что это такое и как работает — OKOCRM
Есть четыре способа:
1. Разработать собственный поисковый алгоритм. Движок — адово сложная вещь. Если разработчик полезет в код, то может сломаться — или код, или разработчик. Поэтому никто из предпринимателей средней руки свои алгоритмы для поиска не разрабатывает. Совсем. Кроме тех, кто один раз попробовал и затянуло. Обычно используют те, что есть. А есть еще три способа.
2. Использовать сторонний поисковый движок. Есть несколько бесплатных общедоступный движков, вроде Elasticsearch и Sphinx. У них открытый исходный код и понятные API. Можете погуглить-посмотреть-почитать отзывы. Минус этого инструмента — нужно устанавливать его на свой сервер и занимать место, а потом долго настраивать. И движок, и админку. Короче, все равно нужны айтишники.
3. Использовать сервисы поиска. Обычно они работают на поисковых движках, но являются облачными — не нужно устанавливать на свой сервер. А еще не нужно сильно заморачиваться с интеграцией — помогут, подскажут, настроят.
4. Использовать стандартный поисковый сервис CMS. Только он не будет сильно умным. Например, поисковик Вордпресса не умеет распознавать ошибки и опечатки. То же самое у Битрикса — потому что штатные поисковики не строят триаграммы. Их предел — распознание окончания слов, да при включенной морфологии.
Короче: реально рассматривать только два способа: движки и сервисы. Посмотрим, какие есть варианты.
Google Programmable Search Engine
Стоимость: $5/1000 запросов, есть бесплатная версия с рекламой на сайте
Реализация: JavaScript на стороне клиента/JSON API на стороне клиента или на стороне сервера
Для чего: простые сайты, блоги, справочники, информационные страницы
Самостоятельная настройка: да
Программируемая поисковая система — это как поисковая строка Гугла у вас на сайте. Вы можете настраивать внешний вид окна поиска и страницы результатов так, чтобы он соответствовал стилю вашего сайта.
В чем плюс: можно бесплатно или за небольшие деньги получить у себя на сайте поисковик от Гугла.
В чем минус: поисковик будет делать поиск не только по вашему сайту, а в целом по интернету. Действительно, результаты с вашего сайта будут иметь более высокий приоритет. Но где гарантия, что после получения выдачи человек не уйдет к конкурентам?
Элемент поисковой выдачи с рекламным блоком. Пользователь может запутаться и подумать, что уже ушел с сайта.
Яндекс Поиск
Стоимость: бесплатно
Реализация: HTML-код для вставки на сайт
Для чего: информационные порталы, интернет-магазины
Самостоятельная настройка: да
Яндекс.Поиск для сайта позволяет легко организовать поиск по вашим сайтам, используя механизмы индексации и ранжирования, реализованные Яндексом. По факту, это филиале Яндекса на вашем сайте. Умеет то же самое, что и сам поисковик: исправляет неправильную раскладку и опечатки, находит ошибки и распознает варианты написания, синонимы и пр.Все настройки в личном кабинете. Можно настраивать поисковые подсказки, работать с уточнениями, менять внешний вид сниппетов и всей поисковой строки.
По факту, это филиале Яндекса на вашем сайте. Умеет то же самое, что и сам поисковик: исправляет неправильную раскладку и опечатки, находит ошибки и распознает варианты написания, синонимы и пр.Все настройки в личном кабинете. Можно настраивать поисковые подсказки, работать с уточнениями, менять внешний вид сниппетов и всей поисковой строки.
Кроме обычного поиска, есть поиск для интернет-магазинов. Ищет позиции по каталогу товаров, загруженному в форме YML-документа. Поисковая выдача оптимизирована для отображения информации о товарах. Можно искать товары по названию и описанию, в наличии или под заказ, фильтровать результаты и получать в результатах поиска основные характеристики.
В чем плюс: полностью бесплатный.
В чем минус: работает только по проиндексированным Яндексом страницам.
В личном кабинете можно настроить внешний вид поисковой строки вплоть до цвета рамки поля для ввода запроса. К — кастомизация.
Solr
Стоимость: бесплатно
Реализация: установка на сервер и подключение через API
Для чего: универсальный
Самостоятельная настройка: нет, нужен программист, а лучше команда
Solr — это автономный быстрый поисковый сервер с открытым исходным кодом и REST-подобным API, построен на Apache Lucene. Отличается высокой надежностью, масштабируемостью и отказоустойчивостью. Обеспечивает распределенное индексирование, репликацию и запросы с балансировкой нагрузки, автоматическое переключение при отказе и восстановление, централизованную настройку и многое другое.
Отличается высокой надежностью, масштабируемостью и отказоустойчивостью. Обеспечивает распределенное индексирование, репликацию и запросы с балансировкой нагрузки, автоматическое переключение при отказе и восстановление, централизованную настройку и многое другое.
