HTML тег noindex | назначение, синтаксис, атрибуты, примеры
Последнее обновление: 22.01.2011
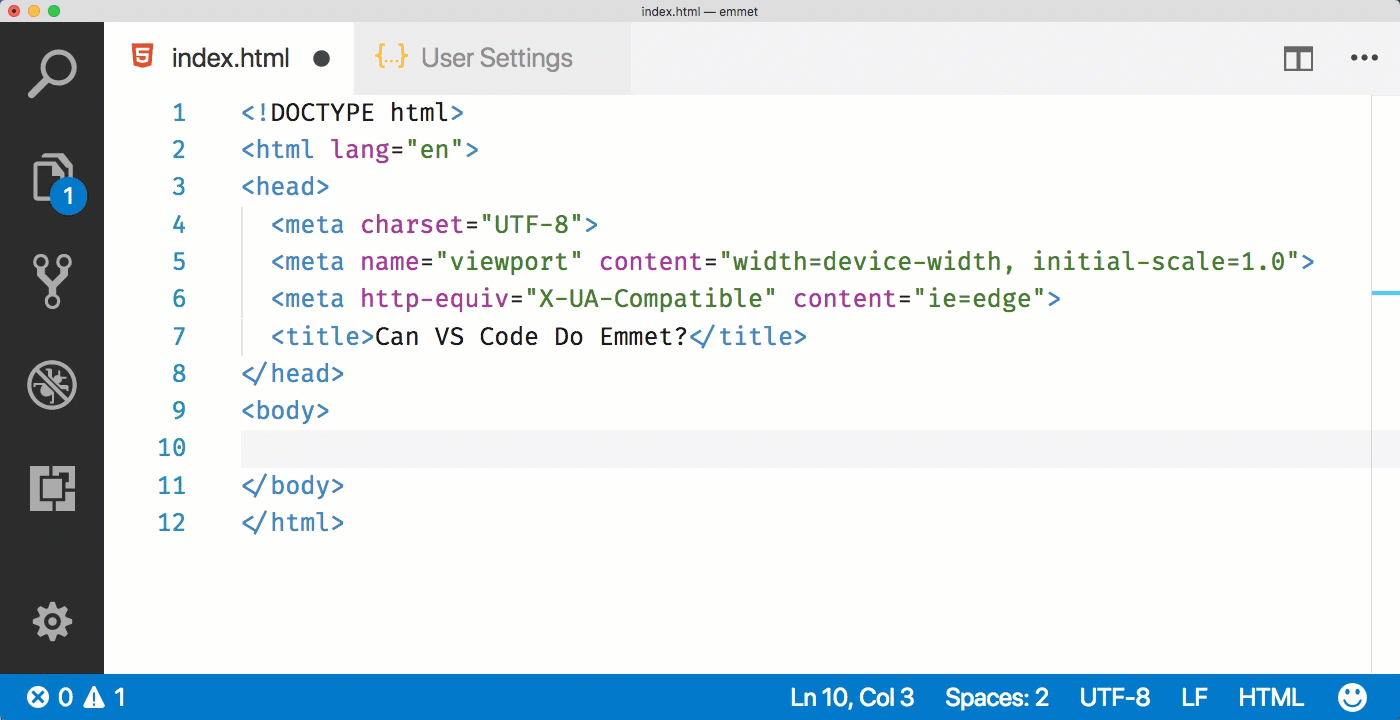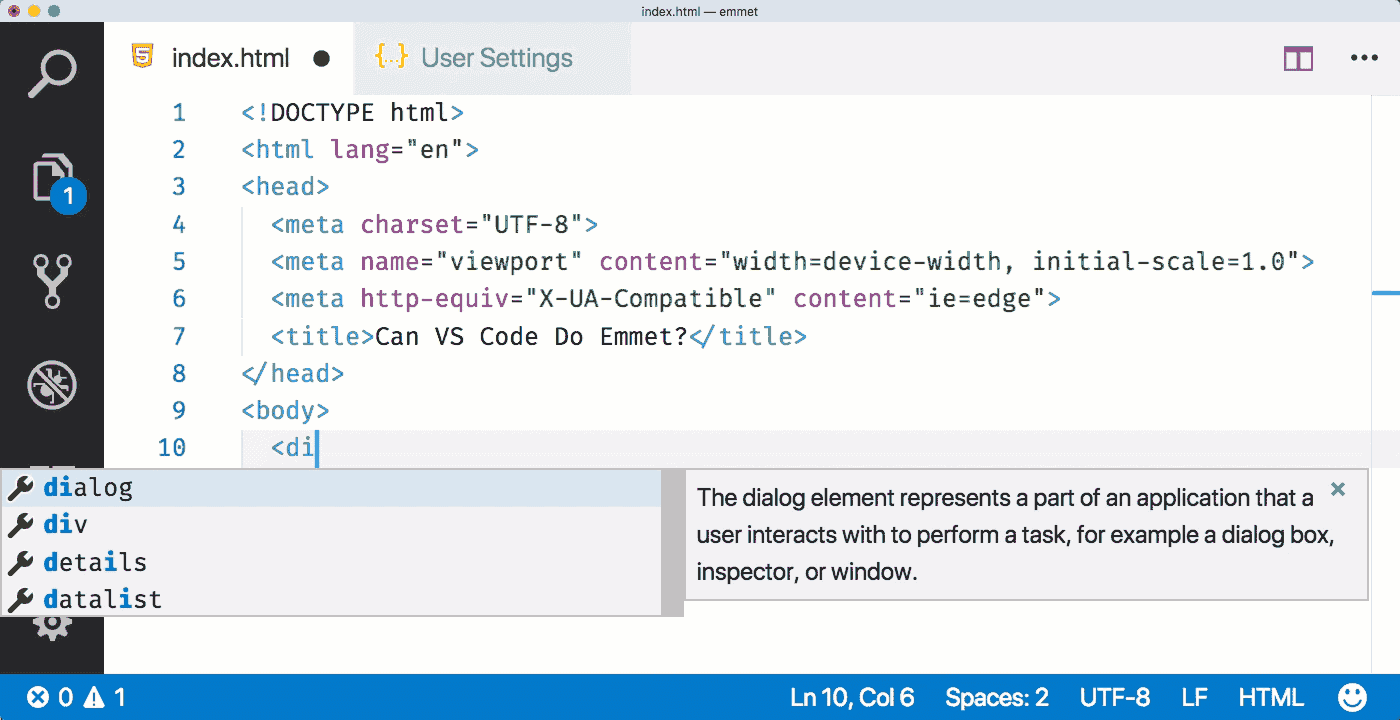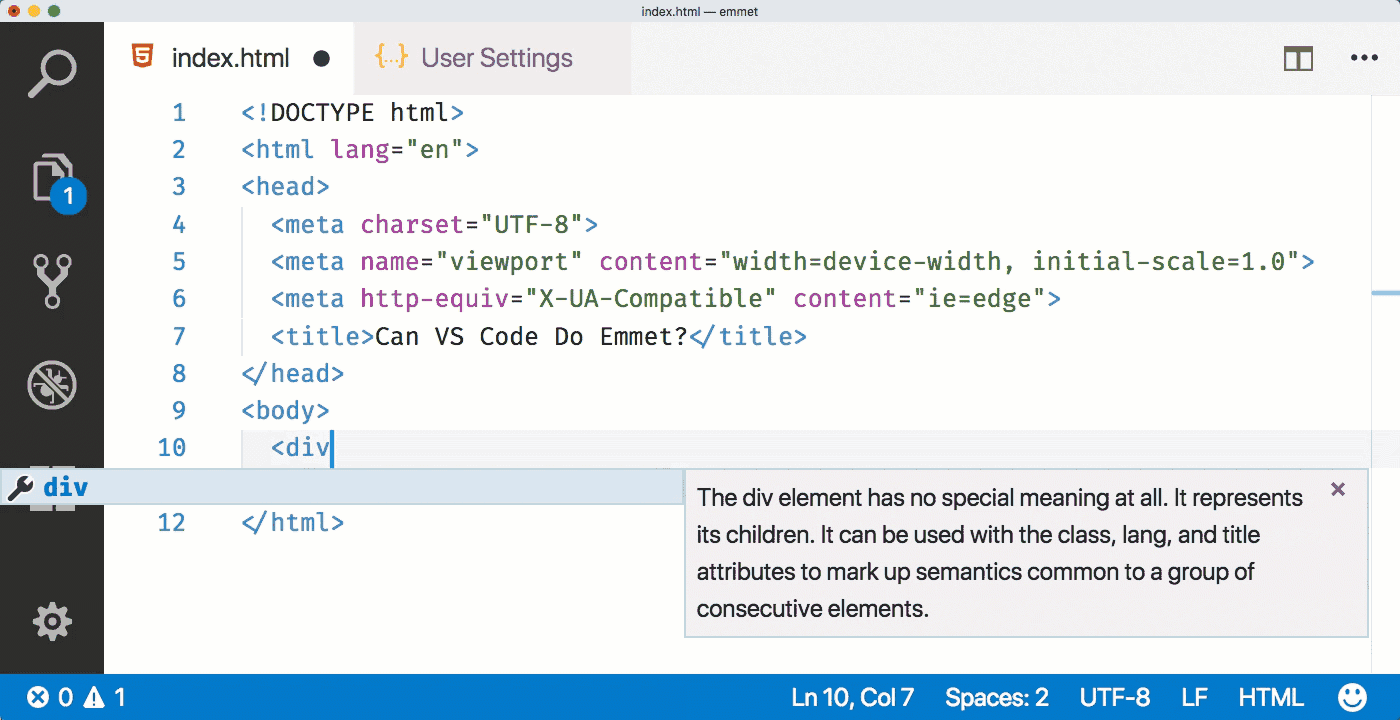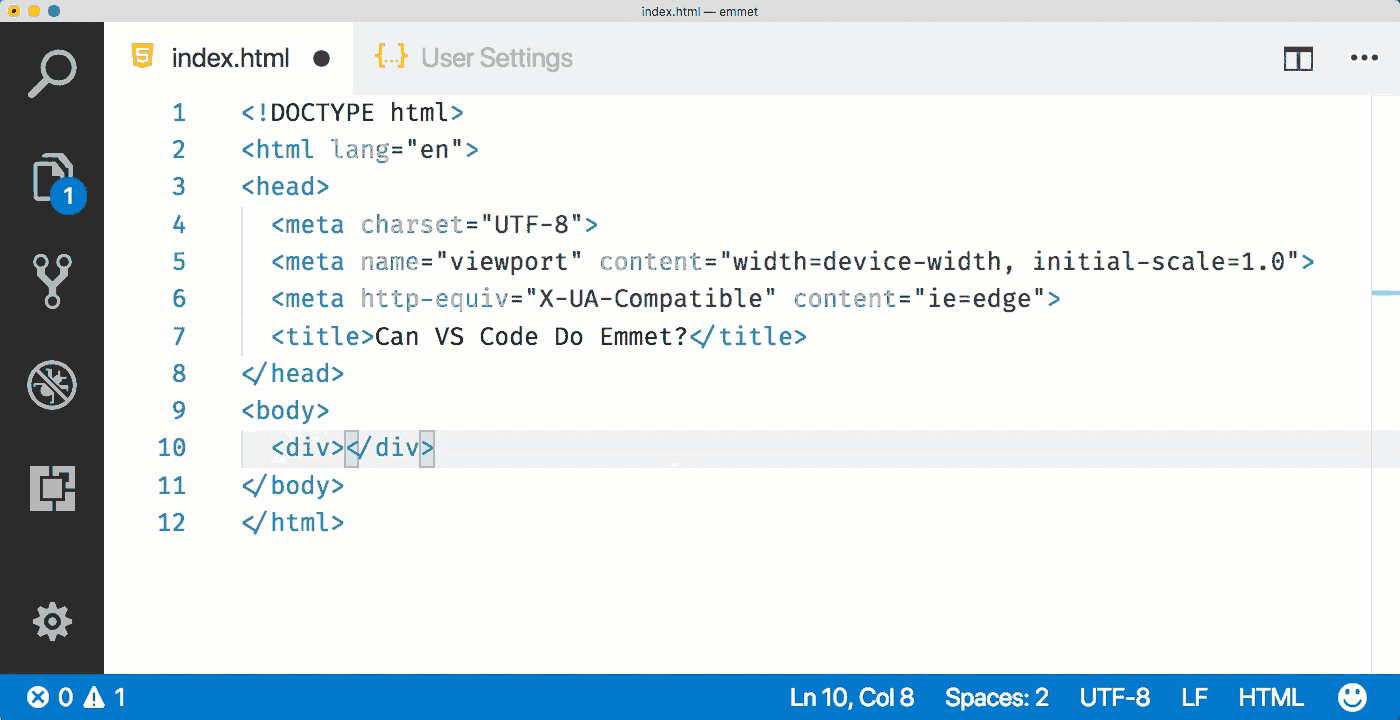
Тег <no index> (англ. no index — нет индекса) — тег-контейнер, запрещает индексацию текста в поисковых системах Яндекс и Рамблер.
Как правило, в тег заключаются коды счетчиков, ссылки на внешние сайты (с целью исключить передачу рейтинга сайту на который ведет ссылка), информация, которая обновляется настолько часто, что индексировать ее нет смысла.
HTML: 3.2 | 4 / XHTML: 1.0 | 1.1
Синтаксис
<noindex>...</noindex>
Пример
Запрещаем индексацию текста:
<noindex>Данный текст не будет индексироваться только в поисковых системах Яндекс и Рамблер</noindex>
Закрываем от индексации ссылку:
Самый продвинутый поисковик — <noindex><a href="http://google.com/">Google</a></noindex>
Твой код:
<html> <head> <title></title> </head> <body> <div> Самый продвинуты поисковик — <noindex><a ref=»nofollow» href=»http://google.
Результат:
большой полигонСледует заметить, что ссылки будут индексироваться внутри данного тега. Чтобы и ссылки не индексировались, добавлем им атрибут rel=»nofollow» (из ответов Палатона).
Google и Yahoo тег <noindex> игнорируют. В этих поисковиках запретить индексацию ссылок можно используя значение nofollow атрибута rel (rel=»nofollow») тега <a>.
Тег <noindex> отсутствует в спецификациях W3C (не пройдет валидацию).
Дополнительно некоторые ответы можно найти на официальном форуме Яндекс.
update 7.06.10 Можно попробовать сделать noindex валидным:
<span><![CDATA[<noindex>]]></span>
То, что запрещено к индексации
<span><![CDATA[</noindex>]]></span>
inv {display:none}
Источник.
update: 29. 06.10 Яндекс ввел поддержку валидного noindex:
06.10 Яндекс ввел поддержку валидного noindex:
<!--noindex-->текст, индексирование которого нужно запретить<!--/noindex-->
Источник — Яндекс.Помощь.Вебмастер.
По теме
Техническая оптимизация сайта — часть вторая — SEO на vc.ru
Пошаговый план от руководителя оптимизаторов в «Ашманов и партнёры» Никиты Тарасова.
{«id»:83683,»url»:»https:\/\/vc.ru\/seo\/83683-tehnicheskaya-optimizaciya-sayta-chast-vtoraya»,»title»:»\u0422\u0435\u0445\u043d\u0438\u0447\u0435\u0441\u043a\u0430\u044f \u043e\u043f\u0442\u0438\u043c\u0438\u0437\u0430\u0446\u0438\u044f \u0441\u0430\u0439\u0442\u0430 \u2014 \u0447\u0430\u0441\u0442\u044c \u0432\u0442\u043e\u0440\u0430\u044f»,»services»:{«facebook»:{«url»:»https:\/\/www.
 ru\/seo\/83683-tehnicheskaya-optimizaciya-sayta-chast-vtoraya&text=\u0422\u0435\u0445\u043d\u0438\u0447\u0435\u0441\u043a\u0430\u044f \u043e\u043f\u0442\u0438\u043c\u0438\u0437\u0430\u0446\u0438\u044f \u0441\u0430\u0439\u0442\u0430 \u2014 \u0447\u0430\u0441\u0442\u044c \u0432\u0442\u043e\u0440\u0430\u044f»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/seo\/83683-tehnicheskaya-optimizaciya-sayta-chast-vtoraya»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u0422\u0435\u0445\u043d\u0438\u0447\u0435\u0441\u043a\u0430\u044f \u043e\u043f\u0442\u0438\u043c\u0438\u0437\u0430\u0446\u0438\u044f \u0441\u0430\u0439\u0442\u0430 \u2014 \u0447\u0430\u0441\u0442\u044c \u0432\u0442\u043e\u0440\u0430\u044f&body=https:\/\/vc.ru\/seo\/83683-tehnicheskaya-optimizaciya-sayta-chast-vtoraya»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
ru\/seo\/83683-tehnicheskaya-optimizaciya-sayta-chast-vtoraya&text=\u0422\u0435\u0445\u043d\u0438\u0447\u0435\u0441\u043a\u0430\u044f \u043e\u043f\u0442\u0438\u043c\u0438\u0437\u0430\u0446\u0438\u044f \u0441\u0430\u0439\u0442\u0430 \u2014 \u0447\u0430\u0441\u0442\u044c \u0432\u0442\u043e\u0440\u0430\u044f»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/seo\/83683-tehnicheskaya-optimizaciya-sayta-chast-vtoraya»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u0422\u0435\u0445\u043d\u0438\u0447\u0435\u0441\u043a\u0430\u044f \u043e\u043f\u0442\u0438\u043c\u0438\u0437\u0430\u0446\u0438\u044f \u0441\u0430\u0439\u0442\u0430 \u2014 \u0447\u0430\u0441\u0442\u044c \u0432\u0442\u043e\u0440\u0430\u044f&body=https:\/\/vc.ru\/seo\/83683-tehnicheskaya-optimizaciya-sayta-chast-vtoraya»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}11 986 просмотров
В первой части мы разобрали, как оптимизировать URL-адреса, корректировать robots.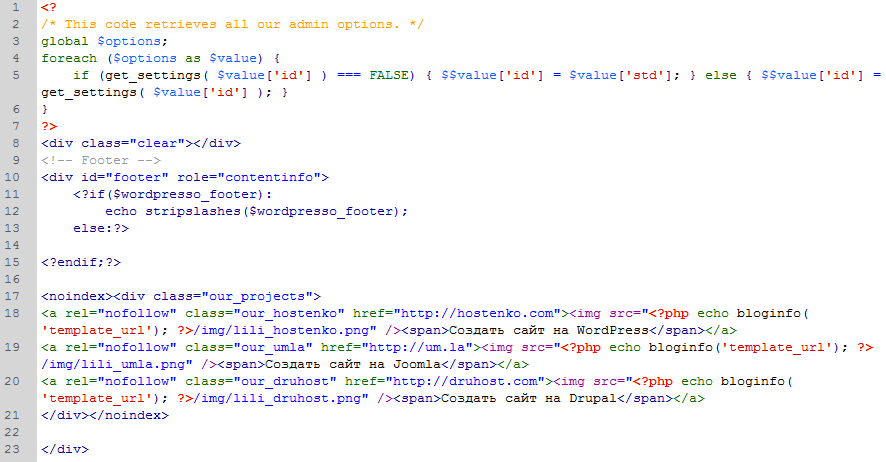 txt, находить и удалять дубли страниц и так далее. Теперь переходим от базовых шагов к действиям, касающимся в основном качества работы сайта.
txt, находить и удалять дубли страниц и так далее. Теперь переходим от базовых шагов к действиям, касающимся в основном качества работы сайта.
Во второй части я расскажу про:
- Улучшение скорости загрузки сайта.
- Проверку оптимизации под мобильные устройства.
- Оптимизацию страниц пагинации.
- Поиск и устранение битых ссылок и редиректов.
- Внедрение микроразметки.
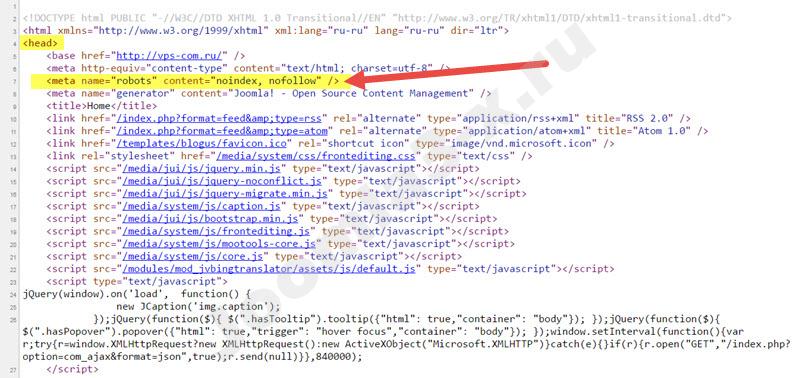
- Использование тега meta name=»robots» content=»…».
- Распределения ссылочного веса по страницам сайта.
- Использование тега noindex.
- Внутреннюю перелинковку.

- HTML- и XML-карты сайта.
- Оптимизацию HTML-кода.
- Внедрение турбо-страниц и AMP.
- Создание progressive web apps (PWA).
- Оптимизацию изображений.
- Требования к хостингу с точки зрения SEO.
Улучшение скорости загрузки сайта
Низкая скорость загрузки отрицательно влияет на удобство сайта, снижает конверсию и поведенческие показатели. Поэтому для пользователей и для поисковых систем одинаково важно, чтобы сайт работал быстро.
Сервис PageSpeed Insights помогает оценить скорость загрузки любой страницы сайта и подсказывает, как улучшить показатели.
Другие способы ускорить сайт:
Оптимизация под мобильные устройства
С внедрением mobile-first indexing Google отдаёт приоритет сайтам, оптимизированным под мобильные устройства.
Это относится к аудитории Google во всем мире, поэтому наличие адаптивной верстки необходимо для ранжирования в поисковой системе.
Представители «Яндекса» также заявляли, что учитывают в ранжировании мобильную версию сайта (алгоритм «Владивосток»).
Проверить, насколько хорошо сайт адаптирован к мобильным устройствам, можно в «Яндекс.Вебмастере» или в Google Search Console.
Массово проверить страницы на оптимальную скорость работы и на оптимизацию под мобильные устройства помогут инструменты от A-Parser и Screaming Frog.
Оптимизация страниц пагинации
 Вопрос в том, нужно ли их оптимизировать и как это делать правильно. Мой коллега Дмитрий Мрачковский очень подробно рассуждал на эту тему в одной из колонок.
