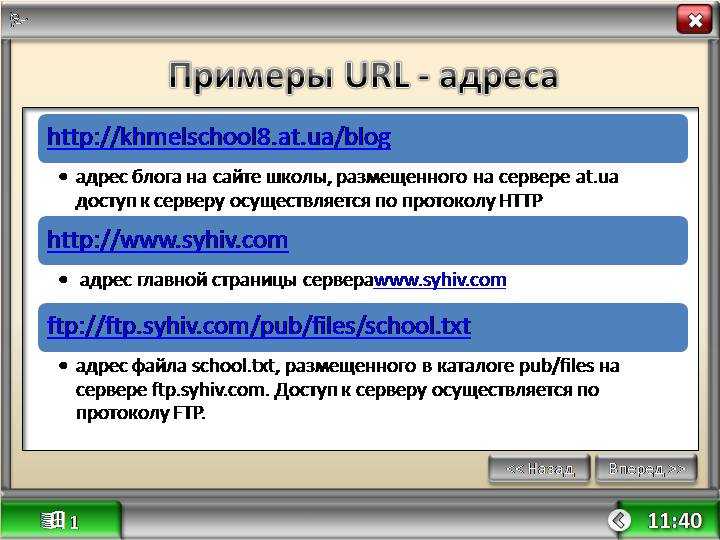
Использование параметров URL—Portal for ArcGIS
Приложения, созданные с помощью Web AppBuilder, можно изменять, используя параметры URL. URL-адрес всегда начинается с <your portal url>/apps/webappviewer/index.html? и включает один или несколько перечисленных ниже параметров. Чтобы включить более одного параметра, используйте знак амперсанта (&) для разделения параметров. Ниже приведен пример:
http://<your portal url>/apps/webappviewer/index.html?id=6815e148ff1c4aee8dc7159816380a4d&webmap=9cf053ea602345ddae060010c470e615
Подсказка:
Теперь есть более простой способ конструировать параметры URL. Добавьте в приложение виджет Опубликовать и щелкните Опции ссылки. Предварительный просмотр ссылки отображает выбранные вами параметры, короткая ссылка с параметрами URL генерируется для вас автоматически. Имейте в виду, что виджет Поиск должен быть включен в приложении, чтобы использовать параметр find.
В настоящее время 3D-приложения не поддерживают параметры URL.
Кодирование параметров запроса
Все параметры запроса должны быть закодированы. Кодировка заменяет некорректные символы знаком %, за которым следует их шестнадцатеричный эквивалент.
Например, так выглядит незакодированный параметр URL:
http://<your portal url>/apps/webappviewer/index.html?find=380 new york street, redlands, ca
А так выглядит тот же параметр после кодирования:
http://<your portal url>/apps/webappviewer/index.html?find=380%20new%20york%20street,%20redlands,%20ca
В Интернет вы можете найти множество бесплатных сайтов и инструментов для создания закодированных адресов URL. Например, на сайте Albion Research Ltd. имеются страницы URLEncode и URLDecode. Для удобства чтения, остальные примеры в данном разделе не закодированы.
Открытие сохраненного приложения
Чтобы открыть сохраненное приложение, которое было создано с помощью Web AppBuilder, необходимо использовать id= и уникальный ID этого приложения, как показано в следующем примере:
http://<your portal url>/apps/webappviewer/index.html?id=6815e148ff1c4aee8dc7159816380a4d
 html?id=6815e148ff1c4aee8dc7159816380a4d
html?id=6815e148ff1c4aee8dc7159816380a4dОпределение веб-карты
Чтобы определить веб-карту, используйте webmap= и уникальный ID этой веб-карты, как показано в следующем примере:
http://<your portal url>/apps/webappviewer/index.html?webmap=9cf053ea602345ddae060010c470e615
Центрирование карты
Чтобы центрировать карту в определенном месте, установите center=, используя географические координаты (x,y) или координаты проекции (x,y,WKID).
Внимание:
В качестве разделителей вы можете использовать запятые или точки с запятой. Используйте точки с запятой, если для десятичных разделителей в ваших числах используется двоеточие.
Ниже приведен пример географических координат:
http://<your portal url>/apps/webappviewer/index.html?center=34,-50
Ниже приведен пример координат проекции:
http://<your portal url>/apps/webappviewer/index.html?center=500000,5500000,102100
Задание уровня масштабирования
Чтобы задать масштаб карты, используйте параметры center= и level=. Параметр level принимает ID масштаба кэширования, который указывается в конечной точке REST картографического сервиса. Ниже приведен пример:
Параметр level принимает ID масштаба кэширования, который указывается в конечной точке REST картографического сервиса. Ниже приведен пример:
http://<your portal url>/apps/webappviewer/index.html?center=20,45&level=4
Указание масштаба
Чтобы задать масштаб карты, используйте параметры center= и scale=. Параметр scale принимает масштаб кэширования, который указывается в конечной точке REST картографического сервиса. Ниже приведен пример:
http://<your portal url>/apps/webappviewer/index.html?center=20,45&scale=4622324
Определение экстента
Используйте extent= для задания экстента карты. Параметр extent допускает географические координаты (GCS) MinX,MinY,MaxX,MaxY, прогнозируемые координаты (PCS) MinX,MinY,MaxX,MaxY,WKID или координаты в тексовом формате Well-Known Text String (WKT) MinX,MinY,MaxX,MaxY,WKT. В качестве разделителей вы можете использовать запятые или точки с запятой. Используйте точки с запятой, если для десятичных разделителей в ваших числах используется двоеточие.
