как защитить деньги и личные данные
Безопасность
Если вы где-то засветили свою почту, например на электронной доске объявлений, — ждите не только безобидного рекламного спама, но и писем от мошенников.
Илья Аноним
жалуется на спам
Они отправляют письма от имени госорганов, сообщают о выигрыше в лотерею, а еще предлагают простую работу с высоким доходом, но итог один: мошенники крадут деньги и личные данные. Рассказываем, по каким признакам понять, что письмо от злоумышленников.
Признак 1
Обезличенное обращениеСложность: 🤔/🤔🤔🤔
Неизвестный отправитель в сочетании с темой письма, которая вам не очень понятна, — повод настрожиться. Стоит с подозрением относиться к письмам от отправителей с иностранными или очень редкими именами — например, от Добрыни Пантелеймонова.
Если отправитель обращается к вам не по имени, а называет «дорогим другом», письмо лучше проигнорировать, и тем более не скачивать вложения из него.
Отнеситесь с сомнением к письму от знакомого человека, если текст не похож на вашу обычную переписку: например, если собеседник пишет, что попал в беду и срочно просит денег или предлагает перейти по ссылке, чтобы скачать что-то интересное. Сначала лучше позвонить знакомому: возможно, его аккаунт взломали.
«Мой дорогой друг» — обезличенное обращение
«От 25 до 100 тыс» — подозрительно большая сумма
«Подробности здесь» — ссылка может быть вредоносной
Иногда мошенники играют на эмоциях: получатель якобы что-то натворил, но некий Fin Moksha все равно готов поделиться «полезной» ссылкойПризнак 2
Слишком щедрое предложениеСложность: 🤔/🤔🤔🤔
Чтобы вынудить человека перейти по ссылке на сайт мошенников, в письме обещают золотые горы: дорогой приз за прохождение опроса, высокооплачиваемую работу, для которой не нужен опыт, или другой способ быстрого заработка по принципу «миллион за неделю — легко».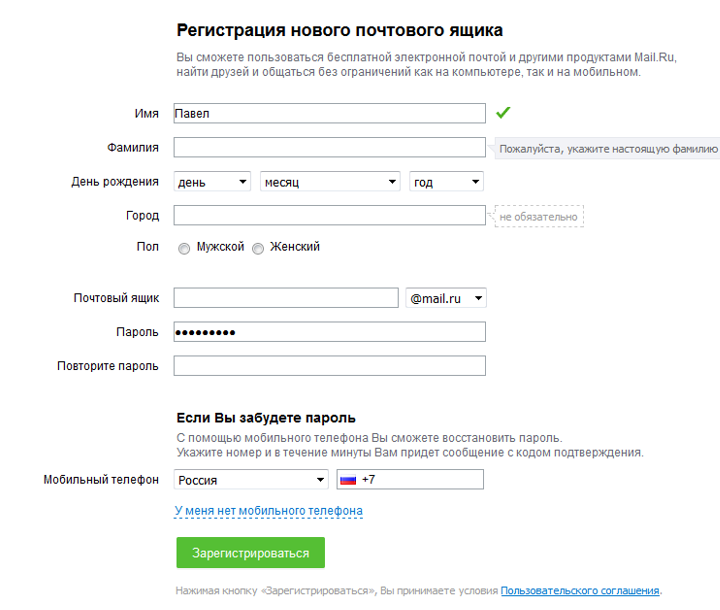
«Теперь вы в нашей команде» — интересно, по какому принципу отбирают в «команду»?
«Около двух штук зеленых за сутки» — мошенники завлекают обещаниями большого заработка, чтобы я прошел по ссылке
После перехода по ссылке компьютер или телефон заражается вирусом, который крадет пароли или повреждает файлы. Ссылка может вести на фишинговый сайт для кражи паролей или на сайт, где попросят оплатить комиссию перед получением приза.
Что делать. Не переходить по ссылкам, если предложение выглядит чересчур заманчивым. Проверить «акцию» в интернете: возможно, кто-то уже попался на удочку и написал гневный отзыв. С работой тоже нужно быть осторожнее: вряд ли компания будет рассылать предложения всем подряд: для вакансий есть специальные сайты.
Если все-таки решили скачать сомнительный файл, сначала проверьте его антивирусом, и только потом открывайте. Не отключайте антивирус по просьбе сайтов или программ.
