java — В html странице выводятся знаки вопрос вместо русских букв
Вопрос задан
Изменён 1 год 5 месяцев назад
Просмотрен 283 раза
Здраствуйте, помогите пожалуйста если кто знает в чём дело. Перепробовал уже всё что нашёл в интернете но пока безрезультатно. Почему то при запуске проекта в Idea на странице отображаются знаки вопроса вместо русских букв
Что я уже попробовал:
Убедился что консоль в ответ на запрос выдаёт 866
Также в параметрах регионального стандарта, во вкладке дополнительно я нажал кнопку «изменить язык системы» и там снял галку с параметра «Бета-версия: Использовать Юникод (UTF-8) для поддержки языка во всем мире.
 « Сохранил и перезагрузил.
« Сохранил и перезагрузил.В фалйах idea.exe.vmoptions и idea64.exe.vmoptions Добавил следующую строку: -Dfile.encoding=UTF-8
 « Сохранил и перезагрузил.
« Сохранил и перезагрузил.Так же добавил её в редакторе Idea > EditConfigurations > Tomcat > VM options Так же добавил её в редакторе Idea > Help > Edit Custom VM Options
Так же в настройках File > Settings > FileEncodings выставил Global Encoding в UTF-8 Project Encoding в UTF-8 Default encoding for project files: UTF-8 Create UTF-8 files with NO BOOM
В правом нижнем углу редактора так же выставил UTF-8
Проверил что в хедере моего index.html который я пытаюсь отобразить стоит
<meta charset="UTF-8">Так же пересохранил на всякий случай мой index.html с помощью блокнота с кодировкой UTF-8
Запустил саму страницу index.
html двойным кликом в папке и она нормально отображает кнопку с руским языком, а так же тестовый текст с русским языком. однако когда я нажимаю в idea кнопку run Tomcat почему то страница показывает знаки вопроса вместо русских букв

- java
- html
- intellij-idea
- tomcat
3
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Краткий курс HTML 5.
 HTML-документ — Exlab
HTML-документ — Exlab
Когда вы набираете в редакторе обычный текст, то не задумываясь начинаете с первого слова. В нашем случае все несколько сложнее, поскольку сначала необходимо сообщить браузеру некоторую служебную информацию, сформировав каркас HTML-документа, а лишь затем приступать к его наполнению. Наш первый документ выглядит вот так:
<!DOCTYPE html> <html> <head> <title>Заголовок документа</title> <meta http-equiv="content-type" content="text/html; charset=utf-8" /> </head> <body> Мой первый HTML-документ </body> </html>
Сохраните это в файл с расширением .html, после чего откройте его в браузере. Вы должны увидеть страницу с единственной надписью «Мой первый HTML-документ», да еще в заголовке браузера написано «Заголовок документа». Если вместо русских букв отображаются квадраты, то сохраните файл, выбрав в вашем редакторе кодировку UTF-8 (команда «Сохранить как…»).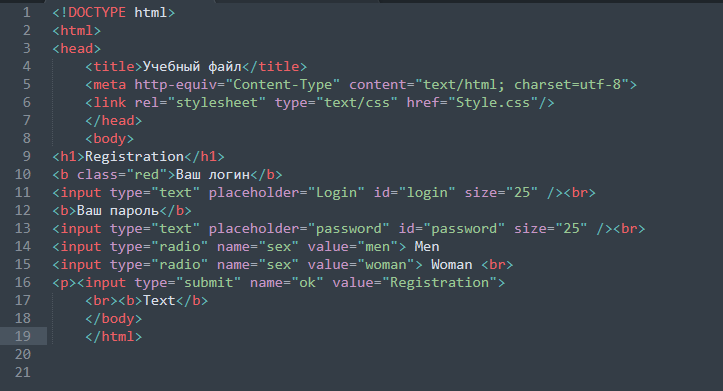 Но давайте по порядку…
Но давайте по порядку…
Определение типа документа
Первая строчка сообщает браузеру, что наш документ составлен в формате HTML 5. Это так называемое
Структура документа
Ниже находится корневой элемент <html>, охватывающий весь документ от DTD до самого конца. Внутри него один за другим расположены <head> и <body>. Как и следует из названия, <head> — это «голова» документа, в которой размещается заголовок <title> (его содержимое отображается в заголовке браузера) и прочая служебная информация (сейчас это единственный элемент <meta />).
<body> — это «тело» документа, в котором и находится основной текст.
Элементы <html>, <head> и <title>, наряду с DTD являются обязательными и должны быть размещены в описанном выше порядке. В противном случае документ не будет соответствовать стандартам W3C (проверьте одним из способов, описанных во введении). Это еще не значит, что он не будет отображаться в каких-либо браузерах, но нет гарантий, что отображение будет верным.
