Индексация WordPress. Как закрыть WordPress от индексации

От автора: приветствую вас, друзья. В этой коротенькой и простой статье мы затронем один из многочисленных вопросов, связанных с SEO оптимизацией сайта WordPress. В частности, мы рассмотрим такой вопрос, как индексация WordPress.
На самом деле перед тем, как сесть за написание данной статьи, я сомневался, нужна ли она. Однако, как показывает практика, статья все же может дать ответ на вопрос, который нет-нет да и возникает порой у некоторых владельцев сайта WordPress.
Что же это за вопрос, связанный с индексацией WordPress? Как ни странно, но иногда от пользователей звучит он так: Почему мой сайт не появляется в поисковике? Почему поисковики не индексируют мой сайт? Они его не любят?
Чтобы ответить на такие вопросы, нужно посмотреть на сам сайт, а также уточнить, сколько времени сайт «живет» в сети. Давайте начнем с последнего момента, поскольку зачастую выясняется, что владелец сайта просто оказался нетерпелив. Думаю, вы знаете, что после того, как сайт готов и выложен в сеть, он не сразу появится в поисковике. И даже не через день или неделю. Однако, рядовые пользователи интернета этого вполне могут не знать.
Соответственно, если в ответ на вопрос, сколько сайт «живет» в сети, вы услышите что-то вроде «да вот только вчера сделали», тогда можете успокоить собеседника и объяснить ему, что процесс индексации сайта — это не быстрый и, тем более, не одномоментный процесс. В зависимости от поисковой системы сайт может появится в ней в среднем через пару месяцев. И все это при условии, что поисковому роботу сообщили о появлении нового сайта на просторах интернета.
Теперь перейдем к первому моменту, к необходимости взглянуть на сайт. Ведь владелец сайта может сказать, что его детищу уже несколько месяцев, а в результатах поиска его все нет и нет. Здесь уже стоит заглянуть в исходный код сайта, посмотреть файл robots.txt, в общем, необходим хотя бы минимальный аудит сайта.

Бесплатный курс «Основы создания тем WordPress»
Изучите курс и узнайте, как создавать мультиязычные темы с нестандартной структурой страниц
Скачать курсНебольшой казус из моей практики. Когда-то давно знакомый обратился ко мне со своей ситуацией: полдня, говорит, просидел в Гугле и Яндексе, добрался до сотой страницы в каждом из них, а моего сайта там нет. После недолгого общения выяснилось, что сайт он сделал сам, воспользовавшись одним из бесплатных шаблонов. Сделал он его около года назад. Никаких посторонних ссылок на сайте не размещал. В общем, было понятно, что сайт должен быть уже проиндексирован, но в поиске его действительно не оказалось.
Когда я заглянул в исходный код сайта, то практически сразу все стало понятно. В исходном коде красовалась вот такая вот строка:
<meta name=’robots’ content=’noindex,follow’ />
<meta name=’robots’ content=’noindex,follow’ /> |
Как вы понимаете, эта строка запрещала индексирование сайта. Когда я задал знакомому риторический вопрос, откуда взялось сие безобразие, то в ответ получил ожидаемый недоуменный взгляд.
Прошерстив тему WordPress на предмет «виновника бед», я нигде этого тега не обнаружил. Чтобы исключить возможность вывода зашифрованной в коде темы зловредной строки, я поменял тему на дефолтную, но строка никуда не делась.
И здесь я вспомнил, что WordPress есть возможность закрыть сайт от индексации. Сделать это можно как на этапе установки, так и в дальнейшем из настроек сайта. Вот эта настройка, которую можно отметить на этапе установки:

А вот эта настройка на уже установленном WordPress:

В процессе вспоминания действительно выяснилось, что галочка ставилась знакомым самолично на этапе установки сайта. Поскольку дело сайтостроения для него было новым, то чтобы сайт на второй день не появился в сети в процессе его экспериментов, эта галочка и была отмечена. Впоследствии о ней как-то забылось, а проблема осталась.
В общем, история имела счастливый конец, как в сказке. Ненужная настройка была выключена, строка, блокирующая индексацию, пропала из исходного кода и вскоре сайт уже появился в поисковике.
Вся эта история рассказана как раз для тех пользователей, которые по каким-то причинам использовали данную настройку, закрыв индексацию, а затем просто забыли о ней. Ну и также для тех веб-мастеров, которые столкнутся с аналогичной ситуацией ![]()
Ну а на этом у меня все. Удачи!
Бесплатный курс «Основы создания тем WordPress»
Изучите курс и узнайте, как создавать мультиязычные темы с нестандартной структурой страниц
Скачать курс
Основы создания тем WordPress
Научитесь создавать мультиязычные темы с нестандартной структурой страниц
Смотретьрецепт быстрой индексации нового сайта Яндексом и Гуглом / Dimox.name
В одной из своих предыдущих статей я уже озадачивался вопросом: «Как заставить Яндекс проиндексировать новый сайт?«. В ней составлен ряд рекомендаций, которые позволяют частично ответить на данный вопрос.
