Поиск информации — это… Что такое Поиск информации?
Поиск по метаданным — это поиск по неким атрибутам документа, поддерживаемым системой — название документа, дата создания, размер, автор и т. д. Пример поиска по реквизитам — диалог поиска в файловой системе (например, MS Windows).
Поиск по изображению — поиск по содержанию изображения. Поисковая система распознает содержание фотографии (загружена пользователем или добавлен URL изображения). В результатах поиска пользователь получает похожие изображения. Так работают поисковые системы:
Методы поиска
Адресный поиск
Процесс поиска документов по чисто формальным признакам, указанным в запросе.
Для осуществления нужны следующие условия:
- Наличие у документа точного адреса
- Обеспечение строгого порядка расположения документов в запоминающем устройстве или в хранилище системы.
Адресами документов могут выступать адреса веб-серверов и веб-страниц и элементы библиографической записи, и адреса хранения документов в хранилище.
Семантический поиск
Процесс поиска документов по их содержанию.
Условия:
- Перевод содержания документов и запросов с естественного языка на информационно-поисковый язык и составление поисковых образов документа и запроса.
- Составление поискового описания, в котором указывается дополнительное условие поиска.
Принципиальная разница между адресным и семантическим поисками состоит в том, что при адресном поиске документ рассматривается как объект с точки зрения формы, а при семантическом поиске — с точки зрения содержания.
При семантическом поиске находится множество документов без указания адресов.
В этом принципиальное отличие каталогов и картотек.
Библиотека — собрание библиографических записей без указания адресов.
Документальный поиск
Процесс поиска в хранилище информационно-поисковой системы первичных документов или в базе данных вторичных документов, соответствующих запросу пользователя.
Два вида документального поиска:
- Библиотечный, направленный на нахождение первичных документов.
- Библиографический, направленный на нахождение сведений о документах, представленных в виде библиографических записей.
Фактографический поиск
Процесс поиска фактов, соответствующих информационному запросу.
К фактографическим данным относятся сведения, извлеченные из документов, как первичных, так и вторичных и получаемые непосредственно из источников их возникновения.
Различают два вида:
- Документально-фактографический, заключается в поиске в документах фрагментов текста, содержащих факты.
- Фактологический (описание фактов), предпологающий создание новых фактографических описаний в процессе поиска путем логической переработки найденной фактографической информации.
Информационный поиск как наука
Информационный поиск — большая междисциплинарная область науки, стоящая на пересечении когнитивной психологии, информатики, информационного дизайна, лингвистики, семиотики, и библиотечного дела.
ИП рассматривает поиск информации в документах, поиск самих документов, извлечение метаданных из документов, поиск текста, изображений, видео и звука в локальных реляционных базах данных, в гипертекстовых базах данных таких, как Интернет и локальные интранет-системы.
Существует некоторая путаница, связанная с понятиями поиска данных, поиска документов, информационного поиска и текстового поиска. Тем не менее, каждое из этих направлений исследования обладает собственными методиками, практическими наработками и литературой.
В настоящее время ИП — это бурно развивающаяся область науки, популярность которой обусловлено экспоненциальным ростом объемов информации, в частности в сети Интернет. ИП посвящена обширная литература и множество конференций. Одной из наиболее известных является Министерством обороны США совместно с Институтом Стандартов и Технологий (NIST) с целью консолидации исследовательского сообщества и развития методик оценки качества ИП.
Запрос и объект запроса
Говоря о системах ИП, употребляют термины запрос и объект запроса.
Запрос — это формализованный способ выражения информационных потребностей пользователем системы. Для выражения информационной потребности используется язык поисковых запросов, синтаксис варьируется от системы к системе. Кроме специального языка запросов, современные поисковые системы позволяют вводить запрос на естественном языке.
Объект запроса — это информационная сущность, которая хранится в базе автоматизированной системы поиска. Несмотря на то, что наиболее распространенным объектом запроса является текстовый документ, не существует никаких принципиальных ограничений. В частности, возможен поиск изображений, музыки и другой мультимедиа информации. Процесс занесения объектов поиска в ИПС называется индексацией. Далеко не всегда ИПС хранит точную копию объекта, нередко вместо неё хранится суррогат.
Задачи информационного поиска
Центральная задача ИП — помочь пользователю удовлетворить его информационную потребность. Так как описать информационные потребности пользователя технически непросто, они формулируются как некоторый запрос, представляющий из себя набор ключевых слов, характеризующий то, что ищет пользователь.
Классическая задача ИП, с которой началось развитие этой области, — это поиск документов, удовлетворяющих запросу, в рамках некоторой статической коллекции документов. Но список задач ИП постоянно расширяется и теперь включает:
- Вопросы моделирования;
- Извлечение информации, в частности аннотирования и реферирования документов;
Оценки эффективности
Существует много способов оценить насколько хорошо документы, найденные ИПС, соответствуют запросу. К сожалению, понятие степени соответствия запроса, или другими словами релевантности, является субъективным понятием, а степень соответствия зависит от конкретного человека, оценивающего результаты выполнения запроса.
Точность (precision)
Определяется как отношение числа релевантных документов, найденных ИПС, к общему числу документов:
 ,
,
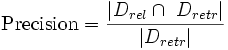 ,
,где Drel — это множество релевантных документов в базе, а Dretr — множество документов, найденных системой. По результатм исследований компании, оценивающей релевантность показателей основных русских и зарубежных поисковых систем.
Точность рамблера~ 0,756. яндекса~0.706, гугла~0.899 апорта~0.705 yahoo~0.689 altavista~0.698 Эти показатели были получены на основе анализа запроса на слово cat и по тому, как много релевантных ссылок выдаёт поисковик на 100 первых ответов.
Полнота (recall)
Отношение числа найденных релевантных документов, к общему числу релевантных документов в базе:
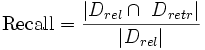
где Drel — это множество релевантных документов в базе, а Dretr — множество документов, найденных системой.
Выпадение (fall-out)
Выпадение характеризует вероятность нахождения нерелевантного ресурса и определяется, как отношение числа найденных нерелевантных документов к общему числу нерелевантных документов в базе:
- ,
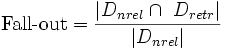 ,
,где Dnrel — это множество нерелевантных документов в базе, а Dretr — множество документов, найденных системой.
F-мера (F-measure, мера Ван Ризбергена)
Традиционно F-мера определяется, как гармоническое среднее точности и полноты:
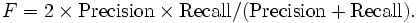
Часто ее также называют F1 мерой, потому что точность и полнота присутствуют в этой формуле с одинаковым весом.
Более общая формула для положительного вещественного α имеет вид:
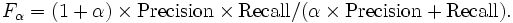
См. также
Ссылки
Литература
- Дональд Кнут Искусство программирования, том 3. Сортировка и поиск = The Art of Computer Programming, vol.3. Sorting and Searching. — 2-е изд. — М.: «Вильямс», 2007. — С. 824. — ISBN 0-201-89685-0
Урок 2. Поиск информации и выбор источников

Оглавление урока:
Что такое информационный поиск?
Впервые понятие «информационный поиск» было употреблено в 1948 году американским математиком и специалистом в области компьютерных технологий Кельвином Муэрсом, но в общедоступной литературе оно начало встречаться лишь с 1950 года.
Изначально автоматизированный информационный поиск (имеются в виду информационно-поисковые системы) применялся с целью поиска научных данных и соответствующей литературы, и использовался он университетами и публичными библиотеками. Однако с появлением и развитием сети Интернет информационный поиск получил широкое распространение.
По сути, поиск информации является процессом выявления в определённом массиве текстовых документов тех данных, которые касаются конкретной темы и удовлетворяют указанным условиям, и в которых имеются необходимые сведения и факты (к примеру, вся необходимая информация по теме самообразования).
Состоит процесс поиска информации из нескольких последовательных этапов, посредством которых обеспечивается сбор данных, их обработка и предоставление. Как правило, поиск осуществляется следующим образом:
- Определяется информационная потребность и формулируется запрос
- Определяется комплекс источников, в которых может находиться нужная информация
- Информация извлекается из выявленных источников
- Происходит ознакомление с данными, и оцениваются результаты поиска
Но, несмотря на то, что на первом этапе нужно как можно правильнее определиться с тем, какую конкретно информацию вы собираетесь искать (а это может показаться первостепенным), наибольшую важность представляет именно второй этап, ведь определиться с тем, где искать информацию, на порядок сложнее.
Где искать информацию?
Вопрос о том, где искать информацию, действительно очень важен. И в первую очередь, по той причине, что XXI век – это век информационный. А это, в свою очередь, значит, что информационный поиск на настоящее время имеет свою специфику.
Давайте вспомним: в конце прошлого века и даже начале настоящего столетия с целью поиска информации люди обращались в специализированные заведения. К таким можно отнести библиотеки, архивы, картотеки и другие подобные органы информации. Но если в то время, чтобы отыскать информацию о том, что интересует, человеку нужно было собраться, выйти из дома, добраться до нужного места, заполнить заявку, отстоять очередь, чтобы её отдать, некоторое время подождать, пока нужная литература будет найдена, а затем провести несколько часов в поиске конкретной информации и её записи на бумагу, то сегодня все эти пункты можно обойти стороной, т.к. практически у каждого дома имеется компьютер и доступ в Интернет. Исходя из этого, актуальные ещё в не таком далёком прошлом информационные базы (архивы, библиотеки и прочее) сегодня если и не потеряли своей актуальности, то, во всяком случае, имеют гораздо меньшее количество клиентов.
Чтобы найти то, что нужно в Интернете, требуется просто ввести запрос в строке поискового сервиса (вспоминаем первый этап), нажать кнопку «Найти» и выбрать наиболее подходящий из предложенных вариантов – интернет-страниц. О поиске информации в Интернете мы продолжим говорить чуть позже, а пока заметим, что пренебрегать традиционными способами поиска информации всё же не стоит, и время от времени можно наведываться в библиотеку, картотеку или архив. Ко всем прочему, это позволит вам разнообразить свою деятельность, развеяться и провести время необычно, с пользой и интересом.
Говоря о подборе источников для поиска информации, нельзя не затронуть вопрос о достоверности, что говорит о необходимости уметь анализировать источники данных и определять те, которым можно доверять.
Как выбирать достоверные источники информации?
Любые рассуждения на тему того, какие источники могут быть, и какие следует считать достоверными, так или иначе, приведут нас к стилистическому пониманию источников информации, а их существует немалое количество. Представим лишь самые распространённые:
- Научные исследования, имеющие под собой реальные доказательства, полученные эмпирическим путём
- Научно-популярные размышления, включающие в себя как фактические эмпирические данные, так и субъективные точки зрения людей, являющихся специалистами в той или иной области
- Философские трактаты и рассуждения, отличающиеся наибольшей оригинальностью, субъективностью и формой подачи
- Художественная литература, служащая, как правило, источником информации – пищи для размышления, но не достоверных эмпирических данных
- Публицистические произведения – категория произведений, которые посвящены актуальным явлениям и проблемам текущей социальной жизни. Нередко в таких произведениях можно отыскать немало достоверных данных и фактов
- Средства массовой информации – комплекс органов публичной передачи информации, таких как телевидение, радио, журналы и газеты, а также Интернет
Всегда следует брать в расчёт то, что практически ни один источник информационных данных не может являться на 100% достоверным. Исключение составляют лишь научные исследования и, в некоторой степени, научно-популярные размышления, т.к., как уже и было подмечено, в них содержатся преимущественно факты, подтверждённые опытом и официально признанные научной общественностью (есть, конечно, и люди, и точки зрения, идущие вразрез с общепринятыми, но в данной статье частные случаи мы рассматривать не будем).
