Урок 2. Поиск информации и выбор источников
 Абсолютно любая деятельность человека в современном мире, если речь идёт хотя бы о малейшем развитии и получении новой информации, предполагает поиск новых данных. Но просто искать информацию – это одно, а искать её профессионально и грамотно – это другое. В этом уроке мы поговорим о том, что вообще представляет собой поиск информации, где и как следует искать информацию, как выбирать источники информации, анализировать их и проверять на достоверность, а также расскажем о правилах поиска информации в Интернете и работе с полученными данными.
Абсолютно любая деятельность человека в современном мире, если речь идёт хотя бы о малейшем развитии и получении новой информации, предполагает поиск новых данных. Но просто искать информацию – это одно, а искать её профессионально и грамотно – это другое. В этом уроке мы поговорим о том, что вообще представляет собой поиск информации, где и как следует искать информацию, как выбирать источники информации, анализировать их и проверять на достоверность, а также расскажем о правилах поиска информации в Интернете и работе с полученными данными.
Оглавление урока:
Что такое информационный поиск?
Впервые понятие «информационный поиск» было употреблено в 1948 году американским математиком и специалистом в области компьютерных технологий Кельвином Муэрсом, но в общедоступной литературе оно начало встречаться лишь с 1950 года.
Изначально автоматизированный информационный поиск (имеются в виду информационно-поисковые системы) применялся с целью поиска научных данных и соответствующей литературы, и использовался он университетами и публичными библиотеками. Однако с появлением и развитием сети Интернет информационный поиск получил широкое распространение.
По сути, поиск информации является процессом выявления в определённом массиве текстовых документов тех данных, которые касаются конкретной темы и удовлетворяют указанным условиям, и в которых имеются необходимые сведения и факты (к примеру, вся необходимая информация по теме самообразования).
Состоит процесс поиска информации из нескольких последовательных этапов, посредством которых обеспечивается сбор данных, их обработка и предоставление. Как правило, поиск осуществляется следующим образом:
- Определяется информационная потребность и формулируется запрос
- Определяется комплекс источников, в которых может находиться нужная информация
- Информация извлекается из выявленных источников
- Происходит ознакомление с данными, и оцениваются результаты поиска
Но, несмотря на то, что на первом этапе нужно как можно правильнее определиться с тем, какую конкретно информацию вы собираетесь искать (а это может показаться первостепенным), наибольшую важность представляет именно второй этап, ведь определиться с тем, где искать информацию, на порядок сложнее.
Где искать информацию?
Вопрос о том, где искать информацию, действительно очень важен. И в первую очередь, по той причине, что XXI век – это век информационный. А это, в свою очередь, значит, что информационный поиск на настоящее время имеет свою специфику.
Давайте вспомним: в конце прошлого века и даже начале настоящего столетия с целью поиска информации люди обращались в специализированные заведения. К таким можно отнести библиотеки, архивы, картотеки и другие подобные органы информации. Но если в то время, чтобы отыскать информацию о том, что интересует, человеку нужно было собраться, выйти из дома, добраться до нужного места, заполнить заявку, отстоять очередь, чтобы её отдать, некоторое время подождать, пока нужная литература будет найдена, а затем провести несколько часов в поиске конкретной информации и её записи на бумагу, то сегодня все эти пункты можно обойти стороной, т.к. практически у каждого дома имеется компьютер и доступ в Интернет. Исходя из этого, актуальные ещё в не таком далёком прошлом информационные базы (архивы, библиотеки и прочее) сегодня если и не потеряли своей актуальности, то, во всяком случае, имеют гораздо меньшее количество клиентов.
Чтобы найти то, что нужно в Интернете, требуется просто ввести запрос в строке поискового сервиса (вспоминаем первый этап), нажать кнопку «Найти» и выбрать наиболее подходящий из предложенных вариантов – интернет-страниц. О поиске информации в Интернете мы продолжим говорить чуть позже, а пока заметим, что пренебрегать традиционными способами поиска информации всё же не стоит, и время от времени можно наведываться в библиотеку, картотеку или архив. Ко всем прочему, это позволит вам разнообразить свою деятельность, развеяться и провести время необычно, с пользой и интересом.
Говоря о подборе источников для поиска информации, нельзя не затронуть вопрос о достоверности, что говорит о необходимости уметь анализировать источники данных и определять те, которым можно доверять.
Как выбирать достоверные источники информации?
Любые рассуждения на тему того, какие источники могут быть, и какие следует считать достоверными, так или иначе, приведут нас к стилистическому пониманию источников информации, а их существует немалое количество. Представим лишь самые распространённые:
- Научные исследования, имеющие под собой реальные доказательства, полученные эмпирическим путём
- Научно-популярные размышления, включающие в себя как фактические эмпирические данные, так и субъективные точки зрения людей, являющихся специалистами в той или иной области
- Философские трактаты и рассуждения, отличающиеся наибольшей оригинальностью, субъективностью и формой подачи
- Художественная литература, служащая, как правило, источником информации – пищи для размышления, но не достоверных эмпирических данных
- Публицистические произведения – категория произведений, которые посвящены актуальным явлениям и проблемам текущей социальной жизни. Нередко в таких произведениях можно отыскать немало достоверных данных и фактов
- Средства массовой информации – комплекс органов публичной передачи информации, таких как телевидение, радио, журналы и газеты, а также Интернет
Всегда следует брать в расчёт то, что практически ни один источник информационных данных не может являться на 100% достоверным. Исключение составляют лишь научные исследования и, в некоторой степени, научно-популярные размышления, т.к., как уже и было подмечено, в них содержатся преимущественно факты, подтверждённые опытом и официально признанные научной общественностью (есть, конечно, и люди, и точки зрения, идущие вразрез с общепринятыми, но в данной статье частные случаи мы рассматривать не будем).
Информацию же из любых других источников следует подвергать тщательной проверке, дабы удостовериться в её актуальности и правдивости. Но прежде чем перейти непосредственно к принципам отбора информации, не будет лишним сказать о том, что для самого процесса информационного поиска является очень удобным и эффективным использование идей особого философского направления – позитивизма, т.к. благодаря этому в ряде случаев (особенно если это касается поиска конкретно научных данных) множество вопросов отпадают сами собой.
Совсем немного о позитивизме
Позитивизм является философским направлением в учении о методах и процедурах научной деятельности, в котором считается, что единственным источником истинного и действительного знания вообще являются только эмпирические (подтверждённые опытным путём) исследования.
Также позитивизм говорит о том, что философское исследование не несёт в себе познавательной ценности. Базовой предпосылкой позитивизма является то, что любые подлинные (они же позитивные) знания – это совокупность результатов специальных наук.
Основной же целью позитивизма является получение объективного знания, что возможно только через проверку информации на деле. Руководствуясь всем этим, мы снова можем вернуться к идее о том, что наиболее достоверными источниками информации являются научные исследования и научно-популярные размышления.
Вооружившись этим принципом как основным, можно начать использовать и другие.
Принципы отбора информации
Можно выделить несколько принципов отбора информации:
1
Принцип наглядности
Исследуемая информация, которая соответствует этому принципу, обладает следующими признаками:
- Информация доступна для восприятия и понимания
- Формируемые информацией образы достоверны, т.к. их можно смоделировать и установить их источники
- Основные понятия, объекты и явления могут быть продемонстрированы
- Информация соответствует запрашиваемым критериям
2
Принцип научности
Принцип научности подразумевает, что исследуемая информация соответствует современным научным данным. Если такое соответствие соблюдается, то появляется возможность обнаруживать неточности и ошибки, воспринимать другие точки зрения, руководствоваться собственной аргументацией и преобразовывать информацию, сопоставляя её с другой.
Вкратце критерии принципа научности можно выразить так:
- Данные соответствуют научным представлениям современности
- Если в массиве данных имеются ошибки и неточности, они не способны повлечь за собой искажения объективной картины, касающейся рассматриваемого вопроса
- Информация может иметь вид исторического документа, который показывает путь развития конкретного научного знания
3
Принцип актуальности
Согласно этому принципу, информация должна быть практичной, злободневной, соответствующей современным запросам, важной на текущий момент времени. Такая информация способна вызвать наибольший интерес, в отличие от неактуальной. Здесь нужно руководствоваться следующими соображениями:
- Желательно, чтобы информация была близка по времени и волновала исследователя
- Информация может представлять собой документ, который расширяет представление об исследуемом объекте
- Информация должна обладать исторической ценностью или быть важной по иным причинам
- Информация может являться классическим примером чего-либо, что знают все
4
Принцип систематичности
Если информация соответствует принципу систематичности, можно наблюдать её многократное повторение в той или иной интерпретации в рамках одного источника или в той же или другой подобной интерпретации в других источниках.
Таким образом, информация достойна внимания и может быть применена, если:
- Аналогичные данные можно найти в различных базах данных
- Различные интерпретации не разрушают целостность представлений об одной и той же проблеме
5
Принцип доступности
Нередко затруднения в поиске и обработке информации могут быть вызваны, во-первых, самим её содержанием, а, во-вторых, стилем, в котором она излагается. По этой причине, работая с информацией, необходимо учитывать, что:
- Информация должна быть не только доступной для понимания с точки зрения терминологии, но и расширять тезаурус исследователя, по причине чего она будет восприниматься интересной, но не банальной
- Информация должна соответствовать той терминологии, которой обладает исследователь, но освещать конкретную тему она должна с разных сторон
- Информация должна предполагать и дидактическую обработку, которая снимает терминологический барьер, другими словами, информацию можно адаптировать под себя, при этом сохранив её смысл
6
Принцип избыточности
Исследуемая информация должна позволять исследователю выделять основную мысль, находить скрытый смысл, если таковой имеется, приходить к пониманию авторской позиции, определять цели изложения и развивать умение соотносить содержание с назначением.
Принципы поиска информации, о которых мы поговорили, могут быть применены в работе с любыми источниками данных: книгами, документами, архивными материалами, газетами и журналами, а также интернет-сайтами. По сути, эти принципы универсальны, но здесь следует чётко понимать для себя, что для поиска информации в традиционных источниках их может быть вполне достаточно, но при поиске информации в сети Интернет во избежание ошибок необходимо соблюдать ещё один ряд правил.
Правила поиска информации в Интернете
Для опытного пользователя поиск информации в Интернете предельно прост, однако, для людей, столкнувшихся с вопросом автоматизированного информационного поиска впервые, этот процесс может показаться довольно сложным из-за обилия всевозможных поисковых операторов. Ниже мы рассмотрим простой поиск и расширенный поиск, а также укажем дополнительную информацию, которая будет полезна при поиске данных в Интернете.
Простой поиск информации в Интернете
Для начала стоит сказать, что наиболее популярной поисковой системой в мире является «Google». В России к нему добавляется «Яндекс», «Поиск@mail.ru» и «Rambler».
Чтобы найти нужную информацию, нужно просто внести в поисковую строку сервиса интересующий запрос, например «Иван Грозный» или «Как правильно водить машину», и нажать «Найти» или клавишу «Enter» на клавиатуре компьютера. В результате поисковик выдаст множество страниц, на которых представлена информация по запрашиваемому запросу. Обратите внимание на то, что наиболее актуальными считаются результаты, расположенные на первой странице поисковой системы.
Расширенный поиск информации в Интернете
По своему принципу расширенный поиск ничем не отличается от простого, кроме того, что можно указывать дополнительные параметры.
При помощи специальных фильтров у пользователя есть возможность задать дополнительные условия для своего запроса. Это может быть ограничение по региону, конкретному сайту, нужному языку, форме слова или фразы, дате размещения материала или типу файла.
Чтобы активировать эти функции, нужно щёлкнуть по специальному значку, расположенному на странице поисковика. Откроется дополнительное меню, где и задаются ограничения. Сбрасываются фильтры (ограничения) нажатием кнопки «Очистить» на странице поисковика.
