Как сделать свой поисковик? / Хабр
Привет! Думаю ты хочешь создать свой поисковик если ты зашел на этот пост, сейчас мы его сделаем за 10 минут с настройкой.
Заходим на официальный сайт Google для создания поисковика.
Если у вас нет поисковиков, то у вас сразу отобразится страница для создания поисковика, а если есть то нажимаем на кнопку: «Добавить».
Сайты на которых выполняется поиск — это сайты откуда будет идти информация из запроса, рекомендую всегда писать google.com
Языки — это язык на котором будет сам поисковик, лучше всего выбрать «русский» или «Все языки»
Название поисковой системы — например: Google, Yandex, Mail.ru
Проходим капчу и нажимаем «создать».
У вас появится эта страница, вы можете сразу посмотреть результат нажав на кнопку «Общедоступный URL», но сейчас надо настроить поисковик, поэтому нажимаем на «панель управления».
У вас появится страница на которой можно запутаться, поэтому ставим настройки как на картинке:
Дальше нажимаем на «внешний вид».
Здесь лучше выбрать «На развороте» или «Накладка».
Темы: это тема вашего интерфейса, лучше всего выглядят: «Зеленый», «Фиолетовый» и «Серебристый», это уже на ваш вкус.
Не забываем сохранять настройки!
Настроить: это глобальная настройка вида вашего поисковика, сначала надо войти в «Фирменное оформление» и отключить его чтобы не было рекламы Google.
Поисковая строка — цвет границы, можно оставить по умолчанию,
Кнопка поиска — можно настроить цвет границы, цвет фона и цвет иконки (лупы)
Уточняющая категория — можно настроить цвет текста, цвет фона по умолчанию, цвет текста выбран и цвет выделяющего фона. Лучше выбрать те настройки — благодаря которым будет хорошо видно.
Настройка результатов — это настройка вида результата поиска, можно оставить также.
Заголовок результата — настройка вида заголовка результата, можно также оставить.
URL результата — настройка ссылки после Снипета, лучше всего поставить: «Отображать URL полностью».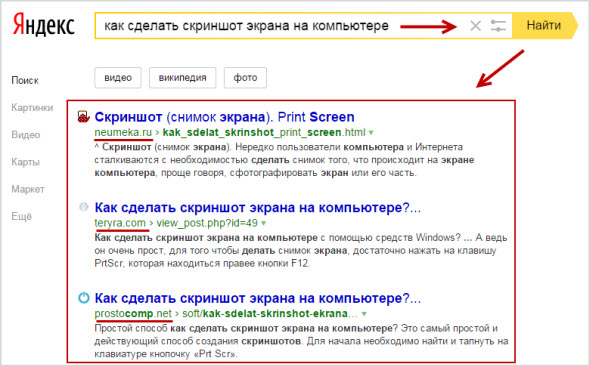
Снипет результата — (снипет — описание страницы) можно настроить цвет снипета.
Настройка продвижений (рекламных страниц) — можно настроить цвет границы и цвет фона.
Название (заголовок) продвижения — можно настроить цвет ссылки по умолчанию, цвет посещенной ссылки, цвет при наведении и активный цвет.
URL продвигаемого сайта — можно настроить цвет URL и как он будет отображаться, лучше всего оставить «Отображать URL полностью»
Снипет (описание) продвигаемого сайта — можно настроить только цвет снипета.
Все настройки внешнего вида закончены, поисковик готов.
Заходим в «настройка» и нажимаем на «получить код»,
Копируем его и создаем новые текстовый документ с расширением .html
Дальше вставляем его в Visual Studio Code (например, можно в другую программу или даже в блокнот),
<!DOCTYPE HTML>
<html>
<head>
<title>Название поисковика</title>
</head>
<body>
. ..
</body>
</html>
..
</body>
</html> ..
</body>
</html>
..
</body>
</html>В <body> мы вставляем код который скопировали
<!DOCTYPE HTML>
<html>
<head>
<title>Название поисковика</title>
</head>
<body>
<script async src="https://cse.google.com/cse.js?cx=ff92b3e28ff855d6c"></script>
<div></div>
</body>
</html><script> надо засунуть в <div>
<!DOCTYPE HTML>
<html>
<head>
<title>Название поисковика</title>
</head>
<body>
<div>
<script async src="https://cse.google.com/cse.js?cx=ff92b3e28ff855d6c"></script>
</div>
</body>
</html> Готово, теперь открываем файл в браузере, и вот что у нас получилось:
Думаю вам был полезен этот туториал, всем пока.
Google готовится сделать свой поисковик более удобным
Заметили, как много инноваций Google предлагала несколько лет назад? В последнее время количество фантастических проектов как-то поубавилось, а свои силы компания направила на доработку тех продуктов, которые у нее уже есть и которые действительно имеют смысл.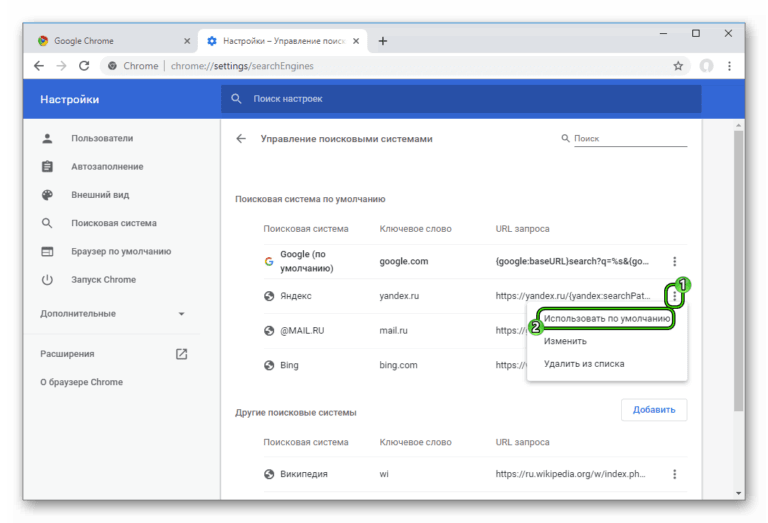 В первую очередь это поисковик, умный дом и гаджеты, вроде смартфонов Google Pixel и компьютеров Chromebook. Несмотря на это, долгое время стартовая страница поиска Google является эталоном минимализма. Она просто есть, и скажите компании за это спасибо. Теперь, похоже, ее ждут изменения. И это действительно будет большое дело, если компания реализует задуманное.
