Правда о регистре символов, которую должны знать программисты / Хабр
На конференции North Bay Python в 2018 году я делал доклад об именах пользователей. Информация из доклада по большей части была собрана мною за 12 лет поддержки django-registration. Этот опыт дал мне гораздо больше знаний, чем я планировал получить, о том, насколько сложными могут быть «простые» вещи.
В начале доклада я, правда, упомянул, что это не будет очередное разоблачение из серии «заблуждения по поводу Х, в которые верят программисты». Таких разоблачений можно найти сколько угодно. Однако мне подобные статьи не нравятся. В них перечисляются разные вещи, якобы являющиеся ложными, однако очень редко объясняется – почему это так, и что нужно делать вместо этого. Подозреваю, что люди просто прочтут такие статьи, поздравят себя с этим достижением, и потом пойдут находить новые интересные способы делать ошибки, не упомянутые в этих статьях. Всё потому, что они на самом деле не поняли проблем, порождающих этих ошибки.
Поэтому в своём докладе я постарался как можно лучше объяснить некоторые проблемы и пояснить, как их решать – такой подход мне нравится гораздо больше. Одна из тем, которой я коснулся лишь вскользь (это был всего один слайд и пара упоминаний на других слайдах) – это сложности, которые могут быть связаны с регистром символов. Для задачи, которую я обсуждал – сравнение идентификаторов без учёта регистра – есть официальный Правильный Ответ™, и в докладе я дал лучшее из известных мне решений, использующее только стандартную библиотеку Python.
Однако я кратко упомянул о более глубоких сложностях с регистром символов в Unicode, и хочу посвятить некоторое время описанию подробностей. Это интересно, и понимание этого может помочь вам принимать решения при проектировании и написании кода, обрабатывающего текст. Поэтому предлагаю вам нечто противоположное статьям «заблуждения по поводу Х, в которые верят программисты» – «правда, которую должны знать программисты».
И ещё одно: в Unicode полно терминологии. В данной статье я буду использовать в основном определения «верхний регистр» и «нижний регистр», поскольку стандарт Unicode использует эти термины. Если вам нравятся другие термины, вроде строчная/прописная буквы – всё нормально. Также я часто буду использовать термин «символ», который некоторые могут счесть некорректным. Да, в Unicode концепция «символа» не всегда совпадает с ожиданиями людей, поэтому часто лучше избегать её, используя другие термины. Однако в данной статье я буду использовать этот термин так, как он используется в Unicode – для описания абстрактной сущности, о которой можно делать заявления. Когда это важно, для уточнения я буду использовать более конкретные термины типа «кодовой позиции» [code point].
В данной статье я буду использовать в основном определения «верхний регистр» и «нижний регистр», поскольку стандарт Unicode использует эти термины. Если вам нравятся другие термины, вроде строчная/прописная буквы – всё нормально. Также я часто буду использовать термин «символ», который некоторые могут счесть некорректным. Да, в Unicode концепция «символа» не всегда совпадает с ожиданиями людей, поэтому часто лучше избегать её, используя другие термины. Однако в данной статье я буду использовать этот термин так, как он используется в Unicode – для описания абстрактной сущности, о которой можно делать заявления. Когда это важно, для уточнения я буду использовать более конкретные термины типа «кодовой позиции» [code point].
Регистров бывает больше двух
Носители европейских языков привыкли к тому, что в их языках регистр символов используется для обозначения конкретных вещей. К примеру, в английском [и русском] языках мы обычно начинаем предложения с буквы в верхнем регистре, а продолжаем чаще всего буквами в нижнем регистре.
И мы обычно считаем, что регистров существует всего два. Есть буква «А», и есть буква «а». Одна в верхнем, другая в нижнем регистре – не правда ли?
Однако в Unicode есть три регистра. Есть верхний, есть нижний, и есть титульный регистр [titlecase]. В английском языке так записываются названия. Например, «Avengers: Infinity War». Обычно для этого первая буква каждого слова просто пишется в верхнем регистре (и в зависимости от разных правил и стилей, некоторые слова, например, артикли, не пишутся с заглавных букв).
