Об особенностях стилистических ошибок в рерайтерских новостных интернет-сообщениях (на примере материалов агентств newsru.com и lenta.ru)
Автор исследует рерайтерское направление создания новостных интернет-сообщений, их специфику, обусловленную как способом производства информационного продукта, так и требованиями потребителя. Автор рассматривает стилистические ошибки в новостных материалах агентств, наиболее последовательно специализирующихся на рерайтерстве.
Ключевые слова: интернет-текст, мультимедийное сообщение, рерайтинг, стилистические ошибки
С распространением и развитием Интернета все большую популярность у потребителей новостной информации приобретают мультимедийные версии сообщений — благодаря их доступности, оперативности, удобству использования. Новостную колонку на своих сайтах сейчас имеют информационные агентства, газеты и журналы, поисковые системы, государственные и общественные организации и т. д.
д.
По предпочитаемым способам работы с информацией электронные СМИ можно разделить на три большие группы.
0. Самостоятельно производящие первичный сбор информации, для этого содержится штат профессиональных корреспондентов. В рунете к ним относятся, например, ИТАР-ТАСС, РИА-Новости, Интерфакс, ИА REGNUM.
1. По договоренности с производителями новостей просто перепечатывающие их материалы у себя со ссылкой на первоисточник: rambler.ru, yandex.ru, utro.ru и многие другие.
2. Компилирующие материал из разных источников с добавлением собственного анализа.
Третья группа представлена в рунете пока очень небольшим количеством агентств, наиболее значимыми из которых являются NEWSru.com и Lenta.ru. Однако это направление является весьма перспективным, и в ближайшие годы следует ожидать его развития. Дело в том, что оно позволяет в наибольшей степени использовать современные технические возможности, предоставляемые Интернетом, мобильной связью и другими цифровыми медиа.
Такой подход позволяет создавать новостные сообщения полнее, оригинальнее, информативнее и оперативнее, чем это делают традиционные агентства (ИТАР-ТАСС, РИА-Новости, Интерфакс). Кроме того, информационный продукт обходится значительно дешевле, поскольку может создаваться одним сотрудником. Как правило, один и тот же человек выбирает тему сообщения, находит для этого материал, оформляет его, редактирует и публикует. Такого сотрудника можно называть автором, редактором, составителем, рерайтером — он совмещает все эти функции. Новостные интернет-сообщения, создаваемые рерайтером путем компиляции, мы будем называть рерайтерскими.
В данной статье рассматриваются стилистические ошибки в новостных материалах агентств, наиболее последовательно специализирующихся на рерайтерстве: NEWSru.com и Lenta.ru.
Одна из особенностей мультимедийного сообщения — та, что публикация на сайте не означает его фиксации и завершения, как это происходит с бумажными носителями и как еще 10 лет назад было даже с интернет-сообщениями. В любой момент редактор может вернуться к своему материалу, внести поправки, изменения, дополнения. На сайте каждый раз сохраняется только последний по времени вариант сообщения. Рерайтеры, в отличие от других поставщиков новостного продукта, этим очень активно пользуются.
Другая важная особенность — повышенное требование к оперативности. Если новостная заметка для периодической печати обычно готовится в пределах одного-двух часов, то у рерайтера в распоряжении, как правило, лишь несколько минут. При освещении быстро развивающегося события (например, митингов оппозиции, проходивших весной этого года, или серии терактов в Днепропетровске на Украине 27 апреля) рерайтеры каждые 5—10 минут добавляли новую информацию, которую еще следовало найти, осмыслить, проверить и подкрепить гиперссылками.
Очевидно, что при таком дефиците времени следует очень рационально подходить к редактированию, в первую очередь устраняя те ошибки и недочеты, которые препятствуют самому главному — получению корректной новостной информации. В полной мере это относится и к стилистике. Не стоит требовать, чтобы стилистическая правка рерайтерских материалов осуществлялось с такой же тщательностью, как и текста, предназначенного для публикации в печатных СМИ.
Повторное обращение к новостному материалу во многих случаях позволяет рерайтеру обнаружить и исправить стилистические ошибки. Многократное повторное редактирование производится, как правило, в отношении сообщений о значимых длящихся событиях. Добавляя и исправляя информацию, рерайтер попутно осуществляет стилистическую правку.
Например, материал агентства NEWSru.com о трагических событиях в Днепропетровске на Украине, где 27 апреля 2012 г. прогремела целая серия взрывов, претерпел более 20 редакций.
Проследим эволюцию всего лишь одного элемента в этом обширном материале — сообщение о количестве пострадавших.
В первой редакции (13:57) было сказано: «В результате взрыва предварительно тяжело пострадало три человека» (явная стилистическая погрешность, нарушение семантических и грамматических закономерностей сочетания слов в конструкции «предварительно тяжело», следовало бы — «по предварительным сведениям»).
Во второй (14:04) и третьей (14:10) редакциях фраза оставалась прежней. Когда же редактор вносил новую информацию, он заодно осуществил и стилистическую правку (четвертая редакция, 14:15): «В результате взрыва тяжелые ранение получили по меньше мере три человека… Точное число пострадавших пока не известно. По предварительным данным, ранены около 12 человек, передает Reuters. Число пострадавших, по-видимому, будет только расти». Прежняя стилистическая погрешность исправлена, но возникла новая: автор хотел сказать, что в последующих сообщениях с места событий будет указываться уточненное количество пострадавших, а получилось, что ожидаются новые жертвы.
В пятой редакции (14:41) она была заменена на наречие «еще», которое более уместно и указывает на наличие возможности, достаточных оснований для совершения/осуществления чего-либо: «По предварительным данным МЧС, пострадали в общей сложности 14 человек. Число пострадавших, по-видимому, будет еще расти».
Шестая (14:48): «По предварительным данным МЧС, пострадали в общей сложности 14 человек. Число раненых, по-видимому, будет еще расти». Слово «раненых» точнее отражает информацию, помогает избежать фактической неясности. Ведь в результате взрывов люди могли пострадать и морально, и материально, а не только физически.
Седьмая (14:52): «По предварительным данным МЧС, ранены в общей сложности 14 человек». Предположение «будет расти» убрано.
Восьмая (15:01): «По последним данным МЧС, ранены в общей сложности 27человек — 25 из них были госпитализированы».
В последней редакции (28 апреля 2012 г., 09:09) сообщалось: «По данным МЧС, ранены 29 человек — 25 из них были госпитализированы». Фраза стала максимально краткой, информативной, однозначно воспринимаемой.
Однако большинство материалов не требует постоянного обновления информации. Как следствие, рерайтер перечитывает публикацию редко и невнимательно, не обращаясь к уже написанному. Редактирование сводится к добавлению попутных сведений — текста, фотографий, видео, гиперссылок.
Стилистические ошибки можно разделить на два взаимосвязанных уровня: всего текста (макроуровень) и отдельной фразы (микроуровень).
Ошибки макроуровня могут иметь вид либо неудачно выбранного стиля изложения, либо так называемого «стилевого разнобоя» — смешения в одной заметке далеко отстоящих друг от друга стилей. Традиционная позиция заключается в том, что основными для новостных сообщений должны быть публицистический и официально-деловой стили; допускаются также элементы разговорного и художественного, например при передаче цитаты или в так называемых «мягких» новостях.
Следует заметить, что в материалах рассматриваемых агентств эти правила нарушаются совершенно явно и даже, можно сказать, демонстративно. Встречаются целые сообщения, построенные на просторечной или жаргонной лексике. Рерайтеры весьма охотно включают в сообщение цитаты с жаргонными, экспрессивными и даже грубыми выражениями и сами эти выражения используют, нередко помещая их в хедлайн:
Lenta.ru, 10 марта 2012 г.: «Установлена личность стрелявшего в американской психбольнице» — слово «психбольница» не только является разговорным, но и несет в русском языке негативную коннотацию, поскольку часто употребляется в переносном смысле. Так как в данном случае рерайтер явно не предусматривал дополнительных смысловых оттенков, лучше было бы написать «психиатрическая клиника».
Так как в данном случае рерайтер явно не предусматривал дополнительных смысловых оттенков, лучше было бы написать «психиатрическая клиника».
Lenta.ru, 29 июня 2012 г.: «Американцам официально разрешили врать про боевые награды».
Lenta.ru, 26 марта 2012 г.: «“Бомбил” выгонят с привокзальных площадей».
NEWSru.com, 15 мая 2012 г.: «Отказ Путина от саммита G8 не дает покоя Западу: его обвинили в “отмазках” и дали два объяснения».
NEWSru.com, 15 мая 2012 г.: «Инициатор миллионных штрафов за митинги резвится в Twitter: “Готовьте кэш, АппАзицЫонЭрыГ».
NEWSru.com, 18 мая 2012 г.: «Березовский обратился к олигархам “по понятиям”: нужно “слушать сердце, а не бабло”».
Единственное, чего избегают рерайтеры, — обсценных выражений.
Надо ли бороться за переход рерайтеров на более «высокий» стиль изложения или следует признать за ними право на собственный стиль, близкий стилю блогеров,— вопрос сложный и требует отдельного исследования. Сами они, несомненно, считают (пользуясь их собственной терминологией), что жаргонные и грубые выражения в материале — «не баг, а фича» (т.е. не ошибка, а сознательно привнесенный элемент). Мы же полагаем, что с развитием рерайтерского направления в цифровых медиа появятся различные подходы к подаче материала; в том числе появятся рерайтеры, которые станут придерживаться традиционных взглядов на стиль изложения, что будет требоваться соответствующей редакционной политикой сетевого ресурса.
Сами они, несомненно, считают (пользуясь их собственной терминологией), что жаргонные и грубые выражения в материале — «не баг, а фича» (т.е. не ошибка, а сознательно привнесенный элемент). Мы же полагаем, что с развитием рерайтерского направления в цифровых медиа появятся различные подходы к подаче материала; в том числе появятся рерайтеры, которые станут придерживаться традиционных взглядов на стиль изложения, что будет требоваться соответствующей редакционной политикой сетевого ресурса.
В общем, говоря о «стилевом разнобое», необходимо учитывать: компиляция собирает материал, созданный разными авторами. Работа по унификации стиля всех использованных фрагментов потребовала бы неоправданно много сил и времени при весьма сомнительной пользе. Полагаем, что следует признать «стилевой разнобой» допустимым явлением, специфической особенностью рерайтерских сообщений.
Стилистические ошибки микроуровня могут возникать как из- за неправильно выбранного слова (без учета его семантики, лексической сочетаемости и т.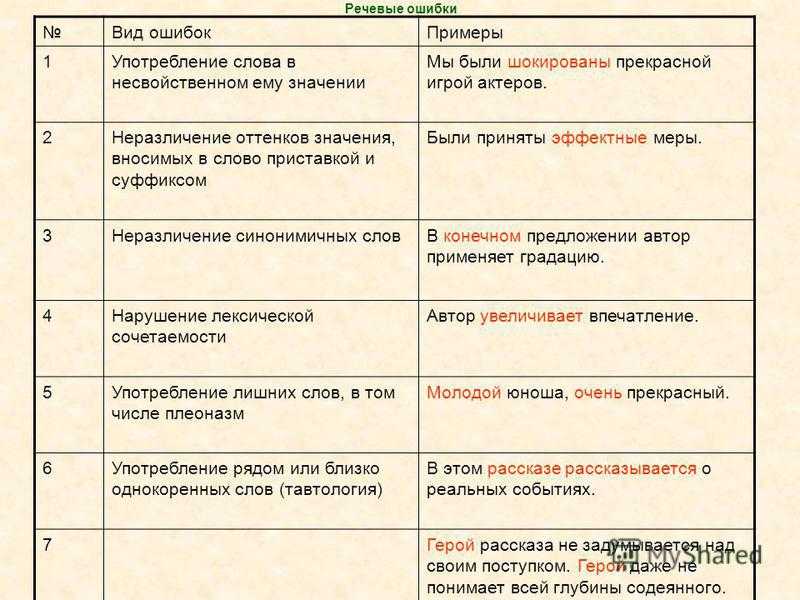 д.), так и из-за неправильного построения фразы в целом (она может быть неблагозвучной, безграмотной, вызывать нежелательные ассоциации и даже искажать информацию):
д.), так и из-за неправильного построения фразы в целом (она может быть неблагозвучной, безграмотной, вызывать нежелательные ассоциации и даже искажать информацию):
Lenta.ru, 29 июня 2012: «…“Наработки уже есть, модель уже создана», —рассказал он, не уточнив другие подробности совместного проекта». Следовало бы использовать слово «сказал», поскольку «рассказал» подразумевает пространное и подробное изложение, а в материале сообщается, что было сделано лишь краткое заявление без подробностей.
