Использование UTF-8 в HTTP заголовках
Как известно, HTTP 1.1 — это текстовой протокол передачи данных. HTTP сообщения закодированы, используя ISO-8859-1 (которую условно можно считать расширенной версией ASCII, содержащей умляуты, диакритику и другие символы, используемые в западноевропейских языках). При этом в теле сообщений можно использовать другую кодировку, которая должна быть обозначена в заголовке «Content-Type». Но что делать, если нам необходимо задать non-ASCII символы не в теле сообщения, а в самих заголовках? Наверное, самый распространенный кейс — это проставление имени файла в «Content-Disposition» заголовке. Это, казалось бы, довольно распространенная задача, но ее реализация не так очевидна.
TL;DR: Используйте кодировку, описанную в RFC 6266, для «Content-Disposition» и преобразуйте текст в латиницу (транслит) в остальных случаях.
Небольшая вводная в кодировки
В статье упоминаются и используются кодировки US-ASCII (часто именуемую просто ASCII), ISO-8859-1 и UTF-8. 8 = 256 вариантов.
8 = 256 вариантов.
ISO-8859-1 — кодировка, предназначенная для западноевропейских языков. Содержит французскую диакритику, немецкие умляуты и т.д.
Кодировка содержит 256 символов и, таким образом, может быть представлена одним байтом. Первая половина (128 символов) полностью совпадает с ASCII. Таким образом, если первый бит = 0, то это обычный ASCII символ. Если 1, то это символ, специфичный для ISO-8859-1.
UTF-8 — одна из самых известных кодировок наравне с ASCII. Способна кодировать 1.112.064 символов. Размер каждого символа варьируется от 1-го до 4-х байт (раньше допускались значения до 6 байт).
Программа, работающая с этой кодировкой, определяет по первым битам, как много байтов входит в символ. Если октет начинается с 0, то символ представлен одним байтом. 110 — два байта, 1110 — три байта, 11110 — 4 байта.
Как и в случае с ISO-8859-1, первые 128 символов полностью соответствуют ASCII. Поэтому тексты, использующие только ASCII символы, будут абсолютно идентичны в бинарном представлении, вне зависимости от того, использовалась ли для кодирования US-ASCII, ISO-8859-1 или UTF-8.
Использование UTF-8 в теле сообщения
Прежде чем перейти к заголовкам, давайте быстро взглянем, как использовать UTF-8 в теле сообщений. Для этого используется заголовок «Content-Type».
Если «Content-Type» не задан, то браузер должен обрабатывать сообщения, как будто они написаны в ISO-8859-1. Браузер не должен пытаться отгадать кодировку и, тем более, игнорировать «Content-Type». Но, что реально отобразится в ситуации, когда «Content-Type» не передан, зависит от реализации браузера. Например, Firefox сделает согласно спецификации и прочитает сообщение, будто оно было закодировано в ISO-8859-1. Google Chrome, напротив, будет использовать кодировку операционной системы, которая для многих российских пользователей равна Windows-1251. В любом случае, если сообщение было в UTF-8, то оно будет отображено некорректно.
Проставляем UTF-8 сообщение в значение заголовка
С телом сообщения все достаточно просто. Тело сообщения всегда следует после заголовков, поэтому здесь не возникает технических проблем. Но как быть с заголовками? В спецификации недвусмысленно заявляется, что порядок заголовков в сообщении не имеет значения. Т.е. задать кодировку в одном заголовке через другой заголовок не представляется возможным.
Но как быть с заголовками? В спецификации недвусмысленно заявляется, что порядок заголовков в сообщении не имеет значения. Т.е. задать кодировку в одном заголовке через другой заголовок не представляется возможным.
Что будет, если просто взять и записать UTF-8 значение в значение заголовка? Мы видели, что такой трюк с телом сообщения приведет к тому, что значение будет просто прочитано в ISO-8859-1. Логично было бы предположить, что то же самое произойдет с заголовком. Но это не так. Фактически, во многих, если не в большинстве, случаях такое решение будет работать. Сюда включаются старые айфончики, IE11, Firefox, Google Chrome. Единственным из находящихся у меня под рукой браузеров, когда я писал эту статью, который не захотел работать с таким заголовком, является Edge.
Такое поведение не зафиксировано в спецификациях. Возможно, разработчики браузеров решили облегчить жизнь разработчиков и автоматически определять, что в заголовках сообщение закодировано в UTF-8. В общем-то, это не является такой сложной задачей. Смотрим на первый бит: если 0, то ASCII, если 1 — то, возможно, UTF-8.
Смотрим на первый бит: если 0, то ASCII, если 1 — то, возможно, UTF-8.
Нет ли в этом случае пересечения с ISO-8859-1? На самом деле, практически нет. Возьмем для примера UTF-8 символ из 2-х октетов (русские буквы представлены двумя октетами). Символ в бинарном представлении будет иметь вид: 110xxxxx 10xxxxxx. В HEX представлении: [0xC0-0x6F] [0x80-0xBF]. В ISO-8859-1 этими символами едва ли можно закодировать что-то, несущее смысловую нагрузку. Поэтому риск того, что браузер неправильно расшифрует сообщение, очень мал.