Ниже приведен пример географических координат:
http://<your portal url>/apps/webappviewer/index.html?extent=-117.20,34.055,-117.19,34.06
Ниже приведен пример координат проекции:
http://<your portal url>/apps/webappviewer/index.html?extent=-13079253.954115,3959110.38566837,-12918205.318785,4086639.70193162,102113
Ниже приводится пример формата Well-Known Text String (WKT):
http://<your portal url>/apps/webappviewer/index.html?extent=1008562.1255,1847133.031,1060087.7901,1877230.7859,wkt=PROJCS["NAD_1983_HARN_StatePlane_Illinois_East_FIPS_1201",GEOGCS["GCS_North_American_1983_HARN",DATUM["D_North_American_1983_HARN",SPHEROID["GRS_1980",6378137.0,298.257222101]]
Поиск местоположения или объекта для открытия карты
Чтобы найти местоположение или объект, использующиеся для открытия карты, примените find=. Карта автоматически масштабируется до ближайшего совпадения, кроме того, к ней добавляется маркер выноски. Параметр find принимает однострочные адреса, частичные адреса (только город или только страна), названия мест, координаты широты-долготы и объекты в слоях с возможностью поиска (такие как 1916352001 в качестве Parcel Identification Number (PIN)). Ниже приведен пример:
Параметр find принимает однострочные адреса, частичные адреса (только город или только страна), названия мест, координаты широты-долготы и объекты в слоях с возможностью поиска (такие как 1916352001 в качестве Parcel Identification Number (PIN)). Ниже приведен пример:
http://<your portal url>/apps/webappviewer/index.html?find=380 new york street, redlands, ca
Внимание:
Все параметры запроса должны быть закодированы, чтобы использовать этот параметр, виджет Поиск должен быть включен в приложении.
Добавить точку
Чтобы добавить точку на карту, используйте marker=<x>,<y>. Точка будет добавлена на карту с указанными координатами x и y. Вы также можете настроить следующие необязательные параметры:
- <wkid> – пространственная привязка координат x,y добавленной на карту точки. Если вы не укажете WKID, то будут использоваться координаты географической системы координат (GCS).
- <encoded title> – заголовок всплывающего окна точки. Если вы не укажете заголовок, то всплывающее окно будет пустым.
- <encoded icon URL> – символ точки. Если вы не укажете символ, то используется символ синего маркера.
- <encoded label> – надпись рядом с символом точки.
 Если вы не укажете заголовок, то всплывающее окно будет пустым.
Если вы не укажете заголовок, то всплывающее окно будет пустым.Следует учитывать следующее:
- <x>,<y> являются обязательными.
- Обязательно используйте параметры заголовок, значок и надпись.
- Необходимо добавлять параметры в следующем порядке: marker=<x>,<y>,<wkid>,<encoded title>,<encoded icon URL>,<encoded label>.
- В качестве разделителей вы можете использовать запятые или точки с запятой. Используйте точки с запятой, если для десятичных разделителей в ваших числах используется двоеточие.
- Использование пустых значений. Не используйте пробелы. Например, если вы хотите указать из необязательных параметров только надпись, то добавьте надпись шестым по счету параметром, а для остальных параметров используйте пустое значение (x;y;;;;label).
- Если вы хотите отобразить карту в определенном масштабе (помимо центрирования в точке), то включите также параметр level=.

Ниже приведен пример:
http://<your portal url>/apps/webappviewer/index.html?marker=-79.234826;38.147884;;Race start and finish;;Grindstone 100 Ultra Marathon&level=7
Запрос объекта
Чтобы запросить объект и приблизиться к нему, можно использовать одну из следующих опций:
- query=<layer name>,<field name>,<field value>
- query=<layer name>, <where clause>
- query=<layer id>,<field name>,<field value>
- query=<layer id>, <where clause>
Подсказка:
Теперь есть интерактивный способ конструировать параметры URL. Добавьте в приложение виджет Опубликовать и щелкните Опции ссылки. Выберите опцию Создайте запрос объекта и приблизьтесь к нему и выберите слой, поле и значение поля, к которому вы хотите снова выполнить запрос. Скопируйте URL в окне Предварительный просмотр ссылки где находятся заданный вами параметры URL. Удалите виджет Опубликовать из приложения, если он не нужен.
Скопируйте URL в окне Предварительный просмотр ссылки где находятся заданный вами параметры URL. Удалите виджет Опубликовать из приложения, если он не нужен.
Внимание:
Все параметры запроса чувствительны к регистру и должны быть кодированы.
Условие where соответствует стандарту SQL. Если условие where содержит, к примеру, операцию IN, используйте для разделения имени или id слоя из условия where точку с запятой вместо запятых, как показано ниже. Причина в том, что запятая используется в условии where специально для построения списка таких значений, как (‘A11’, ‘A12’, ‘A13) или (‘Charlotte’, ‘Chicago’). Это позволяет правильно проанализировать параметр запроса, чтобы отличить условие layer от where.
- query=<layer name>; <where clause>
- query=<layer id>; <where clause>
Поскольку имя слоя может быть изменено, настоятельно рекомендуется использовать в запросе ID слоя. Можно получить ID слоя из ID веб-карты как показано ниже: http://<your portal url>/sharing/rest/content/items/32a83775654249dcae6b8f2eff5d4072/data/?f=pjson
Внимание:
Убедитесь, что веб-карта опубликована для общего доступа при получении ID слоя
Например, слой добавляется на карту в отдельности, как показано ниже в формате JSON. ID слоя – Census_8491, имя поля – POP2000, а значение – 1211537. Вы можете выполнить следующие запросы:
ID слоя – Census_8491, имя поля – POP2000, а значение – 1211537. Вы можете выполнить следующие запросы:
id: "Census_8491", layerType: "ArcGISFeatureLayer", url: "http://sampleserver6.arcgisonline.com/arcgis/rest/services/Census/MapServer/3", visibility: true, opacity: 1, mode: 1, title: "Census - states",
http://<your portal url>/apps/webappviewer/index.html?id=da80a448ac9246148da0811bddc18c94&query=Census_8491,POP2000,1211537
http://<your portal url>/apps/webappviewer/index.html?id=da80a448ac9246148da0811bddc18c94&query=Census_8491,POP2000=1211537
Вы можете также выполнить запрос к текстовому полю или полю ObjectID.
http://<your portal url>/apps/webappviewer/index.html?id=da80a448ac9246148da0811bddc18c94&query=Census_8491,STATE_NAME,California
http://<your portal url>/apps/webappviewer/index.html?id=da80a448ac9246148da0811bddc18c94&query=Census_8491,STATE_NAME='California'
http://<your portal url>/apps/webappviewer/index.
