Document — Интерфейсы веб API
Каждая веб-страница, которая загружается в браузер, имеет свой собственный объект document. Интерфейс документа служит точкой входа для получения содержимого веб-страницы (всего DOM — дерева, включая такие элементы как <body> и <table> (en-US)), а также обеспечивает функциональность, которая является глобальной для документа, например, для получения URL-адреса страницы или создания новых элементов в документе).
Объект document может быть получен из разных API:
- Чаще всего используется прямой доступ к объекту document из сценариев scripts которые подгружаются документом. (Этот же объект доступен как
window.document.) - Через свойство
contentDocumentобъекта iframe. - Как ответ
responseXMLобъектаXMLHttpRequest. - Доступ к документу может быть получен из элемента или узла через свойство
ownerDocument

В зависимости от вида документа (т.е. HTML или XML) у объекта document могут быть доступны разные API.
- Все объекты документов реализуют интерфейс
Document(и следовательноNodeиEventTargetинтерфейсы). Таким образом основные свойства и методы, описанные на этой странице, доступны для всех видов документов. - В современных браузерах некоторые документы (т.е. те, которые содержат контент
text/html) также реагируютHTMLDocumentинтерфейс. - В современных браузерах SVG документы реализуют
SVGDocumentинтерфейс.
В будущем все эти интерфейсы будут сведены в один интерфейс — Document.
Примечание: Интерфейс Document наследует также интерфейсы Node и EventTarget
Document.all- Обеспечивает доступ ко всем элементам с идентификаторами (id). Это нестандартный интерфейс, вместо него рекомендуется использовать метод
Document.getElementById(). Document.async- Используется с
document.loadчтобы обозначить асинхронный запрос. Document.characterSet- Возвращает кодировку документа.
Document.compatMode- Указывает в каком режиме (Quirks или Strict) рендерился документ.
Document.contentType- Возвращает Content-Type из MIME заголовка текущего документа.
Document.doctype- Возвращает Document Type Definition (DTD) текущего документа .
Document.documentElement- Возвращает Element, который является первым дочерним элементом документа. Для HTML документов это HTML элемент.
Document.documentURI- Возвращает URL документа.
Document.domConfig- Должен вернуть
DOMConfigurationобъект. Document.implementation(en-US)- Возвращает DOM implementation связанную с текущим документом.
Document.inputEncoding(en-US)- Возвращает кодировку, которая использовалась во время парсинга документа.
Document.lastStyleSheetSet(en-US)- Возвращает имя последнего включённого набора таблиц стилей. Имеет значение
null, пока таблица стилей не будет изменена путём установки значенияselectedStyleSheetSet(en-US). Document.mozSyntheticDocument(en-US)trueесли этот документ является синтетическим, например, отдельные изображения, видео, аудио файлы, или тому подобные.Document.mozFullScreen(en-US)trueкогда документ находится вfull-screen mode.Document.mozFullScreenElement(en-US)- Элемент, который в данный момент находится в полноэкранном режиме для этого документа.
Document.mozFullScreenEnabled(en-US)trueif callingelement.mozRequestFullscreen()(en-US) would succeed in the curent document.Document.pointerLockElement(en-US)- Returns the element set as the target for mouse events while the pointer is locked.
null Document.preferredStyleSheetSet(en-US)- Returns the preferred style sheet set as specified by the page author.
Document.selectedStyleSheetSet(en-US)- Returns which style sheet set is currently in use.
Document.styleSheets(en-US)- Returns a list of the style sheet objects on the current document.
Document.styleSheetSets(en-US)- Returns a list of the style sheet sets available on the document.
Document.xmlEncoding(en-US)- Returns the encoding as determined by the XML declaration.
Document.xmlStandaloneВышла из употребления с версии Gecko 10.0- Returns
trueif the XML declaration specifies the document to be standalone (e.g., An external part of the DTD affects the document’s content), elsefalse. Document.xmlVersion(en-US) Вышла из употребления с версии Gecko 10.0- Returns the version number as specified in the XML declaration or
"1.0"if the declaration is absent.
 Это нестандартный интерфейс, вместо него рекомендуется использовать метод
Это нестандартный интерфейс, вместо него рекомендуется использовать метод 

The Document interface is extended with the ParentNode interface:
{{page(«/en-US/docs/Web/API/ParentNode»,»Properties»)}}
Extension for HTML documents
Event handlers
Note: The Document interface also inherits from the Node and EventTarget interfaces.
Document.adoptNode(Node node)(en-US)- Adopt node from an external document.
Document. captureEvents(String eventName)- See
window.captureEvents(en-US). Document.caretPositionFromPoint(Number x, Number y)(en-US)- Gets a
CaretPosition(en-US) based on two coordinates. Document.createAttribute(String name)- Creates a new
Attrobject and returns it. Document.createAttributeNS(String namespace, String name)- Creates a new attribute node in a given namespace and returns it.