Однако, при попытке использовать этот способ можно столкнуться с техническими проблемами: ваш веб-сервер или фреймворк может просто не разрешить записывать UTF-8 символы в значение заголовка. Например, Apache Tomcat вместо всех UTF-8 символов проставляет 0x3F (вопросительный знак). Разумеется, это ограничение можно обойти, но, если само приложение бьет по рукам и не дает что-то сделать, то, возможно, вам и не нужно это делать.
Но, независимо от того, разрешает ли вам ваш фреймворк или сервер записать UTF-8 сообщения в заголовок или нет, я не рекомендую этого делать. Это не задокументированное решение, которое в любой момент времени может перестать работать в браузерах.
Это не задокументированное решение, которое в любой момент времени может перестать работать в браузерах.
Транслит
Я думаю, что использовать транслит — eto bolee horoshee reshenie. Многие крупные популярные русские ресурсы не брезгуют использовать транслит в названиях файлов. Это гарантированное решение, которое не сломается с выпуском новых браузеров и которое не надо тестировать отдельно на каждой платформе. Хотя, разумеется, надо подумать, как преобразовывать весь спектр возможных символов, что может быть не совсем тривиально. Например, если приложение рассчитано на российскую аудиторию, то в имя файла могут попасть татарские буквы ә и ң, которые надо как-то обработать, а не просто заменять на «?».
RFC 2047
Как я уже упомянул, томкат не позволил мне проставить UTF-8 в заголовке сообщения. Отражена ли эта особенность поведения в Java docs для сервлетов? Да, отражена:
Упоминается RFC 2047. Я пробовал кодировать сообщения, используя этот формат, — браузер меня не понял. Этот метод кодировки не работает в HTTP. Хотя работал раньше. Вот, например, тикет на удаление поддержки этой кодировки из Firefox.
Этот метод кодировки не работает в HTTP. Хотя работал раньше. Вот, например, тикет на удаление поддержки этой кодировки из Firefox.
RFC 6266
В тикете, ссылка на который содержится в предыдущем разделе, есть упоминания, что даже после прекращения поддержки RFC 2047, все еще есть способ передавать UTF-8 значения в названии скачиваемых файлов: RFC 6266. На мой взгляд, это самое правильно решение на сегодняшний день. Многие популярные интернет ресурсы используют его. Мы в CUBA Platform также используем именно этот RFC для генерации «Content-Disposition».
RFC 6266 — это спецификация, описывающая использование “Content-Disposition” заголовка. Сам способ кодировки подробно описан в другой спецификации — RFC 8187.
Параметр “filename” содержит название файла в ASCII, “filename*” — в любой необходимой кодировке. При наличии обоих атрибутов “filename” игнорируется во всех современных браузерах (включая IE11 и старые версии Safari). Совсем старые браузеры, напротив, игнорируют “filename*”.
При использовании данного способа кодирования в параметре сначала указывается кодировка, после » идет закодированное значение. Видимые символы из ASCII кодирования не требуют. Остальные символы просто пишутся в hex представлении, со стоящим «%» перед каждым октетом.
Что делать с другими заголовками?
Кодирование, описанное в RFC 8187, не является универсальным. Да, можно поместить в заголовок параметр с * префиксом, и это, возможно, будет даже работать для некоторых браузеров, но спецификация предписывает не делать так.
В каждом случае, где в заголовках поддерживается UTF-8, на настоящий момент есть явное упоминание об этом в релевантном RFC. Помимо «Content-Disposition» данная кодировка используется, например, в Web Linking и Digest Access Authentication.
Следует учесть, что стандарты в этой области постоянно меняются. Использование описанной выше кодировки в HTTP было предложено лишь в 2010. Использование данной кодировки именно в «Content-Disposition» было зафиксировано в стандарте в 2011.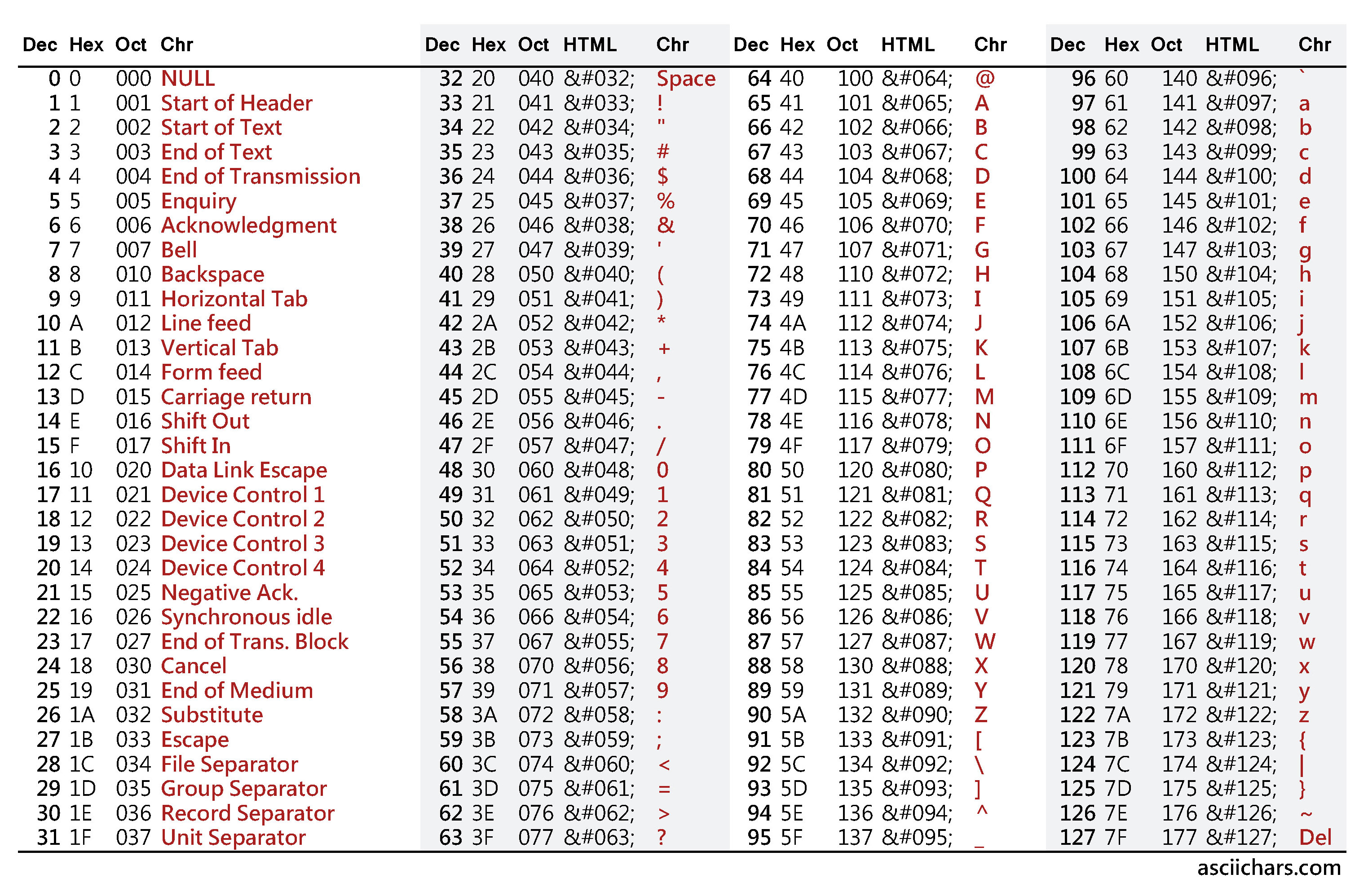 Несмотря на то, что эти стандарты находятся лишь на стадии «Proposed Standard», они поддержаны повсеместно. Вариант, что в будущем нас ожидают новые стандарты, которые позволят более унифицировано работать с различными кодировками в заголовках, не исключен. Поэтому остается только следить за новостями в мире стандартов HTTP и уровня их поддержки на стороне браузеров.
