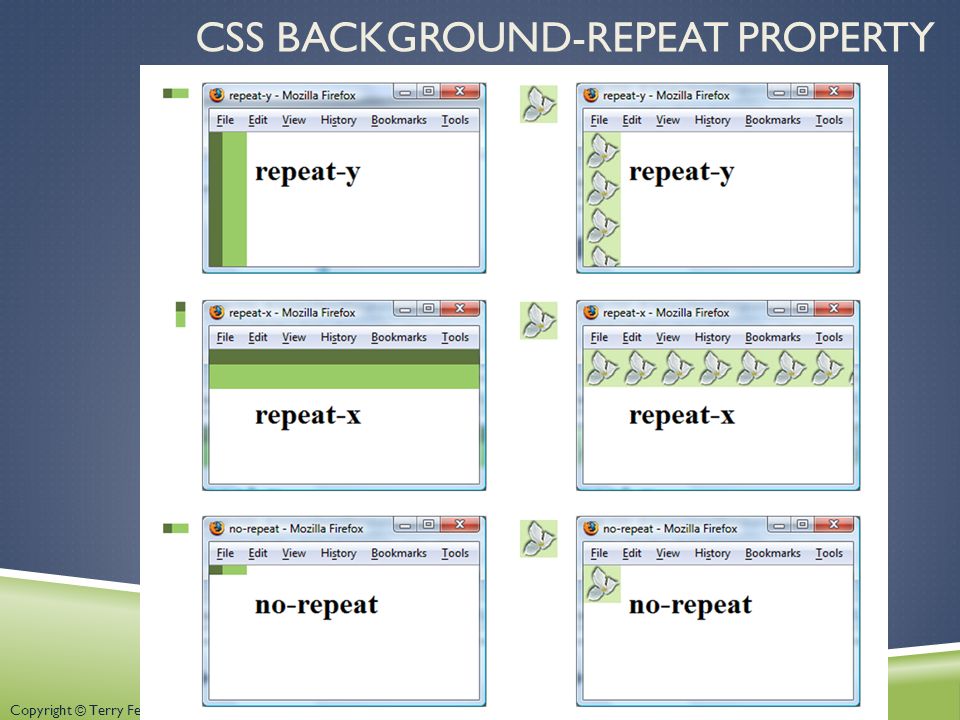
don’t repeat yourself в HTML-разметке / Хабр
Распространение LESS/SCSS, а также ожидаемые движения в мире браузеров и стандартов, появление jQuery, наконец, вернуло фан в вёрстку HTML-страничек и во фронт-энд разработку.
Но представьте, что вам требуется сверстать раздел в интернет-магазине, раздел блога, или целую главную страницу Хабра? Да, мы делим страницу на отдельные блоки и делаем для них разметку, порождаем множество вложенных блоков, делаем для них CSS/LESS/SCSS. Безусловно, существуют такие замечательные средства как Zen-Coding, шаблонизатор jQuery Templates, а для построения сеток (grids) — всевозможные CSS-фреймворки, наподобие Bootstrap или же Zurb Foundation.
Но часто хочется посмотреть как же ведет себя вёрстка списков, когда в них не один только что свёрстанный элемент, а множество элементов. Наверняка, вы копипастили хотя бы раз в жизни разметку блока, чтобы заполнить страницу контентом, особенно когда под рукой нет запущенной любимой CMS или веб-фреймворка с шаблонизатором.
Пару дней назад я создал библиотеку populatejs, которая призвана избавить вас от описанных неприятностей раз и навсегда. Фактически она даёт нам синтаксический сахар в CSS, позволяющий клонировать контент HTML-элементов с помощью CSS-свойств. К примеру, класс «populate-7» у любого элемента отобразит на веб-странице 7 точно таких же элементов вместо одного, а класс «populate-inner-3» отобразит трижды содержимое элемента.
Как использовать?
