Техническая оптимизация сайта, часть первая — SEO на vc.ru
Пошаговый план от руководителя оптимизаторов в «Ашманов и партнёры» Никиты Тарасова.
15 546 просмотров
В предыдущих статьях мы говорили об актуальных методах сбора семантики и текстовой оптимизации. Теперь речь пойдёт о технической, или о внутренней, оптимизации. Она значительно влияет на правильную индексацию и ранжирование и ещё помогает обезопасить сайт от утечки непубличных данных в выдачу поисковых систем.
В первой части статьи разберём:
- Оптимизацию URL-адресов страниц сайта.
- Поиск и устранение «зеркал» сайта.
- Корректировку robots.txt.
- Определение и устранение дублей страниц.
- Работу сайта при отключенном JavaScript.
- Обработку ошибки 404.
Оптимизация URL-адресов страниц сайта
Для правильной индексации важно, чтобы страницы сайта отражали его структуру.
При формировании адресов следует придерживаться простых правил:
Исключить из адресов все специальные символы вроде «?», «=», «&».
Использовать цифры в псевдостатических адресах можно без ограничений.
В качестве разделителя слов в адресе лучше использовать символ «-» (дефис).
- Использовать в адресах транслитерированные ключевые слова, которые в точности соответствуют контенту страницы.
- Использовать в адресах только строчные латинские символы, не кириллицу.
Возьмём в качестве примера интернет-магазин мебели. В каталоге магазина существует раздел «Угловые диваны». Правильный URL-адрес этого раздела выглядит так: domain. ru/catalog/uglovye-divany/.
ru/catalog/uglovye-divany/.
Частая проблема, особенно среди интернет-магазинов, — когда одна страница доступна по нескольким адресам. Например, для одного товара создают несколько адресов в зависимости раздела, в котором он расположен. С точки зрения поисковых систем такие страницы считаются дублями и негативно влияют на индексацию.
Некоторые решают эту проблему при помощи тега link с атрибутом rel=”canonical”. Но этот тег служит рекомендательным и не всегда учитывается поисковыми системами. Лучше задать универсальный адрес. Например, адрес карточки товара для условного дивана «Амстердам» будет выглядеть так: domain.ru/product/amsterdam.
Внедрение данного алгоритма формирования псевдостатических адресов для страниц карточек товаров позволит:
- Избежать чрезмерного уровня вложенности в структуре URL и положительно скажется на индексации.
- Устранит риск возникновения дублей.
Важно: после внедрения или корректировки псевдостатической адресации со всех старых URL на новые настройте редиректы 301. При переходе на страницы по новым адресам сервер не должен выдавать промежуточный код ответа 301. В ответ на запрос страницы сервер должен выдавать содержимое страницы с кодом ответа 200 без перенаправлений.
При переходе на страницы по новым адресам сервер не должен выдавать промежуточный код ответа 301. В ответ на запрос страницы сервер должен выдавать содержимое страницы с кодом ответа 200 без перенаправлений.
Поиск и устранение «зеркал» сайта
Поисковые системы не любят, когда у сайта есть «зеркала», то есть точные копии, размещённые на других доменах.
«Зеркала» обычно возникают по следующим причинам:
- Когда несколько доменов привязаны к одному физическому сайту (набору файлов на хостинге).
- Когда есть служебные домены, автоматически генерируемые хостингом.
- Когда домен с указанием порта (например, domain.ru:8080).
- Из-за IP-адреса (например, если сайт доступен по IP 192.168.1.1).
Несколько шагов, которые помогут обнаружить дубли:
- Проверьте сайт с помощью сервисов для поиска «зеркал» и индексированных доменов.
- Определите IP-адрес сайта (например, в 2ip).

- Выгрузите источники по страницам входа из «Яндекс.Метрики» в таблицу Excel (ставим точность 100% и временной интервал около десяти лет).

Пример выгрузки источников по страницам входа из «Яндекс.Метрики»
Первый столбец данных из «Яндекс.Метрики» нужно скопировать в отдельную вкладку и объединить с данными, которые мы получили в ходе первых двух шагов. Затем в таблице с помощью функции «Заменить на» удалите протоколы HTTP и HTTPS и префиксы WWW. Затем из списка нужно удалить дубли.
Далее, при помощи SeoAG генерируем список всех возможных сочетаний (с WWW и без, с HTTP и без, c HTTPS и без) при помощи функции {http:|https:}{//|//www.}{domain1.ru|domain2.ru}, где domain1.ru|domain2.ru — уникальный список доменов, полученный ранее. Добавляем список доменов при помощи «Мастер ввода».
Пример генерации списка доменов при помощи SEO Anchor Generator
Затем сгенерированный список доменов добавляем в Screaming Frog Seo Spider и переключаемся в режим List. Настраиваем учёт директив robots.txt. Загружаем итоговый список доменов.
Настраиваем учёт директив robots.txt. Загружаем итоговый список доменов.
Далее все URL c кодом ответа 200 Ok проверяем вручную и выясняем, что именно находится по таким адресам.
Пример импорта списка доменов в Screaming Frog Seo Spider для проверки
Найти зеркало можно с помощью поиска по текстовым фрагментам. Для этого необходимо ввести часть текста с сайта (пять-восемь слов, идущих подряд) в поисковую строку и заключить их в кавычки.
Пример поиска зеркала сайта по текстовым фрагментам
Список зеркал нужно закрыть от индексации, разместив в корне каждого из них файл robots.txt следующего содержания:
User-agent: * Disallow: /
В случае с доменными алиасами нужно настроить постраничный редирект 301 с дубля на соответствующий сайт.
Корректировка robots.txt
Данный файл содержит набор директив, позволяющих управлять индексацией сайта. Например, указывать поисковым системам, какие директории сайта должны присутствовать в поиске, а какие нет.
В файле robots.txt закрывают от индексации служебные страницы:
- Версии для печати.
- Корзины товаров.
- Авторизацию, регистрации, личные кабинеты.
- Сортировки.
- Страницы с UTM-метками.
Сервис Screaming Frog Seo Spider поможет определить, какие ещё страницы стоит исключить из индексации. В данном случае помогут фильтры по дублям метатегов title/h2/description.
Фильтр по дублям метатегов title/h2/description в программе Screaming Frog Seo Spider
Часто большая часть служебных страниц имеет дублирующиеся метатеги.
Ещё стоит выгрузить проиндексированные страницы сайта из сервиса «Яндекс.Вебмастер» и проверить, какие из них стоит исключить из индекса.
Проиндексированные страницы в «Яндекс.Вебмастере»
Одним из требований поисковых систем служат открытые для индексации файлы JavaScript и CSS, изображения. Определить список ресурсов, которые необходимо открыть для индексации, можно при помощи сервиса от Google.
Определить список ресурсов, которые необходимо открыть для индексации, можно при помощи сервиса от Google.
Актуальные требования основных поисковых систем к файлу robots.txt можно найти в справочных «Яндекса» и Google.
Есть ещё несколько распространённых ошибок. Например, если проект разрабатывают с нуля или переделывают на тестовом домене (например, test.domain.ru или dev.domain.ru), то разработчики часто забывают закрыть тестовую версию сайта от индексации.
На текущий момент поисковые роботы не отличают тестовый домен от основного и считают его за дубль, что обычно ухудшает позиции основного сайта.
Пример тестовых версий сайтов в выдаче «Яндекса»
Тестовую версию сайта следует закрывать от индексации при помощи следующего набора директив.
User-Agent: * Disallow: /
Также распространена обратная ситуация, когда после разработки тестовую версию выкладывают на основной домен и забывают скорректировать содержимое файла robots. txt. Если сайт новый, то он не индексируется, а в случае редизайна пропадает из результатов поиска.
txt. Если сайт новый, то он не индексируется, а в случае редизайна пропадает из результатов поиска.
После переноса сайта с тестового домена на основной или завершения разработки всегда проверяйте содержимое файла robots.txt.
На текущий момент существуют такие средства отладки robots.txt:
- Редактор в кабинете «Яндекс.Вебмастера». В него можно загрузить актуальный файл и проверить, какие директивы он разрешает или запрещает индексировать поисковым роботам.
- Либо можно воспользоваться встроенным отладчиком сервиса Screaming Frog Seo Spider.
Определение и устранение дублей страниц
Дубли — точные копии страниц сайта, доступные одновременно по нескольким адресам.