Кодировка документа
Элемент <meta /> предназначен для передачи служебной информации браузеру. Атрибут http-equiv определяет «о чем сообщить», а content — «что сообщить».
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
В этой строчке браузеру сообщается, что содержимое документа (content-type) соответствует MIME
text/html в кодировке UTF-8. Более подробно возможности этого элемента будут рассмотрены позже. Тег
Более подробно возможности этого элемента будут рассмотрены позже. Тег <meta /> непарный, поэтому завершается косой чертой «/».
Если нет причин использовать другую кодировку, то сохраняйте HTML-документы в UTF-8 (в большинстве редакторов есть соответствующая опция). К ее недостаткам можно отнести, пожалуй, лишь больший размер файлов. Это связано с тем, что символы, не входящие в ASCII (латиница, цифры, знаки препинания и др.), занимают два байта, вместо одного. Преимущество же в том, что она позволяет использовать любые символы Unicode (включая большинство алфавитов мира). UTF-8 — рекомендуемая кодировка для HTML-документов, и давно является стандартом «де-факто» в интернете.
utf 8 — HTML на русском
спросил
Изменено 5 лет, 3 месяца назад
Просмотрено 25 тысяч раз
Мне нужно разработать русскую версию веба. Я получаю текст от переводчика. Я копирую его в коде Dreamweaver, но он не работает.
Я получаю текст от переводчика. Я копирую его в коде Dreamweaver, но он не работает.
У меня обычный заголовок:
Что мне делать?
- html
- utf-8
- dreamweaver
- кириллица
Вы должны изменить кодировку вашего файла на UTF-8. Вы можете выполнить этот процесс, когда вы Сохранить как файл в Блокноте или вы можете использовать Блокнот ++ (Кодировка -> Кодировать в UTF-8 ) для этого.
2
Документ http://www.mig-marketing.com/proves/nando/ru/ содержит только русский текст в изображении, но ссылается на http://www.mig-marketing.com/proves/nando/ ru/firma.html, который содержит (помимо текста на изображении) русский текст в кодировке ISO-8859-5 (= ISO Latin/Cyrillic). Эта кодировка объявлена в мета-теге
Эта кодировка объявлена в мета-теге , но проблема в том, что объявление не имеет никакого эффекта, так как HTTP-заголовки имеют преимущество перед ними, и они говорят
Тип содержимого: текст/html; кодировка = ISO-8859-1
(Вы можете легко проверить заголовки ответов HTTP, используя Firefox с расширением для веб-разработчиков и выбрав Информация → Просмотреть заголовки ответов.)
Чтобы исправить это, обратитесь к администратору веб-сервера или попробуйте исправить это самостоятельно, если настройки Apache позволяют использование покаталоговых файлов .htaccess , в этом случае просто создайте файл с таким именем (включая начальную точку) в каталоге, содержащем русские файлы, и введите текст
AddType text/html;charset=ISO-8859-5 html
Это заставит сервер отправлять все файлы .html в этом каталоге с заголовками HTTP, которые определяют их как закодированные по стандарту ISO-8859-5.
Принудительно пересохраните все ваши файлы в кодировке UTF8.
4
После стольких попыток я обнаружил, что проблема была в сервере. Я не знаю как именно, но когда я сказал им, что мне нужен веб на русском языке, они что-то изменили, и он работает!.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
URL-Кодировка «кириллицы» — Онлайн
Познакомьтесь с декодированием и кодированием URL, простым онлайн-инструментом, который делает именно то, о чем говорит: декодирует URL-кодирование, а также быстро и легко кодирует его. URL-кодируйте свои данные без проблем или декодируйте их в удобочитаемый формат.
URL-кодируйте свои данные без проблем или декодируйте их в удобочитаемый формат.
URL-кодирование, также известное как «процентное кодирование», представляет собой механизм кодирования информации в унифицированном идентификаторе ресурса (URI). Хотя это известно как URL-кодирование, на самом деле оно более широко используется в основном наборе унифицированных идентификаторов ресурсов (URI), который включает в себя как унифицированный указатель ресурса (URL), так и унифицированное имя ресурса (URN). Как таковой, он также используется при подготовке данных медиа-типа «application/x-www-form-urlencoded», который часто используется при отправке данных формы HTML в HTTP-запросах.
