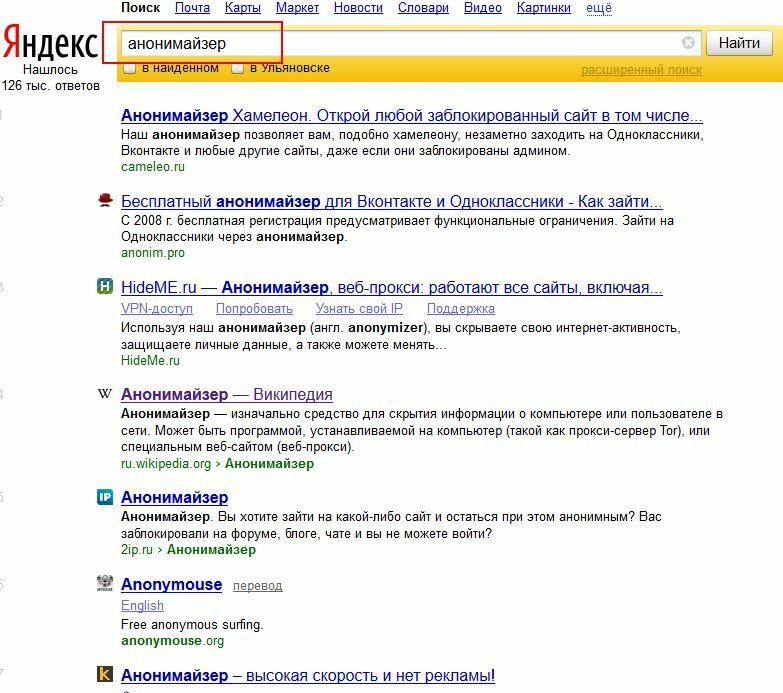
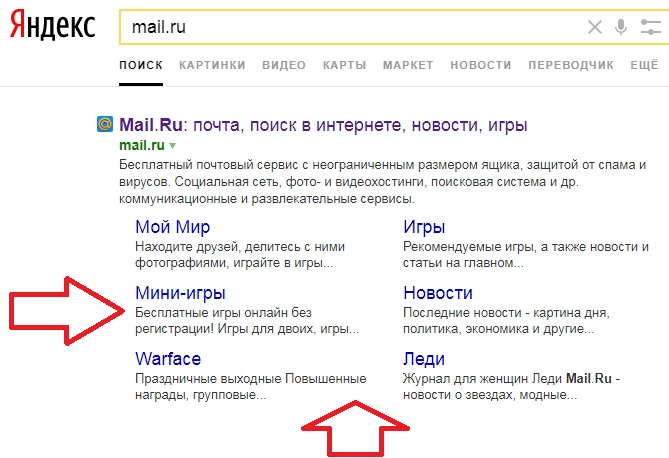
Как создать свой поисковик и возможно ли это сделать самостоятельно?
Каждый пользователь в интернете может назвать несколько популярных поисковых систем. Но при этом некоторые из них не оставляют идею создать собственную такую систему, поэтому вопрос: «Как создать свой поисковик?» остается на слуху.
Свой поисковик может быть двух типов:
большая поисковая система, которая будет работать по всему интернету и составлять конкуренцию Google, Яндекс, Bing и др.;
небольшой поисковик, организованный на своем сайте с различными свойства поиска.
Как создать свой поисковик и создать конкуренцию известным «поисковым гигантам»
Создать свой поисковик наподобие Гугла и Яндекса, на самом деле, не так сложно. Любой более-менее уверенный в себе разработчик сможет это сделать. Любой поисковик состоит из 3-х основных элементов:
Пользовательский интерфейс.
Базы данных с сайтами для их индекса.
Поисковый робот, который будет обходить сайты и обновлять/добавлять информацию о них в базу данных.
Техническая реализация поисковой системы не так сложна, как кажется. Плюс в сети есть уже много готовых скриптов как платных, так и бесплатных, с помощью которых вы сможете реализовать свою идею. Создать свой поисковик можно самостоятельно или в небольшой команде. В принципе, если найти соратников в команду, которые готовы поработать на голом энтузиазме, создать свой поисковик можно практически бесплатно.
Но проблема в другом. Сможете ли вы создать действительно конкурирующий программный продукт? Ведь для того, чтобы конкурировать с известными поисковиками, вам нужно будет:
нанять высококвалифицированных специалистов и организовать им рабочее пространство;
оборудовать собственный дата-центр или арендовать мощности у надежной компании;
быть готовым в течение нескольких лет терпеть убытки.
И при этом никто не даст гарантий, что ваш поисковик станет популярным и вы сможете его монетизировать. Потому что пока вы будете развивать свой продукт, Гугл с Яндексом также будут развиваться. А чтобы их «переплюнуть», вам нужно будет внедрить в свой продукт какую-нибудь «фишку» или ноу-хау, чтобы переманить к себе пользователей — это что касается функционала. А с технической стороны ваш поиск должен быть точнее, быстрее и эффективнее, чем у ваших конкурентов, чтобы пользователи это «почувствовали» и перешли на вашу сторону.
Почему люди в основном пользуются Гуглом или Яндексом (или другими)? Потому что им там комфортно и им там нравится. Поэтому, чтобы пользователи перешли именно к вашему поисковику, вы должны стать лучше.
Вот и получается, что создать свой поисковик нетрудно, но вот развивать его и сделать конкурентоспособным — на это потребуется немало усилий и финансовых вложений. Но с другой стороны, Гугл тоже когда-то был в позиции «новичка», а в кого он превратился спустя годы упорного труда — мы все прекрасно видим.
Другое дело с локальными поисковиками, которые вы можете организовать на собственном сайте.
Как создать небольшой локальный поисковик на своем сайте
Небольшой локальный поисковик — это более «приземленная» идея поисковой системы. И в некоторых ситуациях подобный поисковик будет работать эффективнее, чем глобальный Гугл с Яндексом. Например, когда вам нужно ограничить объем поиска. Допустим, у вас есть некий веб-ресурс, который ведет взаимоотношения с 500 поставщиками и 400 различными партнерами, плюс в качестве дополнительной информации вы используете еще 900 разных источников. Вы можете организовать собственную поисковую систему на 1000+ источников, чтобы вашим клиентам было проще искать нужную информацию, касающуюся ваших услуг или товаров. Если они будут это делать через глобальную поисковую систему, то в выдаче у них будет очень много «мусора», который, по сути, им никогда не пригодится. А ваша ПС даст именно те результаты, которые нужны вашим клиентам.
В качестве дополнения собственная тематическая ПС — это:
удобство поиска для ваших клиентов;
дополнительный способ монетизации вашего проекта;
много плюсов к вашему престижу, брендингу и узнаваемости.
Что самое интересное — подобные локальные системы организовать довольно просто. В сети есть масса готовых решений по этому поводу. Самое узнаваемое решение — это создать свой поисковик, используя поисковый потенциал Google. Для этого пройдите по ссылке.
Заключение
Теперь вы знаете, как можно создать свой поисковик. Если это будет глобальная поисковая система, то к этому нужно подготовиться финансово и морально. Если локальный поисковик на собственном сайте, то самый простой способ — это использовать готовое решение. При этом если вы с программированием на «ты», то для вас не составит труда создать свой собственный поисковик с нуля.




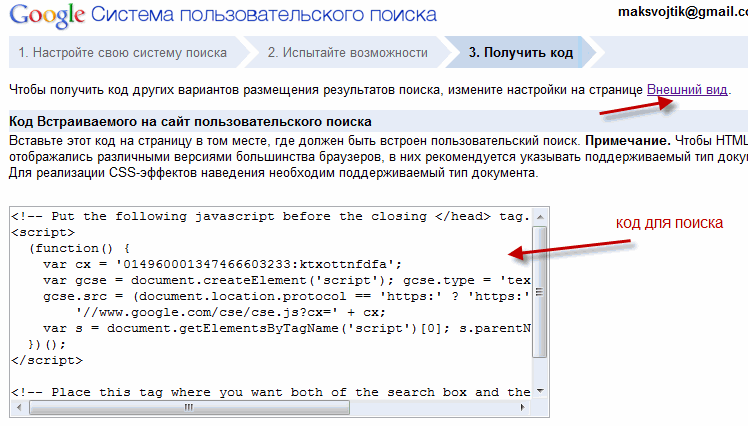
Как создать свою собственную систему пользовательского поиска Google
НЕКЕШЕРОВАННЫЙ КОНТЕНТ
Вы когда-нибудь хотели создать собственную поисковую систему Google, которая будет искать только определенные веб-сайты? Вы можете легко сделать это с помощью системы пользовательского поиска Google. Вы можете добавить свою поисковую систему в закладки и даже поделиться ею с другими людьми.
