Самые необходимые строковые и числовые методы в JavaScript
В этой статье, а скорее памятке, вы найдете все самые необходимые методы для работы со строками и числами (за исключением Math)в JavaScript, которые нужно просто знать, чтобы не городить огородов, а воспользоваться методами, доступными “из коробки”.
Перевод статьи:
JavaScript Reference: String
+ числовые методы оттуда же
У объекта String есть один статический метод, String.fromCharCode(), который обычно используют для создания строкового представления последовательности Unicode символов. В этом примере мы делаем простую строку с использованием ASCII кодов:
String.fromCodePoint(70, 108, 97, 118, 105, 111) //'Flavio'
Вы также можете использовать восьмеричные и шестнадцатеричные числа:
String.fromCodePoint(0x46, 0154, parseInt(141, 8), 118, 105, 111) //'Flavio'
Все другие, описанные ниже методы, это методы “из коробки”, которые работают на строках.
charAt()
Отдаёт символ под заданным индексом i.
Примеры:
'Flavio'.charAt(0) //'F' 'Flavio'.charAt(1) //'l' 'Flavio'.charAt(2) //'a'
Если вы зададите индекс, который не подходит по строке, то на выходе вы получите уже пустую строку.
В JavaScript нет типа char, так что char это строка с длиной 1.
charCodeAt()
Отдаёт код символа под индексом i. Как и с charAt(), отдаёт Unicode 16-битное целое число, представляющее символ:
'Flavio'.charCodeAt(0) //70 'Flavio'.charCodeAt(1) //108 'Flavio'.charCodeAt(2) //97
Вызов toString() после него, отдаст шестнадцатеричное число, которое вы можете найти в любой Unicode таблице, такой как эта.
codePointAt()
Этот метод был представлен уже в ES2015, чтобы работать с Unicode символами, которые не могут быть представлены как единичная 16-ти битная Unicode единица и которым вместо этого нужно их две.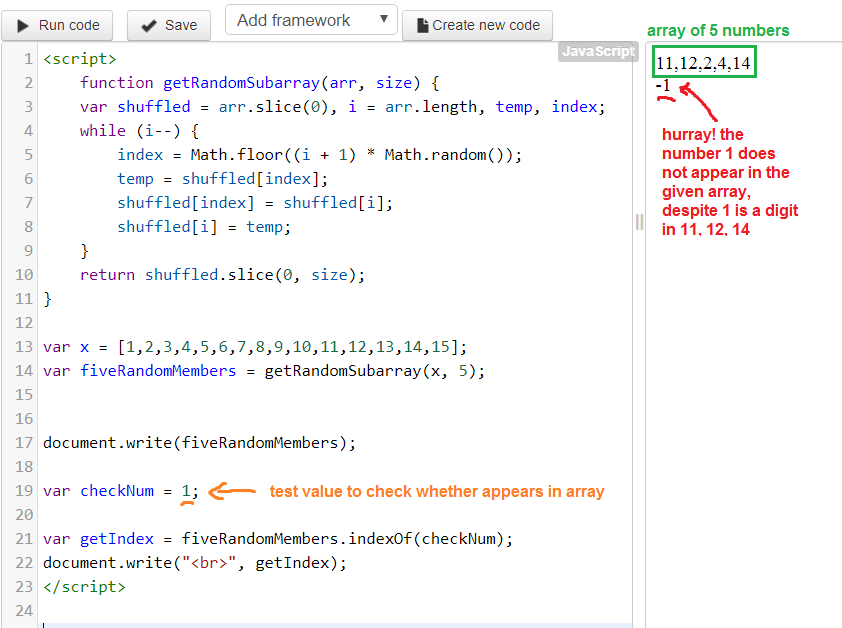
Используя charCodeAt(), вам надо получить первый и второй, и затем совместить их. Используя codePointAt() вы получаете весь символ в одном запросе.
К примеру, этот китайский символ “𠮷” состоит из двух UTF-16 частей:
"𠮷".charCodeAt(0).toString(16) //d842 "𠮷".charCodeAt(1).toString(16) //dfb7
Комбинируем эти два unicode символа:
"\ud842\udfb7" //"𠮷"
Вы можете получить тот же результат, но только используя codePointAt():
"𠮷".codePointAt(0) //20bb7
Если вы создаете новый символ, комбинируя эти unicode символы:
"\u{20bb7}" //"𠮷"concat()
Объединяет актуальную строку со строкой str.
Пример:
'Flavio'.concat(' ').concat('Copes') //'Flavio Copes'Вы можете указывать сколько угодно аргументов и в таком случае, все эти аргументы будут объединены в строку.
'Flavio'.concat(' ', 'Copes') //'Flavio Copes'endsWith()
Проверяет заканчивается ли строка со значением другой строки str.
'JavaScript'.endsWith('Script') //true
'JavaScript'.endsWith('script') //falseВы можете передать второй параметр с целым числом и endWith() будет рассматривать оригинальную строку, как если бы она этой заданной длины:
'JavaScript'.endsWith('Script', 5) //false
'JavaScript'.endsWith('aS', 5) //trueincludes()
Проверяет есть ли в строке значение строки str.
'JavaScript'.includes('Script') //true
'JavaScript'.includes('script') //false
'JavaScript'.includes('JavaScript') //true
'JavaScript'.includes('aSc') //true
'JavaScript'.includes('C++') //false includes() также принимает второй опциональный параметр, целое число, которое указывает на позицию с которой начинать поиск.
'a nice string'.includes('nice') //true
'a nice string'.includes('nice', 3) //false
'a nice string'.includes('nice', 2) //trueindexOf()
Даёт позицию начала заданной строки str в строке, на которой применяется метод.