Письмо, которое вас обчистит
Признак 3
Тревожная темаСложность: 🤔🤔/🤔🤔🤔
Часто обман можно определить по теме письма: «получите в подарок автомобиль», «заработайте миллион без вложений».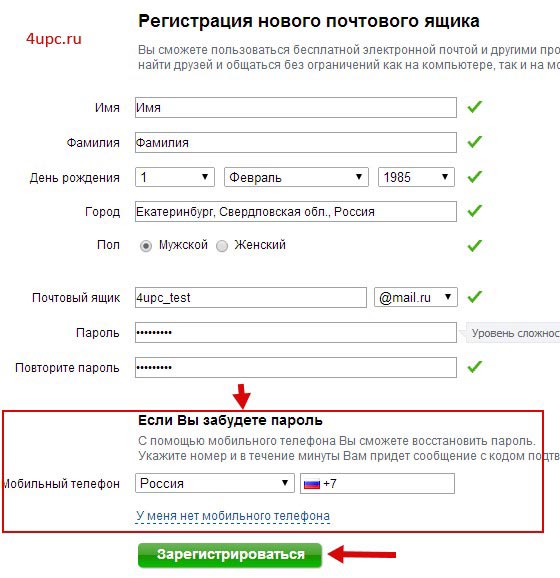 Иногда мошенники специально запугивают получателя, чтобы он открыл письмо: «у вас задолженность по договору», «подтвердите вашу учетную запись, иначе аккаунт будет удален».
Иногда мошенники специально запугивают получателя, чтобы он открыл письмо: «у вас задолженность по договору», «подтвердите вашу учетную запись, иначе аккаунт будет удален».
«Осипов Виктор» — я не знаю человека с таким именем
«nalog.ru» — кажется, что ссылка ведет на знакомый сервис, но nalog.ru — это простой текст, ссылка начинается дальше
«[email protected]» — домен с окончанием de — немецкий, вряд ли это российские налоговики
«Добрый день!» — нет обращения по имени. Госорганы обычно знают, кому пишут
Приятно получить письмо с такой темой, но лучше его не открывать Перед названием темы могут поставить «Re»: так кажется, что вы уже переписывались с отправителемУ вас новое сообщение — это привычная формулировка в письмах от соцсетей
[email protected] — но адрес не похож на знакомый домен
Что делать. Не открывать письма со странными темами и от неизвестных отправителей. Если все же открыли письмо, не паникуйте: за «просто посмотреть» никто не снимет деньги с карты и не оформит кредит по вашему паспорту.
Если все же открыли письмо, не паникуйте: за «просто посмотреть» никто не снимет деньги с карты и не оформит кредит по вашему паспорту.
Признак 4
Адрес, похожий на адрес госорганаСложность: 🤔🤔🤔/🤔🤔🤔
Мошенники пишут от имени госорганов: якобы пенсионный фонд расщедрился на прибавку к пенсии, а отдел соцзащиты готов выплатить компенсацию по СНИЛС. Письмо может быть и от имени банка — тогда преступники сообщают о сбое в системе или необходимости обновить персональные данные.
Цель таких писем — выудить информацию о банковской карте. Мошенники просят ее номер, срок действия, пин и трехзначный код с обратной стороны карты, чтобы перевести деньги из «пенсионного фонда» или занести данные в систему «банка».
Сам факт, что вам неожиданно пришло письмо от госструктуры, уже должен насторожить. Пенсионный фонд предупреждает, что рассылкой не занимается, и просит пользователей не переходить по сомнительным ссылкам на сайт, похожий на ПФР. О том же пишут налоговики.
Как определить фальшивку.
Внимательно посмотрите на окончание электронного адреса. Слово после символа «@» — это домен: он должен совпадать с адресом официального сайта организации. Например, адрес письма от налоговой должен оканчиваться на @nalog.ru, от Сбербанка — на @sberbank.ru. Отправитель попытался замаскировать письмо под рассылку от Сбербанка, но адрес и ошибка в теме выдают его с потрохамиИсключения могут быть, если вы действительно ждете от организации ответ: например, мне приходило письмо от специалиста поддержки госуслуг, чтобы я выслал сканы через почту, так как в системе был сбой. Другой вариант: вы сами когда-то подписались на рассылку — например, я регулярно получаю новости от госстройнадзора области.
Письмо заканчивается настоящим доменом Пенсионного Фонда pfrf.ru, но ссылка внутри письма ведет на сайт мошенников: преступники научились подделывать адреса. И еще обычно настоящие госслужащие оставляют в подписи должность и контактный номер телефона:
Что делать.
Как защитить реквизиты на карте
Как проверить, не от мошенника ли письмо
Поскольку мошенники научились подделывать домены так, что на первый взгляд кажется, что письмо от госоргана, нужно анализировать техническую часть письма.
Мне пришло письмо от @fcod.nalog.ru: выглядит как домен налоговой службы, но лучше в этом убедитьсяТехническая часть письма — это окно с подробной служебной информацией: много непонятных слов и цифр. Нужно смотреть на поля Received и Return-Path: информация об отправителе должна совпадать с доменом письма.
Везде указан один и тот же отправитель: fcod.nalog.ru. Значит, это действительно письмо от налоговиков Вот как найти эту техническую часть в разных почтовых сервисах.
«Яндекс-почта». В панели инструментов найти кнопку с тремя точками, в выпадающем меню нажать на «Свойства письма».