Дополнительная информация
Каждый пользователь должен иметь в виду, что:
- Ограничение по региону запускает поиск в указанном регионе. В качестве стандарта (По умолчанию) обычно выдаются запросы по тому региону, откуда выходит в Сеть пользователь.
- Ограничение по форме запроса запускает поиск по тем документам, где слова имеют конкретно ту форму, которая стоит в запросе, однако порядок слов может меняться. Пользователь может задать регистр букв (заглавные или строчные), любую часть речи и форму, т.е. склонение, число, род, падеж и т.д. По умолчанию поисковые системы ищут все формы запрашиваемого слова, т.е. если задать «написал», поисковик будет искать «написать», «напишу» и т.п. Однокоренные слова поисковик искать не будет.
- Ограничение по сайту запускает поиск информации среди документов, имеющихся на конкретном сайте.
- Ограничение по языку запускает поиск информации на выбранном языке. Есть возможность установить поиск по нескольким языкам одновременно.
- Ограничение по типу файла запускает поиск по конкретному формату документа, т.е. при указании соответствующих расширений можно найти текстовые документы, аудио- и видеофайлы, документы, предназначенные для открытия специальными программами и редакторами и т.д. Есть возможность установить поиск по нескольким типам файлов одновременно.
- Ограничение по дате обновления запускает поиск по конкретной дате размещения документа. Пользователь может найти документ от конкретного числа, месяца и года, а также установить временной промежуток – тогда поисковик выдаст всю информацию, добавленную за этот период времени.
Этих правил будет достаточно для поиска информации в Интернете. Освоить его в состоянии любой человек, причём потребуется на это совсем немного времени – обычно хватает буквально 2-3 трёх практических подходов.
Но что делать с найденной информацией, ведь весь её массив не обязателен для изучения? Неважно, как вы предпочитаете искать данные на интересующую тему – ходить в библиотеку или кликать по сайтам, одновременно попивая кофе – помимо того, что вы должны обладать навыками поиска, вы также должны уметь обрабатывать тот материал, который изучаете. И для этого как нельзя лучше подходит конспектирование и некоторые другие техники.
Работа с полученной информацией: конспекты, ментальные карты, опорные схемы и блок-схемы
Конспектирование по праву считается самым популярным и применяемым способом обработки информации. Учитывая это, мы решили уделить этому процессу наибольшее внимание, а по ментальным картам, опорным схемам и блок-схемам представить лишь ознакомительную информацию.
Что такое конспект?
Как все мы знаем, конспект представляет собой письменный текст, где последовательно и кратко излагаются основные моменты какого-либо источника информации. Конспектирование подразумевает приведение к определённой структуре сведений, взятых из оригинала. Основой этого процесса является систематизация данных. Заметки могут быть либо точными выдержками и цитатами, либо иметь форму свободного письма – главное, чтобы оставался смысл. Стиль, в котором выдерживается конспект, в большинстве случаев близок к первоисточнику.
При правильном составлении конспекта отражается логическая и смысловая связь записываемого. Конспект можно взять через некоторое время или же дать другом человеку, и чтение и понимание материала не вызовут затруднений. Грамотный конспект способствует восприятию даже самой сложной информации, ведь выражена она в понятной форме.
Конспекты также различаются по видам, и чтобы можно было правильно применять тот вид конспекта, который в большей степени подходит выполняемой работе, эти виды нужно уметь различать.
Виды конспектов
Выделяют плановые конспекты, схематические плановые конспекты, текстуальные, тематические и свободные конспекты. Вкратце о каждом из них.
1
Плановый конспект
Основой планового конспекта является предварительно подготовленный материал, а сам конспект включает в себя заголовки и подзаголовки (пункты и подпункты). Каждый из заголовков сопровождается небольшим текстом, по причине чего имеет понятную структуру.
Плановый конспект в наибольшей мере соответствует подготовке к семинарам и публичным выступлениям. Чем чётче будет структура, тем более логично и полноценно можно будет донести информацию до адресата. По мнению специалистов, плановый конспект должен дополняться пометками, указывающими на использовавшиеся источники, ведь запомнить их все довольно сложно.
2
Схематический плановый конспект
Схематический плановый конспект состоит из пунктов плана, представленных в форме предложений-вопросов, на которые нужно ответить. При работе с информацией нужно вносить по несколько пометок под каждое из-предложений-вопросов. В таком конспекте будет отражена структура и внутренняя связь данных. Кроме того, этот вид конспектов помогает хорошо усвоить изучаемый материал.
3
Текстуальный конспект
Текстуальный конспект отличается от всех остальных максимальной насыщенностью, т.к. для его составления используются отрывки и цитаты из первоисточника. Его легко можно дополнить планом, терминами, понятиями и тезисами. Текстуальный конспект рекомендуется составлять тем, кто занят изучением литературы или науки, ведь здесь цитаты представляют особую важность.
Но и составляется этот вид конспектов непросто, т.к. необходимо уметь определять самые важные отрывки текста и цитаты так, чтобы, в конечном счете, они могли дать целостное представление об изученном материале.
4
Тематический конспект
Тематический конспект отличен от других более всего. Его смысл заключается в том, что освещается какая-либо конкретная тема, вопрос или проблема, а для его составления обычно используют целый ряд источников информации.
Посредством тематического конспекта лучше всего можно провести анализ исследуемой темы, раскрыть главные моменты и изучить их с разных ракурсов. Но нужно понимать, что для составления такого конспекта потребуется исследовать массу источников, чтобы суметь создать целостную картину – это является непременным условием действительно качественного материала.
5
Свободный конспект
Свободный конспект является лучшим выбором для людей, способных применять разные способы работы с информацией. В свободный конспект можно включить всё: тезисы, цитаты, отрывки текста, план, пометки, выписки и т.д. Необходимо только уметь быстро и грамотно излагать мысли и работать с материалом. Многие считают, что использование конспекта такой формы является самым полноценным и целостным.
Как только вы определились с тем, какой конспект вы будете составлять, можно приступать к самому процессу. Чтобы выполнить работу качественно, нужно руководствоваться определёнными правилами.
Правила составления конспекта
Таких правил несколько и все они предельно просты:
- Ознакомьтесь с текстом, выявите его основные особенности, характер, сложность; определите, есть ли в нём термины, которые вы видите впервые. Отметьте незнакомые понятия, места, даты, имена.
- Узнайте всю необходимую информацию о том, что вам показалось незнакомым в тексте при первом прочтении. Наведите справки о людях и событиях. Узнайте значение терминов. Полученные данные обязательно зафиксируйте.
- Прочтите текст повторно и проведите его анализ. Это поможет вам выделить основные моменты, разделить для себя информацию на отдельные блоки и наметить план конспекта.
- Изучите отмеченные ранее основные моменты, составьте тезисы или выпишите отдельные фрагменты или цитаты (если их наличие не обязательно, то выразите авторскую мысль своими словами с сохранением смысла). При фиксации цитат и фрагментов обязательно помечайте, откуда взята информация, и кто является автором.
- Если у вас есть возможность выражать авторские мысли своими словами, то старайтесь делать это так, чтобы даже большие объёмы данных были выражены в 2-3 предложениях.
Применяя эти рекомендации на практике, вы овладеете навыком грамотного конспектирования, и фиксировать и обрабатывать информацию у вас будет получаться очень быстро и качественно (в качестве подспорья вы можете использовать дополнительный материал о методах конспектирования).
Помимо конспектов, для фиксации информации можно использовать и другие не менее интересные и эффективные методики.
Ментальные карты
Ментальные карты или, как их ещё принято называть, диаграммы связей, интеллект-карты, карты мыслей или ассоциативные карты являются таким методом структурирования информации, в котором используются графические записи, имеющие форму диаграмм.
Ментальные карты изображаются в виде древовидных схем, на которых присутствуют задачи, термины, факты и/или какие-либо иные данные, которые связаны ветвями. Ветви, как правило, отходят от главного (центрального) понятия.
Эффективность данного метода обусловлена тем, что его можно использовать в качестве удобного и простого инструмента управления информацией, для которого необходимо лишь наличие бумаги и карандаша (также можно использовать маркерную доску и маркеры).
Рекомендуем вам ознакомиться с подробным описанием метода ментальных карт.
Опорные схемы
Опорные схемы наглядно отображают интеллектуальную психологическую структуру человека, которая управляет его мышлением и поведением. Они позволяют изложить информацию при помощи логико-графического языка посредством значимых опор.
При составлении опорной схемы указывается её название, отмечаются ключевые понятия и схематически изображаются показатели и критерии, на основе которых производится группировка материала.
Этот вид структурирования информации очень удобен при подготовке к зачётам, экзаменам, семинарам. Его можно сопровождать конспектами и дополнительными пометками.
Блок-схемы
Блок-схемы – это ещё один действенный метод, помогающий структурировать информацию. Он представляет собой графические модели, которые описывают последовательность мыслительных операций.
Суть блок-схемы заключается в изображении отдельных шагов в форме блоков, имеющих различную форму. Все блоки соединяются друг с другом линиями-стрелками, которые указывают нужную последовательность мышления.
Чаще всего блок-схемы используются для работы с чётко структурированной информацией, когда все шаги являются конкретными. Каждый блок, имея свою форму, указывает на тот или иной мыслительный процесс, и ориентироваться по блок-схеме можно даже с минимальным количеством текстовых данных на ней. Удобно применять в качестве дополнительного инструмента.
В заключение
Как можно заключить, поиск информации и её обработка – это не только интересная, но и увлекательная деятельность. Если научиться применять этот навык с учётом всех особенностей, о которых мы сегодня поговорили, найти нужную информацию и использовать её в своих целях не будет составлять никакого труда, в особенности, если выполнить приемлемый для себя алгоритм действий несколько раз подряд.
В следующем уроке вы узнаете о том, почему в процессе самостоятельного обучения рекомендуется следовать конкретному плану, о том, как его составить, и на что нужно обратить внимание, чтобы обучение было максимально эффективным.
Проверьте свои знания
Если вы хотите проверить свои знания по теме данного урока, можете пройти небольшой тест, состоящий из нескольких вопросов. В каждом вопросе правильным может быть только 1 вариант. После выбора вами одного из вариантов, система автоматически переходит к следующему вопросу. На получаемые вами баллы влияет правильность ваших ответов и затраченное на прохождение время. Обратите внимание, что вопросы каждый раз разные, а варианты перемешиваются.
где и как правильно искать информацию
Чем бы вы ни занимались, где бы ни работали, вы тратите более 30 % своего времени на поиск информации. Если вы хотите работать в сфере консалтинга, аудита или инвест-банкинга, вы будете проводить до 50–60 % трудового дня, работая с данными.
Почему важно уметь искать и обрабатывать информацию
Объем обрабатываемой нами информации удваивается каждый год, а знания, которые мы получаем, устаревают в течение 2–5 лет. Вот почему нам жизненно необходимо уметь работать с данными.
Навык много и хорошо работать с качественной информацией помогает не только сэкономить время, но и работать в 2,5 раза эффективнее. Здесь нужно обратить внимание на три вещи:
- как мы ищем информацию;
- как ее обрабатываем;
- в каком виде представляем целевой аудитории.
И начнем мы с разговора о поиске.
Поиск данных: не интернетом единым
Все мы привыкли искать информацию в интернете, но, помимо обычных интернет-источников, существуют бумажные носители, экспертное мнение и собственная база данных.
Если вы начинаете с интернета, сфокусируйтесь на качественных источниках. Но информация в интернете не структурирована и обрабатывать ее трудно и энергозатратно. Что делать? Тут в игру вступает эксперт. А о ценности собственной информационной базы можно даже не упоминать: вы и сами представляете, за какие деньги свои базы по проектам продают такие компании, как McKinsey.
Алгоритм поиска информации
Исходя из вышесказанного, мы предлагаем вам простой алгоритм поиска информации.