'JavaScript'.indexOf('Script') //4
'JavaScript'.indexOf('JavaScript') //0
'JavaScript'.indexOf('aSc') //3
'JavaScript'.indexOf('C++') //-1Вы можете передать второй параметр, чтобы указать точку старта:
'a nice string'.indexOf('nice') !== -1 //true
'a nice string'.indexOf('nice', 3) !== -1 //false
'a nice string'.indexOf('nice', 2) !== -1 //truelastIndexOf()
Даёт позицию последнего появления строки str в актуальной строке.
Отдаёт -1, если поисковая строка не найдена.
'JavaScript is a great language. Yes I mean JavaScript'.lastIndexOf('Script') //47 'JavaScript'.lastIndexOf('C++') //-1
localeCompare()
Этот метод сравнивает строки и возвращает число (отрицательное или положительное), которое говорит, является ли данная строка меньше, равной или больше, чем строка переданная как аргумент, но в зависимости от языка.
Язык определяется настоящим местоположением или вы можете указать его, как второй аргумент:
'a'.(\d{3})(?:\s)(\w+)$/) //Array [ "123 s", "123", "s" ] 'I saw a bear'.match(/\bbear/) //Array ["bear"] 'I saw a beard'.match(/\bbear/) //Array ["bear"] 'I saw a beard'.match(/\bbear\b/) //null 'cool_bear'.match(/\bbear\b/) //null
 (\d{3})(?:\s)(\w+)$/)
//Array [ "123 s", "123", "s" ]
'I saw a bear'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear\b/) //null
'cool_bear'.match(/\bbear\b/) //null
(\d{3})(?:\s)(\w+)$/)
//Array [ "123 s", "123", "s" ]
'I saw a bear'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear\b/) //null
'cool_bear'.match(/\bbear\b/) //nullnormalize()
В Unicode есть четыре главные формы нормализации. Их коды это NFC, NFD, NFKC и NFKD. На Википедии есть хорошая статья про это.
Метод normalize() возвращает строку, нормализованную в соответствии с указанной формой, которую вы передаёте как параметр. (NFC используется как стандарт, если она не указана в ручную).
Вот пример с MDN:
'\u1E9B\u0323'.normalize() //ẛ̣
'\u1E9B\u0323'.normalize('NFD') //ẛ̣
'\u1E9B\u0323'.normalize('NFKD') //ṩ
'\u1E9B\u0323'.normalize('NFKC') //ṩpadEnd()
Смысл этого метода в том, чтобы добавлять в строку символы и пробелы, пока она не достигнет заданной длины.
padEnd() был представлен в ES2017, как метод добавляющий символы в конец строки.
padEnd(targetLength [, padString])
Простое применение:
Смысл этого метода в том, чтобы добавлять строки или символы как в предыдущем методе, но уже с самого начала строки:
padStart(targetLength [, padString])
repeat()
Этот метод был представлен в ES2015 и повторяет строки заданное количество раз:
'Ho'.repeat(3) //'HoHoHo'
Отдает пустую строку, если параметр не указан или параметр равен нулю. А в случае с отрицательным числом вы получите RangeError.
replace()
Этот метод находит первое упоминание str1 в заданной строке и заменяет его на str2.
Отдаёт новую строку, не трогая оригинальную.
'JavaScript'.replace('Java', 'Type') //'TypeScript'Вы можете передать регулярное выражение как первый аргумент:
'JavaScript'.replace(/Java/, 'Type') //'TypeScript'
replace() заменяет только первое упоминание, но а если вы будете использовать regex как поиск строки, то вы можете использовать (/g):
'JavaScript JavaX'.
 replace(/Java/g, 'Type') //'TypeScript TypeX'
replace(/Java/g, 'Type') //'TypeScript TypeX'Второй параметр может быть функцией. Эта функция будет вызвана с заданным количеством аргументов, когда найдётся совпадение (или каждое совпадение в случае с regex /g):
- Нужная строка
- Целое число, которое указывает позицию в строке, где произошло совпадение
- Строка
Отдающееся значение функции заменит совпадающую часть строки.
Пример:
'JavaScript'.replace(/Java/, (match, index, originalString) => {
console.log(match, index, originalString)
return 'Test'
}) //TestScriptЭто работает и для обычных строк, а не только для регулярок:
'JavaScript'.replace('Java', (match, index, originalString) => {
console.log(match, index, originalString)
return 'Test'
}) //TestScriptВ случае c regex, когда выбираются группы, все эти значения будут переданы как аргументы прямо после параметра совпадения.
'2015-01-02'.replace(/(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/, (match, year, month, day, index, originalString) => {
console. log(match, year, month, day, index, originalString)
return 'Test'
}) //Test
search()
Отдаёт расположение первого совпадения строки str в заданной строке.
Этот метод отдаёт индекс начала упоминания или -1, если такого не было найдено.
'JavaScript'.search('Script') //4
'JavaScript'.search('TypeScript') //-1Вы можете использовать регулярные выражения (и на самом деле, даже если вы передаёте строку, то внутренне оно тоже применяется как регулярное выражение).
'JavaScript'.search(/Script/) //4 'JavaScript'.search(/script/i) //4 'JavaScript'.search(/a+v/) //1
В этой статье подробно рассказывается про метод slice() и его родственников.
Отдает новую строку, которая является частью строки на которой применялся метод, от позиций begin до end.
Оригинальная строка не изменяется.
end опциональна.
'This is my car'.slice(5) //is my car 'This is my car'.
 slice(5, 10) //is my
slice(5, 10) //is myЕсли вы выставите первым параметром отрицательное число, то начальный индекс будет считаться с конца и второй параметр тоже должен быть отрицательным, всегда ведя отсчет с конца:
'This is my car'.slice(-6) //my car 'This is my car'.slice(-6, -4) //my
split()
Этот метод вырезает строку при её нахождении в строке на которой применяется метод (чувствительный к регистру) и отдаёт массив с токенами.
const phrase = 'I love my dog! Dogs are great'
const tokens = phrase.split('dog')
tokens //["I love my ", "! Dogs are great"]startsWith()
Проверяет начинается ли строка со значения
Вы можете вызвать startWith() на любой строке, указать подстроку и проверить отдаёт результат true или false.