 html?id=da80a448ac9246148da0811bddc18c94&query=Census_8491,OBJECTID,1
html?id=da80a448ac9246148da0811bddc18c94&query=Census_8491,OBJECTID,1Часто слой добавляется как группа картографического сервиса. Для выполнения запроса к подслою группы используйте <layer id_sublayer id> в качестве ID слоя. При использовании следующего слоя в качестве примера, его ID будет Census_3217, а ID подслоя – 3. ID слоя для подслоя будет Census_3217_3. Вы можете выполнить следующие запросы:
id: "Census_3217", layerType: "ArcGISMapServiceLayer", url: "http://sampleserver6.arcgisonline.com/arcgis/rest/services/Census/MapServer", visibility: true, opacity: 1, title: "Census"
http://<your portal url>/apps/webappviewer/index.html?id=da80a448ac9246148da0811bddc18c94&query=Census_3217_3,POP2000,1211537
http://<your portal url>/apps/webappviewer/index.html?id=da80a448ac9246148da0811bddc18c94&query=Census_3217_3,POP2000=1211537
http://<your portal url>/apps/webappviewer/index.html?id=da80a448ac9246148da0811bddc18c94&query=Census_8491;STATE_NAME in ('California', '')Переключение языка
Чтобы переключить язык приложения, используйте locale=<language code>. Поддерживаются следующие языковые коды: ar, cs, da, de, en, el, es, et, fi, fr, he, it, ja, ko, lt, lv, nb, nl, pl, pt-br, pt-pt, ro, ru, sv, th, tr, zh-cn, vi, zh-hk и zh-tw.
Поддерживаются следующие языковые коды: ar, cs, da, de, en, el, es, et, fi, fr, he, it, ja, ko, lt, lv, nb, nl, pl, pt-br, pt-pt, ro, ru, sv, th, tr, zh-cn, vi, zh-hk и zh-tw.
Ниже приведен пример:
http://<your portal url>/apps/webappviewer/index.html?locale=fr
Управление мобильной компоновкой
В зависимости от размера экрана в приложении поддерживается два стиля компоновки. Один для настольных и другой для мобильных устройств. Если высота или ширина экрана менее 600 пикселов, автоматически применяется компоновка для мобильных устройств. Однако это может привести к неожиданному поведению при встраивании приложения в веб-сайт, например, когда во всплывающем окне веб-сайта используется мобильный стиль компоновки. Для управления стилем компоновки используйте mobileBreakPoint=<pixel number>. Например, вы можете продолжать работать в стиле desktop до тех пор, пока размер экрана не станет менее 300 пикселов – как показано ниже:
http://<your portal url>/apps/webappviewer/index.
 html?mobileBreakPoint=300
html?mobileBreakPoint=300Отзыв по этому разделу?
#8. Формирование URL-адресов в шаблонах
Смотреть материал на видео
Архив проекта: lesson-8-coolsite.zip
На данный момент мы с вами научились создавать шаблоны, прописывать в них различные теги {% имя_тега %}, переменные {{ имя_переменной }} и фильтры {{value|имя_фильтра}}. Я не приводил подробное описание работы с этими элементами, так как ранее уже создавал курс по этой теме – шаблонизатору Jinja и, при необходимости, каждый из вас может посмотреть этот плейлист:
https://www.youtube.com/watch?v=cFJqMXxVNsI&list=PLA0M1Bcd0w8wfmtElObQrBbZjY6XeA06U
Следующий важный шаг – научиться правильно указывать URL-адреса в наших шаблонах. На предыдущих занятиях почти у всех ссылок я ставил заглушки – символ шарп:
<a href= «#»>…</a>
Пришло время
сформировать полноценные ссылки на страницы. Для этого в Django используется
специальный тег:
Для этого в Django используется
специальный тег:
{% url ‘<URL-адрес или имя маргрута>’ [параметры ссылки] %}
Давайте для начала пропишем с помощью этого тега маршрут к главной странице в шаблоне base.html. В нем имеется вот такая строчка:
<li><a href="/"><div></div></a></li>
Здесь косая черта – это как раз ссылка на главную страницу. Но это не лучший подход, так как URL-адрес главной не обязательно должен совпадать с доменным именем (в нашем случае: http://127.0.0.1:8000/). Мы можем определить ее и как-то иначе, например:
http://127.0.0.1:8000/home/
И тогда везде в шаблонах придется вносить эти изменения. Гораздо практичнее и, чаще всего, так и делают, используют имена маршрутов. Если мы откроем файл women/urls.py, то увидим, что главная страница имеет имя home. Им мы и воспользуемся, указав в теге url:
<li><a href="{% url 'home' %}"><div></div></a></li>Видите, как это
удобно.
urlpatterns = [
path('home/', index, name='home'),
path('about/', about, name='about'),
]И перейти по адресу:
http://127.0.0.1:8000/home/
то ссылка на главную автоматически изменится. В этом удобство именованных ссылок.
Но вернем прежний адрес главной страницы, так будет удобнее. Добавим ссылки для нашего главного меню. Вначале переопределим список menu, указав не только заголовок, но и имя ссылки:
menu = [{'title': "О сайте", 'url_name': 'about'},
{'title': "Добавить статью", 'url_name': 'add_page'},
{'title': "Обратная связь", 'url_name': 'contact'},
{'title': "Войти", 'url_name': 'login'}
]Затем, в файле women/urls.py сформируем маршруты к этим страницам:
urlpatterns = [
path('', index, name='home'),
path('about/', about, name='about'),
path('addpage/', addpage, name='add_page'),
path('contact/', contact, name='contact'),
path('login/', login, name='login'),
]И в файле women/views. py пропишем
указанные функции представлений:
py пропишем
указанные функции представлений:
def about(request):
return render(request, 'women/about.html', {'menu': menu, 'title': 'О сайте'})
def addpage(request):
return HttpResponse("Добавление статьи")
def contact(request):
return HttpResponse("Обратная связь")
def login(request):
return HttpResponse("Авторизация")Пока это просто функции-заглушки. А вот функцию index перепишем в таком виде:
def index(request):
posts = Women.objects.all()
context = {
'posts': posts,
'menu': menu,
'title': 'Главная страница'
}
return render(request, 'women/index.html', context=context)Смотрите, мы
здесь определили отдельный словарь context, в котором
указали все те параметры, что собираемся передавать шаблону index.html, а затем, в
функции render передаем этот
словарь с помощью именованного параметра context. Это будет
эквивалентно предыдущей записи, но так текст программы читается гораздо лучше.