В стандарте Unicode дан такой пример символа в титульном регистре: U+01F2 LATIN CAPITAL LETTER D WITH SMALL Z. Выглядит он так: Dz.Подобные символы иногда требуются для обработки негативных последствий одного из ранних решений разработки стандарта Unicode: совместимости с существующими текстовыми кодировками в обе стороны. Для Unicode было бы удобнее составлять последовательности при помощи имеющихся у стандарта возможностей по комбинированию символов. Однако во многих уже существующих системах уже были отведены места для готовых последовательностей. К примеру, в стандарте ISO-8859-1 («latin-1») у символа «é» есть готовая форма, имеющая номер 0xe9. В Unicode предпочтительнее было бы писать эту букву при помощи отдельной «е» и знака ударения. Но для обеспечения полной совместимости в обе стороны с такими существующими кодировками, как latin-1, в Unicode также назначены кодовые позиции для готовых символов. К примеру, U+00E9 LATIN SMALL LETTER E WITH ACUTE.
Однако во многих уже существующих системах уже были отведены места для готовых последовательностей. К примеру, в стандарте ISO-8859-1 («latin-1») у символа «é» есть готовая форма, имеющая номер 0xe9. В Unicode предпочтительнее было бы писать эту букву при помощи отдельной «е» и знака ударения. Но для обеспечения полной совместимости в обе стороны с такими существующими кодировками, как latin-1, в Unicode также назначены кодовые позиции для готовых символов. К примеру, U+00E9 LATIN SMALL LETTER E WITH ACUTE.
Хотя кодовая позиция этого символа совпадает с его байтовым значением из latin-1, полагаться на это не стоит. Вряд ли кодирование символов в Unicode сохранит эти позиции. К примеру, в UTF-8 кодовая позиция U+00E9 записана в виде байтовой последовательности 0xc3 0xa9.
И, конечно, в уже существующих кодировках есть символы, которым требовалось особое обхождение при использовании титульного регистра, из-за чего они были включены в Unicode «как есть». Если хотите посмотреть на них, поищите в своей любимой базе Unicode символы из категории Lt («Letter, titlecase»).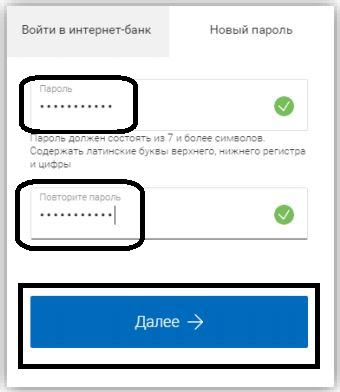
Есть несколько способов определить регистр
В стандарте Unicode (§4.2) перечислено три разных определения регистра. Возможно, выбор одного из трёх за вас делает ваш язык программирования; в противном случае, ваш выбор будет зависеть от конкретной цели. Вот эти определения:
- Символ находится в верхнем регистре, если он принадлежит к категории Lu («Letter, uppercase»), и в нижнем регистре, если принадлежит к категории Ll («Letter, lowercase»). В стандарте признаётся ограниченность этого определения: каждый конкретный символ приходится относить только к одной из категорий. Из-за этого многие символы, которые «должны находиться» в верхнем или нижнем регистре не удовлетворят этому требованию потому, что принадлежат к какой-то другой категории.
- Символ находится в верхнем регистре, если он унаследовал свойство Uppercase, и в нижнем регистре, если унаследовал свойство Lowercase. Это комбинация определения один с другими свойствами символов, среди которых может быть и регистр.

- Символ находится в верхнем регистре, если после применения к нему регистрового отображения в верхний регистр он не меняется. Символ находится в нижнем регистре, если после применения к нему регистрового отображения в нижний регистр он не меняется. Довольно общее определение, однако и оно может вести себя неинутитивно.

Если вы работаете с ограниченным подмножеством символов (конкретно, с буквами), то вам может хватить и 1-го определения. Если ваш репертуар шире – в него входят похожие на буквы символы, не являющиеся буквами, вам может подойти 2-е определение. Его рекомендует и стандарт Unicode, §4.2:
Программистам, манипулирующим строками в Unicode, стоит работать с такими строковыми функциями, как isLowerCase (и её функциональным родственником toLowerCase), если они не работают со свойствами символов напрямую.
