Сервис проверки файла Robots.txt — БЕСПЛАТНЫЙ онлайн-инструмент [2020] года со 100%-й точностью
Есть определенный список ошибок, которые могут повлиять на эффективность файла robots.txt, а также вы можете увидеть при проверке файла список определенных рекомендаций. Это вещи, которые могут повлиять на SEO-оптимизацию сайта, и которые нужно исправить. Предупреждения менее критичны, и это просто советы о том, как улучшить ваш сайт robots.txt.
Ошибки, которые вы можете увидеть:
Invalid URL: эта ошибка сообщает о том, что файл robots.txt на сайте отсутствует.
Potential wildcard error: технически это больше предупреждение, чем сообщение об ошибке. Это сообщение обычно означает, что в вашем файле robots.txt содержится символ (*) в поле Disallow (например, Disallow: /*.rss). Это проблема приемлемого использования синтаксиса: Google не запрещает использование символов в поле Disallow, но это не рекомендуется.
Generic and specific user-agents in the same block of code: это синтаксическая ошибка в файле robots.txt, которую нужно исправить, чтобы избежать проблем с индексацией контента на вашем веб-сайте.
Предупреждения, которые вы можете увидеть:
Allow: / : порядок разрешения не повредит и не повлияет на ваш веб-сайт, но это не стандартная практика. Самые крупные поисковые машины, включая Google и Bing, примут эту директиву, но не все программы-кроулеры будут такими же неразборчивыми. Если говорить начистоту, то всегда лучше сделать файл robots.txt совместимым со всеми программами-индексаторами, а не только с самыми популярными.
Field name capitalization: несмотря на то, что имена полей не чувствительны к регистру, некоторые индексаторы могут требовать писать их заглавными буквами, так что хорошей идеей будет делать это по умолчанию — специально для самых привередливых программ.
Sitemap support: во многих файлах robots.txt содержатся данные о карте сайта, но это не считается хорошим решением. Однако, Google и Bing поддерживают эту возможность.
Файл robots.txt — способы анализа и проверки robots.txt
Поисковые роботы — краулеры начинают знакомство с сайтом с чтения файла robots.txt. В нем содержится вся важная для них информация. Владельцам сайтов следует создать и периодически проводить анализ robots.txt. От корректности его работы зависит скорость индексации страниц и место в поисковой выдачи.
Создание файла
Описание. Файл robots.txt — это документ со служебной информацией. Он предназначен для поисковых роботов. В нем записывают, какие страницы можно индексировать, какие — нет и каким именно краулерам. Например, англоязычный Facebook разрешает доступ только боту Google. Файл robots.txt любого сайта можно посмотреть в браузере по ссылке www.site.ru/robots.txt.
Он не является обязательным элементом сайта, но его наличие желательно, потому что с его помощью владельцы сайта управляют поисковыми роботами. Задавайте разные уровни доступа к сайту, запрет на индексацию всего сайта, отдельных страниц, разделов или файлов. Для ресурсов с высокой посещаемостью ограничивайте время индексации и запрещайте доступ роботам, которые не относятся к основным поисковым системам. Это уменьшит нагрузку на сервер.
Создание. Создают файл в текстовом редакторе Notepad или подобных. Следите за тем, чтобы размер файла не превышал 32 КБ. Выбирайте для файла кодировку ASCII или UTF-8. Учтите, что файл должен быть единственным. Если сайт создан на CMS, то он будет генерироваться автоматически.
Разместите созданный файл в корневой директории сайта рядом с основным файлом index.html. Для этого используют FTP доступ. Если сайт сделан на CMS, то с файлом работают через административную панель. Когда файл создан и работает корректно, он доступен в браузере.
При отсутствии robots.txt поисковые роботы собирают всю информацию, относящуюся к сайту. Не удивляйтесь, когда увидите в выдаче незаполненные страницы или служебную информацию. Определите, какие разделы сайта будут доступны пользователям, остальные — закройте от индексации.
Проверка. Периодически проверяйте, все ли работает корректно. Если краулер не получает ответ 200 ОК, то он автоматически считает, что файла нет, и сайт открыт для индексации полностью. Коды ошибок бывают такими:
-
3хх — ответы переадресации. Робота направляют на другую страницу или на главную. Создавайте до пяти переадресаций на одной странице. Если их будет больше, робот пометит такую страницу как ошибку 404. То же самое относится и к переадресации по принципу бесконечного цикла;
-
4хх — ответы ошибок сайта. Если краулер получает от файла robots.txt 400-ую ошибку, то делается вывод, что файла нет и весь контент доступен. Это также относится к ошибкам 401 и 403;
-
5хх — ответы ошибок сервера. Краулер будет «стучаться», пока не получит ответ, отличный от 500-го.
Правила создания
Начинаем с приветствия. Каждый файл должен начинаться с приветствия User-agent. С его помощью поисковики определят уровень открытости.
| Код | Значение |
| User-agent: * | Доступно всем |
| User-agent: Yandex | Доступно роботу Яндекс |
| User-agent: Googlebot | Доступно роботу Google |
| User-agent: Mail.ru | Доступно роботу Mail.ru |
Добавляем отдельные директивы под роботов. При необходимости добавляйте директивы для специализированных поисковых ботов Яндекса.
Однако в этом случае директивы * и Yandex не будут учитываться.
| YandexBot | Основной робот |
| YandexImages | Яндекс.Картинки |
| YandexNews | Яндекс.Новости |
| YandexMedia | Индексация мультимедиа |
| YandexBlogs | Индексация постов и комментариев |
| YandexMarket | Яндекс.Маркет |
| YandexMetrika | Яндекс.Метрика |
| YandexDirect | Рекламная сеть Яндекса |
| YandexDirectDyn | Индексация динамических баннеров |
| YaDirectFetcher | Яндекс.Директ |
| YandexPagechecker | Валидатор микроразметки |
| YandexCalendar | Яндекс.Календарь |
У Google собственные боты:
| Googlebot | Основной краулер |
| Google-Images | Google.Картинки |
| Mediapartners-Google | AdSense |
| AdsBot-Google | Проверка качества рекламы |
|
AdsBot-Google-Mobile |
Проверка качества рекламы на мобильных устройствах |
| Googlebot-News | Новости Google |
Сначала запрещаем, потом разрешаем. Оперируйте двумя директивами: Allow — разрешаю, Disallow — запрещаю. Обязательно укажите директиву disallow, даже если доступ разрешен ко всему сайту. Такая директива является обязательной. В случае ее отсутствия краулер может не верно прочитать остальную информацию. Если на сайте нет закрытого контента, оставьте директиву пустой.
Работайте с разными уровнями. В файле можно задать настройки на четырех уровнях: сайта, страницы, папки и типа контента. Допустим, вы хотите закрыть изображения от индексации. Это можно сделать на уровне:
- папки — disallow: /images/
- типа контента — disallow: /*.jpg
| Нет | Да |
| Disallow: Yandex |
User-agent: Yandex Disallow: / |
| Disallow: /css/ /images/ |
Disallow: /css/ Disallow: /images/ |
Пишите с учетом регистра. Имя файла укажите строчными буквами. Яндекс в пояснительной документации указывает, что для его ботов регистр не важен, но Google просит соблюдать регистр. Также вероятна ошибка в названиях файлов и папок, в которых учитывается регистр.
Укажите 301 редирект на главное зеркало сайта. Раньше для этого использовалась директива Host, но с марта 2018 г. она больше не нужна. Если она уже прописана в файле robots.txt, удалите или оставьте ее на свое усмотрение; роботы игнорируют эту директиву.
Для указания главного зеркала проставьте 301 редирект на каждую страницу сайта. Если редиректа стоят не будет, поисковик самостоятельно определит, какое зеркало считать главным. Чтобы исправить зеркало сайта, просто укажите постраничный 301 редирект и подождите несколько дней.
Пропишите директиву Sitemap (карту сайта). Файлы sitemap.xml и robots.txt дополняют друг друга. Проверьте, чтобы:
- файлы не противоречили друг другу;
- страницы были исключены из обоих файлов;
- страницы были разрешены в обоих файлах.
Указывайте комментарии через символ #. Все, что написано после него, краулер игнорирует.
Проверка файла
Проводите анализ robots.txt с помощью инструментов для разработчиков: через Яндекс.Вебмастер и Google Robots Testing Tool. Обратите внимание, что Яндекс и Google проверяют только соответствие файла собственным требованиям. Если для Яндекса файл корректный, это не значит, что он будет корректным для роботов Google, поэтому проверяйте в обеих системах.
Если вы найдете ошибки и исправите robots.txt, краулеры не считают изменения мгновенно. Обычно переобход страниц осуществляется один раз в день, но часто занимает гораздо большее время. Проверьте через неделю файл, чтобы убедиться, что поисковики используют новую версию.
Проверка в Яндекс.Вебмастере
Сначала подтвердите права на сайт. После этого он появится в панели Вебмастера. Введите название сайта в поле и нажмите проверить. Внизу станет доступен результат проверки.
Дополнительно проверяйте отдельные страницы. Для этого введите адреса страниц и нажмите «проверить».
Проверка в Google Robots Testing Tool
Позволяет проверять и редактировать файл в административной панели. Выдает сообщение о логических и синтаксических ошибках. Исправляйте текст файла прямо в редакторе Google. Но обратите внимание, что изменения не сохраняются автоматически. После исправления robots.txt скопируйте код из веб-редактора и создайте новый файл через блокнот или другой текстовый редактор. Затем загрузите его на сервер в корневой каталог.
Запомните
-
Файл robots.txt помогает поисковым роботам индексировать сайт. Закрывайте сайт во время разработки, в остальное время — весь сайт или его часть должны быть открыты. Корректно работающий файл должен отдавать ответ 200.
-
Файл создается в обычном текстовом редакторе. Во многих CMS в административной панели предусмотрено создание файла. Следите, чтобы размер не превышал 32 КБ. Размещайте его в корневой директории сайта.
-
Заполняйте файл по правилам. Начинайте с кода “User-agent:”. Правила прописывайте блоками, отделяйте их пустой строкой. Соблюдайте принятый синтаксис.
-
Разрешайте или запрещайте индексацию всем краулерам или избранным. Для этого укажите название поискового робота или поставьте значок *, который означает «для всех».
-
Работайте с разными уровнями доступа: сайтом, страницей, папкой или типом файлов.
-
Включите в файл указание на главное зеркало с помощью постраничного 301 редиректа и на карту сайта с помощью директивы sitemap.
-
Для анализа robots.txt используйте инструменты для разработчиков. Это Яндекс.Вебмастер и Google Robots Testing Tools. Сначала подтвердите права на сайт, затем сделайте проверку. В Google сразу отредактируйте файл в веб-редакторе и уберите ошибки. Отредактированные файлы не сохраняются автоматически. Загружайте их на сервер вместо первоначального robots.txt. Через неделю проверьте, используют ли поисковики новую версию.
Материал подготовила Светлана Сирвида-Льорентэ.
Инструменты проверки файла robots.txt | www.wordpress-abc.ru
Вступление
Если у вас есть желание закрыть некоторые материалы своего сайта от поисковых и других ботов, используется три метода:
Во-первых, создаётся файл robots.txt в котором специальными записями закрываются/открываются части контента. Важно, что файл robots.txt запрещает роботам сканировать URL сайта;
Во-вторых, на HTML(XHTML) страницах или в HTTP заголовке прописывается мета–тег robots с атрибутами noindex (не показывает страницу в поиске) и/или nofollow (не разрешает боту обходить ссылки страницы). Синтаксис мета тега robots:
<meta name="robots" content="noindex, nofollow" />Важно, что мета–тег robots работает, если есть доступ ботов к сканированию страниц, где мета тег прописан. То есть они не закрыты файлом
robots.txt.
В-третьих, можно создавать закрытые разделы сайта.
При составлении файла robots.txt полезно проверять правильность его составления. Для этого предлагаю посмотреть следующие инструменты проверки файла robots.txt.
Инструменты проверки файла robots.txt
Напомню, что в классическом варианте в файле robots.txt создаются отдельные директивы для агента пользователя Yandex (user-agent: yandex) и других поисковых ботов сети, включая Googleboot (user-agent: *).
Инструмент проверки №1
Google в возможностях Searh Console оставил инструмент проверки файла robots.txt. Вот ссылка на него: https://www.google.com/webmasters/tools/robots-testing-tool
Вот скрин:
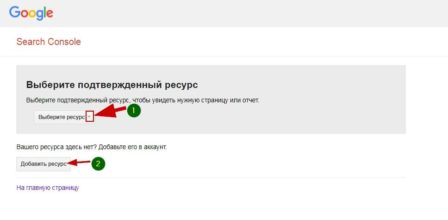
Для использования инструмента вам нужно зарегистрироваться инструментах веб–мастеров Google и добавить в них свой ресурс (сайт). Если вы всё это сделали, просто выберете сайт для проверки.
После выбора сайту откроется инструмент проверки файла robots.txt. Внизу читаем ошибки и предупреждения. Если их нет, то смотрим ещё ниже и видим сам инструмент проверки.
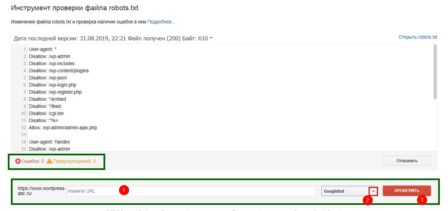
В форме проверки указываете проверяемый URL, выбираете бота Google (по умолчанию Googleboot) и жмёте кнопку «Проверить».
Результат проверки будет показан на этой же станице в виде зелёной надписи «Доступен» или красной надписи «Не доступен». Всё просто и понятно.

