Тег | HTML справочник
Поддержка браузерами
Описание
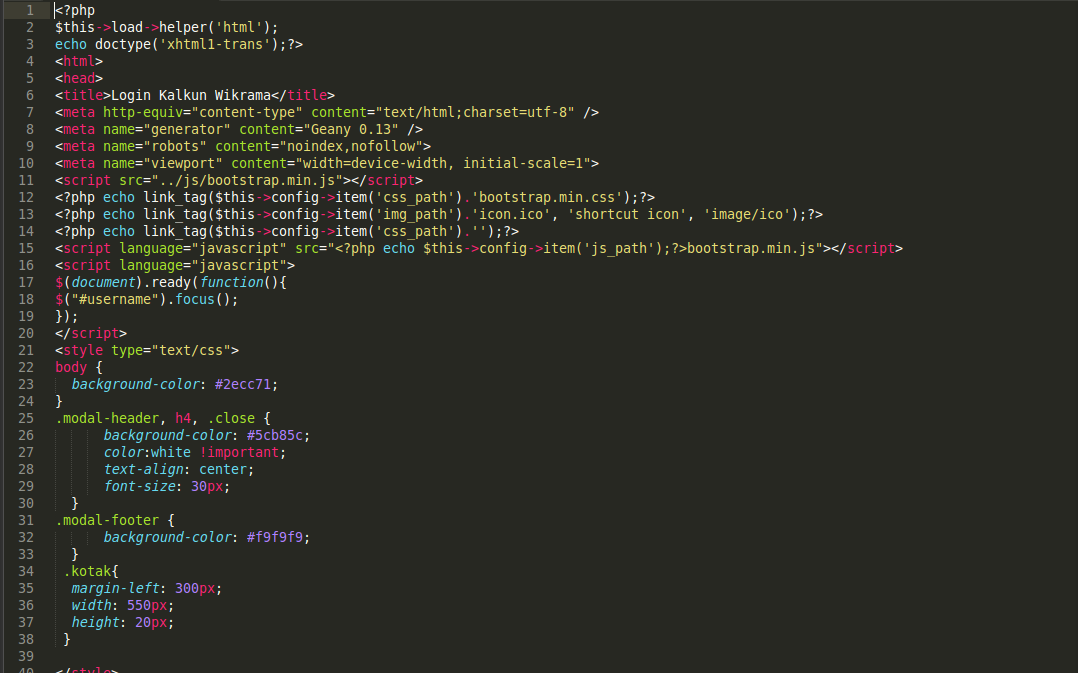
HTML тег <link> определяет отношение между текущим html-документом и внешним ресурсом, на который он ссылается. Он является пустым элементом (не имеет содержимого и закрывающего тега) и всегда должен располагаться внутри элемента <head>. Чаще всего тег <link> используется для подключения внешних таблиц стилей:
<link href="style.css" rel="stylesheet" type="text/css">
Первый атрибут href определяет адрес документа, который может быть как абсолютным так и относительным. Второй атрибут rel указывает связь между HTML файлом и тем, на что вы ссылаетесь, в данном случае мы ссылаемся на таблицу стилей, поэтому используется значение stylesheet. Атрибут type сообщает браузеру MIME тип документа, для таблиц стилей значением всегда будет "text/css".
Примечание: по стандарту HTML5, при подключении к документу внешнего файла CSS, атрибут
type указывать не требуется:
<link href="style.css" rel="stylesheet">
 css" rel="stylesheet">
css" rel="stylesheet">
Предварительная загрузка страниц
Обычно, когда вы кликаете по ссылке на другую страницу приходится ждать несколько секунд пока она загрузится. Однако, вы можете настроить вашу веб-страницу таким образом, чтобы определённые страницы загружались заранее в кэш браузера в то время пока вы находитесь на текущей странице. Это означает, что когда вы кликнете по ссылке для перехода на другую веб-страницу, то она откроется сразу и не надо будет ждать, пока она загрузится. Это называется «предварительное получение страницы». Чтобы сделать это, используется тег <link> с атрибутом rel="prefetch", а также указывается целевая страница, которая будет заранее загружена на компьютер.
<link rel="prefetch" href="httр://www.puzzleweb/html/tag_p.php">
Такая запись позволит заранее закешировать страницу tag_p.php на компьютере, пока вы читаете содержимое текущей страницы. Вы можете использовать тег <link> для предварительной загрузки любого количества страниц вашего собственного сайта или любых других из интернета.
Примечание: вместо адреса на HTML-документ можно указать путь к файлу другого типа (картинку, видео и тд.).
Атрибуты
- href:
- Указывает месторасположение (URL) внешнего файла (путь к файлу может быть указан с помощью абсолютного или относительного адреса).
- hreflang:
- Указывает двухбуквенный код языка, определяющий язык документа, на который ведет ссылка. Атрибут
hreflangиспользуется только совместно с атрибутомhref. - media:
- Определяет под какие устройства оптимизирован файл. Главным образом он используется с файлами таблиц стилей, для определения различных стилей под разные типы носителей. Атрибут
mediaможет принимать сразу несколько значений, разделяемых между собой пробелами. - rel:
- Указывает связь между текущим документом и документом, на который ведет ссылка.
- alternate — ссылка на альтернативную версию документа (то есть страницы для печати, перевод или зеркало).
- author — определяет ссылку страницу об авторе документа или на страницу с контактными данными автора.
- canonical — позволяет пометить страницы с дублирующимся контентом, это значит что все страницы, имеющие одинаковое содержимое должны содержать тег
<link>с атрибутомrel="canonical".Атрибут
href, в этом случае, должен содержать ссылку на страницу с идентичным содержимым, которую поисковые системы должны считать основной:<link rel="canonical" href="httр://www.puzzleweb/html/tag_p.php">
- first
- help — ссылка на документ со справкой.
- icon — определяет путь к иконке, которая будет использована для текущего документа.
- last — указывает ссылку, ведущую на последний документ в последовательности документов.
- licence — ссылка на сведения об авторских правах для документа.
- next — указывает, что этот документ является частью серии, и что ссылка будет вести на следующий документ в этой серии.
- prefetch — указывает, что следует заранее кэшировать файл, на который ведет ссылка.
- prev — указывает, что этот документ является частью серии, и что ссылка ведет на предыдущий документ в этой серии.
- search — ссылка на поиск для документа.
- stylesheet — определяет внешний файл, который будет использоваться в качестве таблицы стилей для данного документа.
- alternate — ссылка на альтернативную версию документа (то есть страницы для печати, перевод или зеркало).
- sizes:
- Указывает размер иконок для визуального отображения. Атрибут
sizesиспользуется только совместно сrel="icon", может принимать следующий значения: - type:
- Указывает MIME-тип (спецификация форматирования сообщений и кодирования информации для передачи по интернету) документа, на который ведет ссылка, используется только совместно с атрибутом
href.



Тег <link> так же поддерживает Глобальные атрибуты
Стиль по умолчанию
link {
display: none;
}
Пример
<head> <link rel="stylesheet" href="style.css"> </head>
Результат данного примера в окне браузера:
HTML и CSS с примерами кода
Тег <link> (от англ. link — ссылка, связь) устанавливает связь с внешним документом вроде файла со стилями или со шрифтами.
Элемент <link> обычно размещается внутри контейнера <head> и не создаёт ссылку, в отличие от элемента <a>.
- base
- link
- meta
- style
- title
Синтаксис
<head> <link href="<адрес>" /> </head>
Закрывающий тег не требуется.
Атрибуты
href- Путь к связываемому файлу.
media- Определяет устройство, для которого следует применять стилевое оформление.
rel- Определяет отношения между текущим документом и файлом, на который делается ссылка.
sizes- Указывает размер иконок для визуального отображения.
type- MIME-тип данных подключаемого файла.
Также для этого элемента доступны универсальные атрибуты.
href
Путь к файлу, на который делается ссылка.
Синтаксис
<link href="<адрес>" />
Значения
В качестве значения принимается полный или относительный путь к файлу.
Значение по умолчанию
Нет.
media
Определяет устройство, для которого следует применять стилевое оформление. Это позволяет сделать разный стиль для отображения документа на экране монитора и при его печати.
Синтаксис
<link media="all | print | screen | speech" />
Значения
all- Все устройства.
print- Печатающее устройство вроде принтера.
screen- Экран монитора.
speech- Речевые синтезаторы, а также программы для воспроизведения текста вслух. Сюда же входят речевые браузеры.
В HTML5 в качестве значений могут быть указаны медиа-запросы.
Значение по умолчанию
all
rel
Атрибут rel определяет отношения между текущим документом и файлом, на который делается ссылка. Это необходимо, чтобы браузер знал, как использовать подключаемый документ.
<link rel="<тип>" />
Значения
alternate- Альтернативный тип, используется, к примеру, для указания ссылки на файл в формате XML для описания ленты новостей, анонсов статей.
author- Указывает ссылку на автора текущего документа или статьи.
help- Указывает ссылку на контекстно-зависимую справку.
icon- Адрес картинки, которая символизирует текущий документ или сайт.
license- Сообщает, что основное содержание текущего документа распространяется по лицензии, описанной в указанном документе.
next- Сообщает, что текущий документ является частью связанных между собой документов, а ссылка указывает на следующий документ.
prefetch- Указывает на предварительно кэшированный ресурс текущей страницы или сайта целиком.
prev- Сообщает, что текущий документ является частью связанных между собой документов, а ссылка указывает на предыдущий документ.
search- Указывает ссылку на ресурс, который применяется для поиска по документу или сайту.
stylesheet- Определяет, что подключаемый файл хранит таблицу стилей (CSS).

Значение по умолчанию
Нет.
sizes
Указывает размер иконок для визуального отображения. Сама иконка может применяться браузером для отображения в адресной строке, при сохранении в избранное, а также поисковыми системами для придания наглядности результатам поиска (именно так поступает Яндекс).
Синтаксис
<link rel="icon" /> <link rel="icon" any" />
Значения
Вначале указывается ширина иконки в пикселах без указания единиц (например, 16), затем пишется латинская буква x в верхнем (X) или нижнем регистре (x), после чего идёт высота иконки. Если в файле хранится сразу несколько иконок, можно задавать их размеры через пробел. Ключевое слово any указывает, что иконка может масштабироваться в любой размер, к примеру, если она хранится в векторном формате SVG.
Значение по умолчанию
Нет.
type
Сообщает браузеру, какой MIME-тип данных используется для внешнего документа. Как правило, применяется для того, чтобы указать, что подключаемый файл содержит CSS.
Синтаксис
<link type="<MIME-тип>" />
Значения
Имя MIME-типа в любом регистре. Для подключаемых таблиц связанных стилей применяется тип text/css.
Значение по умолчанию
text/css
Спецификации
- Preload, определение
<link rel="preload"> - Subresource Integrity, определение атрибута
integrity - WHATWG HTML Living Standard
- HTML 5
- HTML 4.01 Specification
- Resource Hints, определение
dns-prefetch,preconnect,prefetchиprerender
Описание и примеры
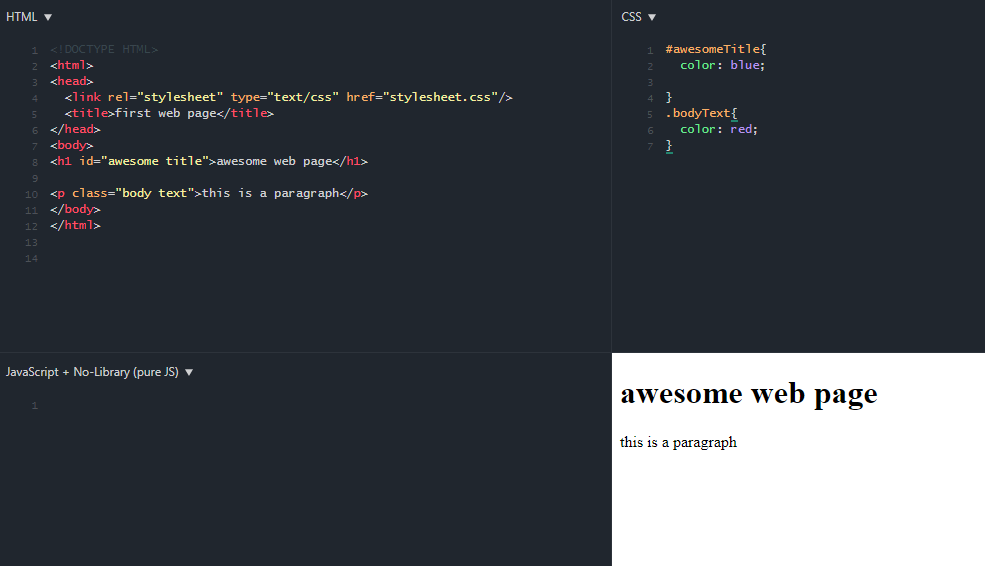
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>LINK</title>
<link rel="stylesheet" href="ie. css" />
<link
rel="alternate"
type="application/rss+xml"
title="Статьи с сайта xsltdev.ru"
href="http://xsltdev.ru/rss.xml"
/>
<link
rel="shortcut icon"
href="http://xsltdev.ru/favicon.ico"
/>
</head>
<body>
<p>...</p>
</body>
</html>
 css" />
<link
rel="alternate"
type="application/rss+xml"
title="Статьи с сайта xsltdev.ru"
href="http://xsltdev.ru/rss.xml"
/>
<link
rel="shortcut icon"
href="http://xsltdev.ru/favicon.ico"
/>
</head>
<body>
<p>...</p>
</body>
</html>
css" />
<link
rel="alternate"
type="application/rss+xml"
title="Статьи с сайта xsltdev.ru"
href="http://xsltdev.ru/rss.xml"
/>
<link
rel="shortcut icon"
href="http://xsltdev.ru/favicon.ico"
/>
</head>
<body>
<p>...</p>
</body>
</html>
Ссылки
- Тег
<link>MDN (рус.)
Модуль BeautifulSoup4 в Python, разбор HTML.
Извлечение данных из документов HTML и XML.
BeautifulSoup4 (bs4) — это библиотека Python для извлечения данных из файлов HTML и XML. Для естественной навигации, поиска и изменения дерева HTML, модуль BeautifulSoup4, по умолчанию использует встроенный в Python парсер html.parser. BS4 так же поддерживает ряд сторонних парсеров Python, таких как lxml, html5lib и xml (для разбора XML-документов).
Установка BeautifulSoup4 в виртуальное окружение:
# создаем виртуальное окружение, если нет $ python3 -m venv .Содержание:
 venv --prompt VirtualEnv
# активируем виртуальное окружение
$ source .venv/bin/activate
# ставим модуль beautifulsoup4
(VirtualEnv):~$ python3 -m pip install -U beautifulsoup4
venv --prompt VirtualEnv
# активируем виртуальное окружение
$ source .venv/bin/activate
# ставим модуль beautifulsoup4
(VirtualEnv):~$ python3 -m pip install -U beautifulsoup4
- Выбор парсера для использования в BeautifulSoup4.