Типичные примеры:
- Со слэшем на конце: http://www.domain.ru/page1/
- Без слэша на конце: http://www.domain.ru/page1
- С index.html на конце: http://www.domain. ru/page1/index.html
- С index.php на конце: http://www.domain.ru/page1/index.php
- С использованием HTTP: http://www.domain.ru/
- С использованием HTTPS: https://www.domain.ru/
- С использованием строчных символов: http://www.domain.ru/
- С использованием прописных символов: http://www.Domain.ru/
 ru/page1/index.html
ru/page1/index.htmlВарианты дублей могут варьироваться в зависимости от системы управления вашего сайта. От дублей нужно избавляться, и все страницы сайта следует привести к единому виду, например
Выбор вида страниц для индексации зависит от того, насколько много страниц этого вида уже находится в индексе поисковых систем.
Для убирания дублей со всех остальных адресов страниц существует несколько способов (можно воспользоваться одним из них или скомбинировать несколько):
- Настройте редирект 301 на конечный вид страницы.
- Скорректируйте настройки сервера таким образом, чтобы при запросе дублей сервер выдавал код ответа 404 Not Found.
- Закройте дубли страниц от индексации в robots.txt.

Работа сайта при отключённом JavaScript
Для индексации важно, чтобы контент и основные ссылки на страницах были доступны при отключенном JavaScript. Тогда поисковые системы могут проиндексировать информацию на страницах полностью и правильно определить её ссылочный вес.
Существует два основных способа проверки работы сайта с отключенным JavaScript.
Если после отключения JS вы видите на сайте белый экран, это не значит, что сайт не работает при отключённых скриптах. Возможно, просто «поехала» вёрстка. Если после отключения JS на странице пропали важные элементы (карточки товаров, цены), стоит открыть исходный код страницы и при помощи поиска найти элементы по фрагментам текста.
Выясните, какой контент не выводится на странице и насколько это критично.
Обработка ошибки 404
Иногда ошибка 404 обрабатывается некорректно и для несуществующей страницы выдаётся, например, код 200 Ok. В подобных случаях могут возникнут проблемы с индексацией страниц вплоть до того, что сайт полностью выпадет из поиска.
Так как сайты обычно состоят из шаблонов страниц, то для проверки корректной обработки ошибки 404 достаточно добавить метку test к каждой из страниц:
- Главная: https://domain.ru/test/
- Категория или подкатегория: https://domain.ru/catalog/category/test/
- Страницы карточки: https://domain.ru/product/name-product/test/
- Страница пагинации: https://domain.ru/catalog/category/page-test/
- Служебные страницы: https://domain.ru/page/test/
А затем проверить код ответа для каждой страницы из списка в Screaming Frog Seo Spider.
Настройте сервер так, чтобы при обращении к несуществующей странице он выдавал ответ HTTP/1. 1 404 Not Found без перенаправлений.
1 404 Not Found без перенаправлений.
Проработайте страницу, выдаваемую пользователю при ошибке 404, так, чтобы она была информативной и имела ссылки на основные разделы меню и главную страницу сайта.
О чём пойдёт речь во второй части
Далее мы разберём:
- Скорость загрузки сайта.
- Оптимизацию под мобильные устройства.
- Страницы пагинации.
- Битые ссылки и редиректы.
- Микроразметку.
- Использование тега meta name=»robots» content=»…».
- Распределение ссылочного веса по страницам сайта.
- Использование тега noindex, внутреннюю перелинковку и другие аспекты технической оптимизации.
Рекомендации по теме
Для погружения в тему технической оптимизации советую ознакомиться с чек-листом, опубликованным в блоге Texterra. Также рекомендую чек-лист от Collaborator в онлайне, который поможет фиксировать внесённые коррективы и оценивать проделанный объём работ относительного всех предстоящих задач.
Также рекомендую чек-лист от Collaborator в онлайне, который поможет фиксировать внесённые коррективы и оценивать проделанный объём работ относительного всех предстоящих задач.
Техническая оптимизация сайта, часть первая — SEO на vc.ru
Пошаговый план от руководителя оптимизаторов в «Ашманов и партнёры» Никиты Тарасова.
15 546 просмотров
В предыдущих статьях мы говорили об актуальных методах сбора семантики и текстовой оптимизации. Теперь речь пойдёт о технической, или о внутренней, оптимизации. Она значительно влияет на правильную индексацию и ранжирование и ещё помогает обезопасить сайт от утечки непубличных данных в выдачу поисковых систем.
В первой части статьи разберём:
- Оптимизацию URL-адресов страниц сайта.
- Поиск и устранение «зеркал» сайта.
- Корректировку robots.txt.
- Определение и устранение дублей страниц.
- Работу сайта при отключенном JavaScript.
- Обработку ошибки 404.

Оптимизация URL-адресов страниц сайта
Для правильной индексации важно, чтобы страницы сайта отражали его структуру. Поэтому уровни вложенности URL должны соответствовать уровню вложенности страниц относительно корня сайта. Но не стоит впадать в крайность и делать адреса c пятью уровнями вложенности и более.
При формировании адресов следует придерживаться простых правил:
Исключить из адресов все специальные символы вроде «?», «=», «&».
Использовать цифры в псевдостатических адресах можно без ограничений.
В качестве разделителя слов в адресе лучше использовать символ «-» (дефис).
- Использовать в адресах транслитерированные ключевые слова, которые в точности соответствуют контенту страницы.
- Использовать в адресах только строчные латинские символы, не кириллицу.

Возьмём в качестве примера интернет-магазин мебели. В каталоге магазина существует раздел «Угловые диваны». Правильный URL-адрес этого раздела выглядит так: domain.ru/catalog/uglovye-divany/.
Частая проблема, особенно среди интернет-магазинов, — когда одна страница доступна по нескольким адресам. Например, для одного товара создают несколько адресов в зависимости раздела, в котором он расположен. С точки зрения поисковых систем такие страницы считаются дублями и негативно влияют на индексацию.
Некоторые решают эту проблему при помощи тега link с атрибутом rel=”canonical”. Но этот тег служит рекомендательным и не всегда учитывается поисковыми системами. Лучше задать универсальный адрес. Например, адрес карточки товара для условного дивана «Амстердам» будет выглядеть так: domain.ru/product/amsterdam.
Внедрение данного алгоритма формирования псевдостатических адресов для страниц карточек товаров позволит:
- Избежать чрезмерного уровня вложенности в структуре URL и положительно скажется на индексации.
- Устранит риск возникновения дублей.

Важно: после внедрения или корректировки псевдостатической адресации со всех старых URL на новые настройте редиректы 301. При переходе на страницы по новым адресам сервер не должен выдавать промежуточный код ответа 301. В ответ на запрос страницы сервер должен выдавать содержимое страницы с кодом ответа 200 без перенаправлений.
Поиск и устранение «зеркал» сайта
Поисковые системы не любят, когда у сайта есть «зеркала», то есть точные копии, размещённые на других доменах.
«Зеркала» обычно возникают по следующим причинам:
- Когда несколько доменов привязаны к одному физическому сайту (набору файлов на хостинге).
- Когда есть служебные домены, автоматически генерируемые хостингом.
- Когда домен с указанием порта (например, domain.ru:8080).
- Из-за IP-адреса (например, если сайт доступен по IP 192. 168.1.1).
 168.1.1).
168.1.1).Несколько шагов, которые помогут обнаружить дубли:
- Проверьте сайт с помощью сервисов для поиска «зеркал» и индексированных доменов.
- Определите IP-адрес сайта (например, в 2ip).
- Выгрузите источники по страницам входа из «Яндекс.Метрики» в таблицу Excel (ставим точность 100% и временной интервал около десяти лет).
Пример выгрузки источников по страницам входа из «Яндекс.Метрики»
Первый столбец данных из «Яндекс.Метрики» нужно скопировать в отдельную вкладку и объединить с данными, которые мы получили в ходе первых двух шагов. Затем в таблице с помощью функции «Заменить на» удалите протоколы HTTP и HTTPS и префиксы WWW. Затем из списка нужно удалить дубли.
Далее, при помощи SeoAG генерируем список всех возможных сочетаний (с WWW и без, с HTTP и без, c HTTPS и без) при помощи функции {http:|https:}{//|//www. }{domain1.ru|domain2.ru}, где domain1.ru|domain2.ru — уникальный список доменов, полученный ранее. Добавляем список доменов при помощи «Мастер ввода».
}{domain1.ru|domain2.ru}, где domain1.ru|domain2.ru — уникальный список доменов, полученный ранее. Добавляем список доменов при помощи «Мастер ввода».