Этот трюк работает так же, как у Google сайт: оператор , но вам не нужно вводить оператор каждый раз при поиске. Это особенно полезно, если вы хотите выполнить поиск по большому количеству сайтов одновременно.
Создание системы пользовательского поиска
Для начала перейдите в
Система пользовательского поиска Google
страницу и нажмите кнопку Создать систему пользовательского поиска. Для этого вам понадобится учетная запись Google — поисковая система будет сохранена в вашей учетной записи Google.
Введите название и описание вашей поисковой системы — это может быть что угодно.
В Сайты для поиска Поле действительно имеет значение. Здесь вы указываете список веб-сайтов, на которых хотите выполнить поиск. Например, если вы хотите выполнить поиск как на howtogeek.com, так и на microsoft.com, вы должны ввести:
новтогеек.ком/*
микрософт.ком/*
Символ * — это подстановочный знак, который может соответствовать чему угодно, поэтому символы / * говорят вашей поисковой системе искать все на обоих этих веб-сайтах.
С этим ящиком можно делать и более сложные действия — мы вернемся к этому чуть позже.
После нажатия кнопки «Далее» вы можете указать стиль результатов поиска и протестировать созданную вами поисковую систему.
Как только вы будете довольны своей поисковой системой, нажмите кнопку «Далее» внизу страницы, и вы попадете на страницу, содержащую код встраивания для вашей поисковой системы.
Вы, вероятно, не веб-разработчик, поэтому не обращайте внимания на эту страницу. Вместо этого нажмите логотип Системы пользовательского поиска Google вверху страницы.
Чтобы перейти на страницу своей поисковой системы, щелкните ее название в списке созданных вами поисковых систем.
Вы можете добавить эту страницу в закладки для быстрого доступа к вашей поисковой системе. Вы также можете поделиться своей поисковой системой с кем угодно, отправив им полный URL-адрес, который отображается в вашей адресной строке.
Уловки URL
При создании системы пользовательского поиска необязательно указывать весь веб-сайт.
Например, указанная выше система пользовательского поиска выполняет поиск во всех областях microsoft.com. Если мы выполним пример поиска, мы можем увидеть, что полезная информация поступает из 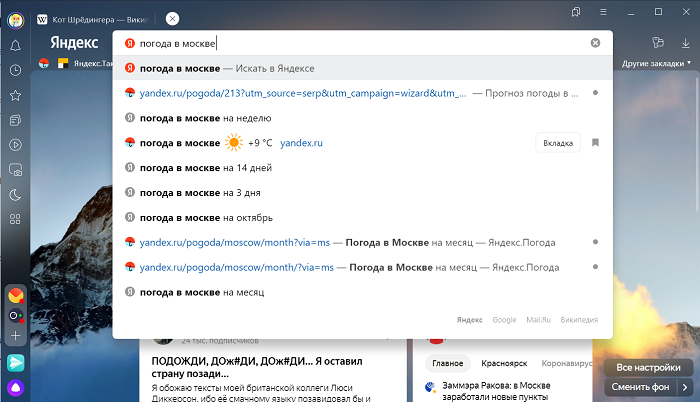 микрософт.ком , но результаты ансверс.микрософт.ком (Форум поддержки Microsoft) не очень полезны.
микрософт.ком , но результаты ансверс.микрософт.ком (Форум поддержки Microsoft) не очень полезны.
Чтобы исключить answers.microsoft.com и включить другие поддомены, мы могли бы использовать следующий список URL-адресов при создании поисковой системы:
новтогеек.ком/*
виндовс.микрософт.ком/*
суппорт.микрософт.ком/*
Обратите внимание, что нельзя исключить конкретный субдомен — мы можем включить только те, которые хотим найти. Этот список будет искать только два поддомена на microsoft.com.
В этом списке можно определить несколько других типов URL-адресов:
- Одна страница : Вы можете определить только одну конкретную страницу, введя ее URL, например эксампле.ком/паге.хтмл . Это будет включать только одну веб-страницу в поисковой системе.

- Часть веб-сайта : Вы можете использовать символ * по-другому. Например, URL суппорт.микрософт.ком/кб/* будет искать только статьи базы знаний Microsoft. Использование URL эксампле.ком/*ворд* будет искать все страницы на example.com, на которых есть слово в своих URL.
Вы можете продолжить тонкую настройку поисковой системы, пока не будете довольны результатами, нажав кнопку вернуться к шагу 1 ссылку, изменив URL-адреса, а затем выполните еще один тестовый поиск.
Когда вы закончите, вы можете даже добавьте свою систему пользовательского поиска в строку поиска своего браузера .
как создать поисковую систему
Поисковые технологии или в чем загвоздка написать свой поисковик
Когда-то давно взбрела мне в голову идея: написать свой собственный поисковик.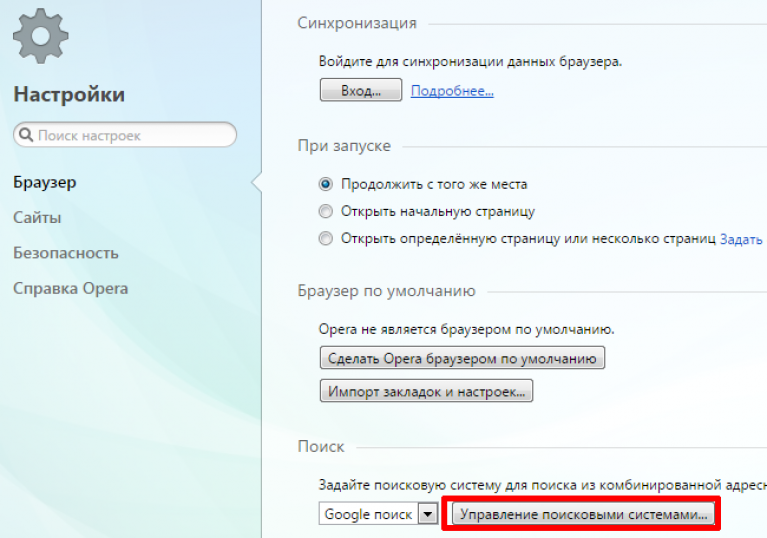 Было это очень давно, тогда я еще учился в ВУЗе, мало чего знал про технологии разработки больших проектов, зато отлично владел парой десятков языков программирования и протоколов, да и сайтов своих к тому времени было понаделано много.
Было это очень давно, тогда я еще учился в ВУЗе, мало чего знал про технологии разработки больших проектов, зато отлично владел парой десятков языков программирования и протоколов, да и сайтов своих к тому времени было понаделано много.
Ну есть у меня тяга к монструозным проектам, да…
В то время про то, как они работают было известно мало. Статьи на английском и очень скудные. Некоторые мои знакомые, которые были тогда в курсе моих поисков, на основе нарытых и мной и ими документов и идей, в том числе тех, которые родились в процессе наших споров, сейчас делают неплохие курсы, придумывают новые технологии поиска, в общем, эта тема дала развитие довольно интересным работам. Эти работы привели в том числе к новым разработкам разных крупных компаний, в том числе Google, но я лично прямого отношения к этому не имею.
На данный момент у меня есть собственный, обучающийся поисковик от и до, со многими нюансами – подсчетом PR, сбором статистик-тематик, обучающейся функцией ранжирования, ноу хау в виде отрезания несущественного контента страницы типа меню и рекламы. Скорость индексации примерно полмиллиона страниц в сутки. Все это крутится на двух моих домашних серверах, и в данный момент я занимаюсь масштабированием системы на примерно 5 свободных серверов, к которым у меня есть доступ.
Скорость индексации примерно полмиллиона страниц в сутки. Все это крутится на двух моих домашних серверах, и в данный момент я занимаюсь масштабированием системы на примерно 5 свободных серверов, к которым у меня есть доступ.
Здесь я в первый раз, публично, опишу то, что было сделано лично мной. Думаю, многим будет интересно как же работают Яндекс, Google и почти все мне известные поисковики изнутри.