- Собственная база. Если это не первый ваш проект, вы сможете быстрее войти в тему, используя свои архивы, структурированные так, как удобно лично вам.
- Вводный поиск в интернете. Только после этого приступайте к preliminary research. Вводный поиск поможет вам приблизительно понять вашу тематику: тренды, игроков на рынке и т. д. Не тратьте на это слишком много времени.
- Первая встреча с экспертом. Теперь можно смело звонить эксперту. Эксперт — это тот незаменимый человек, который раскидает все ваши задачи по пирамиде Минто, поможет структурировать информацию и подскажет, в каком направлении двигаться дальше.
- Погружение в тему. Только после встречи с экспертом вы начинаете полноценный research — детальный и кропотливый.
- Повторная встреча с экспертом. Теперь вам нужен feedback о том, насколько найденная вами информация актуальна и адекватна. Проведите sanity check, или «тест на вшивость». К тому же у вас наверняка накопились вопросы, на которые необходимо получить релевантные ответы.
- Финализация данных. И только в самом конце вы анализируете информацию, основанную на продвинутом поиске и полученных от эксперта инсайтах.
Шесть правил поиска информации
Чтобы сделать работу с данными эффективнее, придерживайтесь шести правил поиска информации:
- Четко понимайте цель поиска. Какую информацию вы хотите найти? Если у вас есть цель, вы не будете терять время, переходя по случайным ссылкам и беспорядочно листая сайты.
- Используйте первичный фильтр. Какие ресурсы вас интересуют? Определите критерии релевантности сайтов и отсеивайте лишнее.
- Составьте список сигнальных слов. Сигнальные слова — это термины, используемые в функциональном жаргоне данной тематики. Составьте список таких слов и используйте их в поисковых запросах. Это позволит вам избежать сайтов непрофессионалов с неправильной информацией.
- Ищите сверху вниз. Работая со структурированными источниками, например с Wikipedia, помните, что определения и базовые тезисы чаще всего располагаются в начале статьи, и вам не обязательно листать дальше в случае их нерелевантности.
- Сканируйте содержимое. Читать каждый документ полностью на этапе вводного поиска необязательно. Пробегитесь по тексту и выделите то, что может быть вам полезно, чтобы избежать многочасового чтения.
- Создайте итоговый список. Проранжируйте источники, чтобы обозначить дальнейшую стратегию работы с ними: какие из источников самые релевантные и требуют детального изучения, а какие пригодятся как дополнительные материалы?
Как это работает? Приведем пример.
Вы ищете ноутбук на «Яндекс.Маркете». В первую очередь задайте нужные вам критерии (технические характеристики, дизайн, ценовой диапазон), но не идите сразу же в магазин, а найдите эксперта с опытом 10–15 лет и задайте ему ваши вопросы. Только не забывайте главное правило: всегда выслушайте как минимум трех экспертов.
Где искать
В интернете есть источники информации, о которых многие из вас не слышали. Если вы привыкли пользоваться исключительно Google, попробуйте новые места для поиска:
- Поисковики — не Яндекс и Google. Например, Wolfram|Alpha. Он значительно упрощает работу с математическими моделями и помогает визуализировать финансовые и экономические показатели.
- Авторитетные новостные сервисы. Мы советуем «Ведомости» как наиболее бизнес-ориентированный ресурс (кстати, студентам предоставляется 75%-ная скидка на подписку), но вы также можете обратиться к политическому «Коммерсантъ» или новостному «РБК». Лучше не выбирать что-то одно, а читать все три. В «Коммерсантъ» есть «Секрет фирмы» — полезный раздел о малом бизнесе. Не экономьте на подписке — она стоит не так много, а вы всегда будете в курсе свежих новостей. Получите доступ к Forbes, The Economist и Wall Street Journal или хотя бы читайте Bloomberg — хороший бесплатный субститут.
- Базы знаний крупнейших мировых университетов. К примеру журнал Harvard Business Review.
- Базы данных международных организаций. Хорошо работает для узкоспециализированных данных. Например, информацию о ВВП разных стран лучше всего искать на сайте ЦРУ США. У них собрана лучшая статистика по всем странам мира, и обновляется она постоянно.
- Сайты презентаций и публикаций (slideshare, scribd). В презентациях можно часто найти любопытную и даже закрытую информацию. Однако искать по этим источникам сложно, ведь слайды не индексируются. Попробуйте найти эксперта в нужной вам сфере и следите за его публикациями.
- Отчеты и инсайты компаний: разделы для инвесторов. Не теряйте время на годовые финансовые отчеты и сразу проверьте раздел для инвесторов. Из него вы узнаете все о рынке, компании и ее конкурентах всего на 15 слайдах. Изучите весь раздел полностью, ведь одна презентация может охватывать не весь рынок, а только его сегмент. Особенно это полезно для изучения маленьких рынков, информация по которым находится в закрытом доступе. Достаточно найти торгующую на нем публичную компанию.
- Экономические и статистические показатели по России и исследования рынков. Эти источники найти несложно — воспользуйтесь официальным сайтом «Росстата» или «РБК».
- Журналы консалтинговых компаний. У каждой компании Big3 есть журнал, содержащий хорошо структурированную информацию по всем крупным рынкам. Обычно они выпускают разные журналы для мировой и национальной аудитории. Так, у BCG есть и международный bcg.perspectives, и российский BCG Review, и их статьи никак не коррелируются.
- Исследования инвестиционных банков. Например, у Deutsche Bank самый подробный гайд по нефтяным рынкам — на 300 страницах.
Еще несколько советов по поиску
-
Научитесь скорочтению и используйте специальные приложения для чтения, такие как Spritz и Blinkist.
-
Работая с Google, не забывайте оптимизировать поиск с помощью команд «», or, + и других.
-
Еще один незаменимый skill — слепая печать (используйте «СОЛО на клавиатуре» для Windows и KeyKey для Mac OS). Это даст вам возможность думать одновременно с тем, как вы набираете текст.
Получите карьерную поддержку
Если вы не знаете, с чего начать карьеру, зашли в тупик или считаете, что совершили какие-то ошибки, спросите совета у специалистов. Заполните заявку и консультанты Changellenge >> окажут вам помощь. Это отличный шанс вместе экспертом проработать проблемные вопросы и составить карьерный план.
Подписаться на карьерную рассылку
Подписывайтесь на рассылку и получайте карьерные советы — от выбора индустрии и компании до лайфхаков по самоорганизации и развитию коммуникативных навыков.
Подвиг народа
Для просмотра сайта c поддержкой основных нововведений рекомендуется использовать приложение-обозреватель Microsoft Internet Explorer 10, Mozilla Firefox 4, Google Chrome 5, Opera 11.5, Safari 5.0 и выше.
Работа с сайтом «Подвиг народа»
- Описание главной страницы.
- Поиск:
Описание главной страницы сайта «Подвиг народа»
В верхней части главной страницы ОБД (а также с любой другой страницы сайта) находятся ссылки, которые соответствуют основным тематическим разделам сайта. Также доступна ссылка для перехода на прежнюю версию сайта и изменение языка интерфейса сайта (доступны английский и русский языки).
В центральной части главной страницы приведено общее описание сайта, а также размещены ссылки для перехода к разделам сайта, таким как:
- Люди и награждения;
- Наградные документы;
- география войны.
- О проекте;
- Отзывы;
- Обратная связь;
- Вопросы-ответы;
- Помощь.
Поиск
Поиск информации по любому из тематических разделов может выполняться в два этапа:
- поиск в обычном режиме, когда при определении условий поиска пользователь вводит данные в одну поисковую строку, указывая их через пробел;
- расширенный поиск, когда пользователь при определении условий поиска заполняет максимально возможное количество полей, указывая детальную информацию об объекте поиска.
Данный вид поиска является наиболее эффективным, поскольку позволяет получить результат, наиболее точно отвечающий запросам пользователя.
Чтобы приступить к поиску информации по любому из тематических разделов, необходимо навести указатель на наименование соответствующего раздела (на ссылку в верхней части страницы или в центральной части главной страницы):
Поиск по тематическому разделу «Люди и награждения»
Поиск по тематическому разделу «Люди и награждения» позволяет найти информацию о награждении, используя личные данные награжденных.
Поиск в обычном режиме
Для быстрого поиска необходимо перейти к разделу «Люди и награждения» нажатием левой кнопки мыши по заголовку раздела.
Указать имеющиеся сведения в строке поиска.
При необходимости, можно выбрать количество записей, которые будут выводиться на одну страницу результатов поиска (по умолчанию выводится по 50 записей на страницу), есть возможность выбрать следующие значения: 10, 30, 50 или 100.
Для получения результата поиска нажать кнопку «Искать» или клавишу на клавиатуре.
Расширенный поиск
Чтобы выполнить расширенный поиск информации о награждении необходимо:
- перейти к разделу «Люди и награждения»;
- нажать кнопку «Расширенный поиск»;
Откроется поисковая форма с доступными для заполнения следующими полями:
- Фамилия;
- Имя
- Отчество;
- Год рождения;
- Звание;
- Место призыва;
- Уточнение «Где искать».
Если необходимо вернуться к поиску в обычном режиме, следует нажать кнопку «Свернуть».
Если необходимо большее количество уточняющих полей для осуществления поиска, следует нажать кнопку «Еще больше». После этого будут доступны дополнительные поля, такие как:
- Наименование награды;
- Номер наградного документа;
- Дата наградного документа;
- Архив;
- Фонд;
- Опись;
- С какого года в КА;
- Единица хранения.
Чтобы удалить введенные значения из всех полей, следует нажать кнопку «Очистить». После этого можно повторно ввести значения.
После чего на экране отобразятся результаты поиска:
Поиск по тематическому разделу «Наградные документы»
Поиск по тематическому разделу «Документы» позволяет найти указы и приказы о награждении.
Поиск в обычном режиме
Для быстрого поиска необходимо перейти к разделу «Наградные документы» нажатием левой кнопки мыши по заголовку раздела.
Указать имеющиеся сведения в строке поиска.
При необходимости, можно выбрать количество записей, которое будет выводиться на одну страницу результатов поиска (по умолчанию выводится по 50 записей на страницу), есть возможность выбрать следующие значения: 10, 30, 50 или 100.
Для получения результата поиска следует нажать кнопку «Искать» или клавишу на клавиатуре.
Расширенный поиск
Чтобы выполнить расширенный поиск документов о награждении необходимо:
- перейти к разделу «Наградные документы»;
- нажать кнопку «Расширенный поиск»;
Откроется поисковая форма с доступными для заполнения следующими полями:
- Дата документа;
- Награда.
Если необходимо вернуться к поиску в обычном режиме, следует нажать кнопку «Свернуть».
Если необходимо большее количество уточняющих полей для осуществления поиска, следует нажать кнопку «Больше». После этого будут доступны дополнительные поля, такие как:
- Номер записи в базе данных;
- Номер документа;
- Автор;
- Архив;
- Фонд;
- Опись;
- Единица хранения.
Чтобы удалить введенные значения из всех полей, следует нажать кнопку «Очистить». После этого можно повторно ввести значения.
После чего на экране отобразятся результаты поиска:
Поиск по тематическому разделу «География войны»
Поиск по тематическому разделу «География войны» позволяет выполнить поиск данных по местоположению и времени события.
Документы в разделе «География войны» могут быть найдены, используя в качестве критериев поиска дату выхода документов, географическую привязку к местам ведения боевых действий, привязку к сведениям о военачальнике, издавшем документ.
Поиск в обычном режиме
Для быстрого поиска необходимо перейти к разделу «География войны» нажатием левой кнопки мыши по заголовку раздела.
Указать имеющиеся сведения в строке поиска.
