что это такое простыми словами и как используется
Программный код — это текст, написанный на языке программирования. Обычно его пишут программисты, и этот процесс называется «кодинг». С помощью кода создают программы: отдают компьютеру команды, которые он выполняет.
Когда человек пишет код, про него говорят, что он кодит. Чаще всего этот термин применяют по отношению к программистам, которых еще называют кодерами.
Код программы изначально воспринимается компьютером как простой текст. Чтобы он заработал, нужно передать его специальному инструменту — компилятору или интерпретатору нужного языка. Тот преобразует код в вид, понятный машине. После этого его можно будет запустить.
Для чего нужен программный кодКомпьютер не понимает человеческие языки. Но и программный код на современных языках программирования ему непонятен: его нужно компилировать или интерпретировать, чтобы он заработал. Возникает вопрос: почему тогда не писать программы на человеческом языке. Но так не получится — код все-таки нужен. Попробуем объяснить простыми словами, почему.
Но так не получится — код все-таки нужен. Попробуем объяснить простыми словами, почему.
Человеческие языки сложные. Практически невозможно создать компилятор, который переводил бы человеческие естественные языки в понятный компьютеру вид. В программировании есть область их распознавания, которая называется NLP, но она очень сложная и не способна распознать все. Поэтому человеческий язык в качестве языка программирования просто не подойдет.
Код помогает быстрее и лаконичнее отдавать команды. Представьте, что вам нужно отсортировать большое количество данных. Описать задачу обычным текстом будет сложнее, чем написать одну или две строчки кода.
Код понятен и структурирован. Современные языки программирования — высокоуровневые. Это значит, что их уровень абстракции выше, ближе к человеческому пониманию, чем к машинному. Поэтому код на них нужно компилировать или интерпретировать. Исходный «язык машины» — длинные машинные коды из нулей и единиц, и писать на них программы человеку практически невозможно.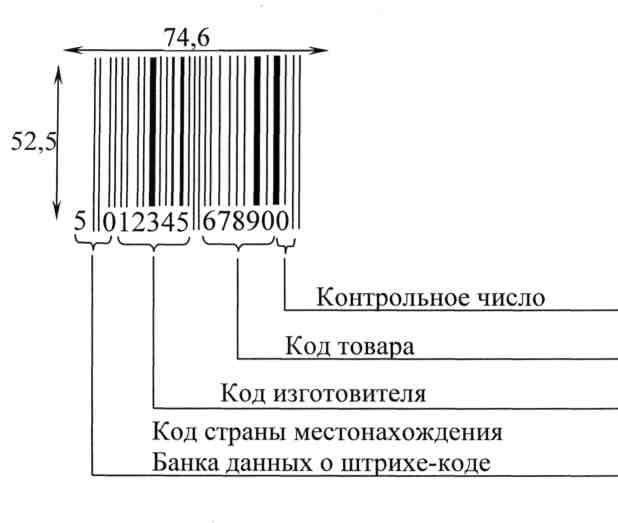 Будет совершенно непонятно. А по программному коду видно, что он делает — его синтаксис приближен к человеческому пониманию.
Будет совершенно непонятно. А по программному коду видно, что он делает — его синтаксис приближен к человеческому пониманию.
Языки программирования служат своеобразным компромиссом между сложными для человека машинными кодами и непонятным для компьютера человеческим языком.
Как выглядит программный кодЭто набор строчек на языке программирования. Языки обычно приближены к английскому: слова из него заимствуются для обозначения команд. По структуре код состоит из команд, связей между ними, различных операторов и знаков препинания, а также переменных и значений. Большие группы команд, которые выполняют конкретное действие, собираются в блоки — функции.
В конце каждой строчки в большинстве языков ставится точка с запятой. Она помогает компилятору или интерпретатору понять, что команда закончилась. Но это не всегда так: например, в Python вместо точки с запятой используется перенос строки.
На картинках с кодом, которые вы наверняка видели в сети, он разноцветный. Это происходит, потому что специальные средства для программирования подсвечивают разные элементы его синтаксиса для наглядности.
Это происходит, потому что специальные средства для программирования подсвечивают разные элементы его синтаксиса для наглядности.
Это не классификация — просто список терминов, которые часто можно услышать в контексте написания кода. Они могут быть похожи, но означают разное.
Исходный код, или сурс, source code — текст программы, который написал разработчик. Может быть открытым или закрытым. Открытый исходный код может просмотреть кто угодно. Закрытый или спрятан от пользователей, или вообще отсутствует в готовом программном продукте — вместо него используются исполняемые коды.
Исполняемый код — код, который может исполнить программа. Иногда противопоставляется исходному. Чаще всего так называют код, который получился в результате компиляции. Компилятор переводит исходный код в машинный, который сможет исполнить операционная система, — на выходе получается исполняемый код.
Чистый код — это понятие другого порядка, которое, скорее, относится к правилам хорошего тона для разработчиков. Чистым называют код, который хорошо написан, не слишком многословен, понятен и лаконичен. Такой код легко прочитать другим разработчикам, а не только автору.
В чем пишут кодЯзыки программирования устроены так, что код можно написать в любом редакторе, даже в «Блокноте». Компьютер в таком случае воспримет его как текст, а для запуска нужно выполнить дополнительные действия: сохранить файл в нужном формате, отправить его компилятору или интерпретатору. Если это код на JavaScript, проще всего запустить его в браузере. А если код на внутренних языках операционной системы — в консоли.
Чаще всего программисты пишут код в специальных программах: средах разработки, они же IDE, и редакторах кода. Среда — более мощный инструмент со множеством дополнительных функций. Код можно запустить прямо из нее одной кнопкой. Редактор проще, в нем легче разобраться, и он менее ресурсоемкий.
Специальные средства для написания кода умеют больше, чем текстовые редакторы. Они подсвечивают синтаксис и делают код разноцветным, чтобы разработчику было понятнее. Они помогают находить неудачные места, отлаживать программы, выводить данные и делать много других вещей. Это удобные и наглядные инструменты.