Упомянутая здесь функция определяется в §3.13 стандарта Unicode. Формально в 3-м определении используются функции isLowerCase и isUpperCase из §3.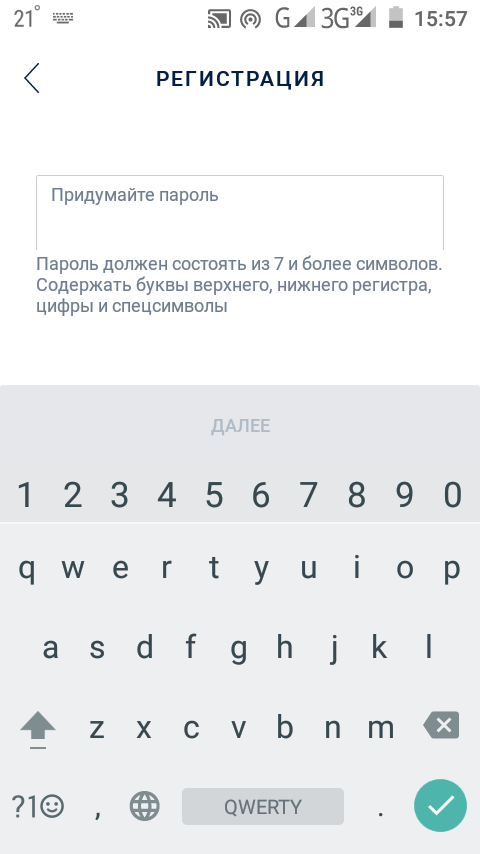
Если в вашем языке программирования есть функции для проверки или преобразования регистра строк или отдельных символов, стоит изучить, какие из упомянутых определений используются в реализации. Если вам интересно, то методы isupper() и islower() в Python используют 2-е определение.
Нельзя понять регистр символа по его внешнему виду или названию
По внешнему виду многих символов можно понять, в каком они регистре. К примеру, «А» находится в верхнем регистре. Это понятно и по названию символа: «LATIN CAPITAL LETTER A». Однако иногда такой метод не работает. Возьмём кодовую позицию U+1D34. Выглядит она так: ᴴ. В Unicode ей назначено имя: MODIFIER LETTER CAPITAL H. Значит, она в верхнем регистре, так?
На самом же деле она наследует свойство Lowercase, поэтому по определению №2 она находится в нижнем регистре, несмотря на то, что визуально напоминает заглавную Н, а в названии есть слово «CAPITAL».
У некоторых символов вообще нет регистра
Определение 135 в §3.13 стандарта Unicode гласит:
Символ С имеет регистр тогда и только тогда, когда у С есть свойство Lowercase или Uppercase, или значение параметра General_Category равно Titlecase_Letter.
Значит, очень много символов из Unicode – на самом деле, большая их часть – регистра не имеет. Не имеют смысла вопросы об их регистре, а изменения регистра на них не действуют. Однако мы можем получить ответ на этот вопрос по определению №3.
Некоторые символы ведут себя так, будто у них несколько регистров
Из этого следует, что если вы используете определение №3, и задаёте вопрос, находится ли символ без регистра в верхнем или нижнем регистре, вы получите ответ «да».
В стандарте Unicode даётся пример (таблица 4-1, строка 7) символа U+02BD MODIFIER LETTER REVERSED COMMA (который выглядит так: ʽ). У него нет унаследованных свойств Lowercase или Uppercase, он не принадлежит к категории Lt, поэтому регистра у него нет.
Кажется, что из-за этого может возникнуть никому не нужная путаница, однако смысл в том, что определение №3 работает с любой последовательностью символов Unicode, и позволяет упростить алгоритмы преобразования регистра (символы без регистра просто превращаются сами в себя).
Регистр зависит от контекста
Можно подумать, что если таблицы преобразования регистра в Unicode покрывают все символы, то это преобразование заключается просто в поиске нужного места в таблице. К примеру, в базе данных Unicode записано, что для символа U+0041 LATIN CAPITAL LETTER A нижним регистром будет U+0061 LATIN SMALL LETTER A. Просто, не так ли?
Один из примеров, в котором этот подход не работает – греческий язык. Символ Σ — то есть, U+03A3 GREEK CAPITAL LETTER SIGMA — сопоставлен двум разным символам при преобразовании в нижний регистр, в зависимости от того, где он находится в слове. Если он стоит на конце слова, тогда в нижнем регистре он будет ς (U+03C2 GREEK SMALL LETTER FINAL SIGMA). В любом другом месте это будет σ (U+03C3 GREEK SMALL LETTER SIGMA).
Символ Σ — то есть, U+03A3 GREEK CAPITAL LETTER SIGMA — сопоставлен двум разным символам при преобразовании в нижний регистр, в зависимости от того, где он находится в слове. Если он стоит на конце слова, тогда в нижнем регистре он будет ς (U+03C2 GREEK SMALL LETTER FINAL SIGMA). В любом другом месте это будет σ (U+03C3 GREEK SMALL LETTER SIGMA).
