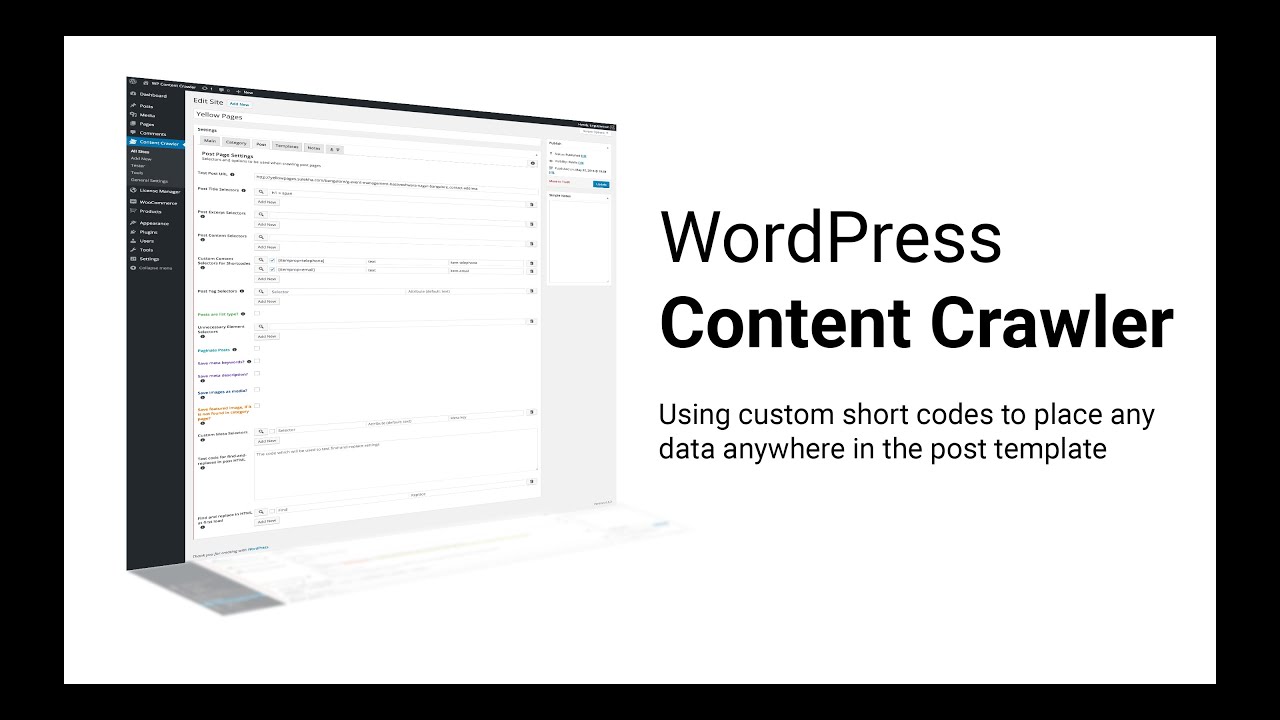
Собирайте статьи или новости с сайтов и экспортируйте результаты прямо в свой WordPress блог. Автоматизируйте наполнение и обновление своего блога!
https://www.youtube.com/watch?v=dRDeFMaWDQ8Video can’t be loaded because JavaScript is disabled: Парсер для WordPress на базе Datacol (https://www.youtube.com/watch?v=dRDeFMaWDQ8)
Автонаполнение WordPress блога
Datacol поможет собрать контент с нужных сайтов и сразу после завершения парсинга загрузит их в ваш WordPress блог или сохранит в файл для дальнейшего импорта.
Создайте тематический блог
Настройте периодический парсинг статей с нескольких популярных источников и у вас на сайте будет свежая и полная подборка тематического контента.
Автообновление блога
Настройте парсинг на получение только свежего контента и ваш блог будет обновляться автоматически при каждом запуске настройки, без вашего непосредственного участия.
Как протестировать Datacol
1. Установите демо-версию программы Datacol. Демо-версия программы имеет все возможности платной, но сохраняет только первые 25 результатов парсинга.