Document.createCDATASection(String data)(en-US)- Creates a new CDATA node and returns it.
Document.createComment(String comment)- Creates a new comment node and returns it.
Document.createDocumentFragment()- Creates a new document fragment.
Document.createElement(String name)- Creates a new element with the given tag name.
Document.(en-US) createElementNS(String namespace, String name)- Creates a new element with the given tag name and namespace URI.
Document.createEntityReference(String name)(en-US) Этот API вышел из употребления и его работа больше не гарантируется.- Creates a new entity reference object and returns it.
Document.createEvent(String interface)(en-US)- Creates an event object.
Document.createNodeIterator(Node root[, Number whatToShow[, NodeFilter filter]])(en-US)- Creates a
NodeIterator(en-US) object. Document.createProcessingInstruction(String target, String data)(en-US)- Creates a new
ProcessingInstruction Document.createRange()- Creates a
Rangeobject. Document.createTextNode(String text)- Creates a text node.
Document. createTreeWalker(Node root[, Number whatToShow[, NodeFilter filter]])- Creates a
TreeWalker(en-US) object. Document.elementFromPoint(Number x, Number y)(en-US)- Returns the element visible at the specified coordinates.
Document.enableStyleSheetsForSet(String name)(en-US)- Enables the style sheets for the specified style sheet set.
Document.exitPointerLock()(en-US)- Release the pointer lock.
Document.getElementsByClassName(String className)- Returns a list of elements with the given class name.
Document.getElementsByTagName(String tagName)- Returns a list of elements with the given tag name.
Document.getElementsByTagNameNS(String namespace, String tagName)(en-US)- Returns a list of elements with the given tag name and namespace.
Document.importNode(Node node, Boolean deep)- Returns a clone of a node from an external document.
document.mozSetImageElement(en-US)- Allows you to change the element being used as the background image for a specified element ID.
Document.normalizeDocument()Этот API вышел из употребления и его работа больше не гарантируется.- Replaces entities, normalizes text nodes, etc.
Document.releaseCapture()(en-US)- Releases the current mouse capture if it’s on an element in this document.
Document.releaseEvents- See
window.releaseEvents(en-US). document.routeEventВышла из употребления с версии Gecko 24- See
window.routeEvent(en-US).
 captureEvents(String eventName)
captureEvents(String eventName) createElementNS(String namespace, String name)
createElementNS(String namespace, String name) createTreeWalker(Node root[, Number whatToShow[, NodeFilter filter]])
createTreeWalker(Node root[, Number whatToShow[, NodeFilter filter]])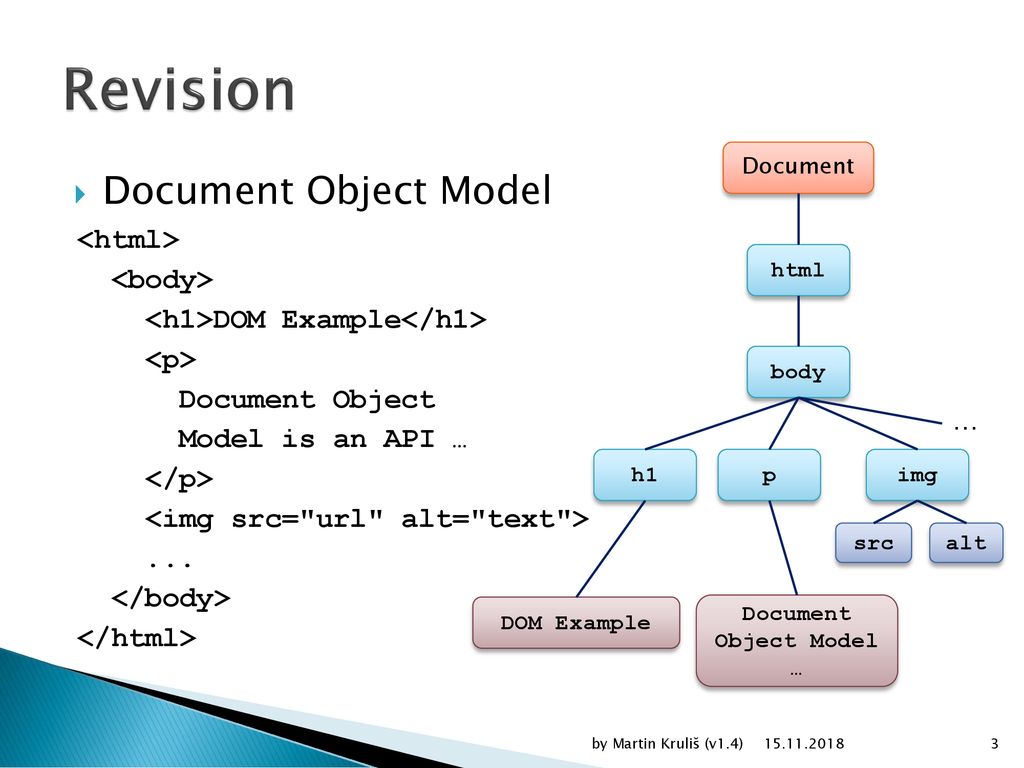
The Document interface is extended with the ParentNode interface:
Document.getElementById(String id)- Returns an object reference to the identified element.
