Как работают поисковики Интернет: общие принципы работы
Вступление
Основная задача оптимизации сайта это повышение позиций сайта в поисковой выдаче поисковых систем. Позиции сайта в выдаче определяются согласно алгоритмам поисковых систем. По алгоритмам, поисковики собирают нужные страницы сайтов, обрабатывают их и заносят в базу поисковой выдаче, ранжируя по соответствию поисковым запросам.
SEO оптимизация сайта
Цель SEO оптимизации сайта, повышение позиций страниц сайта в поисковой выдаче поисковых систем. Всем знакомы названия популярных поисковых систем мира: Google, Yahoo, MSN и Рунета: Яндекс, Рамблер, Апорт. Именно, поисковые системы, осуществляют поиск в сети по запросу пользователя, выявляя по своим алгоритмам, наиболее подходящие страницы сайтов.
Работа поисковых систем основана на взаимосвязанной работе нескольких специальных программ. Перечислим основные компоненты поисковых систем и их принципы работы.
Каждая поисковая система имеет свой алгоритм поиска запрашиваемой пользователем информации. Алгоритмы эти сложные и чаще держатся в секрете. Однако
- Сначала собирает информацию, черпая её со страниц сайтов и вводя её в свою базы данных;
- Индексирует сайты и их страницы, и переводит их из базы данных в базу поисковой выдачи;
- Выдает результаты по поисковому запросу, беря их из базы проиндексированных страниц;
- Ранжирует результаты (выстраивает результаты по значимости).
Как работают поисковики
Всю работу поисковых систем выполняют специальные программы и комбинации этих программ. Перечислим основные составляющие алгоритмов поисковых систем:
- Spider (паук) – это браузероподобная программа, скачивающая веб-страницы. Заполняет базу данных поисковика.
- Crawler (краулер, «путешествующий» паук) – это программа, проходящая автоматически по всем ссылкам, которые найдены на странице.
- Indexer (индексатор) – это программа, анализирующая веб-страницы, скачанные пауками. Анализ страниц сайта для их индексации.
- Database (база данных) – это хранилище страниц. Одна база данных это все страницы загруженные роботом. Вторая база данных это проиндексированные страницы.
- Search engine results engine (система выдачи результатов) – это программа, которая занимается извлечением из базы данных проиндексированных страниц, согласно поисковому запросу.
- Web server (веб-сервер) – веб-сервер, осуществляющий взаимодействие пользователя со всеми остальными компонентами системы поиска.
Реализация механизмов поиска у поисковиков может быть самая различная. Например, комбинация программ Spider+ Crawler+ Indexer может быть создана, как единая программа, скачивающая и анализирующая веб-страницы и находящая новые ресурсы по найденным ссылкам. Тем не менее, нижеупомянутые общие черты программ присущи всем поисковым системам.
Программы поисковых систем
Spider
«Паук» скачивает веб-страницы так же как пользовательский браузер. Отличие в том, что браузер отображает содержащуюся на странице текстовую, графическую или иную информацию, а паук работает с html-текстом страницы напрямую, у него нет визуальных компонент. Именно, поэтому нужно обращать внимание на ошибки в html кодах страниц сайта.
Crawler
Программа Crawler, выделяет все находящиеся на странице ссылки. Задача программы вычислить, куда должен дальше направиться паук, исходя из заданного заранее, адресного списка или идти по ссылках на странице. Краулер «видит» и следует по всем ссылкам, найденным на странице и ищет новые документы, которые поисковая система, пока еще не знает. Именно, поэтому, нужно удалять или исправлять битые ссылки на страниц сайта и следить за качеством ссылок сайта.
Indexer
Программа Indexer (индексатор) делит страницу на составные части, далее анализирует каждую часть в отдельности. Выделению и анализу подвергаются заголовки, абзацы, текст, специальные служебные html-теги, стилевые и структурные особенности текстов, и другие элементы страницы. Именно, поэтому, нужно выделять заголовки страниц и разделов мета тегами (h2-h5,h5,h6), а абзацы заключать в теги <p>.
Database
База данных поисковых систем хранит все скачанные и анализируемые поисковой системой данные. В базе данных поисковиков хранятся все скачанные страницы и страницы, перенесенные в поисковой индекс. В любом инструменте веб мастеров каждого поисковика, вы можете видеть и найденные страницы и страницы в поиске.
Search Engine Results Engine
Search Engine Results Engine это инструмент (программа) выстраивающая страницы соответствующие поисковому запросу по их значимости (ранжирование страниц). Именно эта программа выбирает страницы, удовлетворяющие запросу пользователя, и определяет порядок их сортировки. Инструментом выстраивания страниц называется алгоритм ранжирования системы поиска.
Важно! Оптимизатор сайта, желая улучшить позиции ресурса в выдаче, взаимодействует как раз с этим компонентом поисковой системы. В дальнейшем все факторы, которые влияют на ранжирование результатов, мы обязательно рассмотрим подробно.
Web server
Web server поисковика это html страница с формой поиска и визуальной выдачей результатов поиска.
Повторимся. Работа поисковых систем основана на работе специальных программ. Программы могут объединяться, компоноваться, но общий принцип работы всех поисковых систем остается одинаковым: сбор страниц сайтов, их индексирование, выдача страниц по результатам запроса и ранжирование выданных страниц по их значимости. Алгоритм значимости у каждого поисковика свой.
©wordpress-abc.ru
Еще статьи
Похожие посты:
SEO-дебри, или Как работают поисковые системы?
Зачем маркетологу знать базовые принципы поисковой оптимизации? Все просто: органический трафик — это прекрасный источник входящего потока целевой аудитории для вашего корпоративного сайта и даже лендингов.
