Как запретить индексацию страницы с помощью robots.txt?

От автора: У вас на сайте есть страницы, которые вы бы не хотели показывать поисковым системам? Из этой статье вы узнаете подробно о том, как запретить индексацию страницы в robots.txt, правильно ли это и как вообще правильно закрывать доступ к страницам.
Итак, вам нужно не допустить индексацию каких-то определенных страниц. Проще всего это будет сделать в самом файле robots.txt, добавив в него необходимые строчки. Хочу отметить, что адреса папок мы прописывали относительно, url-адреса конкретных страниц указывать таким же образом, а можно прописать абсолютный путь.
Допустим, на моем блоге есть пару страниц: контакты, обо мне и мои услуги. Я бы не хотел, чтобы они индексировались. Соответственно, пишем:
User-agent: * Disallow: /kontakty/ Disallow: /about/ Disallow: /uslugi/
User-agent: * Disallow: /kontakty/ Disallow: /about/ Disallow: /uslugi/ |

Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнееЕстественно, указываем настоящие url-адреса. Если же вам необходимо не индексировать страничку http://blog.ru/about-me, то в robots.txt нужно прописать так:
Другой вариант
Отлично, но это не единственный способ закрыть роботу доступ к определенным страничкам. Второй – это разместить в html-коде специальный мета-тег. Естественно, разместить только в тех записях, которые нужно закрыть. Выглядит он так:
<meta name = «robots» content = «noindex,nofollow»>
<meta name = «robots» content = «noindex,nofollow»> |
Тег должен быть помещен в контейнер head в html-документе для корректной работы. Как видите, у него два параметры. Name указывается как робот и определяет, что эти указания предназначены для поисковых роботов.
Параметр же content обязательно должен иметь два значения, которые вписываются через запятую. Первое – запрет или разрешение на индексацию текстовой информации на странице, второе – указание насчет того, индексировать ли ссылки на странице.
Таким образом, если вы хотите, чтобы странице вообще не индексировалась, укажите значения noindex, nofollow, то есть не индексировать текст и запретить переход по ссылкам, если они имеются. Есть такое правило, что если текста на странице нет, то она проиндексирована не будет. То есть если весь текст закрыт в noindex, то индексироваться нечему, поэтому ничего и не будет попадать в индекс.
Кроме этого есть такие значения:
noindex, follow – запрет на индексацию текста, но разрешение на переход по ссылкам;
index, nofollow – можно использовать, когда контент должен быть взят в индекс, но все ссылки в нем должны быть закрыты.
index, follow – значение по умолчанию. Все разрешается.
Запрещается использовать более двух значений. Например:
<meta name = «robots» content = «noindex,nofollow, follow»>
<meta name = «robots» content = «noindex,nofollow, follow»> |
И любые другие. В этом случае мы видим противоречие.
Итог
Наиболее удобным способом закрытия страницы для поискового робота я вижу использование мета-тега. В таком случае вам не нужно будет постоянно, сотни раз редактировать файл robots.txt, чтобы открыть или закрыть очередной url, а это решение принимается непосредственно при создании новых страниц.
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Узнать подробнее
Хотите узнать, что необходимо для создания сайта?
Посмотрите видео и узнайте пошаговый план по созданию сайта с нуля!
СмотретьЗакрыть сайт или часть кода от индексации htaccess robots.txt
Иногда, по тем или иным причинам нужно скрыть от поисковых систем часть кода, блок или целый сайт (к примеру, старый).
Файл robots.txt — специальный файл, содержащий инструкции для поисковых систем. Обычно, файл robots.txt уже присутствует в корневой папке сайта на хостинге. Однако, если его нет, нужно создать обычный текстовый документ с именем robots.txt, внести в него необходимые инструкции и загрузить в корневую папку сайта.
Файл .htaccess — специальный файл конфигурации веб-сервера Apache, управляет настройками сайта и работой веб-сервера. Файл .htaccess также должен присутствовать в корневой папке сайта по умолчанию.