Document.querySelector(String selector)- Returns the first Element node within the document, in document order, that matches the specified selectors.
Document.querySelectorAll(String selector)- Returns a list of all the Element nodes within the document that match the specified selectors.

The Document interface is extended with the XPathEvaluator (en-US) interface:
Document.createExpression(String expression, XPathNSResolver resolver)(en-US)- Compiles an
XPathExpressionwhich can then be used for (repeated) evaluations. Document.createNSResolver(Node resolver)(en-US)- Creates an
XPathNSResolver(en-US) object. Document.evaluate(String expression, Node contextNode, XPathNSResolver resolver, Number type, Object result)- Evaluates an XPath expression.
Extension for HTML documents
Firefox notes
Mozilla defines a set of non-standard properties made only for XUL content:
document.currentScript- Returns the
<script>element that is currently executing. document.documentURIObject- (Mozilla add-ons only!) Returns the
nsIURIobject representing the URI of the document. This property only has special meaning in privileged JavaScript code (with UniversalXPConnect privileges). document.popupNode(en-US)- Returns the node upon which a popup was invoked.
document.tooltipNode(en-US)- Returns the node which is the target of the current tooltip.

Mozilla also define some non-standard methods:
Document.execCommandShowHelpВышла из употребления с версии Gecko 14.0- This method never did anything and always threw an exception, so it was removed in Gecko 14.0 (Firefox 14.0 / Thunderbird 14.0 / SeaMonkey 2.11).
Document.getBoxObjectFor(en-US) Этот API вышел из употребления и его работа больше не гарантируется.- Use the
Element.getBoundingClientRect()method instead. Document.loadOverlay- Loads a XUL overlay dynamically. This only works in XUL documents.
document.queryCommandTextВышла из употребления с версии Gecko 14.0- This method never did anything but throw an exception, and was removed in Gecko 14.0 (Firefox 14.0 / Thunderbird 14.0 / SeaMonkey 2.11).

Internet Explorer notes
Microsoft defines some non-standard properties:
document.fileSize* Этот API вышел из употребления и его работа больше не гарантируется.- Returns size in bytes of the document. Starting with Internet Explorer 11, that property is no longer supported. See MSDN.
- Internet Explorer does not support all methods from the
Nodeinterface in theDocumentinterface:
document.contains- As a work-around,
document.body.contains()can be used.
BCD tables only load in the browser
JS JavaScript HTML DOM Document
Объект документа HTML DOM является владельцем всех других объектов на веб-странице.
Объект документа HTML DOM
Объект Document представляет веб-страницу.
Если вы хотите получить доступ к любому элементу на HTML-странице, вы всегда начинаете с доступа к объекту document.
Ниже приведены примеры того, как можно использовать объект Document для доступа к HTML и манипулирования им.
Поиск элементов HTML
| Метод | Описание |
|---|---|
| document.getElementById(id) | Поиск элемента по идентификатору элемента |
| document.getElementsByTagName(name) | Поиск элементов по имени тега |
| document.getElementsByClassName(name) | Поиск элементов по имени класса |
Изменение элементов HTML
| Метод | Описание |
|---|---|
| element.innerHTML = new html content | Изменение внутреннего HTML-кода элемента |
| element.attribute = new value | Изменение значения атрибута элемента HTML |
element. setAttribute(attribute, value) setAttribute(attribute, value) | Изменение значения атрибута элемента HTML |
| element.style.property = new style | Изменение стиля элемента HTML |
Добавление и удаление элементов
| Метод | Описание |
|---|---|
| document.createElement(element) | Создание элемента HTML |
| document.removeChild(element) | Удаление элемента HTML |
| document.appendChild(element) | Добавление элемента HTML |
| document.replaceChild(element) | Замена элемента HTML |
| document.write(text) | Запись в выходной поток HTML |
Добавление обработчиков событий
| Метод | Описание |
|---|---|
| document.getElementById(id).onclick = function(){code} | Добавление кода обработчика событий в событие OnClick |
Поиск объектов HTML
Первый уровень HTML DOM 1 (1998), определенные 11 объектов HTML, коллекции объектов и свойства. Они по-прежнему действительны в HTML5.
Они по-прежнему действительны в HTML5.
