Французский публицист: На антироссийских планах поставлен жирный крест
Свежий номер
РГ-Неделя
Родина
Тематические приложения
Союз
Свежий номер
27.02.2022 21:10
Рубрика:
В мире
Вячеслав Прокофьев (Париж)
Французский предприниматель, публицист Ален Бенажам знает Донбасс не понаслышке. Вместе со своим товарищем Андре Шанклю в середине десятых годов он основал ассоциацию «Коллектив Франция-Донбасс» и в этом качестве организовывал акции в поддержку ЛНР и ДНР в Париже и других городах. Своими мыслями по поводу нынешних судьбоносных событий на Украине он поделился с «Российской газетой».
РИА Новости
— Вы спрашиваете, как я отношусь к специальной военной операции на Украине? Считаю, что она оправдана. Понимаю, что решение в Москве принималось с тяжелым сердцем, но скорее всего иного выхода из сложившейся на востоке Украины ситуации не было. У меня много друзей, как в Луганске, так и в Донецке. Восемь лет население Донбасса было вынуждено жить фактически на линии фронта. Постоянные бомбардировки, нескончаемый артобстрелы. Тысячи погибли, десятки тысяч получили ранения. Мой близкий друг французский офицер, который сражался на стороне ополченцев, получил тяжелое ранение, подорвавшись на мине, но остался в строю. Так что когда Россия признала обе республики и начала спецоперацию, жители Донбасса вздохнули с облегчением, о чем мне с энтузиазмом говорили все, с кем довелось связаться. Кошмар закончился, тучи стали рассеиваться.
Восемь лет население Донбасса было вынуждено жить фактически на линии фронта. Постоянные бомбардировки, нескончаемый артобстрелы. Тысячи погибли, десятки тысяч получили ранения. Мой близкий друг французский офицер, который сражался на стороне ополченцев, получил тяжелое ранение, подорвавшись на мине, но остался в строю. Так что когда Россия признала обе республики и начала спецоперацию, жители Донбасса вздохнули с облегчением, о чем мне с энтузиазмом говорили все, с кем довелось связаться. Кошмар закончился, тучи стали рассеиваться.
Какие только обвинения сейчас не звучат в адрес России! Потоки брани, а также лжи, сдобренной фейками!
При этом на Западе умалчивают о том, что после государственного переворота в феврале 2014 года к власти в Киеве пришел режим, для которого «национальным героем» и политическим маяком стал Степан Бандера. Тот самый палач, что в годы Второй мировой войны сотрудничал с гитлеровцами, организовывал расправы над евреями, поляками, русскими. И этот режим признали и активно поддерживали как за океаном, так и в западноевропейских столицах.
Конечно, главную роль взяли на себя англосаксы. Для американцев бандеровская Украина являлась тем геополитическим инструментом, что был нацелен на нанесение России непоправимого ущерба, на ее развал. У меня не вызывает сомнения, что в их планы входило вовлечение Украины в НАТО, последующее устройство военных баз, захват Крыма с его стратегическим положением. Большой геополитический проект. Причем с давней предысторией. Достаточно хотя бы вспомнить сделанное в нулевых годах заявление Мадлен Олбрайт, госсекретаря США в администрации Клинтона, о том, что единоличное обладание Россией Сибирью со всеми ее богатствами «несправедливо». От американцев недалеко ушли ближайшие союзники — англичане. Русофобия тамошних элит хорошо известна. Тянется еще с давних пор, когда в середине XIX века Лондон развязал Крымскую войну против России, а еще раньше плел заговоры против российских царей. Посмотрите на истерики, который сейчас закатывает Борис Джонсон, и вам все станет понятно.
Будем надеяться, что на этих антироссийских планах сейчас будет поставлен жирный крест.
Надо сказать, что Россия долгое время пыталась решить вопрос Донбасса дипломатическим путем, проявляя невероятное терпение. Убежден, что нынешняя силовая акция — вынужденный шаг. В условиях, когда все дипломатические ресурсы были исчерпаны, и в Москве убедились, что Киев при попустительстве Парижа и Берлина наотрез отказывался от компромисса в рамках Минских договоренностей. Нарыв надо было ликвидировать. К сожалению, приходится это делать хирургическим путем.
И вот что еще я хотел сказать. В очередной раз Евросоюз в целом и входящие в него страны продемонстрировали свою вассальскую зависимость от США. Они не только поддержали «адские» санкции против России, но и запустили свои собственные. У меня была надежда, что свойственную немцам рассудительность и сдержанность проявит новый канцлер. Но и Олаф Шольц прогнулся, распорядившись остановить «Северный поток-2», тем самым, как говорится, выстрелив себе в ногу. Ведь сотрудничать с Россией в области природного газа жизненно важный интерес Германии особенно в условиях тотального отказа от АЭС.
