Джексон — рептилия.
Составной оператор содержит как минимум один простой оператор в качестве компонента
и по крайней мере один оператор или связка.
Джексон не рептилия.
Если Джексон рептилия, то у него рептилоид
потомство.
Символы составных выражений
Чтобы отобразить отношения между утверждениями, мы абстрагируем содержимое и используйте специальные символы для операторов и связок.
Таким образом, мы можем сосредоточиться на форме, а не на содержании.
Используйте заглавные буквы для обозначения конкретных простых утверждений.
Символы составных выражений
Если Майкл Джексон не рептилия, то он
либо человек, либо инопланетянин.
R = Майкл Джексон — рептилия.
H = Майкл Джексон — человек.
A = Майкл Джексон пришелец.
Если не-R, то H или A.
~ R É (H v A)
Операторы и соединители
| ~ тильда | отрицание | отрицает операторы | нет, это не тот дело в том, что |
| * точка | соединение | соединяет соединяет | и, кроме того, но |
| V-образный клин | дизъюнкция | дизъюнкт дизъюнкт | (или/)или, если только |
| É > подкова | импликация, условная | следствие является условным на предшествующем | еслиЭтогда, только если |
| _ тройной бар | эквивалент | тогда и только тогда, когда |
Примечание: тройная черта в этом документе выглядит как «_», а точка выглядит как «*»
Отрицание
| ~ А | Отрицательный простой заявление |
| ~ (А * В) | Отрицательное соединение |
| ~ [(А * В) v С] | Отрицательная дизъюнкция; первый дизъюнкт — это союз |
Соединение
| А * Б | Соединение |
| ~ А * В | Соединение, чье первый конъюнкт — отрицательный оператор |
| (А в Б) * С | Соединение, чье первый конъюнкт является дизъюнктом |
| А * [Б Э > (С против В)] | Соединение, чье второй конъюнкт является условным, следствием которого является дизъюнкция |
Разделение
| А в Б | Дизъюнкция |
| ~ А в Б | Дизъюнкция, чья первый дизъюнкт является отрицательным оператором |
| (А * В) против С | Дизъюнкция, чья первый дизъюнкт — это соединение |
Условный
| А Э > В | Условный |
| (А в Б) Э > ~(В * С) | Условное чье антецедент — это дизъюнкция, а консеквент — отрицательная конъюнкция |
| (А É> БЫТЬ > С | Условное чье антецедент является условным |
Биусловный
| А _ Б | Двойное условие |
| ~ А _ (БЫТЬ > С) | Двойное условие чья левая половина является отрицательным утверждением, а правая половина является условным |
| [~A * (B v C)] _ В | Двойное условие чья левая половина является союзом, первый союз является отрицательным утверждением а второй конъюнктом является дизъюнкт |
Будьте осторожны при использовании символов
| Если А, затем В | Если я прохожу этот курс, я буду счастлив | П Э > Н |
| А если Б | я буду счастлив если Я прохожу этот курс | П Э > Н |
| Только А если Б | я буду счастлив только если я прохожу этот курс | Ч Э > Р |
| Только если А, В | Только если I пройти этот курс буду ли я счастлив | Ч Э > Р |
| А тогда и только тогда, когда B | я буду счастлив если и только если я пройду этот курс | Ч _ Р |
Будьте осторожны при использовании символов
| Нет А, и (/а) В | Гор не тот
Президент, но Клинтон. | ~ Г * С |
| Нет как А, так и В | Не оба Клинтона и Гор являются президентом. | ~ (С*Г) |
| Оба А и Б неверны | И Клинтон, и Гор не безупречен. | ~ С * ~ Г |
| Ни один А или В | Ни Клинтон ни Гор не безупречен. | ~ (C против G) |
| Либо А ложно или Б ложно | Либо Клинтон не президент или гор не президент. | ~ С v ~ G |
Условные обозначения для переводов
Заглавные буквы (A, B, C, É) используются в качестве имен для обозначения
отдельные простые утверждения.
Строчные буквы (p, q, r, É) используются в качестве переменных для обозначения
для любого утверждения (простого или составного).
Следующие символы обозначают операторы и связки: * , v, ~,
Э, _
Скобки и квадратные скобки используются во избежание путаницы при указании
область действия конкретных операторов или связок.