Вопрос в том, нужно ли их оптимизировать и как это делать правильно. Мой коллега Дмитрий Мрачковский очень подробно рассуждал на эту тему в одной из колонок.Я же приведу несколько практических рекомендаций, которые регулярно использую в работе.
Использование атрибута rel=”canonical”
«Яндекс» рекомендует проставлять тег rel=”canonical”. Со второй и последующих страниц пагинации, например, http://domain.ru/category/?PAGEN_1=2 необходимо проставить тег rel=”canonical” на первую страницу.
На странице http://domain. ru/category/?PAGEN_1=2 с учетом рекомендаций в разделе <head>…</head> будет размещена следующая конструкция:
ru/category/?PAGEN_1=2 с учетом рекомендаций в разделе <head>…</head> будет размещена следующая конструкция:
<link rel=»canonical» href=»http://domain.ru/category/»/>
Формирование мета-тегов
Мета-теги title и description для страниц пагинации следует формировать по следующему шаблону:
<title>h2 — страница N из page_last</title>
<meta name=»description» content=»»/>
При этом h2 должен совпадать с тегом <h2>.
Page_last — указывает на суммарное число страниц в разделе.
Пример для страницы https://www.domain.ru/catalog/category/?PAGEN_1=2:
<title> Категория — страница 2 из 201</title>
На второй и последующих страницах пагинации мета-тег description выводиться не должен.
Вывод описаний
На второй и последующих страницах пагинации не стоит выводить текст с описанием, который есть на первых страницах.
Пример некорректного вывода текста на странице https://domain.ru/kuhonnye-divany/?page=2.
Не скрывайте текст на второй и последующих страницах пагинации с помощью стилей (display:none). Исключайте его из кода этих страниц.
Поиск и устранение битых ссылок и редиректов
«Битые» ссылки, ведущие на несуществующий сайт, страницу или файл, снижают уровень удобства сайт. Когда посетитель вместо нужной информации видит 404 ошибку, он теряет доверие к сайту.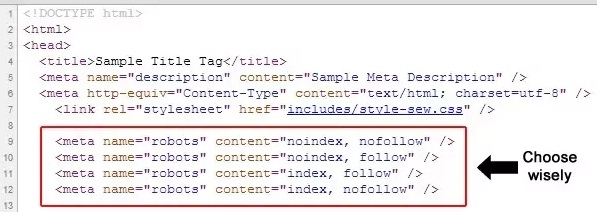 Поисковые системы также не любят битые ссылки.
Поисковые системы также не любят битые ссылки.
- В режиме «Spider» запускаем сканирование сайта и дожидаемся его завершения.
- Далее выгружаем отчет Bulk Export — Response Codes — Client Error (4xx) Inlinks, где Source — ссылающаяся страница, Destination — адрес некорректной ссылки, а Anchor — анкор.
Что касается редиректов, то у «Яндекса» на этот счёт есть подробное руководство. Если коротко, редирект может быть полезен только в том случае, если адреса страниц меняются по техническим причинам и необходимо перенаправить пользователя на новый адрес страницы. В остальных случаях редиректы лучше избегать.
Для поиска редиректов на сайте рекомендуется использовать Screamin Frog Seo Spider
- В режиме «Spider» запускаем сканирование сайта и дожидаемся его завершения.
- Далее выгружаем отчет Bulk Export — Response Codes — Client Error (3xx) Inlinks, где Source — ссылающаяся страница, Destination — URL страницы с редиректом, Anchor — анкор.
- Выгружаем отчет Response Codes — Redirection (3xx).
- Для указания URL конечной страницы используем функцию ВПР =ВПР(B2;'[response_codes_redirection_(3xx).xls]1 — Redirection (3xx)’!$A:$J;9;ЛОЖЬ). В столбце I как раз конечный URL.
- Далее сохраняем данные в таблице как обычные значения.
Внедрение микроразметки
Микроразметка делает сайт понятнее и помогает поисковым системам извлекать и обрабатывать информацию для представления в результатах поиска.
«Яндекс» подтверждает косвенное влияние микроразметки на ранжирование сайта. Добавление микроразметки также положительно влияет на отображение сниппетов в Google.
Ниже приведу наиболее распространенные типы микроразметки.
Видео
Этот тип микроразметки служит для улучшения представления видеоматериалов в результатах поиска. О нем подробно написано в руководстве «Яндекса».
Отзывы
Этот тип разметки позволяет выводить в результатах поиска количество отзывов и рейтинг товара, что положительно влияет на кликабельность результатов в выдаче.
Элементы навигации
Строка навигации представляет собой цепочку ссылок, которая иллюстрирует структуру сайта и помогает пользователям ориентироваться в ней.
Данные навигации, размеченные в «хлебных крошках» сайта, помогут Google лучше их идентифицировать и правильнее отобразить информацию страницы сайта в результатах поиска. Подробнее читайте в руководстве Google.
Изображения
Разметка информации об изображениях помогает улучшить представление изображений в сервисе «Яндекс.Картинки». Подробнее о данной разметке.
Разметка Open Graph для видео
Рекомендую дополнительно разместить видео с помощью разметки Open Graph. Это поможет видео корректно отображаться в соцсетях. Подробнее о разметке.
Это поможет видео корректно отображаться в соцсетях. Подробнее о разметке.
Социальные сети
Если добавить на сайт специальную разметку, ссылки на профили компании в соцсетях будут появляться в блоке знаний Google и пользователи смогут открывать их прямо из «Поиска».
Пример кода для внедрения:
<script type=»application/ld+json»>
{
«@context»: «https://schema.org»,
«@type»: «Person»,
«name»: «Рога и копыта»,
«url»: «https://www. domain.ru/»,
domain.ru/»,
«sameAs»: [
«https://twitter.com/domain»,
«https://www.facebook.com/domain»,
«https://vk.com/domain»,
«http://instagram.com/domain»,
]
}
</script>
Сведения об организации
Внедрение микроразметки элемента «Организация» позволит улучшить отображение сниппета сайта в поисковой выдаче (работает совместно с информацией из «Яндекс.Справочника»).
Использование тега meta name=»robots» content=»…»
Этот тег аналогичен по своему назначению файлу robots. txt и позволяет указывать поисковым роботам, какие страницы индексировать, а какие — нет. Ниже приведу выдержку из руководства «Яндекса», описывающую функциональные возможности тега:
txt и позволяет указывать поисковым роботам, какие страницы индексировать, а какие — нет. Ниже приведу выдержку из руководства «Яндекса», описывающую функциональные возможности тега:
- <meta name=»robots» content=»all»/> — разрешено индексировать текст и ссылки на странице, аналогично <meta name=»robots» content=»index, follow»/>.
- <meta name=»robots» content=»noindex»/> — не индексировать текст страницы.
- <meta name=»robots» content=»nofollow»/> — не переходить по ссылкам на странице.
- <meta name=»robots» content=»none»/> — запрещено индексировать текст и переходить по ссылкам на странице, аналогично <meta name=»robots» content=»noindex, nofollow»/>.
Весь перечень доступных атрибутов для данного тега можно найти в официальных справках поисковых систем.
Стоит провести проверку сайта (например, при помощи Screaming Frog Seo Spider) на предмет запрета индексации страниц через данный тег. В случае если часть продвигаемых страниц запрещена для индексации — следует скорректировать данный тег.
Оптимизация распределения ссылочного веса по страницам сайта
Ссылочный вес — показатель, который формируется из количества страниц, ссылающихся на оцениваемый URL сайта (входящих ссылок), и количества ссылок, ведущих со ссылающихся страниц (исходящих ссылок).
Правильное распределение ссылочного веса помогает подчеркнуть важность определённых страниц сайта в его структуре и улучшить ее оценку со стороны поисковых систем. Это помогает ускорить индексацию и улучшить ранжирование выбранных страниц.
Для оптимизации распределения ссылочного веса на сайте необходимо снабдить часть ссылок атрибутами rel=”nofollow”. Это необходимо сделать для ссылок, которые ведут на страницы, закрытые от индексации в robots.txt.
Например, ссылки с вариантами сортировки товаров по цене, популярности и так далее.
Использование тега noindex
Сразу замечу, что тег воспринимается только поисковой системой «Яндекс», Google его не поддерживает.
Конструкция noindex используется для закрытия от индексации дублирующихся и служебных участков текста.
Для валидности кода необходимо использовать конструкцию вида:
<!—noindex—>код<!—/noindex—>
Например, стоит закрыть от индексации блоки с инфографикой, дублирующиеся на всех страницах.
Внутренняя перелинковка
Перелинковка внутренних страниц сайта способна повышает эффективность продвижения. Когда мы устанавливаем активные гиперссылки на продвигаемые страницы, то увеличиваем их ссылочный «вес».
Когда мы устанавливаем активные гиперссылки на продвигаемые страницы, то увеличиваем их ссылочный «вес».
Добавление «хлебных крошек»
Чтобы упростить навигацию на сложных сайтах, есть старый прием, получивший название «хлебных крошек»: в верхней части страницы располагается навигационная строка, содержащая ссылки вверх по структуре сайта.
Пример реализации: Главная / Каталог / Категория / Подкатегория.
Навигационная цепочка должна соответствовать следующим пунктам:
- Цепочка расположена на всех страницах сайта кроме главной (корневой каталог).
- Данный элемент навигации следует разместить вверху страницы, непосредственно над или под заголовком h2.
- Хлебные крошки не должны дублироваться на странице.
- Ссылками должны являться все пункты, за исключением текущего (последнего).

Элемент «Хлебные крошки» имеет следующие преимущества:
- Страницы сайта, находящиеся выше в иерархической структуре, обеспечиваются ссылочным весом с помощью внутренних ссылок с других страниц сайта.
- Это позволяет обеспечить более эффективное продвижение страниц, релевантных ключевым запросам.
- Пользователю сайта более понятна его структура, проще ориентироваться на сайте. Это ценно в том случае, если пользователь попадает на внутреннюю страницу сайта напрямую из поиска.
 Это ценно в том случае, если пользователь попадает на внутреннюю страницу сайта напрямую из поиска.
Это ценно в том случае, если пользователь попадает на внутреннюю страницу сайта напрямую из поиска.Блок перелинковки для страниц карточек товаров
Внутреннюю переликновку, особенно для интернет-магазинов и сайтов услуг, можно осуществлять не только за счет гиперссылок в текстах, но и за счет блоков с товарными рекомендациями.
Подобная реализация не только позволит более равномерно распределить ссылочный вес, но и поможет улучшить поведенческие характеристики.
Некоторые СMS (например, Bitrix) позволяют выстраивать целые рекомендательные системы, использование которых может увеличить средний чек.
HTML- и XML-карты сайта
HTML-карта
HTML-карта сайта используется для помощи посетителям, чтобы было проще ориентироваться на сайте. Также карту используют, чтобы ускорить индексацию сайта поисковыми роботами и создать древовидную структуру, чтобы все страницы сайта были максимум в двух кликах от главной.
Стоит добавлять в HTML-карту только значимые и важные страницы. Например, ссылки на основные разделы, подразделы сайта.
Интернет-магазинам не стоит добавлять в HTML-карту ссылки на все товары.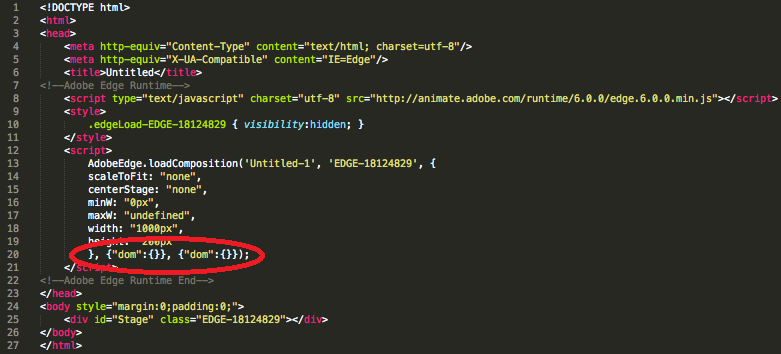 Особенно если товарный ассортимент измеряется сотнями или тысячами товаров.
Особенно если товарный ассортимент измеряется сотнями или тысячами товаров.
Еще одним аргументом за использование ссылок только на основные разделы в HTML-карте является удобство ориентации пользователя на странице. Иначе крайне сложно найти какую-либо информацию на странице, содержащей сотни или тысячи ссылок.
Пример html-карты сайта
XML-карта
XML-карта сайта является обязательным атрибутом активно продвигаемых веб-ресурсов. Для достижения наиболее полной индексации сайта www. domain.ru, настоятельно рекомендуется подготовить файл Sitemap и выложить его на сайт по адресу: http://www.domain.ru/sitemap.xml.
domain.ru, настоятельно рекомендуется подготовить файл Sitemap и выложить его на сайт по адресу: http://www.domain.ru/sitemap.xml.
С помощью файла Sitemap можно сообщать поисковым системам о страницах сайта, которые доступны для индексации. Файл Sitemap представляет собой XML-файл, в котором перечислены URL-адреса сайта в сочетании с метаданными, связанными с каждым URL-адресом (дата его последнего изменения; частота изменений; его приоритетность в рамках сайта). Эти данные помогают поисковым системам оптимизировать процесс индексации сайта.
Отмечу, что карта сайта должна содержать ссылки только на значимые страницы, содержащие уникальный контент. Карта сайта не должна содержать:
- URL-адреса, отдающие заголовки: 4хх, 3хх, 5хх (например, 500, 404, 301 или 302 и так далее).
- Страницы, закрытые от индексации файлом robots.txt или мета-тегом <meta name=»robots» content=»NOINDEX, NOFOLLOW»/>.
- Страницы-дубли, неинформативные или пустые страницы.
- Sitemap может описывать только страницы того домена, на котором он расположен.
После того, как карта сайта будет создана, следует добавить в файл robots.txt, находящийся в корневой директории сайта, директиву Sitemap: http://www.domain.ru/sitemap.xml.
Директива сообщит поисковым роботам, где находится карта сайта.
Желательно, чтобы XML-карта сайта автоматически обновлялась хотя бы раз в сутки.
Оптимизация HTML-кода
Простой код без ошибок помогает поисковым роботам быстрее и без лишних препятствий индексировать сайт. Это положительно сказывается на ранжировании.
Рекомендую проверять на ошибки основные типы страниц сайта:
- Главная — https://domain.ru/.
- Категория/Подкатегория — https://domain.ru/catalog/category/.
- Страницы карточки — https://domain.ru/product/name-product/.
- Страница пагинации — https://domain. ru/catalog/category/.
- Служебные страницы — https://domain.ru/page/.
 ru/catalog/category/.
ru/catalog/category/.Список шаблонов страниц может варьрироваться в зависимости от типа сайта.
Проверить сайт на отсутствующие и лишние теги можно при помощи сервиса FXN.
Также в идеале код не должен содержать большие закомментированные фрагменты, например:
Пример кода с закомментированным фрагментом
Внедрение турбо-страниц и AMP
На текущий момент у «Яндекса» и Google существуют две похожие технологии:
Они помогают ускорить загрузку контента, что положительно сказывается на удобстве сайта и поведенческих метриках.
Турбо-страницы и AMP обычно не содержат большинство вспомогательных элементов, включая виджеты, формы комментирования, блоки рекомендованного контента, рекламные объявления.
Несмотря на то, что есть решения, позволяющие создавать турбо-страницы и AMP для коммерческих ресурсов, я бы не рекомендовал использовать эту технологию для коммерческих страниц сайта, потому что есть риск ухудшить конверсию.
AMP и турбо-страницы хорошо работают на информационных ресурсах. Если у вас контентный проект или у вашего интернет-магазина есть блог или раздел со статьями, то ускоренные страницы внедрять однозначно стоит. Тем более, что с недавних пор «Яндекс» анонсировал отдельный колдунщик (блок) турбо-страниц для десктопной выдачи.
Внедрение турбо-страниц позволит сформировать привлекательный сниппет и привлечь дополнительный трафик из колдунщика.
Пример сниппета при ипользовании турбо-страниц
Создание progressive web apps (PWA)
PWA — сайт, который можно добавить на главный экран телефона, и он будет работать в автономном режиме.
PWA обладает следующими преимуществами:
- Google поднимает PWA значительно выше в поисковой выдаче. Также все прогрессивные веб-приложения работают по протоколу HTTPS, соответственно, Google также позитивно реагирует на это, поскольку наличие защищенного протокола является одним из факторов ранжирования в поисковой системе.
- Кроссплатформенность Progressive Web Apps дает нам возможность делать одно веб-приложение, которое будет работать абсолютно на всех устройствах, где присутствует браузер.
- Возможность продолжать работу с приложением при сбоях интернет-подключения и увеличенная скорость загрузки с помощью PWA обезопасит от утери потенциальных конверсий и от увеличения количества отказов.

Ниже приведены рекомендации по созданию PWA
Создать иконку приложения
Сайт будет располагаться на экране, а значит, нужна иконка. Сгенерировать иконку можно при помощи сервиса Firebase. Затем необходимо разместить иконки на сайте.
Затем необходимо разместить иконки на сайте.
Разместить манифест
Manifest — это файл JSON, который описывает все метаданные вашего Progressive Web App. Такие атрибуты, как название, язык и значок вашего приложения. Эта информация укажет браузерам, как отображать ваше приложение, когда оно будет сохранено в виде ярлыка.
Полное описание всех свойств доступно по ссылке.
Далее следует загрузить полученный файл на сайт, внутри тега <body> разместить ссылку на JSON-файл. Проверить корректность созданного манифеста можно при помощи сервиса manifest-validator.appspot.com
Проверить корректность созданного манифеста можно при помощи сервиса manifest-validator.appspot.com
Добавить service worker
Service Worker — это скрипт, работающий в фоновом режиме, который браузер может запускать даже тогда, когда пользователь не находится на вашей странице. Он предоставляет офлайновую поддержку и просыпается при получении уведомления.
Сгенерировать Service Worker можно при помощи этого сервиса.
Необходимо подключить service worker в шаблонах основных страниц, разместив следующий скрипт внутри тега <body>.
Также необходимо разместить файл pwabuilder-sw.js в корне сайта.
Тестирование
Проверить корректность работы PWA можно при помощи инструмента Lighthouse.
Оптимизация изображений
Чтобы получить дополнительный трафик из поиска по картинкам, рекомендуется настроить «псевдостатическую» адресацию для файлов изображений.
При настройке «псевдостатических» URL изображений следует придерживаться нескольких простых правил:
- Не допускать в URL-адресах использования специальных символов, таких как «?», «=», «&» и других.
- Использование цифр в «псевдостатических» адресах допускается без ограничений.
- В качестве разделителя слов в адресе рекомендуется использовать символ «-» (дефис).
- Для формирования URL необходимо использовать транслитерированные ключевые слова, в точности соответствующие содержимому страницы. Файлы изображений, размещённых на страницах новостей и статей, рекомендуется называть по аналогии с URL страниц с добавлением слова «foto», а если изображений несколько, добавлять числовой идентификатор «foto-1», «foto-2», «foto-3» и так далее.
- В адресах изображений следует использовать только строчные латинские символы, не кириллицу.
Пример, как может выглядеть имя для изображения http://www.domain.ru/upload/iblock/2a6/006.jpg, размещенного на странице http://www. domain.ru: photo-name.jpg
domain.ru: photo-name.jpg
Важно: после внедрения «псевдостатической» адресации со всех старых URL на новые необходимо настроить 301 редиректы.
Отмечу, что у изображений должен быть заполнен атрибут ALT. Он служит для отображения заданного фрагмента текста («alternative text») вместо картинки. Он должен содержать её краткое словесное описание. Этот текст будет доступен для индексации роботам поисковых систем, повысит релевантность каждой конкретной страницы.
Тег ALT необходимо добавить ко всем изображениям.
Основной принцип формирования: в атрибуты ALT основных изображений на сайте (изображения за исключением элементов дизайна) рекомендуется включить предложение, отвечающее следующим требованиям:
- Текст до десяти слов, описывающий содержимое картинки.
- Текст может совпадать с <h2>, если это логически допустимо.
- Текст должен описывать изображение теми словами, по которым сайт могут искать пользователи.
- Допускается дублирование данных атрибутов.
Шаблон облегчит задачу по их добавлению, но при желании можно прописывать атрибуты отдельно, помня, что ALT необходим для поисковых систем. То есть в него желательно включать слова, по которым эту картинку должен найти пользователь.
Требования к хостингу с точки зрения SEO
Проблемы с индексацией страниц сайта могут возникнуть в результате некорректной работы хостинга. Отследить ошибки сайта можно в соответствующем отчете Яндекс.Метрики.
Отследить ошибки сайта можно в соответствующем отчете Яндекс.Метрики.
Переход на протокол HTTPS
Защищенный протокол воспринимается в качестве фактора ранжирования, поэтому следует рассмотреть переход сайта на него.
Использование протокола HTTP/2
Протокол HTTP/2 существенно ускоряет открытие сайтов за счет следующих особенностей:
- Соединения. Несколько запросов могут быть отправлены через одно TCP-соединение, и ответы могут быть получены в любом порядке. Таким образом отпадает необходимость в том, чтобы держать несколько TCP-соединений.
- Приоритеты протоколов. Клиент может задавать серверу приоритеты — какого типа ресурсы для него важнее, чем другие.
- Сжатие заголовка. Размер заголовка HTTP может быть сокращен.
- Push-отправка данных со стороны сервера. Сервер может отправлять клиенту данные, которые тот еще не запрашивал. Например, на основании данных о том, какую страницу скорее всего откроет пользователь следующей.
 Несколько запросов могут быть отправлены через одно TCP-соединение, и ответы могут быть получены в любом порядке. Таким образом отпадает необходимость в том, чтобы держать несколько TCP-соединений.
Несколько запросов могут быть отправлены через одно TCP-соединение, и ответы могут быть получены в любом порядке. Таким образом отпадает необходимость в том, чтобы держать несколько TCP-соединений.Проверку можно провести при помощи сервиса.
Настройка кода ответа 304
Правильно настроенный сервер должен возвращать код 304 Not Modified, если клиент запросил документ методом GET, использовал заголовок If-Modified-Since или If-None-Match, и документ не изменился с указанного момента. При этом сообщение сервера не должно содержать тело страницы.
