Поиск под капотом Глава 1. Сетевой паук / Хабр
Умение искать информацию в Интернете является жизненно необходимым. Когда мы нажимаем на кнопку «искать» в нашей любимой поисковой системе, через доли секунды мы получаем ответ.
Большинство совершенно не задумывается о том, что же происходит «под капотом», а между тем поисковая система — это не только полезный инструмент, но еще и сложный технологический продукт. Современная поисковая система для своей работы использует практически все передовые достижения компьютерной индустрии: большие данные, теорию графов и сетей, анализ текстов на естественном языке, машинное обучение, персонализацию и ранжирование. Понимание того, как работает поисковая система, дает представление об уровне развития технологий, и поэтому разобраться в этом будет полезно любому инженеру.
В нескольких статьях я шаг за шагом расскажу о том, как работает поисковая система, и, кроме того, для иллюстрации я построю свой собственный небольшой поисковый движок, чтобы не быть голословным. Этот поисковый движок будет, конечно же, «учебным», с очень сильным упрощением того, что происходит внутри гугла или яндекса, но, с другой стороны, я не буду упрощать его слишком сильно.
Этот поисковый движок будет, конечно же, «учебным», с очень сильным упрощением того, что происходит внутри гугла или яндекса, но, с другой стороны, я не буду упрощать его слишком сильно.
Первый шаг — это сбор данных (или, как его еще называют, краулинг).
Веб — это граф
Та часть Интернета, которая нам интересна, состоит из веб-страниц. Для того чтобы поисковая система смогла найти ту или иную веб-страницу по запросу пользователя, она должна заранее знать, что такая страница существует и на ней содержится информация, релевантная запросу. Пользователь обычно узнает о существовании веб-страницы от поисковой системы. Каким же образом сама поисковая система узнает о существовании веб-страницы? Ведь никто ей не обязан явно сообщать об этом.
К счастью, веб-страницы не существуют сами по себе, они содержат ссылки друг на друга. Поисковый робот может переходить по этим ссылкам и открывать для себя все новые веб-страницы.
На самом деле структура страниц и ссылок между ними описывает структуру данных под названием «граф». Граф по определению состоит из вершин (веб-страниц в нашем случае) и ребер (связей между вершинами, в нашем случае — гиперссылок).
Граф по определению состоит из вершин (веб-страниц в нашем случае) и ребер (связей между вершинами, в нашем случае — гиперссылок).
Другими примерами графов являются социальная сеть (люди — вершины, ребра — отношения дружбы), карта дорог (города — вершины, ребра — дороги между городами) и даже все возможные комбинации в шахматах (шахматная комбинация — вершина, ребро между вершинами существует, если из одной позиции в другую можно перейти за один ход).
Графы бывают ориентированными и неориентированными — в зависимости от того, указано ли на ребрах направление. Интернет представляет собой ориентированный граф, так как по гиперссылкам можно переходить только в одну сторону.
Для дальнейшего описания мы будем предполагать, что Интернет представляет собой сильно связный граф, то есть, начав в любой точке Интернета, можно добраться до любой другой точки. Это допущение — очевидно неверное (я могу легко создать новую веб-страницу, на которую не будет ссылок ниоткуда и соответственно до нее нельзя будет добраться), но для задачи проектирования поисковой системы его можно принять: как правило, веб-страницы, на которые нет ссылок, не представляют большого интереса для поиска.
Небольшая часть веб-графа:
Алгоритмы обхода графа: поиск в ширину и в глубину
Поиск в глубину
Существует два классических алгоритма обхода графов. Первый — простой и мощный — алгоритм называется поиск в глубину (Depth-first search, DFS). В его основе лежит рекурсия, и он представляет собой следующую последовательность действий:
- Помечаем текущую вершину обработанной.
- Обрабатываем текущую вершину (в случае поискового робота обработкой будет просто сохранение копии).
- Для всех вершин, в которые можно перейти из текущей: если вершина еще не обработана, рекурсивно обрабатываем и ее тоже.
Код на Python, имплементирующий данный подход буквально дословно:
seen_links = set()
def dfs(url):
seen_links.add(url)
print('processing url ' + url)
html = get(url)
save_html(url, html)
for link in get_filtered_links(url, html):
if link not in seen_links:
dfs(link)
dfs(START_URL)Полный код на github
Приблизительно таким же образом работает, например, стандартная линуксовая утилита wget с параметром -r, показывающим, что нужно выкачивать сайт рекурсивно:
wget -r habrahabr.ru
 ru
ru
Метод поиска в глубину целесообразно применять для того, чтобы обойти веб-страницы на небольшом сайте, однако для обхода всего Интернета он не очень удобен:
- Содержащийся в нем рекурсивный вызов не очень хорошо параллелится.