Там же: «Сдать экзамен на минимальные 20 баллов не смогли 3,4процента учащихся». То есть все остальные 96,6% сдали именно на 20 баллов? Здесь стилистическая ошибка сопряжена с логической. Правильнее, например, «набрать минимальные 20 баллов». В этом случае было бы понятно, что остальные набрали 20 и более баллов.
NEWSru.com, 8 мая 2012 г.: «При этом полиция не предупреждала о том, что акция не санкционирована, и начала задержания без предупреждения». Понятно, что если стала задерживать без предупреждения, то не предупреждала; к тому же допущена явная тавтология.
Понятно, что если стала задерживать без предупреждения, то не предупреждала; к тому же допущена явная тавтология.
Ошибки микроуровня частотны и в хедлайнах:
NEWSru.com, 26 июня 2012 г.: «Российские моряки обнаружили в Гвинейском заливе конкурентов сомалийских пиратов». Весьма сомнительно, чтобы гвинейские пираты составляли конкуренцию сомалийским, промышляющим на другом краю Африки. Их можно было бы с долей иронии назвать «коллегами».
NEWSru.com, 29 апреля 2012 г.: «Абсолютный рекорд жары установлен в Москве, воздух раскалился до 29 градусов». Кем «установлен» этот рекорд? Лучше было бы использовать слова «зафиксирован» или «отмечен». Кроме того, речь идет о рекордной только для апреля температуре, то есть рекорд никак не абсолютный.
NEWSru.com, 15 мая 2012 г.: «Газоны на Чистых прудах переоценили: сумма “оппозиционного” ущерба выросла в геометрической прогрессии». Рерайтер хотел подчеркнуть значительность увеличения суммы. Но о геометрической прогрессии можно было бы говорить, если бы имелись, по меньшей мере, три оценки ущерба, находящиеся в соотношении : а1 = аъ: аг В данном случае их только две: прежняя и новая. Поэтому следовало бы сказать: «существенно выросла», «в несколько раз» или даже «на порядок» (если примерно в десятикратном размере). Кроме того, слово «переоценили» имеет два значения: «изменили оценку» и «оценили выше, чем следовало». Если бы первоначальную сумму ущерба, напротив, снизили, получился бы своего рода каламбур. А так — просто двусмысленность из-за неудачно выбранного слова.
Но о геометрической прогрессии можно было бы говорить, если бы имелись, по меньшей мере, три оценки ущерба, находящиеся в соотношении : а1 = аъ: аг В данном случае их только две: прежняя и новая. Поэтому следовало бы сказать: «существенно выросла», «в несколько раз» или даже «на порядок» (если примерно в десятикратном размере). Кроме того, слово «переоценили» имеет два значения: «изменили оценку» и «оценили выше, чем следовало». Если бы первоначальную сумму ущерба, напротив, снизили, получился бы своего рода каламбур. А так — просто двусмысленность из-за неудачно выбранного слова.
Lenta.ru, 29 июня 2012: «Людмиле Алексеевой разрешили отметить несанкционированный юбилей». Если разрешили, значит, его уже нельзя назвать несанкционированным. Следовало уточнить: «ранее несанкционированный».
Lenta.ru, 29 июня 2012: «Спонсоры отказались тратить деньги на “Селигер»». Если отказались — значит, уже не спонсоры. Необходимо было добавить определение «бывшие».
Lenta.ru, 28 июня 2012: «Япония и Корея возобновят военное сотрудничество впервые за 67 лет». Во-первых, есть две Кореи: Республика Корея и КНДР. О какой из них идет речь, непонятно, поскольку отношения у Японии и с той и с другой странами почти одинаково плохие. Следовало бы уточнить этот факт. Во-вторых, 67 лет назад, до 1945 г., Корея являлась колонией Японии и «сотрудничать» с ней не могла — она просто вынуждена была участвовать в японских военных проектах. Сотрудничество подразумевает известное равноправие субъектов. Так что «возобновлять» им нечего, это слово неуместно. Хедлайн можно было написать просто: «Южная Корея и Япония подпишут соглашение о военном сотрудничестве». Именно так это и было сделано в первичном материале, который использовал рерайтер Lenta.ru.
Стилистические, как и прочие, ошибки целесообразно разделять по их возможности исказить восприятие новостного сообщения на: те, которые препятствуют адекватному восприятию информации, и те, которые не влияют на однозначность трактовки. Первые назовем «жесткими», а вторые — «мягкими». Приведенные выше примеры содержат «мягкие» ошибки, поскольку смысл фразы даже при их наличии понятен. «Жесткие» ошибки, как правило, связаны с двусмысленностью, даже с фактической неясностью:
Первые назовем «жесткими», а вторые — «мягкими». Приведенные выше примеры содержат «мягкие» ошибки, поскольку смысл фразы даже при их наличии понятен. «Жесткие» ошибки, как правило, связаны с двусмысленностью, даже с фактической неясностью:
Lenta.ru, 29 июня 2012 г.: «Сын телеведущего Затевахинарассказал об аварии, в которой погибла его пассажирка» — остается вопрос: чья была пассажирка — телеведущего или его сына?
Lenta.ru, 15 мая 2012 г.: «Грузия подала заявку на проведение Евро- 2020 без Азербайджана». Грузия не хочет, чтобы Азербайджан участвовал в Евро-2020, или раньше намеревалась подать совместную с ним заявку, но передумала?
NEWSru.com, 17 апреля 2012 г.: «Хамовнический суд занялся экстремизмом в открытом письме Березовского на сайте “Эха Москвы”». Возникают несколько трактовок этого хэдлайна: то ли суд обнаружил экстремизм в письме Березовского, то ли, наоборот, Березовский в своем письме обвиняет Хамовнический суд в экстремизме (как известно, от Березовского можно было ожидать и не такого). Непонятна также роль в данном сообщении «Эха Москвы», если предположить, что письмо было выложено на их сайт или что новостной материал ссылается на сайт «Эха», где приводится указанный материал.
Непонятна также роль в данном сообщении «Эха Москвы», если предположить, что письмо было выложено на их сайт или что новостной материал ссылается на сайт «Эха», где приводится указанный материал.
В таблице и на рисунке приведены данные о наличии стилистических ошибок в хедлайне, лиде и собственно тексте (корпусе и бэкграунде) новостных сообщений изучаемых агентств. По объясненным выше причинам учитывались только ошибки микроуровня.
Данные по хедлайну, лиду, корпусу и бэкграунду не являются взаимоисключающими. В одном и том же материале ошибки могут присутствовать сразу в нескольких структурных элементах. При подсчете в пределах одного элемента применялся «принцип поглощения»: если имелось сразу несколько стилистических ошибок, считалось, что компонент с ошибкой; если среди них была «жесткая» — с «жесткой».
Менее половины сообщений, опубликованных рерайтерскими агентствами, свободны от стилистических ошибок. Но более важно то, что распределение их по различным композиционным элементам текста оказалось несколько неожиданным. Непропорционально большое количество ошибок, в том числе «жестких», приходится на хедлайны. Это при том, что качеству хедлайнов традиционно уделяется особое внимание, а размер их весьма небольшой.
Но более важно то, что распределение их по различным композиционным элементам текста оказалось несколько неожиданным. Непропорционально большое количество ошибок, в том числе «жестких», приходится на хедлайны. Это при том, что качеству хедлайнов традиционно уделяется особое внимание, а размер их весьма небольшой.
Более подробный анализ текстов дает объяснение этому парадоксу. Стилистические ошибки у рерайтера возникают чаще всего тогда, когда он пытается совместить материалы из различных источников. Наиболее богаты ошибками связующие, переходные фразы и предложения — стыки заимствованных фрагментов, а также те части текста, где рерайтер пересказывает информацию своими словами.
Что касается хедлайна, то он почти всегда является результатом творчества самого рерайтера и не совпадает с хедлайном исходного материала. Иногда же рерайтер берет несколько исходных сообщений (например, о соглашении Японии с Кореей и о колониальной зависимости последней в 1945 г. ), а потом пытается дать им «общее» название. Классические требования к новостным сообщениям предусматривают сообщение в материале одной новости. В рассматриваемых агентствах это правило не соблюдается и не должно соблюдаться.
), а потом пытается дать им «общее» название. Классические требования к новостным сообщениям предусматривают сообщение в материале одной новости. В рассматриваемых агентствах это правило не соблюдается и не должно соблюдаться.
Кстати, малое количество ошибок в более объемном, чем хедлайн, лиде обусловлено именно тем, что лид обычно заимствуется без изменений. Так, в приведенном материале он выглядит следующим образом: «Южная Корея и Япония в ближайшее время подпишут соглашение о военном сотрудничестве, сообщает DefenseNews».
По результатам исследования можно сказать, что исходные материалы в большинстве случаев оказываются стилистически более грамотными, чем заметки рерайтеров. Причины этому можно указать две.
Во-первых, заметку рерайтера читает и правит он сам, а в традиционных агентствах и солидных медиаорганизациях предназначенный для публикации текст помимо автора читает как минимум еще один человек. Чужие стилистические ошибки обычно более заметны, чем собственные.
Во-вторых, уровень грамотности рерайтера в среднем значительно уступает уровню грамотности профессионального корреспондента или редактора. Дело в том, что при назначении на должность рерайтера обычно приходится выбирать, кому отдать предпочтение: опытному словеснику, посредственно владеющему компьютером, или человеку, свободно ориентирующемуся в сети и способному быстро обнаружить интересную информацию, но не обладающему достаточными филологическими знаниями и редакторскими навыками. Очевидно, что умение отлично ориентироваться в потоках электронной информации является для рерайтера более важным, чем безукоризненная грамотность. Конечно, идеальным решением было бы работать со специалистом, который прекрасно владеет и словом, и компьютером. Хотя на примере приведенного выше сообщения о терактах в Днепропетровске показано, что, если позволяет время, рерайтер вполне может осуществлять достаточно качественную стилистическую правку.
Итак, можно сделать следующие выводы:
1. Рерайтерское направление создания новостных интернет-сообщений имеет специфику, обусловленную как способом производства информационного продукта, так и требованиями потребителя. В частности, оно ориентировано на предоставление в электронном виде оперативной, полной и разнообразной информации в условиях развивающегося события.
Рерайтерское направление создания новостных интернет-сообщений имеет специфику, обусловленную как способом производства информационного продукта, так и требованиями потребителя. В частности, оно ориентировано на предоставление в электронном виде оперативной, полной и разнообразной информации в условиях развивающегося события.
2. К стилю и языку рерайтерских материалов нельзя предъявлять те же требования, что и к классическим новостным сообщениям. При рерайтинге допустимы «стилевой разнобой», использование жаргонных и экспрессивных выражений, открытое проявление собственной позиции.