- Парсер
lxml. - Парсер
html5lib. - Встроенный в Python парсер
html.parser.
- Парсер
- Основные приемы работы с BeautifulSoup4.
- Навигация по структуре HTML-документа.
- Извлечение URL-адресов.
- Извлечение текста HTML-страницы.
- Поиск тегов по HTML-документу.
- Поиск тегов при помощи CSS селекторов.
- Дочерние элементы.
- Родительские элементы.
- Изменение имен тегов HTML-документа.
- Добавление новых тегов в HTML-документ.
- Удаление и замена тегов в HTML-документе.
- Изменение атрибутов тегов HTML-документа.
Выбор парсера для использования в BeautifulSoup4.
BeautifulSoup4 представляет один интерфейс для разных парсеров, но парсеры неодинаковы. Разные парсеры, анализируя один и того же документ создадут различные деревья HTML. Самые большие различия будут между парсерами HTML и XML. Так же парсеры различаются скоростью разбора HTML документа.
Разные парсеры, анализируя один и того же документ создадут различные деревья HTML. Самые большие различия будут между парсерами HTML и XML. Так же парсеры различаются скоростью разбора HTML документа.
Если дать BeautifulSoup4 идеально оформленный документ HTML, то различий построенного HTML-дерева не будет. Один парсер будет быстрее другого, но все они будут давать структуру, которая выглядит точно так же, как оригинальный документ HTML. Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Различия в построении HTML-дерева разными парсерами, разберем на короткой HTML-разметке: <a></p>.
Парсер
lxml.Характеристики:
- Для запуска примера, необходимо установить модуль
lxml. - Очень быстрый, имеет внешнюю зависимость от языка C.
- Нестрогий.
>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", "lxml")
# <html><body><a></a></body></html>
Обратите внимание, что тег <a> заключен в теги <body> и <html>, а висячий тег </p> просто игнорируется.
Парсер
html5lib.Характеристики:
- Для запуска примера, необходимо установить модуль
html5lib. - Ну очень медленный.
- Разбирает страницы так же, как это делает браузер, создавая валидный HTML5.
>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", "html5lib")
# <html><head></head><body><a><p></p></a></body></html>
Обратите внимание, что парсер html5lib НЕ игнорирует висячий тег </p>, и к тому же добавляет открывающий тег <p>. Также html5lib добавляет пустой тег <head> (lxml этого не сделал).
Встроенный в Python парсер
html.parser.Характеристики:
- Не требует дополнительной установки.
- Приличная скорость, но не такой быстрый, как
lxml. - Более строгий, чем
html5lib.

>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", 'html.parser')
# <a></a>
Как и lxml, встроенный в Python парсер игнорирует закрывающий тег </p>. В отличие от html5lib, этот парсер не делает попытки создать правильно оформленный HTML-документ, добавив теги <html> или <body>.
Вывод: Парсер html5lib использует способы, которые являются частью стандарта HTML5, поэтому он может претендовать на то, что его подход самый «правильный«.
Основные приемы работы с BeautifulSoup4.
Чтобы разобрать HTML-документ, необходимо передать его в конструктор класса BeautifulSoup(). Можно передать строку или открытый дескриптор файла:
from bs4 import BeautifulSoup
# передаем объект открытого файла
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
# передаем строку
soup = BeautifulSoup("<html>a web page</html>", 'html. parser')
 parser')
parser')
Первым делом документ конвертируется в Unicode, а HTML-мнемоники конвертируются в символы Unicode:
>>> from bs4 import BeautifulSoup >>> html = "<html><head></head><body>Sacré bleu!</body></html>" >>> parse = BeautifulSoup(html, 'html.parser') >>> print(parse) # <html><head></head><body>Sacré bleu!</body></html>
Дальнейшие примеры будут разбираться на следующей HTML-разметке.
html_doc = """<html><head><title>The Dormouse's story</title></head> <body> <p><b>The Dormouse's story</b></p> <p>Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie">Elsie</a>, <a href="http://example.com/lacie">Lacie</a> and <a href="http://example.com/tillie">Tillie</a>; and they lived at the bottom of a well.
 </p>
<p>...</p>"""
</p>
<p>...</p>"""
Передача этого HTML-документа в конструктор класса BeautifulSoup() создает объект, который представляет документ в виде вложенной структуры:
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(html_doc, 'html.parser') >>> print(soup.prettify()) # <html> # <head> # <title> # The Dormouse's story # </title> # </head> # <body> # <p> # <b> # The Dormouse's story # </b> # </p> # <p> # Once upon a time there were three little sisters; and their names were # <a href="http://example.com/elsie"> # Elsie # </a> # , # <a href="http://example.com/lacie"> # Lacie # </a> # and # <a href="http://example.com/tillie"> # Tillie # </a> # ; and they lived at the bottom of a well. # </p> # <p> # ... # </p> # </body> # </html>
Навигация по структуре HTML-документа:
# извлечение тега `title` >>> soup.
 title
# <title>The Dormouse's story</title>
# извлечение имя тега
>>> soup.title.name
# 'title'
# извлечение текста тега
>>> soup.title.string
# 'The Dormouse's story'
# извлечение первого тега `<p>`
>>> soup.p
# <p><b>The Dormouse's story</b></p>
# извлечение второго тега `<p>` и
# представление его содержимого списком
>>> soup.find_all('p')[1].contents
# ['Once upon a time there were three little sisters; and their names were\n',
# <a href="http://example.com/elsie">Elsie</a>,
# ',\n',
# <a href="http://example.com/lacie">Lacie</a>,
# ' and\n',
# <a href="http://example.com/tillie">Tillie</a>,
# ';\nand they lived at the bottom of a well.']
# выдаст то же самое, только в виде генератора
>>> soup.find_all('p')[1].strings
# <generator object Tag._all_strings at 0x7ffa2eb43ac0>
title
# <title>The Dormouse's story</title>
# извлечение имя тега
>>> soup.title.name
# 'title'
# извлечение текста тега
>>> soup.title.string
# 'The Dormouse's story'
# извлечение первого тега `<p>`
>>> soup.p
# <p><b>The Dormouse's story</b></p>
# извлечение второго тега `<p>` и
# представление его содержимого списком
>>> soup.find_all('p')[1].contents
# ['Once upon a time there were three little sisters; and their names were\n',
# <a href="http://example.com/elsie">Elsie</a>,
# ',\n',
# <a href="http://example.com/lacie">Lacie</a>,
# ' and\n',
# <a href="http://example.com/tillie">Tillie</a>,
# ';\nand they lived at the bottom of a well.']
# выдаст то же самое, только в виде генератора
>>> soup.find_all('p')[1].strings
# <generator object Tag._all_strings at 0x7ffa2eb43ac0>
Перемещаться по одному уровню можно при помощи атрибутов . и  previous_sibling
previous_sibling.next_sibling. Например, в представленном выше HTML, теги <a> обернуты в тег <p> — следовательно они находятся на одном уровне.
>>> first_a = soup.a >>> first_a # <a href="http://example.com/elsie">Elsie</a> >>> first_a.previous_sibling # 'Once upon a time there were three little sisters; and their names were\n' >>> next = first_a.next_sibling >>> next # ',\n' >>> next.next_sibling # <a href="http://example.com/lacie">Lacie</a>
Так же можно перебрать одноуровневые элементы данного тега с помощью .next_siblings или .previous_siblings.
for sibling in soup.a.next_siblings:
print(repr(sibling))
# ',\n'
# <a href="http://example.com/lacie">Lacie</a>
# ' and\n'
# <a href="http://example.com/tillie">Tillie</a>
# '; and they lived at the bottom of a well.'
for sibling in soup. find(id="link3").previous_siblings:
print(repr(sibling))
# ' and\n'
# <a href="http://example.com/lacie">Lacie</a>
# ',\n'
# <a href="http://example.com/elsie">Elsie</a>
# 'Once upon a time there were three little sisters; and their names were\n'
 find(id="link3").previous_siblings:
print(repr(sibling))
# ' and\n'
# <a href="http://example.com/lacie">Lacie</a>
# ',\n'
# <a href="http://example.com/elsie">Elsie</a>
# 'Once upon a time there were three little sisters; and their names were\n'
find(id="link3").previous_siblings:
print(repr(sibling))
# ' and\n'
# <a href="http://example.com/lacie">Lacie</a>
# ',\n'
# <a href="http://example.com/elsie">Elsie</a>
# 'Once upon a time there were three little sisters; and their names were\n'
Атрибут .next_element строки или HTML-тега указывает на то, что было разобрано непосредственно после него. Это могло бы быть тем же, что и .next_sibling, но обычно результат резко отличается.
Возьмем последний тег <a>, его .next_sibling является строкой: конец предложения, которое было прервано началом тега <a>:
last_a = soup.find("a",)
last_a
# <a href="http://example.com/tillie">Tillie</a>
last_a.next_sibling
# ';\nand they lived at the bottom of a well.'
Однако .next_element этого тега <a> — это то, что было разобрано сразу после тега <a> — это слово Tillie, а не остальная часть предложения.
last_a_tag.next_element # 'Tillie'
Это потому, что в оригинальной разметке слово Tillie появилось перед точкой с запятой. Парсер обнаружил тег <a>, затем слово Tillie, затем закрывающий тег </a>, затем точку с запятой и оставшуюся часть предложения. Точка с запятой находится на том же уровне, что и тег <a>, но слово Tillie встретилось первым.
Атрибут .previous_element является полной противоположностью .next_element. Он указывает на элемент, который был обнаружен при разборе непосредственно перед текущим:
last_a_tag.previous_element # ' and\n' last_a_tag.previous_element.next_element # <a href="http://example.com/tillie">Tillie</a>
При помощи атрибутов .next_elements и .previous_elements можно получить список элементов, в том порядке, в каком он был разобран парсером.
for element in last_a_tag.
 next_elements:
print(repr(element))
# 'Tillie'
# ';\nand they lived at the bottom of a well.'
# '\n'
# <p>...</p>
# '...'
# '\n'
next_elements:
print(repr(element))
# 'Tillie'
# ';\nand they lived at the bottom of a well.'
# '\n'
# <p>...</p>
# '...'
# '\n'
Извлечение URL-адресов.
Одна из распространенных задач, это извлечение URL-адресов, найденных на странице в HTML-тегах <a>:
>>> for a in soup.find_all('a'):
... print(a.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
Извлечение текста HTML-страницы.
Другая распространенная задача — извлечь весь текст со HTML-страницы:
# Весь текст HTML-страницы с разделителями `\n`
>>> soup.get_text('\n', strip='True')
# "The Dormouse's story\nThe Dormouse's story\n
# Once upon a time there were three little sisters; and their names were\n
# Elsie\n,\nLacie\nand\nTillie\n;\nand they lived at the bottom of a well.\n..."
# а можно создать список строк, а потом форматировать как надо
>>> [text for text in soup.stripped_strings]
# ["The Dormouse's story",
# "The Dormouse's story",
# 'Once upon a time there were three little sisters; and their names were',
# 'Elsie',
# ',',
# 'Lacie',
# 'and',
# 'Tillie',
# ';\nand they lived at the bottom of a well. ',
# '...']
 ',
# '...']
',
# '...']
Поиск тегов по HTML-документу:
Найти первый совпавший HTML-тег можно методом BeautifulSoup.find(), а всех совпавших элементов — BeautifulSoup.find_all().
# ищет все теги `<title>`
>>> soup.find_all("title")
# [<title>The Dormouse's story</title>]
# ищет все теги `<a>` и все теги `<b>`
>>> soup.find_all(["a", "b"])
# [<b>The Dormouse's story</b>,
# <a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
# ищет все теги `<p>` с CSS классом "title"
>>> soup.find_all("p", "title")
# [<p><b>The Dormouse's story</b></p>]
# ищет все теги с CSS классом, в именах которых встречается "itl"
soup.find_all(class_=re.compile("itl"))
# [<p><b>The Dormouse's story</b></p>]
# ищет все теги с
>>> soup. b")):
print(tag.name)
# body
# b
# ищет все теги в документе, но не текстовые строки
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
 b")):
print(tag.name)
# body
# b
# ищет все теги в документе, но не текстовые строки
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
b")):
print(tag.name)
# body
# b
# ищет все теги в документе, но не текстовые строки
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
Поиск тегов при помощи CSS селекторов:
>>> soup.select("title")
# [<title>The Dormouse's story</title>]
>>> soup.select("p:nth-of-type(3)")
# [<p>...</p>]
Поиск тега под другими тегами:
>>> soup.select("body a")
# [<a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie" >Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
>>> soup.select("html head title")
# [<title>The Dormouse's story</title>]
Поиск тега непосредственно под другими тегами:
>>> soup.select("head > title")
# [<title>The Dormouse's story</title>]
>>> soup.select("p > a:nth-of-type(2)")
# [<a href="http://example. com/lacie">Lacie</a>]
>>> soup.select("p > #link1")
# [<a href="http://example.com/elsie">Elsie</a>]
 com/lacie">Lacie</a>]
>>> soup.select("p > #link1")
# [<a href="http://example.com/elsie">Elsie</a>]
com/lacie">Lacie</a>]
>>> soup.select("p > #link1")
# [<a href="http://example.com/elsie">Elsie</a>]
Поиск одноуровневых элементов:
# поиск всех `.sister` в которых нет `#link1`
>>> soup.select("#link1 ~ .sister")
# [<a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie" >Tillie</a>]
# поиск всех `.sister` в которых есть `#link1`
>>> soup.select("#link1 + .sister")
# [<a href="http://example.com/lacie">Lacie</a>]
# поиск всех `<a>` у которых есть сосед `<p>`
Поиск тега по классу CSS:
>>> soup.select(".sister")
# [<a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
Поиск тега по ID:
>>> soup.select("#link1")
# [<a href="http://example.com/elsie">Elsie</a>]
>>> soup. select("a#link2")
# [<a href="http://example.com/lacie">Lacie</a>]
 select("a#link2")
# [<a href="http://example.com/lacie">Lacie</a>]
select("a#link2")
# [<a href="http://example.com/lacie">Lacie</a>]
Дочерние элементы.
Извлечение НЕПОСРЕДСТВЕННЫХ дочерних элементов тега. Если посмотреть на HTML-разметку в коде ниже, то, непосредственными дочерними элементами первого <ul> будут являться три тега <li> и тег <ul> со всеми вложенными тегами.