Как закрыть от индексации с помощью файла robots.txt
Полностью запретить индексацию всего сайта:
User-agent: *
Disallow: /
Запретить индексацию всего сайта только Гуглу:
User-agent: Googlebot
Disallow: /
Запретить индексацию всего сайта только Яндексу:
User-agent: Yandex
Disallow: /
Запретить индексацию всего раздела:
User-agent: *
Disallow: /administrator
Disallow: /plugins
*В этом варианте запрет коснется всех файлов и папок в разделе.
Запретить индексацию отдельной папки:
User-agent: *
Disallow: /administrator/
Disallow: /images/
*В этом варианте запрет коснется только файлов и документов, но не будет распространяться на имеющиеся папки.
Запретить индексацию отдельным страницам:
User-agent: *
Disallow: /reklama.html
Disallow: /sis-pisi.html
Как закрыть от индексации с помощью файла .htaccess
Полностью запретить индексацию всего сайта:
SetEnvIfNoCase User-Agent «^Googlebot» search_bot
SetEnvIfNoCase User-Agent «^Yandex» search_bot
SetEnvIfNoCase User-Agent «^Yahoo» search_bot
SetEnvIfNoCase User-Agent «^Aport» search_bot
SetEnvIfNoCase User-Agent «^msnbot» search_bot
SetEnvIfNoCase User-Agent «^spider» search_bot
SetEnvIfNoCase User-Agent «^Robot» search_bot
SetEnvIfNoCase User-Agent «^php» search_bot
SetEnvIfNoCase User-Agent «^Mail» search_bot
SetEnvIfNoCase User-Agent «^bot» search_bot
SetEnvIfNoCase User-Agent «^igdeSpyder» search_bot
SetEnvIfNoCase User-Agent «^Snapbot» search_bot
SetEnvIfNoCase User-Agent «^WordPress» search_bot
SetEnvIfNoCase User-Agent «^BlogPulseLive» search_bot
SetEnvIfNoCase User-Agent «^Parser» search_bot
*Для каждой поисковой системы отдельная строчка кода.
Как закрыть от индексации страницу сайта с помощью Meta тегов
Между тегами <head> </head> страницы вставить код:
<meta name=»robots» content=»noindex»>
или лучше даже этот:
<meta name=»robots» content=»noindex, nofollow» />
Как закрыть от индексации ссылку
К ссылке нужно добавить rel=»nofollow» и получится:
<a href=»https://epicblog.net/write.html» rel=»nofollow»>Тоже писать на Epic Blog</a>
Запрещают индексацию ссылки обычно для того, чтобы не передавать вес своего сайта
Всем удачи и добра!
Руководство по использованию robots.txt — Robots.Txt по-русски
Цель этого руководства – помочь веб-мастерам и администраторам в использовании robots.txt.
Зто не спецификация – подробное описание и синтаксис можно посмотреть в стандарте исключений для роботов.
Введение
Стандарт исключений для роботов по сути своей очень прост. Вкратце, это работает следующим образом:
Когда робот, соблюдающий стандарт заходит на сайт, он прежде всего запрашивает файл с названием «/robots.txt». Если такой файл найден, Робот ищет в нем инструкции, запрещающие индексировать некоторые части сайта.
Где размещать файл robots.txt
Робот просто запрашивает на вашем сайте URL «/robots.txt», сайт в данном случае – это определенный хост на определенном порту.
На сайте может быть только один файл «/robots.txt». Например, не следует помещать файл robots.txt в пользовательские поддиректории – все равно роботы не будут их там искать. Если вы хотите иметь возможность создавать файлы robots.txt в поддиректориях, то вам нужен способ программно собирать их в один файл robots.txt, расположенный в корне сайта. Вместо этого можно использовать Мета-тег Robots.
Не забывайте, что URL-ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
Как видите, файл robots.txt нужно класть исключительно в корень сайта.