Несмотря на то, что эти стандарты находятся лишь на стадии «Proposed Standard», они поддержаны повсеместно. Вариант, что в будущем нас ожидают новые стандарты, которые позволят более унифицировано работать с различными кодировками в заголовках, не исключен. Поэтому остается только следить за новостями в мире стандартов HTTP и уровня их поддержки на стороне браузеров.
Issue 27716: http.client truncates UTF-8 encoded headers
Issue27716
➜This issue tracker has been migrated to GitHub,
and is currently read-only.
For more information,
see the GitHub FAQs in the Python’s Developer Guide.
Created on 2016-08-09 11:33 by Lukasa, last changed 2022-04-11 14:58 by admin.
| File name | Uploaded | Description | Edit |
|---|---|---|---|
| header-decoding.patch | martin.panter, 2016-09-18 01:57 | review |
| msg272236 — (view) | Author: Cory Benfield (Lukasa) * | Date: 2016-08-09 11:33 | |
|---|---|---|---|
Originally reported as Requests issue #3485: https://github. | |||
| msg272237 — (view) | Author: Cory Benfield (Lukasa) * | Date: 2016-08-09 11:35 | |
Simple repro case:
import http.client
conn = http.client.HTTPConnection('pl.bab.la')
conn.request("GET", '/slownik/angielski-polski/')
resp = conn.getresponse()
resp.read() # Hangs here | |||
| msg272246 — (view) | Author: R. David Murray (r.david.murray) * | Date: 2016-08-09 13:35 | |
utf-8 headers are contrary to the http spec, aren't they? Or has that changed? (It's been a long time since I've looked at any http RFCs.) This could be fixed by using SMTPUTF8 mode when parsing the headers, which in theory ought to be backward compatible. We could make SMTPUTF8 the default for email. | |||
| msg272250 — (view) | Author: Cory Benfield (Lukasa) * | Date: 2016-08-09 13:49 | |
Honestly, David, everything's a mess on this front. The authoritative document here is RFC 7230 Section 3.2.4 (https://tools.ietf.org/html/rfc7230#section-3.2.4). The last paragraph of that section reads: Historically, HTTP has allowed field content with text in the ISO-8859-1 charset [ISO-8859-1], supporting other charsets only through use of [RFC2047] encoding. In practice, most HTTP header field values use only a subset of the US-ASCII charset [USASCII]. Newly defined header fields SHOULD limit their field values to US-ASCII octets. A recipient SHOULD treat other octets in field content (obs-text) as opaque data. In the case of http.client, actually maps pretty closely to Python 3's bytes object: header field values are basically ASCII + arbitrary opaque bytes. | |||
| msg272254 — (view) | Author: R. David Murray (r.david.murray) * | Date: 2016-08-09 14:11 | |
Well, email will happily parse bytes and treat the non-ascii data as opaque (though it does record errors in an internal data structure), but the python3 http api expects the parsed headers to be strings when you access them, so you'd just hit the decoding problem at that point rather than earlier. This is a hard problem. Since headers *can* be latin1 (I'd forgotten that) SMTPUTF8 won't work. | |||
| msg272288 — (view) | Author: Martin Panter (martin.panter) * | Date: 2016-08-10 02:27 | |
For the test case given, the main problem is actually that a header field is being incorrectly split on a Latin-1 “next line” control code U+0085. | |||
| msg276867 — (view) | Author: Martin Panter (martin.panter) * | Date: 2016-09-18 01:57 | |
Thanks to the fix for Issue 22233, now the response is parsed more sensibly, and the body can be read. The 0x85 byte now gets decoded with Latin-1:
>>> print(ascii(resp.getheader("Link")[:100]))
'<http://www.babla.cn/\xe8\x8b\xb1\xe8\xaf\xad-\xe6\xb3\xa2\xe5\x85\xb0\xe8\xaf\xad/>; rel="alternate"; hreflang="zh-Hans", <http://cs.bab.la/slov'