Новичкам мы рекомендуем начать с редакторов кода или IDE. Так удобнее писать и сложнее запутаться.
Из чего состоит кодНабор правил, по которым пишется код, называется синтаксисом. Синтаксис поясняет, какие команды можно использовать, какой должна быть структура кода, как правильно расставлять связи, передавать аргументы и использовать разные операторы. Его можно сравнить с правилами русского языка.
Синтаксис языка программирования ничего не говорит о смысле программы. Он отвечает только за правильность написания.
Код состоит из команд, связей между ними и других элементов синтаксиса. Вот какими они бывают.
Сначала договоримся об общих понятиях.
- Командами мы будем называть непосредственные указания для компьютера, что сделать. Например, напечатать слово: print(“слово”).
- Связями будем называть разные элементы, связывающие команды друг с другом. Чаще всего это знаки пунктуации и различные операторы.
А теперь рассмотрим компоненты более подробно.
Переменные. Когда пользователь оперирует какими-то значениями по нескольку раз, ему бывает нужно куда-то их записать. Для этого в языках программирования существуют переменные. У переменной есть имя, тип и значение.
- Имя показывает, как обращаться к переменной. Например, если мы объявили a = 5, то переменная называется a.
- Значение – это данные, которые лежат в переменной. Для названной выше переменной a это число 5.
- Тип данных показывает, какой вид информации находится в переменной: число, буква, строка или что-то более сложное.
 Есть простые и составные типы данных. В первых хранятся примитивные значения вроде чисел и строк, во вторых – сложные конструкции из нескольких примитивов или даже функций.
Есть простые и составные типы данных. В первых хранятся примитивные значения вроде чисел и строк, во вторых – сложные конструкции из нескольких примитивов или даже функций.
 Есть простые и составные типы данных. В первых хранятся примитивные значения вроде чисел и строк, во вторых – сложные конструкции из нескольких примитивов или даже функций.
Есть простые и составные типы данных. В первых хранятся примитивные значения вроде чисел и строк, во вторых – сложные конструкции из нескольких примитивов или даже функций.Работа с типами данных в разных языках программирования – тема для отдельной статьи. Они могут сильно различаться: где-то тип надо указывать явно, где-то нет. В некоторых языках можно сравнивать или складывать данные разных типов, в других нельзя. Вариаций много, поэтому стоит сразу смотреть, как устроены типы в выбранном вами языке.
Константы. Так называют переменные, значение которых нельзя изменить. Оно задается раз и навсегда. В некоторых языках программирования, например в функциональных, все переменные по сути являются константами.
Ключевые слова. Ключевые слова — это особые зарезервированные слова, которые используются для технических целей. Например, значения True и False, «истинно» или «ложно». Зачастую эти слова — не команды: они рассказывают компьютеру о каком-то значении или формате. Зарезервированными словами нельзя что-то назвать. Например, в программе не может быть переменной, имя которой True.
Зарезервированными словами нельзя что-то назвать. Например, в программе не может быть переменной, имя которой True.
Идентификаторы. Так в информатике называются имена, которые программисты дают сущностям в коде. Например, имя переменной — это ее идентификатор. А если пользователь захочет создать какую-то функцию, то он даст ей имя. Оно тоже будет идентификатором.
Значения и литералы. Литералы еще называют безымянными константами. Это значения какого-то типа, которые используются в коде, но не привязаны к переменной. Они не меняются, ведь их никуда не записывают — это не переменные. Изменить литерал можно только одним способом: переписать исходный код.
Например, когда мы пишем print(“слово”), строка «слово» — это литерал. Нам не нужно записывать ее в переменную, но и обойтись без нее не получится. Она остается в коде как безымянная константа.
Знаки пунктуации и символы. Символы чаще всего бывают связями. Иногда — операторами.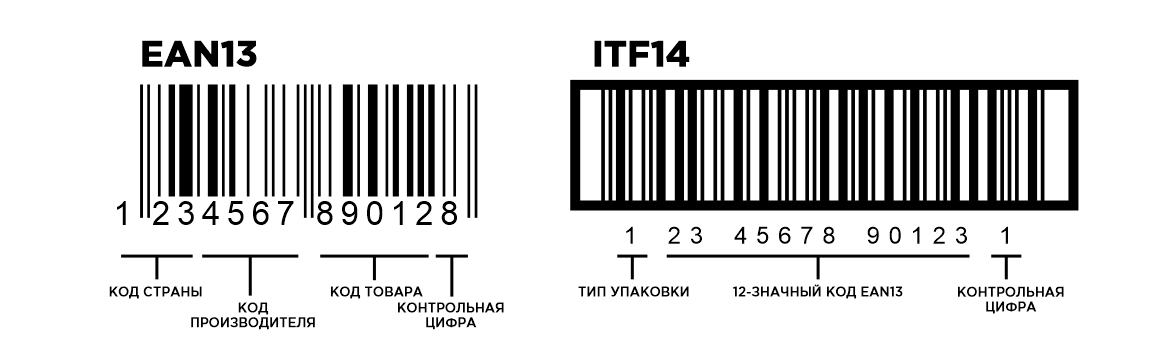
Операции, операторы и операнды. Не пугайтесь. Операции — это определенные действия с данными: сложение, вычитание, сравнение и так далее. Причем речь не всегда идет о действиях в математическом смысле — это просто хороший наглядный пример.
Операции состоят из операндов и операторов.
- Операнд – это переменная или литерал, что-то, с чем мы будем работать.
- Оператор – это символ или слово для обозначения действия.
Например, в операции a + 2 переменная a и литерал 2 будут операндами, а знак + оператором.
Функции. Иногда набор команд бывает нужно объединить в один блок, чтобы потом вызывать его как одну большую команду. Это возможно. Такие блоки в программировании называются функциями.
У функции чаще всего есть имя (исключения встречаются, но редко) и список аргументов — данных, которые передаются ей при вызове. Когда программист вызывает функцию, она выполняет заложенные в ней действия.
Встроенные команды языков программирования — обычно тоже функции. Просто они изначально заложены в язык. Но программист может написать и свои. Более того: разбивать код по функциям — хорошая практика, потому что это улучшает читаемость и гибкость программы.