Осталось в самом шаблоне правильно обработать коллекцию menu. В файле шаблона base.html пропишем следующие строчки:
{% for m in menu %}
{% if not forloop.last %}
<li><a href="{% url m.url_name %}">{{m.title}}</a></li>
{% else %}
<li><a href="{% url m.url_name %}">{{m.title}}</a></li>
{% endif %}
{% endfor %} Теперь, при обновлении страницы мы получаем полноценные ссылки в главном меню.
Формирование динамических URL-адресов
Осталось прописать ссылки у списка наших статей. Во-первых, определим шаблон маршрута, по которому они будут доступны. Для этого в файле women/urls.py добавим строчку в urlpatterns:
path('post/<int:post_id>/', show_post, name='post'),то есть, маршрут постов будет выглядеть так:
http://127. 0.0.1:8000/post/<идентификатор_поста>/
0.0.1:8000/post/<идентификатор_поста>/
Конечно, в реальных проектах вместо post_id, как правило, используется строка (слаг), записанная латиницей и отражающая суть статьи. Такие ссылки лучше ранжируются поисковыми системами и понятнее пользователям сайта. Позже мы тоже будем использовать слаг, но на данном этапе нам важно разобраться, как создавать динамические URL-ссылки на уровне шаблонов.
Итак, маршрут определен, имя маршрута задано как post, осталось прописать функцию представления show_post. Мы ее пока определим вот такой заглушкой:
def show_post(request, post_id):
return HttpResponse(f"Отображение статьи с id = {post_id}")Осталось все это определить в шаблоне index.html, в котором происходит отображение списка статей. Фактически, все что нам нужно – это переписать следующую строчку:
<p><a href="{% url 'post' p.pk %}">Читать пост</a></p>Смотрите, здесь
в параметре href используется
уже знакомый нам тег шаблона url, далее указываем имя ссылки post и через пробел
ее параметр post_id в виде p. pk. Вспоминаем,
что мы перебираем здесь коллекцию posts, которая хранит
ссылки на объекты класса модели Women. И у этих объектов имеется параметр pk, равный
идентификатору записи. Почему мы используем pk, а не id? В принципе,
можно указать е его, но согласно конвенции Django, лучше
использовать атрибут pk.
pk. Вспоминаем,
что мы перебираем здесь коллекцию posts, которая хранит
ссылки на объекты класса модели Women. И у этих объектов имеется параметр pk, равный
идентификатору записи. Почему мы используем pk, а не id? В принципе,
можно указать е его, но согласно конвенции Django, лучше
использовать атрибут pk.
Если теперь обновим главную страницу, то у всех постов появятся сформированные нами ссылки и каждая будет соответствовать своей статье. Щелкая по любой из них, перейдем по адресу, например:
http://127.0.0.1:8000/post/5/
и увидим строчку «Отображение статьи с id = 5» от функции заглушки show_post. Вот так довольно просто можно формировать различные динамические URL-адреса на уровне шаблонов.
Функция get_absolute_url()
Как я уже не раз
отмечал, фреймворк Django работает согласно паттерну MTV (Models, Templates, Views), то есть, ему
постоянно приходится связывать модели с шаблонами и видами, а значит,
формировать URL-ссылки для
выбранных записей из таблиц БД. И мы только что это делали – формировали URL-ссылки для
записей модели Women. При разработке сайтов – это типовая
операция. Поэтому, разработчики Django озаботились упрощением и
автоматизацией этой процедуры. Что они нам предлагают? Смотрите. В классах
моделей можно определять специальный метод под названием:
И мы только что это делали – формировали URL-ссылки для
записей модели Women. При разработке сайтов – это типовая
операция. Поэтому, разработчики Django озаботились упрощением и
автоматизацией этой процедуры. Что они нам предлагают? Смотрите. В классах
моделей можно определять специальный метод под названием:
get_absolute_url()
который бы возвращал полный URL-адрес для каждой конкретной записи (ассоциированной с текущим объектом). Например, в классе модели Women мы можем определить этот метод следующим образом:
def get_absolute_url(self):
return reverse('post', kwargs={'post_id': self.pk})Здесь используется функция reverse, которая строит текущий URL-адрес записи на основе имени маршрута post и словаря параметров kwargs. В данном случае указан один параметр post_id со значением идентификатора объекта self.pk. Разумеется, вначале нам нужно импортировать эту функцию:
from django.
 urls import reverse
urls import reverseВсе, теперь при обращении к методу get_absolute_url объекта класса модели Women, мы будем получать ее URL-адрес.
Где здесь упрощение и автоматизация? Смотрите, в шаблоне index.html, при формировании ссылок статей, мы теперь можем вместо тега шаблона url указать метод get_absolute_url:
<p><a href="{{ p.get_absolute_url }}">Читать пост</a></p>Вспоминаем, что p как раз ссылается на объекты класса Women, следовательно, у нее появился атрибут get_absolute_url, который мы и прописываем. И, обратите внимание, при указании этого метода, мы не пишем в конце круглые скобки, т.к. он здесь самостоятельно не вызывается. Вызов сделает функция render при обработке этого шаблона.