Прошло некоторое время, я все продолжал экспериментировать с созданием сайтов на WordPress (разговор о том, почему я всегда использую этот движок, заслуживает отдельного поста). И вот, наконец, я выявил для себя действенный рецепт того, как заставить Яндекс, а заодно и Google, начать индексировать только что созданный сайт, работающий на движке WordPress.
Поскольку WordPress — универсальная платформа, которая позволяет создавать множество разновидностей сайтов, то, я полагаю, что данная информация может пригодиться многим. Хотя для определенного процента читателей информация, описанная ниже, покажется «баяном».
Мой удачный эксперимент начался с того момента, когда я хотел забабахать самый банальный сапе-сплог, но у меня, ИМХО, получился правильный сплог (контент уникальный, и пишу, в общем-то, для людей). А в моем понимании последний — это самый, что ни на есть настоящий блог (привет DimaX‘у ;).
В общем, так. Чтобы больше «не лить воду», выкладываю по пунктам рецепт быстрой индексации нового WordPress-сайта Яндексом и Гуглом:
- Покупаем новый домен в зоне .ru — Это один из двух самых весомых моментов. На 90% уверен, что нахождение сайта в этой доменной зоне имеет большое значение в плане любви его Яндексом (аля индексация). Этот факт подтверждает и то, что мои сайты в доменах net.ru, org.ru и pp.ru, которые Яндекс никак не хотел индексить, после переезда на ру-домены, сразу полюбились ему.
- Устанавливаем и настраиваем WordPress.
- Заходим в админку WordPress в «Настройки -> Написание» (в английской версии «Options -> Writing») и в поле «Сервисы обновления» вставляем вот этот список пинг-сервисов. Это и есть второй важный момент в решении нашей задачи.
Главное здесь то, что в списке присутствуют пинг-адреса Яндекса и Гугла, которые оперативно уведомляют обе искали о появлении на Вашем WP-сайте новых записей. А это в результате и оборачивается тем, что страницы сайта в скором времени появляются в индексе обозначенных поисковиков (примерно неделя-полторы).
- Начинаем регулярно писать в блог/сайт. Моя практика показывает, что независимо от того, уникальный или неуникальный контент публикуется на сайте, он одинаково хорошо индексируется и Яндексом, и Гуглом.
- После появления в индексе Яндекса первых страниц сайта для пущей уверенности можно добавить сайт в адурилку (в этот момент с искалок начинают приходить первые посетители).
- Дожидаемся полной индексации ресурса.
- Монетизируем сайт (если оно надо), например, пользуемся услугами саперов.
Вот и весь рецепт.
Прошу заметить, что при использовании моего «рецепта приготовления WordPress-сайта» мне не потребовалось ставить на новый сайт ни единой внешней ссылки, ни добавлять его в адурилку.
88817e8e9818ee232dff3861a0ef4537
* * *
Лучший отдых для души и делай вам обеспечат горящие путевки в Турцию, страну солнца, впечатлений и контрастов. Вы обязательно полюбите Турцию.
Индексация WordPress сайтов. Файл robots.txt и мета-тег robots
Правильная настройка индексирования сайта напрямую влияет на успешность его будущего продвижения в поисковых системах. В рамках данной статьи я расскажу, как правильно настроить индексацию сайтов на WordPress и полностью избавиться от дублированного контента. Нижеописанная технология многократно опробована и отлично зарекомендовала себя.
Суть данной технологии заключается в том, чтобы использовать для настройки индексации файл robots.txt в сочетании с мета-тегами robots. Таким образом, мы создаем двухуровневую защиту от дублированного контента. При этом даже двойная защита не гарантирует 100% результат, так как поисковые системы могут игнорировать настройки индексации. К счастью, такое бывает очень редко, но мы все же рассмотрим способы для защиты и от этого.
Прежде чем мы перейдем непосредственно к рассмотрению особенностей настройки индексации, определимся, какие страницы существуют в WordPress, какие нужно разрешить индексировать, а какие запретить. Я придерживаюсь мнения, что разрешать индексировать стоит только те страницы, которые нам необходимы. Все остальное необходимо закрывать.
Основные типы страниц в WordPress
В WordPress существует несколько основных типов страниц, которые могут понадобиться нам в работе:
- Статические страницы.
- Страницы записей (постов).
- Страницы категорий (рубрик).
- Страницы тегов (меток).
- Страницы таксономий (произвольные категории и теги).
- Страницы произвольных типов записей.
Также существуют страницы ошибок 404, поиска, страницы вложений и т.д., но с ними мы работать не будем, так как в 99% случаев в этом нет необходимости.
Большинство обычных проектов используют только первые четыре типа страниц, которые доступны в Wordrpess по умолчанию. Чтобы получить доступ ко всем остальным возможностям движка, потребуется внести соответствующие изменения в код шаблона. Так или иначе, мы рассмотрим полную версию кода, чтобы избежать каких-либо проблем в будущем. Код является универсальным и будет работать даже в том случае, если какой-то функционал не реализован.