- При такой реализации алгоритм будет забираться все глубже и глубже по ссылкам, и в конце концов у него, скорее всего, не хватит места в стеке рекурсивных вызовов и мы получим ошибку stack overflow.
В целом обе эти проблемы можно решить, но мы вместо этого воспользуемся другим классическим алгоритмом — поиском в ширину.
Поиск в ширину
Поиск в ширину (breadth-first search, BFS) работает схожим с поиском в глубину образом, однако он обходит вершины графа в порядке удаленности от начальной страницы. Для этого алгоритм использует структуру данных «очередь» — в очереди можно добавлять элементы в конец и забирать из начала.
- Алгоритм можно описать следующим образом:
- Добавляем в очередь первую вершину и в множество «увиденных».
- Если очередь не пуста, достаем из очереди следующую вершину для обработки.
- Обрабатываем вершину.
- Для всех ребер, исходящих из обрабатываемой вершины, не входящих в «увиденные»:
- Добавить в «увиденные»;
- Добавить в очередь.
- Перейти к пункту 2.

Код на python:
def bfs(start_url):
queue = Queue()
queue.put(start_url)
seen_links = {start_url}
while not (queue.empty()):
url = queue.get()
print('processing url ' + url)
html = get(url)
save_html(url, html)
for link in get_filtered_links(url, html):
if link not in seen_links:
queue.put(link)
seen_links.add(link)
bfs(START_URL)Полный код на github
Понятно, что в очереди сначала окажутся вершины, находящиеся на расстоянии одной ссылки от начальной, потом двух ссылок, потом трех ссылок и т. д., то есть алгоритм поиска в ширину всегда доходит до вершины кратчайшим путем.
Еще один важный момент: очередь и множество «увиденных» вершин в данном случае используют только простые интерфейсы (добавить, взять, проверить на вхождение) и легко могут быть вынесены в отдельный сервер, коммуницирующий с клиентом через эти интерфейсы. Эта особенность дает нам возможность реализовать многопоточный обход графа — мы можем запустить несколько одновременных обработчиков, использующих одну и ту же очередь.
Robots.txt
Прежде чем описать собственно имплементацию, хотелось бы отметить, что хорошо ведущий себя краулер учитывает запреты, установленные владельцем веб-сайта в файле robots.txt. Вот, например, содержимое robots.txt для сайта lenta.ru:
User-agent: YandexBot Allow: /rss/yandexfull/turbo User-agent: Yandex Disallow: /search Disallow: /check_ed Disallow: /auth Disallow: /my Host: https://lenta.ru User-agent: GoogleBot Disallow: /search Disallow: /check_ed Disallow: /auth Disallow: /my User-agent: * Disallow: /search Disallow: /check_ed Disallow: /auth Disallow: /my Sitemap: https://lenta.
 ru/sitemap.xml.gz
ru/sitemap.xml.gzВидно, что тут определены некоторые разделы сайта, которые запрещено посещать роботам яндекса, гугла и всем остальным. Для того чтобы учитывать содержимое robots.txt в языке python, можно воспользоваться реализацией фильтра, входящего в стандартную библиотеку:
In [1]: from urllib.robotparser import RobotFileParser
...: rp = RobotFileParser()
...: rp.set_url('https://lenta.ru/robots.txt')
...: rp.read()
...:
In [3]: rp.can_fetch('*', 'https://lenta.ru/news/2017/12/17/vivalarevolucion/')
Out[3]: True
In [4]: rp.can_fetch('*', 'https://lenta.ru/search?query=big%20data#size=10|sort=2|domain=1
...: |modified,format=yyyy-MM-dd')
Out[4]: FalseИмплементация
Итак, мы хотим обойти Интернет и сохранить его для последующей обработки.
Конечно, в демонстрационных целях обойти и сохранить весь Интернет не выйдет — это стоило бы ОЧЕНЬ дорого, но разрабатывать код мы будем с оглядкой на то, что потенциально его можно было бы масштабировать до размеров всего Интернета.
Это означает, что работать мы должны на большом количестве серверов одновременно и сохранять результат в какое-то хранилище, из которого его можно будет легко обработать.