Обратите внимание, что все переводы строк \n и пробелы между тегами, так же будут считаться дочерними элементами. Так что имеет смысл заранее привести исходный HTML к «нормальному виду«, например так: re.sub(r'>\s+<', '><', html.replace('\n', ''))
html = """
<div>
<ul>
<li>текст 1</li>
<li>текст 2</li>
<ul>
<li>текст 2-1</li>
<li>текст 2-2</li>
</ul>
<li>текст 3</li>
</ul>
</div>
"""
>>> from bs4 import BeautifulSoup
>>> root = BeautifulSoup(html, 'html. parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список непосредственных дочерних элементов
# переводы строк `\n` и пробелы между тегами так же
# распознаются как дочерние элементы
>>> first_ul.contents
# ['\n', <li>текст 1</li>, '\n', <li>текст 2</li>, '\n', <ul>
# <li>текст 2-1</li>
# <li>текст 2-2</li>
# </ul>, '\n', <li>текст 3</li>, '\n']
# убираем переводы строк `\n` как из списка, так и из тегов
# лучше конечно сразу убрать переводы строк из исходного HTML
>>> [str(i).replace('\n', '') for i in first_ul.contents if str(i) != '\n']
# ['<li>текст 1</li>',
# '<li>текст 2</li>',
# '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>',
# '<li>текст 3</li>']
# то же самое, что и `first_ul.contents`
# только в виде итератора
>>> first_ul.children
# <list_iterator object at 0x7ffa2eb52460>
 parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список непосредственных дочерних элементов
# переводы строк `\n` и пробелы между тегами так же
# распознаются как дочерние элементы
>>> first_ul.contents
# ['\n', <li>текст 1</li>, '\n', <li>текст 2</li>, '\n', <ul>
# <li>текст 2-1</li>
# <li>текст 2-2</li>
# </ul>, '\n', <li>текст 3</li>, '\n']
# убираем переводы строк `\n` как из списка, так и из тегов
# лучше конечно сразу убрать переводы строк из исходного HTML
>>> [str(i).replace('\n', '') for i in first_ul.contents if str(i) != '\n']
# ['<li>текст 1</li>',
# '<li>текст 2</li>',
# '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>',
# '<li>текст 3</li>']
# то же самое, что и `first_ul.contents`
# только в виде итератора
>>> first_ul.children
# <list_iterator object at 0x7ffa2eb52460>
parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список непосредственных дочерних элементов
# переводы строк `\n` и пробелы между тегами так же
# распознаются как дочерние элементы
>>> first_ul.contents
# ['\n', <li>текст 1</li>, '\n', <li>текст 2</li>, '\n', <ul>
# <li>текст 2-1</li>
# <li>текст 2-2</li>
# </ul>, '\n', <li>текст 3</li>, '\n']
# убираем переводы строк `\n` как из списка, так и из тегов
# лучше конечно сразу убрать переводы строк из исходного HTML
>>> [str(i).replace('\n', '') for i in first_ul.contents if str(i) != '\n']
# ['<li>текст 1</li>',
# '<li>текст 2</li>',
# '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>',
# '<li>текст 3</li>']
# то же самое, что и `first_ul.contents`
# только в виде итератора
>>> first_ul.children
# <list_iterator object at 0x7ffa2eb52460>
Извлечение ВСЕХ дочерних элементов. Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
>>> import re
# сразу уберем переводы строк из исходного HTML
>>> html = re.sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список ВСЕХ дочерних элементов
>>> list(first_ul.descendants)
# [<li>текст 1</li>,
# 'текст 1',
# <li>текст 2</li>,
# 'текст 2',
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
# <li>текст 2-1</li>,
# 'текст 2-1',
# <li>текст 2-2</li>,
# 'текст 2-2',
# <li>текст 3</li>,
# 'текст 3']
Обратите внимание, что простой текст, который находится внутри тега, так же считается дочерним элементом этого тега.
Если внутри тега есть более одного дочернего элемента (как в примерен выше) и необходимо извлечь только текст, то можно использовать атрибут . или генератор  strings
strings.stripped_strings.
Генератор .stripped_strings дополнительно удаляет все переводы строк \n и пробелы между тегами в исходном HTML-документе.
>>> list(first_ul.strings) # ['текст 1', 'текст 2', 'текст 2-1', 'текст 2-2', 'текст 3'] >>> first_ul.stripped_strings # <generator object Tag.stripped_strings at 0x7ffa2eb43ac0> >>> list(first_ul.stripped_strings) # ['текст 1', 'текст 2', 'текст 2-1', 'текст 2-2', 'текст 3']
Родительские элементы.
Что бы получить доступ к родительскому элементу, необходимо использовать атрибут .parent.
html = """
<div>
<ul>
<li>текст 1</li>
<li>текст 2</li>
<ul>
<li>текст 2-1</li>
<li>текст 2-2</li>
</ul>
<li>текст 3</li>
</ul>
</div>
"""
>>> from bs4 import BeautifulSoup
>>> import re
# сразу уберем переводы строк и пробелы
# между тегами из исходного HTML
>>> html = re. sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем теги `<li>` вложенные во второй `<ul>`,
# используя CSS селекторы
>>> child_ul = root.select('ul > ul > li')
>>> child_ul
# [<li>текст 2-1</li>, <li>текст 2-2</li>]
# получаем доступ к родителю
>>> child_li[0].parent
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>
# доступ к родителю родителя
>>> child_li[0].parent.parent.contents
[<li>текст 1</li>,
<li>текст 2</li>,
<ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
<li>текст 3</li>]
 sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем теги `<li>` вложенные во второй `<ul>`,
# используя CSS селекторы
>>> child_ul = root.select('ul > ul > li')
>>> child_ul
# [<li>текст 2-1</li>, <li>текст 2-2</li>]
# получаем доступ к родителю
>>> child_li[0].parent
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>
# доступ к родителю родителя
>>> child_li[0].parent.parent.contents
[<li>текст 1</li>,
<li>текст 2</li>,
<ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
<li>текст 3</li>]
sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем теги `<li>` вложенные во второй `<ul>`,
# используя CSS селекторы
>>> child_ul = root.select('ul > ul > li')
>>> child_ul
# [<li>текст 2-1</li>, <li>текст 2-2</li>]
# получаем доступ к родителю
>>> child_li[0].parent
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>
# доступ к родителю родителя
>>> child_li[0].parent.parent.contents
[<li>текст 1</li>,
<li>текст 2</li>,
<ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
<li>текст 3</li>]
Taк же можно перебрать всех родителей элемента с помощью атрибута .parents.
>>> child_li[0] # <li>текст 2-1</li> >>> [parent.name for parent in child_li[0].parents] # ['ul', 'ul', 'div', '[document]']
Изменение имен тегов HTML-документа:
>>> soup = BeautifulSoup('<p><b>Extremely bold</b></p>', 'html. parser')
>>> tag = soup.b
# присваиваем новое имя тегу
>>> tag.name = "blockquote"
>>> tag
# <blockquote>Extremely bold</blockquote>
>>> soup
# <p><blockquote>Extremely bold</blockquote></p>
 parser')
>>> tag = soup.b
# присваиваем новое имя тегу
>>> tag.name = "blockquote"
>>> tag
# <blockquote>Extremely bold</blockquote>
>>> soup
# <p><blockquote>Extremely bold</blockquote></p>
parser')
>>> tag = soup.b
# присваиваем новое имя тегу
>>> tag.name = "blockquote"
>>> tag
# <blockquote>Extremely bold</blockquote>
>>> soup
# <p><blockquote>Extremely bold</blockquote></p>
Изменение HTML-тега <p> на тег <div>:
>>> soup = BeautifulSoup('<p><b>Extremely bold</b></p>', 'html.parser')
>>> soup.p.name = 'div'
>>> soup
# <div><b>Extremely bold</b></div>
Добавление новых тегов в HTML-документ.
Добавление нового тега в дерево HTML:
>>> soup = BeautifulSoup("<p><b></b></p>", 'html.parser')
>>> original_tag = soup.b
# создание нового тега `<a>`
>>> new_tag = soup.new_tag("a", href="http://example.com")
# строка нового тега `<a>`
>>> new_tag.string = "Link text"
# добавление тега `<a>` внутрь `<b>`
>>> original_tag. append(new_tag)
>>> original_tag
# <b><a href="http://example.com">Link text.</a></b>
>>> soup
# <p><b><a href="http://example.com">Link text</a></b></p>
 append(new_tag)
>>> original_tag
# <b><a href="http://example.com">Link text.</a></b>
>>> soup
# <p><b><a href="http://example.com">Link text</a></b></p>
append(new_tag)
>>> original_tag
# <b><a href="http://example.com">Link text.</a></b>
>>> soup
# <p><b><a href="http://example.com">Link text</a></b></p>
Добавление новых тегов до/после определенного тега или внутрь тега.
>>> soup = BeautifulSoup("<p><b>leave</b></p>", 'html.parser')
>>> tag = soup.new_tag("i",)
>>> tag.string = "Don't"
# добавление нового тега <i> до тега <b>
>>> soup.b.insert_before(tag)
>>> soup.b
# <p><i>Don't</i><b>leave</b></p>
# добавление нового тега <i> после тега <b>
>>> soup.b.insert_after(tag)
>>> soup
# <p><b>leave</b><i>Don't</i></p>
# добавление нового тега <i> внутрь тега <b>
>>> soup.b.string.insert_before(tag)
>>> soup.b
# <p><b><i>Don't</i>leave</b></p>
Удаление и замена тегов в HTML-документе.
Удаляем тег или строку из дерева HTML:
>>> html = '<a href="http://example.com/">I linked to <i>example.com</i></a>' >>> soup = BeautifulSoup(html, 'html.parser') >>> a_tag = soup.a # удаляем HTML-тег `<i>` с сохранением # в переменной `i_tag` >>> i_tag = soup.i.extract() # смотрим что получилось >>> a_tag # <a href="http://example.com/">I linked to</a> >>> i_tag # <i>example.com</i>
Заменяем тег и/или строку в дереве HTML:
>>> html = '<a href="http://example.com/">I linked to <i>example</i></a>'
>>> soup = BeautifulSoup(html, 'html.parser')
>>> a_tag = soup.a
# создаем новый HTML тег
>>> new_tag = soup.new_tag("b")
>>> new_tag.string = "sample"
# производим замену тега `<i>` внутри тега `<a>`
>>> a_tag.i.replace_with(new_tag)
>>> a_tag
# <a href="http://example. com/">I linked to <b>sample</b></a>
 com/">I linked to <b>sample</b></a>
com/">I linked to <b>sample</b></a>
Изменение атрибутов тегов HTML-документа.
У тега может быть любое количество атрибутов. Тег <b id = "boldest"> имеет атрибут id, значение которого равно boldest. Доступ к атрибутам тега можно получить, обращаясь с тегом как со словарем:
>>> soup = BeautifulSoup('<p><b>bolder</b></p>', 'html.parser')
>>> tag = soup.b
>>> tag['id']
# 'boldest'
# доступ к словарю с атрибутами
>>> tag.attrs
# {'id': 'boldest'}
Можно добавлять и изменять атрибуты тега.
# изменяем `id` >>> tag['id'] = 'bold' # добавляем несколько значений в `class` >>> tag['class'] = ['new', 'bold'] # или >>> tag['class'] = 'new bold' >>> tag # <b>bolder</b>
А так же производить их удаление.
>>> del tag['id'] >>> del tag['class'] >>> tag # <b>bolder</b> >>> tag.
 get('id')
# None
get('id')
# None
Тесты по HTML
Тесты на знание html с ответами
Правильный вариант ответа отмечен знаком +
1. О чем говорит тэг <p align=»right»> … </p>?
— Текст, заключенный в тэг, будет расположен по центру страницы
— Текст, заключенный в тэг, будет расположен по левому краю страницы
+ Текст, заключенный в тэг, будет расположен по центру страницы
2. Какие единицы измерения могут использоваться для атрибута ширины?
+ Пиксели и %
— Миллиметры и сантиметры
— Пиксели и миллиметры
3. Использование тэга … позволяет добавлять одну строку текста без начала нового абзаца.
— <line/>
+ <br/>
— <td/>
4. Объясните смысл кода, представленного ниже:
+ Будет создана таблица, состоящая из 1 ряда и 3 колонок
— Будет создана таблица, состоящая из 3 рядов и 1 колонки
— Будет создана таблица, состоящая из 2 рядов и 3 колонок
5. Напишите код HTML, который бы создавал кнопку отправки заполненной формы. Имя кнопки – ОК.
Напишите код HTML, который бы создавал кнопку отправки заполненной формы. Имя кнопки – ОК.
— <input type=»ОК» value=»Submit»/>
— <p> input type=»submit» value=»OK»< /p>
+ <input type=»submit» value=»ОК»/>
6. Какой тэг при создании страницы добавляет имя страницы, которое будет отображаться в строке заголовка в браузере пользователя?
+ <title> … </title>
— <header> … </header>
— <body> … </body>
7. Заполните поля, чтобы отобразить картинку “flower.jpg” с высотой 300 пикселей и шириной 750 пикселей:
— <img ref=”flower” format=.jpg
high=300 px
width=750 px />
— <src img=”flower.jpg”
height=”300%”
width=”750%”/>
+ <img src=”flower.jpg”
height=”300 px” alt=””
width=”750 px”/>
8. Что содержит в себе атрибут href?
+ URL страницы, на которую произойдет перенаправление
— Имя страницы, на которую произойдет перенаправление
— Указание на то, где будет открываться новая страница: в том же или новом окне
9. Какие из перечисленных тэгов относятся к созданию таблицы?
Какие из перечисленных тэгов относятся к созданию таблицы?
— <header> <body> <footer>
+ <table> <tr> <td>
— <ul> <li> <tr> <td>
тест 10. Укажите тэг, который соответствует элементу списка:
+ <li>
— <ul>
— <ol>
11. О чем говорит следующая запись: <form action=»url» method=»POST»>?
— Создается форма, при заполнении которой вводимые данные будут отображаться
+ Создается форма, при заполнении которой вводимые данные не будут отображаться
— Создается форма, которая будет служить для внесения информации, представленной в виде ссылки (URL)
12. Какое значение следует задать атрибуту type, чтобы оно превращало входной тэг в форму отправки?
+ Submit
— Checkbox
— Radiobutton
13. Для задания размеров тэгу <frameset> требуются следующие атрибуты:
— Высока и ширина
— Площадь и толщина границ
+ Строки и столбцы
14. Выберите верное утверждение.
Выберите верное утверждение.
+ В HTML цвета задаются комбинацией значений шестнадцатеричной системы исчисления: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, A, B, C, D, E, F
— В HTML цвета задаются комбинацией значений двоичной системы исчисления: 0 или 1
— В HTML цвета задаются комбинацией значений восьмеричной системы исчисления: 0, 1, 2, 3, 4, 5, 6, 7
15. Какие тэги делают шрифт текста жирным?
— <ins> и <del>
— <li> и <ul>
+ <b> и <strong>
16. Какие тэги используются для определения заголовков?
