Вам (вероятно) нужны liveness и readiness probes / Хабр
Один из самых частых вопросов, которые мне задают как консультанту это: “В чем разница между liveness и readiness пробами?”. Следующий самый частый вопрос: “Какие из них нужны моему приложению?”.
Любой, кто пробовал за Duck Duck Go-ить этот вопрос знает, что на него непросто найти ответ в интернете. В этой статье, надеюсь, я смогу помочь вам ответить на эти вопросы самостоятельно. Я поделюсь своим мнением о том, каким образом лучше использовать liveness и readiness пробы в приложениях развернутых в Red Hat OpenShift. И я предлагаю не строгий алгоритм, а, скорее, общую схему, которую вы можете использовать для принятия своих собственных архитектурных решений.
Чтобы сделать абстракции более конкретными я предлагаю рассмотреть четыре общих примера приложений. Для каждого из них мы выясним нужно ли нам настраивать liveness и readiness probes, и если нужно, то как. Прежде чем перейти к примерам, давайте ближе посмотрим на эти два разных типа проб.
Примечание: Kubernetes недавно внедрили новую “startup” probe, доступную в OpenShift 4.5 clusters. Вы быстро разберетесь со startup probe, когда поймете liveness и readiness probes. Здесь я не буду рассказывать о startup probes.
Liveness и readiness probes
Liveness (работоспособности) и readiness (готовности) пробы это два основных типа проверок, доступных в OpenShift. Они имеют схожий интерфейс настройки, но разные значения для платформы.
Когда liveness проверка не проходит, то это сигнализирует OpenShift’у, что контейнер мертв и должен быть перезагружен. Когда readiness проверка не проходит, то это опознается OpenShift’ом как то, что проверяемый контейнер не готов к принятию входящего сетевого трафика. В будущем это приложение может прийти в готовность, но сейчас оно не должно принимать трафик.
Если liveness проверка успешна, и в то же время readiness проверка не прошла, OpenShift знает, что контейнер не готов принимать сетевой трафик, но он работает над тем, чтобы прийти в готовность. Например, часто приложениям нужно длительное время для инициализации или для синхронной обработки длительных запросов. (Синхронная обработка длительных запросов — это анти-паттерн, но, к несчастью, мы сталкиваемся с этим в некоторых legacy-приложениях.)
Например, часто приложениям нужно длительное время для инициализации или для синхронной обработки длительных запросов. (Синхронная обработка длительных запросов — это анти-паттерн, но, к несчастью, мы сталкиваемся с этим в некоторых legacy-приложениях.)
Далее мы подробнее рассмотрим специфику использования каждой из этих проверок. Как только мы поймем как работает каждая из них, я покажу примеры того, как они работают вместе в OpenShift.
Для чего нужны liveness проверки?
Liveness проверка отправляет сигнал OpenShift’у, что контейнер либо жив (прошел проверку), либо мертв (не прошел). Если контейнер жив, тогда OpenShift не делает ничего, потому что текущее состояние контейнера в порядке. Если контейнер мертв, то OpenShift пытается починить приложение через его перезапуск.
Название liveness проверки (проверка живучести) имеет семантическое значение. По сути проверка отвечает “Да” или “Нет” на вопрос: “Жив ли этот контейнер?”.
Что если я не установил liveness проверку?
Если вы не задали liveness проверку, тогда OpenShift будет принимать решение о перезапуске вашего контейнера на основе статуса процесса в контейнере с PID 1. Процесс с PID 1 это родительский процесс для всех других процессов, которые запущены внутри контейнера. Так как каждый контейнер начинает жить внутри его собственного пространства имен процессов, первый процесс в контейнере берет на себя особенные обязательства процесса с PID 1.
Процесс с PID 1 это родительский процесс для всех других процессов, которые запущены внутри контейнера. Так как каждый контейнер начинает жить внутри его собственного пространства имен процессов, первый процесс в контейнере берет на себя особенные обязательства процесса с PID 1.
Если процесс с PID 1 завершается и liveness пробы не заданы, OpenShift предполагает (обычно безопасно), что контейнер умер. Перезапуск процесса — это единственное не зависящее от приложения универсально эффективное корректирующее действие. Пока PID 1 жив, не зависимо от того, живы ли дочерние процессы, OpenShift оставит контейнер работать дальше.
Если ваше приложение это один процесс, и он имеет PID 1, то это поведение по умолчанию может быть именно тем, что вам нужно, и тогда нет необходимости в liveness пробах. Если вы используйте init инструменты, такие как tini или dumb-init, тогда это может быть не то, что вы хотите. Решение о том, задавать ли свои liveness вместо того, чтобы использовать поведение по умолчанию, зависит от специфики каждого приложения.
Для чего нужны readiness пробы?
Сервисы OpenShift используют readiness проверки (проверки готовности) для того, чтобы узнать когда проверяемый контейнер будет готов принимать сетевой трафик. Если ваш контейнер вошел в состояние, когда он все ещё жив, но не может обрабатывать входящий трафик (частый сценарий во время запуска), вам нужно, чтобы readiness проверка не проходила. В этом случае OpenShift не будет отправлять сетевой трафик в контейнер, который к этому не готов. Если OpenShift преждевременно отправит трафик в контейнер, это может привести к тому, что балансировщик (или роутер) вернет 502 ошибку клиенту и завершит запрос, либо клиент получит сообщение с ошибкой “connection refused”.
Как и liveness проверки, название readiness проба (проба готовности) передает семантическое значение. Фактически это проверка отвечает на вопрос: “Готов ли этот контейнер принимать сетевой трафик?”.
Что если я не задам readiness пробу?
Если вы не зададите readiness проверку, OpenShift решит, что контейнер готов к принятию трафика как только процесс с PID 1 запустился. Это никогда не является желаемым поведением.
Это никогда не является желаемым поведением.
Принятие готовности без проверки приведет к ошибкам (таким, как 502 от роутера OpenShift) каждый раз при запуске нового контейнера, при масштабировании или развертывании. Без readiness проб вы будете получать пакет ошибок при каждом развертывании, когда старые контейнеры выключаются и запускаются новые. Ели вы используете автоматическое масштабирование, тогда в зависимости от установленного порога метрик новые инстансы могут запускаться и останавливаться в любое время, особенно во время колебаний нагрузки. Когда приложение будет масштабироваться вверх или вниз, вы будете получать пачки ошибок, так как контейнеры, которые не совсем готовы получать сетевой трафик включаются в распределение балансировщиком.
Вы можете легко исправить эти проблемы через задание readiness проверки. Проверка дает OpenShift’у возможность спросить ваш контейнер, готов ли он принимать трафик.
Теперь давайте взглянем на конкретные примеры, которые помогут нам понять разницу между двумя типами проб и то, как важно задать их правильно.
