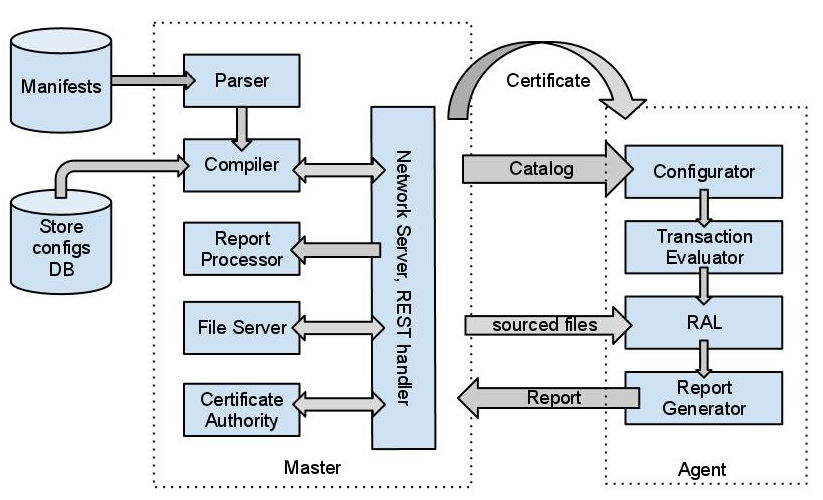
Установка и обновления | Документация | A-Parser
Перед установкой
Перед установкой необходимо выполнить следующие действия:
- В Личном кабинете проверьте верно ли прописан ваш IP-адрес (для пользователей у которых динамический IP-адрес, требуется менять IP-адрес при смене на новый)
- Перейдите во вкладку A-Parser — Загрузки
- Перед скачиванием необходимой версии, следует предварительно нажать Обновить, для обновления до последней версии A-Parser
A-Parser Release — стабильная версия A-Parser, подробнее о выходе новых версий можно прочитать в разделе новости
A-Parser Beta — промежуточная версия A-Parser, которая постоянно дополняется, подробнее об изменениях можно прочитать на форуме в разделе Next Release
Установка A-Parser
⏩ Видео A-Parser: установка, запуск и обновление
Установка на Windows
После того как вы выполните этап Перед установкой необходимо скачать архив программы и разархивировать в нужную вам папку(можно в любую папку, даже на рабочий стол)
Зайдите в папку aparser и запустите aparser. exe
exe
Первый запуск может занять продолжительное время, от 30 секунд до нескольких минут. После появления окна сервера, откройте в браузере http://127.0.0.1:9091/
Пароль по умолчанию пустой. Просто нажмите кнопку Login, после чего появится веб-интерфейс А-Парсера
Устранение проблем
Несовместимые программы
Известны проблемы с совместимостью со следующими антивирусами и программами:
- Norton Internet Security — возможна нестабильная работа парсера
- Emsisoft Anti-Malware — возможна нестабильная работа парсера
- Guard Mail.ru — необходимо полностью удалить из системы
- HTTPDebugger — прерывает работу A-Parser через 2 часа после запуска
Отключение службы индексации Windows
Служба индексации может блокировать доступ к файлам в процессе работы A-Parser. Если парсер не запускается или падает в процессе работы, необходимо просмотреть лог A-Parser’а aparser. на наличие следующих записей:
IO error: ... Append: cannot write
или
sysopen: Permission denied
Для отключения службы индексации выполните следующие действия:
- открываем
Управление службами: Пуск — Выполнить или сочетание клавиш Win + R, вводим services.msc - в открывшемся окне выбираем
Windows Search, нажимаем правую кнопку мыши и выбираемСвойства - в окне свойств на вкладке
Общиеменяем Тип запуска на Отключена и нажимаем Применить - если после этого кнопка Остановить активна — нажимаем ее и останавливаем службу
Ошибка при обновлении дистрибутива
В некоторых случаях Windows может блокировать доступ к файлам дистрибутива A-Parser, в этом случае в логе aparser.log будет следующая запись:
remove_tree failed for dist\nodejs\node_modules\...