'testing'.startsWith('test') //true
'going on testing'.startsWith('test') //falseЭтот метод допускает второй параметр, который позволит вам указать с какого символа вам надо начать проверку:
'testing'.
 startsWith('test', 2) //false
'going on testing'.startsWith('test', 9) //true
startsWith('test', 2) //false
'going on testing'.startsWith('test', 9) //truetoLocaleLowerCase()
Этот метод отдаёт новую строку, которая представляет собой изначальную строку в нижнем регистре, в соответствии с нормами разметки указанной локали.
Собственно, первый параметр представляет локаль, но он опционален. Если его пропустить, то будет использоваться актуальная локаль:
'Testing'.toLocaleLowerCase() //'testing'
'Testing'.toLocaleLowerCase('it') //'testing'
'Testing'.toLocaleLowerCase('tr') //'testing'Как и всегда, мы можем не осознавать все преимущества интернационализации, но я читал на MDN, что правила разметки текста в турецком языке отличаются от других языков, чьё описание основано на латинице.
В общем, это как и toLowerCase(), но с учетом локали.
toLocaleUpperCase()
Этот метод отдаёт новую строку, которая представляет собой изначальную строку в верхнем регистре, в соответствии с нормами разметки указанной локали.
Первым параметром указывается локаль, но это опционально, как и в случае с методом выше:
'Testing'.toLocaleUpperCase() //'TESTING'
'Testing'.toLocaleUpperCase('it') //'TESTING'
'Testing'.toLocaleUpperCase('tr') //'TESTİNG'toLowerCase()
Этот метод отдаёт новую строку с текстом в нижнем регистре.
Не изменяет изначальную строку.
Не принимает параметры.
Использование:
'Testing'.toLowerCase() //'testing'
Работает как и toLocaleLowerCase(), но не учитывает локали.
toString()
Отдает строку из заданного строчного объекта.
const str = new String('Test')
str.toString() //'Test'toUpperCase()
Отдаёт новую строку с текстом в верхнем регистре.
Не изменяет оригинальную строку.
Не принимает параметры.
Использование:
'Testing'.toUpperCase() //'TESTING'
Если вы передадите пустую строку, то он возвратит пустую строку.
Метод похож на toLocaleUpperCase(), но не принимает параметры.
trim()
Отдает новую строку удаляя пробелы вначале и в конце оригинальной строки.
'Testing'.trim() //'Testing' ' Testing'.trim() //'Testing' ' Testing '.trim() //'Testing' 'Testing '.trim() //'Testing'
trimEnd()
Отдаёт новую строку, удаляя пробелы только из конца оригинальной строки.
'Testing'.trimEnd() //'Testing' ' Testing'.trimEnd() //' Testing' ' Testing '.trimEnd() //' Testing' 'Testing '.trimEnd() //'Testing'
trimStart()
Отдаёт новую строку, удаляя пробелы из начала оригинальной строки.
'Testing'.trimStart() //'Testing' ' Testing'.trimStart() //'Testing' ' Testing '.trimStart() //'Testing ' 'Testing'.trimStart() //'Testing'
valueOf()
Отдает строчное представление заданного строчного объекта:
const str = new String('Test')
str.valueOf() //'Test'Это тоже самое, что и toString()
Теперь пройдемся по числовым методам.
isInteger()
Отдаст true, если переданное значение является целым числом.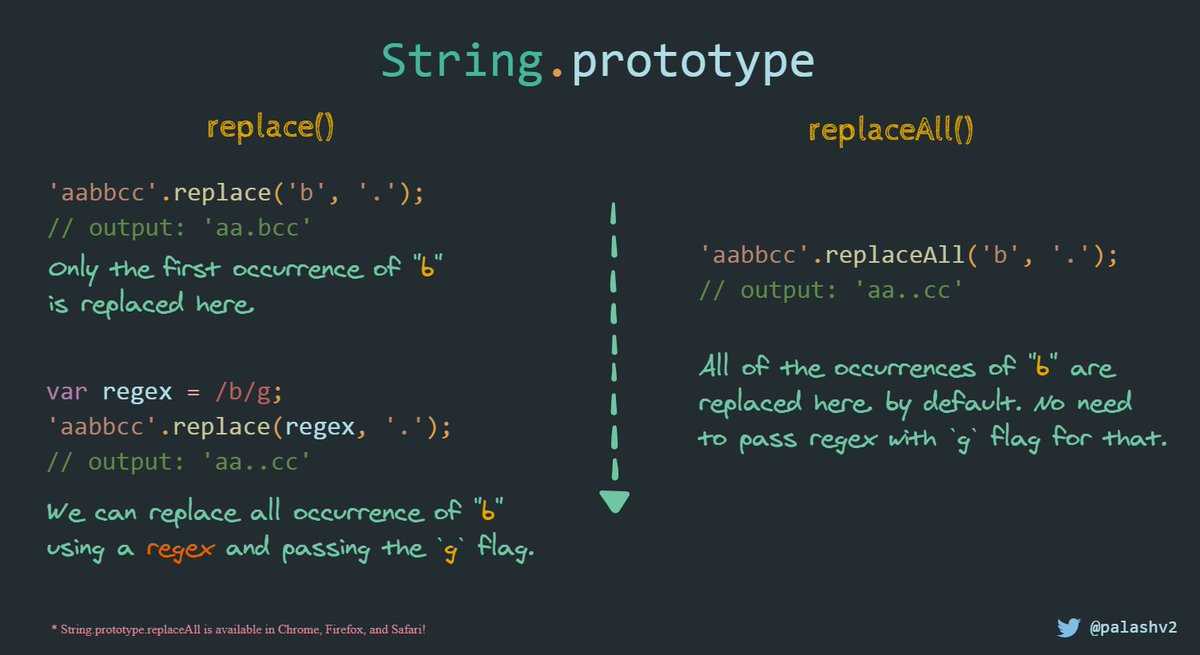 Всё иное, такое как, логические значения, строки, объекты, массивы, отдают
Всё иное, такое как, логические значения, строки, объекты, массивы, отдают false.