Умеет все то, что должен уметь умный поиск. Но запустить его на своем сайте самому не получится. Каталоги для индексирования размещаются через JSON, XML, CSV или двоичный код через HTTP. Отправка запросов — через HTTP GET.
В чем плюс: полностью бесплатный и слишком умный, чтобы быть поиском
В чем минус: полноценный движок — для интеграции нужен специалист.
Панель инструментов в пользовательском интерфейсе Solr. Русскоязычного интерфейса нет. Просто так не разберешься.
Sphinx
Стоимость: бесплатно
Реализация: установка на сервер и подключение через API
Для чего: универсальный, для сайтов с большим трафиком
Самостоятельная настройка: нет, нужен программист, а лучше команда
Полноценный движок с открытым исходным кодом. Один из самых популярных в мире. Его особенность — высокая скорость индексации и поиска, а также интеграция с существующими СУБД (MySQL, PostgreSQL) и API для распространённых языков веб-программирования. Официально поддерживаются PHP, Python, Java. Высокая скорость поиска и масштабирования, поддержка стоп-слов и морфологического поиска (встроенный модуль русского языка). Выдерживает высокие нагрузки.
Один из самых популярных в мире. Его особенность — высокая скорость индексации и поиска, а также интеграция с существующими СУБД (MySQL, PostgreSQL) и API для распространённых языков веб-программирования. Официально поддерживаются PHP, Python, Java. Высокая скорость поиска и масштабирования, поддержка стоп-слов и морфологического поиска (встроенный модуль русского языка). Выдерживает высокие нагрузки.
В чем плюс: полностью бесплатный и очень быстрый.
В чем минус: для интеграции нужен специалист или команда.
Интерфейс Сфинкса в реальном времени показывает степень загрузки серверов. Если будут угрозы для производительности, система предупредит владельца.
Elasticsearch
Стоимость: бесплатно
Реализация:
Для чего: универсальный, для сайтов с большим трафиком, если нужны метрики и аналитика.
Самостоятельная настройка: нет, нужен программист, а лучше команда
Наиболее популярная тиражируемая свободная программная поисковая система. Elasticsearch позволяет выполнять и комбинировать многие типы поиска: структурированный, неструктурированный, географический, метрический — любым удобным способом. В Elasticsearch более сложная и богатая система условий в поисковых запросах. У программы много наворотов, вроде визуализации данных, машинного обучения поиска и индексации каталога без схемы. Из-за этого поисковая машина очень требовательна и кушает много памяти, очень много памяти.
Elasticsearch позволяет выполнять и комбинировать многие типы поиска: структурированный, неструктурированный, географический, метрический — любым удобным способом. В Elasticsearch более сложная и богатая система условий в поисковых запросах. У программы много наворотов, вроде визуализации данных, машинного обучения поиска и индексации каталога без схемы. Из-за этого поисковая машина очень требовательна и кушает много памяти, очень много памяти.
В чем плюс: полностью бесплатный, много наворотов, подойдет, если нужны метрики, аналитика и работа с неструктурированными базами.
В чем минус: для интеграции нужен специалист или команда. Требовательный к ресурсам.
С помощью клиента Kibana Elasticsearch создает информационные панели, которые позволяют пользователям визуализировать данные и поисковую аналитику. Выглядит неплохо.
Searchanise
Стоимость: от $9/месяц. Цена зависит от количества товаров.
Реализация: установка на сайт в качестве плагина
Для чего: для онлайн-магазинов
Самостоятельная настройка: да, есть гайды
Это облачный умный поиск для интернет-магазинов, который работает на движке Sphinx. Получаете тот же функционал, только не нужно ничего устанавливать на сервер. Просто добавляете на сайт плагин, и все работает.
Получаете тот же функционал, только не нужно ничего устанавливать на сервер. Просто добавляете на сайт плагин, и все работает.
В чем плюс: работает в облаке — не будете нагружать сервер. А еще сможете интегрировать самостоятельно или с минимальным вмешательством специалистов.
В чем минус: стоимость — чем больше товаров, тем дороже. Другой минус — подойдет не для всех CMS.
Пример поисковой выдачи Searchanise. Начинаешь вводить запрос и система сразу показывает подсказки и товары. Удобно.