При этом сообщение сервера не должно содержать тело страницы.
Настройка заголовка нужна в первую очередь для снижения нагрузки на сервер и ускорения индексации страниц. Именно поэтому необходимо произвести настройку заголовка Last-Modified, особенно для крупных ресурсов с большим количеством страниц.
Подробней об этом можно прочитать в справках поисковых систем:
Цель этого заголовка — сообщить клиенту (браузеру или поисковику) информацию о последних изменениях конкретной страницы. Клиент передает серверу заголовок If-Modified-Since. Если изменений на странице не обнаружено, то от сервера возвращается заголовок «304 Not Modified». При этом страница не загружается.
При этом страница не загружается.
Проверить код ответа можно при помощи сервиса.
Выводы
К процессу технической оптимизации, как и к процессу продвижения в целом, не стоит подходить шаблонно. Любой проект индивидуален и даже самый обширный чек-лист не всегда способен охватить все рекомендации.
В данной статье я дал список наиболее распространенных технических проблем и привел пути их решения. Но стоит учитывать, что поисковые системы не стоят не месте, поэтому не исключаю, что спустя полгода или год этот список можно будет дополнить или сократить.
Рекомендация по теме
Чтобы быть в курсе последних наработок в области технической оптимизации, рекомендую послушать секцию «Техническое SEO» Сергея Кокшарова, автора самого популярного SEO-канала @DevakaTalk. Она пройдет в Сколково в конце октября в рамках Optimization.
Вопросы, которые Сергей планирует разобрать:
- Опыт внедрения AMP/Turbo страниц на коммерческом (не новостном) сайте.
- Опыт оптимизации SPA/PWA сайта.
- Опыт использования GeoIP редиректов.
- Максимизация видимости сайта продвинутыми техническими методами.
- Использование машинного обучения для SEO задач и другие эксперименты в области технической оптимизации.

Тег noindex. Как правильно пользоваться?
Многие из нас слышали о тегах noindex и nofollow, что ими пользуются, что-то там закрывают в коде страницы и вроде как это даже положительно сказывается на продвижении сайта в поисковой выдаче. Если Вы желаете избавиться от этих самых «что-то там» и «вроде как» в своем понимании использования этих тегов, то этот обзор для Вас.
В этой статье будут рассмотрены все тонкости использования noindex и к чему это в конечном итоге приводит оптимизаторов и «переоптимизаторов». В следующем обзоре мы также тщательно пройдемся по атрибуту nofollow, чтобы окончательно расставить все точки над «и» в использовании этих инструментов.
Как пользоваться?
В рекомендациях для вебмастеров от Яндекса предлагается для использования две версии данного тега.
Первый вариант:
<noindex>Закрытое к индексации содержимое</noindex>
Второй вариант:
<!--noindex-->Закрытое к индексации содержимое<!--/noindex-->
Отличие между ними только в том, что второй вариант валиден (не содержит в себе ошибки с точки зрения документации html). В остальном же оба варианта используются для скрытия от индексации поисковым роботом Яндекса (для гугла используются другие фишки) определенной части html кода страницы.
Пользоваться тегом noindex элементарно – достаточно просто заключить внутрь тега все содержание страницы, которое мы не хотим открывать поисковику.
Любопытным моментом также является то, что при его использовании не обязательно соблюдать принцип вложенности тегов html. Мы просто закрываем содержимое откуда хоти докуда хотим. Главное не забыть поставить закрывающий тег, иначе робот не увидит весь код страницы идущий после открывающего тега.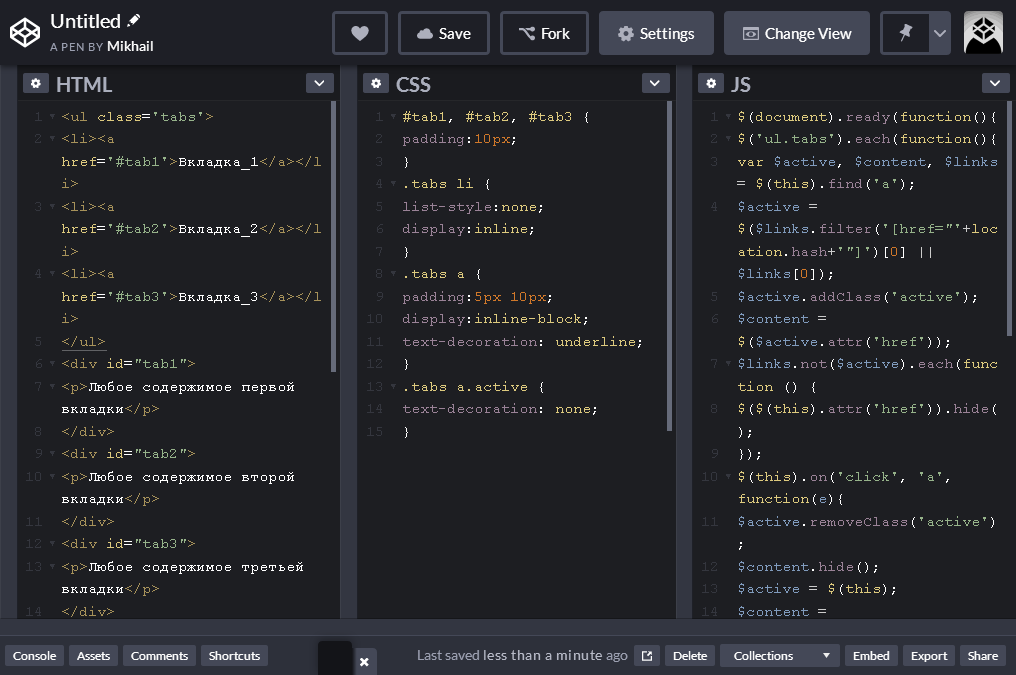
Особенности применения
- Тег noindex закрывает от индексации весь код содержащийся внутри него КРОМЕ картинок и ссылок. Это вызвано в первую очередь тем, что для них предусмотрено использование атрибута nofollow.
- Им СТОИТ пользоваться для скрытия кодов счетчиков сайта, форм подписок на рассылки, баннеров, часто повторяющегося контента (по типу цитат), слишком часто меняющихся фрагментов страницы, нецензурных выражений (рекомендация от авторов- вообще соблюдайте культуру речи и будет вам Добро).
- Бесполезно его использовать для скрытия только ссылок, рекламы от яндекс директ и гугл адсенс.
Осторожно, переоптимизация! Или вредные советы для вебмастеров.
Многие «умелые» оптимизаторы давно приспособили этот тег для удовлетворения своих изощренных желаний в продвижении страниц. Рассмотрим до чего можно дойти и почему этого делать не стоит:
- Исключая лишние фразы и куски текста из содержания страницы можно изменять сниппеты (описания сайта в поисковой выдаче) по своему желания. Помимо глобальной потери времени этот подход еще грозит санкциями от поисковой системы, которая при «осознании» факта мошенничества вполне может ответить санкциями к и злишне ретивому мастеру.
- Если сниппеты для Вас это лишь детский сад, то можно пойти и дальше. А давайте покажем каждому поисковику свое содержание страницы? С учетом того, что noindex работает только в Яше, то достичь этой цели достаточно просто. Даже не знаю стоит ли писать что делают Гугле и Яндекс с теми, кого поймали на манипулировании алгоритмами поиска?
- Если в тексте использовано слишком много ключевых слов, то можно лишние ключи поскрывать этим тегом. Только почему не потратить это время на простое приведение текста в порядок? Вопрос для размышления. Таким подходом мы добиваемся: А- того, что текст остается заспамленным для пользователей ресурса; Б- яндекс не дурак и отлично понимает когда его пытаются обмануть, потому страницы с слишком часто используемым тегом noindex достаточно быстро «проваливаются» в поисковой выдаче.
 Помимо глобальной потери времени этот подход еще грозит санкциями от поисковой системы, которая при «осознании» факта мошенничества вполне может ответить санкциями к и злишне ретивому мастеру.
Помимо глобальной потери времени этот подход еще грозит санкциями от поисковой системы, которая при «осознании» факта мошенничества вполне может ответить санкциями к и злишне ретивому мастеру.
Подводя итоги
Как noindex не крути, а он по-прежнему остается инструментом не белой, а серой оптимизации сайта. Не взирая на оправданность его использования во многих ситуациях, помните, что алгоритмы поисковых систем продолжают активно развиваться и поисковик и так понимает что и где у сайта расположено, хоть пока и не придает этому особого значения.
Из минусов также можно отметить то, что после появления поддержки в Яше атрибута nofollow весь рунет ожидает прекращения поддержки noindex. На сегодняшний день о этом ничего не слышно, но прельщаться этим не стоит.
Оценок: 3 (средняя 5 из 5)
Понравилась статья? Расскажите о ней друзьям:
Еще интересное
Как определить закрыта или нет ссылка тегами «nofollow»и «noindex»
Кто занимается оптимизацией и продвижением сайтов, кому важны показатели тИЦ и PR, используют в своей работе со ссылками теги и атрибуты «nofollow» и «noindex».
В основном они применяются для уменьшения передачи веса на другие сайты. Закрывая индексацию ссылок в поисковых системах, в конечном счёте для повышения показателей ТиЦ и PR своего сайта. Для чего они нужны и как применяются читайте как правильно использовать noindex и nofollow
В связи с этим часто возникает необходимость быстро определить заключена ли ссылка в теги, закрыта или нет. Это можно сделать несколькими способами, но я для этих целей использую плагин RDS Bar.
С помощью этого плагина можно быстро просмотреть многие характеристики сайта, и в том числе сразу увидеть статус ссылок — какие ссылки в какие теги заключены, закрыты ссылки или нет от индексации в поисковиках.
Установка и настройка плагина
Скачайте на компьютер и установите плагин, перейдя по ссылке: https://addons.mozilla.org/ru/firefox/addon/rds-bar/
В правом верхнем углу панелей управления браузером появиться значок
(цифра 10 — означает показатель тиц сайта, как получить жирные ссылки на сайт бесплатно)
Нажмите на значок левой кнопкой мыши, откроется окно где вы увидите многие параметры сайта и страницы на которой находитесь.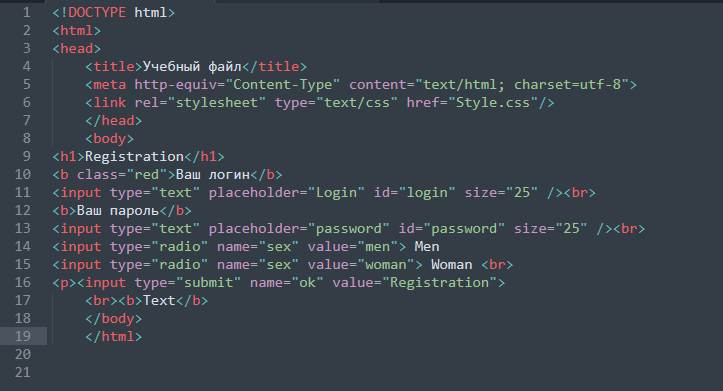 Таким образом вы сможете просматривать многие данные сайтов.
Таким образом вы сможете просматривать многие данные сайтов.
Далее нажмите правой кнопкой мыши по значку, откроется вкладка настроек и управления плагином.
Теперь откройте пункт настройки.
В этом окне можно настроить различные функции плагина RDS Bar.
Нужно ли выводить данные сразу в поисковых системах при поиске сайтов, а также настроить какие показатели будут запрошены.
Но нас интересуют параметры ссылок, поэтому идём вниз в настройки «Подсветка на страницах».
Здесь выбираем, как будут выделяться на сайте ссылки, а так же картинки которые имеют ссылки с различными тегами и статусами.
Выберите и установите цвет, рамку, зачёркивать или другое на ваш выбор: для ссылок с тегом «noindex»и атрибутом «nofollow».
Поэкспериментируйте, найдите удобный для себя вариант.
Теперь, открывая любую страницу любого сайта, вы быстро и сразу увидите статус находящихся здесь ссылок, индексируются ли они в поисковых системах и в какие теги заключены.
Удачи в делах!
- < Назад
- Вперёд >
Noindex, nofollow — чек лист для работы
Noindex и nofollow зачастую называют некорректно: тегами, метатегами, атрибутами. На самом деле noindex — это тег, а nofollow — атрибут внутри тега.
Метатеги — это теги, которые относятся ко всей странице: <meta name=»robots» content=»noindex, nofollow» />
Тег <noindex> создает конструкцию: <noindex> … </noindex>;
атрибут rel=”nofollow” может появляться в конструкции тега.
С помощью этих параметров можно и нужно указывать поисковым роботам Google, Яндекс или других систем, как именно нужно взаимодействовать с контентом, находящимся внутри этих параметров.
Где и как использовать noindex и nofollow
Эти атрибуты могут располагаться в заголовке страницы, и тогда они будут правилом для всего контента. А могут ограждать конкретный текстовый фрагмент, ссылку или изображение.
Для страниц метатеги noindex и nofollow закрывают от индексации:
- страницы регистрации;
- служебные страницы;
- страницы авторов комментариев;
- другие «вредные» для индексации страницы;
Для контента теги noindex и атрибут nofollow закрывают от индексации:
- «вредные» ссылки;
- цитаты из различных источников;
- повторяющийся контент
Чтобы закрыть от индексации страницы — метатеги noindex и nofollow
Когда нужно чтобы страница и контент на ней индексировались, а поисковый робот не переходил по ссылкам. В таком случае используем конструкцию:
<meta name="robots" content="index, nofollow"/>
Когда надо закрыть страницу от индексации, а переходы по ссылкам разрешить, вставляем
<meta name="robots" content="noindex, follow"/>
Чтобы индексировались и ссылки, и сама страница, в заголовке применяем метатег
<meta name="robots" content="index, follow"/>
Для полного закрытия страницы и ссылок на ней от индексации:
<meta name="robots" content="noindex, nofollow"/>
Для примера приведем заголовок страницы, в которой используются метатеги с полным закрытием страницы и ссылок для индексации ее роботом поисковой системы (noindex, nofollow):
<html> <head> <meta name="robots" content="noindex,nofollow"> <meta name="description" content="Description для данной странички"> <title>…</title> </head> <body>
Для контента и ссылок тег noindex и атрибут nofollow
Чтобы скрыть от индексации фрагмент текста (работает только для Яндекс и Рамблер), используем следующее решение:
<!--noindex--> (текст, который нужно скрыть) <!--/noindex-->
Чтобы скрыть от индексации ссылку, используем:
<a href="https://mysite.
 com/" rel="nofollow">Текст ссылки </a>
com/" rel="nofollow">Текст ссылки </a>
Чтобы скрыть ссылку от индексации и Яндекс, и Google, применяем
<noindex><a href="http://mysite.com/" rel="nofollow">текст ссылки</a></noindex>
Google в данной конструкции принимает только rel=»nofollow», а для Яндекса действуют и noindex, и rel=»nofollow».
<noindex> — неофициальный тег
<noindex>…</noindex> используется поисковыми системами Яндекс и Rambler. Цель — скрыть от индексации указанный контент.
Google на данный тег не обращает внимание, ибо он не является принятым тегом разметки html.
rel=”nofollow” — атрибут внутри тега ссылки
rel=”nofollow” запрещает поисковым системам переходить по указанной ссылке. Конструкция:
<a href="signin.php" rel="nofollow">Войти</a>
Как сообщается в ответе поддержки Google для веб-мастеров, поисковая система не переходит по ссылке и не использует для перехода по ней краулинговый бюджет. Но это не значит, что робот туда не заглянет и не проверит. То есть дальнейшая судьба данной ссылки такая: мы про тебя знаем, но молчим, пока это безопасно.
Но это не значит, что робот туда не заглянет и не проверит. То есть дальнейшая судьба данной ссылки такая: мы про тебя знаем, но молчим, пока это безопасно.
Если нужно скрыть от индексации страницы только для Google, можно использовать <meta name=»googlebot» content=»noindex» />.
Если нужно закрыть от индексации только для Яндекс – <meta name=»yandex» content=»noindex»/>.
Закрытие индексации через файл robots.txt
Метатеги, описанные ранее <meta name=»robots» content=»noindex, nofollow»> появляются только после открытия роботом страницы и прочтения заголовка.
Закрытие же страницы через файл robots.txt запрещает даже заходить на страницу.
Если поисковая система раньше проиндексировала эту страницу, то она будет находится в индексе поисковых систем (даже после закрытия в файле robots.txt). А в description нам сообщат, что описание для данной страницы отобразить невозможно, ведь она закрыта от индексации в файле robots. txt.
txt.
# robots.txt for http://www.w3.org/ User-agent: W3C-gsa Disallow: /Out-Of-Date User-agent: W3T_SE Disallow: /Out-Of-Date User-agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT; MS Search 4.0 Robot) Disallow: / # W3C Link checker User-agent: W3C-checklink Disallow: User-agent: Applebot Disallow: /People/domain/ # the following settings apply to all bots User-agent: * # Blogs - WordPress # https://codex.wordpress.org/Search_Engine_Optimization_for_WordPress#Robots.txt_Optimization Disallow: /*/wp-admin/ Disallow: /*/wp-includes/ Disallow: /*/wp-content/plugins/ Disallow: /*/wp-content/cache/ Disallow: /*/wp-content/themes/ Disallow: /blog/*/trackback/ Disallow: /blog/*/feed/ Disallow: /blog/*/comments/ Disallow: /blog/*/category/*/* Disallow: /blog/*/*/trackback/ Disallow: /blog/*/*/feed/ Disallow: /blog/*/*/comments/ Disallow: /blog/*/*?
Поэтому для непроиндексированных страниц можно использовать как вариант закрытия через метатеги в заголовке, так и через файл роботс. тхт.
тхт.
Если страница уже была проиндексирована, рекомендуем вставить в заголовок, в секцию <head> метатег <meta name=»robots» content=»noindex, nofollow» />. Это исключит ее из индексации и предотвратит последующее попадание в нее.
В данном файле есть несколько блоков. Первый — User-agent — команда для определения робота, к которому относится последующие директивы. В коде файла роботс.тхт, что представлен выше — для робота W3C-gsa, W3T_SE, Mozilla/4.0, W3C-checklink, Applebot. А звездочка ( * ) после команды User-agent — говорит что последующие директивы относятся ко всем поисковым роботам.В большинстве случаев нам понадобиться заголовок в файле robots.txt следующего стандартного вида:
User-agent: * # applies to all robots
Последующие директивы позволяют исключить как отдельные страницы, так и целые папки со страницами. Код будет выглядеть так:
Disallow: / # disallow indexing of all pages
В случае, если в данной папке есть одна или несколько страниц, которые должны быть проиндексированы поступаем следующим образом:
User-agent: * Disallow: /help #запрещает страницы к индексированию, которые находятся в каталоге, например: /help.
 html и /help/index.html
Disallow: /help/ #запрещает только те страницы, которые находятся на уровень ниже каталога help, а те, что в этом каталоге - остаются открытыми, например: /help/index.html закрыт, но /help.html - открыт
html и /help/index.html
Disallow: /help/ #запрещает только те страницы, которые находятся на уровень ниже каталога help, а те, что в этом каталоге - остаются открытыми, например: /help/index.html закрыт, но /help.html - открыт
В файле robots.txt обязательно должно быть хотя бы одно поле Disallow. Как же поступить если нам не нужно закрывать ни одной страницы? Оставляем поле пустым:
Disallow: #если после директивы оставить поле пустым - считается что все страницы сайта остаются открытыми для индексирования
Распространенные ошибки:
- Попытка закрыть от индексации ссылку следующей комбинацией: <nofollow><a href=»index.php»>Перейти</a></nofollow>
- Попытка закрыть ссылку от индексации с помощью тега <noindex>. Таким образом можно закрыть только анкор (текст ссылки, а не саму ссылку), и только для Яндекс.
Тег <noindex> для разметки html является неофициальным; в официальной разметке есть только атрибут rel или метатег со значением nofollow.

Выводы
Для экономии краулингового бюджета важно закрывать от индексации лишние ссылки, вес которых не существенен для продвижения.
Для поисковых систем ссылки nofolow выглядят естественно, а их наличие является нормальным. Однако большое количество исходящих ссылок на сайте может оказаться и минусом, несмотря на то, что они были закрыты от индексации.
Заказать сайт
Руководство по метатегам Robots и X-robots-tag
Перед вами дополненный (конечно же, выполненный с любовью) перевод статьи Robots Meta Tag & X-Robots-Tag: Everything You Need to Know c блога Ahrefs. Дополненный, потому что в оригинальном материале «Яндекс» упоминается лишь вскользь, а в главе про HTTP-заголовки затрагивается только сервер Apache. Мы дополнили текст информацией по метатегам «Яндекса», а в части про X-Robots-Tag привели примеры для сервера Nginx. Так что этот перевод актуален для наиболее популярных для России поисковых систем и веб-серверов. Круто, правда?
Круто, правда?
Приятного чтения!
Направить поисковые системы таким образом, чтобы они сканировали и индексировали ваш сайт именно так, как вы того хотите, порой может быть непросто. Хоть robots.txt и управляет доступностью вашего контента для ботов поисковых систем, он не указывает краулерам на то, стоит индексировать страницы или нет.
Для этой цели существуют метатеги robots и HTTP-заголовок X-Robots-Tag.
Давайте проясним одну вещь с самого начала: вы не можете управлять индексацией через robots.txt. Распространенное заблуждение — считать иначе.
Правило noindex в robots.txt официально никогда не поддерживалось Google. 2 июля 2019 года Google опубликовал новость, в которой описал нерелевантные и неподдерживаемые директивы файла robots.txt. С 1 сентября 2019 года такие правила, как noindex в robots.txt, официально не поддерживаются.
Из этого руководства вы узнаете:
- что такое метатег robots;
- почему robots важен для поисковой оптимизации;
- каковы значения и атрибуты метатега robots;
- как внедрить robots;
- что такое X-Robots-Tag;
- как внедрить X-Robots-Tag;
- когда нужно использовать метатег robots, а когда — X-Robots-Tag;
- как избежать ошибок индексации и деиндексации.
Что такое метатег robots
Это фрагмент HTML-кода, который указывает поисковым системам, как сканировать и индексировать определенную страницу. Robots помещают в контейнер <head> кода веб-страницы, и выглядит это следующим образом:
<meta name="robots" content="noindex" />
Почему метатег robots важен для SEO
Метатег robots обычно используется для того, чтобы предотвратить появление страниц в выдаче поисковых систем. Хотя у него есть и другие возможности применения, но об этом позже.