К примеру, требуется тестовый список из элементов , содержащий краткое описание предлагаемых товаров, который вы только что стилизовали:
<ul> <li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li> <li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li> <li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li> <li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li> <li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li> </ul>
 jpg" /><div>Lorem ipsum dolor...</div></li>
<li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li>
<li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li>
</ul>
jpg" /><div>Lorem ipsum dolor...</div></li>
<li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li>
<li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li>
</ul>Вместо копирования блока:
<li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li>
Используйте класс .populate-5:
<li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li>
На странице появится список из 5 элементов. Требуется 5 элементов с двумя картинками товаров? Не проблема:
<li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li>
Или больше текста описания:
<li><img src="images/thumb.jpg" /><div>Lorem ipsum dolor...</div></li>
Как закончите макет, удалите строчку с подключением библиотеки и можете смело преобразовывать в шаблон вашу чистую HTML-разметку!
Естественно, к элементам также будут применяться псевдоклассы :nth-child, декларированные в вашем CSS.
Чтобы подключить библиотеку и начать пользоваться ею прямо сейчас, просто вставьте следующий код в странице после jQuery:
<script type="text/javascript" src="https://rawgithub.com/vladignatyev/populate-js/master/js/populate.js"></script>
А теперь поговорим о том, что под капотом.
Что внутри?
Внутри populatejs очень простой движок, использующий jQuery для селекторов и свой механизм обхода DOM-дерева и обработки деклараций CSS-классов элементов (через аттрибут ‘class’ в jQuery). Весь код библиотеки написан через тесты с использованием замечательного фреймворка QUnit. Чтобы запустить тесты, достаточно открыть test.html в вашем браузере.
Когда HTML-документ загружен браузером, библиотека в ходе инициализации находит узлы DOM-дерева, помеченные классами .populate-* и .populate-inner-* и формирует список терминальных узлов такого поддерева, а на самом деле леса. После этого происходит обратный ход, в ходе которого пройденные узлы помечаются классом . populated и к ним применяется операция «клонирования», копирующая всю иерархию наследников этих узлов.
populated и к ним применяется операция «клонирования», копирующая всю иерархию наследников этих узлов.
Заключение
Буду рад любым отзывам сообщества, и буду особенно счастлив, если кому-то кроме меня эта библиотека сэкономит пару телодвижений, как уже сэкономила мне.
1. Zen coding — пишем HTML/CSS быстрее
2. Bootstrap
3. Zurb Foundation
4. Официальная страница библиотеки PopulateJS
5. QUnit js testing framework
5. Исходный код на GitHub
6. Мой твиттер, если нужна более оперативная поддержка или вы хотите сказать «спасибо».
Fork me on GitHub!
Учебное пособие по регулярным выражениям — повторение со звездочкой и плюсом
Один оператор повторения или квантификатор уже был введен: вопросительный знак. Он говорит движку попытаться сопоставить предыдущий токен ноль раз или один раз, что фактически делает его необязательным.
Звездочка или звездочка сообщают движку, что нужно попытаться сопоставить предыдущий токен ноль или более раз. Плюс сообщает движку, что нужно попытаться сопоставить предыдущий токен один или несколько раз. <[A-Za-z][A-Za-z0-9]*> соответствует тегу HTML без каких-либо атрибутов. Угловые скобки являются литералами. Первый класс символов соответствует букве. Второй класс символов соответствует букве или цифре. Звезда повторяет второй класс символов. Поскольку мы использовали звездочку, ничего страшного, если второй класс символов не соответствует ничему. Таким образом, наше регулярное выражение будет соответствовать тегу типа . При сопоставлении первый класс символов будет соответствовать H. Звездочка приведет к тому, что второй класс символов будет повторяться три раза, сопоставляя T, M и L на каждом шаге.
Я мог бы также использовать <[A-Za-z0-9]+>. Я этого не сделал, потому что это регулярное выражение будет соответствовать <1>, что не является допустимым тегом HTML. Но этого регулярного выражения может быть достаточно, если вы знаете, что строка, которую вы ищете, не содержит таких недопустимых тегов.