3. Следует с особым тщанием выявлять и исправлять те стилистические ошибки, которые препятствуют корректному восприятию информации. Сами рерайтеры этим на должном уровне заниматься физически не могут, даже имея специальную редакторскую подготовку: им следует мониторить события, следить за появлением важной информации и своевременно ее выкладывать. Целесообразно назначить общего редактора (шеф-редактора, выпускающего редактора), который бы просматривал сообщения и исправлял, по крайней мере, самые грубые ошибки.
4. При создании хедлайнов рерайтерам следует придерживаться следующего правила: каждый раз выбирать, какая новость является главной, и именно ее отражать в заголовке. Хедлайн в рерайтерском материале, как и в традиционном новостном сообщении, является важнейшим компонентом текста. Если в корпусе и бэкграунде «мягкие» стилистические недочеты еще простительны, то в хедлайне они крайне нежелательны. Читают в первую очередь хедлайн. По нему создается впечатление о качестве продукции агентства, принимается решение о прочтении всего материала.
Поступила в редакцию 23.01.2013
Урок по русскому языку на тему «Стилистические ошибки и недочеты культуры речи»
ТЕМА. «Стилистические ошибки и недочеты культуры речи».
Цель урока: дать учащимся понятие о стилистических ошибках, развить навыки и умения распознавания и редактирования стилистических ошибок.
Задачи:
Образовательная: сформировать
представление о стилистических ошибках, научить определять вид ошибок, обобщить
и систематизировать знания по теме раздела «Культура речи».
Воспитательная: воспитывать речевой вкус и уважительное отношение к требованиям культуры речи.
Развивающая: развивать речевую культуру учащихся, способствовать развитию выразительной речи.
Учебно – методические ресурсы: слайды, карточки, словари.
Ход урока
I Организационный момент (2 минуты):
— приветствие;
— проверка присутствующих;
— готовность аудитории к занятию;
— постановка целей и задач урока.
II Опрос по домашнему заданию (7 минут).
Задание. Поставьте ударения в словах: клала, затемно, аэропорты, прибыла, шарфы, торты, слилась, банты, звонит, средства, договор, баловать, зави́дно, красивее, жалюзи, сироты, досуг.
Составьте с ними предложения. Выучите правильное произношение слов.
Орфоэпическая минутка.
Проверим,
как вы запомнили ударение в данных словах.
На проекторе стихотворение. Прочтем его.
Клала шарфы, банты, торты,
Кралась затемно домой,
А потом к аэропорту
Прибыла, слилась с толпой.
(Н.А. Шапиро)
III Актуализация опорных знаний (3 минуты)
Фронтальный опрос по предыдущим темам:
1. Что изучает стилистика?
Стилистика — учение о стилях речи, средствах языковой выразительности и условиях использования их в речи.
2. Дайте определение понятию культура речи.
Культура речи — раздел языкознания, изучающий практическую реализацию в речи норм литературного языка.
3. Что такое стиль?
Стиль — система речевых средств, которые используются в какой-либо сфере общения, а также разновидность литературного языка, которая выполняет какую-либо функцию в общении.
4. Прочтем стихотворение (дано на проекторе), вставим вместо точек название стиля.
ЗАБОТА О СТИЛЕ
Артисты говорят в гримерной,
Твой друг беседует с тобой —
Стиль это просто… (разговорный),
А не
какой-нибудь иной.
Рассказ читаешь или стих,
Роман, поэму, пьесу —
Знай, в них… (художественный) стиль,
Стиль очень интересный.
Еще есть стиль… (публицистический) —
Статей в журнале политическом,
Газетных очерков, заметок —
Запомни также стиль и этот.
А биографию открой — … (официально-деловой).
А правила когда мы учим,
Употребляем стиль… (научный).
(В. А. Синицын)
4. Что называют нормой литературного языка?
5. Назовите словари русского языка.
IV Объяснение новой темы (18 минут).
Слово учителя. Раскрывая сегодняшнюю тему занятия, мы должны узнать, что такое стилистические ошибки, каковы последствия их нарушения, как можно их классифицировать и как избежать нарушения норм языка.
Работа с проектором. Комментированное чтение цитат.
А. «Наш язык — важнейшая часть
нашего общего поведения в жизни. И по тому, как человек говорит, мы сразу и
легко можем судить о том, с кем имеем дело» (Д.С. Лихачев)
И по тому, как человек говорит, мы сразу и
легко можем судить о том, с кем имеем дело» (Д.С. Лихачев)
Б. Рассказывают, что, когда к Сократу однажды привели человека, о котором он должен был высказать свое мнение, мудрец долго смотрел на него, а потом воскликнул: «Да заговори же ты, наконец, чтобы я мог тебя узнать».
В. «Единственное средство умственного общения людей есть слово…Если же можно употреблять слова как попало и под словами разуметь, что нам вздумается, то лучше уж не говорить, а показывать знаками» (Л.Н. Толстой).
Слово учителя. Мы всегда должны помнить, что речь человека – это его визитная карточка. Значит, чтобы тебя высоко оценили, твоя речь должна быть соответствующей.
Беседа.
1. Как вы понимаете выражение экология языка?
2. Какую речь можно назвать культурной?
3. Что отстаивал Лев Николаевич в своем высказывании?
Слово учителя. Таким образом, нарушение нормы языка
недопустимо. Оно приводит к ошибке и непониманию. Кроме стилистических ошибок,
лингвисты выделяют орфографические, орфоэпические, лексические,
фразеологические, пунктуационные, синтаксические.
Оно приводит к ошибке и непониманию. Кроме стилистических ошибок,
лингвисты выделяют орфографические, орфоэпические, лексические,
фразеологические, пунктуационные, синтаксические.
Запишите определение термина стилистическая ошибка.
Запись в тетрадь
Стилистические ошибки — это, с одной стороны, употребление неуместных в данном стиле языковых средств, а с другой — нарушение требований ясности, точности, краткости, богатства и выразительности.
Чтение и анализ стилистических ошибок, представленных на слайде.
1. Употребление лишних слов — плеоназм
своя автобиография
патриот Родины
памятные сувениры
2. Смешение паронимов
Были приняты эффектные меры.
Запомните: одеть ребенка, надеть пальто
3. Немотивированное использование высокой книжной лексики
Она 20 лет трудилась на посту санитарки.
4. Ошибки при употреблении фразеологизмов
Львиная часть урожая была потеряна.
5. Тавтология
В этом рассказе рассказывается о реальных событиях.
6. Ошибки в построении предложения с деепричастным оборотом.
Подъезжая к городу, начался сильный ветер.
7. Употребление слов-паразитов вот, так, так сказать, значит, этого, того.
Ну вот, мы с мамой решили, значит, испечь папе праздничный пирог.
Y Закрепление нового материала (15 минут)
Задание. Укажите виды ошибок. Отредактируйте предложения.
1. В ледяной холод и стужу Павел работает на стройке. 2. Сегодня у нас в гостях гость из Алматы. 3. Я уйду, как француз, по-английски. 4. Те, кто обладают детьми и внуками, знают, что дети любят больше смотреть телевизор, чем читать книги. 5. Игрушка была сделана из желтого искусного меха.
Командная работа.
1 команда
Задание. Правильно поставьте ударение в выделенных словах.
Сегодня победительнице
конкурса вруча́т как приз догово́р о рекламном туре на год. Также
жюри решило ее премирова́ть: фотографии будущей звезды бесплатно
разместят в катало́ге. Как Мария восприняла́ эту победу, мы
узнаем из следующего выпуска новостей. А сейчас расскажем вам о том, как
проводят свой досу́г учащиеся ко́лледжа. А ведь они не просто учащиеся
из обычных семей, они сиро́ты. Задание че́рпать знания — для них
не обязанность, а увлечение, так как все свободное время ребята проводят в
научном центре.
Также
жюри решило ее премирова́ть: фотографии будущей звезды бесплатно
разместят в катало́ге. Как Мария восприняла́ эту победу, мы
узнаем из следующего выпуска новостей. А сейчас расскажем вам о том, как
проводят свой досу́г учащиеся ко́лледжа. А ведь они не просто учащиеся
из обычных семей, они сиро́ты. Задание че́рпать знания — для них
не обязанность, а увлечение, так как все свободное время ребята проводят в
научном центре.
2 команда
Задание. Правильно поставьте ударение в выделенных словах.
Сегодня мы находимся на
кондитерской фабрике. Конфеты, то́рты, рулеты — продукция этой фабрики. Процесс
изготовления сладкой продукции идет в определенных цехах. Что же внутри
«сладкого цеха»? Большой стол на фабрике лишь отдаленно похож на наш ку́хонный.
Над нами, как вы видите, находится трубопрово́д. На окнах — жалюзи́.
А работы у тружениц еще очень много: украсить торт. Крем специалист на то́рты кладет аккуратно. Он разноцветный. Для красного оттенка использован краситель,
добытый из све́клы, для синего — сли́вовый. Какой торт самый
лучший, определят покупатели.
Он разноцветный. Для красного оттенка использован краситель,
добытый из све́клы, для синего — сли́вовый. Какой торт самый
лучший, определят покупатели.
3 команда
Ролевая игра.
Прочитайте тексты. Сделайте их стилистический анализ.
1. Представьте ситуацию: подруга рассказывает о выполненной работе.
«Я ускоренными темпами обеспечила восстановление порядка на жилой площади, а также в предназначенном для приготовления пищи подсобном помещении общего пользования. В последующий период времени мною было организовано посещение торговой точки с целью приобретения необходимых продовольственных товаров».
2. Утром.
«Ну, значит, я вот сегодня
утром просыпа-а-юсь, смотрю будильник. Господи, будильник-то! Рано еще. А,
думаю, посплю еще. Вста-а-ла, говорю: ой, как неохота вставать такую рань!. Все
равно встала кое-как. Ну ладно, пока завтрак, туда-сюда, газ зажгла. Так, ну
что? Яишенку, что ли, сделать? То ли два яйца разбить, то ли одно? Разбила три. Думаю, зря, наверно, не съем ведь. А спать хочется… Яишенку приготовила, поела,
а все равно спать хочу. Ох уж этот будильник!»
3. Придумайте диалог «В автобусе» с использованием слов: нет местов, с двести сдачу, выходить-сходить, оплатить за проезд, ложить. Исправьте ошибки в данных словах.
4 команда
Задание. Дайте стилистическую оценку употреблению глагола одеть; если необходимо, исправьте предложения.
1. Зима одела землю снегом. 2. На мебель были одеты чехлы, и это придавало комнате нежилой вид. 3. После завтрака он одел сына и вышел с ним на улицу. 4. Мать, больная гриппом, при кормлении грудного ребенка, должна одевать марлевую повязку из четырех слоев марли. 5. Причину аварии удалось установить: наладчик Конурин неправильно одел наконечник на трубку. 6. Щиты съемной опалубки одеваются на прутья каркасной арматуры.
5 команда.
Задание. Составьте тексты на тему «Вода»,
принадлежащие к разным стилям.
YI Итог, оценивание (3 минуты)
♦ Что такое стилистические ошибки?
♦ Что вы узнали о классификации ошибок в русском языке?
Рефлексия
Что я знал | Что я узнал | Как применить в жизни полученные сведения |
YII Домашнее задание (2 минуты)
Сочинение-рассуждение «Зачем говорить правильно, когда тебя итак все понимают? «
Использованная литература:
1. Ващенко Е.Д. Русский язык и культура речи. Серия «Учебники, учебные пособия». — Ростов н/Дону: «Феникс», 2002.
2. Введенская Л.А., Черкасова М.Н. Русский язык и культура речи: Учебное пособие. — Ростов н/Дону: «Феникс», 2007.
3. Космаровская И.В., Руденко А. К. Русский
язык. Тесты и задания по культуре речи – М.: «АКВАРИУМ ЛТД», 2001.