Есть несколько типов контента, который вы, вероятно, хотели бы закрыть от индексации поисковыми системами. В первую очередь это:
- страницы, ценность которых крайне мала для пользователей или отсутствует вовсе;
- страницы на стадии разработки;
- страницы администратора или из серии «спасибо за покупку!»;
- внутренние поисковые результаты;
- лендинги для PPC;
- страницы с информацией о грядущих распродажах, конкурсах или запуске нового продукта;
- дублированный контент. Не забывайте настраивать тег canonical для того, чтобы предоставить поисковым системам наилучшую версию для индексации.
 Не забывайте настраивать тег canonical для того, чтобы предоставить поисковым системам наилучшую версию для индексации.
Не забывайте настраивать тег canonical для того, чтобы предоставить поисковым системам наилучшую версию для индексации.В общем, чем больше ваш веб-сайт, тем больше вам придется поработать над управлением краулинговой доступностью и индексацией. Еще вы наверняка хотели бы, чтобы Google и другие поисковые системы сканировали и индексировали ваш сайт с максимально возможной эффективностью. Да? Для этого нужно правильно комбинировать директивы со страницы, robots.txt и sitemap.
Какие значения и атрибуты есть у метатега robots
Метатег robots содержит два атрибута: name и content.
Следует указывать значения для каждого из этих атрибутов. Их нельзя оставлять пустыми. Давайте разберемся, что к чему.
Атрибут name и значения user-agent
Атрибут name уточняет, для какого именно бота-краулера предназначены следующие после него инструкции. Это значение также известно как user-agent (UA), или «агент пользователя». Ваш UA отражает то, какой браузер вы используете для просмотра страницы, но вот у Google UA будет, например, Googlebot или Googlebot-image.
Ваш UA отражает то, какой браузер вы используете для просмотра страницы, но вот у Google UA будет, например, Googlebot или Googlebot-image.
Значения user-agent, robots, относится только к ботам поисковых систем. Цитата из официального руководства Google:
Тег
<meta name="robots" content="noindex" />и соответствующая директива применяются только к роботам поисковых систем. Чтобы заблокировать доступ другим поисковым роботам, включая AdsBot-Google, возможно, потребуется добавить отдельные директивы для каждого из них, например<meta name="AdsBot-Google" content="noindex" />.
Вы можете добавить столько метатегов для различных роботов, сколько вам нужно. Например, если вы не хотите, чтобы картинки с вашего сайта появлялись в поисковой выдаче Google и Bing, то добавьте в шапку следующие метатеги:
<meta name="googlebot-image" content="noindex" /><meta name="MSNBot-Media" content="noindex" />
Примечание: оба атрибута — name и content — нечувствительны к регистру. То есть абсолютно не важно, напишите ли вы их с большой буквы или вообще ЗаБоРчИкОм.
То есть абсолютно не важно, напишите ли вы их с большой буквы или вообще ЗаБоРчИкОм.
Атрибут content и директивы сканирования и индексирования
Атрибут content содержит инструкции по поводу того, как следует сканировать и индексировать контент вашей страницы. Если никакие метатеги не указаны или указаны с ошибками, и бот их не распознал, то краулеры расценят гнетущую тишину их отсутствия как «да», т. е. index и follow. В таком случае страница будет проиндексирована и попадет в поисковую выдачу, а все исходящие ссылки будут учтены. Если только ссылки непосредственно не завернуты в тег rel=»nofollow» .
Ниже приведены поддерживаемые значения атрибута content.
all
Значение по умолчанию для index, follow. Вы спросите: зачем оно вообще нужно, если без этой директивы будет равным образом то же самое? И будете чертовски правы. Нет абсолютно никакого смысла ее использовать. Вообще.
<meta name="robots" content="all" />
noindex
Указывает ПС на то, что данную страницу индексировать не нужно. Соответственно, в SERP она не попадет.
Соответственно, в SERP она не попадет.
<meta name="robots" content="noindex" />
nofollow
Краулеры не будут переходить по ссылкам на странице, но следует заметить, что URL страниц все равно могут быть просканированы и проиндексированы, в особенности если на них ведут внешние ссылки.
<meta name="robots" content="nofollow" />
none
Комбинация noindex и nofollow как кофе «два в одном». Google и Yandex поддерживают данную директиву, а вот, например, Bing — нет.
<meta name="robots" content="none" />
noarchive
Предотвращает показ кешированной версии страницы в поисковой выдаче.
<meta name="robots" content="noarchive" />
notranslate
Говорит Google о том, что ему не следует предлагать перевод страницы в SERP. «Яндексом» не поддерживается.
<meta name="robots" content="notranslate" />
noimageindex
Запрещает Google индексировать картинки на странице. «Яндексом» не поддерживается.
<meta name="robots" content="noimageindex" />
Указывает Google на то, что страницу нужно исключить из поисковой выдачи после указанной даты или времени. В целом это отложенная директива noindex с таймером. Бомба деиндексации с часовым механизмом, если изволите. Дата и время должны быть указаны в формате RFC 850. Если время и дата указаны не будут, то директива будет проигнорирована. «Яндекс» ее тоже не знает.
<meta name="robots" content="unavailable_after: Sunday, 01-Sep-19 12:34:56 GMT" />
nosnippet
Отключает все текстовые и видеосниппеты в SERP. Кроме того, работает и как директива noarchive. «Яндексом» не поддерживается.
<meta name="robots" content="nosnippet" />
Важное примечание
С октября 2019 года Google предлагает более гибкие варианты управления отображением сниппетов в поисковой выдаче. Сделано это в рамках модернизации авторского права в Евросоюзе. Франция стала первой страной, которая приняла новые законы вместе со своим обновленным законом об авторском праве.
Новое законодательство хоть и введено только в Евросоюзе, но затрагивает владельцев сайтов повсеместно. Почему? Потому что Google больше не показывает сниппеты вашего сайта во Франции (пока только там), если вы не внедрили на страницы новые robots-метатеги.
Мы описали каждый из нововведенных тегов ниже. Но вкратце: если вы ищете быстрое решение для исправления сложившейся ситуации, то просто добавьте следующий фрагмент HTML-кода на каждую страницу сайта. Код укажет Google на то, что вы не хотите никаких ограничений по отображению сниппетов. Поговорим об этом более подробно далее, а пока вот:
Поговорим об этом более подробно далее, а пока вот:
<meta name="robots" content=”max-snippet:-1, max-image-preview:large, max-video-preview:-1" />
Заметьте, что если вы используете Yoast SEO, этот фрагмент кода уже добавлен на все ваши страницы, при условии, что они не отмечены директивами noindex или nosnippet.
Нижеуказанные директивы не поддерживаются ПС «Яндекс».
max-snippet
Уточняет, какое максимальное количество символов Google следует показывать в своих текстовых сниппетах. Значение «0» отключит отображение текстовых сниппетов, а значение «-1» укажет на то, что верхней границы нет.
Вот пример тега, указывающего предел в 160 символов (стандартная длина meta description):
<meta name="robots" content="max-snippet:160" />
max-image-preview
Сообщает Google, какого размера картинку он может использовать при отображении сниппета и может ли вообще. Есть три опции:
Есть три опции:
- none — картинки в сниппете не будет вовсе;
- standart — в сниппете появится (если появится) картинка обыкновенного размера;
- large — может быть показана картинка максимального разрешения из тех, что могут влезть в сниппет.
<meta name="robots" content="max-image-preview:large" />
max-video-preview
Устанавливает максимальную продолжительность видеосниппета в секундах. Аналогично текстовому сниппету значение «0» выключит опцию показа видео, значение «-1» укажет, что верхней границы по продолжительности видео не существует.
Например, вот этот тег скажет Google, что максимально возможная продолжительность видео в сниппете — 15 секунд:
<meta name="robots" content="max-video-preview:15" />
noyaca
Запрещает «Яндексу» формировать автоматическое описание с использованием данных, взятых из «Яндекс. Каталога». Для Google не поддерживается.
Каталога». Для Google не поддерживается.
Примечание относительно использования HTML-атрибута data-nosnippet
Вместе с новыми директивами по метатегу robots, представленными в октябре 2019 года, Google также ввел новый HTML-атрибут data-nosnippet. Атрибут можно использовать для того, чтобы «заворачивать» в него фрагменты текста, который вы не хотели бы видеть в качестве сниппета.
Новый атрибут может быть применен для элементов <div>, <span> и <section>. Data-nosnippet — логический атрибут, то есть он корректно функционирует со значениями или без них.
Вот два примера:
<p>Фрагмент этого текста может быть показан в сниппете <span data-nosnippet>за исключением этой части.</span></p><div data-nosnippet>Этот текст не появится в сниппете.</div><div data-nosnippet="true">И этот тоже.
 </div>
</div>
Использование вышеуказанных директив
В большинстве случаев при поисковой оптимизации редко возникает необходимость выходить за рамки использования директив noindex и nofollow, но нелишним будет знать, что есть и другие опции.
Вот таблица для сравнения поддержки различными ПС упомянутых ранее директив.
| Директива | «Яндекс» | Bing | |
|---|---|---|---|
| all | ✅ | ✅ | ❌ |
| noindex | ✅ | ✅ | ✅ |
| nofollow | ✅ | ✅ | ✅ |
| none | ✅ | ✅ | ❌ |
| noarchive | ✅ | ✅ | ✅ |
| nosnippet | ✅ | ❌ | ✅ |
| max-snippet | ✅ | ❌ | ❌ |
| max-snippet-preview | ✅ | ❌ | ❌ |
| max-video-preview | ✅ | ❌ | ❌ |
| notranslate | ✅ | ❌ | ❌ |
| noimageindex | ✅ | ❌ | ❌ |
| unavailable_after: | ✅ | ❌ | ❌ |
| noyaca | ❌ | ✅ | ❌ |
| index|follow|archive | ✅ | ✅ | ✅ |
Вы можете сочетать различные директивы.
И вот здесь очень внимательно
Если директивы конфликтуют друг с другом (например, noindex и index), то Google отдаст приоритет запрещающей, а «Яндекс» — разрешающей директиве. То есть боты Google истолкуют такой конфликт директив в пользу noindex, а боты «Яндекса» — в пользу index.
Примечание: директивы, касающиеся сниппетов, могут быть переопределены в пользу структурированных данных, позволяющих Google использовать любую информацию в аннотации микроразметки. Если вы хотите, чтобы Google не показывал сниппеты, то измените аннотацию соответствующим образом и убедитесь, что у вас нет никаких лицензионных соглашений с ПС, таких как Google News Publisher Agreement, по которому поисковая система может вытягивать контент с ваших страниц.
Как настроить метатеги robots
Теперь, когда мы разобрались, как выглядят и что делают все директивы этого метатега, настало время приступить к их внедрению на ваш сайт.
Как уже упоминалось выше, метатегам robots самое место в head-секции кода страницы. Все, в принципе, понятно, если вы редактируете код вашего сайта через разные HTML-редакторы или даже блокнот. Но что делать, если вы используете CMS (Content Management System, в пер. — «система управления контентом») со всякими SEO-плагинами? Давайте остановимся на самом популярном из них.
Внедрение метатегов в WordPress с использованием плагина Yoast SEO
Тут все просто: переходите в раздел Advanced и настраивайте метатеги robots в соответствии с вашими потребностями. Вот такие настройки, к примеру, внедрят на вашу страницу директивы noindex, nofollow:
Строка meta robots advanced дает вам возможность внедрять отличные от noindex и nofollow директивы, такие как max-snippet, noimageindex и так далее.
Еще один вариант — применить нужные директивы сразу по всему сайту: открывайте Yoast, переходите в раздел Search Appearance. Там вы можете указать нужные вам метатеги robots на все страницы или на выборочные, на архивы и структуры сайта.
Там вы можете указать нужные вам метатеги robots на все страницы или на выборочные, на архивы и структуры сайта.
Примечание: Yoast — вовсе не единственный способ управления вашим метатегами в CMS WordPress. Есть альтернативные SEO-плагины со сходным функционалом.
Что такое X-Robots-Tag
Метатеги robots замечательно подходят для того, чтобы закрывать ваши HTML-страницы от индексирования, но что делать, если, например, вы хотите закрыть от индексирования файлы типа изображений или PDF-документов? Здесь в игру вступает X-Robots-Tag.
X-Robots-Tag — HTTP-заголовок, но, в отличие от метатега robots, он находится не на странице, а непосредственно в файле конфигурации сервера. Это позволяет ему сообщать ботам поисковых систем инструкции по индексации страницы даже без загрузки содержимого самой страницы. Потенциальная польза состоит в экономии краулингового бюджета, так как боты ПС будут тратить меньше времени на интерпретацию ответа страницы, если она, например, будет закрыта от индексации на уровне ответа веб-сервера.
Вот как выглядит X-Robots-Tag:
Чтобы проверить HTTP-заголовок страницы, нужно приложить чуть больше усилий, чем требуется на проверку метатега robots. Например, можно воспользоваться «дедовским» методом и проверить через Developer Tools или же установить расширение на браузер по типу Live HTTP Headers.
Последнее расширение мониторит весь HTTP-трафик, который ваш браузер отправляет (запрашивает) и получает (принимает ответы веб-серверов). Live HTTP Headers работает, так сказать, в прямом эфире, так что его нужно включать до захода на интересующий сайт, а уже потом смотреть составленные логи. Выглядит все это следующим образом:
Как правильно внедрить X-Robots-Tag
Конфигурация установки в целом зависит от типа используемого вами сервера и того, какие страницы вы хотите закрыть от индексирования.
Строчка искомого кода для веб-сервера Apache будет выглядеть так:
Header set X-Robots-Tag «noindex»Для nginx — так:
add_header X-Robots-Tag «noindex, noarchive, nosnippet»;
Наиболее практичным способом управления HTTP-заголовками будет их добавление в главный конфигурационный файл сервера. Для Apache обычно это httpd.conf или файлы .htaccess (именно там, кстати, лежат все ваши редиректы). Для nginx это будет или nginx.conf, где лежат общие конфигурации всего сервера, или файлы конфигурации отдельных сайтов, которые, как правило, находятся по адресу etc/nginx/sites-available.
Для Apache обычно это httpd.conf или файлы .htaccess (именно там, кстати, лежат все ваши редиректы). Для nginx это будет или nginx.conf, где лежат общие конфигурации всего сервера, или файлы конфигурации отдельных сайтов, которые, как правило, находятся по адресу etc/nginx/sites-available.
X-Robots-Tag оперирует теми же директивами и значениями атрибутов, что и метатег robots. Это из хороших новостей. Из тех, что не очень: даже малюсенькая ошибочка в синтаксисе может положить ваш сайт, причем целиком. Так что два совета:
- при каких-либо сомнениях в собственных силах, лучше доверьте внедрение X-Robots-Tag тем, кто уже имеет подобный опыт;
- не забывайте про бекапы — они ваши лучшие друзья.
Подсказка: если вы используете CDN (Content Delivery Network), поддерживающий бессерверную архитектуру приложений для Edge SEO, вы можете изменить как метатеги роботов, так и X-Robots-теги на пограничном сервере, не внося изменений в кодовую базу.
Когда использовать метатеги robots, а когда — X-Robots-tag
Да, внедрение метатегов robots хоть и выглядит более простым и понятным, но зачастую их применение ограничено. Рассмотрим три примера.
Файлы, отличные от HTML
Ситуация: нужно впихнуть невпихуемое.
Фишка в том, что у вас не получится внедрить фрагмент HTML-кода в изображения или, например, в PDF-документы. В таком случае X-Robots-Tag — безальтернативное решение.
Вот такой фрагмент кода задаст HTTP-заголовок со значением noindex для всех PDF-документов на сайте для сервера Apache:
Header set X-Robots-Tag «noindex»А такой — для nginx:
location ~* \.pdf$ { add_header X-Robots-Tag «noindex»; }Масштабирование директив
Если есть необходимость закрыть от индексации целый домен (поддомен), директорию (поддиректорию), страницы с определенными параметрами или что-то другое, что требует массового редактирования, ответ будет один: используйте X-Robots-Tag.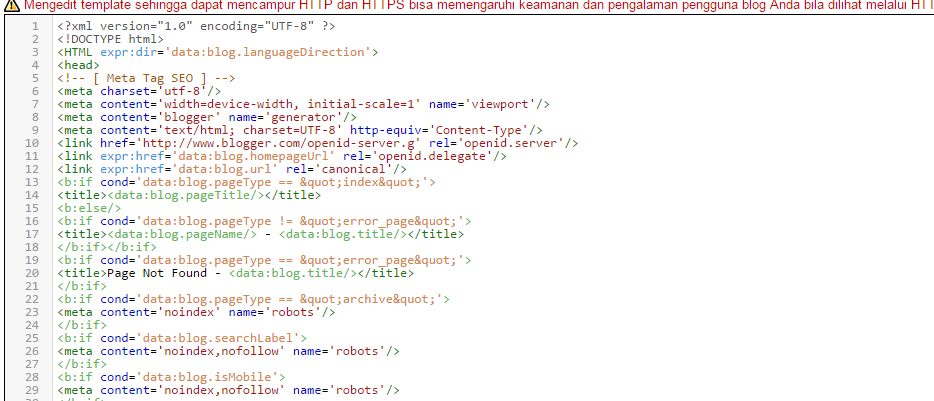 Можно, конечно, и через метатеги, но так будет проще. Правда.
Можно, конечно, и через метатеги, но так будет проще. Правда.
Изменения заголовка HTTP можно сопоставить с URL-адресами и именами файлов с помощью различных регулярных выражений. Массовое редактирование в HTML с использованием функции поиска и замены, как правило, требует больше времени и вычислительных мощностей.
Трафик с поисковых систем, отличных от Google
Google поддерживает оба способа — и robots, и X-Robots-Tag. «Яндекс» хоть и с отставанием, но в конце концов научился понимать X-Robots-Tag и успешно его поддерживает. Но, например, чешский поисковик Seznam поддерживает только метатеги robots, так что пытаться закрыть сканирование и индексирование через HTTP-заголовок не стоит. Поисковик просто не поймет вас. Придется работать с HTML-версткой.
Как избежать ошибок доступности краулинга и деиндексирования страниц
Вам, естественно, нужно показать пользователям все ваши страницы с полезным контентом, избежать дублированного контента, всевозможных проблем и не допустить попадания определенных страниц в индекс. А если у вас немаленький сайт с тысячами страниц, то приходится переживать еще и за краулинговый бюджет. Это вообще отдельный разговор.
А если у вас немаленький сайт с тысячами страниц, то приходится переживать еще и за краулинговый бюджет. Это вообще отдельный разговор.
Давайте пробежимся по распространенным ошибкам, которые допускают люди в отношении директив для роботов.
Ошибка 1. Внедрение noindex-директив для страниц, закрытых через robots.txt
Официальные инструкции основных поисковых систем гласят:
«Яндекс»GoogleНикогда не закрывайте через disallow в robots.txt те страницы, которые вы пытаетесь удалить из индекса. Краулеры поисковых систем просто не будут переобходить такие страницы и, следовательно, не увидят изменения в noindex-директивах.
Если вас не покидает чувство, что вы уже совершили подобную ошибку в прошлом, то не помешает выяснить истину через Ahrefs Site Audit. Смотрите на страницы, отмеченные ошибкой noindex page receives organic traffic («закрытые от индексации страницы, на которые идет органический трафик»).
Если на ваши страницы с директивой noindex идет органический трафик, то очевидно, что они все еще в индексе, и вполне вероятно, что робот их не просканировал из-за запрета в robots.txt. Проверьте и исправьте, если это так.
Ошибка 2. Плохие навыки работы с sitemap.xml
Если вы пытаетесь удалить контент из индекса, используя метатеги robots или X-Robots-Tag, то не стоит удалять их из вашей карты сайта до момента их деиндексации. В противном случае переобход этих страниц может занять у Google больше времени.
— …ускоряет ли процесс деиндексации отправка Sitemap.xml с URL, отмеченным как noindex?
— В принципе все, что вы внесете в sitemap.xml, будет рассмотрено быстрее.
Для того чтобы потенциально ускорить деиндексацию ваших страниц, установите дату последнего изменения вашей карты сайта на дату добавления тега noindex. Это спровоцирует переобход и переиндексацию.
Это спровоцирует переобход и переиндексацию.
Еще один трюк, который вы можете проделать, — загрузить sitemap.xml с датой последней модификации, совпадающей с датой, когда вы отметили страницу 404, чтобы вызвать переобход.
Джон Мюллер говорит здесь про страницы с ошибкой 404, но можно полагать, что это высказывание справедливо и для директив noindex.
Важное замечание
Не оставляйте страницы, отмеченные директивой noindex, в карте сайта на долгое время. Как только они выпадут из индекса, удаляйте их.
Если вы переживаете, что старый, успешно деиндексированный контент по каким-то причинам все еще может быть в индексе, проверьте наличие ошибок noindex page sitemap в Ahrefs Site Audit.
Ошибка 3. Оставлять директивы noindex на страницах, которые уже не находятся на стадии разработки
Закрывать от сканирования и индексации все, что находится на стадии разработки, — это нормальная, хорошая практика. Тем не менее, иногда продукт выходит на следующую стадию с директивами noindex или закрытым через robots.txt доступом к нему. Органического трафика в таком случае вы не дождетесь.
Тем не менее, иногда продукт выходит на следующую стадию с директивами noindex или закрытым через robots.txt доступом к нему. Органического трафика в таком случае вы не дождетесь.
Более того, иногда падение органического трафика может протекать незамеченным на фоне миграции сайта через 301-редиректы. Если новые адреса страниц содержат директивы noindex, или в robots.txt прописано правило disallow, то вы будете получать органический трафик через старые URL, пока они будут в индексе. Их деиндексация поисковой системой может затянуться на несколько недель.
Чтобы предотвратить подобные ошибки в будущем, стоит добавить в чек-лист разработчиков пункт о необходимости удалять правила disallow в robots.txt и директивы noindex перед отправкой в продакшен.