Инструмент проверки №2
По логике составления файла robots.txt о которой я напомнил выше, такой же инструмент проверки должен быть в веб–инструментах Яндекс для ботов Yandex. Смотрим. Действительно, в вашем аккаунте Яндекс Веб–мастер выбираете заранее добавленный ресурс (свой сайт).
В меню «Инструменты» есть вкладка «Анализ robots.txt», где проверяется весь файл robots на ошибки и проверяются отдельные URL сайта на закрытие в файле robots.
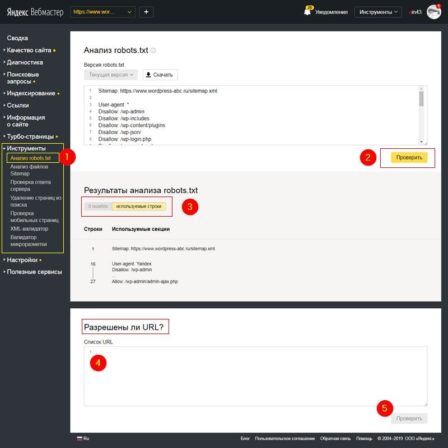
Независимые инструменты проверки файла robots.txt
Встаёт логичный вопрос, можно ли проверить файл robots.txt и его работу независимо от инструментов веб мастеров? Наверняка можно.
Во-первых, чтобы просмотреть доступность своего файла robots впишите в браузер его адрес. Он должен открыться и нормально читаться. Проверку можно сделать в нескольких браузерах.
Адрес файла должен быть:
http(s)://ваш_домен/robots.txt
Во-вторых, используйте для проверки файла следующие инструменты:
Websiteplanet.com
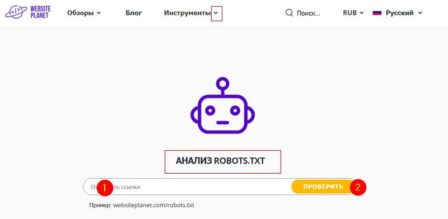
https://www.websiteplanet.com/ru/webtools/robots-txt/
Дотошный инструмент, выявляет ошибки и предупреждения, которые не показывают сами боты.
Seositecheckup.com
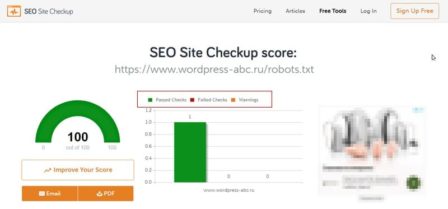
https://seositecheckup.com/tools/robotstxt-test
Англоязычный инструмент проверки файла robots.txt на ошибки. Регистрация не требуется. Хотя навязывается сервисом. Результаты в виде диаграммы.
Стоит отметить, что с июня сего года (2019) правила для составления файла robots.txt стали стандартом и распространяются на всех ботов. Так что выявленные ошибки для бота Google, будут ошибками и для бота Yandex.
Technicalseo.com
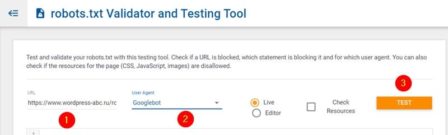
https://technicalseo.com/tools/robots-txt/
Протестируйте и подтвердите ваш robots.txt с помощью этого инструмента тестирования. Проверьте, заблокирован ли URL-адрес, какой оператор его блокирует и для какого агента пользователя. Вы также можете проверить, запрещены ли ресурсы для страницы (CSS, JavaScript, IMG).
en.ryte.com
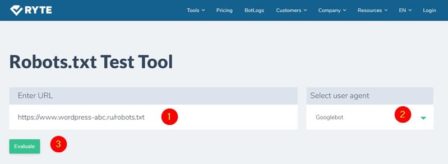
https://en.ryte.com/free-tools/robots-txt/
Просто вписывает адрес своего файла и делаете проверку. Показывает предупреждения по синтаксису файла.
Вывод про инструменты проверки файла robots.txt
По-моему, лучшие инструменты проверки файла robots.txt находятся в инструментах веб–мастеров. Они ближе к источнику и более чувствительны к изменениям правил.
Кстати, есть проверка файла robots.txt в инструментах веб–мастеров Mail поисковика (https://webmaster.mail.ru/) и была у поисковика Bing.
Еще статьи
Похожие посты:
Проверка robots.txt на ошибки | Impuls-Web.ru
В одной из прошлых статей мы с вами подробно рассмотрели, как создать файл robots.txt на примере сайта созданного на WordPress.
В этой статье я хотела бы рассмотреть, как осуществить для robots.txt проверку в поисковых системах Яндекс и Google.
Навигация по статье:

Проверка в Яндекс
В яндексе для robots.txt проверка происходит следующим образом:
- 1.Заходим на сервис Яндекс.Вебмастер (https://webmaster.yandex.ru), проходим авторизацию и в верхней панели слева, в раскрывающемся списке, выбираем сайт для которого нужно провести проверку.
- 2.В левом боковом меню выбираем «Инструменты» = > «Анализ robots.txt»
- 3.Попадаем на страницу проверки robots.txt. Если вы не меняли стандартный файл, то увидите следующую картину:
- 4.Если вы еще не добавляли для своего сайта robots.txt, то вам нужно создать этот файл, следуя указаниям, приведенным в моей прошлой статье. После чего, при помощи FTP-клиента загрузить этот файл в корень вашего сайта:
- 5.После этого, в адресной строке «Проверяемый сайт», вводим адрес нашего сайта и нажимаем на кнопку загрузки.
- 6.Произойдет загрузка файла, расположенного по указанному нами адресу и автоматически будет проведена проверка файла на содержание ошибок. Содержимое файла будет показано в поле «Текст robots.txt»
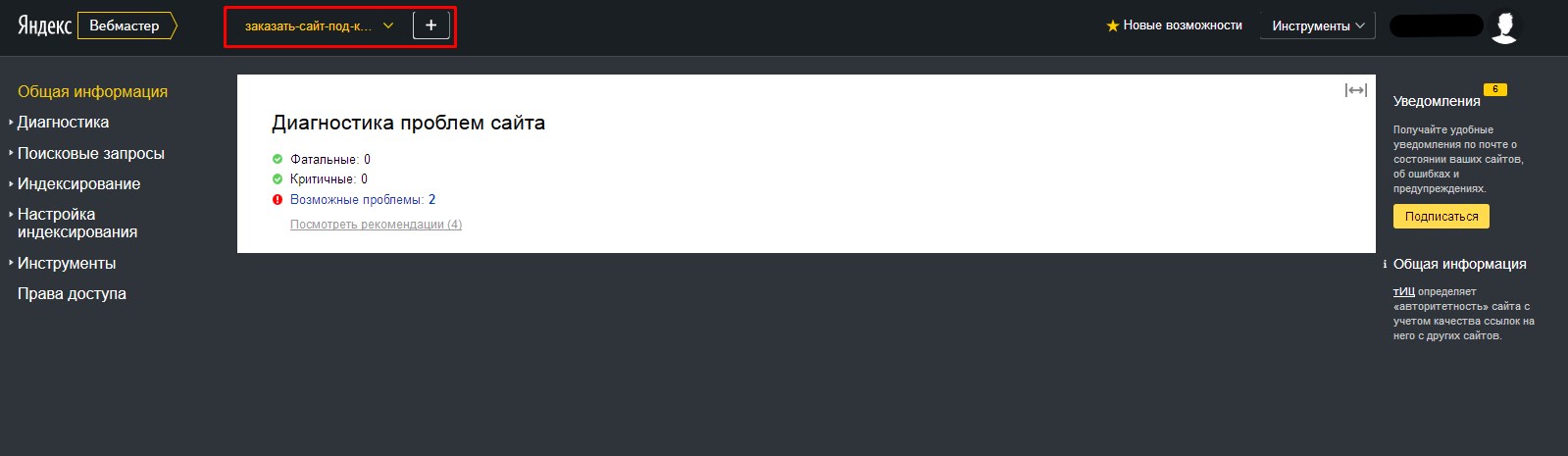