К. Русский
язык. Тесты и задания по культуре речи – М.: «АКВАРИУМ ЛТД», 2001.
4. Кузнецова Н.В. Русский язык и культура речи: Учебник. – М.: ФОРУМ: ИНФРА-М, 2006.
5. Ожегов С.И., Шведова Н.Ю. Толковый словарь русского языка. – М., 1996.
6. Розенталь Д.Э. Практическая стилистика русского языка. – М., 2003.
7. Розенталь Д.Э., Голуб И.Б. Секреты стилистики. Правила хорошей речи.- М.: «Айрис пресс», 2006.
Стилистические ошибки и коммуникативные сбои в текстах СМИ
Определение 1
Коммуникативная норма – это общепринятые стандарты общения.
Стилистические ошибки в текстах СМИ
Ошибки в текстах СМИ бывают:
- Техническими;
- Смысловыми;
- Речевыми.
В свою очередь, речевые ошибки делятся на языковые, стилистические и коммуникативные.
Стилистическими ошибками называют нарушение законов употребления в речи лексических единиц, неправильное употребление слова, недочеты в образовании синтаксических конструкций. Наиболее частой стилистической ошибкой является неразличение паронимов, например «роспись – подпись», «длинный – длительный».
Наиболее частой стилистической ошибкой является неразличение паронимов, например «роспись – подпись», «длинный – длительный».
Еще одна распространенная стилистическая ошибка – тавтология. Под тавтологией понимается повторение в иной форме ранее сказанного. Такая ошибка легко обнаруживается при чтении вслух.
К чрезмерно часто используемым словам относятся «можно», «чтобы», «который».
Для появления в одном абзаце одного и того же слова дважды должны быть особо веские причины. В остальных же случаях это недопустимо (например, вместо словосочетания «наряду с ними имеется ряд других» правильно будет написать «имеются другие»).
Еще одной распространенной стилистической ошибкой является плеоназм.
Определение 2
Плеоназм – это употребление слов, излишних для выражения мысли (например, молодой юноша, май месяц, пожилой старик).
Стилистические ошибки связаны с игнорированием ограничений, которые накладывает стилистическая окраска на употребление слова. Прежде всего это касается употребления канцеляризмов и терминов. Каждый из них связан с определенным типом коммуникативных отношений адресата и субъекта.
Прежде всего это касается употребления канцеляризмов и терминов. Каждый из них связан с определенным типом коммуникативных отношений адресата и субъекта.
Использование узкоспециализированных терминов в тексте создает коммуникативный барьер между адресатом и субъектом. Замена таких терминов на общепонятные слова расширяет круг адресатов. Пояснения, сопровождающие термины, приобщают к специальным знаниям любителей-непрофессионалов.
Употребление в тексте канцеляризмов предполагает, что между субъектом и адресатом существуют официальные отношения, когда каждый выступает не как конкретная личность, а как отвлеченная единица (Заказчик, Клиент, Сторона, Исполнитель, Пассажир и т.д.). Канцеляризмы необходимы в официальных текстах, здесь они придают дополнительную значимость сказанному. Однако их употребление в неофициальной ситуации неуместно.
Использование разговорной лексики предполагает ситуацию неофициальной коммуникации, поэтому ее употребление недопустимо в текстах официального характера и информационных тексах. Но разговорная лексика используется в очерках, публицистических статьях, репортажах, дискуссионных высказываниях, научно-популярной литературе для создания атмосферы доверительности, неофициальности.
Но разговорная лексика используется в очерках, публицистических статьях, репортажах, дискуссионных высказываниях, научно-популярной литературе для создания атмосферы доверительности, неофициальности.
Употребление разговорной лексики в неразговорной ситуации требует самоконтроля, осторожности, так как чрезмерное увлечение ими способно привести к тому, что неофициальность перерастет в фамильярность.
Подход к употреблению нелитературной лексики должен быть еще строже. Жаргонная, диалектная, просторечная лексика используется при описании среды, в которой используется этот тип лексики, однако требует «перевода» и пояснений.
Экспрессивная лексика позволяет лаконично выразить отношение говорящего к высказываемому. Экспрессивность присуща части разговорных и книжных слов. Однако в официально-деловых и информативных текстах такая лексика неуместна.
Коммуникативные сбои в текстах СМИ
Стандарты общения могут быть довольно жесткими, либо, наоборот, обладать широким диапазоном варьирования. Но во всех ситуациях общения они выступают в роли регуляторов процесса коммуникации. Важная составляющая коммуникативных норм – это их ориентация на ценности, которые существуют в данной культуре, в том числе нравственные императивы и этические нормы. В данном случае речь идет о культурных рамках общения. Выход за их границы характеризуется уже как ненормативный коммуникативный акт и представляет собой явление дисфункции.
Но во всех ситуациях общения они выступают в роли регуляторов процесса коммуникации. Важная составляющая коммуникативных норм – это их ориентация на ценности, которые существуют в данной культуре, в том числе нравственные императивы и этические нормы. В данном случае речь идет о культурных рамках общения. Выход за их границы характеризуется уже как ненормативный коммуникативный акт и представляет собой явление дисфункции.
Культурные рамки охватывают все коммуникативное пространство. Создается оно в первую очередь наличием культурем.
Определение 3
Культуремы – это текстовые или поведенческие знаки принадлежности к данной культуре.
Важнейшей культуремой является язык. Коммуникативные нормы в целом являются сплавом коммуникативных стандартов, этикетных правил и прагматических регуляторов. Нарушение коммуникативных норм проявляется следующим образом:
- Прерывание собеседника;
- Вмешательство в разговор других людей;
- Применение физической силы в конфликтных ситуациях;
- Ложь ради выгоды;
- Подчеркнутая книжность разговорной речи;
- Этическая избыточность общения;
- Фамильярность делового дискурса;
- Использование жаргона, нецензурной лексики и других элементов контркультуры;
- Насыщенность речи просторечиями и т.
 д.
д.
 д.
д.Все эти факторы размывают коммуникативные нормы. Привести к коммуникативным ошибкам может и способ введения культурем в текст, другими словами, — неумением пользоваться знаками культуры при их внедрении в текст.
В практике СМИ сложилась типология коммуникативных ошибок. Очевидными являются три типа коммуникативных сбоев:
- Ошибки представления факта;
- Ошибки, которые возникли в результате некорректного представления в тексте реального лица;
- неверное использование культурем.
Наиболее часто коммуникативные сбои при использовании цитат в текстах СМИ возникают в результате несовпадения фоновых знаний адресата.
Избежать коммуникативной неудачи можно путем расширения состава интертекстуального фрагмента. В некоторых случаях адресат воспринимает фрагмент текста как содержащий «чужое слово», но точно определить границы интертекстемы не способен.
Часто стремление к созданию ярких, экспрессивных текстов приводит к обратному эффекту – стиранию экспрессии. Такой эффект возникает при использовании клишированных средств.
Такой эффект возникает при использовании клишированных средств.
Ключ к упражнению по стилю в научном письме
Это упражнение требует, чтобы вы определили основную стилистическую проблему в каждом отрывке. В таблице 1 приведен список типичных стилистических ошибок, которые могут содержаться в отрывке. В скобках указаны номера страниц в The Craft of Scientific Writing , поясняющие каждую проблему. Таблица 1. Список типичных стилистических ошибок
| Непараллельные заголовки (37-40) Слабый переход в секцию (53) Неоднозначность из-за отсутствия знаков препинания (94-96) Неоднозначность от местоимения (93-94) Неоднозначность из-за порядка слов (92-93) Отсутствие разнообразия предложений (129-137) Проблема с тоном (97-101) | Излишне сложные слова (84-85) Излишне сложная именная группа (85-86) Излишне сложное предложение (86-90) Повторный приговор (259-260) Ошибка времени глагола (261) Несогласие между подлежащим и глаголом (260) Ошибка использования (268-272) |
|---|
1: Неоднозначность из-за отсутствия знаков препинания (см. стр. 96)
стр. 96)
Возможная редакция: Выбросы этих опасных веществ происходят в следующих случаях: (1) разливы при загрузке транспортных средств, (2) разливы и переливы при заполнении цистерн, (3) утечки из подающих труб и (4) стыки труб , дыры ржавчины и трещины в швах самих баков.
2: Отсутствие разнообразия предложений (см. стр. 129)
Схема схемы показана в Приложении А. На первой схеме Приложения показан интерфейс EEPROM с HC11. Для этой схемы также были необходимы декодер и битовая защелка. Декодер удостоверился, что EEPROM отвечает на адресные ячейки от $6000 до $7FFF. Защелка хранила адресные строки для EEPROM, когда порт C на EVBU переключался с выходных адресных строк на входные линии данных. Эти интегрированные чипы работали вместе, чтобы дать HC11 расширенную память. (Все предложения начинаются с подлежащего, за которым следует глагол.)
3: Излишне сложная именная группа (см. стр. 85-86)
Возможная редакция (обратите внимание, что вам нужно будет прочитать отчет, чтобы придумать эту редакцию): Значения демпфирования, необходимые для ограничения колебаний системы остановки товарного вагона
4: Слабый переход в секцию (см. стр. 56)
стр. 56)
Возможная версия:
Автономная работа. Работа микропроцессора HC11 в автономном режиме включала как аппаратное, так и программное обеспечение.
5: Излишне сложные слова (см. стр. 84-85)
Возможная редакция: В этом исследовании будет рассмотрено, почему современная солнечная энергия системы, такие как Solar One, не достигли коммерческую стадию и узнаем, какие шаги мы можем сделать эти системы коммерческими.
6: Проблема со звуком (см. стр. 100-101)
Проблемы с тональностью, выделенные жирным шрифтом: Мне стало известно, что ваши внедорожники не настолько технологически продвинуты, как могли бы быть! Микропроцессоры — это больше, чем просто быстро развивающееся технологическое модное слово ; они могут быть легко внедрены в существующие транспортные средства и добавят бесчисленных размеров их возможностей. .. Это , конечно, крошечные примеры в более грандиозной схеме вещей, которые могут быть выполнены с помощью микропроцессоров. Есть гораздо более полезные и инновационные вещи, которые можно было бы сделать для улучшения как механических, так и эргономических аспектов, что позволит вам опередить ближайших конкурентов на световых лет, при этом набивая карманы… Я с энтузиазмом жду встречи. с тобой!
.. Это , конечно, крошечные примеры в более грандиозной схеме вещей, которые могут быть выполнены с помощью микропроцессоров. Есть гораздо более полезные и инновационные вещи, которые можно было бы сделать для улучшения как механических, так и эргономических аспектов, что позволит вам опередить ближайших конкурентов на световых лет, при этом набивая карманы… Я с энтузиазмом жду встречи. с тобой!
7: Излишне сложное предложение (см. стр. 86-87)
Возможная редакция: Огромные горнодобывающие компании продолжают работу на старых золотых приисках и предлагают открытие новых золотых приисков. Примером шахты, продолжающей свою деятельность, является шахта Хоумстейк в Лиде, Южная Дакота. Этот рудник непрерывно работает с 1877 г. и расширяет свою деятельность [Hinds and Trautman, 1983]. Примером предлагаемого нового золотого рудника является рудник Нового Света, предполагаемое местонахождение которого находится примерно в 2,5 милях от границы Йеллоустонского национального парка, недалеко от Кук-Сити, штат Монтана. Как и другие предполагаемые золотые рудники, рудник Нового Света был отложен, потому что он находится в экологически чувствительном регионе.
Как и другие предполагаемые золотые рудники, рудник Нового Света был отложен, потому что он находится в экологически чувствительном регионе.
8: Неоднозначность из-за порядка слов (см. стр. 92-93)
Возможная редакция: У большинства людей фенилкетонурия диагностируется при рождении.