Позже, в HTML DOM Level 3, добавлено больше объектов, коллекций и свойств.
| Свойство | Описание | Dom |
|---|---|---|
| document.anchors | Возвращает все элементы <a>, имеющие атрибут Name | 1 |
| document.applets | Возвращает все элементы <апплета> (устаревшие в HTML5) | 1 |
| document.baseURI | Возвращает абсолютный базовый универсальный код ресурса (URI) документа | 3 |
| document.body | Возвращает элемент <BODY> | 1 |
| document.cookie | Возвращает файл cookie документа | 1 |
| document.doctype | Возвращает документ документа | 3 |
| document.documentElement | Возвращает элемент <HTML> | 3 |
| document.documentMode | Возвращает режим, используемый обозревателем | 3 |
document.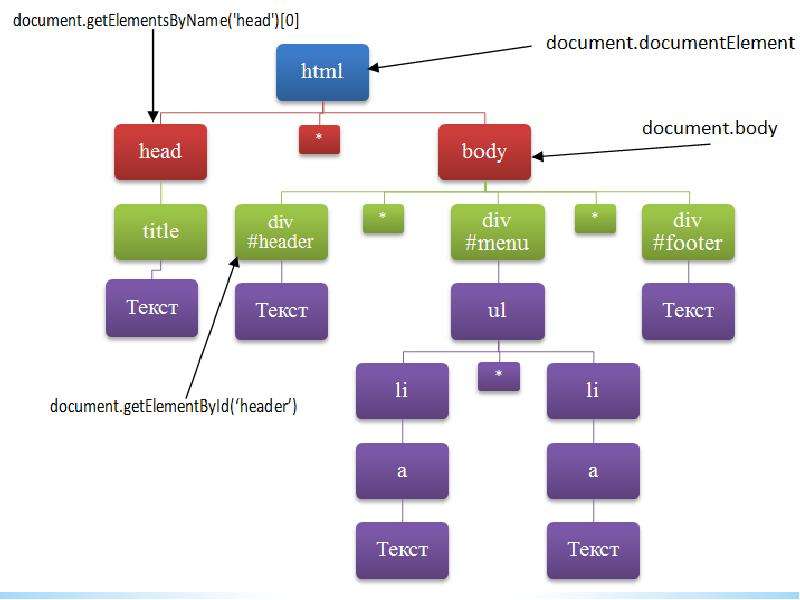 documentURI documentURI | Возвращает универсальный код ресурса (URI) документа | 3 |
| document.domain | Возвращает имя домена сервера документов | 1 |
| document.domConfig | Устарели. Возвращает конфигурацию DOM | 3 |
| document.embeds | Возвращает все элементы <embed> | 3 |
| document.forms | Возвращает все элементы <form> | 1 |
| document.head | Возвращает элемент <head> | 3 |
| document.images | Возвращает все элементы <img> | 1 |
| document.implementation | Возвращает реализацию модели DOM | 3 |
| document.inputEncoding | Возвращает кодировку документа (набор символов) | 3 |
| document.lastModified | Возвращает дату и время обновления документа | 3 |
| document.links | Возвращает все элементы <Area> и <a>, имеющие атрибут href | 1 |
document. readyState readyState | Возвращает состояние (Загрузка) документа | 3 |
| document.referrer | Возвращает универсальный код ресурса (URI) ссылающегося (связывающего документа) | 1 |
| document.scripts | Возвращает все элементы <script> | 3 |
| document.strictErrorChecking | Возвращает при принудительной проверке ошибок | 3 |
| document.title | Возвращает элемент <Title> | 1 |
| document.URL | Возвращает полный URL-адрес документа | 1 |
Что такое DOM и зачем он нужен?
На этом уроке мы рассмотрим, что такое DOM, зачем он нужен, а также то, как он строится.
Что такое DOM
Браузер, когда запрашивает страницу и получает в ответе от сервера её исходный HTML-код, должен сначала его разобрать. В процессе анализа и разбора HTML-кода браузер строит на основе него DOM-дерево.
После выполнения этого действия и ряда других браузер приступает к отрисовке страницы. В этом процессе он, конечно, уже использует созданное им DOM-дерево, а не исходный HTML-код.
В этом процессе он, конечно, уже использует созданное им DOM-дерево, а не исходный HTML-код.
DOM – это объектная модель документа, которую браузер создаёт в памяти компьютера на основании HTML-кода, полученного им от сервера.
Если сказать по-простому, то HTML-код – это текст страницы, а DOM – это набор связанных объектов, созданных браузером при парсинге её текста.
В Chrome исходный код страницы, который получает браузер, можно посмотреть во вкладке «Source» на панели «Инструменты веб-разработчика».
В Chrome инструмента, с помощью которого можно было бы посмотреть созданное им DOM-дерево нет. Но есть представление этого DOM-дерева в виде HTML-кода, оно доступно на вкладке «Elements». С таким представлением DOM веб-разработчику, конечно, намного удобнее работать. Поэтому инструмента, который DOM представлял бы в виде древовидной структуры нет.