Here is a patch to document how to get the original bytes back (by “encoding” to Latin-1). Other than that, I don’t think there is much left to do for this bug. | |||

 bab.la/diccionario/ingles-polaco/>; rel="alternate"; hreflang="es", <http://fi.bab.la/sanakirja/englanti-puola/>; rel="alternate"; hreflang="fi", <http://fr.bab.la/dictionnaire/anglais-polonais/>; rel="alternate"; hreflang="fr", <http://www.babla.in/अंग्रेज़ी-पोलिश/>; rel="alternate"; hreflang="hi", <http://hu.bab.la/szótár/angol-lengyel/>; rel="alternate"; hreflang="hu", <http://www.babla.co.id/bahasa-inggris-bahasa-polandia/>; rel="alternate"; hreflang="id", <http://it.bab.la/dizionario/inglese-polacco/>; rel="alternate"; hreflang="it", <http://ja.bab.la/辞書/英語-ポーランド語/>; rel="alternate"; hreflang="ja", <http://www.babla.kr/영어-폴란드어/>; rel="alternate"; hreflang="ko", <http://nl.bab.la/woordenboek/engels-pools/>; rel="alternate"; hreflang="nl", <http://www.babla.no/engelsk-polsk/>; rel="alternate"; hreflang="no", <http://pl.bab.la/slownik/angielski-polski/>; rel="alternate"; hreflang="pl", <http://pt.bab.la/dicionario/ingles-polones/>; rel="alternate"; hreflang="pt", <http://ro.
bab.la/diccionario/ingles-polaco/>; rel="alternate"; hreflang="es", <http://fi.bab.la/sanakirja/englanti-puola/>; rel="alternate"; hreflang="fi", <http://fr.bab.la/dictionnaire/anglais-polonais/>; rel="alternate"; hreflang="fr", <http://www.babla.in/अंग्रेज़ी-पोलिश/>; rel="alternate"; hreflang="hi", <http://hu.bab.la/szótár/angol-lengyel/>; rel="alternate"; hreflang="hu", <http://www.babla.co.id/bahasa-inggris-bahasa-polandia/>; rel="alternate"; hreflang="id", <http://it.bab.la/dizionario/inglese-polacco/>; rel="alternate"; hreflang="it", <http://ja.bab.la/辞書/英語-ポーランド語/>; rel="alternate"; hreflang="ja", <http://www.babla.kr/영어-폴란드어/>; rel="alternate"; hreflang="ko", <http://nl.bab.la/woordenboek/engels-pools/>; rel="alternate"; hreflang="nl", <http://www.babla.no/engelsk-polsk/>; rel="alternate"; hreflang="no", <http://pl.bab.la/slownik/angielski-polski/>; rel="alternate"; hreflang="pl", <http://pt.bab.la/dicionario/ingles-polones/>; rel="alternate"; hreflang="pt", <http://ro.
 That way, at least, user code can recover the headers and handle them more sensibly.
That way, at least, user code can recover the headers and handle them more sensibly. policy.http, if this is correct per the RFCs.
policy.http, if this is correct per the RFCs. While UTF-8 is not strictly called out as allowed, neither is it called out as forbidden.
In this case, I'd say that there's no need to be too pedantic about Latin 1 at this stage in the pipeline. Python 3 is welcome to decode using Latin 1 *after* the header block has been split, because at least then it can be fixed up due to the round-tripping nature of Latin 1. But doing it here seems to just confuse the email parser.
While UTF-8 is not strictly called out as allowed, neither is it called out as forbidden.
In this case, I'd say that there's no need to be too pedantic about Latin 1 at this stage in the pipeline. Python 3 is welcome to decode using Latin 1 *after* the header block has been split, because at least then it can be fixed up due to the round-tripping nature of Latin 1. But doing it here seems to just confuse the email parser. We are stuck against the problem that python makes a careful distinction between bytes and string, but http does not.
In theory we could pass bytes to email, and then provide a new API for getting at the "raw" (bytes) header so you can decode it however you want. That runs into backward compatibility problems, though, since we currently do decode from latin-1 and many programs are probably relying on that.
Throwing out an idea here: maybe having the http policy decode the parsed bytes header from latin-1 when headers are accessed through the normal API would preserve backward compatibility. I'm not too worried about back-compat in the http policy, since it is provisional until 3.6 comes out and I doubt anyone is currently using it.