Словарные символы—ArcGIS Pro | Документация
Символы словаря используются для обозначения слоев с помощью словаря символов, сконфигурированного с несколькими атрибутами. Этот подход используется, когда спецификации символов приводят к множеству перестановок символов, которые не подходят для символики уникальных значений.
При использовании символики словаря символизация объектов в слое основана на одном или нескольких атрибутах, которые подключаются к словарю правил для отображения символа. ArcGIS Pro включает в себя следующие спецификации символов в виде словарей: спецификации совместной военной символики MIL-STD-2525B Change 2, MIL-STD-2525C и MIL-STD-2525D, а также спецификации объединенной военной символики НАТО APP-6(B) и АРР-6(Д). Пользовательские словари могут быть созданы и использованы для обрабатывать дополнительные спецификации символов. Шаги и инструменты для создание пользовательского словаря можно найти в инструментарии словаря.
Текстовые поля используются для отображения текстовых символов на основе данных из полей атрибутов. Параметры отображения задаются в разделе «Конфигурация».
Параметры отображения задаются в разделе «Конфигурация».
Установить символы словаря
Чтобы настроить символы словаря, выполните следующие действия:
- Выберите векторный слой на панели Содержание.
- На вкладке Векторный слой в группе Рисование щелкните стрелку раскрывающегося списка Символы .
- Под заголовком Символизировать слой с помощью атрибутов символа щелкните Словарь .
Появится панель символов.
- На панели Символы щелкните раскрывающееся меню Словарь и выберите словарь для обозначения данных. Или, чтобы использовать пользовательский словарь, щелкните раскрывающееся меню «Дополнительно» и нажмите «Добавить пользовательский словарь», чтобы перейти к файлу словаря (с расширением .stylx) на диске, или перейдите к веб-стилю в Интернете, чтобы добавить словарь в список. первый.
- Под заголовками Поля символов и Текстовые поля выберите поля символов и текста для данных.
- Под заголовком «Конфигурация» установите параметры, описанные ниже, чтобы уточнить символы.
Рамка
Применяется к окружающей рамке символа.
Заливка
Применяется к внутренней области внутри кадра.
Значок
Применяется к основному значку символа.
Модификаторы
Применяется к модификаторам, связанным с основным значком.
Усилители
Применяется к любому графическому усилителю, отображаемому вокруг рамки.
Текст
Применяется к текстовым полям. Их можно отключить, чтобы они не отображались, но сопоставление сохраняется.
Состояние
Определяет, используется ли основной или альтернативный символ рабочего состояния.
Морская мина
Определяет, используется ли медаль или альтернативная версия символов морской мины.
Модель
Определяет, используется ли геометрия линии для рисования символа или интерпретируются ли вершины линии как упорядоченные опорные точки.


Масштаб символов словаря
Вы можете установить коэффициент масштабирования символов словаря, чтобы увеличить или уменьшить их размер. Коэффициент масштабирования может быть постоянным значением для всех символов на основе поля атрибута в наборе данных, или вы можете написать выражение Arcade.
Коэффициент масштабирования может быть постоянным значением для всех символов на основе поля атрибута в наборе данных, или вы можете написать выражение Arcade.
Чтобы масштабировать словарные символы, выполните следующие действия:
- Выберите векторный слой на панели Содержание.
- На вкладке Векторный слой в группе Рисование щелкните Символы .
- На панели Символы в разделе Дополнительные символы
на вкладке параметров разверните заголовок Символы масштаба и выполните одно из
следующее:
- Выберите коэффициент масштабирования в меню.
- Напишите выражение для определения размера. Щелкните набор кнопку выражения, чтобы открыть диалоговое окно построителя выражений. Напишите выражение и нажмите «Проверить», чтобы подтвердить его.
Примеры конфигурации отображения словаря
На вкладке Основные символы панели Символы используйте настройки под заголовком Конфигурация для уточнения символов. В следующей таблице показаны примеры двух словарных символов с различными комбинациями конфигурации:
В следующей таблице показаны примеры двух словарных символов с различными комбинациями конфигурации:
| Символы | |
|---|---|
Кадр: Вкл. Заливка: Вкл. Значок: Вкл. Модификаторы: Вкл. Усилители: Вкл. Заливка: Выкл Значок: Вкл Модификаторы: Вкл Усилители: Вкл | |
Рамка: Выкл Заливка: Вкл. Значок: Вкл. Модификаторы: Вкл. Усилители: Выкл. | |
Рамка: Вкл. Заливка: Вкл Значок: Выкл Модификаторы: Выкл Усилители: Вкл | |
Рамка: Вкл Заливка: Вкл Значок: Вкл Модификаторы: Выкл Усилители: Выкл | |
Рамка: Выкл Заливка: Вкл Значок: Выкл Модификаторы: Выкл Усилители: Выкл | |
Рамка: Выкл Fill: Off Icon: Off Modifiers: Off Amplifiers: Off |

Related topics
Отзыв по этой теме?
