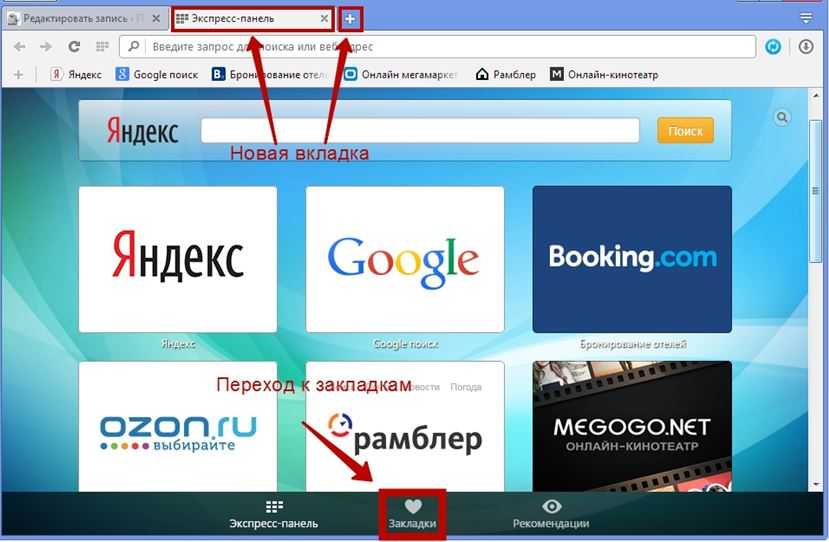
Как создать собственную поисковую систему c помощью CSE. Урок продвинутого сорсинга — Карьера на vc.ru
966 просмотров
Custom Search Engine (CSE) — мощный инструмент профессионального сорсера. С его помощью можно создать поисковый движок, который будет находить нужных вам кандидатов именно в тех источниках, которые вы укажете.
Основатель кадрового агентства Tech-recruiter и Академии IT-рекрутинга Язиля Насибуллина объяснила, как создать и настроить CSE. А для тех, кто не хочет возиться с настройками, Язиля рассказала про готовые движки для поиска на GitHub, LinkedIn, Behance, Хабр Карьере и в других источниках.
Язиля Насибуллина
основатель агентства Tech-recruiter, автор канала IT-рекрутинг
Зачем сорсеру CSE
CSE — это инструмент от компании Гугл, который позволяет настроить поиск под свои задачи:
- выбрать ресурсы или даже разделы сайтов, которые нужно сканировать;
- искать в определенных регионах;
- задать синонимы, которые будут автоматически подставляться в запрос;
- нацелить поиск на конкретные типы файлов;
- и многое другое, о чем я еще расскажу.


Владельцы сайтов пользуются CSE, чтобы организовать внутренний поиск по своим ресурсам. А сорсеры применяют этот инструмент, чтобы экономить время и получать максимально качественные выдачи.
Когда полезен Custom Search Engine:
- Не хватает возможностей X-ray и внутреннего поиска по сайту. Например, можно создать поисковый движок для GitHub и LinkedIn, используя операторы, которые работают только внутри CSE. Кроме того, поисковый запрос в Гугле ограничен 32 словами — Custom Search Engine позволяет обойти этот лимит.
- Нужно ограничить поиск на определенных сайтах, добавить или исключить конкретные регионы. В стандартном поиске Гугла это сделать сложнее — часто в выдачу попадают нерелевантные результаты, несмотря на оператор «-».
- Надо настроить поиск для начинающих ресечеров и рекрутеров. Например, опытный сорсер создает набор движков, которыми будут пользоваться его коллеги — просто вбивать название должности и получать резюме. Но нужно учитывать, что один и тот же запрос может давать разные результаты в зависимости от настроек и страны нахождения пользователя.
- Необходимо найти редкого эксперта с уникальным стеком — можно создать под него отдельный движок. И наоборот: чем стандартнее запрос и больше кандидатов на рынке, тем меньше нужны все эти «сорсинговые штучки».
 Но нужно учитывать, что один и тот же запрос может давать разные результаты в зависимости от настроек и страны нахождения пользователя.