Архитектура разработанного решения
Центральным элементом в моей схеме сбора данных является сервер очереди, хранящий очередь URL, подлежащих скачиванию и обработке, а также множество URL, которые наши обработчики уже «видели». В моей имплементации это они основаны на простейших структурах данных Queue и set языка python.
В реальной продакшн-системе, скорее всего, вместо них стоило бы использовать какое-нибудь существующее решение для очередей (например, kafka) и для распределенного хранения множеств (например, подошли бы решения класса in-memory key-value баз данных типа aerospike). Это позволило бы достичь полной горизонтальной масштабируемости, но в целом нагрузка на сервер очереди оказывается не очень большой, поэтому в таком масштабировании в моем маленьком демо-проекте смысла нет.
Это позволило бы достичь полной горизонтальной масштабируемости, но в целом нагрузка на сервер очереди оказывается не очень большой, поэтому в таком масштабировании в моем маленьком демо-проекте смысла нет.
Рабочие серверы периодически забирают новую группу URL для скачивания (забираем сразу помногу, чтобы не создавать лишнюю нагрузку на очередь), скачивают веб-страницу, сохраняют ее на s3 и добавляют новые найденные URL в очередь на скачивание.
Для того чтобы снизить нагрузку на добавление URL, добавление тоже происходит группами (добавляю сразу все новые URL, найденные на веб-странице). Еще я периодически синхронизирую множество «увиденных» URL с рабочими серверами, чтобы осуществлять предварительную фильтрацию уже добавленных страниц на стороне рабочей ноды.
Скачанные веб-страницы я сохраняю на распределенном облачном хранилище (S3) — это будет удобно впоследствии для распределенной обработки.
Очередь периодически отправляет статистику по количеству добавленных и обработанных запросов в сервер статистики. Статистику отправляем суммарно и в отдельности для каждой рабочей ноды — это необходимо для того, чтобы было понятно, что скачивание происходит в штатном режиме. Читать логи каждой отдельной рабочей машины невозможно, поэтому следить за поведением будем на графиках. В качестве решения для мониторинга скачивания я выбрал graphite.
Статистику отправляем суммарно и в отдельности для каждой рабочей ноды — это необходимо для того, чтобы было понятно, что скачивание происходит в штатном режиме. Читать логи каждой отдельной рабочей машины невозможно, поэтому следить за поведением будем на графиках. В качестве решения для мониторинга скачивания я выбрал graphite.
Запуск краулера
Как я уже писал, для того чтобы скачать весь Интернет, нужно огромное количество ресурсов, поэтому я ограничился только маленькой его частью — а именно сайтами habrahabr.ru и geektimes.ru. Впрочем, ограничение это довольно условное, и расширение его на другие сайты — просто вопрос количества доступного железа. Для запуска я реализовал простенькие скрипты, которые поднимают новый кластер в облаке amazon, копируют туда исходный код и запускают соответствующий сервис:
#deploy_queue.py
from deploy import *
def main():
master_node = run_master_node()
deploy_code(master_node)
configure_python(master_node)
setup_graphite(master_node)
start_urlqueue(master_node)
if __name__ == main():
main()#deploy_workers.
 py
#run as: http://<queue_ip>:88889
from deploy import *
def main():
master_node = run_master_node()
deploy_code(master_node)
configure_python(master_node)
setup_graphite(master_node)
start_urlqueue(master_node)
if __name__ == main():
main()
py
#run as: http://<queue_ip>:88889
from deploy import *
def main():
master_node = run_master_node()
deploy_code(master_node)
configure_python(master_node)
setup_graphite(master_node)
start_urlqueue(master_node)
if __name__ == main():
main()Код скрипта deploy.py, содержащего все вызываемые функции
Использование в качестве инструмента статистики graphite позволяет рисовать красивые графики:
Красный график — найденные URL, зеленый — скачанные, синий — URL в очереди. За все время скачано 5.5 миллионов страниц.
Количество скрауленных страниц в минуту в разбивке по рабочим нодам. Графики не прерываются, краулинг идет в штатном режиме.
Результаты
Скачивание habrahabr и geektimes у меня заняло три дня.
Можно было бы скачать гораздо быстрее, увеличив количество экземпляров воркеров на каждой рабочей машине, а также увеличив количество воркеров, но тогда нагрузка на сам хабр была бы очень большой — зачем создавать проблемы любимому сайту?
В процессе работы я добавил пару фильтров в краулер, начав фильтровать некоторые явно мусорные страницы, нерелевантные для разработки поискового движка.