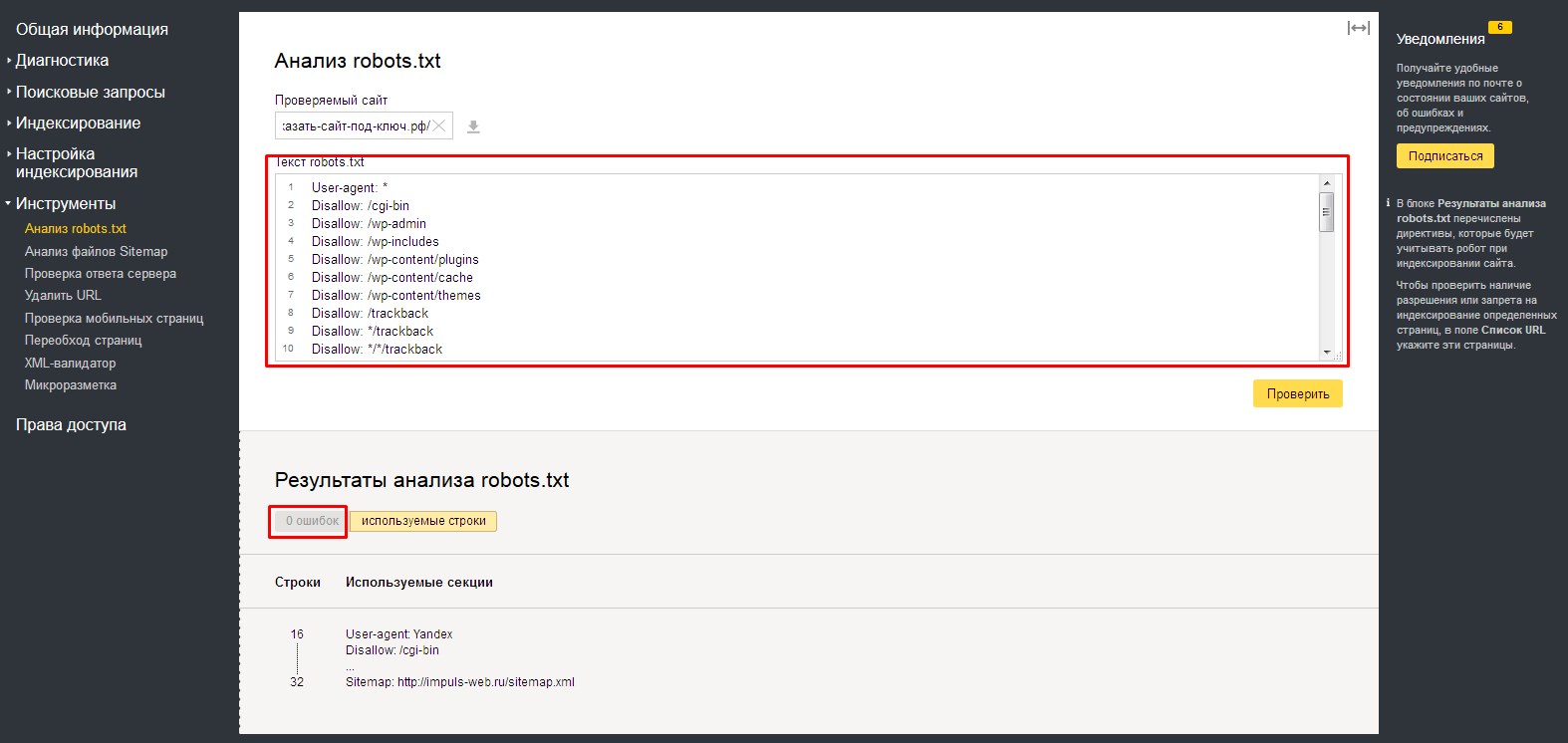
Внизу, в табличке «Результаты анализа robots.txt», вы можете просмотреть количество ошибок в файле.
Проверка в Google
В Google Search Console для robots.txt проверка делается похожим образом:
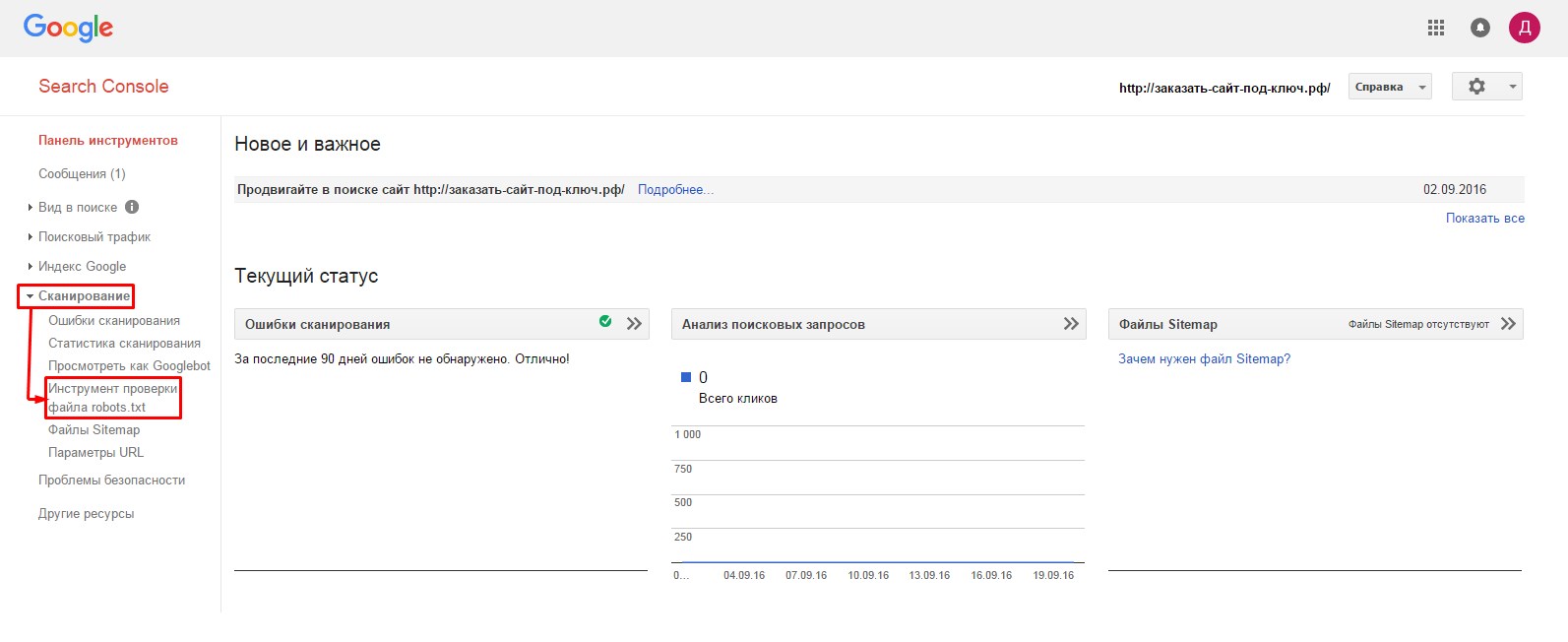
- 1.Заходим на главную страницу сервиса Search Console (//www.google.com/webmasters/tools/dashboard), проходим авторизацию и переходим в раздел «Сканирование» => «Инструмент проверки файла robots.txt»
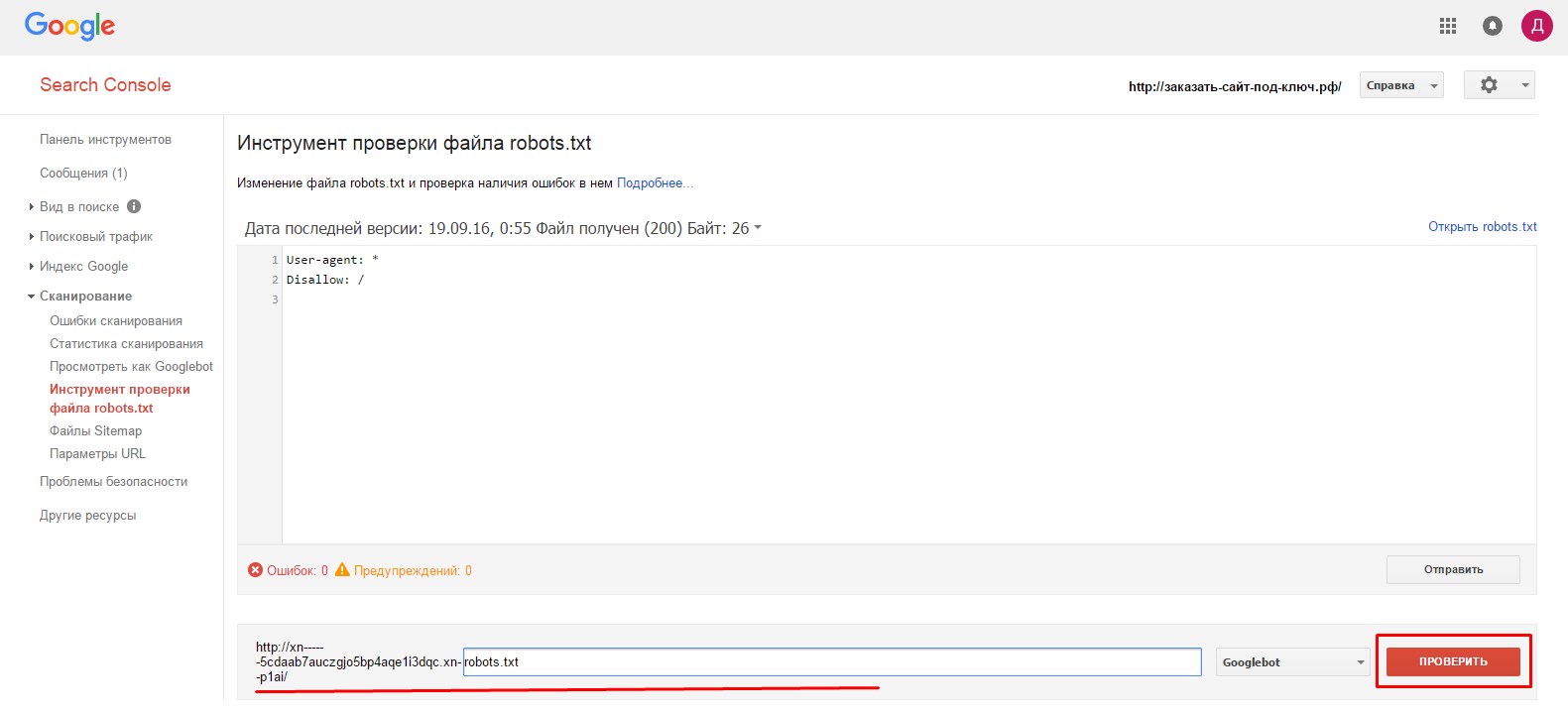
- 2.На следующей странице нам первым делом необходимо удостовериться в доступности файла для гуглбота. В нижней части страницы, в адресной строке вводим путь к нашему файлу robots.txt и нажимаем «Проверить».
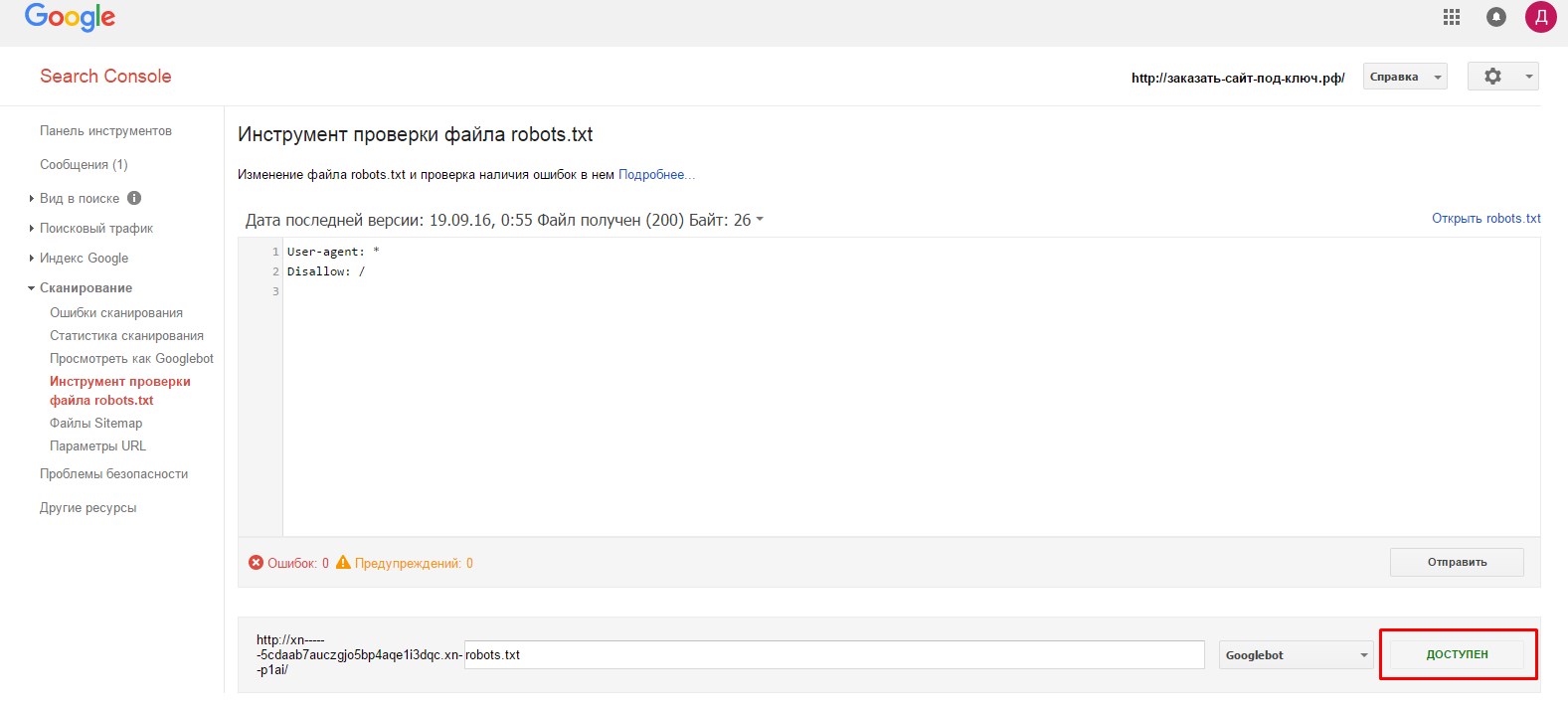
- 3.Если все нормально, то красная кнопка замениться на надпись «Доступен».
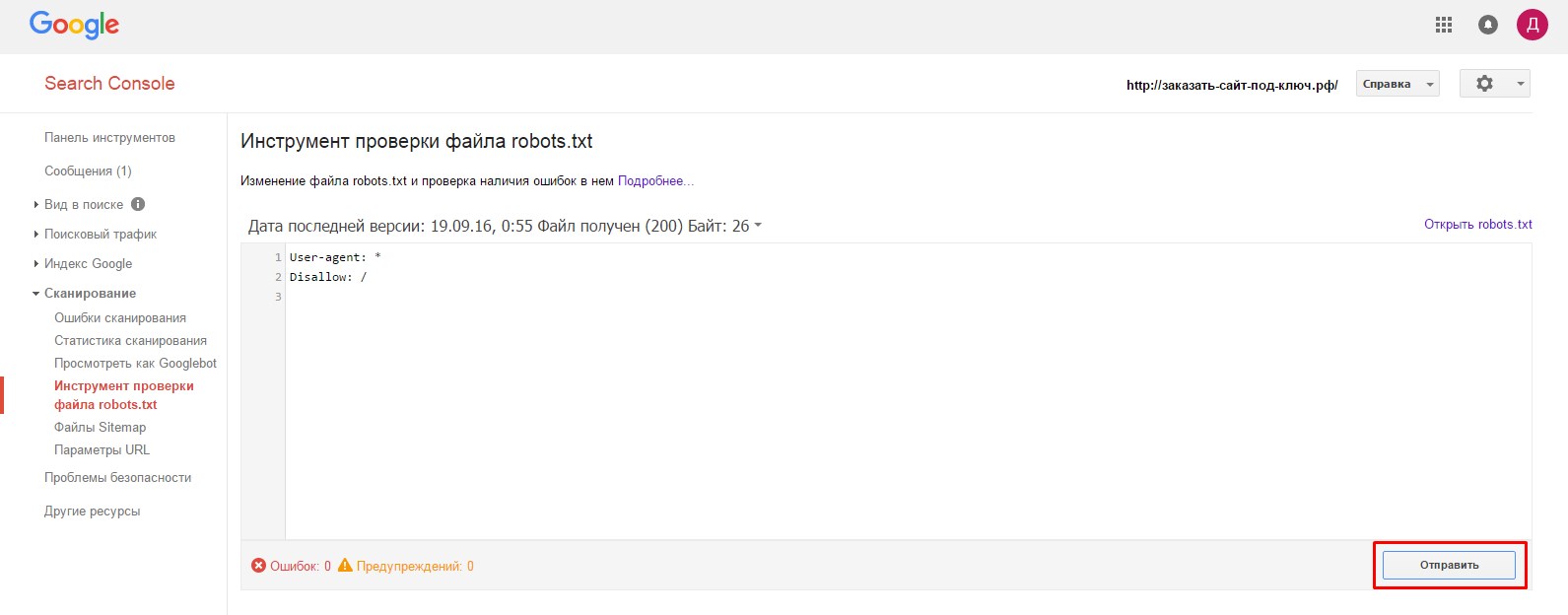
- 4.Далее, нажимаем на кнопку «Отправить».