Что писать в файл robots.txt
В файл robots.txt обычно пишут нечто вроде:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
В этом примере запрещена индексация трех директорий.
Затметьте, что каждая директория указана на отдельной строке – нельзя написать «Disallow: /cgi-bin/ /tmp/». Нельзя также разбивать одну инструкцию Disallow или User-agent на несколько строк, т.к. перенос строки используется для отделения инструкций друг от друга.
Регулярные выражения и символы подстановки так же нельзя использовать. «Звездочка» (*) в инструкции User-agent означает «любой робот». Инструкции вида «Disallow: *.gif» или «User-agent: Ya*» не поддерживаются.
Конкретные инструкции в robots.txt зависят от вашего сайта и того, что вы захотите закрыть от индексации. Вот несколько примеров:
Запретить весь сайт для индексации всеми роботами
User-agent: *
Disallow: /
Разрешить всем роботам индексировать весь сайт
User-agent: *
Disallow:
Или можете просто создать пустой файл «/robots.txt».
Закрыть от индексации только несколько каталогов
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /private/
Запретить индексацию сайта только для одного робота
User-agent: BadBot
Disallow: /
Разрешить индексацию сайта одному роботу и запретить всем остальным
User-agent: Yandex
Disallow:
User-agent: *
Disallow: /
Запретить к индексации все файлы кроме одного
Это довольно непросто, т.к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
User-agent: *
Disallow: /docs/
Либо вы можете запретить все запрещенные к индексации файлы:
User-agent: *
Disallow: /private.html
Disallow: /foo.html
Disallow: /bar.html
Как закрыть сайт от индексации в Robots.txt на время разработки?


Прячем в роботс.тхт всё, кроме главной
Нередко возникает необходимость скрыть в файле Robots.txt разделы или отдельные страницы сайта от «глаз» поисковых роботов. Это дело известное и причины для него могут быть разные: удаление дублей контента из индекса, выкидывание «застрявших» в индексе несуществующих страниц и т.д.
Однако при создании нового сайта бывает полезным закрыть от индексации всё, кроме главной страницы.
Например, вы создаёте интернет-магазин и дальше главной роботу лучше не ходить — чтобы не индексировать пока ещё «кривые» страницы (иначе в дальнейшем могут быть торможения при продвижении..).
Почему лучше оставить главную? В этом случае ПС узнает о существовании нового сайта и начнётся т.н. увеличение траста вашего ресурса (а иначе бы поисковик узнал о вашем проекте только при его полном запуске).
Так что если вам нужно оставить сайт открытым для пользователей, но закрыть всё «нутро» от поисковых систем и в то же время — заявить о себе поисковикам, то можно применить файл Robots.txt для этих целей. Как это делается — написано дальше.
Как закрыть сайт от индексации в Robots.txt, оставив поисковикам главную страницу?
Недавно у меня возникла такая задача, пришлось немного подумать. Как оказалось, всё очень просто — составляем такой Robots.txt:
User-agent: *
Disallow: /
Allow: /$
Вот и всё. Эффект от этого можно проверить инструментом Яндекса для анализа robots.txt.
Как закрыть сайт от индексации с помощью Robots.txt полностью:
Если вообще весь ресурс нужно спрятать от поисковиков, то это совсем просто:
User-agent: *
Disallow: /
Таким образом, если на период разработки сайта вы не желаете «отдавать» ПС внутренние недоделанные страницы, но хотите уже пустить туда пользователей — закрывайте в robots.txt от индексации всё, кроме главной. И не забудьте отредактировать данный файл, когда решите пустить и роботов ![]()
 Loading…
Loading… 
Закрываем сайт от индексации в файле robots.txt
Введение
Сегодня трафик из поисковых систем для многих сайтов является основным источником посетителей. Для того, что бы Ваш ресурс появился в поиске, Yandex
Индексация проводится не один и не два раза. Робот посещает Ваш сайт на протяжении всей его «жизни» или до момента запрета. Именно о запрете сегодня и пойдет речь.