Примечание: Из-за того, что у этих двух разных типов проверок одинаковый интерфейс часто возникает путаница. Но наличие двух или более типов проб — это хорошее решение: это делает OpenShift гибче для разных типов приложений. Доступность обеих liveness и readiness проб критична для репутации OpenShift как Container-as-a-Service, который подходит для широкого спектра приложений.
Пример 1: Сервер для отдачи статического контента (Nginx)
Рис. 1: Пример реализации сервера для отдачи статики NginxВ примере приложение, изображенное на рисунке 1 — это простой сервер для отдачи статики, который использует Nginx, чтобы отдавать файлы. Сервер запускается быстро и проверить, обрабатывает ли сервер трафик легко: вы можете запросить определенную страницу и проверить, что вернулся 200 код HTTP ответа.
Нужны ли liveness пробы?
Приложение запускается быстро и завершается, если обнаружит ошибку, которая не позволит ему отдавать страницы. Поэтому, в данном случае, нам не нужны liveness пробы. Завершенный процесс Nginx означает, что приложение умерло и его нужно перезапустить (отметим, что неполадки, такие как проблемы с SELinux или неправильно настроенные права в файловой системе могут быть причиной выключений Nginx, но перезапуск не исправит их в любом случае).
Завершенный процесс Nginx означает, что приложение умерло и его нужно перезапустить (отметим, что неполадки, такие как проблемы с SELinux или неправильно настроенные права в файловой системе могут быть причиной выключений Nginx, но перезапуск не исправит их в любом случае).
Нужны ли readiness пробы?
Nginx обрабатывает входящий трафик поэтому нам нужны readiness пробы. Всегда, когда вы обрабатываете сетевой трафик вам нужны readiness пробы для предотвращения возникновения ошибок во время запуска контейнеров, при развертывании или масштабировании. Nginx запускается быстро, поэтому может вам повезет и вы не успеете увидеть ошибку, но мы все ещё хотим предотвратить передачу трафика до тех пор, пока контейнер не придет в готовность, в соответствии с best practice.
Добавление readiness проб для сервера
Нам нужно будет сделать определенные изменения для каждого примера, но сначала, приведем здесь первую часть Deployment. Мы изменим этот файл по ходу статьи, но верхняя часть останется той же. В следующих примерах, нам нужно будет изменять только секцию template.
В следующих примерах, нам нужно будет изменять только секцию template.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: application-nginx
name: application-nginx
spec:
replicas: 1
selector:
matchLabels:
app: application-nginx
template:
metadata:
labels:
app: application-nginx
spec:
# Will appear below as it changesЗдесь настройка проверки для первого примера:
spec:
containers:
- image: quay.io/<username>/nginx:latest
name: application-nginx
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
readinessProbe:
httpGet:
scheme: HTTPS
path: /index.html
port: 8443
initialDelaySeconds: 10
periodSeconds: 5Пример 2: Сервер заданий (без REST API)
Многие приложения имеют HTTP веб-компонент, а так же компонент выполняющий асинхронные “задания”. Серверу с “заданиями” не нужны readiness проверки, так как он не обрабатывает входящий трафик. Однако, ему в любом случае нужны liveness проверки. Если процесс, выполняющий задания умирает, то контейнер становится бесполезным, и задания будут накапливаться в очереди. Обычно, перезапуск контейнера является правильным решением, поэтому liveness пробы идеальны для такого случая.
Серверу с “заданиями” не нужны readiness проверки, так как он не обрабатывает входящий трафик. Однако, ему в любом случае нужны liveness проверки. Если процесс, выполняющий задания умирает, то контейнер становится бесполезным, и задания будут накапливаться в очереди. Обычно, перезапуск контейнера является правильным решением, поэтому liveness пробы идеальны для такого случая.
Пример с приложением на рис. 3 это простой сервер заданий который забирает и запускает задания из очереди . Он не обслуживает напрямую входящий трафик.
Рис. 3: Реализация сервера заданий без liveness проверок.Я уже упоминал, что этот тип приложений выигрывает от наличия liveness проб, но более детальное пояснение не повредит в любом случае.
Нужны ли нам liveness пробы?
Когда сервер заданий запущен корректно, это будет живой процесс. Если контейнер сервера заданий перестает работать, это скорее всего означает сбой, необработанное исключение или что-то в этом духе. В этом случае настройка проверки будет зависеть от того, запущен ли процесс нашего задания с PID 1.
Если наш процесс задания запущен с PID 1, то он завершится, когда поймает исключение. Без настроенных liveness проверок OpenShift распознает завершение процесса с PID 1 как смерть и перезапустит контейнер. Для простого сервера заданий перезапуск может быть нежелательным поведением.
Однако, в реальной жизни ситуации могут быть сложнее. Например, если наш процесс с заданием получил deadlock, он может все ещё считаться живым, так как процесс запущен, но он определенно в нерабочем состоянии и должен быть перезапущен.
Чтобы помочь вычислить deadlock, наше приложение будет писать текущее системное время в миллисекундах в файл/tmp/jobs.updateкогда выполняет задание. Это время потом будет проверяться через shell команду (через exec liveness пробы) для того, чтобы убедиться, что текущее задание не запущено дольше определенного значения таймаута. Тогда приложение само сможет проверять себя на liveness выполняя/usr/bin/my-application-jobs --alive.
Мы можем настроить liveness так (опять же, я пропускаю первую часть YAML-файла Deployment’a, который я показывал ранее):
spec:
containers:
- image: quay. io/<username>/my-application-jobs:latest
name: my-application-jobs
imagePullPolicy: Always
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "/usr/bin/my-application-jobs --alive"
initialDelaySeconds: 10
periodSeconds: 5
io/<username>/my-application-jobs:latest
name: my-application-jobs
imagePullPolicy: Always
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "/usr/bin/my-application-jobs --alive"
initialDelaySeconds: 10
periodSeconds: 5 io/<username>/my-application-jobs:latest
name: my-application-jobs
imagePullPolicy: Always
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "/usr/bin/my-application-jobs --alive"
initialDelaySeconds: 10
periodSeconds: 5
io/<username>/my-application-jobs:latest
name: my-application-jobs
imagePullPolicy: Always
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "/usr/bin/my-application-jobs --alive"
initialDelaySeconds: 10
periodSeconds: 5Нужны ли readiness проверки?
В это случае readiness не нужны. Помним, что readiness пробы отправляют OpenShift сигнал о том, что контейнер готов принимать трафик и поэтому может быть добавлен в конфигурацию балансировщика. Так как это приложение не обрабатывает входящий трафик, оно не нуждается в проверке на готовность. Мы можем отключить readiness пробу. Рис. 4 показывает реализацию сервиса заданий с настроенными liveness проверками.
Рис. 4: Реализация сервера заданий с liveness проверкамиПример 3: Приложение с рендерингом на стороне сервера с API
Рис. 5: SSR приложение без каких-либо проверокЭто пример стандартного приложение рендеринга на стороне сервера SSR: оно отрисовывает HTML-страницы на сервере по востребованию, и отправляет его клиенту. Мы можем собрать такое приложение используя Spring Boot, PHP, Ruby on Rails, Django, Node.js, или любой другой похожий фреймворк.