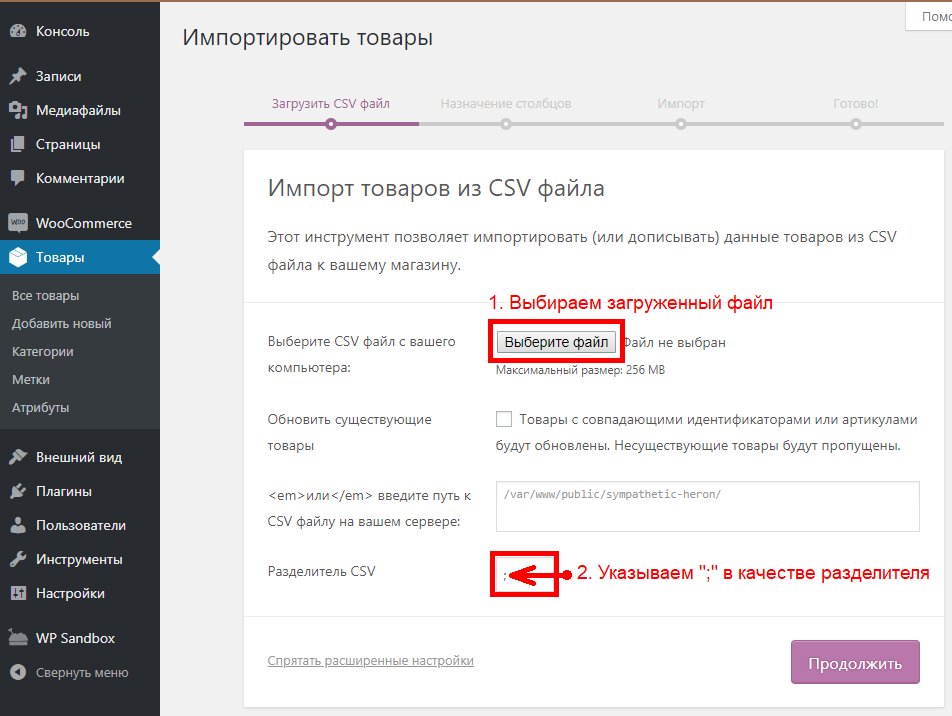
2. В дереве кампаний присутствует кампания content-parsers/kolchaka-net.par. Выберите ее и нажмите кнопку Запуск (Play). Перед запуском вы можете отредактировать Входные данные, чтобы изменить набор ссылок на категории или бренды, которые необходимо спарсить.
3. Дождитесь появления результатов работы парсера блогов. После появления результатов можно принудительно остановить парсинг (нажав кнопку Стоп).
4. После окончания/принудительной остановки парсера в папке Мои документы можно найти текстовые файлы (каждый пост сохраняется в отдельный файл), названия которых генерируются на базе названий постов:
FAQ (Часто задаваемые вопросы)
Почему программа собрала только 25 результатов?
В демо версии программа собирает только первые 25 результатов парсинга. Вы можете купить лицензию. После активации Datacol будет собирать данные без каких-либо ограничений с нашей стороны.
Что делать, если сайт блокирует (банит) парсинг?
Если сайт-источник забанит ваш IP-адрес (обычно в результате этого перестают собираться данные), задействуйте прокси или VPN.
Как разобраться в Datacol?
Начните первое знакомство с программой с этой статьи. Хотите попробовать свои силы в самостоятельной настройке? Ознакомьтесь, пожалуйста, с видеоуроками по Datacol (хотя бы первые 3-5 уроков). Если при дальнейшей настройке программы у вас возникнут вопросы, задайте их нам. Поддержка Datacol отвечает с понедельника по пятницу.
Какие условия покупки Datacol?
Все условия приобретения программы приведены здесь.
Как я получу программу после ее оплаты?
После поступления оплаты за лицензию вы получите код активации программы и информацию о сроках действия вашей лицензии на адрес электронной почты, указанный при покупке. Инструкцию по активации можно посмотреть здесь.
Парсер новостей на CMS WordPress • фриланс-работа для специалиста • категория Парсинг данных ≡ Заказчик Yurii Yatsyk
6 из 6
проект завершен
публикация
прием ставок
утверждение условий
резервирование
выполнение проекта
проект завершен
Нужно создать новостной сайт на WordPress, с парсингом новостей с украинских ресурсов и автоматическим переводом их на английский язык.