При необходимости, можно выбрать количество записей, которое будет выводиться на одну страницу результатов поиска (по умолчанию выводится по 50 записей на страницу), есть возможность выбрать следующие значения: 10, 30, 50 или 100.
Для получения результата поиска нажать кнопку «Искать» или клавишу на клавиатуре.
Расширенный поиск
Чтобы выполнить расширенный поиск документов о награждении необходимо:
- перейти к разделу «География войны»;
- нажать кнопку «Расширенный поиск»;
Откроется поисковая форма с доступными для заполнения следующими полями:
- Тип документа;
- Дата документа;
- Боевая операция;
- Географическое положение.
Если необходимо вернуться к поиску в обычном режиме, следует нажать кнопку «Свернуть».
Если необходимо большее количество уточняющих полей для осуществления поиска, следует нажать кнопку «Больше». После этого будут доступны дополнительные поля, такие как:
- Номер документа;
- Наименование документа;
- Автор;
- Архив;
- Фонд;
- Опись;
- Единица хранения.
Чтобы удалить введенные значения из всех полей, следует нажать кнопку «Очистить». После этого можно повторно ввести значения.
После чего на экране отобразятся результаты поиска:
Особенности заполнения поисковых полей
При заполнении полей в режиме расширенного поиска пользователь может определить для каждого поля способ поиска:
- С начала поля – чтобы выполнять поиск документов, у которых в начале соответствующего индексного поля будет содержаться значение, указанное пользователем в данном поисковом поле;
- Точная фраза — чтобы выполнять поиск документов, у которых в соответствующем индексном поле будет содержаться значение, состоящее из одного или нескольких слов (или цифр) в том же порядке, которое указано пользователем в данном поисковом поле;
- Точное поле — чтобы выполнять поиск документов, у которых в соответствующем индексном поле будет содержаться точное значение, указанное пользователем в данном поисковом поле;
- Полнотекстовый поиск — чтобы выполнять поиск документов, у которых в соответствующем индексном поле будет содержаться информация, указанная пользователем в данном поисковом поле, без учета последовательности слов.
Определение способа поиска происходит в раскрывающемся списке, после нажатия кнопки . Для разных полей перечень доступных способов поиска может отличаться. Например, для поля Фонд доступен только поиск «Точное поле», а для поля Опись доступны поиски «Точная фраза» и «Точное поле». Пример раскрывающего списка приведен на рисунке ниже:
Работа с результатами поиска
Результаты поиска «Люди и награждения»
Результат поиска информации о героях войны выводится на экран монитора в виде списка. При этом на каждой странице результатов поиска будет выводиться то количество найденных записей, которое было задано пользователем при определении условий поиска.
В первом столбце списка указан номер строки результатов поиска.
Во втором столбце списка указан источник данных, например:
— данные из документов о награждении;
— данные из картотеки;
— данные из юбилейной картотеки.
Далее указаны: Дата рождения/Звание/Наименование награды.
Для последовательного перемещения между страницами можно также воспользоваться кнопками:
, для перехода на следующую страницу;
, для перехода на последнюю страницу;
, для перехода на предыдущую страницу;
, для перехода на первую страницу.
Если результаты поиска не соответствуют требованиям пользователя, то он может вернуться на страницу поиска, нажав на наименование раздела, в котором осуществлялся поиск; при этом, все заполненные поисковые поля останутся без изменений. Также для возврата к предыдущей странице можно нажать кнопку «Назад» в окне web-браузера.
Чтобы просмотреть определенную запись из числа найденных, следует навести на нее указатель и нажать левую кнопку мыши – на экране появится страница просмотра информации.
В верхней части страницы отображаются кнопки «К предыдущему результату поиска», «К следующему результату поиска» Данные кнопки позволяют переходить по страницам просмотра информации согласно списку результатов поиска.
Ниже на странице представлены сведения о персоналии. В столбце «Архивные документы о данном награждении» синим подсвечены ссылки для перехода к электронным образам указанных документов.
Электронный образ документа, который представлен на странице, содержит описание подвига, за который была присуждена награда.
Для просмотра текста приказа (указа) необходимо нажать на одну из ссылок:
- первая страница приказа или указа;
- строка в наградном списке;
- наградной лист.
Откроется электронный образ выбранного документа.
Для просмотра изображения предусмотрена область навигации:
переход к предыдущей странице документа;
переход к следующей странице документа;
Рядом с областью навигации представлена панель инструментов с двумя функциями:
увеличение масштаба электронного образа документа;
уменьшение масштаба электронного образа документа;
при нажатии кнопки страница электронного образа документа будет открыта в новой вкладке, далее открытую страницу можно вывести на печать или сохранить на своем ПК;
просмотр страницы документа в полноэкранном режиме, для выхода из полноэкранного режима необходимо нажать кнопку в правом верхнем углу.
Результаты поиска «Наградные документы»
Результат поиска в разделе «Наградные документы» выводится на экран монитора в виде списка. При этом на каждой странице результатов поиска будет выводиться то количество найденных записей, которое было задано пользователем при определении условий поиска.
Информация по столбцам структурирована в следующем виде:
- дата документа;
- кем издан;
- номер документа;
- наименование документа.
Для последовательного перемещения между страницами можно также воспользоваться кнопками:
, для перехода на следующую страницу;
, для перехода на последнюю страницу;
, для перехода на предыдущую страницу;
, для перехода на первую страницу.
Для перехода к странице просмотра документа необходимо нажать левой кнопкой мыши в строке нужного документа в списке результатов поиска.
В верхней части страницы отображаются кнопки К предыдущему результату поиска, К следующему результату поиска Данные кнопки позволяют переходить по страницам просмотра информации согласно списку результатов поиска.
Ниже на странице представлены изображения, относящиеся к найденному документу.
Для просмотра электронного образа документа предусмотрена область навигации:
— переход к предыдущей странице документа;
— переход к следующей странице документа;
Рядом с областью навигации представлена панель инструментов с двумя функциями:
увеличение масштаба электронного образа документа;
уменьшение масштаба электронного образа документа;
при нажатии кнопки страница электронного образа документа будет открыта в новой вкладке, далее открытую страницу можно вывести на печать или сохранить на своем ПК;
просмотр страницы документа в полноэкранном режиме, для выхода из полноэкранного режима необходимо нажать кнопку в правом верхнем углу.
При наведении курсора мыши отдельные строки электронного образа документа могут быть определены как ссылки перехода, например, на страницу персоналии:
Для перехода к странице персоналии необходимо:
- навести указатель мыши на строку электронного образа документа;
- нажать левой кнопкой мыши.
- нажать кнопку
Строка будет подсвечена красным, и в правой части строки появится кнопка перехода.
После чего будет осуществлен переход к странице персоналии:
Результаты поиска «География войны»
Результат поиска в разделе «География войны» выводится на экран монитора в виде списка. При этом на каждой странице результатов поиска будет выводиться то количество найденных записей, которое было задано пользователем при определении условий поиска.
Информация по столбцам структурирована в следующем виде:
- дата документа;
- кем издан;
- номер документа;
- тип документа.
Для последовательного перемещения между страницами можно также воспользоваться кнопками:
, для перехода на следующую страницу;
, для перехода на последнюю страницу;
, для перехода на предыдущую страницу;
, для перехода на первую страницу.
Если результаты поиска не соответствуют требованиям пользователя, то он может вернуться на страницу поиска, нажав на наименование раздела, в котором осуществлялся поиск; при этом, все заполненные поисковые поля останутся без изменений. Также для возврата к предыдущей странице можно нажать кнопку «Назад» в окне web-браузера.
Для перехода к странице просмотра документа необходимо нажать левой кнопкой мыши в строке нужного документа в списке результатов поиска.
В верхней части страницы отображаются ссылки К предыдущему результату поиска, К следующему результату поиска – данные ссылки позволяют переходить по страницам просмотра информации согласно списку результатов поиска.
Ниже на странице представлены сведения о документе.
Для просмотра электронного образа документа предусмотрена область навигации:
— переход к предыдущей странице документа;
— переход к следующей странице документа;
Рядом с областью навигации представлена панель инструментов с двумя функциями:
— при нажатии кнопки страница электронного образа документа будет открыта в новой вкладке, далее открытую страницу можно вывести на печать или сохранить на своем компьютере;
— просмотр страницы документа в полноэкранном режиме, для выхода из полноэкранного режима необходимо нажать кнопку в правом верхнем углу.
To support the site’s latest version and innovations, we recommend using the following browser versions: Microsoft Internet Explorer 10, Mozilla Firefox 4, Google Chrome 5, Opera 11.5, Safari 5.0 and higher.
Main page
At the top of the Main page there is a menu, its items correspond to the main thematic sections of the «Feat of the People» website.
The central part of the Main page provides a general description of the website, as well as links to sections of the site:
- people and awards;
- documents;
- geography of war.
An additional menu with the following sections is available at the bottom of the page:
- About the project, which contains information about the resource, access to which is provided to users of the website «Feat of the People».
- Reviews, which contains reviews about the resource, access to which is provided to users of the website «Feat of the People».
- Feedback, which contains a feedback form for users of the website «Feat of the People».
- FAQ, which provides answers to user questions about the site, most frequently asked to the site Administration.
- Help, which provides information about thematic sections of the site and ways to work with them.
Search (only Russian)
The topic search in every section can be performed in two modes:
- search in normal mode, when you define a search criteria by filling in the set of fields with the minimum information required to perform a search.
- search in advanced mode, when you define the search criteria by filling as many fields as possible and specifying detailed information about the search object.
This type of search proves most effective as it produces the result that most closely meets to user’s needs.
To start searching for information on any of the thematic sections, point to the name of the corresponding section (in the main menu of the site or in the central part of the main page):
People and awards (only Russian)
Search in the thematic section «People and awards» allows you to find information about the award, using the personal data of the awarded ones.
The topic search in every section can be performed in two modes:
Search in Normal mode
For quick search, go to the «People and awards» section by clicking the left mouse button on:
- section title;
- section button in the center of the Main page;
Then type the available information into the search field and click the «Search» button or the «Enter» key on the keyboard.
If necessary, you can select the number of records to be displayed on one page of the search results (by default, 50 records per page): 10, 30, 50, or 100.
The example of the search page in normal mode is given below:
Search in Advanced mode
To perform an advanced search of award information:
- go to the «Search and awards» section;
- click the Advanced Search button;
If you need more fields to refine the search, click the «More» button.
When filling in fields in the advanced search mode, the user can define the search method for each field:
- From the beginning — to search for documents that at the beginning of the corresponding index field will contain the value specified by the user in this search field;;
- Exact phrase — to search for documents that in a corresponding index field will contain a value consisting of one or more words (or digits) in the same order as specified by the user in this search field;
- Exact field — to search for documents that in the corresponding index field will contain the exact value specified by the user in this search field;
- Full text search — to search for documents that in the corresponding index field will contain information specified by the user in this search field, disregarding the sequence of words and their quantity.
Documents (only Russian)
Searching the thematic section «Documents» allows you to find decrees and orders on rewarding.
The topic search in every section can be performed in two modes:
Search in Normal mode
For quick search, go to the «Documents» section by clicking the left mouse button on:
- section title;
- section button in the center of the Main page;
Then type the available information into the search field and click the «Search» button or the «Enter» key on the keyboard.
If necessary, you can select the number of records to be displayed on one page of the search results (by default, 50 records per page): 10, 30, 50, or 100.
Geography of War (only Russian)
Searching the thematic section «Geography of war» allows you to find data by location and time of events.
The documents in the «Geography of war» section can be found using the date of issue of documents as search criteria, or geographical reference to the locations of combat operations, or the information about the military commander who issued the document.
The topic search in every section can be performed in two modes:
Search in Normal mode
For quick search, go to the «Geography of war» section by clicking the left mouse button on:
- section title;
- section button in the center of the Main page;
Then type the available information into the search field and click the «Search» button or the «Enter» key on the keyboard.