Number.isInteger(1) //true
Number.isInteger(-237) //true
Number.isInteger(0) //true
Number.isInteger(0.2) //false
Number.isInteger('Flavio') //false
Number.isInteger(true) //false
Number.isInteger({}) //false
Number.isInteger([1, 2, 3]) //falseisNaN()
NaN это особый случай. Число является NaN, только если оно NaN или если это выражения деления ноль на ноль, что отдаёт NaN. Во всех других случаях мы можем передать ему что захотим, но получим false:
Number.isNaN(NaN) //true
Number.isNaN(0 / 0) //true
Number.isNaN(1) //false
Number.isNaN('Flavio') //false
Number.isNaN(true) //false
Number.isNaN({}) //false
Number.isNaN([1, 2, 3]) //falseisSafeInteger()
Число может удовлетворять Number.isInteger(), но не Number.isSafeInteger(), если оно заходит за пределы безопасных целых чисел.
Так что, всё что выше 2⁵³ и ниже -2⁵³ не является безопасным.
Number.isSafeInteger(Math.pow(2, 53)) // false Number.isSafeInteger(Math.pow(2, 53) - 1) // true Number.isSafeInteger(Math.pow(2, 53) + 1) // false Number.isSafeInteger(-Math.pow(2, 53)) // false Number.isSafeInteger(-Math.pow(2, 53) - 1) // false Number.isSafeInteger(-Math.pow(2, 53) + 1) // true
parseFloat()
Парсит аргумент как дробное число и отдаёт его. Аргумент при этом является строкой:
Number.parseFloat('10') //10
Number.parseFloat('10.00') //10
Number.parseFloat('237,21') //237
Number.parseFloat('237.21') //237.21
Number.parseFloat('12 34 56') //12
Number.parseFloat(' 36 ') //36
Number.parseFloat('36 is my age') //36
Number.parseFloat('-10') //-10
Number.parseFloat('-10.2') //-10.2Как вы видите Number.parseFloat() довольно гибок. Он также может конвертировать строки со словами, выделяя только первое число, но в этом случае строка должна начинаться с числа:
Number.
 parseFloat('I am Flavio and I am 36') //NaN
parseFloat('I am Flavio and I am 36') //NaNparseInt()
Парсит аргумент как целое число и отдаёт его:
Number.parseInt('10') //10
Number.parseInt('10.00') //10
Number.parseInt('237,21') //237
Number.parseInt('237.21') //237
Number.parseInt('12 34 56') //12
Number.parseInt(' 36 ') //36
Number.parseInt('36 is my age') //36Как вы видите Number.parseInt() тоже гибок. Он также может конвертировать строки со словами, выделяя первое число, строка должна начинаться с числа.
Number.parseInt('I am Flavio and I am 36') //NaNВы можете передать второй параметр, чтобы указать систему счисления. Десятичная стоит по-дефолту, но вы можете применять восьмеричные и шестнадцатеричные числовые конверсии:
Number.parseInt('10', 10) //10
Number.parseInt('010') //10
Number.parseInt('010', 8) //8
Number.parseInt('10', 8) //8
Number.parseInt('10', 16) //16Свойства и методы | Основы JavaScript
Для перемещения по курсу нужно зарегистрироваться
1. Введение
↳
теория
Введение
↳
теория
2. Hello, World! ↳ теория / тесты / упражнение
3. Инструкции ↳ теория / тесты / упражнение
4. Арифметические операции ↳ теория / тесты / упражнение
5. Ошибки оформления (синтаксиса и линтера) ↳ теория / тесты / упражнение
6. Строки ↳ теория / тесты / упражнение
7. Переменные ↳ теория / тесты / упражнение
8. Выражения в определениях ↳ теория / тесты / упражнение
9. Именование ↳ теория / тесты / упражнение
10. Интерполяция ↳ теория / тесты / упражнение
11. Извлечение символов из строки ↳ теория / тесты / упражнение
12. Типы данных ↳ теория / тесты / упражнение
13. Неизменяемость и примитивные типы ↳ теория / тесты / упражнение
14. Функции и их вызов ↳ теория / тесты / упражнение
15. Сигнатура функции ↳ теория / тесты / упражнение
16. Вызов функции — выражение ↳ теория / тесты / упражнение
17. Функции с переменным числом параметров ↳ теория / тесты / упражнение
18. Детерминированность ↳ теория / тесты / упражнение
19. Стандартная библиотека
↳
теория
/
тесты
/
упражнение
Стандартная библиотека
↳
теория
/
тесты
/
упражнение
20. Свойства и методы ↳ теория / тесты / упражнение
21. Цепочка вызовов ↳ теория / тесты / упражнение
22. Определение функций ↳ теория / тесты / упражнение
23. Возврат значений ↳ теория / тесты / упражнение
24. Параметры функций ↳ теория / тесты / упражнение
25. Необязательные параметры функций ↳ теория / тесты / упражнение
26. Упрощенный синтаксис функций ↳ теория / тесты / упражнение
27. Логика ↳ теория / тесты / упражнение
28. Логические операторы ↳ теория / тесты / упражнение
29. Результат логических операций ↳ теория / тесты / упражнение
30. Условные конструкции ↳ теория / тесты / упражнение
31. Тернарный оператор ↳ теория / тесты / упражнение
32. Конструкция Switch ↳ теория / тесты / упражнение
33. Цикл while ↳ теория / тесты / упражнение
34. Агрегация данных ↳ теория / тесты / упражнение
35. Обход строк в цикле ↳ теория / тесты / упражнение
36. Условия внутри тела цикла
↳
теория
/
тесты
/
упражнение
Условия внутри тела цикла
↳
теория
/
тесты
/
упражнение
37. Инкремент и декремент ↳ теория / тесты / упражнение
38. Цикл for ↳ теория / тесты / упражнение
39. Модули ↳ теория / тесты / упражнение
Испытания
1. Фибоначчи
2. Найди Fizz и Buzz
3. Переворот числа
4. Счастливый билет
5. Фасад
6. Идеальные числа
7. Инвертированный регистр
8. Счастливые числа
Порой обучение продвигается с трудом. Сложная теория, непонятные задания… Хочется бросить. Не сдавайтесь, все сложности можно преодолеть. Рассказываем, как
Не понятна формулировка, нашли опечатку?