Сделать проверку на наличии картинки в статье, если ее нет, то не парсить на сайт.
Есть установленная тема Wescle можно использовать ее или поставить другую под новости.
Парсер новостей на CMS WordPress
Качество
Профессионализм
Стоимость
Контактность
Сроки
Огромное спасибо Александру. Помог в самые короткие сроки реализовать проект. Проект был направлен в дальнейшем на получение донатов для Украины в период войны с Европы. Сделал большой вклад в наш проект.
Рекомендую его как исполнителя Ваших проектов, а также его магазин готовых сайтов top-bit.biz
Отзыв фрилансера о сотрудничестве с Yurii Yatsyk
Парсер новостей на CMS WordPress
Оплата
Постановка задачи
Четкость требований
Контактность
Ставки 12
дата
онлайн
рейтинг
стоимость
время выполнения
3 дня1200 UAH
3 дня1200 UAH
Здравствуйте Имею большой опыт в разработке парсеров Пишите — обсудим детали
фрилансер больше не работает на сервисе
4 дня8000 UAH
4 дня8000 UAH
Приветствую =)
Готов взять Вашу задачу в работу.
Всегда на связи
1339
25 3
2 дня3000 UAH
Сергій К.
2 дня3000 UAH
Здравствуйте Юрий. Я могу выполнить данную работу. От вас нужны будут лишь небольшие уточнения и ключи для переводчика.
С уважением, Сергей
ставка скрыта фрилансером
1 день1000 UAH
1 день1000 UAH
Добрый день. Занимаюсь качественным созданием сайтов и интернет магазинов, с гарантией и возможностью обслуживания. Заказывая у меня разработку вы всегда можете рассчитывать на апгрейд и бесплатные консультации.
Могу сделать для вас блог с параметром новостей. Подскажу как будет лучше настроить, и какой хостинг будет нужен.
Напишите мне, обсудим с вами подробнее ваш проект. Буду рад сотрудничеству!
3 дня6000 UAH
3 дня6000 UAH
Добрый день,заинтересовал ваш проект, готов взяться за его реализацию. В веб-разработки я более 15ти лет. Основная моя специализация — написание парсеров/ботов и тд. Жду деталей со ссылками в ЛС. Пишите — буду рад сотрудничеству!
15 дней30 000 UAH
15 дней30 000 UAH
Здравствуйте, готов выполнить сайт на WordPress и парсер новостей. Опыт работу 10 лет. Готов обсудить в лс все вопросы и начать работу.
7 дней7000 UAH
7 дней7000 UAH
Доброго дня! Разработаю пд ключ сайт, профессионально, оперативно и также могу настроить рекламную компанию.
Цену указал демократическую в связи с ситуацией в стране! Будем рады взаимовыгодному сотрудничеству!
Всегда на связь!
Телефон для подключения: 073*9000*908
…
С уважением, Александр Доброго дня! Розроблю пд ключ сайт, професійно, оперативно і також можу настроїти рекламну компанію.
Ціну указав демократичну в звязку з ситуацією в країні! Буду радий взаємовигодній співпраці!
Завжди на звязку!
Телефон для звязку: 073*9000*908
…
З повагою, Олександр!
Показать оригинал
Перевести
Победившая ставка1 день500 UAH
Победившая ставка1 день500 UAH
Здравствуйте. Опыт более 10 лет с автонаполняемыми сайтами, агрегаторами и парсингом данных. Могу помочь.
16373
177 0
30 дней32 500 UAH
Anton Y.
30 дней32 500 UAH
Добрый вечер! Готов создать вам такой сайт, с автоматическим парсингом и переводом посредством гугл переводчика. Или Яндекс.
30 дней15 000 UAH
30 дней15 000 UAH
Доброго дня! Разработаю сайт под ключ сайт, профессионально, оперативно и также могу настроить рекламную компанию. Доброго дня! Розроблю сайт под ключ сайт, професійно, оперативно і також можу настроїти рекламну компанію.
Эта библиотека содержит реализации синтаксического анализатора сериализации блоков по умолчанию для документов WordPress. Он предоставляет встроенные анализаторы PHP и JavaScript, которые реализуют спецификацию из @wordpress/block-serialization-spec-parser и обычно работают с документом, хранящимся в post_content .