В первую очередь это поисковик, умный дом и гаджеты, вроде смартфонов Google Pixel и компьютеров Chromebook. Несмотря на это, долгое время стартовая страница поиска Google является эталоном минимализма. Она просто есть, и скажите компании за это спасибо. Теперь, похоже, ее ждут изменения. И это действительно будет большое дело, если компания реализует задуманное.
Google продолжает оставаться для многих поисковиком номер один, но теперь он станет лучше.
Содержание
- 1 Обновление Google
- 2 Можно ли добавить виджеты на главную страницу Google
- 3 Нужны ли кому-то виджеты
- 4 Яндекс или Google
Обновление Google
На днях появилась информация, согласно которой Google, похоже, продвигает новую функцию отображения информации на главной своего поисковика, чтобы больше пользователей могли ее протестировать. Некоторые пользователи замечают подсказку «Познакомьтесь с новым Google.com». Если пользователи не вошли в учетную запись, то им будет предложено сделать это. Только так они смогут добавлять карточки виджетов и редактировать их расположение на главной странице. 9to5Google объясняет, что при нажатии на «Сделать это пространство своим» открывается другое окно, которое позволяет вам настроить карточки, расположенные в нижней части главной страницы поиска.
Только так они смогут добавлять карточки виджетов и редактировать их расположение на главной странице. 9to5Google объясняет, что при нажатии на «Сделать это пространство своим» открывается другое окно, которое позволяет вам настроить карточки, расположенные в нижней части главной страницы поиска.
Как только дочитаешь до конца, переходи в наш Яндекс Дзен! Там очень интересно.
Пользователи впервые начали замечать собственную версию подобных виджетов в начале этого года. Они были доступны при посещении главной страницы Google или приложения поисковика на телефоне Android. Доступные тогда виджеты включали новости, погоду, информацию о Covid и многое другое, что по-видимому все еще имеет место.
С виджетами страница смотрится не только более функционально, но и более современно.
Можно ли добавить виджеты на главную страницу Google
Во время первоначального теста виджеты, расположенные внизу, больше напоминали прямоугольники со скругленными углами. Этот новый этап тестирования, который постепенно появляется, показывает квадраты с закругленными углами, хотя кажется, что некоторые ранние тестировщики также видели карты такой формы. Эксперты предполагают, что использование квадратной формы может быть способом добавить больше таких информационных квадратов на ваш дисплей.
Эксперты предполагают, что использование квадратной формы может быть способом добавить больше таких информационных квадратов на ваш дисплей.
Квадратные значки более компактные.
Изменение формы и оптимизация виджетов является очень хорошей идеей. Ведь когда они впервые появились в феврале, количество отображаемых информационных элементов зависело от размера вашего дисплея, а это означает, что на небольших экранах компьютеров было меньше виджетов, чем на более крупных. То есть домашняя страница поисковика имела разный уровень удобства для разных пользователей.
Кроме того, кажется, что вы не cможете прокручивать виджеты в нижней части главной страницы, а это означает, что вы видите то, что выбрали изначально, и то, что поместилось на экране. Однако вы можете навести указатель мыши на каждый виджет по отдельности, чтобы развернуть его и лучше просмотреть представленную информацию.
Присоединяйтесь к нам в Telegram!
Нужны ли кому-то виджеты
Хотя подобная функция, вероятно, будет приветствоваться среди тех, кто использует Google.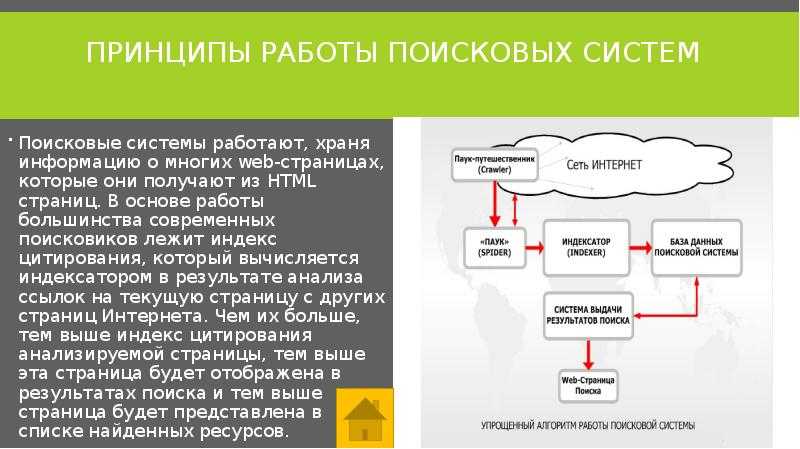 com на настольных компьютерах, не ясно, насколько масштабным является этот новый этап тестирования. Так же пока не ясно, в каких странах это будет реализовано. Проще говоря, обещать появление этой функции в России пока нельзя. Даже авторы многих иностранных изданий, которые писали о новых виджетах стартовой страницы поисковика, подчеркивали, что у них новая функция пока не работает.
com на настольных компьютерах, не ясно, насколько масштабным является этот новый этап тестирования. Так же пока не ясно, в каких странах это будет реализовано. Проще говоря, обещать появление этой функции в России пока нельзя. Даже авторы многих иностранных изданий, которые писали о новых виджетах стартовой страницы поисковика, подчеркивали, что у них новая функция пока не работает.
Похоже, Google готовит пару очень необычных смартфонов.
Сами по себе виджеты довольно удобны, но их использование подойдет не всем. Например, если вы для поиска пользуетесь адресной строкой и никогда не переходите на главную страницу поисковика, то этот способ не для вас. Вы просто не окажетесь в ситуации, когда сможете считать информацию.
Можно выбирать, какие виджеты вы хотите видеть.
Яндекс или Google
Но сам факт появления такой возможности говорит о стремлении Google сделать поисковик не только функциональным, но и удобным. Ведь имея такие возможности, вы получите всю необходимую информацию, просто открыв поисковик. Впрочем, не во всех странах сервисы Google работают хорошо. Например, в России Яндекс предлагает более адаптированные и удобные сервисы, а информация в них зачастую оказывается более точной. А еще Яндекс уже предлагает развитую страницу поиска, которая успела несколько раз измениться и стать по-настоящему удобной. Но это как iOS и Android. Каждый выбирает поисковик для себя сам.