Информацию же из любых других источников следует подвергать тщательной проверке, дабы удостовериться в её актуальности и правдивости. Но прежде чем перейти непосредственно к принципам отбора информации, не будет лишним сказать о том, что для самого процесса информационного поиска является очень удобным и эффективным использование идей особого философского направления – позитивизма, т.к. благодаря этому в ряде случаев (особенно если это касается поиска конкретно научных данных) множество вопросов отпадают сами собой.
Совсем немного о позитивизме
Позитивизм является философским направлением в учении о методах и процедурах научной деятельности, в котором считается, что единственным источником истинного и действительного знания вообще являются только эмпирические (подтверждённые опытным путём) исследования.
Также позитивизм говорит о том, что философское исследование не несёт в себе познавательной ценности. Базовой предпосылкой позитивизма является то, что любые подлинные (они же позитивные) знания – это совокупность результатов специальных наук.
Основной же целью позитивизма является получение объективного знания, что возможно только через проверку информации на деле. Руководствуясь всем этим, мы снова можем вернуться к идее о том, что наиболее достоверными источниками информации являются научные исследования и научно-популярные размышления.
Вооружившись этим принципом как основным, можно начать использовать и другие.
Принципы отбора информации
Можно выделить несколько принципов отбора информации:
1
Принцип наглядности
Исследуемая информация, которая соответствует этому принципу, обладает следующими признаками:
- Информация доступна для восприятия и понимания
- Формируемые информацией образы достоверны, т.к. их можно смоделировать и установить их источники
- Основные понятия, объекты и явления могут быть продемонстрированы
- Информация соответствует запрашиваемым критериям
2
Принцип научности
Принцип научности подразумевает, что исследуемая информация соответствует современным научным данным. Если такое соответствие соблюдается, то появляется возможность обнаруживать неточности и ошибки, воспринимать другие точки зрения, руководствоваться собственной аргументацией и преобразовывать информацию, сопоставляя её с другой.
Вкратце критерии принципа научности можно выразить так:
- Данные соответствуют научным представлениям современности
- Если в массиве данных имеются ошибки и неточности, они не способны повлечь за собой искажения объективной картины, касающейся рассматриваемого вопроса
- Информация может иметь вид исторического документа, который показывает путь развития конкретного научного знания
3
Принцип актуальности
Согласно этому принципу, информация должна быть практичной, злободневной, соответствующей современным запросам, важной на текущий момент времени. Такая информация способна вызвать наибольший интерес, в отличие от неактуальной. Здесь нужно руководствоваться следующими соображениями:
- Желательно, чтобы информация была близка по времени и волновала исследователя
- Информация может представлять собой документ, который расширяет представление об исследуемом объекте
- Информация должна обладать исторической ценностью или быть важной по иным причинам
- Информация может являться классическим примером чего-либо, что знают все
4
Принцип систематичности
Если информация соответствует принципу систематичности, можно наблюдать её многократное повторение в той или иной интерпретации в рамках одного источника или в той же или другой подобной интерпретации в других источниках.
Таким образом, информация достойна внимания и может быть применена, если:
- Аналогичные данные можно найти в различных базах данных
- Различные интерпретации не разрушают целостность представлений об одной и той же проблеме
5
Принцип доступности
Нередко затруднения в поиске и обработке информации могут быть вызваны, во-первых, самим её содержанием, а, во-вторых, стилем, в котором она излагается. По этой причине, работая с информацией, необходимо учитывать, что:
- Информация должна быть не только доступной для понимания с точки зрения терминологии, но и расширять тезаурус исследователя, по причине чего она будет восприниматься интересной, но не банальной
- Информация должна соответствовать той терминологии, которой обладает исследователь, но освещать конкретную тему она должна с разных сторон
- Информация должна предполагать и дидактическую обработку, которая снимает терминологический барьер, другими словами, информацию можно адаптировать под себя, при этом сохранив её смысл
6
Принцип избыточности
Исследуемая информация должна позволять исследователю выделять основную мысль, находить скрытый смысл, если таковой имеется, приходить к пониманию авторской позиции, определять цели изложения и развивать умение соотносить содержание с назначением.
Принципы поиска информации, о которых мы поговорили, могут быть применены в работе с любыми источниками данных: книгами, документами, архивными материалами, газетами и журналами, а также интернет-сайтами. По сути, эти принципы универсальны, но здесь следует чётко понимать для себя, что для поиска информации в традиционных источниках их может быть вполне достаточно, но при поиске информации в сети Интернет во избежание ошибок необходимо соблюдать ещё один ряд правил.
Правила поиска информации в Интернете
Для опытного пользователя поиск информации в Интернете предельно прост, однако, для людей, столкнувшихся с вопросом автоматизированного информационного поиска впервые, этот процесс может показаться довольно сложным из-за обилия всевозможных поисковых операторов. Ниже мы рассмотрим простой поиск и расширенный поиск, а также укажем дополнительную информацию, которая будет полезна при поиске данных в Интернете.
Простой поиск информации в Интернете
Для начала стоит сказать, что наиболее популярной поисковой системой в мире является «Google». В России к нему добавляется «Яндекс», «Поиск@mail.ru» и «Rambler».
Чтобы найти нужную информацию, нужно просто внести в поисковую строку сервиса интересующий запрос, например «Иван Грозный» или «Как правильно водить машину», и нажать «Найти» или клавишу «Enter» на клавиатуре компьютера. В результате поисковик выдаст множество страниц, на которых представлена информация по запрашиваемому запросу. Обратите внимание на то, что наиболее актуальными считаются результаты, расположенные на первой странице поисковой системы.
Расширенный поиск информации в Интернете
По своему принципу расширенный поиск ничем не отличается от простого, кроме того, что можно указывать дополнительные параметры.
При помощи специальных фильтров у пользователя есть возможность задать дополнительные условия для своего запроса. Это может быть ограничение по региону, конкретному сайту, нужному языку, форме слова или фразы, дате размещения материала или типу файла.
Чтобы активировать эти функции, нужно щёлкнуть по специальному значку, расположенному на странице поисковика. Откроется дополнительное меню, где и задаются ограничения. Сбрасываются фильтры (ограничения) нажатием кнопки «Очистить» на странице поисковика.
Дополнительная информация
Каждый пользователь должен иметь в виду, что:
- Ограничение по региону запускает поиск в указанном регионе. В качестве стандарта (По умолчанию) обычно выдаются запросы по тому региону, откуда выходит в Сеть пользователь.
- Ограничение по форме запроса запускает поиск по тем документам, где слова имеют конкретно ту форму, которая стоит в запросе, однако порядок слов может меняться. Пользователь может задать регистр букв (заглавные или строчные), любую часть речи и форму, т.е. склонение, число, род, падеж и т.д. По умолчанию поисковые системы ищут все формы запрашиваемого слова, т.е. если задать «написал», поисковик будет искать «написать», «напишу» и т.п. Однокоренные слова поисковик искать не будет.
- Ограничение по сайту запускает поиск информации среди документов, имеющихся на конкретном сайте.
- Ограничение по языку запускает поиск информации на выбранном языке. Есть возможность установить поиск по нескольким языкам одновременно.
- Ограничение по типу файла запускает поиск по конкретному формату документа, т.е. при указании соответствующих расширений можно найти текстовые документы, аудио- и видеофайлы, документы, предназначенные для открытия специальными программами и редакторами и т.д. Есть возможность установить поиск по нескольким типам файлов одновременно.
- Ограничение по дате обновления запускает поиск по конкретной дате размещения документа. Пользователь может найти документ от конкретного числа, месяца и года, а также установить временной промежуток – тогда поисковик выдаст всю информацию, добавленную за этот период времени.
Этих правил будет достаточно для поиска информации в Интернете. Освоить его в состоянии любой человек, причём потребуется на это совсем немного времени – обычно хватает буквально 2-3 трёх практических подходов.
Но что делать с найденной информацией, ведь весь её массив не обязателен для изучения? Неважно, как вы предпочитаете искать данные на интересующую тему – ходить в библиотеку или кликать по сайтам, одновременно попивая кофе – помимо того, что вы должны обладать навыками поиска, вы также должны уметь обрабатывать тот материал, который изучаете. И для этого как нельзя лучше подходит конспектирование и некоторые другие техники.
Работа с полученной информацией: конспекты, ментальные карты, опорные схемы и блок-схемы
Конспектирование по праву считается самым популярным и применяемым способом обработки информации. Учитывая это, мы решили уделить этому процессу наибольшее внимание, а по ментальным картам, опорным схемам и блок-схемам представить лишь ознакомительную информацию.
Что такое конспект?
Как все мы знаем, конспект представляет собой письменный текст, где последовательно и кратко излагаются основные моменты какого-либо источника информации. Конспектирование подразумевает приведение к определённой структуре сведений, взятых из оригинала. Основой этого процесса является систематизация данных. Заметки могут быть либо точными выдержками и цитатами, либо иметь форму свободного письма – главное, чтобы оставался смысл. Стиль, в котором выдерживается конспект, в большинстве случаев близок к первоисточнику.
При правильном составлении конспекта отражается логическая и смысловая связь записываемого. Конспект можно взять через некоторое время или же дать другом человеку, и чтение и понимание материала не вызовут затруднений. Грамотный конспект способствует восприятию даже самой сложной информации, ведь выражена она в понятной форме.
Конспекты также различаются по видам, и чтобы можно было правильно применять тот вид конспекта, который в большей степени подходит выполняемой работе, эти виды нужно уметь различать.
Виды конспектов
Выделяют плановые конспекты, схематические плановые конспекты, текстуальные, тематические и свободные конспекты. Вкратце о каждом из них.
1
Плановый конспект
Основой планового конспекта является предварительно подготовленный материал, а сам конспект включает в себя заголовки и подзаголовки (пункты и подпункты). Каждый из заголовков сопровождается небольшим текстом, по причине чего имеет понятную структуру.
Плановый конспект в наибольшей мере соответствует подготовке к семинарам и публичным выступлениям. Чем чётче будет структура, тем более логично и полноценно можно будет донести информацию до адресата. По мнению специалистов, плановый конспект должен дополняться пометками, указывающими на использовавшиеся источники, ведь запомнить их все довольно сложно.
2
Схематический плановый конспект
Схематический плановый конспект состоит из пунктов плана, представленных в форме предложений-вопросов, на которые нужно ответить. При работе с информацией нужно вносить по несколько пометок под каждое из-предложений-вопросов. В таком конспекте будет отражена структура и внутренняя связь данных. Кроме того, этот вид конспектов помогает хорошо усвоить изучаемый материал.
3
Текстуальный конспект
Текстуальный конспект отличается от всех остальных максимальной насыщенностью, т.к. для его составления используются отрывки и цитаты из первоисточника. Его легко можно дополнить планом, терминами, понятиями и тезисами. Текстуальный конспект рекомендуется составлять тем, кто занят изучением литературы или науки, ведь здесь цитаты представляют особую важность.
Но и составляется этот вид конспектов непросто, т.к. необходимо уметь определять самые важные отрывки текста и цитаты так, чтобы, в конечном счете, они могли дать целостное представление об изученном материале.