А это значит, что у регистра нет взаимной однозначности или транзитивности. Ещё один пример — ß (U+00DF LATIN SMALL LETTER SHARP S, или эсцет). В верхнем регистре это будет «SS», хотя теперь существует и другая его форма в верхнем регистре (ẞ, U+1E9E LATIN CAPITAL LETTER SHARP S). А при переводе «SS» в нижний регистр получается «ss», поэтому (используя терминологию стандарта Unicode для преобразования регистра): toLowerCase(toUpperCase(ß)) != ß.
Регистр зависит от локали
В разных языках правила преобразования регистра разные. Самый популярный пример: i (U+0069 LATIN SMALL LETTER I) и I (U+0049 LATIN CAPITAL LETTER I) в большинстве локалей преобразовываются друг в друга – в большинстве, но не во всех. В локалях az и tr (тюркские языки), i в верхнем регистре будет İ (U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE), а I в нижнем регистре будет ı (U+0131 LATIN SMALL LETTER DOTLESS I). Иногда правильная запись реально означает разницу между жизнью и смертью.
В локалях az и tr (тюркские языки), i в верхнем регистре будет İ (U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE), а I в нижнем регистре будет ı (U+0131 LATIN SMALL LETTER DOTLESS I). Иногда правильная запись реально означает разницу между жизнью и смертью.
Сам Unicode не обрабатывает все возможные правила преобразования регистра для всех локалей. В базе данных Unicode есть только общие правила преобразования всех символов, не зависящие от локали. Также там есть особые правила для некоторых языков и составных форм – литовского языка, тюркских языков, некоторых особенностей греческого. Всего остального там нет. §3.13 стандарта упоминает это и рекомендует при необходимости вводить правила преобразования, зависящие от локали.
Один пример будет знаком англоговорящим – это титульный регистр определённых имён. «o’brian» нужно преобразовывать в «O’Brian» (а не в «O’brian»). Однако при этом «it’s» нужно преобразовывать в «It’s», а не в «It’S». Ещё один пример, который не обрабатывается в Unicode – это голландское буквосочетание «ij», которое при преобразовании в титульный регистр должно переходить в верхний регистр целиком, если стоит в начале слова. Таким образом, большой залив в Нидерландах в титульном регистре будет «IJsselmeer», а не «Ijsselmeer». В Unicode есть символы IJ U+0132 LATIN CAPITAL LIGATURE IJ и ij U+0133 LATIN SMALL LIGATURE IJ, если они вам нужны. По умолчанию преобразование регистра преобразует их друг в друга (хотя формы нормализации Unicode, использующие эквивалентность совместимости, разделят их на два отдельных символа).
Таким образом, большой залив в Нидерландах в титульном регистре будет «IJsselmeer», а не «Ijsselmeer». В Unicode есть символы IJ U+0132 LATIN CAPITAL LIGATURE IJ и ij U+0133 LATIN SMALL LIGATURE IJ, если они вам нужны. По умолчанию преобразование регистра преобразует их друг в друга (хотя формы нормализации Unicode, использующие эквивалентность совместимости, разделят их на два отдельных символа).
Сравнение без учёта регистра требует приведения к сложенному регистру
Возвращаясь к материалу, представленному в докладе. Сложность работы с регистром в Unicode означает, что регистронезависимое сравнение нельзя проводить при помощи стандартных функций приведения к нижнему или верхнему регистру, имеющихся во многих языках программирования. Для таких сравнений в Unicode есть концепция приведения к сложенному регистру [case folding], а в §3.13 стандарта определяются функции toCaseFold и isCaseFolded.
Можно решить, что приведение к сложенному регистру похоже на приведение к нижнему регистру – но это не так. Стандарт Unicode предупреждает, что строка в сложенном регистре не обязательно будет находиться в нижнем регистре. В качестве примера приводится язык чероки – там в строке, находящейся в сложенном регистре, будут попадаться и символы в верхнем регистре.
Стандарт Unicode предупреждает, что строка в сложенном регистре не обязательно будет находиться в нижнем регистре. В качестве примера приводится язык чероки – там в строке, находящейся в сложенном регистре, будут попадаться и символы в верхнем регистре.