Что касается нового пакета антироссийских санкций, то они бумерангом ударят по Европе, как это было в 2014 году. Тогда пострадало наше сельское хозяйство, а Россия получила стимул поднять свое. Надо думать, что подобное произойдет и сейчас, но уже в других областях экономики.
Российская газета — Федеральный выпуск: №42(8690)
ФранцияСпециальная военная операция по защите ДНР и ЛНР
Главное сегодня
О чем говорил Владимир Путин в Послании. Главное
МО РФ: ВКС России поразили цех производства крупнокалиберных минометов под Сумами
Захарова обвинила Запад в осознанном разрушении международной системы безопасности
Bloomberg: США передадут Украине дальнобойные авиабомбы Jdam-ER с GPS
ФСБ предотвратила диверсию на участке железной дороги в Югре
Подполковник армии США Дэвис назвал поездку Байдена в Киев постановочной
Получите свободное владение уценкой. Вы наверняка слышали о Markdown… | by Shivangi Sareen
Вы наверняка слышали о Markdown.
 Когда-нибудь использовали его? Если нет, то вы должны начать. Сейчас. И это полностью изменит способ ввода обычного текста. Photo by Chris Leggat on Unsplash
Когда-нибудь использовали его? Если нет, то вы должны начать. Сейчас. И это полностью изменит способ ввода обычного текста. Photo by Chris Leggat on UnsplashMarkdown — это синтаксис форматирования, используемый для ввода обычного текста. Это самый простой способ добавить к обычному тексту форматирование, такое как заголовки, полужирный текст, курсив, упорядоченные и неупорядоченные списки, изображения, ссылки, сегменты кода и т. д. Вот некоторые из МНОГО причин начать печатать в Markdown-
- Он может похвастаться ключевой особенностью — возможностью использовать
HTML. Такие теги, как
...
...
- Это ТАК ЛЕГКО и ТАК ПРИЯТНО читать.
- Это везде . Это стандарт по умолчанию (неофициальный), используемый на Github. Markdown принимается на всех видах веб-сайтов, включая Medium.
 Любой контент, написанный в Markdown, можно экспортировать, не нарушая форматирования.
Любой контент, написанный в Markdown, можно экспортировать, не нарушая форматирования. - Он не исчезнет в ближайшее время. В конце концов, это обычный текстовый формат, который никуда не денется.
- С помощью Markdown вы можете использовать возможности текстового процессора без текстового процессора, используя только клавиатуру.
 Любой контент, написанный в Markdown, можно экспортировать, не нарушая форматирования.
Любой контент, написанный в Markdown, можно экспортировать, не нарушая форматирования.Уценка — это очень важно. Насколько важно учиться?
Уценка — это не что иное, как использование специальных символов для форматирования. Взгляни.
Заголовки:
Размер заголовка определяется количеством знаков решетки ( # ) перед текстом.
# Заголовок 1 : Соответствует самому большому размеру. Это то же самое, что использовать в HTML .
## Заголовок 2 : соответствует использованию в HTML .
### Заголовок 3 : Соответствует использованию в HTML .
… и так до .
Пункты:
Markdown автоматически определяет абзац с каждой пустой строкой. Это то же самое, что использовать HTML .
Полужирный и курсив:
Просто заключите текст между двойной звездочкой ( **text** ) или двумя знаками подчеркивания ( __text__ ) для жирного текста. Чтобы выделить текст курсивом, используйте одиночные звездочки ( *text* ) или символы подчеркивания ( _text_ ) до и после текста.
Я **люблю** _писать_ в __Markdown__.
Слова «любовь» и «уценка» будут выделены жирным шрифтом. Слово «письмо» будет выделено курсивом.
Для объединения используйте три звездочки или три символа подчеркивания ( ***текст*** ) или ( ___текст___ ). Также можно использовать комбинацию из двух звездочек и одного подчеркивания и наоборот ( **_text_** ).
Цитаты:
Чтобы сделать абзац цитатой, просто добавьте > перед текстом. Это эквивалентно использованию » 9Вариант 0008 в Medium.
Это эквивалентно использованию » 9Вариант 0008 в Medium.
Упорядоченные списки:
Используйте числа с точками перед каждым элементом списка. Это эквивалентно использованию ...
HTML .
Ненумерованные списки:
Используйте - , + , * перед каждым элементом списка. Добавьте вкладки для отступов вложенных списков, как упорядоченных, так и неупорядоченных.
Код:
Заключите код между обратными кавычками (`text`), чтобы добавить встроенный код. Это эквивалентно использованию в ... HTML .
Это еще не все! Вышеизложенного достаточно для начала. Узнайте больше о синтаксисе Markdown здесь.