Этот пакет предполагает, что ваш код будет работать в среде ES2015+ . Если вы используете среду с ограниченной поддержкой или отсутствием поддержки таких языковых функций и API, вам следует включить в свой код полифилл, поставляемый в @wordpress/babel-preset-default .
API
parse
Функция синтаксического анализатора, преобразующая входной HTML-код в блочную структуру.
Использование
Входной пост:
<дел>
<дел>
Влево
<дел>
Средний
<дел>
Код синтаксического анализа:
import {parse} from '@wordpress/block-serialization-default-parser';
разбор (пост) ===
[
{
blockName: 'ядро/столбцы',
атрибуты: {
столбцы: 3,
},
внутренние блоки: [
{
blockName: 'ядро/столбец',
атрибуты: ноль,
внутренние блоки: [
{
blockName: 'ядро/абзац',
атрибуты: ноль,
внутренние блоки: [],
innerHTML: '\n
ParsedBlock[] : блочное представление входного HTML.
Теория
Чем он отличается от анализатора спецификаций?
Это анализатор с рекурсивным спуском, который линейно сканирует входной документ один раз. Вместо прямой рекурсии используется механизм батута для предотвращения переполнения стека. Это сводит к минимуму копирование и передачу данных за счет использования глобальных переменных для отслеживания состояния при синтаксическом анализе. Между каждым токеном (разделителем комментариев блока) мы можем настроить анализатор и вмешаться, если захотим; например, мы можем установить жесткое ограничение на то, как долго мы можем анализировать документ, или предоставить дополнительную отладочную диагностику для документа.
Синтаксический анализатор спецификации определяется с помощью Грамматика выражения синтаксического анализа (PEG), которая отвечает на многие вопросы, на которые мы должны явно ответить в этом анализаторе. Целью этой реализации является согласование характеристик PEG, чтобы его можно было напрямую заменить и чтобы единственными изменениями были лучшая производительность во время выполнения и использование памяти.
Как это работает?
Каждый сериализованный документ Gutenberg номинально является HTML-документом, который, помимо обычного HTML, может также содержать специально разработанные HTML-комментарии — разделители блочных комментариев, — которые разделяют и изолируют сериализованные в документе блоки.
Этот синтаксический анализатор пытается создать конечный автомат вокруг переходов, запускаемых этими разделителями — «токенами» грамматики. Каждый раз, когда мы находим один, мы должны делать только одно из:
ввести новый блок;
выход из блока.
Эти действия имеют разные эффекты в зависимости от контекста; например, когда мы выходим из блока, нам нужно либо добавить его в список выходных блоков , либо , нам нужно добавить его как следующий innerBlock в родительском блоке под ним в стеке блоков (место, где мы отслеживаем открытые блоки). Подробности задокументированы ниже.
Самой большой проблемой в этом синтаксическом анализаторе является правильный учет индексов, необходимых для построения значений innerHTML для каждого блока на каждом уровне глубины вложенности. Мы используем простой подход:
Начинайте каждый вновь открытый блок с пустого innerHTML .
Всякий раз, когда мы помещаем первый блок в innerBlocks , добавьте содержимое, с которого начинается содержимое родительского блока, туда, где начинается этот внутренний блок.
Всякий раз, когда мы помещаем другой блок в список innerBlocks , добавляем содержимое с того места, где заканчивается предыдущий внутренний блок, туда, где начинается этот внутренний блок.
Когда мы закрываем открытый блок, добавляем содержимое от того места, где заканчивался последний внутренний блок, до того места, где начинается разделитель закрывающего блока.
Если внутренних блоков нет, то мы берем все содержимое между разделителями комментария открывающего и закрывающего блоков как внутреннийHTML .
Я имел в виду, как это работает?
Этот синтаксический анализатор работает намного быстрее, чем созданный синтаксический анализатор из спецификации. Поскольку мы знаем о синтаксическом анализе больше, чем PEG, мы можем воспользоваться несколькими приемами, чтобы повысить скорость и использование памяти:
легко сопоставляется с помощью регулярного выражения. Вместо посимвольного синтаксического анализа мы можем позволить движку PCRE RegExp пропускать для нас большие участки документа, чтобы найти эти токены.