На одном из слайдов моего доклада рекомендации Unicode Technical Report #36 реализуются на Python настолько полно, насколько это возможно. Проводится нормализация NFKC и потом для полученной строки вызывается метод casefold() (доступный только в Python 3+). И даже при этом некоторые крайние случаи выпадают, и это не совсем то, что рекомендуется для сравнения идентификаторов. Сначала плохие новости: Python не выдаёт наружу достаточно свойств Unicode для того, чтобы отфильтровать символы, которых нет в XID_Start или XID_Continue или символы, имеющие свойство Default_Ignorable_Code_Point. Насколько мне известно, он не поддерживает отображение NFKC_Casefold. Также в нём нет простого способа использовать модифицированный NFKC UAX #31§5. 1.
1.
Хорошие новости: большинство этих крайних случаев не связано с какими-либо реальными рисками безопасности, создаваемыми рассматриваемыми символами. И складывание регистра в принципе не определяется как операция, сохраняющая нормализацию (отсюда и отображение NFKC_Casefold, которое повторно нормализуется до NFC после складывания регистра). Как правило, при сравнении вас не волнует, будут ли обе строки нормализованы после предварительной обработки. Вас заботит, не противоречива ли предварительная обработка, и гарантирует ли она, что только строки, которые «должны» отличаться впоследствии, будут отличаться впоследствии. Если вас это беспокоит, вы можете вручную выполнить повторную нормализацию после сложения регистра.
Пока достаточно
Эта статья, как и предыдущий доклад, не является исчерпывающей, и вряд ли можно уложить весь этот материал в единственный пост. Надеюсь, что это был полезный обзор сложностей, связанных с этой темой, и вы найдёте в нём достаточно отправных точек для того, чтобы искать дальнейшую информацию.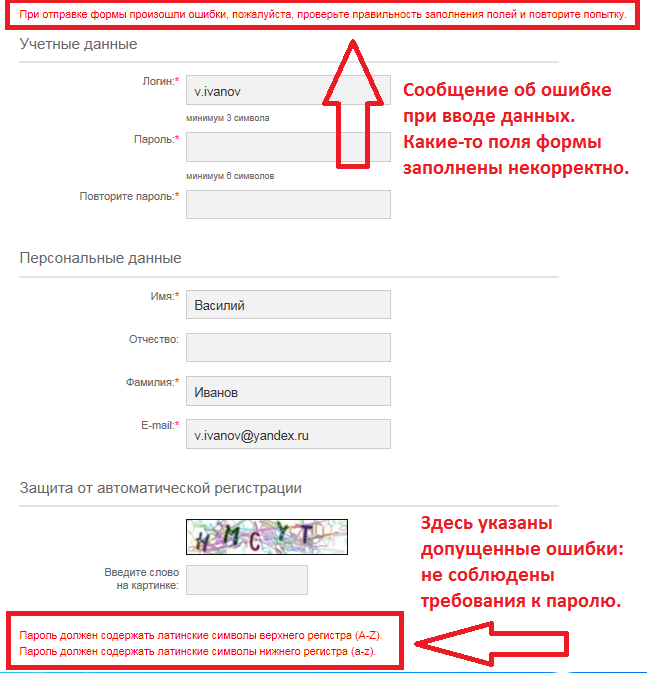 Поэтому в принципе, можно остановиться и тут.
Поэтому в принципе, можно остановиться и тут.
Не будет ли наивной моя надежда на то, что другие люди перестанут писать разоблачения из серии «заблуждения по поводу Х, в которые верят программисты», и начнут уже писать статьи типа «правда, которую должны знать программисты»?
python — Хотя бы один символ верхнего и нижнего регистра, и цифра
Вопрос задан
Изменён 4 года 3 месяца назад
Просмотрен 626 раз
Допустим, есть случайная строка. Если в ней нет хотя бы одного символа верхнего или нижнего регистра или цифры, то исправить ей таким образом, чтобы после исправления был хотя бы один символ верхнего, хотя бы один символ нижнего регистра и любая цифра. Как можно сделать такое без большого количества if’ов, но не меняя длину строки?
- python
- python-3. x
 x
x6
Ну у меня получилось в четыре if-а (а вообще я мог все слить в одно громадное, но это как-то слишком). Да, этот вариант довольно длинный, но все же уместен. И вот почему:цифры и буквы верхнего и нижнего регистра добавляются при необходимости, а не всегда (то есть: если нет цифры, то она добавляется). Если это нужно для паролей, то такой вариант сойдет. Только вот вelsе-ы нужно доработать добавив рандом. Ну это уже не так сложно.