Пример генерации списка доменов при помощи SEO Anchor Generator
Затем сгенерированный список доменов добавляем в Screaming Frog Seo Spider и переключаемся в режим List. Настраиваем учёт директив robots.txt. Загружаем итоговый список доменов.
Далее все URL c кодом ответа 200 Ok проверяем вручную и выясняем, что именно находится по таким адресам.
Пример импорта списка доменов в Screaming Frog Seo Spider для проверки
Найти зеркало можно с помощью поиска по текстовым фрагментам. Для этого необходимо ввести часть текста с сайта (пять-восемь слов, идущих подряд) в поисковую строку и заключить их в кавычки.
Пример поиска зеркала сайта по текстовым фрагментам
Список зеркал нужно закрыть от индексации, разместив в корне каждого из них файл robots. txt следующего содержания:
User-agent: * Disallow: /
В случае с доменными алиасами нужно настроить постраничный редирект 301 с дубля на соответствующий сайт.
Корректировка robots.txt
Данный файл содержит набор директив, позволяющих управлять индексацией сайта. Например, указывать поисковым системам, какие директории сайта должны присутствовать в поиске, а какие нет.
В файле robots.txt закрывают от индексации служебные страницы:
- Версии для печати.
- Корзины товаров.
- Авторизацию, регистрации, личные кабинеты.
- Сортировки.
- Страницы с UTM-метками.
Сервис Screaming Frog Seo Spider поможет определить, какие ещё страницы стоит исключить из индексации. В данном случае помогут фильтры по дублям метатегов title/h2/description.
Фильтр по дублям метатегов title/h2/description в программе Screaming Frog Seo Spider
Часто большая часть служебных страниц имеет дублирующиеся метатеги.
Ещё стоит выгрузить проиндексированные страницы сайта из сервиса «Яндекс.Вебмастер» и проверить, какие из них стоит исключить из индекса.
Проиндексированные страницы в «Яндекс.Вебмастере»
Одним из требований поисковых систем служат открытые для индексации файлы JavaScript и CSS, изображения. Определить список ресурсов, которые необходимо открыть для индексации, можно при помощи сервиса от Google.
Актуальные требования основных поисковых систем к файлу robots.txt можно найти в справочных «Яндекса» и Google.
Есть ещё несколько распространённых ошибок. Например, если проект разрабатывают с нуля или переделывают на тестовом домене (например, test.domain.ru или dev.domain.ru), то разработчики часто забывают закрыть тестовую версию сайта от индексации.
На текущий момент поисковые роботы не отличают тестовый домен от основного и считают его за дубль, что обычно ухудшает позиции основного сайта.
Пример тестовых версий сайтов в выдаче «Яндекса»
Тестовую версию сайта следует закрывать от индексации при помощи следующего набора директив.
User-Agent: * Disallow: /
Также распространена обратная ситуация, когда после разработки тестовую версию выкладывают на основной домен и забывают скорректировать содержимое файла robots.txt. Если сайт новый, то он не индексируется, а в случае редизайна пропадает из результатов поиска.
После переноса сайта с тестового домена на основной или завершения разработки всегда проверяйте содержимое файла robots.txt.
На текущий момент существуют такие средства отладки robots.txt:
- Редактор в кабинете «Яндекс.Вебмастера». В него можно загрузить актуальный файл и проверить, какие директивы он разрешает или запрещает индексировать поисковым роботам.
- Либо можно воспользоваться встроенным отладчиком сервиса Screaming Frog Seo Spider.
Определение и устранение дублей страниц
Дубли — точные копии страниц сайта, доступные одновременно по нескольким адресам.
Типичные примеры:
- Со слэшем на конце: http://www. domain.ru/page1/
- Без слэша на конце: http://www.domain.ru/page1
- С index.html на конце: http://www.domain.ru/page1/index.html
- С index.php на конце: http://www.domain.ru/page1/index.php
- С использованием HTTP: http://www.domain.ru/
- С использованием HTTPS: https://www.domain.ru/
- С использованием строчных символов: http://www.domain.ru/
- С использованием прописных символов: http://www.Domain.ru/
 domain.ru/page1/
domain.ru/page1/Варианты дублей могут варьироваться в зависимости от системы управления вашего сайта. От дублей нужно избавляться, и все страницы сайта следует привести к единому виду, например https://www.domain.ru/.
Выбор вида страниц для индексации зависит от того, насколько много страниц этого вида уже находится в индексе поисковых систем.
Для убирания дублей со всех остальных адресов страниц существует несколько способов (можно воспользоваться одним из них или скомбинировать несколько):
- Настройте редирект 301 на конечный вид страницы.
- Скорректируйте настройки сервера таким образом, чтобы при запросе дублей сервер выдавал код ответа 404 Not Found.
- Закройте дубли страниц от индексации в robots.txt.
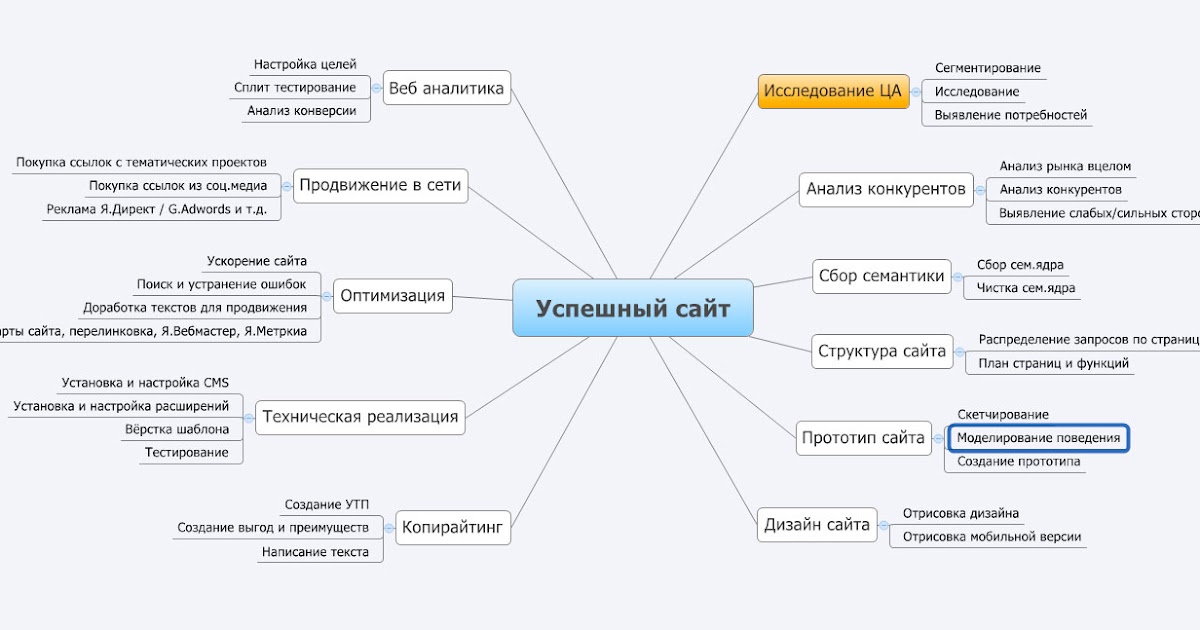
Работа сайта при отключённом JavaScript
Для индексации важно, чтобы контент и основные ссылки на страницах были доступны при отключенном JavaScript. Тогда поисковые системы могут проиндексировать информацию на страницах полностью и правильно определить её ссылочный вес.
Существует два основных способа проверки работы сайта с отключенным JavaScript.
Если после отключения JS вы видите на сайте белый экран, это не значит, что сайт не работает при отключённых скриптах. Возможно, просто «поехала» вёрстка. Если после отключения JS на странице пропали важные элементы (карточки товаров, цены), стоит открыть исходный код страницы и при помощи поиска найти элементы по фрагментам текста.
Выясните, какой контент не выводится на странице и насколько это критично.
Обработка ошибки 404
Иногда ошибка 404 обрабатывается некорректно и для несуществующей страницы выдаётся, например, код 200 Ok. В подобных случаях могут возникнут проблемы с индексацией страниц вплоть до того, что сайт полностью выпадет из поиска.
Так как сайты обычно состоят из шаблонов страниц, то для проверки корректной обработки ошибки 404 достаточно добавить метку test к каждой из страниц:
- Главная: https://domain.ru/test/
- Категория или подкатегория: https://domain.ru/catalog/category/test/
- Страницы карточки: https://domain.ru/product/name-product/test/
- Страница пагинации: https://domain.ru/catalog/category/page-test/
- Служебные страницы: https://domain.ru/page/test/
А затем проверить код ответа для каждой страницы из списка в Screaming Frog Seo Spider.