Так как preg_match() принимает параметр смещения , мы можем сканировать входные данные, не передавая копии входного текста на каждом шаге. Мы можем отслеживать нашу позицию в строке и вместо этого передавать только число.
Отсутствие копирования всех этих строк означает, что мы также пропустим много выделений памяти.
Кроме того, токенизация с помощью RegExp дает дополнительное преимущество. Синтаксический анализатор, сгенерированный PEG, обеспечивает предсказуемые характеристики производительности в обмен на контроль над правилами токенизации — он не позволяет нам определять шаблоны RegExp в правилах, чтобы защититься от напр. катастрофический возврат, который нарушил бы гарантии PEG.
Однако, поскольку наш «токен-язык» разделителей блочных комментариев — это обычный , а можно тривиально сопоставить с шаблонами RegExp, мы можем сделать это здесь, а затем произойдет что-то волшебное: мы выскочим из PHP или JavaScript в высокооптимизированный движок RegExp, написанный на C или C++ в хост-системе. Тем самым мы оставляем виртуальную машину и ее накладные расходы.
Участие в этом пакете
Это отдельный пакет, являющийся частью проекта Gutenberg. Проект организован как монорепозиторий. Он состоит из нескольких автономных программных пакетов, каждый из которых предназначен для определенной цели. Пакеты в этом монорепозитории публикуются в npm и используются WordPress, а также другими программными проектами.
Чтобы узнать больше о вкладе в этот пакет или Gutenberg в целом, ознакомьтесь с основным руководством для участников проекта.
Новости-Парсер для WordPress
News-parser WordPress Plugin
News-parser — это плагин для WordPress, позволяющий легко получать полный текст статьи, а также изображения с сайта с помощью RSS-канала. Обработанная информация с сайта сохраняется в виде черновика, который вы можете просто опубликовать или отредактировать по своему усмотрению. Это упрощает создание контента для вашего сайта.
Особенности
Поддержка редактора Gutenberg.
Средство извлечения визуального содержимого.
Гибкая система создания шаблонов для ускорения парсинга.
Возможность парсить не только из источника RSS XML, но и из URL.
Планы на будущее
Добавить функцию автопилота.
Парсинг видео из других (кроме YouTube) источников.
Сохранение изображений в медиатеку.
Есть идея? — Пожалуйста, не стесняйтесь, дайте мне знать. Сделаем News-Parser еще лучше!
Установка
Вы можете клонировать репозиторий GitHub: https://github.com/zalevsk1y/news-parser.git
Или загрузите его напрямую в виде ZIP-файла: https://github.com/zalevsk1y/news-parser/archive/master.zip
Это загрузит последнюю версию News-parser для разработчиков.
Как использовать NewsParserPlugin\этот плагин?
Парсинг RSS
Для парсинга RSS перейдите в меню Новости-Парсинг->Парсинг RSS в панели администратора вашего сайта. Введите адрес RSS-канала в строку поиска. Нажмите кнопку «Разобрать RSS-канал». Когда проанализированные данные будут получены с сервера, они появятся на вашем экране. Вы можете открыть визуальный экстрактор, нажав на иконку, и создать шаблон для парсинга постов из этого RSS-источника или просто выбрать интересующий вас контент и сохранить его как черновик.
Посмотрите это короткое видео, чтобы узнать, КАК ИСПОЛЬЗОВАТЬ RSS с помощью плагина для анализа новостей:
Чтобы проанализировать несколько сообщений, выберите сообщения и нажмите кнопку «Проанализировать выбранное». Подождите, пока данные будут сохранены, вы будете уведомлены сообщением в верхней части экрана. Значок в нижней части сообщения позволяет вам перейти к редактированию или публикации сохраненного черновика. Обратите внимание, что анализ выбранного сообщения может быть выполнен только в том случае, если вы создали шаблон анализа!
Посмотрите это короткое видео, чтобы узнать, КАК ИСПОЛЬЗОВАТЬ НЕСКОЛЬКО СООБЩЕНИЙ с помощью плагина для анализа новостей:
Визуальный конструктор.