Насторожитесь, если ссылка на личный кабинет налогоплательщика ведёт куда-то кроме lkfl.nalog.ru«Гугл-почта». Рядом со стрелкой «Ответить» есть точки «Еще»: после нажатия на них появится выпадающее меню. Нужно выбрать «Показать оригинал».
Необязательно проверять все письма от учреждений: анализируйте только те, в которых предлагают перейти по ссылке или что-то скачать«Мэйл-ру». Необходимо нажать «Еще» и в выпадающем списке выбрать «Служебные заголовки».
Откроется окно со служебной информациейОстерегаться мошенников и беречь деньги легче, если знать вот эти правила:
- Верить нельзя никому.
- Нагреть могут даже родственники.
- Быть параноиком не стыдно.
Расписание электричек Новый Петергоф — Санкт-Петербург с изменениями. Стоимость проезда.
 Цена билетов на электропоезда. Расписание электричек Новый Петергоф — Санкт-Петербург с изменениями. Стоимость проезда. Цена билетов на электропоезда.
Цена билетов на электропоезда. Расписание электричек Новый Петергоф — Санкт-Петербург с изменениями. Стоимость проезда. Цена билетов на электропоезда.Санкт-Петербург
Зеленогорск
14 мая, 15 мая
Все поезда
Ласточки
| Показать все ушедшие электрички | ||||||
| 05:43 | 06:25 | ежедневно | 42 м | Калище → Санкт-Петербург-Балт. | 65 ₽ | |
| 06:30 Ласточка | 07:12 | ежедневно | 42 м | Калище → Санкт-Петербург-Балт. | 77 ₽ | |
| 07:17 Ласточка | 08:01 | ежедневно | 44 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 77 ₽ | |
| 07:39 | 08:20 | ежедневно | 40 м | Калище → Санкт-Петербург-Балт. | 65 ₽ | |
| 08:12 | 08:54 | ежедневно | 42 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 65 ₽ | |
| 08:55 Ласточка | 09:36 | ежедневно | 41 м | Лебяжье → Санкт-Петербург-Балт. | 77 ₽ | |
| 09:15 Ласточка | 09:58 | ежедневно | 43 м | Калище → Санкт-Петербург-Балт. | 77 ₽ | |
| 09:46 | 10:25 | ежедневно | 39 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 65 ₽ | |
| 10:16 Ласточка | 10:56 | ежедневно | 40 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 77 ₽ | |
| 10:44 | 11:23 | ежедневно | 38 м | Калище → Санкт-Петербург-Балт. | 77 ₽ | |
| 11:26 Ласточка | 12:06 | ежедневно | 40 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 77 ₽ | |
| 12:36 Ласточка | 13:18 | по выходным | 42 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 77 ₽ | |
| 13:21 Ласточка | 14:01 | по выходным | 40 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 77 ₽ | |
| 14:06 Ласточка | 14:50 | ежедневно | 44 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 77 ₽ | |
| 14:40 | 15:21 | ежедневно | 41 м | Калище → Санкт-Петербург-Балт. | 65 ₽ | |
| 15:37 Ласточка | 16:19 | ежедневно | 42 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 77 ₽ | |
| 16:40 Ласточка | 17:10 | ежедневно | 29 м | Калище → Санкт-Петербург-Балт. | 77 ₽ | |
| 17:14 | 17:57 | ежедневно | 43 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 65 ₽ | |
| 17:41 | 18:20 | ежедневно | 39 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 65 ₽ | |
| 18:31 | 19:11 | ежедневно | 40 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 65 ₽ | |
| 18:54 Ласточка | 19:35 | ежедневно | 40 м | Калище → Санкт-Петербург-Балт. | 77 ₽ | |
| 19:16 Ласточка | 19:56 | ежедневно | 39 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 77 ₽ | |
| 20:11 | 20:50 | ежедневно | 39 м | Ораниенбаум-1 → Санкт-Петербург-Балт. | 65 ₽ | |
| 20:34 | 21:14 | ежедневно | 39 м | Лебяжье → Санкт-Петербург-Балт. | 65 ₽ | |
| 20:55 Ласточка | 21:37 | ежедневно | 42 м | Калище → Санкт-Петербург-Балт. | 77 ₽ | |
| 22:34 Ласточка | 23:14 | ежедневно | 39 м | Калище → Санкт-Петербург-Балт. | 77 ₽ |
Mail.ru отрицает массовый взлом паролей; исследователь поддерживает результаты
Эрик Ошар
4 минуты чтения
ФРАНКФУРТ (Рейтер) — Ведущая российская интернет-компания Mail.ru заявила в пятницу, что часть учетных записей электронной почты ее пользователей была уязвима, отрицая, что десятки миллионов других пользователи оказались в опасности после того, как исследователи обнаружили, что его данные циркулируют среди киберпреступников.