Впрочем, не во всех странах сервисы Google работают хорошо. Например, в России Яндекс предлагает более адаптированные и удобные сервисы, а информация в них зачастую оказывается более точной. А еще Яндекс уже предлагает развитую страницу поиска, которая успела несколько раз измениться и стать по-настоящему удобной. Но это как iOS и Android. Каждый выбирает поисковик для себя сам.
В что выбираете вы и интересно ли вам было бы пользоваться виджетами от Google?
Что нужно знать при создании собственной поисковой системы
Итак, вы хотите создать собственную поисковую систему. Мы хотели бы избавить вас от хлопот. А это есть беда, как вы, без сомнения, знаете.
Конечно, можно заняться проектом поисковой системы своими руками. Существуют мощные стартовые наборы — например, Solr. Вы можете создать прекрасную поисковую систему с помощью Solr, если у вас есть нужные люди, достаточно времени и достаточно денег.
Но вам также нужна терпимость к риску и альтернативным издержкам.![]() Создание собственного поиска по сайту требует времени, а это означает, что вы, скорее всего, теряете доход при разработке, создании и настройке поисковой системы сайта.
Создание собственного поиска по сайту требует времени, а это означает, что вы, скорее всего, теряете доход при разработке, создании и настройке поисковой системы сайта.
По мере устранения ошибок и по мере того, как система, которую вы построили, будет работать, вполне вероятно, что предлагаемый вами поисковый опыт будет неудовлетворительным, что означает неудовлетворенных клиентов и необходимость возвращать их обратно, когда ваша поисковая система работает на пределе своих возможностей. приемлемый уровень.
Вкратце, вот семь вещей, которые вам нужно знать перед созданием собственной поисковой системы:
Создание мозга поисковой системы вручную требует времени
Чтобы создать собственную поисковую систему, нужно подумать о том, что вы получаете с нестандартными решениями. Конечно, Solr можно масштабировать прямо с полки. Это также проверенный исполнитель.
Но подумайте о поиске и о том, что нужно для получения релевантных и персонализированных результатов вплоть до индивидуального уровня. Для достижения оптимального уровня обслуживания клиентов требуется:
Для достижения оптимального уровня обслуживания клиентов требуется:
Сложные алгоритмы
Огромные объемы данных
Облачная инфраструктура, настроенная для вашей конкретной поисковой системы
Знаешь, чего ты не найдешь на дне своей большой новой коробки Solr? Сложные алгоритмы, огромные объемы данных и инфраструктура, необходимые для создания мощной поисковой системы сайта.
На самом деле, разработка алгоритмов, сбор данных и проектирование системы для их эффективного использования для прогнозирования намерений цифровых потребителей — это то, что делает самостоятельную поисковую систему Solr.
Solr сам по себе не оптимизирован для ранжирования по доходу. Он не может ранжироваться с помощью персонализации, основанной на намерениях, поведении и предпочтениях клиентов. Он не предназначен для предоставления информации, выходящей за рамки поиска по сайту. Он не загружается данными о продуктах, синонимах или намерениях покупателя. И он не может извлечь контент. На самом деле справедливо будет сказать, что готовый к использованию Solr проведет вас примерно на 20 % пути к тому месту, где вам нужно быть, чтобы правильно выполнять поиск.
И он не может извлечь контент. На самом деле справедливо будет сказать, что готовый к использованию Solr проведет вас примерно на 20 % пути к тому месту, где вам нужно быть, чтобы правильно выполнять поиск.
Если вы хотите, чтобы поисковая система Solr выполняла все необходимые действия — ранжирование по доходам, персонализацию, достижение семантического понимания, понимание поведения пользователей — вы должны сообщить ей, как это сделать. Вам нужно построить мозг двигателя. Или, что более вероятно, команде людей нужно построить мозг двигателя.
И это делается с помощью алгоритмов. Создание мозга поисковой системы вручную требует времени — очень много времени.
Создание вашей поисковой системы может быстро исчерпать все ваши ресурсы
Возьмем, к примеру, синонимы. Очевидно, что надежный тезаурус синонимов является ключом к поиску по сайту. Когда потребитель вводит «малиновое вечернее платье длиной до колен из спандекса» в поле поиска на сайте, система должна знать, что для этого человека платье Herve Leger с тонкими бретельками и кожаным ремнем является одним из
На самом деле, когда мы попросили потребителей описать это самое платье, 500 человек придумали умопомрачительную серию комбинаций, включающую 129 комбинаций. слов для «красного», 275 различных описаний пояса, 105 описаний длины и 216 слов для обозначения случая, по которому можно надеть платье.
слов для «красного», 275 различных описаний пояса, 105 описаний длины и 216 слов для обозначения случая, по которому можно надеть платье.
И знаете, как поисковая система Solr узнает об этом? Вы говорите ему . Или команда людей, которых вы нанимаете, обучает машину тому, что «глубокий румянец» может означать красный цвет, а «корсетный пояс» — кожаный ремень с ремнями.
Неважно, что в сутках не хватает часов, чтобы люди могли придумать сотни вариантов полудюжины слов, которые потребители могли бы использовать для описания платья — разве вы не предпочли бы, чтобы они лучше использовали свое время?
Мы тоже так думаем.
Персонализированные результаты поиска — ключ к успеху
Solr — это впечатляющая, масштабируемая платформа поиска по сайту — насколько она способна. Проблема с его использованием в качестве основы самодельной поисковой системы заключается в том, что этого недостаточно.
В частности, Solr из коробки не включает алгоритмы, данные и инфраструктуру, необходимые для построения поиска, который сегодня востребован потребителями. Сегодняшние цифровые потребители хотят персонализированных и релевантных результатов поиска. Они ожидают от Google опыта на каждом сайте: введите то, что вы ищете, используя свои собственные слова, чтобы описать что-то, что можно описать миллионом разных способов, и вуаля — именно то, что вы искали.
Сегодняшние цифровые потребители хотят персонализированных и релевантных результатов поиска. Они ожидают от Google опыта на каждом сайте: введите то, что вы ищете, используя свои собственные слова, чтобы описать что-то, что можно описать миллионом разных способов, и вуаля — именно то, что вы искали.