Чтобы создать шаблон или просто выбрать интересующий вас контент, воспользуйтесь визуальным конструктором. Вы можете открыть визуальный конструктор, щелкнув значок в нижней части почтового ящика. Для выбора контента нажмите на нужный вам блок в главном окне и он будет отмечен бирюзовой рамкой. При наведении курсора на содержимое ожидаемая область окрашивается в бирюзовый цвет. Чтобы отменить выбор, нажмите на блок еще раз. Попробуйте разделить разные типы контента (картинки, видео, текст) на отдельные блоки. Видео YouTube будет заменено изображением логотипа YouTube. Вы можете выдавить его, и это видео будет вставлено в ваш пост. Парсинг видео из других источников пока не поддерживается. Картинки вставляются в ваш пост в виде ссылки; исключением является избранное изображение, которое сохраняется в вашей медиатеке. На боковой панели вы можете изменить избранное изображение вашего сообщения. Просто выберите подходящее изображение в левой части конструктора и нажмите кнопку «Изменить изображение». Последнее выбранное изображение будет выбрано в качестве избранного изображения. Вы также можете создать публикацию без избранного изображения. Просто нажмите «Нет избранного изображения». Вы можете изменить название поста в следующем подменю «Заголовок поста». Напишите свой вариант заголовка поста в textaria и нажмите кнопку «Изменить заголовок». Чтобы добавить ссылку на источник, установите флажок «Добавить ссылку на источник» в публикацию. в подменю «Дополнительные параметры».
Посмотрите это короткое видео, чтобы узнать, КАК ПОЛЬЗОВАТЬСЯ ВИЗУАЛЬНЫМ КОНСТРУКТОРОМ:
Создать шаблон парсинга
Для сохранения шаблона необходимо отметить содержимое в главном окне визуального конструктора, выбрать «Сохранить шаблон парсинга, который вы можно использовать при автоматическом анализе этого исходного элемента.

 Вы можете купить лицензию. После активации Datacol будет собирать данные без каких-либо ограничений с нашей стороны.
Вы можете купить лицензию. После активации Datacol будет собирать данные без каких-либо ограничений с нашей стороны. Инструкцию по активации можно посмотреть здесь.
Инструкцию по активации можно посмотреть здесь. Сделал большой вклад в наш проект.
Сделал большой вклад в наш проект. 

 Занимаюсь качественным созданием сайтов и интернет магазинов, с гарантией и возможностью обслуживания. Заказывая у меня разработку вы всегда можете рассчитывать на апгрейд и бесплатные консультации.
Занимаюсь качественным созданием сайтов и интернет магазинов, с гарантией и возможностью обслуживания. Заказывая у меня разработку вы всегда можете рассчитывать на апгрейд и бесплатные консультации. Опыт работу 10 лет. Готов обсудить в лс все вопросы и начать работу.
Опыт работу 10 лет. Готов обсудить в лс все вопросы и начать работу.  Опыт более 10 лет с автонаполняемыми сайтами, агрегаторами и парсингом данных. Могу помочь.
Опыт более 10 лет с автонаполняемыми сайтами, агрегаторами и парсингом данных. Могу помочь. 


 Целью этой реализации является согласование характеристик PEG, чтобы его можно было напрямую заменить и чтобы единственными изменениями были лучшая производительность во время выполнения и использование памяти.