Логотип Mail.ru виден перед отображаемым двоичным кодом на этой иллюстрации, сделанной 4 мая 2016 года. REUTERS/Dado Ruvic/Illustration
В заявлении компании говорится, что учетные данные, привязанные к ее учетным записям электронной почты, были украдены с других, не связанных между собой сайтов, таких как социальные сети или сайты электронной коммерции, которые просят пользователей зарегистрироваться, используя адреса электронной почты, такие как Mail. ru, и выбирать пароли. которые чаще всего не будут такими же, как для учетных записей электронной почты.
ru, и выбирать пароли. которые чаще всего не будут такими же, как для учетных записей электронной почты.
«База данных, скорее всего, представляет собой компиляцию нескольких старых дампов данных, собранных путем взлома веб-сервисов, где люди использовали свой адрес электронной почты для регистрации», — заявила московская компания.
Однако эксперт по безопасности, обнаруживший, по его словам, сотни миллионов взломанных имен пользователей и паролей к некоторым из крупнейших в мире веб-сайтов, сказал, что собственный анализ Mail.ru предполагает, что десятки тысяч пользователей находятся в опасности.
Алекс Холден, основатель Hold Security, американской фирмы, которая специализируется на восстановлении украденных у хакеров учетных данных, сообщил агентству Reuters в среду, что его исследователи уговорили молодого российского хакера раскрыть украденные данные.
Агентство Reuters сообщило в среду, что Hold Security обнаружила 272,3 миллиона украденных учетных данных по всему миру, в том числе 57 миллионов на Mail. ru и меньшую часть базы пользователей электронной почты Google, Yahoo и Microsoft. Mail.ru недавно сообщил о 64 миллионах активных пользователей электронной почты в месяц.
ru и меньшую часть базы пользователей электронной почты Google, Yahoo и Microsoft. Mail.ru недавно сообщил о 64 миллионах активных пользователей электронной почты в месяц.
В заявлении московской компании говорится, что ее собственное исследование выборочных данных, предоставленных Холденом, показало, что 99,982 процента учетных данных Mail.ru в списке расстрелянных были недействительны. У большинства были неправильные пароли или использовались поддельные адреса электронной почты.
Но компания признала, что 0,018% имен пользователей и паролей могли сработать, и заявила: «Мы уже уведомили затронутых пользователей о необходимости изменить свои пароли».
Представитель Yahoo заявил, что компания получила образец данных Hold Security и не считает, что «существует какой-либо значительный риск для наших пользователей на основании утверждений, переданных прессе».
Кражи личной информации или финансовые потери могут быть результатом взлома хакерами других учетных записей, использующих те же учетные данные.
Mail.ru заявил, что обнаружил, что 12,42% выборки были отмечены его компьютерами как подозрительные и заблокированы.
Холден сказал, что он предоставил рандомизированную выборку данных, которая представляет менее одной десятой открытых записей Mail.ru. Он сказал, что готов предоставить Mail.ru полный набор данных.
Хакеры знают, что пользователи цепляются за любимые пароли. Вот почему злоумышленники повторно используют старые пароли, найденные в одной учетной записи, чтобы попытаться взломать другие учетные записи того же пользователя.
Mail.ru заявила, что ее специалисты постоянно отслеживают Интернет на наличие дампов данных, чтобы проверить, не скомпрометированы ли учетные данные Mail.ru. В нем говорилось, что «единственной целью» раскрытия возможной кражи учетных данных было создание шумихи в СМИ и продвижение бизнеса Холдена.
Холден, чья фирма получает комиссионные за предоставление информации об угрозах крупным компаниям, сказал, что провел прошлую неделю, информируя любую компанию, чьи учетные данные, по-видимому, были украдены, и делал это бесплатно.
«Мы не претендуем на эту информацию, потому что мы только что получили ее от хакера и делимся ею с сообществом», — сказал он. Hold Security отказывается публиковать базу данных украденных учетных записей, но сообщает, что предоставляет конкретные данные уполномоченному техническому персоналу пострадавших фирм.
Дополнительный отчет Джозефа Менна из Сан-Франциско; Под редакцией Сьюзен Томас и Дэвида Грегорио
Как Mail.Ru сократила объем хранилища электронной почты с 50 до 32 ПБ — Smashing Magazine
- Чтение: 16 мин.
- Кодировка, Оптимизация, Электронная почта
- Поделиться в Twitter, LinkedIn
Об авторе
Технический директор службы почты и портала Mail.ru. Больше о Андрей ↬
Когда два года назад курс российского рубля резко упал, мы задумались о сокращении расходов на оборудование и хостинг почтового сервиса Mail.Ru. Во-первых, нам нужно было посмотреть, из чего состоит электронная почта . На индексы и тела приходится только 15% объема хранилища, тогда как 85% занимают файлы. Итак, оптимизацию файлов (то есть вложений) стоит изучить подробнее.