4
Тематический конспект
Тематический конспект отличен от других более всего. Его смысл заключается в том, что освещается какая-либо конкретная тема, вопрос или проблема, а для его составления обычно используют целый ряд источников информации.
Посредством тематического конспекта лучше всего можно провести анализ исследуемой темы, раскрыть главные моменты и изучить их с разных ракурсов. Но нужно понимать, что для составления такого конспекта потребуется исследовать массу источников, чтобы суметь создать целостную картину – это является непременным условием действительно качественного материала.
5
Свободный конспект
Свободный конспект является лучшим выбором для людей, способных применять разные способы работы с информацией. В свободный конспект можно включить всё: тезисы, цитаты, отрывки текста, план, пометки, выписки и т.д. Необходимо только уметь быстро и грамотно излагать мысли и работать с материалом. Многие считают, что использование конспекта такой формы является самым полноценным и целостным.
Как только вы определились с тем, какой конспект вы будете составлять, можно приступать к самому процессу. Чтобы выполнить работу качественно, нужно руководствоваться определёнными правилами.
Правила составления конспекта
Таких правил несколько и все они предельно просты:
- Ознакомьтесь с текстом, выявите его основные особенности, характер, сложность; определите, есть ли в нём термины, которые вы видите впервые. Отметьте незнакомые понятия, места, даты, имена.
- Узнайте всю необходимую информацию о том, что вам показалось незнакомым в тексте при первом прочтении. Наведите справки о людях и событиях. Узнайте значение терминов. Полученные данные обязательно зафиксируйте.
- Прочтите текст повторно и проведите его анализ. Это поможет вам выделить основные моменты, разделить для себя информацию на отдельные блоки и наметить план конспекта.
- Изучите отмеченные ранее основные моменты, составьте тезисы или выпишите отдельные фрагменты или цитаты (если их наличие не обязательно, то выразите авторскую мысль своими словами с сохранением смысла). При фиксации цитат и фрагментов обязательно помечайте, откуда взята информация, и кто является автором.
- Если у вас есть возможность выражать авторские мысли своими словами, то старайтесь делать это так, чтобы даже большие объёмы данных были выражены в 2-3 предложениях.
Применяя эти рекомендации на практике, вы овладеете навыком грамотного конспектирования, и фиксировать и обрабатывать информацию у вас будет получаться очень быстро и качественно (в качестве подспорья вы можете использовать дополнительный материал о методах конспектирования).
Помимо конспектов, для фиксации информации можно использовать и другие не менее интересные и эффективные методики.
Ментальные карты
Ментальные карты или, как их ещё принято называть, диаграммы связей, интеллект-карты, карты мыслей или ассоциативные карты являются таким методом структурирования информации, в котором используются графические записи, имеющие форму диаграмм.
Ментальные карты изображаются в виде древовидных схем, на которых присутствуют задачи, термины, факты и/или какие-либо иные данные, которые связаны ветвями. Ветви, как правило, отходят от главного (центрального) понятия.
Эффективность данного метода обусловлена тем, что его можно использовать в качестве удобного и простого инструмента управления информацией, для которого необходимо лишь наличие бумаги и карандаша (также можно использовать маркерную доску и маркеры).
Рекомендуем вам ознакомиться с подробным описанием метода ментальных карт.
Опорные схемы
Опорные схемы наглядно отображают интеллектуальную психологическую структуру человека, которая управляет его мышлением и поведением. Они позволяют изложить информацию при помощи логико-графического языка посредством значимых опор.
При составлении опорной схемы указывается её название, отмечаются ключевые понятия и схематически изображаются показатели и критерии, на основе которых производится группировка материала.
Этот вид структурирования информации очень удобен при подготовке к зачётам, экзаменам, семинарам. Его можно сопровождать конспектами и дополнительными пометками.
Блок-схемы
Блок-схемы – это ещё один действенный метод, помогающий структурировать информацию. Он представляет собой графические модели, которые описывают последовательность мыслительных операций.
Суть блок-схемы заключается в изображении отдельных шагов в форме блоков, имеющих различную форму. Все блоки соединяются друг с другом линиями-стрелками, которые указывают нужную последовательность мышления.
Чаще всего блок-схемы используются для работы с чётко структурированной информацией, когда все шаги являются конкретными. Каждый блок, имея свою форму, указывает на тот или иной мыслительный процесс, и ориентироваться по блок-схеме можно даже с минимальным количеством текстовых данных на ней. Удобно применять в качестве дополнительного инструмента.
В заключение
Как можно заключить, поиск информации и её обработка – это не только интересная, но и увлекательная деятельность. Если научиться применять этот навык с учётом всех особенностей, о которых мы сегодня поговорили, найти нужную информацию и использовать её в своих целях не будет составлять никакого труда, в особенности, если выполнить приемлемый для себя алгоритм действий несколько раз подряд.
В следующем уроке вы узнаете о том, почему в процессе самостоятельного обучения рекомендуется следовать конкретному плану, о том, как его составить, и на что нужно обратить внимание, чтобы обучение было максимально эффективным.
Проверьте свои знания
Если вы хотите проверить свои знания по теме данного урока, можете пройти небольшой тест, состоящий из нескольких вопросов. В каждом вопросе правильным может быть только 1 вариант. После выбора вами одного из вариантов, система автоматически переходит к следующему вопросу. На получаемые вами баллы влияет правильность ваших ответов и затраченное на прохождение время. Обратите внимание, что вопросы каждый раз разные, а варианты перемешиваются.
16. Поиск информации в интернете
16.Поиск информации в интернете
Информация, размещенная во Всемирной сети, исчисляется огромным количеством байт. Для поиска информации во Всемирной сети используются специальные веб-сайты – информационно-поисковые системы. Они позволяют по ключевым словам найти информационные ресурсы, связанные с ключевыми словами. Это может быть текст, содержащий ключевые слова, или графическое изображение одного из ключевых слов. Примерами информационно-поисковых систем являются системы Google и Yandex.
Поиск информации – одна из самых востребованных на практике задач, которую приходится решать любому пользователю Интернета.
Существуют три основных способа поиска информации в Интернет:
1. Указание адреса страницы.
2. Передвижение по гиперссылкам.
3. Обращение к поисковой системе (поисковому серверу).
Способ 1: Указание адреса страницы
Это самый быстрый способ поиска, но его можно использовать только в том случае, если точно известен адрес документа или сайта, где расположен документ.
Не стоит забывать возможность поиска по открытой в окне браузера web-странице (Правка-Найти на этой странице…).
Способ 2: Передвижение по гиперссылкам
Это наименее удобный способ, так как с его помощью можно искать документы, только близкие по смыслу текущему документу.
Способ 3: Обращение к поисковой системе
Пользуясь гипертекстовыми ссылками, можно бесконечно долго путешествовать в информационном пространстве Сети, переходя от одной web-страницы к другой, но если учесть, что в мире созданы многие миллионы web-страниц, то найти на них нужную информацию таким способом вряд ли удастся.
На помощь приходят специальные поисковые системы (ихеще называют поисковыми машинами). Адреса поисковых серверов хорошо известны всем, кто работает в Интернете. В настоящее время в русскоязычной части Интернет популярны следующие поисковые серверы:Яндекс (yandex.ru), Google (google.ru) и Rambler (rambler.ru
Поисковая система — веб-сайт, предоставляющий возможность поиска информации в Интернете.
Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet.
По принципу действия поисковые системы делятся на два типа: поисковые каталоги и поисковые индексы.
Поисковые каталоги служат для тематического поиска.
Информация на этих серверах структурирована по темам и подтемам. Имея намерение осветить какую-то узкую тему, нетрудно найти список web-страниц, ей посвященных.
Катало́г ресурсов в Интернете или каталог интернет-ресурсов или просто интернет-каталог — структурированный набор ссылок на сайты с кратким их описанием.
Каталог в котором ссылки на сайты внутри категорий сортируются по популярности сайтов называется рейтинг (или топ).
Поисковые индексы работают как алфавитные указатели. Клиент задает слово или группу слов, характеризующих его область поиска, — и получает список ссылок на web-страницы, содержащие указанные термины.
Первой поисковой системой для Всемирной паутины был «Wandex», уже не существующий индекс, разработанный Мэтью Грэйем из Массачусетского технологического института в 1993.
Как работает поисковой индекс?
Поисковые индексы автоматически, при помощи специальных программ(веб-пауков), сканируют страницы Интернета и индексируют их, то есть заносят в свою огромную базу данных.
Поисковый робот ( «веб-паук») — программа, являющаяся составной частью поисковой системы и предназначенная для обхода страниц Интернета с целью занесения информации о них (ключевые слова) в базу поисковика. По своей сути паук больше всего напоминает обычный браузер. Он сканирует содержимое страницы, забрасывает его на сервер поисковой машины, которой принадлежит и отправляется по ссылкам на следующие страницы.
В ответ на запрос, где найти нужную информацию, поисковый сервер возвращает список гиперссылок, ведущих web-страницам, на которых нужная информация имеется или упоминается. Обширность списка может быть любой, в зависимости от содержания запроса.
http://www.yandex.ru/
Яндекс — российская система поиска в Сети. Сайт компании, Yandex.ru, был открыт 23 сентября 1997 года. Головной офис компании находится в Москве. У компании есть офисы в Санкт-Петербурге, Екатеринбурге, Одессе и Киеве. Количество сотрудников превышает 700 человек.
Слово «Яндекс» (состоящее из буквы «Я» и части слова index; обыгран тот факт, что русское местоимение «Я» соответствует английскому «I») придумал Илья Сегалович, один из основателей Яндекса, в настоящий момент занимающий должность технического директора компании.
Поиск Яндекса позволяет искать по Рунету документы на русском, украинском, белорусском, румынском, английском, немецком и французском языках с учётом морфологии русского и английского языков и близости слов в предложении. Отличительная особенность Яндекса — возможность точной настройки поискового запроса. Это реализовано за счёт гибкого языка запросов.
По умолчанию Яндекс выводит по 10 ссылок на каждой странице выдачи результатов, в настройках результатов поиска можно увеличить размер страницы до 20, 30 или 50 найденных документов.
Время от времени алгоритмы Яндекса, отвечающие за релевантность выдачи, меняются, что приводит к изменениям в результатах поисковых запросов. В частности, эти изменения направлены против поискового спама, приводящего к нерелевантным результатам по некоторым запросам.
http://www.google.ru/
Лидер поисковых машин Интернета, Google занимает более 70 % мирового рынка. Cейчас регистрирует ежедневно около 50 млн поисковых запросов и индексирует более 8 млрд веб-страниц. Google может находить информацию на 115 языках.
По одной из версий, Google — искажённое написание английского слова googol. «Googol (гугол)» – это математический термин, обозначающий единицу со 100 нулями. Этот термин был придуман Милтоном Сироттой, племянником американского математика Эдварда Каснера, и впервые описан в книге Каснера и Джеймса Ньюмена «Математика и воображение»(Mathematics and the Imagination). Использование этого термина компанией Google отражает задачу организовать огромные объемы информации в Интернете.
Интерфейс Google содержит довольно сложный язык запросов, позволяющий ограничить область поиска отдельными доменами, языками, типами файлов и т. д.
http://www.rambler.ru/
Rambler Media Group — интернет-холдинг, включающий в качестве сервисов поисковую систему, рейтинг-классификатор ресурсов российского Интернета, информационный портал.