If necessary, you can select the number of records to be displayed on one page of the search results (by default, 50 records per page): 10, 30, 50, or 100.
Search results
The results of searching for a war hero information are displayed as a list. Each page of the search results will display that number of records, which was specified by the user when determining the search conditions.
The first column in the list contains the row number of the search results.
The second column of the list indicates the data source, for example:
— data from the award documents;
— data from the card index;
— commemorative index data.
To navigate through the search results pages, click the button and select the number of the desired page from the drop-down list at the top of the search results page..
To navigate between pages in sequence, you can also use the buttons:
, to go to the next page;
, to go to the last page;
, to go to the previous page;
, to go to the first page.
If the search results do not meet the user’s needs, then you can return to the search page by clicking on the name of the section in which the search was performed; in this case, all the completed search fields will remain unchanged. You can also click the «Back» button in the browser window to return to the previous page.
To view a particular record from among those found, point to it and click the left mouse button — the View information page will appear on the screen.
The electronic image of the document displayed on the page contains a description of the feat for which the decoration was awarded.
At the top of the page you can find the links To previous search result, To next search results — these links allow you to navigate through the pages with the required information according to the search results list.
The information about the personality is given below on the page. In the column «Archival documents on this award» the links to the electronic images of documents associated with this award and personality are highlighted in blue.
Как искать в Интернете? Способы быстро найти информацию в сети Интернет. Примеры, как правильно искать

В Интернете множество сайтов, однако не всегда информация на сайтах точна или актуальна. В статье я расскажу, как правильно искать информацию в Интернете, и поделюсь способами быстрого нахождения полезной информации. Но перед этим нужно разобраться, каким ресурсам в Интернете можно доверять.
Каким источникам в Интернете можно доверять?
Все ресурсы в сети можно разделить на достоверные и требующие проверки. Как правило, достоверная информация, которая готовится специалистами и проверяется до публикации, находится на следующих сайтах:
- Официальные сайты крупных компаний и государственных органов, либо ресурсы, официально поддерживаемые крупными компаниями и госорганами. Например, Минздав РФ создал и поддерживает сайт о здоровье www.takzdorovo.ru. На сайте указано, что информация перед публикацией проходит проверку специалистов. Как искать информацию в Интернете на специализированных сайтах, мы разберем ниже в статье.
- Корпоративные блоги компаний. Например, по теме ИТ можно искать информацию в официальных блогах ИТ-компаний, которые они ведут на сайте Хабрахабр. Там публикуется много полезной информации. Есть корпоративные блоги, которые находятся на самом сайте компании. Например, корпоративный блог Яндекса. Ниже в статье мы также разберем, как правильно искать информацию на определенных сайтах.
- Официальные сайты СМИ. На таких сайтах внизу будет размещена информация о регистрации сайта в качестве СМИ, указан номер свидетельства и дата регистрации. Перед публикацией информация в СМИ проверяется редакторами. Более того, по закону за достоверность размещаемой информации СМИ несут ответственность. Найти сайты СМИ можно, например, в каталоге Яндекса.
- Официальные каналы на YouTube. Например, компания Яндекс имеет канал Обучение рекламным технологиям, на котором публикует информацию по теме интернет-рекламы. Как правило, ссылки на официальные каналы можно найти на официальных сайтах компаний.
Из всех остальных источников информацию требуется проверять, поскольку вы не знаете, какой человек писал статью, каким опытом он обладает и может ли квалифицированно писать на ту или иную тему, проверял ли кто-то достоверность информации до публикации в Интернете или нет. Если вы напишете статью на основе недостоверных данных, вы можете ввести своих читателей в заблуждение.
Если сайт не относится к типам сайтов, описанных выше, рекомендуется проверить, кто ведет данный сайт и какую квалификацию имеет его автор:
- Посмотрите информацию об авторе сайта. Как правило, она имеется в разделе «Об авторе».
- Прочитайте информацию в разделе «О сайте». Посмотрите, как давно работает сайт, кому он принадлежит.
- Много качественной информации можно найти в блогах экспертов – людей, известных в профессиональной среде. Также много полезной информации можно найти в специализированных сообществах и социальных сетях. Однако информацию из сообществ всегда нужно проверять!
- Обращайте внимание на дату публикации найденной информации. Старые статьи могут терять актуальность.
Как быстро искать информацию в Интернете?
Способ 1. Поиск информации с ограничением по сайту
Данный способ работает в поисковых системах Яндекс и Google.
Например, вам нужно найти информацию о болях в позвоночнике. Мы знаем, что в сети есть сайт www.takzdorovo.ru, который ведут специалисты. Мы можем быстро найти информацию о болях в позвоночнике именно с этого сайта, добавив к запросу в поисковой системе конструкцию site:takzdorovo.ru.
Вот что мы нашли:
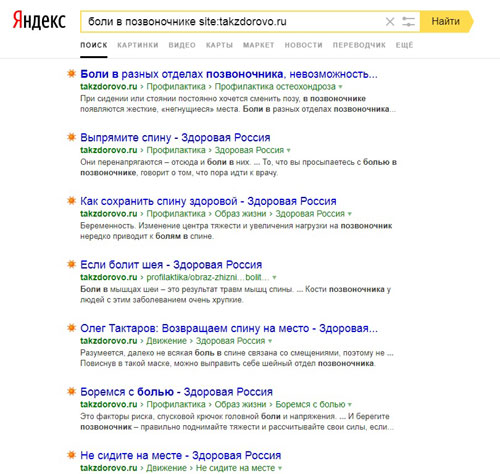
Вы видите, что оператор указал Яндексу, что информацию из запроса необходимо искать на конкретном сайте и в результатах поиска присутствуют ссылки на различные статьи о болях в позвоночнике с указанного нами сайта.
Способ 2. Ограничение по типу документов
Допустим, вам нужно найти типовой договор на оказание услуг, пример должностной инструкции или дипломную работу на определенную тему. Добавьте к своему запросу в поисковой системе оператор mime:pdf, и поиск будет вестись только по указанным вами документам (в примере – файлы PDF).
Пример поискового запроса, цель которого – найти типовой договор на оказание образовательных услуг:
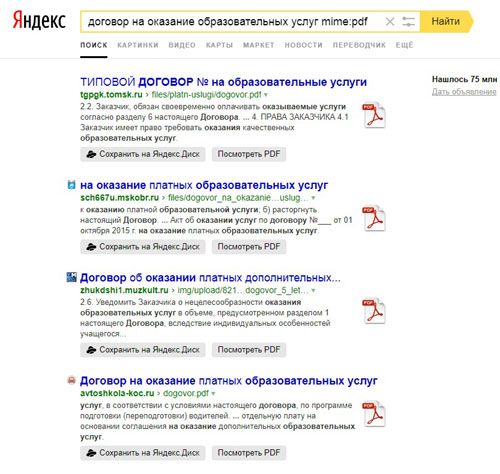
Вы видите, что в результатах поиска выводятся документы PDF, которые, скорее всего, содержат примеры нужных нам договоров.
Оператор mime: работает и для других типов документов, например:
| Оператор | Что можно искать |
| mime:pdf | Ищет документы PDF. Позволяет найти типовые инструкции, договора, коммерческие предложения, иные документы. |
| mime:doc | Ищет по документам MS Word, размещенным в сети Интернет. Помимо документов, позволяет находить рефераты, курсовые, дипломные работы, поскольку они часто оформлены в формате .doc. |
| mime:ppt | Ищет по документам Power Point, размещенным в сети Интернет. Оператор полезен для поиска презентаций на нужную вам тему. |
| mime:xls | Поиск по документам Excel, размещенным в сети Интернет. Позволяет находить полезные шаблоны в Excel. |
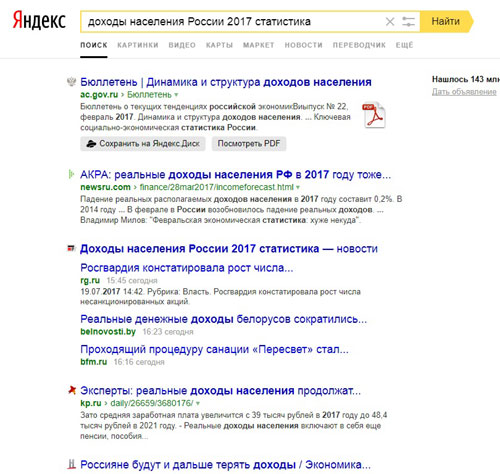
Способ 3. Конкретизация запроса
Старайтесь формулировать конкретные запросы в поисковую систему, состоящие минимум из 3-4 слов. Это позволит поисковой системе лучше понять, какая информация вам нужна, и выдать более точные результаты в поиске.
Пример правильного запроса для поиска статистической информации о доходах населения:
Способ 4. Использование специализированных поисковых систем
Например, для поиска по научным публикациям существует специализированная поисковая система Академия Google. Существуют и другие специализированные поисковые системы, в разных сферах. Их стоит находить и использовать для быстрого поиска нужной информации.
Например:
- На сайте Кинопоиска есть специализированный поиск по фильмам, который можно использовать для создания обзоров кино и поиска интересных для просмотра фильмов.
- На сайте Яндекс.Маркет можно искать информацию о технике. На карточке товара имеются отзывы, а также ссылки на обзоры техники. Это позволяет не только просмотреть технические параметры устройства, но и собрать информацию о сильных и слабых сторонах модели, с которыми сталкиваются потребители в процессе эксплуатации гаджета.
- В социальных сетях имеется встроенный поиск, который позволяет находить аккаунты знаменитостей и прочитать информацию о звездах.
- На сайте Википедии можно искать различную энциклопедическую информацию.
Способ 5. Поиск на английском языке
Не секрет, что объем информации в Интернете на английском языке значительно больше, чем на других языках. Если вы владеете английским, попробуйте задавать запросы в западные поисковые системы, в частности, Google или Yahoo.com, на английском языке. Вероятно, вы сможете найти больше информации по интересующей вас теме.
Способ 6. Использовать специализированные каталоги
Когда речь заходит о том, как правильно искать информацию в Интернете, мы обычно сразу вспоминаем про поисковые системы. Однако до их появления нужные сайты часто искали в каталогах. До настоящего времени ряд каталогов сохранили актуальность и могут помочь в поиске нужной информации.
Например, в каталоге Яндекса собраны полезные ресурсы по различным темам. В Интернете работает множество специализированных каталогов – например, каталоги компаний. Их тоже можно использовать для поиска нужной информации.
Разберем, как правильно искать информацию, на примерах
Допустим, вы – копирайтер, и пишете статьи для сайтов. Вам поручили подготовку материала на определенную тему, и вам нужно найти информацию для статьи. В таблице ниже даны примеры задач и способы поиска информации в Интернете для решения указанной проблемы.
| Задача, поставленная клиентом | Как искать информацию в Интернете для статьи |
| Написать обзор смартфона для интернет-магазина. |
|
| Собрать статистическую информацию для реферата. |
|
| Собрать информацию для статьи на научно-популярную тему. |
|
| Написать обзорную статью для туристов, желающих поехать в Таиланд. |
|
| Написать статью о выборе виртуального хостинга. |
|
Резюме
Мы разобрали, как правильно искать в Интернете быстро и просто. Вы узнали, каким источникам в сети можно доверять, а какую информацию стоит перепроверять. Изучили примеры поиска в зависимости от поставленной задачи.
Если у вас остались вопросы, пожалуйста, задавайте их в комментариях.
Рекомендуем

В этой статье я расскажу, как и сколько можно зарабатывать написанием текстов в Интернете, где искать заказы и как быстро выйти на хороший доход. …

В данной статье я расскажу о доходах копирайтеров в различных сферах. Вы узнаете, сколько можно заработать на копирайтинге, работая в офисе или на …
Поиск информации — это… Что такое Поиск информации?