Почему это лучше
тега url? Представьте,
что в будущем мы изменили шаблон этой ссылки и стали выводить посты не по id, а по слагу. Тогда,
при использовании тега url, нам пришлось бы менять эти ссылки в
каждом шаблоне, заменяя self. pk на self.slug, например. В
этом как раз неудобство и источник потенциальных ошибок. Теперь, с методом get_absolute_url() нам
достаточно изменить маршрут в нем и это автоматически скажется на всех шаблонах,
где она используется.
pk на self.slug, например. В
этом как раз неудобство и источник потенциальных ошибок. Теперь, с методом get_absolute_url() нам
достаточно изменить маршрут в нем и это автоматически скажется на всех шаблонах,
где она используется.
Второй важный момент функции get_absolute_url() заключается в том, что согласно конвенции, модули Django используют этот метод в своей работе (если он определен в модели). Например, стандартная админ-панель обращается к этому методу для построения ссылок на каждую запись наших моделей. И в дальнейшем мы увидим как это работает.
В свою очередь тег {% url %} имеет смысл применять для построения ссылок не связанных с моделями или, для ссылок без параметров, используя только имена маршрутов.
Видео по теме
#1. Django — что это такое, порядок установки
#2. Модель MTV. Маршрутизация. Функции представления
#3. Маршрутизация, обработка исключений запросов, перенаправления
Маршрутизация, обработка исключений запросов, перенаправления
#4. Определение моделей. Миграции: создание и выполнение
#5. CRUD — основы ORM по работе с моделями
#6. Шаблоны (templates). Начало
#7. Подключение статических файлов. Фильтры шаблонов
#8. Формирование URL-адресов в шаблонах
#9. Создание связей между моделями через класс ForeignKey
#10. Начинаем работу с админ-панелью
#11. Пользовательские теги шаблонов
#12. Добавляем слаги (slug) к URL-адресам
#13. Использование форм, не связанных с моделями
#14. Формы, связанные с моделями. Пользовательские валидаторы
#15. Классы представлений: ListView, DetailView, CreateView
#16. Основы ORM Django за час
#17. Mixins — убираем дублирование кода
Mixins — убираем дублирование кода
#18. Постраничная навигация (пагинация)
#19. Регистрация пользователей на сайте
#20. Делаем авторизацию пользователей на сайте
#21. Оптимизация сайта с Django Debug Toolbar
#22. Включаем кэширование данных
#23. Использование капчи captcha
#24. Тонкая настройка админ панели
#25. Начинаем развертывание Django-сайта на хостинге
#26. Завершаем развертывание Django-сайта на хостинге
идентификаторов и URL-адресов и Интернета
В большинстве случаев событие генерируется, когда агент посещает веб-страницу и замечает ссылку между этой веб-страницей и частью зарегистрированного содержимого Crossref. Результатом является событие, где тема — это веб-страница, а объект — зарегистрированный контент. Мы используем «наилучший возможный» URL-адрес для ссылки как на Тему, так и на Объект.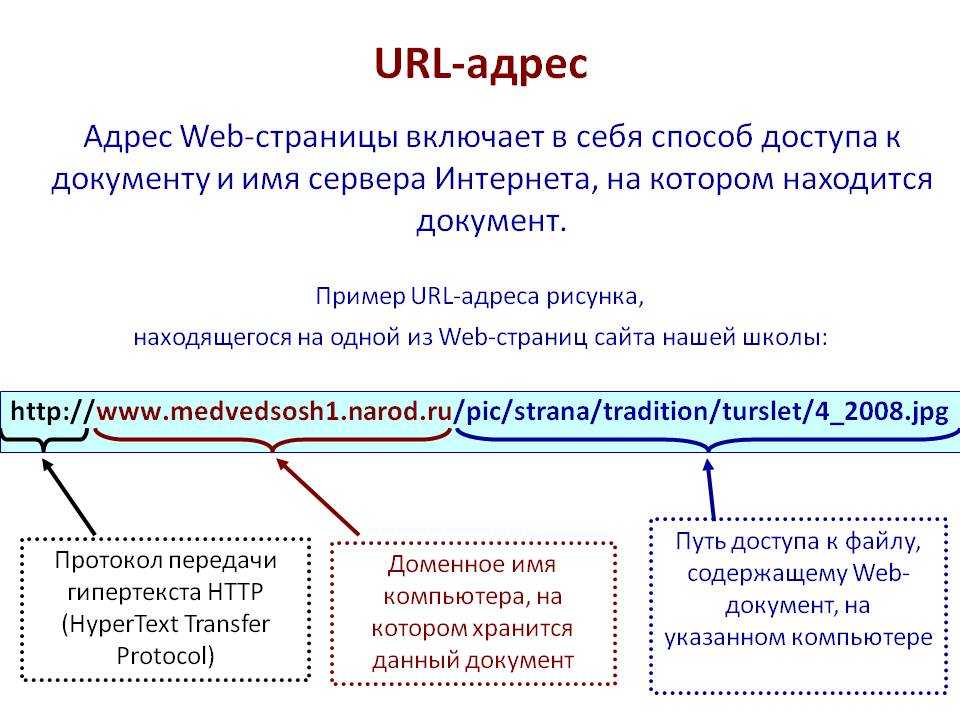
Когда мы говорим «лучший» URL-адрес, мы пытаемся найти URL-адрес, который однозначно представляет контент. Это позволяет людям, использующим данные, находить События, соответствующие одному и тому же контенту. Если на определенный фрагмент контента ссылаются с использованием ряда разных URL-адресов, может быть сложно или невозможно найти события, которые на него ссылаются.
Вообще говоря, лучшим URL-адресом для части зарегистрированного контента (т. е. Объекта, такого как журнальная статья) является DOI. Лучший URL-адрес для веб-страницы (т. е. Тема, например, сообщение в блоге) — это ее канонический URL-адрес.
Канонические URL-адреса для субъектов
Когда агент посещает веб-страницу, он записывает посещенный URL-адрес. Сама веб-страница может указать «лучший» URL-адрес для использования через каноническую URL-ссылку. Включение канонического URL-адреса в метаданные веб-страницы является передовой практикой поисковых систем (рекомендуется, например, Google).