Объекты в этой модели образуются практически из всего, что есть в HTML (тегов, текстового контента, комментариев и т.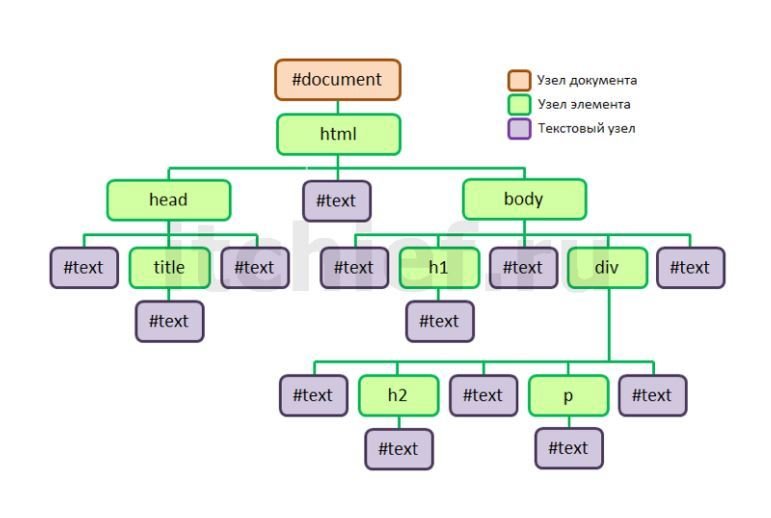 д.), включая при этом сам документ. Связи между этими объектами в модели формируются на основании того, как HTML-элементы расположены в коде относительно друг друга.
д.), включая при этом сам документ. Связи между этими объектами в модели формируются на основании того, как HTML-элементы расположены в коде относительно друг друга.
При этом DOM документа после его формирования можно изменять. При изменении DOM браузер практически мгновенно перерисовывает изображение страницы. В результате у нас отрисовка страницы всегда соответствует DOM.
Для чтения и изменения DOM программно браузер предоставляет нам DOM API или, другими словами, программный интерфейс. По-простому DOM API – это набор огромного количества различных объектов, их свойств и методов, которые мы можем использовать для чтения и изменения DOM.
Для работы с DOM в большинстве случаев используется JavaScript, т.к. на сегодняшний день это единственный язык программирования, скрипты на котором могут выполняться в браузере.
Зачем нам нужен DOM API? Он нам нужен для того, чтобы мы могли с помощью JavaScript изменять страницу на «лету», т.е. делать её динамической и интерактивной.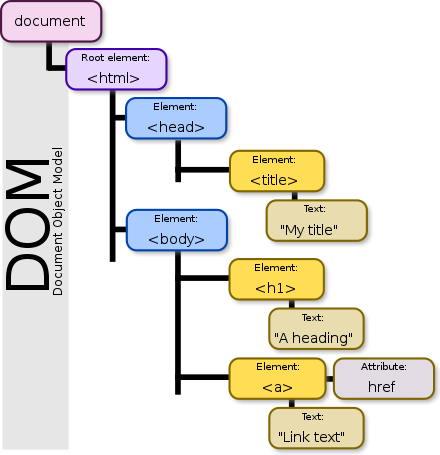
DOM API предоставляет нам (разработчикам) огромное количество методов, с помощью которых мы можем менять всё что есть на странице, а также взаимодействовать с пользователем. Т.е. данный программный интерфейс позволяет нам создавать сложные интерфейсы, формы, выполнять обработку действий пользователей, добавлять и удалять различные элементы на странице, изменять их содержимое, свойства (атрибуты), и многое другое.
Сейчас в вебе практически нет сайтов в сценариях которых отсутствовала бы работа с DOM.
Из чего состоит HTML-код страницы
Перед тем, как перейти к изучению объектной модели документа необходимо сначала вспомнить, что из себя представляет исходный код веб-страницы (HTML-документа).
Исходный код веб-страницы состоит из тегов, атрибутов, комментариев и текста. Теги — это базовая синтаксическая конструкция HTML. Большинство из них являются парными. В этом случае один из них является открывающим, а другой – закрывающим. Одна такая пара тегов образует HTML-элемент. HTML-элементы могут иметь дополнительные параметры – атрибуты.
HTML-элементы могут иметь дополнительные параметры – атрибуты.
В документе для создания определённой разметки одни элементы находятся внутри других. В результате HTML-документ можно представить как множество вложенных друг в друга HTML-элементов.
В качестве примера рассмотрим следующий HTML код:
<html>
<head>
<title>Заголовок страницы</title>
</head>
<body>
<h2>Название статьи</h2>
<div>
<h3>Раздел статьи</h3>
<p>Содержимое статьи</p>
</div>
</body>
</html>
В этом коде корневым элементом является html. В него вложены элементы head и body. Элемент head содержит title, а body – h2 и div. Элемент div в свою очередь содержит h3 и p.