Теперь давайте взглянем на данные, которые необходимы лучшей в своем классе поисковой системе, чтобы обеспечить то качество обслуживания клиентов, которого ожидают потребители.
В отчете Internet Retailer за 2018 г. было обнаружено, что проблема номер один, с которой столкнулись при текущем поиске по сайту, заключалась в том, что «клиенты часто видят нерелевантные результаты или результаты в неправильном порядке», и указал «персонализированные результаты» в качестве главной функции, необходимой в современном поисковом решении.
Чтобы предоставить каждому отдельному пользователю персонализированные и релевантные результаты, поисковая система должна понимать намерения пользователя, данные о продукте и поведение пользователя . Лучшие поисковые системы приходят к такому пониманию, постоянно изучая данные в каждой из этих трех категорий.
Лучшие поисковые системы приходят к такому пониманию, постоянно изучая данные в каждой из этих трех категорий.
Поисковая система должна понимать синонимы, потому что потребители используют разные слова для описания одного и того же товара, и они часто используют слова, которые отличаются от описаний продуктов розничного продавца. Обувью, например, могут быть «ботфорты с низким вырезом» или «высокие кроссовки».
Движок должен знать, что основы слов могут иметь всевозможные дополнения — «ing», «ed», «s», — которые могут резко изменить их значение. «Полотно», например, — это не два «полотна». По сути, белье — это товар, а белье — атрибут товара. Он также должен понимать все способы поиска ваших клиентов, включая числовой поиск.
А как насчет акронимов, сленга и орфографических ошибок, определения которых зависят от контекста? Вы ищете «платье», «рубашку» или «платье-рубашку» (которое также пишется как «платье-рубашка»)?
Это подводит нас к важности коммерческих данных. Готовый Solr не особо разбирается в брендах, цветах и размерах. Когда клиент ищет «красное платье валентино», красный цвет? Валентино это стиль? Или Red Valentino — это бренд?
Готовый Solr не особо разбирается в брендах, цветах и размерах. Когда клиент ищет «красное платье валентино», красный цвет? Валентино это стиль? Или Red Valentino — это бренд?
Это имеет значение. А учитывая ценовой диапазон продуктов Red Valentino, вы хотите, чтобы ваша поисковая система знала, что это бренд.
И вот почему: оказывается, потребители, которые используют поиск по сайту, особенно те, кто ищет Red Valentino, входят в число самых ценных клиентов предприятия. Но они не останутся, если будут разочарованы плохим поиском по сайту, согласно RealDecoy в своем отчете Endeca vs. Bloomreach: увеличение конверсий с помощью поиска по сайту.
В отчете цитируется исследование Forrester, которое показало, что 90 % искателей сайта не читают дальше первой страницы результатов — и что искатели часто просто сдаются, если их разочаровывают плохие результаты.
Прочтите следующее: Что такое многоканальная коммерция?
Вам нужен самообучающийся поиск по сайту
Даже если поисковая система на полную мощность работает с данными о намерениях пользователей и данными о продуктах, вы все равно даже близко не приблизитесь к максимальной производительности, если ваша поисковая система также не обрабатывает поведенческие данные. данные, которые дают представление о производительности продукта и персонализации опыта.
данные, которые дают представление о производительности продукта и персонализации опыта.
Знание того, как посетители взаимодействуют с вашим сайтом, имеет решающее значение для понимания того, как лучше их обслуживать. Они просматривают или используют поиск по сайту? Как они вообще попали на ваш сайт? Какие поисковые запросы они используют? Какие продукты они рассматривают? Какие еще продукты они просматривают в рамках одного сеанса? Что они добавляют в свои корзины? Что они покупают?
Ответы на эти вопросы начинают формировать кучу информации, например:
Самые популярные запросы — на вашем сайте, в Интернете, на мобильных устройствах и в социальных сетях.
Самые популярные товары, снова с разбивкой по каналам.
Эффективность каждого отдельного продукта в ваших цифровых ресурсах.
То, как продукт выполняет заданный запрос.
Список товаров, похожих друг на друга.
Это помогает сайту обслуживать рекомендации, включая продукты, которые слишком новы, чтобы иметь цифровой послужной список.Товары, популярные в определенных категориях.
Наиболее часто переписываемые запросы.
Самые посещаемые ссылки на сайте.

Без возможности собирать и обрабатывать данные, которые предоставляют эту подробную информацию, ваша поисковая система не сможет постоянно учиться и постоянно совершенствоваться. Цель – непревзойденная релевантность для поиска, и без всей этой информации вы застрянете на некачественной поисковой системе.
Прочтите это далее: Как Jenson USA использовала персонализированные результаты поиска для увеличения RPV на 8,5% [пример]
Для превосходного поиска по сайту требуется превосходная инфраструктура того, что лучше построить или купить, чтобы преобразовать поиск по сайту в нынешнюю цифровую эпоху.
Solr никогда не задумывался как система поиска по сайту — по крайней мере, без большой работы и ряда дополнительных модулей. В чем, если подумать, и заключается смысл этой статьи: вам нужна правильная инфраструктура, чтобы ваша поисковая система работала. Потому что поисковая система сайта живет не только на такой платформе, как Solr.
В чем, если подумать, и заключается смысл этой статьи: вам нужна правильная инфраструктура, чтобы ваша поисковая система работала. Потому что поисковая система сайта живет не только на такой платформе, как Solr.
Мы уже говорили о необходимости добавления алгоритмов и данных в ваш новый готовый Solr. Но еще один важный элемент в создании поисковой системы сайта, которая сделает ваших клиентов счастливыми и вернет их, — это добавление модулей — систем, которые помогут вам правильно индексировать, настраивать и ранжировать результаты поиска, чтобы обеспечить превосходное качество обслуживания клиентов.
Представьте себе готовый Solr как элегантный дом с красивым каркасом, но без основных систем или последних штрихов. В доме нужны комнаты — кухня, санузлы, спальни. Может быть, вы занимаетесь кабинетом, винным погребом и домашним кинотеатром. Если да, то они тоже понадобятся.
Если оставить в стороне ваш уровень роскоши, суть в том, что, как этому великолепному дому нужны комнаты, так и Солру нужны модули.
Корпоративный поиск требует гораздо большего, чем предлагает только Solr. Solr сам по себе не является системой управления кластером. Это не система управления конфигурацией. Он не обеспечивает базовую релевантность из коробки. И это те инструменты, которые делают поиск по сайту действительно блестящим.