Разработанный краулер, хоть и является демонстрационным, но в целом масштабируется и может применяться для сбора больших объемов данных с большого количества сайтов одновременно (хотя, возможно, в продакшне есть смысл ориентироваться на существующие решения для краулинга, такие как heritrix. Реальный продакшн-краулер также должен запускаться периодически, а не разово, и реализовывать много дополнительного функционала, которым я пока пренебрег.
За время работы краулера я потратил примерно 60 $ на облако amazon. Всего скачано 5.5 млн страниц, суммарным объемом 668 гигабайт.
В следующей статье цикла я построю индекс по скачанным веб-страницам при помощи технологий больших данных и спроектирую простейший движок собственно поиска по скачанным страницам.
Код проекта доступен на github
Изменение настроек поиска по умолчанию в Firefox
Наладьте Firefox
Очистить Firefox
- Как это работает?
- Загрузить свежую копию
Панель Поиск на странице Настройки
в Firefox позволяет вам настраивать параметры поиска. Вы можете добавить или удалить поисковые системы, изменить поисковую систему по умолчанию, назначить или изменить краткие имена, отключить или включить панель поиска и выбрать, необходимо ли отображать поисковые предложения в первую очередь или вообще не отображать.
Вы можете добавить или удалить поисковые системы, изменить поисковую систему по умолчанию, назначить или изменить краткие имена, отключить или включить панель поиска и выбрать, необходимо ли отображать поисковые предложения в первую очередь или вообще не отображать.
Оглавление
- 1 Как открыть панель поиска
- 2 Панель поиска
- 3 Поисковая система по умолчанию
- 4 Поисковые предложения
- 5 Альтернативы поиска
- 5.1 Добавление или удаление поисковых систем
- 5.2 Удаление поисковой системы
- 5.3 Восстановление поисковых систем по умолчанию
- 5.4 Добавление новой поисковой системы
- 6 Краткие имена поисковых систем
На Панели меню в верхней части экрана щёлкните Firefox и выберите Настройки. Нажмите кнопку и выберите Настройки.Нажмите кнопку и выберите Настройки.
- Выберите Поиск на панели слева.
- Использовать адресную строку для поиска и навигации: Это параметр по умолчанию.
- Добавить панель поиска на панель инструментов: Выберите этот параметр, если вы предпочитаете использовать отдельную панель поиска.

Используйте выпадающее меню под Поисковая система по умолчанию, чтобы выбрать поисковую систему, которую вы желаете использовать по умолчанию.
Примечание: Некоторые расширения, которые добавлены в Firefox, могут устанавливать новую поисковую систему по умолчанию. Вы можете отключить или удалить расширение, которое произвело изменение, или можете выбрать другую поисковую систему из выпадающего меню, если предпочитаете другое умолчание.
Как только вы начинаете набирать текст в панели поиска или адресной строке, ваша поисковая система по умолчанию показывает вам предложения, основанные на популярных или предыдущих поисковых запросах. Прочитайте статью Поисковые предложения в Firefox для получения дополнительной информации.
- Отображать поисковые предложения: Выберите этот параметр, чтобы включить или отключить поисковые предложения.
- Отображать поисковые предложения при использовании панели адреса: Когда поисковые предложения включены, выберите эту настройку, чтобы включить также поисковые предложения в результаты, которые перечисляются, когда вы совершаете поиск в адресной строке Firefox. Может отображаться до двух предложений из вашей Истории поиска. Они будут отображаться со значком часов вместо значка увеличительного стекла.
- Отображать поисковые предложения перед историей веб-сёрфинга при использовании панели адреса: Выберите этот параметр, чтобы показывать поисковые предложения перед вашей историей посещений.
- Показывать поисковые предложения в приватных окнах: Выберите этот параметр, чтобы отобразить поисковые предложения в окнах Приватного Просмотра.
Когда вы начнете набирать в адресной строке или панели поиска, вы увидите значки ниже поисковых предложений, чтобы совершать поиск вместо этого с помощью других поисковых систем, Закладок, Владок и Истории.
Вы можете выбрать альтернативный тип поиска и использовать его для поиска, если не хотите использовать текущий тип поиска по умолчанию.
Чтобы удалить альтернативные поисковые системы, которые вы не хотите отображать в строке поиска или адресной строке, снимите флажок рядом с поисковой системой, указанной на панели поиска в разделе Сочетания клавиш поиска.Это не приведёт к удалению самих поисковых систем.