Поиск на сайте — CMS Magazine
Standalone-модуль поиска нужен далеко не всем сайтам. Если на сайте пять страниц — поиск не нужен. Если сайт обновляется раз в месяц или все обновления отражаются на титульной странице — можно обойтись внешним поиском по сайту от Гугла или Яндекса. Но некоторые задачи внешний поиск решить не сможет. Эта статья о том, какие функции может выполнять встроенный модуль поиска. И часть из этих функций не имеют прямого отношения к процессу поиска.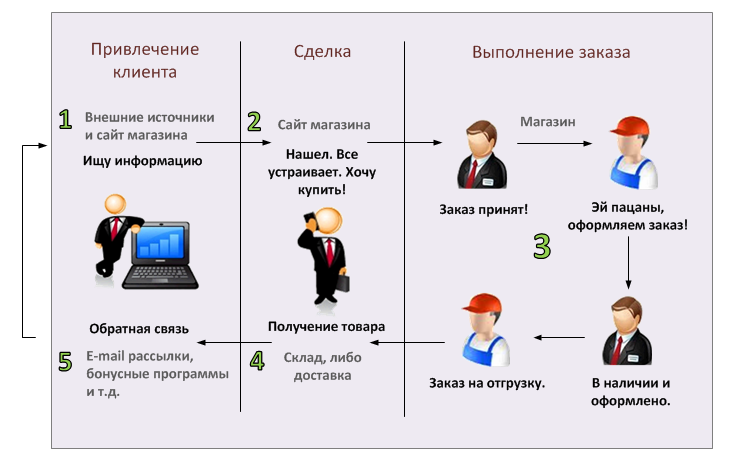
Что не умеет Яндекс
Большие поисковики предоставляют нам возможность пользоваться их многолетними наработками в области релевантности, вычисления поискового спама, морфологии и прочего ранжирования. Но есть задачи, с которыми внешний поисковик не в состоянии справиться в силу своей «внешности».
Мгновенная переиндексация
Вы добавили на сайт статью — и она уже сразу в индексе и доступна для поиска. Вы удалили матерный комментарий — и его уже никто не найдет. Если на вашем сайте установлена форма поиска через глобальный поисковик, вам придется ждать переиндексации подчас неделями. Если встроенный поисковый модуль позволяет переиндексировать фрагмент сайта по событию «добавление», «изменение» или «удаление», счет пойдет на минуты или даже секунды.
Синонимы
Название нашего продукта часто пишут по-русски как «неткэт», «неткат», «неткет». Яндексу в голову не придет, что по таким запросам нужно показать страницы, где написано NetCat (кроме запроса «неткат», его Яндекс распознал). Что уж говорить про случаи типа «CMS — цмс, цмска, сиэмэс». А встроенному поиску мы можем явно задавать подобные синонимы.
Что уж говорить про случаи типа «CMS — цмс, цмска, сиэмэс». А встроенному поиску мы можем явно задавать подобные синонимы.
Управление весом тэгов при расчете коэффициента релевантности
Написание текстов «для Яндекса» имеет кардинальные отличия от написания текстов для людей. В первом случае нам нужно, чтобы из миллиона страниц «на эту тему» Яндекс выше всех показал страницу на нашем сайте. Во втором — чтобы человек, УЖЕ пришедший на сайт, быстро нашел нужную ему страницу и купил наш продукт. Поэтому, если человек ищет на нашем сайте «розовый слоник», нам нужно показать ему не длинную статью с идеально выверенным количеством данных словосочетаний, а страницу с парой фоток и кнопкой «купить». Имея возможность задать веса тэгов и отдельных блоков веб-страниц (например, по атрибуту class) для внутреннего поисковика, мы можем подготовить контент таким образом, чтобы процесс «ввел запрос — купил» занял у пользователя минимум времени.
Гибкое задание запрещенных для индексирования страниц
В файле robots. txt мы можем написать инструкцию Disallow, которая запретит внешним поисковикам индексировать некоторые части сайта. Как показали летние скандалы с попаданием приватной информации в поисковики, это не всегда помогает. Но даже если не брать это в расчет, синтаксис disallow очень примитивен, и было бы куда лучше указать запрещенные области регулярным выражением. Пример: страница sloniki.html?action=add, предназначенная для добавления администратором контента на соответствующую страницу, вполне может попасть в индекс, пусть даже там будет только заголовок «Розовые слоники» и форма авторизации. Но зачем нам замусоривать результаты поиска?
txt мы можем написать инструкцию Disallow, которая запретит внешним поисковикам индексировать некоторые части сайта. Как показали летние скандалы с попаданием приватной информации в поисковики, это не всегда помогает. Но даже если не брать это в расчет, синтаксис disallow очень примитивен, и было бы куда лучше указать запрещенные области регулярным выражением. Пример: страница sloniki.html?action=add, предназначенная для добавления администратором контента на соответствующую страницу, вполне может попасть в индекс, пусть даже там будет только заголовок «Розовые слоники» и форма авторизации. Но зачем нам замусоривать результаты поиска?