Теперь рассмотрим, как браузер на основании HTML-кода строит DOM-дерево.
Как строится DOM-дерево документа
Как уже было описано выше браузер строит дерево на основе HTML-элементов и других сущностей исходного кода страницы. При выполнении этого процесса он учитывает вложенность элементов друг в друга.
В результате браузер полученное DOM-дерево использует не только в своей работе, но также предоставляет нам API для удобной работы с ним через JavaScript.
При строительстве DOM браузер создаёт из HTML-элементов, текста, комментариев и других сущностей этого языка объекты (узлы DOM-дерева).
В большинстве случаев веб-разработчиков интересуют только объекты (узлы), образованные из HTML-элементов.
При этом браузер не просто создаёт объекты из HTML-элементов, а также связывает их между собой определёнными связями в зависимости от того, как каждый из них относится к другому в коде.
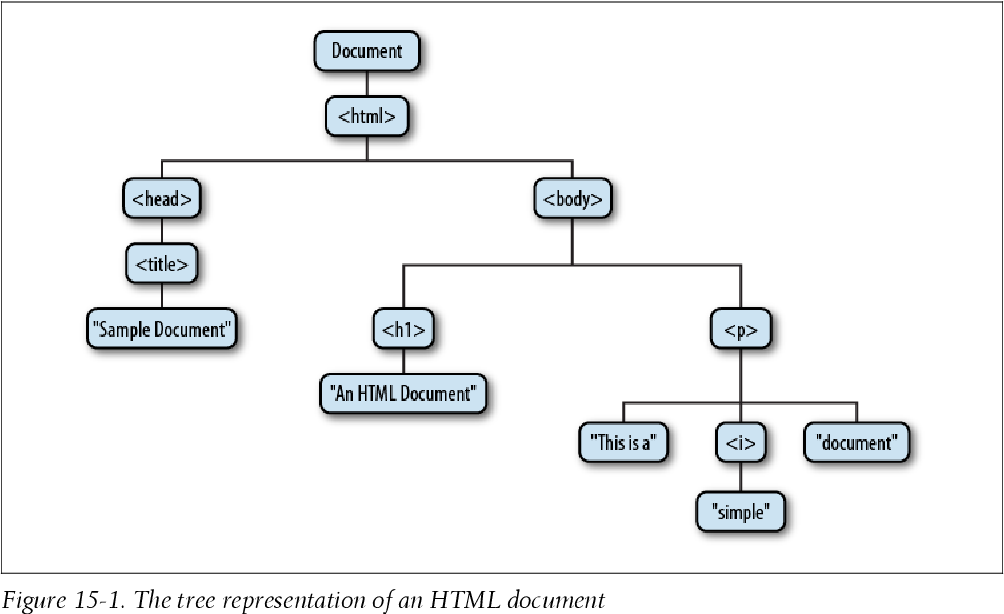
Элементы, которые находятся непосредственно в некотором элементе являются по отношению к нему детьми. А он для каждого из них является родителем. Кроме этого, все эти элементы по отношению друг к другу являются сиблингами (братьями).
А он для каждого из них является родителем. Кроме этого, все эти элементы по отношению друг к другу являются сиблингами (братьями).
При этом в HTML любой элемент всегда имеет одного родителя (HTML-элемент, в котором он непосредственно расположен). В HTML у элемента не может быть несколько родителей. Исключение составляет только элемент html. У него нет родителя.
Чтобы получить DOM-дерево так как его строит браузер, необходимо просто «выстроить» все элементы в зависимости от их отношения друг к другу.
Создание DOM-дерева выполняется сверху вниз.
При этом корнем DOM-дерева всегда является сам документ (узел document). Далее дерево строится в зависимости от структуры HTML кода.
Например, HTML-код, который мы рассматривали выше будет иметь следующее DOM-дерево:
В самом верху этого дерева находится узел document. Данный узел связан с html, он является его ребёнком. Узел html образован элементом html (<html>.). Узлы  ..</html>
..</html>head (<head>...</head>) и body (<body>...</body>) имеют родительскую связь с html. По отношению друг ту другу они являются сиблингами, т.к. имеют одного родителя. Узел head связан с title (lt;title>...</title>), он является его ребёнком. Узлы h2 и div связаны с body, для них он является родителем. Узел div связан с h3 (<h3>...</h3>) и p (<p>...</p>), они являются его детьми.
Начинается дерево как было уже отмечено выше с объекта (узла) document. Он в свою очередь имеет один дочерний узел, образованный элементом html (<html>...</html>). Элементы head (<head>...</head>) и body (<body>...</body>) находятся в html и, следовательно, являются его детьми. Далее узел
Далее узел head является родительским для title (lt;title>...</title>). Элементы h2 и div вложены в body, значит они являются его детьми. В div непосредственно расположены элементы h3 (<h3>...</h3>) и p (<p>...</p>). Это значит, что узел div для каждого из них является родительским.