Добавление или удаление поисковых систем
Чтобы удалить поисковую систему из Firefox, восстановить поисковые системы по умолчанию, которые идут с Firefox, или добавить новую поисковую систему, перейдите в раздел Сочетания клавиш поиска на панели Поиск.
Удаление поисковой системы
- Щёлкните по поисковой системе, которую вы хотите удалить, чтобы выделить её.
- Щёлкните по кнопке Удалить внизу, чтобы убрать её из списка.
Заметка: Вы должны использовать Менеджер дополнений, чтобы удалить все поисковые системы, установленные как дополнения Firefox (прочитайте статью Отключение или удаление дополнений для получения подробной информации).
Восстановление поисковых систем по умолчанию
Если вы удалите какие-либо из поисковых систем, которые поставляются с Firefox по умолчанию, нажмите Восстановить набор поисковых систем систем по умолчанию в нижней части панели Поиск, чтобы вернуть их.
Добавление новой поисковой системы
- Щёлкните по ссылке Найти другие поисковые системы в нижней части панели Поиск.
- Откроется страница дополнений Firefox со списком доступных инструментов поиска.
- Нажмите на поисковую систему, которую вы хотите добавить, и нажмите Добавить в Firefox.
Для получения подробной информации о добавлении или удалении поисковой системы прочитайте статью Добавление или удаление поисковых систем в Firefox.
Вы можете назначить или изменить краткие имена для ваших любимых поисковых систем, чтобы совершать поиск легче. Для получения дополнительной информации прочитайте статью Назначение кратких имён поисковым системам.
Поделитесь этой статьёй: http://mzl. la/1VSkUwR
la/1VSkUwR
Эти прекрасные люди помогли написать эту статью:
Unghost, Harry, Anticisco Freeman, Valery Ledovskoy, SwanMr.pound, Victor Bychek
Станьте волонтёром
Растите и делитесь опытом с другими. Отвечайте на вопросы и улучшайте нашу базу знаний.
Подробнее
Каковы 10 самых популярных поисковых систем?
Вы знаете, кроме самый очевидный поисковик. И, возможно, второй самый очевидный тоже. Начну опять, какие восемь самых популярных поисковых систем после Google и Bing?
Первый список ниже содержит самые популярные поисковые системы, доступные в настоящее время, отсортированные по популярности в США. Рейтинг составлен по версии eBiz в порядке расчетного числа уникальных посетителей в месяц и актуален по состоянию на август 2016 г.
Второй список представляет собой глобальный обзор самых популярных поисковых систем согласно Net Market Share, который ранжируется в порядке доли рынка и снова является точным по состоянию на август 2016 года.
В отличие от нашего предыдущего списка альтернатив поисковых систем для Google, этот список будет сосредоточен исключительно на информационном поиске, а не на… Gif или изображениях без авторских прав.
США
1) Google
Оценка уникальных посетителей в месяц: 1,6 миллиарда
Alexa Rank: 1
Почему вы должны его использовать?
Имея 72,48% доли мирового рынка поиска, у вас как у маркетолога нет выбора не использовать его как для платного, так и для органического охвата.
Как обычный пользователь, несмотря на весь наш цинизм и иногда легкомысленные ссылки на The Circle, вы должны признать, что Google совершенно незаменим в вашей повседневной жизни. На каждое вмешательство (постоянное урезание результатов органической выдачи) приходится 10 триумфов… Google Maps, Gmail, ужасающая релевантность Knowledge Graph, убийство рекламы займов до зарплаты, AMP…
Где бы мы все были без… да, я скажу это… поискового гиганта.
2) Bing
Ресурсы
Приблизительное количество уникальных посетителей в месяц: 400 миллионов
Alexa Rank: 22
Почему вы должны его использовать?
Как я уже говорил ранее в этом году в вышеупомянутом посте «альтернативы Google», есть несколько веских причин для выбора Bing:
- Поиск видео в Bing значительно лучше, чем в Google.
- Bing часто дает в два раза больше предложений автозаполнения, чем Google.
- В Bing есть отличная функция linkfromdomain:[имя сайта] , которая выделяет исходящие ссылки с этого сайта с лучшим рейтингом, помогая вам выяснить, на какие другие сайты больше всего ссылается выбранный вами сайт.
3) Yahoo
Расчетное количество уникальных посетителей в месяц: 300 миллионов
Alexa Rank: н/д
Почему вы должны его использовать?
На данный момент все это находится в подвешенном состоянии, поскольку Verizon только что приобрела Yahoo за 4,8 миллиарда долларов и планирует объединить ее с AoL.