Автоподбор вариантов запроса по мере его ввода
Все знакомы с выпадающим списком, который Яндекс или Гугл показывает нам по мере ввода запроса. Но эта подсказка — лишь список наиболее популярных запросов. Внутренний же поиск может подгружать не только популярные запросы, но и заголовки страниц (то есть названия документов), подходящие под вводимый запрос. Начав вводить «розовы», мы увидим список содержимых тэга title, где содержится этот фрагмент; нажав на нужный нам «Розовые слоники», мы сразу попадем на искомую страницу вместо результатов поиска.
Начав вводить «розовы», мы увидим список содержимых тэга title, где содержится этот фрагмент; нажав на нужный нам «Розовые слоники», мы сразу попадем на искомую страницу вместо результатов поиска.
Гибкое расписание переиндексации
Если наш сайт большой, его полная переиндексация может отнять много времени и ресурсов. Но если раздел «Форум» нужно переиндексировать каждый чаc, «Новости» каждый день, а «О компании» вообще никогда, было бы здорово так и делать. Внутренний поиск вполне может позволить себе разные расписания для разных разделов. Конечно, в sitemap мы можем управлять частотой переидексации при помощи атрибута changefreq, но… Вряд ли Яндекс с Гуглом воспримут наше пожелание как инструкцию к действию.
А также:
- указание области поиска (например, искать везде или только на форуме)
- извлечение дополнительных атрибутов из объектов и поиск по ним (найти все статьи такого-то автора, все товары в таком ценовом диапазоне)
- сортировка результатов поиска не только по релевантности, но и по дате (как на Хабре)
.
 .. и не только поиск
.. и не только поискМодуль поиска между делом может выполнять не только свои прямые обязанности, но и другие общественно-полезные задачи. Вот несколько примеров.
Автоматическое построение sitemap.xml
Кто тщательнее всех составит полный список страниц сайта для внешних поисковиков, как не локальный поисковый робот? При этом, на уровне структуры сайта мы можем задать параметры changefreq и priority, для разных разделов разные.
Поиск битых ссылок
Способов поиска внутренних ссылок на несуществующие страницы как минимум два. Первый — написать обработчик ошибки 404, который будет отправлять письмо с адресом страницы и реферера (или добавлять сообщение в базу сайта) каждый раз, когда кто-то зайдет на такую страницу. Второй — поручить это поисковому роботу. Это явно более правильный способ.
Сбор статистики по запросам
Если поисковый движок собирает статистику по запросам и их результатам, эти данные могут очень сильно нам помочь. Во-первых, мы можем увидеть запросы, по которым пользователи ничего не находят, и добавить соответствующие страницы. Во-вторых, увидев часто встречающиеся опечатки, мы сможем добавить их в словарь синонимов. В-третьих, если какую-то страницу ищут слишком часто, значит, ее сложно найти без поиска; возможно, стоит вынести ее в меню. Ну и так далее.
Во-вторых, увидев часто встречающиеся опечатки, мы сможем добавить их в словарь синонимов. В-третьих, если какую-то страницу ищут слишком часто, значит, ее сложно найти без поиска; возможно, стоит вынести ее в меню. Ну и так далее.
Кстати, отдельный пункт — статистика по запросам конкретных зарегистрированных пользователей. Только не подумайте, что я призываю вас за ними следить 🙂
Не отстаем от «старших»
Все эти навороты хороши только в том случае, если поиск действительно удобен, ищет то, что надо, и им легко и просто пользоваться. Поэтому наш поисковый модуль должен уметь то, что умеют большие поисковики. Так же хорошо, как они. Ну или почти так же.
Полноценная морфология
Многие локальные поисковики для работы со словоформами обходятся стеммингом. Этот термин обозначает отбрасывание окончания слова в попытке найти его корень и как следствие — словоформы. Берем слово «розовый», применяем стемминг, получаем «розов», и теперь все слова, начинающиеся на этот «корень», считаем словоформами. Так мы по запросу «розовый» найдем «розовых», «розовые» и пр. Но стемминг дает слишком большую погрешность и не подходит, к примеру, для изолированных глаголов («идти — пошел — дойти»). Наиболее точный поиск словоформ дают морфологические словари. Для текстов бытовой или деловой тематики они не такие большие (NetCat использует бесплатный словарь от aot.ru, русский и английский словари вместе занимают всего 15 мегабайт, что не так много для современных хостингов; можно использовать другие словари; также можно добавлять словари других языков).
Так мы по запросу «розовый» найдем «розовых», «розовые» и пр. Но стемминг дает слишком большую погрешность и не подходит, к примеру, для изолированных глаголов («идти — пошел — дойти»). Наиболее точный поиск словоформ дают морфологические словари. Для текстов бытовой или деловой тематики они не такие большие (NetCat использует бесплатный словарь от aot.ru, русский и английский словари вместе занимают всего 15 мегабайт, что не так много для современных хостингов; можно использовать другие словари; также можно добавлять словари других языков).