В открывшемся окне нужно нажить на нижнюю кнопку «Отправить»:
- 5.Закрываем окошко и через несколько минут обновляем страницу проверки:
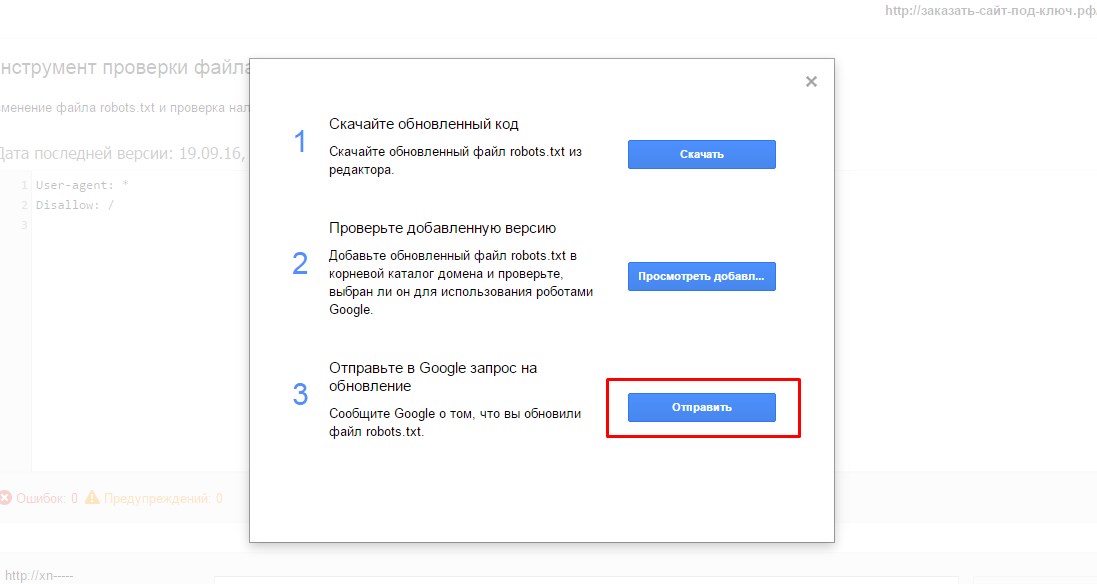
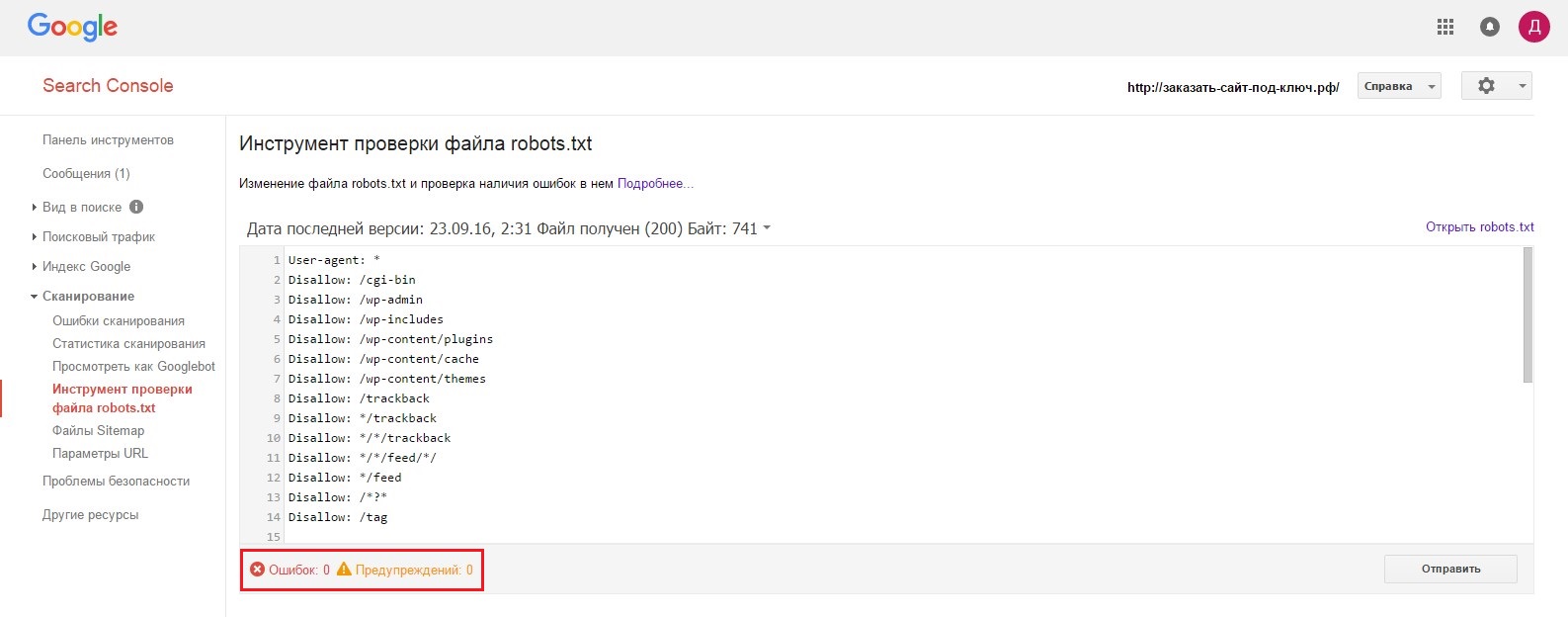
Количество ошибок и предупреждений можно увидеть в нижней части окна.
Как видите, для robots.txt проверка проводится достаточно быстро. Если после проверки у вас найдут какие-то несоответствия, то нужно будет их исправить и повторить процедуру загрузки и проверки файла в той же последовательности.