Для решения проблемы:
- убедитесь что в диспетчере задач нет зависших процессов
aparser.или exe
exeaparser-node.exe - удалите папку
distв каталоге A-Parser, если Windows сообщает об ошибке удаления — переименуйте папкуdistвdist_
 exe
exeУстановка на MacOS
На текущий момент установка на MacOS возможна с использованием Docker
Установка на Linux
Мы рекомендуем использовать docker или docker-compose для установки A-Parser на Linux, для классической установке следуйте данной инструкции
Для удобства скачивания с сервера реализованы временные ссылки, в Личном кабинете необходимо нажать Одноразовая ссылка (в англ. версии Get one-time link) — по полученной ссылке можно один раз скачать дистрибутив
предупреждениеA-Parser реализует свой собственный веб-сервер, поэтому выбирайте для установки директорию без веб доступа
Получите временную ссылку для скачивания нажав на кнопку Одноразовая ссылка (в англ. версии Get one-time link), в терминале переходим в директорию для установки(например ~/) и выполняем следующие команды, используя полученную ссылку:
wget https://a-parser.
tar zxf aparser-linux-x64.tar.gz
rm -f aparser-linux-x64.tar.gz
cd aparser/
chmod +x aparser
./aparser
 com/members/onetime/ce42f308eaa577b5/aparser-linux-x64.tar.gz
com/members/onetime/ce42f308eaa577b5/aparser-linux-x64.tar.gzПервый запуск может занять продолжительное время, от 30 секунд до нескольких минут. После появления окна сервера, откройте в браузере http://127.0.0.1:9091/, вы также можете перейти в A-Parser используя публичный IP адрес сервера
Пароль по умолчанию пустой. Просто нажмите кнопку Login, после чего появится веб-интерфейс А-Парсера
Обратите внимание что по умолчанию A-Parser доступен на всех интерфейсах. Рекомендуем установить надеждный пароль и по необходимости ограничить доступ используя iptables
Устранение проблем
Иногда на сервере может не хватать каких то библиотек, например:
./aparser
./aparser: error while loading shared libraries: libz.so.1: cannot open shared object file: No such file or directory
Необходимо установить недостающие библиотеки:
yum -y install zlib
И заново запускаем апарсер:
.
 /aparser
/aparserЕсли не выдается никаких сообщений — это свидетельствует об успешном запуске A-Parser, убедиться можно командой tail -f aparser.log
Если в aparser.log содержатся такие строки:
./dist/nodejs/bin/aparser-node: /lib64/libc.so.6: version `GLIBC_2.25' not found (required by ./dist/nodejs/bin/aparser-node)
./dist/nodejs/bin/aparser-node: /lib64/libc.so.6: version `GLIBC_2.28' not found (required by ./dist/nodejs/bin/aparser-node)
то это указывает на использование устаревшей версии Linux и в таком случае рекомендуется обновить ОС или использовать docker или docker-compose
Тюнинг Linux для большего числа потоков
По умолчанию Linux лимитирует количество открытых файлов и сокетов до 1024 на пользователя, чтобы увеличить лимит выполните следующие команды:
echo 'root soft nofile 10240' >> /etc/security/limits.conf
echo 'root hard nofile 10240' >> /etc/security/limits.conf
Если вы запускаете парсер не под root, а под другим пользователем, то замените root на имя пользователя
Так же необходимо увеличить размер таблицы ip_conntrack:
sysctl -w net.