Прочтите следующее: Как Boden персонализирует качество обслуживания клиентов с помощью цифрового мерчандайзинга [пример из практики]
Вы не можете масштабировать и управлять своим поиском без мерчендайзинговой аналитики
Поисковая система должна иметь возможность масштабироваться вместе с вашим бизнесом и оттачивать свои возможности для предоставления более качественных и значимых результатов, что невозможно сделать без мерчандайзинговой аналитики. У Solr нет этих возможностей с самого начала, и он не предоставляет интерфейс для продвижения и захоронения продуктов — важные шаги, которые предпринимают мерчендайзеры для улучшения поиска по сайту, полагаясь на свои знания, опыт и интуицию.
Все эти функции должны быть спроектированы и реализованы. В случае создания собственного с помощью Solr вам нужны эксперты, которые разбираются в инфраструктуре — эксперты, которые понимают, что Solr требует много усилий для масштабирования.
Чтобы сделать это самостоятельно, вам нужна команда инженеров для создания модулей, которые перемещают, хранят и обрабатывают все те данные, о которых мы говорили ранее.
Один из способов подумать о необходимых модулях — разбить их функции на три основные области: наука о данных, мерчандайзинг и инвентаризация.
Наука о данных охватывает все возможности обучения и улучшения результатов поисковой системы, которые можно получить, только опираясь на аналитику. Поисковые системы полагаются на данные и модели поведения пользователей. Ваш движок должен сделать вывод из всех исторических поисков и результатов предыдущих запросов, действительно ли пользователи, ищущие «обувь», ищут сандалии или вместо этого они ищут насосы или кроссовки.
Движку нужны модели обработки естественного языка, чтобы он мог понимать бизнес, которым занимается сайт, и понимать ленту продуктов, с которыми он работает. Помимо Solr, требуется ряд машин для хранения и обработки всей этой, казалось бы, случайной, но жизненно важной информации.
Чтобы понять намерение пользователя и создать сайт, который может реагировать на это намерение, требуется способ сбора информации о посещениях в режиме реального времени. И никакие данные не годятся, если нет эффективного способа загрузить их в систему, чтобы система могла извлечь из них уроки.
Команде мерчандайзинга нужны правильные инструменты для работы
Две другие общие функции модулей — мерчандайзинг и инвентаризация — столь же важны для вашей поисковой системы.
Мерчандайзинг — одна из самых важных стратегий электронной коммерции, и вы должны инвестировать в нее, чтобы добиться успеха. Команде мерчандайзинга, отвечающей за продвижение конверсий на цифровом сайте, нужны правильные инструменты для воплощения своих стратегий в жизнь. Им нужна система для написания динамических бизнес-правил, которые они могут быстро изменять при необходимости. Им нужны средства тестирования, которые помогут им определить, являются ли шаги, которые они делают, правильными. И им нужны диагностические инструменты для мониторинга производительности сайта и определения основных причин проблем и тенденций.
Им нужна система для написания динамических бизнес-правил, которые они могут быстро изменять при необходимости. Им нужны средства тестирования, которые помогут им определить, являются ли шаги, которые они делают, правильными. И им нужны диагностические инструменты для мониторинга производительности сайта и определения основных причин проблем и тенденций.
Также необходимо создать системы для управления колебаниями посещаемости сайта. Подумайте о сайте электронной коммерции во время сезона праздничных покупок — инфраструктура, поддерживающая цифровые сайты, должна иметь возможность быстро масштабироваться и уменьшаться, когда дополнительные мощности больше не требуются.
Модули инвентаризации так же важны для ваших отделов мерчандайзинга. Без самых последних и релевантных данных о ваших запасах они не могут оптимизировать рекламные акции или пути клиентов с какой-либо степенью уверенности.
Если вы создаете свой собственный движок с такой платформой, как Solr, ему нужна система ETL (извлечение, преобразование и загрузка) для сбора данных из источников, таких как каталог розничного продавца, и ввода их в поисковую систему в процессе. называется поеданием корма. Также потребуется масштабируемая система хранения данных, способная справиться с постоянно меняющимися потоками данных из-за постоянно меняющихся каталогов. Кроме того, это должна быть распределенная система, способная автоматически справляться с потребностями динамично развивающегося рынка, на котором, например, розничный торговец может внезапно обнаружить, что ему необходимо в одночасье утроить размер своего каталога.
называется поеданием корма. Также потребуется масштабируемая система хранения данных, способная справиться с постоянно меняющимися потоками данных из-за постоянно меняющихся каталогов. Кроме того, это должна быть распределенная система, способная автоматически справляться с потребностями динамично развивающегося рынка, на котором, например, розничный торговец может внезапно обнаружить, что ему необходимо в одночасье утроить размер своего каталога.
Поисковику сайта также нужна система индексации, которая может работать на максимальной скорости. Природа цифровой коммерции сегодня означает, что детали продукта, такие как цены и уровни запасов, постоянно меняются. Чтобы идти в ногу с потребителями и конкуренцией, сайт должен иметь возможность быстро реагировать на изменение ассортимента, чтобы оставаться актуальным.