К веб-странице можно получить доступ через несколько различных URL-адресов. Чтобы взять реальный пример, следующие три URL-адреса соответствуют одному и тому же контенту:
-
https://arstechnica.com/?p=1177597 -
https://arstechnica.com/science/2017/09/new-evidence-would-push-life-back-to-at-least-3-95-billion-years-ago/ -
https://arstechnica.com/science/2017/09/new-evidence-would-push-life-back-to-at-least-3-95-billion-years-ago/?comments=1&post=34078349
Хотя важно записывать, где именно мы искали конкретную ссылку, также важно, чтобы мы представляли контент как можно более последовательно. На приведенной выше веб-странице есть метаданные, указывающие на канонический URL-адрес. Когда мы идентифицируем канонический URL-адрес, мы используем этот URL-адрес как subj_id в событии. Мы сохраняем URL-адрес, который мы посетили, в subj.url , чтобы вы всегда знали, какой URL-адрес мы посетили в первую очередь.
Удаление URL отслеживания
Не все веб-страницы предоставляют канонические URL-адреса. Когда это происходит, мы используем следующий лучший URL-адрес, который мы посетили. Сначала мы применяем несколько шагов очистки:
Если URL-адрес, который мы посетили, привел к какому-либо перенаправлению (например, некоторые агрегаторы RSS включают свой собственный URL-адрес перенаправления), мы запишем конечный URL-адрес, к которому мы пришли. Это означает, что URL-адрес, по которому был записан контент, может отличаться от URL-адреса, который был посещен из ленты новостей. Пример:
- URL найден в ленте новостей:
http://feedproxy.google.com/~r/blogspot/wCeDd/~3/4ut6cGJY2FM/cshardware-inview-multi-pix-camera.html - URL-адрес назначения:
http://nuit-blanche.blogspot.co.uk/2017/09/cshardware-inview-multi-pix-camera.html
Во-вторых, некоторые сервисы (например, в приведенном выше примере) применяют параметры URL отслеживания. Они не влияют на контент, но позволяют людям отслеживать, как передаются URL-адреса. Общие примеры включают
Они не влияют на контент, но позволяют людям отслеживать, как передаются URL-адреса. Общие примеры включают utm_source , utm_medium , utm_campaign , которые используются Google Analytics. Наличие этих параметров URL-адреса может сбивать с толку, поскольку они означают, что один фрагмент контента может быть представлен бесконечным числом различных URL-адресов.
Чтобы противодействовать этому, мы удаляем известный набор параметров отслеживания из URL-адресов, прежде чем использовать их в поле subj_id . Вот пример:
- URL, который мы посетили:
http://nuit-blanche.blogspot.co.uk/2017/09/cshardware-inview-multi-pix-camera.html?utm_source=feedburner&utm_medium=feed&utm_campaign= Лента:+blogspot/wCeDd+(Nuit+Blanche) - URL-адрес, который мы используем для записи контента:
http://nuit-blanche.blogspot.co.uk/2017/09/cshardware-inview-multi-pix-camera.html
Какой URL используется для
subj_id ? При выборе subj_id мы используем следующие параметры по порядку:
- Канонический URL, указанный в метаданных HTML.
- В противном случае URL-адрес, по которому мы нашли контент (если были перенаправления, то конечный пункт назначения), с удаленными параметрами отслеживания.
- В противном случае (например, если были ошибки при удалении параметров отслеживания), URL-адрес, который посетил Агент.

DOI для объектов
В большинстве случаев объектом события является фрагмент содержимого, зарегистрированного в Crossref или DataCite. Для них лучшим URL-адресом для однозначной идентификации контента является DOI. Процесс сопоставления DOI также подтверждает, что это действительно часть зарегистрированного контента. Если мы не можем найти DOI, мы не можем подтвердить, что это контент, зарегистрированный Crossref, поэтому мы не создаем событие.
Мы ищем DOI, а также целевые страницы
Агенты данных событий ищут ссылки на зарегистрированные элементы контента, но люди в Интернете используют различные методы, чтобы найти их. Они могут использовать DOI с гиперссылкой (на которую можно щелкнуть) или DOI в виде простого текста (на которую нельзя щелкнуть). Они также могут использовать целевую страницу статьи (страница, на которую вы попадаете, когда нажимаете на DOI). Каждый источник отличается: мы склонны видеть, что большинство людей используют целевые страницы статей в Твиттере, но в Википедии часто используются DOI.
Они также могут использовать целевую страницу статьи (страница, на которую вы попадаете, когда нажимаете на DOI). Каждый источник отличается: мы склонны видеть, что большинство людей используют целевые страницы статей в Твиттере, но в Википедии часто используются DOI.
Каждый агент будет пытаться сопоставлять зарегистрированные элементы контента как можно более широко, ища связанные и несвязанные DOI и URL-адреса целевых страниц статей. Мы поддерживаем список доменных имен, принадлежащих издателям (дополнительную информацию см. на странице артефактов), а также отслеживаем и запрашиваем эти домены. Когда мы видим URL-адрес, который может быть целевой страницей, мы пытаемся сопоставить его с DOI.
Соответствие целевой страницы не идеальное
Если мы не можем сделать вывод, что целевая страница предназначена для одного из наших зарегистрированных элементов контента, мы не будем генерировать событие. В конце концов, не каждый URL на сайте каждого издателя соответствует статье.
Если кто-то обсуждает статью в Твиттере и использует ее DOI, и этот DOI существует, почти наверняка мы сопоставим ее и создадим событие. Если они обсуждают статью в Твиттере и используют URL ее целевой страницы, есть очень большая вероятность, что мы сопоставим ее, но процесс сопоставления не идеален.
Поэтому вам следует знать о разнице между Событиями, сопоставленными с использованием DOI, и событиями, сопоставленными с использованием URL-адреса целевой страницы, а также о том, что у нас может быть лучший коэффициент сопоставления для DOI.
Сопоставление также зависит от издателя. Для некоторых доменов целевых страниц мы можем легко сопоставить DOI. Для некоторых нам нужно сделать немного больше работы. Для других это невозможно.
Мы производим полную трассировку каждой попытки в протоколах и журналах доказательств. См. служебные страницы для получения информации о том, как получить к ним доступ.