echo 'net.ipv4.netfilter.ip_conntrack_max=262144' >> /etc/sysctl.conf
 ipv4.netfilter.ip_conntrack_max=262144
ipv4.netfilter.ip_conntrack_max=262144При отсутствии фаервола iptables на эту команду выведется ошибка — просто проигнорируйте её
Необходимо перезайти в терминал(ssh), после чего перезапустить A-Parser. Для проверки текущего лимита необходимо выполнить
ulimit -n
На некоторых системах дополнительно требуется прописать в файл /etc/pam.d/common-session следующую строчку:
session required pam_limits.so
Установка на FreeBSD
На текущий момент эмулятор Linux для FreeBSD неспособен стабильно работать с A-Parser
Структура файлов установленной программы
Структура рабочего каталога A-Parser:
| Файл | Описание |
|---|---|
config | Каталог с конфигурационными файлами, рекомендуем делать бекап перед обновлением A-Parser |
dist | Каталог с дистрибутивом A-Parser, включает NodeJS и другие дополнительные модули |
files/proxy | Каталог с настройками прокси-чекеров |
files/parsers | Каталог содержит исходные коды JavaScript парсеров, которые были созданы или импортированы пользователем |
logs | Логи выполнения заданий |
queries | Каталог с запросами для парсеров |
results | Каталог результатов парсинга |
tmp | Временный каталог |
. | Конфигурационный файл веб-сервера apache для защиты рабочего каталога от веб-доступа |
aparser.exe или aparser | Исполняемый файл A-Parser |
aparser.log | Лог работы A-Parser, основной способ диагностики текущего состояния и возможных ошибок |
 htaccess
htaccessСтруктура каталога config:
| Файл | Описание |
|---|---|
tasks | Каталог с файлами заданий(рабочих и завершенных) |
unique | Каталог с файлами уникализаций |
config.db | Основной файл конфигурации, в котором хранятся настройки и пресеты |
queue. | Файл с данными очереди заданий |
scheduler.db | Файл с данными планируемых заданий |
config.txt | Дополнительный файл конфигурации, детальнее… |
 db
dbДля отображения расширений файлов в операционной системе Windows включите следующую настройку:
Начальная настройка
Приступая к работе с A-Parser’ом необходимо предварительно его настроить под себя
- Пароль — пароль по умолчанию задан пустой, в меню Настройки-> Общие настройки вы можете создать новый пароль для входа в систему.
- Language — возможность выбора языка интерфейса, новостей и подсказок — доступны русский и английский язык.
- Проверять обновления и канал обновлений — уведомления о выходе новых версий парсера. Канал обновлений позволяет выбрать между стабильной версией и бета версией.
 Канал обновлений позволяет выбрать между стабильной версией и бета версией.
Канал обновлений позволяет выбрать между стабильной версией и бета версией.Настройка остальных опцией описана в разделе Общие настройки
Сброс пароля
Сбросить пароль доступа к парсеру можно запустив его из командной строки с опцией -resetpassword
Для Windows:
aparser.exe -resetpassword
Для Linux:
./aparser -resetpassword
Пароль будет сброшен на пустой, для входа в A-Parser просто нажмите Login
Обновление A-Parser
Обновление через интерфейс
Выбрать Канал обновления в Общих настройках:
В меню Инструменты перейти во вкладку Обновить A-Parser:
Выберите файлы для обновления, A-Parser будет перезапущен:
предупреждениеВнимание! Если не указано иное, то достаточно обновить только исполняемый файл(aparser.exe или aparser)
Ручное обновление на Windows
В общем случае достаточно заменить исполняемый файл парсера.