Но нужно учитывать, что один и тот же запрос может давать разные результаты в зависимости от настроек и страны нахождения пользователя.Как создать поисковый движок
Зайдите в сервис «Программируемая поисковая система» и выберите, в каком интерфейсе будете работать — в стандартном или новом.
Создание движка в стандартном интерфейсе
Здесь нужно указать:
- сайты для поиска;
- язык;
- название системы — желательно осмысленное, чтобы быстро находить нужный вариант, когда у вас будет набор движков на все случаи жизни.
Например, создаю систему для поиска по профилям пользователей на LinkedIn:
Здесь я указываю адрес linkedin. com/in, где хранятся личные страницы пользователей, и использую символ *, чтобы искать по всем доменам соцсети. В поле «Язык» можно выбрать язык выдаваемого профиля, но я не советую этого делать. Даже если вы ищете русскоязычных разработчиков, то стоит помнить — это международный сайт, поэтому многие пользователи заполняют профиль на английском.
com/in, где хранятся личные страницы пользователей, и использую символ *, чтобы искать по всем доменам соцсети. В поле «Язык» можно выбрать язык выдаваемого профиля, но я не советую этого делать. Даже если вы ищете русскоязычных разработчиков, то стоит помнить — это международный сайт, поэтому многие пользователи заполняют профиль на английском.
Как только докажу, что я не робот, и нажму на кнопку «Создать», меня перебросит на следующую страницу со ссылкой на поисковую систему — движок уже будет работать.
Создание движка в новом интерфейсе
Сначала нужно выбрать название системы и указать сайты, по которым надо искать. Потом этот список сайтов можно будет изменить в настройках. Например, создам движок для Хабр Карьеры:
Кстати, можно не ограничиваться конкретными сайтами, а задать целые доменные зоны, например так: *. ru или *. com. Когда я нажму кнопку «Создать», мне предложат настроить систему:
- Выбрать регион поиска — разрешается указать только один. По моему опыту, лучше оставить «Все регионы», а зоны поиска корректировать с помощью доменов и ключевых слов.
- Добавить в поиск новые сайты.
- Исключить из поиска какие-то адреса. Можно убрать из области поиска не только сайт целиком, но и отдельные веб-страницы или разделы (www. example. com/jobs/*), а также весь домен (*. example. com).
 По моему опыту, лучше оставить «Все регионы», а зоны поиска корректировать с помощью доменов и ключевых слов.
По моему опыту, лучше оставить «Все регионы», а зоны поиска корректировать с помощью доменов и ключевых слов.Я настраиваю поиск кандидатов по Хабр Карьере, так что исключу разделы с вакансиями, курсами и информацией о компаниях:
Продвинутая настройка CSE
Предупрежу сразу: все настройки я буду проводить в стандартном интерфейсе — так привычнее. Кроме того, на момент выхода этой статьи новая версия панели управления считается предварительной — многое еще может поменяться. В целом, различия между версиями косметические. Если научиться работать в старом интерфейсе, то будет легко найти аналогичные разделы в новой панели.
Самые полезные настройки находятся в подразделе «Функции в результатах поиска» раздела «Изменение поисковой системы»:
Добавление запроса
Можно прописать дополнительные запросы, которые будут включаться в поиск автоматически. Для этого:
Для этого:
- В разделе «Функции в результатах поиска» нужно перейти во вкладку «Дополнительно».
- Открыть там раздел «Настройки веб-поиска».
- В поле «Добавление запроса» вписать фразу, которая будет подставляться автоматически — писать ее при каждом запросе не придется.
Например, сделаю движок для поиска файлов в формате pdf и docx — предполагается, что это будут резюме. Использую оператор «filetype»:
Уточнения
Усовершенствую движок для LinkedIn — настрою поиск так, чтобы отдельно показывались профили кандидатов с контактными данными. Это можно сделать с помощью уточнений.
В разделе «Функции в результатах поиска» нужно перейти во вкладку «Уточнения», нажать на кнопку «Добавить» и создать дополнительные условия поиска. Результаты по каждому условию будут выводиться на отдельную вкладку.