Есть много задач при построении таких систем, которые почти нереально решить в общем случае, однако с помощью некоторых ухищрений, придумок и хорошего понимания как работает железячная часть Вашего компьютера можно серьезно упростить. Как пример – пересчет PR, который в случае нескольких десятков миллионов страниц уже невозможно поместить в самой большой оперативной памяти, особенно если Вы, как и я, жадны до информации, и хотите кроме 1 цифры хранить еще много полезностей. Другая задача – хранение и обновление индекса, как минимум двумерной базы данных, в которой конкретному слову сопоставляется список документов, на которых оно встречается.
Просто вдумайтесь, Google хранит, по одной из оценок, более 500 миллиардов страниц в индексе. Если бы каждое слово встречалось на 1 странице только 1 раз, и на хранение этого надо было 1 байт – что невозможно, т.к. надо хранить хотя бы id страницы – уже от 4 байт, так вот тогда объем индекса бы был 500гб. В реальности одно слово встречается на странице в среднем до 10 раз, объем информации на вхождение редко когда меньше 30-50 байт, весь индекс увеличивается в тысячи раз… Ну и как прикажите это хранить? А обновлять?
Ну вот, как это все устроено и работает, я буду рассказывать планомерно, так же как и про то как считать PR быстро и инкрементально, про то как хранить миллионы и миллиарды текстов страниц, их адреса и быстро искать по адресам, как организованы разные части моей базы данных, как инкрементально обновлять индекс на много сотен гигов, ну и наверное расскажу как сделать обучающийся алгоритм ранжирования.
На сегодня объем только индекса, по которому происходит поиск — 57Gb, увеличивается каждый день примерно на 1Gb.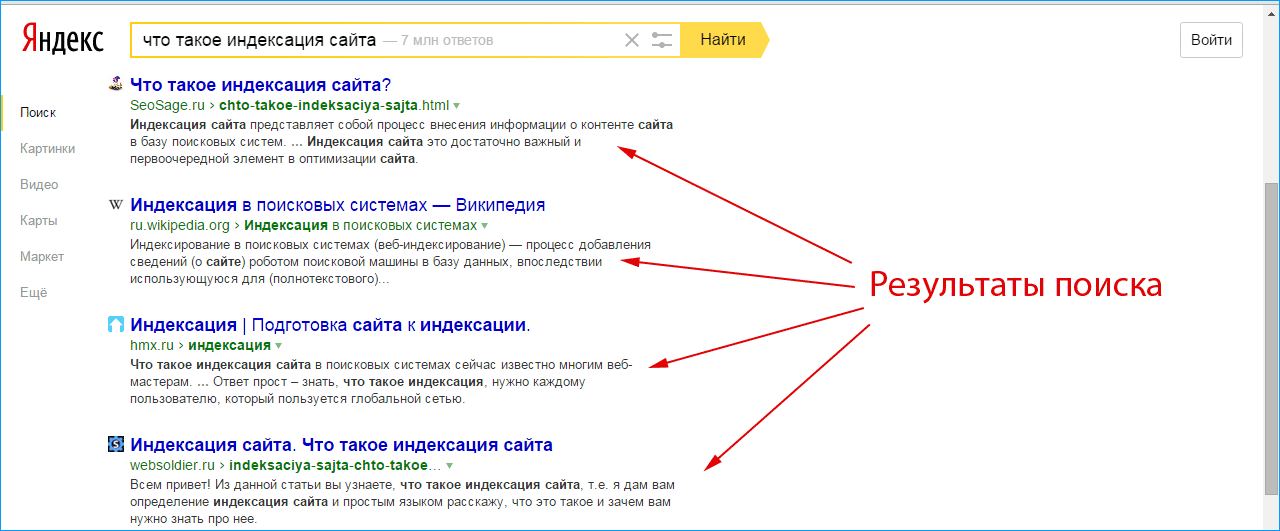 Объем сжатых текстов – 25Gb, ну и я храню кучу другой полезной инфы, объем которой очень трудно посчитать из-за ее обилия.
Объем сжатых текстов – 25Gb, ну и я храню кучу другой полезной инфы, объем которой очень трудно посчитать из-за ее обилия.
Как создать свою поисковую систему в интернете вроде Гугла, Яндекса?
Я думаю, что создание своей поисковой системы не должно составить уж очень большую проблему для человека или группы знакомых с основами программирования. Сложнее будет, и это составит львиную долю в статье расхода, раскрутить свой поисковик на фоне уже состоявшихся деятелей от гугла или яндекса. Ведь популярность того или иного поисковика зависит от удобства работы, скорости выдачи искомых материалов и тех вкусностей, ради которых пользователи гугла или яндекса, с радостью переключатся на ваш поисковик. Это не так уж и трудно будет, конечно при наличии у вас таких задумок и их грамотной реализации в поисковой системе. В конце концов гугл тоже испытал те же трудности и вышел на теперешние позиции.
На самом деле создать поисковую систему в интернете, довольно таки легко, и не требует больших финансовых затрат. Для этого существует куча различных решений(скриптов систем) как платных, так и бесплатных. Но вот создать систему которая сможет конкурировать и окупить себя быстро очень тяжело. Даже если иметь финансовые возможности для этого, выдержать конкуренцию с всеми привыкшими яндексом и гугле будет очень тяжело. Система должна быть не похоже на гугле или яндекс, чтоб люди начали пользоваться ей. Примеров много когда проект имея большие финансовые возможности не мог конкурировать легально с привыкшими нам поисковикам и прибегал даже к черным технологиям, когда устанавливался в качестве домашней страницы без ведома пользователя. Потому что на сегоднешней день переиграть гугле и яндекс и другие старые системы поиска без каких-то ноу-хао практически не реально.
Для этого существует куча различных решений(скриптов систем) как платных, так и бесплатных. Но вот создать систему которая сможет конкурировать и окупить себя быстро очень тяжело. Даже если иметь финансовые возможности для этого, выдержать конкуренцию с всеми привыкшими яндексом и гугле будет очень тяжело. Система должна быть не похоже на гугле или яндекс, чтоб люди начали пользоваться ей. Примеров много когда проект имея большие финансовые возможности не мог конкурировать легально с привыкшими нам поисковикам и прибегал даже к черным технологиям, когда устанавливался в качестве домашней страницы без ведома пользователя. Потому что на сегоднешней день переиграть гугле и яндекс и другие старые системы поиска без каких-то ноу-хао практически не реально.
Как создать свой поисковик и возможно ли это сделать самостоятельно?
Как создать свой поисковик и создать конкуренцию известным «поисковым гигантам»
Пользовательский интерфейс.
Базы данных с сайтами для их индекса.
Поисковый робот, который будет обходить сайты и обновлять /добавлять информацию о них в базу данных.

нанять высококвалифицированных специалистов и организовать им рабочее пространство;
оборудовать собственный дата-центр или арендовать мощности у надежной компании;
быть готовым в течение нескольких лет терпеть убытки.
Как создать небольшой локальный поисковик на своем сайте
удобство поиска для ваших клиентов;
дополнительный способ монетизации вашего проекта;
много плюсов к вашему престижу, брендингу и узнаваемости.
Заключение
Теперь вы знаете, как можно создать свой поисковик. Если это будет глобальная поисковая система, то к этому нужно подготовит ь ся финансово и морально. Если локальный поисковик на собственном сайте, то самый простой способ — это использовать готовое решение. При этом если вы с программированием на «ты», то для вас не составит труда создать свой собственный поисковик с нуля.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Создание собственной поисковой системы с нуля | Дэвид Ястремский
Сколько раз в день вы просматриваете Интернет? 5, 20, 50? Если Google является вашей предпочтительной поисковой системой, вы можете просмотреть свою историю поиска здесь.
Несмотря на то, насколько глубоко поиск лежит в основе нашей повседневной деятельности и взаимодействия с миром, немногие из нас понимают, как он работает. В этом посте я работаю, чтобы осветить основы поиска. Это от реализации поисковой системы, основанной на оригинальной реализации Google.
Photo by Benjamin Dada on UnsplashСначала мы рассмотрим предварительный шаг: понимание веб-серверов . Что такое клиент-сервер инфраструктура ? Как ваш компьютер подключается к веб-сайту?
Вы увидите, что происходит, когда поисковая система подключается к вашему компьютеру, веб-сайту или чему-либо еще.
Затем мы рассмотрим три основные части поисковой системы: сканер, индексатор и алгоритм PageRank . Каждый из них даст вам глубокое понимание связей, составляющих паутина это интернет.
Наконец, мы рассмотрим, как эти компоненты объединяются, чтобы получить наш финальный приз: поисковую систему ! Готовы погрузиться? Пойдем!