Дополнительные наборы функций для каких-то задач называются библиотеками. Они тоже бывают встроенными, уже существующими в языке, и пользовательскими. Чтобы использовать функции из библиотеки, ее нужно подключить к программе, а если библиотеки нет на компьютере, сначала скачать.
Комментарии. В большинстве языков есть возможность писать комментарии — текстовые блоки, которые ничего не делают и нужны для удобства разработчика. Они выделяются специальными символами. Компилятор или интерпретатор игнорирует комментарии и ничего с ними не делает.
Основных назначений у комментариев два:
- документировать и объяснять. Например, разработчик может оставить комментарий около сложной функции и пояснить в нем, что она делает;
- временно скрывать участки кода. К примеру, человек превращает какую-то строку кода в комментарий, чтобы временно исключить ее из выполнения программы.
 К примеру, человек превращает какую-то строку кода в комментарий, чтобы временно исключить ее из выполнения программы.
К примеру, человек превращает какую-то строку кода в комментарий, чтобы временно исключить ее из выполнения программы.Если вы хотите профессионально заниматься программированием, записывайтесь на наши курсы. Мы будем рады помочь вам получить новую профессию.
14)Кодирование товаров
Кодирование — это упорядоченное образование условного обозначения (кода) и присвоение его объектам классификации, а так же классификационным группировкам
Целью кодирования является систематизация объектов путем их классификации, идентификации, ранжирования и присвоения условного обозначения (кода), по которому можно найти и распознать любой объект среди множества других.
Необходимость
в кодировании товаров и других объектов
существовала давно, но особенно значимость
кодирования возросла в последние
десятилетия с внедрением
электронно-вычислительной техники. В
результате расширилось целевое назначение
кодирования, которое облегчает обработку
технико-экономической информации с
помощью ЭВМ, повышает эффективность
функционирования АСУ (автоматизированная
система управления).
Присвоение кодов осуществляется на основе определенных правил и методов.
Правила кодирования состоят в следующем:
код должен иметь определенную структуру построения;
код должен быть выражен с помощью различных, заранее обусловленных знаков;
код должен способствовать упорядочению объектов.
Структура кода — условное обозначение состава и последовательности расположения знаков в нем. Структура кода состоит из таких элементов, как алфавит, основание, разряд и длинаствовать упорядочению объектов.
Алфавит кода — система знаков, принятых для образования кода. В качестве алфавита для кодов наиболее часто применяют цифры, буквы или их сочетания, штрихи и пробелы. Соответственно различают цифровой, буквенный, буквенно-цифровой и штриховой алфавиты кода
Цифровой алфавит кода — алфавит кода, знаками которого являются цифры [5]. Например консервам Молоко сгущенное Общероссийским классификатором продукции (ОКП) присвоен 67
Буквенный
алфавит кода — алфавит кода, знаками
которого являются буквы алфавитов
естественных языков [5]. Например, в
Общероссийском классификаторе стандартов
классу сельскохозяйственной продукции
присвоена буква С, а продукции пищевой
промышленности — Н.
Например, в
Общероссийском классификаторе стандартов
классу сельскохозяйственной продукции
присвоена буква С, а продукции пищевой
промышленности — Н.
Буквенно-цифровой алфавит кода — алфавит кода, знаками которого являются буквы алфавитов естественных языков и цифры [5]. Например, свежие плоды имеют код С3, а овощи — С4.
Штриховой алфавит кода — алфавит кода, знаками которого являются штрихи и пробелы, ширину которых сканеры считывают в виде цифр [5]. Примером могут служить штриховые коды EAN и UPA, широко применяемые в международной практике.
Основанием кода называется общее число знаков в его алфавите [5]. Последовательность расположения знаков в коде определяется его разрядом.
Разряд
кода — позиция знаков в коде [5]. Поскольку
каждый знак характеризует какой-то
заранее обусловленный признак товара,
разряд кода несет определенную смысловую
нагрузку. Например, по ОКП бумага
типографская № 1 с оптическим отбеливанием,
машинной гладкости, рулонная, массой
60г на квадратный метр имеет код 54 3121
1211.
Пробел — определенное расстояние между знаками (буквами, цифрами, штрихами), которое выполняет разделительную функцию и/или выраженное в мм может означать число []. В приведенном выше примере пробелы между 2-й и 3-й, 6-й и 7-й цифрами разделяют знаки (54 — продукция целлюлозно-бумажной промышленности, 3121 — бумага и ее общая характеристика,
1211 — частные признаки бумаги).
Код характеризуется также длиной.
Длина кода — число знаков в коде без учета пробелов [5]. Например,
54 3121 1211 имеет длину кода 10, а основание — 12. Таким образом, длина отличается от основания количеством пробелов.
Во избежание ошибок при считывании кодов обычно вводят контрольное число, используемое для проверки записи кода.
Методы кодирования
Как
правило, при кодировании товаров
используют в основном 10 -разрядный
штриховой код, удобный для машинной
обработки данных.
Для образования кода применяют регистрационный и классификационный методы.
Метод кодирования может носить самостоятельный характер и применятся без предварительной классификации объектов (регистрационные методы кодирования) или быть основанным на предварительной классификации объектов (классификационные методы кодирования).
Регистрационные методы кодирования — это такие методы, при которых кодовыми обозначениями служат или числа натурального цифрового ряда (порядковый метод кодирования), или числа натурального цифрового ряда с закреплением отдельных диапазонов (серий) этих чисел за элементами классификации с одинаковыми признаками (серийно-порядковый метод кодирования). Они полностью идентифицируют объект, но не отражают существенную призначную информацию о нем в коде.
Порядковый
метод является наиболее простым и
заключается в сквозной последовательности
порядковой регистрации объектов. Чаще
всего для удобства обработки информации
используется равномерный код, в котором
число разрядов в каждом кодовом
обозначении одинаково. Число объектов,
которое может быть закодировано при
применении данного метода, зависит от
основания кода и числа разрядов в кодовом
обозначении. Он обладает наибольшей
полнотой и простотой для идентифицирования
объектов, обеспечивает наиболее простое
присвоение кодов новым объектам и
использует наиболее короткие при данном
алфавите кода кодовые обозначения.