Уценка — это так просто! Всего несколько специальных символов, и вы сможете с легкостью отформатировать обычный текст. Не забудьте сохранить файл с расширением .md .
Любой текстовый редактор поддерживает Markdown. Посмотрите Типору.
Примечание. Эта статья была написана с использованием Markdown.
Детали конвейера обработки — документация по версии fmriprep
fMRIPrep адаптирует свой конвейер в зависимости от того, какие данные и метаданные
доступны и используются в качестве входных данных.
Например, временная коррекция среза будет
выполняется только в том случае, если для входных данных найдено поле метаданных SliceTiming .
набор данных.
(очень) общий вид простейшего конвейера (для одноканального набора данных только с одна задача, однократный запуск, без информации о синхронизации срезов и получения карты поля) представлен ниже:
(Исходный код)
Предварительная обработка структурной МРТ
Анатомический подпроцесс начинается с построения среднего изображения путем
согласование всех найденных изображений T1w с ориентацией RAS и
общий размер вокселя, а в случае нескольких изображений усредняет их в
единый эталонный шаблон (см. Продольная обработка).
Продольная обработка).
(Исходный код)
Важно
Иногда открытые наборы данных могут содержать предварительно обработанные анатомические изображения
как бы необработанные.
В случае изображений T1w, извлеченных из мозга (череп зачищен), попытка выполнить
повторная экстракция мозга часто будет иметь плохие результаты и может вызвать ---skull-strip-t1w auto .
Если эта эвристика не работает, и вы знаете, что ваши изображения лишены черепа, вы можете пропустить мозг.
извлечение с помощью --skull-strip-t1w skip .
Точно так же, если вы знаете, что ваши изображения не лишены черепа и эвристика неверна.
определяет, что они есть, вы можете принудительно снять череп с помощью --череп-полоса-t1w сила ,
что является текущим поведением по умолчанию.
См. также sMRIPrep init_anat_preproc_wf() .
Маскирование функции стоимости при пространственной нормализации
При обработке изображений пациентов с очаговыми поражениями головного мозга (например, инсульт, опухолевые
резекции), можно обеспечить маску поражения, которая будет использоваться во время пространственного
нормализация к стандартному пространству [Brett2001].
Муравьи будут использовать эту маску, чтобы свести к минимуму деформацию здоровой ткани в поврежденную.
площади (или наоборот).
Маски поражений должны быть бинарными изображениями NIfTI (поврежденные области = 1, везде = 0)
в том же пространстве и разрешении, что и изображение T1, и следуйте соглашению об именах, указанному в
Предложение расширения BIDS 3: общие производные инструменты
(например, sub-001_T1w_label-lesion_roi.nii.gz ).
Этот файл следует поместить в каталог sub-*/anat набора данных BIDS.
для запуска через fMRIPrep .
.bidsignore в корень каталога вашего набора данных. Это предотвратит
бид-валидатор от жалоб
что ваш набор данных не является действительным BIDS, что препятствует запуску fMRIPrep .
Ваш .bidsignore файл должен содержать следующую строку:*lesion_roi.nii.gz
Продольная обработка
В случае нескольких образов T1w (для сеансов и/или прогонов) изображения T1w
объединены в единое изображение шаблона с помощью mri_robust_template FreeSurfer.
Этот шаблон может быть несмещенным или равноудаленным от всех исходных изображений, или
выровнено по первому изображению (определяется лексикографически по метке сеанса).
Для двух изображений дополнительные затраты на оценку несмещенного шаблона тривиальны,
но выравнивание трех или более изображений слишком дорого, чтобы оправдать поведение по умолчанию.
Для согласованности, в случае нескольких изображений, конструкций fMRIPrep шаблоны выровнены по первому изображению, если не передан --longitudinal флаг, который принудительно оценивает беспристрастный шаблон.
Примечание
Предварительно обработанное изображение T1w определяет пространство T1w .
В случае нескольких изображений T1w это пространство может быть не точно выровнено.
с любым исходным изображением.
Реконструированные поверхности и наборы функциональных данных будут зарегистрированы в T1w пространство, а не входные изображения.
Предварительная обработка поверхности
fMRIPrep использует FreeSurfer для реконструкции поверхностей из T1w/T2w
структурные образы.
Если этот параметр включен, несколько шагов в конвейере --fs-no-reconall .
Примечание
Обработка поверхности будет пропущена, если выходы уже существуют.
Для обхода реконструкции в fMRIPrep разместить существующую реконструированную
предметы в <выходной каталог>/freesurfer перед запуском или указать внешний
каталог предметов с флагом --fs-subjects-dir . fMRIPrep выполнит все недостающие шаги
fMRIPrep выполнит все недостающие шаги recon-all , но не выполнит
любые шаги, выходы которых уже существуют.