Yahoo будет продолжать работать независимо до одобрения сделки регулирующими органами, которая, как ожидается, будет завершена к началу 2017 года. После этого все новостные, финансовые и спортивные платформы Yahoo будут добавлены к медиаактивам AOL, включая The Huffington Post. и TechCrunch.
4) Спросите
Расчетное количество уникальных посетителей в месяц: 245 миллионов
Alexa Rank: 31
Почему вы должны его использовать?
Несмотря на решимость Google быть основным источником всех знаний в своей собственной поисковой выдаче, Ask по-прежнему хорош для поиска, связанного с конкретными вопросами, с результатами, основанными на совпадениях, связанных с вопросами и ответами.
И эй, иногда приятно получить помощь от дворецкого.
5) Aol Search
Расчетное количество уникальных посетителей в месяц: 125 миллионов
Alexa Rank: н/д
Почему вы должны его использовать?
Как упоминалось выше, AOL, которую вы знаете и, возможно, любите, может стать другим зверем после того, как Verizon Communications объединит ее с Yahoo.
Давайте запомним более простые времена…
6) WOW
Оценки уникальных ежемесячных посетителей: 100 млн.
Alexa Rank:
Почему вы должны использовать его?
Потому что он больше похож на новостной сайт, чем на поисковую систему, что удобно, если вам нужно все в одном месте. Существует сильный уклон к новостям и статьям о знаменитостях, а не к чистой информации в стиле Википедии, но удобные ссылки на соответствующие социальные каналы и вики-страницы полезны.
7) WebCrawler
Расчетное количество уникальных посетителей в месяц: 65 миллионов
Alexa Rank: 674
Почему вы должны его использовать?
WebCrawler имеет гораздо более четкое разграничение между платной поисковой рекламой и обычными результатами. Кроме того, кажется, что у него гораздо больше естественных «синих ссылок», чем у Google.
Кроме того, кажется, что у него гораздо больше естественных «синих ссылок», чем у Google.
8) MyWebSearch
Расчетное количество уникальных посетителей в месяц: 60 миллионов
Alexa Rank: 405
Почему вы должны его использовать?
Э… не надо.
Согласно Malware Wikia, MyWebSearch — это программа-шпион и панель инструментов поиска, которая позволяет пользователю запрашивать различные популярные поисковые системы и поставляется в комплекте с утомительным набором «плюшек», таких как Smiley Central, Webfetti, Cursor Mania, My Mail Stationary, My Mail Signature, My Mail Stamps, FunBuddyIcons… веселье продолжается и продолжается.
Самое ужасное, что Malware Wikia сообщает, что, несмотря на отсутствие каких-либо атрибутов вредоносного ПО, независимая ремонтная лаборатория классифицировала панель инструментов как неприятную из-за «замедления работы в обмен на функции, которые уже встроены во многие современные веб-браузеры».
9) Информационное пространство
Расчетное количество уникальных посетителей в месяц: 24 миллиона
Alexa Rank: 2,110
Почему вы должны его использовать?
Возможно, вы уже используете его… InfoSpace является «поставщиком решений для поиска и монетизации с использованием белой этикетки», а также управляет собственными фирменными поисковыми сайтами, включая метапоисковик Dogpile, а также Zoo.com и WebCrawler (как упоминалось выше.)
10) Info.com
Расчетное количество уникальных посетителей в месяц: 13,5 миллионов
Alexa Rank: 1 938
Почему вы должны его использовать?
Info.com собирает результаты из проиндексированных веб-каналов И социальных сетей. Он отслеживает социальные разговоры в режиме реального времени и, по их словам, предоставляет «заслуживающие внимания, актуальные и популярные результаты до того, как они попадут в проиндексированную сеть». Эти потоки классифицируются по структурированным темам, что обеспечивает дополнительный контекст и понимание.
Эти потоки классифицируются по структурированным темам, что обеспечивает дополнительный контекст и понимание.
Бонус: 11) DuckDuckGo
Почетное упоминание DuckDuckGo, новой компании, которая не хранит вашу личную информацию, которая привлекла 13 миллионов уникальных посетителей в месяц и в настоящее время является 11-й по популярности поисковой системой в мире. НАС.