Вместе с тем к существенным недостаткам
порядкового метода кодирования относятся
отсутствие в коде конкретной информации
о существующих признаках, а также
сложность автоматизированной обработки
информации при получении итогов по
группировке объектов классификации со
сходными признаками. Поэтому применение
его в чистом виде малоэффективно.
Число объектов,
которое может быть закодировано при
применении данного метода, зависит от
основания кода и числа разрядов в кодовом
обозначении. Он обладает наибольшей
полнотой и простотой для идентифицирования
объектов, обеспечивает наиболее простое
присвоение кодов новым объектам и
использует наиболее короткие при данном
алфавите кода кодовые обозначения.
Вместе с тем к существенным недостаткам
порядкового метода кодирования относятся
отсутствие в коде конкретной информации
о существующих признаках, а также
сложность автоматизированной обработки
информации при получении итогов по
группировке объектов классификации со
сходными признаками. Поэтому применение
его в чистом виде малоэффективно.
Серийно-порядковый
метод характеризуется назначением
определенной серии порядковых номеров
для кодирования группы сходных объектов
с выделением одного или нескольких
отдельных разрядов (при основании кода,
как правило, равным 10 или кратным ему),
то есть последовательным использованием
нескольких порядковых перечислений
объектов, соподчиненных друг другу. Исходя и этого, его целесообразно
применять для объектов, имеющих два или
несколько порядковых признаков. Строго
говоря, данный метод может рассматриваться
как использование иерархического метода
классификации с серийно-порядковым
методом кодирования.
Исходя и этого, его целесообразно
применять для объектов, имеющих два или
несколько порядковых признаков. Строго
говоря, данный метод может рассматриваться
как использование иерархического метода
классификации с серийно-порядковым
методом кодирования.
Классификационные методы кодирования — это методы, при которых в кодовом обозначении последовательно указываются зависимые (последовательный метод кодирования) или независимые признаки классификации. (параллельный метод кодирования). Они дают существенную призначную информацию об объекте, но обладают ограниченными возможностями идентифицировать их.
Классификационные методы кодирования бывают двух типов: последовательный и параллельный.
Последовательный
метод кодирования предполагает, что
значение признака, записанного в виде
цифры на определенном разряде кодового
обозначения, зависит от значений
признаков, записанных на предыдущих
разрядах кодового обозначения. В этом
случае код нижестоящей группировки
образуется путем добавлений кодов
соответствующего количества разрядов
к коду вышестоящей группировки. Последовательный метод кодирования
чаще всего используется при иерархическом
методе классификации, дающем
последовательное расположение признаков
на каждой ступени классификации.
Последовательный метод кодирования
чаще всего используется при иерархическом
методе классификации, дающем
последовательное расположение признаков
на каждой ступени классификации.
Последовательный метод кодирования может быть проиллюстрирован на примере группы товаров «Продукция кабельная», которая подразделяется на подгруппы и виды по взаимосвязанным признакам.
По классификационной части ОКП:
Код | Наименование | |
35 0000 | продукция кабельная | |
35 8000 | кабели, провода, шнуры межотраслевого и отраслевого назначения | |
35 8200 | провода монтажные/ | |
35 8210 | — с медной жилой | |
35 8212 | — с поливинилхлоридной изоляцией | |
Параллельный
метод кодирования характеризуется
независимым кодированием признаков. В
этом случае значение признака каждой
части кодового обозначения не зависит
от значений
признаков
других. Параллельным методом кодирования
чаще всего пользуются при фасетном
методе классификации. Учитывая, что для
обозначения отдельного фасета в
соответствии с фасетной формулой
выделяется определенный разряд или
группа разрядов кодового обозначения,
то по конкретному кодовому обозначению
легко узнать, набором каких характеристик
описывается рассматриваемый объект.
Параллельный метод кодирования может
применяться также при иерархическом
методе классификации. Причем в одном
случае соподчиненные признаки, обладая
полной однородностью, параллельны во
всех звеньях иерархической цепи, в
другом несоподчиненные параллельные
признаки искусственно устанавливаются
в определенной последовательности.
В
этом случае значение признака каждой
части кодового обозначения не зависит
от значений
признаков
других. Параллельным методом кодирования
чаще всего пользуются при фасетном
методе классификации. Учитывая, что для
обозначения отдельного фасета в
соответствии с фасетной формулой
выделяется определенный разряд или
группа разрядов кодового обозначения,
то по конкретному кодовому обозначению
легко узнать, набором каких характеристик
описывается рассматриваемый объект.
Параллельный метод кодирования может
применяться также при иерархическом
методе классификации. Причем в одном
случае соподчиненные признаки, обладая
полной однородностью, параллельны во
всех звеньях иерархической цепи, в
другом несоподчиненные параллельные
признаки искусственно устанавливаются
в определенной последовательности.
Параллельный
метод кодирования хорошо приспособлен
для машинной обработки и решения
технико-экономических задач, характер
которых часто изменяется. К недостаткам
параллельного метода кодирования, кроме
ограниченных возможностей идентифицирования
объектов, следует отнести большую, по
сравнению с предыдущими методами,
избыточность, что в результате приводит
к меньшей информативности кодового
обозначения и неполному использованию
емкости, созданной классификации.