Настройте сервер так, чтобы при обращении к несуществующей странице он выдавал ответ HTTP/1. 1 404 Not Found без перенаправлений.
1 404 Not Found без перенаправлений.
Проработайте страницу, выдаваемую пользователю при ошибке 404, так, чтобы она была информативной и имела ссылки на основные разделы меню и главную страницу сайта.
О чём пойдёт речь во второй части
Далее мы разберём:
- Скорость загрузки сайта.
- Оптимизацию под мобильные устройства.
- Страницы пагинации.
- Битые ссылки и редиректы.
- Микроразметку.
- Использование тега meta name=»robots» content=»…».
- Распределение ссылочного веса по страницам сайта.
- Использование тега noindex, внутреннюю перелинковку и другие аспекты технической оптимизации.
Рекомендации по теме
Для погружения в тему технической оптимизации советую ознакомиться с чек-листом, опубликованным в блоге Texterra. Также рекомендую чек-лист от Collaborator в онлайне, который поможет фиксировать внесённые коррективы и оценивать проделанный объём работ относительного всех предстоящих задач.
Также рекомендую чек-лист от Collaborator в онлайне, который поможет фиксировать внесённые коррективы и оценивать проделанный объём работ относительного всех предстоящих задач.
Что такое техническое SEO? 8 технических аспектов, которые должен знать каждый • Yoast
В этом посте мы рассмотрим основы технического SEO. Теперь обсуждение основ технического SEO может показаться противоречием в терминах. Тем не менее, некоторые базовые знания о более технической стороне SEO могут означать разницу между сайтом с высоким рейтингом и сайтом, который вообще не ранжируется. Техническое SEO — это непросто, но мы объясним — доступным языком — на какие аспекты вы должны (попросите вашего разработчика) обратить внимание при работе над технической основой вашего сайта.
Что такое техническое SEO?
Техническое SEO направлено на улучшение технических аспектов веб-сайта с целью повышения рейтинга его страниц в поисковых системах. Сделать веб-сайт быстрее, проще для сканирования и сделать его более понятным для поисковых систем — вот столпы технической оптимизации. Техническое SEO является частью внутреннего SEO, которое направлено на улучшение элементов на вашего веб-сайта, чтобы получить более высокий рейтинг. Это противоположность внешнему SEO, которое заключается в привлечении внимания к веб-сайту через другие каналы.
Техническое SEO является частью внутреннего SEO, которое направлено на улучшение элементов на вашего веб-сайта, чтобы получить более высокий рейтинг. Это противоположность внешнему SEO, которое заключается в привлечении внимания к веб-сайту через другие каналы.
Зачем технически оптимизировать сайт?
Google и другие поисковые системы хотят предоставлять своим пользователям наилучшие возможные результаты по их запросам. Поэтому роботы Google сканируют и оценивают веб-страницы по множеству факторов. Некоторые факторы основаны на опыте пользователя, например, насколько быстро загружается страница. Другие факторы помогают роботам поисковых систем понять, о чем ваши страницы. Это то, что, среди прочего, делают структурированные данные. Таким образом, улучшая технические аспекты, вы помогаете поисковым системам сканировать и понимать ваш сайт. Если вы сделаете это хорошо, вы можете быть вознаграждены более высоким рейтингом. Или даже заработайте себе богатые результаты!
Это также работает и наоборот: если вы допустите серьезные технические ошибки на своем сайте, они могут стоить вам денег. Вы не будете первым, кто полностью запретит поисковым системам сканировать ваш сайт, случайно добавив косую черту в конце файла robots.txt не в том месте.
Вы не будете первым, кто полностью запретит поисковым системам сканировать ваш сайт, случайно добавив косую черту в конце файла robots.txt не в том месте.
Но не думайте, что вам следует сосредотачиваться на технических деталях веб-сайта только для того, чтобы угодить поисковым системам. Веб-сайт должен хорошо работать — быть быстрым, понятным и простым в использовании — в первую очередь для ваших пользователей. К счастью, создание прочной технической основы часто совпадает с улучшением опыта как для пользователей, так и для поисковых систем.
Каковы характеристики технически оптимизированного веб-сайта?
Технически исправный веб-сайт быстр для пользователей и легко сканируется роботами поисковых систем. Правильная техническая настройка помогает поисковым системам понять, о чем сайт. Это также предотвращает путаницу, вызванную, например, дублированием контента. Более того, он не загоняет ни посетителей, ни поисковые системы в тупики, вызванные неработающими ссылками. Здесь мы кратко рассмотрим некоторые важные характеристики технически оптимизированного веб-сайта.
Здесь мы кратко рассмотрим некоторые важные характеристики технически оптимизированного веб-сайта.
1. Это быстро
В настоящее время веб-страницы должны загружаться быстро. Люди нетерпеливы и не хотят ждать, пока откроется страница. Уже в 2016 году исследование показало, что 53% посетителей мобильных веб-сайтов уйдут, если веб-страница не откроется в течение трех секунд. И эта тенденция не исчезла — исследования 2022 года показывают, что коэффициент конверсии электронной торговли падает примерно на 0,3% за каждую дополнительную секунду, необходимую для загрузки страницы. Поэтому, если ваш сайт работает медленно, люди разочаровываются и переходят на другой сайт, и вы теряете весь этот трафик.
Google знает, что медленные веб-страницы не обеспечивают оптимальную работу. Поэтому они предпочитают веб-страницы, которые загружаются быстрее. Таким образом, медленная веб-страница также оказывается ниже в результатах поиска, чем ее более быстрый аналог, что приводит к еще меньшему трафику. С 2021 года опыт страницы (насколько быстро люди воспринимают веб-страницу) официально стал фактором ранжирования Google. Поэтому наличие страниц, которые загружаются достаточно быстро, сейчас важнее, чем когда-либо.
С 2021 года опыт страницы (насколько быстро люди воспринимают веб-страницу) официально стал фактором ранжирования Google. Поэтому наличие страниц, которые загружаются достаточно быстро, сейчас важнее, чем когда-либо.
Хотите знать, достаточно ли быстр ваш сайт? Узнайте, как легко проверить скорость вашего сайта. Большинство тестов также подскажут вам, что нужно улучшить. Вы также можете взглянуть на основные веб-жизненные показатели — Google использует их для обозначения опыта Страницы. И мы дадим вам общие советы по оптимизации скорости сайта здесь.
2. Его можно сканировать для поисковых систем
Поисковые системы используют роботов для сканирования вашего веб-сайта. Роботы переходят по ссылкам, чтобы найти контент на вашем сайте. Хорошая внутренняя структура ссылок гарантирует, что они поймут, что является наиболее важным контентом на вашем сайте.
Но есть и другие способы направлять роботов. Вы можете, например, запретить им сканирование определенного контента, если вы не хотите, чтобы они туда ходили. Вы также можете разрешить им сканировать страницу, но запретить показывать эту страницу в результатах поиска или не переходить по ссылкам на этой странице.
Вы также можете разрешить им сканировать страницу, но запретить показывать эту страницу в результатах поиска или не переходить по ссылкам на этой странице.
Файл robots.txt
С помощью файла robots.txt вы можете дать роботам указания на вашем сайте. Это мощный инструмент, с которым нужно обращаться осторожно. Как мы упоминали в начале, небольшая ошибка может помешать роботам сканировать (важные части) вашего сайта. Иногда люди непреднамеренно блокируют файлы CSS и JS своего сайта в файле robots.txt. Эти файлы содержат код, сообщающий браузерам, как должен выглядеть ваш сайт и как он работает. Если эти файлы заблокированы, поисковые системы не смогут определить, правильно ли работает ваш сайт.
В общем, мы рекомендуем по-настоящему погрузиться в robots.txt, если вы хотите узнать, как он работает. Или, что еще лучше, пусть разработчик сделает это за вас!
Метатег robots
Метатег robots — это фрагмент кода, который вы не увидите на странице как посетитель. Он находится в исходном коде в так называемом разделе заголовка страницы. Роботы читают этот раздел при поиске страницы. В нем они найдут информацию о том, что они найдут на странице или что им нужно с ней сделать.
Он находится в исходном коде в так называемом разделе заголовка страницы. Роботы читают этот раздел при поиске страницы. В нем они найдут информацию о том, что они найдут на странице или что им нужно с ней сделать.