+ h2-h6
— Header
— Heading
17. Неотображаемые комментарии в HTML задаются следующим образом:
— <! — Your comment -!>
+ <! — — Your comment — -!>
— <!p> Your comment </!p>
18. Что означает код на картинке?
+ Переход по ссылке произойдет на новой странице
— Переход по ссылке произойдет на текущей странице
— На текущей странице появится текст «Learn Playing»
19. Перечислите основные модули контента, существующие в HTML 5.
Перечислите основные модули контента, существующие в HTML 5.
— Image, Media, Metadata, Link, Heading, Color, Input Value
+ Metadata, Embedded, Interactive, Heading, Phrasing, Flow, Sectioning
— Flow, Static, Link, Header, Body, Footer, Processing, Chase
тест-20. Укажите, какой элемент HTML 5 отвечает за воспроизведение видео:
+ <video>
— <media>
— <movie>
21. Элемент <canvas> используется для:
— Прикрепления таблиц Excel
— Управления данными в базе данных
+ Прорисовки графики
22. Какой тэг содержит навигацию?
+ <nav>
— <geo>
— <metanav>
23. SessionStorage – это клиентское решение в HTML 5, которое позволяет:
— Извлекать и использовать данные предыдущих сессий при условии того, что не были очищены cash и cookie
— Создавать базу данных решений пользователей в памяти браузера
+ Извлекать и использовать данные только текущей сессии
24. Что создастся при исполнении следующего кода:
Что создастся при исполнении следующего кода:
<svg>
<line x1=»50″ y1=»0″ x2=»50″ y2=»100″
style=»stroke:black» />
<line x1=»0″ y1=»50″ x2=»100″ y2=»50″
style=»stroke:black» />
</svg> ?
+ Знак «плюс»
— Знак «минус»
— Знак «равно»
25. Функция HTML 5 «
— Встроенную в основной функционал сайта карту мира
+ Данные о местонахождении пользователя
— Данные о местонахождении сервера
26. Заполните пропуски таким образом, чтобы получился валидный HTML документ. «First paragraph» — комментарий.
<___>
<body>
<! — — First paragraph ___>
<___> This is the first paragraph! </p>
<___>
</html>
— html/; — — ?; p; /body
— html v.5; — — !; /p; /body
+ html; — — !; p; /body
27. HTML – это
HTML – это
+ Язык разметки
— Библиотека гипертекста
— Скриптовый язык
28. Обязательно ли использование тэгов <html> … </html>?
+ Да, без них браузер не распознает HTML-документ
— Да, если HTML-документ создается в блокноте или другом текстовом редакторе. В специальном компиляторе HTML эти тэги можно не использовать
— Не обязательно
29. Какой атрибут позволяет объединить ячейки таблицы по вертикали?
— Union
— Colspan
+ Rowspan
тест_30. Допустимое число заголовков первого уровня в HTML-документе составляет:
+ 1
— 3
— 7
31. Текст, выделенный курсивом, представлен в следующей записи:
— <del> курсив </del>
+ <i> курсив </i>
— <hr> курсив </hr>
32. В HTML не существует … тэгов.
— Одиночных
— Парных
+ Тройных
33.
— ;
+ /
38. Список, в котором элементы перечисления отмечаются буллетами, позволяет создать тэг:
+ <ul>
— <ol>
— <bl>
39. Укажите корректную запись для создания чек-бокса:
— <input checkbox>
— <type input=”checkbox”>
+ <input type=”checkbox”>
тест*40. Укажите корректную запись для создания выпадающего списка:
+ <input type=”dropdown”>
— <input dropdown list>
— <dropdown list>
41. Какой атрибут HTML указывает альтернативный текст для изображения, если данное изображение не отобразится?
— imgalt
— imgvar
+ alt
42. Какой HTML-тэг используется для определения футера документа или раздела?
+ <footer>
— <bottom>
— <section>
43. HTML-тэг, позволяющий воспроизводить аудиозаписи – это:
— <music>
+ <audio>
— <sound>
44. В HTML 5, onblur и onfocus – это:
В HTML 5, onblur и onfocus – это:
+ Атрибуты событий
— Атрибуты стиля
— Атрибуты подключения базы данных
45. Графика, определенная SVG, отображается в формате:
— CSS
— JSOM
+ XML
46. Что определяет тэг <aside>?
+ Дополнительное содержимое, т.е. то, что не включает основной документ
— Ссылку на подключенный документ
— Цветовое решение документа
Подготовка проекта CSS и HTML с помощью Visual Studio Code
12 декабря, 2020 12:02 пп 14 968 views | Комментариев нетDevelopment | Amber | Комментировать запись
Эта серия мануалов покажет вам, как создать и настроить веб-сайт с помощью CSS, языка таблиц стилей, используемого для управления внешним видом сайтов. Вы можете выполнить все мануалы по порядку, чтобы создать тестовый веб-сайт и познакомиться с CSS, или вразброс использовать описанные здесь методы для оптимизации других проектов CSS.
При написании мы использовали Visual Studio Code, редактор кода, свободно доступный для Mac, Windows или Linux
Примечание: Найти все мануалы этой серии можно по тегу CSS-practice
Для работы с CSS вам нужно иметь базовые знания по HTML, стандартному языку разметки, который используется для отображения документов в браузере. Если ранее вы не работали с HTML, рекомендуем предварительно изучить первые десять руководств серии Создание веб-сайта с помощью HTML.
В этом мануале вы узнаете, как создать все папки и файлы, необходимые для сборки вашего тестового веб-сайта CSS.
С помощью редактора кода вы создадите каталог проекта, каталог и файл для кода CSS, файл для кода HTML и папку для изображений. В этой серии мануалов используется Visual Studio Code, редактор кода, свободно доступный для Mac, Windows или Linux, но вы можете использовать редактор кода, который вам нравится больше. Обратите внимание: если вы используете другой редактор, вам нужно будет откорректировать некоторые инструкции мануалов.
Создание файлов и папок HTML и CSS
Запустив текстовый редактор, откройте новую папку для нашего проекта и назовите ее css-practice. Мы будем использовать эту папку для хранения всех файлов и папок, созданных в ходе выполнения этой серии мануалов.
Чтобы создать новую папку проекта в редакторе Visual Studio Code, перейдите к пункту File в верхнем меню и выберите Add Folder to Workspace. В новом окне нажмите кнопку New Folder и создайте новую папку по имени css-practice.
Затем создайте новую папку внутри css-practice и назовите ее css. Внутри этой папки откройте новый файл и сохраните его как styles.css – это файл, который вы будете использовать для хранения правил стилей CSS. Если вы используете Visual Studio Code, вы можете создать новую папку, щелкнув правой кнопкой мыши (в Windows) или нажав CTRL+левая кнопка мыши (на Mac) в папке css-practice, затем выберите New File и создайте папку css. Затем кликните правой кнопкой мыши (в Windows) или нажмите CTRL+левая кнопка (в Mac) в папке css, выберите New File и создайте файл styles. css.
css.
Сохраните файл и оставьте его открытым.
Вам также необходимо создать файл для добавления контента HTML – текста, изображений и HTML-элементов, которые будут отображаться в браузере. В каталоге проекта css-practice откройте еще один новый файл и сохраните его как index.html (так же, как вы создали файл styles.css ранее). Обязательно сохраните этот файл index.html в папке css-practice, а не в папке css.
Затем вам нужно добавить в файл index.html строку кода, которая скажет браузеру использовать файл styles.css в качестве таблицы стилей сайта. Для этого вам понадобится HTML-тег <link> и ссылка на файл styles.css. Добавьте следующий фрагмент кода в свой HTML-документ:
<link rel="stylesheet" href="css/styles.css">
Благодаря этому фрагменту кода браузер будет интерпретировать HTML-код в соответствии с таблицей стилей, расположенной в css/styles.css. На протяжении всей этой серии мануалов будьте внимательны, чтобы случайно не удалить эту строку при изменении кода в файле index. html. Сохраните файл index.html и оставьте его открытым.
html. Сохраните файл index.html и оставьте его открытым.
Теперь создайте дополнительную папку внутри css-practice и назовите ее images. В этой папке вы сохраните все изображения, которые будете использовать при выполнении этой серии мануалов.
Теперь у вас должна быть папка проекта css-practice, содержащая папки и файлы, необходимые для нашего сайта CSS:
- Папка по имени css содержит файл styles.css.
- Пустая папка images.
- Файл index.html
Если вы используете Visual Studio Code, ваш редактор должен теперь отображать следующее дерево файлов:
˅ css-practice
˅ css
# styles.css
> images
˂˃ index.html
Обратите внимание, что имена файлов включают расширения (.html и .css), которые указывают на тип их содержимого. В следующих мануалах этой серии мы добавим контент в эти файлы.
Отладка и устранение неполадок CSS и HTML
При работе с HTML и CSS важна точность. Даже лишний пробел или неправильно введенный символ могут помешать вашему коду работать должным образом.
Если ваш код HTML или CSS не отображается в браузере так, как вы ожидаете, убедитесь, что вы написали код в точности так, как показано в мануале. В целом мы рекомендуем вам вводить код в файлы вручную – так он лучше запоминается, но иногда полезно скопировать и вставить его, чтобы убедиться, что в не мнет ошибки.
Ошибки HTML и CSS могут быть вызваны несколькими причинами. Для начала проверьте свои правила разметки и CSS на наличие лишних или недостающих пробелов, неправильно записанных тегов, а также лишних знаков пунктуации или символов. Вам также следует убедиться, что вы случайно не поставили фигурные или книжные кавычки (“ или “), которые часто используются текстовыми редакторами. Фигурные кавычки предназначены для чтения текста человеком и вызовут ошибку в коде, поскольку они не распознаются браузерами как кавычки. Вводя кавычки прямо в редакторе кода, вы можете быть уверены, что используете правильный тип.
Каждый раз, когда вы вносите в код изменения, обязательно сохраняйте файл перед его перезагрузкой в браузере, чтобы проверить результаты.
Краткое примечание по автоматической поддержке HTML
Некоторые редакторы кода (к ним относится и Visual Studio Code который мы используем в этой серии) предоставляют автоматическую поддержку написания HTML. В Visual Studio Code эта поддержка подразумевает умные подсказки и автозавершение кода. Эта функция бывает полезной, но будьте с ней осторожны: если вы не привыкли работать с ней, вы можете сгенерировать дополнительный код, который вызовет ошибки. Если эти подсказки вас отвлекают, вы можете отключить их в настройках редактора кода.
Заключение
Теперь вы готовы приступить к разработке вашего тестового сайта. В следующем мануале мы покажем, как использовать правила CSS для управления стилем и макетом HTML-страниц.
Tags: CSS, CSS-practice, HTML, Visual Studio Code«Не закрывайте теги!» — CSS-LIVE
С таким провокационным призывом на днях обратился к своим читателям в Твиттере не кто-нибудь, а Таб Аткинс, главный редактор львиной доли спецификаций CSS. Конечно, речь шла не о любых тегах, а об опциональных (необязательных), которые разрешает не ставить сам стандарт HTML. Но всё равно призыв Таба многих шокировал, очень уж вразрез он шел со всем, чему нас учили с самого начала веб-карьеры.
Конечно, речь шла не о любых тегах, а об опциональных (необязательных), которые разрешает не ставить сам стандарт HTML. Но всё равно призыв Таба многих шокировал, очень уж вразрез он шел со всем, чему нас учили с самого начала веб-карьеры.
Может, Таб просто всех троллил? Или же в его совете есть рациональное зерно? Попробуем непредвзято разобраться.
Какие теги можно не закрывать?
Так и хочется воскликнуть «Никакие!» :). Но давайте всё-таки обратимся к стандарту. Он разрешает опускать не только 19 закрывающих тегов, но и 5 открывающих. Все они, вместе с условиями, когда это можно делать, явно перечислены в целом одном страшно секретном разделе 12.1.2.4. И еще 14 тегов закрывать просто нельзя.
В таблицах ниже я попытался максимально упростить формулировку условий из спецификации (если где-то перестарался — прошу поправить):
Необязательные открывающие теги
| Тег | Когда можно не писать |
|---|---|
<html> | Если перед ним не идет <!-- комментарий --> |
<head> | Если перед ним не идет <!-- комментарий --> |
<body> | Если body начинается не с <!-- комментария -->, пробела, либо одного из тегов, который может быть и в head |
<tbody> | Перед <tr>, если перед ним нет незакрытого thead, tfoot или другого tbody |
<colgroup> | Перед <col>, если перед ним нет незакрытого другого colgroup |
Нельзя опускать открывающий тег, если у него есть какие-либо атрибуты (напр.
lang для <html>). Также открывающий <body> необходим, если его первым потомком должен быть script, link или другой элемент, который может быть и в head — иначе он попадет именно туда.
Необязательные закрывающие теги
| Тег | Когда можно не писать |
|---|---|
</html> | Если после него не идет <!-- комментарий --> |
</head> | Если после него не идет <!-- комментарий --> или пробел |
</body> | Если после него не идет <!-- комментарий --> |
</li> | Перед <li> или </ul>/</ol> |
</dt> | Перед <dt> или <dd> |
</dd> | Перед <dt>, <dd> или концом родителя |
</p> | Перед открывающим тегом любого не-фразового потокового («блочного» по-старому:) элемента, либо закрывающим тегом родительского элемента (если у того не прозрачная модель контента) |
</rt> и </rp> | Перед <rt>, <rp> или </ruby> |
</optgroup> | Перед <optgroup> или </select> |
</option> | Перед <option>, <optgroup>, </optgroup> или </select> |
</colgroup> | Если после него не идет <!-- комментарий --> или пробел |
</caption> | Если после него не идет <!-- комментарий --> или пробел |
</thead> | Перед <tbody> или <tfoot> |
</tbody> | Перед другим <tbody>, <tfoot> или </table> |
</tfoot> | Перед </table> |
</tr> | Перед <tr> или концом родителя |
</td> и </th> | Перед <td>, <th> или концом родителя |
Общее правило: закрывающие теги обычно не нужны для однородных сущностей в специализированных контейнерах (пунктов списков, внутренних частей таблиц и т. п.). Напрямую вложенными друг в друга они не бывают, ничего другого в их родителе тоже быть не может, так что если начался следующий — логично, что предыдущий закончился.
п.). Напрямую вложенными друг в друга они не бывают, ничего другого в их родителе тоже быть не может, так что если начался следующий — логично, что предыдущий закончился.
У правила для <p> общая логика похожа, но оно сложнее и потому стоит особняком (мы к нему еще вернемся).
А условие про HTML-комментарий означает лишь требование предсказуемости итоговой DOM. Например, что без явного тега нельзя вставить этот комментарий снаружи элемента. Это всё равно не будет ошибкой, просто в итоговой DOM комментарий окажется внутри него.
Теги, закрывать которые нельзя
Это пустые (void) элементы: area, base, br, col, embed, hr, img, input, link, meta, param, source, track, wbr.