Запретить индексацию означает не дать участвовать в поиске всему сайту или определенному списку страниц.
Для чего нужен запрет индексации
Существует множество причин для полного и частичного запрета. Разберем по порядку.
Нежелание участвовать в поиске. Самая банальная причина. Вы просто не хотите, что бы сайт участвовал в результатах поиска.
Сайт находится в разработке. Робот индексирует сайт всегда, вне зависимости от того, находится он в разработке или уже закончен.
Поэтому, если работы проводятся не на локальном хостинге, то необходимо запретить поисковым системам индексировать сайт до тех пор, пока он не будет готов. Вот лишь ряд причин, почему необходимо скрывать от поисковика все, что еще не доделали.В процессе разработки размещается демо контент, уникальность которого крайне низка. Видеть такой материал поисковая система не должна.
Сайт разрабатывается без наполнения и окончательной структуры. Не нужно вводить в заблуждение поисковую систему, иначе ресурс будет признан не интересным для пользователей еще до того, как его наполнят.
Во время технических работ появляется множество дублей страниц. Нельзя допустить попадания их в индекс.
Ряд других технических причин.
Информация не для поиска. На любом сайте существуют страницы и разделы, которые не должны участвовать в поиске. К ним относится система управления сайта, результаты вычислений, дубликаты URL, неуникальный контент, не индексируемые документы и т.д.
- Страницы в разработке. Если сайт уже давно присутствует в поиске, но часть страниц находится на стадии редактирования, то их необходимо скрыть от индексирующего робота.
Запрещаем индексацию сайта
Для того, что бы полностью запретить индексацию сайта, необходимо, что бы при обращении к нему робот получал запрет в виде инструкции. Сделать это можно двумя способами.
При помощи robots.txt
Это наиболее распространенный и менее трудозатратный способ. Для того, что бы полностью закрыть сайт необходимо прописать в файле robots.txt простую инструкцию:
User-agent: *
Disallow: /
Таким образом вы запрещаете индексацию для любой поисковой системы. Но есть возможность запрета и для конкретного поисковика, к примеру, Яндекса.
User-agent: Yandex
Disallow: /
Подробнее о синтаксисе и работе с файлом robots.txt — https://dh-agency.ru/category/vnutrennyaya-optimizaciya/robots-txt/
При помощи тэгов
Так же, существует способ закрыть свой сайт при помощи специального тэга. Он будет «говорить» индексирующему роботу при обращении к странице, что ее загружать не надо.
<meta name=»robots» content=»noindex»>
Данный тэг необходимо разместить на каждой странице Вашего сайта.
Параметр поля «name» зависит от робота, к которому Вы обращаетесь. К примеру, если речь идет о роботе Google, то данный тэг будет выглядеть следующим образом:
<meta name=»googlebot» content=»noindex»>
О том, какие значения может принимать параметр «content», читайте ниже.
Запрещаем индексацию страницы
Запрет индексации одной единственной страницы отличается от запрета всего сайта только наличием дополнительной инструкции и URL адреса. Причем исключить из индекса можно не только конкретный адрес, но и маску. Однако возможность эта имеется только при работе с файлом robots.txt.
При помощи robots.txt
Для запрета конкретной страницы (спектра страниц по маске) используется инструкция «Disallow:». Синтаксис крайне простой:
Disallow: /wp-admin (исключаем всю папку wp-admin)
Disallow: /wp-content/plugins (исключаем папку plugins, которая находится в wp-content)
Disallow: /img/images.jpg (исключаем изображение images.jpg, которое находится в папке img)
Disallow: /dogovor.pdf (исключаем файл /dogovor.pdf)
Disallow: */trackback (исключаем папку trackback в любой папке первого уровня)
Disallow: /*my (исключаем любую папку заканчивающуюся на my)
Все достаточно просто, не правда ли? Но это позволяет избавиться от множества проблем во время продвижения сайта. Актуализируйте robots.txt каждый месяц в зависимости от апдейтов Яндекса и Гугла.