Если вы издатель, ознакомьтесь с рекомендациями для издателей, чтобы убедиться, что у нас есть наилучшие шансы подобрать события для вашего контента.
Возможно, вам захочется узнать разницу
Когда мы сопоставляем Событие, потому что кто-то обсуждал Элемент, используя его DOI, единственная обработка, которая имеет место, — это нормализация DOI и проверка его существования. Вы можете увидеть весь процесс в протоколе свидетельских показаний для этого события, хотя в нем не так уж много.
Когда мы сопоставляем Событие, потому что кто-то использовал целевую страницу, Агент должен выполнить некоторую работу, чтобы сопоставить его с DOI. Когда мы делаем это, мы делаем неявное утверждение, что «эта целевая страница предназначена для этого DOI». Наши агенты отражают данные, которые они находят, поэтому важно понимать, что этот автоматизированный процесс не может быть на 100% надежным.
Данные о событиях можно использовать по-разному. Вам может быть интересно узнать:
- Как часто люди твитят DOI по сравнению с URL-адресами целевых страниц?
- Меня интересуют только данные, в которых я могу быть на 100% уверен, что используется только DOI.
- Я хочу знать об этих статьях. Меня не волнует, какой URL-адрес использовался для ссылки на них.

Когда событие ссылается на зарегистрированный элемент контента (почти все события делают это), оно будет использовать свой DOI как subj_id или obj_id . Соответствующие необязательные метаданные subj или obj могут содержать поле pid (которое всегда одинаково), но дополнительно оно может содержать поле url .
Если поле URL совпадает с полем PID (т. е. DOI), то вы знаете, что событие было собрано, потому что его DOI был упомянут. Если поле URL-адреса отличается (например, URL-адрес целевой страницы), вы знаете, что оно было собрано, поскольку был упомянут домен целевой страницы.
Всегда не однозначно
DOI можно присваивать книгам и главам книг, статьям и рисункам. Каждый агент будет выполнять свою работу максимально точно, с минимальной очисткой, которая может повлиять на интерпретацию.
Это означает, что если кто-то опубликует в твиттере DOI для рисунка в статье, мы запишем DOI этого рисунка. Если они опубликуют в Твиттере URL-адрес целевой страницы для этой фигуры, мы сделаем все возможное, чтобы сопоставить ее с DOI. В зависимости от используемого метода и того, что сообщает нам целевая страница издателя, мы можем сопоставить DOI статьи или DOI рисунка.
Иногда две страницы могут претендовать на один и тот же DOI. Это может произойти, если издатель запускает два разных сайта с одинаковым содержанием. Также возможно, что у целевой страницы нет метаданных DOI, поэтому мы не можем сопоставить ее с событием.
Верно и обратное: иногда два DOI указывают на одну и ту же целевую страницу. Это может произойти случайно. Это редко, но случается. Это не оказывает существенного влияния на текущие методы сообщения о событиях.
Данные целевой страницы могут быть устаревшими
Мы периодически сканируем наши DOI, берем образцы и находим домены, используемые издателями. Это задокументировано в наших Артефактах, у которых есть версии и даты. Поэтому мы можем пропустить События в период между использованием нового домена и обновлением Артефакта.
Это задокументировано в наших Артефактах, у которых есть версии и даты. Поэтому мы можем пропустить События в период между использованием нового домена и обновлением Артефакта.
Если издатель перестанет использовать домен целевой страницы статьи, мы не удалим его из списка. Агенты могут в любой момент вернуться и повторно обработать старые данные или работать с дампами исторических данных. Люди могут ретвитить старые твиты, которые указывают на старые целевые страницы. Мы все еще хотим попытаться сопоставить их, если это возможно. Поэтому список доменов Artifact только растет. Как и в случае со всеми Артефактами, вы можете просмотреть все прошлые версии, чтобы увидеть, как они меняются с течением времени.
Мы не сопоставляем все домены
Некоторые DOI были зарегистрированы в таких доменах, как youtube.com . У нас нет возможности сопоставить видео на YouTube с DOI. Итак, мы исключаем это небольшое количество доменов, которые мы никогда не сможем сопоставить.
Мы не знаем всех URL-адресов целевых страниц, и невозможно обнаружить их все
Каждый DOI имеет URL-адрес ресурса, на который вы перенаправляетесь, когда вы нажимаете на гиперссылку DOI. Это известно Crossref и может быть получено из системы DOI. Однако в большинстве случаев это не конечный целевой URL. Многие издатели используют свои собственные внутренние службы ссылок и перенаправления, что означает, что когда вы нажимаете на DOI, вы перенаправляетесь через серию перенаправлений, прежде чем попасть на целевую целевую страницу статьи.
Возьмем простой пример DOI для демонстрации Crossref. DOI 10.5555/12345678 имеет URL-адрес ресурса http://psychoceramics.labs.crossref.org/10.5555-12345678.html , который вы можете увидеть в метаданных статьи. Если мы проследим за DOI, мы увидим только одно перенаправление, которое происходит по ссылке DOI.
| URL-адрес | Комментарий |
|---|---|
https://doi. | Начальное перенаправление DOI со ссылки ресурса |
http://psychoceramics.labs.crossref.org/10.5555-12345678.html | Завершено |
 org/10.5555/12345678
org/10.5555/12345678 В подобных случаях целевая страница известна Crossref, поскольку она совпадает со ссылкой на ресурс.
Возьмем другой пример, PLOS DOI 10.1371/journal.pone.0160106 . Ссылка на ресурс, которую вы можете увидеть в метаданных статьи, — http://dx.plos.org/10.1371/journal.pone.0160106 , это внутренний преобразователь ссылок, управляемый PLOS.
Если мы перейдем по URL-адресу DOI, мы увидим следующую цепочку перенаправлений.
| URL-адрес | Комментарий |
|---|---|
http://doi.org/10.1371/journal.pone.0160106 | Начальное перенаправление DOI со ссылки ресурса |
http://dx.plos.org/10.1371/journal. | Внутреннее перенаправление на сайте PLoS |
http://www.plosone.org/article/info%3Adoi%2F10.1371%2Fjournal.pone.0160106 | Внутреннее перенаправление на сайте PLoS |
http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0160106 | Завершено |
 pone.0160106
pone.0160106 В подобных случаях конечная целевая страница отличается от страницы, зарегистрированной в Crossref, поэтому мы не можем знать, не следуя ей.