Worldwide
Вот MarketShare по всему миру для поисковых систем…
1) Google — 72,48%
2) Bing — 10,39%
3) Yahoo — 7,78% 90%
3) Yahoo — 7,78%
3).0023 4) Baidu — 7,14%
5) Спросите — 0,22%
6) AOL — 0,15%
7) Этакуйте — 0,01%
Топ 8 лучших поисковых специалистов (из 2022)
Блог. »Сообщество» Top 8 лучших поисковых систем (из 2022)
от Rapidapi персонал //
СОДЕРЖАНИЕ
- 1. Google
- PROS
- CONS
- 2. Bing
- Плюсы
- Минусы
- 3. Yahoo
- Pros
- Cons
- 4. Baidu
- Pros
- Cons
- 5. Yandex
- Pros
- Cons
- 6. Duckduckgo
- Pros
- CONS
- 7. Контекстуальный поиск в Интернете
- Pros
- CONS
- 8. Yippy Search
- Pros
- CONS
- CONS
 Эта статья направлена на то, чтобы обеспечить ранг некоторых из лучших поисковых систем.
Эта статья направлена на то, чтобы обеспечить ранг некоторых из лучших поисковых систем.Узнайте, как создать систему пользовательского поиска, здесь
Помимо того, что Google является самой популярной поисковой системой, охватывающей более 90% мирового рынка, Google может похвастаться выдающимися функциями, которые делают ее лучшей поисковой системой на рынке. Он может похвастаться передовыми алгоритмами, простым в использовании интерфейсом и персонализированным пользовательским интерфейсом. Платформа известна тем, что постоянно обновляет результаты и функции своей поисковой системы, чтобы предоставить пользователям лучший опыт.
Связано: Учебник по Google Translate API
Pros
- Предоставляет качественные результаты поиска в простом в использовании интерфейсе
- Регулярно обновляет свои результаты и функции
- Имеет самый большой единый каталог веб-страниц
- API
Microsoft Bing — вторая по известности поисковая система в мире. И хотя он значительно уступает Google с точки зрения доли рынка, он может похвастаться некоторыми уникальными функциями, которые могут заинтересовать пользователей. Во-первых, фильтры поисковой системы приводят к различным вкладкам, таким как реклама, изображения, карты, видео и новости. Это также дает пользователям возможность накапливать баллы, которые они позже могут использовать в магазинах Microsoft и Windows. Он также безупречно работает во всех браузерах.
И хотя он значительно уступает Google с точки зрения доли рынка, он может похвастаться некоторыми уникальными функциями, которые могут заинтересовать пользователей. Во-первых, фильтры поисковой системы приводят к различным вкладкам, таким как реклама, изображения, карты, видео и новости. Это также дает пользователям возможность накапливать баллы, которые они позже могут использовать в магазинах Microsoft и Windows. Он также безупречно работает во всех браузерах.
Плюсы
- Одинаково сканирует скрытый и нескрытый контент
- Поисковая система ранжирует домашние страницы, а не блоги
- Может похвастаться выдающимся индексированием видео результаты поиска
Хотя когда-то он был популярнее, чем Google, и даже шел ноздря в ноздрю с Google в первые дни своего существования, Yahoo опустился на третье место с точки зрения доли рынка. Его веб-портал по-прежнему популярен, и, согласно Alexa, он является одиннадцатым по посещаемости сайтом. Yahoo предлагает впечатляющий интерфейс, чистые результаты и впечатляющий каталог веб-сайтов.
Yahoo предлагает впечатляющий интерфейс, чистые результаты и впечатляющий каталог веб-сайтов.
Pros
- Предлагает исчерпывающие органические результаты
- Его поиск покупок имеет больше функций и возможностей, чем любая другая поисковая система
- Может похвастаться другими услугами, такими как Yahoo Finance, Yahoo почта, ответы Yahoo и несколько мобильных приложений
Минусы
- Нечеткая маркировка объявлений затрудняет различие между органическими и неорганическими результатами
- Недатированные результаты поиска
Baidu, основанная в 2000 году, является первоклассной поисковой системой, доминирующей в Китае. На протяжении многих лет платформа демонстрирует устойчивый рост числа пользователей. И хотя он в основном используется в Китае, он по-прежнему может похвастаться интуитивно понятным интерфейсом, множеством параметров поиска и результатами поиска премиум-класса.
Pros
- Отличные функции и высококачественные результаты поиска
- Он поддерживается одной из крупнейших в мире компаний, занимающихся искусственным интеллектом и интернет-услугами
- Множество вариантов рекламы
Минусы
Яндекс был создан в 1997 году и может похвастаться тем, что является наиболее используемой поисковой системой в России. Материнская компания Яндекса позиционирует себя как технологическая компания, специализирующаяся на создании интеллектуальных продуктов и услуг на основе машинного обучения. Тем не менее, он поддерживает одну из самых обширных поисковых систем в России, на долю которой приходится более 65% рынка. С помощью Яндекса вы можете искать что угодно, включая изображения, карты и даже видео.