Кстати, пользуясь случаем, хочу сказать огромное спасибо автору библиотеки морфоанализа phpMorphy, которая оказалась очень полезной для наших задач.
Борьба с опечатками
Бороться с опечатками можно двумя способами. Первый — находить наиболее похожее слово, как делает тот же Яндекс, второй — использовать нечеткий поиск.
А вот исправление раскладки клавиатуры — это гораздо проще.
Экзотические случаи
Следующие возможности мы не стали включать в наш модуль поиска по причине их экзотичности или слишком высокой трудоемкости, хотя для некоторых случаев они могут быть полезны.
RTL-языки и иероглифы
Европейские языки (в т.ч. русский) имеют направление написания слева направо (left-to-right, LTR). Но арабская вязь пишется в обратном направлении. Если ваш проект ориентирован на эту языковую аудиторию, готовьтесь написать (или подключить готовый) стеммер. А иероглифы — вообще отдельный случай, там одним стеммером не обойтись.
Поиск по закрытым областям
Системы разграничения прав в интернет-проектах встречаются разные, в том числе вполне параноидальные (об этом я хочу написать отдельную статью). Пример сложного варианта: издательские системы. Журналист может иметь права на добавление статьи (в определенные разделы!) и ее коррекцию, пока она не откорректирована редактором. Редактор имеет право на просмотр, коррекцию и включение-выключение всех материалов в рамках своей тематики. Главный редактор не имеет права корректировать заказные статьи без одобрения коммерческого отдела. С точки зрения параноидальной системы разграничения прав идеальный поисковый модуль индексировал бы весь контент, размещенный на проекте, а при поиске проверял бы права пользователя и выводил бы только доступные ему материалы.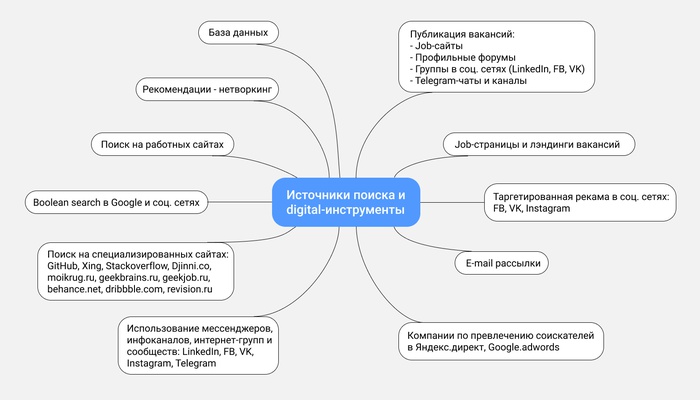 И при этом позволял бы делать фильтр по статусу документа.
И при этом позволял бы делать фильтр по статусу документа.
Автоопределение тематики страниц
Анализируя проиндексированную страницу текста, можно с некоторой долей погрешности определить ее тематику. Полезные эффекты от такой фичи: автоматическая каталогизация материалов и построение облака тэгов, анализ интересов сообщества или отдельных его членов (для UGС-проектов), построение списков связанных материалов (видели блоки «см. также»?). Наиболее же часто такой анализ используется для таргетирования контекстной рекламы.
Сюда же: кэширование результатов поиска, поиск по картинкам, индексация страниц, генерируемых по заполнению форм или ajax-ом, поиск дублей страниц.