Мощный веб-сервер! Веб-сервер — это то, с чем ваш компьютер связывается каждый раз, когда вы ищете URL-адрес в своем браузере. Ваш браузер действует как клиент, отправляя запрос, подобно бизнес-клиенту. Сервер — это торговый представитель, который принимает все эти запросы и обрабатывает их параллельно.
Запросы являются текстовыми. Сервер знает, как их читать, поскольку ожидает их в определенной структуре (самый распространенный протокол/структура сейчас — HTTP/1.1).
Пример запроса:
GET /hello HTTP/1.1
Агент пользователя: Mozilla/4.0 (совместимый; MSIE5.01; Windows NT)
Хост: www.
Accept-Language : en-us
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: user=why-david-y
 sample-why-david-y.com
sample-why-david-y.com Запрос может иметь аргументы, заданные его списком файлов cookie. У него может быть тело с дополнительной информацией. Ответ следует аналогичному формату, позволяя серверу возвращать аргументы и тело для чтения клиентами. Интернет становится все более интерактивным, вся тяжелая работа по созданию контента выполняется на сервере.
Если вы когда-нибудь захотите запрограммировать веб-сервер или клиент, вам доступно множество библиотек для выполнения большей части синтаксического анализа и низкоуровневой работы. Просто имейте в виду, что запросы клиентов и ответы сервера — это всего лишь способ структурирования текста. Это значит, что мы все говорим на одном языке!
Если вы создаете поисковую систему, поисковый робот — это то, на что вы тратите большую часть времени. Сканер просматривает открытый Интернет, начиная с предопределенного списка сидов (например, Wikipedia. com, WSJ.com, NYT.com). Он прочитает каждую страницу, сохранит ее и добавит новые ссылки в свою границу URL-адресов, которая представляет собой очередь ссылок для сканирования
com, WSJ.com, NYT.com). Он прочитает каждую страницу, сохранит ее и добавит новые ссылки в свою границу URL-адресов, которая представляет собой очередь ссылок для сканирования
Почему здесь так много времени? Интернет очень неструктурирован, мечта анархиста. Конечно, у нас могут быть некоторые нормы, с которыми мы согласны, но вы никогда не поймете, насколько они нарушены, пока не напишете сканер .
Например, ваш поисковый робот читает HTML-страницы, поскольку они имеют структуру. Автор все еще может, например, поместить не-ссылки в теги ссылок, которые нарушат некоторую неявную логику в вашей программе. Это могут быть электронные письма (test@test.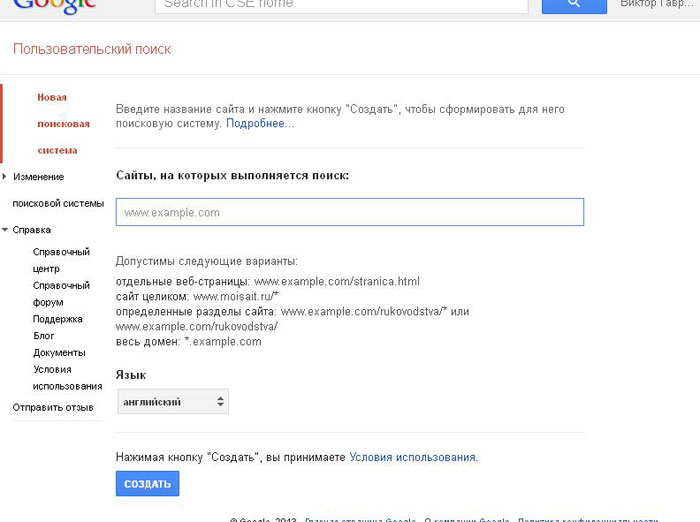 com), предложения и другой текст, который может быть пропущен при проверке.
com), предложения и другой текст, который может быть пропущен при проверке.
Возможно, вы сканируете страницу, которая каждый раз выглядит по-разному, но на самом деле генерирует динамическое содержимое, например включая текущее время? Что, если страница A перенаправляет на B, B перенаправляет на C, а C перенаправляет на A? Что, если в календаре есть бесчисленные ссылки на будущие годы или дни?
Это некоторые из многих случаев, которые могут возникнуть при сканировании миллионов страниц , и каждый пограничный случай должен быть покрыт или устранен .
После того, как вы сохранили просканированный контент в базе данных, наступает очередь индексации! Когда пользователь ищет термин, он хочет получить точные результаты быстро. Вот где индексация так важна. Вы сами решаете, какие показатели для вас наиболее важны, а затем извлекаете их из просканированного документа. Вот некоторые из них:
- Прямой индекс : Это структура данных, содержащая список документов со связанными с ними словами по порядку. Например:
 Например:
Например:документ1, <слово1, слово2, слово3>
документ2, <слово2, слово3>
- Инвертированный индекс : Это структура данных, содержащая список слов с документами с этим словом. Например:
слово1, <документ2, документ3, документ4>
слово2, <документ1, документ2>
- Частота терминов (TF) : это показатель, сохраняемый для каждого уникального слова в каждом документе. Обычно он рассчитывается как количество вхождений этого слова, деленное на количество слов в документе, в результате чего получается значение от 0 до 1. Некоторые слова могут иметь больший вес (например, специальные теги), и TF может быть нормализован. предотвращение экстремальных значений.
- Обратная частота документа (IDF) : Это показатель, сохраняемый для каждого уникального слова. Обычно он рассчитывается делением количества документов с этим словом на общее количество документов. Учитывая, что для этого требуется количество документов, оно обычно рассчитывается после сканирования или во время запроса. Это может быть нормализовано, чтобы предотвратить экстремальные значения.
С помощью этих четырех значений вы можете разработать индексатор, который позволит вам возвращать точные результаты. Благодаря оптимизации текущих баз данных результаты также будут достаточно быстрыми . Используя MongoDB, наш проект использовал их для возврата результатов примерно за 2 секунды даже для более длинных запросов. Вы можете сделать еще больше, используя только эти четыре показателя, например, разрешая запросы на точное соответствие.
Это были основные показатели, используемые поисковыми системами в первые дни. Теперь поисковые системы используют их и многое другое для дальнейшей точной настройки своих результатов.
Как их объединить для получения результатов? Мы обсудим это в разделе интеграции.
PageRank — это алгоритм, определяющий авторитетность страницы в Интернете. Скажем, кто-то ищет «День Земли». Нам нужно посмотреть, насколько надежна страница. Если мы этого не сделаем, наша поисковая система может отправить их на случайную страницу блога, на которой снова и снова написано «День Земли», а не на страницу Википедии или EarthDay.org. При распространении SEO и маркетологов, пытающихся привлечь трафик на страницу, как мы можем гарантировать, что пользователи получат качественные результаты?
Нам нужно посмотреть, насколько надежна страница. Если мы этого не сделаем, наша поисковая система может отправить их на случайную страницу блога, на которой снова и снова написано «День Земли», а не на страницу Википедии или EarthDay.org. При распространении SEO и маркетологов, пытающихся привлечь трафик на страницу, как мы можем гарантировать, что пользователи получат качественные результаты?
PageRank просматривает ссылки между страницами, рассматривая их как граф (набор узлов и вершин) . Каждая вершина представляет собой соединение между двумя узлами в том направлении, в котором она указывает (URL-адрес источника к URL-адресу назначения)
На каждой итерации алгоритм просматривает все URL-адреса, указывающие на страницу, скажем, Google.com. Он дает Google некоторый процент от PageRank своих рефереров в зависимости от того, сколько других URL-адресов также указывают эти страницы. После нескольких итераций значения PageRank становятся относительно стабильными, и алгоритм завершает работу.
Используются и другие уловки, такие как случайный просмотр, который предполагает, что некоторый процент времени пользователь получает скучно и переходит на новую страницу. Эти уловки направлены на то, чтобы избежать угловых случаев с PageRank. Например, приемники — это страницы, которые могут поглотить весь PageRank из-за отсутствия исходящих ссылок.
Теперь у вас есть основные части для поисковой системы.
Когда пользователь выполняет поиск по фразе, вы ищете, в каких документах содержится каждое из условий запроса. Ваша база данных возвращает документы, которые соответствуют всем терминам.
Для каждого документа вы можете взять TFIDF (TF * IDF) для каждого термина запроса и суммировать их вместе. Затем объедините сумму с PageRank этой страницы (например, перемножив их вместе) . Это больше искусство, чем наука, так что оставьте время, чтобы увидеть, что работает, настраивая по ходу дела .