В то время у нас не было дедупликации файлов, но мы подсчитали, что это может уменьшить общий размер хранилища на 36%, потому что многие пользователи получают одни и те же сообщения, такие как прайс-листы из интернет-магазинов и информационные бюллетени из социальных сетей, которые содержать изображения и так далее. В этой статье я опишу, как мы внедрили систему дедупликации под руководством PSIAlt.
На индексы и тела приходится только 15% объема хранилища, тогда как 85% занимают файлы. Итак, оптимизацию файлов (то есть вложений) стоит изучить подробнее.
В то время у нас не было дедупликации файлов, но мы подсчитали, что это может уменьшить общий размер хранилища на 36%, потому что многие пользователи получают одни и те же сообщения, такие как прайс-листы из интернет-магазинов и информационные бюллетени из социальных сетей, которые содержать изображения и так далее. В этой статье я опишу, как мы внедрили систему дедупликации под руководством PSIAlt. На индексы и тела приходится только 15 % объема хранилища, тогда как 85 % занимают файлы. Итак, оптимизацию файлов (то есть вложений) стоит изучить подробнее. В то время у нас не было дедупликации файлов, но мы подсчитали, что это может уменьшить общий размер хранилища на 36%, потому что многие пользователи получают одни и те же сообщения, такие как прайс-листы из интернет-магазинов и информационные бюллетени из социальных сетей, которые содержать изображения и так далее. В этой статье я опишу, как мы внедрили систему дедупликации под руководством PSIAlt.
В этой статье я опишу, как мы внедрили систему дедупликации под руководством PSIAlt.
Дополнительная литература на SmashingMag:
- Как улучшить рабочий процесс электронной почты с помощью модульного дизайна
- Упрощение кодирования электронной почты с адаптивным HTML с помощью MJML
- Шаблоны электронной почты для веб-дизайнеров и разработчиков
- Дизайн для электронной почты (электронная книга) 90 070
Больше после прыжка! Продолжить чтение ниже ↓
Хранилище метаданных
Мы имеем дело с потоком файлов. Когда мы получаем сообщение, мы должны доставить его пользователю как можно скорее. Нам нужно уметь быстро распознавать дубликаты. Простым решением было бы назвать файлы на основе их содержимого. Мы используем SHA-1 для этой цели. Исходное имя файла хранится в самом письме, поэтому нам не нужно об этом беспокоиться.
Как только приходит новое электронное письмо, мы извлекаем файлы, вычисляем их хэши и добавляем результат в электронное письмо. Это необходимый шаг, чтобы иметь возможность легко найти файлы, принадлежащие определенному электронному письму, в нашем будущем хранилище, когда это электронное письмо будет отправлено.
Это необходимый шаг, чтобы иметь возможность легко найти файлы, принадлежащие определенному электронному письму, в нашем будущем хранилище, когда это электронное письмо будет отправлено.
Теперь давайте загрузим файл в наше хранилище и выясним, существует ли там уже другой файл с таким же хешем. Это означает, что нам нужно хранить все хэши в памяти. Назовем это хранилище хэшей FileDB.
Один файл может быть прикреплен к разным электронным письмам, поэтому нам понадобится счетчик, который отслеживает все электронные письма, содержащие этот файл.
Счетчик увеличивается с каждым новым загружаемым файлом. Около 40% всех файлов удаляются, поэтому, если пользователь удаляет электронное письмо, содержащее файлы, загруженные в облако, счетчик должен быть уменьшен. Если счетчик достигает нуля, файл можно удалить.
Здесь мы сталкиваемся с первой проблемой: информация об электронном письме (индексы) хранится в одной системе, а информация о файле — в другой. Это может привести к ошибке. Например, рассмотрим следующий рабочий процесс:
Например, рассмотрим следующий рабочий процесс:
- Система получает запрос на удаление сообщения электронной почты.
- Система проверяет индексы электронной почты.
- Система видит наличие вложения (SHA-1).
- Система отправляет запрос на удаление файла.
- Произошел сбой, поэтому письмо не удаляется.
В этом случае письмо остается в системе, но счетчик уменьшается на 1. Когда система получает второй запрос на удаление этого письма, счетчик снова уменьшается — и мы можем столкнуться с ситуацией, когда файл все еще прикреплен к электронному письму, но счетчик уже на 0,
Очень важно не потерять данные. У нас не может быть ситуации, когда пользователь открывает электронное письмо и не обнаруживает там вложений. При этом хранение некоторых избыточных файлов на дисках не имеет большого значения. Все, что нам нужно, — это механизм, позволяющий однозначно определить, правильно ли счетчик установлен на 0. Поэтому у нас есть еще одно поле — magic .