Основные моменты кода:
1.Добавление строки
string
2.Проверка на её длинну
3.Проверка на содержание цифр
4.Проверка на содержание малых и заглавных букв (у малых букв есть небольшое отличие в проверке: т.к. цифры тоже малые символы, то идет сравнение с длинной списка чисел, содержащихся в строке)
5.Корриктеровка строки в соответствии с вышеперечисленными проверками.

string = input('')
if len(string) > 2:
if len([s for s in string if s in list('1234567890')]) > 0:
if len([s for s in string if s.islower()]) > len([s for s in string if s in list('1234567890')]:
if len([s for s in string if s.isupper()]) > 0:
pass
else:
string = list(string)
string[0] = 'I'
string = ''.join(string)
else:
string = list(string)
string[1] = 'z'
string = ''.join(string)
else:
string = list(string)
string[2] = '8'
string = ''.join(string)
2
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Пароль должен содержать буквы в разных регистрах.
 Как мне придумать один?
Как мне придумать один?Пароль должен содержать буквы в разных регистрах. Как мне придумать один?
Когда пользователи создают учетные записи на веб-сайтах, их часто просят создать пароль, содержащий буквы в разных регистрах (т. е. не только прописные или строчные). Почему это? Каким должен быть пароль, отвечающий современным требованиям безопасности, и как его создать? Мы ответим на все эти вопросы здесь.
Почему в пароле нужны буквы в разных регистрах?
Программы и даже целые операционные системы по-разному обрабатывают буквы. В Windows, например, вы не можете сохранять файлы (или другие папки) с тем же именем в папке, независимо от того, как они написаны. Другими словами, не имеет значения, написаны ли они только прописными или строчными буквами или их комбинацией в любом алфавите. Чтобы дать вам представление об этом, вы не можете создать файл с именем document.doc или DOCUMENT.DOC в том же месте, что и файл с именем Document.doc. Windows считает эти имена файлов одинаковыми. С другой стороны, Linux и построенные на нем операционные системы (например, Ubuntu) позволяют помещать файлы/папки с одинаковыми именами в одну папку, если они имеют буквы в разных регистрах. Это означает, что Linux рассматривает файлы document.doc и DOCUMENT.DOC как совершенно разные.
С другой стороны, Linux и построенные на нем операционные системы (например, Ubuntu) позволяют помещать файлы/папки с одинаковыми именами в одну папку, если они имеют буквы в разных регистрах. Это означает, что Linux рассматривает файлы document.doc и DOCUMENT.DOC как совершенно разные.
Примерно то же самое и с паролями. Каждый символ в пароле имеет свой уникальный код. Этот код отличается для прописной буквы «А» и строчной буквы «а». Это делает пароли или парольные фразы в два или более раза более устойчивыми к взлому, например атаке методом перебора или словарной атакой.
Для справки: атака грубой силы включает в себя отправку множества паролей, содержащих все возможные символы, которые можно использовать для создания пароля. Если защищенная паролем веб-система (файл, программа, веб-сайт и т. д.) одинаково воспринимает прописные и строчные буквы, то список возможных символов для атаки полным перебором сократится на 26 единиц (при использовании английских букв в пароль).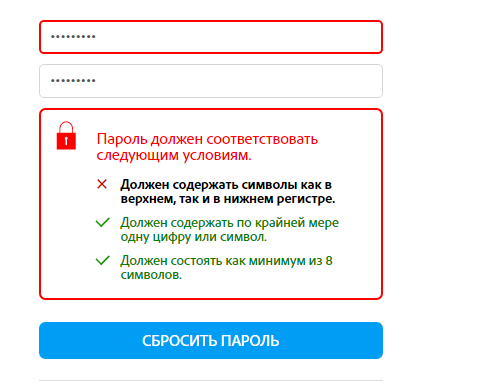 Это может показаться немного, но если пароль состоит из 10 символов, эти 26 заглавных букв создают для него дополнительные варианты написания. Чем больше возможных вариантов, тем сложнее будет взломать пароль.
Это может показаться немного, но если пароль состоит из 10 символов, эти 26 заглавных букв создают для него дополнительные варианты написания. Чем больше возможных вариантов, тем сложнее будет взломать пароль.
Какой самый надежный пароль?