Как методы кодирования, так и методы классификации самостоятельно практически не применяются. Чтобы использовать их преимущества и исключить присущие им недостатки, на практике чаще всего берут различные комбинации методов классификации и кодирования. Выбор той или иной комбинации зависит от назначения классификатора и решаемых им конкретных задач
15)Штриховое кодирование товаров
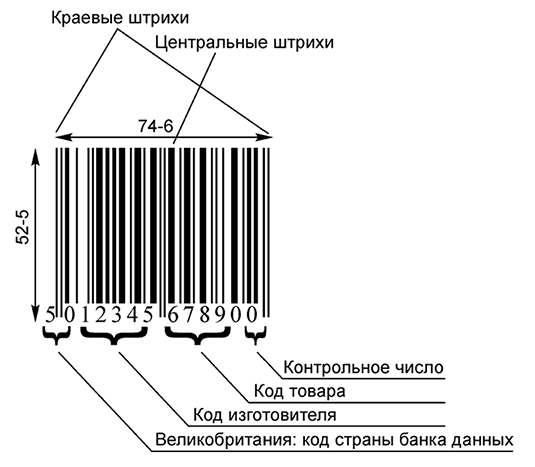
Штриховой код, или штрих-код — это машиночитаемый символ, содержащий закодированную информацию о характеристиках произведенной продукции и позволяющий осуществлять ее автоматизированную идентификацию._
Внешне штрих-код представляет собой комбинацию темных полосок (штрихов) и разделяющих их светлых полосок различной толщины. Каждая единица товара идентифицируется с помощью штрихового и цифрового кода.
Коды стран местонахождения банка данных о штриховых кодах
Страна | Код | Страна | Код |
США | 00—09 | Исландия | 569 |
Франция | 30—37 | Польша | 590 |
Германия | 400—440 | Греция | 520 |
Великобритания | 50 | Кипр | 529 |
Люксембург | 54 | Венгрия | 599 |
Болгария | 380 | Китай | 690 |
Эквадор | 786 | Израиль | 729 |
Россия | 460—469 | Мексика | 750 |
Дания | 57 | Мальта | 535 |
Финляндия | 64 | Перу | 775 |
Норвегия | 70 | Уругвай | 773 |
Швейцария | 76 | Бразилия | 789 |
Швеция | 73 | Куба | 850 |
Япония | 45 и 49 | Турция | 869 |
Италия | 80—83 | Южная Корея | 880 |
Испания | 84 | Чили | 780 |
Таиланд | 885 | ЮАР | 600—601 |
Сингапур | 888 | Марокко | 611 |
Португалия | 560 | Венесуэла | 759 |
Австралия | 93 | Малайзия | 995 |
Нидерланды | 87 | Австрия | 90—91 |
Украина | 482 | Молдова | 484 |
Структура кода определяется зависимостями
Это второе и последнее «аксиоматическое» обсуждение. Тексты, следующие за этим, будут основываться на уже представленных идеях и, в конечном счете, свяжут их вместе.
Тексты, следующие за этим, будут основываться на уже представленных идеях и, в конечном счете, свяжут их вместе.
Структура устанавливает сцену
Естественные законы жизни связаны с ее структурой. Структура вещи определяется ее элементами и отношениями между ними. Элементами жизни являются атомы, органические соединения, пептиды, липиды, РНК, ДНК, аминокислоты и так далее. И то, как они относятся друг к другу, очевидно, имеет большое значение.
Естественные законы кода также относятся к структуре. Так что же такое элементы и отношения в коде?
Ранее мы исследовали, как код передает смысл. Здесь мы рассмотрим, как она устроена. С этой целью мы отложим в сторону техническую и ценностную среду и вместо этого сосредоточимся на фактическом исходном коде, его организационных единицах и схемах.
А кого волнует структура кода? В любом случае код никогда не является проблемой, это просто надоедливые люди, которые хотят, чтобы мы постоянно меняли код, верно?
Требования и технологии постоянно меняются. Чтобы кодовая база выжила, она должна адаптироваться к постоянно меняющейся среде:
Чтобы кодовая база выжила, она должна адаптироваться к постоянно меняющейся среде:
В эволюции организмов и кода гибкость — это устойчивость, а жесткость — это смерть. И именно поэтому структура является центральным вопросом таких сложных, но развивающихся систем.
Программное обеспечение должно быть мягким. У нас скорее будет неверный код, который мы можем легко изменить, чем правильный код, к которому больше никто не осмеливается прикасаться. От того, как структурирован код, зависит, отвечает ли он самому важному требованию — ремонтопригодности, т. е. возможности изменения. Без изменений в программном обеспечении нет разработки программного обеспечения.
Артефакты
Когда мы структурируем исходный код, мы часто думаем о классах и подобных пространствах имен. И существует еще много типов организационных единиц в гораздо большем масштабе: проект, приложение, уровень, микрослужба, модуль, инфраструктура, библиотека, пакет, исходный файл, тип, интерфейс, вложенный тип, функция, свойство, оператор, переменная и т. д. более.
д. более.
В зависимости от контекста эти структурные элементы могут сильно различаться по размеру, использованию и точному техническому определению. Но для целей данного анализа мы считаем их артефакты кода фрагменты кода, структурно отличающиеся друг от друга, независимо от того, что они означают.
Артефакт кода иерархически состоит из других более мелких артефактов, которые можно назвать его частями . Артефакт представляет собой область своих частей:
Помимо этого отношения между частью и областью действия, артефакты кода связаны друг с другом более интересными способами. Подумайте о классе, производном от интерфейса, или о структуре, которая вызывает удаленную микрослужбу:
Все эти отношения определяют структуру кода и лежат в основе архитектурных принципов.
Зависимость
Мы склонны связывать программную архитектуру с принципами и моделями объектно-ориентированного проектирования. На абстрактном уровне все эти принципы, такие как ADP, и шаблоны, такие как Model-View-Controller, определяются в терминах зависимости. Это потому, что когда артефакты кода связаны с другим, они зависят от другого. Структурировать код — значит управлять зависимостями.
Это потому, что когда артефакты кода связаны с другим, они зависят от другого. Структурировать код — значит управлять зависимостями.
В своей знаменательной публикации «Принципы проектирования и шаблоны проектирования» Роберт К. Мартин утверждает:
«Какие изменения приводят к ухудшению дизайна? Изменения, которые вводят новые и незапланированные зависимости. Каждый из четырех симптомов, упомянутых выше, прямо или косвенно вызван неправильными зависимостями между модулями программного обеспечения. Деградирует архитектура зависимостей, а вместе с ней и способность программного обеспечения поддерживаться».