Rambler создан в 1996 году.
Поисковая система Рамблер понимает и различает слова русского, английского и украинского языков. По умолчанию поиск ведётся по всем формам слова.
Поиск информации в интернете — способы поиска информации с применением языка запросов
Становимся профессионалами поиска информации в интернете
Всем привет! В сегодняшней статье я расскажу вам о том, как научиться быстрее и качественнее отыскивать нужную вам информацию. Однажды мне, по долгу службы, пришлось выполнять заказ, информации по которому было совсем мало и найти ее было тяжело. Приходилось перелопачивать пол интернета, чтобы найти нужную информацию. Именно в тот момент, я решил поближе познакомиться с расширенными возможностями поисковых систем. В результате знакомства были найдены интересные способы поиска, которые в дальнейшем очень помогли закончить тот сложный проект.
Содержание статьи
Существуют три основных способа поиска информации в Интернет:
- Указание адреса страницы.
- Передвижение по гиперссылкам.
- Обращение к поисковой системе (поисковому серверу).
О последнем пункте и поговорим дальше. В этой статье речь пойдет об известных поисковиках, о принципах их работы и о расширенных возможностях поисковых систем. Вы узнаете некоторые интересные способы поиска и получите массу полезных советов, которые непременно облегчат вам поиск нужной информации в интернете.
Как работают системы веб-поиска
По данным сервиса статистики LiveInternet.ru распределение поисковых систем в России примерно следующее:
- Яндекс — 53.9%
- Гугл — 35.0%
- Поиск Mail.ru — 8.3%
- Рамблер — 0.9%
- Яндекс (картинки) — 0.6%
- Гугл (картинки) — 0.2%
Теперь, чтобы лучше понять, как работают поисковые системы, сделаем краткий обзор механизма работы. Поисковая система работает в следующем порядке:
- Сбор данных поисковым роботом пауком (Web crawling)
- Индексация найденных данных (Indexing)
- Поиск по индексированным данным (Searching)
Сбор данных поисковым роботом пауком
Обычно делится на 2 этапа – скачивание веб-страницы и анализ ссылок. Первый этап выполняет Spider (быстрый поисковый паук) – программа для последовательного перебора и скачивания веб-страниц для анализа. Она получает веб-страницы с сайтов по определенному алгоритму и отдает их другой программе Crawler-у. После этого в дело вступает Crawler (медленный паук анализатор), который находит все ссылки и составляет дальнейший маршрут для spider-а. У spider-а есть определенный список сайтов для посещения, заранее подготовленный другими подсистемами поиска. Из этого списка spider получает все необходимые данные.
Индексация найденных данных
После того, как проходит первый этап, в дело вступает вторая подсистема – подсистема индексации. Она размещает найденную пауками информацию так, чтобы было удобно в дальнейшем к ней обращаться. Для этого программа Индексатор разбирает страницу на различные ее части и анализирует их. Из страницы выделяются заголовки страниц, ссылки, текст, структурные элементы и т.д. Все полученные данные структурируются по определенному алгоритму и затем полученные данные заносятся в базу данных.
Поиск по индексированным данным
Эта подсистема выдачи результатов, которая использует сформированную индексатором базу данных. Она определяет, какие страницы удовлетворяют запросу пользователя и показывает результаты поиска. Когда вы вводите ключевое слово и делаете поиск, поисковая система отбирает результаты на основании следующих критериев:
- Title (заголовок): Есть ли ключевое слово в заголовке?
- Domain/URL (Домен/адрес): Есть ли ключевое слово в имени домена или в адресе страницы?
- Style (стиль): Анализ стиля текста на страницы. Используется ли Жирный текст или Курсив, используются ли заголовки h2, h3 и т.д.
- Density (плотность): Как часто употреблено ключевое слово на странице? Какова величина плотности ключевого слова?
- MetaInformation (мета данные) – поиск совпадений в метаданных.
- Outbound Links (ссылки наружу): Есть ли ссылки на странице и на кого они ведут, а также встречается ли ключевое слово в тексте ссылки?
- Inbound Links (внешние ссылки): Кто ссылается на искомую страницу? Каков текст ссылки?
- Insite Links (ссылки внутри страницы): На какие страницы данного сайта содержит ссылки эта страница?
В результате этого сравнения подсистема поиска выбирает нужные веб-страницы и показывает их пользователю, который осуществляет поиск.
Что можно найти через поисковики
Технически найти можно любую информацию, которая проиндексирована поисковиком, находиться в общем доступе в сети интернет и не запрещена политикой поисковой системы. При поиске в интернете имейте ввиду следующее:
- Большая часть информации в интернете не контролируется и любой человек с компьютером и доступом в интернет может публиковать информацию. Поэтому нужно понимать, что данные могут быть недостоверными.
- Не всегда легко узнать кто автор найденной информации.
- Вы не всегда знаете откуда приходит информация.
- Информация может быть предвзятой, специально вводящей в заблуждение или просто неверной.
- Дата публикации данных может быть не указано и будет трудно понять, является ли информация актуальной.
Чаще всего люди ищут через поиск (расположено примерно по убыванию):
- Всевозможные социальные сети – Вконтакте, Instagram, Одноклассники, mail.ru и т.д
- Порно
- Фильмы
- Картинки
- Музыку
- Интернет
- Авто
- Youtube
- Игры онлайн
- Компьютеры
- Деньги, финансы
- Отдых
- Недвижимость
- Спорт
- Реклама
- Строительство
- Здоровье
- Информацию о знаменитостях
- Приготовление еды, кулинария
- Логистика
- Заработок в интернете
Примерно 2-3% от всех введенных запросов обычно сформулированы как вопрос. Больше всего вопросительных запросов начинаются с:
- какой
- сколько
- кто
В последнее время все больше запросов (около 10%) стали содержать прямое указание – купить, продать или получить что-то. Самые распространённые уточнения сегодня в рунете – это скачать и бесплатно. Примерно 4% от всех запросов. Самыми часто встречающимися ошибками при поиске – ошибки, возникающие из-за неверной раскладки клавиатуры, недописанные запросы и синтаксические ошибки.]
Методы поиска информации в интернете
5 полезных способов поиска в Google
Итак, давайте рассмотрим несколько хитрых способов поиска информации через поисковую систему. Для примера, используем Google (наверное не совсем удачный пример, ну да ладно 🙂 ).
Ситуация 1 – Поиск по изображению: Есть изображение или логотип какой-то программы или компании и вы хотите найти подробную информацию о нем.
Приведу пример. Я однажды увидел на стенах во дворе примерно следующее изображение:
Значок пацифистови никак не мог вспомнить, откуда оно взялось. Написать в поиске – «Кружочек, внутри которого палочка и еще 2 палочки» вряд ли что-нибудь дал 🙂 . Вот здесь и приходит нам на помощь сервис поиска картинок по цифровому коду изображения от Google. Рисуем на скорую руку изображение в любом графическом редакторе и перетаскиваем его в поиск гугл по картинкам.
Поиск по картинке
Обычно, в результатах поиска по картинкам можно всегда найти искомое, главное — это более-менее сносно нарисовать. Т.к. художник из меня никакой, то результаты поиска оставлю в секрете 🙂
Другой пример. Есть логотип компании, например такой:
Логотип ИнфинитиЛоготип лишь для примера, потому как его наверное многие знают. Перетаскиваем его мышкой в поле для поиска и видим что получилось:
Поиск компании по логотипуИногда изображения наложены друг на друга в одной картинке. Чтобы найти по нужному изображению, придется его аккуратно скопировать каким-нибудь графическим редактором, выделив нужную область. Если вы хорошо владеете каким-нибудь графическим редактором, то прежде чем искать по изображению, можно его обработать и почистить от лишнего «шума». Тогда результат поиска будет намного качественнее.
Ситуация 2 – Поиск внутри файлов с определенным расширением. Для того, чтобы искать текст в файлах, нужно ввести в поисковую строку следующую команду: filetype:xls искомый текст. Xls в данном случае – это расширение файлов Excel. Т.е. поисковая машина будет искать текст внутри файлов с указанным расширением. Например: filetype:xls отчет. В итоге получаем все Excel файлы, в которых встречается слово отчет:
Поиск по типу файлаТаким образом можно, например скачать шаблон какого-нибудь документа, ну или сам документ 🙂 , если его специально в общий доступ положили или просто забыли защитить.
Для поиска доступны следующие типы файлов:
- pdf – поиск указанного текста внутри pdf файлов
- dwf – файлы программы AutoCAD
- ps – файлы Adobe Post Script, специальные сценарии для вывода высококачественной векторной графики на принтеры и плоттеры
- kml и kmz – файлы программы Гугл Планета Земля(Google earth)
- xls – файлы программы Microsoft Office Excel
- ppt – файлы программы Microsoft Office Power Point
- doc – файлы программы Microsoft Office Word
- rtf – файлы Rich Text Format, поддерживаемые большинством текстовых редакторов
- swf – файлы проигрывателя флеш-плеера Shockwave Flash
- txt – поиск внутри обычных текстовых файлов
Ситуация 3 – Ищем точное вхождение поисковой фразы. Иногда нужно найти точное вхождение фразы в каком то тексте. В принципе здесь два пути. Первый подход – вводите в поисковую строку точную и достаточно длинную поисковую фразу и поисковик найдет текст, который наиболее точно содержит то, что мы ищем. Чем больше и точнее будет поисковый запрос, тем более точное совпадение найдет поисковая машина (если конечно такая информация присутствует в сети интернет).
Второй подход – обрамлять кавычками поисковую фразу. В этом случае фраза может состоять из небольшого количества слов. Например, вводим – “Большие города”, получаем:
Поиск по точному вхождению фразыНо если мы попытаемся ввести между этими двумя словами в кавычках что-то бессмысленное, то поиск не даст результатов. И даже если вставить одну бессмысленную букву, поиск не даст результатов, хотя поисковая система и попытается предложить нам подходящие варианты.
Ситуация 4 – Поиск информации только по одному определенному сайту или домену. Если вам нужно найти информацию по определенному сайту, то… можно воспользоваться поиском, который есть на сайте ну или попробовать найти что-то при помощи поисковый системы Google. Глядишь, и найдется что-то, что не хотел (или не смог) искать встроенный в сайт поиск. Для этого вводим в поисковую строку следующее выражение: Разное site:livejournal.ru Разное – это текст, который вы ищете, все что после site: это доменное имя сайта, на котором нужно искать.
Поиск по сайтуТот же механизм работает для доменов. Вместо имени сайта можно указать в каком домене искать информацию, например: Закон site:gov, где .gov — общий домен верхнего уровня для правительственных организаций.
Ситуация 5 – Поиск информации по электронной почте. Иногда необходимо найти информацию по человеку или организации, но на руках есть только адрес электронного почтового ящика (email). Если ввести в поисковую строку адрес почтового ящика, то можно найти все сайты и ресурсы, где человек оставлял свой email. Можно также найти домены, которые зарегистрированы на этот ящик.
Поиск по emailЕще один способ поиска – это использование оператора *, который позволяет заполнить поисковый запрос произвольным текстом и частью почтового адреса. Например можно найти почтовые ящики сотрудников компании, написав *@имякомпании.ru, для примера *@microsoft.com
7 полезных советов при поиске информации
- Составлять поисковый запрос нужно так, чтобы максимально сузить количество вариантов в выдаче
- Используйте фильтрацию по времени – это позволит найти более-менее актуальную информацию. Благо сейчас все крупные поисковые системы предоставляют расширенный поиск, в котором можно установить диапазон дат.