Мы можем собрать такое приложение используя Spring Boot, PHP, Ruby on Rails, Django, Node.js, или любой другой похожий фреймворк.
Нужны ли нам liveness проверки?
Если приложение запускается за несколько секунд или меньше, то liveness проверки, скорее всего, не обязательны. Если запуск занимает больше нескольких секунд, мы должны настроить liveness проверки, чтобы понять, что контейнер инициализировался без ошибок и не произошел сбой.
В этом случае мы могли бы использовать liveness пробы типа exec, которые запускает команду в shell, чтобы убедиться, что приложение по-прежнему работает. Эта команда будет отличаться в зависимости от приложения. Например, если приложение создает PID файл, мы можем проверить, что он все еще жив:
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "[ -f /run/my-application-web.pid ] && ps -A | grep my-application-web"
initialDelaySeconds: 10
periodSeconds: 5 Нужны ли readiness пробы?
Так как данное приложение обрабатывает входящий трафик нам определенно нужны readiness пробы. Без readiness OpenShift немедленно отправит сетевой трафик в наш контейнер после его запуска, независимо от того, готово приложение или нет. Если контейнер начинает отбрасывать запросы, но не завершает работу аварийно, он продолжит получать трафик бесконечно, что, конечно же, не то, что нам нужно.
Без readiness OpenShift немедленно отправит сетевой трафик в наш контейнер после его запуска, независимо от того, готово приложение или нет. Если контейнер начинает отбрасывать запросы, но не завершает работу аварийно, он продолжит получать трафик бесконечно, что, конечно же, не то, что нам нужно.
Мы хотим, чтобы OpenShift удалил контейнер из балансировщика, если приложение перестанет возвращать правильные ответы. Мы можем использовать readiness пробы, подобные этой, чтобы сообщить OpenShift, что контейнер готов к приему сетевого трафика:
readinessProbe:
httpGet:
scheme: HTTPS
path: /healthz
port: 8443
initialDelaySeconds: 10
periodSeconds: 5Для удобства, вот полный YAML для этого приложения из этого примера:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: backend-service
name: backend-service
spec:
replicas: 1
selector:
matchLabels:
app: backend-service
template:
metadata:
labels:
app: backend-service
spec:
containers:
- image: quay. io/<username>/backend-service:latest
name: backend-service
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
readinessProbe:
httpGet:
scheme: HTTPS
path: /healthz
port: 8443
initialDelaySeconds: 10
periodSeconds: 5 На рисунке 6 показана схема приложения SSR с настроенными liveness и readiness пробами.Рис. 6. Приложение SSR с настроенными liveness и readiness пробами.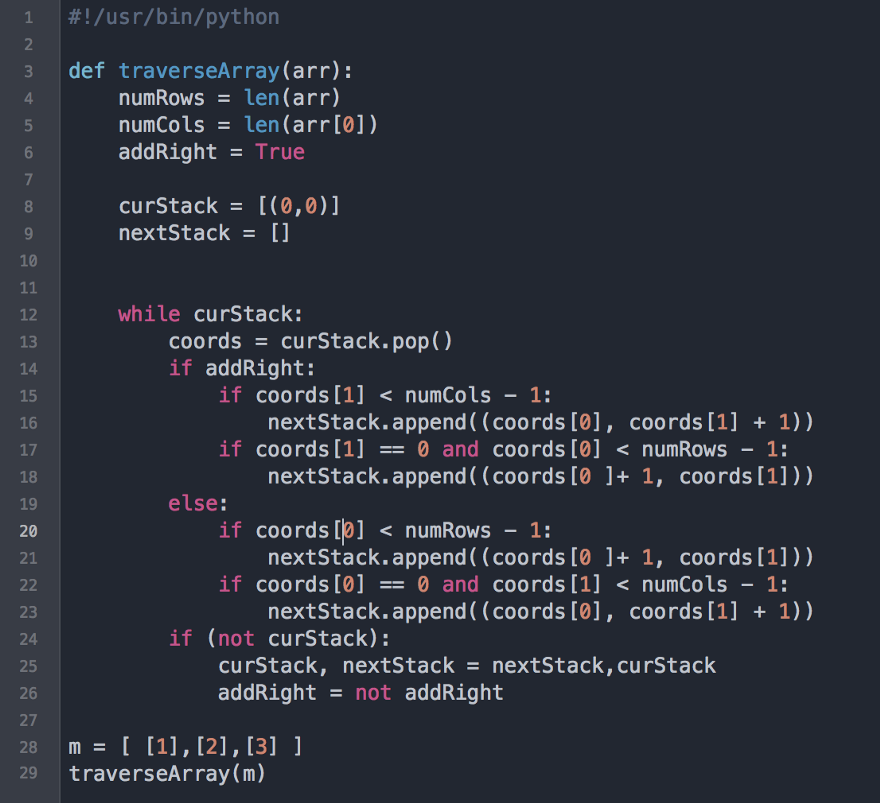 io/<username>/backend-service:latest
name: backend-service
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
readinessProbe:
httpGet:
scheme: HTTPS
path: /healthz
port: 8443
initialDelaySeconds: 10
periodSeconds: 5
io/<username>/backend-service:latest
name: backend-service
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
readinessProbe:
httpGet:
scheme: HTTPS
path: /healthz
port: 8443
initialDelaySeconds: 10
periodSeconds: 5Пример 4: Собираем все вместе
В конечном, сложном и реалистичном приложении у вас могут быть элементы из всех трех предыдущих примеров. Рассмотрение их по отдельности полезно при анализе работы проб, но также полезно увидеть, как они могут работать вместе для обслуживания большого приложения с миллионами запросов. Этот последний пример объединяет остальные три.
Рис. 7: Реалистичный пример приложения в OpenShift для изучения использования проб.В примере приложение состоит из трех частей, это контейнеры:
Сервер приложений: Этот сервер предоставляет REST API и выполняет рендеринг на стороне сервера для некоторых страниц.
Эта конфигурация широко распространена, поскольку приложения, которые создаются в качестве простых серверов для отрисовки, позже расширяются для обеспечения конечных точек REST API.Сервер для отдачи статики Nginx: У этого контейнера есть две задачи: он отображает статические ресурсы для приложения (например, ресурсы JavaScript и CSS). И также он реализует завершение TLS-соединений (Transport Layer Security) для сервера приложений, действуя как обратный прокси для определенных URL. Это также широко используемая настройка.
Сервер заданий: этот контейнер не обрабатывает входящий сетевой трафик самостоятельно, но обрабатывает задания. Сервер приложений помещает каждое задание в очередь, где сервер заданий берет его и выполняет. Сервер заданий разгружает сервер приложений, чтобы он мог сосредоточиться на обработке сетевых запросов, а не на обработке длинных заданий.