Вот так просто строится DOM-дерево в браузере на основании HTML-кода.
Зачем нужно знать, как строится DOM дерево? Во-первых, это понимание той среды, в которой вы хотите что-то изменять. Во-вторых, большинство действий при работе с DOM сводится к поиску (выбору) нужных элементов. Не зная как устроено DOM-дерево и связи между узлами найти какой-то определенный элемент в нём будет достаточно затруднительно.
Задание
На основе DOM-дерева, представленного на рисунке, создайте HTML-код.
JavaScript HTML DOM
С помощью HTML DOM JavaScript может получать доступ ко всем элементам HTML и изменять их. документ.
документ.
HTML DOM (объектная модель документа)
Когда веб-страница загружается, браузер создает сообщение D O bject M odel страницы.
Модель HTML DOM построена как дерево из объектов :
Дерево объектов HTML DOM
Благодаря объектной модели JavaScript получает все возможности, необходимые для создания динамический HTML:
- JavaScript может изменять все элементы HTML на странице
- JavaScript может изменять все атрибуты HTML на странице
- JavaScript может изменять все стили CSS на странице
- JavaScript может удалять существующие элементы и атрибуты HTML
- JavaScript может добавлять новые элементы и атрибуты HTML
- JavaScript может реагировать на все существующие HTML-события на странице
- JavaScript может создавать новые HTML-события на странице
Что вы узнаете
В следующих главах этого руководства вы узнаете:
- Как изменить содержимое элементов HTML
- Как изменить стиль (CSS) элементов HTML
- Как реагировать на события HTML DOM
- Как добавлять и удалять элементы HTML
Что такое DOM?
DOM — это стандарт консорциума W3C (World Wide Web Consortium).
DOM определяет стандарт для доступа к документам:
«Объектная модель документа W3C (DOM) не зависит от платформы и языка. интерфейс, который позволяет программам и скриптам динамически получать доступ и обновлять содержание, структура и стиль документа ».
Стандарт W3C DOM разделен на 3 части:
- Core DOM — стандартная модель для всех типов документов
- XML DOM — стандартная модель для XML-документов
- HTML DOM — стандартная модель для документов HTML
Что такое HTML DOM?
HTML DOM — это стандартная модель объекта , и модель . программный интерфейс для HTML.Он определяет:
- Элементы HTML как объекты
- Свойства всех элементов HTML
- Методы для доступа ко всем элементам HTML
- событий для всех элементов HTML
Другими словами: HTML DOM — это стандарт для получения, изменения, добавления или удаления элементов HTML.
| Свойство / метод | Описание |
|---|---|
| активный элемент | Возвращает текущий сфокусированный элемент в документе |
| addEventListener () | Присоединяет обработчик событий к документу |
| принять узел () | Принимает узел из другого документа |
| анкеры | Возвращает коллекцию всех элементов в документе, имеющих атрибут имени |
| апплеты | Возвращает коллекцию всех элементов |
| baseURI | Возвращает абсолютный базовый URI документа |
| корпус | Задает или возвращает тело документа (элемент) |
| закрыть () | Закрывает выходной поток, ранее открытый с помощью документа.открытый () |
| печенье | Возвращает все пары «имя / значение» файлов cookie в документе |
| кодировка | Не рекомендуется. Вместо этого используйте characterSet. Возвращает кодировку символов для документа Вместо этого используйте characterSet. Возвращает кодировку символов для документа |
| набор символов | Возвращает кодировку символов для документа |
| createAttribute () | Создает узел атрибута |
| createComment () | Создает узел комментария с указанным текстом |
| createDocumentFragment () | Создает пустой узел DocumentFragment |
| createElement () | Создает узел элемента |
| createEvent () | Создает новое событие |
| createTextNode () | Создает текстовый узел |
| по умолчанию Просмотр | Возвращает объект окна, связанный с документом, или null, если его нет. |
| дизайн Режим | Управляет возможностью редактирования всего документа. |
| doctype | Возвращает объявление типа документа, связанное с документом |
| документ Элемент | Возвращает элемент документа документа (элемент) |
| документ Режим | Возвращает режим, используемый браузером для визуализации документа |
| документURI | Задает или возвращает расположение документа |
| домен | Возвращает доменное имя сервера, на котором загружен документ |
| domConfig | Устарело. Возвращает конфигурацию DOM документа Возвращает конфигурацию DOM документа |
| вставки | Возвращает коллекцию всех элементов |
| execCommand () | Вызывает указанную операцию буфера обмена для элемента, имеющего в данный момент фокус. |
| формы | Возвращает коллекцию всех элементов |
| полноэкранный режим Элемент | Возвращает текущий элемент, отображаемый в полноэкранном режиме |
| полноэкранный режим Включено () | Возвращает логическое значение, указывающее, можно ли просмотреть документ в полноэкранном режиме |
| getElementById () | Возвращает элемент с атрибутом ID с указанным значением |