А на этом у меня сегодня все. Надеюсь, моя статья будет для вас полезна. Думаю, у вас не должно возникнут каких-то сложностей в процессе создания и загрузки файла robots.txt, но если что – пишите мне через форму комментариев. Желаю вам успешной проверки! До встречи в следующих статьях!
С уважением Юлия Гусарь
Как посмотреть robots.txt сайта, который вам интересен?

От автора: хотите составить для своего проекта файл с указаниями для робота, но не знаете как? Сегодня разберемся, как посмотреть robots.txt сайта и изменить его под свои нужды.
В интернете каждый день появляются готовые решения по той или иной проблеме. Нет денег на дизайнера? Используйте один из тысяч бесплатных шаблонов. Не хотите нанимать сео-специалиста? Воспользуйтесь услугами какого-нибудь известного бесплатного сервиса, почитайте сами пару статей.
Уже давно нет необходимости самому с нуля писать тот же самый robots.txt. К слову, это специальный файл, который есть практически на любом сайте, и в нем содержатся указания для поисковых роботов. Синтаксис команд очень простой, но все равно на составление собственного файла уйдет время. Лучше посмотреть у другого сайта. Тут есть несколько оговорок:
Сайт должен быть на том же движке, что и ваш. В принципе, сегодня в интернете куча сервисов, где можно узнать название cms практически любого веб-ресурса.
Это должен быть более менее успешный сайт, у которого все в порядке с поисковым трафиком. Это говорит о том, что robots.txt составлен нормально.

Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееИтак, чтобы посмотреть этот файл нужно в адресной строке набрать: доменное-имя.зона/robots.txt
Все неверятно просто, правда? Если адрес не будет найден, значит такого файла на сайте нет, либо к нему закрыт доступ. Но в большинстве случаев вы увидите перед собой содержимое файла:

В принципе, даже человек не особо разбирающийся в коде быстро поймет, что тут написать. Команда allow разрешает что-либо индексировать, а disallow – запрещает. User-agent – это указание поисковых роботов, к которым обращены инструкции. Это необходимо в том случае, когда нужно указать команды для отдельного поисковика.
Что делать дальше?
Скопировать все и изменить под свой сайт. Как изменять? Я уже говорил, что движки сайтов должны совпадать, иначе изменять что-либо бессмысленно – нужно переписывать абсолютно все.
Итак, вам необходимо будет пройтись по строкам и определить, какие разделы из указанных присутствуют на вашем сайте, а какие – нет. На скриншоте выше вы видите пример robots.txt для wordpress сайта, причем в отдельном каталоге есть форум. Вывод? Если у вас нет форума, все эти строки нужно удалить, так как подобных разделов и страниц у вас просто не существует, зачем тогда их закрывать?
Самый простой robots.txt может выглядеть так:
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Allow: /wp-content/uploads/
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Allow: /wp-content/uploads/ |
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееВсе вы наверняка знаете стандартную структуру папок в wordpress, если хотя бы 1 раз устанавливали этот движок. Это папки wp-admin, wp-content и wp-includes. Обычно все 3 закрывают от индексации, потому что они содержат чисто технические файлы, необходимые для работы движка, плагинов и шаблонов.
Каталог uploads открывают, потому что в нем содержаться картинки, а их обыно индексируют.
В общем, вам нужно пройтись по скопированному robots.txt и просмотреть, что из написанного действительно есть на вашем сайте, а чего нет. Конечно, самому определить будет трудно. Я могу лишь сказать, что если вы что-то не удалите, то ничего страшного, просто лишняя строчка будет, которая никак не вредит (потому что раздела нет).
Так ли важна настройка robots.txt?