Встречайте серию образовательных постов на тему SEO.
Что такое поисковая система?
Поисковая система представляет собой большую базу документов (контента). Поисковые роботы обходят ресурсы и индексируют разный тип контента, именно эти сохраненные документы и ранжируют в поиске.
По факту, Яндекс — это «слепок» Рунета (еще Турция и немного англоязычных сайтов), а Google — мирового интернета.
Цель поисковой системы — показывать ссылки на документы, которые максимально соответствуют (релевантны) поисковому запросу.
Поисковый индекс — структура данных, содержащая информацию о документах и расположении в них ключевых слов.
По принципу работы поисковые системы схожи между собой, различия заключаются в формулах ранжирования (упорядочивание сайтов в поисковой выдаче), которые строятся на основе машинного обучения.
Ежедневно миллионы пользователей задают запросы поисковым системам.
«Реферат написать»:
«Купить»:
Но больше всего интересуются…
Как устроена поисковая система?
Чтобы предоставлять пользователям быстрые ответы, архитектуру поиска разделили на 2 части:
- базовый поиск,
- метапоиск.
image source api.yandex.ru
Базовый поиск
Базовый поиск — программа, которая производит поиск по своей части индекса и предоставляет все соответствующие запросу документы.
Метапоиск
Метапоиск — программа, которая обрабатывает поисковый запрос, определяет региональность пользователя, и если запрос популярный, то выдает уже готовый вариант выдачи, а если запрос новый, то выбирает базовый поиск и отдает команду на подбор документов, далее методом машинного обучения ранжирует найденные документы и предоставляет пользователю.
image source api.yandex.ru
Классификация поисковых запросов
Чтобы дать релевантный ответ пользователю, поисковик сначала пытается понять, что ему конкретно нужно. Происходит анализ поискового запроса и параллельный анализ пользователя.
Поисковые запросы анализируются по параметрам:
- Длина;
- четкость;
- популярность;
- конкурентность;
- синтаксис;
- география.
Тип запроса:
- навигационный;
- информационный;
- транзакционный;
- мультимедийный;
- общий;
- служебный.
После разбора и классификации запроса происходит подбор функции ранжирования.
Обозначение типов запросов является конфиденциальной информацией и предложенные варианты — это догадка специалистов по поисковому продвижению.
Если пользователь задает общий запрос, то поисковая система выдает разные типы документов. И стоит понимать, что продвигая коммерческую страницу сайта в ТОП-10 по общему запросу, вы претендуете попасть не на одно из 10 мест, а в число мест
для коммерческих страниц, которое выделяется формулой ранжирования. И следовательно, вероятность вывода в топ по таким запросам ниже.
MatrixNet
Машинное обучение МатриксНет — алгоритм, введенный в 2009 году Яндексом, подбирающий функцию ранжирования документов по определенным запросам.
image source api.yandex.ru
МатриксНет используется не только в поиске Яндекса, но и в научных целях. К примеру, в Европейском Центре ядерных исследований его используют для редких событий в больших объемах данных (ищут бозон Хиггса).
Первичные данные для оценки эффективности формулы ранжирования собирает отдел асессоров. Это специально обученные люди, которые оценивают выборку сайтов по экспериментальной формуле по следующим критериям.
Оценка качества сайта
Витальный — официальный сайт (Сбербанк, LPgenerator). Поисковому запросу соответствует официальный сайт, группы в социальных сетях, информация на авторитетных ресурсах.
Полезный (оценка 5) — сайт, который предоставляет расширенную информацию по запросу.
Пример — запрос: баннерная ткань.
Сайт, соответствующий оценке «полезный», должен содержать информацию:
- что такое баннерная ткань;
- технические характеристики;
- фотографии;
- виды;
- прайс-лист;
- что-то еще.
Примеры запроса в топе:
Релевантный+ (оценка 4) — это оценка означает, что страница соответствует поисковому запросу.
Релевантный- (оценка 3) — страница не точно соответствует поисковому запросу.
Допустим, по запросу «стражи галактики сеансы» выводится страница о фильме без сеансов, страница прошедшего сеанса, страница трейлера на youtube.
Нерелевантный (оценка 2) — страница не соответствует запросу.
Пример: по названию отеля выводится название другого отеля.
Чтобы продвинуть ресурс по общему или информационному запросу, нужно создавать страницу соответствующую оценке «полезный».
Для четких запросов достаточно соответствовать оценке «релевантный+».
Релевантность достигается за счет текстового и ссылочного соответствия страницы поисковым запросам.
Выводы
- Не по всем запросам можно продвинуть коммерческую целевую страницу;
- Не по всем информационным запросам можно продвинуть коммерческий сайт;
- Продвигая общий запрос, создавайте полезную страницу.
Частой причиной, почему сайт не выходит в топ, является несоответствие контента продвигаемой страницы, поисковому запросу.
Об этом поговорим в следующей статье «Чек-лист по базовой оптимизации сайта».
image source Maryanne Gobble
 Автор этого поста:
Автор этого поста:Погодаев Сергей, руководитель компании «Бюро Погодаева»
- Занимается исследованиями алгоритмов поисковых систем с 2009;
- Провел более 150 технических, поисковых и маркетинговых аудитов сайтов;
- Проводил оптимизацию социальных сетей «Мой Мир» и «AlterGeo»;
- Изучает и развивает направление «Продвижение Landing Page».