We are stuck against the problem that python makes a careful distinction between bytes and string, but http does not.
In theory we could pass bytes to email, and then provide a new API for getting at the "raw" (bytes) header so you can decode it however you want. That runs into backward compatibility problems, though, since we currently do decode from latin-1 and many programs are probably relying on that.
Throwing out an idea here: maybe having the http policy decode the parsed bytes header from latin-1 when headers are accessed through the normal API would preserve backward compatibility. I'm not too worried about back-compat in the http policy, since it is provisional until 3.6 comes out and I doubt anyone is currently using it.
 Perhaps just document how the bytes are transformed, and how to get the original bytes back?
FWIW UTF-8 is used in RTSP, which is based on HTTP.
Perhaps just document how the bytes are transformed, and how to get the original bytes back?
FWIW UTF-8 is used in RTSP, which is based on HTTP.| Date | User | Action | Args |
|---|---|---|---|
| 2022-04-11 14:58:34 | admin | set | github: 71903 |
| 2016-09-18 01:57:01 | martin. panter panter | set | files:
+ header-decoding.patch keywords: + patch messages: + msg276867 |
| 2016-08-10 02:27:38 | martin.panter | set | superseder: http.client splits headers on non-\r\n characters messages:
+ msg272288 |
| 2016-08-09 14:11:38 | r.david.murray | set | messages: + msg272254 |
| 2016-08-09 13:49:52 | Lukasa | set | messages: + msg272250 |
| 2016-08-09 13:35:11 | r.david.murray | set | nosy:
+ r.david.murray messages: + msg272246 |
| 2016-08-09 11:35:30 | Lukasa | set | messages: + msg272237 |
| 2016-08-09 11:33:16 | Lukasa | create |
UTF-8 в заголовках HTTP — Jmix
HTTP 1.1 — широко известный гипертекстовый протокол для передачи данных. HTTP-сообщения кодируются с помощью ISO-8859-1 (который номинально можно рассматривать как расширенную версию ASCII, содержащую умлауты, диакритические знаки и другие символы западноевропейских языков). В то же время тело сообщения может использовать другую кодировку, указанную в заголовке Content-Type. Но что делать, если нам нужно прописать не-ASCII-символы не в теле сообщения, а в заголовке? Вероятно, наиболее известным случаем является установка имени файла в заголовке «Content-Disposition». Вроде вполне обычная задача, но ее реализация не очевидна.
В то же время тело сообщения может использовать другую кодировку, указанную в заголовке Content-Type. Но что делать, если нам нужно прописать не-ASCII-символы не в теле сообщения, а в заголовке? Вероятно, наиболее известным случаем является установка имени файла в заголовке «Content-Disposition». Вроде вполне обычная задача, но ее реализация не очевидна.
TL;DR: Используйте кодировку, описанную в RFC 6266 для Content-Disposition, и транслитерируйте на латиницу в других случаях.
Знакомство с кодировками
В статье упоминаются кодировки US-ASCII (обычно называемые просто ASCII), ISO-8859-1 и UTF-8. Вот небольшое введение в эти кодировки. Этот абзац для разработчиков, которые редко работают с этими кодировками или вообще не используют их, частично подзабыв. Если вы не один из них, пропустите эту часть без колебаний. 98 = 256 вариантов.
ISO-8859-1 — это кодировка, предназначенная для западноевропейских языков. Он имеет французские диакритические знаки, немецкие умляуты и т. д.
д.
Кодировка имеет 256 символов, поэтому может быть представлена 1 байтом. Первая половина (128 символов) полностью соответствует ASCII. Следовательно, если первый бит = 0, это обычный символ ASCII. Если 1 — мы распознаем конкретный символ ISO-8859-1.
UTF-8 — одна из самых известных кодировок наряду с ASCII. Он способен кодировать 1 112 064 символа. Размер каждого символа варьируется от 1 до 4 байтов (ранее значения могли быть до 6 байтов).
Программа, обрабатывающая эту кодировку, проверяет первый бит и оценивает размер символа в байтах. Если октет начинается с 0, символ представлен 1 байтом. 110 — 2 байта, 1110 — 3 байта, 11110 — 4 байта.
Как и в случае с ISO-8859-1, первые 128 строк соответствуют ASCII. Поэтому тексты, использующие символы ASCII, будут выглядеть в двоичном представлении абсолютно одинаково, независимо от используемой кодировки: US-ASCII, ISO-8859-1 или UTF-8.
UTF-8 в теле сообщения
Прежде чем мы перейдем к заголовкам, давайте посмотрим, как UTF-8 используется в теле сообщений. Для этого мы используем заголовок «Content-Type» .
Для этого мы используем заголовок «Content-Type» .
Если «Content-Type» не назначен, браузер должен обрабатывать сообщения, как если бы они были в ISO-8859-1. Браузер не должен пытаться угадать кодировку и уж точно не должен игнорировать Content-Type. Итак, если мы будем передавать сообщения UTF-8, но не назначать кодировку в заголовках, они будут читаться так, как если бы они были закодированы с помощью ISO-8859-1.
Ввод сообщения UTF-8 в значение заголовка
В случае с телом сообщения все довольно просто. Тело сообщения всегда следует за заголовком, поэтому здесь нет технических проблем. Но что нам делать с заголовками? Спецификация прямо утверждает, что порядок заголовков в сообщениях не имеет значения. т.е. невозможно назначить кодировку для одного заголовка через другой.