Если вы хотите, чтобы роботы поисковых систем сканировали страницу, но по какой-то причине не показывали ее в результатах поиска, вы можете сообщить им об этом с помощью метатега robots. С помощью метатега robots вы также можете дать им указание сканировать страницу, но не переходить по ссылкам на странице. С Yoast SEO легко запретить индексацию или подписку на публикацию или страницу. Узнайте, для каких страниц вы хотите это сделать.
Подробнее: Что такое сканируемость? »
3. Нет (много) мертвых ссылок
Мы уже обсуждали, что медленные сайты раздражают. Что может быть еще более раздражающим для посетителей, чем медленная страница, так это попадание на страницу, которой вообще не существует. Если ссылка ведет на несуществующую страницу вашего сайта, люди увидят страницу с ошибкой 404. Вот и весь ваш тщательно продуманный пользовательский опыт!
Вот и весь ваш тщательно продуманный пользовательский опыт!
Более того, поисковые системы тоже не любят находить эти страницы с ошибками. И они, как правило, находят даже больше мертвых ссылок, чем посетители, потому что они переходят по каждой ссылке, на которую натыкаются, даже если она скрыта.
К сожалению, на большинстве сайтов есть (по крайней мере, несколько) неработающих ссылок, потому что веб-сайт — это непрерывная работа: люди что-то делают и что-то ломают. К счастью, есть инструменты, которые могут помочь вам восстановить мертвые ссылки на вашем сайте. Прочтите об этих инструментах и о том, как решить ошибку 404.
Во избежание ненужных мертвых ссылок всегда следует перенаправлять URL-адрес страницы при ее удалении или перемещении. В идеале вы должны перенаправить его на страницу, которая заменяет старую страницу. С Yoast SEO Premium вы можете легко делать перенаправления самостоятельно. Разработчик не нужен!
Продолжайте читать: что такое перенаправление? »
4.
 Поисковые системы не сбиваются с толку дублирующимся контентом
Поисковые системы не сбиваются с толку дублирующимся контентомЕсли у вас один и тот же контент на нескольких страницах вашего сайта или даже на других сайтах, поисковые системы могут запутаться. Потому что, если на этих страницах отображается один и тот же контент, какая из них должна иметь самый высокий рейтинг? В результате они могут дать всем страницам с одинаковым содержанием более низкий рейтинг.
К сожалению, у вас могут возникнуть проблемы с дублированием содержимого, даже если вы об этом не подозреваете. По техническим причинам один и тот же контент может отображаться по разным URL-адресам. Для посетителя это не имеет значения, а для поисковой системы имеет значение; он увидит тот же контент по другому URL-адресу.
К счастью, есть техническое решение этой проблемы. С помощью так называемого элемента канонической ссылки вы можете указать, что представляет собой исходная страница — или страница, которую вы хотите ранжировать в поисковых системах. В Yoast SEO вы можете легко установить канонический URL-адрес для страницы. И, чтобы облегчить вам задачу, Yoast SEO добавляет самореферентные канонические ссылки на все ваши страницы. Это поможет предотвратить проблемы с дублированием контента, о которых вы, возможно, даже не подозреваете.
И, чтобы облегчить вам задачу, Yoast SEO добавляет самореферентные канонические ссылки на все ваши страницы. Это поможет предотвратить проблемы с дублированием контента, о которых вы, возможно, даже не подозреваете.
5. Это безопасно
Технически оптимизированный веб-сайт — это безопасный веб-сайт. Сделать ваш сайт безопасным для пользователей, чтобы гарантировать их конфиденциальность, является основным требованием в настоящее время. Есть много вещей, которые вы можете сделать, чтобы сделать ваш (WordPress) веб-сайт безопасным, и одна из самых важных вещей — внедрение HTTPS.
HTTPS гарантирует, что никто не сможет перехватить данные, которые передаются между браузером и сайтом. Так, например, если люди входят на ваш сайт, их учетные данные в безопасности. Вам понадобится нечто, называемое SSL-сертификатом, для реализации HTTPS на вашем сайте. Google признает важность безопасности и поэтому сделал HTTPS сигналом ранжирования: безопасные веб-сайты ранжируются выше, чем небезопасные эквиваленты.
Вы можете легко проверить, является ли ваш сайт HTTPS в большинстве браузеров. В левой части строки поиска вашего браузера вы увидите замок, если это безопасно. Если вы видите слова «небезопасно», вам (или вашему разработчику) есть над чем поработать!
Читайте дальше: Что такое HTTPS? »
6. Плюс: структурированные данные
Структурированные данные помогают поисковым системам лучше понять ваш веб-сайт, контент или даже ваш бизнес. С помощью структурированных данных вы можете сообщить поисковым системам, какой продукт вы продаете или какие рецепты есть на вашем сайте. Кроме того, это даст вам возможность предоставить всевозможную информацию об этих продуктах или рецептах.
Существует фиксированный формат (описанный на Schema.org), в котором вы должны предоставить эту информацию, чтобы поисковые системы могли легко найти и понять ее. Это помогает им разместить ваш контент в более широкой картине. Здесь вы можете прочитать историю о том, как это работает и как Yoast SEO помогает вам в этом. Например, Yoast SEO создает график схемы для вашего сайта и имеет структурированные блоки содержимого данных для вашего контента с практическими рекомендациями и часто задаваемыми вопросами.
Например, Yoast SEO создает график схемы для вашего сайта и имеет структурированные блоки содержимого данных для вашего контента с практическими рекомендациями и часто задаваемыми вопросами.
Внедрение структурированных данных может дать вам больше, чем просто лучшее понимание поисковыми системами. Это также делает ваш контент подходящим для расширенных результатов; те блестящие результаты со звездами или деталями, которые выделяются в результатах поиска.
7. Плюс: карта сайта XML
Проще говоря, карта сайта XML представляет собой список всех страниц вашего сайта. Он служит дорожной картой для поисковых систем на вашем сайте. С его помощью вы убедитесь, что поисковые системы не пропустят важный контент на вашем сайте. XML-карта сайта часто классифицируется по сообщениям, страницам, тегам или другим пользовательским типам сообщений и включает количество изображений и дату последнего изменения для каждой страницы.
В идеале веб-сайту не нужна карта сайта в формате XML. Если у него есть внутренняя структура ссылок, которая хорошо связывает весь контент, роботам это не понадобится. Однако не все сайты имеют хорошую структуру, и карта сайта в формате XML не принесет никакого вреда. Поэтому мы всегда советуем иметь карту сайта в формате XML на вашем сайте.
Если у него есть внутренняя структура ссылок, которая хорошо связывает весь контент, роботам это не понадобится. Однако не все сайты имеют хорошую структуру, и карта сайта в формате XML не принесет никакого вреда. Поэтому мы всегда советуем иметь карту сайта в формате XML на вашем сайте.
8. Плюс: международные веб-сайты используют hreflang
Если ваш сайт ориентирован на более чем одну страну или несколько стран, где говорят на одном языке, поисковым системам потребуется небольшая помощь, чтобы понять, какие страны или языки вы пытаетесь охватить. Если вы поможете им, они смогут показать людям нужный веб-сайт для их области в результатах поиска.
Теги Hreflang помогут вам в этом. Вы можете использовать их, чтобы определить, для какой страны и языка предназначена каждая страница. Это также решает возможную проблему дублирования контента: даже если ваши сайты в США и Великобритании показывают одинаковый контент, Google будет знать, что они написаны для разных регионов.
Оптимизация международных веб-сайтов — это особая специализация. Если вы хотите узнать, как повысить рейтинг своих международных сайтов, мы советуем вам ознакомиться с нашим многоязычным тренингом по поисковой оптимизации.
Хотите узнать больше об этом?
Итак, вкратце, что такое техническое SEO. Это уже довольно много, в то время как мы только поцарапали поверхность здесь. Можно еще многое рассказать о технической стороне SEO!
Хотите узнать больше? У нас есть отличная коллекция обучающих курсов SEO в академии Yoast SEO, включая структурированные данные для начинающих. Кроме того, мы только что добавили новый учебный курс по технической оптимизации, посвященный настройке хостинга и сервера (для WordPress), а также возможности сканирования и индексации.
Хотите узнать все ? Получите Yoast SEO Premium и получите полный доступ ко всем нашим обучающим курсам!
Продолжайте читать: Как научиться SEO: руководство для любого уровня подготовки »
Пройдите наш технический тест по SEO
Это еще не все! Вы также можете пройти нашу викторину по техническому SEO, если хотите узнать, насколько соответствует техническому SEO ваш сайт. Этот тест поможет вам понять, над чем вам нужно поработать, и укажет вам правильное направление, чтобы начать улучшать свой сайт.