Использование мета-тега robots
Мета-тег robots является очень мощным инструментом в настройке индексирования сайта. С его помощью можно произвольно разрешать или запрещать индексацию тех или иных страниц, а также разрешать или запрещать поисковым роботам переход по имеющимся на странице ссылкам. Сам мета-тег robots имеет следующий синтаксис:
<meta name="robots" content="значение">В качестве значения мы будем использовать четыре основных конструкции:
- index, follow – разрешить индексацию страницы и переход по ссылкам на ней
- noindex, follow – запретить индексацию страницы, но разрешить переход по ссылкам
- index, nofollow – разрешить индексацию страницы, но запретить переход по ссылкам
- noindex, nofollow – запретить как индексацию, так и переход по ссылкам
Как вы уже поняли, index/noindex разрешает или запрещает индексацию страницы, а follow/nofollow разрешает или запрещает переход по имеющимся на странице ссылкам.
Существуют и другие конструкции, которые могут использоваться в качестве значения для атрибута content в мета-теге robots. Их мы рассматривать не будем, так как практическое применение их невелико.
Код управления мета-тегом robots для сайтов на WordPress
if ( ( is_single() || is_page() || is_home() || is_category() || is_tag() || is_tax() || is_post_type_archive() ) && !is_paged() ) {
echo '<meta name="robots" content="index, follow" />' . "\n";
}
else {
echo '<meta name="robots" content="noindex, nofollow" />' . "\n";
}Для установки кода на сайт, достаточно просто добавить его в файл header.php между тегами <head>. Теперь давайте немного разберемся с кодом.
Как видно с примера, мы делаем обычную проверку типов страниц и в зависимости от этого выводим мета-тег robots с нужным нам значением. Для определения типов страниц мы используем встроенные функции WordPress, так называемые условные теги.
- is_single() – для определения отдельных записей (постов).
- is_page() – для определения статических страниц.
- is_home() – для определения главной страницы.
- is_category() – для определения страниц категорий (рубрик).
- is_tag() – для определения страниц тегов (меток).
- is_tax() – для определения архивных страниц пользовательских таксономий.
- is_post_type_archive() – для определения архивных страниц произвольных типов записей.
- is_paged() – для определения страниц с постраничной навигацией.
Вышеприведенный код разрешит индексацию всех страниц постов, статических страниц, страниц категорий и тегов, страниц произвольных таксономий и архивных страниц произвольных типов записей, а также страниц самих произвольных записей, где не выводится постраничная навигация. Все остальные страницы будут автоматически закрыты от индексации при помощи мета-тега robots.
Если вам необходимо запретить индексацию какого-то типа страниц, достаточно просто удалить или закомментировать нужную функцию в коде. Например, если мы хотим запретить индексацию тегов, то достаточно удалить функцию is_tag(). Естественно две вертикальные линии || тоже нужно будет удалить, чтобы избежать синтаксической ошибки в коде.
Если же вам нужно запретить только какую-то конкретную страницу записи, то придется немного модернизировать код. Как вариант, можно использовать произвольные поля. С подробными примерами о том, как это сделать, можно ознакомиться в статье о произвольных полях WordPress.
Итак, с мета-тегами мы разобрались. Теперь перейдем ко второй части статьи и рассмотрим пример оптимального, на мой взгляд, файла robots.txt
Файл Robots.txt для сайтов на WordPress
Файл robots.txt используется для настройки индексации сайта в целом. Обычно в нем используются только общие конструкции, которые позволяют запретить индексирование тех или иных разделов сайта. Все же некоторые умудряются перечислять в нем ссылки на отдельные страницы, с целью исключения их из поиска. Я не считаю это хорошей идеей, поэтому в примере ниже будут только общие конструкции.
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /xmlrpc.php
Disallow: /wp-content/uploads
Disallow: /wp-content/themes
Disallow: /trackback/
Disallow: /tag/*
Disallow: /feed/
Disallow: */*/feed/*/
Disallow: */feed
Disallow: */*/feed
Disallow: /*?*
Disallow: /?feed=
Disallow: /?s=*
Disallow: /page/*
Disallow: /author/*
Host: dmitriydenisov.com
Sitemap: https://archive.dmitriydenisov.com/sitemap.xml
Sitemap: https://archive.dmitriydenisov.com/sitemap.xml.gzВышеприведенный пример является универсальным для использования на большинстве проектов, работающих под управлением Wordrpess. Он закрывает от индексации системные папки WordPress, требеки, страницы фидов, тегов, поиска, архивные страницы авторов, постраничную навигацию, а также страницы, содержащие в себе параметры GET. Если необходимо добавить/удалить какую-то директорию или страницу, сделать это можно аналогичным образом, используя пример выше.
Защита от дублированного контента на страницах разделов
К сожалению, даже все вышеперечисленные способы не дают 100% гарантию того, что закрытые от индексации страницы не будут проиндексированы. Как вариант, кто-то может сослаться на закрытую страницу и она все же может появиться в индексе поисковых систем. Такое иногда бывает. В этом нет ничего плохого, если эта страница не является точной копией другой страницы, которую, к тому же, вы можете продвигать.