Многие поспешат возразить: «Это же самозакрывающие(ся) теги, у них свой способ закрытия — слеш перед >!». Что ж, их ждет сюрприз: в HTML этот слеш… не значит ничего! Он не считается ошибкой, чтобы было легче переходить с XHTML, но «самозакрытыми», точнее, не требующими закрытия, их делает не слеш, а «зашитый» в алгоритм парсинга список этих пустых элементов. И «закрыть» по аналогии, скажем,
Что ж, их ждет сюрприз: в HTML этот слеш… не значит ничего! Он не считается ошибкой, чтобы было легче переходить с XHTML, но «самозакрытыми», точнее, не требующими закрытия, их делает не слеш, а «зашитый» в алгоритм парсинга список этих пустых элементов. И «закрыть» по аналогии, скажем, <div /> нельзя — для HTML это будет открывающий тег (притом уже с ошибкой). Только для SVG- и MathML-элементов (напр. <g />) этот слеш означает честное «самозакрытие» (т.е. сокращение для <g></g>).
Аргументы против незакрытия тегов
«Это невалидный код!»
Необязательные теги — часть стандарта HTML. Значит, код, использующий их по правилам, валиден (точнее, соответствует этому стандарту). Так что это — невалидный аргумент:)
Нельзя полагаться на механизм исправления ошибок в браузерах
Вообще-то, в HTML5 алгоритм исправления ошибок «зашит» в стандартный алгоритм парсинга, и все браузеры клянутся, что соблюдают этот стандарт. Так что ошибочная запись
Так что ошибочная запись <a href="...">раз<a href="...">два</a> везде даст две ссылки подряд, а не вложенную ссылку.
Но я согласен: полагаться на ошибочное поведение чего бы то ни было — очень, очень плохая идея.
Вот только разрешенные необязательные теги — не ошибка. А хоть и непривычный, но вариант правильного HTML-кода. И этот аргумент валидный — но мимо:)
Хрупкость
Часто говорят, что код с незакрытыми тегами легче сломать чем-то непредвиденным. Но давайте поищем конкретную ситуацию, где это проявится.
Например, вдруг в нашем шаблоне появился HTML-комментарий. Давайте честно: на что может повлиять, добавится этот комментарий внутрь неявного <head> или <body> или снаружи?
Или возьмем динамически генерируемый список. Если внутрь нашего пункта списка попадет другой <li>, то пункт развалится на два — но это произойдет независимо от того, явно он был закрыт или неявно.
Еще в <head>...</head> нередко попадает то, что не может там находиться. Например, что-то, что браузер считает выводимым на экран текстом (в подключаемых PHP-шаблонах это часто могла быть BOM-метка). Это сразу же неявно закрывает </head> и открывает <body>. И снова независимо от того, где и как стояли соотв. теги.
Другое дело, если кто-то возьмет и не закроет другой тег, скажем, </div> или тот же </a>. Но это уже проблема нарушения стандарта (равно как и закрытие тега в неподходящем месте!). Ее решение — валидация кода (в т.ч. автоматическая, на этапе сборки/CI). И оно снова не зависит от наличия/отсутствия необязательных тегов!
Может быть, в комментариях вы подскажете более убедительный пример, где именно легально незакрытый тег будет причиной хрупкости?
Несовместимость с XML (и JSX)
Факт: HTML и XML — разные языки (а JSX — вообще де-факто третий, хоть отчасти и «косплеит» XML внешне), и правила у них разные. Если нужно соблюсти и те, и те, то, конечно, без явного закрытия тегов никак. Другой вопрос, где и зачем сегодня нужна совместимость HTML с XML?..
Если нужно соблюсти и те, и те, то, конечно, без явного закрытия тегов никак. Другой вопрос, где и зачем сегодня нужна совместимость HTML с XML?..
Несовместимость с редакторами и IDE
Многие редакторы кода при подсветке синтаксиса, сворачивании ветвей и т.п. привязываются к явным закрывающим тегам. Некоторые даже закрывают их автоматически. Что ж, правила инструментов тоже желательно соблюдать. Только стоит отличать их от правил языка.
Несовместимость с кодстайлами и рабочими процессами
Аналогично: если в проекте принят какой-то дополнительный стандарт оформления кода помимо синтаксической корректности HTML — будь то лимит длины строк или требование явно закрывать теги — его тоже надо соблюдать. Но он не должен становиться самоцелью: если на его соблюдение уходит слишком много сил и он мешает использовать какую-то стандартную возможность языка, удобную для конкретной задачи — может, легче будет его пересмотреть или перейти на другой?
Трудность чтения
Большинству из нас, наверное, читать код с незакрытыми тегами труднее: нет привычных маркеров конца элемента. Правда, это во многом вопрос привычки и форматирования исходника (см. далее). Но привычка — важный фактор, не поспорить. Особенно в команде.
Правда, это во многом вопрос привычки и форматирования исходника (см. далее). Но привычка — важный фактор, не поспорить. Особенно в команде.
Сложность правил для запоминания
Таблицы с правилами, когда какой тег можно не закрывать, выглядят внушительно. И это я еще их упростил! Даже сам Таб Аткинс в исходном твиттерском треде запутался, какие теги неявно закрывают <p>, а разница между случаями, когда открывающий <body> обязателен, а когда нет, навскидку еще менее интуитивна. Не лучше ли вместо этого вот всего запомнить одно простое правило «всегда закрывай все теги!»?
Увы: одним простым правилом от HTML не отделаешься:). Как минимум 14 исключений — пустые элементы, которые закрывать нельзя — помнить всё равно надо. А что еще важнее, явное закрытие тега не гарантирует, что элемент действительно закончится именно в этом месте (мы уже мельком видели пару примеров, дальше будет больше). Но разве в других языках нет таких «странных» правил? Одна таблица приведения типов в JS чего стоит.
Простота записи поощряет бардак в коде
Занятно, что этот аргумент часто сочетается с предыдущим.
Да, код в стиле «ляпнул открывающий тег и вперёд» может показаться небрежным и «несерьезным». Но это тоже вопрос привычки. Пример обратного — Markdown: одна звездочка — один пункт списка и никаких «закрывающих тегов», при этом в коде полный порядок и читать его — одно удовольствие. Но да, Markdown и HTML — тоже разные языки:)
В любом случае, закрыть тег много ума не надо не так уж сложно (тем более часто это на автомате делает IDE). Сложнее поставить его там, где надо, по правилам языка. Но не поставить его там, где можно по стандарту и уместно по задаче — сложность примерно сопоставимая. Ниже мы увидим, что чтобы писать правильный HTML — хоть с явными тегами, хоть без — его всё равно придется знать.
Явное лучше неявного
Безусловно!
Когда между ними действительно есть выбор.
Увы, с HTML это не всегда так (подробности чуть ниже).
Аргументы за незакрытие тегов
Всего лишь сокращенная запись
В XML были две равнозначные записи элемента без содержимого — полная (<tag></tag>) и сокращенная (<tag/>). Вторая почему-то до сих пор популярна даже в HTML, хотя там этот слеш ничего не значит (см. выше).
Точно так же и в HTML по сути есть две равнозначные записи конструкции «конец элемента и начало следующего» — полная (напр. </p><p>) и сокращенная (напр. <p>). Т.е. формально в обоих случаях эти теги закрыты, просто не всегда очевидным образом.
Экономия трафика
Принцип прост: если не видно разницы — зачем платить писать (и гонять по сети) больше. Древний «гайд» по оформлению HTML/CSS от Google так этот совет и формулировал: «байты — деньги».
Это может быть и вправду актуально для Гугла с его объемами трафика. Для остальных это скорее всего экономия на спичках. Особенно с gzip или еще лучшими новыми алгоритмами сжатия. Но протестировать всё равно не помешает:)
Но протестировать всё равно не помешает:)
Экономия памяти
Любые символы между тегами — включая пробелы и переносы строк — попадают в DOM в виде текстовых нод. В эпоху верстки инлайн-блоками эти ноды-пробелы доставляли немало хлопот (и одним из решений как раз было не закрывать теги:). Сейчас это неактуально, но сами ноды никуда не делись. Так что в DOM списка с закрытыми тегами <li> на самом деле будет вдвое больше нод, чем в DOM списка с незакрытыми (при обычном форматировании исходника, без минификации):
See the Pen
poJKLzb by Ilya Streltsyn (@SelenIT)
on CodePen.
И эти лишние ноды — полноценные DOM-объекты, с кучей свойств и методов. Другой вопрос, так ли много места они занимают в памяти и сильно ли это влияет на производительность страницы (как всегда, надо тестировать и измерять!)
По правде, этот аргумент выходит не столько за незакрытие тегов, сколько за минификацию кода для продакшна, с убиранием всех ненужных пробелов и т. д. Хотя тот же минификатор можно настроить и на вырезание необязательных тегов. Если тесты покажут, что от этого есть толк. Добавлено 26.03.2020: к счастью, проблемы минификаторов 10-летней давности, не всегда умевших отличить необязательный тег от обязательного, остались в прошлом – нынешняя версия html-minifier использует честный HTML5-парсер и, если не злоупотреблять опциями с «невалидным HTML» на выходе, ничего не сломает.
д. Хотя тот же минификатор можно настроить и на вырезание необязательных тегов. Если тесты покажут, что от этого есть толк. Добавлено 26.03.2020: к счастью, проблемы минификаторов 10-летней давности, не всегда умевших отличить необязательный тег от обязательного, остались в прошлом – нынешняя версия html-minifier использует честный HTML5-парсер и, если не злоупотреблять опциями с «невалидным HTML» на выходе, ничего не сломает.
«Защита от дурака»
Вопреки стереотипу, что «явно закрытые теги надежнее», эти добавочные сущности в DOM — еще и новые потенциальные точки отказа, если случайно поставить закрывающий тег не там:
See the Pen
KKpGBqO by Ilya Streltsyn (@SelenIT)
on CodePen.
Причем для абзацев это и валидатор пропустит. Неявно же элементы закрываются только сразу перед другим элементом, и такой неуправляемый «неприкаянный» текст заведомо не появится.
Удобство чтения
Как ни странно, некоторым проще читать код без закрывающих тегов. Для людей программистского склада, привыкших держать все сущности в контейнерах, это звучит дико, но тем, кто больше работает с текстом, часто привычнее думать о разделителях абзацев, пунктов списка и ячеек таблицы. Именно разделители используются в редакторах типа Word, вышеупомянутом Markdown… и HTML задумывался так же (в одном из ранних черновиков те же <p>, <li> и т.п. так и были одиночными разделителями, вроде <br>).
Сравните две разметки таблицы с внешне идентичным результатом:
<table>
<caption>Цены на продукты<caption>
<thead>
<tr>
<th>Продукт</th>
<th>Февраль</th>
<th>Март</th>
</tr>
</thead>
<tbody>
<tr>
<th>Гречка</th>
<td>80</td>
<td>120</td>
</tr>
<tr>
<th>Соль</th>
<td>5</td>
<td>15</td>
</tr>
<tr>
<th>Икра</th>
<td>1500</td>
<td>900</td>
</tr>
</tbody>
</table>
<table>
<caption>Цены на продукты
<thead>
<tr>
<th>Продукт <th>Февраль <th>Март
<tbody>
<tr>
<th>Гречка <td>80 <td>120
<tr>
<th>Соль <td>5 <td>15
<tr>
<th>Икра <td>1500 <td>900
</table>
Правда, тут повезло, что вся таблица и текст в ячейках короткие, а хороший кодстайл должен быть универсальным и не зависеть от везения. .:)
.:)
Лучшее понимание специфики HTML и защита от сюрпризов
Этот аргумент Таба я вынес отдельно, чтобы он не затерялся (и выделил ключевые, на мой взгляд, слова жирным):
Еще одна причина привыкнуть к этому [не ставить необязательные теги] — то, что HTML-парсер будет делать это [достраивать DOM] в любом случае, и вы сможете заодно выучить соответствующие правила, так что не споткнетесь на этом. Если вы используете закрывающие теги с бездумным фанатизмом, вы можете *полагать*, что знаете, где заканчивается элемент, но окажетесь неправы!
Частый вопрос на форумах, StackOverflow, да и в жизни верстальщика: «Почему мой список внутри абзаца не отображается как надо?» Во всех руководствах по HTML <p>...</p> — пример блочного контейнера. С детства мы помним, что абзац — это «законченная мысль», так что если она включает в себя список чего-либо, подводку к нему и некий итог — логично, чтобы всё это было в одном абзаце. Вот открывающий
Вот открывающий <p>, вот список внутри, вот закрывающий </p>, всё закрыто в правильном порядке… Почему же в DOM-инспекторе список оказался снаружи абзаца?
Да, иногда привычка «мыслить контейнерами» и безоговорочно доверять явным тегам может оказать медвежью услугу не только новичку, маскируя неочевидное поведение парсера. А новичку здесь и валидатор мало поможет: «Найден закрывающий тег без открывающего…» — ну как же его нет, когда вот он? Ладно, <p> допускает лишь «фразовое» («строчное», по-старому) содержимое, а список к нему не относится — но ведь другие теги, даже насквозь «строчный» <span>, от точно такой же неправильной вложенности не рвутся!
А вот знание, что закрывающий </p> необязателен, и открывающий тег любого «блочного» (по-старому) элемента — его стандартный эквивалент, эту ситуацию бы предотвратило. Мы бы сразу обернули эту «мысль» не в <p>., а во что-то другое, без неявного закрытия — хоть  ..</p>
..</p><div>. Что, кстати, рекомендует и спецификация.
Аргумент против тегов вообще
Браузерам, по большому счету, вообще плевать на теги. Они отображают не разметку, а DOM, и оперируют лишь DOM-элементами и их свойствами. DOM может строиться по-разному, и в современном мире куда чаще она строится скриптами, а не парсится прямо из разметки. Разметка — лишь один из способов описания будущей DOM в текстовом формате, в принципе не лучший для машины, зато более понятный для человека.
А люди в наше время тоже редко пишут разметку руками. Чаще эту скучную механическую работу за нас делают инструменты — препроцессоры, шаблонизаторы и всё такое прочее. И это их задача — ставить те теги, которые надо, где надо и как надо, чтобы парсеры, со всеми их странностями и документированными причудами, всё правильно поняли. Их, а не наша.
Не в том ли причина многих проблем нынешней веб-отрасли, что истинную природу веб-платформы от разработчиков всю их жизнь вольно или невольно скрывают — сначала за тегами (и пустяками типа их регистра, словно мы до сих пор в 90-х), а затем за абстракциями фреймворков?. .
.