Алгоритм прост. Вместе с хэшем файла мы храним в электронном письме случайно сгенерированное число. Все запросы на загрузку или удаление файла учитывают это случайное число: В случае запроса на загрузку это число добавляется к текущему значению магического числа; если это запрос на удаление, это случайное число вычитается из текущего значения магического числа.
Таким образом, если все письма увеличивали и уменьшали счетчик нужное количество раз, то магическое число также будет равно 0. В противном случае файл удалять нельзя.
Рассмотрим пример. У нас есть файл с именем sha1 . Он загружается один раз, и письмо генерирует для него случайное (магическое) число, равное 345.
Затем приходит новое письмо с тем же файлом. Он генерирует собственное магическое число (123) и загружает файл. Новое магическое число добавляется к текущему значению магического числа (345), а счетчик увеличивается на 1. В результате в FileDB мы имеем магическое число со значением 468 и счетчиком, установленным на 2.
После того, как пользователь удалит второе письмо, магическое число, сгенерированное для этого письма, вычитается из текущего значения магического числа (468), а счетчик уменьшается на 1.
Давайте сначала посмотрим на нормальный ход событий . Пользователь удаляет первое электронное письмо, и магическое число и счетчик становятся равными 0. Это означает, что данные непротиворечивы и файл можно удалить.
Теперь предположим, что что-то пойдет не так: второе письмо отправляет два запроса на удаление. Значение счетчика, равное 0, означает, что ссылок на файл больше нет, но магическое число, равное 222, сигнализирует о проблеме: файл нельзя удалить, пока данные не будут согласованы.
Давайте еще немного разовьем ситуацию. Предположим, что первое электронное письмо также было удалено. В этом случае магическое число (-123) по-прежнему сигнализирует о несоответствии.
В качестве меры безопасности, когда счетчик достигает 0, а магическое число нет (в нашем случае магическое число равно 222, а счетчик равен 0), файлу присваивается флаг «Не удалять». Таким образом, даже если — после серии удалений и загрузок — и магическое число, и счетчик каким-то образом станут 0, мы все равно будем знать, что этот файл проблемный и его нельзя удалять. Системе не разрешено генерировать магический одноранговый узел 0. Если вы отправите 0 в качестве магического числа, вы получите сообщение об ошибке.
Таким образом, даже если — после серии удалений и загрузок — и магическое число, и счетчик каким-то образом станут 0, мы все равно будем знать, что этот файл проблемный и его нельзя удалять. Системе не разрешено генерировать магический одноранговый узел 0. Если вы отправите 0 в качестве магического числа, вы получите сообщение об ошибке.
Назад к FileDB. Каждая сущность имеет набор флагов. Планируете ли вы их использовать или нет, они вам понадобятся (если, скажем, файл нужно пометить как неудаляемый).
У нас есть все атрибуты файла, кроме того, где файл находится физически. Это место определяется сервером (IP) и диском. Таких серверов и два таких диска должно быть два. Мы храним две копии каждого файла.
Но на одном диске хранится очень много файлов (в нашем случае около 1 млн), а значит эти записи будут идентифицироваться одной и той же парой дисков в FileDB, поэтому хранить эту информацию в FileDB было бы расточительно. Давайте поместим его в отдельную таблицу PairDB, связанную с FileDB через идентификатор пары дисков.
Думаю, само собой разумеется, что помимо ID пары дисков нам также понадобится поле flags . Забегая немного вперед, упомяну, что это поле сигнализирует о том, заблокированы ли диски (скажем, один диск вышел из строя, а другой копируется, поэтому ни на один из них нельзя записать новые данные).
Также нам нужно знать, сколько свободного места есть на каждом диске — отсюда и соответствующие поля.
Чтобы все работало быстро, FileDB и PairDB должны быть резидентными в оперативной памяти. Раньше мы использовали Tarantool 1.5, теперь нужно использовать последнюю версию. FileDB имеет пять полей (длиной 20, 4, 4, 4 и 4 байта), что в сумме дает 36 байтов. Кроме того, каждая запись имеет 16-байтовый заголовок, а также 1-байтовый указатель длины на поле, в результате чего общий размер записи составляет 57 байт. 93) = 179 ГБ
Всего нужно 800 ГБ оперативной памяти. И давайте не будем забывать о репликации, которая удваивает объем требуемой оперативной памяти.
Если мы купим машины с 256 ГБ ОЗУ на борту, нам понадобится восемь из них.
Мы можем оценить размер PairDB. Средний размер файла составляет 1 МБ, а емкость диска — 1 ТБ, что позволяет хранить около 1 миллиона файлов на одном диске; Итак, нам потребуется около 28 000 дисков. Одна запись PairDB описывает два диска. Таким образом, PairDB содержит 14 000 записей — ничтожно мало по сравнению с FileDB.