Дополнительные параметры
- Набор символов: Наш веб-сайт использует набор символов UTF-8, поэтому ваши входные данные передаются в этом формате. Измените этот параметр, если вы хотите преобразовать данные в другой набор символов перед кодированием. Обратите внимание, что в случае текстовых данных схема кодирования не содержит набора символов, поэтому вам может потребоваться указать соответствующий набор в процессе декодирования. Что касается файлов, то по умолчанию используется двоичный вариант, который исключает любое преобразование; эта опция необходима для всего, кроме обычных текстовых документов.
- Разделитель новой строки: В системах Unix и Windows используются разные символы разрыва строки, поэтому перед кодированием любой вариант будет заменен в ваших данных выбранным параметром. Для раздела файлов это частично не имеет значения, так как файлы уже содержат соответствующие разделители, но вы можете определить, какой из них использовать для функций «кодировать каждую строку отдельно» и «разбить строки на куски».
- Каждую строку кодировать отдельно: Даже символы новой строки преобразуются в их процентно-кодированные формы. Используйте эту опцию, если вы хотите закодировать несколько независимых записей данных, разделенных разрывами строк. (*)
- Разделить строки на части: Закодированные данные станут непрерывным текстом без пробелов, поэтому отметьте эту опцию, если хотите разбить их на несколько строк. Применяемое ограничение символов определено в спецификации MIME (RFC 2045), в которой указано, что закодированные строки должны быть не длиннее 76 символов. (*)
- Режим реального времени: Когда вы включаете эту опцию, введенные данные немедленно кодируются встроенными функциями JavaScript вашего браузера, без отправки какой-либо информации на наши серверы. В настоящее время этот режим поддерживает только набор символов UTF-8.
 Что касается файлов, то по умолчанию используется двоичный вариант, который исключает любое преобразование; эта опция необходима для всего, кроме обычных текстовых документов.
Что касается файлов, то по умолчанию используется двоичный вариант, который исключает любое преобразование; эта опция необходима для всего, кроме обычных текстовых документов. Применяемое ограничение символов определено в спецификации MIME (RFC 2045), в которой указано, что закодированные строки должны быть не длиннее 76 символов. (*)
Применяемое ограничение символов определено в спецификации MIME (RFC 2045), в которой указано, что закодированные строки должны быть не длиннее 76 символов. (*) Надежно и надежно
Вся связь с нашими серверами осуществляется через безопасные зашифрованные соединения SSL (https). Мы удаляем загруженные файлы с наших серверов сразу после их обработки, а полученный загружаемый файл удаляется сразу после первой попытки загрузки или 15 минут бездействия (в зависимости от того, что короче). Мы никоим образом не храним и не проверяем содержимое отправленных данных или загруженных файлов. Ознакомьтесь с нашей политикой конфиденциальности ниже для получения более подробной информации.
Ознакомьтесь с нашей политикой конфиденциальности ниже для получения более подробной информации.
Совершенно бесплатно
Наш инструмент можно использовать бесплатно. Отныне вам не нужно скачивать какое-либо программное обеспечение для таких простых задач.
Сведения о кодировке URL
Типы символов URI
Символы, разрешенные в URI, являются зарезервированными или незарезервированными (или символ процента как часть кодировки процента). Зарезервированные символы — это символы, которые иногда имеют особое значение. Например, символы косой черты используются для разделения разных частей URL-адреса (или, в более общем смысле, URI). Незарезервированные символы не имеют такого специального значения. Используя процентное кодирование, зарезервированные символы представляются с помощью специальных последовательностей символов. Наборы зарезервированных и незарезервированных символов, а также обстоятельства, при которых определенные зарезервированные символы имеют особое значение, немного меняются с каждой новой редакцией спецификаций, регулирующих URI и схемы URI.
Другие символы в URI должны быть закодированы в процентах.
Зарезервированные символы с процентным кодированием
Когда символ из зарезервированного набора («зарезервированный символ») имеет особое значение («зарезервированное назначение») в определенном контексте, и схема URI говорит, что необходимо использовать этот символ для какой-либо другой цели, то символ должен быть закодирован в процентах. Процентное кодирование зарезервированного символа означает преобразование символа в соответствующее ему байтовое значение в ASCII, а затем представление этого значения в виде пары шестнадцатеричных цифр. Цифры, которым предшествует знак процента («%»), затем используются в URI вместо зарезервированного символа. (Для символа, отличного от ASCII, он обычно преобразуется в последовательность байтов в UTF-8, а затем каждое значение байта представляется, как указано выше.)
Зарезервированный символ «/», например, если он используется в компоненте «путь» URI, имеет особое значение как разделитель между сегментами пути. Если, в соответствии с заданной схемой URI, «/» должен быть в сегменте пути, то в сегменте должны использоваться три символа «%2F» (или «%2f») вместо «/».