- Останавливаем A-Parser — нажимаем Stop server
- Скачиваем с Личном кабинете архив и перезаписываем aparser.exe
- Запускаем aparser.exe
Ручное обновление на Linux
- Останавливаем A-Parser — в консоли выполняем killall aparser
- Скачиваем с Личном кабинете архив и перезаписываем файл aparser
- Запускаем aparser — в консоли выполняем ./aparser
Обновление с использованием одноразовой ссылки
wget https://a-parser.com/members/onetime/0d19621928c25a48/aparser.tar.gz
kill $(cat files/pid)
sleep 1
tar xzf aparser.tar.gz -O aparser/aparser > aparser
rm -f aparser.tar.gz
chmod +x aparser
./aparser
Установка одной лицензии на несколько компьютеров
Каждую лицензию можно использовать одновременно только на одном ПК/сервере. При этом, имея одну лицензию, не запрещается устанавливать А-Парсер сразу на несколько компьютеров. Но в этом случае, А-Парсер можно будет запустить только на том ПК/сервере, IP которого прописан в Личном кабинете
Но в этом случае, А-Парсер можно будет запустить только на том ПК/сервере, IP которого прописан в Личном кабинете
Примером такого использования может быть рабочий ПК и домашний ноутбук: парсер можно установить на обеих машинах, а использовать либо на рабочем ПК, либо на домашнем ноутбуке. Количество изменений IP в Личном кабинете неограничено, но не рекомендуется это делать более 5 раз в сутки, т.к. в противном случае может потребоваться подтвердить отсутствие мошеннических действий.
Для одновременной работы A-Parser на нескольких компьютерах или серверах выполните следующие действия:
- Добавьте дополнительные лицензии
- В Личном кабинете перейдите на вкладку
A-Parser - Настройка IP - Впишите IP-адреса дополнительных компьютеров
Установка нескольких копий на одном ПК или сервере
Каждая лицензия позволяет установить и запустить одновременно неограниченное количество копий А-Парсера в рамках одной машины. Это позволяет максимально использовать возможности мощных систем, на которых одна копия задействует не все ресурсы и при этом требуется увеличить производительность.
Это позволяет максимально использовать возможности мощных систем, на которых одна копия задействует не все ресурсы и при этом требуется увеличить производительность.
Процесс установки нескольких копий парсера на одной системе:
- необходимо скачать и установить каждую копию в отдельный каталог согласно стандартной инструкций по установке
- в каждой копии парсера необходимо в каталоге config создать файл config.txt и прописать настройку такого вида:
bind: 0.0.0.0:9092
- вместо 9092 укажите порт, на котором будет работать данная копия
После этого парсер можно запускать и он будет доступен на указанному порту
предупреждениеЛюбые способы совместного доступа, а также сдача A-Parser в аренду запрещены и в случае обнаружения лицензия будет аннулирована без возврата средств или возможности восстановления.
10 инструментов, позволяющих парсить информацию с веб-сайтов, включая цены конкурентов + правовая оценка для России / Хабр
Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed.com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени 🙂
10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.1. Import.io
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.
Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.
Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.
Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
5. ParseHub
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.
Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.
ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
7. Spinn3r
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
8. 80legs
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.
Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
9. Scraper
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
Начало работы с awk, мощным инструментом анализа текста
Изображение:Чат WOCinTech. Изменено Opensource.com. СС BY-SA 4.0
Awk — это мощное средство анализа текста для Unix и Unix-подобных систем, но поскольку в нем есть запрограммированные функции, которые можно использовать для выполнения обычных задач анализа, он также считается языком программирования. Вы, вероятно, не будете разрабатывать свое следующее приложение с графическим интерфейсом с помощью awk, и он, вероятно, не заменит ваш язык сценариев по умолчанию, но это мощная утилита для конкретных задач.
Вы, вероятно, не будете разрабатывать свое следующее приложение с графическим интерфейсом с помощью awk, и он, вероятно, не заменит ваш язык сценариев по умолчанию, но это мощная утилита для конкретных задач.
Эти задачи могут быть удивительно разнообразны. Лучший способ узнать, какие из ваших проблем могут быть лучше всего решены с помощью awk, — изучить awk; вы будете удивлены тем, как awk может помочь вам сделать больше, но с гораздо меньшими усилиями.