Если выполняется реконструкция FreeSurfer, реконструированный объект помещается в <выходной каталог>/freesurfer/sub- (см. производные FreeSurfer).
Реконструкция поверхности выполняется в три этапа.
Первая фаза инициализирует субъекта с помощью T1w и T2w (если доступно).
структурных изображений и выполняет базовую реконструкцию ( autorecon1 ) с
за исключением вскрытия черепа.
Снятие черепа пропускается, поскольку рассчитанная ранее маска мозга вводится в соответствующее место для FreeSurfer.
Например, субъект только с одним сеансом с изображениями T1w и T2w.
будет обработано следующей командой:
$ recon-all -sd <выходной каталог>/freesurfer -subjid sub-\ -i /sub-<метка_темы>/anat/sub-<метка_темы>_T1w.nii.gz \ -T2 /sub-<метка_темы>/anat/sub-<метка_темы>_T2w.
 nii.gz \
-авторекон1 \
-полоса черепа
nii.gz \
-авторекон1 \
-полоса черепа
Второй этап импортирует маску мозга, рассчитанную в
Предварительная обработка структурного подпроцесса МРТ.
Заключительный этап возобновляет реконструкцию с использованием изображения T2w, чтобы помочь
в нахождении пиальной поверхности, если таковая имеется.
См.
Реконструированные белые и пиальные поверхности включены в отчет.
Реконструкция поверхности (FreeSurfer)
Если размеры вокселя T1w меньше 1 мм по всем измерениям (округление до ближайшего
.1 мм), используется субмиллиметровая реконструкция, если только она не отключена с помощью --no-submm-recon .
Если доступны изображения T2w или FLAIR, и вы не хотите, чтобы они
Реконструкция FreeSurfer, используйте --игнорировать t2w или --игнорировать чутье ,
соответственно.
lh.midthickness и rh.midthickness поверхности создаются в теме
Каталог Surf/, соответствующий поверхности на полпути между серым и белым
граница и пиальная поверхность.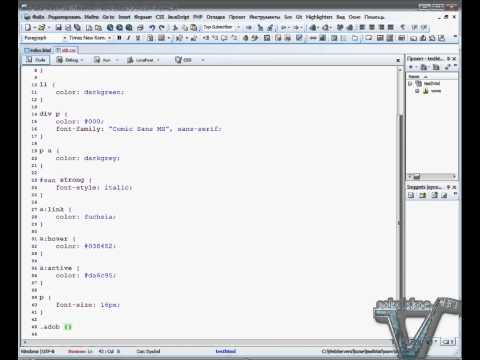
smoothwm , средней толщины , пиал и надутые поверхности также
преобразован в формат GIFTI и настроен для совместимости с несколькими программами
пакеты, включая FreeSurfer и Connectome Workbench.Примечание
Выходные данные поверхности GIFTI выравниваются по изображению FreeSurfer T1.mgz, которое может отличаться от пространства T1w в некоторых случаях для обеспечения совместимости с каталогом FreeSurfer. Любые измерения, взятые на поверхность, учитывают любую разницу в эти изображения.
(Исходный код)
См. также sMRIPrep init_surface_recon_wf()
Доработка маски мозга
Обычно исходная маска мозга рассчитывается с помощью antsBrainExtraction.sh будет содержать некоторые неточности, в том числе небольшое количество МР-сигнала от
вне мозга.
На основе сегментации тканей FreeSurfer (находится в mri/aseg.mgz )
и только когда шаг обработки поверхности был
казнен, aseg., как описано в  mgz
mgz Уточнить мозговую маску .
BOLD предварительная обработка
init_func_preproc_wf()
(Исходный код)
Предварительная обработка файлов BOLD разделить на несколько подпроцессов, описанных ниже.
BOLD оценка эталонного изображения
init_bold_reference_wf()
(Исходный код)
Этот рабочий процесс оценивает эталонное изображение для ЖИРНЫЙ серия.
Если одноканальное эталонное изображение («sbref»), связанное с серией BOLD,
доступен, то он используется напрямую.
Если нет, эталонное изображение оценивается из серии BOLD следующим образом:
Когда эффекты T1-насыщения («фиктивные сканы» или объемы нестационарного состояния)
обнаруживаются, они усредняются и используются в качестве эталонных из-за их
превосходный тканевый контраст.
В противном случае используется медиана подмножества объемов с поправкой на движение.
Эталонное изображение затем используется для расчета маски мозга для BOLD сигнал с использованием NiWorkflows ’ init_enhance_and_skullstrip_bold_wf() .
Далее эталон подается на оценку движения головы.
рабочий процесс и рабочий процесс регистрации для сопоставления
ЖИРНЫЙ ряд в изображение T1w того же объекта.