Исходя из того, что мы обсуждали выше, пароль, содержащий как прописные, так и строчные буквы, явно в несколько раз более надежен, чем пароль, состоящий только из прописных или только строчных букв. Однако наличие обоих типов случаев не обязательно означает, что пароль соответствует требованиям кибербезопасности. Пароль также должен содержать:
- Минимум 8 символов (а лучше 12-14)
- Числа и, если это разрешено регистрационной формой, специальные символы. К ним относятся круглые скобки, математические символы, знаки препинания, буквы других алфавитов (в том числе буквенные) и т. д.
Существуют и другие требования к безопасности пароля, но перечисленные выше являются абсолютно обязательными.
Как создать надежный пароль?
Вы можете создать пароль из прописных и строчных букв вручную (здесь приведены подробные инструкции) или с помощью специального программного обеспечения, такого как генераторы надежных паролей, которые представляют собой компьютерные служебные программы или скрипты, доступные на различных веб-сайтах. При самостоятельном придумывании надежного пароля можно использовать простой метод:
При самостоятельном придумывании надежного пароля можно использовать простой метод:
- Напишите несколько слов на иностранном языке, используя английскую раскладку клавиатуры. Например, вы можете написать «это мой пароль» («это мой пароль»).
- Вы можете сделать некоторые буквы заглавными, чтобы в конце получилось что-то вроде этого: «eTO moY PaRol».
- Теперь замените пробелы (а также в начале и/или конце пароля) цифрами. Двух- или трехзначные числа еще лучше, или вы можете вставить дату. Например: «eTO18moY12PaRol1989».
- Если система, в которой вы создаете учетную запись, позволяет использовать специальные символы, попробуйте добавить некоторые из них: «%eTO18$moY12$PaRol1989%».
Получился довольно длинный пароль, всего 23 символа. Если система не позволяет использовать такие длинные пароли, просто удалите несколько символов.
Создавать безопасные пароли с помощью генераторов паролей намного проще. Вы также можете использовать менеджер паролей MultiPassword со встроенным генератором надежных паролей.
Как выбрать идеальный пароль
Идея невзламываемого пароля выходит за рамки возможного, но есть способы защитить себя и сделать ваш пароль более трудным для угадывания, чем обычный пароль. Специалисты по кибербезопасности устанавливают строгие правила, запрещающие повторное использование паролей, выбирая длинные и сложные пароли и следя за тем, чтобы ваши пароли были безопасными, потому что если есть желание, есть способ. Первый шаг к пониманию того, как подобрать пароль, — понять, как работает взлом пароля.
Как взломать пароль
Допустим, на каком-то веб-сайте требуется ввести четырехзначный пароль, состоящий только из цифр, то есть от 0 до 9. Как хакеру, сколько паролей мне нужно будет ввести, чтобы войти в вашу учетную запись? Что ж, есть 10 возможных цифр, которые вы могли бы выбрать для первого числа, 10 для второго, 10 для третьего и 10 для четвертого. Итак, чтобы рассчитать общее количество комбинаций, мы перемножаем количество вариантов для каждого слота. Итак, в этом случае у нас будет: 94 = 10 000 различных комбинаций
Итак, в этом случае у нас будет: 94 = 10 000 различных комбинаций
Когда я попросил свой обычный ноутбук сгенерировать и распечатать эти возможные комбинации, это заняло 0,120 секунды.
Хакеры и киберпреступники берут эти списки возможных комбинаций и пишут сценарий, чтобы компьютеры пробовали каждую комбинацию, пока не найдут правильную, называемую атакой грубой силы . Атаки грубой силы работают исключительно хорошо, когда требования к паролям имеют ограниченный набор комбинаций или когда люди создают короткие несложные пароли. Тем не менее, атаки грубой силы по-прежнему часты для других систем, они работают сами по себе в течение нескольких дней, недель и, возможно, лет, если специалисты по кибербезопасности не принимают дополнительных мер безопасности.
Теперь, если мы говорим, что пароль должен состоять не менее чем из 8 символов, он должен содержать как минимум 1 заглавную букву, 1 строчную букву, 1 цифру и 1 символ. Теперь, вместо десяти вариантов для каждого слота в пароле, есть 94 возможных значения для каждого:
- 26 строчных букв, это может быть .
- 26 заглавных букв, может быть
- 10 цифр может быть
- Может быть 32 символа (считая только символы на стандартной QWERTY-клавиатуре) 98 = 6 095 689 385 410 816. Это шесть квадриллионов возможных значений для вашего пароля. Даже если мой компьютер может обрабатывать миллион возможных паролей каждую секунду (что не очень много), поиск вашего пароля может занять до 6 095 689 385 секунд или 193 года. Если вы хотите проверить, сколько времени потребуется, чтобы взломать ваш пароль или любую общую строку символов, попробуйте этот веб-сайт: https://random-ize.com/how-long-to-hack-pass/.