Основной синтаксис Awk:
awk [options] 'шаблон {действие}' файл Для начала создайте этот образец файла и сохраните его как colors.txt
имя количество цветов яблоко красное 4 банановый желтый 6 клубнично-красный 3 виноградно-фиолетовый 10 яблочно-зеленый 8 сливово-фиолетовый 2 киви коричневый 4 картофельный коричневый 9ананасовый желтый 5
Эти данные разделены на столбцы одним или несколькими пробелами. Обычно данные, которые вы анализируете, каким-то образом организованы. Это не всегда могут быть столбцы, разделенные пробелом, или даже запятой или точкой с запятой, но, особенно в файлах журналов или дампах данных, обычно существует предсказуемый шаблон. Вы можете использовать шаблоны данных, чтобы помочь awk извлекать и обрабатывать данные, на которых вы хотите сосредоточиться.
Это не всегда могут быть столбцы, разделенные пробелом, или даже запятой или точкой с запятой, но, особенно в файлах журналов или дампах данных, обычно существует предсказуемый шаблон. Вы можете использовать шаблоны данных, чтобы помочь awk извлекать и обрабатывать данные, на которых вы хотите сосредоточиться.
Печать столбца
В awk печать 9Функция 0016 отображает все, что вы укажете. Существует множество предопределенных переменных, которые вы можете использовать, но наиболее распространенными являются целые числа, обозначающие столбцы в текстовом файле. Попробуйте:
$ awk '{print $2;}' colors.txt
цвет
красный
желтый
красный
фиолетовый
зеленый
фиолетовый
коричневый
коричневый
желтый В этом случае awk отображает второй столбец, обозначенный как $2 . Это относительно интуитивно понятно, поэтому вы, вероятно, догадались, что print $1 отображает первый столбец, а print $3 отображает третий и так далее.
Чтобы отобразить все столбцов, используйте $0 .
Число после знака доллара ( $ ) является выражением , поэтому $2 и $(1+1) означают одно и то же.
Условный выбор столбцов
Файл примера, который вы используете, очень структурирован. В нем есть строка, которая служит заголовком, а столбцы напрямую связаны друг с другом. Определив условных требований , вы можете уточнить, что вы хотите, чтобы awk возвращал при просмотре этих данных. Например, чтобы просмотреть элементы в столбце 2, соответствующие «желтому», и распечатать содержимое столбца 1:
awk '$2=="желтый"{print $1}' colors.txt
банан
pineapple Регулярные выражения также работают. Это условное выражение ищет $2 для приблизительного совпадения с буквой p , за которой следует любое количество (один или несколько) символов, за которыми, в свою очередь, следует буква p :
$ awk '$2 ~ /p.
 +p/ {print $0}' colors.txt
виноградно-фиолетовый 10
сливово-фиолетовый 2
+p/ {print $0}' colors.txt
виноградно-фиолетовый 10
сливово-фиолетовый 2 Числа естественным образом интерпретируются awk. Например, чтобы напечатать любую строку с третьим столбцом, содержащим целое число больше 5:
awk '$3>5 {print $1, $2}' colors.txt
имя цвет
банан желтый
виноград фиолетовый
Зеленое яблоко
картофельный коричневый Разделитель полей
По умолчанию awk использует пробел в качестве разделителя полей. Однако не все текстовые файлы используют пробелы для определения полей. Например, создайте файл с именем colors.csv со следующим содержимым:
имя, цвет, количество. яблоко, красное, 4 банан, желтый, 6 клубничный,красный,3 виноград,фиолетовый,10 яблоко, зеленое, 8 слива,фиолетовый,2 киви, коричневый, 4 картофель,коричневый,9pineapple,yellow,5
Awk может обрабатывать данные точно так же, если вы укажете, какой символ он должен использовать в качестве разделителя полей в вашей команде. Используйте параметр —field-separator (или просто -F для краткости) для определения разделителя:
$ awk -F"," '$2=="yellow" {print $1}' file1. csv
банан
pineapple  csv
банан
pineapple
csv
банан
pineapple Сохранение вывода
Используя перенаправление вывода, вы можете записать результаты в файл. Например:
$ awk -F, '$3>5 {print $1, $2} colors.csv > output.txt Это создает файл с содержимым вашего awk-запроса.