Расчет мозговой маски из серии BOLD.
Оценка движения головы
init_bold_hmc_wf()
(Исходный код)
Используя предварительно оцененное эталонное сканирование,
FSL mcflirt используется для оценки движения головы.
В результате одно твердотельное преобразование относительно
эталонное изображение написано для каждого  Для более точной оценки движения головы рассчитаем его параметры
перед любой фильтрацией во временной области (т. е. коррекцией времени среза),
как рекомендовано в [Power2017].
Для более точной оценки движения головы рассчитаем его параметры
перед любой фильтрацией во временной области (т. е. коррекцией времени среза),
как рекомендовано в [Power2017].
Коррекция времени сегмента
init_bold_stc_wf()
(Исходный код)
Если поле SliceTiming доступно в метаданных входного набора данных,
этот рабочий процесс выполняет коррекцию времени среза перед другой передискретизацией сигнала
процессы.
Коррекция времени среза выполняется с помощью AFNI 3dTShift .
Все срезы перестраиваются по времени на середину каждого TR.
Коррекция времени среза может быть отключена с помощью --ignore slicetiming аргумент командной строки.
Если в серии BOLD меньше
5 пригодных для использования (установившихся) объемов, коррекция времени среза будет отключена
для этого пробега.
Коррекция искажения восприимчивости (SDC)
Одна из основных проблем, влияющих на данные EPI . пространственное искажение, вызванное неоднородностью поля внутри
сканер.
пространственное искажение, вызванное неоднородностью поля внутри
сканер.
Применение коррекции искажения на основе восприимчивости на основе оценка полевой карты.
Обратите внимание, что все процедуры для коррекции искажений, основанных на восприимчивости, были вырезаны из fMRIPrep для использования в других проектах (например, dMRIPrep). Для получения более подробной документации по СДК подпрограммы, проверьте компонент SDCFlows.
Теория, методы и ссылки находятся в Документация SDCFlows.
Предварительно обработанный жирный шрифт в собственном пространстве
init_bold_preproc_trans_wf()
(Исходный код)
Генерируется новая серия preproc BOLD из скорректированного тайминга слайсов или исходных данных (если STC не применялся) в
оригинальное пространство.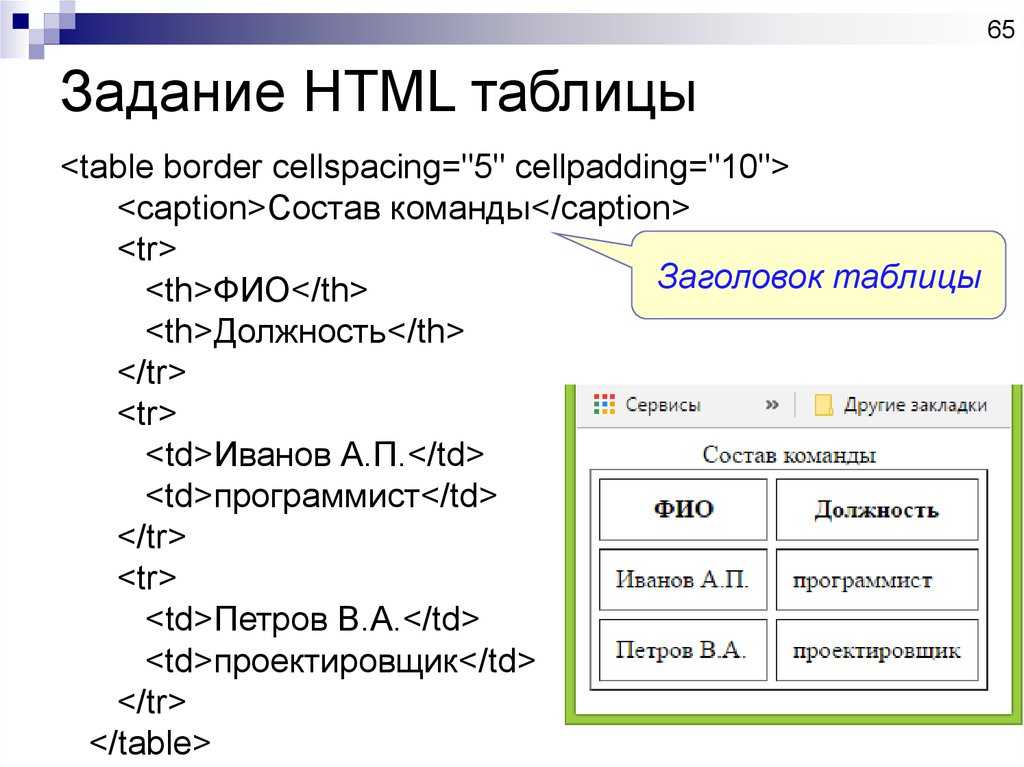 Все тома серии BOLD являются
передискретизированы в их родном пространстве путем объединения отображений, найденных в предыдущих
рабочие процессы коррекции ( HMC и SDC , если выполняется)
для однократного процесса интерполяции.