14-08-2014
Принципы работы поисковых систем — блог Indigo
Karina | 09.09.2014
Две основные функции поисковых систем в Интернете – сканирование сайтов и создание индекса, а также предоставление ответов на поставленные вопросы посредством поиска и структурирования по релевантности имеющихся в индексе страниц данной тематики. Алгоритм, по которому работают поисковики, является тайной, которую пытаются разгадать оптимизаторы и владельцы сайтов.
Сканирование и индексация сайта поисковыми машинами
Как понять, что собой представляет Всемирная паутина? Проще всего вспомнить схему метро со множеством станций, где вместо остановок будут уникальные станицы или файлы. Поисковые системы вынуждены путешествовать по этой сети ежесекундно, используя для перемещения ссылки.
Например, представьте, что ваша страница – это станция метро и, чтобы поисковик до нее добрался, ему понадобится преодолеть значительное количество других станций, т. е. страниц.
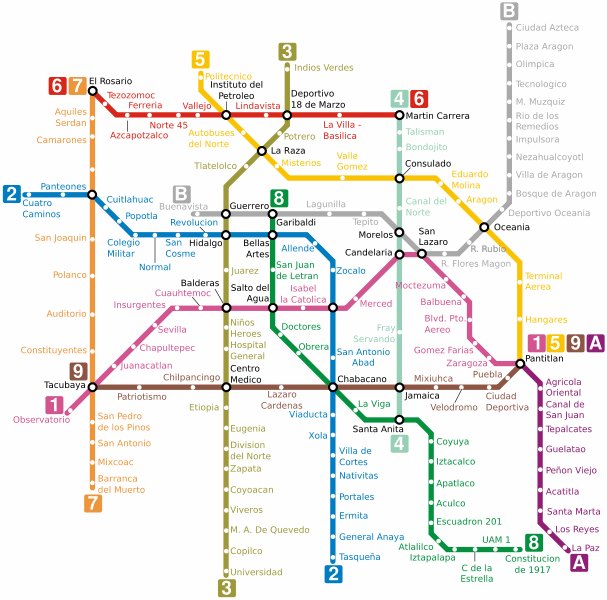 Схема метро как пример структуры Всемирной паутины
Схема метро как пример структуры Всемирной паутиныНаличие ссылок связывает страницы между собой, как перегоны в метро связывают станции, и именно по ним двигаются от материала к материалу поисковые роботы, сканируя бесконечное количество веб-страниц. Найденные страницы расшифровываются (поисковик видит всё как код, а не как страницу с дизайном) и сохраняются на жёстких дисках. Наиболее популярные поисковые системы, например Google, уже имеют распространённую сеть дата-центров по всему миру, где хранится весь объём данных. Огромные здания содержат наиболее современную технику, которая обрабатывает и передаёт информацию с колоссальной скоростью, потому как даже задержка в 1-2 секунды может вызвать недовольство у пользователя и переключить его интерес на другую систему поиска.
Формирование выдачи
Вводя интересующую информацию в поисковик, пользователь хочет получить ответ, который полностью удовлетворит его интерес. Машинный поиск рассматривает множество страниц, чтобы составить список релевантных и актуальных результатов. Современные поисковые системы по одному и тому же запросу включают в выдачу страницы разнообразной тематики, которые могут соответствовать данному ключевому слову. К примеру, если в Google мы вводим запрос «Нептун», поисковая система предложит множество вариантов: информацию о планете, мифологию, компании, рестораны и т. д. с идентичным названием.
То есть, без ввода уточняющего запроса поисковая система предложит пользователю все возможные варианты ответов, которые он предположительно мог искать по данному слову.
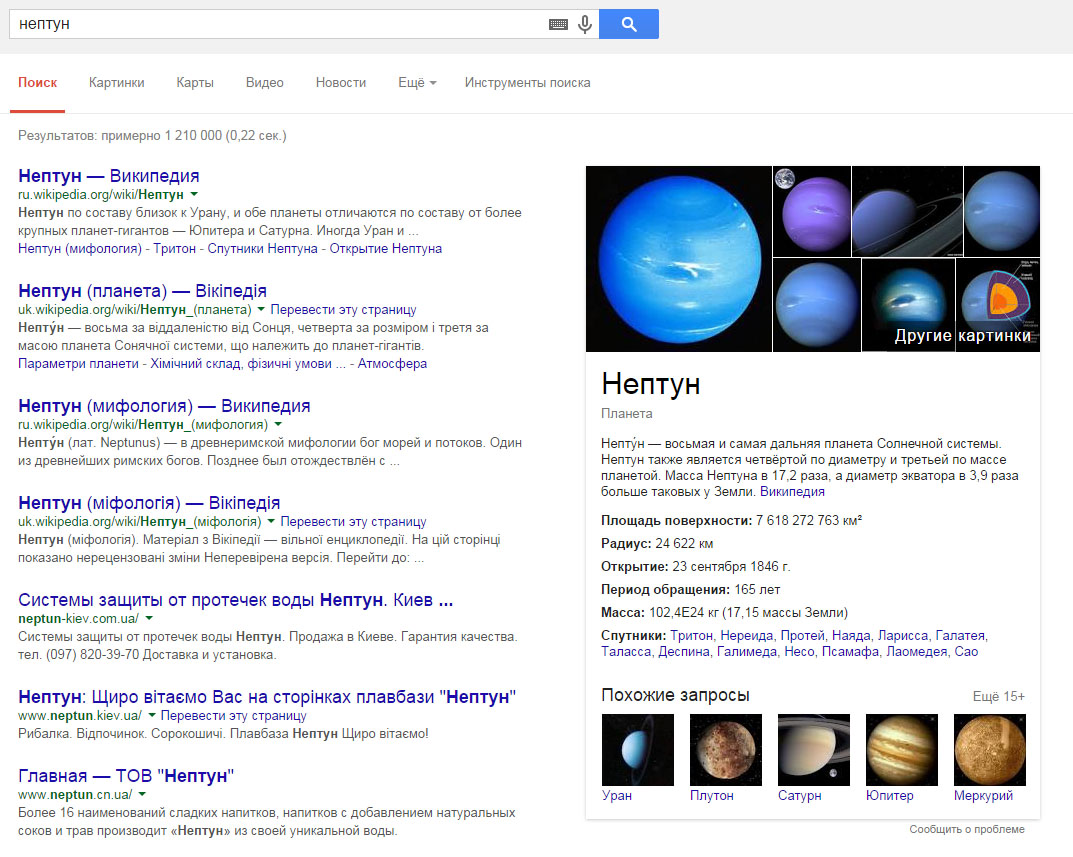
Нептун может быть богом, планетой, плавбазой или системой защиты от потопа
Инженерами было разработано множество факторов, которые дополнительно влияют на ранжирование. По информации Google, на данный момент в их результатах используются сотни таких факторов. Некоторые из них мы подробно рассматриваем в нашем блоге.