Ошибка 4. Добавление «секретных» URL в robots.txt вместо запрета их индексации
Разработчики часто стараются спрятать страницы о грядущих промоакциях, скидках или запуске нового продукта через правило disallow в файле robots. txt. Работает это так себе, потому что кто угодно может открыть такой файл, и, как следствие, информация зачастую сливается в интернет.
txt. Работает это так себе, потому что кто угодно может открыть такой файл, и, как следствие, информация зачастую сливается в интернет.
Не запрещайте их в robots.txt, а закрывайте индексацию через метатеги или HTTP-заголовки.
Заключение
Правильное понимание и правильное управление сканированием и индексацией вашего сайта крайне важны для поисковой оптимизации. Техническое SEO может быть довольно запутанным и на первый взгляд сложным, но метатегов robots уж точно бояться не стоит. Надеемся, что теперь вы готовы применять их на практике!
Зачем в SEO использовать noindex и nofollow
Первое на что стоит обратить внимание, это на то, что существует несколько разных понятий: атрибут – rel=”nofollow”, тег – <noindex> и метатег – <meta name=”robots” content=”noindex, nofollow” />.
Ниже в статье мы подробнее разберёмся с определениями и предназначениями данных понятий.
Тег noindex
С помощью тега noindex можно выделить отдельный фрагмент текста и закрыть его от индексации робота поисковой системы. Также с его помощью, можно блокировать индексацию отдельных страниц сайта, которые предназначены для публикации пользовательского контента например, страницы с отзывами или комментариями и пр.
Также с его помощью, можно блокировать индексацию отдельных страниц сайта, которые предназначены для публикации пользовательского контента например, страницы с отзывами или комментариями и пр.
Данный тег в HTML-коде может прописываться где угодно вне зависимости от уровня вложенности. Пример написания тега выглядит следующим образом:
- < !—noindex— >текст, который мы хотим скрыть от индексации<!—/noindex— >
- <noindex>ссылка, которою необходимо скрыть от индексации</noindex>
Важно знать, что тег noindex не учитывается ПС Google. Система попросту игнорирует его присутствие и проводит полную индексацию текстового содержания на страницах сайта.
Атрибут nofollow
В HTML-коде nofollow, является одним из множества значений, которое способно принимать атрибут rel. Использование данного атрибута rel=”nofollow” полагается в том, что бы запрещать роботам ПС индексировать и переходить по активной ссылке, на которой стоит данный атрибут.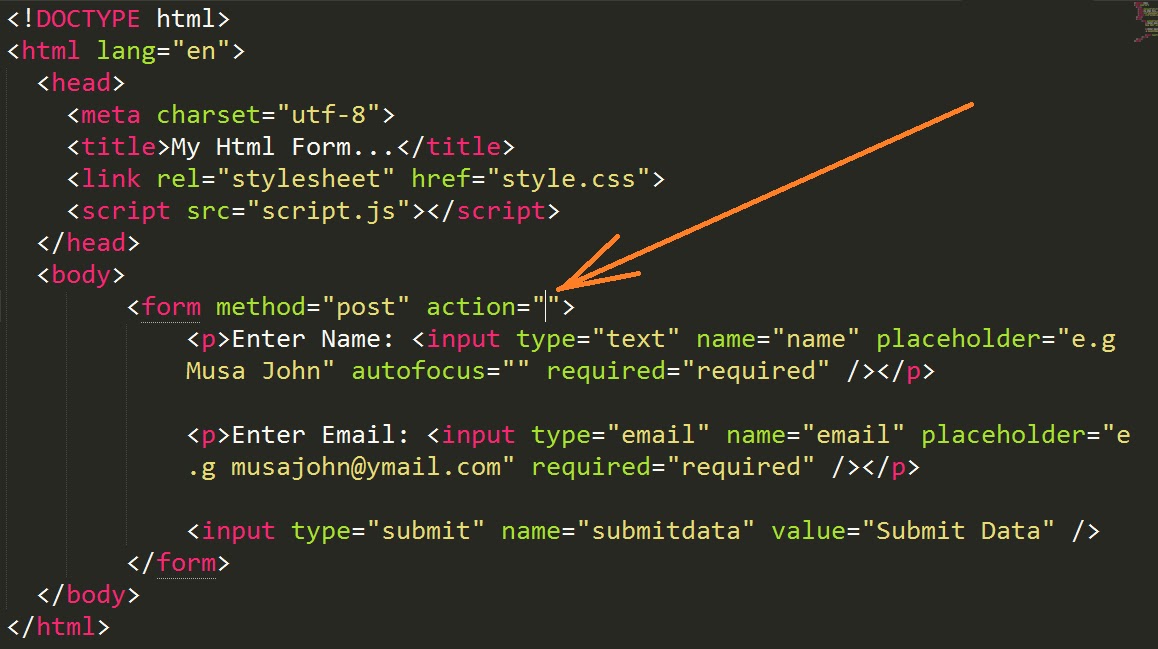
В коде, rel=”nofollow” выглядит следующим образом:
<a href=»https://site.com/» rel=»nofollow»>текст ссылки</a>
Причины, по которым стоит пользоваться атрибутом nofollow
На самом деле есть множество причин, по которым стоит запрещать индексацию ссылок, перечислим самые актуальные и важные из них.
- Ссылка на некачественный или нетематический сайт.
- Огромное количество ссылок ведущие на сторонние ресурсы.
- Защита от тех ссылок, что оставили пользователи в комментариях или отзывах.
- Перераспределение и сохранение веса страниц.
- Потребность в создании естественного ссылочного профиля.
Также, можно использовать одновременно тех noindex и атрибут nofollow, выглядеть данное сочетание будет так:
<noindex><a href=»http://site.com/» rel=»nofollow»>текст ссылки</a></noindex>
Что правда, такой метод работать полноценно не будет для роботов ПС Google, так как они понимают только атрибут – rel=»nofollow».
Мета-тег <meta name=”robots” content=”noindex, nofollow” />
Для начала рассмотрим, что такое метатег robots и зачем он нужен. Мета-тег robots – это код гипертекстовой разметки, который позволяет контролировать индексирование и показ страниц веб-сайта в результатах поиска. Метатег, можно писать на любой странице ресурса в специально отведённом для него месте в HTML-коде в теге <head>. Во время индексирования, Поисковые роботы будут читать значение мета-тега robots и учитывать его в дальнейшей работе над ресурсом.
Выглядит метатег robots следующим образом:
<meta name=»robots» content=» » />
Между кавычек content указываются следующие команды для поисковых роботов:
- Index;
- Noindex;
- Follow;
- Nofollow и пр.
Суть значений в мета-теге robots команд noindex и nofollow
- запрещать индексацию на уровне страницы, при этом не запрещать роботам посещать её и переходить по ссылкам.
- запрещать роботам ПС переходить по внешним и внутреннем ссылкам.

На практике комбинация <meta name=”robots” content=”noindex, nofollow” />, используются в случае, когда нужно запретить поисковым роботом индексировать контент на странице сайта и переходить по ссылкам.
Индексирование поиска блоковс помощью noindex
Вы можете запретить отображение страницы в поиске Google, указав noindex метатег в HTML-коде страницы или путем возврата заголовка noindex в HTTP
запрос. Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, он сбросит
эта страница полностью из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты.
noindex вступила в силу, страница не должен блокировать роботами. txt, иначе должно быть
доступный для краулера. Если страница заблокирована
robots.txt или он не может получить доступ к странице, поисковый робот никогда не увидит
txt, иначе должно быть
доступный для краулера. Если страница заблокирована
robots.txt или он не может получить доступ к странице, поисковый робот никогда не увидит noindex , и страница по-прежнему может отображаться в результатах поиска, например
если на него ссылаются другие страницы. Использование noindex полезно, если у вас нет root-доступа к вашему серверу, так как он
позволяет вам контролировать доступ к вашему сайту на постраничной основе.
Реализация
noindex Есть два способа реализовать noindex : как метатег и как HTTP-ответ.
заголовок.У них такой же эффект; выберите способ, который удобнее для вашего сайта.
Чтобы большинство поисковых роботов поисковых систем не проиндексировали страницу вашего сайта, поместите
следующий метатег в раздел вашей страницы:
Чтобы запретить только веб-сканерам Google индексировать страницу:
Вы должны знать, что некоторые поисковые роботы могут интерпретировать noindex иначе. В результате возможно, что ваша страница может
по-прежнему появляются в результатах других поисковых систем.
В результате возможно, что ваша страница может
по-прежнему появляются в результатах других поисковых систем.
Узнайте больше о метатеге noindex .
Вместо метатега вы также можете вернуть заголовок X-Robots-Tag со значением
либо noindex , либо none в вашем ответе. Вот пример
HTTP-ответ с X-Robots-Tag , инструктирующий сканеры не индексировать страницу:
HTTP / 1.1 200 ОК (…) X-Robots-Tag: noindex (…)
Узнайте больше о заголовке ответа noindex .
Помогите нам определить ваши метатеги
Нам необходимо просканировать вашу страницу, чтобы увидеть метатеги и заголовки HTTP. Если страница все еще
появляется в результатах, вероятно, потому, что мы не сканировали страницу с тех пор, как вы добавили
тег. Вы можете запросить у Google повторное сканирование страницы с помощью
Инструмент проверки URL.Другая причина также может заключаться в том, что файл robots.txt блокирует URL-адрес из сети Google.
сканеры, поэтому они не видят тег. Чтобы разблокировать свою страницу от Google, вы должны отредактировать свой
файл robots.txt. Вы можете редактировать и тестировать свой robots.txt, используя Тестер robots.txt инструмент.
Если страница все еще
появляется в результатах, вероятно, потому, что мы не сканировали страницу с тех пор, как вы добавили
тег. Вы можете запросить у Google повторное сканирование страницы с помощью
Инструмент проверки URL.Другая причина также может заключаться в том, что файл robots.txt блокирует URL-адрес из сети Google.
сканеры, поэтому они не видят тег. Чтобы разблокировать свою страницу от Google, вы должны отредактировать свой
файл robots.txt. Вы можете редактировать и тестировать свой robots.txt, используя Тестер robots.txt инструмент.
Как сказать Google не индексировать страницу в поиске
Индексирование как можно большего количества страниц вашего веб-сайта может быть очень заманчивым для маркетологов, которые пытаются повысить авторитет своей поисковой системы.
Но, хотя это правда, что публикация большего количества страниц, релевантных для определенного ключевого слова (при условии, что они также высокого качества) улучшит ваш рейтинг по этому ключевому слову, иногда на самом деле больше пользы от сохранения определенных страниц на вашем веб-сайте из из индекс поисковой системы.
… Сказать что ?!
Оставайтесь с нами, ребята. В этом посте вы узнаете, почему вы можете захотеть удалить определенные веб-страницы из SERPS (страниц результатов поисковой системы), и как именно это сделать.
Почему вы хотите исключить определенные веб-страницы из результатов поискаВ ряде случаев вам может потребоваться исключить веб-страницу или ее часть из сканирования и индексации поисковой системой.
Для маркетологов одной из распространенных причин является предотвращение индексации дублированного контента (когда поисковыми системами индексируется несколько версий страницы, как в версии вашего контента для печати).
Еще один хороший пример? Страница благодарности (т.д., страница, на которую посетитель попадает после конверсии на одной из ваших целевых страниц). Обычно здесь посетитель получает доступ к любому предложению, которое обещала целевая страница, например, к ссылке на электронную книгу в формате PDF.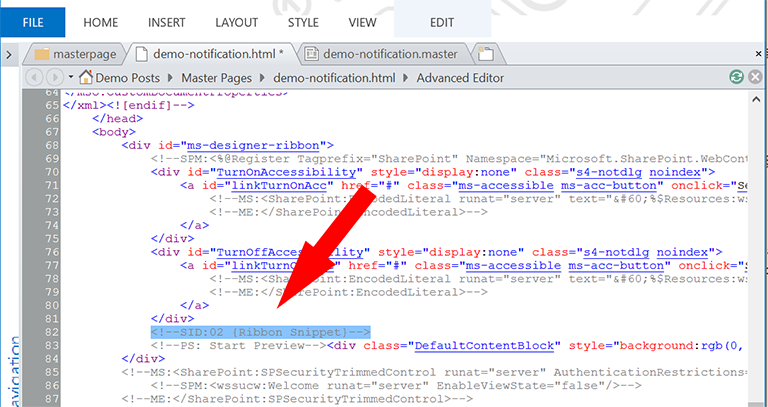
Вот как выглядит страница с благодарностью за нашу электронную книгу с советами по SEO, например:
Вы хотите, чтобы любой, кто попал на ваши страницы благодарности, попал туда, потому что они уже заполнили форму на целевой странице — , а не , потому что они нашли вашу страницу благодарности в поиске.
Почему нет? Потому что любой, кто найдет вашу страницу благодарности в поиске, может получить прямой доступ к вашим предложениям по привлечению потенциальных клиентов — без необходимости предоставлять вам свою информацию для прохождения через форму для сбора потенциальных клиентов. Любой маркетолог, который понимает ценность целевых страниц, понимает, насколько важно сначала привлечь этих посетителей в качестве потенциальных клиентов, прежде чем они смогут получить доступ к вашим предложениям.
Итог: Если ваши страницы благодарности легко обнаружить с помощью простого поиска в Google, возможно, вы оставляете на столе ценных потенциальных клиентов./GettyImages-183273455-58634e4f3df78ce2c3f2ae68.jpg)
Что еще хуже, вы можете даже обнаружить, что некоторые из ваших страниц с самым высоким рейтингом для некоторых из ваших длиннохвостых ключевых слов могут быть вашими страницами благодарности — что означает, что вы можете приглашать сотни потенциальных клиентов, чтобы обойти ваши формы для захвата лидов. Это довольно веская причина, по которой вы захотите удалить некоторые из своих веб-страниц из поисковой выдачи.
Итак, как вы делаете «деиндексирование» определенных страниц из поисковых систем? Вот два способа сделать это.
2 способа деиндексировать веб-страницу из поисковых системВариант №1: Добавить роботов.txt на свой сайт.
Используйте, если: вам нужен больший контроль над тем, что вы деиндексируете, и у вас есть необходимые технические ресурсы.
Один из способов удалить страницу из результатов поиска — добавить на сайт файл robots.txt. Преимущество использования этого метода заключается в том, что вы можете получить больший контроль над тем, что вы разрешаете индексировать ботам. Результат? Вы можете заранее исключить нежелательный контент из результатов поиска.
Результат? Вы можете заранее исключить нежелательный контент из результатов поиска.
В файле robots.txt вы можете указать, хотите ли вы блокировать ботов с одной страницы, со всего каталога или даже с одного изображения или файла.Существует также возможность запретить сканирование вашего сайта, при этом позволяя объявлениям Google AdSense работать, если они у вас есть.
При этом из двух доступных вам вариантов этот требует самого технического кунг-фу. Чтобы узнать, как создать файл robots.txt, прочтите эту статью из Инструментов Google для веб-мастеров.
Клиенты HubSpot: Здесь вы можете узнать, как установить файл robots.txt на свой веб-сайт, а также узнать, как настроить содержимое роботов.txt здесь.
Если вам не нужен полный контроль над файлом robots.txt и вы ищете более простое и менее техническое решение, тогда этот второй вариант для вас.
Вариант № 2: Добавьте метатег «noindex» и / или метатег «nofollow».
Используйте, если: вам нужно более простое решение для деиндексации всей веб-страницы и / или деиндексации ссылок на всей веб-странице.
Использование метатега для предотвращения появления страницы в поисковой выдаче и / или в ссылках на странице — это просто и эффективно.Для этого требуется совсем немного технических ноу-хау — на самом деле, это просто копирование / вставка, если вы используете правильную систему управления контентом.
Теги, которые позволяют делать это, называются «noindex» и «nofollow». Прежде чем я перейду к тому, как добавлять эти теги, давайте определим их и проведем различие. В конце концов, это две совершенно разные директивы, и их можно использовать как по отдельности, так и вместе друг с другом.
Что такое тег noindex?
Когда вы добавляете метатег «noindex» к веб-странице, он сообщает поисковой системе, что, даже если она может сканировать страницу, она не может добавить страницу в свой поисковый индекс.
Таким образом, любая страница с директивой noindex будет , а не попадет в поисковый индекс поисковой системы и, следовательно, не может отображаться на страницах результатов поисковой системы.
Что такое тег nofollow?
Когда вы добавляете на веб-страницу метатег «nofollow», запрещает поисковым системам сканировать ссылки на этой странице. Это также означает, что любой рейтинг, который страница имеет в выдаче, будет , а не , будет передан на страницы, на которые она ссылается.
Таким образом, на любой странице с директивой nofollow все ссылки будут игнорироваться Google и другими поисковыми системами.
Когда бы вы использовали «noindex» и «nofollow» по отдельности или вместе?
Как я сказал ранее, вы можете добавить директиву noindex либо отдельно, либо вместе с директивой nofollow. Вы также можете добавить директиву nofollow отдельно.
Добавьте только тег «noindex»: , если вы, , не хотите, чтобы поисковая система индексировала вашу веб-страницу в поиске, а вы, , хотите, чтобы переходила по ссылкам на этой странице — тем самым давая авторитет ранжирования. на другие страницы, на которые ссылается ваша страница.
на другие страницы, на которые ссылается ваша страница.
Платные целевые страницы — отличный тому пример. Вы не хотите, чтобы поисковые системы индексировали в поиске целевые страницы, за просмотр которых люди должны платить, но вы можете захотеть, чтобы страницы, на которые они ссылаются, извлекали выгоду из его авторитета.
Добавьте только тег «nofollow»: , когда вы хотите, чтобы поисковая система проиндексировала вашу веб-страницу в поиске, но вы, , не хотите, чтобы переходила по ссылкам на этой странице.
Не так много примеров, когда вы добавляете тег «nofollow» на всю страницу без добавления тега «noindex».Когда вы выясняете, что делать на данной странице, больше вопрос в том, добавлять ли ваш тег «noindex» с тегом «nofollow» или без него.
Добавьте теги «noindex» и «nofollow»: , если вы, , не хотите, чтобы поисковые системы индексировали веб-страницу в поиске, и вы не хотите, чтобы они переходили по ссылкам на этой странице.
Страницы с благодарностями — отличный пример такого рода ситуаций. Вы не хотите, чтобы поисковые системы индексировали вашу страницу с благодарностью, и вы также не хотите, чтобы они перешли по ссылке на ваше предложение и начали индексировать содержание этого предложения.
Как добавить метатег «noindex» и / или «nofollow»
Шаг 1: Скопируйте один из следующих тегов.
Для «noindex»:
Для nofollow:
Для noindex и nofollow:
Шаг 2: Добавьте тег в раздел
HTML-кода вашей страницы, a.к.а. заголовок страницы.Если вы являетесь клиентом HubSpot, это очень просто — щелкните здесь или прокрутите вниз, чтобы просмотреть инструкции, предназначенные для пользователей HubSpot.
Если вы , а не клиент HubSpot, , вам придется вручную вставить этот тег в код на своей веб-странице. Не волнуйтесь — это довольно просто. Вот как ты это делаешь.
Не волнуйтесь — это довольно просто. Вот как ты это делаешь.
Сначала откройте исходный код веб-страницы, которую вы пытаетесь деиндексировать. Затем вставьте полный тег в новую строку в разделе
HTML-кода вашей страницы, известном как заголовок страницы.Снимки экрана ниже помогут вам в этом.Тег
обозначает начало вашего заголовка:Вот метатег для «noindex» и «nofollow», вставленный в заголовок:
И тег обозначает конец заголовка:
Бум! Это оно. Этот тег указывает поисковой системе развернуться и уйти, оставив страницу вне результатов поиска.
Клиенты HubSpot: Добавить метатеги noindex и nofollow стало еще проще.Все, что вам нужно сделать, это открыть инструмент HubSpot на странице, на которую вы хотите добавить эти теги, и выбрать вкладку «Настройки».
Затем прокрутите вниз до Advanced Options и нажмите «Edit Head HTML». В появившемся окне вставьте соответствующий фрагмент кода. В приведенном ниже примере я добавил теги «noindex» и «nofollow», поскольку это страница с благодарностью.
В приведенном ниже примере я добавил теги «noindex» и «nofollow», поскольку это страница с благодарностью.
Нажми «Сохранить», и ты золотой.
Ta Da!
Вы только что волшебным образом удалили свою страницу из результатов поиска.Теперь вы можете снова начать собирать больше потерянных потенциальных клиентов.
Имейте в виду, что вы не увидите результаты мгновенно. Ваши изменения не вступят в силу до тех пор, пока поисковая система не просканирует вашу страницу в следующий раз. В зависимости от того, как часто вы обычно публикуете новые страницы на своем веб-сайте, на самом деле это может занять несколько недель. Чем чаще вы публикуете контент, тем чаще поисковые системы будут сканировать ваш сайт. Лучший способ отслеживать, как часто Google посещает ваш веб-сайт, — это просматривать статистику сканирования в Инструментах Google для веб-мастеров.
Итог: если вы заметили, что ваша страница все еще отображается в результатах поиска Google даже с тегом «noindex», вероятно, это потому, что Google не сканировал ваш сайт с тех пор, как вы добавили этот тег. Вы можете запросить у Google повторное сканирование вашей страницы с помощью инструмента Fetch as Google.
Также обратите внимание, что веб-сканеры некоторых поисковых систем могут интерпретировать эти директивы иначе, чем Google, поэтому возможно, что ваша страница все еще может отображаться в результатах других поисковых систем.Но для Google это будет нормально — как только он просканирует ваш сайт. Если вы хотите узнать, как поисковые системы сканируют, индексируют и обслуживают контент, пройдите наш курс по SEO.
Тем не менее, вы сможете спать немного легче, зная, что в конечном итоге вы сделали свой веб-сайт лучшим местом для маркетинга.
Какие еще советы вы можете дать по деиндексации веб-страниц и когда это будет полезно для маркетологов? Поделитесь своими мыслями в комментариях.
Хотите больше трафика? Деиндексируйте свои страницы.Вот почему.