Если, в соответствии с заданной схемой URI, «/» должен быть в сегменте пути, то в сегменте должны использоваться три символа «%2F» (или «%2f») вместо «/».
Зарезервированные символы, которые не имеют зарезервированного назначения в определенном контексте, также могут быть закодированы в процентах, но семантически не отличаются от других символов.
В компоненте «запрос» URI (часть после символа «?»), например, «/» по-прежнему считается зарезервированным символом, но обычно не имеет зарезервированного назначения (если в конкретной схеме URI не указано иное). Символ не нужно кодировать в процентах, если он не имеет зарезервированного назначения.
URI, отличающиеся только тем, является ли зарезервированный символ процентным кодированием или нет, обычно считаются неэквивалентными (обозначающими один и тот же ресурс), за исключением случаев, когда рассматриваемые зарезервированные символы не имеют зарезервированного назначения. Это определение зависит от правил, установленных для зарезервированных символов отдельными схемами URI.
Незарезервированные символы с процентным кодированием
Символы из незарезервированного набора никогда не нуждаются в процентном кодировании.
URI, отличающиеся только тем, является ли незарезервированный символ процентным кодированием или нет, эквивалентны по определению, но на практике процессоры URI не всегда могут обрабатывать их одинаково. Например, потребители URI не должны рассматривать «%41» иначе, чем «A» («%41» — это процентное кодирование «A») или «%7E» иначе, чем «~», но некоторые это делают. Поэтому для обеспечения максимальной совместимости производителям URI не рекомендуется использовать процентное кодирование незарезервированных символов.
Процентное кодирование символа процента
Поскольку символ процента («%») служит индикатором октетов, закодированных в процентах, он должен быть закодирован в процентах как «%25», чтобы этот октет можно было использовать в качестве данных в URI.
Процентное кодирование произвольных данных
Большинство схем URI включают представление произвольных данных, таких как IP-адрес или путь к файловой системе, в виде компонентов URI. Спецификации схемы URI должны, но часто не обеспечивают явное сопоставление между символами URI и всеми возможными значениями данных, представленными этими символами.
Спецификации схемы URI должны, но часто не обеспечивают явное сопоставление между символами URI и всеми возможными значениями данных, представленными этими символами.
Двоичные данные
После публикации RFC 1738 в 1994 г. было указано, что схемы, обеспечивающие представление двоичных данных в URI, должны делить данные на 8-битные байты и кодировать каждый байт в процентах в так же, как указано выше. Значение байта 0F (шестнадцатеричное), например, должно быть представлено как «%0F», но значение байта 41 (шестнадцатеричное) может быть представлено как «A» или «%41». Использование незакодированных символов для буквенно-цифровых и других незарезервированных символов обычно предпочтительнее, поскольку это приводит к более коротким URL-адресам.
Символьные данные
Процедура процентного кодирования двоичных данных часто экстраполируется, иногда неуместно или без полного уточнения, для применения к символьным данным. В годы становления World Wide Web при работе с символами данных в репертуаре ASCII и использовании соответствующих им байтов в ASCII в качестве основы для определения последовательностей с процентным кодированием эта практика была относительно безвредной; многие люди предполагали, что символы и байты сопоставляются один к одному и взаимозаменяемы. Однако потребность в представлении символов за пределами диапазона ASCII быстро росла, и схемы и протоколы URI часто не могли обеспечить стандартные правила подготовки символьных данных для включения в URI. Следовательно, веб-приложения начали использовать различные многобайтовые кодировки, кодировки с отслеживанием состояния и другие кодировки, несовместимые с ASCII, в качестве основы для процентного кодирования, что привело к неоднозначности, а также к трудностям с надежной интерпретацией URI.
Однако потребность в представлении символов за пределами диапазона ASCII быстро росла, и схемы и протоколы URI часто не могли обеспечить стандартные правила подготовки символьных данных для включения в URI. Следовательно, веб-приложения начали использовать различные многобайтовые кодировки, кодировки с отслеживанием состояния и другие кодировки, несовместимые с ASCII, в качестве основы для процентного кодирования, что привело к неоднозначности, а также к трудностям с надежной интерпретацией URI.
Например, многие схемы и протоколы URI, основанные на RFC 1738 и 2396, предполагают, что символы данных будут преобразованы в байты в соответствии с некоторой неуказанной кодировкой символов, прежде чем они будут представлены в URI незарезервированными символами или байтами с процентным кодированием. Если схема не позволяет URI предоставить подсказку о том, какая кодировка использовалась, или если кодировка конфликтует с использованием ASCII для процентного кодирования зарезервированных и незарезервированных символов, то URI нельзя надежно интерпретировать.