Например, добавлю поиск по всем профилям, в которых есть почта на gmail.
Синонимы
Вручную прописывать десятки синонимов через OR при каждом запросе утомительно. В CSE для каждого ключевого слова можно задать набор синонимов, которые будут добавляться автоматически.
Для этого надо:
- Перейти в раздел «Функции в результатах поиска», а оттуда — во вкладку «Синонимы».
- Нажать на кнопку «Добавить».
- На верхней строчке написать ключевое слово, а на нижней — набор синонимов к нему.
Как искать с помощью CSE
Если перейдете по ссылке вашего поискового движка, то вы увидите обычную поисковую строку и больше ничего. Не нужно писать «site:» и название сайта для поиска — этот запрос скрыт «под капотом» системы, как и остальные настройки. А в остальном здесь работают все стандартные операторы, в том числе: OR, —, “” .
Например, так будет выглядеть запрос в движке для LinkedIn на поиск PHP-разработчиков из Москвы:
Сейчас движок сканирует всю страницу пользователя целиком. Но существуют операторы, которые позволяют ориентировать его поиск по конкретным блокам и элементам профиля. Например, в LinkedIn, Xing, ResearchGate, Google Scholar и Speakerhub работают такие операторы:
Но существуют операторы, которые позволяют ориентировать его поиск по конкретным блокам и элементам профиля. Например, в LinkedIn, Xing, ResearchGate, Google Scholar и Speakerhub работают такие операторы:
- «more:p:person-jobtitle:» — поиск по позиции;
- «more:p:person-org:» — поиск по компании или учебному заведению;
- «more:p:person-role:» — поиск в заголовке страницы.
А у GitHub есть свой оператор, который обращается к строке «о себе» — «more:p:metatags-og_description:».
Телеграм-канал Хантфлоу
https://t. me/huntflow
Подписывайтесь🔥
Готовые поисковые движки
Вам не обязательно создавать движок самостоятельно — можно воспользоваться готовыми вариантами, если они подходят под ваши задачи. Например, поисковики от Ирины Шамаевой и Балажа Парочай:
- XING,
- HackerRank,
- MeetUp,
- ResearchGate.
Мои поисковые системы:
- GitHub.
- Behance — поиск резюме. Настройки самые простые: в сайтах для поиска я указала «behance. net/*/resume» — раздел, где хранятся резюме пользователей.
- Хабр Карьера. Здесь к каждому допросу автоматически добавляется фраза «последний визит», чтобы искать только по личным страницам пользователей.
- Европейский LinkedIn. Я занимаюсь международным рекрутингом и ищу кандидатов по всей Европе. Для этого сделала движок поиска по доменным областям LinkedIn тех стран, которые мне интересны.
Наш блог читают более 12 000 рекрутеров и профессионалов HR-индустрии. Подкасты, интервью, тематические статьи и экспертные мнения. Переходите по ссылке:
Elasticsearch как создать поисковую систему
Данная статья посвящена проблеме построения расширенной поисковой системы с использованием ElasticSearch. Мы собираемся создать реальный пример упрощенной версии booking. com, но с некоторыми дополнительными функциями. Представьте, что вы инженер-программист, и ваш начальник дал вам задание построить весь бэкэнд. Проанализировав все макеты дизайна и функциональные требования, вы создали некую общую упрощенную структурную схему будущей системы поиска отелей. Вот как это выглядит:
com, но с некоторыми дополнительными функциями. Представьте, что вы инженер-программист, и ваш начальник дал вам задание построить весь бэкэнд. Проанализировав все макеты дизайна и функциональные требования, вы создали некую общую упрощенную структурную схему будущей системы поиска отелей. Вот как это выглядит:
Вкратце, существующая система должна выполнять полнотекстовый поиск по названию отеля и города в различных языковых вариациях, а также выполнять типичное точное совпадение по количеству звезд, рейтингу, возрасту. Также есть фильтр по географическому расстоянию и возможность поиска по услугам. Кроме того, у каждого отеля есть комментарии и бронирования, данные по которым также доступны для поиска. Система поиска отелей должна удовлетворять всем указанным требованиям. Она также должна быть супер быстрой. Но это не все проблемы, которые у нас есть. Есть и дополнительные требования. Давайте исследуем все по порядку. В первую очередь система должна позволять осуществлять поиск отелей в произвольной геометрической форме, заданной пользователем. Вот пример пользовательского интерфейса:
Вот пример пользовательского интерфейса:
Во-вторых, мы должны отобразить количество отелей на карте, как показано на изображении ниже:
И в-третьих, для каждого отеля необходимо предоставить столбчатую диаграмму среднего рейтинга по всем комментариям за месяц в течение года в каждом документе. Итак, нам нужны дополнительные данные, чтобы отобразить что-то вроде этого:
где X — месяцы года, а Y — количество комментариев.