Загрузка файла
Теперь, когда мы разобрались со структурой базы данных, давайте обратимся к API для взаимодействия с системой. На первый взгляд, нам нужны методы upload и delete . Но не забывайте о дедупликации: велика вероятность, что файл, который мы пытаемся загрузить, уже находится в хранилище, и загружать его второй раз не имеет смысла. Итак, необходимы следующие методы:
-
inc(sha1, magic)увеличивает счетчик. Если файл не существует, он возвращает ошибку. Напомним, что нам также понадобится магическое число, которое поможет предотвратить некорректное удаление файла.
-
upload(sha1, magic)следует вызывать, еслиincвернул ошибку, что означает, что этот файл не существует и должен быть загружен. -
dec(sha1, magic)следует вызывать, если пользователь удаляет электронное письмо. Счетчик сначала уменьшается. -
GET /sha1загружает файл по HTTP.

Давайте подробнее рассмотрим, что происходит во время загрузки. Для демона, реализующего этот интерфейс, мы выбрали протокол IProto. Демоны должны хорошо масштабироваться для любого количества машин, поэтому они не сохраняют состояния. Предположим, мы получаем запрос через сокет:
Имя команды сообщает нам длину заголовка, поэтому мы сначала читаем заголовок. Теперь нам нужно узнать длину файла origin-len . Для его загрузки необходимо выбрать пару серверов. Мы просто извлекаем все записи (несколько тысяч) из PairDB и используем стандартный алгоритм для поиска нужной пары: Берем отрезок длиной, равной сумме свободных мест на всех парах, случайным образом выбираем точку на этом отрезке, и выберите любую пару, которой принадлежит эта точка.
Однако выбирать пару таким образом рискованно. Предположим, что все наши диски заполнены на 90% — и тогда мы добавляем новый пустой диск. С большой долей вероятности все новые файлы будут загружаться на этот диск. Чтобы избежать этой проблемы, мы должны суммировать не свободное пространство пары дисков, а n-й корень этого свободного пространства.
Итак, мы выбрали пару, но наш демон потоковый, и если мы начинаем заливать файл в хранилище, обратного пути нет. При этом перед загрузкой реального файла мы сначала загрузим небольшой тестовый файл. Если тестовая загрузка прошла успешно, мы будем читать filecontent из сокета и загрузить его в хранилище; в противном случае выбирается другая пара. Хэш SHA-1 можно прочитать на лету, поэтому он также проверяется при загрузке.
Теперь рассмотрим загрузку файла из загрузчика на выбранную пару дисков. На машинах с дисками настраиваем nginx и используем протокол WebDAV. Приходит электронное письмо. В FileDB этого файла пока нет, поэтому его нужно залить на пару дисков через загрузчик.
Но ничто не мешает другому пользователю получить то же письмо — допустим, указаны два получателя. Помните, что FileDB еще не имеет этого файла, поэтому еще один загрузчик будет загружать этот самый файл и может выбрать ту же пару дисков для загрузки.
Nginx, скорее всего, решит эту ситуацию правильно, но нам нужно контролировать весь процесс, поэтому мы сохраним файл со сложным именем.
Часть имени, выделенная красным цветом, — это место, где каждый загрузчик помещает случайное число. Таким образом, два метода PUT не будут перекрываться и загружать два разных файла. Как только nginx отвечает 201 (ОК), первый загрузчик выполняет атомарную операцию MOVE , которая указывает окончательное имя файла.
Когда второй загрузчик завершит загрузку файла и также выполнит MOVE , файл перезапишется, но ничего страшного, ведь файл один и тот же. Как только файл окажется на дисках, необходимо добавить новую запись в FileDB. Наша версия Tarantool разделена на два пространства. До сих пор мы использовали только
Наша версия Tarantool разделена на два пространства. До сих пор мы использовали только space0 .
Однако вместо простого добавления новой записи в FileDB мы используем хранимую процедуру, которая либо увеличивает счетчик файлов, либо добавляет новую запись в FileDB. Почему? За то время, которое прошло с тех пор, как загрузчик убедился, что файл не существует в FileDB, загрузил его и приступил к добавлению новой записи в FileDB, кто-то другой мог загрузить этот файл и добавить соответствующую запись. Мы рассмотрели именно такой случай: на одно письмо указываются два получателя, поэтому загружать файл начинают два загрузчика; как только второй загрузчик завершает загрузку, он также добавляет новую запись в FileDB.
В этом случае второй загрузчик просто увеличивает счетчик файлов.
Теперь рассмотрим метод dec . У нашей системы есть две первоочередные задачи: надежно записать файл на диск и быстро отдать его клиенту с этого диска. Физическое удаление файла создает определенную нагрузку и замедляет выполнение этих двух задач. Вот почему мы выполняем удаление в автономном режиме. Сам метод
Вот почему мы выполняем удаление в автономном режиме. Сам метод dec уменьшает значение счетчика. Если последнее становится равным 0, как и магическое число, то это означает, что файл больше никому не нужен, поэтому мы перемещаем соответствующую запись из пробел0 до пробел1 в Tarantool.