Заключение
Думаю, подытожить эту статью можно примерно так:
- Необязательные теги — не ошибка, не «магия», не «браузерная самодеятельность» и т.п. (как часто считают), а документированная особенность стандарта. По сути — еще один инструмент HTML, такой же, как и закрывающие теги. Можно спорить, входят ли они в «The good parts» языка HTML (скорее всего нет!:), но в некоторых задачах (напр. для экстремальной оптимизации) они могут быть полезны;
- Почти все валидные аргументы и за, и против необязательных тегов сводятся к двум фразам: «делайте, как вам удобнее», и «делайте, как у вас (в проекте, в команде, в настройках окружения и т.д.) заведено». Ну и еще «смотрите по задаче и тестируйте!».
Поэтому в подавляющем большинстве случаев все необязательные теги лучше всё-таки ставить. Не потому, что «Так Надо, Ибо Воистину ©», или будто это автоматически «сделает код надежнее», а лишь потому, что:
- так удобнее и понятнее большинству разработчиков;
- так настроено по умолчанию большинство инструментов.

Код должен решать свою задачу. Задача исходников — не столько инструкция для браузеров (им-то стиль кода не важен), сколько коммуникация между разработчиками. Понятнее для большинства — коммуникация лучше.
Но не забывайте, что бывают люди и с другими предпочтениями. И увидев у кого-то непривычный стиль валидного кода, не спешите тыкать пальцем «гы-гы, вот ламер, даже теги не закрыл». Лучше поинтересуйтесь, почему так сделано. Некрасиво — не обязательно плохо, а непривычно — не всегда некрасиво. Иногда красота проявляется лишь в целой картине.
А вообще в веб-платформе масса вещей, куда более важных, чем стиль написания тегов или спор между табами и пробелами. Та же доступность хотя бы!
И всё-таки, к одному из аргументов я хотел бы вернуться. В общем-то, ради него я и затеял эту статью:)
Веб-платформа большая и сложная. В ней много неизвестного и непонятного — даже для авторов спецификаций. Сложность и неизвестность пугает. Это естественно. И людям естественно успокаивать себя, отгораживаться от своих страхов приметами и ритуалами. Сплюнул через левое плечо — «беда обойдет». Успел потрогать пуговицу перед черной кошкой — «неудача отступит». Написал тег со слешем — «код не сломается». И т.п.
И людям естественно успокаивать себя, отгораживаться от своих страхов приметами и ритуалами. Сплюнул через левое плечо — «беда обойдет». Успел потрогать пуговицу перед черной кошкой — «неудача отступит». Написал тег со слешем — «код не сломается». И т.п.
Не надо так. Приметы не работают. Единственная настоящая защита против неизвестности — знание. Не бойтесь узнавать новое. Даже в том, что другие считают «элементарным». В технике нет мелочей. А HTML — давно не смешные буквы в угловых скобках, а целая колоссальная экосистема. В ней надолго хватит места самым неожиданным открытиям.
А лучший способ изучить что-либо — эксперимент. И у веба огромное преимущество перед, скажем, ядерной физикой или генетикой, что здесь в экспериментах «для себя» иногда можно нарушать правила и смотреть, что из этого выйдет — ничего действительно страшного не случится. Зато станет понятнее, почему правила именно такие. И вообще — а правила ли это (а не реликт совсем другой эпохи с совсем другими ограничениями, скажем — это я не про закрытие тегов, а абстрактно:)
Так что не бойтесь экспериментировать! И пусть с каждым днем всё больше особенностей веб-платформы становится для вас не странной «магией», а понятным и предсказуемым инструментом. Который при ненадобности всегда можно отложить в дальний ящик, но иногда, если задача того потребует, использовать на радость себе и пользователям.
Который при ненадобности всегда можно отложить в дальний ящик, но иногда, если задача того потребует, использовать на радость себе и пользователям.
P.S. Это тоже может быть интересно:
ссылок в документах HTML
ссылок в документах HTMLпредыдущий следующий содержимое элементы атрибуты индекс
Содержание
- Введение в ссылки и якоря
- Посещение связанного ресурса
- Другие отношения связи
- Указание якорей и ссылок
- Заголовки ссылок
- Интернационализация и ссылки
- А элемент
- Синтаксис имен якорей
- Вложенные ссылки незаконны
- Якоря с id атрибут
- Недоступен и неидентифицируем ресурсы
- Отношения документов: элемент LINK
- Прямые и обратные связи
- Ссылки и внешний стиль листы
- Ссылки и поисковые системы
- Информация о пути: элемент BASE
- Разрешающий родственник URI
HTML предлагает множество традиционных идиом для публикации форматированного текста и
структурированные документы, но что отличает его от большинства других языков разметки, так это
его функции для гипертекстовых и интерактивных документов. В этом разделе представлены
ссылка (или гиперссылка, или веб-ссылка), основная гипертекстовая конструкция. А
ссылка — это соединение с одного веб-ресурса на другой. Хотя простой
концепции, ссылка была одной из основных сил, определяющих успех
Веб.
В этом разделе представлены
ссылка (или гиперссылка, или веб-ссылка), основная гипертекстовая конструкция. А
ссылка — это соединение с одного веб-ресурса на другой. Хотя простой
концепции, ссылка была одной из основных сил, определяющих успех
Веб.
А звено имеет два конца, называемых якорями , и направление. Ссылка начинается с якоря «источник» и указывает на якорь «назначения», который может быть любым веб-ресурсом (например, изображением, видео клип, звуковой фрагмент, программа, документ HTML, элемент внутри HTML документ и др.).
12.1.1 Посещение связанного ресурса
Поведение по умолчанию, связанное со ссылкой, — получение другой веб-ресурс. Такое поведение обычно и неявно полученный путем выбора ссылки (например, путем нажатия, ввода с клавиатуры, так далее.).
Следующий отрывок HTML содержит две ссылки, одна
целевой якорь которого является документом HTML с именем «chapter2.html», а
другой, якорем назначения которого является изображение GIF в файле «forest. gif»:
gif»:
<ТЕЛО> ...какой-то текст...Вы найдете гораздо больше в второй главе. См. также эту карту зачарованного леса.
При активации этих ссылок (щелчком мыши, через клавиатуру ввод, голосовые команды и т. д.), пользователи могут посещать эти ресурсы. Обратите внимание, что чс атрибут в каждом исходном якоре указывает адрес целевого якоря с URI.
Якорь назначения ссылки может быть элементом в HTML-документе. Якорю назначения должно быть присвоено имя якоря и любой URI, относящийся к нему. якорь должен включать имя в качестве идентификатора фрагмента.
Якоря назначения в документах HTML могут быть указаны либо с помощью A элемент (называя его с помощью имя атрибут) или любым другим элементом (название с id атрибут).
Так, например, автор может создать оглавление, записи которого
ссылка на элементы шапки h3 , h4 и т. д. в этом же документе. Использование элемента A для
создать якоря назначения, мы бы написали:
д. в этом же документе. Использование элемента A для
создать якоря назначения, мы бы написали:
Содержание
Введение
Введение ...раздел 1... Небольшая предыстория ...секция 2... Личное примечание ...раздел 2.1...
Небольшая предыстория
Личное примечание
...остальное содержание... ...тело документа...
Мы можем добиться того же эффекта, сделав сами элементы заголовка якоря:
Содержание
Введение
Небольшая предыстория
Личное примечание
...остальное содержание... ...тело документа...Введение
...раздел 1...Небольшая предыстория
...секция 2.Личное примечание
...раздел 2.1...
 ..
..
12.1.2 Другая ссылка отношения
На сегодняшний день наиболее распространенным использованием ссылки является получение другого веб-сайта. ресурса, как показано в предыдущих примерах. Однако авторы могут вставлять ссылки в своих документах, которые выражают другие отношения между ресурсами чем просто «активировать эту ссылку, чтобы посетить соответствующий ресурс». Ссылки, которые выражать другие типы отношений имеют один или несколько типов ссылок, указанных в их привязке к источнику.
Роли ссылки, определенной A или LINK , указаны через rel и атрибуты версии .
Например, ссылки, определяемые элементом LINK , могут описывать позицию документа в серии документов. В следующем отрывке ссылки в документе под названием «Глава 5» указывают на предыдущую и следующую главы:
<ГОЛОВА> .Глава 5 <ССЫЛКА rel="prev" href="chapter4.html"> <ССЫЛКА rel="следующая" href="chapter6.html">
 ..другая информация о головке...
..другая информация о головке...
Тип первой ссылки — «предыдущая», а второй — «следующая». (два из нескольких распознаваемых типов ссылок). Ссылки, указанные ССЫЛКА , , а не отображаются вместе с документом. содержимое, хотя пользовательские агенты могут отображать его другими способами (например, как средства навигации).
Даже если они не используются для навигации, эти ссылки могут интерпретироваться в интересные способы. Например, пользовательский агент, который печатает серию HTML документы как единый документ могут использовать эту информацию о ссылках в качестве основы для формирование связного линейного документа. Ниже приведена дополнительная информация об использовании ссылки в интересах поисковых систем.
12.1.3 Указание якорей и ссылок
Хотя некоторые элементы и атрибуты HTML создают ссылки на другие
ресурсов (например, элемент IMG , элемент элемент FORM и т. д.), в этой главе обсуждаются ссылки и якоря.
созданные элементами LINK и A . Элемент LINK может появляться только в
глава документа. Элемент A может появляться только в теле.
д.), в этой главе обсуждаются ссылки и якоря.
созданные элементами LINK и A . Элемент LINK может появляться только в
глава документа. Элемент A может появляться только в теле.
Когда Элемент атрибут href установлен, элемент определяет источник привязка для ссылки, которая может быть активирована пользователем для получения веб-ресурса. Исходная привязка — это расположение экземпляра A и целевой привязки. является веб-ресурсом.
Пользовательский агент может обрабатывать полученный ресурс несколькими способами:
открытие нового HTML-документа в том же окне пользовательского агента, открытие нового HTML-документа
документ в другом окне, запуская новую программу для обработки ресурса,
и т.д. С Элемент имеет содержимое (текст, изображения и т. д.), пользовательские агенты могут отображать
этот контент таким образом, чтобы указать на наличие ссылки (например, путем
подчеркивание содержания).
Когда установлены атрибуты name или id элемента A , элемент определяет привязку, которая может быть местом назначения других ссылок.
Авторы могут одновременно устанавливать атрибуты name и href в тот же Экземпляр .
Элемент LINK определяет связь между текущим документом и другой ресурс. Хотя LINK не имеет содержимого, определяемые им отношения могут быть обработаны некоторыми пользовательскими агентами.
12.1.4 Заголовки ссылок
Атрибут title может быть установлен как для A , так и для LINK на добавить информацию о характере ссылки. Эта информация может быть произнесена пользовательский агент, отображаемый в виде всплывающей подсказки, вызывает изменение изображения курсора и т. д.
Таким образом, мы можем дополнить предыдущий пример предоставление заголовка для каждой ссылки:
<ТЕЛО> .Вы найдете гораздо больше в вторая глава. вторая глава. См. также этот карта заколдованный лес.
 ..какой-то текст...
..какой-то текст...
12.1.5 Интернационализация и ссылки
Поскольку ссылки могут указывать на документы, закодированные с использованием разных кодировок символов, A и LINK элементы поддерживают атрибут charset . Этот атрибут позволяет авторам информировать пользовательские агенты о кодировании данных на другом конце ссылки.
Атрибут hreflang предоставляет агентам пользователя информация о языке ресурса в конце ссылки, как и Атрибут lang предоставляет информацию о языке содержимое элемента или значения атрибутов.
Вооруженные этими дополнительными знаниями, пользовательские агенты должны иметь возможность избегать
предоставление «мусора» пользователю. Вместо этого они могут либо найти ресурсы
необходимые для правильного оформления документа или, если они не могут
найти ресурсы, они должны как минимум предупредить пользователя о том, что документ будет
быть нечитаемым и объяснить причину.
Вместо этого они могут либо найти ресурсы
необходимые для правильного оформления документа или, если они не могут
найти ресурсы, они должны как минимум предупредить пользователя о том, что документ будет
быть нечитаемым и объяснить причину.
12.2
А элемент A - - (%inline;)* -(A) -- привязка -->
кодировка %кодировка; #ПРЕДПОЛАГАЕТСЯ -- символьная кодировка связанного ресурса --
тип %ContentType; #ПРЕДПОЛАГАЕТСЯ -- рекомендательный тип контента --
имя CDATA #ПРЕДПОЛАГАЕТСЯ -- именованный конец ссылки --
href %URI; #ПРЕДПОЛАГАЕТСЯ -- URI связанного ресурса --
hreflang %LanguageCode; #ПРЕДПОЛАГАЕТСЯ -- код языка --
отн. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы ссылок вперед --
ред. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы обратной ссылки --
ключ доступа %Символ; #ПРЕДПОЛАГАЕТСЯ -- ключевой символ специальных возможностей --
форма %форма; rect -- для использования с клиентскими картами изображений --
координат %Координаты; #ПРЕДПОЛАГАЕТСЯ -- для использования с клиентскими картами изображений --
tabindex НОМЕР #ПРЕДПОЛАГАЕТСЯ -- позиция в порядке табуляции --
onfocus %Script; #ПРЕДПОЛАГАЕТСЯ -- элемент получил фокус --
onblur %Script; #ПРЕДПОЛАГАЕТСЯ -- элемент потерял фокус --
>
Начальный тег: требуется , Конечный тег: требуется
Определения атрибутов
- имя = cdata [CS]
- Этот атрибут называет текущий якорь так, чтобы он мог быть пунктом назначения. другой ссылки. Значение этого атрибута должно быть уникальным именем привязки.
областью действия этого имени является текущий документ. Обратите внимание, что этот атрибут разделяет
то же пространство имен, что и id атрибут.
- href = uri [CT]
- Этот атрибут указывает местоположение веб-ресурса, тем самым определяя связь между текущим элементом (исходным якорем) и целевым якорем определяется этим атрибутом.
- hreflang = langcode [CI]
- Этот атрибут указывает базовый язык ресурса, обозначенного href и может использоваться только при указании href .
- тип = тип содержимого [CI]
- Этот атрибут дает рекомендательную подсказку относительно типа контента
доступны по целевому адресу ссылки. Это позволяет пользовательским агентам выбрать использование
резервный механизм, а не извлекать содержимое, если им сообщают, что они
получат контент в типе контента, который они не поддерживают.
- Авторы, использующие этот атрибут, берут на себя ответственность за управление рисками, это может стать несовместимым с контентом, доступным в целевой ссылке адрес.
- Актуальный список зарегистрированных типов контента см. [МИМЕТИПЫ].
- отн. = типы ссылок [CI]
- Этот атрибут описывает связь между текущим документом и привязка, указанная атрибутом href . Значение этого атрибута равно разделенный пробелами список типов ссылок.
- rev = типы ссылок [CI]
- Этот атрибут используется для описания обратной ссылки от якоря, указанного атрибут href для текущего документа. значением этого атрибута является список типов ссылок, разделенных пробелами.