Еще одно интересное применение поисковой машины пришло мне в голову в процессе написание этой статьи. Оно подходит, к примеру, для коллективных блогов и СМИ. Анализируя тексты разных авторов, мы можем строить их рейтинги по разным параметрам. Первое, что приходит в голову: словарный запас. Кроме того: рейтинг авторов-холериков (кто чаще остальных использует восклицательные знаки), любителей пространных рассуждений (кто любит знаки вопроса), по словам-паразитам и т.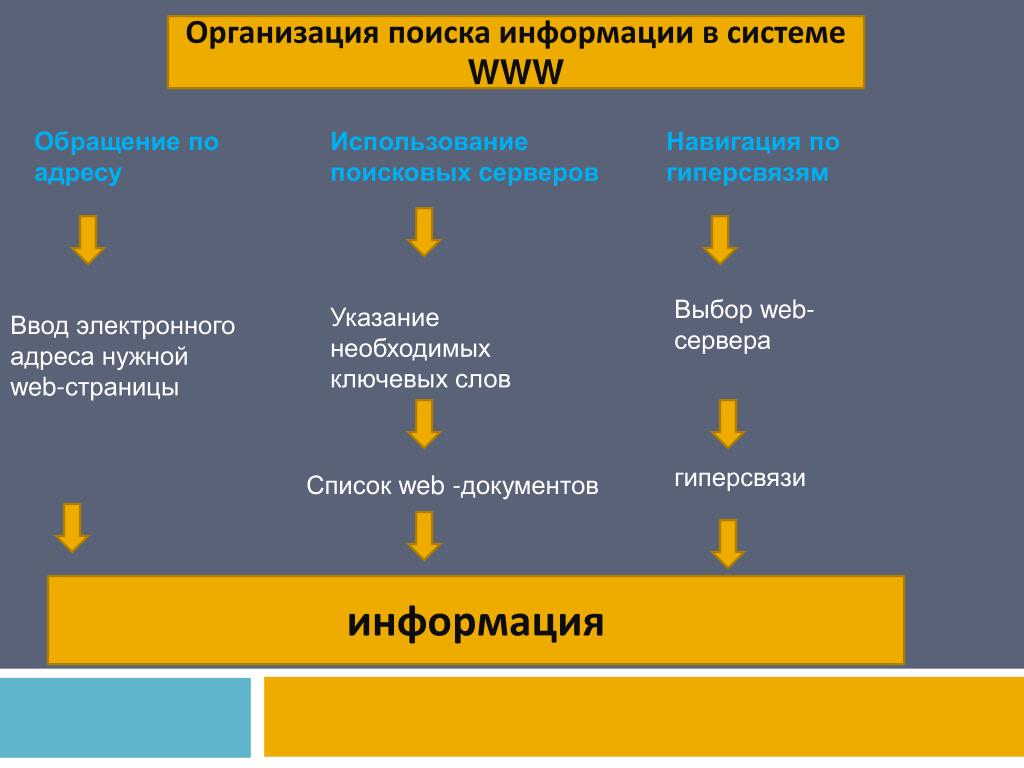 д. Может, предложить Хабраадминистрации сделать что-то подобное? 🙂 Правда, коммерческое обоснование такой игрушки я пока не придумал.
д. Может, предложить Хабраадминистрации сделать что-то подобное? 🙂 Правда, коммерческое обоснование такой игрушки я пока не придумал.
Если вы пишете свой поиск…
… для начала нужно ответить на вопрос, а нужен ли он, не стоит ли использовать уже имеющиеся решения: Яндекс.Сервер, Sphinx и пр. Главное преимущество собственного поисковика: возможность тесной интеграции с другими модулями CMS, используемой на сайте. Речь не только о встраивании интерфейса управления в админку, а об интеграции с системой разграничения прав, управления структурой, пользователями и пр. (об этом я уже писал).
Что касается технологий, то гибких и мощных платформ хватает. В поисковом модуле NetCat по умолчанию используется Zend_Search_Lucene. У этого решения есть недостатки, например, сравнительно низкая скорость работы. В нашем случае это оправдано тем, что сайт под NetCat должен работать на любом стандартном UNIX-хостинге без необходимости установки дополнительных компонентов, а Zend_Search_Lucene не требуется ничего, кроме PHP. Справедливости ради надо заметить, что мы сделали модуль расширяемым, то есть заменять можно не только словари, но и программные компоненты: если проект достаточно крупный, а сервер выделенный, можно заменять компоненты, отвечающие за хранение и извлечение информации, индексацию, приведение к базовой форме и пр. Например, использовать тот же Sphinx или Solr (а если надо, то и Яндекс.XML).
Справедливости ради надо заметить, что мы сделали модуль расширяемым, то есть заменять можно не только словари, но и программные компоненты: если проект достаточно крупный, а сервер выделенный, можно заменять компоненты, отвечающие за хранение и извлечение информации, индексацию, приведение к базовой форме и пр. Например, использовать тот же Sphinx или Solr (а если надо, то и Яндекс.XML).
Если же вы разрабатываете не универсальную CMS, а конкретный крупный проект, выбрать и настроить оптимальную платформу не проблема. Гораздо важнее понять, как использовать ее возможности максимально эффективно.
Все скриншоты в статье сделаны на нашем сайте и в его системе администрирования.
Оригинал статьи: http://habrahabr.ru/company/netcat/blog/136492/
Как Google упорядочивает информацию, чтобы найти то, что вы ищете
Поиск
03 декабря 2020 г.
мин. прочитано
Ник Фокс
Вице-президент по продуктам и дизайну, поиск и помощник
Когда вы приходите в Google и выполняете поиск, могут быть миллиарды страниц, которые потенциально соответствуют вашему запросу, и миллионы новых страниц создаются каждую минуту. Раньше мы обновляли наш поисковый индекс раз в месяц. Теперь, как и другие поисковые системы, Google постоянно индексирует новую информацию, чтобы сделать ее доступной через Поиск.