Конечно, необходимо иметь этот файл и хотя бы основные каталоги через него закрыть. Но критично ли важно его составление? Как показывает практика, нет. Я лично вижу сайты на одних движках с абсолютно разным robots.txt, которые одинаково успешно продвигаются в поисковых системах.
Я не спорю, что можно совершить какую-то ошибку. Например, закрыть изображения или оставить открытым ненужный каталог, но чего-то супер страшного не произойдет. Во-первых, потому что поисковые системы сегодня умнее и могут игнорировать какие-то указание из файла. Во-вторых, написаны сотни статей о настройке robots.txt и уж что-то можно понять из них.
Я видел файлы, в которых было 6-7 строчек, запрещающих индексировать пару каталогов. Также я видел файлы с сотней-другой строк кода, где было закрыто все, что только можно. Оба сайта при этом нормально продвигались.
В wordpress есть так называемые дубли. Это плохо. Многие борятся с этим с помощью закрытия подобных дублей так:
Disallow: /wp-feed Disallow: */trackback Disallow: */feed Disallow: /tag/ Disallow: /archive/
Disallow: /wp-feed Disallow: */trackback Disallow: */feed Disallow: /tag/ Disallow: /archive/ |
Это лишь некоторые из дублей, создаваемых wordpress. Могу сказать, что так можно делать, но защиты на 100% ожидать не стоит. Я бы даже сказал, что вообще не нужно ее ожидать и проблема как раз в том, о чем я уже говорил ранее:
Поисковые системы все равно могут забрать в индекс такие вещи.
Тут уже нужно бороться по-другому. Например, с помощью редиректов или плагинов, которые будут уничтожать дубли. Впрочем, это уже тема для отдельной статьи.
Где находится robots.txt?
Этот файл всегда находится в корне сайта, поэтому мы и можем обратиться к нему, прописав адрес сайта и название файла через слэш. По-моему, тут все максимально просто.
В общем, сегодня мы рассмотрели вопрос, как посмотреть содержимое файла robots.txt, скопировать его и изменить под свои нужды. О настройке я также напишу еще 1-2 статьи в ближайшее время, потому что в этой статье мы рассмотрели не все. Кстати, также много информации по продвижению сайтов-блогов вы можете найти в нашем курсе. А я на этом пока прощаюсь с вами.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее
Хотите узнать, что необходимо для создания сайта?
Посмотрите видео и узнайте пошаговый план по созданию сайта с нуля!
СмотретьЗнакомство с robots.txt. Создание, настройка, проверка. Читайте!
Правильно составленный robots.txt помогает правильно индексировать сайт и избавляет от дублей контента, которые есть в любой CMS. Я знаю, что многих авторов просто пугает необходимость лезть куда-то в корневые папки блога и что-то менять в «служебных» файлах. Но этот ложный страх нужно перебороть. Поверьте: ваш блог не «рухнет», даже если вы поместите в robots.txt собственный портрет (т.е. испортите его!). Зато, любые благотворные изменения повысят его статус в глазах поисковых систем.
Что такое файл robots.txt
Я не буду изображать эксперта, мучая вас терминами. Просто поделюсь своим, довольно простым, пониманием функций этого файла:
robots.txt – это инструкция, дорожная карта для роботов поисковых систем, посещающих наш блог с инспекцией. Нам только нужно указать им, какой контент является, так сказать, служебным, а какой – то самое ценное содержание, ради которого к нам стремятся (или должны стремиться) читатели. И именно эта часть контента должна индексироваться и попадать в поисковую выдачу!
А что случается, если мы не заботимся о подобных инструкциях? – Индексируется все подряд. И поскольку пути алгоритмов поисковых систем, практически, неисповедимы, то анонс статьи, открывающийся по адресу архива, может показаться Яндексу или Гуглу более релевантным, чем полный текст статьи, находящийся по другому адресу. И посетитель, заглянув на блог, увидит совсем не то, чего хотел и чего хотели бы вы: не пост, а списки всех статей месяца… Итог ясен – скорее всего, он уйдет.
Хотя есть примеры сайтов, у которых робоста нет вообще, но они занимают приличные позиции в поисковой выдаче, но это конечно исключение, а не правило.
Из чего состоит файл robots.txt
И здесь мне не хочется заниматься рерайтом. Существуют довольно понятные объяснения из первых уст – например, в разделе помощи Яндекса. Очень советую прочитать их и не один раз. Но я попытаюсь помочь вам преодолеть первую оторопь перед обилием терминов, описав общую структуру файла robots.txt.
В самом верху, в начале robots.txt, мы объявляем, для кого пишем инструкцию:
User-agent: Yandex
Конечно, у каждого уважающего себя поисковика есть множество роботов – поименованных и безымянных. Пока вы не отточили свое мастерство создания robots.txt, лучше придерживаться простоты и возможных обобщений. Поэтому предлагаю отдать должное Яндексу, а всех остальных объединить, прописав общее правило:
User-Agent: * — это все, любые, роботы
Далее мы записываем все, что хотим сообщить указанному роботу.
Disallow: и далее то, что запрещаем
Allow: и далее все, что разрешаем
Также, мы указываем главное зеркало сайта – тот адрес, который будет участвовать в поиске. Это особенно актуально, если у вас несколько зеркал. Еще можно указать и некоторые другие параметры. Но самым важным для нас, все-таки, является возможность закрыть от индексации служебные части блога.
Вот примеры запрещения индексировать:
Disallow: /cgi-bin* — файлы скриптов;
Disallow: /wp-admin* — административную консоль;
Disallow: /wp-includes* — служебные папки;
Disallow: /wp-content/plugins* — служебные папки;
Disallow: /wp-content/cache* — служебные папки;
Disallow: /wp-content/themes* — служебные папки;
Disallow: /feed* — ленту рассылки;
Disallow: */feed
Disallow: /comments* — комментарии;
Disallow: */comments
Disallow: /*/?replytocom=* — ответы на комментарии
Disallow: /tag/* — метки
Disallow: /archive/* — архивы
Disallow: /category/* — рубрики
Как создать собственный файл robots.txt
Самый легкий и очевидный путь – найти пример готового файла robots.txt на каком-нибудь блоге и торжественно переписать его себе. Хорошо, если при этом авторы не забывают заменить адрес блога-примера на адрес своего детища.
Роботс любого сайта доступен по адресу:
https://dramtezi.ru/robots.txt
Я тоже поступал подобным образом и не чувствую себя в праве отговаривать вас. Единственное, о чем очень прошу: разберитесь, что написано в копируемом файле robots.txt! Используйте помощь Яндекса, любые другие источники информации – расшифруйте все строки. Тогда, наверняка, вы увидите, что некоторые правила не подходят для вашего блога, а каких-то правил, наоборот, не хватает.
Теперь посмотрим, как проверить корректность и эффективность нашего файла robots.txt.
Поскольку все, что связано с файлом robots.txt, может поначалу казаться слишком непонятным и даже опасным — я хочу показать вам простой и понятный инструмент его проверки. Это очевидный путь, который поможет вам не просто проверить, но и выверить ваш robots.txt, дополнив его всеми необходимыми инструкциями и убедившись, что роботы поисковых систем понимают, чего вы от них хотите.
Проверка файла robots.txt в Яндексе
Яндекс-вебмастер позволяет нам узнать отношение поискового робота этой системы к нашему творению. Для этого, очевидно, нужно открыть сведения, относящиеся к блогу и:
- перейти по вкладке Инструменты-> Анализ robots.txt
- нажмите кнопку «загрузить» и будем надеяться, что разместили файл robots.txt там, где нужно и робот его найдет:) (если не найдет — проверьте, где находится ваш файл: он должен быть в корне блога, там, где лежат папки wp-admin, wp-includes и т.д., а ниже отдельные файлы — среди них должен быть robots.txt)
- кликаем на «проверить».
Но самая важная информация находится в соседней вкладке — «Используемые секции»! Ведь, собственно, нам важно, чтобы робот понимал основную часть информации — а все остальное пусть пропускает:
На примере мы видим, что Яндекс понимает все, что касается его робота (строки с 1 по 15 и 32) — вот и прекрасно!
Проверка файла robots.txt в Гугле
У Гугл, тоже, есть инструмент проверки, который покажет нам, как эта поисковая система видит (или не видит) наш robots.txt:
- В инструментах для вебмастеров от Гугл (где ваш блог тоже обязательно должен быть зарегистрирован) есть свой сервис для проверки файла robots.txt. Он находится во вкладке Сканирование
- Найдя файл, система показывает анализирует его и выдает информацию об ошибках. Все просто.
На что стоит обратить внимание, анализируя файл robots.txt
Мы недаром рассмотрели инструменты анализа от двух, наиболее важных поисковых систем — Яндекс и Гугл. Ведь нам нужно убедиться, что каждая из них прочитает рекомендации, данные нами в robots.txt.
В примерах, приведенных здесь, можно увидеть, что Яндекс понимает инструкции, которые мы оставили для его робота и игнорирует все остальные (хотя везде написано одно и то же, только директива User-agent: — различная:)))
Важно понимать, что любые изменения в robots.txt нужно производить непосредственно с тем файлом, который находится у вас в корневой папке блога. То есть, вам нужно открыть его в любом блокноте, чтобы переписать, удалить, добавить какие-либо строки. Потом его нужно сохранить обратно в корень сайта и заново проверить реакцию на изменения поисковых систем.
Понять, что в нем написано, что следует добавить — нетрудно. А заниматься продвижением блога, не настроив файл robots.txt как следует (так, как нужно именно вам!) — усложнять себе задачу.
Оптимизация сайта. Как написать и проверить robots.txt для WordPress.
 Приветствую, уважаемые читатели блога PAMMAP.RU.
Приветствую, уважаемые читатели блога PAMMAP.RU.
В этой статье я постараюсь ответить на следующие вопросы:
Зашел я недавно в Яндекс.Вебмастер, чтобы посмотреть, что делает поисковый робот Яндекса на моем сайте. Как подключить свой сайт к Яндекс.Вебмастер Вы можете посмотреть если перейдете по ссылке. И увидел, что в поиск попадает много ненужных страниц, которые там совершенно не нужны. Казалось бы, что плохого, когда в индексе поисковика много страниц, а плохое есть.
- это появление в поиске страниц, которые не несут никакой полезной информации для пользователя, и скорее всего пользователь на них все равно не зайдет, а если зайдет, то ненадолго.
- это появление в поиске копий одной и той же страницы с разными адресами. (Дублирование контента)
- это тратится драгоценное время на индексацию ненужных страниц поисковыми роботами. Поисковый робот вместо того чтобы заниматься нужным и полезным контентом будет тратить время на бесполезное блуждание по сайту. А так как роботы не индексируют весь сайт целиком и сразу (сайтов много и всем нужно уделить внимание), то важные страницы, которые Вы хотите увидеть в поиске, вы можете увидеть очень не скоро.
- возрастает нагрузка на сервер.
Было решено закрыть доступ для поисковых роботов к некоторым страницам сайта. В этом нам поможет файл robots.txt.
Зачем нужен robots.txt.
robots.txt – это обычный текстовый файл, в котором прописаны инструкции для поисковых роботов. Первое что делает поисковый робот при попадании на сайт, это ищет файл robots.txt. Если файл robots.txt не найден или он пустой, то поисковый робот будет бродить по всем доступным страницам и каталогам сайта (включая системные каталоги), в попытке проиндексировать содержимое. И не факт, что он проиндексирует нужную Вам страницу, если вообще доберется до нее.

С помощью robots.txt мы можем указать поисковым роботам, на какие страницы можно заходить и как часто, а куда ходить не стоит. Инструкции могут быть указаны, как для всех роботов, так и для каждого робота в отдельности. Страницы, которые закрыты от поисковых роботов, не будут появляться в поисковиках. Если этого файла нет, то его обязательно необходимо создать.
Файл robots.txt должен находиться на сервере, в корне вашего сайта. Файл robots.txt можно посмотреть на любом сайте в Интернет, для этого достаточно после адреса сайта добавить /robots.txt . Для сайта PAMMAP.RU адрес, по которому можно посмотреть robots.txt будет выглядеть так: pammap.ru/robots.txt.
Файл robots.txt , обычно у каждого сайта имеет свои особенности и бездумное копирование чужого файла, может создать проблемы с индексированием вашего сайта поисковыми роботами. Поэтому нужно четко понимать назначение файла robots.txt и назначение инструкций (директив), которые мы будем использовать, при его создании.
Директивы файла robots.txt.
Разберем основные инструкции (директивы), которые мы будем использовать при создании файла robots.txt.
User-agent: — указываем имя робота, для которого будут работать все нижеприведенные инструкции. Если инструкции нужно использовать для всех роботов, то в качестве имени используем * (звездочку)