Поиск по метаданным — это поиск по неким атрибутам документа, поддерживаемым системой — название документа, дата создания, размер, автор и т. д. Пример поиска по реквизитам — диалог поиска в файловой системе (например, MS Windows).
Поиск по изображению — поиск по содержанию изображения. Поисковая система распознает содержание фотографии (загружена пользователем или добавлен URL изображения). В результатах поиска пользователь получает похожие изображения. Так работают поисковые системы:
Методы поиска
Адресный поиск
Процесс поиска документов по чисто формальным признакам, указанным в запросе.
Для осуществления нужны следующие условия:
- Наличие у документа точного адреса
- Обеспечение строгого порядка расположения документов в запоминающем устройстве или в хранилище системы.
Адресами документов могут выступать адреса веб-серверов и веб-страниц и элементы библиографической записи, и адреса хранения документов в хранилище.
Семантический поиск
Процесс поиска документов по их содержанию.
Условия:
- Перевод содержания документов и запросов с естественного языка на информационно-поисковый язык и составление поисковых образов документа и запроса.
- Составление поискового описания, в котором указывается дополнительное условие поиска.
Принципиальная разница между адресным и семантическим поисками состоит в том, что при адресном поиске документ рассматривается как объект с точки зрения формы, а при семантическом поиске — с точки зрения содержания.
При семантическом поиске находится множество документов без указания адресов.
В этом принципиальное отличие каталогов и картотек.
Библиотека — собрание библиографических записей без указания адресов.
Документальный поиск
Процесс поиска в хранилище информационно-поисковой системы первичных документов или в базе данных вторичных документов, соответствующих запросу пользователя.
Два вида документального поиска:
- Библиотечный, направленный на нахождение первичных документов.
- Библиографический, направленный на нахождение сведений о документах, представленных в виде библиографических записей.
Фактографический поиск
Процесс поиска фактов, соответствующих информационному запросу.
К фактографическим данным относятся сведения, извлеченные из документов, как первичных, так и вторичных и получаемые непосредственно из источников их возникновения.
Различают два вида:
- Документально-фактографический, заключается в поиске в документах фрагментов текста, содержащих факты.
- Фактологический (описание фактов), предпологающий создание новых фактографических описаний в процессе поиска путем логической переработки найденной фактографической информации.
Информационный поиск как наука
Информационный поиск — большая междисциплинарная область науки, стоящая на пересечении когнитивной психологии, информатики, информационного дизайна, лингвистики, семиотики, и библиотечного дела.
ИП рассматривает поиск информации в документах, поиск самих документов, извлечение метаданных из документов, поиск текста, изображений, видео и звука в локальных реляционных базах данных, в гипертекстовых базах данных таких, как Интернет и локальные интранет-системы.
Существует некоторая путаница, связанная с понятиями поиска данных, поиска документов, информационного поиска и текстового поиска. Тем не менее, каждое из этих направлений исследования обладает собственными методиками, практическими наработками и литературой.
В настоящее время ИП — это бурно развивающаяся область науки, популярность которой обусловлено экспоненциальным ростом объемов информации, в частности в сети Интернет. ИП посвящена обширная литература и множество конференций. Одной из наиболее известных является Министерством обороны США совместно с Институтом Стандартов и Технологий (NIST) с целью консолидации исследовательского сообщества и развития методик оценки качества ИП.
Запрос и объект запроса
Говоря о системах ИП, употребляют термины запрос и объект запроса.
Запрос — это формализованный способ выражения информационных потребностей пользователем системы. Для выражения информационной потребности используется язык поисковых запросов, синтаксис варьируется от системы к системе. Кроме специального языка запросов, современные поисковые системы позволяют вводить запрос на естественном языке.
Объект запроса — это информационная сущность, которая хранится в базе автоматизированной системы поиска. Несмотря на то, что наиболее распространенным объектом запроса является текстовый документ, не существует никаких принципиальных ограничений. В частности, возможен поиск изображений, музыки и другой мультимедиа информации. Процесс занесения объектов поиска в ИПС называется индексацией. Далеко не всегда ИПС хранит точную копию объекта, нередко вместо неё хранится суррогат.
Задачи информационного поиска
Центральная задача ИП — помочь пользователю удовлетворить его информационную потребность. Так как описать информационные потребности пользователя технически непросто, они формулируются как некоторый запрос, представляющий из себя набор ключевых слов, характеризующий то, что ищет пользователь.
Классическая задача ИП, с которой началось развитие этой области, — это поиск документов, удовлетворяющих запросу, в рамках некоторой статической коллекции документов. Но список задач ИП постоянно расширяется и теперь включает:
- Вопросы моделирования;
- Извлечение информации, в частности аннотирования и реферирования документов;
Оценки эффективности
Существует много способов оценить насколько хорошо документы, найденные ИПС, соответствуют запросу. К сожалению, понятие степени соответствия запроса, или другими словами релевантности, является субъективным понятием, а степень соответствия зависит от конкретного человека, оценивающего результаты выполнения запроса.
Точность (precision)
Определяется как отношение числа релевантных документов, найденных ИПС, к общему числу документов:
 ,
,
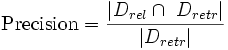 ,
,где Drel — это множество релевантных документов в базе, а Dretr — множество документов, найденных системой. По результатм исследований компании, оценивающей релевантность показателей основных русских и зарубежных поисковых систем.
Точность рамблера~ 0,756. яндекса~0.706, гугла~0.899 апорта~0.705 yahoo~0.689 altavista~0.698 Эти показатели были получены на основе анализа запроса на слово cat и по тому, как много релевантных ссылок выдаёт поисковик на 100 первых ответов.
Полнота (recall)
Отношение числа найденных релевантных документов, к общему числу релевантных документов в базе:
- ,
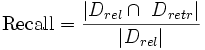 ,
,где Drel — это множество релевантных документов в базе, а Dretr — множество документов, найденных системой.
Выпадение (fall-out)
Выпадение характеризует вероятность нахождения нерелевантного ресурса и определяется, как отношение числа найденных нерелевантных документов к общему числу нерелевантных документов в базе:
- ,
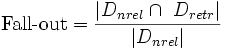 ,
,где Dnrel — это множество нерелевантных документов в базе, а Dretr — множество документов, найденных системой.
F-мера (F-measure, мера Ван Ризбергена)
Традиционно F-мера определяется, как гармоническое среднее точности и полноты:
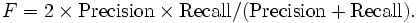
Часто ее также называют F1 мерой, потому что точность и полнота присутствуют в этой формуле с одинаковым весом.
Более общая формула для положительного вещественного α имеет вид:
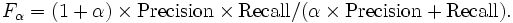
См. также
Ссылки
Литература
- Дональд Кнут Искусство программирования, том 3. Сортировка и поиск = The Art of Computer Programming, vol.3. Sorting and Searching. — 2-е изд. — М.: «Вильямс», 2007. — С. 824. — ISBN 0-201-89685-0
как качественно «пробить» человека в сети Интернет? / Эшелон corporate blog / Habr
Мы постоянно встречаемся в своей жизни с новыми людьми, и стоит констатировать, что помимо хороших друзей нам попадаются мутные товарищи, а иногда и отъявленные мошенники. Любовь наших сограждан оставить свой след в интернете и старания наших ИТ-компаний по автоматизации всего и вся позволяют нам довольно оперативно собирать интересующую информацию о конкретных персонах по открытым источникам. Чтобы это делать быстро и качественно, нам нужно владеть простой методологией разведывательной работы и знать, где и какую информацию о человеке можно добыть в интернете.Как работает разведка?
Доступной моделью работы любой разведывательной службы является так называемый разведывательный цикл. Ниже представлена иллюстрация цикла, взятая с сайта ФБР.
Мы можем творчески перевести и сгруппировать немного по-своему и получить следующие этапы:
- Постановка задачи/формулировка проблемы;
- Планирование;
- Сбор данных;
- Обработка данных;
- Анализ информации;
- Подготовка отчета и презентация результатов.
Возьмем эту модель на вооружение и адаптируем для наших благих целей проверки нечистоплотных товарищей.
Шаг 1. Постановка задачи
Обычно задача про проверке какого-либо человека ставится примерно так: “Надо собрать всю информацию об этом человеке!” По факту чаще всего нам интересно знать его биографию, психологический портрет, круг знакомств.
Шаг 2. Планирование
Не имея плана поиска и анализа данных, мы будем долго и грустно смотреть в экран и отправлять в поисковики различные запросы, содержащие крупицы известных нам данных о нашей цели. Если нам повезет, то мы сможем что-нибудь выловить, если нет – то зря потратим время в попытках перетрясти весь интернет.
Как спланировать наши действия?
1) Нам нужно собрать все, что известно на текущий момент: имя, фото, тел, сфера деятельности, друзья и т.д. и т.п. Как правило, самой ценной информацией является ник, используемый человеком в интернете (чаще всего его можно получить, зная личный адрес электронной почты).
2) Нам нужно сформулировать рабочие гипотезы для поиска данных на основе имеющейся информации. Например:
- Человек работает в компании, занимающей продажей комбикормов, название которой заканчивается на «ва»: мы видели фотографию с выставки и смогли рассмотреть часть названия компании.
- Возраст от 30 до 40: оценили по голосу или описанию.
- Дружит с таким-то человеком.
- и т.п.
Примечание. Талантливый разведчик должен уметь переключаться между двумя состояниями: безудержный креатив и жуткое занудство. В первом случае накидываем гипотезы для проверки, а во втором тщательно их проверяем: находим информацию и отбраковываем гипотезы в случае выявления несоответствий.
3) Имея рабочие гипотезы, продумываем какие источники данных нам могут быть полезны в этом легком деле по выводу на чистую воду.
На поверхности лежат следующие источники интересной информации:
- Социальные сети VKontakte, Facebook, Twitter, Instagram и т.п. (масса интересной информации: фото, гео, друзья, интересы, контакты, психологический портрет и т.п.).
- Сайты судов (если знаем фамилию и место регистрации, то сможем узнать не судится ли человек по базе на сайте конкретного суда).
- База недействительных паспортов (http://services.fms.gov.ru/info-service.htm?sid=2000).
- База судебных приставов: не должен ли наш товарищ чего? (http://fssprus.ru/iss/ip/).
- База дипломов (http://frdocheck.obrnadzor.gov.ru).
- Google с Яндексом.
Замечание. Зная ник, можно быстро посмотреть в каких социальных сетях существуют соответствующие страницы. Для этого существуют специальные сервисы для проверки доступности страниц, например, namechk.com Забытые пользователем аккаунты иногда бывают намного интересней текущих.
Мощным источником информации может стать поисковик, но чтобы извлечь максимальную пользу начинающему разведчику необходимо освоить так называемые операторы продвинутого поиска, среди которых одними из самых полезных являются: “”, -, cache, site:, filetype:, но это тема для отдельной статьи.
Шаг 3. Сбор данных
В рассматриваемом случае сбор данных будет заключаться в формировании запросов к рассмотренным источникам и сохранении результатов для текущего и последующего сопоставления и анализа. Бывает очень полезно в процессе подобного упражнения открыть текстовый редактор и последовательно сохранять в него обнаруженные данные (скриншоты, текст, фото и т.п.).
Шаг 4. Обработка данных
Иногда чтобы получить ценную информацию нужно покопаться в сырых данных. Примерами обработки могут быть:
- Извлечение метаданных из документов (авторство, GPS-координаты).
- Приведение выгрузки данных из социальных сетей к виду, с которым можно работать, например, в том же Excel.
- и т.п.