Но этого регулярного выражения может быть достаточно, если вы знаете, что строка, которую вы ищете, не содержит таких недопустимых тегов.
Ограничение повторения
Имеется дополнительный квантификатор, позволяющий указать, сколько раз может повторяться токен. Синтаксис: { min , max }, где min — это ноль или положительное целое число, указывающее минимальное количество совпадений, а max — целое число, равное или превышающее min , указывающее максимальное количество совпадений. Если запятая присутствует, но max опущено, максимальное количество совпадений бесконечно. Таким образом, {0,1} совпадает с ?, {0,} совпадает с *, а {1,} совпадает с +. Отсутствие запятой и max указывает движку повторять токен ровно мин раз.
Вы можете использовать \b[1-9][0-9]{3}\b для соответствия числу от 1000 до 9999. \b[1-9][0-9]{2,4}\b соответствует числу от 100 до 99999. Обратите внимание на использование границ слов.
Берегись жадности!
Предположим, вы хотите использовать регулярное выражение для соответствия тегу HTML. Вы знаете, что входными данными будет допустимый HTML-файл, поэтому регулярное выражение не должно исключать любое недопустимое использование острых скобок. Если он находится между острыми скобками, это тег HTML.
Большинство людей, плохо знакомых с регулярными выражениями, попытаются использовать <.+>. Они будут удивлены, когда протестируют его на строке типа Это первый тест. Вы можете ожидать, что регулярное выражение будет соответствовать и при продолжении после этого совпадения .
Но это не так. Регулярное выражение будет соответствовать first. Явно не то, что мы хотели. Причина в том, что плюс жадный . То есть плюс заставляет обработчик регулярных выражений повторять предыдущий токен как можно чаще. Только если это приведет к сбою всего регулярного выражения, обработчик регулярных выражений вернет . То есть он вернется к плюсу, заставит отказаться от последней итерации и продолжит оставшуюся часть регулярного выражения. Давайте заглянем внутрь механизма регулярных выражений, чтобы подробно увидеть, как это работает и почему это приводит к сбою нашего регулярного выражения. После этого я представлю вам два возможных решения.
То есть он вернется к плюсу, заставит отказаться от последней итерации и продолжит оставшуюся часть регулярного выражения. Давайте заглянем внутрь механизма регулярных выражений, чтобы подробно увидеть, как это работает и почему это приводит к сбою нашего регулярного выражения. После этого я представлю вам два возможных решения.
Как и плюс, звездочка и повторение с использованием фигурных скобок являются жадными.
Взгляд внутрь механизма регулярных выражений
Первый токен в регулярном выражении <. Это буквально. Как мы уже знаем, первое место, где он будет совпадать, — это первый < в строке. Следующий токен — это точка, которая соответствует любому символу, кроме новой строки. Точка повторяется плюсом. Плюс жадный . Поэтому движок будет повторять точку столько раз, сколько сможет. Точка соответствует E, поэтому регулярное выражение продолжает пытаться сопоставить точку со следующим символом. M соответствует, и точка повторяется еще раз. Следующий символ >. Вы уже должны увидеть проблему. Точка соответствует >, и движок продолжает повторять точку. Точка будет соответствовать всем оставшимся символам в строке. Точка терпит неудачу, когда двигатель достигает пустоты после конца строки. Только в этот момент механизм регулярных выражений продолжает работу со следующим токеном: >.
Вы уже должны увидеть проблему. Точка соответствует >, и движок продолжает повторять точку. Точка будет соответствовать всем оставшимся символам в строке. Точка терпит неудачу, когда двигатель достигает пустоты после конца строки. Только в этот момент механизм регулярных выражений продолжает работу со следующим токеном: >.
На данный момент <.+ соответствует первому тесту, и движок достиг конца строки. > здесь не может совпасть. Движок запоминает, что плюс повторял точку чаще, чем требуется. (Помните, что плюс требует, чтобы точка совпадала только один раз.) Вместо того, чтобы признать ошибку, механизм вернет обратно. Это уменьшит повторение плюса на единицу, а затем продолжит попытку оставшейся части регулярного выражения.