Выделите текст, нажмите ctrl + enter и опишите проблему, затем отправьте нам. В течение нескольких дней мы улучшим формулировку или исправим опечатку
Что-то не получается в уроке?
Загляните в раздел «Обсуждение»:
- Изучите вопросы, которые задавали по уроку другие студенты — возможно, ответ на ваш уже есть
- Если вопросы остались, задайте свой. Расскажите, что непонятно или сложно, дайте ссылку на ваше решение. Обратите внимание — команда поддержки не отвечает на вопросы по коду, но поможет разобраться с заданием или выводом тестов
- Мы отвечаем на сообщения в течение 2-3 дней. К «Обсуждениям» могут подключаться и другие студенты. Возможно, получится решить вопрос быстрее!
 Расскажите, что непонятно или сложно, дайте ссылку на ваше решение. Обратите внимание — команда поддержки не отвечает на вопросы по коду, но поможет разобраться с заданием или выводом тестов
Расскажите, что непонятно или сложно, дайте ссылку на ваше решение. Обратите внимание — команда поддержки не отвечает на вопросы по коду, но поможет разобраться с заданием или выводом тестовПодробнее о том, как задавать вопросы по уроку
основных строковых методов JavaScript | Трей Хаффин
13 наиболее важных функций JavaScript для работы со строками. Индексируйте, нарезайте, разделяйте и обрезайте методы строк JS.
Строки являются фундаментальной частью любого языка программирования, и в JavaScript есть много мощных встроенных функций, упрощающих работу со строками для разработчиков. Этот список охватывает наиболее важные строковые функции, которые вы можете начать использовать в своем коде.
Учим JavaScript — Лучшие учебники по JavaScript (2018) | gitconnected
72 лучших курса по JavaScript.
 Учебники отправляются и голосуются разработчиками, что позволяет вам найти лучшее…
Учебники отправляются и голосуются разработчиками, что позволяет вам найти лучшее…gitconnected.com
Это может показаться очевидным, но, вероятно, это самый важный строковый метод и, несомненно, наиболее часто используемый. Вызов .length для строки вернет количество символов, содержащихся в строке.
Функция trim() удаляет пробелы в начале и в конце строки. Вы обнаружите, что чаще всего используете его при обработке строки пользовательского поля ввода. Легко случайно добавить пробелы, и это гарантирует, что вы обработаете соответствующие символы.
Избавьтесь от необходимости поддерживать и развивать свою карьеру программиста с помощью собственного портфолио и CV/резюме API .
API-интерфейс Portfolio — легко развивайте свою карьеру программиста | gitconnected
Избавьтесь от ручного обновления ваших данных в каждом отдельном месте. Просто измените данные один раз в своем…
gitconnected. com
com
Обновите один раз и наблюдайте, как изменения распространяются повсюду, используя единую конечную точку API.
Функция include() определяет, содержится ли подстрока в большей строке, и возвращает true или false . У этого есть много приложений, но один из распространенных вариантов использования — сопоставление строк для поиска/анализа.
До того, как include() был введен в спецификацию JavaScript, indexOf() был основным способом проверки существования подстроки в строке. Вероятно, вы все еще будете видеть код, использующий indexOf , поэтому важно понимать, как он работает. Функция возвращает индекс подстроки в строке. Если подстрока не содержится в исходной строке, будет возвращено -1 .
Общий шаблон для indexOf() , который имитирует поведение , включает () , который должен проверить, больше ли индекс, чем -1:
Функция toUpperCase () возвращает строку со всеми буквами верхнего регистра.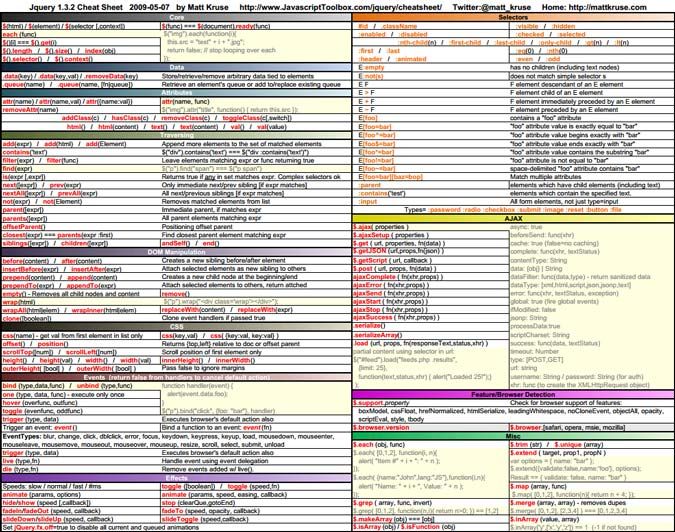
Функция toLowerCase() возвращает строку со всеми строчными буквами.
Функция replace() вызывается для строки и возвращает строку с шаблоном , замененным замещающей строкой . Он принимает либо регулярное выражение, либо строку в качестве узор . С помощью регулярного выражения вы можете глобально заменить все совпадения (используя параметр g ), но со строкой оно заменит только первое вхождение. В приведенном ниже примере вы заметите, что world заменяется только один раз в первом вызове, поскольку он использует строковый шаблон.