Что, если мы просто запишем значение UTF-8 в заголовок? Мы видели, что с таким трюком, примененным к телу сообщения, значение будет читаться в формате ISO-8859. -1. Поэтому можно предположить, что то же самое произойдет и с заголовком. Но нет, не будет. На самом деле, для большинства, может быть, даже для всех случаев такое решение сработает. К таким случаям относятся старые iPhone, IE11, Firefox, Google Chrome. Единственным браузером, который отказался читать такой заголовок, из всех браузеров, которые у меня были на момент написания этой статьи, был Edge.
-1. Поэтому можно предположить, что то же самое произойдет и с заголовком. Но нет, не будет. На самом деле, для большинства, может быть, даже для всех случаев такое решение сработает. К таким случаям относятся старые iPhone, IE11, Firefox, Google Chrome. Единственным браузером, который отказался читать такой заголовок, из всех браузеров, которые у меня были на момент написания этой статьи, был Edge.
Такое поведение не описано в спецификациях. Вероятно, разработчики браузеров решили пойти навстречу другим разработчикам и автоматически определять кодировку сообщений UTF-8. В общем, простая задача. Проверяем первый бит: если 0, то это ASCII, если 1, то скорее всего UTF-8.
Нет ли в таком случае ничего общего с ISO-8859-1? На самом деле, почти нет. В качестве примера возьмем символ UTF-8 из 2 октетов (русские буквы представлены двумя октетами). В двоичном представлении символ будет выглядеть так: 110xxxxxx 10xxxxxx . В шестнадцатеричном представлении: [0xC0-0x6F] [0x80-0xBF] . В ISO-8859-1 эти символы вряд ли можно использовать для выражения чего-то осмысленного. Следовательно, вероятность того, что браузер неправильно декодирует сообщение, очень мала.
В ISO-8859-1 эти символы вряд ли можно использовать для выражения чего-то осмысленного. Следовательно, вероятность того, что браузер неправильно декодирует сообщение, очень мала.
Однако при попытке использовать этот метод вы можете столкнуться с некоторыми проблемами: ваш веб-сервер или фреймворк могут просто запретить запись символов UTF-8 в заголовок. Например, Apache Tomcat вводит 0x3F (вопросительный знак) вместо символов UTF-8. Конечно, это ограничение можно обойти, но если приложение бьет вас по запястью и не дает что-то сделать, то, наверное, не стоит этого делать.
Независимо от того, запрещает или разрешает ваш фреймворк или сервер писать сообщения UTF-8 в заголовке, я не рекомендую этого делать. Это не документированное решение и может перестать работать в браузерах в любой момент.
Транслитерация
На мой взгляд, транслитерация — лучшее решение. Многие популярные русскоязычные ресурсы не против использования транслитерации в именах файлов. Это гарантированное решение, которое не сломается с выходом новых версий браузеров и которое не нужно тестировать отдельно на каждой платформе. Хотя, конечно, стоит продумать способ передачи всего возможного спектра персонажей, что бывает не так просто. Например, если приложение ориентировано на русскоязычную аудиторию, имя файла может содержать татарские буквы ә и ң, с которыми нужно как-то обращаться, а не просто заменять на «?».
Хотя, конечно, стоит продумать способ передачи всего возможного спектра персонажей, что бывает не так просто. Например, если приложение ориентировано на русскоязычную аудиторию, имя файла может содержать татарские буквы ә и ң, с которыми нужно как-то обращаться, а не просто заменять на «?».
RFC 2047
Как я уже говорил, Tomcat не позволял мне вводить UTF-8 в заголовке сообщения. Упоминается ли эта функция в Javadocs для сервлетов? Да, это:
Там упоминается RFC 2047. Пробовал кодировать сообщения в этом формате — браузер не понял. Этот метод кодирования больше не работает для HTTP. Впрочем, бывало. Например, вот тикет об удалении этой поддержки кодировки из Firefox.
RFC 6266
В тикете, указанном выше, сказано, что даже после прекращения поддержки RFC 2047 все еще существует способ передачи значений UTF-8 в именах загружаемых файлов: RFC 6266. С моей точки зрения, на сегодняшний день это самый оптимальное и правильное решение. Его используют многие популярные интернет-ресурсы. Мы в Jmix также используем этот RFC для генерации Content-Disposition.
Мы в Jmix также используем этот RFC для генерации Content-Disposition.
RFC 6266 — это спецификация, описывающая использование заголовка «Content-Disposition». Сама кодировка подробно описана в RFC 8187.
Параметр «filename» содержит имя файла в ASCII, «filename*» в любой другой необходимой кодировке. Если определены оба атрибута, «имя файла» игнорируется во всех современных браузерах (включая IE11 и старые версии Safari). Самые старые браузеры, наоборот, игнорируют «имя файла*».
В этом методе кодирования сначала вы назначаете кодировку в параметре, после » идет закодированное значение. Наблюдаемые символы ASCII не требуют кодирования. Другие символы просто записываются в шестнадцатеричном представлении с «%» перед каждым октетом.
Что делать с другими заголовками?
Кодирование, описанное в RFC 8187, не является универсальным. Конечно, вы можете указать параметр с префиксом * в заголовке, и это, вероятно, будет работать для некоторых браузеров, но спецификация не требует этого.