Интерполяция использует ядро Lanczos.
Все тома серии BOLD являются
передискретизированы в их родном пространстве путем объединения отображений, найденных в предыдущих
рабочие процессы коррекции ( HMC и SDC , если выполняется)
для однократного процесса интерполяции.
Интерполяция использует ядро Lanczos.
EPI для регистрации T1w
init_bold_reg_wf()
(Исходный код)
Выравнивание между эталоном ЭПИ изображение
каждого прогона и реконструированный субъект с использованием границы серого/белого вещества
( ?h.white поверхностей FreeSurfer) вычисляется с помощью подпрограммы bbregister .
Анимация, показывающая регистрацию EPI в T1w (FreeSurfer bbregister )
Если обработка FreeSurfer отключена, запускается FSL flirt с BBR функция стоимости, используя быстрая сегментация для установления границы серого и белого вещества. После BBR выполняется, результирующее аффинное преобразование будет сравниваться с исходным преобразованием, найденным FLIRT.
Чрезмерное отклонение приведет к отклонению уточнения BBR и принятию исходной аффинной регистрации.
После BBR выполняется, результирующее аффинное преобразование будет сравниваться с исходным преобразованием, найденным FLIRT.
Чрезмерное отклонение приведет к отклонению уточнения BBR и принятию исходной аффинной регистрации.
Повторная выборка ЖИРНЫМ шрифтом работает на стандартных пробелах
init_bold_std_trans_wf()
(Исходный код)
Этот подпроцесс объединяет преобразования, вычисленные выше по течению (см.
Оценка движения головы, коррекция искажения восприимчивости (SDC) – если
доступны полевые карты, регистрация EPI в T1w и стандартное анатомическое
преобразование из предварительной обработки структурной МРТ), чтобы отобразить ЭПИ image в стандартные пробелы, заданные аргументом --output-spaces (см. раздел «Определение стандартных и нестандартных пространств, в которых будут производиться повторные выборки данных»).
Он также сопоставляет маску на основе T1w с каждым из этих стандартных пространств.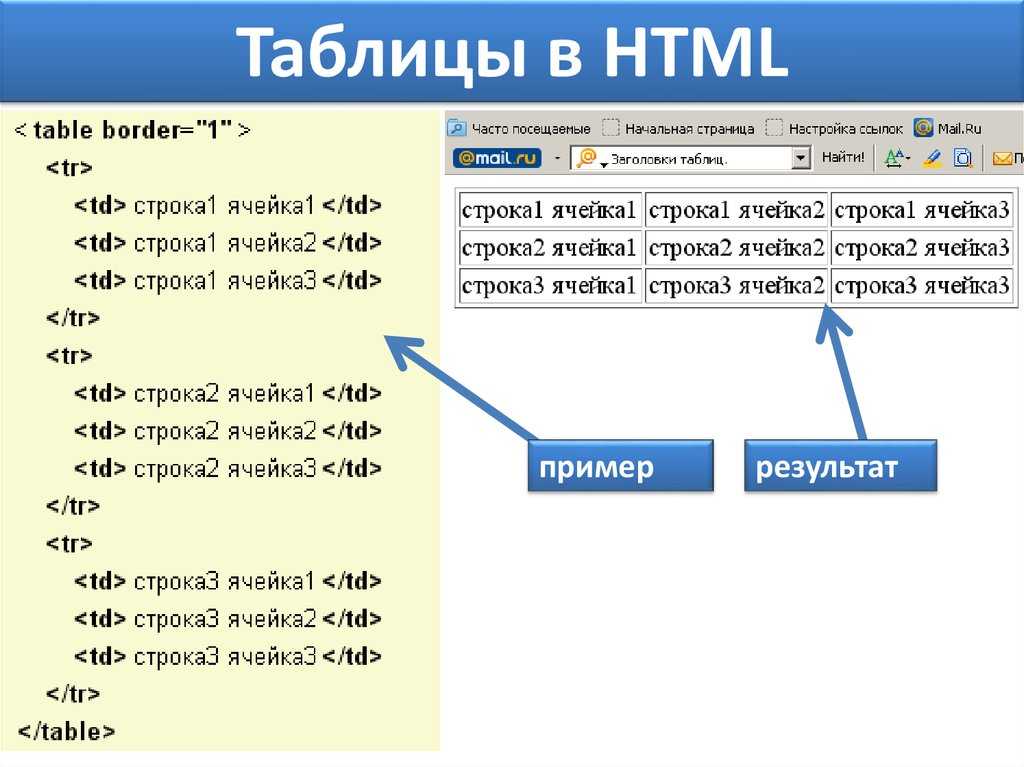
Преобразования объединяются и применяются одновременно, с одной интерполяцией (Ланцош) шаг, чтобы было потеряно как можно меньше информации.