При помощи тэгов
Исключение возможно и при помощи тэга <meta name=»robots» content=»noindex»>. Для этого необходимо просто вписать его в код конкретной страницы, которую Вы хотите закрыть от поисковиков.
Данный тэг размещается в <head> сайта, наряду с другими meta тэгами.
Стоит отметить, что значение параметра «content» может быть не только «noindex». Рассмотрим все возможные варианты.
| noindex | Самый распространенный параметр. Запрещает индексацию. |
| index | Обратный предыдущему параметр. Разрешает индексацию. Обычно не применяется, так как поисковая система по умолчанию индексирует все. |
| follow | Разрешает следовать по ссылкам, которые расположены на странице. Так же редко применяется, так как и без данного тэга краулер будет переходить по ссылкам. |
| nofollow | Запрещает переходить по ссылкам. |
Популярные ошибки
Существует множество мелких и досадных ошибок, из-за которых можно потерять кучу времени и сил.
- Запрет индексации в CMS.
У ряда CMS (к примеру, у WordPress) и шаблонов по умолчанию стоит галочка — «не индексировать сайт». Это сделано для того, что бы разработчик не забыл закрыть сайт во время создания.

К сожалению, не все вспоминают о ней по окончании работ.
- Синтаксические ошибки.
Синтаксические ошибки в файле robots.txt и тэгах часто приводят к совершенно непредсказуемым последствиям. Вам повезет, если после такого недочета в индекс просто попадут лишние страницы. Очень часто весь сайт закрывается, что в последствии приводит к полной потере органического трафика.
Для того, что бы избежать подобных ошибок, необходимо несколько раз перепроверить изменения, а так же воспользоваться инструментами валидации синтаксиса. К примеру, стандартным сервисом Яндекса.
Яндекс Вебмастер -> Инструменты -> Анализ robots.txt
- Неверное использование масок.
Неверное использование масок может привести к исключению целого дерева страниц, документов и разделов. Если Вы сомневаетесь в правильности написания маски — лучше проконсультируйтесь у специалистов. Провести проверку при помощи online сервиса, в большинстве случаев, не получится.

Делаем выводы
Сам по себе технический процесс исключения достаточно прост. Вся работа заключается в выяснении того, что необходимо исключить и на какой срок.
Если Вы не уверены в правильности своих действий, лучше оставьте в индексе все. Поисковая система сама выберет то, что для нее важно.
Но мы настоятельно рекомендуем обратиться за консультацией при малейших сомнениях.
Закрываем бесполезные страницы от индексации директивой в robots.txt
Опубликовано: 07.11.2014. Обновлено: 19.08.2019 2 447 2
Эта статья об использовании файла robots.txt на практике применительно к удалению ненужных страниц из индекса поисковых систем. Какие страницы удалять, как их искать, как убедиться, что не заблокирован полезный контент. По сути статья — об использовании одной лишь директивы — Disallow. Всесторонняя инструкция по использованию файла роботс и других директив в Помощи Яндекса.
В большинстве случаев закрываем ненужные страницы для всех поисковых роботов, то есть правила Disallow указываем для User-agent: *.
User-agent: *
Disallow: /cgi-bin
Что нужно закрывать от индексации?
При помощи директивы Disallow в файле robots.txt нужно закрывать от индексации поисковыми ботами:
Как искать страницы, которые необходимо закрыть от индексации?
ComparseR
Просканировать сайт Компарсером и справа во вкладке «Структура» построить дерево сайта:

Просмотреть все вложенные «ветви» дерева.
Получить во вкладках «Яндекс» и «Google» страницы в индексе поисковых систем. Затем в статистике сканирования просмотреть адреса страниц в «Найдено в Яндекс, не обнаружено на сайте» и «Найдено в Google не обнаружено на сайте».
Яндекс.Вебмастер
В разделе «Индексирование» — «Структура сайта» просмотреть все «ветви» структуры.