В настоящее время в каждом случае, когда в заголовках поддерживается UTF-8, есть прямое упоминание о соответствующем RFC. Помимо «Content-Disposition» это кодирование используется, например, в Web Linking и Digest Access Authentication.
Следует учитывать, что стандарты в этой области постоянно меняются. Использование вышеуказанной кодировки в HTTP было предложено только в 2010 году. Использование этой кодировки в самом «Content-Disposition» было зафиксировано в стандарте 2011 года. Несмотря на то, что эти стандарты находятся только на стадии «Proposed Standard» , они везде поддерживаются. Вполне возможно, что появятся новые стандарты, стандарты, которые позволят более последовательно работать с различными кодировками в заголовках. Итак, нам нужно только следить за новостями о стандартах HTTP и уровне их поддержки на стороне браузера.
Посмотрите, как сделать простое работающее приложение за 12 минут.
Попробуйте Jmix
UTF-8 в заголовках HTTP — DZone
HTTP 1. 1 — широко известный гипертекстовый протокол для передачи данных. HTTP-сообщения кодируются с помощью ISO-8859-1 (который номинально можно рассматривать как расширенную версию ASCII, содержащую умлауты, диакритические знаки и другие символы западноевропейских языков). В то же время тело сообщения может использовать другую кодировку, указанную в заголовке Content-Type. Но что делать, если нам нужно прописать не-ASCII-символы не в теле сообщения, а в заголовке? Вероятно, наиболее известным случаем является установка имени файла в заголовке «Content-Disposition». Вроде обычная задача, но ее реализация неочевидна
1 — широко известный гипертекстовый протокол для передачи данных. HTTP-сообщения кодируются с помощью ISO-8859-1 (который номинально можно рассматривать как расширенную версию ASCII, содержащую умлауты, диакритические знаки и другие символы западноевропейских языков). В то же время тело сообщения может использовать другую кодировку, указанную в заголовке Content-Type. Но что делать, если нам нужно прописать не-ASCII-символы не в теле сообщения, а в заголовке? Вероятно, наиболее известным случаем является установка имени файла в заголовке «Content-Disposition». Вроде обычная задача, но ее реализация неочевидна
TL;DR: Используйте кодировку, описанную в RFC 6266 для Content-Disposition, и транслитерируйте ее на латиницу в других случаях.
Введение в кодирование
В статье упоминаются кодировки US-ASCII (обычно называемые просто ASCII), ISO-8859-1 и UTF-8. Вот небольшое введение в эти кодировки. Этот абзац для разработчиков, которые редко работают с этими кодировками или вообще не используют их, частично подзабыв.
ASCII — это простая кодировка из 128 символов, включая латинский алфавит, цифры, знаки препинания и служебные символы. 98 = 256 вариантов.
ISO-8859-1 — это кодировка, предназначенная для западноевропейских языков. Он имеет диакритические знаки, немецкие умлауты и т. д.
Кодировка имеет 256 символов, поэтому может быть представлена 1 байтом. Первая половина (128 символов) полностью соответствует ASCII. Следовательно, если первый бит = 0, это обычно символ ASCII. Если это 1, мы распознаем определенный символ ISO-8859-1.
UTF-8 — одна из самых известных кодировок наряду с ASCII. Он способен кодировать 1 112 064 символа. Размер каждого символа варьируется от 1 до 4 байтов (ранее значения могли быть до 6 байтов).
Программа, обрабатывающая эту кодировку, проверяет первый бит и оценивает размер символа в байтах. Если октет начинается с 0, символ представлен 1 байтом. 110 — 2 байта, 1110 — 3 байта, 11110 — 4 байта.
Как и в случае с ISO-8859-1, первые 128 будут соответствовать ASCII. Поэтому тексты, использующие символы ASCII, будут выглядеть в двоичном представлении абсолютно одинаково, независимо от используемой кодировки: US-ASCII, ISO-8859-1 или UTF-8.
Поэтому тексты, использующие символы ASCII, будут выглядеть в двоичном представлении абсолютно одинаково, независимо от используемой кодировки: US-ASCII, ISO-8859-1 или UTF-8.
UTF-8 в теле сообщения
Прежде чем мы перейдем к заголовкам, давайте посмотрим, как UTF-8 используется в теле сообщения. Для этого мы будем использовать заголовок «Content-Type».
Если «Content-Type» не назначен, браузер должен обрабатывать сообщения, как если бы они были в ISO-8859-1. Браузер не должен пытаться угадать кодировку и уж точно не должен игнорировать «Content-Type». Итак, если мы будем передавать сообщения UTF-8, но не назначать кодировку в заголовках, они будут читаться так, как если бы они были закодированы с помощью ISO-8859.-1.
Ввод сообщения UTF-8 в значение заголовка
В случае с телом сообщения все довольно просто. Тело сообщения всегда следует за заголовком, поэтому здесь нет технических проблем. Но что нам делать с заголовками? Спецификация прямо утверждает, что порядок заголовков в сообщениях не имеет значения; т. е. невозможно назначить кодировку для одного заголовка через другой.
е. невозможно назначить кодировку для одного заголовка через другой.