Будучи ответственным за создания такой системы, легко потерять голову. Как спроектировать такую систему, как выполнить все эти требования? Всегда сложно выбрать нужный инструмент, особенно в наше время, когда у нас такое большое разнообразие технологий в сфере ИТ. А вот если бы мне пришлось создавать такую систему — сомнений у меня не было вообще. Во-первых, мы должны обеспечить операции полнотекстового поиска, во-вторых, нам нужно выполнить некоторые сложные гео-операции. Кроме того, у нас есть аналитика. И все это должно работать сразу и с высокой скоростью. Я знаю единственный инструмент, который идеально соответствует всем этим требованиям.
Я знаю единственный инструмент, который идеально соответствует всем этим требованиям.
И это Elasticsearch. Я покажу Вам, что мы можем легко получить все эти вещи всего за несколько запросов. И я сомневаюсь, что любая подобная система, построенная с использованием реляционных баз данных (например, mysql, postgres или oracle), сможет составить в этом случае хорошую конкуренцию ElasticSearch. Либо Вы закончите со сверхсложной архитектурой, либо это будет просто медленно.. Ознакомиться с требованиями можно также в текущем видео, которое является первым в моем курсе udemy, посвященном ElasticSearch -> раздел «Расширенная поисковая система». Вы можете просмотреть весь курс на udemy по следующей ссылке со скидкой:
Посмотреть весь курс
Похожие статьи, которые могут вас заинтересовать: Как создать рекомендательную систему с помощью ElasticSearch
гео поиск поисковые системы фреймворк-flask фреймворк-spring-boot фреймворк-symfony язык-java язык-php язык-python языки программирования
Как создать программное обеспечение поисковой системы для вашего бизнеса
Шаг 4.
 Определение структуры индекса
Определение структуры индексаПри создании программного обеспечения поисковой системы вы должны определить структуру индекса. Несмотря на то, что это своего рода база данных, важно помнить, что это не основное хранилище данных и не реляционная база данных. Структура индекса должна быть организована так, чтобы это было удобно для поиска. Хранящиеся там данные также должны быть единственными, необходимыми для поиска.
Шаг 5. Настройка обновления данных
Важно отправлять обновленную информацию из базы данных в поисковую систему. Некоторые движки получают эту информацию непосредственно из базы данных, тогда как в других случаях вам нужно добавить специальный код, который выполняет эту задачу. Поисковая система более эффективна, когда обновления редки. Так что, если запросов десятки в минуту, лучше настроить обновление индекса раз в несколько минут. Это позволит отправлять многочисленные обновления вместе.