Этот тест поможет вам понять, над чем вам нужно поработать, и укажет вам правильное направление, чтобы начать улучшать свой сайт.
Подробнее: WordPress SEO: полное руководство »
Виллемьен Халлебек
Виллемьен является менеджером контента yoast.com. Ей нравится создавать удобный для пользователя контент и делать его легким для поиска людьми и поисковыми системами.
Техническое SEO: Полное руководство
Это полное руководство по техническому SEO.
В этом совершенно новом руководстве вы узнаете все о:
- Сканировании и индексировании
- XML-карты сайта
- Дублированный контент
- Структурированные данные
- Крафт
- Многое другое
Итак, если вы хотите убедиться, что ваше техническое SEO работает на должном уровне, вы должны извлечь большую пользу из сегодняшнего руководства.
Содержание
Глава 1
Технические основы SEO
Глава 2
Структура и навигация. 0003
0003
ГЛАВА 4
Тонкое и дубликатное содержание
Глава 5
PageSpeed
Глава 6
. 1: Технические основы SEO
Давайте начнем с главы, посвященной основам.
В частности, в этой главе я расскажу, почему техническое SEO по-прежнему СУПЕР важно в 2022 году.0003
Я также покажу вам, что считается (и что не считается) «техническим SEO».
Давайте углубимся.
Что такое техническое SEO?
Техническое SEO — это процесс обеспечения соответствия веб-сайта техническим требованиям современных поисковых систем с целью улучшения органического ранжирования. Важные элементы технического SEO включают сканирование, индексирование, рендеринг и архитектуру веб-сайта.
Почему важно техническое SEO?
У вас может быть лучший сайт с лучшим контентом.
А если у вас проблемы с техническим SEO?
Тогда ты не попадешь в рейтинг.
На самом базовом уровне Google и другие поисковые системы должны иметь возможность находить, сканировать, отображать и индексировать страницы вашего веб-сайта.
Но это поверхностно. Даже если Google индексирует весь контент вашего сайта, это не означает, что ваша работа выполнена.
Это потому, что для того, чтобы ваш сайт был полностью оптимизирован для технического SEO, страницы вашего сайта должны быть безопасными, оптимизированными для мобильных устройств, свободными от дублированного контента, быстрой загрузкой… и тысячей других вещей, которые входят в техническую оптимизацию.
Это не значит, что ваше техническое SEO должно быть идеальным для ранжирования. Это не так.
Но чем проще вы сделаете Google доступ к своему контенту, тем выше ваши шансы на ранжирование.
Как улучшить техническое SEO?
Как я уже сказал, «Техническое SEO» — это не просто сканирование и индексация.
Для улучшения технической оптимизации вашего сайта необходимо учитывать:
- Javascript
- XML-карты сайта
- Архитектура сайта
- Структура URL-адреса
- Структурированные данные
- Жидкое содержимое
- Дублированный контент
- Крафт
- Канонические теги
- 404 страницы
- 301 перенаправление
И я, вероятно, забыл несколько 🙂
К счастью, я расскажу обо всех этих вещах (и многом другом) в оставшейся части этого руководства.
На мой взгляд, структура вашего сайта — это «шаг № 1» любой технической SEO-кампании.
(да еще до сканирования и индексации)
Почему?
Во-первых, многие проблемы со сканированием и индексированием происходят из-за плохо спроектированной структуры сайта. Поэтому, если вы сделаете этот шаг правильно, вам не нужно беспокоиться о том, что Google проиндексирует все страницы вашего сайта.
Во-вторых, структура вашего сайта влияет на все, что вы делаете для оптимизации своего сайта… от URL-адресов до карты сайта до использования файла robots.txt для блокировки поисковых систем на определенных страницах.
Суть здесь такова: сильная структура делает любую другую техническую SEO-задачу НАМНОГО проще.
Итак, приступим к шагам.
Используйте плоскую организованную структуру сайта
Структура вашего сайта — это то, как организованы все страницы вашего сайта.
В общем, вам нужна «плоская» структура. Другими словами: все страницы вашего сайта должны находиться всего в нескольких ссылках друг от друга.
Почему это важно?
Плоская структура позволяет Google и другим поисковым системам легко сканировать 100% страниц вашего сайта.
Это не имеет большого значения для блога или сайта местной пиццерии. Но для сайта электронной коммерции с 250 000 страниц продуктов? Плоская архитектура — это БОЛЬШОЕ дело.
Вы также хотите, чтобы ваша структура была суперорганизованной .
Другими словами, вам не нужна такая архитектура сайта:
Эта беспорядочная структура обычно создает «страницы-сироты» (страницы без каких-либо внутренних ссылок, указывающих на них).
Это также затрудняет идентификацию и устранение проблем с индексацией.
Вы можете использовать функцию Semrush «Аудит сайта», чтобы получить представление о структуре вашего сайта с высоты птичьего полета.
Это полезно. Но это не супер визуально.
Но это не супер визуально.
Чтобы получить более наглядное представление о том, как ваши страницы связаны друг с другом, воспользуйтесь Visual Site Mapper.
Это бесплатный инструмент, который дает вам интерактивный взгляд на архитектуру вашего сайта.
Согласованная структура URL-адресов
Нет необходимости слишком долго продумывать структуру URL-адресов. Особенно, если вы ведете небольшой сайт (например, блог).
Тем не менее, вы хотите, чтобы ваши URL-адреса следовали последовательной логической структуре. Это на самом деле помогает пользователям понять, «где» они находятся на вашем сайте.
И размещение ваших страниц в разных категориях дает Google дополнительный контекст о каждой странице в этой категории.
Например, все страницы нашего Центра SEO-маркетинга содержат подпапку «/hub/seo», чтобы Google знал, что все эти страницы относятся к категории «Центр SEO-маркетинга».
Вроде работает. Если вы погуглите «SEO Marketing Hub», вы заметите, что Google добавляет в результаты дополнительные ссылки.
Как и следовало ожидать, все страницы, на которые ссылаются эти дополнительные ссылки, находятся внутри хаба.
Навигация по хлебным крошкам
Ни для кого не секрет, что навигация по хлебным крошкам очень удобна для SEO.
Это потому, что хлебные крошки автоматически добавляют внутренние ссылки в категории и подстраницы на вашем сайте.
Помогает укрепить архитектуру вашего сайта.
Не говоря уже о том, что Google превратил URL-адреса в навигацию в стиле «хлебных крошек» в поисковой выдаче.
Поэтому, когда это имеет смысл, я рекомендую использовать навигационную цепочку.
Глава 3: Сканирование, рендеринг и индексированиеЭта глава посвящена тому, чтобы поисковым системам было СУПЕР легко находить и индексировать весь ваш сайт.
В этой главе я покажу вам, как находить и исправлять ошибки сканирования… и как отправлять роботов поисковых систем на глубокие страницы вашего веб-сайта.
Проблемы с точечным индексированием
Первым делом нужно найти страницы на вашем сайте, которые поисковые роботы не могут просканировать.
Вот 3 способа сделать это.
Отчет о покрытии
Ваша первая остановка должна быть «Отчет о покрытии» в консоли поиска Google.
Этот отчет позволяет узнать, не удается ли Google полностью проиндексировать или отобразить страницы, которые вы хотите проиндексировать.
Screaming Frog
Screaming Frog — самый известный в мире краулер по одной причине: он очень, очень хорош.
Итак, как только вы исправите все ошибки в отчете о покрытии, я рекомендую запустить полное сканирование с помощью Screaming Frog.
Аудит сайта Semrush
У Semrush есть очень хороший инструмент SEO аудита сайта.
Что мне больше всего нравится в этой функции, так это то, что вы получаете информацию об общем техническом состоянии SEO вашего сайта.
Отчет о производительности сайта.
И проблемы с HTML-тегами вашего сайта.
У каждого из этих 3 инструментов есть свои плюсы и минусы. Поэтому, если вы запускаете большой сайт с более чем 10 000 страниц, я рекомендую использовать все три этих подхода. Таким образом, ничего не проваливается сквозь трещины.
Внутренняя ссылка на «глубокие» страницы
У большинства людей нет проблем с индексацией домашней страницы.
Именно эти глубокие страницы (страницы, которые являются несколькими ссылками с главной страницы) обычно вызывают проблемы.
Плоская архитектура обычно предотвращает появление этой проблемы. Ведь ваша «самая глубокая» страница будет всего в 3-4 кликах от главной страницы.