Раньше мы обновляли наш поисковый индекс раз в месяц. Теперь, как и другие поисковые системы, Google постоянно индексирует новую информацию, чтобы сделать ее доступной через Поиск.
Но чтобы вся эта информация была полезной, очень важно организовать ее таким образом, чтобы люди могли быстро найти то, что ищут. Имея это в виду, рассмотрим более подробно, как мы подходим к организации информации в поиске Google.
Систематизация информации с помощью разнообразных и полезных функций
Google индексирует все типы информации — от текста и изображений на веб-страницах до реальной информации, например, есть ли в местном магазине свитер, который вы ищете. Чтобы сделать эту информацию полезной для вас, мы организовали ее на странице результатов поиска таким образом, чтобы ее было легко просматривать и усваивать. При поиске работы вы часто хотите увидеть список конкретных ролей. В то время как если вы ищете ресторан, просмотр карты может помочь вам легко найти место поблизости.
Мы предлагаем широкий спектр функций — от видео и новостных каруселей до результатов с богатыми изображениями и полезных меток, таких как звездные обзоры, — чтобы помочь вам более легко ориентироваться в доступной информации. Эти функции включают ссылки на веб-страницы, поэтому вы можете легко перейти на веб-сайт, чтобы найти дополнительную информацию. Фактически, мы увеличили среднее количество исходящих ссылок на веб-сайты на странице результатов поиска с 10 («10 синих ссылок») до 26 ссылок на странице результатов поиска для мобильных устройств. По мере того, как мы добавляли в поиск Google более богатые функции, люди с большей вероятностью найдут то, что ищут, а веб-сайты имеют больше шансов появиться на первой странице результатов поиска.
Когда вы искали «блин» в 2012 году, вы в основном видели ссылки на веб-страницы. Теперь вы можете легко найти ссылки на рецепты, видеоролики, факты о блинах, информацию о питании, рестораны, где подают блины, и многое другое.
Представление информации в виде расширенных функций, таких как карусель изображений или карта, делает поиск Google более полезным как для людей, так и для компаний. Эти функции предназначены для того, чтобы вы могли найти наиболее актуальную и полезную информацию для вашего запроса. Улучшив нашу способность предоставлять релевантные результаты, мы заметили, что люди проводят больше времени на веб-страницах, которые они находят через Поиск. Количество времени, проведенного на веб-сайтах после клика из Google Поиска, значительно выросло из года в год.
Помощь в изучении тем и навигации по ним
Другим важным элементом организации информации является помощь в изучении темы. В конце концов, большинство вопросов не имеют единственного ответа — это часто открытые вопросы, такие как «идеи десерта».
Наши специалисты по работе с пользователями тратят много времени на то, чтобы сделать процесс поиска простым и интуитивно понятным. Вот почему мы представили такие функции, как карусели, где вы можете легко провести пальцем по экрану телефона, чтобы получить больше результатов. Например, если вы ищете «безе», вы можете увидеть список связанных тем вместе со связанными вопросами, которые другие люди задавали, чтобы помочь вам в вашем путешествии.
Например, если вы ищете «безе», вы можете увидеть список связанных тем вместе со связанными вопросами, которые другие люди задавали, чтобы помочь вам в вашем путешествии.
Как ранжируются функции и результаты
Организация информации в удобные для использования форматы — это только одна часть головоломки. Чтобы вся эта информация была действительно полезной, мы также должны упорядочивать или «ранжировать» результаты таким образом, чтобы наиболее полезная и надежная информация поднималась вверх.
Наши системы ранжирования учитывают ряд факторов — от того, какие слова появляются на странице, до свежести контента, — чтобы определить, какие результаты наиболее релевантны и полезны для данного запроса. В основе этих систем лежит глубокое понимание информации — от языка и визуального контента до контекста, такого как время и место, — что позволяет нам сопоставлять цель вашего запроса с наиболее релевантными и качественными доступными результатами.
В тех случаях, когда есть один ответ, например «Когда была первая церемония вручения премии «Оскар»?», прямое предоставление этого ответа является наиболее полезным результатом, поэтому он будет отображаться вверху страницы. Но иногда запросы могут иметь множество интерпретаций. Возьмем такой запрос, как «пицца» — возможно, вы ищете ближайшие рестораны, способы доставки, рецепты пиццы и многое другое. Наши системы нацелены на создание страницы, которая, скорее всего, содержит то, что вы ищете, ранжируя результаты по наиболее вероятным намерениям в верхней части страницы. Поставить рецепт пиццы на первое место, безусловно, было бы уместно, но наши системы узнали, что люди, которые ищут «пицца», с большей вероятностью будут искать рестораны, поэтому мы, скорее всего, сначала покажем карту с местными ресторанами. Сравните это с таким запросом, как «блин», когда мы обнаруживаем, что люди с большей вероятностью ищут рецепты, поэтому рецепты часто ранжируются выше, а карта с ресторанами, где подают блины, может отображаться ниже на странице.