Большинство людей беспокоятся о том, как заставить Google индексировать их страницы, а не деиндексировать их.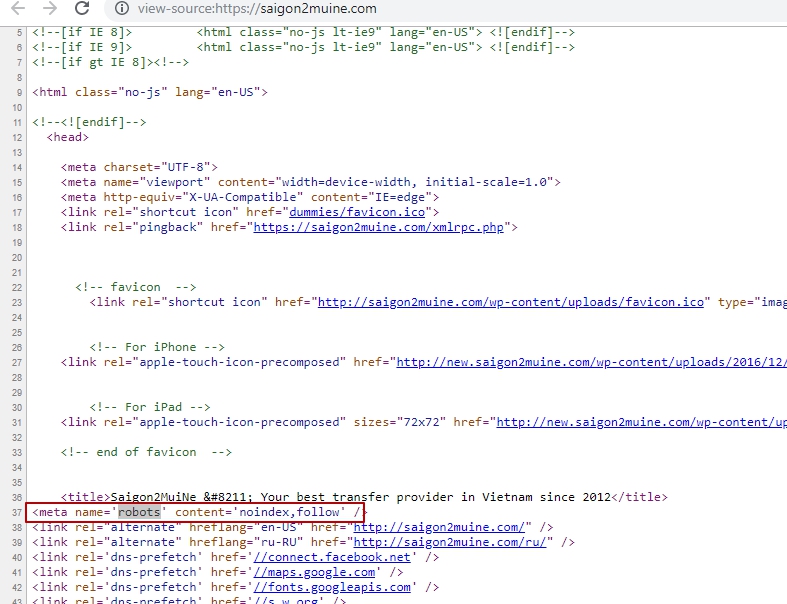 Фактически, большинство людей стараются избежать деиндексации, как чумы.
Фактически, большинство людей стараются избежать деиндексации, как чумы.
Если вы пытаетесь повысить свой авторитет на страницах результатов поисковых систем, у вас может возникнуть соблазн проиндексировать как можно больше страниц на вашем веб-сайте. И в большинстве случаев это работает.
Но это не всегда может помочь вам получить максимально возможное количество трафика.
Почему? Это правда, что публикация большого количества страниц, содержащих целевые ключевые слова, может помочь вам получить рейтинг по этим конкретным ключевым словам.
Однако на самом деле может быть более полезным для вашего рейтинга, если некоторые страницы вашего сайта не попадут в индекс поисковой системы.
Вместо этого он направляет трафик на релевантные страницы и предотвращает появление неважных страниц, когда пользователи ищут контент на вашем сайте с помощью Google.
Вот почему (и как) вам следует деиндексировать свои страницы, чтобы привлечь больше трафика.
Для начала давайте рассмотрим разницу между сканированием и индексированием.
Объяснение сканирования и индексирования
В мире SEO сканирование сайта означает следование по пути.
Под сканированием понимается поисковый робот (также известный как «паук»), который следует по вашим ссылкам и просматривает каждый дюйм вашего сайта.
Сканерымогут проверять HTML-код или гиперссылки. Они также могут извлекать данные с определенных веб-сайтов, что называется веб-парсингом.
Когда боты Google заходят на ваш сайт, чтобы сканировать, они переходят по другим связанным страницам, которые также есть на вашем сайте.
Затем боты используют эту информацию для предоставления поисковикам актуальных данных о ваших страницах. Они также используют его для создания алгоритмов ранжирования.
Они также используют его для создания алгоритмов ранжирования.
Это одна из причин, почему карты сайта так важны. Файлы Sitemap содержат все ссылки на вашем сайте, поэтому боты Google могут легко изучить ваши страницы.
Индексирование, с другой стороны, относится к процессу добавления определенных веб-страниц в индекс всех страниц, доступных для поиска в Google.
Если веб-страница проиндексирована, Google сможет сканировать и проиндексировать эту страницу. После деиндексации страницы Google больше не сможет ее проиндексировать.
По умолчанию индексируются все записи и страницы WordPress.
Хорошо, если релевантные страницы проиндексированы, потому что присутствие в Google может помочь вам заработать больше кликов и привлечь больше трафика, что приведет к увеличению доходов и увеличению узнаваемости бренда.
Но если вы позволите проиндексировать части вашего блога или веб-сайта, которые не являются жизненно важными, вы можете принести больше вреда, чем пользы.
Вот почему деиндексирование страниц может увеличить трафик.
Почему удаление страниц из результатов поиска может увеличить посещаемость
Вы можете подумать, что чрезмерно оптимизировать свой сайт невозможно.
Но это так.
Слишком много SEO может помешать вашему сайту занимать высокие позиции. Не переусердствуйте.
Есть много разных случаев, когда вам может потребоваться (или вы захотите) исключить веб-страницу (или, по крайней мере, ее часть) из индексации и сканирования поисковой системой.
Очевидная причина — предотвратить индексирование дублированного контента.
Дублированный контент означает, что существует более одной версии одной из ваших веб-страниц. Например, одна версия может быть удобной для печати, а другая — нет.
Обе версии не должны появляться в результатах поиска. Только один. Деиндексируйте версию для печати и сохраните индексируемую обычную страницу.
Еще один хороший пример страницы, которую вы, возможно, захотите деиндексировать, — это страница с благодарностью — страница, на которую посетители переходят после выполнения желаемого действия, такого как загрузка вашего программного обеспечения.
Обычно на этой странице посетитель сайта получает доступ ко всему, что вы ему обещали, в обмен на их действия, например, к электронной книге.
Вы хотите, чтобы люди попали на ваши страницы с благодарностью только потому, что они выполнили действие, которое вы хотите, чтобы они предприняли, например, приобрели продукт или заполнили форму для потенциальных клиентов.
Не потому, что они нашли вашу страницу благодарности через поиск Google. Если они это сделают, они получат доступ к тому, что вы предлагаете, без необходимости выполнять желаемое действие.
Это не только бесплатная раздача самого ценного контента, но также может испортить аналитику всего вашего сайта из-за неточных данных.
Если эти страницы проиндексированы, вы подумаете, что привлекаете больше потенциальных клиентов, чем есть на самом деле.
Если на ваших страницах благодарности есть ключевые слова с длинным хвостом, и вы не деиндексировали их, они могут иметь довольно высокий рейтинг, хотя в этом нет необходимости.
Что делает еще проще , чтобы их находило все больше и больше людей.
Вам также необходимо деиндексировать страницы профилей сообщества, распространяющие спам.
Удалить спам на страницах профиля сообщества
Бритни Мюллер из Moz недавно деиндексировала 75% веб-сайта Moz и добилась огромного успеха.
Большинство типов страниц, которые она деиндексировала? Страницы профилей сообщества, рассылающие спам.
Она заметила, что когда она выполняла поиск по сайту: moz.com, более 56% результатов приходилось на страницы профилей сообщества Moz.
Были тысячи этих страниц, которые ей нужно было деиндексировать.
Профили сообществаMoz работают по системе баллов. Пользователи зарабатывают больше очков, называемых MozPoints, за выполнение действий на сайте, например, за комментирование сообщений или публикацию блогов.
Поговорив с разработчиками, Бритни решила деиндексировать страницы профиля, набрав менее 200 баллов.
Мгновенно вырос органический трафик и рейтинг.
Деиндексируя страницы профилей сообщества таких пользователей, как этот, с небольшим количеством баллов MozPoints, нерелевантные профили не попадают на страницы результатов поисковой системы.
Таким образом, только наиболее известные пользователи сообщества Moz с тоннами MozPoints, такие как Бритни, будут отображаться в поисковой выдаче.
Затем профили с наибольшим количеством комментариев и действий появляются, когда кто-то их ищет, так что на сайте легко найти влиятельных людей.
Если вы предлагаете профили сообщества на своем веб-сайте, следуйте примеру Moz и деиндексируйте профили, которые не принадлежат влиятельным или известным пользователям.
Вы можете подумать, что отключения «видимости для поисковых систем» в WordPress достаточно, чтобы уменьшить видимость для поисковых систем, но это не так.
На самом деле поисковые системы должны выполнить этот запрос.
Вот почему вам нужно деиндексировать их вручную, чтобы убедиться, что они не появятся на странице результатов.Во-первых, вы должны понять разницу между тегами noindex и nofollow.
Объяснение тегов Noindex и nofollow
Вы можете легко использовать метатег, чтобы страница не отображалась в поисковой выдаче.
Все, что вам нужно знать, это копировать и вставлять.
Теги, позволяющие удалять страницы, называются «noindex» и «nofollow».
Прежде чем мы перейдем к тому, как вы можете добавить эти теги, вам необходимо знать разницу между тем, как работают эти два тега.
Это два разных тега, но их можно использовать по отдельности или вместе.
Когда вы добавляете на страницу тег noindex, он сообщает поисковым системам, что, хотя они все еще могут сканировать страницу, они не могут добавить страницу в свой индекс.
Любая страница с директивой noindex не попадет в индекс поисковой системы, а это означает, что она не будет отображаться на страницах результатов поисковой системы.
Вот как выглядит тег noindex в HTML-коде сайта:
Когда вы добавляете на веб-страницу тег nofollow, он запрещает поисковым системам сканировать любые ссылки на странице.
Это означает, что любой рейтинг, присвоенный странице, не будет передан страницам, на которые она ссылается.
Тем не менее, любая страница с тегом nofollow может индексироваться в поиске. Вот как выглядит тег nofollow в коде веб-сайта:
Вы можете добавить тег noindex отдельно или с тегом nofollow.
Вы также можете добавить тег nofollow отдельно. Добавляемые вами теги будут зависеть от ваших целей для конкретной страницы.
Добавьте только тег noindex, если вы не хотите, чтобы поисковая система индексировала вашу веб-страницу в результатах поиска, но вы хотите, чтобы она продолжала переходить по ссылкам на этой странице.
Если у вас есть платные целевые страницы, было бы неплохо добавить к ним тег noindex.
Вы не хотите, чтобы поисковые системы приводили к ним посетителей, поскольку люди должны платить за их просмотр, но вы можете захотеть, чтобы связанные страницы извлекали выгоду из его авторитета.
Добавьте только тег nofollow, если вы хотите, чтобы поисковая система проиндексировала определенную страницу на страницах результатов, но вы не хотите, чтобы она переходила по ссылкам, которые есть у вас на этой конкретной странице.
Добавьте на страницу теги noindex и nofollow, если вы не хотите, чтобы поисковые системы индексировали страницу или могли переходить по ссылкам на ней.
Например, вы можете добавить теги noindex и nofollow к страницам благодарности.
Теперь, когда вы знаете, как работают теги noindex и nofollow, вот как добавить их на свой сайт.
Как добавить метатег «noindex» и / или «nofollow»
Если вы хотите добавить тег noindex и / или nofollow, первым делом нужно скопировать желаемый тег.
Для тега noindex скопируйте следующий тег:
Для тега nofollow скопируйте следующий тег:
Для обоих тегов скопируйте следующий тег:
Добавить теги так же просто, как добавить тег, который вы скопировали, в раздел
HTML-кода вашей страницы.Он также известен как заголовок страницы.Просто откройте исходный код веб-страницы, которую вы хотите деиндексировать. Затем вставьте тег в новую строку в разделе
HTML.Вот как выглядит тег для noindex и nofollow в заголовке.
Имейте в виду, что тег обозначает конец заголовка. Никогда не вставляйте теги noindex или nofollow за пределами этой области.
Сохраните обновления кода, и все готово.Теперь поисковая система исключит вашу страницу из результатов поиска.
Вы можете сделать невозможным сканирование нескольких страниц, изменив файл robots.txt.
Что такое robots.txt и как получить к нему доступ?
Robots.txt — это просто текстовый файл, который веб-мастера могут создать, чтобы сообщить роботам поисковых систем, как именно они хотят сканировать свои страницы или переходить по ссылкам.
ФайлыRobots.txt просто указывают, разрешено или не разрешено определенное программное обеспечение для сканирования определенных частей веб-сайта.
Если вы хотите «nofollow» сразу нескольких веб-страниц, вы можете сделать это из одного места, открыв файл robots.txt на своем сайте.
Во-первых, неплохо сначала выяснить, есть ли на вашем сайте файл robots.txt. Чтобы в этом разобраться, перейдите на свой веб-сайт и добавьте файл robots.txt.
Это должно выглядеть примерно так: www.yoursitehere.com/robots.txt.
Вот как выглядит наш файл robots.txt.
На наш сайт добавлена задержка сканирования 10, из-за которой роботы поисковых систем не будут сканировать ваш сайт слишком часто.Это предотвращает перегрузку серверов.
Если по этому адресу ничего не появляется, значит, на вашем веб-сайте нет файла robots.txt. На Disney.com нет файла robots.txt.
Вместо пустой страницы вы также можете увидеть ошибку 404.
Вы можете создать файл robots.txt практически в любом текстовом редакторе. Чтобы узнать, как именно добавить его, прочтите это руководство.
Чистый костяк файла robots.txt должен выглядеть примерно так:
User-agent: *
Disallow: /
Затем вы можете добавить конечные URL-адреса всех страниц, сканирование которых не должно выполняться роботом Googlebot.
Вот несколько кодов robots.txt, которые могут вам понадобиться:
Разрешить индексирование всего:
User-agent: *
Disallow:
или
User-agent: *
Allow: /
Запрет индексирования:
Агент пользователя: *
Запрет: /
Деиндексировать определенную папку:
Пользовательский агент: *
Запретить: / folder /
Запретить роботу Googlebot индексировать папку, кроме одного определенного файла в этой папке:
Пользовательский агент: Googlebot
Запретить: / folder1 /
Разрешить: / folder1 / myfile.html
Google и Bing позволяют людям использовать подстановочные знаки в файлах robots.txt.
Чтобы заблокировать доступ к URL-адресам, которые содержат специальный символ, например вопросительный знак, используйте следующий код:
User-agent: *
Disallow: / *?
Google также поддерживает использование noindex в файле robots.txt.
Для noindex из robots.txt используйте этот код:
User-agent: Googlebot
Disallow: / page-uno /
Noindex: / page-uno /
Вместо этого вы также можете добавить заголовок X-Robots-tag на определенную страницу.
Вот как выглядит тег X-Robots, запрещающий сканирование:
HTTP / 1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Этот тег можно использовать как для кодов nofollow, так и для кодов noindex.
Могут быть случаи, когда вы добавляли теги nofollow и / или noindex или изменяли файл robots.txt, но некоторые страницы по-прежнему отображаются в результатах поиска. Это нормально.
Вот как это исправить.
Почему ваши страницы все еще могут отображаться в поисковой выдаче (сначала)
Если ваши страницы по-прежнему отображаются в результатах поиска, возможно, это связано с тем, что Google не сканировал ваш веб-сайт с тех пор, как вы добавили тег.
Отправьте запрос на повторное сканирование вашего сайта в Google с помощью инструмента «Просмотреть как Google».
Просто введите URL своей страницы, нажмите, чтобы просмотреть результаты Fetch, и проверьте статус отправки URL.
Другая причина того, что ваши страницы все еще отображаются, заключается в том, что в вашем файле robots.txt могут быть ошибки.
Вы можете отредактировать или протестировать файл robots.txt с помощью инструмента robots.txt Tester. Выглядит это примерно так:
Никогда не используйте теги noindex вместе с тегом disallow в robots.текст.
Не использовать мета-индекс noindex И запретить в robots.txt
Когда вы используете метатег noindex для нескольких страниц, но по-прежнему запрещаете их использование в файле robots.txt, боты проигнорируют ваш метатег noindex.
Никогда не используйте оба тега одновременно. Также рекомендуется оставить карты сайта на некоторое время, чтобы их видели сканеры.
Когда Moz деиндексировал несколько страниц своего профиля сообщества, они оставили карту сайта профиля сообщества на месте на пару недель.
Было бы неплохо сделать то же самое.
Существует также возможность запретить сканирование вашего сайта вообще, при этом позволяя Google AdSense работать на страницах.
Подумайте об одной из ваших страниц, например, о странице «Свяжитесь с нами» или даже о странице политики конфиденциальности. Вероятно, он связан с каждой страницей вашего веб-сайта либо в нижнем колонтитуле, либо в главном меню.
На эти страницы идет огромное количество ссылок. Вы же не хотите просто выбросить его. Особенно, когда он появляется прямо из главного меню или нижнего колонтитула.
Имея это в виду, вы никогда не должны включать страницу, которую вы блокируете, в robots.txt в карту сайта XML.
Не включать эти страницы в карты сайта XML
Если вы заблокируете страницу в файле robots.txt, но затем включите ее в карту сайта XML, вы просто дразните Google.
В карте сайта написано: «Вот блестящая страница, которую нужно проиндексировать, Google». Но затем ваш файл robots.txt удалит эту страницу.
Вы должны поместить весь контент на своем сайте в две разные категории:
- Качественные поисковые целевые страницы
- Служебные страницы, которые полезны для пользователей, но не обязательно должны быть целевыми страницами поиска
Нет необходимости блокировать что-либо в первой категории в robots.текст. Этот контент также никогда не должен иметь тега noindex. Включите все эти страницы в карту сайта XML, несмотря ни на что.
Вы должны заблокировать все, что находится во второй категории, с помощью тегов noindex, nofollow или robots.txt. Вы действительно не хотите включать это содержание в карту сайта.
Google будет использовать все, что вы отправляете в свою карту сайта XML, чтобы понять, что должно или не должно быть важным для инструмента на вашем сайте.
Но то, что чего-то нет в вашей карте сайта, не означает, что Google полностью его проигнорирует.
Сделайте сайт: выполните поиск, чтобы увидеть все страницы, которые Google в настоящее время индексирует с вашего сайта, чтобы найти любые страницы, которые вы, возможно, пропустили или забыли.
Самые слабые страницы, которые Google все еще индексирует, будут перечислены последними на вашем сайте: search.
Вы также можете легко просмотреть количество отправленных и проиндексированных страниц в Инструментах Google для веб-мастеров.
Заключение
Большинство людей беспокоятся о том, как они могут индексировать свои страницы, а не деиндексировать их.
Но индексация слишком большого количества неправильных страниц может на самом деле повредить вашему общему рейтингу.
Для начала вы должны понять разницу между сканированием и индексированием.
Сканирование сайта означает сканирование ботов по всем ссылкам на каждой веб-странице, принадлежащей сайту.
Индексирование означает добавление страницы в индекс Google всех страниц, которые могут отображаться на страницах результатов Google.
Удаление ненужных страниц со страниц результатов, таких как страницы с благодарностями, может увеличить трафик, потому что Google сосредоточится только на ранжировании релевантных страниц, а не незначительных.
Удалите страницы профилей сообщества, содержащие спам, если они у вас есть. Moz деиндексировал страницы профилей сообщества, набравшие менее 200 баллов, и это быстро увеличило их посещаемость.
Затем выясните разницу между тегами noindex и nofollow.
Теги Noindex удаляют страницы из индекса Google, доступных для поиска. Теги Nofollow не позволяют Google сканировать ссылки на странице.
Вы можете использовать их вместе или по отдельности. Все, что вам нужно сделать, это добавить код для одного или каждого тега в HTML-заголовок вашей страницы.
Затем узнайте, как работает ваш файл robots.txt. Вы можете использовать эту страницу, чтобы заблокировать сканирование Google нескольких страниц одновременно.
Ваши страницы могут по-прежнему отображаться в поисковой выдаче, но используйте инструмент «Просмотреть как Google», чтобы решить эту проблему.
Не забудьте никогда не индексировать страницу и не разрешать ее в robots.txt. Кроме того, никогда не включайте страницы, заблокированные в файле robots.txt, в карту сайта XML.
Какие страницы вы собираетесь деиндексировать в первую очередь?
Узнайте, как мое агентство может привлечь огромное количество трафика на ваш веб-сайт
- SEO — разблокируйте огромное количество SEO-трафика.Смотрите реальные результаты.
- Контент-маркетинг — наша команда создает эпический контент, которым будут делиться, получать ссылки и привлекать трафик.
- Paid Media — эффективные платные стратегии с четкой рентабельностью инвестиций.
Заказать звонок
Как скрыть веб-страницы с помощью noindex, nofollow и disallow
Это руководство по использованию noindex, nofollow и disallow пригодится, если ваши веб-страницы должны быть невидимы для поисковых систем, индексирующих роботов и сканеров веб-страниц.
Бывают случаи, когда вам нужно сделать свои веб-страницы невидимыми для поисковых систем, роботов-индексаторов и сканеров веб-страниц. В этих случаях вы можете подумать о добавлении «noindex», «nofollow» и / или «disallow» к атрибутам, тегам, метаданным и командам вашей веб-страницы; это включает в себя сайты, используемые для разработки, тестирования или постановки, или если вы хотите ограничить доступ к страницам (например,g., вход на порталы или фотогалереи), или если страницы или определенные ссылки считаются избыточными, устаревшими, заархивированными или содержат тривиальный контент.
Это руководство поможет вам понять, как использовать «noindex», «nofollow» и / или «disallow» как часть процедуры обслуживания и управления вашим веб-сайтом.
Примеры синтаксиса
Индексные веб-страницы
В следующих примерах выделено несколько вариантов и комбинаций, доступных для тегов метаданных, которые могут быть добавлены в тег
.Этот тег метаданных сообщит всем поисковым системам, что нужно проиндексировать весь ваш веб-сайт; он также проиндексирует все ваши другие веб-страницы.
Этот тег метаданных даст указание поисковым системам не индексировать эту страницу в частности, но он будет сканировать остальные веб-страницы вашего веб-сайта.
Этот тег метаданных сообщает поисковым системам только проиндексировать эту страницу и прекратить сканирование дальше.
Этот тег метаданных предписывает поисковым системам не индексировать эту страницу и не сканировать ее дальше.
Предположим, вы хотите запретить роботу googlebot индексировать ваш веб-сайт; вы бы использовали этот синтаксис.
Связывание
Вы также можете использовать «nofollow» в определенных активных ссылках на страницах, которые вы, возможно, не хотите индексировать.Синтаксис ссылки nofollow похож на этот пример тега привязки ColdFusion cfm.
Robots.txt запретить
Вы также можете использовать файл robots.txt и поместить его в корневой или другой каталог в зависимости от конфигурации вашего веб-сервера. Типичный файл robots.txt будет содержать всего несколько строк кода, который дает команду роботам с использованием так называемого протокола / стандарта исключения роботов.Приведенные ниже примеры синтаксиса иллюстрируют несколько способов реализации этой функции.
В этом примере все роботы не заходят на ваш сайт.
Агент пользователя: * Disallow: /
В этом примере всем роботам дается команда держаться подальше от определенных каталогов.
Агент пользователя: * Запретить: / резервное копирование / Запретить: / архив / Disallow: / cgi-mail /
В этом примере всем роботам предписывается избегать доступа к определенному файлу.