Теперь ваш движок может возвращать отсортированные результаты всякий раз, когда клиент отправляет запрос на URL-адрес вашего сервера. Как обсуждалось в части 0, вся эта работа выполняется на сервере. Клиент делает запрос, и ваш сервер возвращает результаты клиенту в ожидаемом формате.
Отсюда вы можете:
- Добавить новые показатели индексации в свою базу данных для получения более качественных результатов
- Оптимизировать запросы для ускорения выполнения запросов
- Встроить новые функции в свой движок теперь вы можете создать свою собственную поисковую систему! Фото Маркуса Винклера на Unsplash
Пять шагов для создания интеллектуальной поисковой системы с нуля
Иногда, устав от общих поисковых систем, наши клиенты хотят сделать что-то другое или более конкретное. В этом случае было бы неплохо создать собственную поисковую платформу с собственным хостингом. Сегодня несложно создать интеллектуальную поисковую программу с помощью существующих технологий с открытым исходным кодом.
Конечно, этот процесс непрост и в некоторых моментах довольно сложен. Также нужно быть готовым к долгосрочному запуску, ведь на сканирование всех данных, а также их обработку и анализ уходит не один месяц.
Благодаря нашему опыту даже новичок может разработать простую поисковую систему для полуструктурированных данных примерно за несколько недель. Но каждый раз разработка поисковой системы — это немного другой процесс из-за постоянного развития технологий.
Надеюсь, есть несколько общих шагов, с которыми мы обычно сталкиваемся, отвечая на вопрос о том, как создать поисковую систему с нуля, и эти шаги мы раскрываем в этой статье. Наша команда надеется, что эта статья поможет вам понять ключевые этапы и сэкономит вам несколько дней на первоначальных исследованиях.
АНАЛИЗ ИСХОДНЫХ ДАННЫХ
Перед началом разработки нам необходимо проанализировать исходные данные, чтобы понять, какие алгоритмы поиска лучше всего подходят для ваших данных.
Данные могут быть структурированными, неструктурированными и частично структурированными:
- Например, структурированные данные — это любые данные, содержащие фиксированное поле, определенный файл или запись. Матрицы, структурированные таблицы и реляционные (SQL) базы данных также можно рассматривать как структурированные данные. Во время начального анализа данных специалист по данным изучает, очищает и преобразует данные, чтобы найти атрибуты.
- Если мы работаем со структурированными данными, мы можем классифицировать данные по разным группам, используя атрибуты данных — уникальные свойства, которые отличают одну запись от другой.
- Если данные неструктурированы — например, фотографии, видео, изображения, документы — самый простой способ поиска в этих данных — преобразовать их в структурированный или полуструктурированный формат с использованием различных методов. В зависимости от типа данных специалисты по данным разрабатывают способ обработки этих данных, чтобы предотвратить ложноположительные результаты.
Этот важный шаг позволяет нам продвинуться вперед к важному результату – согласно нашему опыту, это занимает около 40 минут за все время.
АНАЛИЗ ЗАПРОСОВ ПОЛЬЗОВАТЕЛЯ
Следующим шагом в развитии поисковой системы является анализ запросов пользователей.
На этом этапе специалист по данным анализирует:
- Как пользователь формирует входящий запрос
- Как извлечь из него параметры
- Как эти параметры взаимосвязаны.
Для сложных данных вводить простой запрос в поисковую строку не лучший вариант — нужно разработать конкретный язык запросов, который поможет клиенту быстро и эффективно искать данные по комбинации атрибутов.
Если вы ищете альтернативу для разработки определенного языка запросов, мы предлагаем вам попробовать машинное обучение для извлечения данных из поисковых запросов. Машинное обучение можно использовать для создания семантической поисковой системы на основе расширенного модуля анализа текста.
Основная особенность семантической поисковой системы — она помогает обрабатывать естественный язык, автоматически извлекая атрибуты объектов из поисковых запросов. Он также находит отношения между различными входными характеристиками, которые впоследствии используются для эффективного поиска данных.
РАЗРАБОТКА АЛГОРИТМА ПОИСКОВОЙ СИСТЕМЫ
Существуют различные алгоритмы поиска: разные алгоритмы используются для поиска разных типов данных. Применение неправильного алгоритма к определенным данным может привести к значительному снижению производительности, а поиск общих данных может занять гораздо больше времени, чем ожидалось.
Еще один факт, который следует учитывать – существующие реализации конкретных алгоритмов поиска. Наиболее популярными языками программирования для создания поисковых систем являются Python, Java, PHP, Ruby и C#. Вы можете легко найти различные реализации на GitHub.
Но давайте рассмотрим более конкретный пример — алгоритм поиска строк Бойера–Мура — его можно написать с помощью различных языков программирования. Но важно, чтобы алгоритм, разработанный на C++, работал лучше, чем тот же алгоритм, написанный на PHP.
При разработке интеллектуальной поисковой системы вам необходимо понимать слабые места языка программирования и алгоритма, которые вы планируете использовать.
Это, наверное, не проблема для новичка, но особенно сложно при разработке решения для крупного предприятия.Давайте рассмотрим другой пример, текстовый поиск. Текстовый поиск часто основан на так называемом сопоставлении строк — методе поиска строк, соответствующих определенному шаблону.
Существует несколько типов сопоставления строк: наиболее распространенными являются строгое и нечеткое (приблизительное сопоставление строк). Строгое соответствие — это тип сопоставления, когда данные полностью соответствуют шаблону, а нечеткое сопоставление — когда только часть шаблона соответствует части данных.
Если мы копнем немного глубже, мы обнаружим, что одни и те же правила работают как для строк, так и для сложных объектов. Отлично, когда система находит объект, соответствующий запросу пользователя, но чаще всего не может. В этой ситуации движок оценивает существующие записи и ранжирует их.
Машинное обучение может значительно улучшить этот процесс — оно может анализировать не только пользовательский ввод, но и оценивать данные, имеющие схожие атрибуты с запрошенным объектом.
Вы также можете использовать машинное обучение напрямую. Это даст поисковой системе возможность изучать наиболее релевантные поисковые запросы и постоянно совершенствоваться без ручного программирования.ОЦЕНКА И НАСТРОЙКА АТРИБУТОВ
Четвертым этапом разработки интеллектуальной поисковой системы является настройка SERP. SERP расшифровывается как страница результатов поисковой системы — это страница, созданная поисковой системой, на которой отображаются все релевантные результаты.
Когда поисковая система находит несколько релевантных результатов, она должна расположить их в правильном порядке, чтобы удовлетворить пользователя. Результаты размещаются в правильном порядке из-за оценки атрибутов. Каждый объект, найденный поисковой системой, имеет набор атрибутов или параметров, описывающих конкретную запись.
Каждый атрибут имеет числовое значение, называемое « вес », и эти значения суммируются поисковой системой для определения правильного порядка результатов.
На этом этапе мы обычно анализируем поведение поисковой системы и настраиваем веса атрибутов, чтобы получить результат, который удовлетворит клиента.Машинное обучение может значительно улучшить оценку атрибутов. Благодаря продвинутому машинному обучению мы можем анализировать цепочку поисковых запросов — то, как пользователь ищет конкретную запись.
Принимая во внимание историю поиска, мы можем рассчитать точные веса, динамически корректируя или уменьшая значения в соответствии с уже просмотренными пользователем результатами . С помощью машинного обучения легко анализировать наиболее популярные записи и автоматически выдвигать их наверх, не искажая пользователя или инженера-программиста.
СОЗДАНИЕ СТРАНИЦ РЕЗУЛЬТАТОВ ПОИСКОВОЙ ДВИГАТЕЛЯ
Последним этапом разработки интеллектуальной поисковой системы является генерация SERP. Мы уже упоминали, что SERP — это страница результатов поисковой системы — конкретная страница, на которой пользователь может увидеть релевантные результаты поисковому запросу.
Когда обычный человек думает о том, как должны выглядеть результаты поисковой системы, он обычно представляет себе Google или Yahoo.Что ж, надо признать – Google SERP выглядит хорошо и отображает информацию просто. Но пока мы говорим о более конкретных поисковых системах, пользовательский интерфейс может быть совсем не простым.
Пример страницы результатов поисковой системы из одного из наших последних проектовПоскольку каждая поисковая система обеспечивает поиск данных по различным типам данных, это типичная ситуация, когда страницы результатов выглядят по-разному. Обычно рекомендуется отображать список атрибутов, извлеченных из поискового запроса, но иногда это может быть сложно, так как могут быть сотни различных взаимосвязанных атрибутов.