 Эта конфигурация широко распространена, поскольку приложения, которые создаются в качестве простых серверов для отрисовки, позже расширяются для обеспечения конечных точек REST API.
Эта конфигурация широко распространена, поскольку приложения, которые создаются в качестве простых серверов для отрисовки, позже расширяются для обеспечения конечных точек REST API.Приложение также включает в себя несколько сервисов хранения данных:
Реляционная база данных: реляционная база данных будет хранить состояние для нашего приложения.
Почти каждое приложение нуждается в какой-либо базе данных, и реляционные являются наиболее предпочтительным выбором.Очередь. Очередь предоставляет серверу приложений путь «первым пришел — первым вышел» (FIFO) для передачи задач серверу заданий. Сервер приложений всегда будет пушить задания в очередь, а сервер заданий извлекать.

Наши контейнеры разделены на два пода:
Первый под состоит из нашего сервера приложений и Nginx TLS-прокси или сервера для статики. Это упрощает работу сервера приложений, позволяя ему взаимодействовать напрямую через HTTP. Благодаря расположению в одном поде эти контейнеры могут безопасно и напрямую связываться с минимальной задержкой. Они также могут получить доступ к общему volume space. Эти контейнеры также нужно масштабировать вместе и рассматривать как единое целое, поэтому под является идеальным решением.
Второй под состоит из сервера заданий. Этот сервер необходимо масштабировать независимо от других контейнеров, поэтому он должен находиться в собственном поде.
Поскольку весь стейт хранится в базе данных и очереди, сервер заданий может легко получить доступ к необходимым ему ресурсам.
 Поскольку весь стейт хранится в базе данных и очереди, сервер заданий может легко получить доступ к необходимым ему ресурсам.
Поскольку весь стейт хранится в базе данных и очереди, сервер заданий может легко получить доступ к необходимым ему ресурсам.Если вы читали предыдущие примеры, решению здесь вы не удивитесь. Для интеграции мы переключаем сервер приложений на использование HTTP и порта 8080 вместо HTTPS и 8443 для readiness проб. Мы также добавляем liveness пробы на сервер приложений, чтобы прикрыть нас, если сервер приложений не завершает работу в случае ошибки. Таким образом, наш контейнер будет перезапущен Kubelet’ом, когда он «мертв»:
# Pod One - Application Server and Nginx
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-application-web
name: my-application-web
spec:
replicas: 1
selector:
matchLabels:
app: my-application-web
template:
metadata:
labels:
app: my-application-web
spec:
containers:
- image: quay.io/<username>/my-application-nginx:latest
name: my-application-nginx
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "[ -f /run/nginx. pid ] && ps -A | grep nginx"
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
httpGet:
scheme: HTTPS
path: /index.html
port: 8443
initialDelaySeconds: 10
periodSeconds: 5
- image: quay.io/<username>/my-application-app-server:latest
name: my-application-app-server
imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "/usr/bin/my-application-web --alive"
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
httpGet:
scheme: HTTP
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
# Pod Two - Jobs Server
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-application-jobs
name: my-application-jobs
spec:
replicas: 1
selector:
matchLabels:
app: my-application-jobs
template:
metadata:
labels:
app: my-application-jobs
spec:
containers:
- image: quay. io/<username>/my-application-jobs:latest
name: my-application-jobs
imagePullPolicy: Always
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "/usr/bin/my-application-jobs --alive"
initialDelaySeconds: 10
periodSeconds: 5 pid ] && ps -A | grep nginx"
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
httpGet:
scheme: HTTPS
path: /index.html
port: 8443
initialDelaySeconds: 10
periodSeconds: 5
- image: quay.io/<username>/my-application-app-server:latest
name: my-application-app-server
imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "/usr/bin/my-application-web --alive"
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
httpGet:
scheme: HTTP
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
# Pod Two - Jobs Server
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-application-jobs
name: my-application-jobs
spec:
replicas: 1
selector:
matchLabels:
app: my-application-jobs
template:
metadata:
labels:
app: my-application-jobs
spec:
containers:
- image: quay.
pid ] && ps -A | grep nginx"
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
httpGet:
scheme: HTTPS
path: /index.html
port: 8443
initialDelaySeconds: 10
periodSeconds: 5
- image: quay.io/<username>/my-application-app-server:latest
name: my-application-app-server
imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "/usr/bin/my-application-web --alive"
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
httpGet:
scheme: HTTP
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
# Pod Two - Jobs Server
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-application-jobs
name: my-application-jobs
spec:
replicas: 1
selector:
matchLabels:
app: my-application-jobs
template:
metadata:
labels:
app: my-application-jobs
spec:
containers:
- image: quay.
На рисунке 8 показаны полные примеры приложений с обеими настроенными пробами.
Рис. 8: Полный пример приложений с обеими настроенными пробами.Что насчет одинаковых liveness и readiness проб?
На мой взгляд, хотя этот шаблон используется чересчур часто, в некоторых случаях он имеет смысл. Если приложение начинает некорректно отвечать на HTTP-запросы и, вероятно, никогда не восстановит свою работу без перезапуска, то вы, вероятно, захотите, чтобы OpenShift перезапустил под. Было бы лучше, если бы ваше приложение восстанавливалось само по себе, но это бывает нецелесообразно в реальном мире.
Если у вас есть HTTP endpoint, который может быть исчерпывающим индикатором, вы можете настроить и liveness и readiness пробы на работу с этим endpoint. Используя один и тот же endpoint убедитесь, что ваш под будет перезапущен, если этот endpoint не сможет вернуть корректный ответ.
Используя один и тот же endpoint убедитесь, что ваш под будет перезапущен, если этот endpoint не сможет вернуть корректный ответ.
Финальные мысли
Liveness и readiness пробы отправляют разные сигналы в OpenShift. Каждый имеет свое определенное значение и они не взаимозаменяемы. Не пройденная liveness проверка говорит OpenShift, что контейнер должен быть перезапущен. Не пройденная readiness проба говорит OpenShift придержать трафик от отправки в этот контейнер.
Нет универсального рецепта для проб, потому что “правильный” выбор будет зависеть от того, как написано приложение. Приложению, которое умеет самовосстанавливаться нужна иная настройка от того, которое просто дает сбой и умирает.
Выбирая корректные проверки для приложения я обращаюсь к семантическому смыслу в сочетании с поведением приложения. Зная, что проваленная liveness проба перезапустит контейнер, а проваленная readiness проба удалит его из балансировщика. Обычно это не сложно, определить какие пробы нужны приложению.
Мы рассмотрели реалистичные примеры, но вы можете увидеть значительно более сложные случаи в реальных системах. Для инстанса в сервис-ориентированной архитектуре (SOA), сервис может зависеть от другого сервиса при обработке соединений. Если нисходящий сервис не готов, должен ли проходить readiness проверку восходящий сервис или нет? Ответ зависит от приложения. Вам нужно провести анализ стоимости/преимуществ решения, чтобы определить, что добавочная сложность того стоит.