9: Неоднозначность местоимения (см. стр. 93)
Возможная редакция: С момента изобретения каталитического нейтрализатора одной из проблем, которая ставит в тупик людей, занимающихся контролем выбросов, является недостаточная эффективность нейтрализатора в окислении CO и HC, пока двигатель не прогреется.
10: Отсутствие разнообразия предложений (см. стр. 129)
Процедуры проектирования. Процедуры для этой части лаборатории начались с команды ASM. Эта команда использовалась для дизассемблирования кода. Эта дизассемблирование началось с указанного адреса памяти. Эта команда была полезна при изучении кода, предопределенного дизассемблером Buffalo. Команда «ASM» использовалась в начале адреса $E000. В нем перечислены первые три инструкции по адресу $E000. В таблице 1 показаны как машинный, так и дизассемблированный код этих инструкций. (Все предложения начинаются с подлежащего, за которым следует глагол.)
Команда «ASM» использовалась в начале адреса $E000. В нем перечислены первые три инструкции по адресу $E000. В таблице 1 показаны как машинный, так и дизассемблированный код этих инструкций. (Все предложения начинаются с подлежащего, за которым следует глагол.)
11: Неоднозначность из-за отсутствия знаков препинания (см. стр. 96)
Возможная редакция: Для обеспечения защиты от разливов все резервуары должны были иметь водосборные бассейны и одно из следующих устройств: автоматические запорные устройства, сигнализаторы переполнения или шаровые поплавковые клапаны.
12: Непараллельные направления (см. стр. 39))
Возможная редакция:
Введение
История компьютерных вирусов
Способы борьбы с компьютерными вирусами
Выводы
 стр. 100-101)
стр. 100-101) Проблемы со звуком, выделенные жирным шрифтом: Каждый раз, когда мы подключали шестнадцатеричный дисплей, мы помещали его в другое место на макетной плате. К сожалению, каждый раз шестнадцатеричный дисплей показывал разные показания. В третий раз оказался прелестью , так как шестнадцатеричный дисплей правильно читал все числа.
14: Слабый переход в секцию (см. стр. 56)
Возможная версия:
Взаимодействие с клавиатурой Matrix. Этот раздел лабораторного задания требовал добавления матричной клавиатуры 4×4 и шестнадцатеричного дисплея TIL-311 к оборудованию, подключенному в предыдущем разделе.
15: Излишне сложная именная группа (см. стр. 85-86)
Это название трудно изменить, просто имея название. Вам придется изучить отчет и рассмотреть аудиторию.
Вычитка ошибок // Лаборатория письма Purdue
Резюме:
Вычитка в первую очередь заключается в поиске вашего письма на наличие ошибок, как грамматических, так и типографских, перед отправкой вашей статьи аудитории (учителю, издателю и т. д.). . Используйте этот ресурс, чтобы найти и исправить распространенные ошибки.
д.). . Используйте этот ресурс, чтобы найти и исправить распространенные ошибки.
Вот некоторые распространенные проблемы с корректурой, с которыми сталкиваются многие писатели. В случае грамматических или орфографических ошибок попробуйте подчеркнуть или выделить слова, которые часто сбивают вас с толку. На уровне предложений обратите внимание на то, какие ошибки вы часто делаете. Также обратите внимание на распространенные ошибки в предложениях, такие как повторение предложений, слияние запятых или фрагменты предложений — это поможет вам более эффективно вычитывать в будущем.
Орфография- Не полагайтесь исключительно на проверку орфографии вашего компьютера — она не все проверит!
- Аккуратно проведите карандашом под каждой строкой текста, чтобы увидеть слова по отдельности.
- Будьте особенно осторожны со словами, которые содержат сложные сочетания букв, например «ei/ie».
- Будьте особенно осторожны с омонимами, такими как ваш/ты, к/тоже/два и там/их/они, так как проверка орфографии не распознает их как ошибки.

Медленно прочитайте газету вслух, чтобы убедиться, что вы не пропустили и не повторили ни одного слова. Кроме того, попробуйте читать свою статью по одному предложению в обратном порядке — это позволит вам сосредоточиться на отдельных предложениях.
Фрагменты предложенияФрагменты предложения — это части предложения, которые грамматически не являются целыми предложениями. Например, «Съел бутерброд» — это фрагмент предложения, потому что в нем отсутствует подлежащее.
Убедитесь, что в каждом предложении есть подлежащее:
- «Посмотрел сайт OWL». Фрагмент предложения без подлежащего.
- « учащихся просмотрели веб-сайт OWL». Добавление подлежащего «студенты» делает предложение законченным.
Убедитесь, что в каждом предложении есть полный глагол.
- «Они пытаются улучшить свои навыки письма». — неполное предложение, потому что «пытаться» — неполный глагол.
- «Они были пытающимися улучшить свои навыки письма». В этом предложении «were» необходимо, чтобы сделать «trying» законченным глаголом.

Обратите внимание, что каждое предложение имеет независимое предложение. Помните, что зависимое предложение не может стоять само по себе. В следующих примерах зеленое выделение указывает на зависимые предложения, а желтое — на независимые.
- «Поэтому учащиеся внимательно читают все раздаточные материалы». Это зависимое предложение, которое нуждается в независимом предложении. На данный момент это фрагмент предложения.
- «Студенты знали, что их будут тестировать по раздаточным материалам, поэтому они внимательно прочитали все раздаточные материалы». Первая часть предложения «Студенты знали, что их будут тестировать» является независимым предложением. Соединение его с зависимым предложением делает этот пример полным предложением.
- Просмотрите каждое предложение, чтобы увидеть, содержит ли оно более одного независимого предложения.
- Если существует более одного независимого предложения, убедитесь, что предложения разделены соответствующими пунктуационными знаками.
- Иногда столь же эффективно (или даже более эффективно) просто разбить предложение на два отдельных предложения вместо того, чтобы ставить знаки препинания для разделения предложений.

Примеры:
- Продолжайте: «Мне нужно написать исследовательскую работу для своего класса об экстремальных видах спорта, все, что я знаю об этом предмете, это то, что он меня интересует». Это два независимых предложения без каких-либо знаков препинания или союзов, разделяющих их.
- Отредактированная версия: «Мне нужно написать исследовательскую работу для своего класса об экстремальных видах спорта, и все, что я знаю об этом предмете, это то, что он мне интересен». Две выделенные части являются независимыми предложениями. Они соединяются соответствующим союзом «и» и запятой.
- Другая отредактированная версия: «Мне нужно написать исследовательскую работу для своего класса об экстремальных видах спорта. Все, что я знаю об этом предмете, это то, что он меня интересует». В этом случае эти два независимых предложения разделяются на отдельные предложения, разделенные точкой и заглавными буквами.
 Все, что я знаю об этом предмете, это то, что он меня интересует». В этом случае эти два независимых предложения разделяются на отдельные предложения, разделенные точкой и заглавными буквами.
Все, что я знаю об этом предмете, это то, что он меня интересует». В этом случае эти два независимых предложения разделяются на отдельные предложения, разделенные точкой и заглавными буквами.- Посмотрите внимательно на предложения, в которых есть запятые.
- Проверьте, содержит ли предложение два независимых предложения. Независимые придаточные предложения – это законченные предложения.
- Если есть два самостоятельных предложения, они должны быть соединены запятой и союзом (и, но, для, или, так, еще, ни). Запятые не нужны для некоторых подчинительных союзов (потому что, для, поскольку, пока и т. д.), потому что эти союзы используются для соединения зависимых и независимых предложений.
- Другой вариант — убрать запятую и вместо нее поставить точку с запятой.
Примеры:
- Запятая: «Я хотел бы написать свою статью о баскетболе, это тема, о которой я могу говорить долго». Выделенные части являются независимыми предложениями. Одной запятой недостаточно, чтобы соединить их.
- Отредактированная версия: «Я хотел бы написать свою статью о баскетболе , потому что это тема, о которой я могу говорить долго». Здесь часть, выделенная желтым цветом, является независимым предложением, а часть, выделенная зеленым цветом, является зависимым предложением. Подчинительный союз «потому что» соединяет эти два предложения.
- Отредактированный вариант, с точкой с запятой: «Я хотел бы написать статью о баскетболе; это тема, о которой я могу говорить долго». Здесь точка с запятой соединяет два одинаковых независимых предложения.
 Выделенные части являются независимыми предложениями. Одной запятой недостаточно, чтобы соединить их.
Выделенные части являются независимыми предложениями. Одной запятой недостаточно, чтобы соединить их.- Найдите подлежащее в каждом предложении.
- Найдите глагол, соответствующий подлежащему.
- Число подлежащего и глагола должно совпадать, т. е. если подлежащее стоит во множественном числе, то и глагол должен совпадать.
- Проще всего это сделать, подчеркнув все темы. Затем обведите или выделите глаголы по одному и посмотрите, совпадают ли они.

Примеры:
- Неверное согласие глагола подлежащего: « Студенты на университетском уровне обычно очень заняты». Здесь подлежащее «студенты» стоит во множественном числе, а глагол «есть» в единственном числе, поэтому они не совпадают.
- Отредактированная версия: « Студенты на университетском уровне обычно очень заняты». «Are» — это глагол во множественном числе, который соответствует существительному во множественном числе «студенты».
Внимательно прочитайте свои предложения, чтобы убедиться, что они не начинаются с одной структуры предложения и не переходят к другой. Предложение, которое делает это, называется смешанной конструкцией.
Примеры:
- «Поскольку у меня много работы, я не могу выйти сегодня вечером». Обе части предложения, выделенные зеленым цветом, являются зависимыми предложениями. Два зависимых предложения не образуют законченного предложения.
- Отредактированная версия: «Поскольку у меня много работы, я не могу выйти сегодня вечером». Часть, выделенная зеленым цветом, является зависимым предложением, а желтым — независимым предложением. Таким образом, этот пример является полным предложением.
 Обе части предложения, выделенные зеленым цветом, являются зависимыми предложениями. Два зависимых предложения не образуют законченного предложения.
Обе части предложения, выделенные зеленым цветом, являются зависимыми предложениями. Два зависимых предложения не образуют законченного предложения.Просмотрите свою газету на наличие серий пунктов, обычно разделенных запятыми. Кроме того, убедитесь, что эти элементы находятся в параллельной форме, то есть все они используют одинаковую форму.
- Пример: «Быть хорошим другом означает слушать , быть внимательным и уметь веселиться». В этом примере «слушание» стоит в настоящем времени, «быть» — в форме инфинитива, а «что вы умеете развлекаться» — это фрагмент предложения. Эти предметы в серии не совпадают.

- Отредактированная версия: «Быть хорошим другом означает слушать , быть внимательным и получать удовольствие». В этом примере «слушание», «бытие» и «обладание» стоят в настоящем продолженном времени (окончания -ing). Они в параллельной форме.
- Просмотрите свою статью в поисках местоимений.
- Найдите существительное, которое заменяет местоимение.
- Если вы не можете найти ни одного существительного, вставьте его заранее или замените местоимение на существительное.
- Если вы можете найти существительное, убедитесь, что оно совпадает по числу и лицу с вашим местоимением.
Примеры:
- “ Сэм съел на завтрак три вафли. Он снова не был голоден до обеда. Здесь ясно, что Сэм — это «он», о котором идет речь во втором предложении. Таким образом, местоимение третьего лица единственного числа «он» совпадает с Сэмом.
- “ Тереза и Ариэль выгуливали собаку. Собака укусила ее ». В данном случае неясно, кого укусила собака, потому что местоимение «ее» может относиться либо к Терезе, либо к Ариэлю.
- “ Тереза и Ариэль выгуливали собаку. Позже он укусил их ». Здесь местоимение третьего лица множественного числа «их» соответствует существительным, которые ему предшествуют. Понятно, что собака укусила обоих людей.