Шаг 5. Анализ информации
1. Тестируем гипотезы. Собирая по крупицам информацию, мы сразу же проводим ее анализ и тут снова могут быть полезны гипотезы и их тестирование на жизнеспособность. Сопоставляя с ними выявленные факты, косвенные признаки, логические заключения из фактов, можно определить наиболее вероятную гипотезу.
| Факты/Суждения | Гипотеза 1 | Гипотеза 2 | Гипотеза 3 | Гипотеза 4 |
|---|---|---|---|---|
| Факт 1 | + | + | + | + |
| Факт 2 | — | + | + | + |
| Суждение 1 | — | — | + | + |
| Факт 3 | — | — | — | + |
2. Элементарные операции с данными: сортировка, сопоставление элементов и т.п. могут открыть массу интересного. Например, можно выгрузить списки друзей друзей интересующего человека и, сопоставив их, определить сообщества, структуры, к которым может иметь и интересующее нас лицо. В этом нелегком деле нам может помочь Excel с его возможностью условного форматирования в случае совпадения элементов.
3. Анализ фото- и видео-изображений. От опытного глаза начинающего интернет-разведчика не уйдут не только случайно попавшие в кадр: вид из окна, часть названия географического пункта или пикантное отражение в зеркале на заднем плане, но и различные невербальные сигналы, которые позволят судить о человеке:
- складки на лице, открывающие превалирующую эмоцию человека;
- любимые жесты;
- характер взаимоотношений с другими людьми и т.п.
4. Анализ содержимого текстов интересующего человека или его собеседников. Обратите внимание на то, как человек описывает свое отношение к другим, что его друзья пишут о нем самом. Тут, конечно, стоит не только уметь внимательно читать, но и знать различного рода тонкости, например, то, что можно в соцсети VKontakte искать упоминания о человеке с помощью следующего URL-запроса: vk.com/feed?obj=ID&q=§ion=mentions, где ID – это идентификатор пользователя, который можно узнать, наведя курсор, например, на кнопку «Отправить сообщение»: цифры в ссылке и будут его ID.
5. Анализ лайков. Некоторые ставят лайки всему, что видят, от кого-то лайка никогда не дождешься, но, в основном, люди довольно избирательны в этом деле и вот тут очень интересно посмотреть статистику того, кто или что собирает максимум лайков от нашего человека. Хорошо, что появляются сервисы, позволяющие этот интересный процесс анализа автоматизировать, например, такие как searchlikes.ru
Тема анализа информации очень обширная и интересная, и мы к ней еще не раз вернемся в будущих статьях.
Шаг 6. Подготовка отчета и презентация результатов
Настоящие разведчики много пишут, так как работают на государство. Нам же, так как мы занимаемся подобными вещами исключительно в личных целях и в рамках закона, отчеты строчить не нужно. Тем не менее упражняться в письменном изложении процесса анализа и его результатов очень полезно, так как мы можем тем самым развивать логическое мышление и приобретать навыки анализа текстовой и числовой информации.
Вместо заключения
Итак, мы рассмотрели процесс сбора и анализа информации о конкретном человеке в интернете, воспользовавшись моделью разведывательного цикла и знанием о том, где в интернете есть интересные данные.
UPDATE:
Следующая статья посвящена том, как «пробить» целую группу пользователей социальной сети (на практическом примере): Интернет-разведка в действии: who is Mr./Ms. Habraman?
Как найти информацию о человеке: Гид по OSINT-инструментам
OSINT, расшифровывающееся как Open-source intelligence, — это поиск, сбор, выбор и анализ разведовательной информации из открытых источников. Данные таким образом используют маркетологи, криминалисты, специалисты по компьютерной и интернет-безопасности и др. Существующие OSINT-инструменты могут использовать и журналисты для работы над расследовательскими материалами. О том, как найти информацию о человеке или, наоборот, проверить свои цифровые следы, читайте в нашем переводе статьи Петро Черкасца.
В поиске и анализе OSINT-информации можно выделить следующие шаги:
- Начните с того, что у вас есть — email человека, его юзернейм и т.д.
- Определите цель — что конкретно вы хотите узнать
- Соберите данные
- Проанализируйте их
- Внесите корректировки на основе новых данных и определите основные моменты
- Проверьте предположения
- Подведите итоги
А теперь приступим к деталям.
Поиск по реальному имени
Источник: IntelTechniques.comВ 2002 году появились так называемые Google Dorks — поисковые запросы, касающиеся уязвимых систем и утечки информации. С помощью верно сформулированных запросов можно посмотреть комментарии и лайки даже закрытых аккаунтов.
Вот как выглядят некоторые Google Dorks:
- “john doe” site:instagram.com — находит пользователя Инстаграма по точному имени;
- “john doe” -“site:instagram.com/johndoe” site:instagram.com — прячет посты самого пользователя, но показывает его комментарии под постами других аккаунтов;
- “john” “doe” -site:instagram.com — находит пользователя вне Инстаграма по точному имени и фамилии в разных комбинациях;
- “CV” OR “Curriculum Vitae” filetype:PDF “john” “doe” — находит резюме с такими же именами и фамилиями в формате PDF.
Если вы наверняка знаете имя и фамилию своего персонажа, «заворачивайте» их в кавычки. Иначе Google постарается привести их к схожим популярным запросам, которые отличаются, однако, от ваших.
Не ограничивайтесь одним Google: проверьте человека также в других поисковиках — Bing, Яндекс и DuckDuckGo. Возможно они покажут другую информацию.
Специальные сайты
Подсказать информацию о реальном имени, юзернейме, электронной почте или телефонном номере могут следующие вебсайты:
- https://pipl.com
- https://www.spokeo.com
- https://thatsthem.com
- https://www.beenverified.com
- https://www.fastpeoplesearch.com
- https://www.truepeoplesearch.com
- https://www.familytreenow.com
- https://people.yandex.ru
Если вы нашли себя на подобных сайтах, можете попросить оттуда вас убрать. Однако на этом дело не закончится: вы можете всплыть в другой базе. Почему так происходит? Дело в том, что компании покупают одни и те же данные. Закрывая одни сайты, они размещают тот же контент на других. Поэтому удалить полностью свои данные сложно.
Что касается журналистов-расследователей: если искомый персонаж сумел подчистить свои цифровые следы, то можно попробовать поискать его в новых базах данных. Для этого стоит посмотреть, какими доменами владеет компания, у которой есть поисковик людей.
Поиск по имени пользователя
Источник: IntelTechniques.comИтак, если поиск по реальному имени ничего не дал или нужна дополнительная информация, поищем ее по юзернейму. Пробуем комбинации ФИО, названия электронной почты или домена сайта, которым человек владеет.
Самый простой способ — поискать эти комбинации в поисковиках. Также можно воспользоваться специальными сайтами — socialcatfish.com, usersearch.org или peekyou.com. Или опять пустить в ход Google Dorks. Например, если есть некий John Doe, проживающий предположительно в Нью-Йорке:
allinurl:john doe ny site:instagram.com — такой запрос найдет страницы Инстаграма со словами “john“, “doe” и “ny”, которые есть в URL этих страниц.
Если у вас получился целый список с ключевыми словами, которые могут быть в юзернейме, можно воспользоваться небольшой Python-программкой, которая сгенерирует всевозможные комбинации из этих слов.
Источник: medium.com/@Peter_UXerТакже пригодятся следующие сайты — instantusername.com и namechk.com. Проверить искомого персонажа лучше на обоих, потому как сайты выдают разные результаты.
Существуют также открытые коды для программ на платформе Github — к примеру, WhatsMyName. В нем есть несколько инструментов, среди них для расширенного поиска предназначены Spiderfoot and Recon-ng. Однако некоторые интернет-провайдеры могут блокировать сайты, где ищет WhatsMyName, поэтому лучше предварительно включить прокси или VPN. Впрочем, ими лучше пользоваться всегда, чтобы вас не раскрыли.
Источник: medium.com/@Peter_UXerНе стоит забывать следующую вещь: даже если вы нашли кого-то с искомым юзернеймом, не факт, что это тот человек, который нужен вам.
Электронная почта
Источник: IntelTechniques.comGoogle Dorks
- “@example.com” site:example.com — находит почтовые ящики на определенном домене.
- HR “email” site:example.com filetype:csv | filetype:xls | filetype:xlsx — находит контакты HR в формате xls, xlsx и csv на определенном домене.
- site:example.com intext:@gmail.com filetype:xls — вытаскивает ID электронных почтовых ящиков (в данном случае Gmail) из определенного домена.
Дополнительные инструменты
- Hunter.io — сканирует домен на наличие почтовых ящиков и показывает схемы между ними;
- Email permutator — генерирует комбинации названий почтовых ящиков из имен, фамилий, прозвищ и доменов;
- Proofy — проверяет существование электронной почты. Удобно использовать при наличии сгенерированного списка email-адресов. Можно проверять сразу несколько ящиков.
- Verifalia — тоже проверяет существование той или иной электронной почты. В бесплатном варианте без регистрации сверяет адреса по одному. Если зарегистрируетесь, сможете прогонять сразу несколько.
Плагины для браузера
- Prophet — взяв за основу имя, компанию и другие данные, предсказывает название электронной почты и сам же проверяет ее существование. По сравнению с остальными Prophet способен на более детальный и сложный поиск.
- Расширение для браузера OSINT — содержит множество полезных ссылок, в том числе для поиска email и верификации. Есть версия для Firefox и Chrome.
- LinkedIn Sales Navigator — плагин для Chrome, который связывает Twitter-аккаунт с соответствующим профилем человека в LinkedIn и показывает его электронную почту.
Слитые базы данных
Haveibeenpwned.com, созданный специалистом по безопасности Троем Хантом, позволяет проверить, не утекли ли в интернет ваши пароли от электронной почты, Dropbox, Bookmate, Minecraft и прочих сервисов. Этим же сайтом можно воспользоваться и в расследовательских целях: если у вас на руках email вашего Петра Иванова, можно посмотреть, какими сайтами он пользовался с помощью этого почтового ящика.
Другой вариант — dehashed.com. Бесплатный аккаунт предлагает примерно то же, что и сайт Ханта, а вот платный покажет пароли открытым текстом или в виде хеша. Если использовать их чисто с расследовательской точки зрения, то поиск по паролям может показать не только, какими сайтами пользовался человек, но и электронную почту, которая к ним привязана. Однако не факт, что найденное вами принадлежит вашему Иванову: пароли могут быть не уникальными, кто-то может использовать точно такой же пароль.
Номер телефона
Источник: IntelTechniques.comИногда люди подвязывают к аккаунту в Facebook номер телефона, поэтому будет не лишним вбить номер в поисковую строчку социальной сети. Если Иванов проживает в Америке или Европе, попробуйте сервис whocalledme.com с базами абонентов. Схожие данные предоставляют и мобильные приложения — privacystar.com, getcontact.com и everycaller.com. Попробуйте поискать другие: возможно среди них есть те, что привязаны непосредственно к стране вашего персонажа.
PhoneInfoga
Пожалуй, самый навороченный сервис для сканирования телефонных номеров, причем использует он только бесплатные ресурсы. Работает для любых международных номеров с большой точностью. Главное иметь на руках страну проживания Иванова, область, оператора и тип связи. Далее PhoneInfoga определяет VoIP провайдера и другие данные, с помощью которых можно продолжить искать цифровые следы.
Источник: medium.com/@Peter_UXerAndroid-эмулятор
Еще раз про безопасность: чтобы не засвечивать свои контакты и другие данные при использовании приложений, подобных PhoneInfoga, можно воспользоваться эмулятором — программой, которая создает симуляцию дополнительной операционной системы. Эмуляторы существуют в частности для Android-систем.
Большинство приложений ладят с эмуляторами, однако у некоторых могут быть сбои, например у Viber.
Иногда с помощью эмуляторов можно узнать и другую информацию. Некоторые приложения позволяют пользователям загружать аватары, имя и краткую биографию, которые можно узнать при наличии номера телефона. Среди них:
- Bluestacks — создавалось изначально для геймеров. Есть версии для Windows, Mac и Linux. Запускается без эмуляторов, поэтому установить проще, чем Genymotion.