Материнская компания Яндекса позиционирует себя как технологическая компания, специализирующаяся на создании интеллектуальных продуктов и услуг на основе машинного обучения. Тем не менее, он поддерживает одну из самых обширных поисковых систем в России, на долю которой приходится более 65% рынка. С помощью Яндекса вы можете искать что угодно, включая изображения, карты и даже видео.
Pros
- Предоставляет результаты поиска мирового класса, соответствующие местным условиям
- Уникальная опция поиска изображений
- Может быть настроена для разных стран
- Предоставляет геокодер, перевод, места и статическую карту Сервисы.
Минусы
- Собирает пользовательские данные, как и большинство других поисковых систем
Еще одна выдающаяся поисковая система — Duckduckgo. В отличие от других поисковых систем, Duckduckgo ценит конфиденциальность пользователей, поскольку они не отслеживают и не хранят личную информацию о поиске. Поисковая система позволяет вам искать все, начиная от изображений, карт и видео. Он может похвастаться выдающимися функциями, такими как информация без щелчка, когда все ответы появляются на первой странице. Подсказки по устранению неоднозначности поясняют, что вы ищете, для получения более точных результатов.
Поисковая система позволяет вам искать все, начиная от изображений, карт и видео. Он может похвастаться выдающимися функциями, такими как информация без щелчка, когда все ответы появляются на первой странице. Подсказки по устранению неоднозначности поясняют, что вы ищете, для получения более точных результатов.
Pros
- Не отслеживает и не каталогизирует информацию о пользователе
- Предоставляет быстрые результаты для мгновенного поиска
- Обладает чистым и понятным интерфейсом
Cons
- Его изображения ограничены Результаты поиска не персонализированы 8
Контекстный веб-поиск — это надежный API, который предоставляет пользователям доступ к миллиардам веб-страниц, новостей и изображений с помощью одного вызова API. API связывает вас с поисковой системой, которая имитирует то, как человеческий мозг индексирует воспоминания для получения более информативных результатов поиска. Этот API использует комбинацию информации о пользователях и их поведении для создания контекста для персонализированного поиска.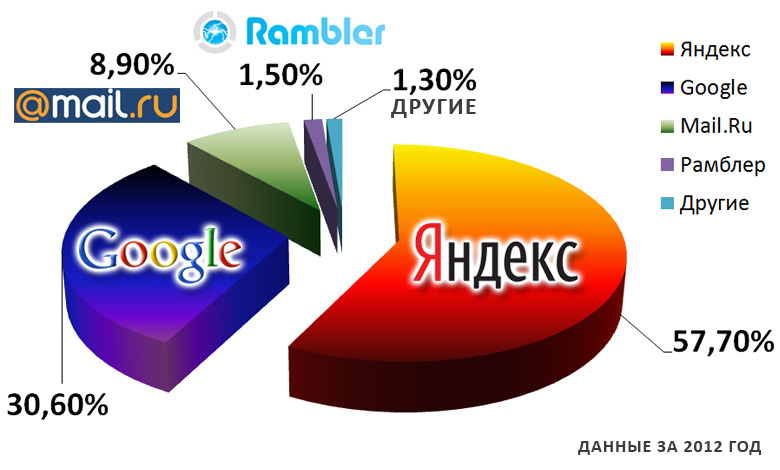 Это поможет вам настроить свой опыт и получить точные и релевантные результаты поиска.
Это поможет вам настроить свой опыт и получить точные и релевантные результаты поиска.
Pros
- Обеспечивает быстрые и точные результаты
- Использует контекстную технологию и лежащую в основе семантику для предоставления персонализированного опыта
- Предоставляет доступ к базе данных с миллиардами веб-страниц
Минусы
- API быть сложным для нетехнических пользователей
Yippy Search — это современный механизм глубокого Интернета, который помогает пользователям исследовать то, что не могут найти другие поисковые системы. Поскольку глубокие веб-страницы труднее найти при обычном поиске, Yippy Search поможет вам найти эти веб-страницы. Это позволяет вам искать труднодоступную информацию, такую как каналы, связанные с правительством, блоги по интересам, научные исследования или необычные новости.
Плюсы
- Блокирует нежелательные веб-сайты
- Показывает множество связанных тем на экране результатов поиска
- Предварительный просмотр на экране результатов много рекламы.