- кодировка = кодировка [CI]
- Этот атрибут указывает кодировку символов назначенного ресурса
по ссылке. Пожалуйста, обратитесь к разделу о характере
кодировки для более подробной информации.
 другой ссылки. Значение этого атрибута должно быть уникальным именем привязки.
областью действия этого имени является текущий документ. Обратите внимание, что этот атрибут разделяет
то же пространство имен, что и id атрибут.
другой ссылки. Значение этого атрибута должно быть уникальным именем привязки.
областью действия этого имени является текущий документ. Обратите внимание, что этот атрибут разделяет
то же пространство имен, что и id атрибут.

Атрибуты, определенные в другом месте
- id , class (идентификаторы всего документа)
- язык (язык информация), дир (текст направление)
- title (заголовок элемента)
- стиль (встроенный информация о стиле)
- формы и координаты (изображение карты)
- onfocus , onblur , onclick , ondblclick , onmousedown , onmouseup , onmouseover , onmousemove , , нажатие клавиши , onkeydown , onkeyup (внутренние события)
- цель (цель информация о кадре)
- tabindex (навигация с помощью вкладок)
- ключ доступа (ключи доступа)
Каждый Элемент определяет якорь
- Содержимое элемента определяет позицию привязки.
- Атрибут name именует якорь так, чтобы он мог быть местом назначения ноль или более ссылок (см. также анкоры с идентификатор ).
- Атрибут href делает этот якорь исходным якорем ровно для одного ссылка на сайт.

Авторы также могут создать элемент A , не определяющий якорей, т. е. не указывает href , имя или идентификатор . Значения этих атрибутов могут быть установить позже через скрипты.
В следующем примере Элемент определяет ссылку. Исходный якорь текст «Веб-сайт W3C» и якорь назначения — «http://www.w3.org/»:
Для получения дополнительной информации о W3C обратитесь к веб-сайт W3C.
Эта ссылка указывает на домашнюю страницу консорциума World Wide Web. Когда
пользователь активирует эту ссылку в пользовательском агенте, пользовательский агент получит
ресурс, в данном случае HTML-документ.
Пользовательские агенты обычно отображают ссылки таким образом, чтобы сделать их очевидной для пользователей (подчеркивание, перевернутое видео и т. д.). Точный рендеринг зависит от пользовательского агента. Рендеринг может варьироваться в зависимости от того, есть ли у пользователя уже побывали по ссылке или нет. Возможный визуальный рендеринг предыдущего ссылка может быть:
Дополнительные сведения о W3C см. на веб-сайте W3C.
~~~~~~~~~~~~~
Чтобы явно указать агентам пользователя, какая кодировка символов целевая страница, установите кодировка атрибут:
Для получения дополнительной информации о W3C обратитесь к Веб-сайт W3C
Предположим, мы определили привязку с именем «anchor-one» в файле «one.html».
...текст перед якорем... Это расположение первой привязки. ..
 .текст после якоря...
.текст после якоря...
Это создает привязку вокруг текста «Это расположение привязки один.». Обычно содержимое A не отображаются особым образом, когда A определяет только якорь.
Определив якорь, мы можем ссылаться на него с того же или другого документ. URI, обозначающие якоря, содержат символ «#», за которым следует имя якоря (фрагмент идентификатор). Вот несколько примеров таких URI:
- Абсолютный URI: http://www.mycompany.com/one.html#anchor-one
- Относительный URI: ./one.html#anchor-one или one.html#anchor-один
- Когда ссылка определена в том же документе: #anchor-one
Таким образом, ссылка, определенная в файле «two.html» в том же каталоге, что и «one.html» будет ссылаться на якорь следующим образом:
. ...текст перед ссылкой... Для получения дополнительной информации см. якорь один. ...текст после ссылки...
Элемент в следующем примере указывает ссылку (с href ) и одновременно создает именованный якорь (с именем ):
Я только что вернулся из отпуска! Вотsomecompany.com/People/Ian/vacation/family.png"> фото моей семьи на озере..
Этот пример содержит ссылку на веб-ресурс другого типа (файл PNG изображение). Активация ссылки должна привести к получению ресурса изображения. из Интернета (и, возможно, отображается, если система настроена на выполнение так).
Примечание. Пользовательские агенты должны уметь находить якоря создан пустыми элементами A , но некоторые не могут этого сделать. Например, какой-то пользователь агенты могут не найти «пустой якорь» в следующем фрагменте HTML:
...немного HTML... Ссылка на пустой якорь
12.2.1 Синтаксис привязки имена
Имя привязки представляет собой значение либо имя или идентификатор атрибут при использовании в контексте якорей. Имена якорей должны соответствовать следующие правила:
- Уникальность: Имена якорей должны быть
уникальный в пределах документа. Имена якорей, отличающиеся только регистром, могут не отображаться
в том же документе.
- Сопоставление строк: сравнений между идентификаторами фрагментов и имена якорей должны быть выполнены путем точного (с учетом регистра) совпадения.
 Имена якорей, отличающиеся только регистром, могут не отображаться
в том же документе.
Имена якорей, отличающиеся только регистром, могут не отображаться
в том же документе.Таким образом, следующий пример корректен в отношении сопоставления строк и должны рассматриваться агентами пользователя как совпадения:
... ...дополнительный документ...
НЕЗАКОННЫЙ ПРИМЕР:
Следующий пример недопустим с точки зрения уникальности, так как два имени
те же, за исключением регистра:
Хотя следующий отрывок является допустимым HTML, поведение пользовательского агента не определено; некоторые пользовательские агенты могут (ошибочно) считать это совпадением и другие не могут.
... ...дополнительный документ.
 ..
..
Имена якорей должны быть ограничены ASCII персонажи. Пожалуйста, обратитесь к приложению для получения дополнительной информации о не-ASCII-символы в URI значения атрибутов.
12.2.2 Вложенные ссылки недопустимы
Ссылки и анкоры, определенные Элемент не должен быть вложенным; элемент A не должен содержать никаких других A элементов.
Поскольку DTD определяет LINK элемент должен быть пустым, LINK элементы также не могут быть вложенными.
12.2.3 Анкеры с
идентификатор атрибутАтрибут id может использоваться для создания якоря в начальном теге любого элемент (включая элемент A ).
Этот пример иллюстрирует использование атрибута id для позиционирования привязки в элемент h3 . Якорь связан с через А элемент.
Подробнее об этом можно прочитать в разделе втором.Раздел второй
... далее в документеСм. раздел второй выше. Больше подробностей.
 ... далее в документе
... далее в документе
В следующем примере якорь назначения именуется с идентификатором . атрибут:
Я только что вернулся из отпуска! Вот фото моей семьи на озере..
Атрибуты id и name имеют одно и то же пространство имен. Это означает, что они не могут оба определить якорь с тем же именем в том же документе. Это допустимо используйте оба атрибута, чтобы указать уникальный идентификатор элемента для следующих элементы: А , ПРИЛОЖЕНИЕ , ФОРМА , РАМА , IFRAME , IMG и MAP . Когда оба атрибута используются в одном элементе, их значения должны быть идентичный.
НЕЗАКОННЫЙ ПРИМЕР:
Следующий отрывок является недопустимым HTML, так как эти атрибуты объявляют одно и то же
имя дважды в одном и том же документе.
... ......страниц и страниц... <А имя="a1">
В следующем примере показано, что id и name должны быть одинаковыми, когда оба появляются в начальном теге элемента:
Из-за спецификации в HTML DTD имя атрибут может содержать ссылки на символы. Таким образом, значение Dürst является действительный значение атрибута name , как Dürst . идентификатор Атрибут, с другой стороны, не может содержать ссылки на символы.
Использовать id или имя ? Авторы должны учитывать следующее проблемы при принятии решения об использовании id или имя для имени якоря:
- Атрибут id может действовать не только как имя привязки (например, стиль
селектор листов, идентификатор обработки и т. д.).
- Некоторые старые пользовательские агенты не поддерживают привязки, созданные с идентификатором атрибут.
- Атрибут name позволяет использовать более богатые имена привязок (с сущностями).
 д.).
д.). 12.2.4 Недоступно и неидентифицируемые ресурсы
Ссылка на недоступный или неидентифицируемый ресурс является ошибкой. Хотя пользовательские агенты могут по-разному обрабатывать такую ошибку, мы рекомендуем следующее поведение:
- Если пользовательский агент не может найти связанный ресурс, он должен предупредить пользователь.
- Если пользовательский агент не может определить тип связанного ресурса, он должен еще попробуй обработать. Это должно предупредить пользователя и может позволить пользователю вмешаться и определить тип документа.
12.3 Отношения документов:
ССЫЛКА элемент LINK - O EMPTY -- независимая от носителя ссылка -->
кодировка %кодировка; #ПРЕДПОЛАГАЕТСЯ -- символьная кодировка связанного ресурса --
href %URI; #ПРЕДПОЛАГАЕТСЯ -- URI связанного ресурса --
hreflang %LanguageCode; #ПРЕДПОЛАГАЕТСЯ -- код языка --
тип %ContentType; #ПРЕДПОЛАГАЕТСЯ -- рекомендательный тип контента --
отн. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы ссылок вперед --
ред. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы обратной ссылки --
медиа %MediaDesc; #ПРЕДПОЛАГАЕТСЯ -- для рендеринга на этих носителях --
>
 %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы ссылок вперед --
ред. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы обратной ссылки --
медиа %MediaDesc; #ПРЕДПОЛАГАЕТСЯ -- для рендеринга на этих носителях --
>
%LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы ссылок вперед --
ред. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы обратной ссылки --
медиа %MediaDesc; #ПРЕДПОЛАГАЕТСЯ -- для рендеринга на этих носителях --
>
Начальный тег: требуется , Конечный тег: запрещено
Атрибуты, определенные в другом месте
- id , class (идентификаторы всего документа)
- язык (язык информация), дир (текст направление)
- title (заголовок элемента)
- стиль (встроенный информация о стиле)
- onclick , ondblclick , onmousedown , onmouseup , onmouseover , onmousemove , onmouseout , onkeypress , onkeydown , onkeyup (внутренние события)
- ссылка , hreflang , тип , rel , rev (ссылки и анкеры)
- цель (цель информация о кадре)
- носитель (заголовок информация о стиле)
- кодировка (символ кодировки)
Этот элемент определяет ссылку. В отличие от A , он может появиться только в HEAD .
раздел документа, хотя он может появляться любое количество раз. Хотя ССЫЛКА не имеет содержания, он передает информацию об отношениях, которая может быть представлена
пользовательские агенты различными способами (например, панель инструментов с раскрывающимся меню
ссылки).
В отличие от A , он может появиться только в HEAD .
раздел документа, хотя он может появляться любое количество раз. Хотя ССЫЛКА не имеет содержания, он передает информацию об отношениях, которая может быть представлена
пользовательские агенты различными способами (например, панель инструментов с раскрывающимся меню
ссылки).
В этом примере показано, как несколько определений LINK могут отображаться в HEAD раздел документа. Текущий документ — «Chapter2.html». отн. атрибут определяет отношение связанного документа с текущим документ. Значения «Index», «Next» и «Prev» объясняются в разделе по типам ссылок.
<ГОЛОВА>Глава 2 <ССЫЛКА rel="Предыдущая" href="Глава1.html"> .
 ..остальная часть документа...
..остальная часть документа...
12.3.1 Прямые и обратные ссылки
Атрибуты rel и rev играют взаимодополняющие роли — rel атрибут указывает прямую ссылку, а атрибут rev указывает обратную ссылка на сайт.
Рассмотрим два документа A и B.
Документ А:
Имеет то же значение, что и:
.Документ Б:
Оба атрибута могут быть указаны одновременно.
12.3.2 Ссылки и внешние таблицы стилей
Когда Элемент LINK связывает внешнюю таблицу стилей с документом, элемент Атрибут type определяет язык таблицы стилей и тип . Атрибут media указывает предполагаемый носитель или носитель рендеринга. Пользовательские агенты могут сэкономить время, извлекая из сети только те листы, которые относятся к текущему устройству.
Типы носителей далее
обсуждалось в разделе о таблицах стилей.
12.3.3 Ссылки и поисковые системы
Авторы могут использовать элемент LINK для предоставления разнообразной информации поисковые системы, в том числе:
- Ссылки на альтернативные версии документа, написанные другим человеком язык.
- Ссылки на альтернативные версии документа, предназначенные для разных носителей, например, версия, специально подходящая для печати.
- Ссылки на стартовую страницу сборника документов.
В приведенных ниже примерах показано, как информация о языке, типах мультимедиа и типы ссылок могут быть объединены для улучшения обработки документов поисковыми системами.
В следующем примере мы используем атрибут hreflang , чтобы сообщить поиску
Engines, где можно найти версии документа на голландском, португальском и арабском языках.
Обратите внимание на использование атрибута charset для арабского руководства. Обратите также внимание на
использование lang атрибут, чтобы указать, что значение заголовка Атрибут элемента LINK , обозначающий руководство на французском языке, указан на французском языке.
<ГОЛОВА>Руководство на английском языке
В следующем примере мы сообщаем поисковым системам, где найти вариант руководства.
<ГОЛОВА>Справочное руководство com/manual/postscript.ps">
В следующем примере мы сообщаем поисковым системам, где найти переднюю страница сборника документов.
<ГОЛОВА>Справочное руководство -- стр. 5
Дополнительная информация приведена в примечаниях в приложении о том, как помочь поисковым системам проиндексировать ваш веб-сайт. сайт.
12.4 Информация о пути:
БАЗА элементBASE - O EMPTY -- URI базы документов --> href %URI; #REQUIRED -- URI, который действует как базовый URI -- >
Начальный тег: требуется , Конечный тег: запрещено
Определения атрибутов
- href = uri [CT]
- Этот атрибут указывает абсолютный URI, который действует как базовый URI для
разрешение относительных URI.

Атрибуты, определенные в другом месте
- цель (цель информация о кадре)
В HTML ссылки и ссылки на внешние изображения, апплеты, обработку форм программы, таблицы стилей и т. д. всегда указываются с помощью URI. Относительные URI разрешается в соответствии с базовым URI, который может поступать из разных источников. Элемент BASE позволяет авторам явно указывать базовый URI документа.
При наличии Элемент BASE должен появиться в HEAD раздел HTML-документа перед любым элементом, ссылающимся на внешний источник. Информация о пути, указанная элементом BASE , влияет только на URI в документ, в котором появляется элемент.
Например, учитывая следующее объявление BASE и A декларация:
<ГОЛОВА>Наши продукты aviary.com/products/intro.html"> <ТЕЛО>
Вы видели наши клетки для птиц?
относительный URI «../cages/birds.gif» будет разрешаться в:
http://www.aviary.com/cages/birds.gif
12.4.1 Разрешение относительных URI
Пользовательские агенты должны вычислять базовый URI для разрешения относительных URI. согласно [RFC1808], раздел 3. Ниже описано, как [RFC1808] относится конкретно к HTML.