ПЕРЕВОД МАТЕМАТИЧЕСКОГО ИЗЛОЖЕНИЯ В СИМВОЛЫ
ЦЕЛИ:
1. Понимать утверждения, чтобы составить правильное уравнение.
Понимать утверждения, чтобы составить правильное уравнение.
2.Перевести математическую формулировку в символы.
3.Понимать использование различных символов в математике.
Преобразование слов в символы
Практические задачи редко, если вообще когда-либо, решаются в виде уравнений. Задача решателя задач состоит в том, чтобы перевести проблему из фраз и утверждений в математические выражения и уравнения, а затем решить уравнения.
Как решатели задач, наша работа станет проще, если мы сможем перевести словесные фразы в математические выражения и если будем следовать пятиступенчатому методу решения прикладных задач. Чтобы помочь нам перевести слова на символы, мы можем использовать следующий математический словарь.
| МАТЕМАТИЧЕСКИЙ СЛОВАРЬ | |
| Слово или фраза | Математическая операция |
| Сумма, сумма, прибавленная, увеличенная на, более чем и плюс | + |
| Разница, минус, вычтенная, уменьшенная на, меньше, меньше | – |
| Продукт, произведение, умноженное на, раз, на | ⋅ |
| Частное, деленное на отношение, на | ÷ |
| Равно, равно, есть, результат есть, становится | = |
| Число, неизвестное количество, неизвестное количество | x (или любой символ) |
Переведите каждую фразу или предложение в математическое выражение или уравнение.
1. На двенадцать больше, чем число.
РЕШЕНИЕ
12+x
2. Восемь минус число.
Восемь минус число.
РЕШЕНИЕ
8−x
3. Неизвестная величина меньше четырнадцати.
РЕШЕНИЕ
x−14
4. Шесть раз число равно пятидесяти четырем.
РЕШЕНИЕ
6x=54
5.Две девятых числа равно одиннадцати.
РЕШЕНИЕ
2/9x=11
6.Число, умноженное на три и более семи, равно числу, умноженному на девять и более чем в пять раз.
РЕШЕНИЕ
3+7x=9+5x
7.Удвоенное число меньше восьми равно числу, умноженному на единицу более чем в три раза.
РЕШЕНИЕ
2x−8=3x+1 или 2x−8=1+3x
Упражнения… на два меньше исходного числа.УПРАЖНЕНИЕ 2
Если из числа, умноженного на три, вычесть единицу, результат будет в восемь раз меньше исходного числа, умноженного на шесть.
УПРАЖНЕНИЕ 3
Когда число вычитается из шести, результат на четыре больше, чем исходное число.
УПРАЖНЕНИЕ 4
Когда число вычитается из двадцати четырех, результат на шесть меньше, чем удвоенное число.
УПРАЖНЕНИЕ 5
Из девяти вычитается число. Затем этот результат увеличивается на единицу. В результате получается восемь больше, чем в три раза больше числа.
УПРАЖНЕНИЕ 6
Пять раз число увеличивается на два. Затем этот результат уменьшается в три раза. Результат в три раза больше, чем в три раза.
УПРАЖНЕНИЕ 7
Дважды число уменьшается на семь. Этот результат уменьшается в четыре раза. Результат — отрицательное исходное число минус шесть.
УПРАЖНЕНИЕ 8
Если из некоторого числа вычесть два, получится десять.
УПРАЖНЕНИЕ 9
Если из некоторого числа вычесть четыре, получится тридцать один.
УПРАЖНЕНИЕ 10
На три меньше некоторого числа равно удвоенному числу минус шесть.
ВИКТОРИНА!!
Переведите каждую фразу или предложение в математическое выражение или уравнение.
1.Количество меньше двенадцати.
2.Шесть больше, чем неизвестное число.
3. Число минус четыре.
4. Число плюс семь.
5.Число, увеличенное на единицу.