Сетка выходного пространства может быть указана с помощью модификаторов --output-spaces аргумент.
EPI для поверхностей FreeSurfer
init_bold_surf_wf()
(Исходный код)
Если обработка FreeSurfer включена, функциональный ряд с поправкой на движение (после однократной повторной выборки в пространство T1w) сэмплируется в поверхности путем усреднения по кортикальной ленте. В частности, в каждой вершине сегмент нормали к поверхности белого вещества, простирающийся до пиальной поверхность, отбирается через 6 интервалов и усредняется.
Поверхности генерируются для «собственной» поверхности, а также преобразуются в fsaverage пространство шаблона.
Все выходы поверхности в формате GIFTI.
HCP Серые координаты
Если выход CIFTI включен, функциональные временные ряды с поправкой на движение (в пространстве T1w) отображаются первыми.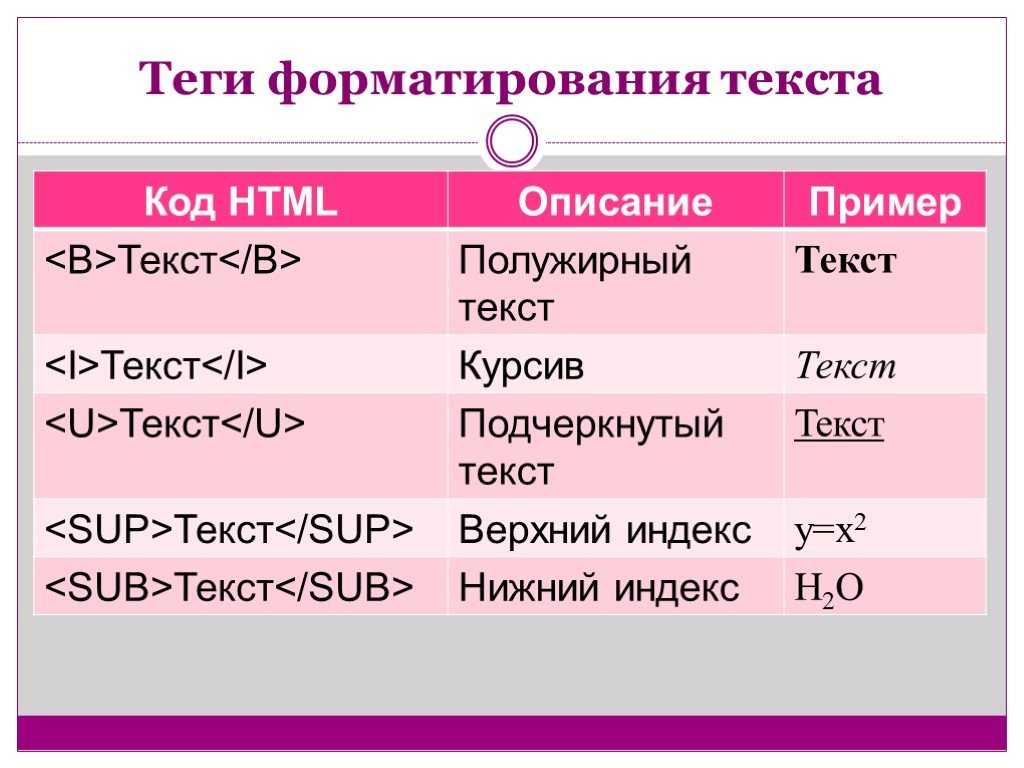 выборка с высоким разрешением 164k вершин (на полушарие)
выборка с высоким разрешением 164k вершин (на полушарие) fsaverage . После этого
повторно выбранный временной ряд выбирается по HCP Pipelines_ s fsLR mesh (с левым и
выровнено по правому полушарию) с использованием Connectome Workbench -metric-resample для создания
поверхностные временные ряды для каждого полушария. Затем эти поверхности объединяются с соответствующими
объемные временные ряды для создания файла CIFTI2.
Оценка путаницы
init_bold_confs_wf()
(Исходный код)
Учитывая фМРТ с поправкой на движение, маску мозга, mcflirt параметры движения и
сегментации, подпроцесс discovery_wf вычисляет потенциальные
путаницы на том.
Расчетные погрешности включают средний общий сигнал, средний сигнал класса ткани,
tCompCor, aCompCor, покадровое смещение, 6 параметров движения, DVARS, регрессоры спайков,
а если --use-aroma Флаг включен, компоненты шума, идентифицированные ICA-AROMA
(те, которые должны быть удалены «агрессивной» стратегией шумоподавления). Конкретные подробности об ICA-AROMA приведены ниже.