декремент (sha1, магия) {
прилавок--
current_magic –= магия
если (счетчик == 0 && current_magic == 0){
двигаться (ша1, пробел1)
}
}
Valkyrie
В каждом хранилище есть демон Valkyrie, который следит за целостностью и согласованностью данных и работает с space1 . На каждый диск приходится один экземпляр демона. Демон выполняет итерацию по всем файлам на диске и проверяет наличие пробела1 9.0105 содержит запись, соответствующую конкретному файлу, что означало бы, что этот файл следует удалить.
Но после вызова метода dec и перемещения файла по адресу space1 Valkyrie может потребоваться некоторое время, чтобы найти этот файл. Это означает, что за время между этими двумя событиями файл может быть перезалит и, таким образом, снова перемещен на
Это означает, что за время между этими двумя событиями файл может быть перезалит и, таким образом, снова перемещен на space0 .
Вот почему Valkyrie также проверяет, существует ли файл в space0 . Если это так и pair_id соответствующей записи указывает на пару дисков, на которых работает данный экземпляр Valkyrie, затем запись удаляется из space1 .
Если в пробеле не найдено ни одной записи, то файл является потенциальным кандидатом на удаление. Однако между запросом к space0 и физическим удалением файла все еще есть временное окно, в котором новая запись, соответствующая этому файлу, может появиться в space0 . Чтобы справиться с этим, мы помещаем файл в карантин.
Вместо удаления файла мы добавляем к его имени удалено и метку времени. Это означает, что мы физически удалим файл с отметкой времени плюс некоторое время, указанное в файле конфигурации. Если произойдет сбой и файл будет удален по ошибке, пользователь придет, чтобы вернуть его. Мы сможем восстановить его и решить проблему без потери данных.
Если произойдет сбой и файл будет удален по ошибке, пользователь придет, чтобы вернуть его. Мы сможем восстановить его и решить проблему без потери данных.
Теперь вспомним, что есть два диска, на каждом из которых работает экземпляр Valkyrie. Два экземпляра не синхронизированы. Отсюда вопрос: Когда запись должна быть удалена с пробел1 ?
Мы сделаем две вещи. Во-первых, для рассматриваемого файла давайте сделаем один из экземпляров Valkyrie мастером. Это легко сделать, используя первый бит имени файла: если он равен нулю, то disk0 является мастером; в противном случае disk1 является ведущим.
Введем задержку обработки. Напомним, что когда запись находится в space0 , она содержит поле magic для проверки согласованности. Когда запись перемещается на space1 , это поле не используется, поэтому поставим туда временную метку, соответствующую времени появления этой записи в space1 . Таким образом, главный инстанс Valkyrie начнет обрабатывать записи в
Таким образом, главный инстанс Valkyrie начнет обрабатывать записи в space1 сразу, тогда как ведомый добавит некоторую задержку к отметке времени и будет обрабатывать и удалять записи из space1 чуть позже.
У этого подхода есть еще одно преимущество. Если файл был ошибочно помещен в карантин на мастере, это будет видно из журнала, как только мы запросим мастер. При этом клиент, запросивший файл, вернется к слейву — и пользователь получит нужный файл.
Итак, мы рассмотрели ситуацию, в которой демон Valkyrie находит файл с именем sha1 , и этот файл (являющийся потенциальным кандидатом на удаление) имеет соответствующую запись в space1 . Какие еще варианты возможны?
Предположим, что файл находится на диске, но в FileDB нет соответствующей записи. Если в рассмотренном выше случае мастер-экземпляр Valkyrie по каким-то причинам какое-то время не работал, это будет означать, что у слейва было достаточно времени, чтобы поместить файл в карантин и удалить соответствующую запись из пробел1 . В этом случае мы также помещаем файл в карантин, используя
В этом случае мы также помещаем файл в карантин, используя sha1.deleted.timestamp .
Другая ситуация: запись существует, но указывает на другую пару дисков. Это могло произойти во время загрузки, если для одного письма указаны два получателя. Вспомните эту схему:
Что произойдет, если второй загрузчик загрузит файл в другую пару, чем первый? Он увеличит счетчик на space0 , но пара дисков, на которую был загружен файл, будет содержать несколько ненужных файлов. Что нам нужно сделать, так это убедиться, что эти файлы могут быть прочитаны и что они соответствуют ша1 . Если все в порядке, такие файлы можно сразу удалить.
Кроме того, Valkyrie может обнаружить файл, помещенный в карантин. Если карантин закончится, этот файл будет удален.
Теперь представьте, что Валькирия нашла хороший файл. Его нужно прочитать с диска, проверить на целостность и сравнить с sha1 . Затем Valkyrie необходимо запросить второй диск, чтобы узнать, есть ли на нем тот же файл.