- Genymotion — используется в основном разработчиками. Есть также бесплатная версия для личного использования. Работает на Windows, Mac и Linux, можно подключить другие виртуальные устройства.
- AMIDuOS — работает только на Windows и практически имитирует Android-среду. Установка достаточно простая. Единственный минус — цена в $10.
Домены
Источник: IntelTechniques.comGoogle Dorks
И вновь возвращаемся к Google:
- Site:example.com — поиск на определенном сайте.
- filetype:DOC —ищет файлы в формате DOC. Также можно искать другие форматы — PDF, XLS и INI. Если нужно найти одновременно несколько типов файлов, используйте между ними знак “|”.
- Intext:word1 — поиск по страницам сайтов и сайтам, которые содержат ключевое слово.
- allintext: word1 word2 word3 — поиск ключевых слов по странице или вебсайту. Related:example.com — поиск веб-страниц, которые поисковик считает похожими на заданную вами .
- site:*.example.com —показывает все субдомены.
Whois
Whois показывает информацию, на кого зарегистрирован или с кем связан веб-ресурс, будь то домен, IP-адрес или автономная система. Существует множество сервисов для поиска Whois-информации, среди них — whois.icann.org и whois.com.
Обратный Whois
Показывает список доменов, зарегистрированных на одну и ту же организация или email. Эта возможность есть у сервиса viewdns.info, который предлагает также расширенные функции.
Одинаковый IP
Иногда список сайтов, находящихся на одном и том же сервере, может дать дельную информацию. Можно, к примеру, найти субдомены или сайты, находящиеся в разработке. Проверить эту информацию позволяют atsameip.intercode.ca и sameip.org.
Пассивная DNS информация
Обычные DNS-записи показывают, к какому IP-адресу или имени привязан сайт. Если этой информации недостаточно,стоит обратиться к пассивной DNS информации: сервисы наподобие RiskIQ Community Edition, VirusTotal или SecurityTrails позволяют увидеть историю владельцев домена или IP-адреса.
Интернет-архивы и кэш
WaybackMachine и Archive.today позволяют увидеть предыдущие версии веб-страниц, в том числе посмотреть удаленные. Кроме этого Archive.today предлагает пользователям вручную сохранять страницы для архива.
Помимо архивных сайтов схожие функции есть и у Google. Их можно найти на cachedview.com или через поисковый запрос cache:website.com. Схожие вещи есть и у других поисковиков. Однако не забывайте, что кэш показывает страницу такой, какой она была индексирована последний раз. То есть вы можете наткнуться на страницу с отсутствующими изображениями или неактуальной информацией.
Другой сервис, visualping.io, делает скриншоты страницы в заданное время и при изменениях посылает уведомление.
Проверка репутации, вредоносных программ и реферальный анализ
Перед тем, как открыть сайт, лучше проверить его репутацию. В этом помогут:
- www.siteworthtraffic.com — анализирует веб-трафик (количество пользователей, просмотров страниц) и примерно прикидывает, сколько денег сайт получает за размещенную на нем рекламу.
- www.alexa.com — анализирует веб-трафик, сравнивает конкурентов, дает SEO-советы
- www.similarweb.com — тоже занимается аналитикой, показывает информацию о месте сайта в нишевых и географических рейтингах, источники трафика и др. Помимо этого умеет делать реферальный анализ — то есть на основе исходящих и входящих HTML-ссылок способен показать связанные между собой домены.
- https://sitecheck.sucuri.net — сканирует сайты на наличие вредоносных программ, подозрительных файлов, ошибок сайта, присутствия в черном списке и др.
- www.quttera.com — бесплатный сервис, схож с предыдущим сайтом owww.urlvoid.com — также проверяет сайты на вирусы, а также дает информацию о домене — IP адрес, DNS записи и т.п.
Поисковики по интернету вещей
Показывают девайсы, подключенные к киберпространству, а вместе с ними информацию об открытых портах, приложениях и протоколах. Какие поисковики умеют это делать:
- Shodan.io — популярный сервис с открытым API и интеграцией со многими инструментами. Маркетологи используют его для получения информации о своих пользователях и их месторасположении. Специалисты по безопасности используют его для поиска незащищенных систем и девайсов, подключенных к интернету.
- Есть и другие варианты — Censys или его китайские аналоги Fofa и ZoomEye.
Геолокация
Источник: IntelTechniques.comБесплатный инструмент Creepy определяет месторасположение на основе данных из социальных сетей и сайтов с изображениями. Сервис Echosec умеет схожее, но он платный: месячная подписка на него обойдется в $500. Исключения есть для журналистов и работников НПО.
Геолокация по IP-адресу
Привязать IP или MAC-адрес к реальному географическому месту умеют многие сервисы, в том числе iplocation.net. Если же вы знаете, к каким WI-FI точкам подключался ваш Иванов, используйте wigle.net, чтобы обнаружить их на карте и далее воспроизвести детальный поиск в Google Earth.
Другие полезности
- emporis.com — архитектурная база данных, где есть здания со всего мира. Может пригодится, если надо опознать здание на изображении.
- snradar.azurewebsites.net — поиск по постам ВКонтакте, которые открыты для всех и где есть геолокационная метка. Фильтрует результаты по времени.
- Photo-map.ru — умеет то же, что и предыдущий сайт, однако требует авторизации.
- www.earthcam.com —глобальная сеть уличных веб-камер. Полезно для подтверждения локации.
- insecam.org — база с камерами безопасности. Координаты приблизительны: указывают не на физический адрес камеры, а на ISP-адрес.
Изображения
Чтобы узнать, где использовалось изображение или где оно появилось впервые, используйте поиск по изображениям. Он есть в основных поисковиках — Google Images, Bing Images, Яндекс Картинки и Baidu Images. Также стоит воспользоваться сервисом TinEye, чьи алгоритмы отличаются от Google.
Поиск по изображениям есть и в социальных сетях: Findclone и Findmevk.com для ВКонтакте, karmadecay — для Reddit.
Помимо этого существуют специализированные плагины — RevEye для Chrome, Image Search Options для Firefox. Мобильные приложения наподобие CamFind могут опознать вещи из реального мира. А Image Identification Project использует для этого искусственный интеллект.
Если изображение содержит EXIF-данные (информацию о камере, геокоординаты и т.п.), то стоит их проанализировать. Увидеть (и изменить) их можно с помощью любого редактора изображений или небольшой программы Exiftool . Есть также похожие онлайн-сервисы — exifdata.com и viewexifdata.com.
Удалить EXIF-данные можно с помощью exifpurge.com или verexif.com.
Другой ресурс, stolencamerafinder.com, определяет камеру по серийному номеру и ищет в интернете, какие еще фото были сделаны ею.
Проверить изображение на фотошоп и другие манипуляции можно с помощью Forensically или FotoForensics. Если вы не хотите загружать картинку в интернет, используйте программы Phoenix или Ghiro. В Ghiro функции более автоматизированы и дают больше возможностей, чем предыдущие сервисы.
Если вам нужно сделать изображение более четким, пригодятся следующие инструменты:
- Smartdeblur — убирает размытие, восстанавливает фокус, а также умеет улучшать в целом четкость картинки
- Blurity — убирает размытие. Запускается только на Mac.
- Letsenhance.io — улучшает и масштабирует изображение онлайн, используя искусственный интеллект.
SOCMINT
SOCMINT — это подраздел OSINT, фокусирующийся на сборе и мониторинге данных в социальных сетях.
- Stalkscan — показывает всю публично доступную информацию о человеке.
- ExractFace — выгружает данные из Facebook для оффлайн-использования и дальнейшего анализа.
- Facebook Sleep Stats — показывает примерный режим бодрствования человека, беря за основу онлайн и оффлайн-статусы.
- Lookup-id.com — находит ID профиля или группы
- Расширенный поиск в Twitter — говорит само за себя 🙂
- TweetDeck — панель, где ленту можно настроить под себя, объединив твиты в тематические группы или колонки
- Trendsmap — показывает популярные тренды, хештеги и ключевые слова по всему миру.
- Foller — показывает информацию о любом открытом аккаунте, включая число твитов и подписчиков, списки, хэштеги и упоминания.
- Socialbearing — бесплатная аналитическая платформа. Ищет твиты, таймлайны и twitter-карты. Умеет сортировать твиты и людей по степени вовлеченности, влиятельности, локации, настроению и т. д.
- Sleepingtime — показывает примерный режим бодрствования публичных аккаунтов.
- Tinfoleak — показывает девайсы, операционные системы и социальные сети, используемые пользователем. Также показывает локации, соотнося твиты пользователя с местами в Google Earth.
- www.picodash.com — выгружает статистику по подписчикам конкретного пользователя или выбранного хэштега в формате CSV. Также выгружает лайки и комментарии.
- https://web.stagram.com — подходит для просмотра и выгрузки видео и изображений
- https://codeofaninja.com/tools/find-instagram-user-id — находит ID пользователя. Имя аккаунта пользователь может менять, с помощью ID можно не потерять его из виду.
- http://instadp.com — показывает аватар в полном размере.
- https://sometag.org — ищет популярные хэштеги, локации и аккаунты. Кроме того, сравнивает аккаунты и выгружает статистику по подписчикам и хэштегам.
- InSpy — Python-программка, которая умеет находить работников той или иной компании. Также находит технологии, применяющиеся в компании, по заданным ключевым словам.
- LinkedInt — находит e-mail людей, работающих в одной и той же компании. Умеет определять почтовые ящики также по заданному домену, который принадлежит компании.
- ScrapedIn — Python-программка. Выгружает информацию с профайла в XLSX файл.
Автоматизация OSINT
Если из всего вышеперечисленного вам нужно нужны только пара-другая проверок, тогда можно обойтись без установки дополнительных программ. А если предстоит тщательный и долгий поиск, лучше воспользоваться специальным софтом, который поможет сэкономить время. Перед этим необходимо будет установить эмулятор — Buscador OS, работающий на Linux и заточенный специально под OSINT. Он необходим для всех следующих программ за исключением FOCA.
SpiderFoot
Обрабатывает одновременно более 100 открытых источников, доступна расширенная настройка. Также есть фильтр по кейсам: поиск всевозможного о человеке, поиск цифровых следов с помощью поисковых роботов и поисковиков, черные списки и другие открытые источники для проверки на вредоносность и сбора информации. Последний лучше всего подходит для расследования.
theHarvester
Простой, но эффективный инструмент. Сканирует домен и относящуюся к нему информацию, собирает почтовые ящики, анализирует DNS-данные. Использует поисковые службы Bing, Baidu, Yahoo, Google, а также социальные сети — LinkedIn, Twitter и Google Plus.
Recon-ng
Похожие функции выполняет и Recon-ng. Отличный инструмент, управление осуществляется через командную строку, есть интерактивный туториал. Помимо прочего проверяет, насколько представлена компания в интернете. Схожий сервис — Metasploit.
Maltego
Продвинутая платформа для анализа сложных связей. Помимо сбора информации считает корреляцию и визуализирует данные. Позволяет отобразить взаимосвязи между структурами — людьми, компаниями, сайтами, документами и пр. Есть также отдельная библиотека плагинов “transforms”, которая дает возможность проводить различные тесты и интеграции со сторонними приложениями.
FOCA
FOCA (Fingerprinting Organizations with Collected Archives) выгружает спрятанную информацию и метаданные из загруженных документов, а также проверяет, кто их создал, на каком сервере и был ли задействован принтер. Последняя версия программы доступна только на Windows.
Metagoofil
Позволяет выгрузить документы с сайтов с последующим анализом. Показывает также метаданные. Работает с форматами pdf, doc, xls, ppt и др. Управляется через командную строку.
Пользуйтесь, делитесь с коллегами и не забывайте подписываться на Factcheck.kz в мессенджерах и/или в соцсетях.