Дополнительная защита от дублированного контента особенно актуальна при продвижении страниц с постраничной навигацией. Такими являются страницы разделов, тегов и т.д. Чтобы избежать полных дублей, есть очень простой способ – отключить вывод основного описания страницы при активной постраничной навигации.
if ( !is_paged() ) {
основной текст
}Таким образом, описание будет отображаться только на первой странице. При переходе на вторую, третью и т.д. описание выводиться не будет. Это позволит избежать дублирования основного текста на страницах с постраничной навигацией.
При использовании всех трех методов можно добиться 100% качества сайта. Под 100% качеством в данном случае я подразумеваю ситуацию, когда в индексе поисковых систем присутствуют только целевые страницы и полностью отсутствуют мусорные. Самый простой способ проверить, все ли сделано правильно – обратиться к поисковой системе Google.
Данная поисковая система очень удобна для проверки сайта тем, что все страницы, которые считает полезными, она заносит в основной индекс. Все остальное попадает в так называемый дополнительный индекс. Сразу хочу заметить, что в поиске участвуют только страницы с основного индекса, поэтому чем ниже качество сайта по мнению Google, тем хуже.
Для проверки качества вы можете использовать следующие конструкции, которые необходимо будет ввести в строку поиска Google.
site:domen.com
site:domen.com/&Первая конструкция позволит узнать, какое общее количество страниц проиндексировано поисковой системой. Вторая же конструкция покажет, сколько страниц сайта находится в основном индексе Google. Разделив второе значение на первое и умножив на 100 мы узнаем качество сайта в % по мнению поисковой системы Google.
Для наглядности привожу данные по одному из моих старых проектов.


Также для проверки качества можно использовать плагин для браузера RDS Bar. В нем все расчеты происходят в автоматическом режиме.

Заключение
Использование вышеописанных методов позволит значительно повысить качество сайта в глазах поисковых систем за счет избавления от дублированного контента, что в свою очередь позитивно скажется на динамике продвижения. В индексе будут присутствовать только целевые страницы и ничего больше.
В некоторых случаях это может привести к небольшим потерям трафика за счет уменьшения общего количества страниц в индексе. Это происходит по той причине, что часть страниц с дублями все же попадает в индекс поисковых систем и приносит какой-то трафик. Когда же мы закрываем их от индексации, то исключаем возможность появления этого дополнительного трафика. Это небольшая плата за повышение качества сайта в целом. Так или иначе, каждый сам выбирает, что ему нужно больше.
На этом данная статья подошла к концу. Если у вас остались какие-то вопросы по данному материалу, вы всегда можете задать их в комментариях.
На этом все. Удачи вам и успеха в продвижении сайтов!
Обнаружили ошибку? Выделите ее и нажмите Ctrl+Enter
Как улучшить индексацию сайта
12.03.2016 | Seo | Теги: seo комментария 3 | 24218 просмотров | Автор статьи: Александр РусУспешность любого интернет-ресурса во многом зависит от его посещаемости. Существует прямая зависимость между высоким процентом посетителей и хорошей системой индексации WordPress сайта. Ниже помещено несколько рекомендаций по соответствующим настройкам и параметрам.
Начнем с описания основных шагов. Для настройки индексации необходимо:
- Создать файл с расширением robots.txt . С помощью него будут определяться разделы, необходимые для индексирования, а также места, запрещенные к доступу.
- Создать sitemap.xml – карту, благодаря которой будут видны ссылки на нужные страницы
- Создать зеркало сайта. Это необходимо для правильного определения главного источника сайта.
Прохождение всех трех шагов крайне важно. Если выпадает какая-либо стратегия, то велика вероятность, что сайт будет индексироваться неправильно или с большим количеством погрешностей.
Основные моменты каждой составляющей
Основным правилом является, наличие и правильная настройка файла robots.txt. Что бы сайт на WordPress нормально индексировался, в нём должно быть прописано следующее
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | User-agent: * Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /themes/ Disallow: /trackback/ Disallow: /feed/ Disallow: /comment/ Disallow: /tag/ Disallow: /author/ Disallow: /search/ Disallow: /rss/ Disallow: /*.js Disallow: /*.inc Disallow: /*.css Disallow: /*? Disallow: /*.gz Host: www.site.net Sitemap: http://www.site.net/sitemap.xml |
User-agent: * Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /themes/ Disallow: /trackback/ Disallow: /feed/ Disallow: /comment/ Disallow: /tag/ Disallow: /author/ Disallow: /search/ Disallow: /rss/ Disallow: /*.js Disallow: /*.inc Disallow: /*.css Disallow: /*? Disallow: /*.gz Host: www.site.net Sitemap: http://www.site.net/sitemap.xml
Но в зависимости от тематике, шаблона и многих других аспектов — этот файл подстраивают под сайт, что то удаляют или что то добавляют.