В любом случае, если есть определенная глубокая страница или набор страниц, которые вы хотите проиндексировать, ничто не сравнится со старой доброй внутренней ссылкой на эту страницу.
Особенно, если страница, на которую вы ссылаетесь из , имеет большой авторитет и постоянно сканируется.
Используйте XML-карту сайта
В наш век мобильной индексации и AMP нужна ли Google карта сайта в формате XML для поиска URL-адресов вашего сайта?
Ага.
Фактически, представитель Google недавно заявил, что карты сайта в формате XML являются «вторым по важности источником» для поиска URL-адресов.
(Первый? Не сказали. Но предполагаю внешние и внутренние ссылки).
Если вы хотите дважды проверить, все ли в порядке с вашей картой сайта, перейдите к функции «Карты сайта» в Search Console.
Это покажет вам карту сайта, которую Google видит для вашего сайта.
GSC «Inspect»
URL вашего сайта не индексируется?
Что ж, функция проверки GSC может помочь вам докопаться до сути вещей.
Он не только скажет вам, почему страница не индексируется…
Но для страниц, которые проиндексированы, вы можете увидеть, как Google отображает страницу.
Таким образом, вы можете еще раз убедиться, что Google может сканировать и индексировать 100% контента на этой странице.
Если вы пишете уникальный оригинальный контент для каждой страницы своего сайта, вам, вероятно, не нужно беспокоиться о дублирующемся контенте.
Тем не менее:
Технически дублированный контент может появиться на любом сайте… особенно если ваша CMS создала несколько версий одной и той же страницы с разными URL-адресами.
То же самое и с тонким контентом: для большинства веб-сайтов это не проблема. Но это может повредить общему рейтингу вашего сайта. Так что стоит найти и исправить.
В этой главе я покажу вам, как заблаговременно устранять проблемы с дублированием и недостатком контента на вашем сайте.
Используйте инструмент SEO-аудита для поиска дублирующегося контента
Есть два инструмента, которые отлично справляются с поиском дублированного и некачественного контента.
Первый — аудитор сайта Raven Tools.
Сканирует ваш сайт на наличие дублирующегося контента (или некачественного контента). И позволяет узнать, какие страницы необходимо обновить.
И позволяет узнать, какие страницы необходимо обновить.
Инструмент аудита сайта Semrush также имеет раздел «Качество контента», который показывает, имеет ли ваш сайт одинаковый контент на нескольких разных страницах.
Тем не менее:
Эти инструменты сосредоточены на дублировании контента на вашем собственном веб-сайте.
«Повторяющийся контент» также охватывает страницы, которые копируют контент с других сайтов .
Чтобы дважды проверить уникальность контента вашего сайта, я рекомендую функцию «Пакетный поиск» Copyscape.
Здесь вы загружаете список URL-адресов и видите, где этот контент появляется в Интернете.
Если вы найдете фрагмент текста, который отображается на другом сайте, найдите этот текст в кавычках.
Если Google показывает вашу страницу первой в результатах, они считают вас первоначальным автором этой страницы.
И все готово.
Примечание: Если другие люди копируют ваш контент и размещают его на своем веб-сайте, это их проблема дублированного контента. Не ваша. Вам нужно беспокоиться только о контенте на вашем сайте, который скопирован (или очень похож) на контент с других сайтов.
Не ваша. Вам нужно беспокоиться только о контенте на вашем сайте, который скопирован (или очень похож) на контент с других сайтов.
Noindex Страницы с неуникальным содержимым
На большинстве сайтов будут страницы с дублирующимся содержимым.
И это нормально.
Это становится проблемой, когда страницы с повторяющимся содержанием индексируются .
Решение? Добавьте тег «noindex» на эти страницы.
Тег noindex указывает Google и другим поисковым системам не индексировать страницу.
Вы можете дважды проверить правильность настройки тега noindex, используя функцию «Проверить URL» в GSC.
Вставьте свой URL-адрес и нажмите «Проверить URL-адрес в реальном времени».
Если Google все еще индексирует страницу, вы увидите сообщение «URL доступен для Google». Это означает, что ваш тег noindex настроен неправильно.
Но если вы видите сообщение «Исключено тегом noindex», значит, тег noindex выполняет свою работу.
(Это один из немногих случаев, когда вы ХОТИТЕ увидеть красное сообщение об ошибке в GSC 🙂 )
В зависимости от вашего краулингового бюджета Google может занять несколько дней или недель, чтобы повторно просканировать страницы, которые вам не нужны. не хочу индексировать.
Поэтому я рекомендую проверить вкладку «Исключено» в отчете о покрытии, чтобы убедиться, что ваши неиндексированные страницы удаляются из индекса.
Например, некоторые сообщения на Backlinko содержат комментарии, разбитые на страницы.
И на каждой странице комментариев есть оригинальный пост в блоге.
Если бы эти страницы были проиндексированы Google, у нас были бы проблемы с дублированием контента.
Вот почему мы добавляем тег noindex на каждую из этих страниц.
Примечание: Вы также можете полностью запретить поисковым роботам сканировать страницу, заблокировав их отдельные поисковые роботы в файле robots.txt.
Использовать канонические URL-адреса
К большинству страниц с дублирующимся содержимым следует добавить старую метку no index. Или замените повторяющийся контент уникальным контентом.
Или замените повторяющийся контент уникальным контентом.
Но есть и третий вариант: канонические URL.
Канонические URL идеально подходят для страниц с очень похожим содержанием… с небольшими различиями между страницами.
Допустим, вы управляете сайтом электронной коммерции, на котором продаются головные уборы.
И у вас есть страница продукта, настроенная только для ковбойских шляп.
В зависимости от того, как настроен ваш сайт, каждый размер, цвет и вариация могут привести к разным URL-адресам.
Нехорошо.
К счастью, вы можете использовать тег canonical, чтобы сообщить Google, что ванильная версия страницы вашего продукта является «основной». А все остальные — вариации.
Глава 5: PageSpeed Повышение скорости страницы — одна из немногих технических стратегий SEO, которые могут напрямую повлиять на рейтинг вашего сайта.
Это не значит, что быстро загружаемый сайт поднимет вас на вершину первой страницы Google.
(Для этого вам нужны обратные ссылки)
Но повышение скорости загрузки вашего сайта может существенно повлиять на ваш органический трафик.
В этой главе я покажу вам 3 простых способа увеличить скорость загрузки вашего сайта.
Уменьшить размер веб-страницы
CDN. Кэш. Ленивая загрузка. Минификация CSS.
Уверен, вы уже тысячу раз читали об этих подходах.
Но я не вижу, чтобы так много людей говорили о столь же важном факторе скорости страницы:
Размер веб-страницы.
На самом деле, когда мы провели крупномасштабное исследование скорости страницы, мы обнаружили, что общий размер страницы коррелирует со временем загрузки больше, чем любой другой фактор .
Вывод таков:
Когда дело доходит до скорости страниц, бесплатных обедов не бывает.
Вы можете сжимать изображения и кэшировать ваш сайт.
Но если ваши страницы огромны, то их загрузка займет некоторое время.
Это то, с чем мы боремся здесь, в Backlinko. Поскольку мы используем много изображений в высоком разрешении, наши страницы имеют тенденцию быть огромными.
Поскольку мы используем много изображений в высоком разрешении, наши страницы имеют тенденцию быть огромными.
Я сознательно решил жить с более медленной загрузкой. Я предпочитаю медленную, красиво выглядящую страницу быстрой странице с зернистыми изображениями.
Что ухудшает наши оценки в Google PageSpeed Insights.
Но если повышение скорости вашего сайта является главным приоритетом, вы должны сделать все возможное, чтобы уменьшить общий размер вашей страницы.
Тестовое время загрузки с CDN и без него
Одним из самых удивительных результатов нашего исследования скорости загрузки страниц было то, что CDN были связаны с худшим временем загрузки.
Вероятно, это связано с тем, что многие CDN настроены неправильно.
Итак, если ваш сайт использует CDN, я рекомендую проверить скорость вашего сайта на webpagetest.org с включенной или выключенной CDN.
Устранение сторонних скриптов
Каждый сторонний скрипт, который есть на странице, увеличивает время загрузки страницы в среднем на 34 мс.
Некоторые из этих скриптов (например, Google Analytics) вам наверняка понадобятся.
Но никогда не помешает просмотреть скрипты вашего сайта, чтобы увидеть, есть ли какие-то, от которых можно избавиться.
Глава 6: Дополнительные технические советы по SEOТеперь пришло время дать несколько быстрых технических советов по SEO.