Как поисковики находят необходимый контент
В настоящее время всё ещё актуально мнение, что чем популярнее страница, тем более релевантный контент на ней размещен. Этот фактор не определяется вручную – существуют определённые алгоритмы, которые и помогают выяснить, какие ресурсы интересны пользователям.
Принцип отбора постоянно меняется и, судя по результатам в выдаче одного и того же сайта, может значительно отличаться в разных поисковиках. Зачастую в отборе популярных веб-страниц участвуют социальные факторы, наличие тематических ссылок, посещаемость страниц ресурса.
Как видят сайт поисковые системы
У каждого поисковика в Интернете свои, достаточно сложные алгоритмы поиска, информацией о которых они делятся неохотно. Но понять их основные принципы можно, проанализировав рекомендации для веб-мастеров, которые размещены на официальных сайтах систем. В русскоязычном сегменте наиболее популярными являются поисковые системы Google и Яндекс, и вот что они рекомендуют.
Рекомендации для веб-мастеров (Google)
Для увеличения ранжирования в этой поисковой системе желательно:
- создавать страницы для людей, не делать искусственную оптимизацию под поисковые системы, не создавать скрытый контент для поисковых роботов;
- разрабатывать сайт с чёткой иерархией, органичными текстовыми ссылками, к каждой странице делать хоть одну статичную текстовую ссылку;
- создавать интересный информационный ресурс, который будет наполнен актуальными и уникальными материалами с сопутствующими тегами, полностью соответствующими содержанию;
- использовать ключевые слова для создания понятных людям адресов URL;
- не допускать появления дублей страниц, использовать 301-й редирект или
rel="canonical", в зависимости от необходимости.

Советы веб-мастеру (Яндекс)
Чтобы в этой поисковой системе находилось всё, что вы разместили для пользователей в Интернете, будет полезно делать следующее:
- писать оригинальный контент или предоставлять уникальные услуги, которые заинтересуют посетителей;
- думать о пользователях, а не о поисковиках, продумывать мелочи, чтобы людям было удобно на сайте;
- делать полезные и органичные ссылки на сторонние ресурсы;
- разрабатывать хороший и понятный дизайн с акцентом на основную информацию;
- оптимизировать страницы в соответствии с их содержанием.
Универсальные рекомендации по оптимизации
Несмотря на наличие множества рекомендаций для веб-мастеров, прямой информации о том, как осуществляется поиск и почему именно так, в открытом доступе нет. Чтобы успешно развивать веб-ресурсы, маркетологи и SEO-специалисты постоянно проводят различные эксперименты, которые дают приблизительную информацию о том, что именно может влиять на хорошие позиции в выдаче и подводят к пониманию того, как работают поисковые системы.

Вот некоторые рекомендации:
- Зарегистрируйте домен, включающий название бренда, тип товара или услуг, которые на нём предлагаются.
- Создавайте страницы, в адресах которых будет ключевая информация о размещённом материале, товаре.
- Форматируйте текст одинаково, равномерно используйте ключевые слова, органично вписывайте ссылки. Делайте текст приятным для чтения.
- Размещайте актуальный контент, который может заинтересовать другие сайты со схожей тематикой и побудить их написать о вас и сделать на вас ссылку. Не усердствуйте с покупкой множества ссылок, делайте их интересными для пользователей – это поможет увеличить количество и качество посещений.
- Отслеживайте индексацию и ранжирование страниц (результаты в выдаче) для интересующих регионов.
- Делайте различные изменения на схожих страницах для выявления более действенных методов.
- Отмечайте действия, давшие результат, проверяйте их на других доменах, и в случае успеха радуйтесь тому, что нашли один из принципов ранжирования этой поисковой системы.
- Постоянно обновляйте контент на сайте тематическими статьями и новостями.
Таким образом, становится понятным, что SEO – это не набор законов и правил, выполнение которых повлечёт стабильный результат. Раскрутка в поисковых системах – это эксперименты, риски и опыт, который приобретается с каждым новым достижением. Самостоятельная оптимизация – достаточно сложный путь, который потребует больших затрат времени и сил.
Поисковые роботы — как они работают и что делают
Роботы поисковой системы, иногда их называют «пауки» или «кроулеры» (crawler) — это программные модули, занимающиеся поиском web-страниц. Как они работают? Что же они делают в действительности? Почему они важны?