Агент пользователя: * Запретить: / любой-каталог / любой-файл.htm
Вы можете указать несколько конкретных роботов, чтобы они не попадали в определенные или все области вашего веб-сайта. Ниже приведены несколько примеров.
Пользовательский агент: badbot Disallow: / private / Пользовательский агент: anybot-news Запретить: / Пользовательский агент: googlebot Disallow: /
Caveat
Хотя эти стратегии помогут вам в поисках управления доступом, их использование не гарантирует автоматически, что назначенные вами теги или команды noindex, nofollow и / или disallow будут соблюдаться всеми поисковыми системами. , пауки и ползунки.Для того, чтобы эти методы вступили в силу, может потребоваться время, особенно если страницы ранее были разрешены для индексации или отслеживания, а затем для них было установлено значение nofollow или noindex. Вы все еще можете видеть страницы в результатах поисковой системы, потому что их индексирование не обновлялось или обновлялось в последнее время.
мета-тегов | Документация Swiftype
Сканер поиска по сайту поддерживает гибкий набор метатегов для управления тем, как вы загружаете контент своего сайта.
Когда сканер посещает вашу веб-страницу, по умолчанию он извлекает стандартный набор полей (например,грамм. название, тело).
Затем он индексирует это содержимое, чтобы его можно было найти.
С помощью этих метатегов вы можете изменить набор полей, извлекаемых поисковым роботом, для создания идеальных документов.
Примечание …
Ваши страницы должны быть просканированы повторно , прежде чем любые изменения уровня кода будут приняты поиском по сайту!
См. Раздел «Устранение неполадок сканера», если ваши документы не синхронизируются с текущим контентом.
Шаблон метатега для поиска по сайту :
Каждое поле должно определять конкретное имя , тип и содержимое значений.
Тип поля , который указан в атрибуте типа данных , должен быть типом поля, поддерживаемым поиском по сайту.
После того, как новый метатег проиндексирован, создаются поля настраиваемой схемы.
После создания тип данных не может быть изменен.
Тщательно выбирайте тип данных вашего поля . Поле нельзя удалить!
В следующем примере показано создание нескольких полей.
Как видите: поле tags повторяется, и в результате поисковый робот извлекает массив тегов для этого URL.
Все типы полей могут быть извлечены в виде массивов.
заголовок страницы | название веб-сайта
Важно отметить, что поисковый робот не будет захватывать метатеги по умолчанию для SEO, например:
Чтобы их проиндексировал сканер, они должны стать Поиск по сайту :
И помните: как только поле было создано, его можно удалить , а не .
Теги атрибутов данных, внедренные в тело
Добавьте атрибуты данных к существующим элементам, чтобы не повторять тонны текста в вашей страницы:
заголовок здесь
Сюда уходит много телесного содержимого ...
Сюда же идет и другой контент, он может быть любого типа, например, с ценой:
$ 3.99
Теги миниатюрных изображений
Индексируйте изображения с вашего веб-сайта и показывайте их пользователям в качестве эскизов в результатах поиска.
Добавьте тег изображения в тег , который указывает, где расположены изображения на различных типах страниц:
Управляйте сканированием контента на ваших веб-страницах с помощью метатегов robots.
Использование метатега robots
Разместите метатег robots в разделе своей страницы:
Содержание страницы здесь
Значения содержимого метатега роботов
Site Search поддерживает значения NOFOLLOW , NOINDEX и NONE для тега robots.
FOLLOW и INDEX являются значениями по умолчанию и не обязательны, если вы не переопределяете метатег robots для поиска по сайту.
Другие значения - например, NOARCHIVE - игнорируются.
Используйте NOINDEX , чтобы сканер не индексировал страницу,:
Ссылки с неиндексированной страницы по-прежнему будут отслеживаться.
Используйте NOFOLLOW , чтобы запретить поисковому роботу переходить по ссылкам со страницы.
Содержимое страницы, на которой указано NOFOLLOW , все равно будет проиндексировано.
Чтобы не переходить по ссылкам и не индексировать контент со страницы, используйте NOINDEX, NOFOLLOW или NONE .
НЕТ является синонимом вышеуказанного:
Мы рекомендуем указывать директивы robots в одном теге, но несколько тегов будут объединены, если они есть.
Инструкции по направлению только для сканера поиска по сайту
meta name = "robots" применит ваши инструкции ко всем поисковым роботам, включая поисковый робот Swiftbot.
Используйте st: robots в качестве имени вместо robots , чтобы направлять специальные инструкции сканеру.
В этом примере говорится, что другие поисковые роботы не должны индексировать и не переходить по ссылкам со страницы, но разрешают поиску по сайту индексировать и переходить по ссылкам.
Когда любое мета-имя из st: robots присутствует на странице, все остальные мета-правила для роботов будут проигнорированы в пользу правила st: robots .
Повторяющиеся значения содержимого
Сканер будет использовать самые строгие директивы для роботов, если они повторяются.
Вышеуказанное эквивалентно NOINDEX .
Кожух, расстояние и порядок
Теги, имена атрибутов и значения атрибутов нечувствительны к регистру.
Несколько значений атрибутов должны быть разделены запятой, но пробелы игнорируются.
Порядок не важен: NOINDEX, NOFOLLOW совпадает с NOFOLLOW, NOINDEX .
Аналогичными считаются:
Застрял? Нужна помощь? Обратитесь в службу поддержки или посетите форум сообщества Поиска по сайту!
Стандартные имена метаданных - HTML: язык разметки гипертекста
Элемент может использоваться для предоставления метаданных документа в виде пар имя-значение, при этом атрибут name задает имя метаданных, а атрибут содержимого задает значение.
Стандартные имена метаданных, определенные в спецификации HTML
Спецификация HTML определяет следующий набор стандартных имен метаданных:
Примечание:имя-приложения: имя приложения, запущенного на веб-странице.- Браузеры могут использовать это для идентификации приложения. Он отличается от элемента
</code>, который обычно содержит имя приложения, но может также содержать такую информацию, как имя документа или статус.</li><li> Простые веб-страницы не должны определять имя приложения.</li></ul></li><li> <code> автор </code>: имя автора документа.</li><li> <code> description </code>: краткое и точное изложение содержания страницы. Некоторые браузеры, такие как Firefox и Opera, используют это описание по умолчанию для страниц с закладками.</li><li> <code> генератор </code>: идентификатор программного обеспечения, сгенерировавшего страницу.</li><li> <code> ключевых слов </code>: слова, относящиеся к содержанию страницы, разделенные запятыми.</li><li> <code> referrer </code>: управляет заголовком HTTP <code> Referer </code> для запросов, отправленных из документа:<table><caption> Значения атрибута содержимого <code> </code> для <code><meta name = "referrer"> </code></caption><tbody><tr><td> <code> без реферера </code></td><td> Не отправлять заголовок HTTP <code> Referer </code>.</td></tr><tr><td> <code> происхождение </code></td><td> Отправьте источник документа.</td></tr><tr><td> <code> no-referrer-when-downgrade </code></td><td> Отправлять полный URL-адрес, если уровень безопасности по крайней мере такой же, как у текущей страницы (HTTP (S) → HTTPS), но не отправлять реферер, если он менее безопасен (HTTPS → HTTP).Это поведение по умолчанию.</td></tr><tr><td> <code> происхождение при перекрестном происхождении </code></td><td> Отправлять полный URL (без параметров) для запросов с одним и тем же источником, но отправлять только источник для других случаев.</td></tr><tr><td> <code> одного происхождения </code></td><td> Отправить полный URL (без параметров) для запросов с одинаковым происхождением. Запросы с разными источниками не будут содержать заголовка реферера.</td></tr><tr><td> <code> строгое происхождение </code></td><td> Отправлять источник, если уровень безопасности по крайней мере такой же, как у текущей страницы (HTTP (S) → HTTPS), но не отправлять реферер, если он менее безопасен (HTTPS → HTTP).</td></tr><tr><td> <code> строгое происхождение при перекрестном происхождении </code></td><td> Отправить полный URL (без параметров) для запросов с одинаковым происхождением. Отправляйте источник, когда адресат по крайней мере так же безопасен, как текущая страница (HTTP (S) → HTTPS). В противном случае не отправляйте реферера.</td></tr><tr><td> <code> небезопасный URL </code></td><td> Отправлять полный URL (без параметров) для запросов с одним и тем же источником или с другим источником.</td></tr></tbody></table> <strong> Примечания: </strong><ul><li> Динамическая вставка <code><meta name = "referrer"> </code> (с <code> document.write () </code> или <code> appendChild () </code>) делает поведение реферера непредсказуемым.</li><li> Если определено несколько конфликтующих политик, применяется политика </code> без реферера <code>.</li></ul></li><li> <code> theme-color </code>: указывает предлагаемый цвет, который пользовательские агенты должны использовать для настройки отображения страницы или окружающего пользовательского интерфейса. Атрибут содержимого <code> </code> содержит действительный CSS <code> <color> </code>.</li><li><p> <code> цветовая схема </code>: задает одну или несколько цветовых схем, с которыми совместим документ.</p><p> Браузер будет использовать эту информацию вместе с настройками браузера или устройства пользователя, чтобы определить, какие цвета использовать для всего, от фона и переднего плана до элементов управления и полос прокрутки. Основное использование <code><meta name = "color-scheme"> </code> - указать совместимость с режимами светлого и темного цвета и порядок предпочтения для них.</p><p> Значение свойства </code> содержимого <code> для цветовой схемы <code> </code> может быть одним из следующих:</p><dl><dt> <code> нормальный </code></dt><dd> В документе отсутствуют цветовые схемы, поэтому его следует отображать с использованием цветовой палитры по умолчанию.</dd><dt> [<code> светлый </code> | <code> темный </code>] +</dt><dd> Одна или несколько цветовых схем, поддерживаемых документом. Указание одной и той же цветовой схемы более одного раза дает тот же эффект, что и указание ее только один раз. Указание нескольких цветовых схем указывает на то, что первая схема предпочтительна для документа, но что вторая указанная схема приемлема, если пользователь предпочитает ее.</dd><dt> <code> только свет </code></dt><dd> Указывает, что документ <em> только </em> поддерживает светлый режим со светлым фоном и темными цветами переднего плана.По спецификации <code> только темный </code> <em> недействителен </em>, потому что принудительное отображение документа в темном режиме, когда он не полностью совместим с ним, может привести к нечитаемому содержанию; все основные браузеры по умолчанию работают в облегченном режиме, если не настроено иное.</dd></dl><p> Например, чтобы указать, что документ предпочитает темный режим, но выполняет функциональную визуализацию и в светлом режиме:</p><pre> <code> <meta name = "color-scheme" content = "dark light"> </code> </pre><p> Это работает на уровне документа так же, как свойство </code> цветовой схемы CSS <code> позволяет отдельным элементам указывать свои предпочтительные и принятые цветовые схемы.Ваши стили можно адаптировать к текущей цветовой схеме с помощью медиа-функции CSS <code> prefers-color-scheme </code>.</p></li></ul><h4><span class="ez-toc-section" id="i-36"> Стандартные имена метаданных, определенные в других спецификациях </span></h4><p> Спецификация CSS Device Adaptation определяет следующее имя метаданных:</p><ul><li><p> <code> область просмотра </code>: дает подсказки о размере начального размера области просмотра. Используется только мобильными устройствами.</p><table><caption> Значения для содержимого <code><meta name = "viewport"> </code></caption><thead><tr><th scope="col"> Значение</th><th scope="col"> Возможные подзначения</th><th scope="col"> Описание</th></tr></thead><tbody><tr><td> <code> ширина </code></td><td> Положительное целое число или текст <code> device-width </code></td><td> Определяет ширину в пикселях области просмотра, в которой должен отображаться веб-сайт.</td></tr><tr><td> <code> высота </code></td><td> Положительное целое число или текст <code> device-height </code></td><td> Определяет высоту области просмотра. Не используется ни одним браузером.</td></tr><tr><td> <code> начальная </code></td><td> Положительное число от <code> 0,0 </code> до <code> 10,0 </code></td><td> Определяет соотношение между шириной устройства (<code> device-width </code> в портретном режиме или <code> device-height </code> в альбомном режиме) и размером области просмотра.</td></tr><tr><td> <code> максимальный масштаб </code></td><td> Положительное число от <code> 0,0 </code> до <code> 10,0 </code></td><td> Определяет максимальное значение для увеличения. Оно должно быть больше или равно <code> минимальному масштабу </code>, иначе поведение не определено. Настройки браузера могут игнорировать это правило, а iOS10 + игнорирует его по умолчанию.</td></tr><tr><td> <code> минимальный </code></td><td> Положительное число от <code> 0,0 </code> до <code> 10.0 </code></td><td> Определяет минимальный уровень масштабирования. Оно должно быть меньше или равно <code> максимальному масштабу </code>, иначе поведение не определено. Настройки браузера могут игнорировать это правило, а iOS10 + игнорирует его по умолчанию.</td></tr><tr><td> <code> с возможностью масштабирования пользователем </code></td><td> <code> да </code> или <code> нет </code></td><td> Если установлено значение <code> no </code>, пользователь не может увеличивать масштаб веб-страницы. По умолчанию <code> да </code>. Настройки браузера могут игнорировать это правило, а iOS10 + игнорирует его по умолчанию.</td></tr><tr><td> <code> с размером окна </code></td><td> <code> авто </code>, <code> содержат </code> или <code> крышка </code></td><td><p> Значение <code> auto </code> не влияет на исходное окно просмотра макета, и вся веб-страница доступна для просмотра.</p><p> Значение <code>, содержащее </code>, означает, что область просмотра масштабируется, чтобы соответствовать самому большому прямоугольнику, вписанному в экран.</p><p> Значение <code> cover </code> означает, что область просмотра масштабируется для заполнения дисплея устройства.Настоятельно рекомендуется использовать переменные-вставки безопасной области, чтобы важный контент не попал за пределы экрана.</p></td></tr></tbody></table> <strong> Примечания: </strong><ul><li> Хотя это заявление не является стандартизованным, оно соблюдается большинством мобильных браузеров из-за фактического доминирования.</li><li> Значения по умолчанию могут различаться в зависимости от устройства и браузера.</li><li> Чтобы узнать об этом объявлении в Firefox для мобильных устройств, прочтите эту статью.</li></ul><h5><span class="ez-toc-section" id="i-37"> Проблемы доступности при масштабировании области просмотра </span></h5><p> Отключение возможностей масштабирования путем установки для <code> настраиваемого пользователем </code> на значение <code> no </code> не позволяет людям с нарушениями зрения читать и понимать содержимое страницы.</p><h5><span class="ez-toc-section" id="i-38"> См. Также </span></h5><p> Ат-правило CSS <code> @viewport </code>.</p></li></ul><h4><span class="ez-toc-section" id="i-39"> Другие имена метаданных </span></h4><p> Страница WHATWG Wiki MetaExtensions содержит большой набор нестандартных имен метаданных, которые еще не были официально приняты; тем не менее, некоторые из включенных там имен уже довольно часто используются на практике, в том числе следующие:</p><ul><li> <code> создатель </code>: имя создателя документа, например организации или учреждения.Если их несколько, следует использовать несколько элементов <code><meta> </code>.</li><li> <code> googlebot </code>, синоним <code> robots </code>, за ним следует только Googlebot (поисковый робот для индексации Google).</li><li> <code> издатель </code>: имя издателя документа.</li><li> <code> роботы </code>: поведение, которое совместные сканеры или «роботы» должны использовать со страницей. Это список перечисленных ниже значений, разделенных запятыми:<table><caption> Значения для содержимого <code><meta name = "robots"> </code></caption><thead><tr><th scope="col"> Значение</th><th scope="col"> Описание</th><th scope="col"> Используется</th></tr></thead><tbody><tr><td> <code> индекс </code></td><td> Позволяет роботу индексировать страницу (по умолчанию).</td><td> Все</td></tr><tr><td> <code> noindex </code></td><td> Запрашивает, чтобы робот не индексировал страницу.</td><td> Все</td></tr><tr><td> <code> следовать </code></td><td> Позволяет роботу переходить по ссылкам на странице (по умолчанию).</td><td> Все</td></tr><tr><td> <code> nofollow </code></td><td> Запрашивает, чтобы робот не переходил по ссылкам на странице.</td><td> Все</td></tr><tr><td> <code> все </code></td><td> Эквивалентно индексу <code>, следуйте </code></td><td> Google</td></tr><tr><td> <code> нет </code></td><td> Эквивалентно <code> noindex, nofollow </code></td><td> Google</td></tr><tr><td> <code> нет архива </code></td><td> Запрашивает поисковую систему не кэшировать содержимое страницы.</td><td> Google, Yahoo, Bing</td></tr><tr><td> <code> носниппет </code></td><td> Запрещает отображение любого описания страницы в результатах поиска.</td><td> Google, Bing</td></tr><tr><td> <code> noimageindex </code></td><td> Запрашивает, чтобы эта страница не отображалась в качестве ссылающейся страницы проиндексированного изображения.</td><td> Google</td></tr><tr><td> <code> nocache </code></td><td> Синоним <code> noarchive </code>.</td><td> Bing</td></tr></tbody></table> <strong> Примечания: </strong><ul><li> Этим правилам следуют только кооперативные роботы. Не надейтесь, что вам удастся помешать им по электронной почте.</li><li> Робот все еще должен получить доступ к странице, чтобы прочитать эти правила. Чтобы предотвратить потребление полосы пропускания, используйте файл <em> robots.txt </em>.</li><li> Если вы хотите удалить страницу, <code> noindex </code> будет работать, но только после того, как робот снова посетит страницу. Убедитесь, что файл <code> robots.txt </code> не предотвращает повторных посещений.</li><li> Некоторые значения являются взаимоисключающими, например <code> index </code> и <code> noindex </code>, или <code> следуют за </code> и <code> nofollow </code>. В этих случаях поведение робота не определено и может различаться между ними.</li><li> Некоторые роботы-краулеры, такие как Google, Yahoo и Bing, поддерживают одинаковые значения для HTTP-заголовка <code> X-Robots-Tag </code>; это позволяет документам, не относящимся к HTML, таким как изображения, использовать эти правила.</li></ul></li></ul><p> Таблицы BCD загружаются только в браузере</p><h2><span class="ez-toc-section" id="_Noindex_Nofollow"> Какие страницы мне использовать Noindex или Nofollow? </span></h2><p> Многие маркетологи и владельцы веб-сайтов прилагают много усилий для повышения рейтинга своих страниц в результатах поиска Google.Для этого эти страницы должны быть проиндексированы и доступны в поисковых системах. Тем не менее, есть некоторые страницы, которые вам не нужно индексировать, поскольку они ничего не помогают или просто существуют, чтобы соответствовать правилам веб-сайта.</p><p> Аналогичным образом, иногда Google не обязательно должен переходить по определенным ссылкам на каждой странице. Они могут привести к плохим или некачественным сайтам, которые могут повредить вашему рейтингу.</p><p> Индексирование как можно большего числа страниц для повышения вашего авторитета в результатах поиска - не всегда хороший вариант, равно как и переход по ссылкам.Это объясняет, почему вам следует тщательно решить, какие страницы использовать для noindex, а какие - для nofollow.</p><p> Этот пост описывает, как работают noindexing и nofollowing, и обсуждает, какие типы страниц или ссылок следует применять. Он также охватывает некоторые простые способы создания страниц noindex и ссылок nofollow в WordPress. Приступим к основам!</p><h3><span class="ez-toc-section" id="_Noindex_Nofollow-2"> Краткое описание Noindex и Nofollow </span></h3><h4><span class="ez-toc-section" id="i-40"> Как работают индексация и отслеживание поисковыми системами? </span></h4><p> Поисковые системы создают ботов для исследования ваших веб-сайтов, пытаясь понять, о чем ваш контент, как он организован и т. Д.Прежде чем генерировать результаты с ваших веб-страниц, они должны просканировать все ссылки на сайте, проиндексировать эти ссылки в своей базе данных, а затем отобразить их на страницах результатов поиска.</p><p> Боты Google переходят по всем ссылкам на вашем сайте, чтобы с легкостью глубже изучить ваши страницы, а затем предоставить пользователям актуальные данные. В результате, набирая запрос в Google, вы фактически ищете информацию через его обширный индекс сайтов и файлов.</p><p> Очевидно, имеет смысл проиндексировать релевантные и важные страницы, что поможет вам зарабатывать больше кликов и увеличивать посещаемость.Но наличие неактивных страниц и ссылок, проиндексированных и отслеживаемых, определенно вредит вашим усилиям по SEO.</p><h4><span class="ez-toc-section" id="_noindex_nofollow-9"> В чем разница между noindex и nofollow? </span></h4><p> Noindex и nofollow - это метатеги, которые можно добавить в исходный HTML-код веб-страницы. Эти метатеги предназначены для непосредственного взаимодействия с программами поисковых систем (ботами), которые сканируют ваш сайт.</p> Тег<p> Noindex сообщает поисковым системам сканировать страницу, но не индексировать или отображать ее в результатах поиска. По умолчанию веб-страница настроена на «индекс».Поэтому всякий раз, когда вы хотите удалить или скрыть страницу от поисковых систем, вы можете изменить термин в метатегах робота. Это позволяет вам лучше контролировать, какие страницы попадают в поисковую выдачу.</p><p> Атрибут nofollow требует от поисковых систем игнорировать веб-страницы, на которые вы ссылаетесь. Хотя ссылки играют решающую роль в поисковой оптимизации, только внешние ссылки с авторитетных и мощных веб-сайтов и внутренние ссылки помогают укрепить доверие к вашему сайту и повысить его рейтинг. Ссылки Nofollow, которые не проходят через PageRank, вряд ли повлияют на рейтинг в поисковых системах.