В этой главе мы рассмотрим перенаправления, структурированные данные, Hreflang и многое другое.
Внедрение hreflang для международных веб-сайтов
Существуют ли на вашем сайте разные версии страницы для разных стран и языков?
Если это так, тег hreflang может оказать ОГРОМНУЮ помощь.
Единственная проблема с тегом hreflang?
Сложно настроить. И документация Google о том, как его использовать, не очень ясна.
Введите: Генератор Hreflang Алейды Солис.
Этот инструмент позволяет (относительно) легко создать тег hreflang для нескольких стран, языков и регионов.
Проверьте свой сайт на наличие неработающих ссылок
Наличие множества неработающих ссылок на вашем сайте не улучшит и не сломает вашу поисковую оптимизацию.
На самом деле, Google даже сказал, что неработающие ссылки «не являются проблемой SEO».
А если у вас битые внутренние ссылки?
Это другая история.
Неработающие внутренние ссылки могут затруднить роботу Googlebot поиск и сканирование страниц вашего сайта.
Поэтому я рекомендую проводить ежеквартальный SEO-аудит, который включает исправление неработающих ссылок.
Вы можете найти неработающие ссылки на своем сайте, используя практически любой инструмент SEO-аудита, например Semrush:
или Screaming Frog.
Как видите, проблем у меня нет. Что я могу сказать? Я хорошо разбираюсь в SEO 😉
Настройка структурированных данных
Считаю ли я, что настройка Schema напрямую помогает SEO вашего сайта?
№
На самом деле, наше исследование факторов ранжирования поисковой системы не обнаружило корреляции между рейтингом Schema и первой страницы.
Сказал:
Использование Schema МОЖЕТ предоставить расширенные фрагменты некоторых ваших страниц.
И поскольку расширенные сниппеты выделяются в поисковой выдаче, они могут значительно улучшить ваш органический рейтинг кликов.
Проверка XML-файлов Sitemap
Если у вас огромный сайт, сложно отслеживать все страницы в карте сайта.
Фактически, многие карты сайта, которые я просматриваю, имеют страницы с кодами состояния 404 и 301. Учитывая, что основная цель вашей карты сайта — показать поисковым системам все ваши живые страницы, вы хотите, чтобы 100% ссылок в вашей карте сайта указывали на живые страницы.
Поэтому я рекомендую запустить вашу карту сайта через Map Broker XML Sitemap Validator.
Просто введите карту сайта с вашего сайта.
И посмотрите, не работают ли какие-либо из ваших ссылок или перенаправляют.
Страницы тегов и категорий без индексации
Если ваш сайт работает на WordPress, я настоятельно рекомендую не индексировать страницы категорий и тегов.
(Если, конечно, эти страницы не приносят много трафика).
Эти страницы обычно не представляют большой ценности для пользователей. И они могут вызвать проблемы с дублированием контента.
Если вы используете Yoast, вы можете легко запретить индексацию этих страниц одним щелчком мыши.
Проверка на наличие проблем с юзабилити для мобильных устройств
Сейчас 2022 год. Так что мне не нужно говорить вам, что ваш сайт должен быть оптимизирован для мобильных устройств.
Тем не менее:
Даже сайты, оптимизированные для мобильных устройств, могут столкнуться с проблемами.
И если пользователи не начнут присылать вам жалобы по электронной почте, эти проблемы будет трудно обнаружить.
То есть, если вы не используете отчет Google Search Console об удобстве использования мобильных устройств.
Если Google обнаружит, что страница на вашем сайте не оптимизирована для мобильных пользователей, они дадут вам об этом знать.
Они даже сообщают вам о конкретных ошибках на странице.
Таким образом, вы точно знаете, что нужно исправить.
Дополнительная глава: Примеры технического SEOДавайте завершим это руководство набором совершенно новых тематических исследований технического SEO.
В частности, вы увидите, как четыре читателя Backlinko повысили свой рейтинг в Google на:
- Схема даты
- Внутренняя связь
- Схема часто задаваемых вопросов
- Передовой опыт миграции веб-сайтов
Итак, без лишних слов, давайте сразу приступим к изучению конкретных случаев.
Пример из практики #1
Как Феликс использовал внутренние ссылки для увеличения органического трафика на 250 %
Когда Феликс Нортон проводил аудит веб-сайта одного из своих клиентов (рынок найма для проведения мероприятий) на предмет технических проблем с поисковой оптимизацией, он заметил одну вещь:
Они не использовали никаких внутренних ссылок! И внутренние ссылки, которые сайт ДЕЙСТВУЕТ, не используют анкорный текст, богатый ключевыми словами.
К этому моменту этот клиент проработал в агентстве Феликса 3 месяца. Феликс и его команда публиковали ТОННУ высококачественного контента в блоге своего клиента. Но трафик и рейтинги оставались на прежнем уровне.
Что ж, во время этого аудита Феликс понял, что ни один из этих удивительных материалов не связан вместе. Хуже того: в контенте не было ссылок на важные страницы товаров и услуг.
Именно тогда Феликс решил добавить внутренние ссылки к своим высокоприоритетным материалам.
Страницы товаров.
И части связанного содержания.
Что привело к увеличению трафика на 250% в течение недели после добавления этих стратегических внутренних ссылок.
Пример из практики #2
Как Салман использовал схему дат, чтобы удвоить трафик своей страницы в Google
Читатель Backlinko Салман Бейг управляет сайтом технических обзоров под названием Voxel Reviews.
Одним из самых важных ключевых слов Салмана является «Лучшие игровые ноутбуки до 500».
Это может звучать как ключевое слово с длинным хвостом. Потому что это так.
Но это узкоспециализированное ключевое слово с высоким поисковым намерением. Это означает, что время Салмана стоило того, чтобы найти способ повысить рейтинг этого термина.
И когда он просмотрел поисковую выдачу по этому ключевому слову, он увидел возможность. Возможность, которую он мог использовать для технического SEO.
В частности, он заметил, что большинство страниц на первой странице имеют текущий месяц и год в теге title.
Однако многие из этих страниц на самом деле не обновляли страницу (или дату «публикации» в своем HTML).
Например, эта страница добавляет текущий месяц к тегу заголовка, как по часам.
Но если вы ищете URL-адрес этой страницы с диапазоном дат…
… вы можете увидеть фактическую дату, которую Google сохранил для этой статьи:
Это была возможность, которую увидел Салман:
Добавление текущего месяца к своему заголовку тег может помочь его органическому CTR. Но Google явно игнорирует это.
Но Google явно игнорирует это.
Но если Google увидит, что страница Салмана действительно обновлена, он может подняться в рейтинге.
И чтобы показать Google, что его страница действительно актуальна, он добавил дату вверху своего поста.
Он также обновил свою схему, чтобы обновить даты «datePublished» и «dateModified».
Это изменение помогло сайту Салмана попасть в Featured Snippet.
Этот избранный фрагмент, а также повышение рейтинга его целевого ключевого слова увеличили трафик на эту страницу более чем на 200%.
Практический пример № 3
Как Нил обратил вспять катастрофическую миграцию веб-сайта
SEO-агентство Нила Шета, Only Way Online, взяло на себя нового клиента, рейтинг которого полностью упал.
Как оказалось сайт перевел свой сайт на последнюю версию Magento.
Они также решили объединить эту миграцию с несколькими изменениями на своем веб-сайте (например, удаление URL-адресов, которые получали поисковый трафик) без учета влияния на обычный поиск.
За 2 месяца посещаемость сайта увеличилась с 30 000 до 3 000 посетителей в месяц.
И когда Нил провел полный SEO-аудит сайта, чтобы выяснить, что пошло не так, он обнаружил множество технических проблем SEO, таких как:
- Страницы без внутренних ссылок, указывающих на них (страницы-сироты)
- Страницы, которые канонизировались до неиндексируемых страниц
- Страницы перенаправляются на страницу, которая затем перенаправляется на другую страницу (цепочки перенаправления)
- Неработающие внутренние и внешние ссылки
- Карта сайта, включающая страницы, которые не следует индексировать
- Плохо оптимизированные теги title и description
И вы можете начать видеть всплеск органического трафика в течение нескольких недель после этих технических исправлений SEO.
Фактически, с июля 2019 года по октябрь сайт увеличил органический трафик на 228%.
Практический пример #4
Как Билл увеличил количество кликов на 15,23% с помощью схемы часто задаваемых вопросов
Билл Видмер ведет блог о жилых автофургонах под названием The Wandering RV.