Пользовательские агенты должны вычислять базовый URI в соответствии со следующим приоритеты (от наивысшего приоритета к низшему):
- Базовый URI задается Элемент BASE .
- Базовый URI задается метаданными, обнаруженными во время протокола взаимодействие, например заголовок HTTP (см. [RFC2616]).
- По умолчанию базовым URI является URI текущего документа. Не весь HTML
документы имеют базовый URI (например, действительный HTML-документ может появиться в электронном письме
и не может обозначаться URI). Такие HTML-документы считаются
ошибочны, если они содержат относительные URI и полагаются на базовый URI по умолчанию.
 Такие HTML-документы считаются
ошибочны, если они содержат относительные URI и полагаются на базовый URI по умолчанию.
Такие HTML-документы считаются
ошибочны, если они содержат относительные URI и полагаются на базовый URI по умолчанию.Кроме того, Элементы OBJECT и APPLET определяют атрибуты, которые имеют приоритет над значением, установленным элементом BASE . Пожалуйста, проконсультируйтесь с определения этих элементов для получения дополнительной информации о проблемах URI, характерных для их.
Примечание. Для версий HTTP, определяющих заголовок Link, пользовательские агенты должны обрабатывать эти заголовки точно так же, как LINK элементы в документе. HTTP 1.1, как определено в [RFC2616], не включить поле заголовка Link (см. раздел 19.6.3).
предыдущий следующий содержимое элементы атрибуты индекс
Ссылки HTML — Бесплатный учебник для изучения HTML и CSS
Ссылки необходимы в HTML, так как Интернет изначально был разработан как информационная сеть документов связанных друг с другом.
Часть HTML «Гипертекст» определяет, какие ссылки мы используем: гипертекст ссылки, также известные как гиперссылки .
В HTML количество ссылок равно встроенных элементов , записанных с помощью тега .
Чтобы что-то найти, зайдите в Google.
Ссылки — это первичное взаимодействие веб-страницы: вы переходите от одного документа к другому, нажимая на ссылки.
Существует 3 типов целей, которые вы можете определить.
- якорь целей для навигации по той же странице
- относительные URL-адреса, обычно для навигации по одному и тому же веб-сайту
- абсолютные URL-адреса, обычно для перехода на другой веб-сайт
Анкерные мишени
Привязка к цели для навигации внутри той же страницы.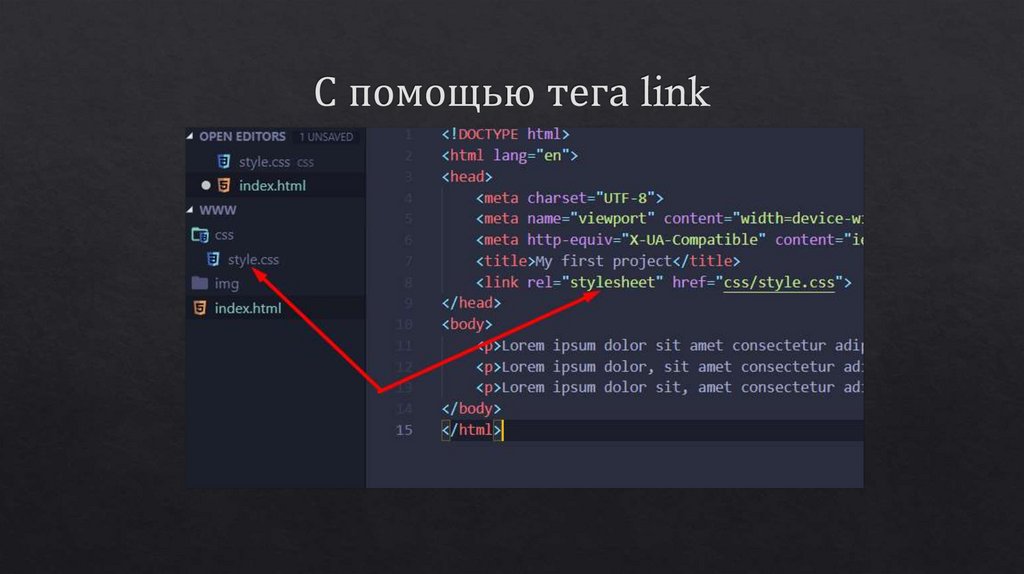 Поставив перед вашим href цифру
Поставив перед вашим href цифру # , вы можете настроить таргетинг на элемент HTML с помощью определенного атрибута id .
Например, перейдет к
в том же документе HTML. Этот тип href часто используется для возврата к началу страницы.Относительные URL-адреса
Если вы хотите определить ссылку на другую страницу того же веб-сайта , вы можете использовать относительных URL-адресов.
Но относительно чего? Ну, относительно текущая страница .
Давайте рассмотрим простой пример, где папка my-first-website содержит 2 HTML-файла:
- мой первый сайт
- home.html
- контакт.html
В home.html вы хотите определить ссылку на contact.html .
Поскольку два файла находятся в одной папке можно просто написать в home. : html
html
Перейти на страницу контактов.
На реальном веб-сайте процесс аналогичен.
Допустим, у вас есть веб-сайт с именем https://ireallylovecats.com , на котором у вас есть 2 веб-страницы: index.html и Gallery.html :
- www.reallylovecats.com
- index.html
- галерея.html
В index.html можно написать следующую ссылку:
Посетите галерею!
Помните: веб-сайты размещены на компьютерах точно так же, как тот, который вы используете в настоящее время. Их просто называют «серверами» , потому что их единственной целью является размещение веб-сайтов. Но у них все еще есть файлы и папки как на «обычных» компьютерах.
Абсолютные URL-адреса
Если вы хотите поделиться своей галереей кошек с другом, вы не сможете просто отправить Gallery.html , так как этот относительный URL-адрес работает только для документов HTML, которые находятся на том же компьютере или том же . домен .
Вам нужен полный URL-адрес вашего HTML-документа: https://ireallylovecats.com/gallery.html .
Этот URL можно разделить на 3 части:
- протокол
https:// - домен
ireallylovecats.com - путь к файлу
галерея.html
Этот абсолютный URL является самодостаточным : независимо от того, где вы используете форму ссылки, она содержит всю информацию, необходимую для поиска правильного файла в правильном домене с правильным протоколом.
Обычно вы используете абсолютные URL-адреса, определяющие ссылку с вашего веб-сайта на другой веб-сайт .
В вашем файле https://ireallylovecats.com/gallery.html вы можете написать:
Найдите больше изображений моих кошек в моем аккаунте Twitter!
Относительные или абсолютные ссылки?
Допустим, вы хотите сделать ссылку с первого на второй. Самый прямой подход — использовать абсолютный URL. Таким образом, вы добавляете Перейдите на вторую страницу в файле index.html .
Поскольку два файла находятся в одном каталоге, вы можете использовать относительный URL-адрес , указав . Это полезно, если вы решите переместить свой каталог: ваши ссылки не будут нарушены, потому что цели ссылки относятся друг к другу, если вы одновременно перемещаете оба файла и сохраняете их в одном каталоге. Этот относительный подход особенно полезен при переключении доменов.
Этот относительный подход особенно полезен при переключении доменов.
HTML-ссылки · WebPlatform Docs
Резюме
В этой статье мы обеспечиваем базовую обработку привязок HTML, или элементов , более известных как HTML-ссылки.
Введение

Что такое ссылки?
Ссылки — это части HTML-документа, указывающие на другие ресурсы — другие HTML-документы, текстовые файлы, PDF-файлы и т. д. По некоторым ссылкам браузер переходит автоматически, созданные с помощью <ссылка> (с некоторыми из них вы уже встречались в предыдущих статьях, например, когда они использовались для импорта файлов CSS в документ HTML). Но обычно, когда мы говорим о ссылках, мы имеем в виду те, которые созданы автором страницы и не являются обязательными для активации пользователем. Они называются якорями , и вы добавляете их в HTML-документ с помощью элемента .
Анатомия якоря
Вы можете превратить любой встроенный элемент или текст в HTML-ссылку, добавив элемент вокруг него. Например, в следующем HTML-документе текст Opera Software является ссылкой.
<голова> <мета-кодировка="utf-8">Пример ссылки css"> <тело>
Ссылка на Opera
Посетители, активировавшие эту ссылку (щелкнув ее мышью, активировав ее с помощью клавиатуры или даже голосом в некоторых случаях), покинут текущую страницу и перейдут на домашнюю страницу Opera. С самой ссылкой происходит больше изменений, и мы рассмотрим их позже, когда будем говорить о стиле ссылок.
Тег привязки имеет несколько атрибутов, которые вы можете добавить:
-
href— ресурс, на который указывает ссылка (либо внешний файл, либо идентификатор привязки). -
id— уникальный идентификатор ссылки, полезный для оформления ссылки с помощью CSS или ссылки на нее с помощью JavaScript. Вы также можете использовать атрибутid, чтобы сделать ссылку на якорь страницы и ссылаться на нее из других элементов -
class— имя класса CSS для применения к ссылке, полезно, например, если вы хотите стилизовать определенные ссылки на странице, но не другие. -
title— дополнительная информация о ссылке, которую браузер должен отображать при наведении.

Атрибут href
Элемент может играть несколько ролей, в зависимости от установленных атрибутов. Чаще всего вы будете использовать атрибут href , который определяет, на какой ресурс указывает ссылка. Этот атрибут может содержать различные значения:
- URL-адрес относительно текущей папки, например, «…/…/help/help.html» (две точки означают «подняться на один уровень вверх в иерархии папок сайта») или URL-адрес, абсолютный корень сервера, например, «/help/help.html» (косая черта в начале URL-адреса означает, что адрес начинается в корне иерархии папок, в которой находится текущая страница).
- URL-адрес на другом сервере, например «ftp://ftp. opera.com/» или «http://developer.yahoo.com/yui».
- Идентификатор фрагмента или идентификатор, которому предшествует знак решетки, например, «#menu». Это указывает на цель внутри текущего документа, а не на внешний URL.
- Сочетание URL-адресов и идентификаторов фрагментов. То есть вы можете напрямую ссылаться на раздел другого документа, указав в атрибуте
hrefURL-адрес, за которым следует идентификатор фрагмента, например «http://dev.opera.com/articles/view/new-structural». -elements-in-html5/#aside».
 opera.com/» или «http://developer.yahoo.com/yui».
opera.com/» или «http://developer.yahoo.com/yui».Создание внутристраничной навигации с помощью атрибутов id
Вы также можете поместить атрибут id в элемент , чтобы сделать его якорем страницы. Якоря страницы — это внутристраничные цели для других ссылок на этой странице. Вы связываетесь с ними, помещая идентификатор в атрибут href другой ссылки. Например, вот якорь, закодированный как цель ссылки:
Раздел #1
Эта цель может быть связана с этой ссылкой:
Первый раздел
Удобно, что сегодня большинство браузеров позволяют вам написать это «сокращенно», поместив идентификатор непосредственно на элемент, на который вы хотите сослаться, например:
Раздел #1
Это намного проще, и мы рекомендуем по возможности делать это именно так.
Следующий HTML содержит примеры различных типов ссылок:
<голова> <мета-кодировка="utf-8">Пример различных ссылок <тело>Разные ссылки
Пример внутристраничной навигации с идентификаторами фрагментов, ссылками и привязками
<дел>
 opera.com">Сеть разработчиков Opera
opera.com">Сеть разработчиков Opera Этот идентификатор фрагмента должен начинаться со знака решетки (#).
Этот идентификатор фрагмента должен начинаться со знака решетки (#). Читатели верят, что когда вы предлагаете им ссылку, они могут перейти по ней и получить полезную и актуальную информацию. Если ваши ссылки не работают, потому что связанный ресурс недоступен или имеет формат, который браузер посетителя не может использовать, вы предадите это доверие и потеряете доверие. Не позволяйте этому случиться.
Читатели верят, что когда вы предлагаете им ссылку, они могут перейти по ней и получить полезную и актуальную информацию. Если ваши ссылки не работают, потому что связанный ресурс недоступен или имеет формат, который браузер посетителя не может использовать, вы предадите это доверие и потеряете доверие. Не позволяйте этому случиться. css">
<тело>
css">
<тело>

 Вот несколько примеров:
Вот несколько примеров: Если вы смешаете эту информацию с умным стилем, вы даже можете сделать такие ссылки привлекательными и интуитивно понятными, например, присвоив разным типам ссылок легко узнаваемые значки (подробнее об этом см. в руководствах/Стили списков и ссылок). Если вы хотите быть в полной безопасности, вы также можете предложить раздел справки, в котором объясняется, что такое различные форматы файлов и где вы можете получить программное обеспечение, необходимое для их отображения.
Если вы смешаете эту информацию с умным стилем, вы даже можете сделать такие ссылки привлекательными и интуитивно понятными, например, присвоив разным типам ссылок легко узнаваемые значки (подробнее об этом см. в руководствах/Стили списков и ссылок). Если вы хотите быть в полной безопасности, вы также можете предложить раздел справки, в котором объясняется, что такое различные форматы файлов и где вы можете получить программное обеспечение, необходимое для их отображения.
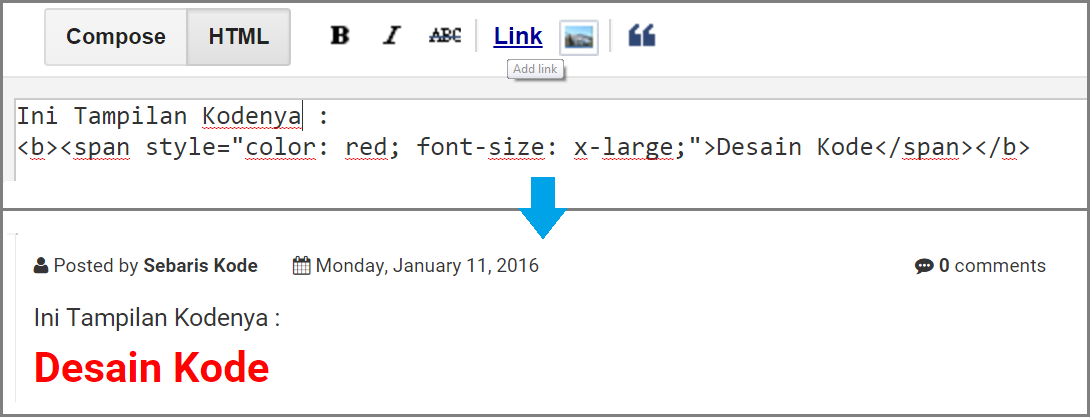


 ibb.co/jxrtqf/purpleflower.jpg">
ibb.co/jxrtqf/purpleflower.jpg"> 
{kind=link}
{kind=link}
{kind=link}