Как упоминалось ранее, идеи Мартина об архитектуре применимы не только к «модулям». Мы можем читать «модули» как «артефакты кода», чтобы действительно понять универсальную силу зависимости. И размышление об этой силе должно быть первым шагом в любом путешествии в глубины и высоты крутого кодирования.
Явная зависимость
Как именно один артефакт кода зависит от другого? Два типа явной зависимости легко идентифицировать:
Вложенность: Если B вложена внутрь A и поэтому является неотъемлемой частью A, то A явно зависит от B:
Вызов: Если A непосредственно ссылается на B или любой из интерфейсов B в любой форме, тогда A явно зависит от B:
способ, который потребует изменения A для повторной компиляции обоих, тогда A явно зависит от B.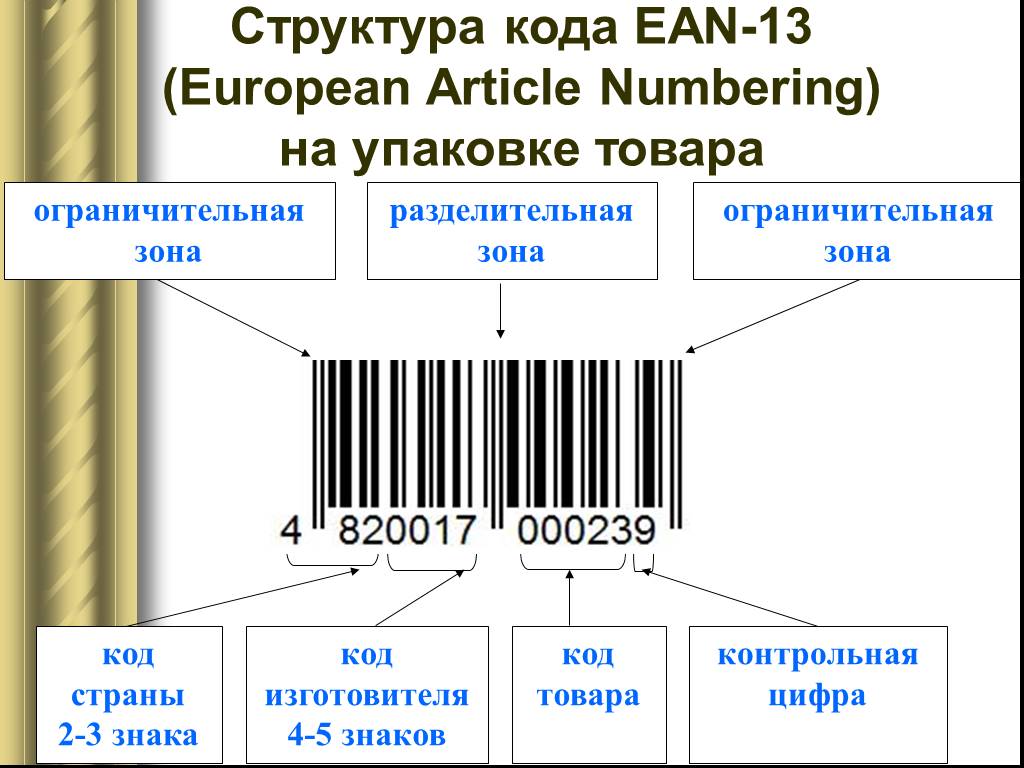
Неявная зависимость
Данный набор зависимостей может подразумевать, что артефакт фактически, хотя и косвенно, имеет другую зависимость, которая будет составлять неявную зависимость . Существует два типа неявной зависимости :
Транзитивность: Если A зависит от B, а B зависит от C, то A неявно зависит от C:
Связывание: Если A зависит от часть B из C, в то время как A сам по себе не является частью C, тогда A неявно зависит от C:
Объединение — это то, как артефакт кода C обобщает свои части с точки зрения входящих зависимостей. Это происходит только потому, что такие зависимости пересекают границу артефакта. Поскольку A находится вне C, он должен знать о C или, по крайней мере, требовать присутствия C, чтобы зависеть от любой части B внутри C. Если бы A сам был частью C, он мог бы зависеть от любой другой такой части, полное игнорирование всеохватывающей области C:
Связывание зависимостей может показаться академическим, но оно влияет на практику. Подумайте о том, как исходный файл A использует тип B, объявленный в другом файле C. В большинстве языков программирования A будет иметь нет явного оператора импорта/включения/требования для C и, таким образом, неявно зависит от C. Немногие языки, такие как C/C++, PHP и HTML/CSS, делают зависимости между исходными файлами явными.
Подумайте о том, как исходный файл A использует тип B, объявленный в другом файле C. В большинстве языков программирования A будет иметь нет явного оператора импорта/включения/требования для C и, таким образом, неявно зависит от C. Немногие языки, такие как C/C++, PHP и HTML/CSS, делают зависимости между исходными файлами явными.
Неявная зависимость менее прямая, но структурно и логически не менее актуальна. Нам лучше не обманывать себя, думая, что такие методы, как многослойность, инкапсуляция, сокрытие информации или шаблон фасада, приравниваются к настоящей развязке. Косвенность не изменяет эффективную структуру зависимостей и имеет сравнительно косметический эффект.
Теперь мы можем описать структуру кода точно как ряд иерархически составленных артефактов, которые зависят друг от друга. Иногда мы будем называть эту структуру архитектурой.
Ад зависимостей
Перечисленные типы зависимостей позволяют сделать некоторые дикие выводы.
Прежде всего, обратите внимание, что части артефакта не зависят автоматически от этого артефакта. Другими словами, артефакт не неявно зависит от окружающей его области. Однако возможно, что артефакт явно зависит от области его действия, и в этом случае вложение создает цикл зависимости между ними:
Вложенность и транзитивность подразумевают, что если А зависит от В, то А зависит от всех частей В: части D из C:
И если только одна из этих других частей имеет внешнюю зависимость E, то каждый клиент A из C также зависит от E, даже если A не особенно заинтересован в E и даже если B он заинтересован in ничего не требует от E:
Таким образом, артефакт кода C объединяет исходящие зависимости своих частей, а также входящие. И вот как четыре типа зависимости апокалипсиса вместе создают ад зависимости.