В некоторых случаях сайты издателей реализуют проверки, предотвращающие автоматический доступ, такие как запрос файлов cookie и выполнение перенаправлений с использованием JavaScript. В этом примере DOI анонимизирован, но основан на реальном примере. Попытка решить DOI 10.XXX/YYY.06.008 без включенных файлов cookie выдает:
| URL | Комментарий |
|---|---|
http://doi. | Начальное перенаправление DOI |
http://FFF.AAA.com/retrieve/pii/DDD | Внутреннее перенаправление |
http://FFF.AAA.com/retrieve/articleSelectPrefsTemp?Redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&key=71835a2ddc744fbddf6d9а5а9003а4асед4б81а1 | Внутреннее перенаправление |
http://www.CCC.com/retrieve/pii/DDD | Внутреннее перенаправление |
https://secure.BBB.com/action/getSharedSiteSession?redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&rc=0&code=EEE | Внутреннее перенаправление |
https://secure.BBB.com/action/getSharedSiteSession?rc=1&redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE | Внутреннее перенаправление |
https://secure.BBB.com/action/getSharedSiteSession?rc=2&redirect=http%3A%2F%2Fwww. | Внутреннее перенаправление |
https://secure.BBB.com/action/getSharedSiteSession?rc=3&redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE | Внутреннее перенаправление |
https://secure.BBB.com/action/getSharedSiteSession?rc=4&redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE | Внутреннее перенаправление |
https://secure.BBB.com/action/getSharedSiteSession?rc=5&redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE | Внутреннее перенаправление |
https://secure.BBB.com/action/getSharedSiteSession?rc=6&redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE | Внутреннее перенаправление |
https://secure.BBB.com/action/getSharedSiteSession?rc=7&redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE | Внутреннее перенаправление |
https://secure. | Внутреннее перенаправление |
https://secure.BBB.com/action/getSharedSiteSession?rc=9&redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE | Внутреннее перенаправление |
https://secure.BBB.com/action/getSharedSiteSession?rc=10&redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE | Внутреннее перенаправление |
http://secure.BBB.com/action/cookieAbsent | Последняя страница ошибки |
 org/10.XXX/YYY.06.008
org/10.XXX/YYY.06.008  CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE
CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE  BBB.com/action/getSharedSiteSession?rc=8&redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE
BBB.com/action/getSharedSiteSession?rc=8&redirect=http%3A%2F%2Fwww.CCC.com%2Fretrieve%2Fpii%2FDDD&code=EEE Последним шагом в этой цепочке является страница с ошибкой, в которой говорится, что файлы cookie необходимы, и поэтому невозможно разрешить DOI с помощью HTTP.
Правила членства в Crossref № 7 гласят:
Вы должны разрешить свои DOI на страницу, содержащую полную библиографическую информацию для контента со ссылкой или информацией о получении полного текста контента.

Если издатели нарушат эти правила, мы сообщим им об этом.
Из-за таких ограничений, а также других практических ограничений мы не можем и не пытаемся посетить каждый DOI заранее, чтобы найти его целевую страницу.
Внешние стороны, сопоставляющие контент с DOI
Агенты перекрестных ссылок не единственные, кто создает События, и, следовательно, не единственные, кто создает сопоставления DOI с URL-адресами.
Внешняя сторона может хранить сведения об активности, связанной с Элементами, и использовать свои собственные системы для сопоставления Элементов с DOI, целевыми страницами и другими идентификаторами. Хотя их API можно запрашивать с помощью DOI, они могли зафиксировать действия в отношении элемента, используя URL-адрес его целевой страницы или другой идентификатор. Внутренние сопоставления между различными идентификаторами могут время от времени меняться, что может означать, что определенные действия могут быть зарегистрированы в отношении одного элемента в один момент времени, а затем в отношении другого элемента в другой момент времени. Таким образом, данные могут меняться со временем, и это может быть вызвано обновлением алгоритмов, а не действиями пользователя.
Таким образом, данные могут меняться со временем, и это может быть вызвано обновлением алгоритмов, а не действиями пользователя.
Данные о событиях предоставляют все доступные свидетельства для всех событий, но не могут обеспечить видимость сопоставлений во внешних службах. С учетом этого следует интерпретировать данные из этих источников данного типа.
перезапись URL — Где добавить идентификатор в URL?
спросил
Изменено 15 дней назад
Просмотрено 5к раз
Я использую удобные URL-адреса, например:
http://localhost/gallery/photo/this-is-a-url-friendly-photo-caption
В удобный URL-адрес мне нужно добавить идентификатор фотографии, но, осмотревшись, я видел два способа добавления идентификатора в удобный URL-адрес, предварительно и после, например,
http://localhost/ галерея/фото/это-это-удобная-ссылка-фото-подпись.
 529
529
или
http://localhost/gallery/photo/529/this-is-a-url-friendly-photo-caption
Есть ли преимущество в одну сторону? Или это просто вопрос предпочтений/личного вкуса?
- url-rewriting
- seo
- url-design
Небольшое преимущество наличия ID в предпоследнем и slug в последнем сегменте пути ( /gallery/photo/529/this-is… ):
В некоторых контекстах URL-адрес может быть обрезан, например, разрывом строки в текстовых сообщениях электронной почты. Если ID приходит до (обычно длинного) слага, больше шансов, что идентификатор останется неповрежденным, а URL-адрес продолжит функционировать (при условии, что вы перенаправляете на канонический вариант с слагом).
Пример
Ваш вопрос в настоящее время имеет этот URL:
https://stackoverflow.com/questions/27343034/seo-friendly-url-where-to-add-the-id
При таком обрезании (=ID остается нетронутым) перенаправляет на канонический вариант и пользователь доволен:
https://stackoverflow.