</p><h3><span class="ez-toc-section" id="_noindex-_nofollow"> Почему вам следует использовать noindex-страницы или nofollow-ссылки? </span></h3><p> Если важные страницы, сообщения в блогах и целевые страницы не индексируются и не отслеживаются, вы можете потерять огромный источник трафика на свой сайт. Это объясняет, почему большинству владельцев сайтов не нужны ни индексированные страницы, ни страницы без перехода. Они всегда проверяют, сканируют ли поисковые роботы и индексируют ли их веб-страницы.</p><p> Тем не менее, в некоторых случаях страницы noindex и ссылки nofollow могут оказаться полезными.</p><h4><span class="ez-toc-section" id="Noindex"> Noindex страниц </span></h4><p> Могут быть разные случаи, когда вам нужно исключить некоторые страницы из индексации Google.Давайте рассмотрим две основные причины, по которым вам следует защищать страницы от индексаторов Google.</p><h5><span class="ez-toc-section" id="i-41"> Предотвращение дублирования содержимого </span></h5><p> Часть вашего контента может появляться несколько раз с разными версиями. Довольно излишне разрешать Google индексировать все эти страницы.</p><h5><span class="ez-toc-section" id="i-42"> Защита конфиденциального содержимого </span></h5><p> Некоторые из ваших страниц, содержащих важные источники и продукты, не должны публиковаться и загружаться на страницах поиска Google. Важно держать их подальше от глаз Google.</p><h4><span class="ez-toc-section" id="_Nofollow"> Ссылки Nofollow </span></h4><h5><span class="ez-toc-section" id="i-43"> Борьба со спамом в блогах </span></h5><p> Спамеры обычно оставляют ссылки на свои сайты на странице ваших комментариев. Ссылки Nofollow не полностью предотвращают спам, но каким-то образом удерживают спамеров от нацеливания на ваш сайт.</p><p> Какова основная цель спамеров, оставляющих свои ссылки на вашем сайте? Они воспользуются кликами ваших пользователей, чтобы увеличить свой трафик и занять более высокое место в Google. Однако для ссылок nofollow их ссылки больше не учитываются при расчете PageRank.</p><h5><span class="ez-toc-section" id="i-44"> Увеличить посещаемость сайта </span></h5><p> Имейте в виду, что ссылки полезны не только для целей SEO. Ссылки Nofollow могут увеличить посещаемость вашего веб-сайта и повысить узнаваемость вашего бренда или услуг. Действительно, хорошая и качественная ссылка создает для посетителей шлюз для доступа к вашему контенту. Если посетитель найдет ваш контент полезным, он может поделиться им в своих сообщениях. Таким образом, можно сказать, что ссылки nofollow косвенно ведут к ссылкам, на которые вы переходите.</p><h5><span class="ez-toc-section" id="i-45"> Правильно переходите по ссылке </span></h5><p> Ссылочный вес - это фактор ранжирования поисковой системы, описывающий мощность между страницами.Поскольку мощная страница будет распределять мощность по ссылкам в своем содержании, вы должны убедиться, что отдаете силу страницы основным ссылкам. Важным элементом SEO является обеспечение того, чтобы ваши ссылки работали хорошо и имели логический смысл.</p><h3><span class="ez-toc-section" id="_Noindex"> страницы, которые вы должны Noindex </span></h3><h4><span class="ez-toc-section" id="i-46"> Страница благодарности </span></h4><p> Эта страница обычно отображается после того, как посетители совершают желаемое действие, например вводят адрес электронной почты в поле подписки, регистрируются для загрузки программного обеспечения или покупают ваши продукты.</p><p> Люди видят страницу благодарности только тогда, когда они выполняют действие, которое вы ожидаете от них.Если посетители могут попасть на эту страницу через поиск Google, вы не только бесплатно предлагаете самый ценный контент, но и потеряете все аналитические данные вашего сайта.</p><h4><span class="ez-toc-section" id="i-47"> Авторский архив </span></h4><p> Поскольку у большинства блогов один или два автора, страница автора почти такая же, как и домашняя страница блога. Если вы показываете эти два типа страниц в результатах поиска, контент будет дублироваться. Их не нужно индексировать, чтобы избежать этого обстоятельства.</p><h4><span class="ez-toc-section" id="i-48"> Пользовательские типы сообщений </span></h4><p> Пользовательские типы сообщений, такие как товары в WooCommerce, содержат тонкий или некачественный контент.Более того, при установке плагинов могут появиться нежелательные пользовательские типы сообщений. Эти страницы бесполезны для посетителей и вашего собственного сайта, поэтому держите их подальше от страниц результатов поиска.</p><h4><span class="ez-toc-section" id="i-49"> Страницы администратора и входа </span></h4><p> Эти страницы автоматически не индексируются, поскольку администраторы или авторизованные пользователи обычно входят в систему через прямые URL-адреса. Однако страницы входа, которые обслуживают сообщество, такие как Mediafire, Dropbox, являются исключением.</p><h4><span class="ez-toc-section" id="i-50"> Результаты внутреннего поиска на вашем собственном веб-сайте </span></h4><p> Эта страница испортит поисковую систему, как только посетители увидят ее в поисковой выдаче.Вместо того, чтобы получать результаты, они должны снова выполнить поиск. Он может быть представлен как виджет поиска в WordPress или панель поиска продукта в WooCommerce.</p><h4><span class="ez-toc-section" id="i-51"> Страницы профилей сообщества </span></h4><p> Знаете ли вы, что 75% веб-сайта Moz было деиндексировано? Бритни Мюллер ранее обнаружила, что более 56% проиндексированных страниц были страницами профилей сообщества, которые содержат неактивные профили или профили, содержащие спам, с плохими обратными ссылками. После того, как они решили не индексировать URL-адреса профилей сообщества ниже 200 баллов, сайт в конечном итоге оказал положительное влияние на трафик.Этот пример доказывает, что важно не допускать, чтобы нерелевантные профили не попадали на страницы результатов поисковых систем.</p><h4><span class="ez-toc-section" id="i-52"> Вложения страниц </span></h4><p> WordPress создаст отдельную страницу вложения при загрузке изображения. Неудивительно, что Google индексирует и показывает посетителям эти страницы, которые в основном пустые с изображением и некоторыми словами описания. Сделаете ли вы страницы вложений доступными для вашей аудитории? Возможно, нет.</p><h3><span class="ez-toc-section" id="i-53"> Ссылки, по которым вы не должны следовать </span></h3><h4><span class="ez-toc-section" id="i-54"> Ссылки, отправленные пользователями, или ссылки в комментариях </span></h4><p> Ссылки в комментариях блога часто неактуальны и могут вести на вредоносные сайты.Когда люди размещают эти ссылки на вашей странице, они должны делиться силой с бесценными сайтами. Помните, что Google сканирует и индексирует ваш сайт на основе всех ссылок в вашем контенте, поэтому будет очень плохо, если ваш сайт связан с ненадежными ссылками или веб-сайтами.</p><p> Установив для этой ссылки значение «nofollow», вы можете способствовать продвижению обсуждения, не отвлекаясь от бессмысленных комментариев. Поскольку ссылки в комментариях не приносят никакой SEO-ценности, спамеры могут больше не беспокоиться об этом.</p><h4><span class="ez-toc-section" id="i-55"> Платные ссылки </span></h4><p> Обычно вы монетизируете свой блог, прикрепляя к своим страницам спонсируемый контент.Вы можете добавлять логотипы или ссылки на сайты спонсоров и получать деньги за реферальный трафик от вашей аудитории. Однако необходимо указать Google, что ваш контент спонсируется и вы не несете ответственности за какие-либо веб-сайты, на которые есть ссылки. Что еще более важно, эти ссылки не должны влиять на ваше SEO и рейтинг.</p><p> Ссылки Nofollow в этом случае оказываются хорошим вариантом. Вы по-прежнему получаете прибыль от этих сайтов, добавляя ценные ссылки для удобства пользователей и привлечения трафика.</p><h4><span class="ez-toc-section" id="i-56"> Сомнительные и ненадежные ссылки </span></h4><p> Google предпочел бы, чтобы на вашем веб-сайте была интуитивно понятная навигация и понятные URL-адреса. Это означает, что он может сосредоточиться на достоверной информации, чтобы эффективно направлять своих ботов через каждый уголок вашего сайта.</p><p> Вы должны добавить метатег nofollow к ссылкам, содержание которых не имеет отношения к вашему или поступает из подозрительных источников.</p><h3><span class="ez-toc-section" id="_Noindex-2"> Как создавать страницы Noindex </span></h3><p> Ознакомьтесь с 3 способами запретить поисковым системам индексировать определенные страницы вашего сайта!</p><h4><span class="ez-toc-section" id="i-57"> Использовать метатег «Без индекса» </span></h4><p> Этот тег добавляется в раздел заголовка HTML-кода страницы и сообщает поисковым системам не индексировать вашу страницу.Поместите метатег robots в раздел <strong><head> </strong> данной страницы, например:</p><pre> <! DOCTYPE html> <html> <head> <meta name = "robots" content = "noindex" /> (…) </head> <body> (…) </body> </html> </pre><p> «<strong> Robots </strong>» после мета-имени означает, что этот метатег применяется ко всем поисковым роботам. Если вы хотите, чтобы ваши страницы не индексировались конкретным сканером, например Google, обновите тег следующим образом:</p><pre> <meta name = "googlebot" content = "noindex" /> </pre><p> Этот тег указывает боту Google не показывать страницу в результатах поиска.Однако он по-прежнему отображается в результатах поиска других поисковых систем, таких как Bing или Ask.com.</p><p> Можно использовать несколько метатегов роботов одновременно:</p><pre> <meta name = "googlebot" content = "noindex"> <meta name = "googlebot-news" content = "nosnippet"> </pre><h4><span class="ez-toc-section" id="_HTTP-_X-Robots-Tag"> Использовать HTTP-заголовок X-Robots-Tag </span></h4><p> X-Robots-Tag может использоваться как фактор ответа HTTP-заголовка. Разместите синтаксис ниже, чтобы сканеры не индексировали страницу.</p><pre> HTTP / 1.1 200 ОК Дата: Вт, 25 мая 2010 г., 21:42:43 GMT (…) X-Robots-Tag: noindex (…) </pre><h4><span class="ez-toc-section" id="_robotstxt-3"> Используйте файл robots.txt </span></h4><p> Отредактируйте файл robot.txt через клиент FPT или «Файловый менеджер» в cPanel хостинга WordPress.</p><pre> Агент пользователя: * Запретить: / логин / </pre><p> Вы можете настроить таргетинг на определенных ботов с помощью строки пользовательского агента. Вторая строка определяет часть URL-адреса, идущую после вашего доменного имени. Если вы хотите запретить Google индексировать вашу страницу входа с URL-адресом <strong> <em> http: // example.com / login / </em> </strong>, просто добавьте в эту строку <strong> <em> / login / </em> </strong>.</p><p> Поскольку добавление неверных инструкций в этот файл отрицательно сказывается на вашем сайте, использование файла robots.txt не рекомендуется для начинающих. Помните, что этот файл доступен всем, поэтому боты или пользователи знают, какую страницу вы пытаетесь скрыть. Более того, вы можете только защитить свою страницу от поисковых роботов Google на вашем сайте. Если на вашу страницу ведет ссылка из сообщения другого сайта, она все равно будет отображаться в результатах поиска.</p><h4><span class="ez-toc-section" id="i-58"> Используйте сторонний плагин </span></h4><p> Это самый простой способ даже для любителей. Есть несколько плагинов, которые помогут вам создавать страницы noindex, в том числе Yoast SEO и Protect WordPress Pages & Posts.</p><p> Ниже описано, как использовать Yoast SEO, чтобы не индексировать ваши страницы WordPress. После установки и активации плагина выполните 3 простых шага:</p><ol><li> Посетите редактор страниц, который вы хотите заблокировать от поисковых систем</li><li> Прокрутите вниз до мета-поля Yoast SEO внизу страницы и нажмите кнопку <strong> Настройки </strong> слева</li><li> Проверьте <strong> № </strong> под вопросом <strong> Должны ли поисковые системы переходить по ссылкам на этой странице? </strong></li></ol><p></p><p> Что делать, если вы хотите одновременно не индексировать и защищать свои страницы? Использование плагина Protect WordPress Pages & Posts помогает запретить роботам Google индексировать ваши страницы и делает страницы видимыми для авторизованных пользователей.</p><p> При активации вам необходимо:</p><ol><li> Перейдите на страницу плагина <strong> Настройки </strong>, вставленную в меню навигации WordPress <br/></li><li> Включить индексирование поиска блоков <strong> </strong> Расширенные функции <br/></li><li> Выберите страницу, не требующую индексации и защиты</li><li> Нажмите <strong> Редактировать </strong></li><li> Нажмите <strong> Защитите этот файл </strong> кнопка</li></ol><h3><span class="ez-toc-section" id="_nofollow-4"> Как сделать ссылки nofollow </span></h3><h4><span class="ez-toc-section" id="_nofollow-5"> Добавить атрибут nofollow вручную </span></h4><p> Фактически, WordPress уже помечает все отправленные пользователями ссылки или ссылки в комментариях как nofollow, что уменьшает спам в комментариях на вашем веб-сайте.Больше всего вас беспокоило добавление nofollow к создаваемым ссылкам.</p><p> Сначала перейдите на страницу или пост, где есть ссылки. Затем откройте вкладку <strong> Text </strong> редактора и вставьте следующий код</p><pre> <a href="http://example.com/page" rel="nofollow"> текст привязки </a> </pre><p> Измените URL-адрес примера на свою ссылку и замените фразу «якорный текст» на свой форматированный текст.</p><p> Этот ручной метод кажется простым, но требует много времени для редактирования различных сообщений и страниц, содержащих ссылки.Напротив, вы можете использовать плагин для автоматизации этого ручного процесса.</p><h4><span class="ez-toc-section" id="_nofollow-6"> Используйте плагин для добавления ссылок nofollow </span></h4> Плагин<p> Ultimate Nofollow предоставляет простое решение для добавления и управления всеми ссылками nofollow в WordPress</p><p> После установки и активации плагинов</p><ol><li> Перейдите на страницу со ссылками, на которые вы хотите перейти на nofollow</li><li> Выберите ссылку и щелкните значок карандаша, чтобы отредактировать ее <br/></li><li> Щелкните значок шестеренки, чтобы открыть параметры связи <strong> </strong> <br/></li><li> Установите новый флажок рядом с <strong> Добавьте rel = ”nofollow” </strong> для ссылки <br/></li><li> Нажмите <strong> Добавить ссылку </strong></li></ol><h3><span class="ez-toc-section" id="i-59"> Завершение </span></h3><p> Теги noindex и nofollow не ухудшают видимость вашего сайта в результатах поиска, как вы думали.Прежде чем думать о том, как вы можете проиндексировать свои страницы, задайте себе 2 вопроса: Вы хотите, чтобы эта страница отображалась в результатах поиска? Следует ли разрешить поисковым системам переходить по всем ссылкам на этой странице?</p> Тег<p> Noindex запрашивает у поисковой системы удаление страниц из индекса доступных для поиска страниц. Тег Nofollow не позволяет Google передавать ссылочную массу через ссылки на веб-странице.</p><p> Google обращает внимание только на ранжирование релевантных страниц и анализ качественных ссылок. Убедитесь, что вы обслуживаете значимый контент и ссылки, которые могут повысить ваш рейтинг в поиске и иметь наибольшее значение для вашей аудитории.</p><p> Noidexing некоторых страниц, таких как страницы с благодарностями, архив авторов или страницы администратора и входа в систему, помогает предотвратить отображение дублированного контента, а также защитить конфиденциальную информацию. Отправленные пользователем ссылки, платные ссылки и сомнительные ссылки «Nofollow» заблокируют спам в комментариях и перестанут распространять силу вашего контента на отображаемые в нем ссылки.</div></div></div></article><nav class="navigation post-navigation" aria-label="Записи"><h2 class="screen-reader-text">Навигация по записям</h2><div class="nav-links"><div class="nav-previous"><a href="https://xn--90abhccf7b.xn--p1ai/raznoe/dizajn-master-mbdou-detskij-sad-21-belochka-uste-inn-6809004930-ogrn-1026800680818.html" rel="prev">Дизайн мастер – МБДОУ Детский Сад № 21 «Белочка», Устье (ИНН 6809004930, ОГРН 1026800680818)</a></div><div class="nav-next"><a href="https://xn--90abhccf7b.xn--p1ai/raznoe/kak-ustanovit-javascript-rasshireniya-dlya-vs-code-i-programmirovanie-na-javascript-ruvds-com-corporate-blog-habr.html" rel="next">Как установить javascript – Расширения для VS Code и программирование на JavaScript / RUVDS.com corporate blog / Habr</a></div></div></nav><div id="comments" class="comments-area"><div id="respond" class="comment-respond"><h3 id="reply-title" class="comment-reply-title">Добавить комментарий <small><a rel="nofollow" id="cancel-comment-reply-link" href="/html/noindex-html-code-how-to-tell-google-not-to-index-a-page-in-search.html#respond" style="display:none;">Отменить ответ</a></small></h3><form action="https://xn--90abhccf7b.xn--p1ai/wp-comments-post.php" method="post" id="commentform" class="comment-form" novalidate><p class="comment-notes"><span id="email-notes">Ваш адрес email не будет опубликован.</span> <span class="required-field-message">Обязательные поля помечены <span class="required">*</span></span></p><p class="comment-form-comment"><label for="comment">Комментарий <span class="required">*</span></label><textarea id="comment" name="comment" cols="45" rows="8" maxlength="65525" required></textarea></p><p class="comment-form-author"><label for="author">Имя <span class="required">*</span></label> <input id="author" name="author" type="text" value="" size="30" maxlength="245" autocomplete="name" required /></p><p class="comment-form-email"><label for="email">Email <span class="required">*</span></label> <input id="email" name="email" type="email" value="" size="30" maxlength="100" aria-describedby="email-notes" autocomplete="email" required /></p><p class="comment-form-url"><label for="url">Сайт</label> <input id="url" name="url" type="url" value="" size="30" maxlength="200" autocomplete="url" /></p><p class="form-submit"><input name="submit" type="submit" id="submit" class="submit" value="Отправить комментарий" /> <input type='hidden' name='comment_post_ID' value='20881' id='comment_post_ID' /> <input type='hidden' name='comment_parent' id='comment_parent' value='0' /></p></form></div></div></main></div><div id="sidebar-primary" class="widget-area sidebar " role="complementary"><div class="sidebar-main"><div id="yandex_rtb_R-A-744004-7" class="yandex-adaptive classYandexRTB"></div> <script type="text/javascript"> window.yaContextCb.push(()=>{Ya.Context.AdvManager.render({renderTo: "yandex_rtb_R-A-744004-7",blockId: "R-A-744004-7",pageNumber: 11,onError: (data) => { var g = document.createElement("ins"); g.className = "adsbygoogle"; g.style.display = "inline"; g.style.width = "300px"; g.style.height = "600px"; g.setAttribute("data-ad-slot", "9935184599"); g.setAttribute("data-ad-client", "ca-pub-1812626643144578"); g.setAttribute("data-alternate-ad-url", "https://chajnov.ru/back.php"); document.getElementById("yandex_rtb_[rtbBlock]").appendChild(g); (adsbygoogle = window.adsbygoogle || []).push({}); }})}); window.addEventListener("load", () => { var ins = document.getElementById("yandex_rtb_R-A-744004-7"); if (ins.clientHeight == "0") { ins.innerHTML = stroke2; } }, true); </script><section id="search-2" class="widget widget_search"><div class="zita-widget-content"><form role="search" method="get" id="searchform" action="https://xn--90abhccf7b.xn--p1ai/"><div class="form-content"> <input type="text" placeholder="search.." name="s" id="s" value=""/> <input type="submit" value="Search" /></div></form></div></section><section id="nav_menu-4" class="widget widget_nav_menu"><div class="zita-widget-content"><h2 class="widget-title">Рубрики</h2><div class="menu-2-container"><ul id="menu-2" class="menu"><li id="menu-item-19021" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-19021"><a href="https://xn--90abhccf7b.xn--p1ai/category/css">Css</a></li><li id="menu-item-19022" class="menu-item menu-item-type-taxonomy menu-item-object-category current-post-ancestor current-menu-parent current-post-parent menu-item-19022"><a href="https://xn--90abhccf7b.xn--p1ai/category/html">Html</a></li><li id="menu-item-19023" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-19023"><a href="https://xn--90abhccf7b.xn--p1ai/category/js">Js</a></li><li id="menu-item-19024" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-19024"><a href="https://xn--90abhccf7b.xn--p1ai/category/adaptiv">Адаптивный сайт</a></li><li id="menu-item-19025" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-19025"><a href="https://xn--90abhccf7b.xn--p1ai/category/verstk">Верстка</a></li><li id="menu-item-19026" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-19026"><a href="https://xn--90abhccf7b.xn--p1ai/category/idei">Идеи</a></li><li id="menu-item-19028" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-19028"><a href="https://xn--90abhccf7b.xn--p1ai/category/chego-nachat">С чего начать</a></li><li id="menu-item-19029" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-19029"><a href="https://xn--90abhccf7b.xn--p1ai/category/sovety">Советы</a></li><li id="menu-item-19031" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-19031"><a href="https://xn--90abhccf7b.xn--p1ai/category/shablon">Шаблоны</a></li><li id="menu-item-19027" class="menu-item menu-item-type-taxonomy menu-item-object-category menu-item-19027"><a href="https://xn--90abhccf7b.xn--p1ai/category/raznoe">Разное</a></li></ul></div></div></section></div></div></div></div><footer id="zita-footer"><div class="footer-wrap widget-area"><div class="bottom-footer"><div class="bottom-footer-bar ft-btm-one"><div class="container"><div class="bottom-footer-container"> © Компания <a href="http://вебджем.рф"> Вебджем.рф </a> 2009 - 2025 | Все права защищены.</a></div></div></div></div></div></footer> <noscript><style>.lazyload{display:none}</style></noscript><script data-noptimize="1">window.lazySizesConfig=window.lazySizesConfig||{};window.lazySizesConfig.loadMode=1;</script><script async data-noptimize="1" src='https://xn--90abhccf7b.xn--p1ai/wp-content/plugins/autoptimize/classes/external/js/lazysizes.min.js'></script> <!-- noptimize --> <style>iframe,object{width:100%;height:480px}img{max-width:100%}</style><script>new Image().src="//counter.yadro.ru/hit?r"+escape(document.referrer)+((typeof(screen)=="undefined")?"":";s"+screen.width+"*"+screen.height+"*"+(screen.colorDepth?screen.colorDepth:screen.pixelDepth))+";u"+escape(document.URL)+";h"+escape(document.title.substring(0,150))+";"+Math.random();</script> <!-- /noptimize --></body></html>
- Браузеры могут использовать это для идентификации приложения. Он отличается от элемента