Разработчики, работающие с Elastic и использующие Python, могут использовать службу Github и Celery для планирования обновления индекса.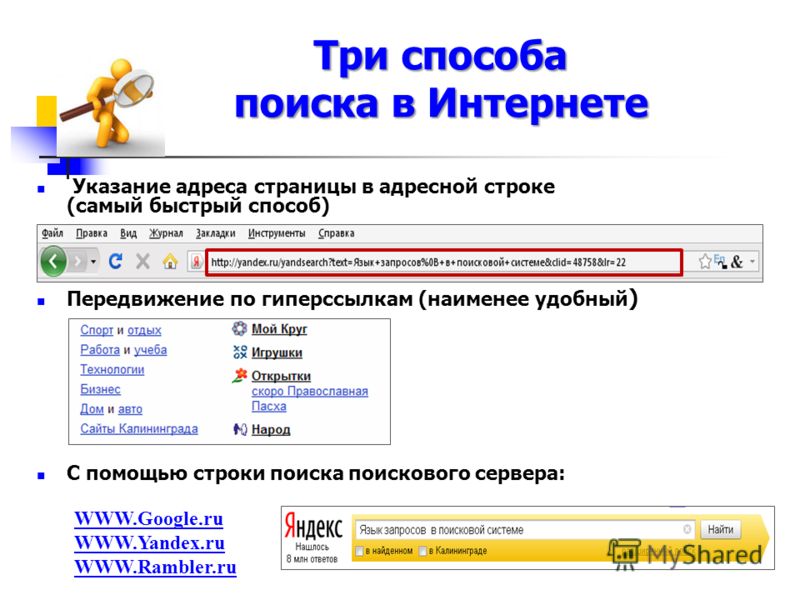
Шаг 6. Начните делать запросы
На этом этапе ваша поисковая система работает хорошо и может не требовать дополнительной работы. Поэтому можно начинать делать запросы.
Можно использовать разные алгоритмы ранжирования, применяющие данные о частоте слова в текстах и движок знает, что главное слово в запросе «кардиологические услуги», например, кардиология. Вы можете использовать различные алгоритмы ранжирования, применяющие данные о частоте слов в текстах. Так, во фразе «кардиологические услуги» движок может выделить слово «кардиология» как основное. Следовательно, результаты, соответствующие обоим словам, идут первыми. Затем будут те, которые соответствуют «кардиологии», и другие, которые соответствуют «услугам».
При работе с Elastic мы предпочитаем Elastic DSL. На это есть несколько причин:
- Умеет строить индекс автоматически, что очень удобно на этапе прототипирования.
- Его API на основе http удобен для пользователя и позволяет программировать на любом языке программирования. Узнайте больше об услугах по разработке API.
- Доступно множество инструментов, таких как Kibana и Logstash.
- Amazon предлагает Elastic как услугу, упрощающую запуск и администрирование поисковой системы.
 Узнайте больше об услугах по разработке API.
Узнайте больше об услугах по разработке API.На этом заканчивается первый этап развития поисковой системы и начинается второй.
Второй этап
На этом этапе рассматриваются другие процессы, помогающие понять, как создать поисковую систему, подобную Google.
Шаг 7. Назначить ответственного за сбор данных
В первую очередь необходимо нанять специалиста, специализирующегося на базах данных. Несмотря на то, что настройка поиска является технической задачей, технический специалист может не понять, какие данные нужны пользователям и зачем. Это когда специалист по данным приходит на помощь.
Шаг 8. Просмотр истории поиска пользователей
Важно выяснить, подходят ли результаты вашей поисковой системы для определенных запросов. Это можно сделать, проверив историю поиска пользователя, выбрав первую десятку запросов по популярности и предоставив эксперту проверить их релевантность.
Шаг 9. Сформулируйте, какие документы ожидаются в результате
Далее необходимо сформулировать, какие документы потребуются в результате. Это когда вам нужно подумать о том, как вы, как человек, будете обрабатывать такие запросы. Например, вы работаете над научными статьями и в результате можете получить следующее:
- Совпадения в названии статьи важнее, чем совпадения в тексте.
- Совпадения в тексте более важны, чем совпадения в ссылках.
- Совпадения имени автора более важны, чем совпадения в тексте и в списке цитат.
- Имя и фамилию нужно искать вместе, а не по отдельности.
- Слово «вакцина» обычно пишется с ошибкой как «вакцина», и этот запрос также необходимо обработать.
Шаг 10. Выяснение источника проблем
Последний шаг — выяснить, почему возникают проблемы, если они есть. Полезным может оказаться чтение информации о том, как устроен поисковый движок и методы его устранения. Иногда вам может потребоваться изменить основные принципы, чтобы найти проблему. Однако рано или поздно проблемы, требующие режима отладки и детального анализа, появятся.