Метод slice() извлечет часть строки на основе предоставленного индекса и вернет ее как новую строку. Это полезно, когда вы знаете структуру строки и хотите получить определенную часть, или ее можно использовать с indexOf метод, который мы изучили ранее, где вы можете найти индекс первого вхождения подстроки и использовать его в качестве ориентира для нарезки.
slice() принимает начальный индекс в качестве первого параметра и необязательный конечный индекс в качестве второго параметра — str.slice(beginIndex[ endIndex]) . Если конечный индекс не указан, он срезается до конца строки, начиная с вашего beginIndex . Если используется отрицательный beginIndex , он будет срезаться назад с конца строки. Ниже приведен пример из MDN, в котором показаны эти случаи.
Метод split() принимает разделитель , на который вы хотите разделить строку, и возвращает массив строк. Это полезно, когда вы знаете, что ваша строка использует определенный символ для разделения данных или если вы хотите работать с определенными подстроками по отдельности.
Функция repeat() возвращает строку, состоящую из элементов объекта, повторяющихся заданное количество раз.
Метод match() извлекает совпадения при сопоставлении строка против регулярного выражения . Пример ниже ищет в нашей строке все заглавные буквы. Он возвращает массив строк для значений, соответствующих регулярному выражению.
Пример ниже ищет в нашей строке все заглавные буквы. Он возвращает массив строк для значений, соответствующих регулярному выражению.
Функция charAt() возвращает строковый символ с заданным индексом.
Метод charCodeAt() возвращает юникод символа по указанному индексу в строке. Это целое число конуса UTF-16 от 0 до 65535.
Этот список охватывает основной список строковых методов, используемых в JavaScript. . Методы, не включенные в этот список, включают lastIndexOf , search , substring , substr , concat , localeCompare и другие. Дело не в том, что эти функции не важны, но они не являются основными методами, используемыми в JavaScript, и вы вряд ли увидите их или нуждаетесь в них. Более полный список см. в документации по строке MDN.
Если эта статья оказалась вам полезной, нажмите на значок 👏. Следуйте за мной для получения дополнительных статей о React, JavaScript и программном обеспечении с открытым исходным кодом! Вы также можете найти меня на Twitter или gitconnected .
10 полезных строковых методов в JavaScript
В JavaScript конструктор String имеет множество методов, которые наследуют все строки. Эти методы являются вспомогательными функциями, которые служат различным целям.
В этой статье я расскажу о десяти полезных строковых методах.
TLDR
- split: разбить строку на массив подстрок
- replace: заменить подстроки в строке
- совпадение: возвращает массив подстрок, соответствующих шаблону RegEx
- startsWith и endWith: для проверки того, начинается ли строка с подстроки или заканчивается подстрокой соответственно
- toUpperCase и toLowerCase: для преобразования строк в верхний и нижний регистр соответственно
- включает: для проверки наличия подстроки в строке
- подстрока: для вырезания части строки
- поиск: возвращает индекс первой подстроки, которая соответствует регулярному выражению
- charAt: возвращает char актер по адресу в указанной позиции
- обрезка: удаление пробелов с обоих концов строки
Подробнее об этих методах читайте далее.
10 строковых методов JavaScript
.split()
Этот метод используется для разделения строки на массив подстрок на основе указанной точки останова. Вот синтаксис:
string.split(точка останова) // точка останова может быть строкой или регулярным выражением
Возвращает массив разделенных подстрок.
Этот метод принимает любую строку для использования в качестве точки останова, например:
const string = "Hello world, Holla" const breakpoint = " " // точка останова по пробелу const splitted = string.split(точка останова) console.log(разделенный) // ["Hello", "world,", "Holla"]
И он может принимать регулярное выражение в качестве точки останова. Символы в строке, соответствующие регулярному выражению, будут использоваться в качестве разделителя для строки следующим образом:
const string = "Привет, мир, Холла" // регулярное выражение, которое соответствует символам e или o постоянная точка останова = /e|o/ const splitted = string.
 split(точка останова)
console.log(разделенный)
// ['H', 'll', 'w', 'rld' ]
split(точка останова)
console.log(разделенный)
// ['H', 'll', 'w', 'rld' ] Как вы заметили, регулярное выражение соответствует букве «e» в «Hello», «o» в слове «Hello» и «o» » в мире». Он использует совпадения в качестве точек останова для строки.
.replace()
Этот метод используется для замены подстрок в строке новыми строками. Вот синтаксис:
string.replace(searchValue, replaceValue) // searchValue может быть строкой или регулярным выражением // replaceValue — это строка
Возвращает новую строку с замененными подстроками.
replaceValue заменяет подстроки в строке, соответствующие searchValue .
searchValue может быть такой строкой:
const string = "hello world" const searchValue = "привет" const replaceValue = "Привет" const replace = string.replace(searchValue, replaceValue) console.log(заменено) // привет мир
или с таким RegEx:
const string = "hello world" const searchValue = /e|o/g константа replaceValue = "--" const replace = string.
 replace(searchValue, replaceValue)
console.log(заменено)
// h--ll-- w--rld
replace(searchValue, replaceValue)
console.log(заменено)
// h--ll-- w--rld В этом случае регулярное выражение должно иметь флаг «g», чтобы оно соответствовало всем вхождениям совпадающих строк. Без флага «g» будет заменена только первая совпавшая строка.
Регулярное выражение соответствует «e» или «o», и, как вы можете видеть, в «hello» и «world» совпадающие символы заменяются двойными дефисами.