- Корректный вопрос, задаваемый поисковику, должен состоять как минимум из двух ключевых слов тогда поисковику будет гораздо проще отыскать нужную информацию
- Для поиска информации используйте разные поисковые машины. Несмотря на то, что все поисковики построены на общих принципах, алгоритмы у них могут различаться. Поэтому может случиться так, что то, что не смог найти Yandex, выдаст Google
- Если вы ищете какие-либо товары или услуги в вашем городе, уточняйте регион поиска(например Москва). Это уменьшит количество результатов, но найденные результаты будут более релеванты вашим поисковым запросам
- Используйте больше существительных для поиска.
- Используйте синонимы, если по запросу не было найдено то, что нужно
Главный фактор успешного и быстрого поиска – это формулировка запроса для поисковой системы. Если вы умеете сообразить, какие нужны ключевые слова для устраивающего вас результата – вы король поиска!
«Горячий» расширенный поиск от Google. 16 способов
Некоторые методы я уже затрагивал выше, некоторые еще нет. Привожу для полноты весь список.
Исключение из Google поиска
Чтобы исключить из поисковой выдачи какое либо слово, фразу, символ и т.п., достаточно перед ним поставить знак “-” (минус), и оно не появится в результатах поиска. Для примера, я ввёл в строку поиска следующую фразу: “бесплатный хостинг – ru” и в поисковой выдаче нет ни одного .ru сайта, кроме оплаченных рекламных объявлений.
Поиск по синонимам
Используйте символ “~” для поиска схожих слов к выбранному. Например в результате выражения: “~лучшие фильмы -лучшие” вы увидите все ссылки на страницы, содержащие синонимы слова “лучшие”, но ни одно из них не будет содержать этого слова.
Неопределённый поиск
На тот случай, если вы не определились с конкретным ключевым словом для поиска, поможет оператор “*”. Например фраза “лучший редактор * изображений” подберёт лучшие редакторы для всех типов изображений, будь то цифровые, растровые, векторные и т.д.
Поиск на выбор из вариантов
Используя оператор “|”, можно осуществить Google поиск по нескольким сочетаниям фраз, заменяя несколько слов в различных местах. Например, введём фразу “купить чехол | ручку” выдаст нам страницы, содержащие либо “купить чехол”, либо “купить ручку”
Значение слова
Чтобы узнать значение того или иного слова, достаточно ввести в поисковую строку “define:” и после двоеточия искомую фразу.
Точное совпадение
Для нахождения точного совпадения поисковой выдачи с запросом достаточно заключить ключевики в кавычки.
Поиск по определённому сайту
Чтобы осуществить поиск ключевых слов только по одному сайту, достаточно прибавить к искомой фразе следующий синтаксис – “site:”.
Обратные ссылки
Чтобы узнать расположение ссылок на интересующий сайт, достаточно ввести следующий синтаксис: “links:” и далее адрес интересующего сайта.
Конвертер величин
Поисковая система Google также умеет конвертировать величины по запросу пользователя. Например, нам нужно узнать, сколько составляет 1 кг в фунтах. Набираем следующий запрос: “1 кг в фунтах”
Конвертер валют
Для того, чтобы узнать курс валют по официальному курсу, набираем следующий поисковой запрос: “1 [валюта] в [валюта]”
Время по городу
Если хотите узнать время по какому либо городу, то используйте синтаксис: “time” или русский аналог “время” и название города.
Google калькулятор
Google умеет считать онлайн! Достаточно вбить пример в строку поиска и он выдаст результат.
Поиск по типам файлов
Если вам необходимо найти что-то по конкретному типу файла, то у Google есть оператор “filetype:” который осуществляет поиск по заданному расширению файла.
Поиск кэшированной страницы
У Google есть собственные сервера, где он хранит кэшированные страницы. Если нужна именно такая, то воспользуйтесь оператором: “cached:”
Прогноз погоды по городу
Ещё одним оператором поиска у Google является оператор погоды. Достаточно вбить “weather” и город, как вы увидите, будет у вас дождь или нет
Переводчик
Можно переводить слова сразу, не отходя от поисковика. За перевод отвечает следующий синтаксис: “translate [слово] into [язык]”
P.S. Комбинируя различные варианты параметров можно очень сильно сократить диапазон поиска и найти то что нужно. Надеюсь, приведенные выше примеры помогут вам в поиске информации.
Поисковая система — Википедия
Поиск информации во Всемирной паутине был трудной и не самой приятной задачей, но с прорывом в технологии поисковых систем в конце 1990-х годов осуществлять поиск стало намного удобнейПоиско́вая систе́ма (англ. search engine) — это компьютерная система, предназначенная для поиска информации[источник не указан 371 день]. Одно из наиболее известных применений поисковых систем — веб-сервисы для поиска текстовой или графической информации во Всемирной паутине. Существуют также системы, способные искать файлы на FTP-серверах, товары в интернет-магазинах, информацию в группах новостей Usenet.
Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос[1]. Работа поисковой системы заключается в том, чтобы по запросу пользователя найти документы, содержащие либо указанные ключевые слова, либо слова, как-либо связанные с ключевыми словами[2]. При этом поисковая система генерирует страницу результатов поиска. Такая поисковая выдача может содержать различные типы результатов, например: веб-страницы, изображения, аудиофайлы. Некоторые поисковые системы также извлекают информацию из подходящих баз данных и каталогов ресурсов в Интернете.
Поисковая система тем лучше, чем больше документов, релевантных запросу пользователя, она будет возвращать. Результаты поиска могут становиться менее релевантными из-за особенностей алгоритмов (см. «Пузырь фильтров»[⇨]) или вследствие человеческого фактора[⇨]. По состоянию на 2015 год самой популярной поисковой системой в мире является Google, однако есть страны, где пользователи отдали предпочтение другим поисковикам. Так, например, в России «Яндекс» обгоняет Google больше, чем на 10 %[⇨].
По методам поиска и обслуживания разделяют четыре типа поисковых систем: системы, использующие поисковых роботов, системы, управляемые человеком, гибридные системы и мета-системы[⇨]. В архитектуру поисковой системы обычно входят:
- поисковый робот, собирающий информацию с сайтов сети Интернет или из других документов,
- индексатор, обеспечивающий быстрый поиск по накопленной информации, и
- поисковик — графический интерфейс для работы пользователя[⇨].
На раннем этапе развития сети Интернет Тим Бернерс-Ли поддерживал список веб-серверов, размещённый на сайте ЦЕРН[3]. Сайтов становилось всё больше, и поддерживать вручную такой список становилось всё сложнее. На сайте NCSA был специальный раздел «Что нового!» (англ. What’s New!)[4], где публиковали ссылки на новые сайты.
Первой компьютерной программой для поиска в Интернете была программа Арчи[en] (англ. archie — архив без буквы «в»). Она была создана в 1990 году Аланом Эмтэджем (Alan Emtage), Биллом Хиланом (Bill Heelan) и Дж. Питером Дойчем (J. Peter Deutsch), студентами, изучающими информатику в университете Макгилла в Монреале. Программа скачивала списки всех файлов со всех доступных анонимных FTP-серверов и строила базу данных, в которой можно было выполнять поиск по именам файлов. Однако, программа Арчи не индексировала содержимое этих файлов, так как объём данных был настолько мал, что всё можно было легко найти вручную.
Развитие и распространение сетевого протокола Gopher, придуманного в 1991 году Марком Маккэхилом (Mark McCahill) в университете Миннесоты, привело к созданию двух новых поисковых программ, Veronica[en] и Jughead[en]. Как и Арчи, они искали имена файлов и заголовки, сохранённые в индексных системах Gopher. Veronica (англ. Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) позволяла выполнять поиск по ключевым словам большинства заголовков меню Gopher во всех списках Gopher. Программа Jughead (англ. Jonzy’s Universal Gopher Hierarchy Excavation And Display) извлекала информацию о меню от определённых Gopher-серверов. Хотя название поисковика Арчи не имело отношения к циклу комиксов «Арчи»[en], тем не менее Veronica и Jughead — персонажи этих комиксов.
К лету 1993 года ещё не было ни одной системы для поиска в вебе, хотя вручную поддерживались многочисленные специализированные каталоги. Оскар Нирштрасс (Oscar Nierstrasz) в Женевском университете написал ряд сценариев на Perl, которые периодически копировали эти страницы и переписывали их в стандартный формат. Это стало основой для W3Catalog, первой примитивной поисковой системы сети, запущенной 2 сентября 1993 года[5].
Вероятно, первым поисковым роботом, написанным на языке Perl, был «World Wide Web Wanderer» — бот Мэтью Грэя (Matthew Gray) из Массачусетского технологического института в июне 1993 года. Этот робот создавал поисковый индекс «Wandex». Цель робота Wanderer состояла в том, чтобы измерить размер всемирной паутины и найти все веб-страницы, содержащие слова из запроса. В 1993 году появилась и вторая поисковая система «Aliweb». Aliweb не использовала поискового робота, но вместо этого ожидала уведомлений от администраторов веб-сайтов о наличии на их сайтах индексного файла в определённом формате.
JumpStation[en], [6] созданный в декабре 1993 года Джонатаном Флетчером, искал веб-страницы и строил их индексы с помощью поискового робота, и использовал веб-форму в качестве интерфейса для формулирования поисковых запросов. Это был первый инструмент поиска в Интернете, который сочетал три важнейших функции поисковой системы (проверка, индексация и собственно поиск). Из-за ограниченности ресурсов компьютеров того времени индексация и, следовательно, поиск были ограничены только названиями и заголовками веб-страниц, найденных поисковым роботом.
Первой полнотекстовой индексирующей ресурсы при помощи робота («craweler-based») поисковой системой, стала система «WebCrawler»[en], запущенная в 1994 году. В отличие от своих предшественниц, она позволяла пользователям искать по любым словам, расположенным на любой веб-странице — с тех пор это стало стандартом для большинства поисковых систем. Кроме того, это был первый поисковик, получивший широкое распространение. В 1994 году была запущена система «Lycos», разработанная в Университете Карнеги-Меллон и ставшая серьёзным коммерческим предприятием.
Вскоре появилось множество других конкурирующих поисковых машин, таких как: «Magellan»[en], «Excite», «Infoseek»[en], «Inktomi»[en], «Northern Light»[en] и «AltaVista». В некотором смысле они конкурировали с популярными интернет-каталогами, такими как «Yahoo!». Но поисковые возможности каталогов ограничивались поиском по самим каталогам, а не по текстам веб-страниц. Позже каталоги объединялись или снабжались поисковыми роботами с целью улучшения поиска.
В 1996 году компания Netscape хотела заключить эксклюзивную сделку с одной из поисковых систем, сделав её поисковой системой по умолчанию на веб-браузере Netscape. Это вызвало настолько большой интерес, что Netscape заключила контракт сразу с пятью крупнейшими поисковыми системами (Yahoo!, Magellan, Lycos, Infoseek и Excite). За 5 млн долларов США в год они предлагались по очереди на поисковой странице Netscape[7][8].