Хотя концептуально пробы очень просты, они могут быть сложны на практике. Лучший подход для нахождения оптимального решения — это итеративный! Проведите тестирование производительности и хаотичное тестирование для наблюдения за поведением вашей конфигурации и улучшайте её в процессе. Мы редко делаем все правильно с первого раза.
JS Course · The Rolling Scopes School
Курс «JavaScript/Front-end»
Бесплатный курс от сообщества The Rolling Scopes для тех, кто хочет получить знания и опыт, достаточные для трудоустройства на позицию Junior Software Engineer в области JavaScript/Front-end.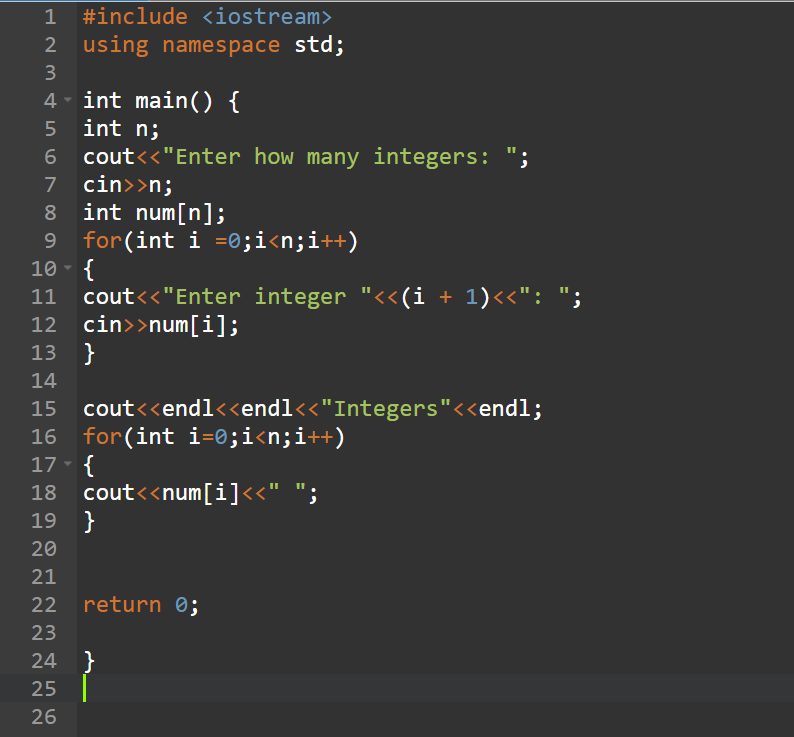
Начало занятий: 5 марта 2023
Записаться
Бесплатное обучение
В RS School работает принцип «Pay it forward». Мы бесплатно делимся с учащимися своими знаниями сейчас, надеясь, что в будущем они вернутся к нам в качестве менторов и точно так же передадут свои знания следующему поколению студентов.
Для всех желающих
Новый набор студентов стартует каждые полгода и насчитывает около 6000-7000 человек.
В RS School может учиться каждый, независимо от возраста, профессиональной занятости и места жительства. Однако для обучения необходимо иметь БАЗОВЫЕ ЗНАНИЯ.
World Wide Менторы и Тренеры
В обучении участвуют 430 менторов. Наши менторы — это front-end и javascript разработчики из различных компаний и стран.
Как стать ментором?
Формат обучения
Вебинары 3 раза в неделю в вечернее время.
Для успешного прохождения программы вам потребуется 20-40 часов в неделю.
Чат
Открытый чат для абитуриентов и учащихся.
Сертификат
Сертификат об успешном прохождении курсов выдается всем прошедшим два этапа обучения.
Материалы
Документация школы — https://docs.rs.school
Все материалы находятся в открытом доступе на YouTube и GitHub.
Также предлагаем ознакомиться с конспектом первого этапа обучения.
Срок обучения: 5-7 месяцев
Вводный вебинар состоится 5 марта 2023 года.
Запись вебинара будет размещена на YouTube канале школы.
Регистрация на вебинар
Регистрация на курс открыта до 5 марта года
Записаться
Необходимые базовые знания
Какие базовые знания должны быть ОБЯЗАТЕЛЬНО перед началом обучения?
- Понимание основ HTML и CSS, наличие практических навыков вёрстки.
- Знание основ JavaScript (типы данных, операторы, циклы, условные констуркции, функции).
- Знание структуры данных и их организации (массив, список, стек, очередь, дерево и т.д.).
- Уметь реализовать достаточно простой алгоритм на языке программирования JavaScript. Например, сортировку или поиск элементов массива.
- Уметь решать задачи уровня 8-7 kyu на сайте https://www.codewars.com/.
- Английский язык уровня Pre-intermediate (желательно).

Что делать, если не хватает базовых знаний?
Этапы обучения
1
Зачисляются все желающие.
Формат: самообучение, вебинары и общение в Discord.
Практические занятия проверяются и оцениваются автоматически, а также методом перекрёстной проверки.
Темы:
- Знакомство студентов с The Rolling Scopes и RS School.
- Git, GitHub, оформление commit и pull request.
- Верстка адаптивного макета.
- Core JS.
- Решения алгоритмических задач.
- DOM, DOM Events, Browser API.
- Основы NodeJS.
- Собеседование по основам HTML/CSS/JS/Алгоритмам.
- Проект Match-Match Game на Core JS.

2
Для зачисления необходимо успешно выполнить задания 1 этапа и пройти собеседование с ментором.
Формат: менторинг, самообучение, вебинары и общение в Discord.
Практические занятия проверяются и оцениваются ментором, а также методом перекрёстной проверки. В ходе обучения проводятся тренировочные интервью у разных менторов.
Темы:
- OOP.
- Asynchronous programming.
- TypeScript.
- NodeJS.
- Подготовка презентации на английском языке.
- Собеседование по Core JS.
3
Курс по React или Angular на выбор.
Для зачисления необходимо успешно закончить два этапа обучения.
Формат: менторинг, самообучение, вебинары и общение в Discord.