Учитывая весь шум вокруг поисковой оптимизации и индексных баз данных поисковиков, вы, наверное думаете, что роботы должно быть великие и могущественные существа. Неправда. Роботы поисковика обладают лишь базовыми функциями, похожими на те, которыми обладали одни из первых броузеров, в отношении того, какую информацию они могут распознать на сайте. Как и ранние броузеры, роботы попросту не могут делать определенные вещи. Роботы не понимают фреймов, Flash анимаций, изображений или JavaScript. Они не могут зайти в разделы, защищенные паролем и не могут нажимать на все те кнопочки, которые есть на сайте. Они могут «заткнуться» в процессе индексирования динамических адресов URL и работать очень медленно, вплоть до остановки и безсилием над JavaScript-навигацией.
Поисковые роботы стоит воспринимать, как программы автоматизированного получения данных, путешествующие по сети в поисках информации и ссылок на информацию.
Когда, зайдя на страницу «Submit a URL», вы регистрируете очередную web-страницу в поисковике — в очередь для просмотра сайтов роботом добавляется новый URL. Даже если вы не регистрируете страницу, множество роботов найдет ваш сайт, поскольку существуют ссылки из других сайтов, ссылающиеся на ваш. Вот одна из причин, почему важно строить ссылочную популярность и размещать ссылки на других тематических ресурсах.
Прийдя на ваш сайт, роботы сначала проверяют, есть ли файл robots.txt. Этот файл сообщает роботам, какие разделы вашего сайта не подлежат индексации. Обычно это могут быть директории, содержащие файлы, которыми робот не интересуется или ему не следовало бы знать.
Роботы хранят и собирают ссылки с каждой страницы, которую они посещают, а позже проходят по этим ссылкам на другие страницы. Вся всемирная сеть построена из ссылок. Начальная идея создания Интернет сети была в том, что бы была возможность перемещаться по ссылкам от одного места к другому. Вот так перемещаются и роботы.
«Остроумность» в отношении индексирования страниц в реальном режиме времени зависит от инженеров поисковых машин, которые изобрели методы, используемые для оценки информации, получаемой роботами поисковика. Будучи внедрена в базу данных поисковой машины, информация доступна пользователям, которые осуществляют поиск. Когда пользователь поисковой машины вводит поисковый запрос, производится ряд быстрых вычислений для уверенности в том, что выдается действительно правильный набор сайтов для наиболее релевантного ответа.
Вы можете просмотреть, какие страницы вашего сайта уже посетил поисковый робот, руководствуясь лог-файлами сервера, или результатами статистической обработки лог-файла. Идентифицируя роботов, вы увидите, когда они посетили ваш сайт, какие страницы и как часто. Некоторые роботы легко идентифицируются по своим именам, как Google’s «Googlebot». Другие более скрытые, как, например, Inktomi’s «Slurp». Другие роботы так же могут встречаться в логах и не исключено, что вы не сможете сразу их идентифицировать; некоторые из них могут даже оказаться броузерами, которыми управляют люди.
Помимо идентификации уникальных поисковых роботов и подсчета количества их визитов, статистика также может показать вам агрессивных, поглощающих ширину катала пропускания роботов или роботов, нежелательных для посещения вашего сайта.
Когда поисковой робот посещает страницу, он просматривает ее видимый текст, содержание различных тегов в исходном коде вашей страницы (title tag, meta tags, и т.д.), а так же гиперссылки на странице. Судя по словам ссылок, поисковая машина решает, о чем страница. Есть много факторов, используемых для вычисления ключевых моментов страницы «играющих роль». Каждая поисковая машина имеет свой собственный алгоритм для оценки и обработки информации. В зависимости от того, как робот настроен, информация индексируется, а затем доставляется в базу данных поисковой системы.
После этого, информация, доставленная в индексные базы данных поисковой системы, становится частью поисковика и процесса ранжирования в базе. Когда посетитель существляет запрос, поисковик просматривает всю базу данных для выдачи конечного списка, релевантного поисковому запросу.
Базы данных поисковых систем подвергаются тщательной обработке и приведению в соответствие. Если вы уже попали в базу данных, роботы будут навещать вас периодически для сбора любых изменений на страницах и уверенности в том, что обладают самой последней информацией. Количество посещений зависит от установок поисковой машины, которые могут варьироваться от ее вида и назначения.
Иногда поисковые роботы не в состоянии проиндексировать web-сайт. Если ваш сайт упал или на сайт идет большое количество посетителей, робот может быть безсилен в попытках его индексации. Когда такое происходит, сайт не может быть переиндексирован, что зависит от частоты его посещения роботом. В большинстве случаев, роботы, которые не смогли достичь ваших страниц, попытаются позже, в надежде на то, что ваш сайт в ближайшее время будет доступен.
Многие поисковые роботы не могут быть идентифицированы, когда вы просматриваете логи. Они могут посещать вас, но логи утверждают, что кто-то использует Microsoft броузер и т.д. Некоторые роботы идентифицируют себя использованием имени поисковика (googlebot) или его клона (Scooter = AltaVista).
В зависимости от того, как робот настроен, информация индексируется, а затем доставляется в базы данных поисковой машины.
Базы данных поисковых машин подвергаются модификации в различные сроки. Даже директории, имеющие вторичные поисковые результаты используют данные роботов как содержание своего web-сайта.
Собственно, роботы не используются поисковиками лишь для вышеизложенного. Существуют роботы, которые проверяют баз данных на наличие нового содержания, навещают старое содержимое базы, проверяют, не изменились ли ссылки, загружают целые сайты для просмотра и так далее.