Таким образом, совпадение .+ сокращается до EM>first tes. Следующий токен в регулярном выражении по-прежнему >. Но теперь следующий символ в строке — это последний t. Опять же, они не могут совпадать, что приводит к дальнейшему возврату двигателя назад. Общее совпадение на данный момент сводится к первому te. Но > все еще не может соответствовать. Таким образом, движок продолжает откат до тех пор, пока совпадение .+ не уменьшится до EM>first может соответствовать следующему символу в строке. Совпал последний токен в регулярном выражении. Механизм сообщает, что first успешно сопоставлен.
Общее совпадение на данный момент сводится к первому te. Но > все еще не может соответствовать. Таким образом, движок продолжает откат до тех пор, пока совпадение .+ не уменьшится до EM>first может соответствовать следующему символу в строке. Совпал последний токен в регулярном выражении. Механизм сообщает, что first успешно сопоставлен.
Помните, что механизм регулярных выражений стремится вернуть совпадение. Он не будет продолжать откат, чтобы увидеть, есть ли другое возможное совпадение. Он сообщит о первом найденном действительном совпадении. Из-за жадности это самое левое и самое длинное совпадение.
Лень вместо жадности
Быстрое решение этой проблемы состоит в том, чтобы сделать плюс ленивым вместо жадного. Ленивые квантификаторы иногда также называют «нежадными» или «неохотными». Вы можете сделать это, поставив вопросительный знак после плюса в регулярном выражении. Вы можете сделать то же самое со звездой, фигурными скобками и самим вопросительным знаком. Таким образом, наш пример становится <.+?>. Давайте еще раз заглянем внутрь механизма регулярных выражений.
Таким образом, наш пример становится <.+?>. Давайте еще раз заглянем внутрь механизма регулярных выражений.
Опять же, < соответствует первому < в строке. Следующий токен — точка, на этот раз повторяемая ленивым плюсом. Это говорит механизму регулярных выражений повторять точку как можно меньше раз. Минимум один. Таким образом, движок сопоставляет точку с E. Требование выполнено, и движок продолжает работу с > и M. Это не удается. Опять же, двигатель будет давать задний ход . Но на этот раз откат заставит ленивый плюс расширяться, а не уменьшать охват. Таким образом, совпадение .+ расширяется до EM, и движок снова пытается продолжить с >. Теперь > успешно сопоставляется. Совпал последний токен в регулярном выражении. Механизм сообщает, что успешно сопоставлен. Это больше походит на это. 9>]+>. Причина, по которой это лучше, заключается в откате. При использовании ленивого плюса движок должен возвращаться для каждого символа в теге HTML, которому он пытается соответствовать. При использовании класса символов с отрицанием возврат не происходит вообще, когда строка содержит допустимый HTML-код. Возврат замедляет работу механизма регулярных выражений. Вы не заметите разницы при однократном поиске в текстовом редакторе. Но вы сэкономите много циклов процессора при многократном использовании такого регулярного выражения в жестком цикле в сценарии, который вы пишете, или, возможно, в пользовательской схеме окраски синтаксиса для EditPad Pro.
При использовании класса символов с отрицанием возврат не происходит вообще, когда строка содержит допустимый HTML-код. Возврат замедляет работу механизма регулярных выражений. Вы не заметите разницы при однократном поиске в текстовом редакторе. Но вы сэкономите много циклов процессора при многократном использовании такого регулярного выражения в жестком цикле в сценарии, который вы пишете, или, возможно, в пользовательской схеме окраски синтаксиса для EditPad Pro.
Только движки, управляемые регулярными выражениями, возвращаются назад. Текстовые движки этого не делают и, следовательно, не получают штрафа за скорость. Но они также не поддерживают ленивые квантификаторы.