Проверить, что случайно не был заблокирован полезный контент
Перечисленные далее методы дополняют друг друга.
robots.txt
Просмотреть содержимое файла robots.txt.
Comparser (проверка на закрытие мета-тегом роботс)
В настройках Компарсера перед сканированием снять галочку:

Проанализировать результаты сканирования справа:

Search Console (проверка полезных заблокированных ресурсов)
Важно убедиться, что робот Google имеет доступ к файлам стилей и изображениям, используемым при отображении страниц. Для этого нужно выборочно просканировать страницы инструментом «Посмотреть, как Googlebot», нажав на кнопку «Получить и отобразить». Полученные в результате два изображения «Так увидел эту страницу робот Googlebot» и «Так увидит эту страницу посетитель сайта» должны выглядеть практически одинаково. Пример страницы с проблемами:

Увидеть заблокированные части страницы можно в таблице ниже:

Подробнее о результатах сканирования в справке консоли. Все заблокированные ресурсы нужно разблокировать в файле robots.txt при помощи директивы Allow (не получится разблокировать только внешние ресурсы). При этом нужно точечно разблокировать только нужные ресурсы. В приведённом примере боту Гугла запрещён доступ к папке /templates/, но открыт некоторым типам файлов внутри этой папки:
User-agent: Googlebot
Allow: /templates/*.css
Allow: /templates/*.js
Allow: /templates/*.png
Allow: /templates/*.jpg
Allow: /templates/*.woff
Allow: /templates/*.ttf
Allow: /templates/*.svg
Disallow: /templates/
Как настроить robots.txt? Проверить файл robots.txt, закрыть от индексации страницы на сайте

Файл robots.txt управляет индексацией сайта. В нем содержатся команды, которые разрешают или запрещают поисковым системам добавлять в свою базу определенные страницы или разделы на сайте. Например, на Вашем сайте имеется раздел с конфиденциальной информацией или служебные страницы. Вы не хотите, чтобы они находились в индексе поисковых систем, и настраиваете запрет на их индексацию в файле robots.txt.
В данной статье мы рассмотрим, как настроить robots.txt и проверить правильность указанных в нем команд. Как закрыть от индексации сайт целиком или отдельные страницы или разделы.
Чтобы поисковые системы нашли файл, он должен располагаться в корневой папке сайта и быть доступным по адресу ваш_сайт.ru/robots.txt. Если файла на сайте нет, поисковые системы будут считать, что можно индексировать все документы на сайте. Это может привести к серьезным проблемам, в частности, попаданию в базы страниц-дублей, документов с конфиденциальной информацией.
Структура файла robots.txt
В файле robots.txt для каждой поисковой системы можно прописать свои команды. Например, на скриншоте ниже Вы можете увидеть команды для робота Яндекса, Google и для всех остальных поисковых систем:
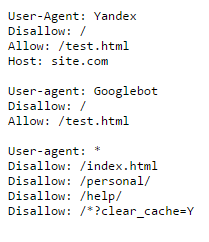
Каждая команда начинается с новой строки. Между блоками команд для разных поисковых систем оставляют пустую строку.
Настройка файла robots.txt: основные директивы
Чтобы правильно настроить файл robots.txt, необходимо знать директивы – команды, которые воспринимают роботы поисковых систем. Ниже рассмотрим основные директивы для настройки индексации сайта в файле robots.txt:
| Директива | Назначение |
| User-agent: | Указывает робота поисковой системы, для которого предназначены команды ниже. Названия роботов можно посмотреть в справочной информации, которую предоставляют поисковые системы. |
| Disallow: | Данная директива в файле robots.txt закрывает индексацию определенной страницы или раздела на сайте. Сама страница или раздел указываются от корневой папки сайта, без домена (см. скриншот в начале статьи). |
| Allow: | Разрешает индексацию определенной страницы или раздела на сайте. Директивы Allow необходимо располагать ниже директив Disallow. |
| Host: | Указывает главное зеркало сайта (либо с www, либо без www). Учитывается только Яндексом. |
| Sitemap: | В данной директиве необходимо прописать путь к карте сайта, если она имеется на сайте. |
Существуют другие директивы, которые используется реже. Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь.