Создать такую систему можно, но это сложная задача. По нашим подсчетам, среднему и крупному ритейлеру, пытающемуся создать собственную высококачественную поисковую систему на базе Solr, потребовалось бы от 30 до 40 инженеров в течение двух лет.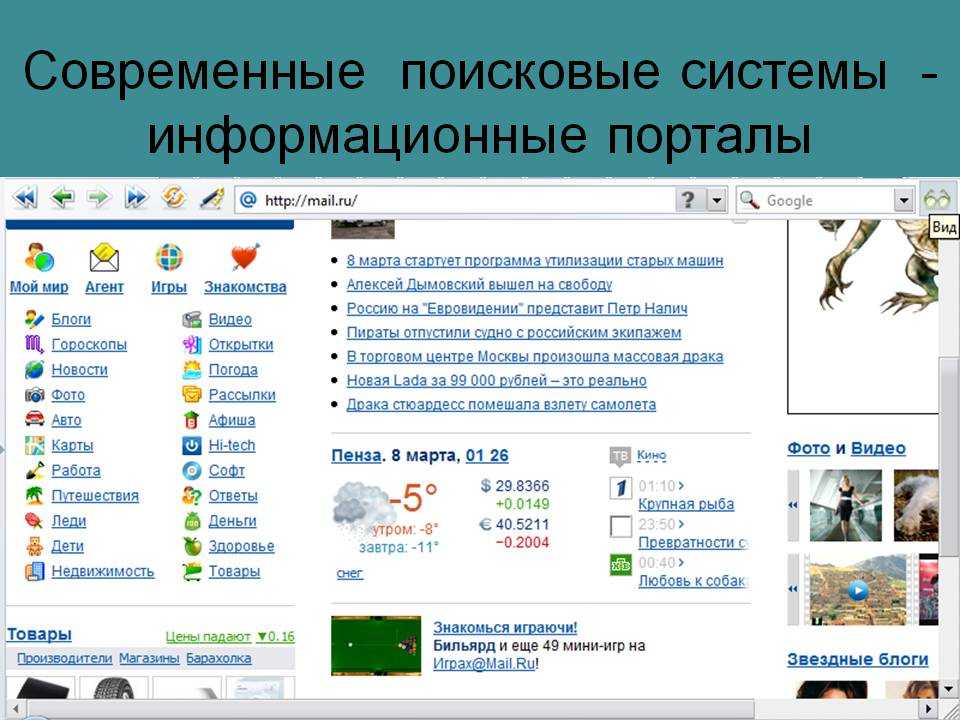
Очевидно, что это огромные затраты времени и денег. Но это также представляет собой огромные альтернативные издержки. В то время как работа по созданию высококачественной поисковой системы продолжается, клиенты компании страдают от низкого качества поиска. И поисковая система не может полностью учиться на взаимодействиях с клиентами, пока она не запущена и не работает.
Все это не тривиально, особенно когда до 30% потребителей используют поиск по сайту. И эти потребители являются одними из самых ценных клиентов предприятия, учитывая их более высокую склонность к конверсии. С другой стороны, клиенты, которые не получают результатов по своим поисковым запросам на сайте, в три раза чаще покидают сайт, чем другие.
Неудивительно, что команды, отвечающие за продажу продуктов и предоставление контента в Интернете, мучаются из-за серьезных изменений в поиске по сайту, и особенно из-за принятия решения о создании или покупке, когда приходит время капитального ремонта.
Bloomreach завершает работу с коммерцией
Если вы все еще думаете о создании своей поисковой системы, позвольте Bloomreach избавить вас от проблем. Bloomreach Discovery предлагает мощную комбинацию поиска по сайту на основе ИИ, SEO, рекомендаций и мерчендайзинга продуктов, чтобы вы могли предоставлять своим клиентам идеальные результаты — и все это без необходимости создавать это самостоятельно.
Если вы хотите узнать больше, запланируйте индивидуальную демонстрацию сегодня.
Создадим поисковую систему
Как работает поисковая система? Давайте узнаем —
, построив один!Поисковые системы стали воротами в современный Интернет. Как часто вы точно знаете, какая страница вам нужна, но все равно ищете ее, вместо того чтобы вводить URL-адрес в веб-браузере?
Как и многие великие машины, простой интерфейс поисковой системы — единственное поле ввода — скрывает целый мир технических фокусов. Когда вы думаете об этом, есть несколько серьезных проблем, которые нужно преодолеть.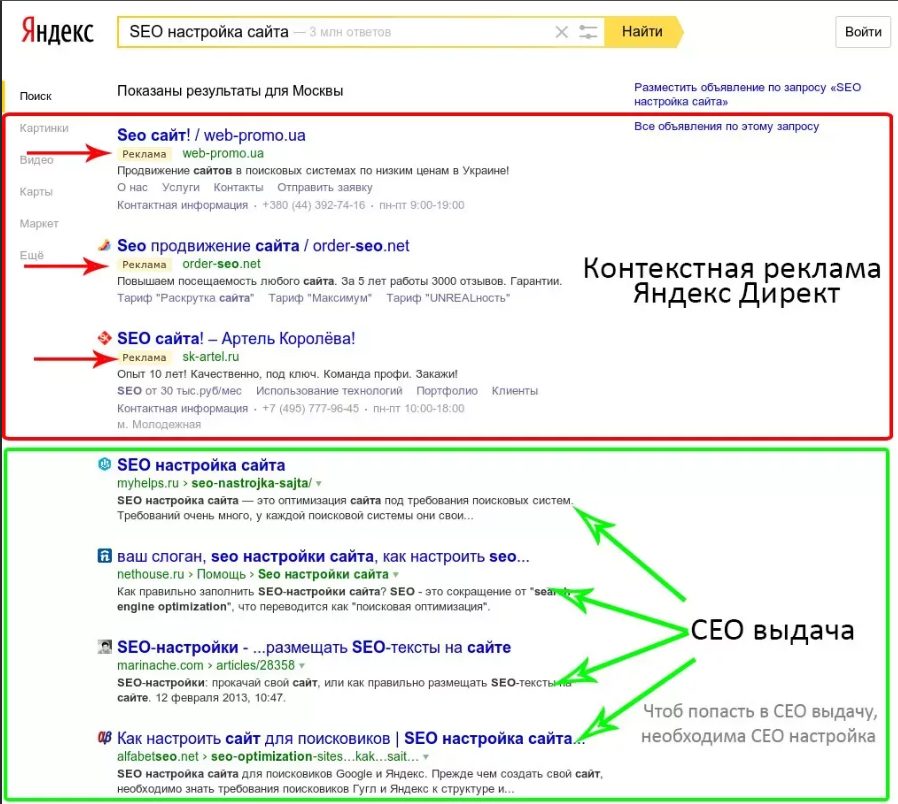 Как собрать все существующие действительные URL-адреса? Как угадать, чего хочет пользователь, и вернуть только релевантные страницы в разумном порядке? И как вы делаете это для 130 триллионов страниц быстрее, чем время реакции человека?
Как собрать все существующие действительные URL-адреса? Как угадать, чего хочет пользователь, и вернуть только релевантные страницы в разумном порядке? И как вы делаете это для 130 триллионов страниц быстрее, чем время реакции человека?
Я буду ближе к пониманию этих проблем, когда создам для себя поисковую систему. Я буду использовать только Python (даже для пользовательского интерфейса), и мой код будет достаточно простым, чтобы включить его в этот пост в блоге.