Сама структура кода может быть достаточно сложной. Кроме того, его легко спутать с двумя связанными, но разными точками зрения:
- Конкретный, но произвольный экземпляр кода во время выполнения.
- Абстрактное значение кода, структура которого может быть различной.

Эта путаница особенно возникает, когда мы рисуем архитектурные диаграммы, заимствуя визуальные элементы из UML. Итак, давайте посмотрим на них поближе.
Структура кода не связана со средой выполнения
Когда мы начинаем думать о среде выполнения, мы загрязняем архитектурные рассуждения и диаграммы отношениями, отличными от структурной зависимости, в частности ссылками времени выполнения и информационным потоком.
Справочник по зависимости и среде выполнения
Архитектура идентифицирует и связывает артефакты кода, а не экземпляры среды выполнения. Последние в основном представляют собой области памяти, которые приложения выделяют во время выполнения. Это могут быть объекты, являющиеся экземплярами классов, или даже процессы, являющиеся экземплярами соответствующего им программного кода. Экземпляры среды выполнения могут ссылаться друг на друга через указатели адресов памяти, URL-адреса и другие механизмы.
Ситуация во время выполнения может быть интересной, но она слабо связана со структурой кода. Смешение обеих точек зрения удивительно заманчиво, поэтому их различие затуманивается в случайных разговорах и небрежных зарисовках, но на самом деле оно глубоко. Объединение структурной зависимости и ссылки на экземпляр на одной диаграмме сделало бы эту диаграмму бессмысленной.
Обратите внимание, что шаблоны объектно-ориентированного проектирования определяются в терминах классов, а не объектов. Вот диаграмма классов и одна из многих возможных соответствующих диаграмм объектов:
Ссылка во время выполнения даже не подразумевает зависимости от типа. Из-за полиморфизма, протоколов и связанных с ними методов экземпляр a типа A может ссылаться на экземпляр b типа B без зависимости A от B. Вспомним, например, шаблон делегата.
Кроме того, может существовать несколько экземпляров одного и того же артефакта кода во время выполнения. На приведенных выше диаграммах b и b2 предполагаются экземплярами B.
Зависимость и информационный поток
Информационный поток развертывается во время выполнения и обычно неявно присутствует в последовательности взаимодействующих экземпляров во время выполнения. Диаграммы последовательности UML – это соответствующий визуальный язык:
Экземпляр, инициирующий взаимодействие, должен иметь ссылку на другой экземпляр. Однако одной ссылки (в «направлении управления») уже достаточно, чтобы информация текла в обоих направлениях. Таким образом, информационный поток сам по себе очень мало говорит нам об исходном направлении.
Настоящий хаос начинается, когда мы рисуем поток информации на архитектурных диаграммах, где это даже не применимо. В конце концов, информация передается между экземплярами среды выполнения, а не между артефактами кода.
Когда различие еще не было для меня столь ясным, я иногда начинал отмечать информационные потоки на структурных диаграммах. Рано или поздно я застрял, потому что подорвал значимость этих диаграмм, в конечном итоге сделав их бесполезными. Когда мы объединяем разные уровни анализа в одном представлении, мы мыслим неясно.
Когда мы объединяем разные уровни анализа в одном представлении, мы мыслим неясно.
Структура кода не связана со смыслом
Диаграммы классов UML
Диаграмма классов UML — это широко известный язык моделирования, который должен передавать смысл, а не структуру кода. Поскольку существует также неявное предположение о том, что значение более или менее соответствует структуре, и поскольку наши структурные диаграммы выглядят как упрощенные диаграммы классов UML, стоит пояснить разницу.
Прежде всего, семантика того, как связаны артефакты, совершенно не имеет отношения к самой структурной зависимости. Независимо от того, вызывает ли класс A функцию класса B, имеет ли он свойство типа B, состоит ли он из свойств типа B или является производным от B, тот факт, что A зависит от B, не меняет того факта, что A зависит от B. В терминах диаграмм классов UML стрелки обозначают зависимость, но типы стрелок не имеют значения в этом отношении:
Кроме того, композиция на диаграмме классов UML описывает, как два понятия (из технической или ценностной среды) соотносятся с другим, заявляя, что композит состоит из компонента, в то время как компонент не может существовать в одиночку вне композита. Это описание может иметь смысл, но оно очень мало говорит нам о том, как соотносятся фактические артефакты кода:
Это описание может иметь смысл, но оно очень мало говорит нам о том, как соотносятся фактические артефакты кода:
A должен зависеть от B, но ссылается ли он только на B или это область действия его части B? Концептуальная и структурная композиция имеют схожие, но ортогональные черты. Мы можем иметь друг без друга.
UML предлагает бесчисленное множество вариантов диаграмм, и все они имеют свое место. Просто обратите внимание, что мы не используем UML, если это явно не указано. Мы просто заимствуем некоторые из его визуальных элементов, например, мы используем стрелку наследования, чтобы пометить явную зависимость, более конкретно, как наследование типа или соответствие интерфейса/протокола:
Неправильный код
Путаница между структурой и значением выходит за рамки UML.
Представьте, что в базе кода имеется несколько классов кнопок. Теперь дизайнер решает, что кнопки «ОК» должны быть зелеными, поэтому разработчик устанавливает цвет во всех классах кнопок, которые используют заголовок «ОК»:
Разве это не вводит зависимости между этими классами? В конце концов, если мы сейчас изменим цвет одной кнопки «ОК», нам придется настроить все остальные кнопки «ОК».
Что если дизайнер вдруг объявит, что все кнопки на самом деле уникальны и могут иметь разные цвета? Теперь цвета зеленых кнопок перестанут быть зависимостями. Как зависимость в коде может меняться в зависимости от настроения дизайнера?
Это не настоящая зависимость. Ни один из классов кнопок не ссылается и не содержит другого. «Должны ли мы» менять другие кнопки при изменении одной из них, полностью зависит от нашего представления о дизайне и, следовательно, от ценностной среды. Так является ли кнопка «ОК» или, по крайней мере, цвет кнопки «ОК» реальной концепцией или нет?