Какие пароли самые безопасные?
Из приведенных выше примеров видно, что лучше всего сделать возможные значения для каждого символа вашего пароля как можно более значащим числом. Идеальный пароль должен состоять из букв верхнего и нижнего регистра, цифр и символов. Также обратите внимание, что в приведенном выше примере с паролем мы рассмотрели только восьмисимвольные пароли.
_`{|}~ ) - НЕ МОЖЕТ содержать более двух одинаковых символов подряд
- НЕ МОЖЕТ содержать имя, фамилию, адрес электронной почты, почтовый ящик или домен, название компании или часто используемые пароли
- МОЖЕТ НЕ совпадать с часто используемыми шаблонами символов пароля
- НЕ МОЖЕТ содержать более двух одинаковых символов подряд
- НЕ МОЖЕТ содержать имя, фамилию, адрес электронной почты, почтовый ящик или домен, название компании или часто используемые пароли
- МОЖЕТ НЕ совпадать с часто используемыми шаблонами символов пароля
 _`{|}~ )
_`{|}~ )Хотя я объяснил математику некоторых из них, мы должны изучить остальные. Первое требование — это требование длины, которое, как мы только что показали, значительно усложняет подбор вашего пароля. Требования 2-5 предназначены для увеличения количества возможных символов, содержащихся в вашем пароле, что отлично подходит для более длинных паролей.
Остальные требования необычны:
Давайте еще раз посмотрим на наш пример PIN-кода. Если мы применяем правило, согласно которому 2 одинаковых символа не могут стоять рядом друг с другом в нашем 4-значном пароле, наши возможности становятся немного более ограниченными. Первое число по-прежнему может быть любым из 10 чисел, но второе число имеет только 9.параметры, поскольку она не может совпадать с первой цифрой. Третье и четвертое число также имеют только 9 вариантов, потому что они не могут совпадать с предыдущими. Итак, теперь наши возможные комбинации выглядят так:
Если мы применяем правило, согласно которому 2 одинаковых символа не могут стоять рядом друг с другом в нашем 4-значном пароле, наши возможности становятся немного более ограниченными. Первое число по-прежнему может быть любым из 10 чисел, но второе число имеет только 9.параметры, поскольку она не может совпадать с первой цифрой. Третье и четвертое число также имеют только 9 вариантов, потому что они не могут совпадать с предыдущими. Итак, теперь наши возможные комбинации выглядят так:
10*9*9*9 = 7290
Этот набор инструкций удалил почти 3000 возможных комбинаций! Почему это правило должно соблюдаться? Ну, это потому, что люди склонны использовать пароли, которые легко запомнить. Когда хакеры пытаются взломать пароли, они понимают, что существует высокая вероятность того, что люди будут повторно использовать старые пароли, что сделает их легко запоминающимися и не будет проявлять изобретательность, когда это необходимо.
Часто используемые пароли
Большинство хакеров не сразу прибегают к генерации всех возможных комбинаций символов для проведения атак методом перебора. Вместо этого они ищут легкие цели, такие как упомянутые выше, и начинают с угадывания простых вещей, таких как ваше имя, адрес электронной почты, домен или название компании. Это правило предотвращает работу этих трюков.
Вместо этого они ищут легкие цели, такие как упомянутые выше, и начинают с угадывания простых вещей, таких как ваше имя, адрес электронной почты, домен или название компании. Это правило предотвращает работу этих трюков.
Общие пароли (такие как «Пароль», «Пароль1», «1234», «0000» и т. д.) находятся в списках, используемых хакерами. Эти списки обычно называют радужными таблицами. Пароли в этих файлах можно проверить против вашей учетной записи, чтобы увидеть, будут ли работать какие-либо общие, прежде чем хакеру придется прибегнуть к грубой силе, генерирующей все возможные комбинации.
Совет 3: Не повторяйте пароли и не используйте общие!
Подводя итог, можно сказать, что не существует надежного способа предотвратить доступ хакеров к вашим учетным записям, но есть способы защитить себя и усложнить им задачу. Если вы сделаете свой пароль длинным, сложным и уникальным и будете часто его менять, хакеру придется постоянно повторять попытку, и вы с меньшей вероятностью станете жертвой взлома пароля.