Практические занятия проверяются и оцениваются ментором, а также методом перекрёстной проверки. В ходе обучения проводятся тренировочные интервью у разных менторов.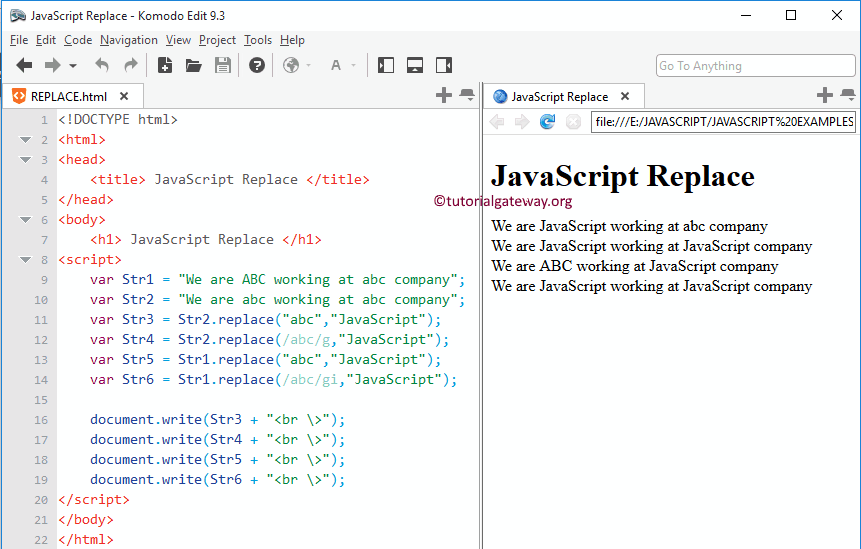
Темы:
- Фреймворк на выбор: React или Angular.
- Разработка финального проекта в команде.
- Собеседование по фреймворку.
Что следует сделать до старта курса
2
Присоединиться в Discord чат курса и указать в нике свой GitHub аккаунт. Инструкция.
3
Прочитать отзывы о курсе студентов набора 2020q1.
4
Запомнить правила хорошего тона RS School:
- Если вам помогли, не забудьте написать спасибо. Желательно использовать специальный канал чата
- Если вам помогли с каким-то вопросом и вы видите, что у других студентов возникли подобные сложности, то очень желательно не проходить мимо и помочь в свою очередь
- Если у вас какие-либо проблемы с выполнением тасков или платформой школы (RS App) — не следует писать в личные сообщения администраторам или модераторам
5
Выполнить задания и пройти тесты подготовительного этапа.
Присоединяйтесь к нашим Telegram группам
Беларусь
- вся Беларусь
- Минск
- Могилев
- Витебск
- Гомель
- Брест
Россия
- вся Россия
- Москва
- Ижевск
- Рязань
- Самара
- Саратов
- Сергиев Посад
- Тольятти
- Тверь
- Санкт-Петербург
- Нижний Новгород
- Волгоград
Казахстан
- весь Казахстан
- Нур-Султан
- Алматы
- Караганда
Кыргызстан
- весь Кыргызстан
Казахстан и Кыргызстан
- Общий Discord чат
Украина
- вся Украина
Узбекистан
- весь Узбекистан
Преподаватели курса
Сергей Шаляпин
6+ лет во фронтенде, выпускник РФиКТ БГУ, еще во времена учебы увлекавшийся программированием и разработкой алгоритмов. Тренер в RS School без малого 4 года. Одно из первых лиц, которые вы видите при поступлении 🙂
Тренер в RS School без малого 4 года. Одно из первых лиц, которые вы видите при поступлении 🙂
Дмитрий Цебрук
Дмитрий учился в RS School 2018Q3 и стал лучшим студентом этого набора. Теперь работает в EPAM Systems как Software Engineer. Любит создавать всякие полезные интерактивные штуки на любимом языке JavaScript. Участвует в разработке RS School App, а также выступает в роли ментора и лектора.
Виктор Ковалев
Выпускник RS School, c марта 2019 года работает инженером-программистом в Webilesoft. Занимается разработкой web-приложений (JS, React), мобильных приложений (react-native, swift). Как выпускник RS School, который до курсов никогда не занимался программированием, понимает возможные трудности в процессе обучения и всегда готов помочь студентам. Занялся менторингом, как только понял, что уже накопил достаточно знаний, которыми можно поделиться с другими.
Павел Разувалов
Павел Разувалов работает инженером-программистом в EPAM Systems, опыт разработки клиентских приложений более 2 лет.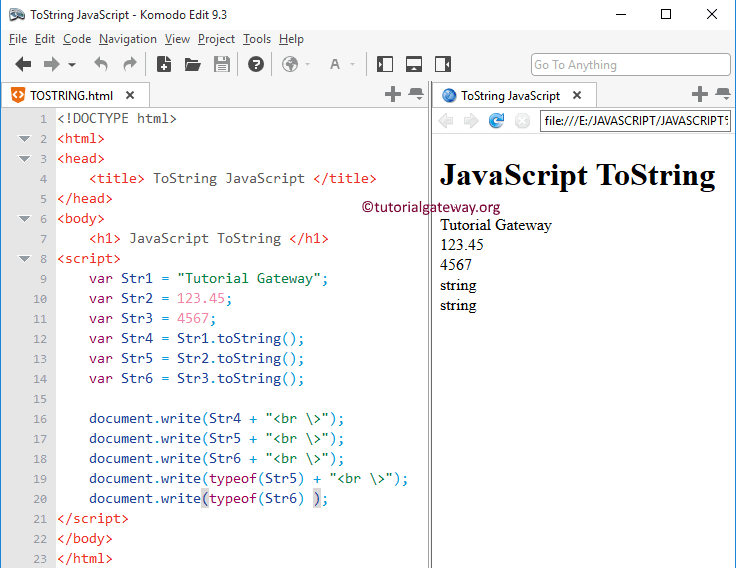 После окончания RS School в 2017 Павел успешно начал свою карьеру. Он делает все возможное не только в самосовершенствовании, но и в обмене знаниями, помогая другим. Павел решил следовать принципу «Pay it forward» и начал участвовать в школе Rolling Scopes не только в качестве наставника, но и тренера в EPAM JS Lab.
После окончания RS School в 2017 Павел успешно начал свою карьеру. Он делает все возможное не только в самосовершенствовании, но и в обмене знаниями, помогая другим. Павел решил следовать принципу «Pay it forward» и начал участвовать в школе Rolling Scopes не только в качестве наставника, но и тренера в EPAM JS Lab.