Вы можете скопировать окончательную версию, попробовать ее и построить самостоятельно:
Открыто в Анвиле
Это будет три части.
Во-первых, я собираюсь создать базовую поисковую систему, которая загружает страницы и соответствует вашим поисковый запрос по их содержимому. (Вот этот пост)
Затем я собираюсь внедрить алгоритм Google PageRank, чтобы улучшить результаты. (см. Часть 2)
Наконец, я поиграю с одним из мощных инструментов информатики — индексированием — чтобы ускорить поиск и сделать ранжирование даже лучше.
(см. Часть 3)
 (см. Часть 3)
(см. Часть 3)Сбор URL-адресов
Давайте начнем строить машину, которая сможет загружать всю сеть.
Я собираюсь создать веб-краулер, который итеративно работает в сети следующим образом:
- Начать с известного URL-адреса
- Скачать страницу
- Запишите все содержащиеся в нем URL-адреса
- GOTO 1 (для новых URL-адресов, которые я нашел)
Для начала мне нужен известный URL. Я позволю веб-мастерам и другим добропорядочным гражданам отправлять URL-адреса, о которых они знают. я буду хранить их в базе данных (я использую таблицы данных Anvil), и если я уже знаю URL-адрес, я не буду хранить его дважды.
@anvil.server.callable
деф submit_url (url):
url = url.rstrip('/') # URL-адреса с косой чертой и без нее эквивалентны
если не app_tables.urls.get(url=url):
app_tables.urls.add_row(url=url) Я также сделал возможным отправку файлов Sitemap, которые содержат списки многих URL-адресов (см. наш учебник по фоновым задачам
для более подробной информации.) Я использую BeautifulSoup для разбора XML.
наш учебник по фоновым задачам
для более подробной информации.) Я использую BeautifulSoup для разбора XML.
из импорта bs4 BeautifulSoup
@anvil.server.callable
def submit_sitemap (sitemap_url):
ответ = наковальня.http.request(sitemap_url)
суп = BeautifulSoup(response.get_bytes())
для loc в супе.find_all('loc'):
submit_url (лок. строка) Если я отправлю карту сайта Anvil, моя таблица будет заполнена URL-адресами:
Я в хорошей компании, позволяя людям отправлять URL-адреса и карты сайта для сканирования — Google Search Console делает это. Это один из способов избежать застревания моего поискового робота в локальной части Интернета, которая не имеет ссылок ни на что другое.
Бесстыдно украв Google Search Console, я создал консоль веб-мастера с кнопками «отправить», которые
вызовите мои функции submit_url и submit_sitemap :
def button_sitemap_submit_click(self, **event_args):
"""Этот метод вызывается при нажатии кнопки"""
self. label_sitemap_requested.visible = Ложь
anvil.server.call('submit_sitemap', self.text_box_sitemap.text)
self.label_sitemap_requested.visible = Истина
def button_url_submit_click (я, ** event_args):
"""Этот метод вызывается при нажатии кнопки"""
self.label_url_requested.visible = Ложь
anvil.server.call('submit_url', self.text_box_url.text)
self.label_url_requested.visible = Истина  label_sitemap_requested.visible = Ложь
anvil.server.call('submit_sitemap', self.text_box_sitemap.text)
self.label_sitemap_requested.visible = Истина
def button_url_submit_click (я, ** event_args):
"""Этот метод вызывается при нажатии кнопки"""
self.label_url_requested.visible = Ложь
anvil.server.call('submit_url', self.text_box_url.text)
self.label_url_requested.visible = Истина
label_sitemap_requested.visible = Ложь
anvil.server.call('submit_sitemap', self.text_box_sitemap.text)
self.label_sitemap_requested.visible = Истина
def button_url_submit_click (я, ** event_args):
"""Этот метод вызывается при нажатии кнопки"""
self.label_url_requested.visible = Ложь
anvil.server.call('submit_url', self.text_box_url.text)
self.label_url_requested.visible = Истина Ползание
Теперь, когда я знаю некоторые URL-адреса, я могу загружать страницы, на которые они указывают. Я создам фоновую задачу, которая просматривает мой список URL-адресов. делать запросы:
@anvil.server.background_task
деф обход():
для URL-адреса в app_tables.urls.search():
# Получить страницу
пытаться:
ответ = наковальня.http.request(url)
html = ответ.get_bytes().decode('utf-8')
кроме:
# Если выборка не удалась, просто попробуйте другие URL-адреса
Продолжать
row = app_tables.pages.get(url=url) или app_tables. pages.add_row(url=url)
строка['html'] = HTML  pages.add_row(url=url)
строка['html'] = HTML
pages.add_row(url=url)
строка['html'] = HTML Поскольку это фоновая задача, я могу запустить сканер и загрузить все известные мне страницы в фоновом режиме. без блокировки взаимодействия пользователя с моим веб-приложением.
Это все очень хорошо, но еще не сканирует . Умная вещь в веб-краулерах заключается в том, как они переходят по ссылкам между страницами. Сеть представляет собой ориентированный граф , другими словами, он состоит из страниц с односторонними связями между ними. Вот почему это такое замечательное хранилище информации — если вас интересует тема одной страницы, вас, вероятно, заинтересуют темы страниц, на которые она ссылается. Если вы когда-нибудь были в тисках сафари по Википедии до рассвета, вы поймете, о чем я говорю.
Итак, мне нужно найти URL-адреса на страницах, которые я загружаю, и добавить их в свой список. BeautifulSoup, блестящий парсер HTML/XML, снова помогает мне.
Я также записываю, какие URL-адреса я нашел на каждой странице — это пригодится, когда я буду внедрять PageRank.
из импорта bs4 BeautifulSoup
суп = BeautifulSoup(html)
# Разобрать URL-адреса
для супа.find_all('a', href=True):
submit_url (а ['href'])
# Запишите URL-адреса этой страницы
страница['forward_links'] += a['href'] Пока я этим занимаюсь, я возьму заголовок страницы, чтобы сделать результаты поиска более удобочитаемыми:
# Выделить заголовок из страницы
title = str(soup.find('title').string) или 'Нет названия' Сканер стал похож на классического осла, следующего за морковкой: чем дальше он продвигается по списку URL-адресов, чем больше URL-адресов он находит, тем больше работы ему приходится выполнять. Я визуализировал это, построив длину списка URL-адресов. наряду с количеством обработанных URL-адресов.