- «Тереза и Ариэль выгуливали собаку. Тереза отцепила поводок, и собака укусила ее ». В этих предложениях предполагается, что Тереза — это «она» во втором предложении, потому что ее имя непосредственно предшествует местоимению единственного числа «она».
 Таким образом, местоимение третьего лица единственного числа «он» совпадает с Сэмом.
Таким образом, местоимение третьего лица единственного числа «он» совпадает с Сэмом.- Пролистайте свою статью, останавливаясь только на тех словах, которые заканчиваются на «s». Если «s» используется для обозначения владения, должен быть апостроф, как в «книге Марии».
- Просмотрите сокращения, такие как «вы» вместо «вы», «это» вместо «это» и т. д. Каждое из них должно включать апостроф.
- Помните, что апострофы не используются для образования множественного числа слов. При образовании слова во множественном числе добавляется только «s», а не апостроф и «s».
 Если «s» используется для обозначения владения, должен быть апостроф, как в «книге Марии».
Если «s» используется для обозначения владения, должен быть апостроф, как в «книге Марии».Примеры:
- « Хороший день для прогулки». Это предложение правильно, потому что «это» можно заменить на «это».
- «На том дереве гнездится птица. Видишь, — это яиц?» В данном случае «его» — это местоимение, описывающее существительное «птица». Поскольку это местоимение, апостроф не нужен.
- «Занятия сегодня отменяются» — это правильное предложение, тогда как «Занятия сегодня отменяются» неверно, потому что форма множественного числа класса просто добавляет «-es» в конец слова.
- « Маркеры Сандры не работают». Здесь Sandra нужен апостроф, потому что существительное является притяжательным. Апостроф сообщает читателю, что маркеры принадлежат Сандре.
 Здесь Sandra нужен апостроф, потому что существительное является притяжательным. Апостроф сообщает читателю, что маркеры принадлежат Сандре.
Здесь Sandra нужен апостроф, потому что существительное является притяжательным. Апостроф сообщает читателю, что маркеры принадлежат Сандре.Инструменты и рекомендации — Real Python
В этой статье мы определим высококачественный код Python и покажем вам, как улучшить качество вашего собственного кода.
Мы проанализируем и сравним инструменты, которые вы можете использовать, чтобы вывести свой код на новый уровень. Независимо от того, используете ли вы Python некоторое время или только начинаете, вы можете извлечь пользу из описанных здесь методов и инструментов.
Что такое качество кода?
Конечно, вам нужен качественный код, а кому бы не хотелось? Но чтобы улучшить качество кода, мы должны определить, что это такое.
Быстрый поиск в Google дает много результатов, определяющих качество кода. Как оказалось, этот термин может означать для людей много разных вещей.
Один из способов определить качество кода — посмотреть на один конец спектра: высококачественный код. Надеюсь, вы согласитесь со следующими высококачественными идентификаторами кода:
Надеюсь, вы согласитесь со следующими высококачественными идентификаторами кода:
- Он делает то, что должен делать.
- Не содержит дефектов или проблем.
- Легко читать, поддерживать и расширять.
Эти три идентификатора, хотя и являются упрощенными, кажутся общепризнанными. Чтобы еще больше расширить эти идеи, давайте углубимся в то, почему каждая из них важна в сфере программного обеспечения.
Удалить рекламу
Почему качество кода имеет значение?
Чтобы понять, почему важен качественный код, давайте еще раз рассмотрим эти идентификаторы. Посмотрим, что произойдет, если код им не соответствует.
, а не делает то, что должен делать Соблюдение требований является основой любого продукта, программного обеспечения или чего-либо еще. Мы делаем программное обеспечение, чтобы что-то делать. Если в итоге не получится… ну это точно не качественно. Если он не соответствует базовым требованиям, его даже трудно назвать некачественным.
Если он не соответствует базовым требованиям, его даже трудно назвать некачественным.
Это
содержит ли дефекты и проблемыЕсли что-то, что вы используете, вызывает проблемы или вызывает у вас проблемы, вы, вероятно, не назовете это высококачественным. На самом деле, если это достаточно плохо, вы можете вообще прекратить его использовать.
Чтобы не использовать программное обеспечение в качестве примера, предположим, что ваш пылесос отлично работает на обычном ковре. Убирает всю пыль и кошачью шерсть. В одну роковую ночь кошка опрокидывает растение, рассыпая повсюду грязь. Когда вы пытаетесь использовать пылесос, чтобы убрать кучу грязи, он ломается, извергая грязь повсюду.
Несмотря на то, что пылесос работал при определенных обстоятельствах, он неэффективно справлялся со случайной дополнительной нагрузкой. Так что качественным пылесосом его не назовешь.
Это проблема, которую мы хотим избежать в нашем коде. Если что-то ломается в крайних случаях, а дефекты вызывают нежелательное поведение, у нас нет качественного продукта.
Представьте себе: клиент запрашивает новую функцию. Человек, написавший исходный код, ушел. Человек, который заменил их, теперь должен разобраться в уже существующем коде. Этот человек — вы.
Если код легко понять, вы сможете проанализировать проблему и найти решение гораздо быстрее. Если код сложный и запутанный, вы, вероятно, потратите больше времени и, возможно, сделаете несколько неверных предположений.
Также хорошо, если можно легко добавить новую функцию, не нарушая работу предыдущих функций. Если код , а не , который легко расширить, ваша новая функция может сломать другие вещи.
Никто не хочет, чтобы находились в положении, когда им приходится читать, поддерживать или расширять некачественный код. Это означает больше головной боли и больше работы для всех.
Достаточно того, что вам приходится иметь дело с некачественным кодом, но не ставьте других в такую же ситуацию. Вы можете улучшить качество кода, который вы пишете.
Вы можете улучшить качество кода, который вы пишете.
Если вы работаете с командой разработчиков, вы можете начать внедрять методы для повышения общего качества кода. При условии, что у вас есть их поддержка, конечно. Возможно, вам придется завоевать расположение некоторых людей (не стесняйтесь, присылайте им эту статью 😃).
Как улучшить качество кода Python
На пути к созданию высококачественного кода необходимо учитывать несколько моментов. Во-первых, это путешествие не является путешествием чистой объективности. Есть некоторые сильные представления о том, как выглядит высококачественный код.
Хотя мы надеемся, что все могут согласиться с упомянутыми выше идентификаторами, способ их достижения является субъективным. Наиболее упрямые темы обычно возникают, когда вы говорите о достижении удобочитаемости, сопровождения и расширяемости.
Так что имейте в виду, что, хотя в этой статье мы попытаемся сохранить объективность, в мире существует очень свое мнение, когда дело доходит до кода.
Итак, начнем с самой спорной темы: стиля кода.
Удалить рекламу
Руководства по стилю
Ах, да. Извечный вопрос: пробелы или табы?
Независимо от вашего личного взгляда на то, как представлять пробелы, можно с уверенностью предположить, что вы, по крайней мере, хотите согласованности кода.
Руководство по стилю служит для определения согласованного способа написания кода. Как правило, все это носит косметический характер, то есть не меняет логический результат кода. Хотя некоторые стилистические решения позволяют избежать типичных логических ошибок.
Руководства по стилюпомогают облегчить чтение, поддержку и расширение кода.
Что касается Python, то существует хорошо принятый стандарт. Его частично написал автор самого языка программирования Python.
PEP 8 предоставляет соглашения о кодировании для кода Python. Код Python довольно часто следует этому руководству по стилю. Это отличное место для начала, поскольку оно уже четко определено.
Это отличное место для начала, поскольку оно уже четко определено.
Родственное предложение по улучшению Python, PEP 257, описывает соглашения для строк документации Python, которые представляют собой строки, предназначенные для документирования модулей, классов, функций и методов. В качестве дополнительного бонуса, если строки документации непротиворечивы, существуют инструменты, способные генерировать документацию непосредственно из кода.
Все эти руководства определяют способ оформления кода. Но как вы обеспечиваете его соблюдение? А дефекты и проблемы в коде, как их обнаружить? Вот где на помощь приходят линтеры.
Линтеры
Что такое линтер?
Сначала поговорим о ворсе. Эти крошечные, раздражающие маленькие дефекты, которые каким-то образом появляются на всей одежде. Одежда выглядит и чувствует себя намного лучше без всего этого ворса. Ваш код ничем не отличается. Мелкие ошибки, стилистические несоответствия и опасная логика не сделают ваш код лучше.
Но все мы ошибаемся. Вы не можете ожидать, что всегда будете их вовремя ловить. Ошибки в именах переменных, забывание закрывающей скобки, неправильное использование табуляции в Python, вызов функции с неправильным количеством аргументов — список можно продолжать и продолжать. Линтеры помогают выявить эти проблемные области.
Кроме того, большинство редакторов и IDE имеют возможность запускать линтеры в фоновом режиме по мере ввода. Это приводит к среде, способной выделять, подчеркивать или иным образом идентифицировать проблемные области в коде перед его запуском. Это похоже на расширенную проверку орфографии для кода. Он подчеркивает проблемы волнистыми красными линиями, как это делает ваш любимый текстовый процессор.
Линтеры анализируют код для обнаружения различных категорий линтов. Эти категории можно в общих чертах определить следующим образом:
- Logical Lint
- Ошибки кода
- Код с потенциально непредвиденными результатами
- Опасные шаблоны кода
- Stylistic Lint
- Код, не соответствующий определенным соглашениям
Существуют также инструменты анализа кода, которые позволяют получить другие сведения о вашем коде. Хотя, возможно, это и не линтеры по определению, эти инструменты обычно используются бок о бок с линтерами. Они тоже надеются улучшить качество кода.
Хотя, возможно, это и не линтеры по определению, эти инструменты обычно используются бок о бок с линтерами. Они тоже надеются улучшить качество кода.
Наконец, существуют инструменты, которые автоматически форматируют код в соответствии с определенной спецификацией. Эти автоматизированные инструменты гарантируют, что наши низшие человеческие умы не нарушат условности.
Каковы параметры моего линтера для Python?
Прежде чем углубляться в ваши варианты, важно признать, что некоторые «линтеры» — это просто несколько линтеров, красиво упакованных вместе. Ниже приведены некоторые популярные примеры таких комбо-линтеров:
.Flake8 : Способен обнаруживать как логические, так и стилистические ворсинки. Он добавляет проверки стиля и сложности pycodestyle к логическому обнаружению ворсинок PyFlakes. Он объединяет следующие линтеры:
- PyFlakes
- pycodestyle (ранее pep8)
- Маккейб
Pylama : Инструмент аудита кода, состоящий из большого количества линтеров и других инструментов для анализа кода. Он сочетает в себе следующее:
Он сочетает в себе следующее:
- pycodestyle (ранее pep8)
- pydocstyle (ранее pep257)
- PyFlakes
- Маккейб
- Пилинт
- Радон
- gjslint
Вот несколько автономных линтеров, распределенных по категориям с краткими описаниями:
| Линтер | Категория | Описание |
|---|---|---|
| Пилинт | Логика и стилистика | Проверяет наличие ошибок, пытается обеспечить соблюдение стандарта кодирования, ищет запахи кода |
| PyFlakes | Логический | Анализирует программы и обнаруживает различные ошибки |
| пикокодстиль | Стилистический | Проверяет соответствие некоторым соглашениям о стилях в PEP 8 |
| пидокстайл | Стилистический | Проверяет соответствие со строками документации Python |
| Бандит | Логический | Анализирует код для поиска общих проблем безопасности |
| MyPy | Логический | Проверяет необязательные статические типы |
А вот некоторые инструменты для анализа кода и форматирования:
| Инструмент | Категория | Описание |
|---|---|---|
| Маккейб | Аналитический | Проверяет сложность Маккейба |
| Радон | Аналитический | Анализирует код по различным показателям (строки кода, сложность и т. д.) д.) |
| Черный | Форматер | Форматирует код Python без компромиссов |
| Изорт | Форматер | Импорт форматов путем сортировки по алфавиту и разделения на разделы |
Сравнение линтеров Python
Давайте лучше разберемся, что разные линтеры способны отлавливать и как выглядит результат. Для этого я прогнал один и тот же код через несколько разных линтеров с настройками по умолчанию.