Вы также можете разделить файл на несколько файлов, сгруппированных по данным столбца. Например, если вы хотите разделить colors.txt на несколько файлов в соответствии с тем, какой цвет отображается в каждой строке, вы можете заставить awk перенаправлять на запрос , включив перенаправление в свой оператор awk:
$ awk '{print > $2".txt"}' colors.txt Это создает файлы с именами yellow.txt , red.txt и так далее.
В следующей статье вы узнаете больше о полях, записях и некоторых мощных переменных awk.
Эта статья адаптирована из эпизода Hacker Public Radio, подкаста сообщества технологий.
Эта работа находится под лицензией Creative Commons Attribution-Share Alike 4.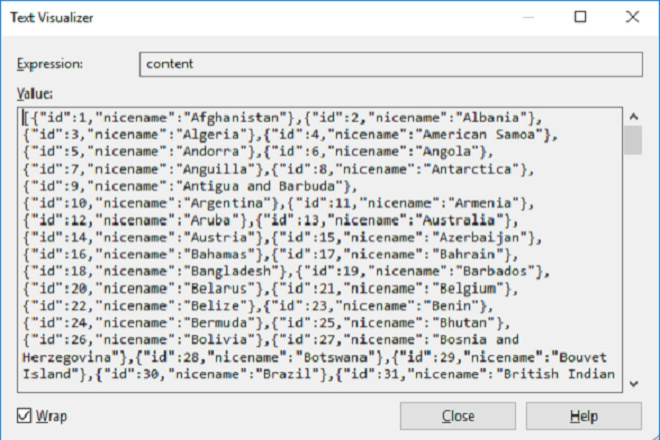 0 International License.
0 International License.значение разбора
Еще 10 обсуждений, которые могут вас заинтересовать
1. Программирование оболочки и создание сценариев 91 доллар — перевернуть строку: слово становится дроу Заранее спасибо за ваш… (4 ответа)
Обсуждение начато: bibelo
2. Программирование оболочки и создание сценариев
Пожалуйста, дайте мне знать значение приведенных ниже операторов в сценариях оболочки. 1) выход -99 ——————————— 2) установить prgdir = `pwd` установить runFlag = runFlag:FALSE ————————————- 3) если (-f $prgdir/maillst.eml) то set distEmail = `cat $prgdir/maillst.eml`… (1 ответ)
Обсуждение начато: lg123
3. UNIX для чайников Вопросы и ответы
Привет всем, Я хочу знать значение последнего слова «<
Обсуждение начато: sudharson
4.
 $$\$» ; затем
echo `date`»: Скрипт $ScritName уже запущен»
Выход
фи
Большое спасибо заранее
Пожалуйста, используйте теги кода при размещении данных и кода… (8 ответов)
$$\$» ; затем
echo `date`»: Скрипт $ScritName уже запущен»
Выход
фи
Большое спасибо заранее
Пожалуйста, используйте теги кода при размещении данных и кода… (8 ответов)Обсуждение начато: Pratik4891
5. Программирование оболочки и создание сценариев
может кто-нибудь сказать, что означает !* в синтаксисе оболочки. С уважением, (3 ответа)
Обсуждение начато: busyboy
6. Программирование оболочки и создание сценариев
Привет, Может ли кто-нибудь рассказать об использовании «$_» компакт-диск $_ ? и лс $_ ? (4 ответа)
Обсуждение начато: giri_luck
7. Программирование оболочки и создание сценариев
Привет, ребята!
У меня есть этот файл, сгенерированный мной… я хочу создать из него HTML-вывод.
Проблема в том, что я действительно не понимаю, как мне читать файл.
Файл имеет следующий формат:
TID1 Name1 ATime=xx AResult=yyy AExpected=yyy BTime=xx BResult=yyy.