Поисковые системы участвовали в «Пузыре доткомов» конца 1990-х[9]. Несколько компаний эффектно вышли на рынок, получив рекордную прибыль во время их первичного публичного предложения. Некоторые отказались от рынка общедоступных поисковых движков и стали работать только с корпоративным сектором, например, Northern Light[en].
Google взял на вооружение идею продажи ключевых слов в 1998 году, тогда это была маленькая компания, обеспечивавшая работу поисковой системы по адресу goto.com[en]. Этот шаг ознаменовал для поисковых систем переход от соревнований друг с другом к одному из самых выгодных коммерческих предприятий в Интернете[10]. Поисковые системы стали продавать первые места в результатах поиска отдельным компаниям.
Поисковая система Google занимает видное положение с начала 2000-х[11]. Компания добилась высокого положения благодаря хорошим результатам поиска с помощью алгоритма PageRank. Алгоритм был представлен общественности в статье «The Anatomy of Search Engine», написанной Сергеем Брином и Ларри Пейджем, основателями Google[12]. Этот итеративный алгоритм ранжирует веб-страницы, основываясь на оценке количества гиперссылок на веб-страницу в предположении, что на «хорошие» и «важные» страницы ссылаются больше, чем на другие. Интерфейс Google выдержан в спартанском стиле, где нет ничего лишнего, в отличие от многих своих конкурентов, которые встраивали поисковую систему в веб-портал. Поисковая система Google стала настолько популярной, что появились подражающие ей системы, например, Mystery Seeker[en](тайный поисковик).
К 2000 году Yahoo! осуществлял поиск на основе системы Inktomi. Yahoo! в 2002 году купил Inktomi, а в 2003 году купил Overture, которому принадлежали AlltheWeb[en] и AltaVista. Затем Yahoo! работал на основе поисковой системы Google вплоть до 2004 года, пока не запустил, наконец, свой собственный поисковик на основе всех купленных ранее технологий.
Фирма Microsoft впервые запустила поисковую систему Microsoft Network Search (MSN Search) осенью 1998 года, используя результаты поиска от Inktomi. Совсем скоро в начале 1999 года сайт начал отображать выдачу Looksmart[en], смешанную с результатами Inktomi. Недолго (в 1999 году) MSN search использовал результаты поиска от AltaVista. В 2004 году фирма Microsoft начала переход к собственной поисковой технологии с использованием собственного поискового робота — msnbot[en]. После проведения ребрендинга компанией Microsoft 1 июня 2009 года была запущена поисковая система Bing. 29 июля 2009 Yahoo! и Microsoft подписали соглашение, согласно которому Yahoo! Search[en] работал на основе технологии Microsoft Bing. На момент 2015 года союз Bing и Yahoo! дал первые настоящие плоды. Теперь Bing занимает 20,1 % рынка, а Yahoo! 12,7 %, что в общем занимает 32,60 % от общего рынка поисковых систем в США по данным из разных источников.
Поиск информации на русском языке[править | править код]
В 1996 году был реализован поиск с учётом русской морфологии на поисковой машине Altavista и запущены оригинальные российские поисковые машины Рамблер и Апорт. 23 сентября 1997 года была открыта поисковая машина Яндекс. 22 мая 2014 года компанией Ростелеком была открыта национальная поисковая машина Спутник, которая на момент 2015 года находится в стадии бета-тестировании. 22 апреля 2015 года был открыт новый сервис Спутник. Дети специально для детей с повышенной безопасностью.
Большую популярность получили методы кластерного анализа и поиска по метаданным. Из международных машин такого плана наибольшую известность получила «Clusty»[en] компании Vivisimo[en]. В 2005 году в России при поддержке МГУ запущен поисковик «Нигма», поддерживающий автоматическую кластеризацию. В 2006 году открылась российская метамашина Quintura, предлагающая визуальную кластеризацию в виде облака тегов. «Нигма» тоже экспериментировала[13] с визуальной кластеризацией.
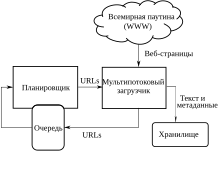 Высокоуровневая архитектура стандартного краулера
Высокоуровневая архитектура стандартного краулераОсновные составляющие поисковой системы: поисковый робот, индексатор, поисковик[14].
Как правило, системы работают поэтапно. Сначала поисковый робот получает контент, затем индексатор генерирует доступный для поиска индекс, и наконец, поисковик обеспечивает функциональность для поиска индексируемых данных. Чтобы обновить поисковую систему, этот цикл индексации выполняется повторно[14].
Поисковые системы работают, храня информацию о многих веб-страницах, которые они получают из HTML-страниц. Поисковый робот или «краулер» (англ. Crawler) — программа, которая автоматически проходит по всем ссылкам, найденным на странице, и выделяет их. Краулер, основываясь на ссылках или исходя из заранее заданного списка адресов, осуществляет поиск новых документов, ещё не известных поисковой системе. Владелец сайта может исключить определённые страницы при помощи robots.txt, используя который можно запретить индексацию файлов, страниц или каталогов сайта.
Поисковая система анализирует содержание каждой страницы для дальнейшего индексирования. Слова могут быть извлечены из заголовков, текста страницы или специальных полей — метатегов. Индексатор — это модуль, который анализирует страницу, предварительно разбив её на части, применяя собственные лексические и морфологические алгоритмы. Все элементы веб-страницы вычленяются и анализируются отдельно. Данные о веб-страницах хранятся в индексной базе данных для использования в последующих запросах. Индекс позволяет быстро находить информацию по запросу пользователя[15].
Ряд поисковых систем, подобных Google, хранят исходную страницу целиком или её часть, так называемый кэш, а также различную информацию о веб-странице. Другие системы, подобные системе AltaVista, хранят каждое слово каждой найденной страницы. Использование кэша помогает ускорить извлечение информации с уже посещённых страниц[15]. Кэшированные страницы всегда содержат тот текст, который пользователь задал в поисковом запросе. Это может быть полезно в том случае, когда веб-страница обновилась, то есть уже не содержит текст запроса пользователя, а страница в кэше ещё старая[15]. Эта ситуация связана с потерей ссылок (англ. linkrot[en]) и дружественным по отношению к пользователю (юзабилити) подходом Google. Это предполагает выдачу из кэша коротких фрагментов текста, содержащих текст запроса. Действует принцип наименьшего удивления, пользователь обычно ожидает увидеть искомые слова в текстах полученных страниц (User expectations[en]). Кроме того, что использование кэшированных страниц ускоряет поиск, страницы в кэше могут содержать такую информацию, которая уже нигде более не доступна.
Поисковик работает с выходными файлами, полученными от индексатора. Поисковик принимает пользовательские запросы, обрабатывает их при помощи индекса и возвращает результаты поиска[14].
Когда пользователь вводит запрос в поисковую систему (обычно при помощи ключевых слов), система проверяет свой индекс и выдаёт список наиболее подходящих веб-страниц (отсортированный по какому-либо критерию), обычно с краткой аннотацией, содержащей заголовок документа и иногда части текста[15]. Поисковый индекс строится по специальной методике на основе информации, извлечённой из веб-страниц[11]. С 2007 года поисковик Google позволяет искать с учётом времени создания искомых документов (вызов меню «Инструменты поиска» и указание временного диапазона).
Большинство поисковых систем поддерживает использование в запросах булевых операторов И, ИЛИ, НЕ, что позволяет уточнить или расширить список искомых ключевых слов. При этом система будет искать слова или фразы точно так, как было введено. В некоторых поисковых системах есть возможность приближённого поиска[en], в этом случае пользователи расширяют область поиска, указывая расстояние до ключевых слов[15]. Есть также концептуальный поиск[en], при котором используется статистический анализ употребления искомых слов и фраз в текстах веб-страниц. Эти системы позволяют составлять запросы на естественном языке. Примером такой поисковой системы является сайт ask com.
Полезность поисковой системы зависит от релевантности найденных ею страниц. Хоть миллионы веб-страниц и могут включать некое слово или фразу, но одни из них могут быть более релевантны, популярны или авторитетны, чем другие. Большинство поисковых систем использует методы ранжирования, чтобы вывести в начало списка «лучшие» результаты. Поисковые системы решают, какие страницы более релевантны, и в каком порядке должны быть показаны результаты, по-разному[15]. Методы поиска, как и сам Интернет со временем меняются. Так появились два основных типа поисковых систем: системы предопределённых и иерархически упорядоченных ключевых слов и системы, в которых генерируется инвертированный индекс на основе анализа текста.
Большинство поисковых систем являются коммерческими предприятиями, которые получают прибыль за счёт рекламы, в некоторых поисковиках можно купить за отдельную плату первые места в выдаче для заданных ключевых слов. Те поисковые системы, которые не берут денег за порядок выдачи результатов, зарабатывают на контекстной рекламе, при этом рекламные сообщения соответствуют запросу пользователя. Такая реклама выводится на странице со списком результатов поиска, и поисковики зарабатывают при каждом клике пользователя на рекламные сообщения.
Существует четыре типа поисковых систем: с поисковыми роботами, управляемые человеком, гибридные и мета-системы[16].
- системы, использующие поисковые роботы
- Состоят из трёх частей: краулер («бот», «робот» или «паук»), индекс и программное обеспечение поисковой системы. Краулер нужен для обхода сети и создания списков веб-страниц. Индекс — большой архив копий веб-страниц. Цель программного обеспечения — оценивать результаты поиска. Благодаря тому, что поисковый робот в этом механизме постоянно исследует сеть, информация в большей степени актуальна. Большинство современных поисковых систем являются системами данного типа.
- Эти поисковые системы получают списки веб-страниц. Каталог содержит адрес, заголовок и краткое описание сайта. Каталог ресурсов ищет результаты только из описаний страницы, представленных ему веб-мастерами. Достоинство каталогов в том, что все ресурсы проверяются вручную, следовательно, и качество контента будет лучше по сравнению с результатами, полученными системой первого типа автоматически. Но есть и недостаток — обновление данных каталогов выполняется вручную и может существенно отставать от реального положения дел. Ранжирование страниц не может мгновенно меняться. В качестве примеров таких систем можно привести каталог Yahoo[en], dmoz и Galaxy.
- гибридные системы
- Такие поисковые системы, как Yahoo, Google, MSN, сочетают в себе функции систем, использующие поисковых роботов, и систем, управляемых человеком.
- Метапоисковые системы объединяют и ранжируют результаты сразу нескольких поисковиков. Эти поисковые системы были полезны, когда у каждой поисковой системы был уникальный индекс, и поисковые системы были менее «умными». Поскольку сейчас поиск намного улучшился, потребность в них уменьшилась. Примеры: MetaCrawler[en] и MSN Search.
Google — самая популярная поисковая система в мире с долей на рынке 69,24 %. Bing занимает вторую позицию, его доля 12,26 %[17].
Самые популярные поисковые системы в мире[18]:
| Поисковая система | Доля рынка в июле 2014 | Доля рынка в октябре 2014 | Доля рынка в сентябре 2017 |
|---|---|---|---|
| 68,69 % | 58,01 % | 69,24 % | |
| Bing | 17,17 % | 29,06 % | 12,26 % |
| Baidu | 6,22 % | 8,01 % | 6,48 % |
| Yahoo! | 6,74 % | 4,01 % | 5,19 % |
| AOL | 0,13 % | 0,21 % | 1,11 % |
| Excite | 0,22 % | 0,00 % | 0,00 % |
| Ask | 0,13 % | 0,10 % | 0,24 % |
Азия[править | править код]
В восточноазиатских странах и в России Google — не самая популярная поисковая система. В Китае, например, более популярна поисковая система Soso.