Блог на edium
Как устроена The Rolling Scopes School
Дмитрий Воробей, Организатор RS School
Ментор RS школы про мифы и студентов
Денис Шеко, Ментор RS School
The Rolling Scopes School глазами бывшего студента
Юрий Старовойтов, Студент RS School
Все статьи
Наши партнеры
RS School в социальных сетях
JS-зондов | sfink @ Mozilla
Случалось ли вам когда-нибудь, что ваш браузер периодически загадочно зависал, и вы задавались вопросом: «Что за #@$! это делает?!” Или, возможно, вы работаете над чем-то, скажем, над сборщиком мусора, и хотите посмотреть, какой эффект произведут ваши изменения. Или, может быть, даже написать небольшой анализ, который постобрабатывает какие-то следы того, что происходит, и выясняет, какой будет оптимальная схема действий. («Если бы я выбросил этот большой кусок данных из кеша здесь, у меня было бы место для всех этих маленьких вещей, которые были выселены вместо этого, и было бы намного меньше промахов…»)
Или, может быть, даже написать небольшой анализ, который постобрабатывает какие-то следы того, что происходит, и выясняет, какой будет оптимальная схема действий. («Если бы я выбросил этот большой кусок данных из кеша здесь, у меня было бы место для всех этих маленьких вещей, которые были выселены вместо этого, и было бы намного меньше промахов…»)
Обычный способ сделать что-то подобное — вручную добавить некоторый инструментальный код (вероятно, просто зарегистрировать кучу событий) и постобработать результаты. Это прекрасно работает, но имеет несколько недостатков: (1) вам нужно выяснить, куда вставить инструментарий, часто в незнакомый код; (2) вам нужно будет перекомпилировать, возможно, несколько раз; (3) журналы могут очень быстро стать очень большими; и (4) вы, вероятно, закончите тем, что напишете очень специальный постпроцессор, который (5) сбрасывает информацию в текстовый файл, который только вы знаете, как интерпретировать, и даже вы будете помнить, что все это значит, только неделю или две. . В следующий раз, когда вам нужно будет сделать что-то подобное, вы обнаружите, что весь ваш инструментальный код сильно испорчен и пропускает некоторые пути, которые были добавлены за это время, поэтому вы начнете все с нуля.
. В следующий раз, когда вам нужно будет сделать что-то подобное, вы обнаружите, что весь ваш инструментальный код сильно испорчен и пропускает некоторые пути, которые были добавлены за это время, поэтому вы начнете все с нуля.
Что ж, не повезло. Иногда это просто факты жизни, и вам нужно смириться с этим. Хватит ныть, черт возьми.
Но часто интересующие события (или, точнее, «зондовые точки») представляют общий интерес. Если вам удастся внедрить их в код и таким образом заставить других разработчиков поддерживать их для вас по мере внесения изменений, тогда каждый может положиться на то, что эти зонды постоянно находятся примерно в нужном месте. Это № 1 выше, и в зависимости от того, как они реализованы, есть большая вероятность, что вам даже не потребуется перекомпилировать, так что № 2.
Я реализовал подобные запросы в движке SpiderMonkey Javascript. Есть такие контрольные точки, как «запускается сборщик мусора (и он локальный для одного отсека)», «размер кучи был изменен» и «вызывается/возвращается функция javascript F». Некоторые из них легко вставить в код — например, нетрудно было понять начало сборщика мусора. Некоторые из них были не такими простыми, например вызовы функций JS (они могут показаться простыми, но что, если вы используете JITted? Какой JIT? Вы все еще используете JITted к моменту возврата из функции?). передавать информацию различным бэкендам — от Windows ETW (сообщение в блоге появится всякий раз, когда мне удастся реализовать функцию запуска/остановки), до dtrace/systemtap (еще одно сообщение в блоге, возможно, появится раньше, так как я недавно собрал демо), до простой механизм обратного вызова (см. JS_SetFunctionCallback на MDN) и другие специальные механизмы, которые заботятся только о небольшом подмножестве зондов.
Некоторые из них легко вставить в код — например, нетрудно было понять начало сборщика мусора. Некоторые из них были не такими простыми, например вызовы функций JS (они могут показаться простыми, но что, если вы используете JITted? Какой JIT? Вы все еще используете JITted к моменту возврата из функции?). передавать информацию различным бэкендам — от Windows ETW (сообщение в блоге появится всякий раз, когда мне удастся реализовать функцию запуска/остановки), до dtrace/systemtap (еще одно сообщение в блоге, возможно, появится раньше, так как я недавно собрал демо), до простой механизм обратного вызова (см. JS_SetFunctionCallback на MDN) и другие специальные механизмы, которые заботятся только о небольшом подмножестве зондов.
#3 (логирование всего по сравнению с онлайн-обработкой) выходит на религиозную территорию. Проще всего бездумно регистрировать все интересующее и постобрабатывать. Но что, если вам нужны обновления в реальном времени? Или если вы хотите отслеживать различную информацию в зависимости от того, что вы узнали из других контрольных точек? Или что, если объем записи вашего журнала мешает тому, что вы пытаетесь измерить (например, дисковому вводу-выводу)? Или, может быть, вам нужно отслеживать какое-то состояние, чтобы придать зондам смысл. (GC при простое => хорошо. Сбор мусора, которого можно избежать, когда пользователь ожидает => плохо.)
(GC при простое => хорошо. Сбор мусора, которого можно избежать, когда пользователь ожидает => плохо.)
Именно эти аргументы привели к созданию таких инструментов, как DTrace и Systemtap. Оба предоставляют вам среду сценариев, которая может собирать информацию от зондов по мере их запуска, точно контролировать, какая информация отслеживается по мере того, как что-то происходит, и может быть присоединена/отсоединена в любое время. Они довольно крутые и бесценны, как только вы с ними познакомитесь. Они также чрезвычайно зависят от системы и обычно требуют root-доступа, специальных сборок, отладочной информации ядра или чего-то еще, что в конечном итоге означает, что вы часто не можете просто передать скрипты анализа другим людям и позволить этим людям извлечь из них какую-то пользу. . И даже вы, возможно, не сможете взять их в другую среду.
Тем не менее, они довольно хорошо справляются с № 4 (избегая одноразовых процессоров специального назначения), по крайней мере, для сред, соответствующих той, для которой они были написаны. И если они могут рисовать из статически вставленных контрольных точек (типа, о котором я говорил выше), они на самом деле могут быть довольно общими. Тем не менее, № 5 по-прежнему убийца — по крайней мере, так, как я пишу сценарии systemtap, все они заканчиваются своеобразными способами вывода результатов определенного анализа, и никто другой не получит много информации, не изучив сценарий для пока первый.
И если они могут рисовать из статически вставленных контрольных точек (типа, о котором я говорил выше), они на самом деле могут быть довольно общими. Тем не менее, № 5 по-прежнему убийца — по крайней мере, так, как я пишу сценарии systemtap, все они заканчиваются своеобразными способами вывода результатов определенного анализа, и никто другой не получит много информации, не изучив сценарий для пока первый.
Что, если бы мы могли добиться большего? Что, если бы мы могли вставить эти статические зонды, но вместо того, чтобы передавать информацию какому-то нишевому инструменту, который может использовать только горстка людей, мы делаем данные доступными для простого старого дополнения Firefox? Вы можете собирать, агрегировать, суммировать, искажать, складывать, веретено или дробить данные непосредственно в коде JS. Тогда мы могли бы позволить авторам дополнений сходить с ума от визуализаций и библиотек анализа. Это было бы круто, правда?
График поведения сборщика мусора.
 Предупредите пользователя, когда происходят медленные или подозрительные действия. Выясните, что происходит во время длинных обработчиков событий. График процента времени, проведенного в различных подсистемах. Соотнесите данные о производительности/трассировке с действиями пользователя. Сделайте запись полета различных показателей и дайте пользователю пройтись по истории. Ваши идеи здесь.