Важно помнить, что рейтинг динамичен. В мире всегда происходит что-то новое, поэтому доступная информация и смысл запросов могут меняться изо дня в день. Этим летом запросы «почему небо оранжевое» превратились из общего вопроса о закатах в конкретный, актуальный для местных условий запрос о погодных условиях на западном побережье США из-за лесных пожаров. Мы постоянно оцениваем качество наших результатов, чтобы гарантировать, что даже при изменении запросов или контента мы по-прежнему предоставляем полезную информацию. Более 10 000 оценщиков качества поиска по всему миру помогают нам проводить сотни тысяч тестов каждый год, и благодаря этому процессу мы знаем, что наши инвестиции в поиск Google действительно приносят пользу людям.
Мы слышали, как люди спрашивают, разрабатываем ли мы наши системы ранжирования в поиске в интересах рекламодателей, и хотим прояснить: это абсолютно не так. Мы никогда не предоставляем рекламодателям особого отношения к тому, как наши поисковые алгоритмы ранжируют их веб-сайты, и никто не может нам за это платить. Чтобы узнать больше об объявлениях и о том, как они отображаются в поиске, ознакомьтесь со следующей записью в нашей серии «Как работает поиск».
Чтобы узнать больше об объявлениях и о том, как они отображаются в поиске, ознакомьтесь со следующей записью в нашей серии «Как работает поиск».
Постоянные инвестиции в высокое качество обслуживания
Как мы видели на протяжении многих лет, и это стало особенно очевидным после COVID-19, информационные потребности могут быстро меняться. Поскольку мир меняется, мы всегда ищем новые способы улучшить поиск Google и помочь людям улучшить свою жизнь с помощью доступа к информации.
Каждый год мы вносим тысячи улучшений в Поиск Google, все из которых мы проверяем, чтобы убедиться, что они действительно делают его более интуитивно понятным, современным, приятным, полезным и во всех отношениях лучше для миллиардов запросов, которые мы получаем каждый день. . Поиск никогда не станет решенной проблемой, но мы стремимся продолжать внедрять инновации, чтобы сделать Google лучше для вас.
ОПУБЛИКОВАНО В:
Систематизация информации – Как работает поиск Google
Как Google
Поиск систематизирует информацию
Когда вы выполняете поиск, Google просматривает сотни миллиардов веб-страниц и другого контента, хранящегося в нашем поисковом индексе, чтобы найти полезную информацию – больше информации, чем во всех библиотеках мира.
Поиск информации путем сканирования
Большая часть нашего поискового индекса создается с помощью программного обеспечения, известного как сканеры. Они автоматически посещают общедоступные веб-страницы и переходят по ссылкам на этих страницах, как если бы вы просматривали контент в Интернете. Они переходят со страницы на страницу и сохраняют информацию о том, что они находят на этих страницах, и другой общедоступный контент в поисковом индексе Google.
Организация информации путем индексирования
Когда поисковые роботы находят веб-страницу, наши системы отображают ее содержимое так же, как это делает браузер. Мы принимаем к сведению ключевые сигналы — от ключевых слов до свежести веб-сайта — и отслеживаем все это в поисковом индексе.
Индекс поиска Google содержит сотни миллиардов веб-страниц и имеет размер более 100 000 000 гигабайт. Это похоже на индекс в конце книги — с записью для каждого слова, увиденного на каждой веб-странице, которую мы индексируем. Когда мы индексируем веб-страницу, мы добавляем ее в записи для всех слов, которые она содержит.
Когда мы индексируем веб-страницу, мы добавляем ее в записи для всех слов, которые она содержит.
Постоянный поиск новой информации
Поскольку Интернет и другое содержимое постоянно меняется, наши процессы сканирования постоянно работают, чтобы не отставать. Они узнают, как часто контент, который они видели раньше, меняется и пересматривается по мере необходимости. Они также обнаруживают новый контент по мере появления новых ссылок на эти страницы или информацию.
Google также предоставляет бесплатный набор инструментов под названием Search Console, который авторы могут использовать, чтобы помочь нам лучше сканировать их контент. Они также могут использовать установленные стандарты, такие как карты сайта или robots.txt, чтобы указать, как часто контент следует посещать или его вообще не следует включать в наш поисковый индекс.
Google никогда не принимает плату за более частое сканирование сайта — мы предоставляем одни и те же инструменты для всех веб-сайтов, чтобы обеспечить наилучшие результаты для наших пользователей.