В Южной Корее поисковым порталом собственной разработки Naver пользуется около 70 % жителей[19]Yahoo! Japan и Yahoo! Taiwan — самые популярные системы для поиска в Японии и Тайване соответственно[20].
Россия и русскоязычные поисковые системы[править | править код]
Яндексом пользуются 53,3 % пользователей в России (Google — 42,9 %)[21].
Согласно данным LiveInternet в декабре 2017 года об охвате русскоязычных поисковых запросов[22]:
- Всеязычные:
- Англоязычные и международные:
- Русскоязычные — большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках — украинском, белорусском, английском, татарском и других. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что, в основном, индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык, или другими способами ограничивают своих роботов русскоязычными сайтами.
Некоторые из поисковых систем используют внешние алгоритмы поиска.
Количественные данные поисковой системы Google[править | править код]
Число пользователей Интернета и поисковых систем и требований пользователей к этим системам постоянно растёт. Для увеличений скорости поиска нужной информации крупные поисковые системы содержат большое количество серверов. Сервера обычно группируют в серверные центры (дата-центры). У популярных поисковых систем серверные центры разбросаны по всему миру[23].
В октябре 2012 года Google запустила проект «Где живёт Интернет», где пользователям предоставляется возможность познакомиться с центрами обработки данных этой компании[24].
О работе дата-центров поисковой системе Google известно следующее[23]:
- Суммарная мощность всех дата-центров Google, по состоянию на 2011 год, оценивалась в 220 МВт.
- Когда в 2008 году Google планировала открыть в Орегоне новый комплекс, состоящий из трёх зданий общей площадью 6,5 млн м², в журнале Harper’s Magazine подсчитали, что такой большой комплекс потребляет свыше 100 МВт электроэнергии, что сравнимо с потреблением энергии города с населением 300 000 человек.
- Ориентировочное число серверов Google в 2012 году — 1 000 000.
- Расходы Google на дата-центры составили в 2006 году — $1,9 млрд, а в 2007 году — $2,4 млрд.
Размер всемирной паутины, проиндексированной Google на декабрь 2014 года, составляет примерно 4,36 миллиарда страниц[25].
Поисковые системы, учитывающие религиозные запреты[править | править код]
Глобальное распространение Интернета и увеличение популярности электронных устройств в арабском и мусульманском мире, в частности, в странах Ближнего Востока и Индийского субконтинента, способствовало развитию локальных поисковых систем, учитывающих исламские традиции. Такие поисковые системы содержат специальные фильтры, которые помогают пользователям не попадать на запрещённые сайты, например, сайты с порнографией, и позволяют им пользоваться только теми сайтами, содержимое которых не противоречит исламской вере.
Незадолго до мусульманского месяца Рамадан, в июле 2013 года, миру был представлен Halalgoogling[en] — система, выдающая пользователям только халяльные «правильные» ссылки[26], фильтруя результаты поиска, полученные от других поисковых систем, таких как Google и Bing. Двумя годами ранее, в сентябре 2011 года, был запущен поисковый движок I’mHalal, предназначенный для обслуживания пользователей Ближнего Востока. Однако этот поисковый сервис пришлось вскоре закрыть, по сообщению владельца, из-за отсутствия финансирования[27].
Отсутствие инвестиций и медленный темп распространения технологий в мусульманском мире препятствовали прогрессу и мешали успеху серьёзного исламского поисковика. Очевиден провал огромных инвестиций в веб-проекты мусульманского образа жизни, одним из которых был Muxlim[en]. Он получил миллионы долларов от инвесторов, таких как Rite Internet Ventures, и теперь — в соответствии с последним сообщением от I’mHalal перед его закрытием — выступает с сомнительной идеей о том, что «следующий Facebook или Google могут появиться только в странах Ближнего Востока, если вы поддержите нашу блестящую молодёжь»[28].
Тем не менее исламские эксперты в области Интернета в течение многих лет занимаются определением того, что соответствует или не соответствует шариату, и классифицируют веб-сайты как «халяль» или «харам». Все бывшие и настоящие исламские поисковые системы представляют собой просто специальным образом проиндексированный набор данных либо это главные поисковые системы, такие как Google, Yahoo и Bing, с определённой системой фильтрации, использующейся для того, чтобы пользователи не могли получить доступ к харам-сайтам, таким как сайты о наготе, ЛГБТ, азартных играх и каким-либо другим, тематика которых считается антиисламской[28].
Среди других религиозно-ориентированных поисковых систем распространёнными являются Jewogle — еврейская версия Google и SeekFind.org — христианский сайт, включающий в себя фильтры, оберегающие пользователей от контента, который может подорвать или ослабить их веру[29].
Персональные результаты и пузыри фильтров[править | править код]
Многие поисковые системы, такие как Google и Bing, используют алгоритмы выборочного угадывания того, какую информацию пользователь хотел бы увидеть, основываясь на его прошлых действиях в системе. В результате, веб-сайты показывают только ту информацию, которая согласуется с прошлыми интересами пользователя. Этот эффект получил название «пузырь фильтров»[30].
Всё это ведёт к тому, что пользователи получают намного меньше противоречащей своей точке зрения информации и становятся интеллектуально изолированными в своём собственном «информационном пузыре». Таким образом, «эффект пузыря» может иметь негативные последствия для формирования гражданского мнения[31].
Несмотря на то, что поисковые системы запрограммированы, чтобы оценивать веб-сайты на основе некоторой комбинации их популярности и релевантности, в реальности экспериментальные исследования указывают на то, что различные политические, экономические и социальные факторы оказывают влияние на поисковую выдачу[32][33].
Такая предвзятость может быть прямым результатом экономических и коммерческих процессов: компании, которые рекламируются в поисковой системе, могут стать более популярными в результатах обычного поиска в ней. Удаление результатов поиска, не соответствующих местным законам, является примером влияния политических процессов. Например, Google не будет отображать некоторые неонацистские веб-сайты во Франции и Германии, где отрицание Холокоста незаконно[34].
Предвзятость может также быть следствием социальных процессов, поскольку алгоритмы поисковых систем часто разрабатываются, чтобы исключить неформатные точки зрения в пользу более «популярных» результатов[35]. Алгоритмы индексации главных поисковых систем отдают приоритет американским сайтам[33].
Поисковая бомба — один из примеров попытки управления результатами поиска по политическим, социальным или коммерческим причинам.
- ↑ Chu & Rosenthal, 1996, p. 129.
- ↑ Tarakeswar & Kavitha, 2011, p. 29.
- ↑ World-Wide Web Servers.
- ↑ What’s New.
- ↑ Oscar Nierstrasz.
- ↑ Archive of NCSA.
- ↑ Yahoo! And Netscape.
- ↑ Netscape, 1996.
- ↑ The dynamics of competition, 2001.
- ↑ Intro to Computer Science.
- ↑ 1 2 Google`s history.
- ↑ Брин и Пейдж, p. 3.
- ↑ Nigma.
- ↑ 1 2 3 Risvik & Michelsen, 2002, p. 290.
- ↑ 1 2 3 4 5 6 Knowledge Management, 2011.
- ↑ Tarakeswar & Kavitha, 2011, p. 29.
- ↑ NMS.
- ↑ Статистика.
- ↑ Naver.
- ↑ Age of Internet Empires.
- ↑ LiveInternet.
- ↑ Liveinternet
- ↑ 1 2 Antula.
- ↑ Where the Internet lives.
- ↑ World wide web size.
- ↑ Islam.
- ↑ I’mHalal
- ↑ 1 2 Halalblog
- ↑ ChristianNews.
- ↑ Pariser, 2011.
- ↑ Auralist, 2012, p. 13.
- ↑ Segev, 2010.
Поисковые системы
Поиско́вая систе́ма — программно-аппаратный комплекс с веб-интерфейсом, предоставляющий возможность поиска информации в интернете.
Все поисковые системы объединяет то, что они расположены на специально-выделенных мощных серверах и привязаны к эффективным каналам связи. Поисковые системы называют еще информационно-поисковыми системами (ИПС). Количество одновременно обслуживаемых посетителей наиболее популярных систем достигает многих тысяч. Самые известные обслуживают в сутки миллионы клиентов. В случаях, когда поисковая система имеет в своей основе каталог, она называется каталогом. В ее основе лежит работа модераторов. В основе же ИПС с полнотекстовым поиском лежит автоматический сбор информации. Он осуществляется специальными программами. Эти программы периодически исследуют содержимое всех ресурсов Интернета. Для этого они перемещаются, или как говорят, ползают, по разным ресурсам. Соответственно такие программы называются роботы. Есть и другие названия: поскольку WWW – это аббревиатура выражения Всемирная паутина, то такую программу естественно назвать спайдером по англ. – паук. В последнее время используются другие названия: автоматические индексы или директории. Все эти программы исследуют и «скачивают» информацию с разных URL-адресов. Программы указанного типа посещают каждый ресурс через определенное время. Ни одна поисковая система не в состоянии проиндексировать весь Интернет. Поэтому БД, в которых собраны адреса проиндексированных ресурсов, у разных поисковых систем разные. Тем не менее, многие из них стремятся, по возможности, охватывать в своей работе все пространство мировой Сети.
Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос. На основании запроса пользователя поисковая система генерируетстраницу результатов поиска. Такая поисковая выдача может сочетать различные типы файлов, например: веб-страницы, изображения, видеофайлы. Некоторые поисковые системы также извлекают данные из баз данных икаталогов ресурсов в Интернете.
По методам поиска и обслуживания разделяют четыре типа поисковых систем:
1.системы использующие поисковых роботов.
2.системы управляемые человеком
3.гибридные системы
4.мета-системы.
В архитектуру поисковой системы включены: поисковый робот сканирующий сайты сети Интернет, индексатор обеспечивающий быстрый поиск, и поисковик — графический интерфейс для работы пользователя.
Цель поисковой системы заключается в том, чтобы находить документы, содержащие либо ключевые слова, либо слова как-либо связанные с ключевыми словами. Поисковая система тем лучше, чем больше документов релевантных запросу пользователя она будет возвращать.
Примеры поисковых систем
Google— одна из самых полных и популярных зарубежных ИПС. Отличительной особенностью ИПС Google является технология определения степени релевантности документа путем анализа ссылок других источников на данный ресурс. Чем больше ссылок на какую-либо страницу имеется на других страницах, тем выше ее рейтинг в ИПС Google. Google использует алгоритм расчёта авторитетности PageRank. PageRank является одним из вспомогательных факторов приранжированиисайтов в результатах поиска. PageRank не единственный, но очень важный способ определенияположения сайтав результатах поиска Google. Google использует показатель PageRank найденных по запросу страниц, чтобы определить порядок выдачи этих страниц посетителю в результатах поиска.В 2010 году компания запустила голосовой поиск в России. Чтобы осуществить поиск, необходимо нажать в телефоне кнопку рядом со строкой поиска и произнести свой запрос, телефон отправит ваш голос на сервер, и браузер выдаст строку с распознанным вашим запросом и результатами поиска по нему.