У каждого web-ресурса обязательно должна быть карта.
Карта сайта легко создается с помощью соответствующего плагина, как например Google XML sitemap. Его настройки подойдут как для сайтов, так и для блогов. С помощью карты сайта яндекс-робот безошибочно определит все необходимые ссылки. Дополнительно рекомендуется присоединить карту и к панели Вебмастера Яндекса. Для этого полный маршрут к карте вводится в единственное существующее поле.
Зеркало сайта
Необходимо, чтобы главное зеркало сайта находилось в двух важных местах — на вкладке, отвечающей за настройку индексирования, а также в файле robots.txt
Не лишним будет сделать дополнительный редирект 301 с не главного зеркала с помощью файла ht.access.
Настройки индексации через Яндекс
Поисковая система Яндекс имеет удобный интерфейс и является привлекательной для установки индексации для платформы WordPress. Для этого необходимо сделать следующие простые шаги:
- Разрешить доступ систем к сайту
- Добавить желаемый сайт в очередь индексации
- Перед вторым шагом необходимо убедиться, что сайт достаточно наполнен информацией
- Оптимизировать сайт, наполнив его нужным количеством ссылок.
Разрешение/запрещение индексации на WordPress
Важно помнить об установке «по умолчанию», согласно которой на платформе запрещена индексация. Это сделано для защиты поисковых систем от сайтов-«пустышек». Если пользователь уверен, что количества информации на сайте достаточно, можно приступить к следующему шагу — разрешению на индексацию.
Для этого необходимо реализовать следующую цепочку действий. Зайдя в Панель администратора WordPress, необходимо найти вкладку «Параметры-Чтение». На соответствующей странице будет предложено поставить галочку рядом со словами «Запретить» или «Разрешить».
В случае настройки на запрещение индексации, нужно найти опцию «Видимость для поисковых систем». Галочка, расположенная напротив нее, должна быть снята. Еще раз необходимо подчеркнуть, что успешной для индексации является ее правильная настройка. Этой операции должно быть уделено особое внимание.
Условия для ускорения индексации
Существует возможность создания так называемой «быстрой» индексации, которая дает возможность более успешного продвижения сайта в поисковых системах. Данная модель будет работать на основе простого механизма. Поисковый робот будет индексировать страницу только в том случае, если на ней содержится ссылка на другую страницу. Поэтому необходимо правильно настроить систему оповещения.
Оповещение настраивается также пошагово. Необходимо зайти во вкладку «Параметры – Написание». В нижней части странице нужно найти опцию «Сервисы обновления». В ней предстоит работа с текстовым блоком. В него добавляются все адреса систем, которые должны быть уведомлены о поступлении новой информации. Рекомендуемые для уведомления пингаторы можно найти в соответствующих ресурсах в интернете. После того, как система настроек завершена, службы будут уведомлены при каждом новом обновлении сайта/блога.
Установление плагина WordPress Ping Optimizer
Существует опасность, что сигналы об обновлении информации будут поступать слишком часто, и ваш ресурс попадет в черный список. Чтобы этого не случилось, установите плагин WordPress Ping Optimizer. Благодаря ему будет запрещено отправлять пинги при каждом обновлении, но сигнал будет регулярно поступать при создании новой информации.
Данные рекомендации позволят произвести оптимальную индексацию WordPress сайта и обеспечат его эффективную работу.
Автор статьи, Александр Рус.
← Как произвести диагностику сайта через Yandex. Повышение траста сайта. Как оценивается доверие к ресурсу. Что влияет на траст. →Нажимая на кнопку, я даю согласие на рассылку, обработку персональных данных и принимаю политику конфиденциальности.
Как запретить поисковым системам индексировать сайт на WordPress
Недавно один из наших пользователей спросил, как можно запретить поисковым системам обходить сайт на WordPress и индексировать его. Существует множество ситуаций, когда необходимо закрыть сайт от индексации и появления его в результатах выдачи. В сегодняшней статье мы покажем вам как запретить поисковым системам индексировать сайт на WordPress.
Зачем и кому может понадобиться запрещать поисковые системы на сайте
Для большинства сайтов, поисковые системы являются основным источником трафика. Поэтому возникает вопрос, кто может захотеть блокировать поисковых роботов?
Верите или нет, существует множество пользователей, которые работают над своими сайтами, размещая их на публично доступном домене вместо того, чтобы тестировать его на локальном сервере.
Некоторые люди создают сайты по управлению проектами на WordPress. Также многие используют WordPress для создания личных блогов. Во всех этих ситуациях как раз и понадобится закрыть сайт от индексации поисковыми системами, чтобы вас не нашли раньше, чем вы этого захотите.
Распространенным является заблуждение, что если вы не будете размещать ссылки на свой домен, то поисковые системы никогда не найдут ваш сайт. Это не совсем правда.
Существует множество способов, когда поисковые системы смогут найти сайт, даже если вы нигде его не «засветили». Например:
- Ваш домен мог ранее принадлежать кому-то другому и, соответственно, существуют ссылки на домен, размещенные предыдущим владельцем.