Целью этой реализации является согласование характеристик PEG, чтобы его можно было напрямую заменить и чтобы единственными изменениями были лучшая производительность во время выполнения и использование памяти.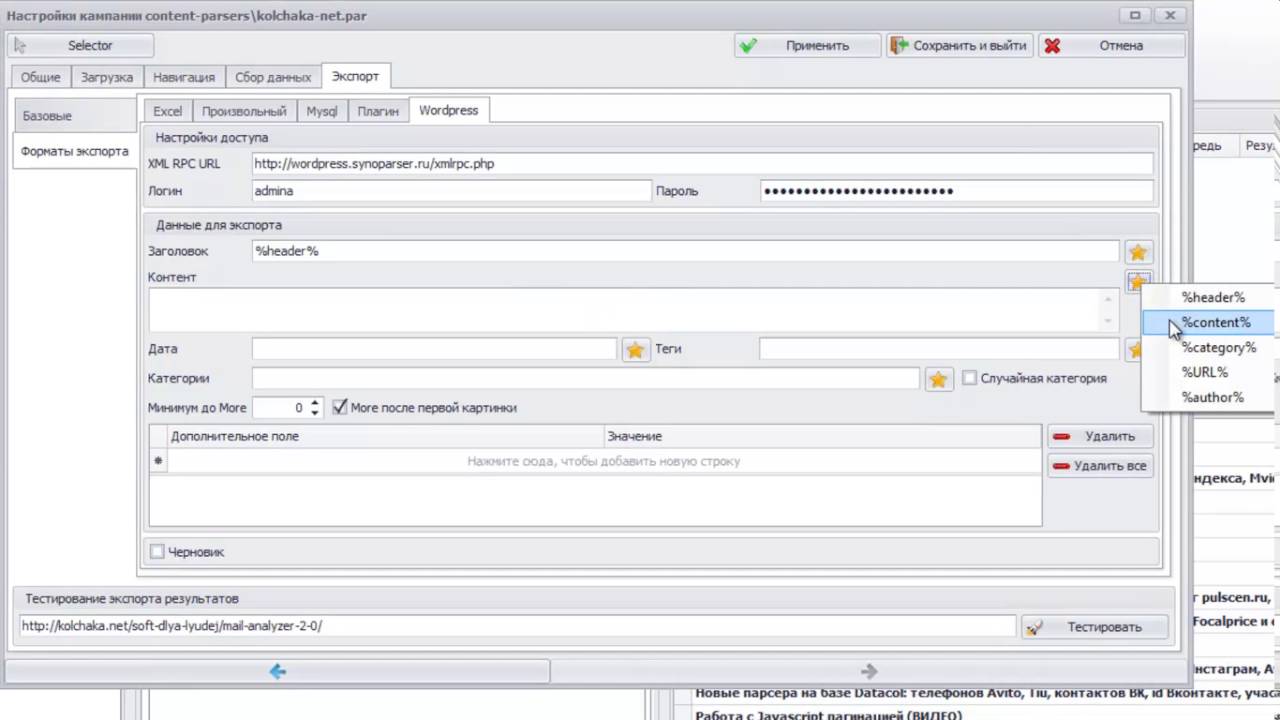 Подробности задокументированы ниже.
Подробности задокументированы ниже.
 Синтаксический анализатор, сгенерированный PEG, обеспечивает предсказуемые характеристики производительности в обмен на контроль над правилами токенизации — он не позволяет нам определять шаблоны RegExp в правилах, чтобы защититься от напр. катастрофический возврат, который нарушил бы гарантии PEG.
Синтаксический анализатор, сгенерированный PEG, обеспечивает предсказуемые характеристики производительности в обмен на контроль над правилами токенизации — он не позволяет нам определять шаблоны RegExp в правилах, чтобы защититься от напр. катастрофический возврат, который нарушил бы гарантии PEG.
 Подождите, пока данные будут сохранены, вы будете уведомлены сообщением в верхней части экрана. Значок в нижней части сообщения позволяет вам перейти к редактированию или публикации сохраненного черновика. Обратите внимание, что анализ выбранного сообщения может быть выполнен только в том случае, если вы создали шаблон анализа!
Подождите, пока данные будут сохранены, вы будете уведомлены сообщением в верхней части экрана. Значок в нижней части сообщения позволяет вам перейти к редактированию или публикации сохраненного черновика. Обратите внимание, что анализ выбранного сообщения может быть выполнен только в том случае, если вы создали шаблон анализа! Видео YouTube будет заменено изображением логотипа YouTube. Вы можете выдавить его, и это видео будет вставлено в ваш пост. Парсинг видео из других источников пока не поддерживается. Картинки вставляются в ваш пост в виде ссылки; исключением является избранное изображение, которое сохраняется в вашей медиатеке.
Видео YouTube будет заменено изображением логотипа YouTube. Вы можете выдавить его, и это видео будет вставлено в ваш пост. Парсинг видео из других источников пока не поддерживается. Картинки вставляются в ваш пост в виде ссылки; исключением является избранное изображение, которое сохраняется в вашей медиатеке.