Частные случаи команд в файле robots.txt
Разберем некоторые команды, которые потребуются Вам в работе:
| Команда | Что обозначает |
| User-agent: Yandex | Начало блока команд для основного робота поисковой системы Яндекс. |
| User-agent: Googlebot | Начало блока команд для основного робота поисковой системы Google. |
| User-agent: * Disallow: / | Данная команда в файле robots.txt полностью закрывает сайт от индексации всеми поисковыми системами. |
| User-agent: * Disallow: / Allow: /test.html | Данные команды закрывают все документы на сайте от индексации, кроме страницы /test.html |
| Disallow: /*.doc | Данная команда запрещает индексировать файлы MS Word на сайте. Если на сайте содержится конфиденциальная информация в файлах определенного типа, имеет смысл закрыть такие файлы от индексации. |
| Disallow: /*.pdf | Данная команда в robots.txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах. |
| Disallow: /basket/ | Команда запрещает индексировать все документы в разделе /basket/. |
| Host: www.yandex.ru | Команда задает для сайта yandex.ru основным зеркалом адрес сайта с www. Соответственно, в поиске с высокой вероятностью будут выводиться адреса страниц с www. |
| Host: yandex.ru | Данная команда задает для сайта yandex.ru в качестве основного зеркала адрес yandex.ru (без www). |
Использование спецсимволов в командах robots.txt
В командах robots.txt может использоваться два спецсимвола: * и $:
- Звездочка * заменяет собой любую последовательность символов.
- По умолчанию в конце каждой команды добавляется *. Чтобы отменить это, в конце строки необходимо поставить символ $.
Допустим, у нас имеется сайт с адресом site.com, и мы хотим настроить файл robots.txt для нашего проекта. Разберем действие спецсимволов на примерах:
| Команда | Что обозначает |
| Disallow: /basket/ | Запрещает индексацию всех документов в разделе /basket/, например: site.com/basket/ |
| Disallow: /basket/$ | Запрещает индексацию только документа: site.com/basket/ Документы: остаются открытыми для индексации. |
Пример настройки файла robots.txt
Давайте разберем на примере, как настроить файл robots.txt. Ниже находится пример файла, значение команд из которого будет подробно рассмотрено в статье.
В данном файле мы видим, что от поисковых систем Яндекс и Google закрыты от индексации все документы на сайте, кроме страницы /test.html
Остальные поисковые системы могут индексировать все документы, кроме:
- документов в разделах /personal/ и /help/
- документа по адресу /index.html
- документов, адреса которых включают параметр clear_cache=Y
Последние две команды требуют отдельного внимания.
Командой /index.html закрыт от индексации дубль главной страницы сайта. Как правило, главная страница доступна по двум адресам:
- site.com
- site.com/index.html или site.com/index.php
Если не закрыть второй адрес от индексации, то в поиске может появиться две главных страницы!
Команда Disallow: /*?clear_cache=Y закрывает от индексации все страницы, в адресах которых используется последовательность символов ?clear_cache=Y. Часто различный функционал на сайте, например, сортировки или формы подбора добавляют к адресам страниц различные параметры, из-за чего генерируется множество страниц-дублей. Закрывая дубли с параметрами от индексации, Вы решаете проблему попадания дублей в базу поисковых систем.
Посмотрите, какие страницы необходимо закрывать от индексации, в статье про проведение технического аудита сайта.
Как проверить файл robots.txt?