- Некоторые результаты поиска домена могут проиндексоироваться с сохранением ссылки на ваш ресурс.
- Существуют буквально тысячи страниц со списками имен доменов, и ваш сайт может оказаться среди них.
Множество вещей происходят в сети и ни одна из них не подконтрольна вам. Однако, ваш сайт — в вашей власти, и вы можете заставить поисковые системы не индексировать свой сайт.
Блокируем обход и индексацию своего сайта от поисковых систем
В WordPress есть встроенная функция, которая позволяет вам сообщить поисковым системам о том, что не нужно индексировать ваш сайт. Все, что вам нужно сделать, это перейти в Настройки » Чтение и отметить галочку рядом с «Попросить поисковые системы не индексировать сайт».
![search-engine-visibility-settings[1]](/800/600/https/wpincode.com/wp-content/uploads/2014/11/search-engine-visibility-settings1.png)
Когда галочка отмечена, WordPress добавляет следующую строку в хидер сайта:
<meta name='robots' content='noindex,follow' />
Также WordPress изменяет ваш файл robots.txt и добавляет в него:
User-agent: * Disallow: /
Эти строки «попросят» робота поисковых систем не индексировать ваши страницы. Однако, тут уже будут решать поисковики, реагировать на эти инструкции или нет. Даже не смотря на то, что эти инструкции воспринимаются, некоторые страницы или случайная картинка может быть проиндексирована.
Как убедиться в том, что ваш сайт не появится в выдаче?
Наиболее эффективным способом заблокировать поисковики — защитить паролем весь сайт на WordPress на уровне сервера. Это означает, что любой, кто попробует получить доступ к сайту, увидит запрос имени пользователя и пароля еще до того, как они увидят сам сайт. К поисковикам это тоже относится. Если вход не удастся, отобразится ошибка 401 и робот уйдет. Защитить весь сайт паролем можно следующим образом.
Защищаем весь сайт паролем с помощью cPanel
Если ваш хостер предлагает cPanel для управления хостингом, то можно воспользоваться панелью для защиты сайта. Просто логинимся в cPanel и кликаем на меню «password protect directories».
![password-protect-cpanel[1]](/800/600/https/wpincode.com/wp-content/uploads/2014/11/password-protect-cpanel1.png)
Выскочит всплывающее окно, где нужно будет выбрать корневую директорию.
![choose-document-root[1]](/800/600/https/wpincode.com/wp-content/uploads/2014/11/choose-document-root1.png)
На следующей странице выберите папку, в которой установлен ваш WordPress. Обычно это либо public_html, либо www. После этого отметьте галочку ‘Password protect this directory’. Далее, укажите название для защищенной директории и сохраните изменения.
![username-password[1]](/800/600/https/wpincode.com/wp-content/uploads/2014/11/username-password1.png)
Далее, вы увидите сообщение о том, что все прошло успешно и ссылку для возврата. Нажмите на эту ссылку, и вы попадете на страницу защиты паролем. Теперь вам нужно указать имя пользователя и пароль, который будет нужен для просмотра вашего сайта.
Вот и все, ваш сайт теперь защищен паролем, и никто, включая поисковые системы, не сможет получить доступ к вашему сайту.
У нас также есть статья о том, как защитить паролем ваш сайт WordPress. Однако, в той статье вам нужно будет использовать плагин. В случае же, если вам придется отключить этот плагин, то сайт станет доступен для поисковиков.
Мы надеемся, что эта статья помогла вам запретить поисковым системам индексировать сайт на WordPress.
Если вы только начинаете разбираться с WordPress, то не забудьте посетить нашу рубрику WordPress для новичков, где мы публикуем материалы специально для новых пользователей WordPress.
По всем вопросам и отзывам просьба писать в комментарии ниже.
Не забывайте, по возможности, оценивать понравившиеся записи количеством звездочек на ваше усмотрение.
VN:F [1.9.22_1171]
Rating: 5.0/5 (3 votes cast)
Как быстро проиндексировать ваш WordPress сайт в Google
Вы сделали это! После стольких принятых решений, потраченного времени и усилий, вы смогли запустить новый веб-сайт, и теперь вы хотите, чтобы его увидел весь мир. Волнующе, не правда ли? Мир стал казаться немного лучшим и полным возможностей!



Но вы, наверняка, уже поняли, что это только начало. Одной из наиболее важных вещей, которую нужно сделать после запуска сайта в интернете, это индексировать его в Google. Без индексирования, Google никогда не отобразит ваш контент в результатах поиска по ключевым словам. И ваши мечты разобьются, не успев свершиться.
Смотрите также:
И хотя Google многое изменил в SEO, но индексирование сайта осталось простым. Некоторые справятся с этим за несколько часов, другим же потребуется больше времени. Но главное результат! Давайте прекратим пустую болтовню и приступим к делу.
Вот несколько советов для быстрого индексирования вашего сайта на WordPress в Google.