Код, который я прогнал через линтеры, приведен ниже. Он содержит различные логические и стилистические вопросы:
1""" 2code_with_lint.py 3Пример кода с большим количеством мусора! 4""" 5импорт io 6из математического импорта * 7 8 9из времени импортировать время 10 11some_global_var = 'ГЛОБАЛЬНЫЕ ПЕРЕМЕННЫЕ НАЗВАНИЯ ДОЛЖНЫ БЫТЬ В ALL_CAPS_WITH_UNDERSCOES' 12 13def умножить (х, у): 14 """ 15 Это возвращает результат умножения входных данных 16 """ 17 some_global_var = 'на самом деле это локальная переменная.
 ..'
18 результат = х * у
19 вернуть результат
20, если результат == 777:
21 print("джекпот!")
22
23def is_sum_lucky(x, y):
24 """Это возвращает строку, описывающую, удачна ли сумма ввода.
25 Эта функция сначала проверяет правильность введенных данных, а затем вычисляет
26 сум. Затем он определит сообщение для возврата в зависимости от того,
27 эту сумму следует считать "счастливой"
28 """
29если х != Нет:
30, если y не None:
31 результат = х+у;
32, если результат == 7:
33 вернуть "счастливое число!"
34 еще:
35 return('несчастливое число!')
36
37 return («просто обычный номер»)
38
39класс
40
41 def __init__(self, some_arg, some_other_arg, verbose = False):
42 self.some_other_arg = some_other_arg
43 self.some_arg = some_arg
44 list_comprehension = [((100/значение)*pi) для значения в some_arg, если значение != 0]
45 время = время()
46 из даты и времени импортировать дату и время
47 date_and_time = datetime.now()
48 возвращение
..'
18 результат = х * у
19 вернуть результат
20, если результат == 777:
21 print("джекпот!")
22
23def is_sum_lucky(x, y):
24 """Это возвращает строку, описывающую, удачна ли сумма ввода.
25 Эта функция сначала проверяет правильность введенных данных, а затем вычисляет
26 сум. Затем он определит сообщение для возврата в зависимости от того,
27 эту сумму следует считать "счастливой"
28 """
29если х != Нет:
30, если y не None:
31 результат = х+у;
32, если результат == 7:
33 вернуть "счастливое число!"
34 еще:
35 return('несчастливое число!')
36
37 return («просто обычный номер»)
38
39класс
40
41 def __init__(self, some_arg, some_other_arg, verbose = False):
42 self.some_other_arg = some_other_arg
43 self.some_arg = some_arg
44 list_comprehension = [((100/значение)*pi) для значения в some_arg, если значение != 0]
45 время = время()
46 из даты и времени импортировать дату и время
47 date_and_time = datetime.now()
48 возвращение
В приведенном ниже сравнении показаны линтеры, которые я использовал, и время их выполнения для анализа вышеуказанного файла. Я должен отметить, что они не полностью сопоставимы, поскольку они служат разным целям. PyFlakes, например, не идентифицирует стилистические ошибки, как это делает Pylint.
Я должен отметить, что они не полностью сопоставимы, поскольку они служат разным целям. PyFlakes, например, не идентифицирует стилистические ошибки, как это делает Pylint.
| Линтер | Команда | Время |
|---|---|---|
| Пилинт | пилинт code_with_lint.py | 1,16 с |
| Пифлейкс | pyflakes code_with_lint.py | 0,15 с |
| пикокодстиль | pycodestyle code_with_lint.py | 0,14 с |
| пидокстайл | pydocstyle code_with_lint.py | 0,21 с |
Выходы каждого из них см. в следующих разделах.
Пилинт
Pylint — один из старейших линтеров (около 2006 г.), который до сих пор поддерживается в хорошем состоянии. Некоторые могут назвать это программное обеспечение закаленным в боях. Он существует уже достаточно давно, чтобы участники исправили большинство серьезных ошибок, а основные функции хорошо проработаны. (плохой пробел)
С: 29(плохой пробел)
C: 40, 0: отсутствует последняя новая строка (missing-final-newline)
W: 6, 0: переопределение встроенного ‘pow’ (redefined-builtin)
W: 6, 0: математика импорта подстановочных знаков (импорт подстановочных знаков)
C: 11, 0: имя константы «some_global_var» не соответствует стилю именования UPPER_CASE (недопустимое имя)
C: 13, 0: имя аргумента «x» не соответствует стилю именования змеиного регистра (недопустимое имя)
C: 13, 0: имя аргумента «y» не соответствует стилю именования змеиного регистра (недопустимое имя)
C: 13, 0: Отсутствует строка документации функции (отсутствует строка документации)
W: 14, 4: переопределение имени ‘some_global_var’ из внешней области видимости (строка 11) (переопределенное-внешнее-имя)
W: 17, 4: Недостижимый код (недостижимый)
W: 14, 4: неиспользуемая переменная ‘some_global_var’ (неиспользуемая переменная)
…
R: 24,12: Ненужное «else» после «return» (без возврата)
R: 20, 0: либо все операторы return в функции должны возвращать выражение, либо ни один из них не должен возвращать выражение.
(плохой пробел)
С: 29(плохой пробел)
C: 40, 0: отсутствует последняя новая строка (missing-final-newline)
W: 6, 0: переопределение встроенного ‘pow’ (redefined-builtin)
W: 6, 0: математика импорта подстановочных знаков (импорт подстановочных знаков)
C: 11, 0: имя константы «some_global_var» не соответствует стилю именования UPPER_CASE (недопустимое имя)
C: 13, 0: имя аргумента «x» не соответствует стилю именования змеиного регистра (недопустимое имя)
C: 13, 0: имя аргумента «y» не соответствует стилю именования змеиного регистра (недопустимое имя)
C: 13, 0: Отсутствует строка документации функции (отсутствует строка документации)
W: 14, 4: переопределение имени ‘some_global_var’ из внешней области видимости (строка 11) (переопределенное-внешнее-имя)
W: 17, 4: Недостижимый код (недостижимый)
W: 14, 4: неиспользуемая переменная ‘some_global_var’ (неиспользуемая переменная)
…
R: 24,12: Ненужное «else» после «return» (без возврата)
R: 20, 0: либо все операторы return в функции должны возвращать выражение, либо ни один из них не должен возвращать выражение. (несовместимые операторы возврата)
C: 31, 0: Отсутствует строка документации класса (отсутствует строка документации)
W: 37, 8: Переопределение имени «время» из внешней области (строка 9) (переопределенное-внешнее-имя)
E: 37,15: Использование переменной «время» перед назначением (используется перед назначением)
W: 33,50: неиспользуемый аргумент «подробный» (неиспользованный аргумент)
W: 36, 8: неиспользуемая переменная list_comprehension (неиспользуемая переменная)
W: 39, 8: Неиспользуемая переменная date_and_time (неиспользуемая переменная)
R: 31, 0: Слишком мало общедоступных методов (0/2) (слишком мало общедоступных методов)
W: 5, 0: Неиспользованный импорт io (unused-import)
W: 6, 0: неиспользуемый импорт acos из импорта подстановочных знаков (unused-wildcard-import)
…
W: 9, 0: Неиспользованное время, импортированное из времени (unused-import)
(несовместимые операторы возврата)
C: 31, 0: Отсутствует строка документации класса (отсутствует строка документации)
W: 37, 8: Переопределение имени «время» из внешней области (строка 9) (переопределенное-внешнее-имя)
E: 37,15: Использование переменной «время» перед назначением (используется перед назначением)
W: 33,50: неиспользуемый аргумент «подробный» (неиспользованный аргумент)
W: 36, 8: неиспользуемая переменная list_comprehension (неиспользуемая переменная)
W: 39, 8: Неиспользуемая переменная date_and_time (неиспользуемая переменная)
R: 31, 0: Слишком мало общедоступных методов (0/2) (слишком мало общедоступных методов)
W: 5, 0: Неиспользованный импорт io (unused-import)
W: 6, 0: неиспользуемый импорт acos из импорта подстановочных знаков (unused-wildcard-import)
…
W: 9, 0: Неиспользованное время, импортированное из времени (unused-import)
Обратите внимание, что я сжал это многоточием для похожих линий. Это довольно сложно понять, но в этом коде есть много ворса.
Обратите внимание, что Pylint ставит перед каждой проблемной областью префикс R , C , W , E или F , что означает:
- [R]efactor для нарушения метрики «хорошей практики»
- [C]конвенция о нарушении стандарта кодирования
- [Предупреждение о стилистических проблемах или незначительных проблемах с программированием
- [E]ошибка из-за важных проблем с программированием (то есть, скорее всего, ошибка)
- [F]атал для ошибок, препятствовавших дальнейшей обработке
Приведенный выше список взят непосредственно из руководства пользователя Pylint.
PyFlakes
Pyflakes «дает простое обещание: он никогда не будет жаловаться на стиль и будет очень, очень стараться никогда не выдавать ложных срабатываний». Это означает, что Pyflakes не сообщит вам об отсутствующих строках документации или именах аргументов, не соответствующих стилю именования. Основное внимание уделяется логическим проблемам кода и потенциальным ошибкам.
Основное внимание уделяется логическим проблемам кода и потенциальным ошибкам.
Преимущество здесь в скорости. PyFlakes работает за долю времени, которое занимает Pylint.
Вывод после запуска заполненного ворсом кода сверху:
code_with_lint.py:5: 'io' импортирован, но не используется code_with_lint.py:6: используется «из математического импорта *»; не удалось обнаружить неопределенные имена code_with_lint.py:14: локальная переменная 'some_global_var' назначена, но никогда не используется code_with_lint.py:36: 'pi' может быть не определено или определено из звездного импорта: math code_with_lint.py:36: локальная переменная list_comprehension назначена, но никогда не используется code_with_lint.py:37: локальная переменная «время» (определена в охватывающей области в строке 9) ссылка перед назначением code_with_lint.py:37: локальная переменная «время» назначена, но никогда не используется code_with_lint.py:39: локальная переменная date_and_time назначается, но никогда не используется
Недостатком здесь является то, что синтаксический анализ этого вывода может быть немного сложнее. Различные проблемы и ошибки не помечены и не организованы по типу. В зависимости от того, как вы это используете, это может вообще не быть проблемой.
Различные проблемы и ошибки не помечены и не организованы по типу. В зависимости от того, как вы это используете, это может вообще не быть проблемой.
pycodestyle (ранее pep8)
Используется для проверки некоторых соглашений о стиле из PEP8. Соглашения об именах не проверяются, как и строки документации. Ошибки и предупреждения, которые он улавливает, классифицируются в этой таблице.