Однако рано или поздно проблемы, требующие режима отладки и детального анализа, появятся.
В зависимости от правил вашей поисковой системы вам могут понадобиться различные способы исправления запроса, которые всегда будут интерактивными. Итак, определите проблемы, разберитесь с ними и постарайтесь получить удовольствие от процесса.
Если вы работаете с Elastic, вот несколько советов, которые помогут вам создать поисковую систему для вашего бизнеса:
- Прочтите обо всех анализаторах. Обычно используются только два или три из них, но вам нужно знать об остальных.
- Понять, как работают составные запросы, особенно запрос Bool. Дополнительную информацию об этом можно найти здесь.
Используйте соответствующие веса и усилители. Есть замечательная книга «Relevant Search With Applications for Solr and Elasticsearch» Дуга Тернбулла и Джона Берримана, которая может оказаться полезной.
Как нанять разработчиков
Собирая информацию о том, как разработать поисковую систему, не следует забывать о найме специалистов, отвечающих вашим требованиям. Есть несколько альтернатив. Давайте рассмотрим плюсы и минусы каждого из них.
Есть несколько альтернатив. Давайте рассмотрим плюсы и минусы каждого из них.
Собственная команда
Одним из вариантов является создание собственной команды.
Плюсы:
- Такая команда обычно более профессиональна и вовлечена в процесс.
- Вы полностью контролируете работу команды.
Минусы:
- Вы должны заплатить довольно высокую цену за разработку программного обеспечения поисковой системы для команды квалифицированных специалистов.
- Может быть трудно найти квалифицированных разработчиков.
- Нет никакой гарантии, что они будут хорошо работать в команде.
Фрилансеры
Если у вас нет возможности нанять штатную команду, вы можете попробовать работать с фрилансерами.
Плюсы:
- Они берут гораздо меньше денег, чем штатная команда.
Минусы:
- Найти опытных внештатных разработчиков непросто.
- Есть определенные риски: они могут внезапно исчезнуть или не уложиться в сроки.
- Возможно, вам придется нанять менеджера проекта, чтобы держать процесс под контролем.
- Общение между участниками проекта требует дополнительной помощи.

Аутсорсинг агентству
Третий способ, которым сегодня успешно пользуются многие компании, — это передача задачи по созданию программного обеспечения поисковой системы агентству, например, Gearheart.
Плюсы:
- В таких агентствах работают умелые и профессиональные сотрудники, имеющие большой опыт работы в данной сфере.
- Вы платите только за реально потраченное время на разработку.
Минусы:
- Иногда такие агентства могут не уложиться в срок или предоставить продукт ожидаемого качества.
Вы можете избежать таких проблем при аутсорсинге веб-разработки, выбрав агентство с умом — оно должно иметь хорошую репутацию, а навыки разработчиков должны соответствовать вашим потребностям (это можно проверить в их портфолио). И, конечно же, вы никогда не должны стесняться задавать вопросы, когда бы они ни возникали.
И, конечно же, вы никогда не должны стесняться задавать вопросы, когда бы они ни возникали.
Подведение итогов
Создание программного обеспечения для поисковых систем — отличный способ расширить возможности вашего бизнеса. Более того, это может быть интересно и весело, если соблюдать определенные правила и получать удовольствие от процесса. Мы надеемся, что эта статья прольет свет на то, как создать собственную поисковую систему. Привлечение профессиональной команды разработчиков веб-приложений, такой как Gearheart, всегда является преимуществом для вашего проекта, поскольку работа выполняется опытными разработчиками. Так что выбирайте подход, отвечающий всем вашим потребностям, и отправляйтесь в путь развития.
Как создать поисковую систему. Создание надежного полнотекстового поиска в… | Джош Тейлор
Создание надежного полнотекстового поиска на Python с помощью нескольких строк кода
код.
Источник: АвторЦенность поиска
Возможность поиска данных — это то, что мы считаем само собой разумеющимся. Современные поисковые системы настолько сложны, что большинство наших поисковых запросов «просто работают». На самом деле, мы часто замечаем поиск на веб-сайте или в приложении только тогда, когда он не работает. Наши ожидания в этом пространстве никогда не были выше.