| getElementsByClassName () | Возвращает HTMLCollection, содержащую все элементы с указанным именем класса |
| getElementsByName () | Возвращает HTMLCollection, содержащую все элементы с указанным именем |
| getElementsByTagName () | Возвращает HTMLCollection, содержащую все элементы с указанным именем тега |
| hasFocus () | Возвращает логическое значение, указывающее, находится ли документ в фокусе |
| головка | Возвращает элемент документа |
| изображений | Возвращает коллекцию всех элементов |
| реализация | Возвращает объект DOMImplementation, который обрабатывает этот документ |
| importNode () | Импортирует узел из другого документа |
| inputEncoding | Возвращает кодировку, набор символов, используемый для документа |
| последнее Изменено | Возвращает дату и время последнего изменения документа |
| ссылки | Возвращает коллекцию всех элементов и в документе, которые имеют атрибут href |
| нормализовать () | Удаляет пустые текстовые узлы и соединяет соседние узлы |
| normalizeDocument () | Удаляет пустые текстовые узлы и соединяет соседние узлы |
| открытый () | Открывает выходной поток HTML для сбора выходных данных из документа. написать () написать () |
| querySelector () | Возвращает первый элемент, который соответствует указанным селекторам CSS в документе |
| querySelectorAll () | Возвращает статический список узлов, содержащий все элементы, соответствующие указанному селектору (-ам) CSS в документе. |
| состояние готовности | Возвращает статус (загрузки) документа |
| реферер | Возвращает URL-адрес документа, в который загружен текущий документ |
| removeEventListener () | Удаляет обработчик событий из документа (который был прикреплен с помощью метода addEventListener ()) |
| renameNode () | Переименовывает указанный узел |
| скрипты | Возвращает коллекцию элементов В приведенном выше примере Метод getElementById Самый распространенный способ доступа к HTML-элементу - использовать В приведенном выше примере метод Свойство innerHTML Самый простой способ получить содержимое элемента - использовать свойство Свойство Свойство Документ - веб-API | MDN Интерфейс Интерфейс Этот интерфейс также наследуется от интерфейсов Ниже вы найдете полное описание каждой строки этого минимального документа. Каждый документ HTML должен начинаться с объявления Как и все эти ярлыки, этот код был специально разработан для того, чтобы «обмануть» текущие браузеры (которые еще не поддерживают HTML5), заставив их рассматривать документ как полноценный документ HTML4.Версии браузеров, начиная с Internet Explorer 6, будут отображать страницу в наиболее соответствующем стандартам режиме визуализации. Затем мы отмечаем начало документа открывающим тегом Далее идет тег Первым битом в заголовке должен быть тег Еще раз, HTML5 значительно укорачивает этот тег по сравнению с его эквивалентом HTML4, но, как и раньше, этот ярлык использует преимущества существующего поведения обработки ошибок во всех текущих браузерах, поэтому его можно безопасно использовать сегодня: Установив кодировку, мы можем безопасно записать первую часть фактического содержания на странице - страницу Если вы хотите связать файл CSS со страницей, чтобы контролировать его внешний вид (что вы обычно делаете), тег Атрибут Если вы хотите связать сценарий JavaScript со страницей, и сценарий предназначен для вызова из заголовка, вставьте в этот момент тег Атрибут Вот и все. Вы можете закончить заголовок, а затем начать тело страницы с тега Как вам это нравится? Есть сюрпризы? Если вы похожи на меня, некоторые из представленных здесь ярлыков заставят вас почувствовать себя немного неловко с первого взгляда.Насколько безопасно использовать объявление HTML5 Как ни странно это может показаться заимствованием кода из еще не поддерживаемой спецификации, HTML5 был разработан для того, чтобы быть принятым именно таким образом. Ярлыки, подобные представленным выше, не являются особенностями нового стандарта, а представляют собой более эффективное использование функций синтаксического анализа HTML, которые уже были встроены в браузеры в течение многих лет. Теперь, когда W3C HTML Validator поддерживает HTML5, он будет проверять документы, содержащие эти ярлыки; действительно нет причин делать это долгим путем. И если вам понравился этот пост, вам понравится Learnable; место для обучения новым навыкам и техникам от мастеров. Участники получают мгновенный доступ ко всем электронным книгам и интерактивным онлайн-курсам SitePoint, таким как HTML5 и CSS3 For the Real World. Комментарии к статье закрыты. |
 Он обеспечивает глобальную функциональность для документа, например, получение URL-адреса страницы и создание новых элементов в документе.
Он обеспечивает глобальную функциональность для документа, например, получение URL-адреса страницы и создание новых элементов в документе. characterSet
characterSet 
 hidden
hidden 