Как проверить, индексирован ли ваш сайт в Google

Прежде, чем заняться индексацией сайта, стоит проверить, а не сделал ли Google это уже за вас.
Вот небольшой хак, как проверить, есть ли вы в системе. Подставьте в поисковую строку следующее:
site:yourURL.com
Вы увидите, какой контент и страницы уже индексированы. Если Google уже добавил ваш сайт, то ваш сайт появится в результатах страниц, которые Google каталогизировал:

Если ваш сайт не появился, то это значит, что вам придется делать это самостоятельно.
Подготовка контента для вашего сайта
Для того, чтобы Google заметил ваш сайт, вам нужно понять его требования. Google можно назвать онлайн библиотекой, которая содержит информацию обо всём на свете. Как любая библиотека, Google разбивает полученную информацию по категориям, чтобы её было легко найти.
Обдумайте это:
Что если библиотека получит книгу на тему дизайна, но открыв её мы увидим, что она пустая? Что нужно сделать? Наверное, отложить книгу в сторону потому, что она бесполезна.
То же самое делает Google. Если он заходит на веб-сайт, а там пусто, то он просто откладывает его в сторону. Вот почему первым шагом является заполнение сайта контентом. Все страницы и записи сайта должны иметь полезный и уникальный контент. Тогда при индексации ваш сайт будет иметь успех.
Создание и отправка карты сайта

Когда вы создадите достойный контент, придёт время привлечь внимание Google. Самым лучшим и быстрым способом будет создать карту сайта. Недавно мы публиковали подробную инструкцию, как создать карту сайта на WordPress.
Не беспокойтесь, это только звучит страшно, на самом деле создать и загрузить карту очень просто. Для этого лучше всего использовать специальный плагин. В топ таких плагинов входят Yoast, Squirrly SEO и даже Jetpack.
Перед созданием карты сайта вам стоит сделать еще несколько вещей.
Проверка вашего сайта в Google Search Console
У вас, наверняка, уже есть Google Analytics аккаунт, но многие люди забывают настроить аккаунт в Google Search Console (ранее известный как Google Webmasters).
Если вы отправляете карту сайта в Google, то начать стоит именно с проверки сайта. Если у вас пока нет аккаунта, то самое время его создать.
Отправка вашей карты сайта в Google
После подсоединения вашего сайта к Google Search Console, настало время отправить вашу карту сайта. К счастью, это очень просто.
Войдите в Search Console и найдите пункт меню Crawl → Sitemaps.

В правом верхнем углу нажмите на кнопку Add/Test Sitemap.

Появится параметр добавления URL к вашей XML карте сайта.

Потом добавьте URL (который должен выглядеть примерно так: wpcafe.org/sitemap.xml) и отправьте его.
Вот и всё! Теперь Google может внимательно осмотреть ваш сайт и определить его в какую-то категорию.
Вы можете прекратить читать уже сейчас, но наша задача в том, чтобы помочь вам индексировать ваш сайт быстро. Мы хотим поделиться несколькими советами, которые помогут привлечь внимание Google.
Начните получать трафик на ваш сайт
Даже если ваш сайт ещё не индексирован, это всё равно живой сайт, и на него могут заходить люди. Поисковая система Google становится умнее и смотрит теперь не только на контент веб-сайта.
Направление трафика на ваш сайт – это отличный способ помочь Google понять, что ваш сайт стоит индексировать как можно скорее потому, что люди уже заходят на него, а значит он им полезен.
Также есть несколько способов привлечь посетителей для более быстрой индексации.
Социальные сети
Это может прозвучать не очень современно, но использование социальных сетей и кнопок может направить на ваш сайт много трафика.
Частично это и есть причиной, почему мы настаиваем, что контент должен быть первым шагом, если вы хотите привлечь посетителей.
Facebook, ВКонтакте, Twitter, Google+ помогут вам в этом.
Комментарии
Использование комментариев для обратных ссылок практически мертво. Хотя жизнь в нём еще теплится, но этот метод не подходит для солидной SEO стратегии.
Однако, оставлять действительно полезные комментарии в топовых блогах по вашей теме — это отличный способ привлечь посетителей на ваш новый сайт.
Харш Агравал использовал этот метод на своём новом сайте, чтобы индексировать сайт за 24 часа, так что попробовать однозначно стоит.Слишком много комментариев в блогах за один присест можно рассматривать, как схему для привлечения внимания, и это может больше повредить, чем помочь.
Участие в группах в социальных сетях
Нет ограничений в количестве групп в социальных сетях, к которым вы можете присоединиться. Facebook, LinkedIn и Google Plus имеют широкий выбор.
Поищите группы на этих платформах и вступите в понравившиеся. Когда выдастся удачная возможность, вы сможете там поделиться ссылкой на ваш сайт, что привлечёт немного посетителей.
Это немного трудоемко, но может окупиться со временем.
Начните создавать собственные ссылки
Публикация гостевых записей – это отличный способ размещения высококачественных ссылок на своём сайте, пусть он даже не проиндексирован.