Современные поисковые системы настолько сложны, что большинство наших поисковых запросов «просто работают». На самом деле, мы часто замечаем поиск на веб-сайте или в приложении только тогда, когда он не работает. Наши ожидания в этом пространстве никогда не были выше.
Интеллект поисковых систем растет по очень простой причине: ценность, которую эффективный поисковый инструмент может принести бизнесу, огромна; ключевой объект интеллектуальной собственности. Часто панель поиска является основным интерфейсом между клиентами и бизнесом. Таким образом, хорошая поисковая система может создать конкурентное преимущество за счет улучшения взаимодействия с пользователем.
По оценкам MckKinsey, это значение, агрегированное по всему миру, составило 780 миллиардов долларов в год в 2009 году. Таким образом, стоимость каждого выполненного поиска составит 0,50 доллара[1]. Конечно, это значение, без сомнения, существенно увеличилось с 2009 года.…
Имея это в виду, вам простительно, что создание современной поисковой системы было бы не по силам большинству команд разработчиков, требующих огромных ресурсов и сложных алгоритмов. Однако несколько удивительно, что большое количество корпоративных поисковых систем на самом деле основаны на очень простых и интуитивно понятных правилах, которые можно легко реализовать с помощью программного обеспечения с открытым исходным кодом.
Однако несколько удивительно, что большое количество корпоративных поисковых систем на самом деле основаны на очень простых и интуитивно понятных правилах, которые можно легко реализовать с помощью программного обеспечения с открытым исходным кодом.
Например, Elasticsearch используют Uber, Udemy Slack и Shopify (наряду с 3000 других предприятий и организаций [2]). Эта поисковая система работала на невероятно простом термин-частота, обратная частота документа (или tf-idf) оценка слов до 2016 года. (Подробнее о том, что это такое, я писал о tf-idf здесь и здесь).
После этого он переключился на более сложный (но все же очень простой) BM25, который используется до сих пор. Этот же алгоритм реализован в Azure Cognitive Search[4].
BM25: самый важный алгоритм, о котором вы никогда не слышали
Так что же такое BM25? Это означает «Лучший матч 25» (остальные 24 попытки были явно не очень удачными). Он был выпущен в 1994 на третьей конференции по текстовому поиску, да, действительно была конференция, посвященная текстовому поиску…
Вероятно, лучше всего рассматривать его как tf-idf «на стероидах», реализуя два ключевых уточнения:
- Насыщение частоты терминов . BM25 обеспечивает убывающую отдачу для количества терминов, сопоставленных с документами. Это довольно интуитивно понятно, если вы ищете определенный термин, который очень часто встречается в документах, тогда должна возникнуть точка, в которой количество вхождений этого термина станет менее полезным для поиска.
- Длина документа. BM25 учитывает длину документа в процессе сопоставления. Опять же, это интуитивно понятно; если более короткая статья содержит то же количество терминов, что и более длинная статья, то более короткая статья, вероятно, будет более актуальной.
 BM25 обеспечивает убывающую отдачу для количества терминов, сопоставленных с документами. Это довольно интуитивно понятно, если вы ищете определенный термин, который очень часто встречается в документах, тогда должна возникнуть точка, в которой количество вхождений этого термина станет менее полезным для поиска.
BM25 обеспечивает убывающую отдачу для количества терминов, сопоставленных с документами. Это довольно интуитивно понятно, если вы ищете определенный термин, который очень часто встречается в документах, тогда должна возникнуть точка, в которой количество вхождений этого термина станет менее полезным для поиска.Эти уточнения также вводят два гиперпараметра для настройки влияния этих элементов на функцию ранжирования. «k» для настройки влияния насыщенности терминов и «b» для настройки длины документа.
Собрав все вместе, BM25 рассчитывается как:
Алгоритм BM25 упрощен. Источник: AuthorВнедрение BM25, рабочий пример
Внедрение BM25 невероятно просто. Благодаря библиотеке Python rank-bm25 это можно сделать всего за несколько строк кода.