По этой причине, чтение лог-файлов и слежение за выдачей поисковой системы помогает вам наблюдать за индексацией ваших проектов.
Принцип работы поисковых систем в глобальной сети интернет
 Здравствуйте, уважаемые читатели!
Здравствуйте, уважаемые читатели!
Поисковых систем в мировом интернет-пространстве в настоящий момент достаточно много. У каждой из них имеются собственные алгоритмы индексирования и ранжирования сайтов, но в целом принцип работы поисковиков довольно похож.
Знания о том, как работает поисковая система в условиях стремительно растущей конкуренции являются весомым преимуществом при продвижении не только коммерческих, но и информационных сайтов и блогов. Эти знания помогают выстраивать эффективную стратегию оптимизации сайта и с меньшими усилиями попадать в ТОП выдачи по продвигаемым группам запросов.
Содержание:
Принципы работы поисковых систем
Смысл работы оптимизатора состоит в том, чтобы «подстроить» продвигаемые страницы под поисковые алгоритмы и, тем самым, помочь этим страницам достичь высоких позиций по определенным запросам. Но до начала работ по оптимизации сайта или блога необходимо хотя бы поверхностно разбираться в особенностях работы поисковых систем, чтобы понимать, как они могут реагировать на предпринимаемые оптимизатором действия.
Разумеется, детальные подробности формирования поисковой выдачи – информация, которую поисковые системы не разглашают. Однако, для правильных усилий по продвижению сайта достаточно понимания главных принципов, по которым работают поисковые системы.
Методы поиска информации
Два основных метода, используемых сегодня поисковыми машинами, отличаются подходом к поиску информации.
- Алгоритм прямого поиска, предполагающий сопоставление каждому из документов, сохраненных в базе поисковой системы, ключевой фразы (запроса пользователя), является достаточно надежным методом, который позволяет найти всю необходимую информацию. Недостаток этого метода заключается в том, что при поиске в больших массивах данных время, требуемое для нахождения ответа, достаточно велико.
- Алгоритм обратных индексов, когда ключевой фразе сопоставляется список документов, в которых она присутствует, удобен при взаимодействии с базами данных, содержащими десятки и сотни миллионов страниц. При таком подходе поиск производится не по всем документам, а только по специальным файлам, включающим списки слов, содержащихся на страницах сайтов. Каждое слово в подобном списке сопровождается указанием координат позиций, где оно встречается, и прочих параметров. Именно этот метод применяется сегодня в работе таких известных поисковых систем, как Яндекс и Гугл.
Здесь следует отметить, что при обращении пользователя к поисковой строке браузера поиск производится не непосредственно в интернете, а в предварительно собранных, сохраненных и актуальных на данный момент базах данных, содержащих обработанные поисковиками блоки информации (страницы сайтов). Быстрое формирование результатов поиска возможно именно благодаря работе с обратными индексами.

Текстовое содержимое страниц (прямые индексы) поисковыми машинами тоже сохраняется и используется при автоматическом формировании сниппетов из наиболее подходящих запросу текстовых фрагментов.
Математическая модель ранжирования
С целью ускорения поиска и упрощения процесса формирования выдачи, максимально отвечающей запросу пользователя, применяется определенная математическая модель. Задача этой математической модели — нахождение нужных страниц в актуальной базе обратных индексов, оценка их степени соответствия запросу и распределение в порядке убывания релевантности.
Простого нахождения нужной фразы на странице недостаточно. При определении релевантности поисковиками применяется расчет веса документа относительно пользовательского запроса. По каждому запросу этот параметр рассчитывается на основе следующих данных: частоты использования ключевого слова на анализируемой странице и коэффициентом, отражающим насколько редко встречается это же слово в других документах базы данных поисковика. Произведение этих двух величин и соответствует весу документа.
Разумеется, представленный алгоритм является весьма упрощенным, поскольку в распоряжении поисковых машин есть ряд других дополнительных коэффициентов, используемых при расчетах, но смысл от этого не меняется. Чем чаще отдельное слово из запроса пользователя встречается в каком-либо документе, тем выше вес последнего. При этом текстовое содержимое страницы признается спамным, если будут превышены определенные пределы, являющиеся для каждого запроса различными.
Основные функции поисковой системы
Все существующие системы поиска призваны выполнять несколько важных функций: поиск информации, ее индексирование, качественную оценку, правильное ранжирование и формирование поисковой выдачи. Первоочередная задача любого поисковика – предоставление пользователю той информации, которую он ищет, максимально точного ответа на конкретный запрос.
Поскольку большинство пользователей понятия не имеют о том, как работают поисковые системы в интернете и возможности обучить пользователей «правильному» поиску весьма ограничены (например, поисковыми подсказками), разработчики вынуждены улучшать сам поиск. Последнее подразумевает создание алгоритмов и принципов работы поисковых систем, позволяющих находить требуемую информацию независимо от того, насколько «правильно» сформулирован поисковый запрос.
Сканирование
Это отслеживание изменений в уже проиндексированных документах и поиск новых страниц, которые могут быть представлены в результатах выдачи на запросы пользователей. Сканирование ресурсов в сети интернет поисковики осуществляют с помощью специализированных программ, называемых пауками или поисковыми роботами.
Сканирование интернет-ресурсов и сбор данных производится поисковыми ботами автоматически. После первого посещения сайта и включения его в базу данных поиска, роботы начинают периодически посещать этот сайт, чтобы отслеживать и фиксировать произошедшие в контенте изменения.
Поскольку количество развивающихся ресурсов в интернете велико, а новые сайты появляются ежедневно, описанный процесс не останавливается ни на минуту. Такой принцип работы поисковых систем в интернете позволяет им всегда располагать актуальной информацией о доступных в сети сайтах и их контенте.