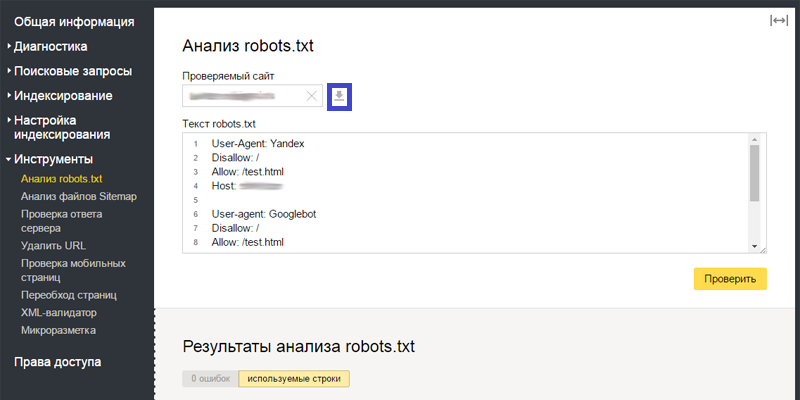
После добавления файла robots.txt на сайт Вы можете проверить корректность его настройки. Для этого поисковые системы предлагают специальные инструменты. В статье рассмотрим инструмент от Яндекса, который позволяет проверить правильность настройки robots.txt. Он доступен в сервисе Яндекс.Вебмастер во вкладке «Инструменты» – «Анализ robots.txt».
В верхней части страницы Вы можете увидеть проверяемый сайт (на скриншоте затерт), содержание файла robots.txt, известное Яндексу. Обязательно проверьте, что содержание файла указано корректно. Если в Яндекс.Вебмастер выводятся старые команды, нажмите на кнопку «Загрузить» (серый значок справа от ссылки на проверяемый сайт, выделен на скриншоте рамкой):
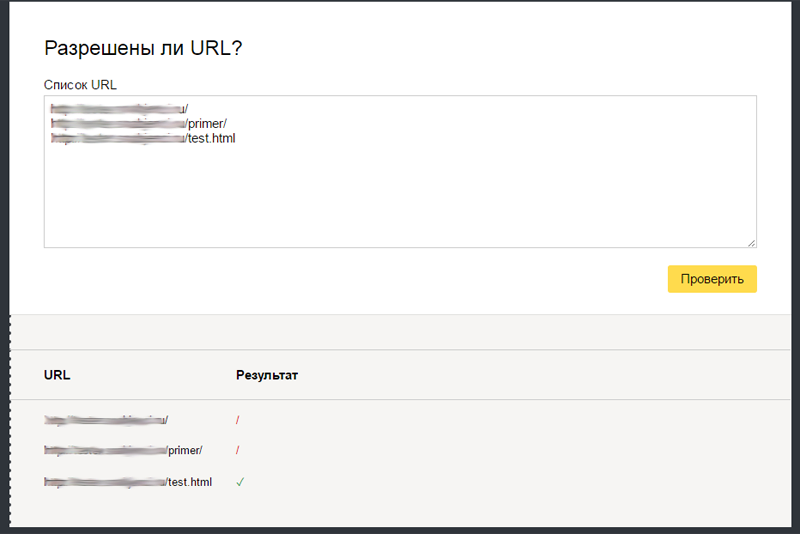
В нижней части страницы добавьте в поле «Разрешены ли URL?» список страниц, по которым Вы хотите проверить, разрешена их индексация или нет. Нажмите кнопку «Проверить», и ниже выведутся результаты. Красный значок означает, что страница запрещена к индексации, зеленый – разрешена:
Аналогичные инструменты проверки файла имеются в Центре вебмастеров Google.
Время от времени в структуру сайта вносятся изменения. Поэтому необходимо периодически проверять, какие страницы и документы находятся в индексе поисковых систем. При появлении в индексе документов, которые не должны там быть, их индексацию необходимо закрыть в файле robots.txt.
Рекомендуем

Ссылки с других сайтов – один из важнейших факторов для поисковых систем, особенно для Google. Если говорить о Яндексе, то влияние ссылочных …

Технический аудит сайта выявляет ошибки в работе веб-ресурса, которые могут вызвать проблемы в поисковых системах. Например, усложнить индексацию …