.match()
Этот метод используется для поиска подстроки в строке, которая соответствует шаблону RegEx. Вот синтаксис:
string.match(regex)
Возвращает массив из:
- первой совпадающей подстроки (вместе с другими свойствами), если
gфлаг не находится в регулярном выражении - всех совпавших подстрок (без выраженных свойств)), если в регулярном выражении присутствует флаг
g
Вот пример:
const string = "Hello world"
const регулярное выражение1 = /(e|o).{1}l/
const regex2 = /(e|o). {1}l/g
константа match2 = строка.match(regex1)
console.log(match2)
// ['ell', 'e', index: 1, input: 'Hello world', groups: undefined ]
const match3 = string.match(regex2)
console.log(match3)
// ['элл', 'орл']  {1}l/g
константа match2 = строка.match(regex1)
console.log(match2)
// ['ell', 'e', index: 1, input: 'Hello world', groups: undefined ]
const match3 = string.match(regex2)
console.log(match3)
// ['элл', 'орл']
{1}l/g
константа match2 = строка.match(regex1)
console.log(match2)
// ['ell', 'e', index: 1, input: 'Hello world', groups: undefined ]
const match3 = string.match(regex2)
console.log(match3)
// ['элл', 'орл'] Оба шаблона регулярных выражений должны соответствовать подстроке либо с e , либо с o , символом любого типа, за которым следует символ «l».
Первый шаблон не имеет глобального флага, поэтому в выводе вы видите массив с двумя элементами: ‘ell’ (совпадающая подстрока) и ‘e’ (совпадающий символ в скобках), а также другие свойства. .
Второй шаблон с глобальным флагом возвращает массив всех подстрок в строке, соответствующих шаблону.
.startsWith() и .endsWith()
Как следует из названия, эти методы соответственно используются для проверки того, начинается ли строка подстрокой или заканчивается ею. Оба метода чувствительны к регистру.
Для startWith это может быть начало строки по умолчанию, или вы также можете указать позицию для начала проверки.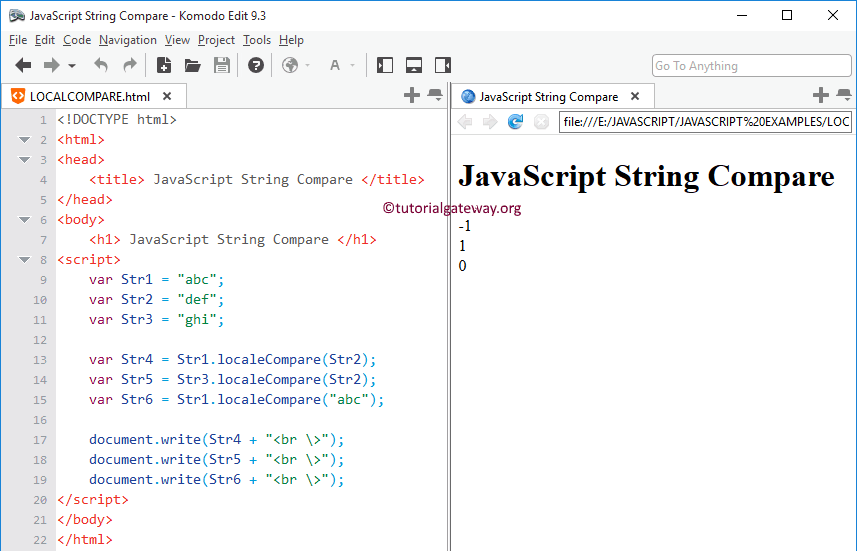 Вот синтаксис:
Вот синтаксис:
string.startsWith(подстрока, позиция) // позиция необязательна и используется по умолчанию // в 0 индекс
Возвращаемое значение равно true или false , если строка начинается с подстроки или нет.
Вот пример:
const string = "Hello world"
const check1 = string.startsWith("ello")
// ЛОЖЬ
const check2 = string.startsWith("ello", 1)
// true Во второй проверке, используя индекс позиции 1, метод startsWith начинает проверку со второго символа и возвращает true, поскольку второй символ справа начинается с «ello».
Для концовС , это может быть конец строки по умолчанию, или вы также можете указать конечную точку, с которой начинается проверка. Вот синтаксис:
string.endsWith(подстрока, длина) // длина необязательна и используется по умолчанию // в string.length
Возвращаемое значение равно true или false , если строка заканчивается подстрокой или нет.
Вот пример:
const string = "Hello world"
const check1 = string.endsWith("мир")
// ЛОЖЬ
const check2 = string.endsWith ("мир", string.length - 1)
// правда Во второй проверке с использованием указанного аргумента длины string.length - 1 . Это означает, что метод endWith начинает проверку с символа «l», так как это символ указанной длины, и возвращает true, поскольку последний символ слева заканчивается на «worl».
.toUpperCase() и .toLowerCase()
Как следует из названия, оба метода используются для преобразования строки в верхний и нижний регистр соответственно. Их синтаксис:
строка.toUpperCase() string.toLowerCase()
Их возвращаемые значения представляют собой строку (вызывается метод) в верхнем и нижнем регистре соответственно. Примеры:
const string = "Привет, мир" const верхний = string.toUpperCase() // ПРИВЕТ, МИР const нижний = string.toLowerCase() // привет, мир
.
 includes()
includes()Этот метод проверяет, можно ли найти подстроку в строке. Синтаксис:
string.includes(подстрока, позиция) // позиция необязательна и используется по умолчанию // до 0
Подобно методу startWith, он имеет аргумент position , указывающий точку, с которой метод должен начать проверку.
Возвращаемое значение true , если подстрока может быть найдена; иначе ложно . Например:
const string = "Привет, мир"
const check1 = string.includes("llo")
// истинный
const check2 = string.includes("привет", 4)
// false Для второй проверки включает , начинает проверку с позиции 4, символ «o» после «ll», поэтому не находит подстроку «llo» и возвращает ложь .