Если вы не очень хорошо пишете, то есть парочка других вариантов:
- Практиковаться в написании контента для вашего блога, пока не сможете писать гостевые записи для блогов вашей сферы.
- Найти писателя-фрилансера или контент-менеджера и работать с ним. Большинству писателей не платят за размещение ссылок в блогах. Но построив с ними хорошие взаимоотношения, у вас будет больше шансов получить высококачественную ссылку.
Итоги
После того, как вы направили трафик на ваш сайт и отправили карту сайта, вернитесь в Google Search и попробуйте найти ваш URL снова.
Если ваш сайт индексирован, то мы вас поздравляем, если ещё нет, то продолжайте в том же духе!
А вы когда-либо индексировали ваш сайт? Расскажите нам в комментариях!
Источник: elegantthemes.com
Смотрите также:
Не индексировать сайт WordPress просто и быстро – INFO-EFFECT
 WordPress
WordPressНа чтение 1 мин. Опубликовано
![]() Привет ! Мы продолжаем разбирать Супер движок WordPress ! Сегодня вы узнаете как можно очень просто и быстро запретить индексацию своего сайта. Поисковые системы не смогут индексировать ваш сайт. В исходном коде вашего сайта появится специальный мета тег “ноиндекс”.
Привет ! Мы продолжаем разбирать Супер движок WordPress ! Сегодня вы узнаете как можно очень просто и быстро запретить индексацию своего сайта. Поисковые системы не смогут индексировать ваш сайт. В исходном коде вашего сайта появится специальный мета тег “ноиндекс”.
Чтобы ваш сайт не индексировался поисковыми системами, зайдите в свою админ-панель WordPress. В меню слева перейдите на страницу: Настройки – Чтение. Внизу страницы поставьте галочку возле параметра “Попросить поисковые системы не индексировать сайт” и сохраните изменения.
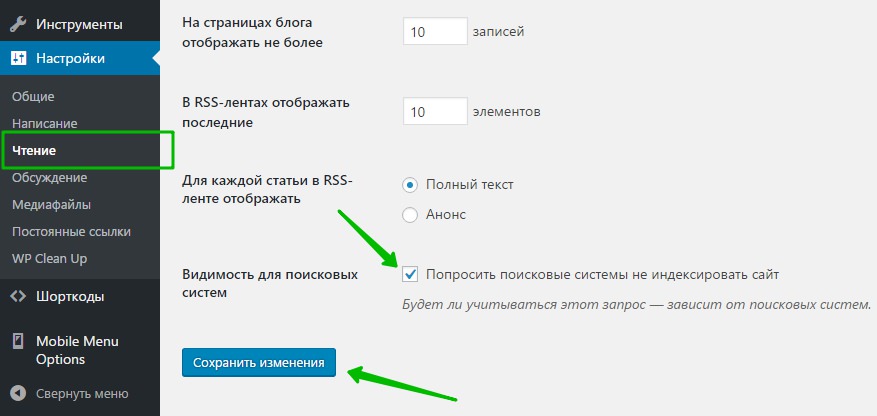
Далее, чтобы проверить, действительно ли ваш сайт закрыт от индексации, перейдите на основной сайт. Нажмите правой кнопкой мыши по области сайта. В открывшемся окне нажмите на вкладку “Просмотр кода страницы” или “Посмотреть исходный код”.
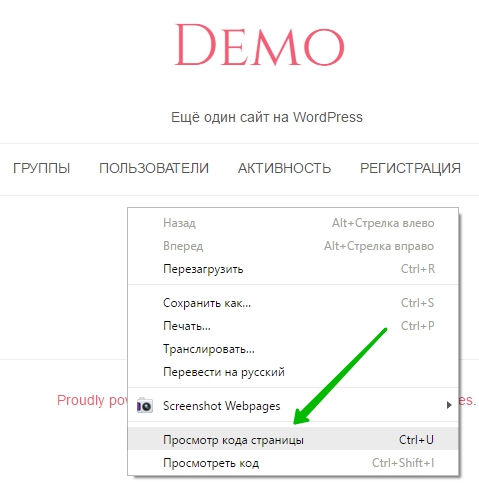
Далее, обратите внимание, в исходном коде, вверху, у вас появится специальный мета тег для запрета индексации данной страницы. Такой мета тег будет отображаться на каждой странице вашего сайта.
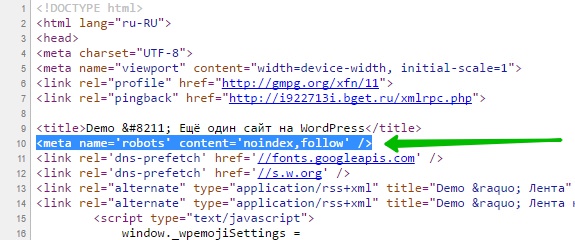
Таким образом, через определённое время, после очередного посещения вашего сайта поисковым роботом, ваш сайт будет постепенно удалён из поиска.
Остались вопросы ? Напиши комментарий ! Удачи !