Повторяющиеся управляющие последовательности \Q…\E
Последовательность \Q…\E экранирует строку символов, сопоставляя их как буквальные символы. Экранированные символы рассматриваются как отдельные символы. Если вы поместите квантификатор после \E, он будет применяться только к последнему символу.![]() Например. если вы примените \Q*\d+*\E+ к *\d+**\d+*, совпадение будет *\d+**. Только звездочка повторяется. В Java 4 и 5 есть ошибка, из-за которой повторяется вся последовательность \Q…E, в результате чего в качестве совпадения выдается вся тематическая строка. Это было исправлено в Java 6.9.0003
Например. если вы примените \Q*\d+*\E+ к *\d+**\d+*, совпадение будет *\d+**. Только звездочка повторяется. В Java 4 и 5 есть ошибка, из-за которой повторяется вся последовательность \Q…E, в результате чего в качестве совпадения выдается вся тематическая строка. Это было исправлено в Java 6.9.0003
| Быстрый старт | Учебник | Инструменты и языки | Примеры | Ссылка | Обзоры книг |
| Введение | Содержание | Специальные символы | Непечатаемые символы | Внутреннее устройство механизма регулярных выражений | Классы персонажей | Вычитание класса символов | Пересечение классов персонажей | Классы сокращенных символов | Точка | Якоря | Границы слов | Чередование | Дополнительные элементы | Повтор | Группировка и захват | Обратные ссылки | Обратная ссылка, часть 2 | Именованные группы | Относительные обратные ссылки | Группы сброса ветвей | Свободный интервал и комментарии | Юникод | Модификаторы режима | Атомная группировка | Притяжательные квантификаторы | Просмотр вперед и назад | Осмотр, часть 2 | Не допускайте попадания текста в матч | Условные операторы | Балансирующие группы | Рекурсия | Подпрограммы | Бесконечная рекурсия | Рекурсия и квантификаторы | Рекурсия и захват | Рекурсия и обратные ссылки | Рекурсия и поиск с возвратом | Скобочные выражения POSIX | Совпадения нулевой длины | Продолжающиеся матчи |
HTML Marquee — повторите, чтобы указать количество прокруток текста с помощью цикла
Тег бегущей строки HTML-тег бегущей строки Бегущая строка Скорость Поведение бегущей строки Направление бегущей строки Бегущая строка MouseOver
Указывает, сколько раз повторяется текстовый эффект в выделенной области. Возможные значения: «Непрерывно» или количество раз, которое текст должен повторяться.
Возможные значения: «Непрерывно» или количество раз, которое текст должен повторяться.Пример:
Пожалуйста, проверьте это в Internet Explorer (IE)Это пример выделения (контур: 1)
Код: цикл = 1
Пример:
Это пример выделения (цикл: бесконечный). Код: цикл = бесконечный
.Это пример Marquee (Цикл: 3)
Код: Цикл = 3
<шаговая рамка bgcolor="#000080" scrollamount="5" loop="3">Это пример Marquee (цикл: 3)
Первое и третье выделение остановятся после завершения заданного количества циклов, вам нужно снова обновить эту страницу, чтобы переместить их.
← HTML-тег выделения Запуск и остановка прокрутки с помощью наведения и отвода мыши →Повторить:
Эта статья написана plus2net. com 9Команда 0115.
com 9Команда 0115.
plus2net.com
| Нажмите, чтобы просмотреть дополнительные инструкции по тегу выделения для прокрутки текста |
|---|
18-06-2020 | |
| But why is their not any action taking place in both loop1 and loop3 | |
24-06-2020 | |
| loop1 и loop3 останавливаются после завершения своих циклов. Вам нужно обновить страницу, чтобы переместить их снова. | |
28-11-2020 | |
| Я использовал бегущую строку для сеанса закрытия титров фильма на кнопке «a href» и комбинировал ее с функцией окна предупреждения прежде чем мы откроем ссылку, как заставить эту бегущую строку работать только тогда, когда мы нажимаем на ссылку, я думаю, что это с использованием какого-то JS/jQuery держите тег div или span скрытым по умолчанию. | |