.substring()
Этот метод используется для вырезания подстроки из всей строки. Вот синтаксис:
string.substring(indexStart, indexEnd) // indexEnd необязателен, и // по умолчанию длина строки
Возвращаемое значение этой строки представляет собой вырезанную подстроку в зависимости от указанной начальной и конечной позиции.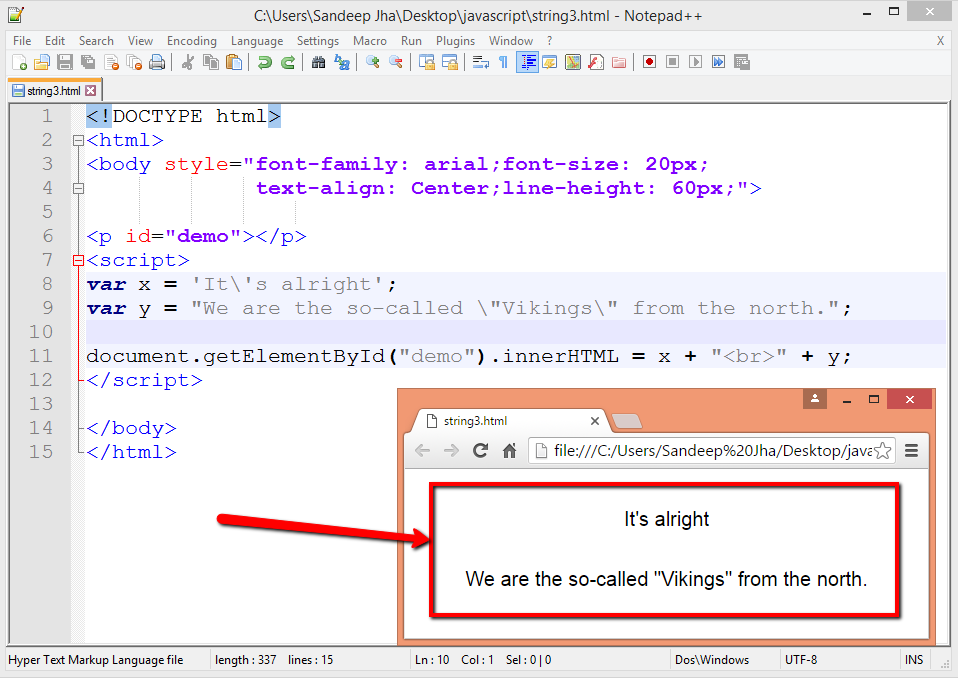 Вот пример:
Вот пример:
const string = "Hello world" const sub1 = строка.подстрока (5) // мир const sub2 = строка.подстрока (5, 8) // работа
Если конечная позиция не указана, метод выполняет срез от начальной позиции до конца строки, но, как вы можете видеть во втором примере, конечная позиция указывает позицию остановки для метода, который нужно разрезать.
.search()
Этот метод используется для поиска в строке подстроки, соответствующей указанному шаблону регулярного выражения. Вот синтаксис:
string.search(regex)
Возвращаемым значением этого метода является индекс первого совпадения или -1 , если совпадений нет. Примеры:
const string = "Привет, мир"
const search2 = string.search(/l.{1}o/)
// 2
const search3 = string.search(/l.{5}o/)
// -1 Первое регулярное выражение ищет «l», любой другой символ, за которым следует «o». Метод search находит, что по индексу 2 . Второе регулярное выражение ищет «l», пять других символов, за которыми следует «o».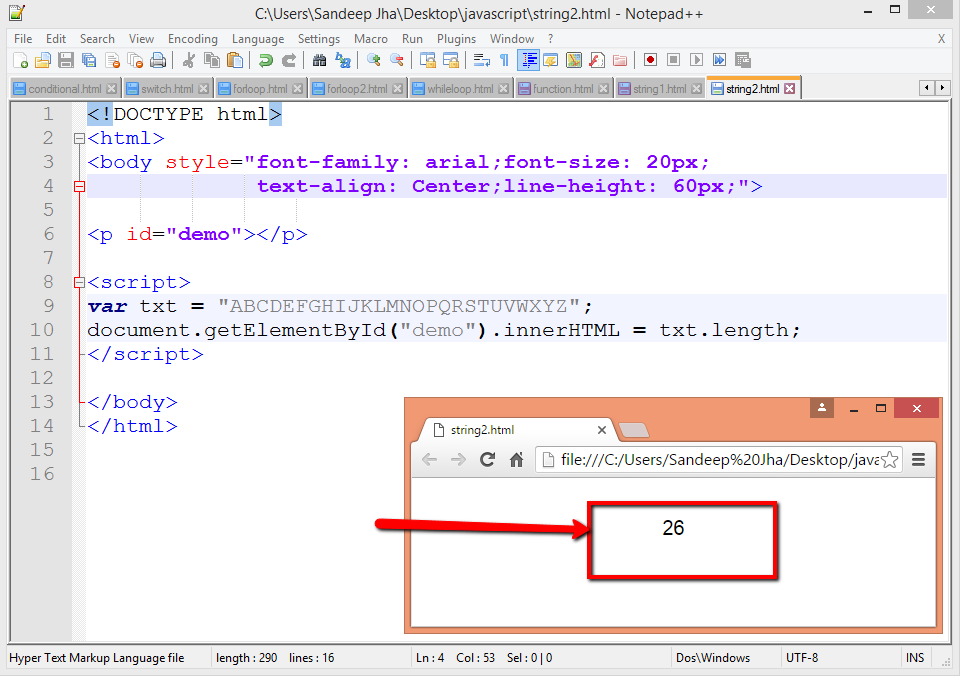 Он этого не находит, поэтому возвращает
Он этого не находит, поэтому возвращает -1 .
.charAt()
Этот метод используется для получения char актер по указанная позиция. Вот синтаксис:
string.charAt(position) // если позиция не указана // по умолчанию 0
Возвращает строку по указанному индексу. Например:
const string = "Привет, мир" константа char0 = строка.charAt() // Н константа char5 = строка.charAt(6) // w
.trim()
Этот метод используется для удаления пробелов с обоих концов строки. Пробелы здесь включают вкладки, пробелы, точки останова и т. д. Синтаксис:
string.trim()
Возвращает новую строку без пробелов на обоих концах. Вот пример:
const string1 = "Привет, мир"
константная строка2 = `
Привет, мир
`
const trimmed1 = string1.trim()
// Привет, мир
const trimmed2 = string2.trim()
// Привет, мир Он обрезает только пробелы на обоих концах, а не между символами.