Основная задача поискового робота – поиск новых данных и передача их поисковику для дальнейшей обработки.

Индексирование
Поисковая система способна находить данные только на сайтах, представленных в ее базе – иначе говоря, проиндексированных. На этом шаге поисковик должен определить, следует ли найденную информацию заносить в базу данных и, если заносить, то в какой из разделов. Этот процесс также выполняется в автоматическом режиме.
Считается, что Google индексирует почти всю доступную в сети информацию, Яндекс же к индексации контента подходит более избирательно и не так быстро. Оба поисковых гиганта рунета работают на благо пользователя, но общие принципы работы поисковой системы Гугл и Яндекс несколько отличаются, так как основаны на уникальных, составляющих каждую систему программных решениях.
Общим же для поисковых систем моментом является то, что процесс индексирования всех новых ресурсов занимает более продолжительное время, чем индексирование нового контента на известных системе сайтах. Информация, появляющаяся на сайтах, доверие поисковиков к которым высоко, попадает в индекс практически моментально.
Ранжирование
Ранжирование – это оценка алгоритмами поисковика значимости проиндексированных данных и выстраивание их в соответствии c факторами, свойственными данному поисковику. Полученная информация обрабатывается с целью формирования результатов поиска по всему спектру пользовательских запросов. То, какая именно информация будет представлена в результатах поиска выше, а какая ниже, полностью определяется тем, как работает выбранная поисковая система и ее алгоритмы.
Сайты, находящиеся в базе поисковой системы, распределяются по тематикам и группам запросов. Для каждой группы запросов формируется предварительная выдача, подвергающаяся в дальнейшем корректировке. Позиции большинства сайтов изменяются после каждого апдейта выдачи — обновления ранжирования, которое в Google происходит ежедневно, в поиске Яндекса – раз в несколько дней.
Человек как помощник в борьбе за качество выдачи
Реальность такова, что даже самые продвинутые системы поиска, такие как Яндекс и Гугл, на данный момент все еще нуждаются в помощи человека для формирования выдачи, соответствующей принятым стандартам качества. Там, где поисковый алгоритм срабатывает недостаточно хорошо, результаты его корректируются вручную – путем оценки содержимого страницы по множеству критериев.
Многочисленной армии специально обученных людей из разных стран – модераторов (асессоров) поисковых систем – приходится ежедневно выполнять огромный объем работы по проверке соответствия страниц сайтов пользовательским запросам, фильтрации выдачи от спама и запрещенного контента (текстов, изображений, видео). Работа асессоров позволяет делать выдачу чище и способствует дальнейшему развитию самообучающихся поисковых алгоритмов.

Заключение
С развитием сети интернет и постепенным изменением стандартов и форм представления контента меняется и подход к поиску, совершенствуются процессы индексирования и ранжирования информации, используемые алгоритмы, появляются новые факторы ранжирования. Все это позволяет поисковым системам формировать наиболее качественную и адекватную запросам пользователя выдачу, но при этом усложняет жизнь вебмастерам и специалистам, занимающимся продвижением сайтов.
В комментариях под статьей предлагаю высказаться о том, какая из основных поисковых систем рунета – Яндекс или Гугл, по вашему мнению, работает лучше, предоставляя пользователю более качественный поиск, и почему.
Что такое поисковая система? Как работают поисковики, принципы работы поисковых систем
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Как работает поисковая система – основные положения
Находить нужную информацию с помощью поисковика умеет любой более-менее опытный интернет-пользователь. Однако лишь немногие знают о том, как работают поисковые системы. Действительно, каким образом Google или Яндекс успевает за считанные доли секунды проанализировать запрос юзера и выбрать наиболее подходящие сайты из миллионов web-проектов, присутствующих в сети?
Чтобы понять принцип работы поисковых систем, нужно познакомиться с такими понятиями, как индексация и формирование выдачи. Фактически, роль поисковика сводится к анализу существующих в сети сайтов и к выводу информации, максимально соответствующей запросам интернет пользователя.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA

Как работает поисковик – индексация сайтов
Существуют поисковые боты, которые постоянно «гуляют» по сети, посещая все известные им сайты с определенной периодичностью. Обнаружив новый материал, робот добавляет его в свою индексную базу в виде простого текста. Каждая поисковая система располагает своеобразной «картотекой», в которой хранятся копии проиндексированных web-страниц.
Если робот посещает ранее проиндексированную страницу, то он сравнивает имеющуюся копию с текущим состоянием документа. При наличии существенных расхождений (если материал был обновлен) в индексную базу вносятся изменения.
Совет! Чем чаще обновляется сайт, тем чаще его будут посещать поисковые роботы. Это положительно отразится на индексации.
Формирование релевантной выдачи
Точные принципы работы поисковых систем сохраняются в строгом секрете. Более того – алгоритмы постоянно совершенствуются и изменяются. Однако вполне очевидно, что тематика документа определяется на основании анализа его семантики. Поисковики могут обращать внимание на следующие аспекты:
- частота употребления ключевых запросов;
- тематическое соответствие материала основной тематике сайта;
- наличие синонимов ключевых фраз;
- присутствие ключей в заголовках, метатегах и т.п.
Разумеется, поисковики принимают во внимание не только качество текста, но и многие другие параметры. Имеет значение траст сайта, возраст домена, состояние ссылочной базы. В последнее время большое значение приобрели поведенческие факторы (пользовательская активность – количество просмотренных страниц, комментарии и т.п.).