Конкретные подробности об ICA-AROMA приведены ниже.
ИКА-АРОМАТ
init_ica_aroma_wf()
ICA-AROMA выполняется в пространстве MNI152NLin6Asym , которое автоматически
добавлен в список --output-spaces , если он еще не был запрошен пользователем.
Количество компонентов ICA-AROMA зависит от оценки размерности, сделанной
ФСЛ МЕЛОДИКА.
Для наборов данных с очень коротким TR и большим количеством моментов времени это может привести к
в необычно большом количестве компонентов.
По умолчанию размерность ограничена максимум 200 компонентами.
Чтобы переопределить этот верхний предел, можно указать количество компонентов, которые необходимо извлечь.
с --аромат-мелодичность-размерность .
Более подробная информация о реализации приведена в процессе создания рабочего процесса.
функция ( init_ica_aroma_wf() ).
Примечание : не -агрессивный АРОМАТ шумоподавления — принципиально другая процедура
от своего «агрессивного» аналога и не может быть выполнено только с помощью набора шумов
регрессоры (необходимо использовать отдельный GLM с регрессорами шума и сигнала).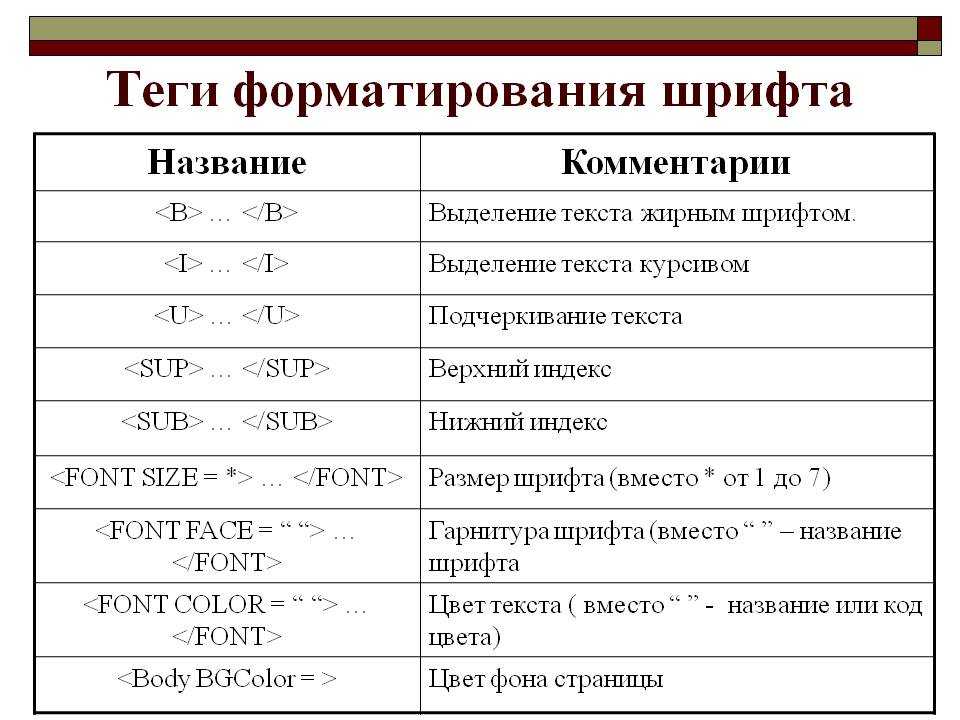 Поэтому вместо регрессоров fMRIPrep производит не — агрессивный шумоглушитель 4D NIFTI
файлов в пространстве MNI:
Поэтому вместо регрессоров fMRIPrep производит не — агрессивный шумоглушитель 4D NIFTI
файлов в пространстве MNI:
*space-MNI152NLin6Asym_desc-smoothAROMAnonaggr_bold.nii.gz
Кроме того, индексы микса MELODIC и шумового компонента будут
быть сгенерирован, поэтому неагрессивное шумоподавление может быть выполнено вручную в пространстве T1w с fsl_regfilt , , например. :
fsl_regfilt -i sub-_task- _space-T1w_desc-preproc_bold.nii.gz \ -f $(cat sub- _task- _AROMAnoiseICs.csv) \ -d sub- _task- _desc-MELODIC_mixing.tsv \ -o sub- _task- _space-T1w_desc-AROMAnonaggr_bold.nii.gz
Примечание : Нестационарные объемы удалены для определения компонентов мелодии.
Таким образом, *MELODIC_mixing.tsv может иметь заполненные нулями строки для учета объемов, не используемых в
мелодическая оценка компонентов.