Промышленные поисковые системы обычно имеют динамический пользовательский интерфейс , созданный с использованием популярных интерфейсных фреймворков, таких как React или Vue.
Эти фреймворки позволяют просматривать богатые результаты поисковой выдачи без перезагрузки страницы, что снижает нагрузку на веб-сервер.Итак, если вы думаете о создании поисковой системы для сложных данных, вам следует подумать о том, как легко визуализировать результаты и какие технологии использовать.
ИТОГ
Мы живем в увлекательном мире данных, поэтому невозможно представить нашу жизнь без современных поисковых систем, таких как Google или Yahoo. Но есть также типы данных, которые обычные поисковые системы не могут обработать, и для этих данных вам, вероятно, понадобится что-то другое.
Если вы думаете о том, как сделать свою собственную поисковую систему для сложных структурированных или неструктурированных данных, пункты, перечисленные в этой статье, будут вам полезны — теперь вы знаете, с чего начать и с какими проблемами вы можете столкнуться.
В Азати мы уже создали дюжину различных поисковых систем для нескольких клиентов в различных отраслях, таких как: розничная торговля, биоинформатика, подбор персонала и т.
д., и у нас есть интересный опыт, которым можно поделиться. Итак, если вы сейчас разрабатываете свой движок или только думаете об этом — напишите нам, и мы поговорим об этом. Создание поисковой системы с нуля | by Halvor Fladsrud Bø
Задумывались ли вы когда-нибудь, что происходит, когда вы вводите «в чем смысл жизни» в Google?
Если да, это означает две вещи:
- У нас много общего.
- Возможно, эта статья покажется вам интересной.
Поисковые системы бесконечно сложны. Миллионы серверов: собирают веб-сайты из Интернета, хранят и собирают информацию, выполняют огромные матричные вычисления и постепенно приближают мир к сингулярности.
Тем не менее, основы того, что делает поисковая система, относительно просты. Вы задаете ему вопрос в форме запроса. Поисковая система находит страницы, релевантные данному запросу. На определение релевантности определенной страницы определенному запросу влияет множество факторов, но самый важный из них:
Соответствует ли текст на странице тексту, указанному пользователем в запросе.
Мы сделаем еще один шаг вперед и создадим полнофункциональную систему полнотекстового поиска на Python, которая воспроизводит функции Google, о существовании которых вы, вероятно, даже не подозревали.
Полнотекстовый поиск можно определить как возможность масштабируемым образом запрашивать термины в наборе документов. Этот термин чаще всего встречается как рекламируемая функция базы данных. Давайте сломаем это.
Документ : Набор слов.
Сделай это. Просто сделай это. Не позволяй своим мечтам оставаться мечтами. Вчера ты сказал завтра. Так что просто сделай это. Воплотите свои мечты в жизнь. Просто сделай это. Кто-то мечтает об успехе, а ты проснешься и будешь упорно трудиться. Нет ничего невозможного. Вы должны дойти до того момента, когда любой другой уволится, и вы не собираетесь останавливаться на достигнутом. Нет, чего ты ждешь? Сделай это! Просто сделай это! Да, ты можешь. Просто сделай это.
Если вы устали начинать сначала, перестаньте сдаваться.
Термин : чаще всего слово в документе .
только
Токен: Все экземпляры термина в документе .
… Не позволяй своим мечтам стать мечтами . … Воплотите свои мечты в реальность. …
Запрос : Вопрос в формате определенного языка запросов.
просто сделать
Срок просто или срок сделать .
Это непросто сделать с помощью обычного индекса базы данных. Что делает обычный индекс базы данных, так это то, что он хранит упорядоченное сопоставление значений строк с индексами строк. Типичная структура данных обычно представляет собой упорядоченную карту (например, реализованную с помощью B-дерева).
Это позволяет обеспечить эффективный диапазон и точное совпадение запросов. Это означает, что легко ответить на такие вопросы, как:У кого есть имя пользователя «боб»?
Сколько пользователей в возрасте от 5 до 15 лет?Эти вопросы не имеют отношения к документам. Вы никогда не будете искать в Google все содержание статьи в Википедии. Вас скорее интересуют документы, содержащие определенные слова или фразы. Обычный индекс не позволяет вам сделать это эффективно.
Здесь на помощь приходит полнотекстовый поиск, позволяющий эффективно выполнять запрос выше («просто сделайте»), а также такие запросы, как:
просто И делать
Срок просто и срок делать .
«просто сделай»
Точная фраза « просто сделай».
просто — сделать
Срок просто но не срок сделать .
просто-сделать
Срок просто , но не термин до .
делать И «можешь» -завтра
Срок делать и фраза « можно », но не срок завтра .
Если вы хотите освоить полнотекстовый поиск прямо сейчас, попробуйте ввести приведенные выше запросы в Google. Все эти запросы понимает Google. Самая распространенная поисковая система с открытым исходным кодом, используемая миллионами сайтов, Elasticsearch также понимает все вышеперечисленные запросы.
В случае с Google многие из перечисленных выше типов запросов также будут неявно использоваться. Например, когда вы ищете Сан-Франциско, он будет искать точные совпадения, даже если вы явно не сказали, что говорите о городе Сан-Франциско.
Google Elasticsearch
Но подождите, становится лучше.
Каждый документ получает балл.Оценка : Поисковые системы присваивают оценку каждому документу по определенному запросу.
9000.001
Elasticsearch построен на основе Lucene, библиотеки полнотекстового поиска, использующей алгоритм под названием tf-idf. Не вдаваясь в подробности, документ будет оцениваться на основе того, сколько раз термин встречается в документе по сравнению с тем, насколько он распространен в целом.
TL;DR: Сначала мы разбиваем документ на токены. Затем мы вставляем токены в инвертированный индекс. Наконец, мы используем этот инвертированный индекс для эффективного выполнения запросов.
Создание поисковой системы — нетривиальная задача. Тысячи инженеров участвуют в создании таких сервисов, как Google, Bing и Elasticsearch.
Чтобы уместить весь процесс в сообщение в блоге, я сделал несколько упрощений:
- Наша библиотека поддерживает только указанные выше типы запросов.
- Мы используем самую простую структуру данных, которая выполнит эту работу.
- Мы индексируем все данные, а затем запрашиваем их. Обычные библиотеки полнотекстового поиска поддерживают так называемое добавочное индексирование — это означает, что вы можете добавлять документы в индекс и выполнять запросы во время индексирования.
- Мы игнорируем такие темы, как планирование запросов, AST и сжатие.
На каждую из этих тем я планирую написать отдельные посты. Реализация должна дать хорошее понимание того, как работает оптимизированная библиотека. Например, наша реализация для точных запросов использует те же высокооптимизированные библиотеки, что и Lucene и Tantivy, только гораздо медленнее.
Конвейер
Индексирование можно рассматривать как конвейер, где последним шагом является запрос.
- Документы: Начнем с комплекта документов. Откуда они берутся, выходит за рамки этого поста в блоге. В своих примерах я использую 3 мотивационных выступления, хранящихся в локальной файловой системе.
- Анализ: Как упоминалось выше, нам нужно разбить документ на термины. Наиболее распространенный способ сделать это — записать все слова в нижнем регистре — так мы и поступим.
- Индекс: Это когда мы вставляем токены в структуру данных, которую собираемся запрашивать.
- Запрос: Мы преобразуем неявную логику запроса (предоставленную языком запросов) в эффективный поиск нужных документов.
Визуально это выглядит так.
Итак, приступим.
Анализ
Как указано выше, целью этого шага является преобразование строк документа в токены, а метод заключается в извлечении слов нижнего регистра. Приведенный ниже метод очень примитивен и не работает во многих случаях правильно, но для демонстрационных целей он работает.
def tokenize(document: str) -> List[str]:
# преобразовать документ в нижний регистр
lowercase_document = document.lower()
# извлечь все слова с помощью регулярного выражения
слова = re. findall(r"\w+", нижний регистр_документа)
возвращаемый список(слова)tokenized_documents = [tokenize(document) для документа в документах]для tokenized_document в tokenized_documents:
print(tokenized_document[:3], ".. .", tokenized_document[-3:])[‘дюйм’, ‘на’, ‘дюйм’] … [‘ты’, ‘собираюсь’, ‘сделать’]
[‘просто’, ‘сделать’, ‘это’] … [‘стоп’, ‘дать’, ‘вверх’]
[‘то’, ‘преследование’, ‘из’] … [‘получить’, ‘это’, ‘точка’]Сейчас у нас есть токены для каждого документа.