В нашем примере мы собираемся создать поисковую систему для запроса уведомлений о контрактах, которые были опубликованы организациями государственного сектора Великобритании.
Нашей отправной точкой является набор данных, который содержит заголовок уведомления о контракте, описание и ссылку на само уведомление. Для простоты мы объединили заголовок и описание, чтобы создать столбец «текст» в наборе данных. Именно этот столбец мы будем использовать для поиска. Мы хотим найти 50 000 документов:
Формат данных для использования в поисковой системе (первые две строки из 50 000). Источник: АвторСсылку на данные и код можно найти внизу этой статьи.
Первым шагом в этом упражнении является извлечение всех слов в столбце «текст» этого набора данных для создания «списка списков», состоящего из каждого документа и слов в них. Это известно как токенизация и может быть обработано отличной библиотекой spaCy:
import spacy
from rank_bm25 import BM25Okapi
from tqdm import tqdm
nlp = spacy.
tok_text=[] # для нашего токенизированного корпуса#Токенизация с использованием SpaCy:
для документа в tqdm( nlp.pipe(text_list, disable=["tagger", "parser","ner"])):
tok = [t.text для t в документе, если t.is_alpha]
tok_text.append(tok)
 load("en_core_web_sm")text_list = df.text.str.lower().values
load("en_core_web_sm")text_list = df.text.str.lower().values Building индекс BM25 можно создать одной строкой кода:
bm25 = BM25Okapi(tok_text)
Для запроса этого индекса требуется только поисковый ввод, который также был токенизирован:
запрос = "Защита от наводнений" tokenized_query = query.lower().split(" ")import timet0 = time.time()
results = bm25.get_top_n(tokenized_query, df.text.values, n=3)
t1 = time.time()print(f'Искано 50 000 записей за {round(t1-t0,3)} секунд \n')для i в результатах:
print(i) Это возвращает следующие 3 лучших результата, которые явно высоко релевантна поисковому запросу «Защита от наводнений»:
Поиск 50 000 записей за 0,061 секунды: Защита от наводнений и работы на территории Кузнечного острова Награда за работы по защите от наводнений и общественным работам вдоль набережной канала на острове Фордж, Маркет-стрит , Ротерхэм в рамках программы по борьбе с наводнениями эпохи Возрождения Ротерхэма.
 Работы по техническому обслуживанию защиты от наводнений в Колледже Льюишем и Саутварк **НАГРАДА** После RfQ NCG заключила контракт с T Gunning на работы по техническому обслуживанию защиты от наводнений в колледже Льюишем и Саутварк Фреклтон-Стрит-Байром-Стрит Стены реки Фреклтон-Сент-Байром-Стрит Стены реки Фреклтон-Сент-Байром-Стрит Укрепление существующих парапетов стен реки обеспечить мероприятия по защите от наводнений
Работы по техническому обслуживанию защиты от наводнений в Колледже Льюишем и Саутварк **НАГРАДА** После RfQ NCG заключила контракт с T Gunning на работы по техническому обслуживанию защиты от наводнений в колледже Льюишем и Саутварк Фреклтон-Стрит-Байром-Стрит Стены реки Фреклтон-Сент-Байром-Стрит Стены реки Фреклтон-Сент-Байром-Стрит Укрепление существующих парапетов стен реки обеспечить мероприятия по защите от наводнений Мы могли бы точно настроить значения «k» и «b» на основе ожидаемых предпочтений пользователей, выполняющих поиск, однако значения по умолчанию k = 1,5 и b = 0,75, похоже, здесь хорошо работают.
В заключение
Надеюсь, этот пример показывает, насколько просто реализовать надежный полнотекстовый поиск в Python. Это можно легко использовать для запуска простого веб-приложения или интеллектуального инструмента поиска документов. Также есть значительные возможности для дальнейшего улучшения производительности, об этом рассказывается в последующем посте ниже!
Как создать интеллектуальную поисковую систему
Создание интеллектуальной службы поиска на Python
в направлении datascience.