Что, если мы просто запишем значение UTF-8 в заголовок? Мы видели, что с таким трюком, примененным к телу сообщения, значение будет читаться как ISO-8859.-1. Поэтому можно предположить, что то же самое произойдет и с заголовком. Но нет, не будет. На самом деле, для большинства, может быть, даже для всех случаев такое решение сработает. К таким случаям относятся старые iPhone, IE11, Firefox и Google Chrome. Единственным браузером, который отказался читать такой заголовок, из всех браузеров, которые у меня были на момент написания этой статьи, был Edge.
Такое поведение не описано в спецификациях. Разработчики браузеров, вероятно, решили пойти навстречу другим разработчикам и автоматически определять кодировку сообщений UTF-8. В общем, простая задача. Проверяем первый бит: если 0, то это ASCII, если 1, то скорее всего UTF-8.
В таком случае есть ли что-то общее с ISO-8859-1? На самом деле, почти нет. В качестве примера возьмем символ UTF-8 из 2 октетов (русские буквы представлены двумя октетами). В двоичном представлении символ будет выглядеть следующим образом: 110xxxxxx 10xxxxxx . В шестнадцатеричном представлении: [0xC0-0x6F] [0x80-0xBF] . В ISO-8859-1 эти символы вряд ли можно использовать для выражения чего-то осмысленного. Поэтому вероятность того, что браузер неправильно расшифрует сообщение, очень мала.
В качестве примера возьмем символ UTF-8 из 2 октетов (русские буквы представлены двумя октетами). В двоичном представлении символ будет выглядеть следующим образом: 110xxxxxx 10xxxxxx . В шестнадцатеричном представлении: [0xC0-0x6F] [0x80-0xBF] . В ISO-8859-1 эти символы вряд ли можно использовать для выражения чего-то осмысленного. Поэтому вероятность того, что браузер неправильно расшифрует сообщение, очень мала.
Однако при попытке использовать этот метод вы можете столкнуться с некоторыми проблемами: ваш веб-сервер или фреймворк могут просто запретить запись символов UTF-8 в заголовок. Например, Apache Tomcat вводит 0x3F (вопросительный знак) вместо символов UTF-8. Конечно, это ограничение можно обойти, но если приложение бьет вас по запястью и не дает что-то сделать, то, наверное, не стоит этого делать.
Независимо от того, запрещает или разрешает ваш фреймворк или сервер писать сообщения UTF-8 в заголовке, я не рекомендую этого делать. Это не документированное решение и может перестать работать в браузерах в любой момент.
Транслитерация
На мой взгляд, транслитерация — лучшее решение. Многие популярные русскоязычные ресурсы не против использования транслитерации в именах файлов. Это гарантированное решение, которое не сломается с выходом новой версии браузера и не требует отдельного тестирования на каждой платформе. Хотя, конечно, нужно подумать о способе переноса всех возможных диапазонов символов, что не так просто. Например, если приложение ориентировано на русскоязычную аудиторию, имя файла может содержать татарские буквы ә и ң, с которыми нужно как-то обращаться, а не просто заменять на «?».
RFC 2047
Как я уже говорил, Tomcat не позволял мне вводить UTF-8 в заголовке сообщения. Упоминается ли эта функция в Javadocs для сервлетов? Да, это:
Там упоминается RFC 2047. Пробовал кодировать сообщения в этом формате — браузер не понял. Этот метод кодирования больше не работает для HTTP, но раньше работал. Например, вот тикет об удалении этой поддержки кодировки из Firefox.
RFC 6266
В упомянутом выше тикете сказано, что даже после прекращения поддержки RFC 2047, все еще есть способ передавать значения UTF-8 в именах загружаемых файлов: RFC 6266. С моей точки зрения, на сегодняшний день это оптимальное и правильное решение . Его используют многие популярные интернет-ресурсы. Мы здесь, на платформе CUBA, также используем этот RFC для генерации Content-Disposition.
RFC 6266 — это спецификация, описывающая использование заголовка «Content-Disposition». Само кодирование подробно описано в RFC 8187.
Параметр «имя файла» содержит имя файла в ASCII, «имя файла*» в любой другой необходимой кодировке. Если определены оба атрибута, «имя файла» игнорируется во всех современных браузерах (включая IE11 и старые версии Safari). Самые старые браузеры, наоборот, игнорируют «имя файла*».
В этом методе кодирования сначала вы назначаете кодировку в параметре, после "" приходит закодированное значение. Наблюдаемые символы ASCII не требуют кодирования. Другие символы просто записываются в шестнадцатеричном представлении с «%» перед каждым октетом.
Наблюдаемые символы ASCII не требуют кодирования. Другие символы просто записываются в шестнадцатеричном представлении с «%» перед каждым октетом.
Что делать с другими заголовками?
Кодирование, описанное в RFC 8187, не является универсальным. Конечно, вы можете указать в заголовке параметр с префиксом * , и, вероятно, он будет работать для некоторых браузеров, но спецификация не требует этого.
В настоящее время в каждом случае, когда в заголовках поддерживается UTF-8, есть прямое упоминание о соответствующем RFC. Помимо «Content-Disposition», это кодирование используется, например, в Web Linking и Digest Access Authentication.
Следует учитывать, что стандарты этой области постоянно меняются. Использование вышеуказанной кодировки в HTTP было предложено только в 2010 году. Использование этой кодировки в самом «Content-Disposition» было зафиксировано в стандарте 2011 года. Несмотря на то, что эти стандарты находятся только на стадии «Proposed Standard» , они везде поддерживаются.