Это нужно знать!Поисковики не любят избыточную оптимизацию текстов. Анализ «естественности» документов производится на основании закона Ципфа. Проверить статью или опубликованный материал можно здесь. Хорошим считается значение свыше 85%.
Как работают поисковики – ответ на запрос
На основании заведенного поискового запроса система производит анализ проиндексированных материалов. Затем робот формирует ссылки на сайты, наиболее полно отвечающие запросу юзера. Недавно в принцип работы поисковой системы были внесены некоторые изменения. Теперь роботы формируют выдачу с учетом пользовательских предпочтений.
Поясним на конкретном примере: есть два пользователя, один из которых интересуется кулинарными рецептами, а другой часто заказывает фастфуд на дом. Эти пользователи могут завести одинаковый запрос «вкусная пицца», но поисковик предоставит им ссылки на разные сайты. Первый получит перечень рецептов приготовления пиццы, а второй – адреса ресторанов, специализирующихся на доставке этого блюда.
Как работают поисковые системы | Белые окошки
Поиск в Google, Яндекс или иной поисковой системе сегодня представляется нам чем-то совершенно естественным и даже обыденным, но так было не всегда. Когда интернет был совсем молод, поисковиков не существовало, а немногочисленные пользователи тогда ещё далеко не всемирной сети были вынуждены записывать названия сайтов в файл и вручную проверять их обновления. Тем не менее, отсутствие каких-либо индексов мало кого из них смущало, так как количество сайтов по сравнению с тем, что мы имеем сейчас было просто ничтожным.
Иное дело программисты, они смотрели куда дальше и понимали, что без создания единой базы сайтов интернет не сможет развиваться. В 1990 году монреальскими студентами была разработана программа под названием Арчи, ставшая прототипом поисковых систем. Переходя от одного FTP-сервера к другому, она скачивала списки расположенных на них файлов и составляла из них базу данных, предоставляя таким образом возможность поиска по их именам. Недостаток её был очевиден — база не была централизованной и не содержала текст веб-страниц.
Это нужно было как-то исправить и вот в 1993 году разработчик Мэтью Грэй из Массачусетского технологического института создаёт первого поискового робота, способного индексировать текстовое содержимое сайтов и выдавать результаты поиска по запросу. Так появилась Wandex — вероятно, первая в мире поисковая система. По нынешним меркам назвать её полноценной, конечно, трудно. Алгоритмы Wandex, впрочем, равно как и всех ранних поисковых систем были весьма далеки от совершенства. Релевантные ссылки выдавались безо всякого семантического анализа и ранжирования, поэтому нет ничего удивительного в том, что первым поисковикам приходилось конкурировать с тогда ещё популярными каталогами веб-ресурсов.

Алгоритмы современных поисковых систем — Google, Яндекса, МайлРу и им подобные куда более сложны и изощрённы. Раскрыть все их тонкости в рамках одной статьи задача едва ли выполнимая, поскольку это заняло бы слишком много времени, к тому же некоторые алгоритмы держатся компаниям в строгом секрете, но в целом и в общем дать некое представление о принципах работы поисковых систем представляется нам вполне реальным.
Весь процесс от сбора до выдачи данных состоит из трёх этапов: сканирование, индексация и ранжирование. Всё начинается с того, что поисковая программа-робот или иначе краулер, используя полученную в ходе предыдущих сканирований базу URL, посещает миллионы сайтов, переходит по имеющимся на них ссылкам и производит первичный анализ содержимого страниц. В процессе сканирования поисковыми роботами обнаруживается новый и изменённый контент, устанавливаются систематические связи между страницами и сайтами, выявляются нерабочие ссылки. Не нужно, однако, думать, что краулер посещает каждый сайт. Чтобы ресурс попал в базу отслеживаемых, он должен быть достаточно важен с точки зрения поисковой системы, но если он в неё всё же попадает, робот начинает посещать её постоянно.
Собрав контент с разных сайтов, поисковик переходит к индексации — занесению данных в индексную базу, из которой впоследствии будет осуществляться выдача. На этом этапе происходит сортировка информации по разным параметрам. С применением лексических и морфологических алгоритмов страницы разбиваются на части, извлекаются и анализируются ключевые слова, метатеги, перекрестные ссылки. Индексация — едва ли не самая сложная задача, стоящая перед поисковиками, что неудивительно, ведь в процессе выдачи приходится учитывать всю вариативность человеческого языка. Это означает, что поисковая система должна буквально с полуслова понимать пользователя, ведь далеко не всегда запросы бывают полностью корректными, взять хотя бы нередко допускаемыми людьми грамматические ошибки или неверные склонения.

На третьем и последнем этапе выполняется ранжирование, а если говорить более простым языком, определение того, какая информация по одному и тому же запросу должна выводиться в списке поисковой выдачи первой, какая второй, третьей, четвёртой и так далее. По неофициальным данным, для определения релевантности поисковый гигант Google использует более 200 различных факторов, среди которых самые почётные места занимают уникальность и актуальность.
С момента своего появление поисковые системы проделали огромный путь. Начав некогда с простого поиска по ключевым словам, сегодня поисковики используют сложные алгоритмы отбора, предлагая пользователям только самую полезную и актуальную информацию. Увы, наряду с борьбой за чистоту информационного пространства со стороны поисковых компаний нередко можно видеть нарушение прав на защиту, получение и распространение информации. В какой-то мере это продиктовано необходимостью, но эта же необходимость может привести к тому, что бывший некогда символом свободы интернет со временем превратится в инструмент контроля над сознанием, став ещё одним средством управления общественным мнением.