Например:
User-agent:*
#инструкции действуют на всех поисковых роботов
User-agent: Yandex
#инструкции действуют только на поискового робота Яндекс
Имена самых популярных поисковиков Рунета это Googlebot (для Google) и Yandex (для Яндекса). Имена остальных поисковиков, если интересно, можно найти на просторах Интернет, но создавать для них отдельные правила, мне кажется, нет необходимости.
Disallow – запрещает для поисковых роботов доступ к некоторым частям сайта или сайту целиком.
Например:
Disallow /wp-includes/
#запрещает роботам доступ в wp-includes
Disallow /
# запрещает роботам доступ ко всему сайту.
Allow – разрешает для поисковых роботов доступ к некоторым частям сайта или сайту целиком.
Например:
Allow /wp-content/
#разрешает роботам доступ в wp-content
Allow /
#разрешает роботам доступ ко всему сайту.
Sitemap: — можно использовать для указания пути к файлу с описанием структуры вашего сайта (карты сайта). Она нужна для ускорения и улучшения индексации сайта поисковыми роботами.
Например:
Sitemap: //pammap.ru/sitemap_index.xml
Host: — Если у вашего сайта есть зеркала (копии сайта на другом домене). Например pammap.ru и www.pammap.ru. С помощью файла Host можно указать главное зеркало сайта. В поиске будет участвовать только главное зеркало.
Например:
Host: pammap.ru
Также можно использовать спецсимволы. * # и $
*(звездочка) – обозначает любую последовательность символов.
Например:
Disallow /wp-content*
#запрещает роботам доступ в /wp-content/plugins, /wp-content/themes и.т.д.
$(знак доллара) – По умолчанию в конце каждого правила предполагается наличие *(звездочка) чтобы отменить симовол *(звездочка) можно использовать символ $(знак доллара).
Например:
Disallow /example$
#запрещает роботам доступ в /example но не запрещает в /example.html
#(знак решетки) – можно использовать для комментариев в файле robots.txt
Подробнее с этими директивами, а также несколькими дополнительными, можно ознакомиться на сайте Яндекса.
Как написать robots.txt для WordPress.
Теперь приступим к созданию файла robots.txt. Так как наш блог работает на WordPress, то разберем процесс создания robots.txt для WordPress более подробно.
Вначале нужно определиться, что мы хотим разрешить поисковым роботам, а что запретить. Я для себя решил оставить только самое необходимое, это записи, страницы и разделы. Все остальное будем закрывать.
Какие папки есть в WordPress и что необходимо закрыть мы можем увидеть, если посмотрим в директорию нашего сайта. Я сделал это через панель управления хостингом на сайте reg.ru, и увидел следующую картину.
 Разберемся с назначением каталогов и решим, что можно закрыть.
Разберемся с назначением каталогов и решим, что можно закрыть.
/cgi-bin (каталог скриптов на сервере – в поиске он нам не нужен.)
/files (каталог с файлами для загрузки. Здесь, например, лежит архивный файл с таблицей Excel для подсчета прибыли, о которой я писал в статье «Как посчитать прибыль от инвестиций в ПАММ счета«. В поиске этот каталог нам не нужен.)
/playlist(этот каталог я сделал для себя, для плейлистов на IPTV – в поиске не нужен.)
/test (этот каталог я создал для экспериментов, в поиске этот каталог не нужен)
/wp-admin/ (админка WordPress, в поиске она нам не нужна)
/wp-includes/ (системная папка от WordPress, в поиске она нам не нужна)
/wp-content/ (из этого каталога нам нужен только /wp-content/uploads/ в этом каталоге находятся картинки с сайта, поэтому каталог /wp-content/ мы запретим, а каталог с картинками разрешим отдельной инструкцией.)
Также нам не нужны в поиске следующие адреса:
Архивы – адреса вида //pammap.ru/2013/ и похожие.
Метки — в адресе меток содержится /tag/
RSS фиды — в адресе всех фидов есть /feed
Записи автора — в адресе есть /author/ (тем более, что автор всего один)
На всякий случай закрою адреса с PHP на конце так, как многие страницы доступны, как с PHP на конце, так и без. Это, как мне кажется, позволит избежать дублирования страниц в поиске.
Также закрою адреса с /GOTO/ я их использую для перехода по внешним ссылкам, в поиске им точно делать нечего.
И напоследок, уберем из поиска короткие адреса, вида //pammap.ru/?p=209 и поиск по сайту //pammap.ru/?s=, а также комментарии (адреса в которых содержится /?replytocom= )
А вот что у нас должно остаться:
/images (в этот каталог я закидываю некоторые картинки, пускай этот каталог роботы посещают)
/wp-content/uploads/ — содержит картинки от сайта.
Статьи, страницы и разделы, которые содержат понятные, читаемые адреса.
Например: //pammap.ru/portfel/ или Мои инвестиции
А теперь придумаем инструкции для robots.txt. Вот, что у меня получилось:
#Указываем, что эти инструкции будут выполнять все роботы
User-agent: *
#Разрешаем роботам бродить по каталогу uploads.
Allow: /wp-content/uploads/
#Запрещаем папку со скриптами
Disallow: /cgi-bin/
#Запрещаем папку files
Disallow: /files/
#Запрещаем папку playlist
Disallow: /playlist/
#Запрещаем папку test
Disallow: /test/
#Запрещаем все, что начинается с /wp- , это позволит закрыть сразу несколько папок, имена которых начинаются с /wp- , эта команда вполне может помешать индексации страниц или записей которые начинаются с /wp-, но давать таких имен я не планирую.
Disallow: /wp-*
#Запрещаем адреса, в которых содержится /?p= и /?s=. Это короткие ссылки и поиск.
Disallow: /?p=
Disallow: /?s=
#Запрещаем все архивы до 2099 года.
Disallow: /20
#Запрещаем адреса с расширением PHP на конце.
Disallow: /*.php
#Запрещаем адреса, которые содержат /goto/. Можно было не прописывать, но на всякий случай вставлю.
Disallow: /goto/
#Запрещаем адреса меток
Disallow: /tag/
#Запрещаем статьи по автору.
Disallow: /author/
#Запрещаем все фиды.
Disallow: */feed
#Запрещаем индексацию комментариев.
Disallow: /?replytocom=
#Ну и напоследок прописываем путь к нашей карте сайта.
Sitemap: //pammap.ru/sitemap_index.xml
Написать файл robots.txt для WordPress можно с помощью обычного блокнота. Создадим файл и запишем в него следующие строки.
User-agent: *
Allow: /wp-content/uploads/
Disallow: /cgi-bin/
Disallow: /files/
Disallow: /playlist/
Disallow: /test/
Disallow: /wp-*
Disallow: /?p=
Disallow: /?s=
Disallow: /20
Disallow: /*.php
Disallow: /goto/
Disallow: /tag/
Disallow: /author/
Disallow: */feed
Disallow: /?replytocom=
Sitemap: //pammap.ru/sitemap_index.xml
Вначале я планировал сделать один общий блок правил для всех роботов, но Яндекс работать с общим блоком отказался. Пришлось сделать для Яндекса отдельный блок правил. Для этого просто скопировал общие правила, изменил имя робота и указал роботу главное зеркало сайта, с помощью директивы Host.
User-agent: Yandex
Allow: /wp-content/uploads/
Disallow: /cgi-bin/
Disallow: /files/
Disallow: /playlist/
Disallow: /test/
Disallow: /wp-*
Disallow: /?p=
Disallow: /?s=
Disallow: /20
Disallow: /*.php
Disallow: /goto/
Disallow: /tag/
Disallow: /author/
Disallow: */feed
Disallow: /?replytocom=
Sitemap: //pammap.ru/sitemap_index.xml
Host: pammap.ru
Указать главное зеркало сайта можно также через Яндекс.Вебмастер, в разделе «Главное зеркало»

Теперь, когда файл robots.txt для WordPress создан, нам его необходимо загрузить на сервер, в корневой каталог нашего сайта. Это можно сделать любым удобным для Вас способом.
Также для создания и редактирования robots.txt можно воспользоваться плагином WordPress SEO. Подробнее об этом полезном плагине я напишу позже. В этом случае файл robots.txt на рабочем столе можно не создавать, а просто вставить код файла robots.txt в соответствующий раздел плагина.

Как проверить robots.txt
Теперь, когда мы создали файл robots.txt, его нужно проверить. Для этого заходим в панель управления Яндекс.Вебмастер. Далее заходим в раздел “Настройка индексирования”, а далее “анализ robots.txt” . Здесь нажимаем кнопку «Загрузить robots.txt с сайта», после этого в соответствующем окне должно появиться содержимое вашего robots.txt.

Затем нажимаем «добавить» и в появившемся окне вводим различные url с вашего сайта, которые вы хотите проверить. Я ввел несколько адресов, которые должны быть запрещены и несколько адресов, которые должны быть разрешены.

Нажимаем кнопку «Проверить», после этого Яндекс выдаст нам результаты проверки файла robots.txt. Как видим, наш файл проверку удачно прошел. То, что должно быть запрещено для поисковых роботов, у нас запрещено. То, что должно быть разрешено, у нас разрешено.

Такую же проверку можно провести для робота Google, через GoogleWebmaster, но она не сильно отличается от проверки через Яндекс, поэтому я ее описывать не буду.
Вот и все. Мы создали robots.txt для WordPress и он отлично работает. Остается только иногда поглядывать за поведением поисковых роботов на нашем сайте. Чтобы вовремя заметить ошибку и в случае необходимости внести изменения в файл robots.txt. Страницы которые были исключены из индекса и причину исключения можно посмотреть в соответствующем разделе Яндекс.ВебМастер (или GoogleWebmaster).
Актуальную версию моего файла robots.txt всегда можно посмотреть по ссылке pammap.ru/robots.txt
Удачных Инвестиций и успехов во всех ваших делах.
С уважением Сергей,
Автор блога Pammap.ru