Предупредите пользователя, когда происходят медленные или подозрительные действия. Выясните, что происходит во время длинных обработчиков событий. График процента времени, проведенного в различных подсистемах. Соотнесите данные о производительности/трассировке с действиями пользователя. Сделайте запись полета различных показателей и дайте пользователю пройтись по истории. Ваши идеи здесь. Итак, я вас обманул. Я не собираюсь рассказывать вам, как это сделать. Этот пост в блоге — дразня, реклама работы, которую Брайан Бург проделал этим летом во время стажировки в Mozilla. Если вам интересно, он проведет итоговую презентацию своей стажировки завтра (сегодня, когда вы читаете это, или, возможно, вчера или в прошлом месяце для тех из вас, кто отстал от чтения Планеты). Это 13:30 PDT. в четверг, 22 сентября, в штаб-квартире Mozilla в Маунтин-Вью, и мне 97,2% уверены, что он будет транслироваться и через Air Mozilla. И заклеен, кажется? (К сожалению, я не могу найти, где они заархивированы. Кто-нибудь, пожалуйста, скажите мне, и я обновлю этот пост.) Будет демоверсия. С красивыми картинками! И он очень скоро напишет об этом в своем блоге. Больше пока ничего не скажу — все равно ошибусь.
Кто-нибудь, пожалуйста, скажите мне, и я обновлю этот пост.) Будет демоверсия. С красивыми картинками! И он очень скоро напишет об этом в своем блоге. Больше пока ничего не скажу — все равно ошибусь.
Обновление: Арх! Я ошибся с датой! Сегодня не среда, 21 сентября, как я изначально написал. Сегодня, , четверг, , 22 сентября. Извините за путаницу!
Теги: стажер, Mozilla, планета
Эта запись была опубликована в среду, 21 сентября 2011 г., в 23:36 и размещена в рубрике «Без рубрики». Вы можете следить за любыми комментариями к этой записи через ленту RSS 2.0. Вы можете оставить комментарий или вернуться на свой сайт.
Ученый-компьютерщик обнаружил уязвимость JavaScript на тысячах веб-сайтов
Перейти к основному содержанию
Кредит: Getty Images
Платформа ProbeTheProto, разработанная ученым-компьютерщиком Иньчжи Цао, помогает выявлять и предупреждать веб-сайты, уязвимые к уязвимости, которая позволяет злоумышленникам «загрязнять» важный веб-код
По Кэтрин Грэм
/ Опубликовано
14 марта 2022 г.
Миллионы разработчиков используют JavaScript для создания веб-сайтов и мобильных приложений, что делает его одним из самых популярных языков программирования в мире. Но, по мнению исследователей из Университета Джона Хопкинса, тысячи веб-сайтов на JavaScript уязвимы из-за уязвимости в системе безопасности, которая может привести к манипулированию URL-адресом сайта или краже информации профиля пользователя.
Эта уязвимость, известная как «загрязнение прототипа», позволяет злоумышленникам модифицировать или «загрязнять» прототип, который является встроенным свойством объекта JavaScript. Злоумышленник, которому удается изменить прототип объекта JavaScript, может выполнить множество вредоносных действий.
С помощью платформы, которую они назвали ProbeTheProto, исследователи из Института информационной безопасности Джона Хопкинса проанализировали один миллион веб-сайтов, работающих на JavaScript, и обнаружили, что более 2700 веб-сайтов — некоторые из них являются наиболее посещаемыми в мире — имеют множество недостатков, которые могут подвергнуть их риску загрязнение прототипа.
Десять сайтов вошли в число 1000 самых посещаемых веб-сайтов года, включая Weebly.com, CNET.com и McKinsey.com.
«Наш инструмент ProbeTheProto может автоматически и точно обнаруживать широкий спектр потенциальных атак. И мы обнаружили, что многие разработчики довольны тем, что мы помогаем им опережать угрозы кибербезопасности».
Yinzhi Cao
Доцент кафедры компьютерных наук
«Только недавно исследователи начали внимательно изучать загрязнение прототипов и поняли, что это вызывает серьезную озабоченность», — сказал эксперт по кибербезопасности Yinzhi Cao, доцент кафедры компьютерных наук в Университете Джонса Хопкинса. Инженерная школа Уайтинга. «Многие в сообществе разработчиков могут не знать, что уязвимости, связанные с загрязнением прототипа, могут иметь серьезные последствия».
В Javascript объект представляет собой набор связанных данных или функций; например, объект учетной записи пользователя может содержать такие данные, как имена пользователей, пароли и адреса электронной почты. Как только злоумышленник внесет изменение в прототип объекта, это повлияет на работу объекта во всем приложении и откроет двери для более серьезных уязвимостей, добавляет Цао.
Как только злоумышленник внесет изменение в прототип объекта, это повлияет на работу объекта во всем приложении и откроет двери для более серьезных уязвимостей, добавляет Цао.
Он и его команда приступили к изучению этого эффекта снежного кома с помощью динамического анализа испорченных данных, метода, при котором входные данные приложения помечаются специальным маркером «испорченные», а исследователи наблюдают, как испорченные данные распространяются через программу. Если маркер все еще присутствует на выходе программы, исследователи знают, что приложение уязвимо для эксплойтных атак ввода, которые могут привести к некоторым незапланированным действиям.
«Представьте себе очень длинную трубу в большом черном ящике, и я хочу знать, соединены ли точки А и Б. Если да, я могу поместить в точку А ядовитую жидкость, чтобы атаковать точку Б. Что мы делаем, так это сбрасываем немного красного красителя в воде в точке А, а затем наблюдаю за цветом воды в точке Б. Если я вижу, что точка Б тоже красная, я знаю, что А и Б связаны, и тогда мы можем атаковать», — сказал Цао.
Исследователи определили три основные атаки ввода, которые могут быть вызваны загрязнением прототипа: межсайтовый скриптинг (XSS), манипулирование файлами cookie и манипулирование URL. Такие уязвимости на общедоступных веб-сайтах предоставляют киберпреступникам широкие возможности для перехвата паролей и установки вредоносных программ, а также для других гнусных действий.
Цао говорит, что исследователи обязаны сообщать владельцам веб-сайтов об уязвимостях прототипов и даже рекомендовать лучший патч для их кода. Благодаря команде Цао, бьющей тревогу, пока что 29Разработчики уже исправили 3 уязвимости.
«Организации даже не знают о существовании этих уязвимостей. Наш инструмент ProbeTheProto может автоматически и точно обнаруживать широкий спектр потенциальных атак. И мы обнаружили, что многие разработчики довольны тем, что мы помогаем им опережать угрозы кибербезопасности», — сказал Цао.
Студенты-выпускники компьютерных наук Цзыфэн Кан и Сун Ли внесли свой вклад в исследование.