Индексирование
Следующим шагом является преобразование токенов в структуру данных, которую можно легко запрашивать. Это называется инвертированный индекс.
Требования к инвертированному индексу заключаются в том, что вы можете легко определить, в каких документах он находится. Многим сразу же придет в голову HashMap. В реальной поисковой системе индекс представляет собой ансамбль различных структур данных.
inverted_index = {}для document_id, tokenized_document в перечислении (tokenized_documents):
для token_index, token in enumerate(tokenized_document):
token_position = (document_id, token_index)
if token inverted_index:
inverted_index[token]. append(token_position)
else:
inverted_index[token] = [token_position]print(" просто ->", inverted_index["the"])
print("do ->", inverted_index["the"])just -> [(1, 0), (1, 5), (1, 20), (1, 28), (1, 76), (1, 82)]
do -> [(0, 94), (0, 399), (0, 455), (0, 493), (1, 1), (1, 3), (1, 6), (1, 21), (1, 29)), (1, 74), (1, 77), (1, 83), (2, 15), (2, 33), (2, 44)]Причина, по которой мы сохраняем позиции каждого термина, а не частоты, заключается в том, что он позволяет выполнять эффективные запросы на точное соответствие.
Запрос
Мы хотим поддерживать следующие операторы:
- OR : Учитывая, что между двумя терминами нет оператора, мы предполагаем, что существует отношение ИЛИ, поэтому, учитывая «a b», мы интерпретируем это как «a ИЛИ б».
- И: Если между двумя терминами есть оператор «И», мы возвращаем только те документы, которые соответствуют обоим терминам.
- ВКЛЮЧИТЬ : Если термину предшествует «+», мы исключаем все документы, которые не содержат этот термин.
- ИСКЛЮЧИТЬ: Если термину предшествует «-», мы исключаем все документы, содержащие этот термин.
У нас также есть возможность точного соответствия. Все, что заключено в кавычки, будет рассматриваться как один термин, и будут возвращены только те документы, которые точно совпадают.
Я использую следующий алгоритм:
- Разделите запрос на список, содержащий как операторы, так и термины.
- Оцените запрос слева направо за один проход, отслеживая текущую оценку каждого документа, какие документы были исключены и какие документы были включены.
- В конце верните идентификаторы документов в виде списка, отсортированного по количеству баллов, с отфильтрованными правильными документами на основе включения и исключения.
В этом алгоритме отсутствует одна вещь: мы не поддерживаем круглые скобки.
Это еще более усложнило бы это и без того чрезвычайно сложное объяснение.Структура алгоритма
Рассмотрим следующий запрос:
сделать И «вы можете» -завтра
Первый шаг — разделить термины и операторы в запросе.
query_expressions = re.findall(r"[\"\-\+]|[\w]+", query)
[‘делать’, ‘И’, ‘“’, ‘вы’, ‘можете ‘, ‘“’, ‘-‘, ‘завтра’]
Затем мы инициируем глобальное состояние, которое мы будем обновлять по мере обработки запроса.
document_scores: DocumentScores = {}
exclude_document_ids: Set[DocumentId] = set()
include_document_ids: Set[DocumentId] = set()Алгоритм оценки использует режим и указатель. По умолчанию режим установлен на ИЛИ , но когда он достигает операнда, он меняет его на соответствующий режим. Способ обработки термина зависит от режима. Точные совпадения обрабатываются так же, как термины, за исключением более сложной логики для получения оценки.
режим = режим.ИЛИ
указатель = 0, в то время как указатель < len(query_expressions):
query_expression = query_expressions[pointer]
if query_expression in MODES:
# установить режим
else:
if query_expression == QUOTE:
# обработать EXACT CASE
new_document_scores = ...
# установить указатель на расположение закрывающей цитаты
else:
# обработка TERM CASE
new_document_scores = ...
# обновление глобальных переменных переменных
# использование new_document_scores и режима
# И, ИЛИ, ВКЛЮЧИТЬ, ИСКЛЮЧИТЬ
указатель += 1# вычислить итоговые баллы
# фильтрация на основе исключения и включенияВычисление оценок
TERM CASE
Чтобы получить оценку для термина, мы сначала получаем все позиции токенов из инвертированного индекса.
token_positions = inverted_index[term]document_term_scores = term_scores(token_positions)
document_term_scores = {1: 10, 5: 3, 5: 3} Основной алгоритм:
- Начните с первого члена.
- Найти все расположения токенов, соответствующие термину.
- Вычислить ожидаемые следующие местоположения. Итак, где в документе будет следующий ожидаемый термин.
- Пока терминов больше, повторите описанный выше процесс.
Фактический код более сложен для обработки различных случаев ошибок, но счастливый путь эквивалентен следующему:
указатель += 1matches = [
(document_id, token_position + 1)
для document_id, token_position в inverted_index.get (
query_expressions[pointer], []
)
]pointer += 1while query_expressions[pointer] != QUOTE:
если не совпадает:
break
term = query_expressions[pointer]
совпадения = next_token_position_matches(inverted_index[term], совпадения)
указатель += 1document_term_scores = term_scores(token_positions)Метод term_scores
Метод подсчета очков, используемый в этом примере, представляет собой простое количество раз, когда термин появляется в документе.
Метод расчета выглядит следующим образом:def term_scores(token_positions: TokenPositions) -> DocumentScores:
document_term_scores: DocumentScores = {}
for document_id, _ in token_positions:
if document_id в document_term_scores:
document_term_scores[document_id] += 1
document_scores[document_id] else: = 1
return document_term_scoresОбновление глобальных переменных на основе режима
Когда мы вычислили document_term_scores, нам нужно объединить их с глобальным состоянием. Как мы это делаем, зависит от режима.
ИЛИ
Операция ИЛИ проста и просто добавляет текущие баллы.
def merge_or (текущий: DocumentScores, новый: DocumentScores):
для document_id, оценка в new.items():
, если document_id в текущем:
текущий [document_id] += оценка
еще:
текущий [document_id] = оценкаИ
При вычислении И нам нужно удалить документы, которые не содержат термин, и добавить только те термины, которые уже существуют в таблице результатов.
9set(new.keys())
для document_id в списке(current.keys()):
, если document_id в filtered_out и document_id в текущем:
del current[document_id]
для document_id, оценка в списке(new.items()) ):
, если document_id не в filtered_out:
current[document_id] += scoreВыше я использую некоторую магию набора, но это эквивалентно разнице.
ВКЛЮЧИТЬ
include_document_ids.update(document_term_scores.keys())
ИСКЛЮЧИТЬ
exclude_document_ids.update(document_term_scores.keys())
Вычисление результатов
В конце мы отфильтровываем документы, которые должны быть исключены или не были явно включены.
возвращаемый список(
отсортированный(
(
(document_id, оценка)
для document_id, оценка в document_scores.items()
если (no_include_in_query или document_id в включенных_документах)
и document_id не в exclude_document_ids x=lambda ключ
),
: -х[1],
)
)Результат будет следующим:
[(1, 'ПОГОНА СЧАСТЬЯ', 5)]
Некоторые другие примеры.
просто сделай
[(2, 'ПРОСТО СДЕЛАЙ ЭТО', 14), (0, 'ДЮЙМ ЗА ДЮЙМОМ', 4), (1, 'В ПОИСКАХ СЧАСТЬЯ', 3)]
просто И сделай
[( 2, 'ПРОСТО СДЕЛАЙ ЭТО', 14)]
"просто сделай это" И это
[(2, 'ПРОСТО СДЕЛАЙ ЭТО', 15)]
+ "просто сделай это" И завтра
[(2, 'ПРОСТО СДЕЛАЙ ЭТО' , 7)]
-просто сделать
[(0, 'ДЮЙМ ЗА ДЮЙМОМ', 4), (1, 'ПОГОНА СЧАСТЬЯ', 3)]Итак, мы успешно воспроизвели поведение поиска Google в 100 строках кода.
Контрольные показатели
Используя больший набор текстовых данных всех произведений Шекспира, мы получаем следующие показатели производительности.