Вывод после запуска заполненного ворсом кода сверху:
code_with_lint.py:13:1: E302 ожидал 2 пустые строки, нашел 1
code_with_lint.py:15:15: E225 отсутствует пробел вокруг оператора
code_with_lint.py:20:1: E302 ожидал 2 пустые строки, нашел 1
code_with_lint.py:21:10: сравнение E711 с None должно быть «если условие не равно None:»
code_with_lint.py:23:25: оператор E703 заканчивается точкой с запятой
code_with_lint.py:27:24: пробел E201 после '('
code_with_lint.py:31:1: E302 ожидал 2 пустые строки, нашел 1
code_with_lint.py:33:58: E251 неожиданные пробелы вокруг ключевого слова/параметра равны
code_with_lint. py:33:60: E251 неожиданные пробелы вокруг ключевого слова/параметра равны
code_with_lint.py:34:28: E221 несколько пробелов перед оператором
code_with_lint.py:34:31: E222 несколько пробелов после оператора
code_with_lint.py:35:22: E221 несколько пробелов перед оператором
code_with_lint.py:35:31: E222 несколько пробелов после оператора
code_with_lint.py:36:80: строка E501 слишком длинная (83 > 79персонажи)
code_with_lint.py:40:15: W292 без новой строки в конце файла
 py:33:60: E251 неожиданные пробелы вокруг ключевого слова/параметра равны
code_with_lint.py:34:28: E221 несколько пробелов перед оператором
code_with_lint.py:34:31: E222 несколько пробелов после оператора
code_with_lint.py:35:22: E221 несколько пробелов перед оператором
code_with_lint.py:35:31: E222 несколько пробелов после оператора
code_with_lint.py:36:80: строка E501 слишком длинная (83 > 79персонажи)
code_with_lint.py:40:15: W292 без новой строки в конце файла
py:33:60: E251 неожиданные пробелы вокруг ключевого слова/параметра равны
code_with_lint.py:34:28: E221 несколько пробелов перед оператором
code_with_lint.py:34:31: E222 несколько пробелов после оператора
code_with_lint.py:35:22: E221 несколько пробелов перед оператором
code_with_lint.py:35:31: E222 несколько пробелов после оператора
code_with_lint.py:36:80: строка E501 слишком длинная (83 > 79персонажи)
code_with_lint.py:40:15: W292 без новой строки в конце файла
Что хорошо в этом выводе, так это то, что ворсинки помечены по категориям. Вы можете игнорировать определенные ошибки, если не хотите придерживаться определенного соглашения.
pydocstyle (ранее pep257)
Очень похоже на pycodestyle, за исключением того, что вместо проверки соглашений о стиле кода PEP8 он проверяет строки документации на соответствие соглашениям PEP257.
Вывод после запуска заполненного ворсом кода сверху:
code_with_lint.py:1 на уровне модуля:
D200: однострочная строка документации должна помещаться на одной строке с кавычками (найдено 3)
code_with_lint. py:1 на уровне модуля:
D400: первая строка должна заканчиваться точкой (не '!').
code_with_lint.py:13 в публичной функции `multiply`:
D103: Отсутствует строка документации в общедоступной функции.
code_with_lint.py:20 в публичной функции is_sum_lucky:
D103: Отсутствует строка документации в общедоступной функции.
code_with_lint.py:31 в публичном классе SomeClass:
D101: Отсутствует строка документации в общедоступном классе.
code_with_lint.py:33 в общедоступном методе `__init__`:
D107: Отсутствует строка документации в __init__
 py:1 на уровне модуля:
D400: первая строка должна заканчиваться точкой (не '!').
code_with_lint.py:13 в публичной функции `multiply`:
D103: Отсутствует строка документации в общедоступной функции.
code_with_lint.py:20 в публичной функции is_sum_lucky:
D103: Отсутствует строка документации в общедоступной функции.
code_with_lint.py:31 в публичном классе SomeClass:
D101: Отсутствует строка документации в общедоступном классе.
code_with_lint.py:33 в общедоступном методе `__init__`:
D107: Отсутствует строка документации в __init__
py:1 на уровне модуля:
D400: первая строка должна заканчиваться точкой (не '!').
code_with_lint.py:13 в публичной функции `multiply`:
D103: Отсутствует строка документации в общедоступной функции.
code_with_lint.py:20 в публичной функции is_sum_lucky:
D103: Отсутствует строка документации в общедоступной функции.
code_with_lint.py:31 в публичном классе SomeClass:
D101: Отсутствует строка документации в общедоступном классе.
code_with_lint.py:33 в общедоступном методе `__init__`:
D107: Отсутствует строка документации в __init__
Опять же, как и pycodestyle, pydocstyle помечает и классифицирует различные найденные ошибки. И список не конфликтует ни с чем из pycodestyle, так как все ошибки имеют префикс D для строки документации. Список этих ошибок можно найти здесь.
Код без ворса
Вы можете настроить ранее заполненный линтом код на основе вывода линтера, и вы получите что-то вроде следующего:
1"""Пример кода с меньшим количеством ворсинок.
 """
2
3из математики импорт пи
4от времени импорта времени
5из даты и времени импортировать дату и время
6
7SOME_GLOBAL_VAR = 'ГЛОБАЛЬНЫЕ НАЗВАНИЯ VAR ДОЛЖНЫ БЫТЬ В ALL_CAPS_WITH_UNDERSCOES'
8
910def умножить (первое_значение, второе_значение):
11 """Вернуть результат умножения входных данных."""
12 результат = первое_значение * второе_значение
13
14, если результат == 777:
15 print("джекпот!")
16
17 вернуть результат
18
19
20def is_sum_lucky(первое_значение, второе_значение):
21 """
22 Возвращает строку, описывающую, является ли сумма ввода удачной.
23
24 Эта функция сначала проверяет правильность введенных данных, а затем вычисляет
25 сум. Затем он определит сообщение для возврата в зависимости от того,
26 эту сумму следует считать «счастливой».
27 """
28, если first_value не равно None и second_value не равно None:
29результат = первое_значение + второе_значение
30, если результат == 7:
31 сообщение = 'счастливое число!'
32 еще:
33 сообщение = 'несчастливое число!'
34 еще:
35 сообщение = 'неизвестный номер! Не удалось подсчитать сумму.
"""
2
3из математики импорт пи
4от времени импорта времени
5из даты и времени импортировать дату и время
6
7SOME_GLOBAL_VAR = 'ГЛОБАЛЬНЫЕ НАЗВАНИЯ VAR ДОЛЖНЫ БЫТЬ В ALL_CAPS_WITH_UNDERSCOES'
8
910def умножить (первое_значение, второе_значение):
11 """Вернуть результат умножения входных данных."""
12 результат = первое_значение * второе_значение
13
14, если результат == 777:
15 print("джекпот!")
16
17 вернуть результат
18
19
20def is_sum_lucky(первое_значение, второе_значение):
21 """
22 Возвращает строку, описывающую, является ли сумма ввода удачной.
23
24 Эта функция сначала проверяет правильность введенных данных, а затем вычисляет
25 сум. Затем он определит сообщение для возврата в зависимости от того,
26 эту сумму следует считать «счастливой».
27 """
28, если first_value не равно None и second_value не равно None:
29результат = первое_значение + второе_значение
30, если результат == 7:
31 сообщение = 'счастливое число!'
32 еще:
33 сообщение = 'несчастливое число!'
34 еще:
35 сообщение = 'неизвестный номер! Не удалось подсчитать сумму. ..'
36
37 ответное сообщение
38
39
40класс
41 """Это строка документации класса."""
42
43 def __init__(self, some_arg, some_other_arg):
44 """Инициализировать экземпляр SomeClass."""
45 self.some_other_arg = some_other_arg
46 self.some_arg = some_arg
47 list_comprehension = [
48 ((100/значение)*пи)
49для значения в some_arg
50, если значение != 0
51 ]
52 текущее_время = время()
53 date_and_time = datetime.now()
54 print(f'создал экземпляр SomeClass во время unix: {current_time}')
55 print(f'дата-время: {дата_и_время}')
56 print(f'некоторые вычисляемые значения: {list_comprehension}')
57
58 по определению some_public_method(self):
59 """Это строка документации метода."""
60 проходов
61
62 по определению some_other_public_method(self):
63 """Это строка документации метода."""
64 прохода
..'
36
37 ответное сообщение
38
39
40класс
41 """Это строка документации класса."""
42
43 def __init__(self, some_arg, some_other_arg):
44 """Инициализировать экземпляр SomeClass."""
45 self.some_other_arg = some_other_arg
46 self.some_arg = some_arg
47 list_comprehension = [
48 ((100/значение)*пи)
49для значения в some_arg
50, если значение != 0
51 ]
52 текущее_время = время()
53 date_and_time = datetime.now()
54 print(f'создал экземпляр SomeClass во время unix: {current_time}')
55 print(f'дата-время: {дата_и_время}')
56 print(f'некоторые вычисляемые значения: {list_comprehension}')
57
58 по определению some_public_method(self):
59 """Это строка документации метода."""
60 проходов
61
62 по определению some_other_public_method(self):
63 """Это строка документации метода."""
64 прохода
Согласно приведенным выше линтерам, этот код не содержит ворсинок. Хотя сама логика в основном бессмысленна, вы можете видеть, что как минимум обеспечивается согласованность.
В приведенном выше случае мы запускали линтеры после написания всего кода. Однако это не единственный способ проверки качества кода.
Однако это не единственный способ проверки качества кода.
Удалить рекламу
Когда я смогу проверить качество своего кода?
Вы можете проверить качество своего кода:
- Как пишешь
- Когда он зарегистрирован
- Когда вы запускаете свои тесты
Полезно часто запускать линтеры для вашего кода. Если нет автоматизации и согласованности, большая команда или проект могут легко упустить из виду цель и начать создавать код более низкого качества. Это происходит медленно, конечно. Какая-то плохо написанная логика или, может быть, какой-то код с форматированием, не соответствующим соседнему коду. Со временем вся эта грязь накапливается. В конце концов, вы можете застрять с чем-то глючным, трудным для чтения, трудным для исправления и трудным в обслуживании.
Чтобы этого избежать, чаще проверяйте качество кода!
Как вы пишете
Вы можете использовать линтеры при написании кода, но настройка вашей среды для этого может потребовать дополнительной работы. Как правило, это вопрос поиска плагина для вашей IDE или редактора. На самом деле в большинстве IDE уже есть встроенные линтеры.
Как правило, это вопрос поиска плагина для вашей IDE или редактора. На самом деле в большинстве IDE уже есть встроенные линтеры.
Вот некоторая общая информация о линтинге Python для различных редакторов:
- возвышенный текст
- VS Код
- Атом
- Вим
- Emacs
Перед регистрацией Код
Если вы используете Git, можно настроить хуки Git для запуска линтеров перед фиксацией. В других системах контроля версий есть аналогичные методы для запуска скриптов до или после некоторых действий в системе. Вы можете использовать эти методы для блокировки любого нового кода, который не соответствует стандартам качества.
Хотя это может показаться радикальным, принудительная проверка каждого бита кода на наличие ворсинок — важный шаг к обеспечению постоянного качества. Автоматизация этого скрининга на входе в ваш код может быть лучшим способом избежать заполнения кода ворсинками.
При выполнении тестов
Вы также можете размещать линтеры непосредственно в любой системе, которую вы можете использовать для непрерывной интеграции. Линтеры могут быть настроены на сбой сборки, если код не соответствует стандартам качества.
Линтеры могут быть настроены на сбой сборки, если код не соответствует стандартам качества.
Опять же, это может показаться радикальным шагом, особенно если в существующем коде уже есть много ошибок линтера. Чтобы бороться с этим, некоторые системы непрерывной интеграции позволяют вам отказаться от сборки только в том случае, если новый код увеличивает количество уже присутствующих ошибок линтера. Таким образом, вы можете начать улучшать качество, не переписывая весь существующий код.
Заключение
Высококачественный код делает то, что должен делать, без сбоев. Его легко читать, поддерживать и расширять. Он работает без проблем и дефектов и написан так, чтобы с ним было легко работать следующему человеку.
Надеюсь, само собой разумеется, что вы должны стремиться иметь такой высококачественный код. К счастью, существуют методы и инструменты, помогающие улучшить качество кода.
Руководства по стилю сделают ваш код согласованным. PEP8 — отличная отправная точка для Python.