Первоначально список увеличивается, но сканер в конечном итоге находит все URL-адреса.
и линии сходятся. Он сходится, потому что я ограничил его https://anvil.works (я не
хочу случайно заблокировать чей-либо сайт. ) Если бы он сканировал открытую сеть, я представляю, как
будет расходиться навсегда — страницы, вероятно, добавляются быстрее, чем мой краулер может сканировать.
) Если бы он сканировал открытую сеть, я представляю, как
будет расходиться навсегда — страницы, вероятно, добавляются быстрее, чем мой краулер может сканировать.
К тому времени, как он закончился, в таблице страниц меня ждало большое количество данных о страницах.
Поиск
Время реализовать поиск. Я собрал классический пользовательский интерфейс «поле ввода и кнопка» с помощью редактора перетаскивания. Также есть сетка данных для перечисления результатов, которая дает мне разбиение на страницы бесплатно. Каждый результат будет содержать заголовок страницы и ссылку.
Самый простой алгоритм поиска просто разбивает запрос на слова и возвращает страницы, содержащие любое из этих слов. Это совсем нехорошо, и я могу сделать лучше прямо сейчас.
Я уберу слишком распространенные слова. Допустим, пользователь вводит «как создать веб-приложение». Если страница содержит именно текст «как создать веб-приложение»,
он будет возвращен. Но они также получали страницы с текстом «как сосать ягненка».
Поэтому я уберу такие слова, как «как» и «чтобы». На жаргоне они называются стоп-словами.
Я включу слова, которые тесно связаны со словами в запросе. Поиск «как создать веб-приложение» вероятно, должны возвращать страницы со словом «конструктор приложений», даже если ни одно из этих слов не присутствует в запросе.
На жаргоне это называется стеммингом.
Оба этих требования удовлетворяются оператором Anvil full_text_match , так что я могу сразу запустить жизнеспособный поиск:
# На сервере: @anvil.server.callable определение базового_поиска (запрос): вернуть app_tables.pages.search(html=q.full_text_match(query))
# На клиенте:
def button_search_click(я, **event_args):
"""Этот метод вызывается при нажатии кнопки"""
self.repeating_panel_1.items = anvil.server.call('basic_search', self.text_box_query.text) Позже мы поговорим об индексации и токенизации, которые дойдут до сути того, как оптимизировать поиск. Но пока у меня есть рабочая поисковая система. Давайте попробуем выполнить несколько запросов.
Но пока у меня есть рабочая поисковая система. Давайте попробуем выполнить несколько запросов.
Тестовые запросы
Для каждого этапа разработки я буду запускать три запроса, чтобы посмотреть, как улучшатся результаты по мере повышения моего рейтинга. система. Каждый запрос выбирается для отражения определенного типа проблемы поиска.
Я посмотрю только первую страницу из десяти результатов. Никто никогда не смотрит дальше первой страницы!
(Если вам интересно, почему все результаты с одного и того же сайта, имейте в виду, что я ограничил поисковый робот https://anvil.works чтобы избежать вполне законной блокировки моего IP-адреса программным обеспечением для защиты от DoS-атак и сохранить мой тестовый набор данных в управляемом размере.)
«Участки»
«Сюжеты» — довольно общее слово, которое, как вы ожидаете, будет встречаться повсюду в технической документации. Соревнование
состоит в том, чтобы возвращать страницы, посвященные непосредственно графику, а не те, на которых это слово используется мимоходом.
Когда я ищу «сюжеты», я получаю это:
Первый результат — «Использование Matplotlib с Anvil», что определенно актуально. Тогда есть справочные документы, в которых есть раздел о компоненте Plot. И результат номер девять первоначальное объявление относится к тому времени, когда мы сделали Plotly доступным в клиентском коде Python.
Но здесь также много общих страниц. Вероятно, они упоминают слово «сюжет» один или два раза, но они не совсем то, что я ищу, когда ищу «сюжеты».
«Восходящий канал»
«Восходящий канал» отличается от «графиков», потому что он вряд ли будет использован случайно. Это название конкретной функции Anvil. и это не очень распространенное слово в обычном использовании. Если это на странице, эта страница почти наверняка говоря об аплинке Anvil.
Если вы не знакомы с этим, Uplink позволяет вам anvil.server.call работает в любой среде Python за пределами Anvil.
Так что я ожидаю, что учебник «Использование кода вне Anvil» окажется на первом месте в списке результатов. Он появляется на четвертой позиции.
Он появляется на четвертой позиции.
Я также получаю аварийные люки и катапультируемые сиденья, в которых канал связи упоминается как один из «Спасательные люки». И под номером 10 у нас есть панель удаленного управления, которая использует Uplink для запуска набора тестов на удаленная машина.
Хорошо, что появляются все трое, но было бы лучше, если бы они имели более высокий рейтинг. Остальная часть результаты, вероятно, каким-то образом говорят об восходящем канале, но восходящий канал не является их основной темой.
«Создание информационной панели на Python»
Это включено в качестве примера запроса из нескольких слов. Я ожидаю, что поисковой системе будет сложнее с этим справиться, поскольку слова «сборка» и «Python» будут часто использоваться на сайте Anvil, но пользователь, вводящий это, особенно интересует панель инструментов Python .
Я ожидаю увидеть здесь две страницы: «Создание бизнес-панели на Python» и «Панель инструментов Python». цех. Ни один из них не появляется в результатах.
цех. Ни один из них не появляется в результатах.
Несколько страниц косвенно связаны с созданием информационной панели, но в целом сигнал, по-видимому, ошеломлен шумом, вызванным словами «сборка» и «Питон».
Ну и как?
Базовая поисковая система, которую я собрал, выдает релевантные результаты для запросов, состоящих из одного слова. Пользователь должен просматривать первые несколько результатов, чтобы найти то, что они ищут, но основные интересующие страницы где-то там.
Это сбивает с толку многословными запросами. Он не может очень хорошо различать слова, которые имеют значение, и те, которые не имеют значения.
Наковальня full_text_match действительно удаляет такие слова, как «а» и «в», но, очевидно, не догадается, что «сборка» менее важна
чем «приборная панель» в этой конкретной ситуации.
Следующие шаги
Я собираюсь внести два улучшения, пытаясь решить эти проблемы. Сначала постараюсь ранжировать поинтереснее
страницы выше.