Яndex – самая популярная в настоящее время отечественная поисковая система. Начала работу в 1997 г. Она поддерживает собственный каталог Интернет-ресурсов. Также является лучшей поисковой системой для выявления иллюстраций. Англоязычный вариант снабжен справочником ресурсов Интернет. Обладает развернутой системой формирования запроса. В частности, допускается ввод поискового предписания на естественном языке — в этом случае все необходимые расширения производятся автоматически.
Помимо веб-страниц в формате HTML, Яндекс индексирует документы в форматах PDF (Adobe Acrobat), Rich Text Format (RTF), двоичных форматах Word (.doc), Excel (.xls), PowerPoint(.ppt), RSS(блоги и форумы).
Поисковая система компании Mail.ruначала работать в 2007 году. Объем индексного файла весной 2009 г. составлял более 1.5 миллиарда страниц, расположенных на русскоязычных серверах. Помимо разыскания текстов, системой осуществляется поиск иллюстраций и видеофрагментов, размещенных на специализированных «самонаполняемых» российских серверах: Фото@Mail.Ru, Flamber.Ru, 35Photo.ru, PhotoForum.ru, Видео@Mail.Ru, RuTube, Loadup, Rambler Vision и им подобных. Gogo.ru позволяет ограничивать область поиска сайтами коммерческой направленности, информационными сайтами, а также форумами и блогами. Форма «Расширенного поиска» также дает возможность ограничить разыскания определенными типами файлов (PDF, DOC, XLS, PPT), местом положения искомых слов в документе или определенным доменом. В ноябре 2013 в Google Play появилась новая версия поискового приложения от компании Mail.Ru, позволяющего переходить с главного экрана в любые социальные сети и содержащего быстрый доступ к поиску по картинам, видео и новостям. Android-приложение превратилось в мини-браузер, заточенный под эффективный поиск нужной информации. Утилита также научилась распознавать поисковые запросы, заданные не текстом, а голосом. Разработчики также отмечают, что создали специальный виджет, который можно поместить на главный экран смартфона или планшета на базе системы Google Android. Подразумевается, что это позволит еще сильнее сократить время, затрачиваемое на поиск.
AltaVista– одна из старейших поисковых систем занимает одно из первых мест по объему документов – более 350 миллионов. AltaVista позволяет осуществлять простой и расширенный поиск. «Help» позволяет даже неподготовленным пользователям правильно составлять простые и сложные запросы.
Rambler – одна из первых российских ИПС, открыта в 1996 году. В конце 2002 года была произведена коренная модернизация, после которой Rambler вновь вошел в группу лидеров сетевого поиска. В настоящее время объем индекса составляет порядка 150 миллионов документов. Для составления сложных запросов рекомендуется использовать режим «Детальный запрос», который предоставляет широкие возможности для составления поискового предписания с помощью пунктов меню.
АПОРТ. На сегодняшний день объем ее базы составляет более 20 миллионов документов. Система обладает широким спектром поисковых возможностей. АПОРТ обладает функцией встроенного переводчика, это дает пользователю возможность формулировать запросы, как на русском, так и на английском языках. Кроме того, АПОРТ имеет специальные режимы для поиска иллюстраций и аудио файлов.
Поисковые механизмы последнего поколения индексируют все слова на web-странице или в статье из конференции, в то время как ранее область индексирования ограничивалась как правило названием, заголовками, первыми несколькими строками и адресом документа. Это существенно ограничивало возможность выявления материалов по узкой тематике, поскольку результаты поиска не всегда отражали реально существующие данные. Устранив этот недостаток, современные поисковые системы стали намного более надежными, чем их предшественники.
Следующая важнейшая черта — совершенствование внутреннего поискового механизма, выражающееся в увеличении числа операторов и других элементов составления запросов. Несколько лет назад применение находили только два, в лучшем случае, три классических булевых оператора: AND (и), OR (или) и NOT (не). Теперь появились NEAR (рядом, около) в Alta Vista и FOLLOWED BY (следует за) в OpenText — в высшей степени полезные операторы расстояния, которые дают возможность в максимальной степени конкретизировать запрос. Многие системы позволяют усекать окончания терминов, ограничивать поиск по дате создания документа, искать ключевые слова только в обозначенных элементах web-страниц (названии, заголовках, электронном адресе и т.д.), а также вести разыскание на точное словосочетание. Новейшие разработки также позволяют выявлять файлы определенного вида (например графические или аудио) и обладают чувствительностью к строчным и заглавным буквам. Общепринятой становится возможность искать данные на любых языках. Все это дает возможность составлять поисковое предписание с большой степенью точности, что конечно же повышает релевантность получаемых результатов.
На данный момент самые популярные поисковики Google и Яндекс, сравним их:
Количество проиндексированных страниц. У Google 8 миллиардов, а у Яндекса всего 2 миллиарда. То есть, в четыре раза меньше. Победа за Google.
Скорость индексации страниц. Google индексирует новые страницы в течение суток, тогда как Яндексу на это может потребоваться несколько дней. Опять побеждает Google.
Релевантность выдачи. Под релевантностью понимается соответствие результатов, отображенных на странице поисковика, вашему запросу. Сразу скажу, победителя тут сложно определить. Google показал хорошие результаты в зарубежном сегменте интернета, зато в Рунете, Яндекс всегда был немного впереди.
Дополнительные интернет сервисы. Тут преимущество однозначно за Яндексом. У него есть десятки разнообразных сервисов, которые удобно сгруппированы по категориям, тогда как у Google их поменьше, плюс есть интеграция с социальной сетью Google+, которая многим не нравится.
Практическая работа №7.1 Поисковые системы. Пример поиска информации на государственных образовательных порталах.
Практическая работа №7.1 Поисковые системы. Пример поиска информации на государственных образовательных порталах. | |||||||||||||||||||||||||||||||
Задание 3.
| Лексическое значение | ||||||||||||||||||||||||||||||
Метонимия | |||||||||||||||||||||||||||||||
Видеокарта | |||||||||||||||||||||||||||||||
Железо | |||||||||||||||||||||||||||||||
Папирус | |||||||||||||||||||||||||||||||
Скальпель | |||||||||||||||||||||||||||||||
Дебет |
Задание 4. С помощью одной из поисковых систем найдите информацию и занесите ее в таблицу:
Личности 20 векаФамилия, имя
Годы жизни
Род занятий
Джеф Раскин
Лев Ландау
Юрий Гагарин
Задание 5. Заполните таблицу, используя поисковую систему Яндекс: www.yandex.ru.
Слова,входящие в запрос
Структура запроса
Количество
найденных
страниц
Электронный адрес первой найденной ссылки
Информационная
система
Информационная! Система!
Информационная + система
Информационная — система
«Информационная система»
Персональный
компьютер
Персональный компьютер
Персональный & компьютер
$title (Персональный компьютер)
$anchor (Персональный компьютер)
Задание 6. Произвести поиск сайтов в наиболее популярных поисковых системах общего назначения в русскоязычном Интернете (Рунете).
Краткая справка. Наиболее популярными русскоязычными поисковыми системами являются:
Rambler — www.rambler.ru;
Апорт — www.aport.ru;
Яndex— www.yandex.ru.
Англоязычные поисковые системы:
Yahoo — www.yahoo.com.
Специализированные поисковые системы позволяют искать информацию в специализированных слоях Интернета. К ним можно отнести поиск файлов на серверах FTP и систему поиска адресов электронной почты WhoWhere.
Порядок выполнения:
1. Создайте папку на рабочем столе с именем: Фамилия–Группа.
2. Запустите Internet Explorer.
Для перехода в определенное место или на определенную страницу воспользуйтесь адресной строкой главного окна Internet Explorer.
Краткая справка: Адрес узла (URL) обычно начинается с имени протокола, за которым следует обслуживающая узел организация, например в адресе http://www.rambler.ru «http://www» указывает, что это сервер Web, который использует протокол http, домен «.ru» определяет адрес российских узлов.
3. Произведите поиск в поисковой системе Rambler.
Введите в адресную строку адрес (URL) русскоязычной поисковой системы Rambler — www.rambler.ru и нажмите клавишу Enter. Подождите, пока загрузится страница. В это же время на панели, инструментов активизируется красная кнопка Остановить, предназначенная для остановки загрузки.
Рассмотрите загрузившуюся главную страницу – Вы видите поле для ввода ключевого слова и ряд рубрик. Для перехода на ссылки, имеющиеся на странице, подведите к ссылке курсор и щелкните левой кнопкой мыши. Ссылка может быть рисунком или текстом другого цвета (обычно с подчеркнутым шрифтом). Чтобы узнать, является ли элемент страницы ссылкой, подведите к нему указатель. Если указатель принимает вид руки с указательным пальцем, значит, элемент является ссылкой.
4. Введите в поле поиска словосочетание «Энциклопедия финансов» и нажмите кнопку Найти.
5. Убедитесь, что каталог Web работает достаточно быстро. Программа через некоторое время сообщит вам, что найдено определенное количество документов по этой тематике. Определите, сколько документов нашла поисковая система:_________
6. Запомните страницу из списка найденных, представляющую для вас интерес, командой Избранное/Добавить в папку.
7. Сохраните текущую страницу на компьютере. Выполните команду Файл/Сохранить как, выберите созданную ранее папку на рабочем столе для сохранения, задайте имя файла и нажмите кнопку Сохранить.
8. Для поиска информации на текущей странице выполните команду Правка/Найти на этой странице (или нажмите клавиши Ctrl-F). В окне поиска наберите искомое выражение, например «Финансы», и нажмите кнопку Найти далее. Откройте страничку одной из найденных энциклопедий.
9. Скопируйте сведения страницы в текстовый документ. Для копирования содержимого всей страницы выполните команду Правка/Выделить все и команду Правка/Копировать. Откройте новый документ текстового редактора MS Word и выполните команду Правка/Вставить.
Краткая справка: невозможно копирование сведений с одной Web-страницы на другую.
10. Произведите поиск в поисковой системе Yandex. Откройте поисковый сервер YAndex — www.yandex.ru. В поле поиска задайте «Энциклопедии», нажмите кнопку Найти, сравните результаты с поиском в Рамблере.
11. Сузьте круг поиска и найдите информацию, например, об управлении финансами (в поле поиска введите «Управление финансами»). Сравните полученные результаты с предыдущим поиском.
12. Введите одно слово «Финансы» в поле поиска. Отличается ли результат от предыдущего поиска? Попробуйте поставить перед поисковой системой задачу найти информацию о какой-нибудь конкретной валюте, предположим «Доллар». Сравните результаты поиска.
Краткая справка: не бойтесь повторять свой запрос на разных поисковых серверах. Зачастую один и тот же запрос на другом сервере дает совершенно иные результаты.
13. Произведите поиск картинок и фотографий в поисковой системе Yandex. В поле поиска наберите по-английски «Dollar» и укажите категорию поиска «Картинки». Запрос «Dollar» найдет в Интернете картинки, в имени которых встречается слово «Dollar». Высока вероятность того, что эти картинки связаны с финансами.
5. Содержание отчета
Отчет должен содержать:
Название работы.
Цель работы.
Задание и его решение.
Вывод по работе.
6. Контрольные вопросы
Что понимают под поисковой системой?
Перечислите популярные русскоязычные поисковые системы.
Что такое ссылка и как определить, является ли элемент страницы ссылкой
Возможно ли копирование сведений с одной Web-страницы на другую?
Каким образом производится поиск картинок и фотографий в поисковых системах Интернет?