Проблема настройки всех цветов кнопок возникает, когда мы думаем, что концепция цвета кнопки «ОК» существует, но не выражаем ее в коде, что означает, что мы лжем. Если бы эта концепция существовала и в коде, было бы только одно место для ее изменения:
Создание неверного кода — это не то же самое, что введение зависимостей. Это относится к архитектуре, поскольку нарушает принцип, согласно которому код выражает ценностную и техническую среду, и что эффективный код скорее говорит правду. Это дает представление о том, как значение должно определять структуру, и мы свяжем эти две идеи вместе в нашем следующем обсуждении.
Это дает представление о том, как значение должно определять структуру, и мы свяжем эти две идеи вместе в нашем следующем обсуждении.
Структура программы Visual Basic — Visual Basic
Редактировать Твиттер LinkedIn Фейсбук Электронная почта- Статья
Программа Visual Basic состоит из стандартных строительных блоков. Решение включает один или несколько проектов. В свою очередь проект может содержать одну или несколько сборок. Каждая сборка компилируется из одного или нескольких исходных файлов. Исходный файл обеспечивает определение и реализацию классов, структур, модулей и интерфейсов, которые в конечном итоге содержат весь ваш код.
Дополнительные сведения об этих строительных блоках программы Visual Basic см. в разделе Решения, проекты и сборки в .NET.
Элементы программирования на уровне файлов
Когда вы запускаете проект или файл и открываете редактор кода, вы видите, что некоторый код уже находится на месте и в правильном порядке. Любой код, который вы пишете, должен следовать следующей последовательности:
ОпциивыпискиИмпортотчетыОператоры пространства имени элементы уровня пространства имен
Если операторы вводятся в другом порядке, могут возникнуть ошибки компиляции.
Программа также может содержать операторы условной компиляции. Вы можете вставить их в исходный файл среди операторов предыдущей последовательности.
Описание опций
Операторы Option устанавливают основные правила для последующего кода, помогая предотвратить синтаксические и логические ошибки. Оператор Option Explicit гарантирует, что все переменные объявлены и написаны правильно, что сокращает время отладки. Оператор Option Strict помогает свести к минимуму логические ошибки и потерю данных, которые могут возникнуть при работе с переменными разных типов данных. Оператор Option Compare определяет, как строки сравниваются друг с другом на основе их
Оператор Option Explicit гарантирует, что все переменные объявлены и написаны правильно, что сокращает время отладки. Оператор Option Strict помогает свести к минимуму логические ошибки и потерю данных, которые могут возникнуть при работе с переменными разных типов данных. Оператор Option Compare определяет, как строки сравниваются друг с другом на основе их Двоичные или Текстовые значения.
Операторы импорта
Вы можете включить оператор импорта (пространство имен и тип .NET) для импорта имен, определенных вне вашего проекта. Оператор Imports позволяет вашему коду ссылаться на классы и другие типы, определенные в импортированном пространстве имен, без необходимости их уточнения. Вы можете использовать любое количество операторов Imports . Дополнительные сведения см. в разделах Ссылки и Заявление об импорте.
Операторы пространства имен
Пространства имен помогают организовать и классифицировать программные элементы для упрощения группировки и доступа. Оператор пространства имен используется для классификации следующих операторов в определенном пространстве имен. Дополнительные сведения см. в разделе Пространства имен в Visual Basic.
Оператор пространства имен используется для классификации следующих операторов в определенном пространстве имен. Дополнительные сведения см. в разделе Пространства имен в Visual Basic.
Операторы условной компиляции
Операторы условной компиляции могут появляться практически в любом месте исходного файла. Они заставляют части вашего кода включаться или исключаться во время компиляции в зависимости от определенных условий. Вы также можете использовать их для отладки своего приложения, поскольку условный код работает только в режиме отладки. Дополнительные сведения см. в разделе Условная компиляция.
Элементы программирования на уровне пространства имен
Классы, структуры и модули содержат весь код исходного файла. Это элементов уровня пространства имен , которые могут появляться внутри пространства имен или на уровне исходного файла. Они содержат объявления всех других элементов программирования. Интерфейсы, которые определяют сигнатуры элементов, но не обеспечивают реализацию, также появляются на уровне модуля.![]() Для получения дополнительной информации об элементах уровня модуля см. следующее:
Для получения дополнительной информации об элементах уровня модуля см. следующее:
Заявление о классе
Структурное заявление
Заявление о модуле
Заявление об интерфейсе
Элементы данных на уровне пространства имен являются перечислениями и делегатами.
Элементы программирования на уровне модуля
Процедуры, операторы, свойства и события являются единственными элементами программирования, которые могут содержать исполняемый код (операторы, выполняющие действия во время выполнения). Это модуль уровня 9.0026 элементов вашей программы. Для получения дополнительной информации об элементах уровня процедуры см. следующее:
Оператор функции
Подвыписка
Заявление о декларации
Заявление оператора
Отчет об имуществе
Заявление о событии
Элементами данных на уровне модуля являются переменные, константы, перечисления и делегаты.
Элементы программирования уровня процедуры
Большая часть содержимого элементов уровня процедуры представляет собой исполняемые операторы, которые составляют исполняемый код вашей программы. Весь исполняемый код должен находиться в некоторой процедуре ( Функция , Sub , Оператор , Получить , Установить , AddHandler , RemoveHandler , RaiseEvent ). Дополнительные сведения см. в разделе Заявления.
Элементы данных на уровне процедуры ограничены локальными переменными и константами.
Основная процедура
Основная процедура — это первый код, который запускается при загрузке приложения. Main служит в качестве отправной точки и общего управления вашим приложением. Существует четыре разновидности Main :
Sub Main()Sub Main (ByVal cmdArgs() As String)Функция Main() как целое числоФункция Main(ByVal cmdArgs() As String) As Integer
Наиболее распространенным вариантом этой процедуры является Sub Main() .