функция query_index заняла 1,389 мс
просто выполните
[(15, 'othello', 229), (37, 'hamlet', 162), (32, 'troilus_cressida', 149)]
функция query_index заняла 1,336 мс
просто И сделать
[(15, 'othello', 229), (37, 'деревня', 162), (32, 'troilus_cressida', 149)]
функция query_index заняла 3,134 мс
"просто сделать" И это
[]
функция query_index заняла 0,737 мс
+ "просто сделать" И завтра
[]
функция query_index заняла 0,901 мс
-просто сделать
[(6, 'кориолан', 130), (20, 'середина лета', 107), (26, 'lll', 95)]
функция query_index заняла 12,303 мс
сделать И "вы можете" -завтра
[(37, 'деревня' , 161), (32, 'troilus_cressida', 146), (18, 'cleopatra', 127)Сопоставимая производительность повторения токенов для «просто сделай» составляет 101 мс, поэтому наш подход в 100 раз быстрее.
Целью этого поста было дать более глубокое понимание того, как поисковая система работает «под капотом». В будущих сообщениях в блоге я хочу углубиться в следующие темы:
- Анализ: Как мы можем использовать НЛП и другие методы для создания лучших токенов.
- Индексирование: Какие структуры данных хороши и почему.
- Запрос: Как мы можем оптимизировать запросы? Как мы можем дать более высокие оценки?
- Инкрементальное индексирование: Как мы индексируем документы и делаем обновления доступными в режиме реального времени.
- Распределенный поиск: Каковы типичные шаблоны, используемые для масштабирования до нескольких компьютеров.
Код проекта находится здесь:
halvorboe/search-engine
Внесите свой вклад в разработку halvorboe/search-engine, создав учетную запись на GitHub.
github.com
Классные проекты:
tantivy-search/tantivy
Tantivy — полнотекстовая поисковая библиотека, написанная на Rust.
- Например, структурированные данные — это любые данные, содержащие фиксированное поле, определенный файл или запись.

 Матрицы, структурированные таблицы и реляционные (SQL) базы данных также можно рассматривать как структурированные данные. Во время начального анализа данных специалист по данным изучает, очищает и преобразует данные, чтобы найти атрибуты.
Матрицы, структурированные таблицы и реляционные (SQL) базы данных также можно рассматривать как структурированные данные. Во время начального анализа данных специалист по данным изучает, очищает и преобразует данные, чтобы найти атрибуты.

 Это, наверное, не проблема для новичка, но особенно сложно при разработке решения для крупного предприятия.
Это, наверное, не проблема для новичка, но особенно сложно при разработке решения для крупного предприятия.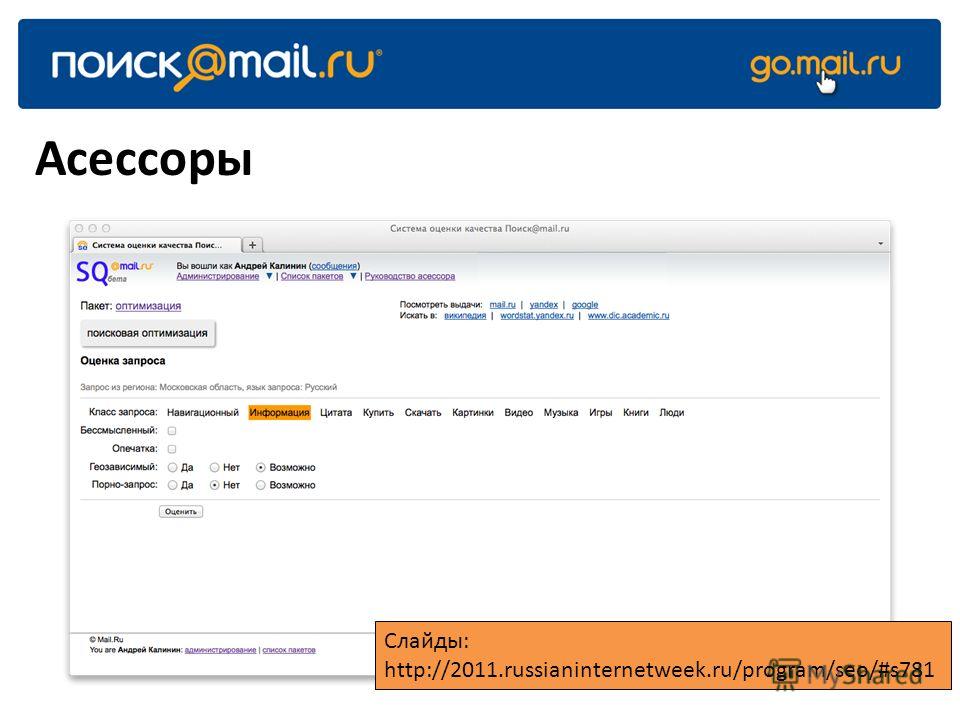 Вы также можете использовать машинное обучение напрямую. Это даст поисковой системе возможность изучать наиболее релевантные поисковые запросы и постоянно совершенствоваться без ручного программирования.
Вы также можете использовать машинное обучение напрямую. Это даст поисковой системе возможность изучать наиболее релевантные поисковые запросы и постоянно совершенствоваться без ручного программирования. На этом этапе мы обычно анализируем поведение поисковой системы и настраиваем веса атрибутов, чтобы получить результат, который удовлетворит клиента.
На этом этапе мы обычно анализируем поведение поисковой системы и настраиваем веса атрибутов, чтобы получить результат, который удовлетворит клиента. Когда обычный человек думает о том, как должны выглядеть результаты поисковой системы, он обычно представляет себе Google или Yahoo.
Когда обычный человек думает о том, как должны выглядеть результаты поисковой системы, он обычно представляет себе Google или Yahoo. Эти фреймворки позволяют просматривать богатые результаты поисковой выдачи без перезагрузки страницы, что снижает нагрузку на веб-сервер.
Эти фреймворки позволяют просматривать богатые результаты поисковой выдачи без перезагрузки страницы, что снижает нагрузку на веб-сервер. д., и у нас есть интересный опыт, которым можно поделиться. Итак, если вы сейчас разрабатываете свой движок или только думаете об этом — напишите нам, и мы поговорим об этом.
д., и у нас есть интересный опыт, которым можно поделиться. Итак, если вы сейчас разрабатываете свой движок или только думаете об этом — напишите нам, и мы поговорим об этом. 
 Это позволяет обеспечить эффективный диапазон и точное совпадение запросов. Это означает, что легко ответить на такие вопросы, как:
Это позволяет обеспечить эффективный диапазон и точное совпадение запросов. Это означает, что легко ответить на такие вопросы, как:
 Каждый документ получает балл.
Каждый документ получает балл.
 findall(r"\w+", нижний регистр_документа)
findall(r"\w+", нижний регистр_документа)  append(token_position)
append(token_position) 
 Это еще более усложнило бы это и без того чрезвычайно сложное объяснение.
Это еще более усложнило бы это и без того чрезвычайно сложное объяснение.
 Метод расчета выглядит следующим образом:
Метод расчета выглядит следующим образом: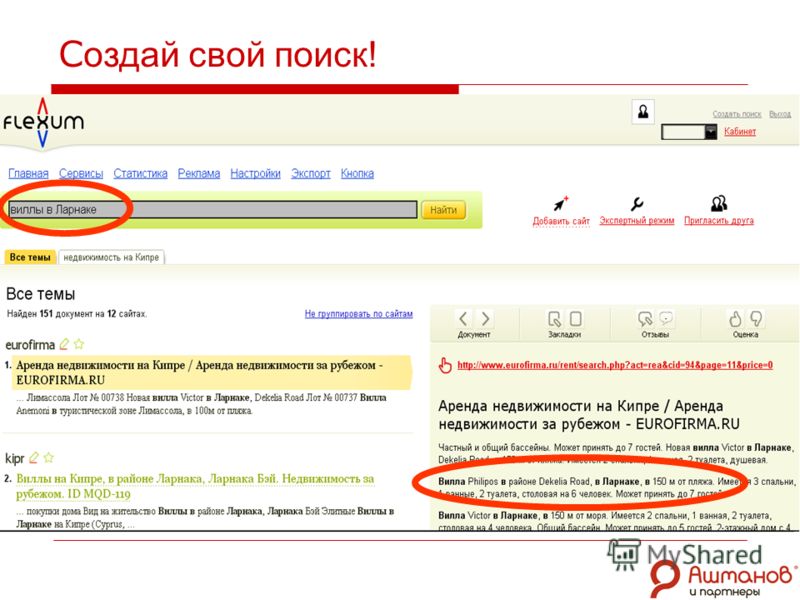 9set(new.keys())
9set(new.keys())